Comparte este contenido
Descripción
1. Introducción
Las visualizaciones son una representación gráfica que nos permite comunicar de una manera sencilla la información ligada a los datos. Mediante elementos visuales, como gráficos, mapas o nubes de palabras, las visualizaciones, también nos ayudan a comprender tendencias, patrones o valores atípicos que pueden presentar los datos.
Las visualizaciones se pueden generar a partir de datos de diferente naturaleza, como pueden ser las palabras que conforman una noticia, un libro o una canción. Para realizar visualizaciones a partir de este tipo de datos, es necesario que las maquinas, mediante programas de software, sean capaces de entender, interpretar y reconocer las palabras que configuran el lenguaje humano (escrito o hablado) en múltiples idiomas. El campo de estudio enfocado en el tratamiento de estos datos se denomina Procesamiento del Lenguaje Natural (PLN). Es un campo interdisciplinar que combina el poder de la inteligencia artificial, la lingüística computacional y la informática. Los sistemas basados en PLN han permitido grandes innovaciones como el buscador de Google, el asistente de voz de Amazon, los traductores automáticos, el análisis de sentimientos de diferentes redes sociales o incluso detección de spam en una cuenta de correo electrónico.
En este ejercicio práctico, vamos a implementar una visualización gráfica de un resumen de palabras clave representativas de varios textos extraídas mediante la aplicación de técnicas de PLN. En concreto, vamos a crear una nube de palabras que resuma cuál son los términos que más se repiten en varios posts del portal.
Esta visualización se engloba dentro de la serie de ejercicios prácticos, en los cuales se utilizan datos abiertos disponibles en el portal datos.gob.es. En estos se abordan y describen de manera sencilla las etapas necesarias para obtener los datos, realizar transformaciones y análisis que resulten pertinentes para la creación de la visualización, extrayendo la máxima información. En cada uno de los ejercicios prácticos se usan sencillos desarrollos de código que estarán convenientemente documentados, así como herramientas de uso libre y gratuito. Todo el material generado estará disponible para su reutilización en el repositorio Laboratorio de datos en GitHub.
2. Objetivos
El objetivo principal de este post es aprender a realizar una visualización que incluya imágenes, generadas a partir de conjuntos de palabras representativas de diversos textos, conocidas popularmente como “nubes de palabras”. Para este ejercicio práctico hemos escogido 6 post publicados en la sección de blog del portal de datos.gob.es. A partir de estos textos y utilizando técnicas de PLN generaremos una nube de palabras para cada texto que nos permitirá detectar de manera sencilla y visual la frecuencia e importancia de cada palabra, facilitando la identificación de las palabras clave y la temática principal de cada uno de los posts.

A partir de un texto construimos una nube de palabras aplicando técnicas de Procesamiento de Lenguaje Natural (PLN)
3. Recursos
3.1. Herramientas
Para la realización del tratamiento previo de los datos (entorno de trabajo, programación y redacción del mismo), como la visualización propiamente dicha, se utiliza Python (versión 3.7) y Jupyter Notebook (versión 6.1), herramientas que encontraras integradas en, junto con muchas otras, en Anaconda, una de las plataformas más populares para instalar, actualizar y administrar software para trabajar en ciencia de datos. Para abordar las tareas relacionadas con el Procesamiento del Lenguaje Natural, utilizamos dos librerías, Scikit-Learn (sklearn) y wordcloud. Todas estas herramientas son Open Source y están disponibles de manera gratuita.
Scikit-Learn es una amplia librería muy popular, diseñada principalmente para llevar a cabo tareas de aprendizaje automático sobre datos en forma de texto. Entre otros, cuenta con algoritmos para realizar tareas de clasificación, regresión, clustering y reducción de dimensionalidades. Además, está diseñada para el aprendizaje profundo sobre datos textuales, siendo útil para el manejo de conjuntos de características textuales en forma de matrices, la realización de tareas como el cálculo de similitudes, la clasificación de texto y la agrupación de clústeres. En Python, para realizar este tipo de tareas, también es posible trabajar con otras librerías igualmente populares como NLTK o spacy, entre otras.
wordcloud es una librería especializada en la creación de nubes de palabras utilizando un algoritmo simple y que puede ser modificado fácilmente.
Para favorecer el entendimiento de los lectores no especializados en programación, el código en Python que se incluye a continuación, al que puedes acceder haciendo click en el botón “Código” de cada sección, no está diseñado para maximizar su eficiencia, sino para facilitar su comprensión, por lo que es posible que lectores más avanzados en este lenguaje consideren formas alternativas más eficientes para codificar algunas funcionalidades. El lector podrá reproducir este análisis si lo desea, ya que el código fuente está disponible en la cuenta de GitHub de datos.gob.es. La forma de proporcionar el código es a través de un Jupyter Notebook, que una vez cargado en el entorno de desarrollo podrá ejecutarse o modificarse de manera sencilla si se desea.
3.2. Conjuntos de datos
Para este análisis se han seleccionado 6 posts publicados recientemente en el portal de datos abiertos datos.gob.es, en su sección de blog. Estos posts están relacionado con diferentes temáticas relativas a los datos abiertos:
- Lo último en el procesamiento del lenguaje natural: resúmenes de obras clásicas en tan solo unos cientos de palabras.
- La importancia de la anonimización y la privacidad de datos.
- El valor de los datos en tiempo real a través de un ejemplo práctico.
- Nuevas iniciativas para abrir y aprovechar datos para investigación en salud.
- Kaggle y otras plataformas alternativas para aprender ciencia de datos.
- La infraestructura de Datos Espaciales de España (IDEE), un referente de la información geoespacial.
4. Tratamiento de datos
Antes de lanzarnos a construir una visualización efectiva, debemos realizar un tratamiento previo de los datos o preprocesamiento de los datos, prestando atención a la obtención de los mismos, asegurando que no contienen errores y se encuentran en un formato adecuado para su procesamiento. Un tratamiento previo de los datos es esencial para construir cualquier representación visual efectiva y consistente.
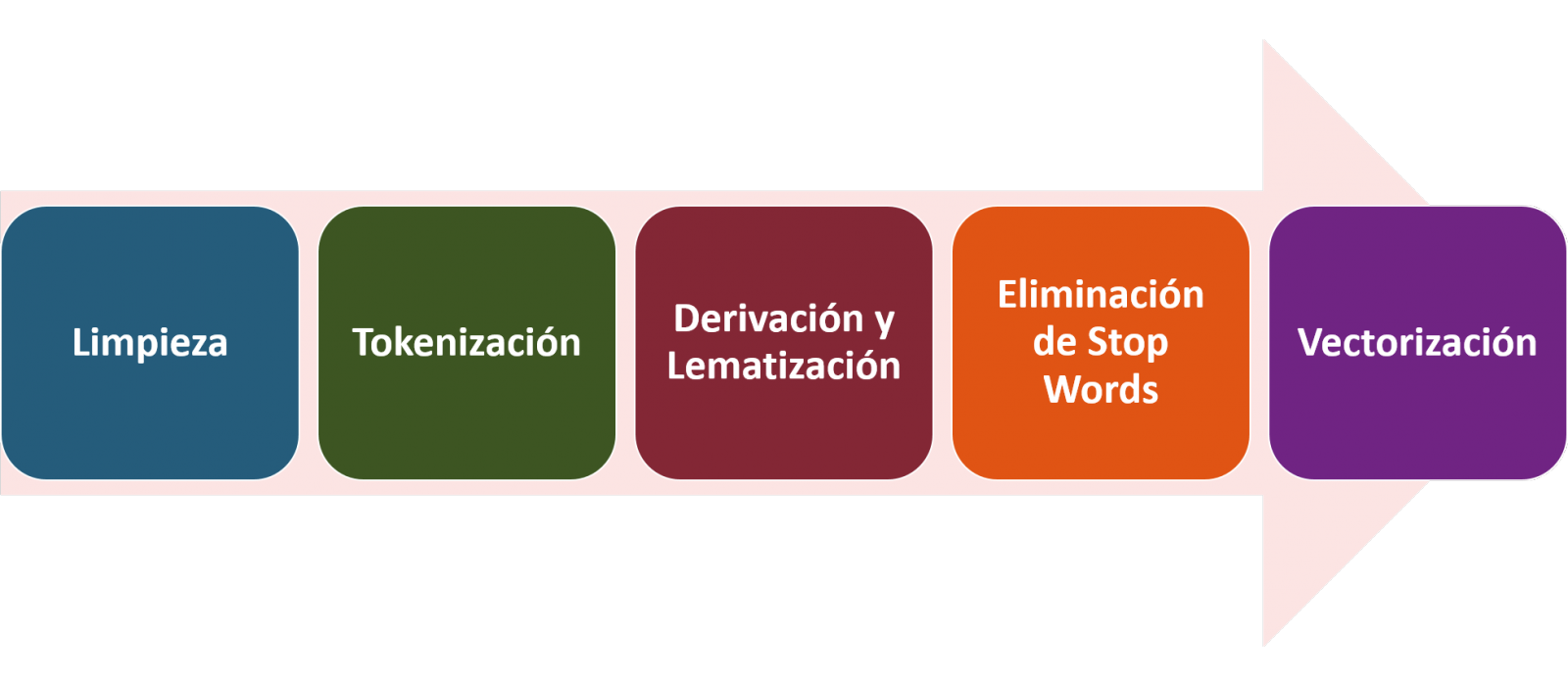
En PLN, el preprocesamiento de los datos consiste fundamentalmente en una serie de transformaciones que se realizan sobre los datos de entrada, en nuestro caso varios posts en formato TXT, con el objetivo de obtener datos uniformes y sin elementos que puedan afectar a la calidad de los resultados, con el fin de facilitar su posterior procesamiento para realizar tareas como, generar una nube de palabras, realizar minería de opiniones/sentimientos o generar resúmenes automatizados a partir de textos de entrada. De forma general, el flujograma que se sigue para realizar un preprocesamiento de texto incluye las siguientes etapas:
- Limpieza: eliminación de los caracteres y símbolos especiales que contribuyen a distorsionar los resultados, por ejemplo, los signos de puntuación.
- Tokenizar: la tokenización es el proceso de separar un texto en unidades más pequeñas, tokens. Los tokens pueden ser oraciones, palabras o incluso caracteres.
- Derivación y Lematización: este proceso consiste en transformar las palabras a su forma básica, es decir a su forma canónica o lema, eliminando plurales, tiempos verbales o géneros. Esta acción en ocasiones no es necesaria ya que no siempre se requiere para el procesamiento posterior saber la similitud semántica entre las diferentes palabras del texto.
- Eliminación de stop words: las stop words o palabras vacías son aquellas palabras de uso común pero que no contribuyen de una manera significativa en el texto. Estas palabras deben eliminarse antes del procesamiento del texto ya que no aportan ninguna información única que pueda ser usada para la clasificación o agrupación del texto, por ejemplo, los artículos determinantes como ‘los’, ‘las’, ‘una’ ‘unos’, etc.
- Vectorización: en este paso transformamos cada uno de los tokens obtenidos en el paso anterior a un vector de números reales que se genera en base a la frecuencia de la aparición de cada palabra en el texto. La vectorización permite que las maquinas sean capaces de procesar texto y aplicar, entre otras, técnicas de aprendizaje automático.
4.1. Instalación y carga de librerías
Antes de empezar con el preprocesamiento de datos, debemos importar las librerías con las cuales vamos a trabajar. Python dispone de una gran cantidad de librerías que permiten implementar funcionalidades para muchas tareas, como visualización de datos, Machine Learning, Deep Learning o Procesamiento del Lenguaje Natural, entre muchas otras. Las librerías que utilizaremos para este análisis y visualización son:
- os, que permite acceder a funcionalidades dependientes del sistema operativo, como manipular la estructura de directorios.
- re, proporciona funciones para procesar expresiones regulares.
- pandas, es una librería muy popular y esencial para procesar tablas de datos.
- string, proporciona una serie de funciones muy útiles para el manejo de cadenas de caracteres.
- matplotlib.pyplot, contiene una colección de funciones que nos permitirán generar las representaciones gráficas de las nubes de palabras.
- sklearn.feature_extraction.text (librería Scikit-Learn), convierte una colección de documentos de texto en una matriz de vectores. De esta librería usaremos algunos comandos que comentaremos más adelante.
- wordcloud, librería con la cual podremos generar la nube de palabras.
# Importaremos las librerías necesarias para realizar este análisis y la visualización. import os import re import pandas as pd import string import matplotlib.pyplot as plt from sklearn.feature_extraction.text import CountVectorizer from sklearn.feature_extraction.text import TfidfTransformer from wordcloud import WordCloud4.2. Carga de datos
Una vez cargadas las librerías, preparamos los datos con los cuales vamos a trabajar. Antes de comenzar a cargar los datos, en el directorio de trabajo debemos tener: (a) una carpeta denominada “post” que contendrá todos los archivos en formato TXT con los cuales vamos a trabajar y que están disponibles en el repositorio de este proyecto del GitHub de datos.gob.es; (b) un archivo denominado “stop_words_spanish.txt” que contiene el listado de las stop words en español, que también está disponible en dicho repositorio y (c) una carpeta llamada “imagenes” donde guardaremos las imágenes de las nubes de palabras en formato PNG, que crearemos a continuación.
# Generamos la carpeta \"imagenes\".nueva_carpeta = \"imagenes/\" try: os.mkdir(nueva_carpeta)except OSError: print (\"Ya existe una carpeta llamada %s\" % nueva_carpeta)else: print (\"Se ha creado la carpeta: %s\" % nueva_carpeta)Seguidamente, procederemos a cargar los datos. Los datos de entrada, como ya hemos comentado anteriormente, se encuentran en ficheros TXT y cada fichero contiene un post. Como queremos realizar el análisis y la visualización de varios posts al mismo tiempo, cargaremos en nuestro entorno de desarrollo todos los textos que nos interesen, para posteriormente insertarlos en una única tabla o dataframe.
# Generamos una lista donde incluiremos todos los archivos que debe leer, indicándole la carpeta donde se encuentran.filePath = []for file in os.listdir(\"./post/\"): filePath.append(os.path.join(\"./post/\", file))# Generamos un dataframe en el cual incluiremos una fila por cada post.post_df = pd.DataFrame()for file in filePath: with open (file, \"rb\") as readFile: post_df = pd.DataFrame([readFile.read().decode(\"utf8\")], append(post_df)# Nombramos la columna que contiene los textos en el dataframe.post_df.columns = [\"texto\"]4.3. Preprocesamiento de datos
Para el objetivo que nos hemos planteado, generar nubes de palabras para cada post, vamos a realizar las siguientes tareas de preprocesamiento.
a) Limpieza de datos
Una vez generada la tabla que contiene los textos con los cuales vamos a trabajar, debemos eliminar el ruido ajeno al texto que nos interesa: caracteres especiales, signos de puntuación y retornos de carro.
En primer lugar, ponemos en minúscula todos los caracteres para evitar cualquier error en los procesos que distinguen entre mayúsculas y minúsculas, mediante el uso del comando lower().
Seguidamente eliminamos los signos de puntuación, como puntos, comas, exclamaciones, interrogaciones, entre muchos otros. Para la eliminación de estos recurriremos a la cadena preinicializada string.punctuacion de la librería string, que devuelve un conjunto de símbolos considerados signos de puntuación. Además, debemos eliminar las tabulaciones, saltos de carro y espacios extra, que no aportan información en este análisis, mediante el uso de expresiones regulares.
Es fundamental aplicar todos estos pasos en una única función para que se procesen de forma secuencial, debido a que todos los procesos están altamente relacionados.
# Eliminamos los signos de puntuación, los saltos de carro/tabulaciones y espacios en blanco extra.# Para ello generamos una función en la cual indicamos todos los cambios que queremos aplicar al texto.def limpiar_texto(texto): texto = texto.lower() texto = re.sub(\"\\[.*?¿\\]\\%\", \" \", texto) texto = re.sub(\"[%s]\" % re.escape(string.punctuation), \" \", texto) texto re.sub(\"\\w*\\d\\w*\", \" \", texto) return texto# Aplicamos los cambios al texto.limpiar_texto = lambda x: limpiar_texto(x)post_clean = pd.DataFrame(post_clean.texto.apply/limpiar_texto)b) Tokenizar
Una vez que hemos eliminado el ruido en los textos con los cuales vamos a trabajar, “tokenizaremos” en palabras cada uno de los textos. Para ello utilizaremos la funció split(), usando como separador entre palabras, el espacio. Esto permitirá separar las palabras de manera independiente (tokens) para análisis futuros.
# Tokenizar los textos. Se crea una nueva columna en la tabla con los tokens con el texto \"tokenizado\".def tokenizar(text): text = texto.split(sep = \" \") return(text)post_df[\"texto_tokenizado\"] = post_df[\"texto\"].apply(lambda x: tokenizar(x))c) Eliminación de \"stop words\"
Después de eliminar los signos de puntuación y otros elementos que pueden distorsionar la visualización objetivo, eliminaremos las “stop words” o palabras vacías. Para la realización de este paso usamos una lista de stop words del castellano dado que cada idioma posee su propia lista. Esta lista consta de un total de 608 palabras, en las que se incluyen artículos, preposiciones, verbos copulativos, adverbios, entre otros y está actualizada recientemente. Esta lista puede descargarse desde la cuenta de GitHub de datos.gob.es en formato TXT y debe estar ubicada en el directorio de trabajo.
# Leemos el archivo que contiene las palabras vacías en castellano.with open \"stop_words_spanish.txt\", encoding = \"UTF8\") as f: lines = f.read().splitlines()En esta lista de palabras, incluiremos nuevas palabras que no aportan información relevante a nuestros textos o aparecen recurrentemente debido al contexto de los mismos. En este caso, existe una serie de palabras, que nos conviene eliminar ya que están presentes en todos los posts de manera repetitiva dado que todos tratan sobre el tema de datos abiertos y existe una alta probabilidad de que éstas sean las palabras más significativas. Algunas de estas palabras son, “datos”, “dato”, “abiertos”, “caso”, entre otras. Esto permitirá obtener una representación gráfica más representativa del contenido de cada post.
Por otro lado, una inspección visual de los resultados obtenidos permite detectar palabras o caracteres derivados de errores incluidos en los textos, que evidentemente no tienen significado y que no han sido eliminados en los pasos anteriores. Estos, deben ser retirados del análisis para que no distorsionen los resultados posteriores. Se trata de palabras como, “nen”, “nun” o “nla”.
# Actualizamos nuestra lista de stop words.stop_words.extend((\"caso\", \"forma\",\"unido\", \"abiertos\", \"post\", \"espera\", \"datos\", \"dato\", \"servicio\", \"nun\", \"día\", \"nen\", \"data\", \"conjuntos\", \"importantes\", \"unido\", \"unión\", \"nla\", \"r\", \"n\"))# Eliminamos las stop words de nuestra tabla.post_clean = post_clean [~(post_clean[\"texto_tokenizado\"].isin(stop_words))]d) Vectorización
Las maquinas no son capaces de comprender palabras y oraciones, por lo que estas deben convertirse en alguna estructura numérica. El método consiste en generar vectores a partir de cada token. En este post utilizamos una técnica sencilla conocida como bolsa de palabras (BoW). Consiste en asignar un peso a cada token proporcional a la frecuencia de aparición de dicho token en el texto. Para ello, trabajamos sobre una matriz en la que cada fila representa un texto y cada columna un token. Para realizar la vectorización recurriremos a los comandos CountVectorizer() y TfidTransformer() de la lirería Scikit-Learn.
La función CountVectorizer() permite transformar un texto en un vector de frecuencias o recuentos de palabras. En este caso obtendremos 6 vectores con tantas dimensiones como tokens hay en cada texto, uno por cada post, que integraremos en una única matriz, donde las columnas serán los tokens o palabras y las filas serán los posts.
# Calculamos la matriz de frecuencia de palabras del texto.vectorizador = CountVectorizer()post_vec = vectorizador.fit_transform(post_clean.texto_tokenizado)Una vez generada la matriz de frecuencia de palabras, es necesario convertirla en una forma vectorial normalizada con el objetivo de reducir el impacto de los tokens que ocurren con mucha frecuencia en el texto. Para ello utilizaremos la función TfidfTransformer().
# Convertimos una matriz de frecuencia de palabras en una forma vectorial regularizada.transformer = TfidfTransformer()post_trans = transformer.fit_transform(post_vec).toarray()Si quieres saber más sobre la importancia de aplicar está técnica, encontrarás numerosos artículos en Internet que hablan sobre ello y lo relevante que es, entre otras cuestiones, para la optimización de SEO.
5. Creación de la nube de palabras
Una vez que hemos realizado un preprocesamiento del texto, como indicábamos al inicio del post, es posible realizar tareas propias de PLN. En este ejercicio crearemos una nube de palabras o “WordCloud” para cada uno de los textos analizados.
Una nube de palabras, es una representación visual de las palabras con mayor número de ocurrencias en el texto. Permite detectar de manera sencilla la frecuencia e importancia de cada una de las palabras, facilitando la identificación de las palabras clave y descubriendo con un solo golpe de vista la temática principal tratada en el texto.
Para ello vamos a utilizar la librería “wordcloud” que incorpora las funciones necesarias para construir cada representación. En primer lugar, debemos indicar las características que presentará cada nube de palabras, como es el color de fondo (función background_color), el mapa de colores que tomaran las palabras (función colormap), el tamaño máximo de letra (función max_font_size) o fijar una semilla para que la nube de palabras generada siempre sea igual (función random_state) en futuras ejecuciones. Podemos aplicar estas y muchas otras funciones para personalizar cada nube de palabras.
# Indicamos las características que presentará cada nube de palabras.wc = WordCloud(stopwords = stop_words, background_color = \"black\", colormap = \"hsv\", max_font_size = 150, random_state = 123)Una vez que hemos indicado las características que queremos que presente cada nube de palabras, procedemos a crearla y guardarla como imagen en formato PNG. Para generar la nube de palabras, usaremos un bucle en el cual le indicaremos diferentes funciones de la librería matplotlib (representada por el prefijo plt) necesarias para generar gráficamente la nube de palabras según la especificación definida en el paso anterior. Debemos indicarle que debe realizar una nube de palabras por cada fila de la tabla, es decir por cada texto, con la función plt.subplot(). Con el comando plt.imshow() indicamos que el resultado es una imagen en 2D. Si queremos que no se muestren los ejes debemos indicárselo con la función plt.axis(). Por último, con la función plt.savefig() guardaremos la visualización generada.
# Generamos las nubes de palabras para cada uno de los posts.for index, i in enumerate(post.columns): wc.generate(post.texto_tokenizado[i]) plt.subplot(3, 2, index+1 plt.imshow(wc, interpolation = \"bilinear\") plt.axis(\"off\") plt.savefig(\"imagenes/.png\")# Mostramos las nubes de palabras resultantes.plt.show()La visualización obtenida es:

Visualización de las nubes de palabras obtenidas a partir de los textos de diferentes posts de la sección de blog de datos.gob.es
5. Conclusiones
La visualización de datos es uno de los mecanismos más potentes para explotar y analizar el significado implícito de los datos, independientemente del tipo de dato y el grado de conocimiento tecnológico del usuario. Las visualizaciones nos permiten construir significado sobre los datos y la creación de narrativas basadas en la representación gráfica.
Las nubes de palabras son una herramienta que permite agilizar el análisis de datos textuales, puesto que a través de ellas podemos identificar e interpretar de manera rápida y sencilla las palabras con mayor relevancia en el texto analizado, lo que nos da una idea de la temática.
Si quieres aprender más sobre el Procesamiento del Lenguaje Natural, puedes consultar la guía \"Tecnologías emergentes y datos abiertos: Procesamiento del lenguaje natural\" y los posts \"Procesamiento del lenguaje natural\" y \"Lo último en procesamiento del lenguaje natural: resúmenes de obras clásicas en tan solo unos cuentos de palabras\".
Esperemos que esta visualización paso a paso te haya enseñado algunas cosas sobre los entresijos del Procesamiento del Lenguaje Natural y la creación de nubes de palabras. Volveremos para mostraros nuevas reutilizaciones de datos. ¡Hasta pronto!
Documentación
| Código fuente en Python | 6.28 KB | RMD |
|

Comentarios