Blog
La regulación europea de Datos de Alto Valor (HVD, High-Value Datasets), establecida por el Reglamento de Ejecución (UE) 2023/138, consolida el papel de las APIcomo infraestructura esencial para la reutilización de la información pública, convirtiendo su disponibilidad en una obligación legal y no solo en una buena práctica tecnológica.
Desde el 9 de junio de 2024, los organismos públicos de todos los Estados miembros están obligados a publicar los conjuntos de datos clasificados como HVD de forma gratuita, en formatos legibles por máquina y accesibles mediante API. Las seis categorías reguladas son: datos geoespaciales, observación de la Tierra, medio ambiente, estadística, información empresarial y movilidad.
Este marco no es meramente declarativo. Los Estados miembros deben reportar a la Comisión Europea el estado de cumplimiento cada dos años, incluyendo enlaces persistentes a las API que dan acceso a dichos datos. La situación de España en materia de transparencia, datos abiertos y provisión sistemática de API puede consultarse en los indicadores publicados por el Open Data Maturity Report.
En la práctica, esto significa que las API son el puente entre la norma y la realidad. La regulación no solo dice qué datos deben abrirse, sino que obliga a hacerlo de forma que puedan integrarse automáticamente en aplicaciones, estudios o servicios digitales. Por eso, revisar las API públicas disponibles en España es una forma concreta de entender cómo se está aplicando este marco en el día a día.
Inventario de API públicas en España
INE — API JSON (Tempus3)
El Instituto Nacional de Estadística ofrece una API REST que expone toda la base de datos de difusión Tempus3 en formato JSON, que incluye series estadísticas oficiales sobre demografía, economía, mercado laboral, industria, servicios, precios, condiciones de vida y otros indicadores socioeconómicos que incluye series estadísticas oficiales sobre demografía, economía, mercado laboral, industria, servicios, precios, condiciones de vida y otros indicadores socioeconómicos.
Para realizar llamadas, la estructura debe seguir el patrón https://servicios.ine.es/wstempus/js/{idioma}/{función}/{input}. El parámetro tip=AM permite obtener metadatos junto con los datos, y tv filtra por variables específicas. Por ejemplo, para obtener las cifras de población por provincia, basta con consultar la operación correspondiente (IOE 30243) y filtrar por la variable geográfica deseada.
No requiere autenticación ni API key: cualquier petición GET bien formada devuelve datos directamente.
Ejemplo en Python — obtener la serie de población residente con metadatos:
import requests
url = ("https://servicios.ine.es/wstempus/js/ES/"
"DATOS_TABLA/t20/e245/p08/l0/01002.px?tip=AM")
response = requests.get(url)
data = response.json()
for serie in data[:3]: # primeras 3 series
nombre = serie["Nombre"]
ultimo = serie["Data"][-1]
print(f"{nombre}: {ultimo['Valor']:,.0f} ({ultimo['NombrePeriodo']})")
TOTAL EDADES, TOTAL, Ambos sexos: 39,852,651 (1998)
TOTAL EDADES, TOTAL, Hombres: 19,488,465 (1998)
TOTAL EDADES, TOTAL, Mujeres: 20,364,186 (1998)AEMET — OpenData API REST
La Agencia Estatal de Meteorología expone sus datos a través de una API REST, documentada con Swagger UI (herramienta de código abierto que genera documentación interactiva), datos meteorológicos observados y predicciones oficiales, incluyendo temperatura, precipitación, viento, alertas y fenómenos adversos.
A diferencia del INE, AEMET requiere una API key gratuita, que se obtiene proporcionando un correo electrónico en el portal opendata.aemet.es. Una API key funciona como un tipo de “contraseña” o identificador: sirve para para que el organismo pueda saber quién está usando el servicio, controlar el volumen de peticiones y garantizar un uso adecuado de la infraestructura.
Un aspecto técnico relevante es que AEMET implementa un modelo de doble llamada: la primera petición devuelve un JSON con una URL temporal en el campo datos, y una segunda petición a esa URL recupera el dataset real. El rate limit es de 50 peticiones por minuto.
Ejemplo en Python — datos climatológicos diarios (doble llamada):
import requests
API_KEY = "tu_api_key_aqui"
headers = {"api_key": API_KEY}
# 1ª llamada: obtener URL temporal de datos
url = ("https://opendata.aemet.es/opendata/api/"
"valores/climatologicos/diarios/datos/"
"fechaini/2025-01-01T00:00:00UTC/"
"fechafin/2025-01-10T23:59:59UTC/"
"todasestaciones")
resp1 = requests.get(url, headers=headers).json()
# 2ª llamada: descargar el dataset real
datos = requests.get(resp1["datos"], headers=headers).json()
for estacion in datos[:3]:
print(f"{estacion['nombre']}: "
f"Tmax={estacion.get('tmax','N/A')}°C, "
f"Prec={estacion.get('prec','N/A')}mm")
CITFAGRO_88_GAITERO: Tmax=8,8°C, Prec=0,0mm
ABANILLA: Tmax=14,8°C, Prec=0,0mm
LA RODA DE ANDALUCÍA: Tmax=15,7°C, Prec=0,2mmCNIG / IDEE — Servicios OGC y OGC API Features
El Centro Nacional de Información Geográfica publica datos geoespaciales oficiales —cartografía base, modelos digitales del terreno, redes hidrográficas, límites administrativos y otros elementos topográficos— mediante servicios interoperables. Estos han evolucionado desde WMS/WFS hacia los estándares OGC API (Features, Maps y Processes), implementados con software abierto como pygeoapi.
La ventaja principal de OGC API Features frente a WFS es el formato de respuesta: en lugar de GML (pesado y complejo), los datos se sirven en GeoJSON y HTML, formatos nativos del ecosistema web. Esto permite consumirlos directamente desde bibliotecas como Leaflet, OpenLayers o GDAL. Los datasets disponibles incluyen direcciones de Cartociudad, hidrografía, redes de transporte y nomenclátor geográfico.
Ejemplo en Python — consultar features geográficas vía OGC API:
import requests
# OGC API Features - Nomenclátor Geográfico Básico de España
base = "https://api-features.idee.es/collections"
collection = "falls" # Cascadas
url = f"{base}/{collection}/items?limit=5&f=json"
resp = requests.get(url).json()
for feat in resp["features"]:
props = feat["properties"]
coords = feat["geometry"]["coordinates"]
print(f"{props['nombre']}: ({coords[0]:.4f}, {coords[1]:.4f})")
None: (-6.2132, 42.8982)
Cascada del Cervienzo: (-6.2572, 42.9763)
Cascada el Xaral: (-6.3815, 42.9881)
Cascada de Rexiu: (-7.2256, 42.5743)
Cascada de Santalla: (-7.2543, 42.6510)MITECO — Portal de Datos Abiertos (CKAN)
El Ministerio para la Transición Ecológica mantiene un portal basado en CKAN que expone tres capas de acceso: la CKAN Action API para búsqueda de metadatos y datasets, el Datastore API (OpenAPI) para consultas en vivo sobre recursos tabulares, y endpoints RDF/JSON-LD conformes con DCAT-AP y GeoDCAT-AP. En su catálogo pueden encontrarse datos sobre calidad del aire, emisiones y cambio climático, agua (estado de masas y planificación hidrológica), biodiversidad y espacios protegidos, residuos, energía y evaluación ambiental.
Entre los datasets destacados figuran las áreas protegidas de la Red Natura 2000 masas de agua, y proyecciones de emisiones de gases de efecto invernadero.
Ejemplo en Python — buscar datasets:
import requests
BASE = "https://catalogo.datosabiertos.miteco.gob.es/catalogo"
# Buscar datasets que contengan 'natura 2000'
busqueda = requests.get(
f"{BASE}/api/3/action/package_search",
params={"q": "natura 2000", "rows": 3},
).json()
for ds in busqueda["result"]["results"]:
print(f"{ds['title']} ({ds['num_resources']} recursos)")
Espacios Protegidos de la Red Natura 2000 (13 recursos)
Base de datos de los espacios protegidos Red Natura 2000 de España (CNTRYES) (1 recursos)
Espacios Protegidos de la Red Natura 2000 - API - Datos Alto Valor (1 recursos)Comparativa técnica
| Organismo | Protocolo | Formato | Autenticación | Rate limit | HVD |
|---|---|---|---|---|---|
| INE | REST | JSON | Ninguna | No declarado | Sí (estadística) |
| AEMET | REST | JSON | API key (gratuita) | 50 reg/min | Sí (medio ambiente) |
| CNIG/IDEE | OGC API/WFS | GeoJSON/GML | Ninguna | No declarado | Sí (geoespacial) |
| MITECO | CKAN/REST | JASON/RDF | Ninguna (token opc) | No declarado | Sí (medio ambiente) |
Figura 1.Tabla comparativa de las API de diferentes organismos públicos que se presentan en este post. Fuente: elaboración propia - datos.gob.es.
La disponibilidad de API públicas no es solo una cuestión de conveniencia técnica. Desde la perspectiva de datos, estas interfaces habilitan tres capacidades críticas:
- Automatización de pipelines: la ingesta periódica de datos públicos puede orquestarse con herramientas estándar (Airflow, Prefect, cron) sin intervención manual ni descargas de ficheros.
- Reproducibilidad: las URL de las API actúan como referencias estáticas a fuentes autoritativas, lo que facilita auditorías y trazabilidad en proyectos de analítica.
- Interoperabilidad: el uso de estándares abiertos (REST, OGC API, DCAT-AP) permite cruzar fuentes heterogéneas sin depender de formatos propietarios.
El ecosistema de API públicas en España presenta distintos niveles de desarrollo según el organismo y el ámbito sectorial. Mientras que entidades como el INE y AEMET disponen de interfaces consolidadas y bien documentadas, en otros casos el acceso se articula a través de portales CKAN o servicios OGC tradicionales. La regulación relativa a los High Value Datasets (HVD) está impulsando la adopción progresiva de estándares REST, si bien el grado de implantación evoluciona a ritmos diferentes. Para los profesionales de datos, estas API constituyen ya una fuente plenamente operativa cuya integración en arquitecturas de datos resulta cada vez más habitual en entornos analíticos y de ingeniería.
Contenido elaborado por Juan Benavente, ingeniero superior industrial y experto en Tecnologías ligadas a la economía del dato. Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Blog
La visualización de datos no es una disciplina reciente. Desde hace siglos, las personas han utilizado gráficos, mapas y esquemas para representar información compleja. Ejemplos clásicos como los mapas estadísticos del siglo XIX o los gráficos utilizados en la prensa muestran que la necesidad de “ver” los datos para entenderlos ha existido siempre.
Durante mucho tiempo, la creación de visualizaciones requería conocimientos especializados y acceso a herramientas profesionales, lo que limitaba su producción a perfiles muy concretos. Sin embargo, la revolución digital y tecnológica ha transformado profundamente este panorama. En la actualidad, cualquier persona con acceso a un ordenador y a datos puede crear visualizaciones. Las herramientas se han democratizado, muchas de ellas son gratuitas o de código abierto, y el trabajo de visualización se ha extendido más allá del diseño para integrarse en ámbitos como la estadística, la ciencia de datos, la investigación académica, la administración pública o la educación.
Hoy en día, la visualización de datos es una competencia transversal que permite a la ciudadanía explorar información pública, a las instituciones comunicar mejor sus políticas y a los reutilizadores generar nuevos servicios y conocimientos a partir de los datos abiertos. En este post presentamos algunas de las opciones más accesibles y utilizadas en visualización de datos.
Un ecosistema amplio y diverso de herramientas
El ecosistema de herramientas de visualización de datos es amplio y diverso, tanto en funcionalidades como en niveles de complejidad. Existen opciones pensadas para una primera exploración de los datos, otras orientadas al análisis en profundidad y algunas diseñadas para crear visualizaciones interactivas o narrativas digitales complejas.
Esta variedad permite adaptar la visualización a distintos contextos y objetivos: desde comprender un conjunto de datos de forma preliminar hasta publicar gráficos interactivos, paneles de control o mapas en la web.
La encuesta anual de la Data Visualization Society refleja esta diversidad y muestra cómo el uso de determinadas herramientas evoluciona con el tiempo, consolidando algunas opciones ampliamente conocidas y dando paso a nuevas soluciones que responden a necesidades emergentes. Estas son algunas de las herramientas que se mencionan en la encuesta, ordenadas según perfiles de uso.
Para la elaboración de este listado se ha tenido en cuenta los siguientes criterios:
- Grado de uso y madurez de la herramienta.
- Acceso libre, gratuito o con versiones abiertas.
- Utilidad para proyectos relacionados con datos públicos.
- Prioridad a herramientas abiertas o con versiones gratuitas.
Herramientas sencillas para empezar
Estas herramientas se caracterizan por contar con interfaces visuales, una curva de aprendizaje baja y la posibilidad de crear gráficos básicos de forma rápida. Son especialmente útiles para comenzar a explorar conjuntos de datos abiertos o para actividades de divulgación.
- Excel: es una de las herramientas más extendidas y conocidas. Permite realizar gráficos básicos y primeras exploraciones de datos de forma sencilla. Aunque no está diseñada específicamente para la visualización avanzada, sigue siendo una puerta de entrada habitual al trabajo con datos y su representación gráfica.
- Google Sheets: funciona como una alternativa gratuita y colaborativa a Excel. Su principal ventaja es la posibilidad de trabajar de forma compartida y publicar gráficos sencillos en línea, lo que facilita la difusión de visualizaciones básicas.
- Datawrapper: muy utilizada en comunicación pública y periodismo de datos. Permite crear gráficos claros, mapas y tablas interactivas sin necesidad de conocimientos técnicos. Es especialmente adecuada para explicar datos de forma comprensible a un público amplio.
- RAWGraphs: herramienta de software libre orientada a la exploración visual. Permite experimentar con tipos de gráficos menos habituales y descubrir nuevas formas de representar datos. Resulta especialmente útil en fases exploratorias.
- Canva: aunque su enfoque es más divulgativo que analítico, puede ser útil para crear piezas visuales sencillas que integren gráficos básicos con elementos de diseño. Es adecuada para la comunicación visual de resultados, no tanto para el análisis de datos.
Herramientas de análisis y exploración de datos
Este grupo de herramientas está orientado a perfiles que desean ir más allá de los gráficos básicos y realizar análisis más estructurados. Muchas de ellas son abiertas y están ampliamente consolidadas en el ámbito del análisis de datos.
- R: lenguaje de programación libre muy utilizado en estadística y análisis de datos. Dispone de un amplio ecosistema de paquetes que permiten trabajar con datos públicos de forma reproducible y transparente.
- Ggplot2: librería de visualización del lenguaje R. Es una de las herramientas más potentes para crear gráficos rigurosos y bien estructurados, tanto para análisis como para comunicación de resultados.
- Python (Matplotlib y Plotly): Python es uno de los lenguajes más utilizados en análisis de datos. Matplotlib permite crear gráficos estáticos personalizables, mientras que Plotly facilita la creación de visualizaciones interactivas. Juntas ofrecen un buen equilibrio entre potencia y flexibilidad.
- Apache Superset: plataforma de código abierto para análisis de datos y creación de paneles de control. Tiene un enfoque más institucional y escalable, lo que la hace adecuada para organizaciones que trabajan con grandes volúmenes de datos públicos.
Este bloque resulta especialmente relevante para reutilizadores de datos abiertos y perfiles técnicos intermedios que buscan combinar análisis y visualización de forma sistemática.
Herramientas para visualización interactiva y web
Estas herramientas permiten crear visualizaciones avanzadas para su publicación en entornos web. Aunque requieren mayores conocimientos técnicos, ofrecen una gran flexibilidad y posibilidades expresivas.
- D3.js: es uno de los referentes en visualización web. Se basa en estándares abiertos y permite un control total sobre la representación visual de los datos. Su flexibilidad es muy alta, aunque también lo es su complejidad.
En este ejercicio práctico puedes ver cómo se utiliza esta librería
- Vega y Vega-Lite: lenguajes declarativos para visualización que simplifican el uso de D3. Permiten definir gráficos de forma estructurada y reproducible, ofreciendo un buen equilibrio entre potencia y simplicidad.
- Observable: entorno interactivo muy ligado a D3 y Vega. Es especialmente útil para crear ejemplos educativos, prototipos y visualizaciones exploratorias que combinan código, texto y gráficos.
- Three.js y WebGL: tecnologías orientadas a visualizaciones avanzadas y en tres dimensiones. Su uso es más experimental y suele estar vinculado a proyectos de divulgación o investigación visual.
En este apartado conviene destacar que, aunque las barreras técnicas son mayores, estas herramientas permiten crear experiencias interactivas ricas que pueden resultar muy eficaces para comunicar datos públicos complejos.
Herramientas de cartografía y datos geoespaciales
La visualización geográfica es especialmente relevante en el ámbito de los datos abiertos, ya que una gran parte de la información pública tiene una dimensión territorial. En este campo, el software libre tiene un peso destacado y está muy alineado con el uso en administraciones públicas.
- QGIS: referente en software libre para sistemas de información geográfica (GIS). Es ampliamente utilizado en administraciones públicas y permite analizar y visualizar datos espaciales con gran detalle.
- ArcGIS: muy extendido en el ámbito institucional. Aunque no es software libre, su uso está muy consolidado y forma parte del ecosistema habitual de muchas organizaciones públicas.
- Mapbox: plataforma orientada a la creación de mapas web interactivos. Es muy utilizada en proyectos de visualización online y permite integrar datos geográficos en aplicaciones web.
- Leaflet: librería de código abierto muy popular para crear mapas interactivos en la web. Es ligera, flexible y ampliamente utilizada en proyectos de reutilización de datos abiertos geográficos.
Este conjunto de herramientas facilita la representación territorial de los datos y su reutilización en contextos locales, regionales o nacionales.
En conclusión, la elección de una herramienta de visualización depende en gran medida del objetivo que se persiga. No es lo mismo aprender y experimentar que analizar datos en profundidad o comunicar resultados a un público amplio. Por ello, resulta útil reflexionar previamente sobre el tipo de datos disponibles, el público al que se dirige la visualización y el mensaje que se quiere transmitir.
Apostar por herramientas accesibles y abiertas permite que más personas puedan explorar, interpretar y comunicar datos públicos. En este sentido, visualizar datos es también una forma de acercar la información a la ciudadanía y fomentar su reutilización.
Blog
En 2010, tras el devastador terremoto de Haití, cientos de organizaciones humanitarias llegaron al país dispuestas a ayudar. Se encontraron con un obstáculo inesperado: no había mapas actualizados. Sin información geográfica fiable, coordinar recursos, localizar comunidades aisladas o planificar rutas seguras era casi imposible.
Ese vacío marcó un antes y un después: fue el momento en que la comunidad global de OpenStreetMap (OSM) demostró su enorme potencial humanitario. Más de 600 voluntarios de todo el mundo se organizaron y comenzaron a mapear Haití en tiempo récord. Este hecho impulsó el proyecto Humanitarian OpenStreetMap Team.
¿Qué es Humanitarian OpenStreetMap Team?
Humanitarian OpenStreetMap Team, conocida por el acrónimo HOT, es una organización internacional sin ánimo de lucro dedicada a mejorar la vida de las personas mediante datos geográficos precisos y accesibles. Su labor está inspirada en los principios de OSM, el proyecto colaborativo que busca crear un mapa digital abierto, gratuito y editable por cualquiera.
La diferencia con OSM es que HOT se orienta específicamente a contextos donde la falta de datos afecta de manera directa a la vida de las personas: se trata de aportar datos y herramientas que permitan tomar decisiones más informadas en situaciones críticas. Es decir, aplica los principios del software y datos abiertos al mapeo colaborativo con impacto social y humanitario.
En este sentido, el equipo de HOT no sólo produce mapas: también facilita las herramientas, las capacidades técnicas e impulsa nuevas formas de trabajo para distintos actores que necesitan datos espaciales precisos. Su labor va desde la respuesta inmediata cuando ocurre un desastre hasta programas estructurales que fortalecen la resiliencia local ante desafíos como el cambio climático o la expansión urbana.
Cuatro zonas geográficas prioritarias
Aunque HOT no se limita a un único país o región, sí ha establecido áreas prioritarias donde sus esfuerzos de mapeo tienen un mayor impacto debido a la existencia de brechas significativas en los datos o a necesidades humanitarias urgentes. Actualmente trabaja en más de 90 países y organiza sus actividades a través de cuatro Hubs de Mapeo Abierto (centros regionales) que coordinan iniciativas según las necesidades locales:
- Asia-Pacífico: los desafíos incluyen desde desastres naturales frecuentes (como tifones y terremotos) hasta el acceso a zonas rurales remotas con poca cobertura cartográfica.
- África Oriental y Meridional: esta región enfrenta múltiples crisis entrelazadas (sequías, movimientos migratorios, deficiencias en infraestructura básica) por lo que contar con mapas actualizados es clave para la planificación sanitaria, la gestión de recursos y la respuesta a emergencias.
- África Occidental y Norte de África: en esta zona, HOT impulsa actividades que combinan el fortalecimiento de capacidades locales con proyectos tecnológicos, promoviendo la participación activa de comunidades en la creación de mapas útiles para su entorno.
- América Latina y el Caribe: con frecuencia afectada por huracanes, terremotos y riesgos volcánicos, esta región ha visto una adopción creciente de mapeo colaborativo tanto en respuesta a emergencias como en iniciativas de desarrollo urbano y resiliencia climática.
La elección de estas zonas prioritarias no es arbitraria: responde a contextos en los que la falta de datos abiertos puede limitar respuestas rápidas y efectivas, así como la capacidad de gobiernos y comunidades para planificar su futuro con información fiable.
Herramientas de código abierto desarrolladas por HOT
Una parte esencial del impacto de HOT reside en las herramientas y plataformas de código abierto que facilitan el mapeo colaborativo y el uso de datos espaciales en escenarios reales. Para ello se desarrolló una Cadena de Valor de Mapeo E2E, la cual es la metodología central que permite a las comunidades pasar de la captura de imágenes y el mapeo al impacto. Esta cadena de valor respalda todos sus programas, garantizando que el mapeo sea un proceso transformador, basado en datos abiertos, educación y poder comunitario.
Estas herramientas no sólo apoyan el trabajo de HOT, sino que están disponibles para que cualquier persona o comunidad las utilice, adapte o amplíe. En concreto se han desarrollado herramientas para crear, acceder, gestionar, analizar y compartir datos de mapas abiertos. Puedes explorarlas en el Centro de Aprendizaje, un espacio de formación que ofrece desarrollo de capacidades, fortalecimiento de habilidades y un proceso de acreditación para personas y organizaciones interesadas. A continuación se describen estas herramientas:
Permite planificar vuelos de drones para obtener imágenes aéreas actualizadas de alta resolución, algo fundamental cuando las imágenes comerciales son demasiado costosas. De esta forma, cualquier persona con acceso a un dron -incluidos modelos de bajo coste y de uso común-, puede contribuir a un repositorio global de imágenes libres y abiertas, lo que democratiza el acceso a datos geoespaciales críticos para la respuesta ante desastres, la resiliencia comunitaria y la planificación local.
La plataforma coordina a múltiples operadores y genera planes de vuelo automatizados para cubrir áreas de interés, lo que facilita la captura de imágenes 2D y 3D con precisión y eficiencia. Además, incluye planes de formación y promueve la seguridad y el cumplimiento de regulaciones locales, apoyando la gestión de proyectos, la visualización de datos y el intercambio colaborativo entre pilotos y organizaciones.

Figura 1. Captura Drone Tasking Manager (DroneTM). Fuente: Equipo Humanitario de OpenStreetMap (HOT).
Es una plataforma de código abierto que ofrece acceso a una biblioteca comunitaria de imágenes aéreas con licencia abierta, obtenidas desde satélites, drones u otras aeronaves. Cuenta con una interfaz sencilla donde se puede hacer zoom sobre un mapa para buscar imágenes disponibles. OAM permite tanto descargar como contribuir con nuevas imágenes, ampliando así un repositorio global de datos visuales que cualquiera puede usar y trazar en OpenStreetMap.
Todas las imágenes alojadas en OpenAerialMap están licenciadas bajo CC-BY 4.0, lo que significa que son de acceso público y pueden ser reutilizadas con atribución, facilitando su integración en aplicaciones de análisis geoespacial, proyectos de respuesta ante emergencias o iniciativas de planificación local. OAM se apoya en la Open Imagery Network (OIN) para estructurar y servir estas imágenes.
Facilita el mapeo colaborativo en OpenStreetMap. Su propósito principal es coordinar a miles de voluntarios de todo el mundo para añadir datos geográficos de forma organizada y eficiente. Para ello, divide un proyecto de mapeo grande en pequeñas “tareas” que pueden completarse rápidamente por personas que trabajan de forma remota.
El funcionamiento es sencillo: los proyectos se subdividen en cuadrículas, cada una asignable a un voluntario para que trace elementos como calles, edificios o puntos de interés en OSM. Cada tarea es validada por mappers experimentados para asegurar la calidad de los datos. La plataforma muestra claramente qué zonas aún necesitan mapeo o revisión, evitando duplicaciones y mejorando la eficiencia del trabajo colaborativo.

Figura 2. Captura Tasking Manager. Fuente: Equipo Humanitario de OpenStreetMap (HOT).
Utiliza inteligencia artificial para asistir el proceso de mapeo en OpenStreetMap con fines humanitarios. A través de modelos de computer vision, fAIr analiza imágenes satelitales o aéreas y sugiere la detección de elementos geográficos como edificios, caminos, cursos de agua o vegetación a partir de imágenes libres como las de OpenAerialMap. La idea es que los voluntarios puedan usar estas predicciones como asistencia para mapear más rápido y con mayor precisión, sin realizar importaciones masivas automatizadas, integrando siempre el juicio humano en la validación de cada elemento.
Una de las características más destacadas de fAIr es que la creación y entrenamiento de los modelos de IA está en manos de las propias comunidades mapeadoras: los usuarios pueden generar sus propios conjuntos de entrenamiento ajustados a su región o contexto, lo que ayuda a reducir sesgos de los modelos estándar y hace que las predicciones sean más relevantes para las necesidades locales.
Es una aplicación móvil y web que facilita la coordinación de campañas de mapeo directamente en el terreno. Field-TM se usa junto con OpenDataKit (ODK), una plataforma de recolección de datos en Android que permite introducir información sobre el terreno usando los propios dispositivos móviles. Gracias a ella, los voluntarios pueden introducir información geoespacial verificada por observación local, como la finalidad de cada edificio (si es una tienda, un hospital, etc.).
La aplicación proporciona una interfaz para asignar tareas, seguir el avance y asegurar la consistencia de los datos. Su propósito principal es mejorar la eficiencia, organización y calidad del trabajo de campo al enriquecerlo con información local, así como reducir duplicidades, evitar zonas no cubiertas y permitir un seguimiento claro del progreso de cada colaborador en una campaña de mapeo.
Transforma conversaciones de aplicaciones de mensajería instantánea (como WhatsApp) en mapas interactivos. En muchas comunidades, especialmente en zonas propensas a desastres o con poca alfabetización tecnológica, las personas ya utilizan apps de chat para comunicarse y compartir su ubicación. ChatMap aprovecha esos mensajes exportados, extrae datos de ubicación junto con textos, fotos y videos, y los representa automáticamente sobre un mapa, sin necesidad de instalaciones complejas o conocimientos técnicos avanzados.
Esta solución funciona incluso en condiciones de conectividad limitada o sin conexión, basándose en la señal GPS del teléfono para registrar ubicaciones y almacenarlas hasta que se pueda subir la información.

Figura 3. Captura de ChatMap. Fuente: Equipo Humanitario de OpenStreetMap (HOT).
Facilitar el acceso y descarga de datos geoespaciales actualizados de OpenStreetMap en formatos útiles para análisis y proyectos. A través de esta plataforma web se puede seleccionar un área de interés en el mapa, elegir qué datos se quieren (como carreteras, edificios o servicios) y descargar esos datos en múltiples formatos, como GeoJSON, Shapefile, GeoPackage, KML o CSV. Esto permite usar la información en un software SIG (Sistemas de Información Geográfica) o integrarla directamente en aplicaciones personalizadas. También se pueden exportar todos los datos de una zona o descargar datos asociados a un proyecto concreto del Tasking Manager.
La herramienta está diseñada para ser accesible tanto a analistas técnicos como a personas que no son expertas en SIG: en cuestión de minutos se pueden generar extractos personalizados de OSM sin necesidad de instalar software especializado. También ofrece una API y métricas de calidad de datos.
Es una plataforma de creación de mapas interactivos de código abierto que permite a cualquier persona visualizar, personalizar y compartir datos geoespaciales fácilmente. Sobre una base de mapas de OpenStreetMap, uMap deja añadir capas personalizadas, marcadores, líneas y polígonos, administrar colores e íconos, importar datos en formatos comunes (como GeoJSON, GPX o KML) y elegir licencias para los datos, sin necesidad de instalar software especializado. Los mapas creados pueden incrustarse en sitios web o compartirse mediante enlaces.
La herramienta ofrece plantillas y opciones de integración con otras herramientas de HOT, como ChatMap y OpenAerialMap, para enriquecer los datos en el mapa.
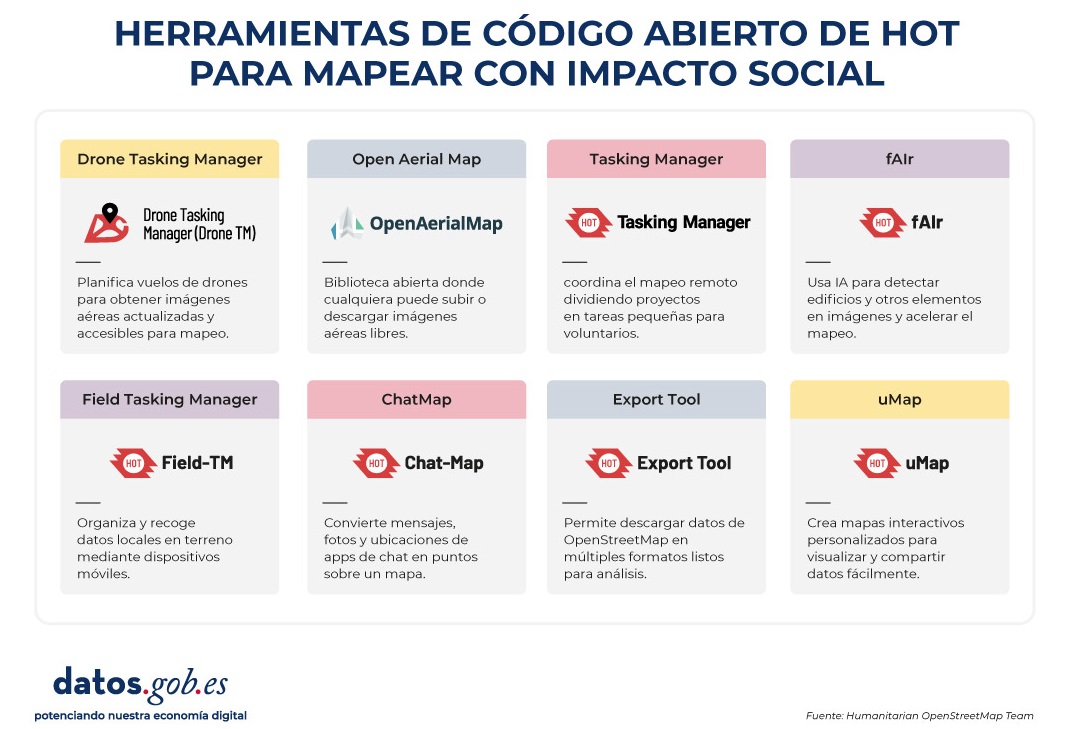
Figura 4. Herramientas de código abierto de HOT para mapear con impacto social. Fuente: Equipo Humanitario de OpenStreetMap (HOT).
Todas estas herramientas están a disposición de las comunidades locales de todo el mundo. Desde HOT también se ofrece formación para fomentar su uso y mejorar el impacto de los datos abiertos en las respuestas humanitarias.
¿Cómo puedes sumarte al impacto de HOT?
HOT se construye junto a una comunidad global que impulsa el uso de datos abiertos para fortalecer la toma de decisiones y salvar vidas. Si representas a una organización, universidad, colectivo, agencia pública o iniciativa comunitaria y tienes una idea de proyecto o interés en una alianza, el equipo de HOT está abierto a explorar colaboraciones. Puedes escribirles a partnerships@hotosm.org.
Cuando las comunidades tienen acceso a datos precisos, herramientas abiertas y el conocimiento para generar información geoespacial de forma continua, se convierten en agentes informados, listos para tomar decisiones en cualquier situación. Están mejor preparadas para identificar riesgos climáticos, responder ante emergencias, resolver problemas locales y movilizar apoyo. El mapeo abierto, por tanto, no solo representa territorios: empodera a las personas para transformar su realidad con datos que pueden salvan vidas.
Blog
Una de las misiones de la inteligencia artificial contemporánea es ayudarnos a encontrar, ordenar y digerir información, especialmente con la ayuda de los grandes modelos de lenguaje. Estos sistemas han llegado cuando más necesitamos gestionar un conocimiento que producimos y compartimos en masa, pero que después nos cuesta abarcar y consumir. Su valor radica en encontrar rápidamente las ideas y los datos que necesitamos, con el fin de que podamos dedicar nuestro esfuerzo y tiempo a pensar o, lo que es lo mismo, empezar a subir la escalera con uno o dos peldaños de ventaja.
Los sistemas basados en IA nos ayudan a navegar cualquier ecosistema de conocimiento, algo que es útil tanto en la investigación académica como en los estudios de tendencias en el mundo de la empresa. Las herramientas de IA analítica pueden analizar miles de papers para mostrarnos qué autores colaboran entre sí o cómo se agrupan los temas, creándonos a demanda un mapa interactivo y filtrable de la literatura. La IA generativa, la gran esperada, puede partir de una pregunta de investigación y devolvernos subcontenido útil como una síntesis o un contraste de enfoques. La primera nos muestra el terreno sobre el mapa, mientras que la segunda nos sugiere por dónde podemos avanzar.
Herramientas prácticas
Empezando por las más analíticas y dejando las mixtas o generativas para el final, recorremos cuatro herramientas prácticas para la investigación que integran la IA como funcionalidad, y una bola extra.
Es una herramienta basada sobre todo en la conexión entre autores, temas y artículos, que nos muestra redes de citas y nos permite crear el grafo completo de la literatura en torno a un tema. Como punto de partida, Inciteful nos pide el título o la URL de un paper, aunque también podemos simplemente buscar por nuestro tema de investigación. También existe la posibilidad de introducir los datos de dos artículos, para que nos enseñe cómo se conectan entre sí.
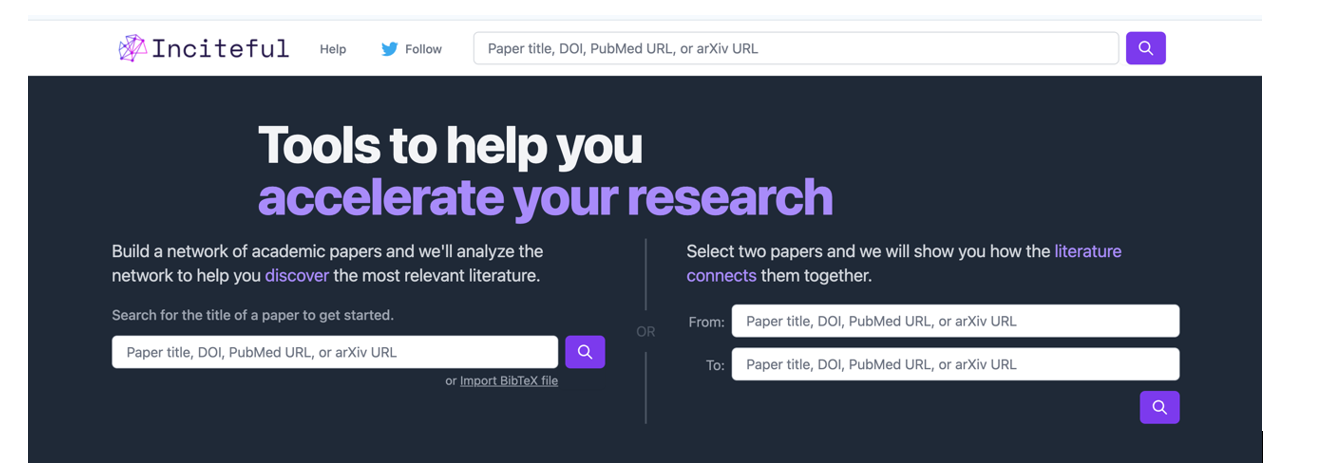
Figura 1. Captura de pantalla en Inciteful: pantalla inicial de búsqueda y conexión entre papers.
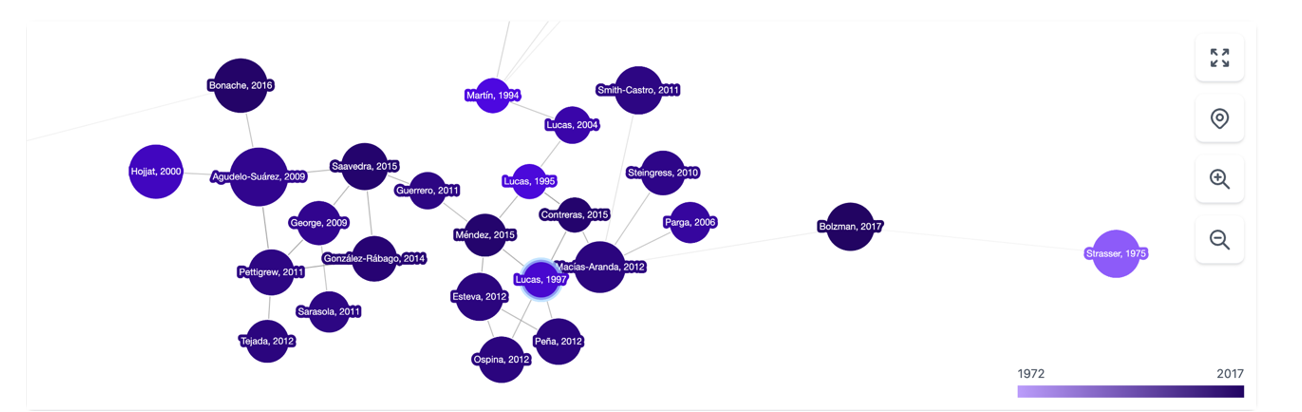
Figura 2. Captura de pantalla en Inciteful: red de nodos con artículos y autores.
En Scite, la integración de la IA es más evidente y práctica: ante una pregunta, crea una única respuesta resumen combinando la información de todas las referencias. La herramienta analiza la semántica de los papers para extraer cuál es la naturaleza de cada cita: cuántas citas lo apoyan (símbolo del check), lo cuestionan (interrogación) o solo lo mencionan (barra). Esto nos permite algo tan valioso como añadir contexto a las métricas de impacto de un artículo en nuestra bibliografía.
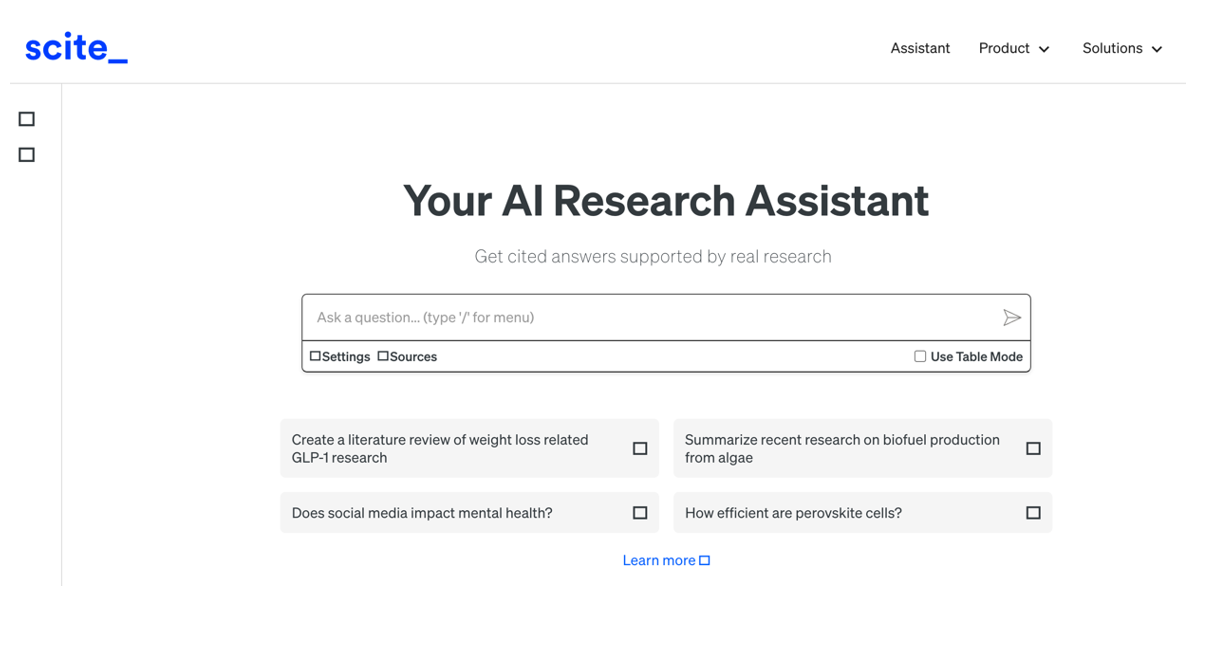
Figura 3. Captura de pantalla en Scite: pantalla inicial de búsqueda.

Figura 4. Captura de pantalla en Scite: valoración de las citas de un artículo.
Además de integrar las funcionalidades de las anteriores, se trata de un producto digital muy completo que no solo permite navegar de paper en paper en forma de red visual, sino que también hace posible establecer alertas sobre un tema o un autor al que seguimos y crear listas de papers. Además, el propio sistema sugiere qué otros papers te pueden interesar, todo en el estilo de un sistema de recomendación como los de Spotify o Netflix. También permite hacer listas públicas, como en Google Maps, y trabajar de forma colaborativa con otros usuarios.
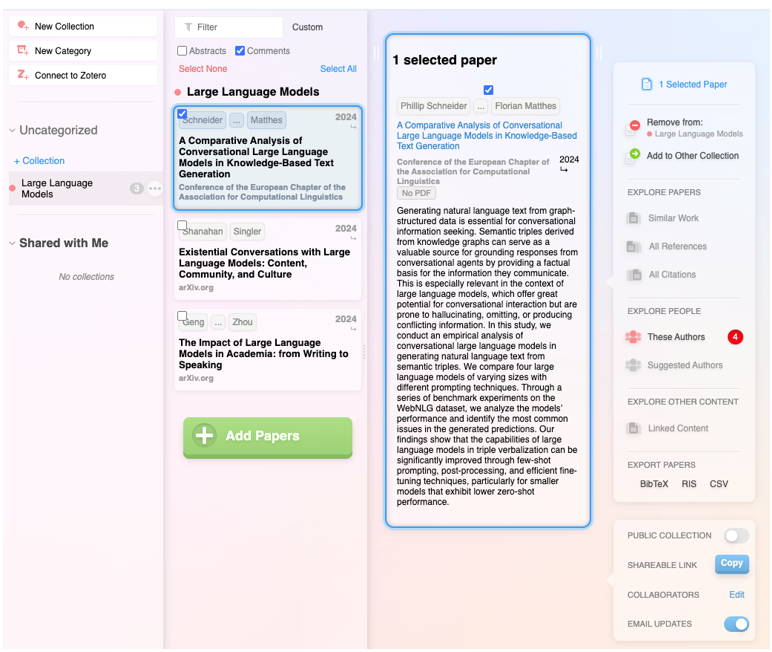
Figura 5. Captura de pantalla en Research Rabbit: lista personalizada de artículos.
Cuenta con el aval del gobierno británico, la Universidad de Stanford o la NASA, y está basada al cien por cien en IA generativa. Su funcionalidad estrella es la capacidad de hacer preguntas directas a un paper o a una colección de artículos, y finalmente obtener un informe dirigido a cuestiones concretas con todas las referencias. Aunque, en realidad, la característica más sorprendente es la capacidad de mejora de la pregunta inicial del usuario: la herramienta evalúa de forma instantánea la calidad de la pregunta y realiza sugerencias para hacerla más precisa o interesante.

Figura 6. Captura de pantalla en Elicit: sugerencias de mejora para la pregunta inicial.
Bola extra: Consensus
Lo que empezó como un humilde GPT personalizado dentro de la versión Plus de ChatGPT ha terminado siendo todo un producto digital para la investigación. A partir de una pregunta, intenta sintetizar el consenso científico en torno a esa temática, indicando si hay acuerdo o discrepancia entre los estudios. De una manera sencilla y visual muestra cuántos apoyan una afirmación, cuántos la ponen en duda y qué conclusiones predominan, además de proporcionar un pequeño informe para obtener una orientación rápida.
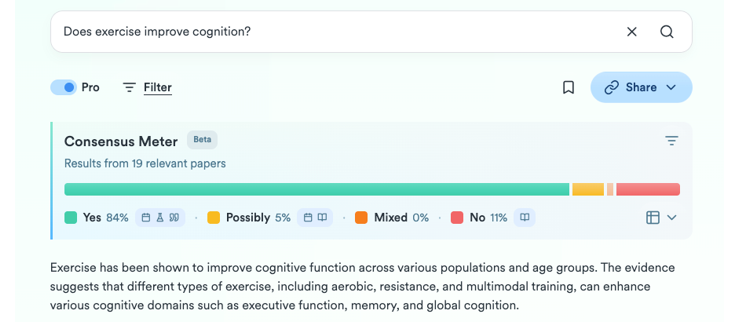
Figure 7. Screenshot on Consensus: impact metrics from a question.
El botón de la profundidad
En los últimos meses ha aparecido una nueva funcionalidad en las plataformas de los grandes modelos de lenguaje comerciales enfocada a la investigación en profundidad. En concreto, se trata de un botón con este mismo nombre, “investigación en profundidad” o “deep research”, que ya podemos encontrar en ChatGPT, versión Plus (con peticiones limitadas) o Pro, y en Gemini Advanced, aunque prometen que gradualmente se irá abriendo al uso gratuito y permiten algunas pruebas sin coste.
Figura 8. Captura de pantalla en ChatGPT Plus: botón Investigación en profundidad.
Figura 9. Captura de pantalla en Gemini Advanced: botón Deep Research.
Esta opción, que debemos activar antes de lanzar el prompt, funciona como un atajo: el modelo genera un informe sintético y organizado sobre el tema, reuniendo información clave, datos y contexto. Antes de iniciar la investigación, es posible que el sistema nos haga alguna pregunta adicional para centrar mejor la búsqueda.

Figura 10. Captura de pantalla en ChatGPT Plus: preguntas para acotar la investigación
Debemos tener en cuenta que, una vez resueltas estas dudas, el sistema inicia un proceso que puede tardar mucho más que una respuesta normal. En concreto, en ChatGPT Plus puede requerir hasta 10 minutos. Una barra de progreso nos va indicando el avance.
Figura 11. Captura de pantalla en ChatGPT Plus: inicio de la investigación y barra de progreso
Lo que obtenemos ahora es un informe completo, considerablemente preciso, incluyendo ejemplos y enlaces que nos pueden poner rápidamente en la pista de lo que estamos buscando.

Figura 12. Captura de pantalla de ChatGPT Plus: resultado de la investigación (fragmento).
Cierre
Las herramientas diseñadas para aplicar la IA a favor de la investigación no son infalibles ni definitivas, pueden todavía incurrir en errores y alucinaciones, pero no es menos cierto que la investigación con IA ya es un proceso radicalmente distinto a la investigación sin ella. La búsqueda asistida consiste, como prácticamente todo cuando hablamos de IA, en no desdeñar por imperfecto lo que puede ser útil, dedicar algo de tiempo a probar nuevos usos que pueden ahorrarnos muchas horas más adelante, y centrar su papel en lo que sí puede hacer para mantener nuestro enfoque en los siguientes pasos..
Contenido elaborado por Carmen Torrijos, experta en IA aplicada al lenguaje y la comunicación. Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Blog
La creciente complejidad de los modelos de aprendizaje automático y la necesidad de optimizar su rendimiento lleva años impulsando el desarrollo del AutoML (Automated Machine Learning). Esta disciplina busca automatizar tareas clave en el ciclo de vida del desarrollo de modelos, como la selección de algoritmos, el procesamiento de datos y la optimización de hiperparámetros.
El AutoML permite a los usuarios desarrollar modelos de manera más sencilla y rápida. Se trata de un enfoque que facilita el acceso a la disciplina, haciéndola accesible a los profesionales con menos experiencia en programación y acelerando los procesos para aquellos que cuentan con más experiencia. Así, para un usuario con conocimientos profundos de programación, el AutoML también puede ser interesante. Gracias al auto machine learning, este usuario podría aplicar automáticamente las configuraciones técnicas necesarias, como definir variables o interpretar los resultados de manera más ágil.
En este post, abordaremos las claves de estos procesos de automatización y recopilaremos una serie de herramientas de código abierto gratuitas y/o con modelo freemium, que te pueden servir para profundizar en el AutoML.
Aprende a crear tu propio modelado de aprendizaje automático
Como se indicaba anteriormente, gracias a la automatización, el proceso de entrenamiento y evaluación de modelos en base a herramientas de AutoML es más rápido que en un proceso de machine learning (ML) habitual, si bien las etapas para la creación de modelos son similares.
En general, los componentes clave del AutoML son:
- Preprocesamiento de datos: automatiza tareas como la limpieza, transformación y selección de características de los datos.
- Selección de modelos: examina una variedad de algoritmos de machine learning y elige el más adecuado para la tarea específica.
- Optimización de hiperparámetros: ajusta automáticamente los parámetros de los modelos para mejorar su rendimiento.
- Evaluación de modelos: proporciona métricas de rendimiento y valida modelos utilizando técnicas como la validación cruzada.
- Implementación y mantenimiento: facilita la implementación de modelos en producción y, en algunos casos, su actualización.
Todos estos elementos ofrecen, en su conjunto, una serie de ventajas como las que vemos en la imagen
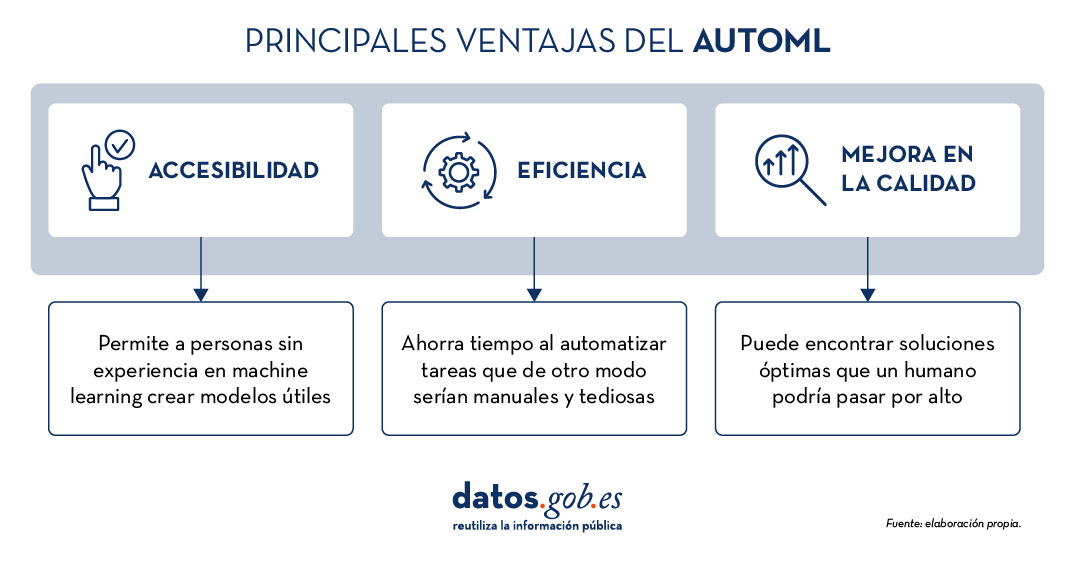
Figura 1. Fuente: elaboración propia.
Ejemplos de herramientas de AutoML
A pesar que el AutoML puede llegar a ser muy útil, es importante destacar algunas de sus limitaciones como el riesgo de overfitting (cuando el modelo se ajusta demasiado a los datos de entrenamiento y no generaliza bien el conocimiento), la pérdida de control sobre el proceso de modelado o la interpretabilidad de ciertos resultados.
No obstante, a medida que el AutoML continúa ganando terreno en el ámbito del aprendizaje automático, diversas herramientas han surgido para facilitar su implementación y uso. A continuación, exploraremos algunas de las herramientas de AutoML de código abierto más destacadas:
H2O.ai, versátil y escalable, ideal para empresas
H2O.ai es una plataforma de AutoML que incluye modelos de deep learning y machine learning como XGBoost (biblioteca de machine learning diseñada para mejorar la eficiencia de los modelos) y una interfaz de usuario gráfica. Esta herramienta se utiliza en proyectos a gran escala y permite un alto nivel de personalización. H2O.ai incluye opciones para modelos de clasificación, regresión y series temporales, y se destaca por su capacidad para manejar grandes volúmenes de datos.
Aunque H2O facilita el acceso al machine learning a no expertos, sí son necesarios algunos conocimientos y experiencia en ciencia de datos para sacarle el máximo partido a la herramienta. Además, permite realizar un gran número de tareas relacionadas con el modelado que normalmente requerirían muchas líneas de código, facilitando la tarea del analista de datos. H2O ofrece un modelo freemium y también cuenta con una versión comunitaria de código abierto.
TPOT, basado en algoritmos genéticos, buena opción para experimentar
TPOT (Tree-based Pipeline Optimization Tool) es una herramienta gratuita y de código abierto para el aprendizaje automático con Python que optimiza los procesos mediante programación genética.
Esta solución busca la mejor combinación de preprocesamiento de datos y modelos de aprendizaje automático para un conjunto de datos específico. Para ello, utiliza algoritmos genéticos que le permiten explorar y optimizar diferentes pipelines, transformación de datos y modelos. Se trata de una opción más experimental que puede resultar menos intuitiva, pero ofrece soluciones innovadoras.
Además, TPOT está construido sobre la popular biblioteca scikit-learn, así que los modelos generados por TPOT se pueden utilizar y ajustar con las mismas técnicas que se usarían en scikit-learn.
Auto-sklearn, accesible para usuarios de scikit-learn y eficiente en problemas estructurados
Como TPOT, Auto-sklearn está basada en scikit-learn y sirve para automatizar la selección de algoritmos y la optimización de hiperparámetros en modelos de aprendizaje automático en Python.
Además de ser una opción gratuita y de código abierto, incluye técnicas para manejar datos ausentes, una funcionalidad muy útil a la hora de trabajar con conjuntos de datos del mundo real. Por otro lado, Auto-sklearn ofrece una API sencilla y fácil de usar, lo que permite a los usuarios iniciar el proceso de modelado con pocas líneas de código.
BigML, integración mediante API REST y modelos de precios flexibles
BigML es una plataforma de aprendizaje automático consumible, programable y escalable que, como el resto de herramientas mencionadas, facilita la resolución y automatización de tareas de clasificación, regresión, pronóstico de series de tiempo, análisis de clústeres, detección de anomalías, descubrimiento de asociaciones y modelado de temas. Cuenta con una interfaz intuitiva y un enfoque hacia la visualización que facilita la creación y gestión de modelos de ML, incluso para usuarios con pocas nociones de programación.
Además, BigML tiene una API REST que posibilita la integración con diversas aplicaciones y lenguajes, y es escalable para manejar grandes volúmenes de datos. Por otro lado, ofrece un modelo de precios flexible basado en el uso, y cuenta con una comunidad activa que actualiza regularmente los recursos didácticos disponibles.
La siguiente tabla muestra una comparativa entre estas herramientas:
| H2O.ai | TPOT | Auto-sklearn | BigML | |
|---|---|---|---|---|
| Uso | Para proyectos a gran escala. | Para experimentar con algoritmos genéticos y optimizar pipelines. | Para usuarios de scikit-learn que desean automatizar el proceso de selección de modelos y para tareas estructuradas. | Para crear y desplegar modelos de ML de forma accesible y sencilla. |
| Dificultad de configuración | Sencilla, con opciones avanzadas. | Dificultad media. Una opción más técnica por los algoritmos genéticos. | Dificultad media. Precisa una configuración técnica, pero es fácil para usuarios de scikit-learn. | Sencilla. Interfaz intuitiva con opciones de personalización. |
| Facilidad de uso | Fácil de usar con los lenguajes de programación más habituales. Tiene interfaz gráfica y APIs para R y Python. | Fácil de usar, pero requiere conocimientos de Python. | Fácil de usar, pero requiere conocimientos previos. Opción sencilla para usuarios de scikit-learn. | Fácil de usar, enfocada a la visualización, no requiere grandes conocimientos de programación. |
| Escalabilidad | Escalable a grandes volúmenes de datos. | Enfocada en conjuntos de datos pequeños y medianos. Menos eficiente en datasets grandes. | Efectivo en conjuntos de datos tamaño pequeño y medio. | Escalable para diferentes tamaños de datasets. |
| Interoperabilidad | Compatible con varias bibliotecas y lenguajes, como Java, Scala, Python y R. | Basado en Python. | Basado en Python integrando scikit-learn. | Compatible con API REST y varios lenguajes. |
| Comunidad | Amplia y activa que comparte documentación de referencia. | Menos extensa, pero en proceso de crecimiento. | Cuenta con el soporte de la comunidad scikit-learn. | Comunidad activa y soporte disponible. |
| Desventajas | Aunque es versátil, su personalización avanzada podría ser desafiante para principiantes sin experiencia técnica. | Puede ser menos eficiente en grandes conjuntos de datos debido a la naturaleza intensiva de los algoritmos genéticos. | Su rendimiento está optimizado para tareas estructuradas (datos estructurados), lo que podría limitar su uso en otros tipos de problemas. | Su personalización avanzada podría ser desafiante para principiantes sin experiencia técnica. |
Figura 2. Tabla comparativa de herramientas de autoML. Fuente:elaboración propia.
Cada herramienta tiene su propia propuesta de valor, y la elección dependerá de las necesidades específicas y del entorno en el que trabaje el usuario.
Estos son algunos ejemplos de herramientas gratuitas y de código abierto que puedes explorar para adentrarte en el AutoML. Te invitamos a compartir tu experiencia con estas u otras herramientas en la sección de comentarios.
Si estás buscando herramientas para ayudarte en el procesamiento de datos, desde datos.gob.es ponemos a tu disposición el informe “Herramientas de procesado y visualización de datos”, así como los siguientes artículos monográficos:
Blog
La Directiva INSPIRE (Infrastructure for Spatial Information in Europe) establece las reglas generales para el establecimiento de una Infraestructura de Información espacial en la Comunidad Europea basada en las Infraestructuras de los Estados miembro. Aprobada por el Parlamento Europeo y el Consejo el 14 de marzo de 2007 (Directiva 2007/2/CE), esta entró en vigor el 25 de abril de 2007.
INSPIRE permite encontrar, compartir y utilizar con más facilidad los datos espaciales de diferentes países. La información está disponible a través de un portal online desde el que se pueden encontrar desglosados en distintos formatos y temáticas de interés.
Para asegurar que estos datos sean compatibles e interoperables en un contexto comunitario y transfronterizo, la Directiva exige que se adopten Normas de Ejecución comunes (Implementing Rules) específicas para las siguientes áreas:
- Metadatos
- Conjuntos de datos
- Servicios de red
- Uso compartido de datos y servicios
- Servicios de datos espaciales
- Monitoreo e informes
La implementación técnica de estas normas se realiza mediante las Guías Técnicas o Directrices (Technical Guidelines), documentos técnicos basados en estándares y normas internacionales.
Inspire e interoperabilidad semántica
Estas normas se consideran decisiones o reglamentos de la Comisión y, por lo tanto, son de obligado cumplimiento en cada uno de los países de la Unión. La transposición de esta Directiva al ordenamiento jurídico español se desarrolla a través de la Ley 14/2010 de 5 de julio, la cual hace referencia a las infraestructuras y los servicios de información geográfica de España (LISIGE) y el portal IDEE, ambos son el resultado de la implementación de la Directiva INSPIRE en España.
En INSPIRE juega un papel decisivo la interoperabilidad semántica. Gracias a esta, existe un lenguaje común en los datos espaciales, pues la integración del conocimiento solo es posible cuando se logra una homogenización o entendimiento común de los conceptos que constituyen un dominio o área de conocimiento. Así, en INSPIRE, la interoperabilidad semántica es la encargada de asegurar que el contenido de la información intercambiada sea entendido de la misma manera por cualquier sistema.
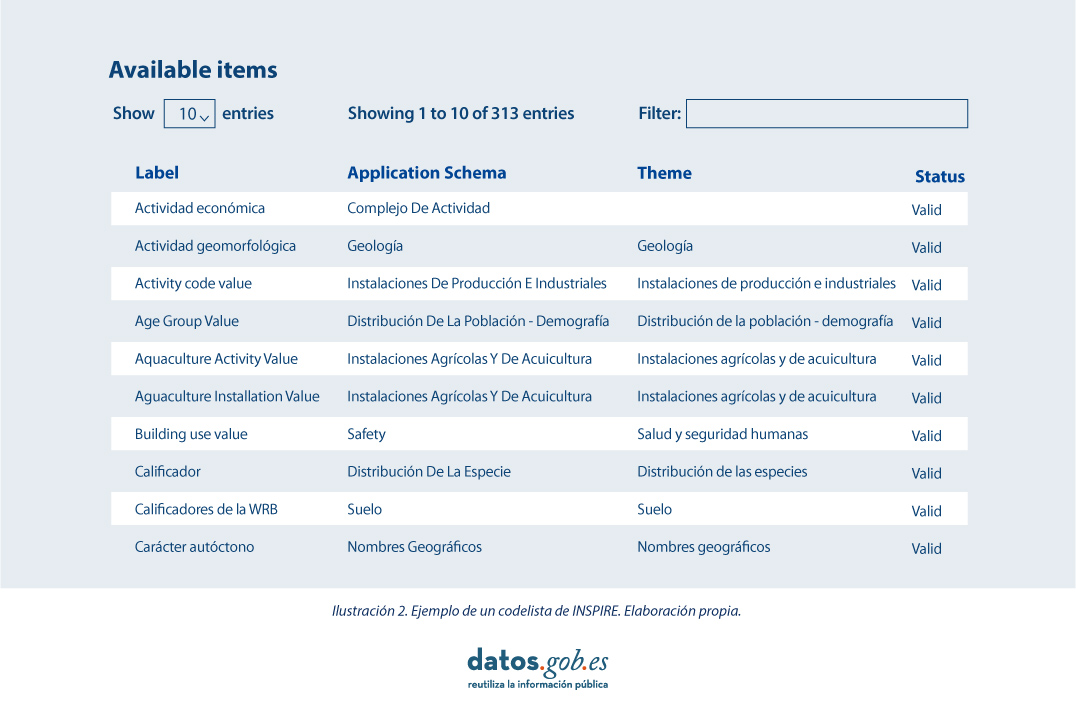
Por ello, en la implementación de los modelos de datos espaciales en INSPIRE, en formato de intercambio GML, podemos encontrar los codelist que son una parte importante de las especificaciones de datos de INSPIRE y contribuyen sustancialmente a la interoperabilidad.
En general, una codelist o lista de códigos contiene varios términos cuyas definiciones son universalmente aceptadas y comprendidas. Las listas de códigos favorecen la interoperabilidad de los datos y constituyen un vocabulario compartido por una comunidad. Incluso pueden ser multilingües.
Las listas de códigos INSPIRE se administran y mantienen comúnmente en Registro Inspire Central Federado (ROR) que proporciona capacidades de búsqueda, de modo que tanto los usuarios finales como las aplicaciones cliente pueden acceder fácilmente a los valores de la lista de códigos como referencia.
Los registros son necesarios porque:
- Proporcionan los códigos definidos en las Directrices Técnicas (Guidelines), Reglamentos y Especificaciones técnicas necesarios para implementar la Directiva
- Permiten referencias inequívocas de los elementos
- Proporcionna identificadores únicos y persistentes para los recursos
- Permiten una gestión y control de versiones coherentes de los diferentes elementos
Las listas de códigos utilizados en INSPIRE se mantienen en:
- El Registro Inspire Central Federado (ROR)
- El registro de listas de códigos de un estado miembro
- El registro de listas de un tercero externo reconocido que mantiene una lista de códigos específica de dominio.
Para agregar una nueva lista de códigos, tendrá que configurar su propio registro o trabajar con la administración de uno de los registros existentes para publicar su lista de códigos. Este puede ser un proceso bastante complicado pero una nueva herramienta nos ayuda en esta labor.
Re3gistry es una solución de código abierto reutilizable y publicado bajo licencia EUPL, que permite a las empresas y organizaciones administrar y compartir \"códigos de referencia\" a través de URI persistentes, asegurando que los conceptos se referencian inequívocamente en cualquier dominio y facilitando la gestión de estos recursos gráficamente durante todo su ciclo de vida.
Financiado por ELISE, ISA2 es una solución reconocida por los europeos en el Marco de interoperabilidad como una herramienta de apoyo.Ilustración 3 Imagen de la interface de Re3gister.
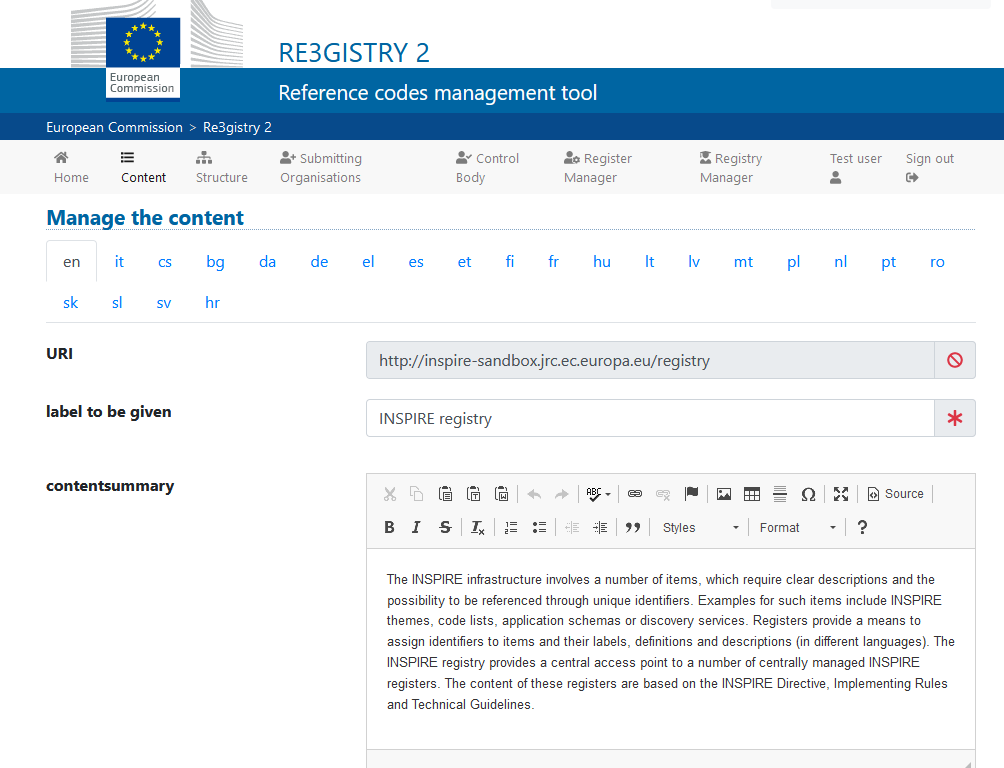
Ilustración 3: Imagen de la interface de Re3gister
Re3gistry está disponible tanto para Windows como para Linux y ofrece una Interfaz Web fácil de usar para agregar, editar y administrar los registros y códigos de referencia. Además, permite la gestión del ciclo de vida completo de los códigos de referencia (basado en la norma ISO 19135: 2005 Procedimientos integrados para el registro de códigos de referencia)
La interfaz de edición también proporciona un indicador para permitir que el sistema exponga el código de referencia en el formato que permite su integración con RoR, de esta manera, eventualmente se puede importar en la federación de registro INSPIRE. Para esta integración, Reg3gistry hace una exportación en un formato basado en las siguientes especificaciones:
- El vocabulario del Catálogo de datos del W3C (DCAT) que se utiliza para modelar el registro de entidades (dcat:Catalog).
- El Sistema de Organización Simple del Conocimiento (SKOS) del W3C que se utiliza para modelar el registro de entidades (skos:ConceptScheme) y el elemento (skos:Concept).
Otras características destacables de Re3gistry
- Modelos de datos altamente flexibles y personalizables
- Soporte de contenido en varios idiomas
- Soporte para el control de versiones
- API RESTful con negociación de contenido (incluido el descriptor OpenAPI 3)
- Búsqueda de texto-libre
- Formatos soportados: HTML, ISO 19135 XML, JSON
- Los formatos de servicio se pueden agregar o personalizar fácilmente (formatos predeterminados: JSON e ISO 19135 XML)
- Múltiples opciones de autentificación
- Elementos gobernados externamente a los que se hace referencia a través de URIs
- Soporte de formato de federación de registro INSPIRE (opción para crear automáticamente el formato RoR)
- Fácil exportación y reindexación de datos (SOLR)
- Guías para usuarios, administradores y desarrolladores
- Fuente RSS
En definitiva, Re3gistry proporciona un punto de acceso central donde las etiquetas y descripciones de los códigos de referencia son fácilmente accesibles tanto para humanos como para máquinas, al tiempo que fomenta la interoperabilidad semántica entre organizaciones ya que permite:
- Evitar errores comunes como faltas de ortografía, ingresar sinónimos o completar formularios en línea.
- Facilitar la internacionalización de las interfaces de usuario proporcionando etiquetas multilingües.
- Garantizar la interoperabilidad semántica en el intercambio de datos entre sistemas y aplicaciones.
- El rastreo de los cambios a lo largo del tiempo a través de un sistema de control de versiones bien documentado.
- Aumentar el valor de los códigos de referencia, si se reutilizan y referencian ampliamente.
Más acerca de Re3gistry:
|
|
Soporte | https://github.com/ec-jrc/re3gistry |
|
|
Manual de usuario | https://github.com/ec-jrc/re3gistry/blob/master/documentation/user-manual.md |
|
|
Manual de administrador | https://github.com/ec-jrc/re3gistry/blob/master/documentation/administrator-manual.md |
|
|
Manual de desarrollador |
https://github.com/ec-jrc/re3gistry/blob/master/documentation/developer-manual.md
|




Referencias
https://github.com/ec-jrc/re3gistry
https://inspire.ec.europa.eu/codelist
https://ec.europa.eu/isa2/solutions/re3gistry_en/
https://live.osgeo.org/en/quickstart/re3gistry_quickstart.html
Contenido elaborado por Mayte Toscano, Senior Consultant in Tecnologías ligadas a la economía del dato.
Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Blog
La administración pública trabaja para garantizar el acceso a los datos abiertos, y así, empoderar a la ciudadanía en su derecho a la información. En línea con este objetivo, el portal de datos abiertos europeo (data.europa.eu) referencia un gran volumen de datos de temáticas variadas.
Sin embargo, aunque los datos pertenecen a ámbitos de información diferentes o se encuentran en formatos diversos, resulta complejo explotarlos conjuntamente para maximizar su valor. Una forma de lograrlo es mediante el uso de RDF (Resource Description Framework), un modelo de datos que permite la interoperabilidad semántica de datos en la web, estándar del W3C, y destacado en los principios FAIR. RDF ocupa los niveles superiores del esquema de cinco estrellas en la publicación de datos abiertos, propuesto por Tim Berners-Lee, el padre de la web.
En RDF, se interconectan datos y metadatos de manera automática generando una red de datos abiertos enlazados (LOD, por sus siglas en inglés, Linked Open Data) aportando el contexto semántico necesario mediante relaciones explicitas entre datos procedentes de diferentes fuentes para facilitar su interconexión. Este modelo maximiza el potencial de explotación de los datos enlazados.
Se trata de un paradigma de compartición de datos que cobra especial relevancia dentro de la iniciativa de espacio de datos de la UE que explicamos en este post.
RDF ofrece grandes ventajas a la comunidad. Sin embargo, para poder maximizar la explotación de datos abiertos enlazados es necesario conocer el lenguaje de consulta SPARQL, un requerimiento técnico que puede dificultar el acceso público a los datos.
Un ejemplo del uso de RDF es el de los catálogos de datos abiertos disponibles en portales como datos.gob.es o data.europa.eu que están desarrollados siguiendo el estándar DCAT que es un modelo de datos en RDF para facilitar su interconexión. Estos portales disponen de interfaces para configurar consultas en lenguaje SPARQL, y recuperar los metadatos de los conjuntos de datos disponibles.
Una nueva aplicación para hacer accesibles los datos entrelazados: Vinalod
Ante esta situación y con el objetivo de facilitar el acceso a datos enlazados, Teresa Barrueco, científica de datos y especialista en visualización que participó en el EU Datathon de 2018, la competición de la UE para fomentar el diseño de soluciones y servicios digitales relacionadas con los datos abiertos, desarrolló junto a la Oficina de Publicaciones Europea una aplicación.
El resultado es una herramienta que permite explorar LOD sin necesidad de estar familiarizado con la sintaxis SPARQL bautizada con el nombre de Vinalod: Visualisation and navigation of linked open data. La aplicación, como indica su nombre, permite navegar y visualizar estructuras de datos en grafos de conocimiento que representan objetos de datos vinculados entre si mediante el uso de vocabularios que representan las relaciones existentes entre ellos. Así, mediante una interacción visual e intuitiva, el usuario puede acceder a diferentes fuentes de datos:
- Vocabularios de la UE. Datos de referencia de la UE que contiene, entre otros, información de Digital Europa Thesaurus, clasificación NUTS (sistema jerárquico para dividir el territorio económico de la UE) y vocabularios controlados del Named Authority Lists.
- Quién es quién en la UE. Directorio oficial de la UE para identificar a las instituciones que componen la estructura de la administración europea.
- Datos de la UE. Conjuntos y visualizaciones de datos publicados en el portal de datos abiertos de la UE que pueden explorarse según origen y temática.
- Publicaciones de la UE. Informes publicados por la Unión Europea clasificados según su temática.
- Legislación de la UE. Tratados de la UE y su clasificación.
La buena noticia es que la versión BETA de Vinalod ya está disponible para su utilización, un avance que permite filtrar temporalmente conjuntos de datos por país o idioma.
Para poner a prueba a la herramienta, probamos a buscar catálogos de datos publicados en español, que han sido modificados en los últimos tres meses. La respuesta de la herramienta es la siguiente:

que se puede interpretar de la siguiente forma:

Por lo tanto, el portal data.europa.eu alberga (“has catalog”) varios catálogos que cumplen con los criterios definidos: están en idioma español y han sido editados en los últimos tres meses. El usuario puede profundizar en cada nodo (“to”) y conocer cuáles son los conjuntos de datos publicados en cada uno de los portales.
En el ejemplo anterior, hemos explorado el apartado ‘Datos de la UE’. Sin embargo, podríamos hacer un ejercicio similar con cualquiera de los otros apartados. Estos son: Vocabularios de la UE; Quién es quién en la UE; Publicaciones de la UE y Legislación de la UE.
Todos estos los apartados están relacionados entre sí, es decir, un usuario puede empezar navegando por los ‘Datos de la UE’, como sucede en el ejemplo anteriormente explicado, y acabar en ‘Quién es quién de la UE’ con el directorio de cargos públicos europeos.

Como puede deducirse de las pruebas anteriores, la navegación por Vinalod es un ejercicio práctico en sí mismo que animamos a probar a todos los usuarios interesados en la gestión, explotación y reutilización de los datos abiertos.
Para ello, en este enlace vinculamos la versión BETA de la herramienta que contribuye a hacer más accesibles los datos abiertos sin la necesidad de conocer SPARQL, lo que significa que cualquier persona con un mínimo conocimiento técnico pueda trabajar con los datos abiertos enlazados.
Se trata de un aporte de valor para la comunidad de desarrolladores y reutilizadores de datos abiertos porque es un recurso al que puede acceder cualquier perfil de usuario, independientemente de su formación técnica. En definitiva, Vinalod es una herramienta que empodera a la ciudadanía, respeta su derecho a la información y contribuye a la apertura aún mayor de los datos abiertos.
Blog
Garantizar la calidad de los datos es una tarea primordial para cualquier iniciativa open data. Antes de su publicación, es necesario validar los conjuntos de datos para comprobar que no contienen errores, duplicidades, etc. De esta manera, su potencial de reutilización crecerá.
La calidad de los datos está condicionada por muchos aspectos. En ese sentido, en el marco de de la Iniciativa Aporta se ha elaborado la “Guía práctica para la mejora de la calidad de datos abiertos”, que proporciona un compendio de directrices para actuar sobre las distintas características que definen la calidad e impulsar su mejora.
La guía incluye un listado con algunas herramientas gratuitas dirigidas a aplicar medidas correctoras sobre los datos en origen. En este artículo te mostramos algunos ejemplos. Se trata de herramientas útiles para trabajar aspectos concretos relacionados con la calidad, por lo que su mayor o menor utilidad dependerá de los datos con los que estés trabajando y sus características.
Se trata de una colección de herramientas online para realizar tareas de conversión de formatos y codificación de caracteres. Puedes seleccionar entre distintos conversores, pero destacamos las herramientas para trabajar con la codificación UTF8. Esta colección compila un amplio catálogo de herramientas de programación, que ofrecen funcionalidades de conversión, encriptación, generación de contraseñas, edición y gestión de textos e imágenes, conversión de fechas y horas, realización de operaciones matemáticas, etc.
Todas las herramientas son gratuitas, sin anuncios intrusivos, y fáciles de usar gracias a una interfaz de usuario sencilla. Además, cada una de ellas incluye ejemplos de uso.
Gestionada por el Open Data Institute, esta herramienta online permite comprobar si un archivo CSV es legible por máquinas y verificar que incluye las columnas y los tipos de valores que debería. También permite añadir esquemas a los archivos de datos. Tras el análisis, genera un informe con los resultados y una marca que puede ser embebida en el portal de datos desde el que se sirve el dataset evaluado.
Aunque es muy sencilla de utilizar (solo hay que cargar el archivo que se quiere verificar y hacer clic en el botón de validar), la web incluye un apartado de ayuda. Trabaja bien con archivos de hasta 100 Mb de tamaño. También ofrece un sencillo manual con directrices sobre cómo crear un archivo en formato CSV correctamente y evitar los errores más comunes.
DenCode ofrece herramientas de codificación y descodificación online. Entre las funcionalidades que ofrece destaca esta herramienta que ayuda a los publicadores en la conversión de datos tipo fecha al formato ISO 8601, que es el estándar internacional que facilita la homogenización de este tipo de datos y su interoperabilidad.
La herramienta es muy intuitiva, ya que solo es necesario escribir, en el apartado habilitado para ello, la fecha y hora a convertir.
XML Escape / Unescape es una herramienta online de código abierto, utilizada para el “escapado” o enmascaramiento de caracteres especiales en XML y la realización del proceso inverso. La herramienta se encarga de eliminar los rastros de aquellos caracteres que podrían ser interpretados erróneamente.
Al igual que en el caso anterior, la herramienta es muy intuitiva. Solo es necesario copiar y pegar el fragmento a tratar en el editor.
JSONLint es un validador y reformulador para JSON, que permite chequear si el código es válido de acuerdo a dicha especificación. Cuenta con un editor donde escribir o copiar y pegar el código, aunque también se puede introducir directamente una url para su validación. JSONLint analizará dicho código para encontrar y sugerir la corrección de los errores explicando, además, los multiples motivos por los que se pueden producir. La herramienta también puede ser utilizada como compresor, reduciendo de esta forma el tamaño de los archivos.
En su web incluye información sobre buenas prácticas a la hora de trabajar con el formato JSON, así como información sobre errores comunes.
Open Refine es una herramienta pensada para el tratamiento y enriquecimiento de datos: permite limpiarlos, transformar su formato y ampliarlos con servicios web y datos externos. Una de sus principales características es que utiliza un lenguaje propio, GREL (Google Refine Expression Languaje), que permite realizar tareas de depuración avanzadas. Está disponible en más de 15 idiomas.
En su página web ofrece varios vídeos que explican su funcionamiento. También cuenta con una sección de documentación con cursos online, guías y preguntas frecuentes. Además, los usuarios pueden recurrir a su amplia comunidad y a los grupos de discusión en Google, Gitter y Stackoverflow, para solucionar dudas y compartir experiencias.
OpenRefine permite añadir diferentes extensiones. Una de ellas es la que permite transformar datos tabulares a un esquema RDF a través de un punto SPARQL. Los formatos concretos con los que permite trabajar son: TSV, CSV, SV, XLS, XLSX, JSON, XML, RDF como XML y Google sheet. La interfaz visual guía en la elección de los predicados, la definición de los mapeos de tipos de datos a RDF y la implementación de transformaciones complejas utilizando el lenguaje GREL.
En su web incluye información sobre cómo utilizar la herramienta, así como casos de uso.
Esta herramienta permite generar y validar JSON schemas a partir de archivos JSON. Estos esquemas permiten describir formatos de datos existentes, proporcionando una documentación clara y legible tanto para las personas como para las máquinas.
En la web de JSON Schema tienes distintos materiales formativos a tu disposición, incluyendo ejemplos, e información sobre distintas implementaciones. También puedes aprender más sobre JSON schema en su perfil de Github.
Se trata de una herramienta online de validación para la especificación SHACL, estándar del W3C para validar grafos RDF contra un conjunto de condiciones expresadas en SHACL. Al igual que en las herramientas anteriores, solo es necesario cortar y pegar el código para que se proceda a su validación.
La herramienta ofrece algunos ejemplos de uso. Además, todo el código está disponibles en Github.
Swagger es una herramienta para la edición y validación de especificaciones que siguen el estándar OpenAPI. Aunque cuenta con una versión de pago con más funcionalidades, los usuarios pueden crear una cuenta gratuita que les permitirá diseñar la documentación de APIS de forma rápida y estandarizada. Dicha versión gratuita cuenta con funcionalidades de detección inteligente de errores y autocompletado de sintaxis.
Sphinx es un software de código abierto para generar cualquier tipo de documentación sobre los datos. Permite crear estructuras jerárquicas de contenidos e índices automáticos, así como ampliar las referencias cruzadas a través del marcado semántico y los enlaces automáticos para funciones, clases, citas, términos de glosario y piezas de información similares. Utiliza el lenguaje de marcado reStructuredText por defecto, y puede leer MyST markdown a través de extensiones de terceros.
A través de su web puedes acceder a una gran cantidad de tutoriales y guías. Además, cuenta con una importante comunidad de usuarios.
Se trata de un software de código abierto para alojar y documentar la semántica de los datos, similar al anterior. Su objetivo es simplificar la generación de documentación del software al automatizar la creación, el control de versiones y el alojamiento de documentaciones.
Cuenta con un extenso tutorial donde indica los pasos a seguir para crear un proyecto de documentación.
Esta herramienta permite convertir las palabras que integran un texto en mayúsculas y/o minúsculas. El usuario solo tiene que introducir un texto y la herramienta lo convierte a distintos formatos: todo mayúsculas, todo minúsculas, Title Case (donde todas las palabras importantes comienzan con mayúsculas, mientras que los términos menores, como artículos o preposiciones, van en minúsculas) o AP-Style Title Case (donde todos los términos comienzan con mayúsculas).
Esto es solo un ejemplo de algunas herramientas online que pueden ayudar a trabajar sobres aspectos relacionados con la calidad de los datos. Si quieres recomendar alguna otra herramienta, puedes dejarnos un comentario o escribir a dinamizacion@datos.gob.es.
Contenido elaborado por el equipo de datos.gob.es.
Documentación
La visualización es crítica para el análisis de datos. Aporta una primera línea de ataque, revelando estructuras intrincadas en datos que no pueden ser absorbidas de otro modo. Descubrimos efectos inimaginables y cuestionamos aquellos que han sido imaginados.”
William S. Cleveland (de Visualizing Data, Hobart Press)
A lo largo de los años se ha generado y almacenado una enorme cantidad de información pública. Esta información, si se observa de forma lineal, consta de una gran cantidad de números y hechos inconexos que, fuera de contexto, carecen de cualquier significado. Por ello, la visualización se presenta como una fácil solución hacia la comprensión e interpretación de la información.
Para obtener buenas visualizaciones es preciso trabajar con datos que cumplan dos características:
- Tienen que ser datos de calidad. Es necesario que sean precisos, completos, fiables, actuales y relevantes.
- Tienen que estar bien tratados. Es decir, convenientemente identificados, correctamente extraídos, de forma estructurada, etc.
Por tanto, es importante procesar adecuadamente la información antes de su tratamiento gráfico. El tratamiento de los datos y su visualización forman un tándem atractivo para el usuario que demanda, cada vez más, poder interpretar datos de forma ágil y rápida.
Existen un gran número de herramientas destinado a este fin. El informe “Herramientas de procesado y visualización de datos” nos ofrece un listado de diferentes herramientas que nos ayudan en el procesamiento de los datos, desde la obtención de los mismos hasta la creación de una visualización que nos permita interpretarlos de manera sencilla.
¿Qué puedes encontrar en el informe?
La guía incluye una recopilación de herramientas de:
- Web scraping
- Depuración de datos
- Conversión de datos
- Análisis de datos para programadores y no programadores
- Servicios de visualización genéricos, geoespaciales y librerías y APIs.
- Análisis de redes
Todas las herramientas presentes en la guía tienen una versión de libre disposición para que cualquier usuario pueda acceder a ellas.
Nueva edición 2021: incorporación de nuevas herramientas
La primera versión de este informe vio la luz en 2016. Cinco años después se ha procedido a su actualización. Las novedades y cambios efectuados son:
- Se han incorporado nuevas herramientas de procesado y visualización de datos actualmente populares como Talend Open Studio, Python, Kibana o Knime.
- Se han eliminado algunas herramientas desfasadas.
- Se ha actualizado la maquetación.
Si conoces alguna herramienta adicional, no incluida actualmente en la guía, te invitamos a compartir la información en los comentarios.
Además, hemos preparado una serie de post donde se explican los distintos tipos de herramientas que pueden encontrar en el informe:
Blog
Mucha gente no lo sabe, pero estamos rodeados de APIs. Las APIs son el mecanismo mediante el cual se comunican los servicios en Internet. Las APIs son las que hacen posible que iniciemos sesión en nuestro correo electrónico o que realicemos una compra por Internet.
API significa Application Programming Interface, que para la mayoría de usuarios en Internet no significa nada. Sin embargo, la realidad es que gracias a las APIs hoy podemos hacer todas esas cosas fantásticas que tanto nos gustan del mundo digital. Desde iniciar sesión en cualquier servicio de Internet, realizar una compra en Amazon o reservar una habitación de hotel en Booking. Todos estos servicios son posibles gracias a las APIs.
Una forma sencilla de explicar para qué sirve una API es la siguiente: un mecanismo mediante el cual dos programas de software pueden “hablar” e intercambiar los datos que necesiten para cumplir con la funcionalidad para la que han sido diseñados. Por ejemplo, para iniciar sesión en nuestro proveedor de correo electrónico, existe un programa encargado de validar que disponemos de un usuario y contraseña correctos. Sin embargo, este programa debe de recibir ese usuario y contraseña de una persona que interactúa con un navegador web o una aplicación móvil. Para que la aplicación móvil sepa enviarle a ese programa el usuario y la contraseña de la persona que quiere acceder al servicio, utiliza una API cómo lenguaje de intercambio. Esta API define la forma en la que la app móvil envía esos datos y la forma en la que el programa de validación los consume. Así, cuándo una nueva aplicación móvil requiera de ese mismo proceso de validación, bastará con seguir la misma API para comprobar las credenciales del usuario.
La importancia de las APIs en la creación de productos de datos
En este nuevo post, ponemos el foco en el ámbito de las APIs cómo base tecnológica clave para la creación de productos de datos. La disrupción digital tiene como característica fundamental el papel de los datos cómo principal elemento transformador de las organizaciones y la sociedad. Es por esto que los productos de datos son cada vez más habituales y valiosos. Los productos de datos son aplicaciones y servicios digitales creados con la componente de datos integrada desde su diseño. La componente de datos no tiene por qué ser la única característica del producto o servicio, pero sí juega un papel fundamental en el funcionamiento del producto (físico o digital) o servicio. Pensemos, por ejemplo, en una aplicación móvil de mapas. Su principal funcionalidad puede ser mostrarnos un mapa y ubicar físicamente nuestra posición actual. Sin embargo, la aplicación puede entenderse cómo un producto de datos donde, además de nuestra posición actual, encontramos servicios cercanos cómo restaurantes, gasolineras, bibliotecas, etc. Además, podemos sobre-impresionar información meteorológica o el estado del tráfico actual. Una aplicación de este tipo no puede entenderse sin un ecosistema de APIs que permitan la intercomunicación de los diferentes servicios (meteorología, tráfico, puntos de interés, etc.) con la aplicación en sí misma.
Cómo gestionar las APIs en los productos de datos: el ejemplo de API Friendliness Checker
Una vez entendida con claridad la importancia de las APIs en los productos de datos, pasemos ahora a analizar la complejidad de gestionar una o varias APIs extensas en un producto de datos. Crear buenas APIs es un trabajo complicado. Es necesario determinar qué datos va a proporcionar y aceptar nuestra API. Hay que estimar el volumen de peticiones que vamos a tener que asumir. Debemos de pensar en los mecanismos de actualización así como en la monitorización del uso que está teniendo la API. Por no hablar de la seguridad y la privacidad de los datos que va a manejar la API.
Por estas y otras muchas razones, el Support Centre for Data Sharing (en español, el Centro de apoyo para la puesta en común de datos) ha creado la herramienta API Friendliness Checker. El Support Centre for Data Sharing (SCDS) es un proyecto europeo liderado por un consorcio de tres empresas: Capgemini Invent, Fraunhofer Fokus y Timelex.
La herramienta API Friendliness Checker permite a los desarrolladores de APIs analizar si sus APIs cumplen con la especificación OpenAPI: un estándar establecido y ampliamente reconocido para desarrollar APIs. La especificación OpenAPI se desarrolló teniendo en cuenta criterios de accesibilidad. El objetivo es que los servicios y las aplicaciones que la implementan puedan ser entendidos por humanos y máquinas por igual, sin necesidad de acceder al código de programación o la documentación. Es decir, una API desarrollada bajo especificación OpenAPI es autocontenida y puede usarse desde el primer momento sin necesidad de documentación ni código adicional.
Cuando utilizamos la herramienta, el validador de compatibilidad de la API permite al desarrollador comparar su API contra los criterios esenciales de calidad y usabilidad definidos por la especificación de OpenAPI. La herramienta permite copiar la url de especificación de nuestra API para evaluar la compatibilidad de ésta. También es posible copiar y pegar la descripción de nuestra API en el editor de la herramienta. Con tan solo presionar el botón validar, el verificador de compatibilidad evaluará la API y mostrará cualquier comentario para mejorarla.
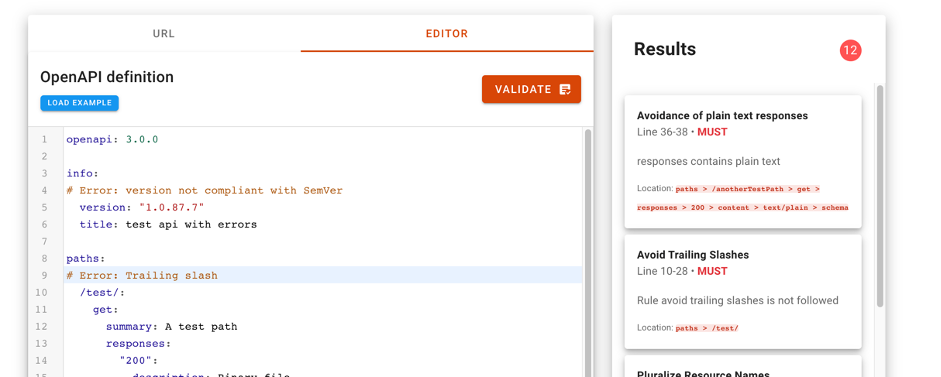
Para más información sobre las características técnicas de esta herramienta de validación se puede consultar toda la información en la página web del SCDS https://eudatasharing.eu/es/node/578.
Si estáis pensando en crear un nuevo producto de datos, estamos seguros que esta herramienta para validar vuestra API antes de ponerla en producción será de gran ayuda. Por último, si vuestro producto digital se basa en datos en tiempo real, seguro que os resulta de interés explorar estos otros conceptos cómo los sistemas orientados a eventos y las APIs asíncronas.
¿Quieres saber más sobre las APIs?
Como hemos visto las APIS son un elemento fundamental dentro del mundo de los datos. Tanto si eres un publicador como un reutilizador de datos abiertos, en datos.gob.es tienes a tu disposición algunos materiales que te pueden ayudar:
- Informe “Cómo generar valor a partir de los datos: formatos, técnicas y herramientas para analizar datos abiertos”. Dirigido a reutilizadores, en él se discute con más detalle el mundo de las APIs incluyendo ejemplos prácticos sobre su uso en Internet.
- “Guía práctica para la publicación de Datos Abiertos usando APIs”. Dirigida a aquellos portales de datos que todavía no cuenten con una API, esta guía ofrece pautas para definir y poner en marcha este mecanismo de acceso a los datos.
Contenido elaborado por Alejandro Alija,experto en Transformación Digital e Innovación.
Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.