Blog
La regulación europea de Datos de Alto Valor (HVD, High-Value Datasets), establecida por el Reglamento de Ejecución (UE) 2023/138, consolida el papel de las APIcomo infraestructura esencial para la reutilización de la información pública, convirtiendo su disponibilidad en una obligación legal y no solo en una buena práctica tecnológica.
Desde el 9 de junio de 2024, los organismos públicos de todos los Estados miembros están obligados a publicar los conjuntos de datos clasificados como HVD de forma gratuita, en formatos legibles por máquina y accesibles mediante API. Las seis categorías reguladas son: datos geoespaciales, observación de la Tierra, medio ambiente, estadística, información empresarial y movilidad.
Este marco no es meramente declarativo. Los Estados miembros deben reportar a la Comisión Europea el estado de cumplimiento cada dos años, incluyendo enlaces persistentes a las API que dan acceso a dichos datos. La situación de España en materia de transparencia, datos abiertos y provisión sistemática de API puede consultarse en los indicadores publicados por el Open Data Maturity Report.
En la práctica, esto significa que las API son el puente entre la norma y la realidad. La regulación no solo dice qué datos deben abrirse, sino que obliga a hacerlo de forma que puedan integrarse automáticamente en aplicaciones, estudios o servicios digitales. Por eso, revisar las API públicas disponibles en España es una forma concreta de entender cómo se está aplicando este marco en el día a día.
Inventario de API públicas en España
INE — API JSON (Tempus3)
El Instituto Nacional de Estadística ofrece una API REST que expone toda la base de datos de difusión Tempus3 en formato JSON, que incluye series estadísticas oficiales sobre demografía, economía, mercado laboral, industria, servicios, precios, condiciones de vida y otros indicadores socioeconómicos que incluye series estadísticas oficiales sobre demografía, economía, mercado laboral, industria, servicios, precios, condiciones de vida y otros indicadores socioeconómicos.
Para realizar llamadas, la estructura debe seguir el patrón https://servicios.ine.es/wstempus/js/{idioma}/{función}/{input}. El parámetro tip=AM permite obtener metadatos junto con los datos, y tv filtra por variables específicas. Por ejemplo, para obtener las cifras de población por provincia, basta con consultar la operación correspondiente (IOE 30243) y filtrar por la variable geográfica deseada.
No requiere autenticación ni API key: cualquier petición GET bien formada devuelve datos directamente.
Ejemplo en Python — obtener la serie de población residente con metadatos:
import requests
url = ("https://servicios.ine.es/wstempus/js/ES/"
"DATOS_TABLA/t20/e245/p08/l0/01002.px?tip=AM")
response = requests.get(url)
data = response.json()
for serie in data[:3]: # primeras 3 series
nombre = serie["Nombre"]
ultimo = serie["Data"][-1]
print(f"{nombre}: {ultimo['Valor']:,.0f} ({ultimo['NombrePeriodo']})")
TOTAL EDADES, TOTAL, Ambos sexos: 39,852,651 (1998)
TOTAL EDADES, TOTAL, Hombres: 19,488,465 (1998)
TOTAL EDADES, TOTAL, Mujeres: 20,364,186 (1998)AEMET — OpenData API REST
La Agencia Estatal de Meteorología expone sus datos a través de una API REST, documentada con Swagger UI (herramienta de código abierto que genera documentación interactiva), datos meteorológicos observados y predicciones oficiales, incluyendo temperatura, precipitación, viento, alertas y fenómenos adversos.
A diferencia del INE, AEMET requiere una API key gratuita, que se obtiene proporcionando un correo electrónico en el portal opendata.aemet.es. Una API key funciona como un tipo de “contraseña” o identificador: sirve para para que el organismo pueda saber quién está usando el servicio, controlar el volumen de peticiones y garantizar un uso adecuado de la infraestructura.
Un aspecto técnico relevante es que AEMET implementa un modelo de doble llamada: la primera petición devuelve un JSON con una URL temporal en el campo datos, y una segunda petición a esa URL recupera el dataset real. El rate limit es de 50 peticiones por minuto.
Ejemplo en Python — datos climatológicos diarios (doble llamada):
import requests
API_KEY = "tu_api_key_aqui"
headers = {"api_key": API_KEY}
# 1ª llamada: obtener URL temporal de datos
url = ("https://opendata.aemet.es/opendata/api/"
"valores/climatologicos/diarios/datos/"
"fechaini/2025-01-01T00:00:00UTC/"
"fechafin/2025-01-10T23:59:59UTC/"
"todasestaciones")
resp1 = requests.get(url, headers=headers).json()
# 2ª llamada: descargar el dataset real
datos = requests.get(resp1["datos"], headers=headers).json()
for estacion in datos[:3]:
print(f"{estacion['nombre']}: "
f"Tmax={estacion.get('tmax','N/A')}°C, "
f"Prec={estacion.get('prec','N/A')}mm")
CITFAGRO_88_GAITERO: Tmax=8,8°C, Prec=0,0mm
ABANILLA: Tmax=14,8°C, Prec=0,0mm
LA RODA DE ANDALUCÍA: Tmax=15,7°C, Prec=0,2mmCNIG / IDEE — Servicios OGC y OGC API Features
El Centro Nacional de Información Geográfica publica datos geoespaciales oficiales —cartografía base, modelos digitales del terreno, redes hidrográficas, límites administrativos y otros elementos topográficos— mediante servicios interoperables. Estos han evolucionado desde WMS/WFS hacia los estándares OGC API (Features, Maps y Processes), implementados con software abierto como pygeoapi.
La ventaja principal de OGC API Features frente a WFS es el formato de respuesta: en lugar de GML (pesado y complejo), los datos se sirven en GeoJSON y HTML, formatos nativos del ecosistema web. Esto permite consumirlos directamente desde bibliotecas como Leaflet, OpenLayers o GDAL. Los datasets disponibles incluyen direcciones de Cartociudad, hidrografía, redes de transporte y nomenclátor geográfico.
Ejemplo en Python — consultar features geográficas vía OGC API:
import requests
# OGC API Features - Nomenclátor Geográfico Básico de España
base = "https://api-features.idee.es/collections"
collection = "falls" # Cascadas
url = f"{base}/{collection}/items?limit=5&f=json"
resp = requests.get(url).json()
for feat in resp["features"]:
props = feat["properties"]
coords = feat["geometry"]["coordinates"]
print(f"{props['nombre']}: ({coords[0]:.4f}, {coords[1]:.4f})")
None: (-6.2132, 42.8982)
Cascada del Cervienzo: (-6.2572, 42.9763)
Cascada el Xaral: (-6.3815, 42.9881)
Cascada de Rexiu: (-7.2256, 42.5743)
Cascada de Santalla: (-7.2543, 42.6510)MITECO — Portal de Datos Abiertos (CKAN)
El Ministerio para la Transición Ecológica mantiene un portal basado en CKAN que expone tres capas de acceso: la CKAN Action API para búsqueda de metadatos y datasets, el Datastore API (OpenAPI) para consultas en vivo sobre recursos tabulares, y endpoints RDF/JSON-LD conformes con DCAT-AP y GeoDCAT-AP. En su catálogo pueden encontrarse datos sobre calidad del aire, emisiones y cambio climático, agua (estado de masas y planificación hidrológica), biodiversidad y espacios protegidos, residuos, energía y evaluación ambiental.
Entre los datasets destacados figuran las áreas protegidas de la Red Natura 2000 masas de agua, y proyecciones de emisiones de gases de efecto invernadero.
Ejemplo en Python — buscar datasets:
import requests
BASE = "https://catalogo.datosabiertos.miteco.gob.es/catalogo"
# Buscar datasets que contengan 'natura 2000'
busqueda = requests.get(
f"{BASE}/api/3/action/package_search",
params={"q": "natura 2000", "rows": 3},
).json()
for ds in busqueda["result"]["results"]:
print(f"{ds['title']} ({ds['num_resources']} recursos)")
Espacios Protegidos de la Red Natura 2000 (13 recursos)
Base de datos de los espacios protegidos Red Natura 2000 de España (CNTRYES) (1 recursos)
Espacios Protegidos de la Red Natura 2000 - API - Datos Alto Valor (1 recursos)Comparativa técnica
| Organismo | Protocolo | Formato | Autenticación | Rate limit | HVD |
|---|---|---|---|---|---|
| INE | REST | JSON | Ninguna | No declarado | Sí (estadística) |
| AEMET | REST | JSON | API key (gratuita) | 50 reg/min | Sí (medio ambiente) |
| CNIG/IDEE | OGC API/WFS | GeoJSON/GML | Ninguna | No declarado | Sí (geoespacial) |
| MITECO | CKAN/REST | JASON/RDF | Ninguna (token opc) | No declarado | Sí (medio ambiente) |
Figura 1.Tabla comparativa de las API de diferentes organismos públicos que se presentan en este post. Fuente: elaboración propia - datos.gob.es.
La disponibilidad de API públicas no es solo una cuestión de conveniencia técnica. Desde la perspectiva de datos, estas interfaces habilitan tres capacidades críticas:
- Automatización de pipelines: la ingesta periódica de datos públicos puede orquestarse con herramientas estándar (Airflow, Prefect, cron) sin intervención manual ni descargas de ficheros.
- Reproducibilidad: las URL de las API actúan como referencias estáticas a fuentes autoritativas, lo que facilita auditorías y trazabilidad en proyectos de analítica.
- Interoperabilidad: el uso de estándares abiertos (REST, OGC API, DCAT-AP) permite cruzar fuentes heterogéneas sin depender de formatos propietarios.
El ecosistema de API públicas en España presenta distintos niveles de desarrollo según el organismo y el ámbito sectorial. Mientras que entidades como el INE y AEMET disponen de interfaces consolidadas y bien documentadas, en otros casos el acceso se articula a través de portales CKAN o servicios OGC tradicionales. La regulación relativa a los High Value Datasets (HVD) está impulsando la adopción progresiva de estándares REST, si bien el grado de implantación evoluciona a ritmos diferentes. Para los profesionales de datos, estas API constituyen ya una fuente plenamente operativa cuya integración en arquitecturas de datos resulta cada vez más habitual en entornos analíticos y de ingeniería.
Contenido elaborado por Juan Benavente, ingeniero superior industrial y experto en Tecnologías ligadas a la economía del dato. Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Blog
El acceso a datos a través de API se ha convertido en una de las piezas clave del ecosistema digital actual. Administraciones públicas, organismos internacionales y empresas privadas publican información para que terceros puedan reutilizarla en aplicaciones, análisis o proyectos de inteligencia artificial. En esta situación, hablar de datos abiertos es, casi inevitablemente, hablar también de API.
Sin embargo, el acceso a una API rara vez es completamente libre e ilimitado. Existen restricciones, controles y mecanismos de protección que buscan equilibrar dos objetivos que, a primera vista, pueden parecer opuestos: facilitar el acceso a los datos y garantizar la estabilidad, seguridad y sostenibilidad del servicio. Estas limitaciones generan dudas frecuentes: ¿son realmente necesarias?, ¿van contra el espíritu de los datos abiertos?, ¿hasta qué punto pueden aplicarse sin cerrar el acceso?
Este artículo aborda cómo se gestionan estas limitaciones, por qué son necesarias y cómo encajan —lejos de lo que a veces se piensa— dentro de una estrategia coherente de datos abiertos.
Por qué es necesario limitar el acceso a una API
Una API no es simplemente un “grifo” de datos. Detrás suele haber infraestructura tecnológica, servidores, procesos de actualización, costes operativos y equipos responsables de que el servicio funcione correctamente.
Cuando un servicio de datos se expone sin ningún tipo de control, aparecen problemas bien conocidos:
- Saturación del sistema, provocada por un número excesivo de consultas simultáneas.
- Uso abusivo, intencionado o no, que degrade el servicio para otros usuarios.
- Costes descontrolados, especialmente cuando la infraestructura está desplegada en la nube.
- Riesgos de seguridad, como ataques automatizados o scraping masivo.
En muchos casos, la ausencia de límites no conduce a más apertura, sino a un deterioro progresivo del propio servicio.
Por este motivo, limitar el acceso no suele ser una decisión ideológica, sino una necesidad práctica para asegurar que el servicio sea estable, predecible y justo para todos los usuarios.
La API Key: control básico, pero efectivo
El mecanismo más habitual para gestionar el acceso es la API Key. Mientras que en algunos casos como la API del catálogo nacional de datos abiertos de datos.gob.es no se requiere ningún tipo de clave para poder acceder a la información publicada, otros catálogos solicitan una clave única que identifica a cada usuario o aplicación y que se incluye en cada llamada a la API.
Aunque desde fuera pueda parecer una simple formalidad, la API Key cumple varias funciones importantes. Permite identificar quién consume los datos, medir el uso real del servicio, aplicar límites razonables y actuar ante comportamientos problemáticos sin afectar al resto de usuarios.
En el contexto español existen ejemplos claros de plataformas de datos abiertos que funcionan así. La Agencia Estatal de Meteorología (AEMET), por ejemplo, ofrece acceso abierto a datos meteorológicos de alto valor, pero exige solicitar una API Key gratuita para consultas automatizadas. El acceso es libre y gratuito, pero no anónimo ni descontrolado.
Hasta aquí, el enfoque es relativamente conocido: identificación del consumidor y límites básicos de uso. Sin embargo, en muchas situaciones nos esto ya no es suficiente.
Cuando la API se convierte en un activo estratégico
Las plataformas líderes de gestión de API, como MuleSoft o Kong entre otros, fueron pioneras en implantar mecanismos avanzados de control y protección del acceso a las API. Su foco inicial estaba ligado a entornos empresariales complejos, donde múltiples aplicaciones, organizaciones y países consumen servicios de datos de forma intensiva y continuada.
Con el tiempo, muchas de estas prácticas han ido extendiéndose también a plataformas de datos abiertos. A medida que ciertos servicios de datos abiertos ganan relevancia y se convierten en dependencias clave para aplicaciones, investigaciones o modelos de negocio, los retos asociados a su disponibilidad y estabilidad se vuelven similares. La caída o degradación de servicios de datos abiertos de gran escala —como los relacionados con observación de la Tierra, clima o ciencia— puede tener un impacto significativo en múltiples sistemas que dependen de ellos.
En este sentido, la gestión avanzada del acceso deja de ser una cuestión exclusivamente técnica y pasa a formar parte de la propia sostenibilidad de un servicio que se vuelve estratégico. No se trata tanto de quién publica los datos, sino del papel que esos datos juegan dentro de un ecosistema más amplio de reutilización. Por ello, muchas plataformas de open data están adoptando, de forma progresiva, mecanismos ya probados en otros ámbitos, adaptándolos a sus principios de apertura y acceso público. A continuación, se detallan algunos de ellos.
Limitar el caudal: regular el ritmo, no el derecho de acceso
Una de las primeras capas adicionales es la limitación del caudal de uso, lo que habitualmente se conoce como rate limiting. En lugar de permitir un número ilimitado de llamadas, se define cuántas peticiones pueden realizarse en un intervalo de tiempo determinado.
La clave aquí no es impedir el acceso, sino regular el ritmo. Un usuario puede seguir utilizando los datos, pero se evita que una única aplicación monopolice los recursos. Este enfoque es habitual en las API de datos meteorológicos, movilidad o estadísticas públicas, donde muchos usuarios acceden simultáneamente.
Las plataformas más avanzadas van un paso más allá y aplican límites dinámicos, que se ajustan según la carga del sistema, el momento del día o el comportamiento histórico del consumidor. El resultado es un control más justo y flexible.
Contexto, origen y comportamiento: más allá del volumen
Otra evolución importante es dejar de mirar solo cuántas llamadas se hacen y empezar a analizar desde dónde y cómo se realizan. Aquí entran medidas como la restricción por direcciones IP, el control geográfico (geofencing) o la diferenciación entre entornos de prueba y producción.
En algunos casos, estas limitaciones responden a marcos regulatorios o licencias de uso. En otros, simplemente permiten proteger partes más sensibles del servicio sin cerrar el acceso general. Por ejemplo, una API puede ser accesible globalmente en modo consulta, pero limitar determinadas operaciones a situaciones muy concretas.
Las plataformas también analizan patrones de comportamiento. Si una aplicación empieza a realizar consultas repetitivas, incoherentes o muy distintas a su uso habitual, el sistema puede reaccionar automáticamente: reducir temporalmente el caudal, lanzar alertas o exigir un nivel adicional de validación. No se bloquea “porque sí”, sino porque el comportamiento deja de encajar con un uso razonable del servicio.
Medir impacto, no solo llamadas
Una tendencia especialmente relevante es dejar de medir únicamente el número de peticiones y empezar a considerar el impacto real de cada una. No todas las consultas consumen los mismos recursos: algunas transfieren grandes volúmenes de datos o ejecutan operaciones más costosas.
Un ejemplo claro en datos abiertos sería una API de movilidad urbana. Consultar el estado de una parada o el tráfico en un punto concreto implica pocos datos y un impacto limitado. En cambio, descargar de una sola vez todo el histórico de posiciones de vehículos de una ciudad durante varios años supone una carga mucho mayor para el sistema, aunque se realice en una única llamada.
Por este motivo, muchas plataformas introducen cuotas basadas en volumen de datos transferidos, tipo de operación o peso de la consulta. Esto evita situaciones en las que un uso aparentemente moderado genera una carga desproporcionada sobre el sistema.
¿Cómo encaja todo esto con el open data?
Llegados a este punto, surge inevitablemente la pregunta: ¿siguen siendo abiertos los datos cuando existen todas estas capas de control?
La respuesta depende menos de la tecnología y más de las reglas del juego. Los datos abiertos no se definen por la ausencia total de control técnico, sino por principios como el acceso no discriminatorio, la ausencia de barreras económicas, la claridad en las licencias y la posibilidad real de reutilización.
Solicitar una API Key, limitar el caudal o aplicar controles contextuales no contradice estos principios si se hace de forma transparente y equitativa. De hecho, en muchos casos es la única manera de garantizar que el servicio siga existiendo y funcionando correctamente a medio y largo plazo.
La clave está en el equilibrio: reglas claras, acceso gratuito, límites razonables y mecanismos pensados para proteger el servicio, no para excluir. Cuando este equilibrio se consigue, el control deja de percibirse como una barrera y pasa a ser parte natural de un ecosistema de datos abiertos, útiles y sostenibles.
Contenido elaborado por Juan Benavente, ingeniero superior industrial y experto en Tecnologías ligadas a la economía del dato. Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Blog
Las ciudades, las infraestructuras y el medio ambiente generan hoy un flujo constante de datos procedentes de sensores, redes de transporte, estaciones meteorológicas y plataformas de Internet of Things (IoT), entendidas como redes de dispositivos físicos (semáforos digitales, sensores de calidad de aire, etc.) capaces de medir y transmitir información a través de sistemas digitales. Este volumen creciente de información permite mejorar la prestación de servicios públicos, anticipar emergencias, planificar el territorio y responder a retos asociados al clima, la movilidad o la gestión de recursos.
El incremento de fuentes conectadas ha transformado la naturaleza del dato geoespacial. Frente a los conjuntos tradicionales —actualizados de forma periódica y orientados a cartografía de referencia o inventarios administrativos— los datos dinámicos incorporan la dimensión temporal como componente estructural. Una observación de calidad del aire, un nivel de ocupación de tráfico o una medición hidrológica no solo describen un fenómeno, sino que lo sitúan en un momento concreto. La combinación espacio-tiempo convierte a estas observaciones en elementos fundamentales para sistemas operativos, modelos predictivos y análisis basados en series temporales.
En el ámbito de los datos abiertos, este tipo de información plantea tanto oportunidades como requerimientos específicos. Entre las oportunidades se encuentran la posibilidad de construir servicios digitales reutilizables, de facilitar la supervisión en tiempo casi real de fenómenos urbanos y ambientales, y de fomentar un ecosistema de reutilización basado en flujos continuos de datos interoperables. La disponibilidad de datos actualizados incrementa además la capacidad de evaluación y auditoría de políticas públicas, al permitir contrastar decisiones con observaciones recientes.
No obstante, la apertura de datos geoespaciales en tiempo real exige resolver problemas derivados de la heterogeneidad tecnológica. Las redes de sensores utilizan protocolos, modelos de datos y formatos diferentes; las fuentes generan volúmenes elevados de observaciones con alta frecuencia; y la ausencia de estructuras semánticas comunes dificulta el cruce de datos entre dominios como movilidad, medio ambiente, energía o hidrología. Para que estos datos puedan publicarse y reutilizarse de manera consistente, es necesario un marco de interoperabilidad que normalice la descripción de los fenómenos observados, la estructura de las series temporales y las interfaces de acceso.
Los estándares abiertos del Open Geospatial Consortium (OGC) proporcionan ese marco. Definen cómo representar observaciones, entidades dinámicas, coberturas multitemporales o sistemas de sensores; establecen API basadas en principios web que facilitan la consulta de datos abiertos; y permiten que plataformas distintas intercambien información sin necesidad de integraciones específicas. Su adopción reduce la fragmentación tecnológica, mejora la coherencia entre fuentes y favorece la creación de servicios públicos basados en datos actualizados.
Interoperabilidad: el requisito básico para abrir datos dinámicos
Las administraciones públicas gestionan hoy datos generados por sensores de distinto tipo, plataformas heterogéneas, proveedores diferentes y sistemas que evolucionan de forma independiente. La publicación de datos geoespaciales en tiempo real exige una interoperabilidad que permita integrar, procesar y reutilizar información procedente de múltiples fuentes. Esta diversidad provoca inconsistencias en formatos, estructuras, vocabularios y protocolos, lo que dificulta la apertura del dato y su reutilización por terceros. Veamos qué aspectos de la interoperabilidad están afectados:
- La interoperabilidad técnica: se refiere a la capacidad de los sistemas para intercambiar datos mediante interfaces, formatos y modelos compatibles. En los datos en tiempo real, este intercambio requiere mecanismos que permitan consultas rápidas, actualizaciones frecuentes y estructuras de datos estables. Sin estos elementos, cada flujo dependería de integraciones ad hoc, aumentando la complejidad y reduciendo la capacidad de reutilización.
- La interoperabilidad semántica: los datos dinámicos describen fenómenos que cambian en periodos cortos —niveles de tráfico, parámetros meteorológicos, caudales, emisiones atmosféricas— y deben interpretarse de forma coherente. Esto implica contar con modelos de observación, vocabularios y definiciones comunes que permitan a aplicaciones distintas entender el significado de cada medición y sus unidades, condiciones de captura o restricciones. Sin esta capa semántica, la apertura de datos en tiempo real genera ambigüedad y limita su integración con datos procedentes de otros dominios.
- La interoperabilidad estructural: los flujos de datos en tiempo real tienden a ser continuos y voluminosos, lo que hace necesario representarlos como series temporales o conjuntos de observaciones con atributos consistentes. La ausencia de estructuras normalizadas complica la publicación de datos completos, fragmenta la información e impide consultas eficientes. Para proporcionar acceso abierto a estos datos, es necesario adoptar modelos que representen adecuadamente la relación entre fenómeno observado, momento de la observación, geometría asociada y condiciones de medición.
- La interoperabilidad en el acceso vía API: constituye una condición esencial para los datos abiertos. Las API deben ser estables, documentadas y basadas en especificaciones públicas que permitan consultas reproducibles. En el caso de datos dinámicos, esta capa garantiza que los flujos puedan ser consumidos por aplicaciones externas, plataformas de análisis, herramientas cartográficas o sistemas de monitorización que operan en contextos distintos al que genera el dato. Sin API interoperables, el dato en tiempo real queda limitado a usos internos.
En conjunto, estos niveles de interoperabilidad determinan si los datos geoespaciales dinámicos pueden publicarse como datos abiertos sin generar barreras técnicas.
Estándares OGC para publicar datos geoespaciales en tiempo real
La publicación de datos georreferenciados en tiempo real requiere mecanismos que permitan que cualquier usuario —administración, empresa, ciudadanía o comunidad investigadora— pueda acceder a ellos de forma sencilla, con formatos abiertos y a través de interfaces estables. El Open Geospatial Consortium (OGC) desarrolla un conjunto de estándares que permiten exactamente esto: describir, organizar y exponer datos espaciales de forma interoperable y accesible, que contribuyan a la apertura de datos dinámicos.
Qué es OGC y por qué sus estándares son relevantes
El OGC es una organización internacional que define reglas comunes para que distintos sistemas puedan entender, intercambiar y usar datos geoespaciales sin depender de tecnologías concretas. Estas reglas se publican como estándares abiertos, lo que significa que cualquier persona o institución puede utilizarlos. En el ámbito de los datos en tiempo real, estos estándares permiten:
- Representar lo que un sensor mide (por ejemplo, temperatura o tráfico).
- Indicar dónde y cuándo se hizo la observación.
- Estructurar series temporales.
- Exponer datos a través de API abiertas.
- Conectar dispositivos y redes IoT con plataformas públicas.
En conjunto, este ecosistema de estándares permite que los datos geoespaciales —incluyendo los generados en tiempo real— puedan publicarse y reutilizarse siguiendo un marco coherente. Cada estándar cubre una parte específica del ciclo del dato: desde la definición de las observaciones y los sensores, hasta la forma en la que se exponen los datos mediante API abiertas o servicios web. Esta organización modular facilita que administraciones y organizaciones seleccionen los componentes que necesitan, evitando dependencias tecnológicas y garantizando que los datos puedan integrarse entre plataformas distintas.
La familia OGC API: API modernas para acceder a datos abiertos
Dentro de OGC, la línea más reciente es la familia OGC API, un conjunto de interfaces web modernas diseñadas para facilitar el acceso a datos geoespaciales mediante URL y formatos como JSON o GeoJSON, habituales en el ecosistema de datos abiertos.
Estas API permiten:
- Obtener solo la parte del dato que interesa.
- Realizar búsquedas espaciales (“dame solo lo que está en esta zona”).
- Acceder a datos actualizados sin necesidad de software especializado.
- Integrarlos fácilmente en aplicaciones web o móviles.
En este informe: “Cómo utilizar las OGC API para potenciar la interoperabilidad de los datos geoespaciales”, ya te hablamos de algunas las API más populares del OGP. Mientras que el informe se centra en cómo utilizar las OGC API para la interoperabilidad práctica, este post amplía el foco explicando los modelos de datos subyacentes del OGC —como O&M, SensorML o Moving Features— que sustentan esa interoperabilidad.
A partir de esta base, este post pone el foco en los estándares que hacen posible ese intercambio fluido de información, especialmente en contextos de datos abiertos y en tiempo real. Los estándares más importantes en el contexto de datos abiertos en tiempo real son:
|
Estándar OGC |
Qué permite hacer |
Uso principal en datos abiertos |
|---|---|---|
|
Es una interfaz web abierta que permite acceder a conjuntos de datos formados por “entidades” con geometría, como sensores, vehículos, estaciones o incidentes. Utiliza formatos simples como JSON y GeoJSON y permite realizar consultas espaciales y temporales. Es útil para publicar datos que se actualizan con frecuencia, como movilidad urbana o inventarios dinámicos. |
Consultar entidades con geometría; filtrar por tiempo o espacio; obtener datos en JSON/GeoJSON. |
Publicación abierta de datos dinámicos de movilidad, inventarios urbanos, sensores estáticos. |
|
OGC API – Environmental Data Retrieval (EDR) Proporciona un método sencillo para recuperar observaciones ambientales y meteorológicas. Permite solicitar datos en un punto, una zona o un intervalo temporal, y es especialmente adecuado para estaciones meteorológicas, calidad del aire o modelos climáticos. Facilita el acceso abierto a series temporales y predicciones. |
Solicitar observaciones ambientales en un punto, zona o intervalo temporal. |
Datos abiertos de meteorología, clima, calidad del aire o hidrología. |
|
Es el estándar más utilizado para datos IoT abiertos. Define un modelo uniforme para sensores, lo que miden y las observaciones que producen. Está diseñado para manejar grandes volúmenes de datos en tiempo real y ofrece un modo claro para publicar series temporales, datos de contaminación, ruido, hidrología, energía o alumbrado. |
Gestionar sensores y sus series temporales; transmitir grandes volúmenes de datos IoT. |
Publicación de sensores urbanos (aire, ruido, agua, energía) en tiempo real. |
|
OGC API – Connected Systems |
Describir redes de sensores, dispositivos e infraestructuras asociadas. |
Documentar como dato abierto la estructura de sistemas IoT municipales. |
|
OGC Moving Features |
Representar objetos móviles mediante trayectorias espacio-tiempo. |
Datos abiertos de movilidad (vehículos, transporte, embarcaciones). |
|
WMS-T |
Visualizar mapas que cambian en el tiempo |
Publicación de mapas meteorológicos o ambientales multitemporales |
Tabla 1. Estándares OGC relevantes para datos geoespaciales en tiempo real
Modelos que estructuran observaciones y datos dinámicos
Además de las API, OGC define varios modelos conceptuales de datos que permiten describir de forma coherente observaciones, sensores y fenómenos que cambian en el tiempo:
- O&M (Observations & Measurements): modelo que define los elementos esenciales de una observación —fenómeno medido, instante, unidad y resultado— y que sirve como base semántica para datos de sensores y series temporales.
- SensorML: lenguaje que describe las características técnicas y operativas de un sensor, incluyendo su ubicación, calibración y proceso de observación.
- Moving Features: modelo que permite representar objetos móviles mediante trayectorias espacio-temporales (como vehículos, embarcaciones o fauna).
Estos modelos facilitan que diferentes fuentes de datos puedan interpretarse de forma uniforme y combinarse en análisis y aplicaciones.
El valor de estos estándares para los datos abiertos
El uso de los estándares OGC facilita la apertura de datos dinámicos porque:
- Proporciona modelos comunes que reducen la heterogeneidad entre fuentes.
- Facilita la integración entre dominios (movilidad, clima, hidrología).
- Evita dependencias de tecnología propietaria.
- Permite que el dato sea reutilizado en análisis, aplicaciones o servicios públicos.
- Mejora la transparencia, al documentar sensores, métodos y frecuencias.
- Asegura que los datos pueden ser consumidos directamente por herramientas comunes.
En conjunto, forman una infraestructura conceptual y técnica que permite publicar datos geoespaciales en tiempo real como datos abiertos, sin necesidad de desarrollar soluciones específicas para cada sistema.
Casos de uso de datos geoespaciales abiertos en tiempo real
Los datos georreferenciados en tiempo real ya se publican como datos abiertos en distintos ámbitos sectoriales. Estos ejemplos muestran cómo diferentes administraciones y organismos aplican estándares abiertos y API para poner a disposición del público datos dinámicos relacionados con movilidad, medio ambiente, hidrología y meteorología.
A continuación, se presentan varios dominios donde las Administraciones Públicas ya publican datos geoespaciales dinámicos utilizando estándares OGC.
Movilidad y transporte
Los sistemas de movilidad generan datos de forma continua: disponibilidad de vehículos compartidos, posiciones en tiempo casi real, sensores de paso en carriles bici, aforos de tráfico o estados de intersecciones semaforizadas. Estas observaciones dependen de sensores distribuidos y requieren modelos de datos capaces de representar variaciones rápidas en el espacio y en el tiempo.
Los estándares OGC desempeñan un papel central en este ámbito. En particular, OGC SensorThings API permite estructurar y publicar observaciones procedentes de sensores urbanos mediante un modelo uniforme –incluyendo dispositivos, mediciones, series temporales y relaciones entre ellos– accesible a través de una API abierta. Esto facilita que diferentes operadores y municipios publiquen datos de movilidad de forma interoperable, reduciendo la fragmentación entre plataformas.
El uso de estándares OGC en movilidad no solo garantiza compatibilidad técnica, sino que posibilita que estos datos se puedan reutilizar junto con información ambiental, cartográfica o climática, generando análisis multitemáticos para planificación urbana, sostenibilidad o gestión operativa del transporte.
Ejemplo:
El servicio abierto de Toronto Bike Share, que publica en formato SensorThings API el estado de sus estaciones de bicicletas y la disponibilidad de vehículos.
Aquí cada estación es un sensor y cada observación indica el número de bicicletas disponibles en un momento concreto. Este enfoque permite que analistas, desarrolladores o investigadores integren estos datos directamente en modelos de movilidad urbana, sistemas de predicción de demanda o paneles de control ciudadano sin necesidad de adaptaciones específicas.
Calidad del aire, ruido y sensores urbanos
Las redes de monitorización de calidad del aire, ruido o condiciones ambientales urbanas dependen de sensores automáticos que registran mediciones cada pocos minutos. Para que estos datos puedan integrarse en sistemas de análisis y publicarse como datos abiertos, es necesario disponer de modelos y API coherentes.
En este contexto, los servicios basados en estándares OGC permiten publicar datos procedentes de estaciones fijas o sensores distribuidos de forma interoperable. Aunque muchas administraciones utilizan interfaces tradicionales como OGC WMS para servir estos datos, la estructura subyacente suele apoyarse en modelos de observaciones derivados de la familia Observations & Measurements (O&M), que define cómo representar un fenómeno medido, su unidad y el instante de observación.
Ejemplo:
El servicio Defra UK-AIR Sensor Observation Service proporciona acceso a datos de mediciones de calidad del aire en tiempo casi real desde estaciones in situ en Reino Unido.
La combinación de O&M para la estructura del dato y API abiertas para su publicación facilita que estos sensores urbanos formen parte de ecosistemas más amplios que integran movilidad, meteorología o energía, permitiendo análisis urbanos avanzados o paneles ambientales en tiempo casi real.
Ciclo del agua, hidrología y gestión del riesgo
Los sistemas hidrológicos generan datos cruciales para la gestión del riesgo: niveles y caudales en ríos, precipitaciones, humedad del suelo o información de estaciones hidrometeorológicas. La interoperabilidad es especialmente importante en este dominio, ya que estos datos se combinan con modelos hidráulicos, predicción meteorológica y cartografía de zonas inundables.
Para facilitar el acceso abierto a series temporales y observaciones hidrológicas, varios organismos utilizan OGC API – Environmental Data Retrieval (EDR), una API diseñada para recuperar datos ambientales mediante consultas sencillas en puntos, áreas o intervalos temporales.
Ejemplo:
El USGS (United States Geological Survey), que documenta el uso de OGC API – EDR para acceder a series de precipitación, temperatura o variables hidrológicas.
Este caso muestra cómo EDR permite solicitar observaciones específicas por ubicación o fecha, devolviendo únicamente los valores necesarios para el análisis. Aunque los datos concretos de hidrología del USGS se sirven mediante su API propia, este caso demuestra cómo EDR encaja con la estructura de datos hidrometeorológicos y cómo se aplica en flujos operativos reales.
El empleo de estándares OGC en este ámbito permite que los datos hidrológicos dinámicos se integren con zonas inundables, ortoimágenes o modelos climáticos, creando una base sólida para sistemas de alerta temprana, planificación hidráulica y evaluación del riesgo.
Observación y predicción meteorológica
La meteorología es uno de los dominios con mayor producción de datos dinámicos: estaciones automáticas, radares, modelos numéricos de predicción, observaciones satelitales y productos atmosféricos de alta frecuencia. Para publicar esta información como datos abiertos, la familia de OGC API se está convirtiendo en un elemento clave, especialmente mediante OGC API – EDR, que permite recuperar observaciones o predicciones en ubicaciones concretas y en distintos niveles temporales.
Ejemplo:
El servicio NOAA OGC API – EDR, que proporciona acceso a datos meteorológicos y variables atmosféricas del National Weather Service (Estados Unidos).
Esta API permite consultar datos en puntos, áreas o trayectorias, facilitando la integración de observaciones meteorológicas en aplicaciones externas, modelos o servicios basados en datos abiertos.
El uso de OGC API en meteorología permite que datos procedentes de sensores, modelos y satélites puedan consumirse mediante una interfaz unificada, facilitando su reutilización para pronósticos, análisis atmosféricos, sistemas de soporte a la decisión y aplicaciones climáticas.
Buenas prácticas para publicar datos geoespaciales abiertos en tiempo real
La publicación de datos geoespaciales dinámicos requiere adoptar prácticas que garanticen su accesibilidad, interoperabilidad y sostenibilidad. A diferencia de los datos estáticos, los flujos en tiempo real presentan requisitos adicionales relacionados con la calidad de las observaciones, la estabilidad de las API y la documentación del proceso de actualización. A continuación, se presentan algunas prácticas recomendadas para administraciones y organizaciones que gestionan este tipo de datos.
- Formatos y API abiertas estables: el uso de estándares OGC —como OGC API, SensorThings API o EDR— facilita que los datos puedan consumirse desde múltiples herramientas sin necesidad de adaptaciones específicas. Las API deben ser estables en el tiempo, ofrecer versiones bien definidas y evitar dependencias de tecnologías propietarias. Para datos ráster o modelos dinámicos, los servicios OGC como WMS, WMTS o WCS siguen siendo adecuados para visualización y acceso programático.
- Metadatos compatibles con DCAT-AP y modelos OGC: la interoperabilidad de catálogos requiere describir los conjuntos de datos utilizando perfiles como DCAT-AP, complementado con metadatos geoespaciales y de observación basados en O&M (Observations & Measurements) o SensorML. Estos metadatos deben documentar la naturaleza del sensor, la unidad de medida, la frecuencia de muestreo y posibles limitaciones del dato.
- Políticas de calidad, frecuencia de actualización y trazabilidad: los datasets dinámicos deben indicar explícitamente su frecuencia de actualización, la procedencia de las observaciones, los mecanismos de validación aplicados y las condiciones bajo las cuales se generaron. La trazabilidad es esencial para que terceros puedan interpretar correctamente los datos, reproducir análisis e integrar observaciones procedentes de fuentes distintas.
- Documentación, límites de uso y sostenibilidad del servicio: la documentación debe incluir ejemplos de uso, parámetros de consulta, estructura de respuesta y recomendaciones para gestionar el volumen de datos. Es importante establecer límites razonables de consulta para garantizar la estabilidad del servicio y asegurar que la administración puede mantener la API a largo plazo.
- Aspectos de licencias para datos dinámicos: la licencia debe ser explícita y compatible con la reutilización, como CC BY 4.0 o CC0. Esto permite integrar datos dinámicos en servicios de terceros, aplicaciones móviles, modelos predictivos o servicios de interés público sin restricciones innecesarias. La consistencia en la licencia facilita también el cruce de datos procedentes de distintas fuentes.
Estas prácticas permiten que los datos dinámicos se publiquen de forma fiable, accesible y útil para toda la comunidad reutilizadora.
Los datos geoespaciales dinámicos se han convertido en una pieza estructural para comprender fenómenos urbanos, ambientales y climáticos. Su publicación mediante estándares abiertos permite que esta información pueda integrarse en servicios públicos, análisis técnicos y aplicaciones reutilizables sin necesidad de desarrollos adicionales. La convergencia entre modelos de observación, API OGC y buenas prácticas en metadatos y licencias ofrece un marco estable para que administraciones y reutilizadores trabajen con datos procedentes de sensores de forma fiable. Consolidar este enfoque permitirá avanzar hacia un ecosistema de datos públicos más coherente, conectado y preparado para usos cada vez más demandantes en movilidad, energía, gestión del riesgo y planificación territorial.
Contenido elaborado por Mayte Toscano, Senior Consultant en Tecnologías ligadas a la economía del dato. Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autora
Blog
El diseño de API web es una disciplina fundamental para el desarrollo de aplicaciones y servicios, al facilitar el intercambio fluido de datos entre diferentes sistemas. En el contexto de las plataformas de datos abiertos, las API cobran especial importancia, ya que permiten a los usuarios acceder de manera automática y eficiente a la información necesaria, ahorrando costes y recursos.
Este artículo explora los principios esenciales que deben guiar la creación de API web eficaces, seguras y sostenibles, en base a los principios recopilados por el Grupo de Arquitectura Técnica ligado a World Wide Web Consortium (W3C), siguiendo estándares éticos y técnicos. Aunque estos principios hacen referencia al diseño de API, muchos son aplicables al desarrollo web en general.
Se busca que los desarrolladores puedan garantizar que sus API no solo cumplan con los requisitos técnicos, sino que también respeten la privacidad y seguridad de los usuarios, promoviendo una web más segura y eficiente para todos.
En este post, analizaremos algunos consejos para los desarrolladores de las API y cómo se pueden poner en práctica.
Prioriza las necesidades del usuario
Al diseñar una API, es crucial seguir la jerarquía de necesidades establecida por el W3C:
- Primero, las necesidades del usuario final.
- Segundo, las necesidades de los desarrolladores web.
- Tercero, las necesidades de los implementadores de navegadores.
- Por último, la pureza teórica.
Así podremos impulsar una experiencia de usuario que sea intuitiva, funcional y atractiva. Esta jerarquía debe guiar las decisiones de diseño, aunque reconociendo que en ocasiones estos niveles se interrelacionan: por ejemplo, una API más fácil de usar para los desarrolladores suele resultar en mejor experiencia para el usuario final.
Garantiza la seguridad
Garantizar la seguridad al desarrollar una API es crucial para proteger, tanto los datos de los usuarios, como la integridad del sistema. Una API insegura puede ser un punto de entrada para atacantes que buscan acceder a información sensible o comprometer la funcionalidad del sistema. Por ello, al añadir nuevas funcionalidades, debemos cumplir las expectativas del usuario y garantizar su seguridad.
En este sentido, es esencial considerar factores relacionados con la autenticación de usuarios, encriptación de datos, validación de entradas, gestión de tasas de solicitud (o Rate Limiting, para limitar la cantidad de solicitudes que un usuario puede hacer en un periodo determinado y evitar ataques de denegación de servicio), etc. También es necesario monitorear continuamente las actividades de la API y mantener registros detallados para detectar y responder rápidamente a cualquier actividad sospechosa.
Desarrolla una interfaz de usuario que transmita confianza
Es necesario considerar cómo las nuevas funcionalidades impactan en las interfaces de usuario. Las interfaces deben ser diseñadas para que los usuarios puedan confiar y verificar que la información proporcionada es genuina y no ha sido falsificada. Aspectos como la barra de direcciones, los indicadores de seguridad y las solicitudes de permisos deben dejar claro con quién se están interactuando y cómo.
Por ejemplo, la función alert de JavaScript, que permite mostrar un cuadro de diálogo modal que parece parte del navegador, es un caso histórico que ilustra esta necesidad. Esta función, creada en los primeros días de la web, ha sido frecuentemente utilizada para engañar a usuarios haciéndoles creer que están interactuando con el navegador, cuando en realidad lo hacen con la página web. Si esta funcionalidad se propusiera hoy, probablemente no sería aceptada por estos riesgos de seguridad.
Pide consentimiento explicito a los usuarios
En el contexto de satisfacer una necesidad de usuario, una página web puede utilizar una función que suponga una amenaza. Por ejemplo, el acceso a la geolocalización del usuario puede ser de ayuda en algunos contextos (como una aplicación de mapas), pero también afecta a la privacidad.
En estos casos es necesario que el usuario consienta su uso. Para ello:
- El usuario debe entender a qué está accediendo. Si no puedes explicar a un usuario tipo a qué está consintiendo de forma inteligible, deberás reconsiderar el diseño de la función.
- El usuario debe poder elegir entre otorgar o rechazar ese permiso de manera efectiva. Si se rechaza una solicitud de permiso, la página web no podrá hacer nada que el usuario crea que ha descartado.
Al pedir consentimiento, podemos informar al usuario de qué capacidades tiene o no tiene la página web, reforzando su confianza en la seguridad del sitio. Sin embargo, el beneficio de una nueva función debe justificar la carga adicional que supone para el usuario decidir si otorga o no permiso para una función.
Usa mecanismos de identificación adecuados al contexto
Es necesario ser transparente y permitir a las personas controlar sus identificadores y la información adjunta a ellos que proporcionan en diferentes contextos en la web.
Las funcionalidades que utilizan o dependen de identificadores vinculados a datos sobre una persona conllevan riesgos de privacidad que pueden ir más allá de una sola API o sistema. Esto incluye datos generados pasivamente (como su comportamiento en la web) y aquellos recopilados activamente (por ejemplo, a través de un formulario). En este sentido, es necesario entender el contexto en el que se usarán y cómo se integrarán con otras funcionalidades de la web, asegurando de que el usuario pueda dar un consentimiento adecuado.
Es recomendable diseñar API que recopilen la mínima cantidad de datos necesarios y usar identificadores temporales de corta duración, a menos que sea absolutamente necesario un identificador persistente.
Crea funcionalidades compatibles con toda la gama de dispositivos y plataformas
En la medida de lo posible, asegura que las funcionalidades de la web estén operativas en diferentes dispositivos de entrada y salida, tamaños de pantalla, modos de interacción, plataformas y medios, favoreciendo la flexibilidad del usuario.
Por ejemplo, los modelos de diseño 'display: block', 'display: flex' y 'display: grid' en CSS, por defecto, colocan el contenido dentro del espacio disponible y sin solapamientos. De este modo funcionan en diferentes tamaños de pantalla y permiten a los usuarios elegir su propia fuente y tamaño sin causar desbordamiento de texto.
Agrega nuevas capacidades con cuidado
Añadir nuevas capacidades a la web requiere tener en consideración las funcionalidades y el contenido ya existentes, para valorar cómo va a ser su integración. No hay que asumir que un cambio es posible o imposible sin verificarlo primero.
Existen muchos puntos de extensión que permiten agregar funcionalidades, pero hay cambios que no se pueden realizar simplemente añadiendo o eliminando elementos, porque podrían generar errores o afectar a la experiencia de usuario. Por ello es necesario verificar antes la situación actual, como veremos en el siguiente apartado.
Antes de eliminar o cambiar funcionalidades, comprende su uso actual
Es posible eliminar o cambiar funciones y capacidades, pero primero hay que conocer bien la naturaleza y el alcance de su impacto en el contenido existente. Para ello puede ser necesario investigar cómo se utilizan las funciones actuales.
La obligación de comprender el uso existente se aplica a cualquier función de la que dependan los contenidos. Las funciones web no se definen únicamente en las especificaciones, sino también en la forma en que los usuarios las utilizan.
La práctica recomendada es priorizar la compatibilidad de las nuevas funciones con el contenido existente y el comportamiento del usuario. En ocasiones, una cantidad significativa de contenido puede depender de un comportamiento concreto. En estas situaciones, se desaconseja eliminar o cambiar dicho comportamiento.
Deja la web mejor de lo que la encontraste
La forma de añadir nuevas capacidades a una plataforma web es mejorando la plataforma en su conjunto, por ejemplo, sus características de seguridad, privacidad o accesibilidad.
La existencia de un defecto en una parte concreta de la plataforma no debe servir de excusa para añadir o ampliar funcionalidades adicionales con el fin de solucionarlo, ya que con ello se pueden duplicar problemas y disminuir la calidad general de la plataforma. Siempre que sea posible, hay que crear nuevas capacidades web que mejoren la calidad general de la plataforma, mitigando los defectos existentes de forma global.
Minimiza los datos del usuario
Hay que diseñar las funcionalidades para que sean operativas con la mínima cantidad necesaria de datos aportados por el usuario para llevar a cabo sus objetivos . Con ello, limitamos los riesgos de que se divulguen o utilicen indebidamente.
Se recomienda diseñar las API de forma que a los sitios web les resulte más fácil solicitar, recopilar y/o transmitir una pequeña cantidad de datos (datos más granulares o específicos), que trabajar con datos más genéricos o masivos. Las API deben proporcionar granularidad y controles de usuario, en particular si trabajan sobre datos personales.
Otras recomendaciones
El documento también ofrece consejos para el diseño de API utilizando diversos lenguajes de programación. En este sentido, proporciona recomendaciones ligadas a HTML, CSS, JavaScript, etc. Puedes leer las recomendaciones aquí.
Además, si estás pensando en integrar una API en tu plataforma de datos abiertos, te recomendamos la lectura de la Guía práctica para la publicación de Datos Abiertos usando APIs.
Siguiendo estas indicaciones podrás desarrollar sitios web consistentes y útiles para los usuarios, que les permitan alcanzar sus objetivos de manera ágil y optimizando recursos.
Documentación
En un mundo donde la información geoespacial es crucial para abordar desafíos globales como el cambio climático y la gestión de recursos naturales, la interoperabilidad y la creación de estándares son esenciales. La interoperabilidad facilita la colaboración entre organizaciones, impulsa la innovación y asegura que los datos sean accesibles y utilizables por todos. El Open Geospatial Consortium (OGC) desempeña un papel vital en este contexto, desarrollando estándares abiertos que garantizan la compatibilidad y el intercambio eficiente de datos geoespaciales.
Uno de los estándares que ofrece OGC son una serie de API, que representan un avance significativo en la gestión y compartición de datos geoespaciales. Diseñadas para facilitar el acceso y uso de datos geográficos a través de la web, estas API utilizan tecnologías modernas como REST y JSON, lo que las hace compatibles con una amplia variedad de aplicaciones y plataformas. Además, las OGC API promueven la interoperabilidad, escalabilidad y seguridad, facilitando la integración y el análisis de datos geoespaciales en tiempo real.
Actualmente, el OGC está trabajando con la implementación de los estándares siguiendo el concepto de Building Blocks, que son componentes modulares diseñados para facilitar la creación y gestión de datos geoespaciales y servicios relacionados. Estos bloques proporcionan un marco estándar y reutilizable que permite integrar y operar eficientemente con datos de localización en diversas aplicaciones y sistemas. Entre sus ventajas se destacan la interoperabilidad, la reutilización, la eficiencia y la precisión en la gestión de datos geoespaciales.
En España, la implementación de las OGC API está avanzando con éxito en diversas instituciones y sectores. Organismos como el Centro Nacional de Información Geográfica con la publicación de los productos del Sistema Cartográfico Nacional, la IDE de Navarra y la IDE de Catalunya ya han adoptado estos estándares para mejorar la gestión y accesibilidad de los datos geoespaciales. La integración de información espacial con otros tipos de datos, como los estadísticos, proporciona una visión más completa y útil para la toma de decisiones, mejorando significativamente la calidad y utilidad de las aplicaciones geoespaciales.
En resumen, los nuevos estándares y Building Blocks del OGC ofrecen numerosas ventajas que mejoran la eficiencia, interoperabilidad y calidad de las aplicaciones y servicios geoespaciales. Estos beneficios se extienden a desarrolladores, organizaciones y usuarios finales, promoviendo un ecosistema geoespacial más integrado y robusto. Al adoptar estos estándares, se asegura que las soluciones sean interoperables, reutilizables y accesibles a largo plazo, beneficiando a toda la comunidad geoespacial.
Este es el tema central del informe “Cómo utilizar OGC API para mejorar la interoperabilidad de los datos geoespaciales”, donde se explica cómo funcionan las OGC API, acercándonos también al concepto de los Building Blocks, con el objetivo de que el lector pueda implementar su uso en su organización. Puedes leer el informe completo aquí.
Para profundizar en el contenido del informe, hemos grabado un pódcast y una video-entrevista donde el autor nos cuenta sus claves.
Escucha el pódcast con la autora
Mira la video-entrevista con la autora
Documentación
A continuación, se recogen dos infografías con la definición de diversos términos relacionados con los datos abiertos y la reutilización de datos del sector público.
Glosario de términos sobre datos abiertos

Glosario de términos sobre reutilización de datos del sector público

Blog
¿Qué retos afrontan los publicadores de datos?
En la era digital actual, la información es un activo estratégico que impulsa la innovación, la transparencia y la colaboración en todos los sectores de la sociedad. Es por ello por lo que las iniciativas de publicación de datos han experimentado un enorme desarrollo como mecanismo fundamental para desbloquear el potencial de estos datos, permitiendo que gobiernos, organizaciones y ciudadanos accedan, utilicen y compartan.
No obstante, existen aún muchos retos tanto para publicadores de datos como para consumidores de los mismos. Aspectos como el mantenimiento de las APIs (Application Programming Interfaces) que nos permiten acceder y consumir los conjuntos de datos publicados o la correcta replicación y sincronización de conjuntos de datos cambiantes siguen siendo desafíos muy relevantes para estos actores.
En este post, exploraremos cómo los Linked Data Event Streams (LDES), un nuevo mecanismo de publicación de datos, pueden ayudarnos a solventar estos retos. ¿Qué es exactamente LDES? ¿Cómo difiere de las prácticas tradicionales de publicación de datos? Y, lo más importante, ¿cómo puede ayudar a publicadores y consumidores de datos a facilitar el uso de los conjuntos de datos disponibles?
Destilando los aspectos claves de LDES
Cuando desde la Universidad de Gante se comenzó a trabajar en un nuevo mecanismo para la publicación de datos abiertos, la pregunta a la que pretendían dar respuesta era: ¿Cuál es la mejor API posible que podemos diseñar para exponer conjuntos de datos abiertos?
En la actualidad, los organismos publicadores de datos recurren a múltiples mecanismos para publicar sus diferentes conjuntos de datos. Por un lado, es fácil encontrarnos APIs. Destacan las de tipo SPARQL, estándar para consulta de datos enlazados (Link Data), pero también de tipo REST o de tipo WFS, para el acceso a conjuntos de datos con componente geoespacial. Por otro lado, es muy común que encontremos la posibilidad de acceder a volcados de datos en diferentes formatos (i.e. CSV, JSON, XLS, etc.) que podamos descargar para su utilización.
En el caso de los volcados de datos, es muy fácil encontrarnos con problemas de sincronización. Esto ocurre cuando, tras un primer volcado, se produce un cambio que requiere la modificación del conjunto de datos original como, por ejemplo, el cambio del nombre de una calle en un callejero previamente descargado. Ante este cambio, si el tercero opta por modificar el nombre de la calle sobre el volcado inicial en lugar de esperar a que el publicador actualice sus datos en el repositorio maestro para realizar un nuevo volcado, los datos manejados por el tercero quedarán desincronizados frente a los manejados por el publicador. De igual forma, si es el publicador el que actualiza su repositorio maestro pero estos cambios no son descargados por el tercero, ambos manejarán diferentes versiones del conjunto de datos.
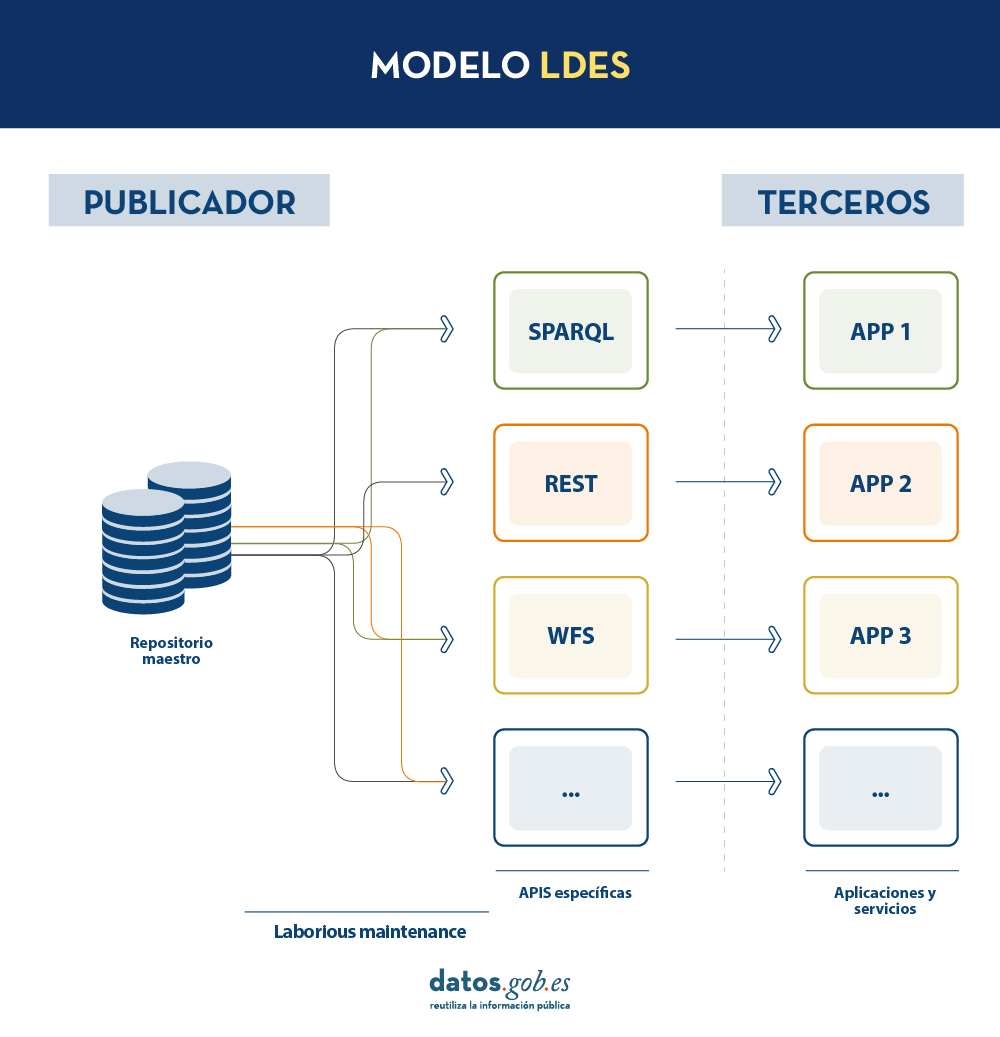
Por otra parte, si el publicador ofrece el acceso a los datos a través de APIs de consulta, en lugar de mediante volcados de los datos a los terceros, se solucionan los problemas de sincronización, pero la construcción y mantenimiento de un alto y variado volumen de las mismas supone un elevado esfuerzo a los publicadores de datos.
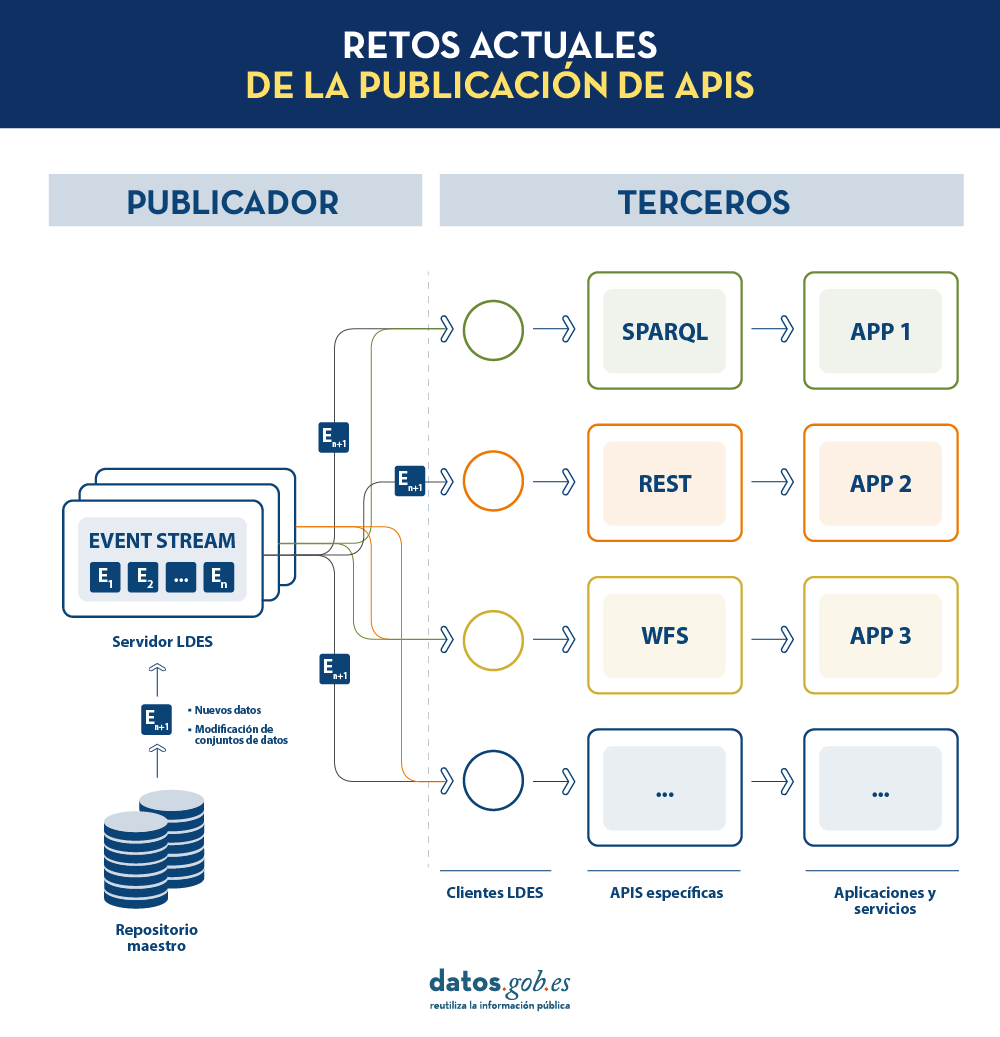
LDES busca solventar estas diferentes problemáticas aplicando el concepto de Linked Data a un event stream o flujo de datos. Según la definición que aparece en su propia especificación, un Linked Data Event Stream (LDES) es una colección de objetos inmutables donde cada objeto está descrito en ternas RDF.
En primer lugar, el hecho de que los LDES apuesten por Linked Data aporta principios de diseño que permiten combinar datos diversos y/o pertenecientes a diferentes fuentes, así como su consulta a través de mecanismos semánticos que permiten legibilidad tanto por humanos como por máquinas. En resumen, aporta interoperabilidad y consistencia entre conjuntos de datos, y facilita por tanto su búsqueda y descubrimiento.
Por otro lado, los event streams o flujos de datos, permiten a los consumidores replicar la historia de los conjuntos de datos, así como sincronizar los cambios recientes. Cualquier nuevo registro añadido a un conjunto de datos o cualquier modificación de los registros existentes (en definitiva, cualquier cambio), se registra como un nuevo evento incremental en el LDES que no alterará los eventos anteriores. Por tanto, pueden publicarse y consumirse datos como una secuencia de eventos, lo cual es útil para datos que cambian con frecuencia, como información en tiempo real o información que sufre actualizaciones constantes, ya que permite la sincronización de las últimas actualizaciones sin necesidad de hacer una nueva descarga completa de todo el repositorio maestro tras cada modificación.
En un modelo de este tipo, el editor solo necesitará desarrollar y mantener una API, el LDES, en lugar de múltiples APIs como WFS, REST o SPARQL. Los diferentes terceros que deseen utilizar los datos publicados se conectarán (cada tercero implementará su cliente LDES) y recibirán los eventos de los streams a los que se hayan suscrito. Cada tercero creará a partir de la información recabada las APIs específicas que considere oportunas en base al tipo de aplicaciones que quieran desarrollar o fomentar. En definitiva, el publicador no tendrá que resolver todas las potenciales necesidades que tenga cada tercero en la publicación de datos, sino que dando un interfaz LDES (API base mínima) cada tercero se centrará en su problemática.
Además, para facilitar el acceso en grandes volúmenes de datos o a datos que pueden estar distribuidos en diferentes fuentes, como un inventario de puntos de recarga eléctrica en Europa, LDES aporta la capacidad de fragmentación de los conjuntos de datos. A través de la especificación TREE (en inglés, árbol), LDES permite establecer diferentes tipos de relaciones entre fragmentos de datos. Esta especificación permite publicar colecciones de entidades, llamados miembros, y ofrece la capacidad de generar una o más representaciones de estas colecciones. Estas representaciones se organizan como vistas, distribuyendo los miembros a través de páginas o nodos interconectados mediante relaciones. Así, si deseamos que los datos se puedan consultar a través de índices temporales, se podrá establecer una fragmentación temporal y acceder solo a las páginas de un intervalo temporal. De igual forma, se podrán plantear índices alfabéticos o geoespaciales y así un consumidor podrá acceder sólo a aquellos datos necesarios sin la necesidad de realizar el “volcado” del conjunto de datos completo.
¿Qué conclusiones podemos extraer de LDES?
En este post hemos observado el potencial de LDES como mecanismo para la publicación de datos. Algunos de los aprendizajes más relevantes son:
- LDES persigue facilitar la publicación de datos a través de APIs base mínimas que sirvan como punto de conexión para cualquier tercero que desee consultar o construir aplicaciones y servicios sobre conjuntos de datos.
- La construcción de un servidor LDES, no obstante, tiene cierto nivel de complejidad técnica a la hora de establecer la arquitectura necesaria para el manejo de los flujos de datos publicados y su adecuada consulta por parte de consumidores de datos.
- El diseño de LDES permite la gestión tanto de datos con una elevada tasa de cambios (i.e. datos provenientes de sensores), como datos con una baja tasa de cambios (i.e. datos provenientes de un callejero). Ambos escenarios pueden manejar cualquier modificación del conjunto de datos como un flujo de datos.
- LDES soluciona de forma eficiente la gestión de registros históricos, versiones y fragmentos de conjuntos de datos. Para ello se apoya en la especificación TREE pudiendo establecer diferentes tipos de fragmentación sobre el mismo conjunto de datos.
¿Te gustaría saber más?
Dejamos a continuación algunas referencias que han servido para redactar este post y pueden servir al lector que desee profundizar en el mundo de LDES:
- Linked Data Event Streams: the core API for publishing base registries and sensor data, Pieter Colpaert. ENDORSE, 2021. https://youtu.be/89UVTahjCvo?si=Yk_Lfs5zt2dxe6Ve&t=1085
- Webinar on LDES and Base registries. Interoperable Europe, 17 January 2023. https://www.youtube.com/watch?v=wOeISYms4F0&ab_channel=InteroperableEurope
- SEMIC Webinar on the LDES specification. Interoperable Europe, 21 April 2023. https://www.youtube.com/watch?v=jjIq63ZdDAI&ab_channel=InteroperableEurope
- Linked Data Event Streams (LDES). SEMIC Support Centre. https://joinup.ec.europa.eu/collection/semic-support-centre/linked-data-event-streams-ldes
- Publishing data with Linked Data Event Streams: why and how. EU Academy. https://academy.europa.eu/courses/publishing-data-with-linked-data-event-streams-why-and-how
Contenido elaborado por Juan Benavente, ingeniero superior industrial y experto en Tecnologías ligadas a la economía del dato. Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Blog
La Directiva INSPIRE (Infrastructure for Spatial Information in Europe) establece las reglas generales para el establecimiento de una Infraestructura de Información espacial en la Comunidad Europea basada en las Infraestructuras de los Estados miembro. Aprobada por el Parlamento Europeo y el Consejo el 14 de marzo de 2007 (Directiva 2007/2/CE), esta entró en vigor el 25 de abril de 2007.
INSPIRE permite encontrar, compartir y utilizar con más facilidad los datos espaciales de diferentes países. La información está disponible a través de un portal online desde el que se pueden encontrar desglosados en distintos formatos y temáticas de interés.
Para asegurar que estos datos sean compatibles e interoperables en un contexto comunitario y transfronterizo, la Directiva exige que se adopten Normas de Ejecución comunes (Implementing Rules) específicas para las siguientes áreas:
- Metadatos
- Conjuntos de datos
- Servicios de red
- Uso compartido de datos y servicios
- Servicios de datos espaciales
- Monitoreo e informes
La implementación técnica de estas normas se realiza mediante las Guías Técnicas o Directrices (Technical Guidelines), documentos técnicos basados en estándares y normas internacionales.
Inspire e interoperabilidad semántica
Estas normas se consideran decisiones o reglamentos de la Comisión y, por lo tanto, son de obligado cumplimiento en cada uno de los países de la Unión. La transposición de esta Directiva al ordenamiento jurídico español se desarrolla a través de la Ley 14/2010 de 5 de julio, la cual hace referencia a las infraestructuras y los servicios de información geográfica de España (LISIGE) y el portal IDEE, ambos son el resultado de la implementación de la Directiva INSPIRE en España.
En INSPIRE juega un papel decisivo la interoperabilidad semántica. Gracias a esta, existe un lenguaje común en los datos espaciales, pues la integración del conocimiento solo es posible cuando se logra una homogenización o entendimiento común de los conceptos que constituyen un dominio o área de conocimiento. Así, en INSPIRE, la interoperabilidad semántica es la encargada de asegurar que el contenido de la información intercambiada sea entendido de la misma manera por cualquier sistema.
Por ello, en la implementación de los modelos de datos espaciales en INSPIRE, en formato de intercambio GML, podemos encontrar los codelist que son una parte importante de las especificaciones de datos de INSPIRE y contribuyen sustancialmente a la interoperabilidad.
En general, una codelist o lista de códigos contiene varios términos cuyas definiciones son universalmente aceptadas y comprendidas. Las listas de códigos favorecen la interoperabilidad de los datos y constituyen un vocabulario compartido por una comunidad. Incluso pueden ser multilingües.
Las listas de códigos INSPIRE se administran y mantienen comúnmente en Registro Inspire Central Federado (ROR) que proporciona capacidades de búsqueda, de modo que tanto los usuarios finales como las aplicaciones cliente pueden acceder fácilmente a los valores de la lista de códigos como referencia.
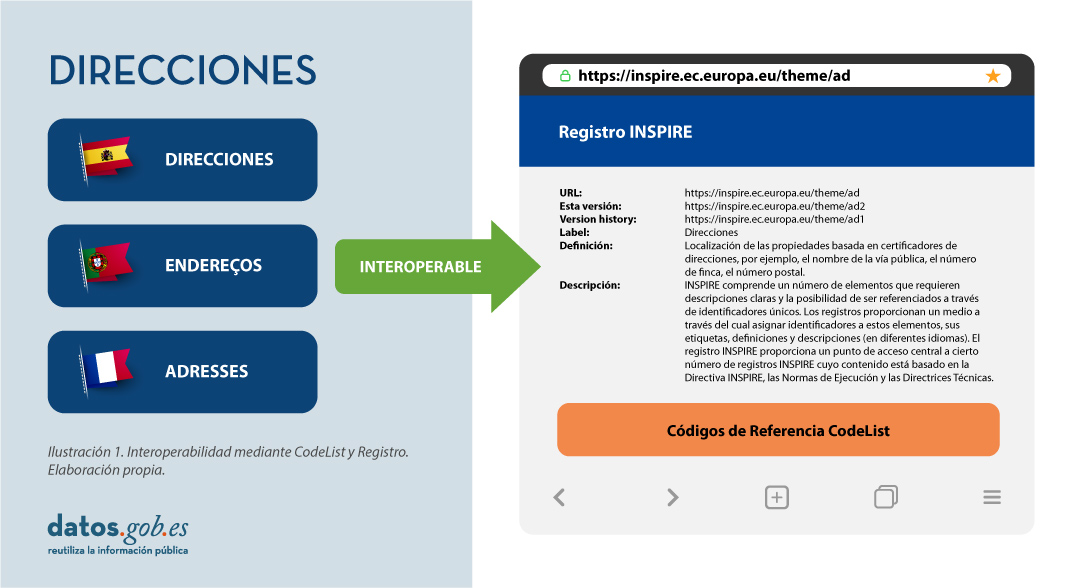
Los registros son necesarios porque:
- Proporcionan los códigos definidos en las Directrices Técnicas (Guidelines), Reglamentos y Especificaciones técnicas necesarios para implementar la Directiva
- Permiten referencias inequívocas de los elementos
- Proporcionna identificadores únicos y persistentes para los recursos
- Permiten una gestión y control de versiones coherentes de los diferentes elementos
Las listas de códigos utilizados en INSPIRE se mantienen en:
- El Registro Inspire Central Federado (ROR)
- El registro de listas de códigos de un estado miembro
- El registro de listas de un tercero externo reconocido que mantiene una lista de códigos específica de dominio.
Para agregar una nueva lista de códigos, tendrá que configurar su propio registro o trabajar con la administración de uno de los registros existentes para publicar su lista de códigos. Este puede ser un proceso bastante complicado pero una nueva herramienta nos ayuda en esta labor.
Re3gistry es una solución de código abierto reutilizable y publicado bajo licencia EUPL, que permite a las empresas y organizaciones administrar y compartir \"códigos de referencia\" a través de URI persistentes, asegurando que los conceptos se referencian inequívocamente en cualquier dominio y facilitando la gestión de estos recursos gráficamente durante todo su ciclo de vida.
Financiado por ELISE, ISA2 es una solución reconocida por los europeos en el Marco de interoperabilidad como una herramienta de apoyo.Ilustración 3 Imagen de la interface de Re3gister.
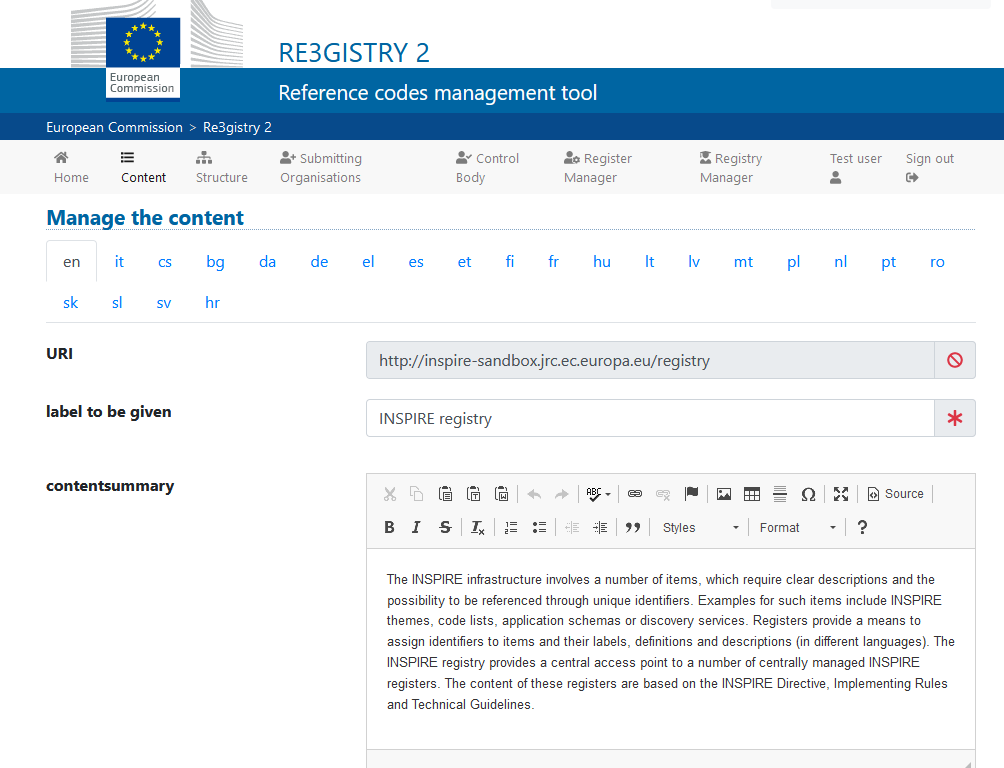
Ilustración 3: Imagen de la interface de Re3gister
Re3gistry está disponible tanto para Windows como para Linux y ofrece una Interfaz Web fácil de usar para agregar, editar y administrar los registros y códigos de referencia. Además, permite la gestión del ciclo de vida completo de los códigos de referencia (basado en la norma ISO 19135: 2005 Procedimientos integrados para el registro de códigos de referencia)
La interfaz de edición también proporciona un indicador para permitir que el sistema exponga el código de referencia en el formato que permite su integración con RoR, de esta manera, eventualmente se puede importar en la federación de registro INSPIRE. Para esta integración, Reg3gistry hace una exportación en un formato basado en las siguientes especificaciones:
- El vocabulario del Catálogo de datos del W3C (DCAT) que se utiliza para modelar el registro de entidades (dcat:Catalog).
- El Sistema de Organización Simple del Conocimiento (SKOS) del W3C que se utiliza para modelar el registro de entidades (skos:ConceptScheme) y el elemento (skos:Concept).
Otras características destacables de Re3gistry
- Modelos de datos altamente flexibles y personalizables
- Soporte de contenido en varios idiomas
- Soporte para el control de versiones
- API RESTful con negociación de contenido (incluido el descriptor OpenAPI 3)
- Búsqueda de texto-libre
- Formatos soportados: HTML, ISO 19135 XML, JSON
- Los formatos de servicio se pueden agregar o personalizar fácilmente (formatos predeterminados: JSON e ISO 19135 XML)
- Múltiples opciones de autentificación
- Elementos gobernados externamente a los que se hace referencia a través de URIs
- Soporte de formato de federación de registro INSPIRE (opción para crear automáticamente el formato RoR)
- Fácil exportación y reindexación de datos (SOLR)
- Guías para usuarios, administradores y desarrolladores
- Fuente RSS
En definitiva, Re3gistry proporciona un punto de acceso central donde las etiquetas y descripciones de los códigos de referencia son fácilmente accesibles tanto para humanos como para máquinas, al tiempo que fomenta la interoperabilidad semántica entre organizaciones ya que permite:
- Evitar errores comunes como faltas de ortografía, ingresar sinónimos o completar formularios en línea.
- Facilitar la internacionalización de las interfaces de usuario proporcionando etiquetas multilingües.
- Garantizar la interoperabilidad semántica en el intercambio de datos entre sistemas y aplicaciones.
- El rastreo de los cambios a lo largo del tiempo a través de un sistema de control de versiones bien documentado.
- Aumentar el valor de los códigos de referencia, si se reutilizan y referencian ampliamente.
Más acerca de Re3gistry:
|
|
Soporte | https://github.com/ec-jrc/re3gistry |
|
|
Manual de usuario | https://github.com/ec-jrc/re3gistry/blob/master/documentation/user-manual.md |
|
|
Manual de administrador | https://github.com/ec-jrc/re3gistry/blob/master/documentation/administrator-manual.md |
|
|
Manual de desarrollador |
https://github.com/ec-jrc/re3gistry/blob/master/documentation/developer-manual.md
|




Referencias
https://github.com/ec-jrc/re3gistry
https://inspire.ec.europa.eu/codelist
https://ec.europa.eu/isa2/solutions/re3gistry_en/
https://live.osgeo.org/en/quickstart/re3gistry_quickstart.html
Contenido elaborado por Mayte Toscano, Senior Consultant in Tecnologías ligadas a la economía del dato.
Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Blog
Continuamos con la serie de posts sobre Chat GPT-3. La expectación levantada por el sistema conversacional justifica con creces la publicación de varios artículos sobre sus características y aplicaciones. En este post, profundizamos sobre una de las últimas novedades publicadas por openAI relacionadas con Chat GPT-3. En este caso introducimos su API, es decir, su interfaz de programación con la que podemos integrar Chat GPT-3 en nuestras propias aplicaciones.
Introducción.
En nuestro último post sobre Chat GPT-3 realizamos un ejercicio de co-programación o programación asistida en el que le solicitamos a la IA que nos escribiera un programa sencillo, en lenguaje de programación R, para visualizar un conjunto de datos. Como vimos en el post, utilizamos la propia interfaz disponible de Chat GTP-3. La interfaz es muy minimalista y funcional, tan solo tenemos que preguntar a la IA en el cuadro de texto y ella nos contesta en el cuadro de texto posterior. Tal y como concluimos en el post, el resultado del ejercicio fue más que satisfactorio. Sin embargo, también detectamos algunos puntos de mejora. Por ejemplo, la interfaz estándar puede resultar un poco lenta. Para un ejercicio largo, con múltiples interacciones conversacionales con la IA (un diálogo largo), la interfaz tarda bastante en escribir las respuestas. Varios usuarios reportan la misma sensación y por eso algunos, como este desarrollador, han creado su propia interfaz con el asistente conversacional para mejorar su velocidad de respuesta.
Pero, ¿cómo es posible esto? La razón es sencilla, gracias al API de Chat GPT-3. En este espacio de divulgación hemos hablado mucho sobre las APIs en el pasado. No en vano, las APIs son los mecanismos estándar en el mundo de las tecnologías digitales para integrar servicios y aplicaciones. Cualquier app en nuestro smartphone hace uso de las APIs para mostrarnos los resultados. Cuando consultamos el tiempo, los resultados deportivos o el horario del transporte público, las apps hacen llamadas a las APIs de los servicios para consultar la información y mostrar los resultados.
El API de Chat GPT-3
Como cualquier otro servicio actual, openAI pone a disposición de sus usuarios una API con la que poder invocar (llamar) a sus diferentes servicios basados en el modelo entrenado de lenguaje natural GPT-3. Para usar el API, tan solo tenemos que iniciar sesión con nuestra cuenta en https://platform.openai.com y localizar el menú (superior derecha) View API Keys. Hacemos click en create a new secret key y ya tenemos nuestra nueva clave de acceso al servicio.

¿Qué hacemos ahora? Bien, para ilustrar lo que podemos hacer con esta nueva y flamante clave veamos algunos ejemplos:
Como decíamos en la introducción, podemos querer probar interfaces alternativas a Chat GPT-3 como https://www.typingmind.com/. Cuando accedemos a esta web, lo primero que debemos hacer es ingresar nuestra API Key.
Una vez dentro, hagamos un ejemplo y veamos cómo se comporta esta nueva interfaz. Preguntemos a Chat GPT-3 ¿Qué es datos.gob.es?
| Nota: Es importante notar que la mayoría de servicios no funcionarán si no activamos algún medio de pago en la web de OpenAI. Lo normal es que, si no hemos configurado una tarjeta de crédito, las llamadas al API devuelvan un mensaje de error similar a \"You exceeded your current quota, please check your plan and billing details”. |

Veamos ahora otra aplicación del API de Chat GPT-3.
Acceso programático con R para acceder a Chat GPT-3 de modo programático (o lo que es lo mismo, con algunas líneas de código en R tenemos acceso a la potencia conversacional del modelo GPT-3). Esta demostración está basada en el reciente post publicado en R Bloggers. Vamos a acceder a Chat GPT-3 de modo programático con el siguiente ejemplo.
| Nota: Notar que el API Key se ha ocultado por motivos de seguridad y privacidad |

En este ejemplo, utilizamos código en R para hacer una llamada HTTPs de tipo POST y le preguntamos a Chat GPT-3 ¿Qué es datos.gob.es? Vemos que estamos utilizando el modelo gpt-3.5-turbo que, tal y como se especifica en la documentación está indicado para tareas de tipo conversacional. Toda la información sobre la API y los diferentes modelos está disponible aquí. Pero, veamos el resultado:

¿Nada mal verdad? Como dato curioso podemos ver que unas pocas llamadas al API de Chat GPT-3 han tenido el siguiente uso del API:

El uso del API se cotiza por tokens (algo similar a las palabras) y los precios públicos pueden consultarse aquí. En concreto el modelo que estamos utilizando tiene estos precios:

Para pequeñas pruebas y ejemplos, nos lo podemos permitir. En caso de aplicaciones empresariales para entornos productivos existe un modelo premium que permite tener un control de los costes sin depender tanto del uso.
Conclusión
Como no podía ser de otra manera, Chat GPT-3 habilita un API para proporcionar acceso programático a su motor conversacional. Este mecanismo permite la integración de aplicaciones y sistemas (es decir, todo lo que no son humanos) abriendo la puerta al despegue definitivo del Chat GPT-3 como modelo de negocio. Gracias a este mecanismo, el buscador Bing ahora integra Chat GPT-3 para respuestas a las búsquedas en modo conversacional. De la misma forma, Microsoft Azure acaba de anunciar la disponibilidad de Chat GPT-3 como un nuevo servicio de la nube pública. Sin lugar a dudas, en las próximas semanas veremos comunicaciones de todo tipo de aplicaciones, apps y servicios, conocidos y desconocidos, anunciando su integración con Chat GPT-3 para mejorar las interfaces conversacionales con sus clientes. Nos vemos en el próximo episodio, quién sabe sin con GPT-4.
Contenido elaborado por Alejandro Alija, experto en Transformación Digital.
Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Documentación
En este artículo recopilamos una serie de infografías dirigidas tanto a publicadores como reutilizadores que trabajen con datos abiertos. En ellas se muestras normas y buenas prácticas para facilitar tanto la publicación como el tratamiento de datos.
Interoperabilidad: la clave para trabajar con datos de diversas fuentes
 |
Publicada: marzo 2026 La interoperabilidad funciona como un sistema de cuatro capas: técnica, semántica, organizativa y jurídica. Es necesario que todas funcionen correctamente para que podamos combinar datos de diversas fuentes sin fricción, sin malentendidos y sin sorpresas. |
¿Cómo publicar datos abiertos en datos.gob.es?
 |
Publicada: febrero 2026 Esta infografía describe el proceso recomendado para que un organismo publique datos abiertos en el Catálogo Nacional de Datos Abiertos albergado en datos.gob.es. El camino se divide en cinco fases principales: planificación previa, alta de organismo y usuario, catalogación, federación y mantenimiento. |
Guía técnica control de versiones de datos
 |
Publicada: enero 2026 El Control de Versiones de Datos (CVD) permite registrar y documentar la evolución completa de un conjunto de datos, facilitando la colaboración, la auditoría y la recuperación de versiones anteriores. Sin un sistema claro para gestionar esos cambios es fácil perder trazabilidad. En esta infografía te contamos cómo llevar a cabo un CVD. |
DCAT-AP-ES: Guías y materiales de apoyo para facilitar su uso
 |
Publicada: agosto 2025 Este nuevo modelo de metadatos adopta las directrices del esquema europeo de intercambio de metadatos DCAT-AP (Data Catalog Vocabulary-Aplication Profile) con algunas restricciones y ajustes adicionales. |
Guía para el despliegue de portales de datos abiertos
 |
Publicada: abril 2025 Esta infografía resume buenas prácticas y recomendaciones para diseñar, desarrollar y desplegar portales de datos abiertos en el ámbito municipal. En concreto recoge: marco estratégico, requisitos generales y pautas técnicas y funcionales. |
Ley de Datos (Data Act o DA)
 |
Publicada: febrero 2024 La Ley de Datos (Data Act) es una regulación de la Unión Europea para facilitar la accesibilidad de los datos de forma horizontal. Es decir, estableciendo principios y directrices para todos los sectores, haciendo hincapié en el acceso justo a los datos, los derechos de los usuarios y la protección de los datos personales. Descubre cuáles son sus claves en esta infografía. También se ha creado una versión a una página para facilitar su impresión: accede aquí |
Reglamento europeo de gobernanza de datos (Data Governance Act o DGA)
 |
Publicada: enero 2024 El Reglamento europeo de gobernanza de datos (Data Governance Act o DGA) es un instrumento horizontal para regular la reutilización de datos e impulsar su intercambio bajo los principios y valores de la Unión Europea (UE). Descubre cuáles son sus claves en esta infografía. También se ha creado una versión a una página para facilitar su impresión: accede aquí |
Las claves de las especificaciones UNE sobre el dato
 |
Publicada: septiembre 2023 Todo tipo de instituciones deben disponer de datos bien gobernados, gestionados y con niveles adecuados de calidad, siendo necesaria una metodología de evaluación común. La siguiente infografía resumen cuáles son las claves de las Especificaciones UNE sobre el dato y sus principales ventajas. |
Principales obligaciones de la Ley 37/2007
 |
Publicada: marzo 2023 En aplicación de la última Directiva europea de datos abiertos, se ha modificado la Ley 37/2007 para que incida en el concepto de los datos abiertos desde el diseño y por defecto. Esta infografía destaca los principales cambios de la normativa. |
Cómo crear un plan de medidas para impulsar la apertura y reutilización de datos abiertos
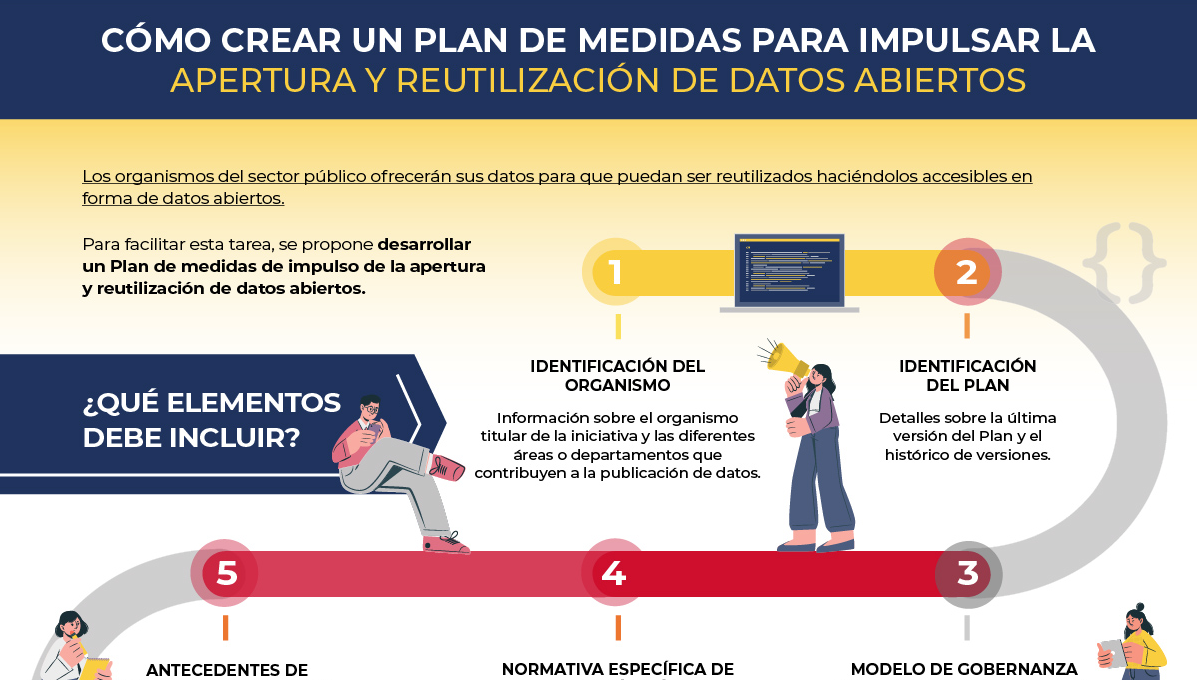 |
Publicada: noviembre 2022 Esta infografía recoge los diferentes elementos que debe contener un Plan de medidas de impulso de la apertura y reutilización de datos abiertos. El objetivo es que las unidades responsables de la apertura puedan trazar una hoja de ruta factible de apertura de datos, que además permita su seguimiento y evaluación. |
8 guías para mejorar la publicación y el tratamiento del dato
 |
Publicada: octubre 2022 Desde datos.gob.es hemos elaborado diferentes guías para ayudar a publicadores y reutilizadores a la hora de preparar los datos datos para su publicación y/o análisis. En esta infografía te resumimos el contenido de ocho de ellas. |
Pautas generales para garantizar la calidad de los datos abiertos
 |
Publicada: septiembre 2022 Esta infografía detalla una serie pautas generales para garantizar la calidad de los datos abiertos, como, por ejemplo, utilizar una codificación de caracteres estandarizada, evitar la duplicidad de registros o incorporar variables con información geográfica. |
Pautas para asegurar la calidad usando formatos específicos de datos
 |
Publicada: septiembre 2022 Esta infografía recoge pautas concretas para asegurar la calidad de los datos abiertos según el formato de datos utilizado. Se han incluido pautas específicas para los formatos CSV, XML, JSON, RDF y APIs. |
Normas para un correcto gobierno del dato
 |
Publicada: mayo 2022 Esta infografía recoge la normas a tener en cuenta para un correcto gobierno del dato, según la Asociación Española de Normalización (UNE) . Estas normas se basan en 4 principios: Gobernanza, Gestión, Calidad y Seguridad y privacidad de datos. |
APIs para el acceso a datos abiertos
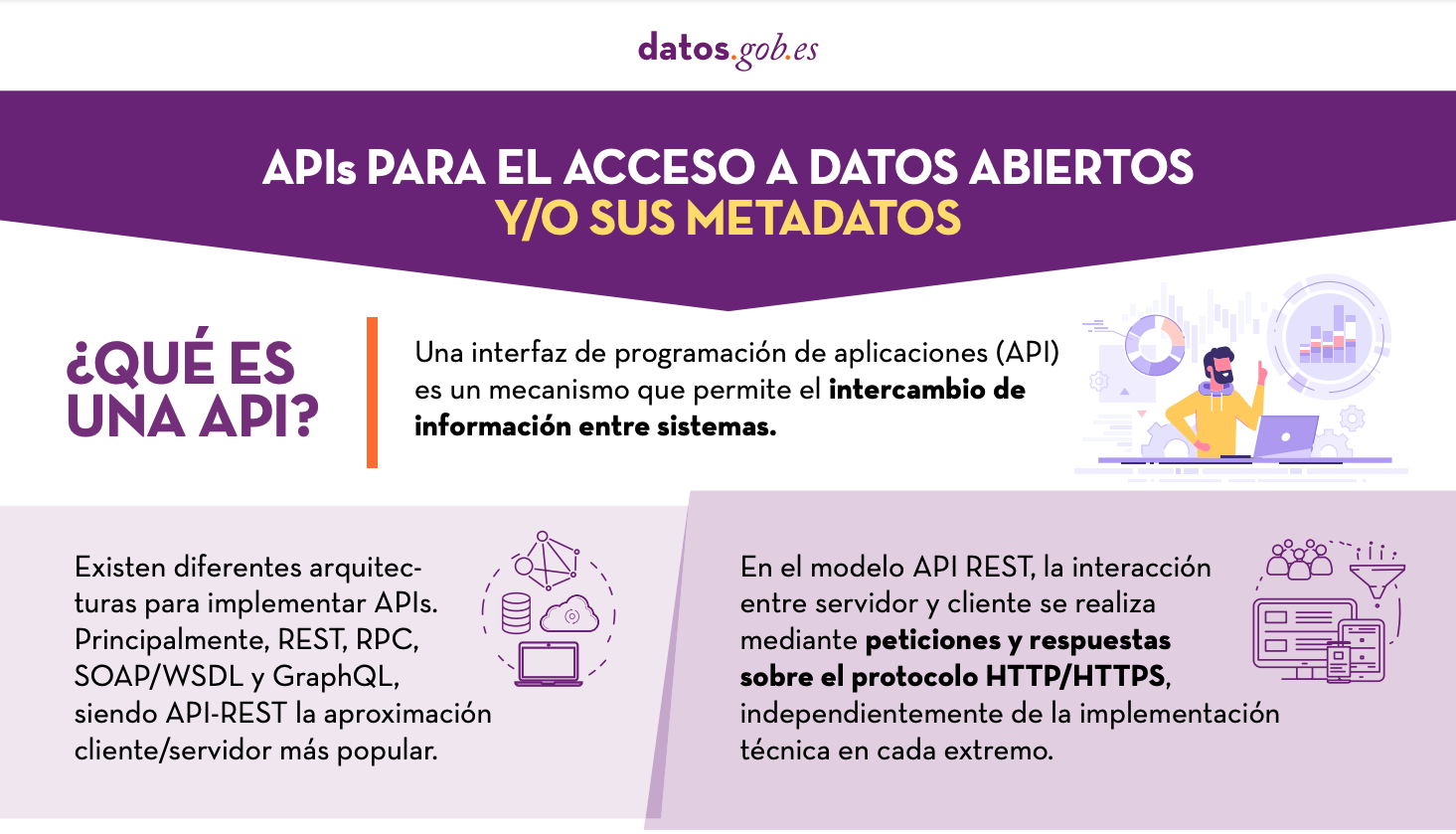 |
Publicada: enero 2022 Muchos portales de datos abiertos en España ya cuentan con sus propias APIs para facilitar el acceso a datos y metadatos. Esta infografía muestra algunos ejemplos a nivel nacional, autonómico y local, incluyendo información sobre la API de datos.gob.es. |