Blog
The European High-Value Datasets (HVD) regulation, established by Implementing Regulation (EU) 2023/138, consolidates the role of APIs as an essential infrastructure for the reuse of public information, making their availability a legal obligation and not just a good technological practice.
Since 9 June 2024, public bodies in all Member States are required to publish datasets classified as HVDs free of charge, in machine-readable formats and accessible via APIs. The six categories regulated are: geospatial data, Earth observation, environment, statistics, business information and mobility.
This framework is not merely declarative. Member States must report to the European Commission compliance status every two years, including persistent links to APIs that give access to such data. The situation in Spain in terms of transparency, open data and Systematic API Provisioning can be consulted in the indicators published by the Open Data Maturity Report.
In practice, this means that APIs are the bridge between the norm and reality. The regulation not only says what data must be opened, but also requires it to be done in such a way that it can be automatically integrated into applications, studies or digital services. Therefore, reviewing the public APIs available in Spain is a concrete way to understand how this framework is being applied on a day-to-day basis.
Inventory of public APIs in Spain
INE — API JSON (Tempus3)
The National Institute of Statistics offers a API REST that Exposes the entire database Tempus3 broadcast format JSON, which includes official statistical series on demography, economy, labour market, industry, services, prices, living conditions and other socio-economic indicators.
To make calls, the structure must follow the pattern https://servicios.ine.es/wstempus/js/{language}/{function}/{input}. The tip=AM parameter allows you to get metadata along with the data, and tv filters by specific variables. For example, to obtain the population figures by province, simply consult the corresponding operation (IOE 30243) and filter by the desired geographical variable.
No authentication or API key required: any well-formed GET request returns data directly.
Example in Python — get the resident population series with metadata:
import requests
url = ("https://servicios.ine.es/wstempus/js/ES/"
"DATOS_TABLA/t20/e245/p08/l0/01002.px?tip=AM")
response = requests.get(url)
data = response.json()
for serie in data[:3]: # primeras 3 series
name = series["Name"]
last = series["Date"][-1]
print(f"{name}: {last['Value']:,.0f} ({last['PeriodName']})")
TOTAL AGES, TOTAL, Both sexes: 39,852,651 (1998)
TOTAL AGES, TOTAL, Males: 19,488,465 (1998)
TOTAL EDADES, TOTAL, Mujeres: 20,364,186 (1998)AEMET — OpenData API REST
The State Meteorological Agency exposes its data through a REST API, documented with Swagger UI (an open-source tool that generates interactive documentation), observed meteorological data and official predictions, including temperature, precipitation, wind, alerts and adverse phenomena.
Unlike the INE, AEMET requires a Free API key, which is obtained by providing an email address in the portal opendata.aemet.es. A API key works as A type of "password" or identifier: it is used to allow the agency to know who is using the service, control the volume of requests and ensure proper use of the infrastructure.
A relevant technical aspect is that AEMET implements a two-call model: the first request returns a JSON with a temporary URL in the data field, and a second request to that URL retrieves the actual dataset. The rate limit is 50 requests per minute.
Example in Python — daily weather data (double call):
import requests
API_KEY = "tu_api_key_aqui"
headers = {"api_key": API_KEY}
#1st call: Get temporary data URLs
url = ("https://opendata.aemet.es/opendata/api/"
"Values/Climatological/Daily/Data/"
"fechaini/2025-01-01T00:00:00UTC/"
"fechafin/2025-01-10T23:59:59UTC/"
"allseasons")
resp1 = requests.get(url, headers=headers).json()
#2nd call: Download the actual dataset
datos = requests.get(resp1["datos"], headers=headers).json()
for estacion in datos[:3]:
print(f"{station['name']}: "
f"Tmax={station.get('tmax','N/A')}°C, "
f"Prec={estacion.get('prec','N/A')}mm")
CITFAGRO_88_GAITERO: Tmax=8.8°C, Prev=0.0mm
ABANILLA: Tmax=14,8°C, Prec=0,0mm
LA RODA DE ANDALUCÍA: Tmax=15.7°C, Prec=0.2mmCNIG / IDEE — Servicios OGC y OGC API Features
The National Center for Geographic Information It publishes official geospatial data – base mapping, digital terrain models, river networks, administrative boundaries and other topographic elements – through interoperable services. These have evolved from WMS/WFS to the OGC API (Features, Maps and Processes), implemented with open software such as pygeoapi.
The main advantage of OGC API Features over WFS is the response format: instead of GML (heavy and complex), the data is served in GeoJSON and HTML, native formats of the web ecosystem. This allows them to be consumed directly from libraries such as Leaflet, OpenLayers or GDAL. Available datasets include Cartociudad addresses, hydrography, transport networks and geographical gazetteer.
Example in Python — query geographic features via OGC API:
import requests
# OGC API Features - Basic Geographical Gazetteer of Spain
base = "https://api-features.idee.es/collections"
collection = "falls" # Waterfalls
url = f"{base}/{collection}/items?limit=5&f=json"
resp = requests.get(url).json()
for feat in resp["features"]:
props = feat["properties"]
coords = feat["geometry"]["coordinates"]
print(f"{props['number']}: ({coords[0]:.4f}, {coords[1]:.4f})")
None: (-6.2132, 42.8982)
Cascada del Cervienzo: (-6.2572, 42.9763)
El Xaral Waterfall: (-6.3815, 42.9881)
Rexiu Waterfall: (-7.2256, 42.5743)
Santalla Waterfall: (-7.2543, 42.6510)MITECO — Open Data Portal (CKAN)
The Ministry for the Ecological Transition maintains a CKAN-based portal that exposes three access layers: the CKAN Action API for metadata and dataset search, the Datastore API (OpenAPI) for live queries on tabular resources, and RDF/JSON-LD endpoints compliant with DCAT-AP and GeoDCAT-AP. In its catalogue you can find data on air quality, emissions and climate change, water (state of masses and hydrological planning), biodiversity and protected areas, waste, energy and environmental assessment.
Featured datasets include Natura 2000 Network protected areas, bodies of water, and greenhouse gas emissions projections.
Example in Python — search for datasets:
import requests
BASE = "https://catalogo.datosabiertos.miteco.gob.es/ catalog"
# Search for datasets containing 'natura 2000'
busqueda = requests.get(
f"{BASE}/api/3/action/package_search",
params={"q": "natura 2000", "rows": 3},
).json()
for ds in busqueda["result"]["results"]:
print(f"{ds['title']} ({ds['num_resources']} resources)")
Protected Areas of the Natura 2000 Network (13 resources)
Database of Natura 2000 Network Protected Areas of Spain (CNTRYES) (1 resources)
Protected Areas of the Natura 2000 Network - API - High Value Data (1 resources)Technical comparison
| Organisim | Protocol | Format | Authentication | Rate limit | HVD |
|---|---|---|---|---|---|
| INE | REST | JSON | None | Undeclared | Yes (statistic) |
| AEMET | REST | JSON | API key (free) | 50 reg/min | Yes (environment) |
| CNIG/IDEA | OGC API/WFS | GeoJSON/GML | None | Undeclared | Yes (geoespatial) |
| MITECO | CKAN/REST | JSON/RDF | None | Undeclared | Yes (environment) |
Figure 1. Comparative table of the APIs from various public agencies discussed in this post. Source: Compiled by the author – datos.gob.es.
The availability of public APIs isn't just a matter of technical convenience. From a data perspective, these interfaces enable three critical capabilities:
- Pipeline automation: the periodic ingestion of public data can be orchestrated with standard tools (Airflow, Prefect, cron) without manual intervention or file downloads.
- Reproducibility: API URLs act as static references to authoritative sources, facilitating auditing and traceability in analytics projects.
- Interoperability: the use of open standards (REST, OGC API, DCAT-AP) allows heterogeneous sources to be crossed without depending on proprietary formats.
The public API ecosystem in Spain has different levels of development depending on the body and the sectoral scope. While entities such as the INE and AEMET have consolidated and well-documented interfaces, in other cases access is articulated through CKAN portals or traditional OGC services. The regulation regarding High Value Datasets (HVDs) is driving the progressive adoption of REST standards, although the degree of implementation evolves at different rates. For data professionals, these APIs are already a fully operational source that is increasingly common to integrate into data architectures in engineering and analytical environments.ás habitual en entornos analíticos y de ingeniería.
Content produced by Juan Benavente, a senior industrial engineer and expert in technologies related to the data economy. The content and views expressed in this publication are the sole responsibility of the author.
Blog
Access to data through APIs has become one of the key pieces of today's digital ecosystem. Public administrations, international organizations and private companies publish information so that third parties can reuse it in applications, analyses or artificial intelligence projects. In this situation, talking about open data is, almost inevitably, also talking about APIs.
However, access to an API is rarely completely free and unlimited. There are restrictions, controls and protection mechanisms that seek to balance two objectives that, at first glance, may seem opposite: facilitating access to data and guaranteeing the stability, security and sustainability of the service. These limitations generate frequent doubts: are they really necessary, do they go against the spirit of open data, and to what extent can they be applied without closing access?
This article discusses how these constraints are managed, why they are necessary, and how they fit – far from what is sometimes thought – within a coherent open data strategy.
Why you need to limit access to an API
An API is not simply a "faucet" of data. Behind it there is usually technological infrastructure, servers, update processes, operational costs and equipment responsible for the service working properly.
When a data service is exposed without any control, well-known problems appear:
- System saturation, caused by an excessive number of simultaneous queries.
- Abusive use, intentional or unintentional, that degrades the service for other users.
- Uncontrolled costs, especially when the infrastructure is deployed in the cloud.
- Security risks, such as automated attacks or mass scraping.
In many cases, the absence of limits does not lead to more openness, but to a progressive deterioration of the service itself.
For this reason, limiting access is not usually an ideological decision, but a practical necessity to ensure that the service is stable, predictable and fair for all users.
The API Key: basic but effective control
The most common mechanism for managing access is the API Key. While in some cases, such as the datos.gob.es National Open Data Catalog API , no key is required to access published information, other catalogs require a unique key that identifies each user or application and is included in each API call.
Although from the outside it may seem like a simple formality, the API Key fulfills several important functions. It allows you to identify who consumes the data, measure the actual use of the service, apply reasonable limits and act on problematic behavior without affecting other users.
In the Spanish context there are clear examples of open data platforms that work in this way. The State Meteorological Agency (AEMET), for example, offers open access to high-value meteorological data, but requires requesting a free API Key for automated queries. Access is free of charge, but not anonymous or uncontrolled.
So far, the approach is relatively familiar: consumer identification and basic limits of use. However, in many situations this is no longer enough.
When API becomes a strategic asset
Leading API management platforms, such as MuleSoft or Kong among others, were pioneers in implementing advanced mechanisms for controlling and protecting access to APIs. Its initial focus was on complex business environments, where multiple applications, organizations, and countries consume data services intensively and continuously.
Over time, many of these practices have also been extended to open data platforms. As certain open data services gain relevance and become key dependencies for applications, research, or business models, the challenges associated with their availability and stability become similar. The downfall or degradation of large-scale open data services—such as those related to Earth observation, climate, or science—can have a significant impact on multiple systems that depend on them.
In this sense, advanced access management is no longer an exclusively technical issue and becomes part of the very sustainability of a service that becomes strategic. It's not so much about who publishes the data, but the role that data plays within a broader ecosystem of reuse. For this reason, many open data platforms are progressively adopting mechanisms that have already been tested in other areas, adapting them to their principles of openness and public access. Some of them are detailed below.
Limiting the flow: regulating the pace, not the right of access
One of the first additional layers is the limitation of the flow of use, which is usually known as rate limiting. Instead of allowing an unlimited number of calls, it defines how many requests can be made in a given time interval.
The key here is not to prevent access, but to regulate the rhythm. A user can still use the data, but it prevents a single application from monopolizing resources. This approach is common in the Weather, Mobility, or Public Statistics APIs, where many users access it simultaneously.
More advanced platforms go a step further and apply dynamic limits, which are adjusted based on system load, time of day, or historical consumer behavior. The result is fairer and more flexible control.
Context, Origin, and Behavior: Beyond Volume
Another important evolution is to stop looking only at how many calls are made and start analyzing where and how they are made from. This includes measures such as restriction by IP addresses, geofencing, or differentiation between test and production environments.
In some cases, these limitations respond to regulatory frameworks or licenses of use. In others, they simply allow you to protect more sensitive parts of the service without shutting down general access. For example, an API can be globally accessible in query mode, but limit certain operations to very specific situations.
Platforms also analyze behavior patterns. If an application starts making repetitive, inconsistent queries or very different from its usual use, the system can react automatically: temporarily reduce the flow, launch alerts or require an additional level of validation. It is not blocked "just because", but because the behavior no longer fits with a reasonable use of the service.
Measuring impact, not just calls
A particularly relevant trend is to stop measuring only the number of requests and start considering the real impact of each one. Not all queries consume the same resources: some transfer large volumes of data or execute more expensive operations.
A clear example in open data would be an urban mobility API. Checking the status of a stop or traffic at a specific point involves little data and limited impact. On the other hand, downloading the entire vehicle position history of a city at once for several years is a much greater load on the system, even if it is done in a single call.
For this reason, many platforms introduce quotas based on the volume of data transferred, type of operation, or query weight. This avoids situations where seemingly moderate usage places a disproportionate load on the system.
How does all this fit in with open data?
At this point, the question inevitably arises: is data still open when all these layers of control exist?
The answer depends less on technology and more on the rules of the game. Open data is not defined by the total absence of technical control, but by principles such as non-discriminatory access, the absence of economic barriers, clarity in licensing, and the real possibility of reuse.
Requesting an API Key, limiting flow, or applying contextual controls does not contradict these principles if done in a transparent and equitable manner. In fact, in many cases it is the only way to guarantee that the service continues to exist and function correctly in the medium and long term.
The key is in balance: clear rules, free access, reasonable limits and mechanisms designed to protect the service, not to exclude. When this balance is achieved, control is no longer perceived as a barrier and becomes a natural part of an ecosystem of open, useful and sustainable data.
Content created by Juan Benavente, senior industrial engineer and expert in technologies related to the data economy. The content and views expressed in this publication are the sole responsibility of the author.
Blog
Cities, infrastructures and the environment today generate a constant flow of data from sensors, transport networks, weather stations and Internet of Things (IoT) platforms, understood as networks of physical devices (digital traffic lights, air quality sensors, etc.) capable of measuring and transmitting information through digital systems. This growing volume of information makes it possible to improve the provision of public services, anticipate emergencies, plan the territory and respond to challenges associated with climate, mobility or resource management.
The increase in connected sources has transformed the nature of geospatial data. In contrast to traditional sets – updated periodically and oriented towards reference cartography or administrative inventories – dynamic data incorporate the temporal dimension as a structural component. An observation of air quality, a level of traffic occupancy or a hydrological measurement not only describes a phenomenon, but also places it at a specific time. The combination of space and time makes these observations fundamental elements for operating systems, predictive models and analyses based on time series.
In the field of open data, this type of information poses both opportunities and specific requirements. Opportunities include the possibility of building reusable digital services, facilitating near-real-time monitoring of urban and environmental phenomena, and fostering a reuse ecosystem based on continuous flows of interoperable data. The availability of up-to-date data also increases the capacity for evaluation and auditing of public policies, by allowing decisions to be contrasted with recent observations.
However, the opening of geospatial data in real time requires solving problems derived from technological heterogeneity. Sensor networks use different protocols, data models, and formats; the sources generate high volumes of observations with high frequency; and the absence of common semantic structures makes it difficult to cross-reference data between domains such as mobility, environment, energy or hydrology. In order for this data to be published and reused consistently, an interoperability framework is needed that standardizes the description of observed phenomena, the structure of time series, and access interfaces.
The open standards of the Open Geospatial Consortium (OGC) provide that framework. They define how to represent observations, dynamic entities, multitemporal coverages or sensor systems; establish APIs based on web principles that facilitate the consultation of open data; and allow different platforms to exchange information without the need for specific integrations. Its adoption reduces technological fragmentation, improves coherence between sources and favours the creation of public services based on up-to-date data.
Interoperability: The basic requirement for opening dynamic data
Public administrations today manage data generated by sensors of different types, heterogeneous platforms, different suppliers and systems that evolve independently. The publication of geospatial data in real time requires interoperability that allows information from multiple sources to be integrated, processed and reused. This diversity causes inconsistencies in formats, structures, vocabularies and protocols, which makes it difficult to open the data and reuse it by third parties. Let's see which aspects of interoperability are affected:
- Technical interoperability: refers to the ability of systems to exchange data using compatible interfaces, formats and models. In real-time data, this exchange requires mechanisms that allow for fast queries, frequent updates, and stable data structures. Without these elements, each flow would rely on ad hoc integrations, increasing complexity and reducing reusability.
- The Semantic interoperability: Dynamic data describe phenomena that change over short periods – traffic levels, weather parameters, flows, atmospheric emissions – and must be interpreted consistently. This implies having observation models, Vocabularies and common definitions that allow different applications to understand the meaning of each measurement and its units, capture conditions or constraints. Without this semantic layer, the opening of data in real time generates ambiguity and limits its integration with data from other domains.
- Structural interoperability: Real-time data streams tend to be continuous and voluminous, making it necessary to represent them as time series or sets of observations with consistent attributes. The absence of standardized structures complicates the publication of complete data, fragments information and prevents efficient queries. To provide open access to these data, it is necessary to adopt models that adequately represent the relationship between observed phenomenon, time of observation, associated geometry and measurement conditions.
- Interoperability in access via API: it is an essential condition for open data. APIs must be stable, documented, and based on public specifications that allow for reproducible queries. In the case of dynamic data, this layer guarantees that the flows can be consumed by external applications, analysis platforms, mapping tools or monitoring systems that operate in contexts other than the one that generates the data. Without interoperable APIs, real-time data is limited to internal uses.
Together, these levels of interoperability determine whether dynamic geospatial data can be published as open data without creating technical barriers.
OGC Standards for Publishing Real-Time Geospatial Data
The publication of georeferenced data in real time requires mechanisms that allow any user – administration, company, citizens or research community – to access them easily, with open formats and through stable interfaces. The Open Geospatial Consortium (OGC) develops a set of standards that enable exactly this: to describe, organize and expose spatial data in an interoperable and accessible way, which contributes to the openness of dynamic data.
What is OGC and why are its standards relevant?
The OGC is an international organization that defines common rules so that different systems can understand, exchange and use geospatial data without depending on specific technologies. These rules are published as open standards, which means that any person or institution can use them. In the realm of real-time data, these standards make it possible to:
- Represent what a sensor measures (e.g., temperature or traffic).
- Indicate where and when the observation was made.
- Structure time series.
- Expose data through open APIs.
- Connect IoT devices and networks with public platforms.
Together, this ecosystem of standards allows geospatial data – including data generated in real time – to be published and reused following a consistent framework. Each standard covers a specific part of the data cycle: from the definition of observations and sensors, to the way data is exposed using open APIs or web services. This modular organization makes it easier for administrations and organizations to select the components they need, avoiding technological dependencies and ensuring that data can be integrated between different platforms.
The OGC API family: Modern APIs for accessing open data
Within OGC, the newest line is family OGC API, a set of modern web interfaces designed to facilitate access to geospatial data using URLs and formats such as JSON or GeoJSON, common in the open data ecosystem.
Estas API permiten:
- Get only the part of the data that matters.
- Perform spatial searches ("give me only what's in this area").
- Access up-to-date data without the need for specialized software.
- Easily integrate them into web or mobile applications.
In this report: "How to use OGC APIs to boost geospatial data interoperability", we already told you about some of the most popular OGP APIs. While the report focuses on how to use OGC APIs for practical interoperability, this post expands the focus by explaining the underlying OGC data models—such as O&M, SensorML, or Moving Features—that underpin that interoperability.
On this basis, this post focuses on the standards that make this fluid exchange of information possible, especially in open data and real-time contexts. The most important standards in the context of real-time open data are:
|
OGC Standard |
What it allows you to do |
Primary use in open data |
|---|---|---|
|
OGC API – Features |
Query features with geometry; filter by time or space; get data in JSON/GeoJSON. |
Open publication of dynamic mobility data, urban inventories, static sensors. |
|
OGC API – Environmental Data Retrieval (EDR) |
Request environmental observations at a point, zone or time interval. |
Open data on meteorology, climate, air quality or hydrology. |
|
OGC SensorThings API |
Manage sensors and their time series; transmit large volumes of IoT data. |
Publication of urban sensors (air, noise, water, energy) in real time. |
|
OGC API – Connected Systems |
Describe networks of sensors, devices and associated infrastructures. |
Document the structure of municipal IoT systems as open data. |
|
OGC Moving Features |
Represent moving objects using space-time trajectories. |
Open mobility data (vehicles, transport, boats). |
|
WMS-T |
View maps that change over time. |
Publication of multi-temporal weather or environmental maps. |
Table 1. OGC Standards Relevant to Real-Time Geospatial Data
Models that structure observations and dynamic data
In addition to APIs, OGC defines several conceptual data models that allow you to consistently describe observations, sensors, and phenomena that change over time:
- O&M (Observations & Measurements): A model that defines the essential elements of an observation—measured phenomenon, instant, unity, and result—and serves as the semantic basis for sensor and time series data.
- SensorML: Language that describes the technical and operational characteristics of a sensor, including its location, calibration, and observation process.
- Moving Features: A model that allows mobile objects to be represented by means of space-time trajectories (such as vehicles, boats or fauna).
These models make it easy for different data sources to be interpreted uniformly and combined in analytics and applications.
The value of these standards for open data
Using OGC standards makes it easier to open dynamic data because:
- It provides common models that reduce heterogeneity between sources.
- It facilitates integration between domains (mobility, climate, hydrology).
- Avoid dependencies on proprietary technology.
- It allows the data to be reused in analytics, applications, or public services.
- Improves transparency by documenting sensors, methods, and frequencies.
- It ensures that data can be consumed directly by common tools.
Together, they form a conceptual and technical infrastructure that allows real-time geospatial data to be published as open data, without the need to develop system-specific solutions.
Real-time open geospatial data use cases
Real-time georeferenced data is already published as open data in different sectoral areas. These examples show how different administrations and bodies apply open standards and APIs to make dynamic data related to mobility, environment, hydrology and meteorology available to the public.
Below are several domains where Public Administrations already publish dynamic geospatial data using OGC standards.
Mobility and transport
Mobility systems generate data continuously: availability of shared vehicles, positions in near real-time, sensors for crossing in cycle lanes, traffic gauging or traffic light intersection status. These observations rely on distributed sensors and require data models capable of representing rapid variations in space and time.
OGC standards play a central role in this area. In particular, the OGC SensorThings API allows you to structure and publish observations from urban sensors using a uniform model – including devices, measurements, time series and relationships between them – accessible through an open API. This makes it easier for different operators and municipalities to publish mobility data in an interoperable way, reducing fragmentation between platforms.
The use of OGC standards in mobility not only guarantees technical compatibility, but also makes it possible for this data to be reused together with environmental, cartographic or climate information, generating multi-thematic analyses for urban planning, sustainability or operational transport management.
Example:
The open service of Toronto Bike Share, which publishes in SensorThings API format the status of its bike stations and vehicle availability.
Here each station is a sensor and each observation indicates the number of bicycles available at a specific time. This approach allows analysts, developers or researchers to integrate this data directly into urban mobility models, demand prediction systems or citizen dashboards without the need for specific adaptations.
Air quality, noise and urban sensors
Networks for monitoring air quality, noise or urban environmental conditions depend on automatic sensors that record measurements every few minutes. In order for this data to be integrated into analytics systems and published as open data, consistent models and APIs need to be available.
In this context, services based on OGC standards make it possible to publish data from fixed stations or distributed sensors in an interoperable way. Although many administrations use traditional interfaces such as OGC WMS to serve this data, the underlying structure is usually supported by observation models derived from the Observations & Measurements (O&M) family, which defines how to represent a measured phenomenon, its unit and the moment of observation.
Example:
The service Defra UK-AIR Sensor Observation Service provides access to near-real-time air quality measurement data from on-site stations in the UK.
The combination of O&M for data structure and open APIs for publication makes it easier for these urban sensors to be part of broader ecosystems that integrate mobility, meteorology or energy, enabling advanced urban analyses or environmental dashboards in near real-time.
Water cycle, hydrology and risk management
Hydrological systems generate crucial data for risk management: river levels and flows, rainfall, soil moisture or information from hydrometeorological stations. Interoperability is especially important in this domain, as this data is combined with hydraulic models, weather forecasting, and flood zone mapping.
To facilitate open access to time series and hydrological observations, several agencies use OGC API – Environmental Data Retrieval (EDR), an API designed to retrieve environmental data using simple queries at points, areas, or time intervals.
Example:
The USGS (United States Geological Survey), which documents the use of OGC API – EDR to access precipitation, temperature, or hydrological variable series.
This case shows how EDR allows you to request specific observations by location or date, returning only the values needed for analysis. While the USGS's specific hydrology data is served through its proprietary API, this case demonstrates how EDR fits into the hydrometeorological data structure and how it is applied in real operational flows.
The use of OGC standards in this area allows dynamic hydrological data to be integrated with flood zones, orthoimages or climate models, creating a solid basis for early warning systems, hydraulic planning and risk assessment.
Weather observation and forecasting
Meteorology is one of the domains with the highest production of dynamic data: automatic stations, radars, numerical prediction models, satellite observations and high-frequency atmospheric products. To publish this information as open data, the OGC API family is becoming a key element, especially through OGC API – EDR, which allows observations or predictions to be retrieved in specific locations and at different time levels.
Example:
The service NOAA OGC API – EDR, which provides access to weather data and atmospheric variables from the National Weather Service (United States).
This API allows data to be consulted at points, areas or trajectories, facilitating the integration of meteorological observations into external applications, models or services based on open data.
The use of OGC API in meteorology allows data from sensors, models, and satellites to be consumed through a unified interface, making it easy to reuse for forecasting, atmospheric analysis, decision support systems, and climate applications.
Best Practices for Publishing Open Geospatial Data in Real-Time
The publication of dynamic geospatial data requires adopting practices that ensure its accessibility, interoperability, and sustainability. Unlike static data, real-time streams have additional requirements related to the quality of observations, API stability, and documentation of the update process. Here are some best practices for governments and organizations that manage this type of data.
- Stable open formats and APIs: The use of OGC standards – such as OGC API, SensorThings API or EDR – makes it easy for data to be consumed from multiple tools without the need for specific adaptations. APIs must be stable over time, offer well-defined versions, and avoid dependencies on proprietary technologies. For raster data or dynamic models, OGC services such as WMS, WMTS, or WCS are still suitable for visualization and programmatic access.
- DCAT-AP and OGC Models Compliant Metadata: Catalog interoperability requires describing datasets using profiles such as DCAT-AP, supplemented by O&M-based geospatial and observational metadata or SensorML. This metadata should document the nature of the sensor, the unit of measurement, the sampling rate, and possible limitations of the data.
- Quality, update frequency and traceability policies: dynamic datasets must explicitly indicate their update frequency, the origin of the observations, the validation mechanisms applied and the conditions under which they were generated. Traceability is essential for third parties to correctly interpret data, reproduce analyses and integrate observations from different sources.
- Documentation, usage limits, and service sustainability: Documentation should include usage examples, query parameters, response structure, and recommendations for managing data volume. It is important to set reasonable query limits to ensure the stability of the service and ensure that management can maintain the API over the long term.
- Licensing aspects for dynamic data: The license must be explicit and compatible with reuse, such as CC BY 4.0 or CC0. This allows dynamic data to be integrated into third-party services, mobile applications, predictive models or services of public interest without unnecessary restrictions. Consistency in the license also facilitates the cross-referencing of data from different sources.
These practices allow dynamic data to be published in a way that is reliable, accessible, and useful to the entire reuse community.
Dynamic geospatial data has become a structural piece for understanding urban, environmental and climatic phenomena. Its publication through open standards allows this information to be integrated into public services, technical analyses and reusable applications without the need for additional development. The convergence of observation models, OGC APIs, and best practices in metadata and licensing provides a stable framework for administrations and reusers to work with sensor data reliably. Consolidating this approach will allow progress towards a more coherent, connected public data ecosystem that is prepared for increasingly demanding uses in mobility, energy, risk management and territorial planning.
Content created by Mayte Toscano, Senior Consultant in Technologies related to the data economy. The content and views expressed in this publication are the sole responsibility of the author.
Blog
Web API design is a fundamental discipline for the development of applications and services, facilitating the fluid exchange of data between different systems. In the context of open data platforms, APIs are particularly important as they allow users to access the information they need automatically and efficiently, saving costs and resources.
This article explores the essential principles that should guide the creation of effective, secure and sustainable web APIs, based on the principles compiled by the Technical Architecture Group linked to the World Wide Web Consortium (W3C), following ethical and technical standards. Although these principles refer to API design, many are applicable to web development in general.
The aim is to enable developers to ensure that their APIs not only meet technical requirements, but also respect users' privacy and security, promoting a safer and more efficient web for all.
In this post, we will look at some tips for API developers and how they can be put into practice.
Prioritise user needs
When designing an API, it is crucial to follow the hierarchy of needs established by the W3C:
- First, the needs of the end-user.
- Second, the needs of web developers.
- Third, the needs of browser implementers.
- Finally, theoretical purity.
In this way we can drive a user experience that is intuitive, functional and engaging. This hierarchy should guide design decisions, while recognising that sometimes these levels are interrelated: for example, an API that is easier for developers to use often results in a better end-user experience.
Ensures security
Ensuring security when developing an API is crucial to protect both user data and the integrity of the system. An insecure API can be an entry point for attackers seeking to access sensitive information or compromise system functionality. Therefore, when adding new functionalities, we must meet the user's expectations and ensure their security.
In this sense, it is essential to consider factors related to user authentication, data encryption, input validation, request rate management (or Rate Limiting, to limit the number of requests a user can make in a given period and avoid denial of service attacks), etc. It is also necessary to continually monitor API activities and keep detailed logs to quickly detect and respond to any suspicious activity.
Develop a user interface that conveys trust and confidence
It is necessary to consider how new functionalities impact on user interfaces. Interfaces must be designed so that users can trust and verify that the information provided is genuine and has not been falsified. Aspects such as the address bar, security indicators and permission requests should make it clear who you are interacting with and how.
For example, the JavaScript alert function, which allows the display of a modal dialogue box that appears to be part of the browser, is a case history that illustrates this need. This feature, created in the early days of the web, has often been used to trick users into thinking they are interacting with the browser, when in fact they are interacting with the web page. If this functionality were proposed today, it would probably not be accepted because of these security risks.
Ask for explicit consent from users
In the context of satisfying a user need, a website may use a function that poses a threat. For example, access to the user's geolocation may be helpful in some contexts (such as a mapping application), but it also affects privacy.
In these cases, the user's consent to their use is required. To do this:
- The user must understand what he or she is accessing. If you cannot explain to a typical user what he or she is consenting to in an intelligible way, you will have to reconsider the design of the function.
- The user must be able to choose to effectively grant or refuse such permission. If a permission request is rejected, the website will not be able to do anything that the user thinks they have dismissed.
By asking for consent, we can inform the user of what capabilities the website has or does not have, reinforcing their confidence in the security of the site. However, the benefit of a new feature must justify the additional burden on the user in deciding whether or not to grant permission for a feature.
Uses identification mechanisms appropriate to the context
It is necessary to be transparent and allow individuals to control their identifiers and the information attached to them that they provide in different contexts on the web.
Functionalities that use or rely on identifiers linked to data about an individual carry privacy risks that may go beyond a single API or system. This includes passively generated data (such as your behaviour on the web) and actively collected data (e.g. through a form). In this regard, it is necessary to understand the context in which they will be used and how they will be integrated with other web functionalities, ensuring that the user can give appropriate consent.
It is advisable to design APIs that collect the minimum amount of data necessary and use short-lived temporary identifiers, unless a persistent identifier is absolutely necessary.
Creates functionalities compatible with the full range of devices and platforms
As far as possible, ensure that the web functionalities are operational on different input and output devices, screen sizes, interaction modes, platforms and media, favouring user flexibility.
For example, the 'display: block', 'display: flex' and 'display: grid' layout models in CSS, by default, place content within the available space and without overlaps. This way they work on different screen sizes and allow users to choose their own font and size without causing text overflow.
Add new capabilities with care
Adding new capabilities to the website requires consideration of existing functionality and content, to assess how it will be integrated. Do not assume that a change is possible or impossible without first verifying it.
There are many extension points that allow you to add functionality, but there are changes that cannot be made by simply adding or removing elements, because they could generate errors or affect the user experience. It is therefore necessary to verify the current situation first, as we will see in the next section.
Before removing or changing functionality, understand its current use
It is possible to remove or change functions and capabilities, but the nature and extent of their impact on existing content must first be understood. This may require investigating how current functions are used.
The obligation to understand existing use applies to any function on which the content depends. Web functions are not only defined in the specifications, but also in the way users use them.
Best practice is to prioritise compatibility of new features with existing content and user behaviour. Sometimes a significant amount of content may depend on a particular behaviour. In these situations, it is not advisable to remove or change such behaviour.
Leave the website better than you found it
The way to add new capabilities to a web platform is to improve the platform as a whole, e.g. its security, privacy or accessibility features.
The existence of a defect in a particular part of the platform should not be used as an excuse to add or extend additional functionalities in order to fix it, as this may duplicate problems and diminish the overall quality of the platform. Wherever possible, new web capabilities should be created that improve the overall quality of the platform, mitigating existing shortcomings across the board.
Minimises user data
Functionalities must be designed to be operational with the minimal amount of user input necessary to achieve their objectives. In doing so, we limit the risks of disclosure or misuse.
It is recommended to design APIs so that websites find it easier to request, collect and/or transmit a small amount of data (more granular or specific data), than to work with more generic or massive data. APIs should provide granularity and user controls, in particular if they work on personal data.
Other recommendations
The document also provides tips for API design using various programming languages. In this sense, it provides recommendations linked to HTML, CSS, JavaScript, etc. You can read the recommendations here.
In addition, if you are thinking of integrating an API into your open data platform, we recommend reading the Practical guide to publishing Open Data using APIs.
By following these guidelines, you will be able to develop consistent and useful websites for users, allowing them to achieve their objectives in an agile and resource-optimised way.
Documentación
In a world where geospatial information is crucial to address global challenges such as climate change and natural resource management, interoperability and the creation of standards are essential. Interoperability facilitates collaboration between organisations, drives innovation and ensures that data are accessible and usable by all. The Open Geospatial Consortium (OGC) plays a vital role in this context, developing open standards that ensure compatibility and efficient exchange of geospatial data.
One of the standards offered by OGC are a series of APIs which represent a significant advance in the management and sharing of geospatial data. Designed to facilitate the access and use of geographic data via the web, these APIs use modern technologies such as REST and JSON, making them compatible with a wide variety of applications and platforms. In addition, OGC APIs promote interoperability, scalability and security, facilitating the integration and analysis of real-time geospatial data.
The OGC is currently working with the implementation of the standards following the concept of Building Blocks, which are modular components designed to facilitate the creation and management of geospatial data and related services. These building blocks provide a standard and reusable framework that allows for efficient integration and operation of location data in various applications and systems. Its advantages include interoperability, reusability, efficiency and accuracy in geospatial data management.
In Spain, the implementation of API OGCs is progressing successfully in various institutions and sectors. Organisations such as the National Centre for Geographic Information with the publication of the products of the National Cartographic System, the SDI of Navarre and the SDI of Catalonia have already adopted these standards to improve the management and accessibility of geospatial data. The integration of spatial information with other types of data, such as statistical data, provides a more complete and useful view for decision making, significantly improving the quality and usefulness of geospatial applications.
In summary, the new OGC standards and Building Blocks offer numerous benefits that improve the efficiency, interoperability and quality of geospatial applications and services. These benefits extend to developers, organisations and end users, promoting a more integrated and robust geospatial ecosystem. Adopting these standards ensures that solutions are interoperable, reusable and accessible in the long term, benefiting the entire geospatial community.
This is the central theme of the report "How to use OGC APIs to improve the interoperability of geospatial data", which explains how OGC APIs work, also approaching the concept of Building Blocks, with the aim of enabling the reader to implement their use in their organisation. You can read the full report here.
To explore the content of the report in greater depth, we have recorded a podcast and a video interview in which the author explains the key points of the Decalogue. In addition, an infographic and an executive summary have been produced.
Listen to the podcast with the author (in Spanish)
Watch the video-interview with the author
Documentación
Blog
What challenges do data publishers face?
In today's digital age, information is a strategic asset that drives innovation, transparency and collaboration in all sectors of society. This is why data publishing initiatives have developed enormously as a key mechanism for unlocking the potential of this data, allowing governments, organisations and citizens to access, use and share it.
However, there are still many challenges for both data publishers and data consumers. Aspects such as the maintenance of APIs(Application Programming Interfaces) that allow us to access and consume published datasets or the correct replication and synchronisation of changing datasets remain very relevant challenges for these actors.
In this post, we will explore how Linked Data Event Streams (LDES), a new data publishing mechanism, can help us solve these challenges. what exactly is LDES? how does it differ from traditional data publication practices? And, most importantly, how can you help publishers and consumers of data to facilitate the use of available datasets?
Distilling the key aspects of LDES
When Ghent University started working on a new mechanism for the publication of open data, the question they wanted to answer was: How can we make open data available to the public? What is the best possible API we can design to expose open datasets?
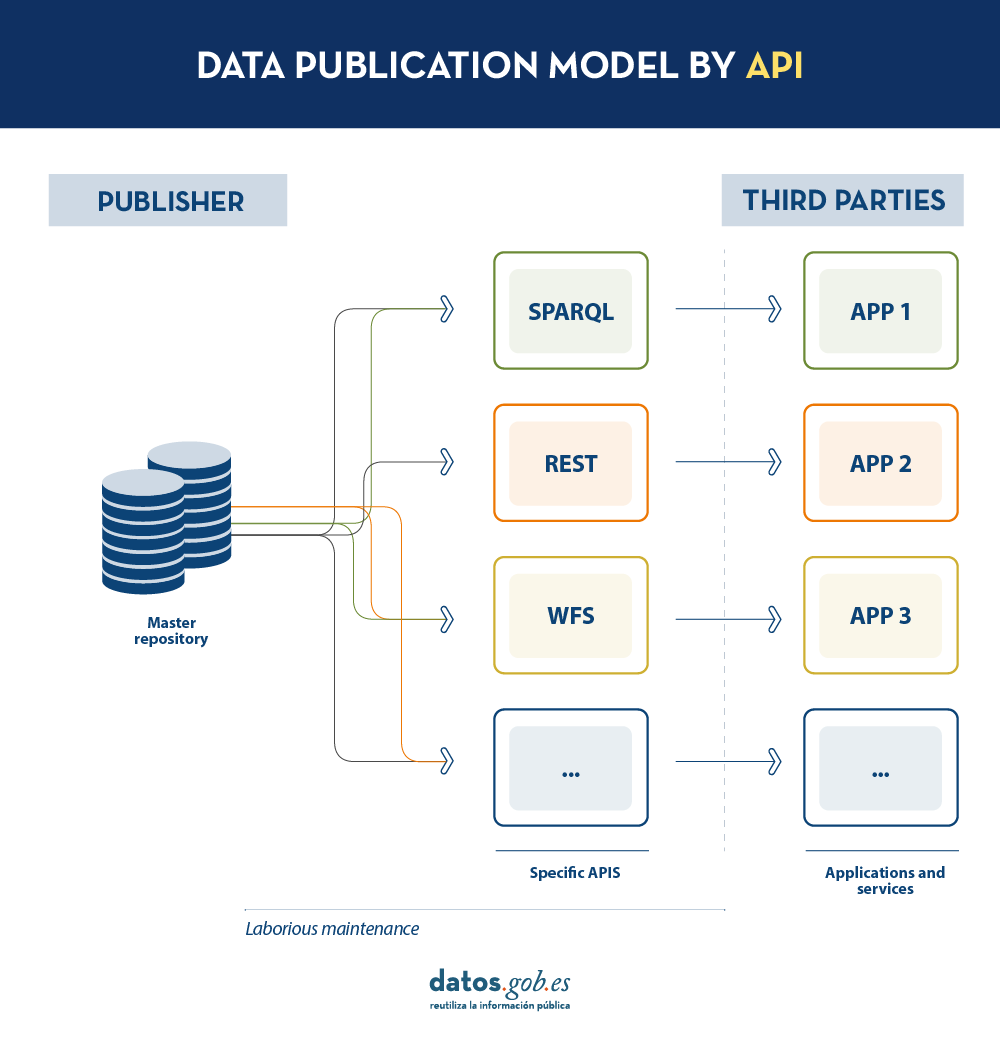
Today, data publishers use multiple mechanisms to publish their different datasets. On the one hand, it is easy to find APIs. These include SPARQL, a standard for querying linked data(Link Data), but also REST or WFS, for accessing datasets with a geospatial component. On the other hand, it is very common that we find the possibility to access data dumps in different formats (i.e. CSV, JSON, XLS, etc.) that we can download for use.
In the case of data dumps, it is very easy to encounter synchronisation problems. This occurs when, after a first dump, a change occurs that requires modification of the original dataset, such as changing the name of a street in a previously downloaded street map. Given this change, if the third party chooses to modify the street name on the initial dump instead of waiting for the publisher to update its data in the master repository to perform a new dump, the data handled by the third party will be out of sync with the data handled by the publisher. Similarly, if it is the publisher that updates its master repository but these changes are not downloaded by the third party, both will handle different versions of the dataset.
On the other hand, if the publisher provides access to data through query APIs, rather than through data dumps to third parties, synchronisation problems are solved, but building and maintaining a high and varied volume of query APIs is a major effort for data publishers.
LDES seeks to solve these different problems by applying the concept of Linked Data to an event stream . According to the definition in its own specification, a Linked Data Event Stream (LDES) is a collection of immutable objects where each object is described in RDF terns.
Firstly, the fact that the LDES are committed to Linked Data provides design principles that allow combining diverse data and/or data from different sources, as well as their consultation through semantic mechanisms that allow readability by both humans and machines. In short, it provides interoperability and consistency between datasets, thus facilitating search and discovery.
On the other hand, the event streams or data streams, allow consumers to replicate the history of datasets, as well as synchronise recent changes. Any new record added to a dataset, or any modification of existing records (in short, any change), is recorded as a new incremental event in the LDES that will not alter previous events. Therefore, data can be published and consumed as a sequence of events, which is useful for frequently changing data, such as real-time information or information that undergoes constant updates, as it allows synchronisation of the latest updates without the need for a complete re-download of the entire master repository after each modification.
In such a model, the publisher will only need to develop and maintain one API, the LDES, rather than multiple APIs such as WFS, REST or SPARQL. Different third parties wishing to use the published data will connect (each third party will implement its LDES client) and receive the events of the streams to which they have subscribed. Each third party will create from the information collected the specific APIs it deems appropriate based on the type of applications they want to develop or promote. In short, the publisher will not have to solve all the potential needs of each third party in the publication of data, but by providing an LDES interface (minimum base API), each third party will focus on its own problems.
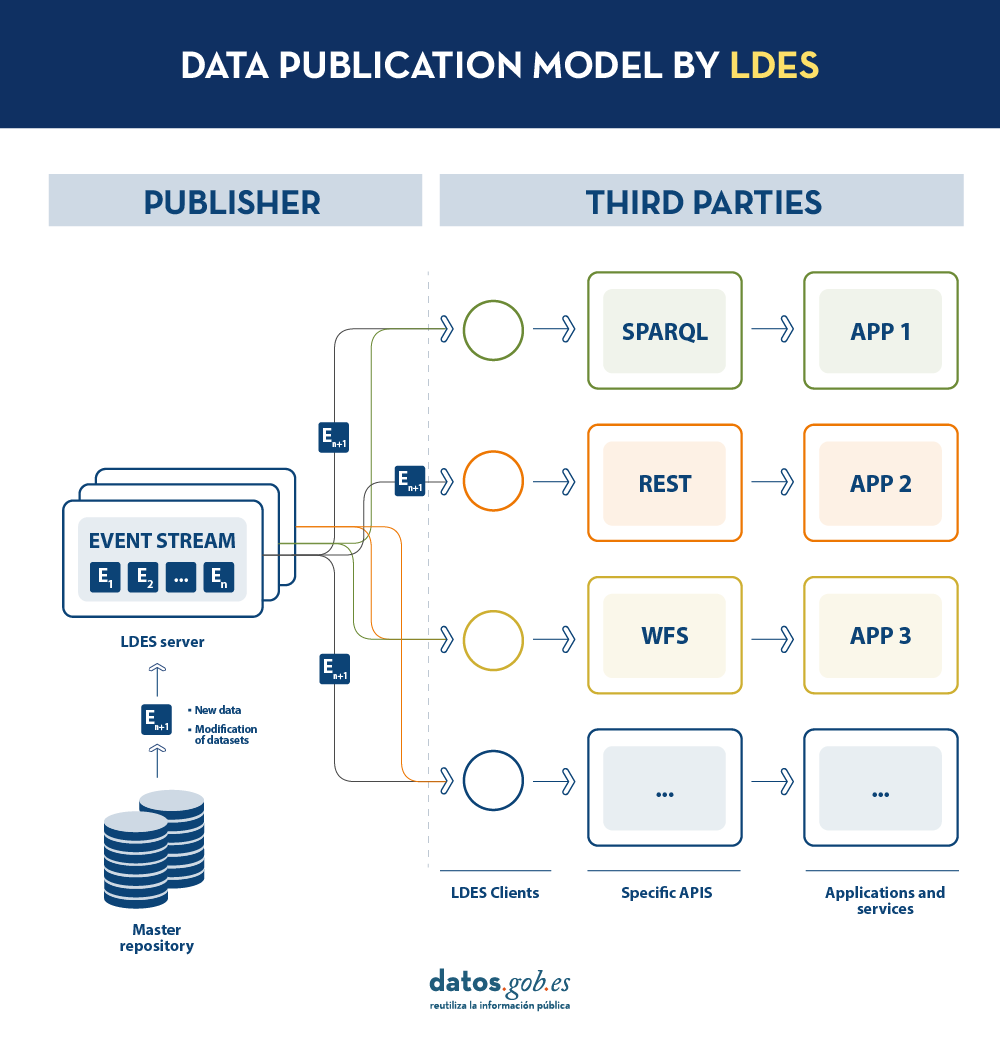
In addition, to facilitate access to large volumes of data or to data that may be distributed across different sources, such as an inventory of electric charging points in Europe, LDES provides the ability to fragment datasets. Through the TREE specification, LDES allows different types of relationships between data fragments to be established. This specification allows publishing collections of entities, called members, and provides the ability to generate one or more representations of these collections. These representations are organised as views, distributing the members through pages or nodes interconnected by relationships. Thus, if we want the data to be searchable through temporal indexes, it is possible to set a temporal fragmentation and access only the pages of a temporal interval. Similarly, alphabetical or geospatial indexes can be provided and a consumer can access only the data needed without the need to 'dump' the entire dataset.
What conclusions can we draw from LDES?
In this post we have looked at the potential of LDES as a mechanism for publishing data. Some of the most relevant learnings are:
- LDES aims to facilitate the publication of data through minimal base APIs that serve as a connection point for any third party wishing to query or build applications and services on top of datasets.
- The construction of an LDES server, however, has a certain level of technical complexity when it comes to establishing the necessary architecture for the handling of published data streams and their proper consultation by data consumers.
- The LDES design allows the management of both high rate of change data (i.e. data from sensors) and low rate of change data (i.e. data from a street map). Both scenarios can handle any modification of the dataset as a data stream.
- LDES efficiently solves the management of historical records, versions and fragments of datasets. This is based on the TREE specification, which allows different types of fragmentation to be established on the same dataset.
Would you like to know more?
Here are some references that have been used to write this post and may be useful to the reader who wishes to delve deeper into the world of LDES:
- Linked Data Event Streams: the core API for publishing base registries and sensor data, Pieter Colpaert. ENDORSE, 2021. https://youtu.be/89UVTahjCvo?si=Yk_Lfs5zt2dxe6Ve&t=1085
- Webinar on LDES and Base registries. Interoperable Europe, 17 January 2023. https://www.youtube.com/watch?v=wOeISYms4F0&ab_channel=InteroperableEurope
- SEMIC Webinar on the LDES specification. Interoperable Europe, 21 April 2023. https://www.youtube.com/watch?v=jjIq63ZdDAI&ab_channel=InteroperableEurope
- Linked Data Event Streams (LDES). SEMIC Support Centre. https://joinup.ec.europa.eu/collection/semic-support-centre/linked-data-event-streams-ldes
- Publishing data with Linked Data Event Streams: why and how. EU Academy. https://academy.europa.eu/courses/publishing-data-with-linked-data-event-streams-why-and-how
Content prepared by Juan Benavente, senior industrial engineer and expert in technologies linked to the data economy. The contents and points of view reflected in this publication are the sole responsibility of the author.
Blog
The INSPIRE (Infrastructure for Spatial Information in Europe) Directive sets out the general rules for the establishment of an Infrastructure for Spatial Information in the European Community based on the Infrastructures of the Member States. Adopted by the European Parliament and the Council on 14 March 2007 (Directive 2007/2/EC), it entered into force on 25 April 2007.
INSPIRE makes it easier to find, share and use spatial data from different countries. The information is available through an online portal where it can be found broken down into different formats and topics of interest.
To ensure that these data are compatible and interoperable in a Community and cross-border context, the Directive requires the adoption of common Implementing Rules specific to the following areas:
- Metadata
- Data sets
- Network services
- Data sharing and services
- Spatial data services
- Monitoring and reporting
The technical implementation of these standards is done through Technical Guidelines, technical documents based on international standards and norms.
Inspire and semantic interoperability
These rules are considered Commission decisions or regulations and are therefore binding in each EU country. The transposition of this Directive into Spanish law is developed through Law 14/2010 of 5 July, which refers to the infrastructures and geographic information services of Spain (LISIGE) and the IDEE portal, both of which are the result of the implementation of the INSPIRE Directive in Spain.
Semantic interoperability plays a decisive role in INSPIRE. Thanks to this, there is a common language in spatial data, as the integration of knowledge is only possible when a homogenisation or common understanding of the concepts that constitute a domain or area of knowledge is achieved. Thus, in INSPIRE, semantic interoperability is responsible for ensuring that the content of the information exchanged is understood in the same way by any system.
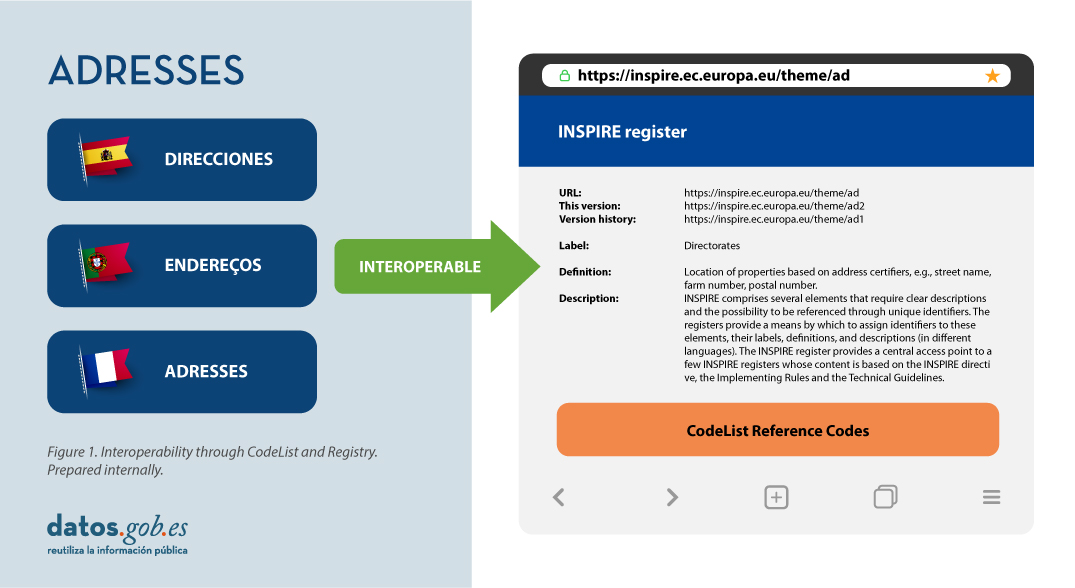
Therefore, in the implementation of spatial data models in INSPIRE, in GML exchange format, we can find codelists that are an important part of the INSPIRE data specifications and contribute substantially to interoperability.
In general, a codelist (or code list) contains several terms whose definitions are universally accepted and understood. Code lists promote data interoperability and constitute a shared vocabulary for a community. They can even be multilingual.
INSPIRE code lists are commonly managed and maintained in the central Federated INSPIRE Registry (ROR) which provides search capabilities, so that both end-users and client applications can easily access code list values for reference.
Registers are necessary because:
- They provide the codes defined in the Technical Guidelines, Regulations and Technical Specifications necessary to implement the Directive.
- They allow unambiguous references of the elements.
- Provides unique and persistent identifiers for resources.
- Enable consistent management and version control of different elements
The code lists used in INSPIRE are maintained at:
- The Inspire Central Federated Registry (ROR).
- The register of code lists of a member state,
- The list registry of a recognised external third party that maintains a domain-specific code list.
To add a new code list, you will need to set up your own registry or work with the administration of one of the existing registries to publish your code list. This can be quite a complicated process, but a new tool helps us in this task.
Re3gistry is a reusable open-source solution, released under EUPL, that allows companies and organisations to manage and share \"reference codes\" through persistent URIs, ensuring that concepts are unambiguously referenced in any domain and facilitating the management of these resources graphically throughout their lifecycle.
Funded by ELISE, ISA2 is a solution recognised by the Europeans in the Interoperability Framework as a supporting tool.
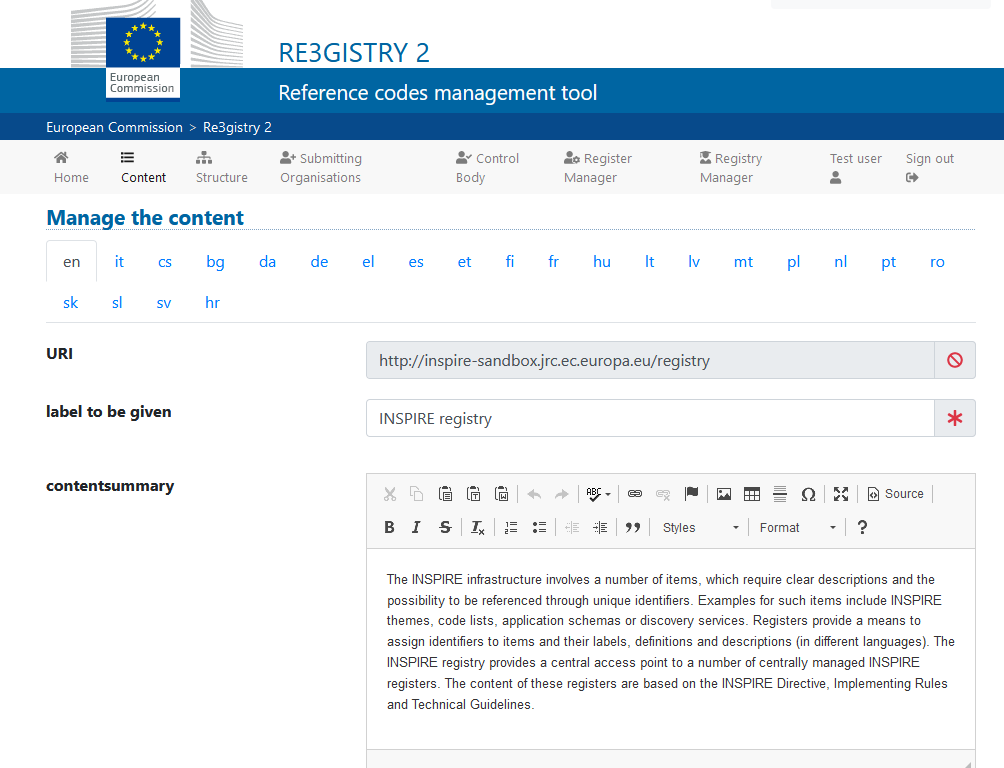
Illustration 3: Image of the Re3gister interface
Re3gistry is available for both Windows and Linux and offers an easy-to-use Web Interface for adding, editing, and managing records and reference codes. In addition, it allows the management of the complete lifecycle of reference codes (based on ISO 19135: 2005 Integrated procedures for the registration of reference codes)
The editing interface also provides a flag to allow the system to expose the reference code in the format that allows its integration with RoR, so that it can eventually be imported into the INSPIRE registry federation. For this integration, Reg3gistry makes an export in a format based on the following specifications:
- The W3C Data Catalogue (DCAT) vocabulary used to model the entity registry (dcat:Catalog).
- The W3C Simple Knowledge Organisation System (SKOS) which is used to model the entity registry (skos:ConceptScheme) and the element (skos:Concept).
Other notable features of Re3gistry
- Highly flexible and customisable data models
- Multi-language content support
- Support for version control
- RESTful API with content negotiation (including OpenAPI 3 descriptor)
- Free-text search
- Supported formats: HTML, ISO 19135 XML, JSON
- Service formats can be easily added or customised (default formats): JSON and ISO 19135 XML
- Multiple authentication options
- Externally governed elements referenced through URIs
- INSPIRE record federation format support (option to automatically create RoR format)
- Easy data export and re-indexing (SOLR)
- Guides for users, administrators, and developers
- RSS feed
Ultimately, Re3gistry provides a central access point where reference code labels and descriptions are easily accessible to both humans and machines, while fostering semantic interoperability between organisations by enabling:
- Avoid common mistakes such as misspellings, entering synonyms or filling in online forms.
- Facilitate the internationalisation of user interfaces by providing multilingual labels.
- Ensure semantic interoperability in the exchange of data between systems and applications.
- Tracking changes over time through a well-documented version control system.
- Increase the value of reference codes if they are widely reused and referenced.
More about Re3gistry:




References
https://github.com/ec-jrc/re3gistry
https://inspire.ec.europa.eu/codelist
https://ec.europa.eu/isa2/solutions/re3gistry_en/
https://live.osgeo.org/en/quickstart/re3gistry_quickstart.html
Content prepared by Mayte Toscano, Senior Consultant in Technologies linked to the data economy.
The contents and views expressed in this publication are the sole responsibility of the author.
Blog
We continue with the series of posts about Chat GPT-3. The expectation raised by the conversational system more than justifies the publication of several articles about its features and applications. In this post, we take a closer look at one of the latest news published by openAI related to Chat GPT-3. In this case, we introduce its API, that is, its programming interface with which we can integrate Chat GPT-3 into our own applications.
Introduction.
In our last post about Chat GPT-3 we carried out a co-programming or assisted programming exercise in which we asked the AI to write us a simple program, in R programming language, to visualise a set of data. As we saw in the post, we used Chat GTP-3's own available interface. The interface is very minimalistic and functional, we just have to ask the AI in the text box and it answers us in the subsequent text box. As we concluded in the post, the result of the exercise was more than satisfactory. However, we also detected some points for improvement. For example, the standard interface can be a bit slow. For a long exercise, with multiple conversational interactions with the AI (a long dialogue), the interface takes quite a long time to write the answers. Several users report the same feeling and so some, like this developer, have created their own interface with the conversational assistant to improve its response speed.
But how is this possible? The reason is simple, thanks to the GPT-3 Chat API. We have talked a lot about APIs in this space in the past. Not surprisingly, APIs are the standard mechanisms in the world of digital technologies for integrating services and applications. Any app on our smartphone makes use of APIs to show us results. When we consult the weather, sports results or the public transport timetable, apps make calls to the APIs of the services to consult the information and display the results.
The GPT-3 Chat API
Like any other current service, openAI provides its users with an API with which they can invoke (call) its different services based on the trained natural language model GPT-3. To use the API, we just have to log in with our account at https://platform.openai.com/ and locate the menu (top right) View API Keys. Click on create a new secret key and we have our new access key to the service.

What do we do now? Well, to illustrate what we can do with this brand new key, let's look at some examples:
As we said in the introduction, we may want to try alternative interfaces to Chat GPT-3 such as https://www.typingmind.com/. When we access this website, the first thing we have to do is enter our API Key.
Once inside, let's do an example and see how this new interface behaves. Let's ask Chat GPT-3 What is datos.gob.es?
| Note: It is important to note that most services will not work if we do not activate a means of payment on the OpenAI website. Normally, if we have not configured a credit card, the API calls will return an error message similar to \"You exceeded your current quota, please check your plan and billing details\". |

Let's now look at another application of the GPT-3 Chat API.
Programmatic access with R to access Chat GPT-3 programmatically (in other words, with a few lines of code in R we have access to the conversational power of the GPT-3 model). This demonstration is based on the recent post published in R Bloggers. Let's access Chat GPT-3 programmatically with the following example.
| Note: Note that the API Key has been hidden for security and privacy reasons. |

En este ejemplo, utilizamos código en R para hacer una llamada HTTPs de tipo POST y le preguntamos a Chat GPT-3 ¿Qué es datos.gob.es? Vemos que estamos utilizando el modelo gpt-3.5-turbo que, tal y como se especifica en la documentación está indicado para tareas de tipo conversacional. Toda la información sobre la API y los diferentes modelos está disponible aquí. Pero, veamos el resultado:

Not bad, right? As a curious fact we can see that a few GPT-3 Chat API calls have had the following API usage:

The use of the API is priced per token (something similar to words) and the public prices can be consulted here. Specifically, the model we are using has these prices:
For small tests and examples, we can afford it. In the case of enterprise applications for production environments, there is a premium model that allows you to control costs without being so dependent on usage.
Conclusion
Naturally, Chat GPT-3 enables an API to provide programmatic access to its conversational engine. This mechanism allows the integration of applications and systems (i.e. everything that is not human) opening the door to the definitive take-off of Chat GPT-3 as a business model. Thanks to this mechanism, the Bing search engine now integrates GPT-3 Chat for conversational search responses. Similarly, Microsoft Azure has just announced the availability of GPT-3 Chat as a new public cloud service. No doubt in the coming weeks we will see communications from all kinds of applications, apps and services, known and unknown, announcing their integration with GPT-3 Chat to improve conversational interfaces with their customers. See you in the next episode, maybe with GPT-4.
Documentación
In this article we compile a series of infographics aimed at both publishers and reusers working with open data. They show standards and good practices to facilitate both the publication and the processing of data.
How to publish open data on datos.gob.es
 |
Published: February 2026 This infographic outlines the recommended process for an agency to publish open data in the National Open Data Catalog hosted on datos.gob.es. The process is divided into five main phases: preliminary planning, agency and user registration, cataloging, federation, and maintenance. |
Technical guide: Data version control
 |
Published: January 2026 Data Version Control (DVC) allows you to record and document the complete evolution of a data set, facilitating collaboration, auditing, and recovery of previous versions. Without a clear system for managing these changes, it is easy to lose traceability. In this infographic, we explain how to implement DVC. |
DCAT-AP-ES: A step forward in open data interoperability
 |
Published: august 2025 This new metadata model adopts the guidelines of the European metadata exchange schema DCAT-AP (Data Catalog Vocabulary-Application Profile) with some additional restrictions and adjustments.
|
Guide for the deployment of data portals. Good practices and recommendations
 |
Published: april 2025 This infographic summarizes best practices and recommendations for designing, developing and deploying open data portals at the municipal level. Specifically, it includes: strategic framework, general requirements and technical and functional guidelines. |
Data Act (DA)
 |
Published: February 2024 The Data Act is a European Union regulation to facilitate data accessibility in a horizontal way. In other words, it establishes principles and guidelines for all sectors, emphasizing fair access to data, user rights and the protection of personal data. Find out what its keys are in this infographic. A one-page version has also been created for easy printing: click here. |
Data Governance Act (DGA)
 |
Published: January 2024 The European Data Governance Act (DGA) is a horizontal instrument to regulate the reuse of data and promote its exchange under the principles and values of the European Union (EU). Find out what are its keys in this infographic. A one-page version has also been created to make printing easier: click here. |
The keys to the UNE data specifications
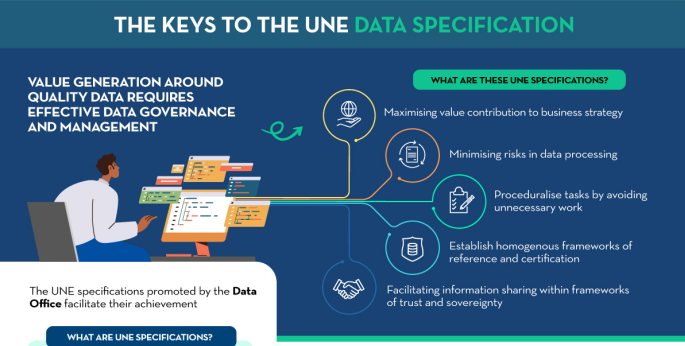 |
Published: September 2023 All types of institutions must have well-governed, managed data of adequate quality, requiring a common evaluation methodology. The following infographic summarizes the key aspects of the UNE Specifications on data and their main advantages. |
Main obligations of Law 37/2007
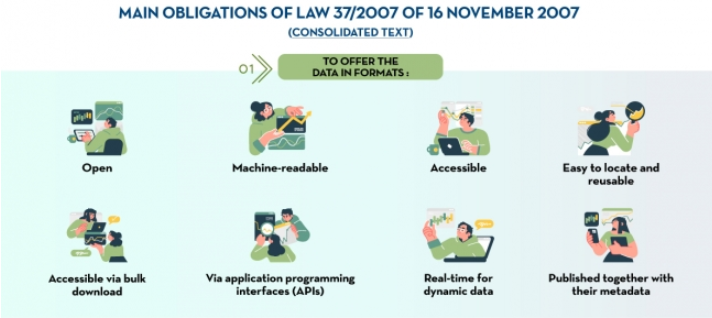 |
Published: March 2023 In accordance with the latest European Open Data Directive, Law 37/2007 has been amended to emphasize the concept of open data by design and by default. This infographic highlights the main changes in the legislation. |
How to create an action plan to drive openness and reuse of open data
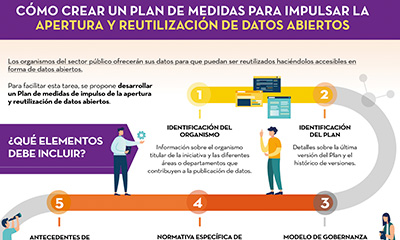 |
Published: November 2022 This infographic shows the different elements that should be included in a Plan of measures to promote openness and reuse of open data. The aim is that the units responsible for openness can draw up a feasible roadmap for open data, which also allows for its monitoring and evaluation. |
8 guides to improve data publication and processing
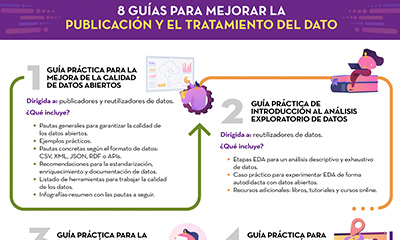 |
Published: October 2022 At datos.gob.es we have prepared different guides to help publishers and reusers when preparing data for publication and/or analysis. In this infographic we summarise the content of eight of them. |
General guidelines for quality assurance of open data
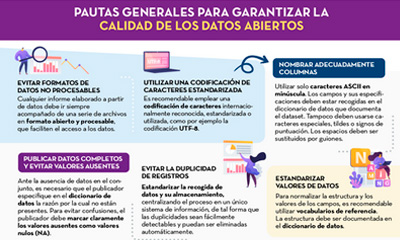 |
Published: September 2022 This infographic details general guidelines for ensuring the quality of open data, such as using standardised character encoding, avoiding duplicate records or incorporating variables with geographic information. |
Guidelines for quality assurance using specific data formats
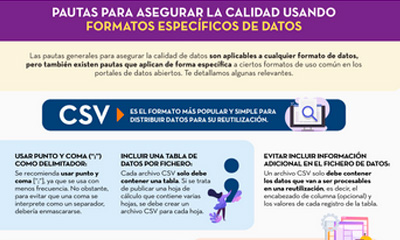 |
Published: September 2022 This infographic provides specific guidelines for ensuring the quality of open data according to the data format used. Specific guidelines have been included for CSV, XML, JSON, RDF and APIs. |
Technical standards for good data governance
 |
Published: May 2022 This infographic shows the standards to be taken into account for proper data governance, according to the Spanish Association for Standardisation (UNE). These standards are based on 4 principles: Governance, Management, Quality and Security and data privacy. |
APIs for open data access
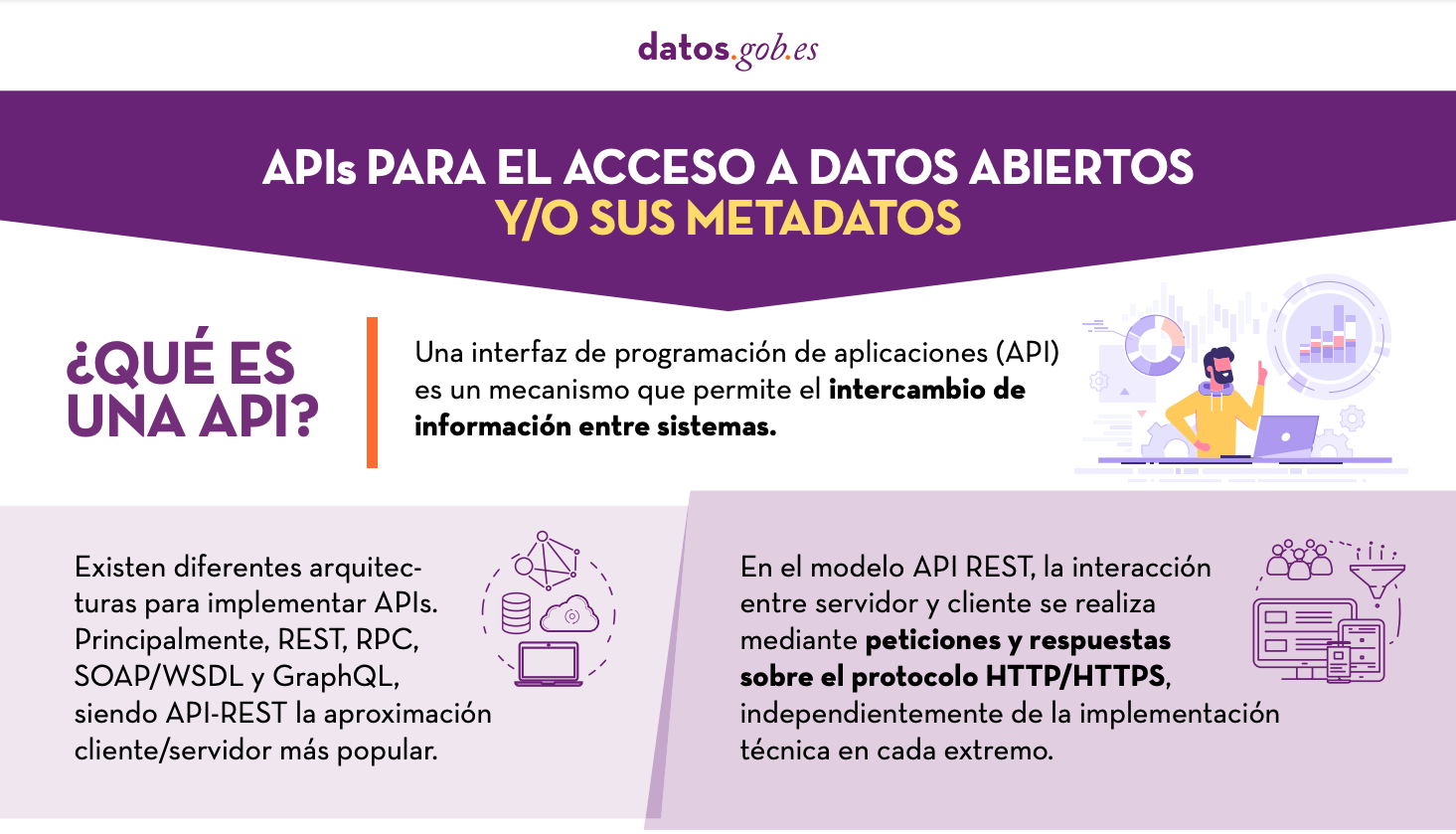 |
Published: January 2022 Many open data portals in Spain already have their own APIs to facilitate access to data and metadata. This infographic shows some examples at national, regional and local level, including information about the datos.gob.es API.. |