Blog
¿Te has preguntado alguna vez cómo Alexa es capaz de reconocer nuestra voz y entender lo que le estamos diciendo (algunas veces mejor que otras)? ¿Te has parado a pensar cómo Google es capaz de buscar imágenes similares a la que le estamos proporcionando? Probablemente sepas que estas técnicas pertenecen al ámbito de la inteligencia artificial. Pero no te engañes, construir estos modelos sofisticados solo está al alcance de unos pocos. En este post te contamos por qué y qué podemos hacer el común de los mortales para entrenar modelos de inteligencia artificial.
Introducción
En los últimos años hemos sido testigos de avances increíbles y sorprendentes en el ámbito del entrenamiento de modelos de Deep Learning. En anteriores ocasiones hemos citado los ejemplos más relevantes cómo GPT-3 o Megatron-Turing NLG. Estos modelos, optimizados para el procesamiento de lenguaje natural (en inglés, NLP), son capaces de escribir artículos completos (prácticamente indistinguibles de los escritos por un humano) o realizar resúmenes coherentes de obras clásicas, de cientos de páginas, sintetizando el contenido en tan solo unos párrafos. Impresionante ¿verdad?
Sin embargo, estos logros no son ni mucho menos baratos. Es decir, la complejidad de estos modelos es tal que, se necesitan miles de gigabytes de información pre-procesada - lo que denominamos datasets anotados- que han sido previamente analizados (etiquetados) por un humano experto en la materia. Por ejemplo, el último entrenamiento del modelo Megatron-Turing NLG, creado en colaboración por Microsoft y NVIDIA, utilizó 270.000 millones de tokens (pequeños trozos de texto que pueden ser palabras o sub-palabras que constituyen la base para el entrenamiento de estos modelos de lenguaje natural). Además de la información necesaria para poder entrenar estos modelos, está el hecho de las necesidades especiales de computación que requieren estos entrenamientos. Para ejecutar tareas de entrenamiento de estos modelos, se necesitan las máquinas (los ordenadores) más avanzados del mundo y los tiempos de entrenamiento se cuentan por semanas. Aunque no existen datos oficiales, algunas fuentes citan que el coste de entrenamiento de los últimos modelos como GPT-3 o Megatron-Turing se cuentan por decenas de millones de dólares. Así, cabría preguntarnos, cómo podemos utilizar y entrenar modelos si no tenemos acceso a los clusters de cálculo más potentes del mundo.
La respuesta: Transfer Learning
Cuando trabajamos en un proyecto de machine learning o deep learning y no disponemos de acceso a grandes conjuntos de datos preparados para entrenamiento, podemos partir de modelos pre-entrenados para crear un nuevo modelo ajustado o afinado a nuestro caso de uso concreto. Es decir, cargamos un modelo previamente entrenado con un conjunto muy grande de datos de entrenamiento y re-entrenamos sus últimas capas para ajustarlo a nuestro conjunto concreto de datos. Esto es lo que se conoce como Transfer Learning.
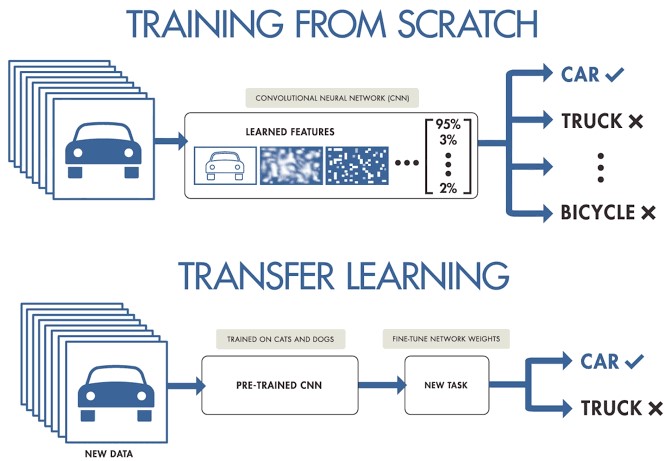
Fuente original: Transfer Learning en Deep Learning: Más allá de nuestros modelos. Post de Josu Alonso en Medium.
Simplificando mucho, se podría decir que el Machine Learning tradicional aplica en tareas de aprendizaje aisladas, donde no es necesario retener el conocimiento adquirido, mientras que en un proyecto de Transfer Learning el aprendizaje es fruto de tareas previas, logrando una buena precisión precisión en menos tiempo y con menos datos. Esto conlleva muchas oportunidades, aunque también algunos retos, como por ejemplo que el nuevo dominio herede sesgos del dominio anterior.
Veamos un ejemplo concreto. Supongamos que tenemos un nuevo desafío de Deep Learning y queremos hacer un clasificador automático de razas de perros. En este caso, podemos aplicar la técnica de transfer learning a partir de un modelo general de clasificación de imágenes, para posteriormente ajustarlo a un conjunto concreto de fotografías de razas de perro. La mayoría de los modelos pre-entrenados parten de un subconjunto de la base de datos de ImageNet, de la que ya hemos hablado en varias ocasiones. La red neuronal (de ImageNet), que es el tipo de algoritmo base que se utiliza en estos modelos de clasificación de imágenes, ha sido entrenada con 1.2 millones de imágenes de más de 1000 categorías de objetos diferentes como teclados, tazas de café, lápices y muchos animales. Al utilizar una red pre-entrenada para aplicar Transfer Learning, conseguimos resultados mucho más rápidos y sencillos que si tuviéramos que entrenar una red desde cero.
Por ejemplo, en este fragmento de código, se muestra el proceso de partir de un modelo pre-entrenado con ImageNet y re-entrenar o añadir nuevas capas para conseguir ajustes finos sobre el modelo original.
# creamos la base del modelo pre-entrenado partiendo de ImageNET
base_model <- application_inception_v3(weights = 'imagenet', include_top = FALSE)
# Añadimos capas adicionales a nuestra red neuronal
predictions <- base_model$output %>%
layer_global_average_pooling_2d() %>%
layer_dense(units = 1024, activation = 'relu') %>%
layer_dense(units = 200, activation = 'softmax')
# creamos un nuevo modelo para entrenar
model <- keras_model(inputs = base_model$input, outputs = predictions)
# Nos aseguramos de entrenar solo nuestras nuevas capas para no destruir el entrenamiento previo.
freeze_weights(base_model)
# compilamos el modelo
model %>% compile(optimizer = 'rmsprop', loss = 'categorical_crossentropy')
# entrenamos el modelo
model %>% fit_generator(...)
Conclusiones
Entrenar un modelo de deep learning para propósito general no está al alcance de todo el mundo. Las barreras son varias, desde la dificultad de acceso a los datos de entrenamiento de calidad y en suficiente volumen, cómo la capacidad de computación necesaria para procesar billones de imágenes o textos. Para casos de uso más acotados, donde solamente requerimos un refinamiento de los modelos generalistas, aplicar la técnica de Transfer Learning, nos posibilita conseguir resultados fantásticos en términos de precisión y tiempo de entrenamiento, con un coste asumible por la mayoría de científicos de datos. Las aplicaciones de Transfer Learning son muy numerosas y los sitios web especializados están llenos de ejemplos de aplicación. Alineado con esta tendencia, recientemente se ha popularizado mucho la técnica de Style Transfer Learning, que consiste en reconstruir imágenes basándose en el estilo de una imágen previa. Seguiremos hablando sobre este tema en próximos posts.

Ejemplo de Style Transfer Learning en Kaggle
No es el objetivo de este post explicar con detalle cada una de las secciones de este fragmento de código.
Contenido elaborado por Alejandro Alija,experto en Transformación Digital e Innovación.
Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Blog
Hoy en día las aplicaciones de Inteligencia Artificial (IA) están presentes en múltiples ámbitos de la vida cotidiana, desde televisores y altavoces inteligentes que son capaces de entender lo que les solicitamos, hasta sistemas de recomendación que nos ofrecen servicios y productos adaptados a nuestras preferencias.
Estas IA “aprenden” gracias a las diversas técnicas que existen, entre las que destacan el aprendizaje supervisado, no supervisado y el aprendizaje por refuerzo. En este artículo nos centraremos en el aprendizaje por refuerzo, que se enfoca principalmente en el método de prueba y error, de forma similar a cómo aprendemos los humanos y los animales en general.
La clave de este tipo de sistemas está en fijar correctamente los objetivos a largo plazo para encontrar una solución global óptima, sin focalizarse en exceso en las recompensas inmediatas, que no permiten realizar una exploración adecuada del conjunto de soluciones posibles.
Entornos de simulación como complemento a los conjuntos de datos abiertos
Al contrario que en otros tipos de aprendizaje, donde normalmente se aprende a partir de conjuntos de datos históricos, este tipo de técnicas requieren de entornos de simulación que permitan entrenar a un agente virtual mediante su interacción con un entorno, donde recibe recompensas o penalizaciones en función del estado y las acciones que realiza. Este ciclo entre agente y entorno puede verse en el siguiente diagrama:
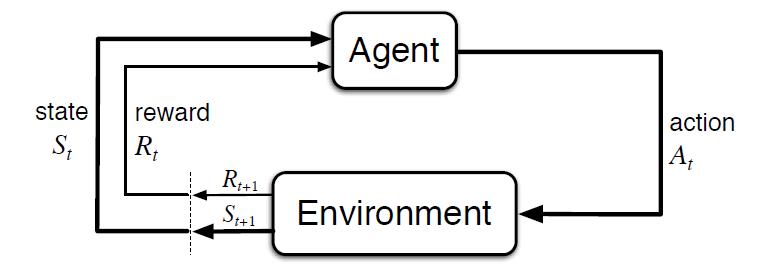
Figura 1 - Esquema de aprendizaje por refuerzo [Sutton & Barto, 2015]
Es decir, partiendo de un entorno simulado, con un estado inicial, el agente realiza una acción que genera un nuevo estado y una posible recompensa o penalización, que depende de los estados anteriores y la acción realizada. El agente aprende la mejor estrategia en este entorno simulado a partir de la experiencia, explorando el conjunto de estados, y siendo capaz de recomendar la mejor política de actuación si se configura de forma adecuada.
El ejemplo más conocido a nivel mundial fue el éxito conseguido por AlphaGo, al vencer al 18 veces campeón del mundo Lee Sedol en 2016. El Go es un juego ancestral, considerado una de las 4 artes básicas en la cultura China, junto con la música, la pintura y la caligrafía. Al contrario que con el ajedrez, el número de combinaciones de juego posibles es superior al número de átomos del Universo, siendo un problema imposible de resolver por algoritmos tradicionales.
Curiosamente, el avance tecnológico demostrado por AlphaGo al resolver un problema que se afirmaba fuera del alcance de una IA, quedó eclipsado un año después por su sucesor AlphaGo Zero. En esta versión sus creadores optaron por no emplear datos históricos, ni reglas heurísticas. AlphaGo Zero sólo emplea las posiciones del tablero y aprende por prueba y error jugando contra sí mismo.
Siguiendo esta innovadora estrategia de aprendizaje, en 3 días de ejecución consiguió superar a AlphaGo, y después de 40 días se convirtió en el mejor jugador de Go, acumulando miles de años de conocimiento en cuestión de días, y descubriendo incluso estrategias desconocidas hasta la fecha.
El impacto de este hito tecnológico abarca infinidad de ámbitos, pudiendo contar con soluciones de IA que aprendan a resolver problemas complejos desde la experiencia. Desde la gestión de recursos, la planificación de estrategias, o la calibración y optimización de sistemas dinámicos.
El desarrollo de soluciones en este ámbito está especialmente limitado por la necesidad de contar con entornos de simulación adecuados, siendo el componente más complejo de construir. Si bien existen múltiples repositorios donde se pueden obtener entornos de simulación abiertos que nos permitan probar este tipo de soluciones.
El referente más conocido es Open AI Gym, el cual incluye un extenso conjunto de librerías y entornos de simulación abiertos para el desarrollo y validación de algoritmos de aprendizaje por refuerzo. Entre otros incluye simuladores para el control básico de elementos mecánicos, aplicaciones de robótica y simuladores físicos, videojuegos ATARI en dos dimensiones, e incluso el aterrizaje de un módulo lunar. Además, permite integrar y publicar nuevos simuladores abiertos para el desarrollo de simuladores propios adaptados a nuestras necesidades que puedan ser compartidos con la comunidad:

Figura 2 - Ejemplos de entornos visuales de simulación ofrecidos por Open AI Gym
Otra referencia interesante es Unity ML Agents, donde también encontramos múltiples librerías y varios entornos de simulación, ofreciendo además la posibilidad de integrar nuestro propio simulador:

Figura 3 - Ejemplos de entornos visuales de simulación ofrecidos por Unity ML Agents
Posibles aplicaciones del aprendizaje por refuerzo en las administraciones públicas
Este tipo de aprendizaje se emplea especialmente en áreas como la robótica, la optimización de recursos o los sistemas de control, permitiendo definir políticas o estrategias óptimas de actuación en entornos concretos.
Uno de los ejemplos prácticos más conocidos, es el algoritmo de DeepMind empleado por Google para reducir un 40% el consumo de energía necesario para enfriar sus centros de datos en 2016, consiguiendo una reducción significativa en el consumo de energía durante su uso, como puede observarse en el siguiente gráfico (extraído del artículo anterior):
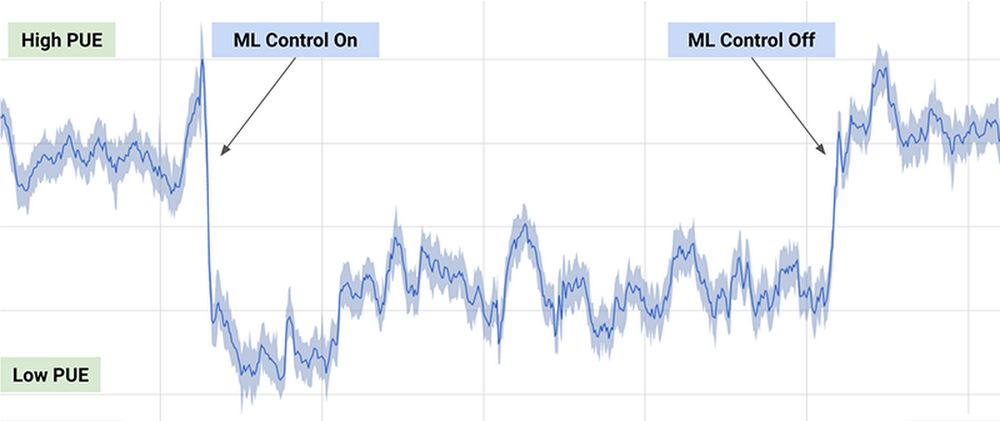
Figura 4 - Resultados del algoritmo de DeepMind sobre el consumo energético de los centros de datos de Google
El algoritmo empleado usa una combinación de técnicas de aprendizaje profundo y aprendizaje por refuerzo, junto con un simulador de propósito general para comprender sistemas dinámicos complejos que podría aplicarse en múltiples entornos como la transformación entre tipos de energía, el consumo de agua o la optimización de recursos en general.
Otras posibles aplicaciones en el ámbito público incluyen la búsqueda y recomendación de conjuntos de datos abiertos a través de chatbots, o la optimización de políticas públicas, como es el caso del proyecto europeo Policy Cloud, aplicado por ejemplo en el análisis de futuras estrategias de las diferentes denominaciones de origen de los vinos de Aragón.
En general, la aplicación de este tipo de técnicas podría optimizar el uso de recursos públicos mediante la planificación de políticas de actuación que reviertan en un consumo más sostenible, reduciendo la contaminación, los residuos y el gasto público.
Contenido elaborado por Jose Barranquero, experto en Ciencia de datos y computación cuántica.
Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Entrevista
Los datos abiertos no son solo cosa de las Administraciones públicas, cada vez más empresas también apuestan por ellos. Es el caso de Microsoft, quien ha proporcionado acceso a datos abiertos seleccionados en Azure pensados para el entrenamiento de modelos de Machine Learning. También colabora en el desarrollo de múltiples proyectos con el fin de impulsar el open data. En España, ha colaborado en el desarrollo de la plataforma HealthData 29, destinada a la publicación de datos en abierto para impulsar la investigación médica.
Hemos entrevistado a Belén Gancedo, Directora de Educación en Microsoft Ibérica y miembro del jurado en la III edición del Desafío Aporta, centrado en el valor de los datos para el sector educativo. Nos hemos reunido con ella para que nos hable de la importancia de la educación digital y de las soluciones innovadoras basadas en datos, así como de la importancia de los datos abiertos en el sector empresarial.
Entrevista completa:
1. ¿Qué retos del sector educativo, a los que urge dar respuesta, ha puesto de manifiesto la pandemia en España?
La tecnología se ha convertido en elemento imprescindible en la nueva forma de aprender y enseñar. Durante los últimos meses, marcados por la pandemia, hemos visto cómo se ha pasado en muy poco tiempo a un modelo de educación híbrido -presencial y en remoto-. Hemos visto ejemplos de centros que, en tiempo récord, en menos de 2 semanas, han tenido que acelerar los planes de digitalización que ya tenían en mente.
La tecnología ha pasado de ser un salvavidas temporal, que permitió dar clases en la peor etapa de la pandemia, a convertirse en una parte totalmente integrada de la metodología de enseñanza de muchos centros educativos. Según una encuesta reciente de YouGov encargada por Microsoft, el 71% de los educadores de Primaria y Secundaria señala que la tecnología les ha ayudado a mejorar su metodología y ha mejorado su capacidad de enseñar. Asimismo, el 82% del profesorado señala que, este último año, se ha acelerado el ritmo al que la tecnología ha impulsado la innovación en la enseñanza y el aprendizaje.
Antes de esta pandemia, de alguna forma, quienes veníamos dedicándonos a la educación, éramos quienes defendíamos la necesidad de transformar digitalmente el sector y los beneficios que la tecnología introducía en él. Sin embargo, lo vivido ha servido para que todo mundo sea consciente de los beneficios de la aplicación de la tecnología en el entorno educativo. En ese sentido ha habido un enorme avance. Nosotros hemos observado un gran incremento en el uso de nuestra herramienta Teams, que ya usan más de 200 millones de estudiantes, profesores y personal del sector educativo en todo el mundo.
Los mayores retos, pues, actualmente, son conseguir no sólo aprovechar los datos y la Inteligencia Artificial para proporcionar experiencias más personalizadas y operar con mayor agilidad sino también la integración de la tecnología con la pedagogía, lo que permitirá experiencias de aprendizaje más flexibles, atractivas e inclusivas. Los estudiantes son cada vez más diversos, y también lo son sus expectativas sobre el papel de la educación universitaria en su camino hacia el empleo.
Los mayores retos, pues, actualmente, son conseguir no sólo aprovechar los datos y la Inteligencia Artificial para proporcionar experiencias más personalizadas y operar con mayor agilidad sino también la integración de la tecnología con la pedagogía, lo que permitirá experiencias de aprendizaje más flexibles, atractivas e inclusivas
2. Cada vez hay más demanda de capacidades y competencias digitales relacionadas con los datos. En este sentido, se ha lanzado el Plan Nacional de Competencias Digitales, donde se incluye la digitalización de la educación y el desarrollo de las competencias digitales para el aprendizaje. ¿Qué cambios habría que hacer en los programas educativos de cara a impulsar la adquisición de conocimientos digitales por parte de los alumnos?
Sin duda, uno de los mayores retos a los que nos enfrentamos en la actualidad es la falta de capacitación y habilidades digitales. Según un estudio llevado a cabo por Microsoft y EY, el 57% de las compañías encuestadas esperan que la IA tenga un alto o muy alto impacto en las áreas de negocios que son “totalmente desconocidas para las compañías en la actualidad”.
Hay una clara oportunidad para que España lidere en Europa en talento digital, consolidándose como uno de los países más atractivos para atraer y retener este talento. Un reciente estudio de LinkedIn anticipa que en los próximos cinco años se crearán en España dos millones de puestos de trabajo relacionados con la tecnología, no sólo en la industria tecnológica, sino también, y sobre todo, en empresas de otros sectores de actividad que buscan incorporar el talento necesario para llevar a cabo su transformación. Sin embargo, hay un déficit de profesionales con habilidades y formación en competencias digitales. De acuerdo con los datos del Digital Economy and Society Index Report que publica anualmente la Comisión Europea, España se encuentra por debajo de la media europea en la mayoría de los indicadores que hacen referencia a las competencias digitales de los profesionales españoles.
Existe, por tanto, una demanda urgente de formar talento cualificado con capacidades digitales, gestión del dato, IA, machine learning… Los perfiles relacionados con la tecnología se encuentran entre los más difíciles de encontrar y, en un futuro próximo, los relacionados con la analítica de datos, la computación en la nube y el desarrollo de aplicaciones.
Para ello, es necesaria una adecuada formación, ya no solo en la forma de enseñar, sino también en el contenido curricular. Cualquier carrera, ya no solo las del ámbito STEM, necesitaría incluir materias relacionadas con la tecnología y la IA, que será la que defina el futuro. El uso de la IA llega a cualquier ámbito, no solo al tecnológico, por lo tanto, el alumnado de cualquier tipo de carrera -Derecho, Periodismo…- por poner algunos ejemplos de carreras no STEM, necesita formación cualificada en tecnología como la IA o la ciencia de datos, puesto que lo van a tener que aplicar en su futuro profesional.
Debemos apostar por las colaboraciones público-privadas e involucrar a la industria tecnológica, las administraciones públicas, la comunidad educativa, adecuando los contenidos curriculares de la Universidad a la realidad laboral- y las entidades del tercer sector, con el objetivo de impulsar la empleabilidad y el reciclaje profesional. De esta forma, se impulsará la capacitación de los profesionales en áreas como computación cuántica, Inteligencia Artificial, o analítica de datos y podremos aspirar al liderazgo digital.
En los próximos cinco años se crearán en España dos millones de puestos de trabajo relacionados con la tecnología, no sólo en la industria tecnológica, sino también, y sobre todo, en empresas de otros sectores de actividad que buscan incorporar el talento necesario para llevar a cabo su transformación.
3. Todavía hoy encontramos disparidad entre el número de hombre y mujeres que eligen ramas profesionales relacionadas con la tecnología. ¿Qué se necesita para impulsar el papel de la mujer en el ámbito tecnológico?
Según el Observatorio Nacional de Telecomunicaciones y Sociedad de la Información -ONTSI- (julio 2020), la brecha digital de género se ha reducido progresivamente en España, pasando de 8,1 a 1 punto, aunque las mujeres mantienen una posición desfavorable en competencias digitales y usos de Internet. En competencias avanzadas, como programación, la brecha en España es de 6,8 puntos, siendo la media de la UE de 8 puntos. El porcentaje de investigadoras en el sector de servicios TIC se reduce al 23,4%. Y en cuanto al porcentaje de graduados/as en STEM, España se sitúa en la posición 12 dentro de la UE, con una diferencia entre sexos de 17 puntos.
Sin duda, queda mucho camino por recorrer. Una de las principales barreras con las que se encuentran las mujeres en el sector de la tecnología y a la hora de emprender son los estereotipos y la tradición cultural. El entorno masculinizado de las carreras técnicas y los estereotipos sobre quienes se dedican a la tecnología las convierte en carreras poco atractivas para las mujeres.
La digitalización está dinamizando la economía y favoreciendo la competitividad empresarial, así como generando un incremento en la creación de empleo especializado. Quizá lo más interesante del impacto de la digitalización en el mercado laboral es que estos nuevos puestos de trabajo no se están creando sólo en la industria tecnológica, sino también en empresas de todos los sectores, que necesitan incorporar talento especializado y con habilidades digitales.
Por lo tanto, existe una demanda urgente de formar talento cualificado con capacidades digitales y este talento debe ser diverso. La mujer no puede quedar atrás. Es el momento de atajar la desigualdad de género, y alertar de esta enorme oportunidad a todos, con independencia de su género. Las carreras STEM son una opción ideal de futuro para cualquier persona, independientemente de su género.
Para favorecer la presencia femenina en el sector tecnológico, en pro de una era digital sin exclusión, en Microsoft hemos puesto en marcha diferentes iniciativas que buscan desterrar estereotipos y animar a las niñas y jóvenes a interesarse por la ciencia y la tecnología y hacerlas ver que ellas también pueden ser las protagonistas de la sociedad digital. Además de los Premios WONNOW que convocamos con CaixaBank, también participamos y colaboramos en muchas iniciativas, como los Premios Ada Byron junto a Universidad de Deusto, para ayudar a dar visibilidad al trabajo de mujeres en el ámbito STEM, para que sean referentes de las que están por venir.
La brecha digital de género se ha reducido progresivamente en España, pasando de 8,1 a 1 punto, aunque las mujeres mantienen una posición desfavorable en competencias digitales y usos de Internet. En competencias avanzadas, como programación, la brecha en España es de 6,8 puntos, siendo la media de la UE de 8 puntos
4. ¿Cómo pueden iniciativas como los hackathons, desafío o retos ayudar a impulsar la innovación basada en datos? ¿Cómo ha sido su experiencia en el III Desafío Aporta?
Este tipo de iniciativas son clave para ese cambio tan necesario. En Microsoft estamos constantemente organizando hackathons tanto a escala global, como regional y local, para innovar en distintas áreas prioritarias para la compañía como, por ejemplo, la educación.
Pero vamos más allá. También usamos estas herramientas en clase. Una de las apuestas de Microsoft son los proyectos Hacking STEM. Se trata de proyectos en los que se mezcla el concepto “maker” de aprender haciendo con la programación y la robótica, mediante el uso de materiales cotidianos. Además, están integrados por actividades que permiten a los docentes guiar a sus alumnos para construir y crear instrumentos científicos y herramientas basadas en proyectos para visualizar datos a través de la ciencia, la tecnología, la ingeniería y las matemáticas. Nuestros proyectos -tanto de Hacking STEM como de codificación y lenguaje computacional mediante el uso de herramientas gratuitas como Make Code- pretenden llevar la programación y la robótica a cualquier asignatura de forma transversal, y por qué no, aprender programación en una clase de latín o en una de biología.
Mi experiencia en el III Desafío Aporta ha sido fantástica porque me ha permitido conocer ideas y proyectos increíbles donde se hace realidad la utilidad de la cantidad de datos disponibles y se ponen al servicio de la mejora de la educación de todos. Ha habido muchísima participación y, además, con presentaciones muy cuidadas y trabajadas. La verdad es que me gustaría aprovechar esta oportunidad para dar las gracias a todos los que han participado y también dar la enhorabuena a los ganadores.
5. Hace un año Microsoft lanzó una campaña para impulsar la apertura de datos de cara a cerrar la brecha entre los países y empresas que tienen los datos necesarios para innovar y aquellos que no. ¿En qué ha consistido el proyecto? ¿Qué avances se han logrado?
La iniciativa global de Microsoft Open Data Campaign busca contribuir a cerrar la creciente “brecha de datos” entre el pequeño número de empresas tecnológicas que más se benefician de la economía de los datos en la actualidad y otras organizaciones que se ven obstaculizadas por la falta de acceso a ellos o por no tener capacidades para utilizar los que ya tienen.
Microsoft cree que se debe hacer más para ayudar a las organizaciones a compartir y colaborar en torno a los datos, de modo que las empresas y los gobiernos puedan utilizarlos para afrontar los retos que se les presentan, pues la capacidad de compartir datos conlleva enormes beneficios. Y no solo para el entorno empresarial, sino que también juegan un rol crítico a la hora de ayudarnos a entender y abordar grandes desafíos, como el cambio climático, o crisis sanitarias, como la pandemia COVID-19. Para aprovecharlos al máximo, es necesario desarrollar la capacidad de compartirlos de una forma segura y confiable, y permitir que puedan ser utilizados de manera efectiva.
Dentro de la iniciativa Open Data Campaign, Microsoft ha anunciado 5 grandes principios que guiarán cómo la propia compañía aborda la forma de compartir sus datos con otros:
- Abiertos – Trabajará para hacer que los datos relevantes sobre problemas sociales de gran envergadura se encuentren tan abiertos como sea posible.
- Utilizables– Invertirá en crear nuevas tecnologías y herramientas, mecanismos de gobernanza y políticas para que los datos puedan ser usados por todos.
- Impulsores – Microsoft ayudará a las organizaciones a generar valor a partir de sus datos y a desarrollar talento en IA para utilizarlos de manera efectiva.
- Seguros– Microsoft va a emplear controles de seguridad para garantizar que la colaboración en torno a datos sea segura a nivel operacional.
- Privados – Microsoft ayudará a las organizaciones a proteger la privacidad de los individuos en colaboraciones donde se compartan datos y que involucren información de identificación personal.
Seguimos avanzado en este sentido. El año pasado, Microsoft España, junto a Fundación 29, la Cátedra sobre la Privacidad y Transformación Digital Microsoft-Universitat de València y con el asesoramiento legal del despacho de abogados J&A Garrigues han creado la Guía “Health Data” que describe el marco técnico y legal para llevar a cabo la creación de un repositorio público de datos de los sistemas de Salud, y que estos puedan compartirse y utilizarse en entornos de investigación. Y LaLiga es una de las entidades que ha compartido, en junio de este año, sus datos anonimizados.
El Dato es el principio de todo. Y una de nuestras mayores responsabilidades como empresa de tecnología es ayudar a la conservación del ecosistema a gran escala, a nivel planetario. Para ello el mayor reto es consolidar no solo todos los datos disponibles, sino los algoritmos de inteligencia artificial que permitan acceder a ello y permitan tomar decisiones, crear modelos predictivos, escenarios con información actualizada desde múltiples fuentes. Por eso, Microsoft lanzó el concepto de Planetary Computer, basado en Open Data, para poner a disposición de científicos, biólogos, startups y empresas, de forma gratuita, más de 10 Petabytes de datos -y creciendo- de múltiples fuentes (biodiversidad, electrificación, forestación, biomasa, satélite), APIs, Entornos de Desarrollo y aplicaciones (modelo predictivo, etc.) para crear un mayor impacto para el planeta.
La iniciativa global de Microsoft Open Data Campaign busca contribuir a cerrar la creciente “brecha de datos” entre el pequeño número de empresas tecnológicas que más se benefician de la economía de los datos en la actualidad y otras organizaciones que se ven obstaculizadas por la falta de acceso a ellos o por no tener capacidades para utilizar los que ya tienen.
6. También ofrecen algunos conjuntos de datos en abierto a través de su iniciativa Azure Open Datasets. ¿Qué tipo de datos ofrecen? ¿Cómo los pueden utilizar los usuarios?
Esta iniciativa busca que las empresas mejoren la precisión de las predicciones de sus modelos de Machine Learning y reduzcan el tiempo de preparación de los datos, gracias a conjuntos de datos seleccionados de acceso público, listos para usar y a los que se puede acceder fácilmente desde los servicios de Azure.
Hay datos de todo tipo: salud y genómica, transporte, mano de obra y economía, población y seguridad, datos comunes… que se pueden utilizar de múltiples maneras. Y también es posible aportar datasets a la comunidad.
7. ¿Cuáles son los planes de futuro de Microsoft en relación con los datos abiertos?
Tras un año con la Opendata campaign, hemos tenido muchos aprendizajes y, en colaboración con nuestros partners, vamos a enfocarnos el próximo año a aspectos prácticos que hagan el proceso de la compartición de datos más sencilla. Acabamos de empezar a publicar materiales para que las organizaciones vean los aspectos prácticos de cómo empezar a compartir datos. Continuaremos identificando posibles colaboraciones para solventar retos sociales en temas de sostenibilidad, salud, equidad e inclusión. También queremos conectar a aquellos que están trabajando con datos o quieren explorar ese ámbito con las oportunidades que ofrecen las Certificaciones de Microsoft en Data e Inteligencia Artificial. Y, sobre todo, este tema requiere de un buen marco regulatorio y, para ello, es necesario que quienes definen las políticas se reúnan con la industria, la academia y la sociedad civil para desarrollar incentivos, infraestructuras y mecanismos que permitan compartir datos del sector público y privado -dentro y a través de fronteras organizacionales y nacionales,- siempre salvaguardando los derechos humanos, con el fin de hacer un uso efectivo de dichos datos en pro de la innovación.
Blog
Ya ha llovido bastante desde que en 2012 se publicara aquel famoso artículo titulado "Data Scientist: The Sexiest Job of the 21st Century". Desde entonces el campo de la ciencia de datos se ha profesionalizado mucho. Se han desarrollado multitud de técnicas, frameworks y herramientas que aceleran el proceso de convertir datos brutos en información de valor. Una de estas técnicas se conoce cómo Auto ML o Machine Learning automático. En este artículo revisaremos las ventajas y características de este método.
En un proceso de ciencia de datos (data science), cualquier científico de datos (data scientist) suele utilizar un método de trabajo sistemático, según el cual va destilando los datos crudos hasta conseguir extraer información de valor para el negocio del cual parten esos datos. Existen varias definiciones del proceso de análisis de datos, aunque suelen ser todas muy similares con pequeñas variantes. En la siguiente figura mostramos un ejemplo de proceso o workflow de análisis de datos.

Cómo vemos, podemos distinguir tres etapas:
-
Importación y limpieza.
-
Exploración y modelado.
-
Comunicación.
Dependiendo del tipo de datos de origen y del resultado que busquemos alcanzar con estos datos, el proceso de modelado puede variar. Sin embargo, independientemente del modelo, el científico de datos debe de ser capaz de obtener un conjunto de datos limpios y preparados para servir como entrada al modelo. En este post vamos a centrarnos en la segunda etapa: exploración y modelado.
Una vez obtenidos estos datos limpios y libres de errores (tras su importación y limpieza en la etapa 1), el científico de datos debe de decidir qué transformaciones aplica a dichos datos, con el objetivo de que algunos datos derivados de los originales (en conjunto con los originales), sean los mejores indicadores del modelo subyacente al conjunto de datos. A estas transformaciones las denominamos características (en inglés, features).
El siguiente paso es dividir nuestro conjunto de datos en dos partes: una parte, por ejemplo, un 60% del conjunto total, servirá cómo conjunto de datos de entrenamiento. El 40% restante lo reservaremos para aplicar nuestro modelo, una vez entrenado. A este segundo lo denominamos subset de prueba o test. Este proceso de división de los datos de origen se realiza con la intención de evaluar la fiabilidad del modelo antes de aplicarlo sobre nuevos datos desconocidos para el modelo. Ahora se desarrolla un proceso iterativo en el que el científico de datos prueba varios tipos de modelos que cree que pueden funcionar sobre este conjunto de datos. Cada vez que aplica un modelo, observa y mide los parámetros matemáticos (cómo precisión y reproducibilidad) que expresan cuánto de bien el modelo es capaz de reproducir los datos de prueba. Además de probar diferentes tipos de modelos, el científico de datos puede variar el conjunto de datos de entrenamiento con nuevas transformaciones, calculando nuevas y diferentes características, con el fin de dar con algunas características que hagan que el modelo en cuestión se ajuste mejor a los datos.
Podemos imaginar que este proceso, repetido decenas o centenas de veces, es un gran consumidor de recursos tanto humanos como de cómputo. El científico de datos intenta realizar diferentes combinaciones de algoritmos, modelos, características y porcentajes de datos, en base a su experiencia y habilidad con las herramientas. Sin embargo, ¿qué pasaría si fuera un sistema el que llevará a cabo todas estas combinaciones por nosotros y diera, finalmente, con la mejor combinación? Precisamente para responder a esta herramienta se han creado los sistemas Auto ML.
En mi opinión, un sistema o herramienta de Auto ML no tiene el objetivo de sustituir al científico de datos, pero sí de complementarlo, ayudando a éste a ahorrar mucho tiempo en el proceso iterativo de probar diferentes técnicas y datos para alcanzar el mejor modelo. De forma general, podríamos decir que un sistema de Auto ML tiene (o tendría que) aportar los siguientes beneficios al científico de datos:
-
Sugerir las mejores técnicas de Machine Learning y generar automáticamente modelos optimizados (ajustando automáticamente los parámetros), habiendo probado una gran cantidad de conjuntos de datos de entrenamiento y test respectivamente.
-
Informar al científico de datos de aquellas características (recordar que son transformaciones de los datos originales) que tienen el mayor impacto en el resultado final del modelo.
-
Generar visualizaciones que permitan al científico de datos entender el resultado del proceso llevado a cabo por el Auto ML. Es decir, enseñar al usuario del Auto ML los indicadores clave del resultado del proceso.
-
Generar un entorno interactivo de simulación que permita a los usuarios explorar rápidamente el modelo para ver cómo funciona.
Para terminar, mencionamos algunos de los sistemas y herramientas Auto ML más conocidos, como H2O.ai, Auto-Sklearn y TPOT. Hay que destacar que estos tres sistemas cubren la totalidad del proceso de Machine Learning que veíamos al principio. Sin embargo, existen más soluciones y herramientas que cubren parcialmente alguno de los pasos del proceso completo. También existen artículos en los que se compara la eficacia de estos sistemas ante determinados problemas de machine learning sobre conjuntos de datos abiertos y accesibles.
En conclusión, estas herramientas proporcionan soluciones valiosas a problemas comunes de ciencia de datos y tienen la capacidad de mejorar drásticamente la productividad de los equipos de ciencia de datos. Sin embargo, la ciencia de datos sigue teniendo un componente importante de arte y no todos los problemas se resuelven con herramientas de automatización. Animamos a todos los alquimistas de algoritmos y artesanos de datos a seguir dedicando tiempo y esfuerzo en el desarrollo de nuevas técnicas y algoritmos que nos permitan convertir datos en valor de forma rápida y efectiva.
El objetivo de este post es explicar al público general, de forma sencilla y asequible, cómo las técnicas de auto ML pueden simplificar el proceso de análisis avanzado de datos. En ocasiones puede recurrirse a simplificaciones excesivas con el fin de no complicar en exceso el contenido de este post.
Contenido elaborado por Alejandro Alija,experto en Transformación Digital e Innovación.
Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Entrevista
Ahora que está abierta la convocatoria de la tercera edición del Desafío Aporta, centrada en esta ocasión en el ámbito de la educación, hemos hablado con el ganador de la edición de 2019, Mariano Nieves, que se hizo con el primer puesto gracias a su solución Optimacis. Mariano nos ha explicaco cómo fue su experiencia y ha transmitido una serie de consejos para los participantes de este año.
Entrevista completa:
1. ¿En qué consiste Optimacis?
Optimacis es un proyecto para la optimización del mercado de las lonjas de pescado fresco, que busca el equilibrio de los precios frente a situaciones de monopsonio.
El éxito del proyecto radica en la entrega de valor para los tres actores principales en estos mercados:
- las empresas pesqueras como productores
- los mayoristas y empresas de hostelería, como mediadores en la entrega hacia el mercado;
- y las propias lonjas como centros de distribución primarios.
Los valores para cada actor son concretos: en el caso de los pescadores, mediante el conocimiento anticipado de los precios más ventajosos para la venta; en el caso de los mayoristas y restauradores, mediante el conocimiento de los puntos de aprovisionamiento con mayor capacidad; y en el caso de las lonjas, mediante el conocimiento anticipado de la afluencia esperable en sus instalaciones, para la organización interna de los recursos.
2. ¿Qué le impulsó a participar en el Desafío Aporta?
Sin lugar a dudas, el respado institucional de datos.gob.es como referente en la Administración Pública, dado que el proyecto tiene un marcado carácter de sostenibilidad para un colectivo que requiere habitualmente de recursos adicionales a la explotación.
No ha sido un proyecto preconcebido que viniera a aprovechar la convocatoria. Más bien al contrario, el proyecto se forjó tras la lectura de la convocatoria. Sinceramente, llegué a formular una pregunta formal en la Sede Electrónica de Red.es para asegurarme de que la pesca era un ámbito cubierto por las bases del Desafío Aporta de 2019.
Pensé que contar con el reconocimiento y la difusión del Desafío Aporta impulsaría mi carrera profesional, como así ha sido. Este es un valor que quiero destacar para animar a otros participantes en la nueva convocatoria: actualmente hay muchos profesionales con una carrera impreionante, que pueden hacer brillar su CV con el éxito en el Desafío Aporta.
3. ¿Cómo fue su experiencia?
El reto fue impresionante. Para quien conoce el mundo apasionante de los datos, me parece importante destacar la importancia de manejar más de 3.500 modelos predictivos en tiempo real (bueno, con un ciclo de regeneración de 24 horas).
Esto está soportado por diversas fuentes de ingestión, destacando la información desde Meteogalicia y la Agencia Estatal de Meteorología, la ingestión en tiempo real desde dos sistemas de radar (en realidad, se llaman Sistemas de Identificación Automática) emplazados en As Pontes de García Rodríguez y en Vigo, y la extracción diaria de los datos de precios publicados desde las lonjas de Galicia.
Barajar todas esta fuentes de información en un tiempo récord (con siete máquinas trabajando en modo continuo 24x7), ingestando y monitorizando los modelos predictivos supuso un esfuerzo importante para mí, al que me dediqué todo el verano de 2019 y los meses de septiembre y octubre, en tareas de geolocalización y machine learning.
La principal ventaja que me ha proporcionado el desafío ha sido la de conocer fuentes de grandes masas de datos que están disponibles para proyectos de todo tipo, con la solvencia de las fuentes de la Administración Pública.
4. ¿En qué punto se encuentra actualmente el desarrollo del Sistema Optimacis?
Estamos ya en una fase de promoción de la solución, para coordinarnos con organismos públicos que impulsan proyectos sostenibles en el ámbito pesquero tanto a nivel estatal como a nivel local y autonómico. El equilibrio de las condiciones de mercado está siendo un factor que despierta interés para las administraciones locales.
5. ¿Qué consejos daría a los participantes del Desafío Aporta 2020?
Bueno, sólo desde la experiencia de mi partición como es lógico. Creo que la dedicación y el esfuerzo resultaron decisivos en mi caso, porque el resto de los participantes tenía un nivel muy alto al que yo no podía aspirar. La mayoría eran grupos de personas, mientras que mi participación fue con carácter personal. Sin embargo, el hecho de conseguir levantar todo ese bloque de modelos predictivos, y revisar concienzudamente los resultados resultó determinante.
Por otro lado, creo que también me ayudó el haber cuidado meticulosamente la presentación. Haber aportado una envoltura cuidada al contenido fue algo bien valorado, ya que dispuse de una maqueta plenamente funcional.
6. Cierre y despedida.
Quiero transmitir todo el ánimo a los particpantes de esta convocatoria, y que no duden en incluir dedicación y esfuerzo porque merece la pena. No todos los días recibe uno el reconocimiento de una institución gubernamental como es datos.gob.es. ¡Que gane el mejor!
Blog
El machine learning es una rama dentro del campo de la Inteligencia Artificial que proporciona a los sistemas la capacidad de aprender y mejorar de manera automática, a partir de la experiencia. Estos sistemas transforman los datos en información, y con esta información pueden tomar decisiones. Para que un modelo realice predicciones de manera robusta, necesita alimentarse de datos. Cuantos más, mejor. Afortunadamente, hoy en día la red está repleta de fuentes de datos. En muchas ocasiones, los datos son recolectados por empresas privadas para su propio beneficio, pero también existen otras iniciativas, como, por ejemplo, portales de datos abiertos.
Una vez disponemos de los datos, estamos en disposición de comenzar el proceso de aprendizaje. Este proceso, llevado a cabo por un algoritmo, trata de analizar y explorar los datos en búsqueda de patrones ocultos. El resultado de este aprendizaje, a veces, no es más que una función que opera sobre los datos para calcular una determinada predicción.
En este artículo vamos a ver los tipos de aprendizaje automático que existen incluyendo algunos ejemplos.
Tipos de aprendizaje automático
Dependiendo de los datos disponibles y la tarea que queramos abordar, podemos elegir entre distintos tipos de aprendizaje. Estos son: aprendizaje supervisado, aprendizaje no supervisado, aprendizaje semi-supervisado y aprendizaje por refuerzo.
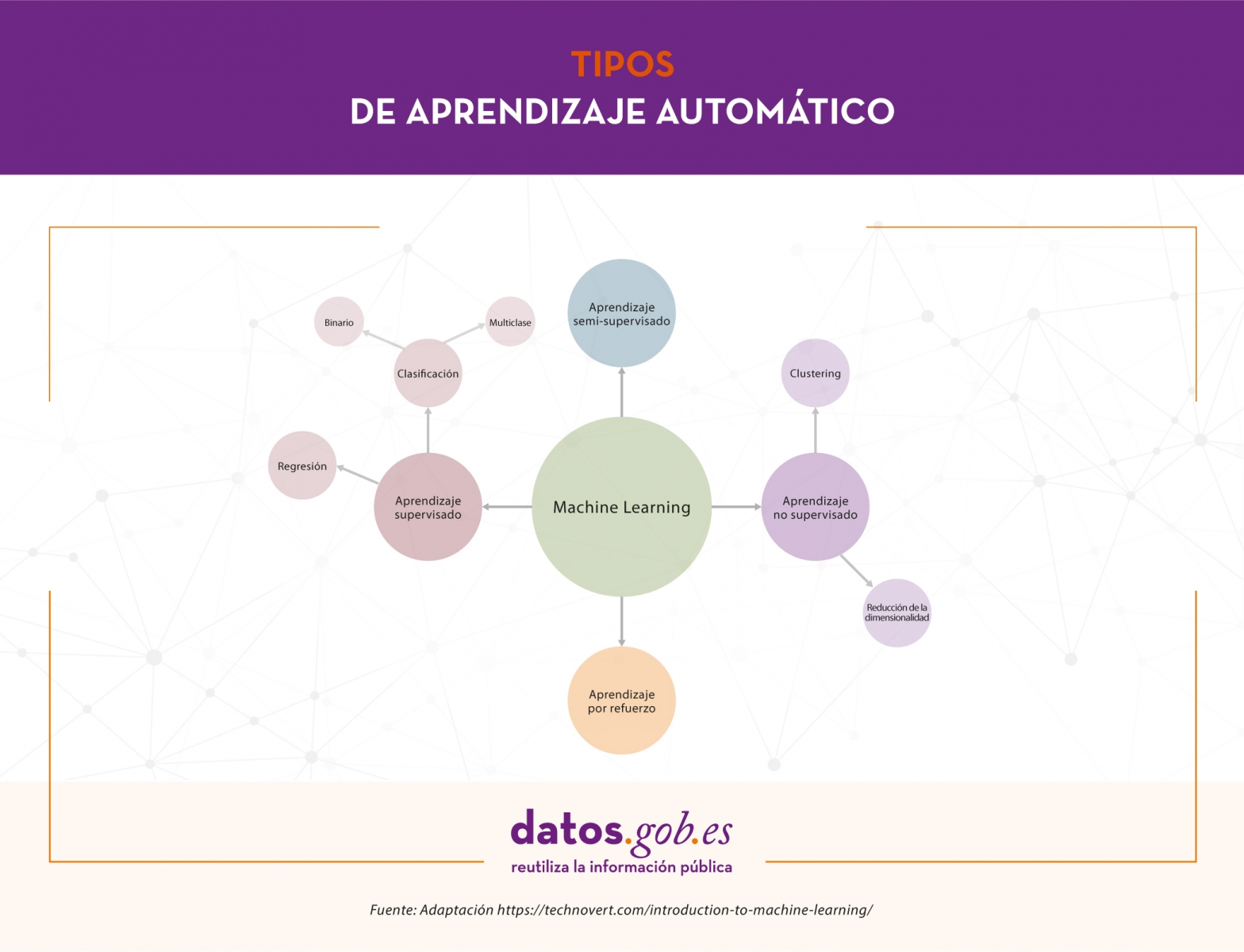
Aprendizaje supervisado
El aprendizaje supervisado necesita conjuntos de datos etiquetados, es decir, le decimos al modelo qué es lo que queremos que aprenda. Supongamos que tenemos una heladería y durante los últimos años hemos estado registrando diariamente datos climatológicos, temperatura, mes, día de la semana, etc., y también hemos hecho lo propio con el número de helados vendidos cada día. En este caso, seguramente nos interesaría entrenar un modelo que, a partir de los datos climatológicos, temperatura, etc. (características del modelo) de un día concreto, nos diga cuántos helados se van a vender (la etiqueta a predecir).
Dependiendo del tipo de etiqueta, dentro del aprendizaje supervisado existen dos tipos de modelos:
- Los modelos de clasificación, que producen como salida una etiqueta discreta, es decir, una etiqueta dentro de un conjunto finito de etiquetas posibles. A su vez, los modelos de clasificación pueden ser binarios si tenemos que predecir entre dos clases o etiquetas (enfermedad o no enfermedad, clasificación de correos electrónicos como “spam” o no “spam”) o multiclase, cuando se tiene que clasificar más de dos clases (clasificación de imágenes de animales, análisis de sentimientos, etc.).
- Los modelos de regresión producen como salida un valor real, como el ejemplo que comentábamos de los helados.
Aprendizaje no supervisado
Por su parte, el aprendizaje no supervisado trabaja con datos que no han sido etiquetados. No tenemos una etiqueta que predecir. Estos algoritmos se usan principalmente en tareas donde es necesario analizar los datos para extraer nuevo conocimiento o agrupar entidades por afinidad.
Este tipo de aprendizaje también tiene aplicaciones para reducir dimensionalidad o simplificar conjuntos de datos. En el caso de agrupar datos por afinidad, el algoritmo debe definir una métrica de similitud o distancia que le sirva para comparar los datos entre sí. Como ejemplo de aprendizaje no supervisado tenemos los algoritmos de agrupamiento o clustering, que podrían aplicarse para encontrar clientes con características similares a los que ofrecer determinados productos o destinar una campaña de marketing, descubrimiento de tópicos o detección de anomalías, entre otros. Por otro lado, en ocasiones, algunos conjuntos de datos como los relacionados con información genómica tienen grandes cantidades de características y por varias razones, como, por ejemplo, reducir el tiempo de entrenamiento de los algoritmos, mejorar el rendimiento del modelo o facilitar la representación visual de los datos, necesitamos reducir la dimensionalidad o número de columnas del conjunto de datos. Los algoritmos de reducción de dimensionalidad utilizan técnicas matemáticas y estadísticas para convertir el conjunto de datos original en uno nuevo con menos dimensiones a cambio de perder un poco de información. Ejemplos de algoritmos de reducción de dimensionalidad son PCA, t-SNE o ICA.
Aprendizaje semi-supervisado
En ocasiones, es muy complicado disponer de un conjunto de datos completamente etiquetado. Imaginemos que somos los dueños de una empresa de fabricación de productos lácteos y queremos estudiar la imagen de marca de nuestra empresa a través de los comentarios que los usuarios han publicado en redes sociales. La idea es crear un modelo que clasifique cada comentario como positivo, negativo o neutro para, después, hacer el estudio. Lo primero que hacemos es bucear por las redes sociales y recolectar dieciséis mil mensajes donde se menciona a nuestra empresa. El problema ahora es que no tenemos etiqueta en los datos, es decir, no sabemos cuál es el sentimiento de cada comentario. Aquí entra en juego el aprendizaje semi-supervisado. Este tipo de aprendizaje tiene un poco de los dos anteriores. Usando este enfoque, se comienza etiquetando manualmente algunos de los comentarios. Una vez tenemos una pequeña porción de comentarios etiquetados, entrenamos uno o varios algoritmos de aprendizaje supervisado sobre esa pequeña parte de datos etiquetados y utilizamos los modelos resultantes del entrenamiento para etiquetar el resto de comentarios. Finalmente, entrenamos un algoritmo de aprendizaje supervisado utilizando como etiquetas las etiquetadas manualmente más las generadas por los modelos anteriores.
Aprendizaje por refuerzo
Por último, el aprendizaje por refuerzo es un método de aprendizaje automático que se basa en recompensar los comportamientos deseados y penalizar los no deseados. Aplicando este método, un agente es capaz de percibir e interpretar el entorno, ejecutar acciones y aprender a través de prueba y error. Es un aprendizaje que fija objetivos a largo plazo para obtener una recompensa general máxima y lograr una solución óptima. El juego es uno de los campos más utilizados para poner a prueba el aprendizaje por refuerzo. AlphaGo o Pacman son algunos juegos donde se aplica esta técnica. En estos casos, el agente recibe información sobre las reglas del juego y aprende a jugar por sí mismo. Al principio, evidentemente, se comporta de manera aleatoria, pero con el tiempo empieza a aprender movimientos más sofisticados. Este tipo de aprendizaje se aplica también en otras áreas como la robótica, la optimización de recursos o sistemas de control.
El aprendizaje automático es una herramienta muy poderosa que convierte los datos en información y facilita la toma de decisiones. La clave está en definir de manera clara y concisa el objetivo del aprendizaje para, dependiendo de las características del conjunto datos que disponemos, seleccionar el tipo de aprendizaje que mejor se ajusta para dar una solución que responda a las necesidades.
Contenido elaborado por Jose Antonio Sanchez, experto en Ciencia de datos y entusiasta de la Inteligencia Artificial .
Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Evento
Vivimos en una era en la que la formación se ha vuelto un elemento imprescindible, tanto para ingresar y progresar en un mercado laboral cada vez más competitivo, como a la hora de formar parte de proyectos de investigación que puedan llegar a conseguir grandes mejoras en nuestra vida.
Se acerca el verano y con él nos llega una oferta formativa renovada que no descansa en absoluto en la época estival, sino todo lo contrario. Cada año, aumenta el número de cursos relacionados con la ciencia de datos, la analítica o los datos abiertos. El actual mercado laboral demanda y requiere profesionales especializados en este abanico de campos tecnológicos, tal y como refleja la CE en su Estrategia Europea de Datos, donde se destaca que la UE proporcionará financiación “para ampliar la reserva de talento digital a alrededor de 250.000 personas que sean capaces de implantar las últimas tecnologías en empresas de toda la UE”.
En este sentido, las posibilidades que ofrecen las nuevas tecnologías para realizar cualquier tipo de formación online, desde tu propio hogar con las máximas garantías, ayudan a que más profesionales apuesten por este tipo de cursos cada año.
Desde datos.gob.es hemos seleccionado una serie de cursos online, tanto gratuitos como de pago, relacionados con datos que pueden ser de tu interés:
- Comenzamos con el Curso de Aprendizaje automático y ciencia de datos impartido por la Universitat Politécnica de Valencia destaca por ofrecer a sus futuros alumnos el aprendizaje necesario para extraer conocimiento técnico a partir de los datos. Con un programa de 5 semanas de duración, en este curso podrás introducirte al lenguaje R y aprender, entre otras cosas, diferentes técnicas de preprocesamiento y visualización de datos.
- El curso de Métodos Modernos en el Análisis de Datos (Modern Methods in Data Analytics) es otra de las opciones si lo que buscas es ampliar tu formación sobre datos y aprender inglés al mismo tiempo. La Universidad de Utrecht comenzará a impartir este curso totalmente online a partir del 31 de agosto, totalmente centrado en el estudio de modelos lineares y análisis de datos longitudinal, entre otros campos.
- Otro de los cursos en inglés que dará comienzo el próximo 16 de junio es una formación de 9 semanas de duración enfocada a Data Analytics y que está impartido por la Ironhack International School. Se trata de un curso recomendable para quienes quieran aprender a cargar, limpiar, explorar y extraer información de una amplia gama de datasets, así como a utilizar Python, SQL y Tableau, entre otros aspectos.
- A continuación te descubrimos el curso de Digitalización Empresarial y Big Data: Datos, Información y Conocimiento en Mercados Altamente Competitivos, impartido por la FGUMA (Fundación General de la Universidad de Málaga). Su duración es de 25 horas y su fecha límite de matriculación es el 15 de junio. Si eres un profesional relacionado con la gestión empresarial y/o el emprendimiento, este curso seguro que resulta de tu interés.
- R para ciencia de Datos, es otro de los cursos que ofrece la FGUMA. Su principal objetivo es mostrar una visión introductoria al lenguaje de programación R para tareas de análisis de datos, incluyendo la realización de informes y visualizaciones avanzadas, presentando técnicas propias del aprendizaje computacional como un valor extra. Al igual que el curso anterior, el plazo límite de matrícula para esta formación es el 15 de junio.
- Por su parte, Google Cloud ofrece una ruta de aprendizaje totalmente online y gratuita destinada a profesionales de datos que buscan perfeccionar el diseño, compliación, análisis y optimización de soluciones de macrodatos. Seguro que este Programa especializado: Data Engineering, Big Data, and Machine Learning on GCP encaja dentro de la formación que tenías planeada.
Además, de estos cursos puntuales, cabe destacar la existencia de plataformas de formación online que ofrecen cursos relacionados con las nuevas tecnologías de manera continua. Estos cursos se conocen como MOOC y son una alternativa a la formación tradicional, en áreas como Machine Learning, Analítica del Dato, Business Intelligence o Deep Learning, unos conocimientos cada vez más demandados por las empresas.
Esta es tan solo una selección de los muchos cursos que existen como oferta formativa relacionada con datos. Sin embargo, nos encantaría contar con tu colaboración haciéndonos llegar, a través de los comentarios, otros cursos de interés en el campo de los datos y que puedan completar esta lista en el futuro.
Blog
La ciencia de datos es un campo interdisciplinar que busca extraer conocimiento actuable a partir de conjuntos de datos, estructurados en bases de datos o no estructurados como textos, audios o vídeos. Gracias a la aplicación de nuevas técnicas, la ciencia de datos nos está permitiendo responder preguntas que no son fáciles de resolver a través de otros métodos. El fin último es diseñar acciones de mejora o corrección a partir del nuevo conocimiento que obtenemos.
El concepto clave en ciencia de datos es CIENCIA, y no tanto datos, ya que incluso se ha comenzado a hablar de un cuarto paradigma de la ciencia, añadiendo el enfoque basado en datos a los tradicionales teórico, empírico y computacional.
La ciencia de datos combina métodos y tecnologías que provienen de las matemáticas, la estadística y la informática, y entre las que encontramos el análisis exploratorio, el aprendizaje automático (machine learning), el aprendizaje profundo (deep learning), el procesamiento del lenguaje natural, la visualización de datos y el diseño experimental.
Dentro de la Ciencia de Datos, las dos tecnologías de las que más se está hablando son el Aprendizaje Automático (Machine Learning) y el Aprendizaje profundo (Deep Learning), ambas englobadas en el campo de la inteligencia artificial. En los dos casos se busca la construcción de sistemas que sean capaces de aprender a resolver problemas sin la intervención de un humano y que van desde los sistemas de predicción ortográfica o traducción automática hasta los coches autónomos o los sistemas de visión artificial aplicados a casos de uso tan espectaculares como las tiendas de Amazon Go.
En los dos casos los sistemas aprenden a resolver los problemas a partir de los conjuntos de datos que les enseñamos para entrenarlos en la resolución del problema, bien de forma supervisada cuando los conjuntos de datos de entrenamiento están previamente etiquetados por humanos, o bien de forma no supervisada cuando estos conjuntos de datos no están etiquetados.
En realidad lo correcto es considerar el aprendizaje profundo como una parte del aprendizaje automático por lo que, si tenemos que buscar un atributo que nos permita diferenciarlas, éste sería su forma de aprender, que es completamente diferente. El aprendizaje automático se basa en algoritmos (redes bayesianas, máquinas de vectores de soporte, análisis de clusters, etc) que son capaces de descubrir patrones a partir de las observaciones incluidas en un conjunto de datos. En el caso del aprendizaje profundo se emplea un enfoque que está inspirado, salvando las distancias, en el funcionamiento de las conexiones de las neuronas del cerebro humano y existen también numerosas aproximaciones para diferentes problemas, como por ejemplo las redes neuronales convolucionales para reconocimiento de imágenes o las redes neuronales recurrentes para procesamiento del lenguaje natural.
La idoneidad de un enfoque u otro la marcará la cantidad de datos que tengamos disponibles para entrenar nuestro sistema de inteligencia artificial. En general podemos decir que para pequeñas cantidades de datos de entrenamiento, el enfoque basado en redes neuronales no ofrece un rendimiento superior al enfoque basado en algoritmos. El enfoque basado en algoritmos se suele estancar a partir de una cierta cantidad de datos, no siendo capaz de ofrecer una mayor precisión aunque le enseñemos más casos de entrenamiento. Sin embargo, a través del aprendizaje profundo podemos extraer un mejor rendimiento a partir de esa mayor disponibilidad de datos, ya que el sistema suele ser capaz de resolver el problema con una mayor precisión, cuanto más casos de entrenamiento tenga a su disposición.

Ninguna de estas tecnologías es nuevas en absoluto, ya que llevan décadas de desarrollo teórico. Sin embargo en los últimos años se han producido avances que han rebajado enormemente la barrera para trabajar con ellas: liberación de herramientas de programación que permiten trabajar a alto nivel con conceptos muy complejos, paquetes de software open source para administrar infraestructuras de gestión de datos, herramientas en la nube que permiten acceder a una potencia de computación casi sin límites y sin necesidad de administrar la infraestructura, e incluso formación gratuita impartida por algunos de los mejores especialistas del mundo.
Todo ello está contribuyendo a que capturemos datos a una escala sin precedentes y los almacenemos y procesemos a unos costes aceptables que permiten resolver problemas antiguos con enfoques novedosos. La inteligencia artificial está además al alcance de muchas más personas, cuya colaboración en un mundo cada vez más conectado están dando lugar a innovaciones que avanzan a un ritmo cada vez más veloz en todos los ámbitos: el transporte, la medicina, los servicios, la industria, etc.
Por algo el trabajo de científico de datos ha sido denominado el trabajo más sexy del siglo 21.
Contenido elaborado por Jose Luis Marín, Head of corporate Technology Strategy en MADISON MK y CEO de Euroalert.
Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Blog
No todos los titulares de prensa sobre Inteligencia Artificial son ciertos, pero tampoco cometas el error de subestimar los cambios que se avecinan en los próximos años gracias al desarrollo de la IA.
La inteligencia artificial no ha cambiado aún nuestras vidas y sin embargo estamos viviendo un ciclo de sobreexpectación sobre sus resultados y aplicaciones en el corto plazo. Los medios de comunicación no especializados y los departamentos de marketing de empresas y otras organizaciones potencian un clima de optimismo excesivo en cuanto a los logros actuales en el desarrollo de la IA.
Indudablemente, todos podemos hacerle a nuestro smartphone algunas preguntas sencillas y obtener respuestas bastante razonables. En nuestras compras on-line (por ejemplo en Amazon.com), experimentamos la recomendación de productos personalizados en base a nuestro perfil como compradores. Podemos buscar eventos en nuestra biblioteca de fotografías digitales alojada en algún servicio on-line como Google Photos. Con tan solo escribir, “cumpleaños de mama” en segundos obtendremos una lista de fotos de ese día con una precisión relativamente alta. Sin embargo, todavía no ha llegado el momento donde la IA modifique nuestra experiencia diaria al consumir productos y servicios digitales o físicos. A día de hoy, nuestro médico no usa la IA para apoyar su diagnóstico y nuestro abogado o asesor financiero no usa la IA para preparar un recurso o invertir mejor nuestro dinero.
La actualidad nos inunda con infografías fotorealistas de un mundo lleno de coches autónomos y asistentes virtuales con los que conversamos como si de una persona se tratara. El riesgo de la sobreexpectación en el corto plazo es que, en todo proceso de desarrollo de una tecnología disruptiva y exponencial, la tecnología, necesariamente, falla. Esto conduce a un estado de decepción que conlleva una reducción de las inversiones por parte de empresas y estados, lo que a su vez produce una ralentización en el desarrollo de dicha tecnología. El desarrollo de la IA no es ajena a este proceso y ya ha conocido dos etapas de ralentización. Estas etapas históricas se conocen como los “inviernos de la inteligencia artificial”. El primer invierno de la IA tuvo lugar tras los primeros años de la década de 1970. Tras el nacimiento de lo que hoy conocemos como IA - en la década de 1950 - a finales de los años 60, Marvin Minsky llegó a asegurar en 1967 que “... en el transcurso de una generación … el problema de crear una inteligencia artificial estará prácticamente solucionado...”. Tan solo tres años más tarde, el mismo Minsky precisaba: “... dentro de tres a ocho años habremos logrado una máquina con una inteligencia artificial superior a la del ser humano...”
En la actualidad ningún experto se atrevería a precisar cuándo (si es que) pudiera ocurrir esto. El conocido como segundo invierno de la IA llegaba en los primeros años de la década de los noventa del siglo pasado. Tras un periodo de sobreexpectación de los entonces conocidos como “sistemas expertos”. Los sistemas expertos son programas informáticos que contienen reglas lógicas que codifican y parametrizan el funcionamiento de sistemas sencillos. Por ejemplo, un programa informático que codifica las reglas del juego de ajedrez pertenece al tipo de programas que conocemos como sistemas experto. La codificación de reglas lógicas fijas para simular el comportamiento de un sistemas es lo que se conoce como inteligencia artificial simbólica y fue el primer tipo de inteligencia artificial que se desarrolló.
Entre 1980 y 1985 las empresas habían llegado a invertir más de mil millones de dólares estadounidenses cada año en el desarrollo de estos sistemas. Tras este periodo, se demostró que éstos resultaban ser extremadamente caros de mantener así como muy poco escalables y con escasos resultados para la inversión que suponían. El recorrido histórico del desarrollo de la IA desde sus inicios en 1950 hasta la actualidad es una lectura muy recomendada y apasionante.
¿Que ha conseguido la inteligencia artificial hasta el momento?
Si bien decimos que debemos de ser prudentes con las expectativas en cuanto a las aplicaciones de la inteligencia artificial que veremos en el corto plazo, debemos puntualizar aquí, cuáles han sido los principales logros de la inteligencia artificial desde un punto de vista estrictamente riguroso. Para ello nos basaremos en el libro de Francois Chollet con J.J. Allaire, Deep Learning with R. Manning Shelter Island (2018)
-
Clasificación de imágenes a nivel casi-humano.
-
Reconocimiento de lenguaje hablado a nivel casi-humano
-
Transcripción de lenguaje escrito a nivel casi-humano.
-
Mejora sustancial en la conversión de texto a lenguaje hablado.
-
Mejora sustancial en las traducciones.
-
Conducción autónoma a nivel casi humano.
-
Capacidad de responder a preguntas en lenguaje natural.
-
Jugadores (Ajedrez o Go) que superan con creces las capacidades humanas.
Tras esta breve introducción del momento histórico en el que nos encontramos con respecto a la IA, estamos en condiciones de definir de forma ligeramente más formal qué es la inteligencia artificial y a qué campos de la ciencia y la tecnología afecta directamente en su desarrollo.
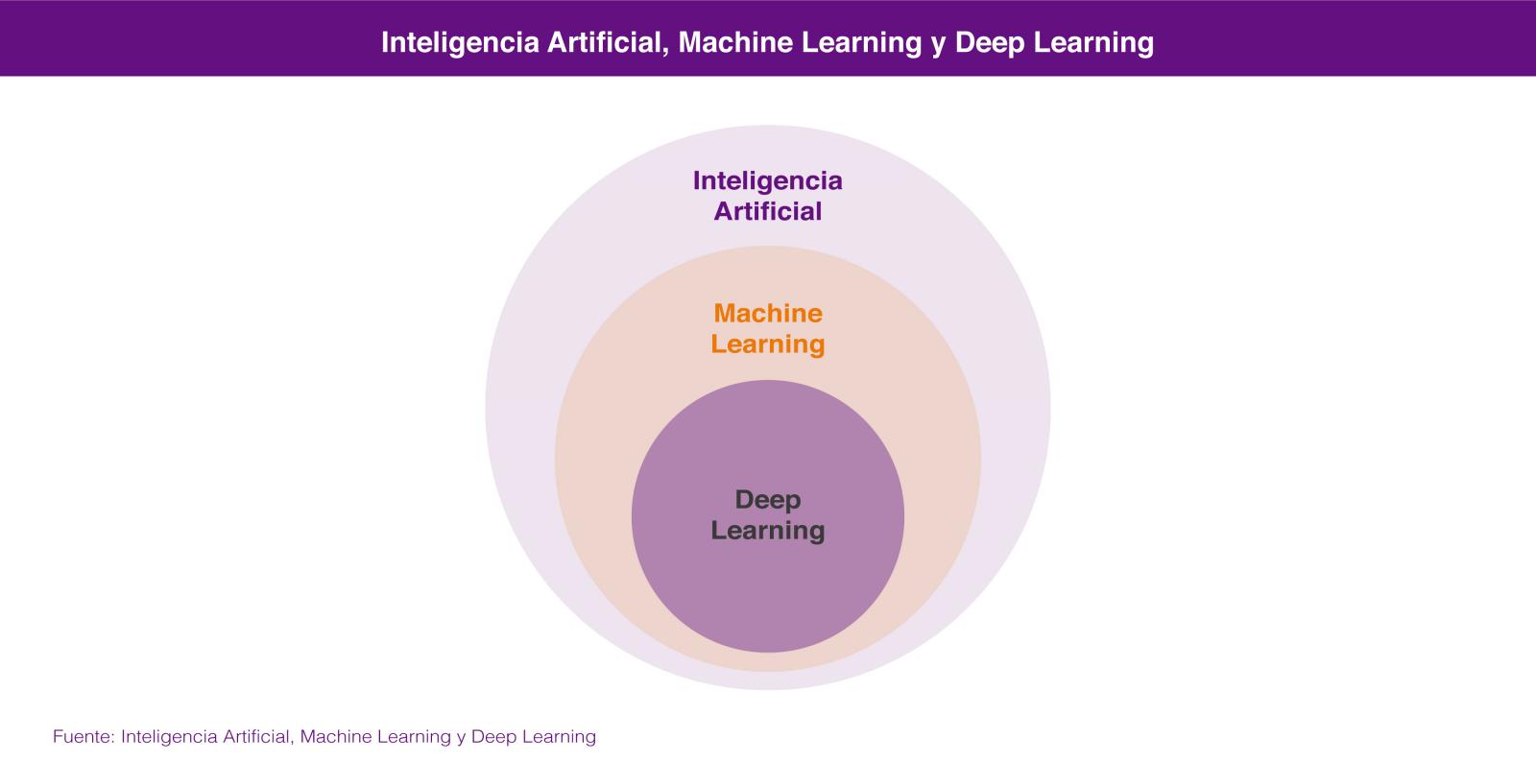
La inteligencia Artificial podría definirse como: el campo de la ciencia que estudia la posibilidad de automatizar tareas intelectuales que normalmente son ejecutadas por humanos. La realidad es que el dominio científico de la IA se divide normalmente en dos sub-campos de las ciencias de la computación y la matemática denominadas Machine Learning y Deep Learning. La representación de esta afirmación se puede ver en la figura 1.

Figura 1. Inteligencia Artificial y sub-campos como el Machine Learning y el Deep Learning.
No vamos a entrar aquí en consideraciones técnicas sobre la diferencia entre machine learning y deep learning (puedes conocer más sobre estos conceptos en este post). Sin embargo, quizás lo más interesante es entender el cambio de paradigma que se produce desde los primeros desarrollo de la IA basados en reglas lógicas hasta la concepción moderna de nuestros días, donde las máquinas averiguan esas reglas que gobiernan un cierto proceso (por ejemplo, el riesgo de padecer un infarto de miocardio) en base a unos datos de entrada y a las experiencias previas que han sido registradas y analizadas por un cierto algoritmo. La figura 2 representa ese cambio de paradigma entre la programación clásica de reglas lógicas y la aproximación del machine learning o el aprendizaje autónomo de las máquinas.

Figura 2. El cambio de paradigma del Machine Learning con respecto a la programación clásica.
El rápido desarrollo que está viviendo la IA en nuestros días es fruto de múltiples factores. Sin embargo todos los expertos coinciden en que dos de ellos han sido y son claves para potenciar esta tercera ola de desarrollo de la inteligencia artificial: el abaratamiento del coste de computación por los ordenadores y la explosión de datos disponibles gracias a Internet y los dispositivos conectados.
Al igual que Internet ha impactado, y más que lo va a hacer, en todos los ámbitos de nuestras vidas - desde el consumidor final hasta los procesos y modelos operativos de las empresas y las industrias más tradicionales -, la IA va a cambiar radicalmente la forma en que los humanos utilizamos nuestras capacidades para el desarrollo de nuestra especie. No son pocas las noticias sobre la repercusión negativa que la IA va a tener sobre los puestos de trabajo en los próximos 10-20 años. Si bien es indudable que la automatización de ciertos procesos va a eliminar algunos puestos de trabajo que aún existen en la actualidad, no es menos cierto que, son precisamente, aquellos puestos de trabajo que nos hacen ser “menos humanos” los que primero van a desaparecer. Aquellos puestos de trabajo que emplean a las personas como máquinas para repetir las mismas acciones, una tras otra, serán sustituidos por agentes dotados con IA, bien sean en forma de software o en forma de robots equipados con IA.
Las tareas iterativas y predecibles caerán en el dominio exclusivo de las máquinas. Por el contrario, aquellas tareas que requieren de liderazgo, empatía, creatividad y juicios de valor seguirán perteneciendo únicamente a los humanos. ¿Entonces, ya está? ¿No tenemos nada más que hacer que esperar a que las máquinas hagan parte del trabajo y nosotros la otra parte? La respuesta es no. La realidad es que se crea un gran espacio en el medio de estos dos extremos. El espacio en que el humano es amplificado por la IA y a cambio la IA es entrenada por humanos para retroalimentar este ciclo intermedio. Paul R. Daugherty y H. James Wilson, definen en su libro Human + Machine este espacio como “The missing middle”, algo así como el espacio intermedio perdido. En este espacio intermedio, las máquinas dotadas con IA aumentan las capacidades humanas, nos hacen más fuertes con exoesqueletos capaces de levantar cargas pesadas o devolvernos la capacidad de andar tras una parálisis; nos hacen menos vulnerables al trabajar en ambientes potencialmente dañinos como el espacio, el fondo del mar o en una tubería con gases mortales; Nos aumentan nuestras capacidades sensoriales en tiempo real con gafas que portan cámaras y sensores que complementan nuestro campo de visión con información contextual superpuesta.
Con la ayuda de las máquinas dotadas con una IA mejorada, no es difícil imaginar cómo cambiarán los procesos y las tareas de mantenimiento en una fábrica, la forma tan diferente en la que se cultivarán nuestros campos, como trabajarán los almacenes del futuro y la eficiencia con la que se auto-gestionarán nuestros hogares.
En conclusión, dejemos de mirar a las máquinas y la IA como rivales por los que nos disputaremos nuestros puestos de trabajo y comencemos a pensar en la forma en la que vamos a fusionar nuestras habilidades más humanas con las capacidades superiores de las máquinas en cuanto a resistencia, velocidad y precisión.
Hagamos las cosas diferentes ahora para hacer cosas diferentes en el futuro.
Contenido elaborado por Alejandro Alija,experto en Transformación Digital e Innovación.
Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Empresa reutilizadora
GIS4tech es una empresa Spin-Off española fundada en 2016, fruto de la actividad investigadora del grupo Territorial Cluster y del Departamento de Urbanística y Ordenación del Territorio de la Universidad de Granada. Está dedicada a la asistencia técnica, asesoramiento, formación e investigación y desarrollo apoyados en Sistemas de Información Geográfica y tecnologías afines. Su equipo cuenta con más de 20 años de experiencia en estudios del territorio, elaboración de cartografía y Sistemas de Información Geográfica.