Blog
Los datos abiertos son una pieza central de la innovación digital en torno a la inteligencia artificial ya que permiten, entre otras cosas, entrenar modelos o evaluar algoritmos de aprendizaje automático. Pero entre “descargar un CSV de un portal” y acceder a un conjunto de datos listo para aplicar técnicas de aprendizaje automático hay, todavía, un abismo.
Buena parte de ese abismo tiene que ver con los metadatos, es decir cómo se describen los conjuntos de datos (a qué nivel de detalle y con qué estándares). Si los metadatos se limitan a título, descripción y licencia, el trabajo de comprensión y preparación de datos se hace más complejo y tedioso para la persona que diseña el modelo de aprendizaje automático. Si, en cambio, se usan estándares que faciliten la interoperabilidad, como DCAT, los datos se vuelven más FAIR (Findable, Accessible, Interoperable, Reusable) y, por tanto, más fáciles de reutilizar. No obstante, es necesario metadatos adicionales para que los datos sean más fáciles de integrar en flujos de aprendizaje automático.
Este artículo realiza un itinerario por las diversas iniciativas y estándares necesarios para dotar a los datos abiertos de metadatos útiles para la aplicación de técnicas de aprendizaje automático.
DCAT como columna vertebral de los portales de datos abiertos
El vocabulario DCAT (Data Catalog Vocabulary) fue diseñado por la W3C para facilitar la interoperabilidad entre catálogos de datos publicados en la Web. Describe catálogos, conjuntos de datos y distribuciones, siendo la base sobre la que se construyen muchos portales de datos abiertos.
En Europa, DCAT se concreta en el perfil de aplicación DCAT-AP, recomendado por la Comisión Europea y ampliamente adoptado para describir conjuntos de datos en el sector público, por ejemplo, en España con DCAT-AP-ES. Con DCAT-AP se responde a preguntas como:
- ¿Qué conjuntos de datos existen sobre un tema concreto?
- ¿Quién los publica, bajo qué licencia y en qué formatos?
- ¿Dónde están las URL de descarga o las API de acceso?
El uso de un estándar como DCAT es imprescindible para descubrir conjuntos de datos, pero es necesario ir un paso más allá con el fin de saber cómo se utilizan en modelos de aprendizaje automático o qué calidad tienen desde la perspectiva de estos modelos.
MLDCAT-AP: aprendizaje automático en el catálogo de un portal de datos abiertos
MLDCAT-AP (Machine Learning DCAT-AP) es un perfil de aplicación de DCAT desarrollado por SEMIC y la comunidad Interoperable Europe, en colaboración con OpenML, que extiende DCAT-AP al dominio del aprendizaje automático.
MLDCAT-AP incorpora clases y propiedades para describir:
- Modelos de aprendizaje automático y sus características.
- Conjuntos de datos utilizados en el entrenamiento y la evaluación.
- Métricas de calidad obtenidas sobre los conjuntos de datos.
- Publicaciones y documentación asociadas a los modelos de aprendizaje automático.
- Conceptos relacionados con riesgo, transparencia y cumplimiento del contexto regulatorio europeo del AI Act.
Con ello, un catálogo basado en MLDCAT-AP ya no solo responde a “qué datos hay”, sino también a:
- ¿Qué modelos se han entrenado con este conjunto de datos?
- ¿Cuál ha sido el rendimiento de ese modelo según determinadas métricas?
- ¿Dónde se describe este trabajo (artículos científicos, documentación, etc.)?
MLDCAT-AP representa un gran avance en trazabilidad y gobernanza, pero se mantiene la definición de metadatos a un nivel que todavía no considera la estructura interna de los conjuntos de datos ni qué significan exactamente sus campos. Para eso, se necesita bajar a nivel de la propia estructura de la distribución de conjunto de datos.
Metadatos a nivel de estructura interna del conjunto de datos
Cuando se quiere describir qué hay dentro de las distribuciones de los conjuntos de datos (campos, tipos, restricciones), una iniciativa interesante es Data Package, parte del ecosistema de Frictionless Data.
Un Data Package se define por un archivo JSON que describe un conjunto de datos. En este archivo se incluyen no sólo metadatos generales (como el nombre, título, descripción o licencia) y recursos (es decir, los ficheros de datos con su ruta o una URL de acceso a su correspondiente servicio), sino también se define un esquema con:
- Nombres de campos.
- Tipos de datos (integer, number, string, date, etc.).
- Restricciones, como rangos de valores válidos, claves primarias y ajenas, etc.
Desde la óptica del aprendizaje automático, esto se traduce en la posibilidad de realizar una validación estructural automática antes de usar los datos. Además, también permite una documentación precisa de la estructura interna de cada conjunto de datos y mayor facilidad para compartir y versionar conjuntos de datos.
En resumen, mientras que MLDCAT-AP indica qué conjuntos de datos existen y cómo encajan en el ámbito de modelos de aprendizaje automático, Data Package especifica exactamente “qué hay” dentro de los conjuntos de datos.
Croissant: metadatos que preparan datos abiertos para aprendizaje automático
Aun con el concurso de MLDCAT-AP y de Data Package, faltaría conectar los conceptos subyacentes en ambas iniciativas. Por una parte, el ámbito del aprendizaje automático (MLDCAT-AP) y por otro el de las estructuras internas de los propios datos (Data Package). Es decir, se puede estar usando los metadatos de MLDCAT-AP y de Data Package pero para solventar algunas limitaciones que adolecen ambos, es necesario complementarlo. Aquí entra en juego Croissant, un formato de metadatos para preparar los conjuntos de datos para la aplicación de aprendizaje automático. Croissant está desarrollado en el marco de MLCommons, con participación de industria y academia.
Específicamente, Croissant se implementa en JSON-LD y se construye sobre schema.org/Dataset, un vocabulario para describir conjuntos de datos en la Web. Croissant combina los siguientes metadatos:
- Metadatos generales del conjunto de datos.
- Descripción de recursos (archivos, tablas, etc.).
- Estructura de los datos.
- Capa semántica sobre aprendizaje automático (separación de datos de entrenamiento/validación/test, campos objetivo, etc.)
Cabe destacar que Croissant está diseñado para que distintos repositorios (como Kaggle, HuggingFace, etc.) puedan publicar conjuntos de datos en un formato que las librerías de aprendizaje automático (TensorFlow, PyTorch, etc.) puedan cargar de forma homogénea. También existe una extensión de CKAN para usar Croissant en portales de datos abiertos.
Otras iniciativas complementarias
Merece la pena mencionar brevemente otras iniciativas interesantes relacionadas con la posibilidad de disponer de metadatos que permitan preparar a los conjuntos de datos para la aplicación de aprendizaje automático (“ML-ready datasets”):
- schema.org/Dataset: usado en páginas web y repositorios para describir conjuntos de datos. Es la base sobre la que se apoya Croissant y está integrado, por ejemplo, en las directrices de datos estructurados de Google para mejorar la localización de conjuntos de datos en buscadores.
- CSV on the Web (CSVW): conjunto de recomendaciones del W3C para acompañar ficheros CSV con metadatos en JSON (incluyendo diccionarios de datos), muy alineado con las necesidades de documentación de datos tabulares que luego se usan en aprendizaje automático.
- Datasheets for Datasets y Dataset Cards: iniciativas que permiten desarrollar una documentación narrativa y estructurada para describir el contexto, la procedencia y las limitaciones de los conjuntos de datos. Estas iniciativas son ampliamente adoptadas en plataformas como Hugging Face.
Conclusiones
Existen diversas iniciativas que ayudan a realizar una definición de metadatos adecuada para el uso de aprendizaje automático con datos abiertos:
- DCAT-AP y MLDCAT-AP articulan el nivel de catálogo, modelos de aprendizaje automático y métricas.
- Data Package describe y valida la estructura y restricciones de los datos a nivel de recurso y campo.
- Croissant conecta estos metadatos con el flujo de aprendizaje automático, describiendo cómo los conjuntos de datos son ejemplos concretos para cada modelo.
- Iniciativas como CSVW o Dataset Cards complementan las anteriores y son ampliamente utilizadas en plataformas como HuggingFace.
Estas iniciativas pueden usarse de manera combinada. De hecho, si se adoptan de forma conjunta, se permite que los datos abiertos dejen de ser simplemente “ficheros descargables” y se conviertan en una materia prima preparada para el aprendizaje automático, reduciendo fricción, mejorando la calidad y aumentando la confianza en los sistemas de IA construidos sobre ellos.
Jose Norberto Mazón, Catedrático de Lenguajes y Sistemas Informáticos de la Universidad de Alicante. Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Blog
Los datos son un recurso fundamental para mejorar nuestra calidad de vida porque permiten mejorar los procesos de toma de decisiones para crear productos y servicios personalizados, tanto en el sector público como en el privado. En contextos como la salud, la movilidad, la energía o la educación, el uso de datos facilita soluciones más eficientes y adaptadas a las necesidades reales de las personas. No obstante, en el trabajo con datos, la privacidad juega un papel clave. En este post, analizaremos cómo los espacios de datos, el paradigma de computación federada y el aprendizaje federado, una de sus aplicaciones más potentes, plantean una solución equilibrada para aprovechar el potencial de los datos sin poner en riesgo la privacidad. Además, resaltaremos cómo el aprendizaje federado también puede usarse con datos abiertos para mejorar su reutilización de forma colaborativa, incremental y eficiente.
La privacidad, clave en la gestión de datos
Como se ha mencionado anteriormente, el uso intensivo de datos exige una creciente atención a la privacidad. Por ejemplo, en salud digital, un mal uso secundario de datos de historias clínicas electrónicas podría vulnerar derechos fundamentales de pacientes. Una forma eficaz de preservar la privacidad es mediante ecosistemas de datos que prioricen la soberanía de los datos, como es el caso de los espacios de datos. Un espacio de datos es un sistema de gestión federada de datos que permite su intercambio de manera confiable entre proveedores y consumidores. Además, el espacio de datos garantiza la interoperabilidad de los datos para crear productos y servicios que generen valor. En un espacio de datos, cada proveedor mantiene sus propias normas de gobernanza, conservando el control sobre sus datos (es decir, la soberanía sobre sus datos), a la vez que se posibilita su reutilización por consumidores. Esto implica que cada proveedor debe poder decidir qué datos comparte, con quién y bajo qué condiciones, garantizando el cumplimiento de sus intereses y obligaciones legales.
Computación federada y espacios de datos
Los espacios de datos representan una evolución en la gestión de datos, relacionada con un paradigma denominado computación federada (federated computing), donde los datos se reutilizan sin necesidad de que haya un trasiego de datos desde los proveedores de datos hacia los consumidores. En la computación federada, los proveedores transforman sus datos en resultados intermedios que preservan la privacidad con el fin de poder ser enviados a los consumidores de datos. Además, esto posibilita que puedan aplicarse otras técnicas de mejora de la privacidad de datos (Privacy-Enhancing Technologies). La computación federada se alinea perfectamente con arquitecturas de referencia como Gaia-X y su Trust Framework, que establece los principios y requisitos para garantizar un intercambio de datos seguro, transparente y conforme a reglas comunes entre proveedores y consumidores de datos.
Aprendizaje federado
Una de las aplicaciones más potentes de la computación federada es el aprendizaje automático federado (federated learning), una técnica de inteligencia artificial que permite entrenar modelos sin necesidad de centralizar los datos. Es decir, en lugar de enviar los datos a un servidor central para procesarlos, lo que se envía son los modelos entrenados localmente por cada participante.
Estos modelos se combinan posteriormente de manera centralizada para crear un modelo global. A modo de ejemplo, imaginemos un consorcio de hospitales que quiere desarrollar un modelo predictivo para detectar una enfermedad rara. Cada hospital posee datos sensibles de sus pacientes, y compartirlos abiertamente no es viable por cuestiones de privacidad (incluso otras cuestiones legales o éticas). Con el aprendizaje federado, cada hospital entrena localmente el modelo con sus propios datos, y solo comparte los parámetros del modelo (resultados del entrenamiento) de manera centralizada. Así, el modelo final aprovecha la diversidad de datos de todos los hospitales sin comprometer la privacidad individual y las reglas de gobernanza de datos de cada hospital.
El entrenamiento en el aprendizaje federado suele seguir un ciclo iterativo:
- Un servidor central inicia un modelo base y lo envía a cada uno de los nodos distribuidos participantes.
- Cada nodo entrena el modelo localmente con sus datos.
- Los nodos devuelven solo los parámetros del modelo actualizado, no los datos (es decir, se evita el trasiego de datos).
- El servidor central agrega las actualizaciones en los parámetros, resultados del entrenamiento en cada nodo y actualiza el modelo global.
- El ciclo se repite hasta alcanzar un modelo suficientemente preciso.
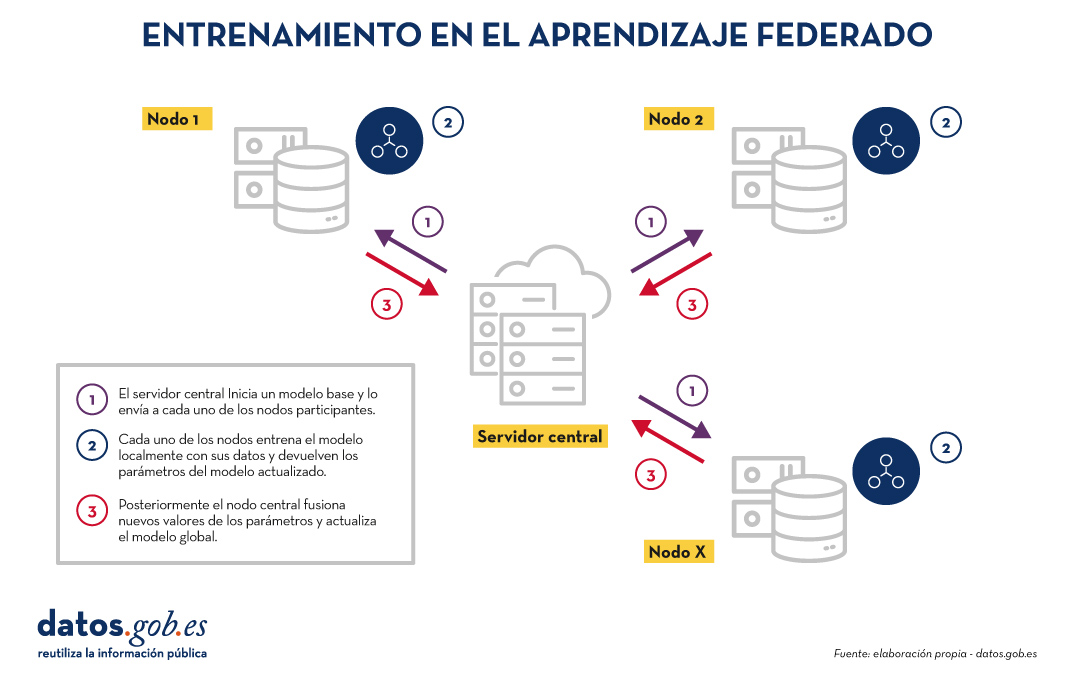
Figura 1. Visual que representa el proceso de entrenamiento del aprendizaje federados. Elaboración propia
Este enfoque es compatible con diversos algoritmos de aprendizaje automático, incluyendo redes neuronales profundas, modelos de regresión, clasificadores, etc.
Beneficios y desafíos del aprendizaje federado
El aprendizaje federado ofrece múltiples beneficios al evitar el trasiego de datos. Destacamos los siguientes:
- Privacidad y cumplimiento normativo: al permanecer en su origen, se reducen significativamente los riesgos de exposición de los datos y se facilita el cumplimiento de regulaciones como el Reglamento General de Protección de Datos (RGPD).
- Soberanía de los datos: cada entidad mantiene el control total sobre sus datos, lo que evita conflictos de competitividad.
- Eficiencia: evita los costes y la complejidad de intercambiar grandes volúmenes de datos, lo que acelera los tiempos de procesamiento y desarrollo.
- Confianza: facilita la colaboración entre organizaciones sin fricciones.
Existen diversos casos de uso en los cuales el aprendizaje federado es necesario, por ejemplo:
- Salud: hospitales y centros de investigación pueden colaborar en modelos predictivos sin compartir datos de pacientes.
- Finanzas: bancos y aseguradoras pueden construir modelos de detección de fraude o análisis de riesgo compartido, respetando la confidencialidad de sus clientes.
- Turismo inteligente: los destinos turísticos pueden analizar flujos de visitantes o patrones de consumo sin necesidad de unificar las bases de datos de sus actores (tanto públicos como privados).
- Industria: empresas del mismo sector pueden entrenar modelos para mantenimiento predictivo o eficiencia operativa sin revelar datos competitivos.
Aunque sus beneficios son claros en diversidad de casos de uso, el aprendizaje federado también presenta retos técnicos y organizativos:
- Heterogeneidad de datos: los datos locales pueden tener diferentes formatos o estructuras, lo que dificulta el entrenamiento. Además, el esquema de estos datos puede cambiar con el tiempo, lo que representa una dificultad añadida.
- Datos desbalanceados: algunos nodos pueden tener más datos o de mayor calidad que otros, lo que puede sesgar el modelo global.
- Costes computacionales locales: cada nodo necesita recursos suficientes para entrenar el modelo localmente.
- Sincronización: el ciclo de entrenamiento requiere buena coordinación entre nodos para evitar latencias o errores.
Más allá del aprendizaje federado
Aunque la aplicación más destacada de la computación federada es el aprendizaje federado, están surgiendo muchas otras aplicaciones adicionales en la gestión de datos como, por ejemplo, el análisis de datos federado (federated analytics). El análisis de datos federado permite realizar análisis estadísticos y descriptivos sobre datos distribuidos sin necesidad de moverlos a los consumidores, sino que cada proveedor realiza localmente los cálculos estadísticos requeridos y solo comparte con el consumidor los resultados agregados según sus requisitos y permisos. En la siguiente tabla se muestran las diferencias entre aprendizaje federado y análisis de datos federado.
|
Criterio |
Aprendizaje federado |
Análisis de datos federado |
|
Objetivo |
Predicción y entrenamiento de modelos de aprendizaje automático. | Análisis descriptivo y cálculo de estadísticas. |
| Tipo de tarea | Tareas predictivas (por ejemplo, clasificación o regresión). | Tareas descriptivas (por ejemplo, medias o correlaciones). |
| Ejemplo | Entrenar modelos de diagnóstico de enfermedades a través de imágenes médicas procedentes de diversos hospitales. | Cálculo de indicadores sanitarios de un área de salud sin mover los datos entre hospitales. |
| Salida esperada | Modelo global entrenado. | Resultados estadísticos agregados. |
| Naturaleza | Iterativa. | Directa. |
| Complejidad computacional | Alta. | Media. |
| Algoritmos | Aprendizaje automático. | Algoritmos estadísticos. |
Figura 1. Tabla comparativa. Fuente: elaboración propia
Aprendizaje federado y datos abiertos: una simbiosis por explorar
En principio, los datos abiertos resuelven los problemas de privacidad antes de su publicación, por lo que se podría pensar que no es preciso hacer uso de técnicas de aprendizaje federado. Nada más lejos de la realidad. El uso de técnicas de aprendizaje federado puede aportar ventajas significativas en la gestión y explotación de los datos abiertos. De hecho, el primer aspecto a resaltar es que los portales de datos abiertos como datos.gob.es o data.europa.eu son entornos federados. Por ello, en estos portales, la aplicación de aprendizaje federado sobre conjuntos de datos de gran tamaño permitiría entrenar modelos directamente en origen, evitando costes de transferencia y procesamiento. Por otro lado, el aprendizaje federado facilitaría la combinación de datos abiertos con otros datos sensibles sin comprometer la privacidad de estos últimos. Finalmente, la naturaleza de una gran variedad de tipos de datos abiertos es muy dinámica (como los datos de tráfico), por lo que el aprendizaje federado habilitaría un entrenamiento incremental, considerando automáticamente nuevas actualizaciones de conjuntos de datos abiertos a medida que se publican, sin necesidad de reiniciar costosos procesos de entrenamiento.
Aprendizaje federado, base para una IA respetuosa con la privacidad
El aprendizaje automático federado representa una evolución necesaria en la forma en que desarrollamos servicios de inteligencia artificial, especialmente en contextos donde los datos son sensibles o están distribuidos entre varios proveedores. Su alineación natural con el concepto de espacio de datos lo convierte en una tecnología clave para impulsar la innovación basada en la compartición de datos, teniendo en cuenta la privacidad y manteniendo la soberanía de los datos.
A medida que la regulación (como el Reglamento relativo al Espacio Europeo de Datos de Salud) y las infraestructuras de espacios de datos evolucionen, el aprendizaje federado, y otros tipos de computación federada, jugarán un papel cada vez más importante en la compartición de datos, maximizando el valor de los datos, pero sin comprometer la privacidad. Finalmente, cabe destacar que, lejos de ser innecesario, el aprendizaje federado puede convertirse en un aliado estratégico para mejorar la eficiencia, gobernanza e impacto de los ecosistemas de datos abiertos.
Jose Norberto Mazón, Catedrático de Lenguajes y Sistemas Informáticos de la Universidad de Alicante. Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Blog
Los modelos de lenguaje se encuentran en el epicentro del cambio de paradigma tecnológico que está protagonizando la inteligencia artificial (IA) generativa en los últimos dos años. Desde las herramientas con las que interaccionamos en lenguaje natural para generar texto, imágenes o vídeos y que utilizamos para crear contenido creativo, diseñar prototipos o producir material educativo, hasta aplicaciones más complejas en investigación y desarrollo que incluso han contribuido de forma decisiva a la consecución del Premio Nobel de Química de 2024, los modelos de lenguaje están demostrando su utilidad en una gran variedad de aplicaciones, que por otra parte, aún estamos explorando.
Desde que en 2017 Google publicó el influyente artículo "Attention is all you need", donde se describió la arquitectura de los Transformers, tecnología que sustenta las nuevas capacidades que OpenAI popularizó a finales de 2022 con el lanzamiento de ChatGPT, la evolución de los modelos de lenguaje ha sido más que vertiginosa. En apenas dos años, hemos pasado de modelos centrados únicamente en la generación de texto a versiones multimodales que integran la interacción y generación de texto, imágenes y audio.
Esta rápida evolución ha dado lugar a dos categorías de modelos de lenguaje: los SLM (Small Language Models), más ligeros y eficientes, y los LLM (Large Language Models), más pesados y potentes. Lejos de considerarlos competidores, debemos analizar los SLM y LLM como tecnologías complementarias. Mientras los LLM ofrecen capacidades generales de procesamiento y generación de contenido, los SLM pueden proporcionar soporte a soluciones más ágiles y especializadas para necesidades concretas. Sin embargo, ambos comparten un elemento esencial: dependen de grandes volúmenes de datos para su entrenamiento y en el corazón de sus capacidades están los datos abiertos, que son parte del combustible que se utiliza para entrenar estos modelos de lenguaje en los que se basan las aplicaciones de IA generativa.
LLM: potencia impulsada por datos masivos
Los LLM son modelos de lenguaje a gran escala que cuentan con miles de millones, e incluso billones, de parámetros. Estos parámetros son las unidades matemáticas que permiten al modelo identificar y aprender patrones en los datos de entrenamiento, lo que les proporciona una extraordinaria capacidad para generar texto (u otros formatos) coherente y adaptado al contexto de los usuarios. Estos modelos, como la familia GPT de OpenAI, Gemini de Google o Llama de Meta, se entrenan con inmensos volúmenes de datos y son capaces de realizar tareas complejas, algunas incluso para las que no fueron explícitamente entrenados.
De este modo, los LLM son capaces de realizar tareas como la generación de contenido original, la respuesta a preguntas con información relevante y bien estructurada o la generación de código de software, todas ellas con un nivel de competencia igual o superior al de los humanos especializados en dichas tareas y siempre manteniendo conversaciones complejas y fluidas.
Los LLM se basan en cantidades masivas de datos para alcanzar su nivel de desempeño actual: desde repositorios como Common Crawl, que recopila datos de millones de páginas web, hasta fuentes estructuradas como Wikipedia o conjuntos especializados como PubMed Open Access en el campo biomédico. Sin acceso a estos corpus masivos de datos abiertos, la capacidad de estos modelos para generalizar y adaptarse a múltiples tareas sería mucho más limitada.
Sin embargo, a medida que los LLM continúan evolucionando, la necesidad de datos abiertos aumenta para conseguir progresos específicos como:
- Mayor diversidad lingüística y cultural: aunque los LLM actuales manejan múltiples idiomas, en general están dominados por datos en inglés y otros idiomas mayoritarios. La falta de datos abiertos en otras lenguas limita la capacidad de estos modelos para ser verdaderamente inclusivos y diversos. Más datos abiertos en idiomas diversos garantizarían que los LLM puedan ser útiles para todas las comunidades, preservando al mismo tiempo la riqueza cultural y lingüística del mundo.
- Reducción de sesgos: los LLM, como cualquier modelo de IA, son propensos a reflejar los sesgos presentes en los datos con los que se entrenan. Esto, en ocasiones, genera respuestas que perpetúan estereotipos o desigualdades. Incorporar más datos abiertos cuidadosamente seleccionados, especialmente de fuentes que promuevan la diversidad y la igualdad, es fundamental para construir modelos que representen de manera justa y equitativa a diferentes grupos sociales.
- Actualización constante: los datos en la web y en otros recursos abiertos cambian constantemente. Sin acceso a datos actualizados, los LLM generan respuestas obsoletas muy rápidamente. Por ello, incrementar la disponibilidad de datos abiertos frescos y relevantes permitiría a los LLM mantenerse alineados con la actualidad.
- Entrenamiento más accesible: a medida que los LLM crecen en tamaño y capacidad, también lo hace el coste de entrenarlos y afinarlos. Los datos abiertos permiten que desarrolladores independientes, universidades y pequeñas empresas entrenen y afinen sus propios modelos sin necesidad de costosas adquisiciones de datos. De este modo se democratiza el acceso a la inteligencia artificial y se fomenta la innovación global.
Para solucionar algunos de estos retos, en la nueva Estrategia de Inteligencia Artificial 2024 se han incluido medidas destinadas a generar modelos y corpus en castellano y lenguas cooficiales, incluyendo también el desarrollo de conjuntos de datos de evaluación que consideran la evaluación ética.
SLM: eficiencia optimizada con datos específicos
Por otra parte, los SLM han emergido como una alternativa eficiente y especializada que utiliza un número más reducido de parámetros (generalmente en millones) y que están diseñados para ser ligeros y rápidos. Aunque no alcanzan la versatilidad y competencia de los LLM en tareas complejas, los SLM destacan por su eficiencia computacional, rapidez de implementación y capacidad para especializarse en dominios concretos.
Para ello, los SLM también dependen de datos abiertos, pero en este caso, la calidad y relevancia de los conjuntos de datos son más importantes que su volumen, por ello los retos que les afectan están más relacionados con la limpieza y especialización de los datos. Estos modelos requieren conjuntos que estén cuidadosamente seleccionados y adaptados al dominio específico para el que se van a utilizar, ya que cualquier error, sesgo o falta de representatividad en los datos puede tener un impacto mucho mayor en su desempeño. Además, debido a su enfoque en tareas especializadas, los SLM enfrentan desafíos adicionales relacionados con la accesibilidad de datos abiertos en campos específicos. Por ejemplo, en sectores como la medicina, la ingeniería o el derecho, los datos abiertos relevantes suelen estar protegidos por restricciones legales y/o éticas, lo que dificulta su uso para entrenar modelos de lenguaje.
Los SLM se entrenan con datos cuidadosamente seleccionados y alineados con el dominio en el que se utilizarán, lo que les permite superar a los LLM en precisión y especificidad en tareas concretas, como por ejemplo:
- Autocompletado de textos: un SLM para autocompletado en español puede entrenarse con una selección de libros, textos educativos o corpus como los que se impulsarán en la ya mencionada Estrategia de IA, siendo mucho más eficiente que un LLM de propósito general para esta tarea.
- Consultas jurídicas: un SLM entrenado con conjuntos de datos jurídicos abiertos pueden proporcionar respuestas precisas y contextualizadas a preguntas legales o procesar documentos contractuales de forma más eficaz que un LLM.
- Educación personalizada: en el sector educativo, SLM entrenados con datos abiertos de recursos didácticos pueden generar explicaciones específicas, ejercicios personalizados o incluso evaluaciones automáticas, adaptadas al nivel y las necesidades del estudiante.
- Diagnóstico médico: un SLM entrenado con conjuntos de datos médicos, como resúmenes clínicos o publicaciones abiertas, puede asistir a médicos en tareas como la identificación de diagnósticos preliminares, la interpretación de imágenes médicas mediante descripciones textuales o el análisis de estudios clínicos.
Desafíos y consideraciones éticas
No debemos olvidar que, a pesar de los beneficios, el uso de datos abiertos en modelos de lenguaje presenta desafíos significativos. Uno de los principales retos es, como ya hemos mencionado, garantizar la calidad y neutralidad de los datos para que estén libres de sesgos, ya que estos pueden amplificarse en los modelos, perpetuando desigualdades o prejuicios.
Aunque un conjunto de datos sea técnicamente abierto, su utilización en modelos de inteligencia artificial siempre plantea algunas implicaciones éticas. Por ejemplo, es necesario evitar que información personal o sensible se filtre o pueda deducirse de los resultados generados por los modelos, ya que esto podría causar daños a la privacidad de las personas.
También debe tenerse en cuenta la cuestión de la atribución y propiedad intelectual de los datos. El uso de datos abiertos en modelos comerciales debe abordar cómo se reconoce y compensa adecuadamente a los creadores originales de los datos para que sigan existiendo incentivos a los creadores.
Los datos abiertos son el motor que impulsa las asombrosas capacidades de los modelos de lenguaje, tanto en el caso de los SLM como de los LLM. Mientras que los SLM destacan por su eficiencia y accesibilidad, los LLM abren puertas a aplicaciones avanzadas que no hace mucho nos parecían imposibles. Sin embargo, el camino hacia el desarrollo de modelos más capaces, pero también más sostenibles y representativos, depende en gran medida de cómo gestionemos y aprovechemos los datos abiertos.
Contenido elaborado por Jose Luis Marín, Senior Consultant in Data, Strategy, Innovation & Digitalization. Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Blog
La transferencia de conocimiento humano hacia los modelos de aprendizaje automático es la base de toda la inteligencia artificial actual. Si queremos que los modelos de IA sean capaces de resolver tareas, primero tenemos que codificar y transmitirles tareas resueltas en un lenguaje formal que puedan procesar. Entendemos como tarea resuelta la información codificada en diferentes formatos, como el texto, la imagen, el audio o el vídeo. En el caso del procesamiento del lenguaje, y con el fin de conseguir sistemas con una alta competencia lingüística para que puedan comunicarse de manera ágil con nosotros, necesitamos trasladar a estos sistemas el mayor número posible de producciones humanas en texto. A estos conjuntos de datos los llamamos corpus.
Corpus: conjuntos de datos en texto
Cuando hablamos de los corpus, corpora (su plural latino) o datasets que se han utilizado para entrenar a los grandes modelos de lenguaje (LLMs por Large Language Models) como GPT-4, hablamos de libros de todo tipo, contenido escrito en páginas web, grandes repositorios de texto e información del mundo como Wikipedia, pero también producciones lingüísticas menos formales como las que escribimos en redes sociales, en reseñas públicas de productos o servicios, o incluso en correos electrónicos. Esta variedad permite que estos modelos de lenguaje puedan procesar y manejar texto en diferentes idiomas, registros y estilos.
Para las personas que trabajan en Procesamiento del Lenguaje Natural (PLN), ciencia e ingeniería de datos, son conocidos y habituales los grandes facilitadores como Kaggle o repositorios como Awesome Public Datasets en GitHub, que proporcionan acceso directo a la descarga de fuentes de datos públicas. Algunos de estos ficheros de datos han sido preparados para su procesamiento y están listos para analizar, mientras que otros se encuentran en un estado no estructurado, que requiere un trabajo previo de limpieza y ordenación antes de poder empezar a trabajar con ellos. Aunque también contienen datos numéricos cuantitativos, muchas de estas fuentes presentan datos en texto que pueden utilizarse para entrenar modelos de lenguaje.
El problema de la legitimidad
Una de las complicaciones que hemos encontrado en la creación de estos modelos es que los datos en texto que están publicados en internet y han sido recogidos mediante API (conexiones directas que permiten la descarga masiva de una web o repositorio) u otras técnicas, no siempre son de dominio público. En muchas ocasiones, tienen copyright: escritores, traductores, periodistas, creadores de contenido, guionistas, ilustradores, diseñadores y también músicos reclaman a las grandes tecnológicas un licenciamiento por el uso de sus contenidos en texto e imagen para entrenar modelos. Los medios de comunicación, en concreto, son actores enormemente impactados por esta situación, aunque su posicionamiento varía en función de su situación y de diferentes decisiones de negocio. Por ello es necesario que existan corpus abiertos que se puedan utilizar para estas tareas de entrenamiento, sin perjuicio de la propiedad intelectual.
Características idóneas para un corpus de entrenamiento
La mayoría de las características, que tradicionalmente han definido a un buen corpus en investigación lingüística, no han variado al utilizarse en la actualidad estos conjuntos de datos en texto para entrenar modelos de lenguaje.
- Sigue siendo beneficioso utilizar textos completos y no fragmentos, para asegurar su coherencia.
- Los textos deben ser auténticos, procedentes de la realidad lingüística y de situaciones naturales del lenguaje, recuperables y verificables.
- Es importante asegurar una diversidad amplia en la procedencia de los textos en cuanto a sectores de la sociedad, publicaciones, variedades locales de los idiomas y emisores o hablantes.
- Además del lenguaje general, debe incluirse una amplia variedad de lenguajes de especialidad, tecnicismos y textos específicos de diferentes áreas del conocimiento.
- El registro es fundamental en una lengua, por lo que debemos cubrir tanto el registro formal como el informal, en sus extremos y regiones intermedias.
- El lenguaje debe estar bien formado para evitar interferencias en el aprendizaje, por lo que es conveniente eliminar marcas de código, números o símbolos que correspondan a metadatos digitales y no a la formación natural del lenguaje.
Como recomendaciones específicas para los formatos de los archivos que van a formar parte de estos corpus, encontramos que los corpus de texto con anotaciones deben almacenarse en codificación UTF-8 y en formato JSON o CSV, no en PDF. Los corpus sonoros tienen como formato preferente WAV 16 bits, 16 KHz. (para voz) o 44.1 KHz (para música y audio). Los corpus en vídeo es conveniente recopilarlos en formato MPEG-4 (MP4), y las memorias de traducción en TMX o CSV.
El texto como patrimonio colectivo
Las bibliotecas nacionales en Europa están digitalizando activamente sus ricos depósitos de historia y cultura, asegurando el acceso público y la preservación. Instituciones como la Biblioteca Nacional de Francia o la British Library lideran con iniciativas que digitalizan desde manuscritos antiguos hasta publicaciones actuales en web. Este atesoramiento digital no solo protege el patrimonio contra el deterioro físico, sino que también democratiza el acceso para los investigadores y el público y, desde hace algunos años, también permite la recopilación de corpus de entrenamiento para modelos de inteligencia artificial.
Los corpus proporcionados de manera oficial por bibliotecas nacionales permiten que las colecciones de textos sirvan para crear tecnología pública al alcance de todos: un patrimonio cultural colectivo que genera un nuevo patrimonio colectivo, esta vez tecnológico. La ganancia es mayor cuando estos corpus institucionales sí están enfocados a cumplir con las leyes de propiedad intelectual, proporcionando únicamente datos abiertos y textos libres de restricciones de derechos de autor, con derechos prescritos o licenciados. Esto, unido al hecho esperanzador de que la cantidad de datos reales necesaria para entrenar modelos de lenguaje va reduciéndose a medida que avanza la tecnología, por ejemplo, con la generación de datos sintéticos o la optimización de determinados parámetros, indica que es posible entrenar grandes modelos de texto sin infringir las leyes de propiedad intelectual que operan en Europa.
En concreto, la Biblioteca Nacional de España está haciendo un gran esfuerzo de digitalización para poner sus valiosos repositorios de texto a disposición de la investigación, y en particular de las tecnologías del lenguaje. Desde que en 2008 se realizó la primera gran digitalización masiva de colecciones físicas, la BNE ha abierto el acceso a millones de documentos con el único objetivo de compartir y universalizar el conocimiento. En 2023, y gracias a la inversión procedente de los fondos de Recuperación, Transformación y Resiliencia de la Unión Europea, la BNE impulsa un nuevo proyecto de preservación digital en su Plan Estratégico 2023-2025, centrada en cuatro ejes:
- la digitalización masiva y sistemática de las colecciones,
- BNELab como catalizador de innovación y reutilización de datos en ecosistemas digitales,
- alianzas y nuevos entornos de cooperación,
- e integración y sostenibilidad tecnológica.
La alineación de estos cuatro ejes con las nuevas tecnologías de inteligencia artificial y procesamiento del lenguaje natural es más que notoria, ya que una de las principales reutilizaciones de datos es el entrenamiento de grandes modelos de lenguaje. Tanto los registros bibliográficos digitalizados como los índices de catalogación de la Biblioteca son materiales de valor para la tecnología del conocimiento.
Modelos de lenguaje en español
En el año 2020, y como una iniciativa pionera y relativamente temprana, en España se presentaba MarIA, un modelo de lenguaje impulsado por la Secretaría de Estado de Digitalización e Inteligencia Artificial y desarrollado por el Centro Nacional de Supercomputación (BSC-CNS), a partir de los archivos de la Biblioteca Nacional de España. En este caso, el corpus estaba compuesto por textos procedentes de páginas web, que habían sido recopilados por la BNE desde el año 2009 y que habían servido para nutrir un modelo basado originalmente en GPT-2.
Han ocurrido muchas cosas entre la creación de MarIA y el anuncio en el Mobile World Congress de 2024 de la construcción de un gran modelo fundacional de lenguaje, entrenado específicamente en español y lenguas cooficiales. Este sistema será de código abierto y transparente, y únicamente utilizará en su entrenamiento contenido libre de derechos. Este proyecto es pionero a nivel europeo, ya que busca proporcionar desde las instituciones una infraestructura lingüística abierta, pública y accesible para las empresas. Al igual que MarIA, el modelo se desarrollará en el BSC-CNS, en un trabajo conjunto con la Biblioteca Nacional de España y otros actores como la Academia Española de la Lengua y la Asociación de Academias de la Lengua Española.
Además de las instituciones que pueden aportar colecciones lingüísticas o bibliográficas, existen muchas más instituciones en España que pueden proporcionar corpus de calidad que pueden servir también para el entrenamiento de modelos en español. El Estudio sobre datos reutilizables como recursos lingüísticos, publicado en 2019 en el marco del Plan de Tecnologías del Lenguaje, ya apuntaba a distintas fuentes: las patentes y los informes técnicos de la Oficina de Patentes y Marcas, tanto españolas como europeas, los diccionarios terminológicos del Centro de Terminología, o datos tan elementales como el padrón, del Instituto Nacional de Estadística, o los topónimos del Instituto Geográfico Nacional. Cuando hablamos de contenido audiovisual, que puede ser transcrito para su reutilización, contamos con el archivo en vídeo de RTVE A la carta, el Archivo Audiovisual del Congreso de los Diputados o los archivos de las diferentes televisiones autonómicas. El propio Boletín Oficial del Estado y sus materiales asociados son una fuente importante de información en texto que contiene conocimientos amplios sobre nuestra sociedad y su funcionamiento. Por último, en ámbitos específicos como la salud o la justicia, contamos con las publicaciones de la Agencia Española de Medicamentos y Productos Sanitarios, los textos de jurisprudencia del CENDOJ o las grabaciones de vistas judiciales del Consejo General del Poder Judicial.
Iniciativas europeas
En Europa no parece haber un precedente tan claro como MarIA o el próximo modelo basado en GPT en español, como proyectos impulsados a nivel estatal y entrenados con datos patrimoniales, procedentes de bibliotecas nacionales u organismos oficiales.
Sin embargo, en Europa hay un buen trabajo previo de disponibilidad de la documentación que podría utilizarse ahora para entrenar sistemas de IA de fundación europea. Un buen ejemplo es el proyecto Europeana, que busca digitalizar y hacer accesible el patrimonio cultural y artístico de Europa en conjunto. Es una iniciativa colaborativa que reúne contribuciones de miles de museos, bibliotecas, archivos y galerías, proporcionando acceso gratuito a millones de obras de arte, fotografías, libros, piezas de música y vídeos. Europeana cuenta con casi 25 millones de documentos en texto, que podrían ser la base para crear modelos fundacionales multilingües o competentes en las distintas lenguas europeas.
Existen también iniciativas no gubernamentales, pero con impacto global, como Common Corpus, que son la prueba definitiva de que es posible entrenar modelos de lenguaje con datos abiertos y sin infringir las leyes de derechos de autor. Common Corpus se liberó en marzo de 2024, y es el conjunto de datos más extenso creado para el entrenamiento de grandes modelos de lenguaje, con 500 mil millones de palabras procedentes de distintas iniciativas de patrimonio cultural. Este corpus es multilingüe y es el más grande hasta la fecha en inglés, francés, neerlandés, español, alemán e italiano.
Y finalmente, más allá del texto, es posible encontrar iniciativas en otros formatos como el audio, que también pueden servir para entrenar modelos de IA. En 2022, la Biblioteca Nacional de Suecia proporcionó un corpus sonoro de más de dos millones de horas de grabación procedentes de la radio pública local, podcasts y audiolibros. El objetivo del proyecto era generar un modelo basado en IA de transcripción de audio a texto competente en el idioma, que maximizase el número de hablantes para conseguir un dataset disponible para todos, diverso y democrático.
Hasta ahora, en la recopilación y la puesta a disposición de la sociedad de datos en texto era suficiente el sentido de lo colectivo y el patrimonio. Con los modelos de lenguaje, esta apertura consigue un beneficio mayor: el de crear y mantener una tecnología que aporte valor a las personas y a las empresas, alimentada y mejorada a partir de nuestras propias producciones lingüísticas.
Contenido elaborado por Carmen Torrijos, experta en IA aplicada al lenguaje y la comunicación. Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.