Blog
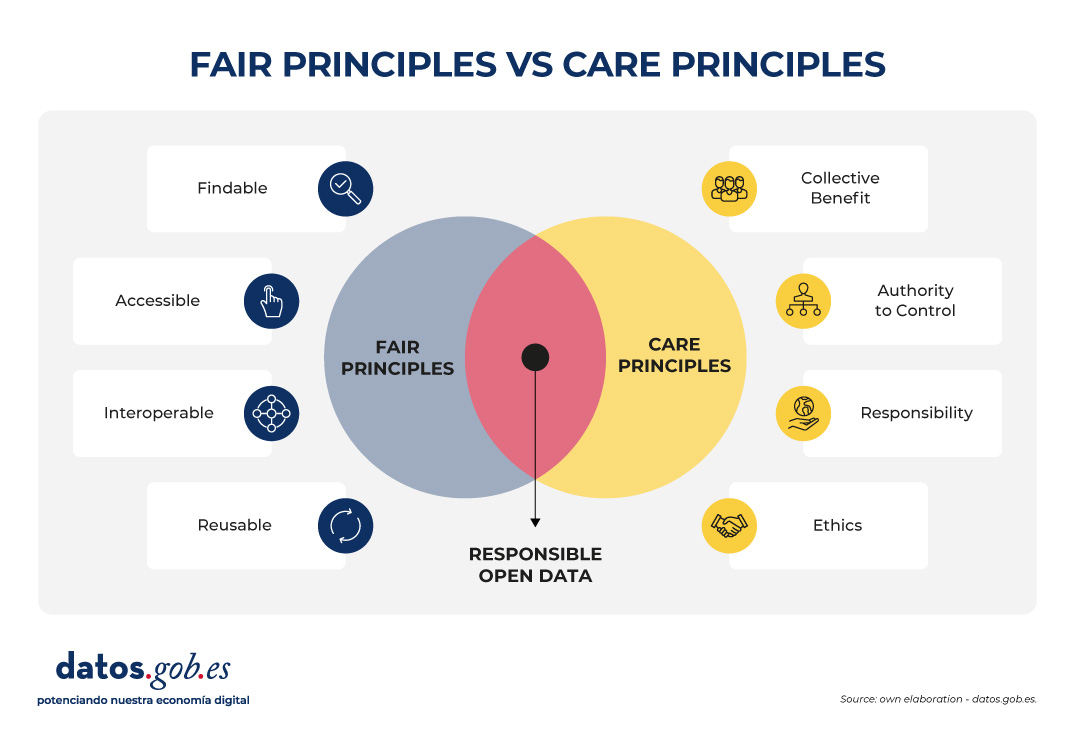
In recent years, open data initiatives have transformed the way in which both public institutions and private organizations manage and share information. The adoption of FAIR (Findable, Accessible, Interoperable, Reusable) principles has been key to ensuring that data generates a positive impact, maximizing its availability and reuse.
However, in contexts of vulnerability (such as indigenous peoples, cultural minorities or territories at risk) there is a need to incorporate an ethical framework that guarantees that the opening of data does not lead to harm or deepen inequalities. This is where the CARE principles (Collective Benefit, Authority to Control, Responsibility, Ethics), proposed by the Global Indigenous Data Alliance (GIDA), come into play, which complement and enrich the FAIR approach.
It is important to note that although CARE principles arise in the context of indigenous communities (to ensure indigenous peoples' effective sovereignty over their data and their right to generate value in accordance with their own values), these can be extrapolated to other different scenarios. In fact, these principles are very useful in any situation where data is collected in territories with some type of social, territorial, environmental or even cultural vulnerability.
This article explores how CARE principles can be integrated into open data initiatives generating social impact based on responsible use that does not harm vulnerable communities.
The CARE principles in detail
The CARE principles help ensure that open data initiatives are not limited to technical aspects, but also incorporate social, cultural and ethical considerations. Specifically, the four CARE principles are as follows:
-
Collective Benefit: data must be used to generate a benefit that is shared fairly between all parties involved. In this way, open data should support the sustainable development, social well-being and cultural strengthening of a vulnerable community, for example, by avoiding practices related to open data that only favour third parties.
-
Authority to Control: vulnerable communities have the right to decide how the data they generate is collected, managed, shared, and reused. This principle recognises data sovereignty and the need to respect one’s own governance systems, rather than imposing external criteria.
-
Responsibility: those who manage and reuse data must act responsibly towards the communities involved, recognizing possible negative impacts and implementing measures to mitigate them. This includes practices such as prior consultation, transparency in the use of data, and the creation of accountability mechanisms.
-
Ethics: the ethical dimension requires that the openness and re-use of data respects the human rights, cultural values and dignity of communities. It is not only a matter of complying with the law, but of going further, applying ethical principles through a code of ethics.
Together, these four principles provide a guide to managing open data more fairly and responsibly, respecting the sovereignty and interests of the communities to which that data relates.
CARE and FAIR: complementary principles for open data that transcend
The CARE and FAIR principles are not opposite, but operate on different and complementary levels:
-
FAIR focuses on making data consumption technically easier.
-
CARE introduces the social and ethical dimension (including cultural considerations of specific vulnerable communities).
The FAIR principles focus on the technical and operational dimensions of data. In other words, data that comply with these principles are easily locatable, available without unnecessary barriers and with unique identifiers, use standards to ensure interoperability, and can be used in different contexts for purposes other than those originally intended.
However, the FAIR principles do not directly address issues of social justice, sovereignty or ethics. In particular, these principles do not contemplate that data may represent knowledge, resources or identities of communities that have historically suffered exclusion or exploitation or of communities related to territories with unique environmental, social or cultural values. To do this, the CARE principles, which complement the FAIR principles, can be used, adding an ethical and community governance foundation to any open data initiative.
In this way, an open data strategy that aspires to be socially just and sustainable must articulate both principles. FAIR without CARE risks making collective rights invisible by promoting unethical data reuse. On the other hand, CARE without FAIR can limit the potential for interoperability and reuse, making the data useless to generate a positive benefit in a vulnerable community or territory.
An illustrative example is found in the management of data on biodiversity in a protected natural area. While the FAIR principles ensure that data can be integrated with various tools to be widely reused (e.g., in scientific research), the CARE principles remind us that data on species and the territories in which they live can have direct implications for communities who live in (or near) that protected natural area. For example, making public the exact points where endangered species are found in a protected natural area could facilitate their illegal exploitation rather than their conservation, which requires careful definition of how, when and under what conditions this data is shared.
Let's now see how in this example the CARE principles could be met:
-
First, biodiversity data should be used to protect ecosystems and strengthen local communities, generating benefits in the form of conservation, sustainable tourism or environmental education, rather than favoring isolated private interests (i.e., collective benefit principle).
-
Second, communities living near or dependent on the protected natural area have the right to decide how sensitive data is managed, for example, by requiring that the location of certain species not be published openly or published in an aggregated manner (i.e., principle of authority).
-
On the other hand, the people in charge of the management of these protected areas of the park must act responsibly, establishing protocols to avoid collateral damage (such as poaching) and ensuring that the data is used in a way that is consistent with conservation objectives (i.e. the principle of responsibility).
-
Finally, the openness of this data must be guided by ethical principles, prioritizing the protection of biodiversity and the rights of local communities over economic (or even academic) interests that may put ecosystems or the populations that depend on them at risk (principle of ethics).
Notably, several international initiatives, such as Indigenous Environmental Data Justice related to the International Indigenous Data Sovereignty Movement and the Research Data Alliance (RDA) through the Care Principles for Indigenous Data Governance, are already promoting the joint adoption of CARE and FAIR as the foundation for more equitable data initiatives.
Conclusions
Ensuring the FAIR principles is essential for open data to generate value through its reuse. However, open data initiatives must be accompanied by a firm commitment to social justice, the sovereignty of vulnerable communities, and ethics. Only the integration of the CARE principles together with the FAIR will make it possible to promote truly fair, equitable, inclusive and responsible open data practices.
Jose Norberto Mazón, Professor of Computer Languages and Systems at the University of Alicante. The contents and views reflected in this publication are the sole responsibility of the author.
Blog
Over the last few years we have seen spectacular advances in the use of artificial intelligence (AI) and, behind all these achievements, we will always find the same common ingredient: data. An illustrative example known to everyone is that of the language models used by OpenAI for its famous ChatGPT, such as GPT-3, one of its first models that was trained with more than 45 terabytes of data, conveniently organized and structured to be useful.
Without sufficient availability of quality and properly prepared data, even the most advanced algorithms will not be of much use, neither socially nor economically. In fact, Gartner estimates that more than 40% of emerging AI agent projects today will end up being abandoned in the medium term due to a lack of adequate data and other quality issues. Therefore, the effort invested in standardizing, cleaning, and documenting data can make the difference between a successful AI initiative and a failed experiment. In short, the classic principle of "garbage in, garbage out" in computer engineering applied this time to artificial intelligence: if we feed an AI with low-quality data, its results will be equally poor and unreliable.
Becoming aware of this problem arises the concept of "AI Data Readiness" or preparation of data to be used by artificial intelligence. In this article, we'll explore what it means for data to be "AI-ready", why it's important, and what we'll need for AI algorithms to be able to leverage our data effectively. This results in greater social value, favoring the elimination of biases and the promotion of equity.
What does it mean for data to be "AI-ready"?
Having AI-ready data means that this data meets a series of technical, structural, and quality requirements that optimize its use by artificial intelligence algorithms. This includes multiple aspects such as the completeness of the data, the absence of errors and inconsistencies, the use of appropriate formats, metadata and homogeneous structures, as well as providing the necessary context to be able to verify that they are aligned with the use that AI will give them.
Preparing data for AI often requires a multi-stage process. For example, again the consulting firm Gartner recommends following the following steps:
- Assess data needs according to the use case: identify which data is relevant to the problem we want to solve with AI (the type of data, volume needed, level of detail, etc.), understanding that this assessment can be an iterative process that is refined as the AI project progresses.
- Align business areas and get management support: present data requirements to managers based on identified needs and get their backing, thus securing the resources required to prepare the data properly.
- Develop good data governance practices: implement appropriate data management policies and tools (quality, catalogs, data lineage, security, etc.) and ensure that they also incorporate the needs of AI projects.
- Expand the data ecosystem: integrate new data sources, break down potential barriers and silos that are working in isolation within the organization and adapt the infrastructure to be able to handle the large volumes and variety of data necessary for the proper functioning of AI.
- Ensure scalability and regulatory compliance: ensure that data management can scale as AI projects grow, while maintaining a robust governance framework in line with the necessary ethical protocols and compliance with existing regulations.
If we follow a strategy like this one, we will be able to integrate the new requirements and needs of AI into our usual data governance practices. In essence, it is simply a matter of ensuring that our data is prepared to feed AI models with the minimum possible friction, avoiding possible setbacks later in the day during the development of projects.
Open data "ready for AI"
In the field of open science and open data, the FAIR principles have been promoted for years. These acronyms state that data must be locatable, accessible, interoperable and reusable. The FAIR principles have served to guide the management of scientific and open data to make them more useful and improve their use by the scientific community and society at large. However, these principles were not designed to address the new needs associated with the rise of AI.
Therefore, the proposal is currently being made to extend the original principles by adding a fifth readiness principle for AI, thus moving from the initial FAIR to FAIR-R or FAIR². The aim would be precisely to make explicit those additional attributes that make the data ready to accelerate its responsible and transparent use as a necessary tool for AI applications of high public interest

What exactly would this new R add to the FAIR principles? In essence, it emphasizes some aspects such as:
- Labelling, annotation and adequate enrichment of data.
- Transparency on the origin, lineage and processing of data.
- Standards, metadata, schemas and formats optimal for use by AI.
- Sufficient coverage and quality to avoid bias or lack of representativeness.
In the context of open data, this discussion is especially relevant within the discourse of the "fourth wave" of the open data movement, through which it is argued that if governments, universities and other institutions release their data, but it is not in the optimal conditions to be able to feed the algorithms, A unique opportunity for a whole new universe of innovation and social impact would be missing: improvements in medical diagnostics, detection of epidemiological outbreaks, optimization of urban traffic and transport routes, maximization of crop yields or prevention of deforestation are just a few examples of the possible lost opportunities.
And if not, we could also enter a long "data winter", where positive AI applications are constrained by poor-quality, inaccessible, or biased datasets. In that scenario, the promise of AI for the common good would be frozen, unable to evolve due to a lack of adequate raw material, while AI applications led by initiatives with private interests would continue to advance and increase unequal access to the benefit provided by technologies.
Conclusion: the path to quality, inclusive AI with true social value
We can never take for granted the quality or suitability of data for new AI applications: we must continue to evaluate it, work on it and carry out its governance in a rigorous and effective way in the same way as it has been recommended for other applications. Making our data AI-ready is therefore not a trivial task, but the long-term benefits are clear: more accurate algorithms, reduced unwanted bias, increased transparency of AI, and extended its benefits to more areas in an equitable way.
Conversely, ignoring data preparation carries a high risk of failed AI projects, erroneous conclusions, or exclusion of those who do not have access to quality data. Addressing the unfinished business on how to prepare and share data responsibly is essential to unlocking the full potential of AI-driven innovation for the common good. If quality data is the foundation for the promise of more humane and equitable AI, let's make sure we build a strong enough foundation to be able to reach our goal.
On this path towards a more inclusive artificial intelligence, fuelled by quality data and with real social value, the European Union is also making steady progress. Through initiatives such as its Data Union strategy, the creation of common data spaces in key sectors such as health, mobility or agriculture, and the promotion of the so-called AI Continent and AI factories, Europe seeks to build a digital infrastructure where data is governed responsibly, interoperable and prepared to be used by AI systems for the benefit of the common good. This vision not only promotes greater digital sovereignty but reinforces the principle that public data should be used to develop technologies that serve people and not the other way around.
Content prepared by Carlos Iglesias, Open data Researcher and consultant, World Wide Web Foundation. The contents and views reflected in this publication are the sole responsibility of the author.
Documentación
Blog
Books are an inexhaustible source of knowledge and experiences lived by others before us, which we can reuse to move forward in our lives. Libraries, therefore, are places where readers looking for books, borrow them, and once they have used them and extracted from them what they need, return them. It is curious to imagine the reasons why a reader needs to find a particular book on a particular subject.
In case there are several books that meet the required characteristics, what might be the criteria that weigh most heavily in choosing the book that the reader feels best contributes to his or her task. And once the loan period of the book is over, the work of the librarians to bring everything back to an initial state is almost magical.
The process of putting books back on the shelves can be repeated indefinitely. Both on those huge shelves that are publicly available to all readers in the halls, and on those smaller shelves, out of sight, where books that for some reason cannot be made publicly available rest in custody. This process has been going on for centuries since man began to write and to share his knowledge among contemporaries and between generations.
In a sense, data are like books. And data repositories are like libraries: in our daily lives, both professionally and personally, we need data that are on the "shelves" of numerous "libraries". Some, which are open, very few still, can be used; others are restricted, and we need permissions to use them.
In any case, they contribute to the development of personal and professional projects; and so, we are understanding that data is the pillar of the new data economy, just as books have been the pillar of knowledge for thousands of years.
As with libraries, in order to choose and use the most appropriate data for our tasks, we need "data librarians to work their magic" to arrange everything in such a way that it is easy to find, access, interoperate and reuse data. That is the secret of the "data wizards": something they warily call FAIR principles so that the rest of us humans cannot discover them. However, it is always possible to give some clues, so that we can make better use of their magic:

- It must be easy to find the data. This is where the "F" in the FAIR principles comes from, from "findable". For this, it is important that the data is sufficiently described by an adequate collection of metadata, so that it can be easily searched. In the same way that libraries have a shingle to label books, data needs its own label. The "data wizards" have to find ways to write the tags so that the books are easy to locate, on the one hand, and provide tools (such as search engines) so that users can search for them, on the other. Users, for our part, have to know and know how to interpret what the different book tags mean, and know how the search tools work (it is impossible not to remember here the protagonists of Dan Brown's "Angels and Demons" searching in the Vatican Library).
- Once you have located the data you intend to use, it must be easy to access and use. This is the A in FAIR's "accessible". Just as you have to become a member and get a library card to borrow a book from a library, the same applies to data: you have to get a licence to access the data. In this sense, it would be ideal to be able to access any book without having any kind of prior lock-in, as is the case with open data licensed under CC BY 4.0 or equivalent. But being a member of the "data library" does not necessarily give you access to the entire library. Perhaps for certain data resting on those shelves guarded out of reach of all eyes, you may need certain permissions (it is impossible not to remember here Umberto Eco's "The Name of the Rose").
- It is not enough to be able to access the data, it has to be easy to interoperate with them, understanding their meaning and descriptions. This principle is represented by the "I" for "interoperable" in FAIR. Thus, the "data wizards" have to ensure, by means of the corresponding techniques, that the data are described and can be understood so that they can be used in the users' context of use; although, on many occasions, it will be the users who will have to adapt to be able to operate with the data (impossible not to remember the elvish runes in J.R.R. Tolkien's "The Lord of the Rings").
- Finally, data, like books, has to be reusable to help others again and again to meet their own needs. Hence the "R" for "reusable" in FAIR. To do this, the "data wizards" have to set up mechanisms to ensure that, after use, everything can be returned to that initial state, which will be the starting point from which others will begin their own journeys.
As our society moves into the digital economy, our data needs are changing. It is not that we need more data, but that we need to dispose differently of the data that is held, the data that is produced and the data that is made available to users. And we need to be more respectful of the data that is generated, and how we use that data so that we don't violate the rights and freedoms of citizens. So it can be said, we face new challenges, which require new solutions. This forces our "data wizards" to perfect their tricks, but always keeping the essence of their magic, i.e. the FAIR principles.
Recently, at the end of February 2023, an Assembly of these data wizards took place. And they were discussing about how to revise the FAIR principles to perfect these magic tricks for scenarios as relevant as European data spaces, geospatial data, or even how to measure how well the FAIR principles are applied to these new challenges. If you want to see what they talked about, you can watch the videos and watch the material at the following link: https://www.go-peg.eu/2023/03/07/go-peg-final-workshop-28-february-20203-1030-1300-cet/
Content prepared by Dr. Ismael Caballero, Lecturer at UCLM
The contents and views reflected in this publication are the sole responsibility of the author.