Blog
Have you ever wondered how Alexa is able to recognise our voice and understand what we are saying (sometimes better than others)? Have you ever stopped to think about how Google is able to search for images similar to the one we are providing it with? You probably know that these techniques belong to the field of artificial intelligence. But don't be fooled, building these sophisticated models is only within the reach of a few. In this post we tell you why and what we ordinary mortals can do to train artificial intelligence models.
Introduction
In recent years we have witnessed incredible and surprising advances in the field of training Deep Learning models. On previous occasions we have cited the most relevant examples such as GPT-3 or Megatron-Turing NLG. These models, optimised for natural language processing (NLP), are capable of writing complete articles (practically indistinguishable from those written by a human) or making coherent summaries of classic works, hundreds of pages long, synthesising the content in just a few paragraphs. Impressive, isn't it?
However, these achievements are far from cheap. That is, the complexity of these models is such that thousands of gigabytes of pre-processed information - what we call annotated datasets - are needed, which have been previously analysed (labelled) by a human expert in the field. For example, the latest training of the Megatron-Turing NLG model, created in collaboration between Microsoft and NVIDIA, used 270 billion tokens (small pieces of text that can be words or sub-words that form the basis for training these natural language models). In addition to the information needed to be able to train these models, there is the fact of the special computational needs that these trainings require. To execute training tasks for these models, the most advanced machines (computers) in the world are needed, and training times are counted in weeks. Although there is no official data, some sources quote the cost of training the latest models such as GPT-3 or Megatron-Turing in the tens of millions of dollars. So how can we use and train models if we do not have access to the most powerful computing clusters in the world?
The answer: Transfer Learning
When working on a machine learning or deep learning project and we do not have access to large datasets ready for training, we can start from pre-trained models to create a new model adjusted or tuned to our specific use case. In other words, we load a previously trained model with a very large set of training data and re-train its final layers to fit our particular data set. This is known as Transfer Learning.
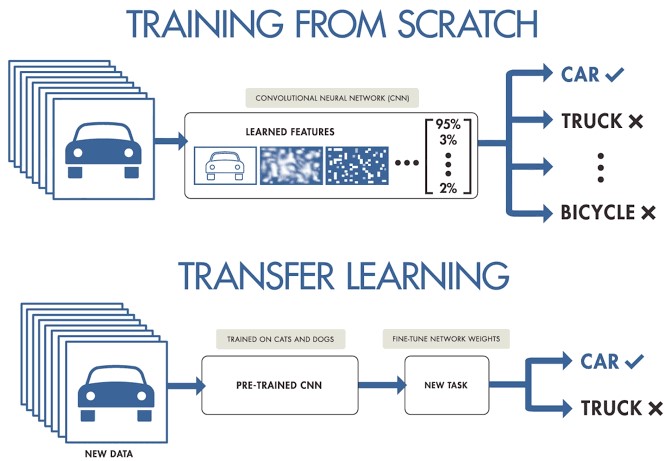
Original source: Transfer Learning in Deep Learning: Beyond our models. Post by Josu Alonso on Medium.
Simplifying a lot, we could say that traditional Machine Learning applies to isolated learning tasks, where it is not necessary to retain the acquired knowledge, while in a Transfer Learning project the learning is the result of previous tasks, achieving good precision in less time and with less data. This brings many opportunities, but also some challenges, such as the new domain inheriting biases from the previous domain.
Let's look at a concrete example. Suppose we have a new Deep Learning challenge and we want to make an automatic dog breed classifier. In this case, we can apply the transfer learning technique starting from a general image classification model, and then fit it to a specific set of dog breed photographs. Most of the pre-trained models are based on a subset of the ImageNet database, which we have already discussed on several occasions. The neural network (from ImageNet), which is the base type of algorithm used in these image classification models, has been trained on 1.2 million images of over 1000 different object categories such as keyboards, coffee cups, pencils and many animals. By using a pre-trained network to apply Transfer Learning, we get much faster and easier results than if we had to train a network from scratch.
For example, this code snippet shows the process of starting from a pre-trained model with ImageNet and re-training or adding new layers to achieve fine adjustments to the original model.
# we create the basis of the pre-trained model starting from ImageNET
base_model <- application_inception_v3(weights = 'imagenet', include_top = FALSE)
# We add additional layers to our neural network
predictions <- base_model$output %>%
layer_global_average_pooling_2d() %>%
layer_dense(units = 1024, activation = 'relu') %>%
layer_dense(units = 200, activation = 'softmax')
# we create a new model for training
model <- keras_model(inputs = base_model$input, outputs = predictions)
# We make sure to train only our new layers so as not to destroy previous training
freeze_weights(base_model)
# we compile the model
model %>% compile(optimizer = 'rmsprop', loss = 'categorical_crossentropy')
# we train the model
model %>% fit_generator(...)
Conclusions
Training a general-purpose deep learning model is not within everyone's reach. There are several barriers, from the difficulty of accessing quality training data in sufficient volume, to the computational capacity needed to process billions of images or texts. For more limited use cases, where we only require a refinement of generalist models, applying the Transfer Learning technique allows us to achieve fantastic results in terms of accuracy and training time, at a cost that is affordable for most data scientists. Transfer Learning applications are very numerous and specialised websites are full of application examples. In line with this trend, Style Transfer Learning, which consists of reconstructing images based on the style of a previous image, has recently become very popular. We will continue to discuss this topic in future posts.

Example of Style Transfer Learning in Kaggle
[1] It is not the purpose of this post to explain in detail each of the sections of this code snippet.
Content prepared by Alejandro Alija, expert in Digital Transformation and Innovation.
The contents and views expressed in this publication are the sole responsibility of the author.
Blog
Today, Artificial Intelligence (AI) applications are present in many areas of everyday life, from smart TVs and speakers that are able to understand what we ask them to do, to recommendation systems that offer us services and products adapted to our preferences.
These AIs "learn" thanks to various techniques, including supervised, unsupervised and reinforcement learning. In this article we will focus on reinforcement learning, which focuses mainly on trial and error, similar to how humans and animals in general learn.
The key to this type of system is to correctly set long-term goals in order to find an optimal global solution, without focusing too much on immediate rewards, which do not allow for an adequate exploration of the set of possible solutions.
Simulation environments as a complement to open data sets.
Unlike other types of learning, where learning is usually based on historical datasets, this type of technique requires simulation environments that allow training a virtual agent through its interaction with an environment, where it receives rewards or penalties depending on the state and actions it performs. This cycle between agent and environment can be seen in the following diagram:
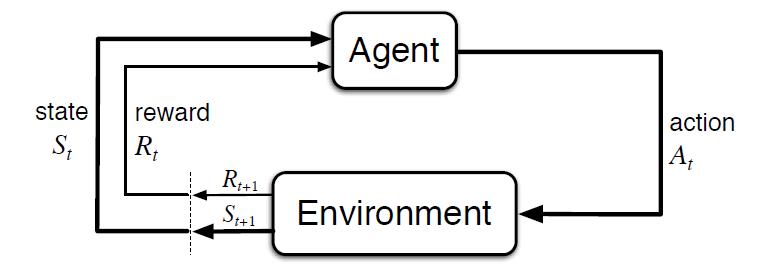
Figure 1 - Scheme of learning by reinforcement [Sutton & Barto, 2015]
That is, starting from a simulated environment, with an initial state, the agent performs an action that generates a new state and a possible reward or penalty, which depends on the previous states and the action performed. The agent learns the best strategy in this simulated environment from experience, exploring the set of states, and being able to recommend the best action policy if configured appropriately.
The best-known example worldwide was the success achieved by AlphaGo, beating 18-time world champion Lee Sedol in 2016. Go is an ancient game, considered one of the 4 basic arts in Chinese culture, along with music, painting and calligraphy. Unlike chess, the number of possible game combinations is greater than the number of atoms in the Universe, being a problem impossible to solve by traditional algorithms.
Curiously, the technological breakthrough demonstrated by AlphaGo in solving a problem that was claimed to be beyond the reach of an AI, was eclipsed a year later by its successor AlphaGo Zero. In this version, its creators chose not to use historical data or heuristic rules. AlphaGo Zero only uses the board positions and learns by trial and error by playing against itself.
Following this innovative learning strategy, in 3 days of execution he managed to beat AlphaGo, and after 40 days he became the best Go player, accumulating thousands of years of knowledge in a matter of days, and even discovering previously unknown strategies.
The impact of this technological milestone covers countless areas, and AI solutions that learn to solve complex problems from experience can be counted on. From resource management, strategy planning, or the calibration and optimization of dynamic systems.
The development of solutions in this area is especially limited by the need for appropriate simulation environments, being the most complex component to build. However, there are multiple repositories to obtain open simulation environments that allow us to test this type of solutions.
The best known reference is Open AI Gym, which includes an extensive set of libraries and open simulation environments for the development and validation of reinforcement learning algorithms. Among others, it includes simulators for the basic control of mechanical elements, robotics applications and physics simulators, two-dimensional ATARI video games, and even the landing of a lunar module. In addition, it allows to integrate and publish new open simulators for the development of our own simulators adapted to our needs that can be shared with the community:

Figure 2 - Examples of visual simulation environments offered by Open AI Gym
Another interesting reference is Unity ML Agents, where we also find multiple libraries and several simulation environments, also offering the possibility of integrating our own simulator:

Figure 3 - Examples of visual simulation environments offered by Unity ML Agents
Potential applications of reinforcement learning in public administrations
This type of learning is used especially in areas such as robotics, resource optimization or control systems, allowing the definition of optimal policies or strategies for action in specific environments.
One of the best-known practical examples is the DeepMind algorithm used by Google to reduce by 40% the energy consumption required to cool its data centers in 2016, achieving a significant reduction in energy consumption during use, as can be seen in the following graph (taken from the previous article):
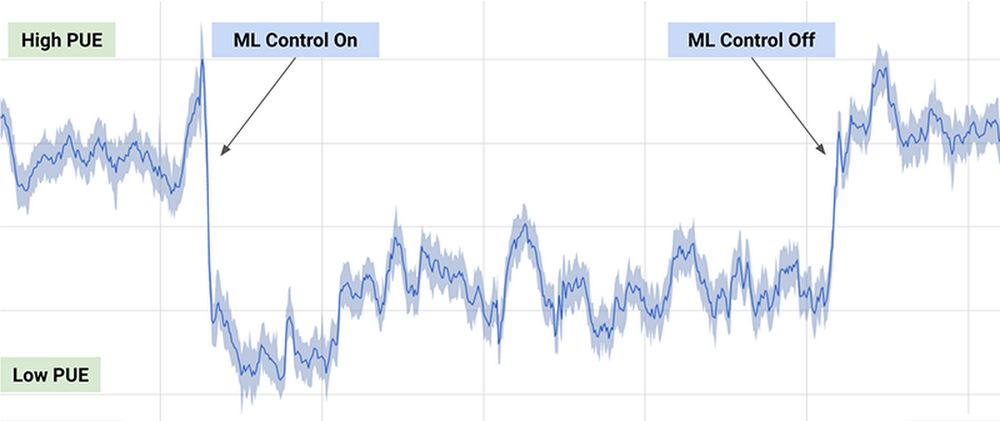
Figure 4 - Results of the DeepMind algorithm on the energy consumption of Google's data centers.
The algorithm employed uses a combination of deep learning and reinforcement learning techniques, together with a general purpose simulator to understand complex dynamic systems that could be applied in multiple environments such as transformation between energy types, water consumption or resource optimization in general.
Other possible applications in the public domain include the search and recommendation of open datasets through chatbots, or the optimization of public policies, as is the case of the European project Policy Cloud, applied for example in the analysis of future strategies of the different designations of origin of wines from Aragon.
In general, the application of this type of techniques could optimize the use of public resources by planning action policies that result in more sustainable consumption, reducing pollution, waste and public spending.
Content prepared by Jose Barranquero, expert in Data Science and Quantum Computing.
The contents and views expressed in this publication are the sole responsibility of the author.
Entrevista
Open data is not only a matter of public administrations, more and more companies are also betting on them. This is the case of Microsoft, who has provided access to selected open data in Azure designed for the training of Machine Learning models. He also collaborates in the development of multiple projects in order to promote open data. In Spain, it has collaborated in the development of the platform HealthData 29, intended for the publication of open data to promote medical research.
We have interviewed Belén Gancedo, Director of Education at Microsoft Ibérica and member of the jury in the III edition of the Aporta Challenge,focused on the value of data for the education sector. We met with her to talk about the importance of digital education and innovative data-driven solutions, as well as the importance of open data in the business sector.
Complete interview:
1. What challenges in the education sector, to which it is urgent to respond, has the pandemic in Spain revealed?
Technology has become an essential element in the new way of learning and teaching. During the last months, marked by the pandemic, we have seen how a hybrid education model - face-to-face and remotely - has changed in a very short time. We have seen examples of centers that, in record time, in less than 2 weeks, have had to accelerate the digitization plans they already had in mind.
Technology has gone from being a temporary lifeline, enabling classes to be taught in the worst stage of the pandemic, to becoming a fully integrated part of the teaching methodology of many schools. According to a recent YouGov survey commissioned by Microsoft, 71% of elementary and middle school educators say that technology has helped them improve their methodology and improved their ability to teach. In addition, 82% of teachers report that the pace at which technology has driven innovation in teaching and learning has accelerated in the past year.
Before this pandemic, in some way, those of us who had been dedicating ourselves to education were the ones who defended the need to digitally transform the sector and the benefits that technology brought to it. However, the experience has served to make everyone aware of the benefits of the application of technology in the educational environment. In that sense, there has been an enormous advance. We have seen a huge increase in the use of our Teams tool, which is already used by more than 200 million students, teachers, and education staff around the world.
The biggest challenges, then, currently, are to not only take advantage of data and Artificial Intelligence to provide more personalized experiences and operate with greater agility, but also the integration of technology with pedagogy, which will allow more flexible, attractive learning experiences and inclusive. Students are increasingly diverse, and so are their expectations about the role of college education in their journey to employment.
The biggest challenges, then, currently, are to not only take advantage of data and Artificial Intelligence to provide more personalized experiences and operate with greater agility, but also the integration of technology with pedagogy, which will allow more flexible, attractive learning experiences and inclusive.
2. How can open data help drive these improvements? What technologies need to be implemented to drive improvements in the efficiency and effectiveness of the learning system?
Data is in all aspects of our lives. Although it may not be related to the mathematics or algorithm that governs predictive analytics, its impact can be seen in education by detecting learning difficulties before it is too late. This can help teachers and institutions gain a greater understanding of their students and information on how to help solve their problems.
Predictive analytics platforms and Artificial Intelligence technology have already been used with very positive results by different industries to understand user behavior and improve decision-making. With the right data, the same can be applied in classrooms. On the one hand, it helps to personalize and drive better learning outcomes, to create inclusive and personalized learning experiences, so that each student is empowered to succeed. If its implementation is correct, it allows a better and greater monitoring of the needs of the student, who becomes the center of learning and who will enjoy permanent support.
At Microsoft we want to be the ideal travel companion for the digital transformation of the education sector. We offer educational entities the best solutions -cloud and hardware- to prepare students for their professional future, in a complete environment of collaboration and communication for the classroom, both in face-to-face and online models. Solutions like Office 365 Education and the Surface device are designed precisely to drive collaboration both inside and outside the classroom. The educational version of Microsoft Teams makes a virtual classroom possible. It is a free tool for schools and universities that integrates conversations, video calls, content, assignments and applications in one place, allowing teachers to create learning environments that are lively and accessible from mobile devices,
And, in addition, we make available to schools, teachers and students devices specifically designed for the educational environment, such as the Surface Go 2, expressly designed for the educational environment. It is an evolutionary device, that is, it adapts to any educational stage and boosts the creativity of students thanks to its power, versatility and safety. This device allows the mobility of both teachers and students inside and outside the classroom; connectivity with other peripheral devices (printers, cameras ...); and includes the Microsoft Classroom Pen for natural writing and drawing in digital ink.
3. There is increasing demand for digital skills and competencies related to data. In this sense, the National Plan for Digital Skills, which includes the digitization of education and the development of digital skills for learning. What changes should be made in educational programs in order to promote the acquisition of digital knowledge by students?
Without a doubt, one of the biggest challenges we face today is the lack of training and digital skills. According to a study carried out by Microsoft and EY, 57% of the companies surveyed expect AI to have a high or very high impact in business areas that are "totally unknown to companies today."
There is a clear opportunity for Spain to lead in Europe in digital talent, consolidating itself as one of the most attractive countries to attract and retain this talent. A recent LinkedIn study anticipates that two million technology-related jobs will be created in Spain in the next five years, not only in the technology industry, but also,and above all, in companies in other sectors of activity that seek to incorporate the necessary talent to carry out their transformation. However, there is a shortage of professionals with skills and training in digital skills. According to data from the Digital Economy and Society Index Report published annually by the European Commission, Spain is below the European average in most of the indicators that refer to the digital skills of Spanish professionals.
There is, therefore, an urgent demand to train qualified talent with digital skills, data management, AI, machine learning ... Technology-related profiles are among the most difficult to find and, in the near future, those related to technology data analytics, cloud computing and application development.
For this, adequate training is necessary, not only in the way of teaching, but also in the curricular content. Any career, not just those in the STEM field, would need to include subjects related to technology and AI, which will define the future. The use of AI reaches any field, not only technology, therefore, students of any type of career -Law, Journalism ... - to give some examples of non-STEM careers, need qualified training in technology such as AI or data science, since they will have to apply it in their professional future.
We must bet on public-private collaborations and involve the technology industry, public administrations, the educational community, adapting the curricular contents of the University to the labor reality- and third sector entities, with the aim of promoting employability and professional recycling. In this way, the training of professionals in areas such as quantum computing, Artificial Intelligence, or data analytics and we can aspire to digital leadership.
In the next five years, two million technology-related jobs will be created in Spain, not only in the technology industry, but also, and above all, in companies in other sectors of activity that seek to incorporate the necessary talent to lead carry out your transformation.
4. Even today we find a disparity between the number of men and women who choose professional branches related to technology. What is needed to promote the role of women in technology?
According to the National Observatory of Telecommunications and Information Society -ONTSI- (July 2020), the digital gender gap has been progressively reduced in Spain, going from 8.1 to 1 point, although women maintain an unfavorable position in digital skills and Internet use. In advanced skills, such as programming, the gap in Spain is 6.8 points, the EU average being 8 points. The percentage of researchers in the ICT services sector drops to 23.4%. And in terms of the percentage of graduates in STEM, Spain ranks 12th within the EU, with a difference between the sexes of 17 points.
Without a doubt, there is still a long way to go. One of the main barriers that women face in the technology sector and when it comes to entrepreneurship are stereotypes and cultural tradition. The masculinized environment of technical careers and stereotypes about those who are dedicated to technology make them unattractive careers for women.
Digitization is boosting the economy and promoting business competitiveness,as well as generating an increase in the creation of specialized employment. Perhaps the most interesting thing about the impact of digitization on the labor market is that these new jobs are not only being created in the technology industry, but also in companies from all sectors, which need to incorporate specialized talent and digital skills.
Therefore, there is an urgent demand to train qualified talent with digital capabilities and this talent must be diverse. The woman cannot be left behind. It is time to tackle gender inequality, and alert everyone to this enormous opportunity, regardless of their gender. STEM careers are an ideal future option for anyone, regardless of gender.
Forfavor the female presence in the technology sector, in favor of a digital era without exclusion, at Microsoft we have launched different initiatives that seek to banish stereotypes and encourage girls and young people to take an interest in science and technology and make them see that they they can also be the protagonists of the digital society. In addition to the WONNOW Awards that we convened with CaixaBank, we also participate and collaborate in many initiatives, such as the Ada Byron Awards together with the University of Deusto, to help give visibility to the work of women in the STEM field, so that they are references of those who They are about to come.
The digital gender gap has been progressively reduced in Spain, going from 8.1 to 1 point, although women maintain an unfavorable position in digital skills and Internet use. In advanced skills, such as programming, the gap in Spain is 6.8 points, the EU average being 8 points.
5. How can initiatives like hackathons, challenge or challenges help drive data-driven innovation? How was your experience in the III Aporta Challenge?
These types of initiatives are key to that much-needed change. At Microsoft we are constantly organizing hackathons on a global, regional and local scale, to innovate in different priority areas for the company, such as education.
But we go further. We also use these tools in class. One of Microsoft's bets is the projects STEM hacking.These are projects in which the “maker” concept of learning by doing with programming and robotics is mixed, through the use of everyday materials. What's more,They are made up of activities that allow teachers to guide their students to construct and create scientific instruments and project-based tools to visualize data through science, technology, engineering, and mathematics. Our projects -both Hacking STEM as well as coding and computational language through the use of free tools such as Make Code- aim to bring programming and robotics to any subject in a transversal way, and why not, learn programming in a Latin class or in a biology one.
My experience in the III Aporta Challenge has been fantastic because it has allowed me to learn about incredible ideas and projects where the usefulness of the amount of data available becomes a reality and is put at the service of improving the education of all. There has been a lot of participation and, in addition, with very careful and worked presentations. The truth is that I would like to take this opportunity to thank everyone who has participated and also congratulate the winners.
6. A year ago, Microsoft launched a campaign to promote open data in order to close the gap between countries and companies that have the necessary data to innovate and those that do not. What has the project consisted of? What progress has been made?
Microsoft's global initiative Open Data Campaign seeks to help close the growing “data gap” between the small number of technology companies that benefit most from the data economy today and other organizations that are hampered by lack of access to data or lack of capabilities to use the ones you already have.
Microsoft believes that more needs to be done to help organizations share and collaborate around data so that businesses and governments can use it to meet the challenges they face, as the ability to share data has huge benefits. And not only for the business environment, but they also play a critical role in helping us understand and address major challenges, such as climate change, or health crises, such as the COVID-19 pandemic. To take full advantage of them, it is necessary to develop the ability to share them in a safe and reliable way, and to allow them to be used effectively.
Within the Open Data Campaign initiative, Microsoft has announced 5 great principles that will guide how the company itself approaches how to share its data with others:
- Open- Will work to make relevant data on large social issues as open as possible.
- Usable- Invest in creating new technologies and tools, governance mechanisms and policies so that data can be used by everyone.
- Boosters- Microsoft will help organizations generate value from their data and develop AI talent to use it effectively.
- Insurance- Microsoft will employ security controls to ensure data collaboration is secure at the operational level.
- Private- Microsoft will help organizations protect the privacy of individuals in data-sharing collaborations that involve personally identifiable information.
We continue to make progress in this regard. Last year, Microsoft Spain, next to Foundation 29, the Chair on Privacy and Digital Transformation Microsoft-Universitat de València and with the legal advice of the law firm J&A Garrigues have created the Guide "Health Data"that describes the technical and legal framework to carry out the creation of a public repository of health systems data, and that these can be shared and used in research environments and LaLiga is one of the entities that has shared, in June of this year, its anonymized data.
Data is the beginning of everything and one of our biggest responsibilities as a technology company is to help conserve the ecosystem on a large scale, on a planetary level. For this, the greatest challenge is to consolidate not only all the available data, but the artificial intelligence algorithms that allow access to it and allow making decisions, creating predictive models, scenarios with updated information from multiple sources. For this reason, Microsoft launched the concept of Planetary Computer, based on Open Data, to make more than 10 Petabytes of data - and growing - available to scientists, biologists, startups and companies, free of charge, from multiple sources (biodiversity, electrification , forestry, biomass, satellite), APIs, Development Environments and applications (predictive model, etc.) to create a greater impact for the planet.
Microsoft's global initiative Open Data Campaign seeks to help close the growing “data gap” between the small number of technology companies that benefit most from the data economy today and other organizations that are hampered by lack of access to data or lack of capabilities to use the ones you already have.
7. They also offer some open data sets through their Azure Open Datasets initiative. What kind of data do they offer? How can users use them?
This initiative seeks that companies improve the accuracy of the predictions of their Machine Learning models and reduce the time of data preparation, thanks to selected data sets of public access, ready to use and easily accessible from the Azure services.
There is data of all kinds: health and genomics, transport, labor and economy, population and security, common data ... that can be used in multiple ways. And it is also possible to contribute datasets to the community.
8. Which are the Microsoft's future plans for open data?
After a year with the Opendata campaign, we have had many learnings and, in collaboration with our partners, we are going to focus next year on practical aspects that make the process of data sharing easier. We just started publishing materials for organizations to see the nuts and bolts of how to start sharing data. We will continue to identify possible collaborations to solve social challenges on issues of sustainability, health, equity and inclusion. We also want to connect those who are working with data or want to explore that realm with the opportunities offered by the Microsoft Certifications in Data and Artificial Intelligence. And, above all, this issue requires a good regulatory framework and, for this, it is necessary that those who define the policies meet with the industry.
Blog
It has been a long time since that famous article entitled “Data Scientist: The Sexiest Job of the 21st Century” was published in 2012. Since then, the field of data science has become highly professionalised. A multitude of techniques, frameworks and tools have been developed that accelerate the process of turning raw data into valuable information. One of these techniques is known as Auto ML or Automatic Machine Learning. In this article we will review the advantages and characteristics of this method.
In a data science process, any data scientist usually uses a systematic working method, whereby raw data is distilled until information of value to the business from which the data is derived is extracted. There are several definitions of the data analysis process, although they are all very similar with minor variations. The following figure shows an example of a data analysis process or workflow.

As we can see, we can distinguish three stages:
- Importing and cleaning.
- Scanning and modelling.
- Communication.
Depending on the type of source data and the result we seek to achieve with this data, the modelling process may vary. However, regardless of the model, the data scientist must be able to obtain a clean dataset ready to serve as input to the model. In this post we will focus on the second stage: exploration and modelling.
Once this clean and error-free data has been obtained (after import and cleaning in step 1), the data scientist must decide which transformations to apply to the data, with the aim of making some data derived from the originals (in conjunction with the originals), the best indicators of the model underlying the dataset. We call these transformations features.
The next step is to divide our dataset into two parts: one part, for example 60% of the total dataset, will serve as the training dataset. The remaining 40% will be reserved for applying our model, once it has been trained. We call this second part the test subset. This process of splitting the source data is done with the intention of assessing the reliability of the model before applying it to new data unknown to the model. An iterative process now unfolds in which the data scientist tests various types of models that he/she believes may work on this dataset. Each time he/she applies a model, he/she observes and measures the mathematical parameters (such as accuracy and reproducibility) that express how well the model is able to reproduce the test data. In addition to testing different types of models, the data scientist may vary the training dataset with new transformations, calculating new and different features, in order to come up with some features that make the model in question fit the data better.
We can imagine that this process, repeated dozens or hundreds of times, is a major consumer of both human and computational resources. The data scientist tries to perform different combinations of algorithms, models, features and percentages of data, based on his or her experience and skill with the tools. However, what if it were a system that would perform all these combinations for us and finally come up with the best combination? Auto ML systems have been created precisely to answer this question.
In my opinion, an Auto ML system or tool is not intended to replace the data scientist, but to complement him or her, helping the data scientist to save a lot of time in the iterative process of trying different techniques and data to reach the best model. Generally speaking, we could say that an Auto ML system has (or should have) the following benefits for the data scientist:
- Suggest the best Machine Learning techniques and automatically generate optimised models (automatically adjusting parameters), having tested a large number of training and test datasets respectively.
- Inform the data scientist of those features (remembering that they are transformations of the original data) that have the greatest impact on the final result of the model.
- Generate visualisations that allow the data scientist to understand the outcome of the process carried out by Auto ML. That is, to teach the Auto ML user the key indicators of the outcome of the process.
- Generate an interactive simulation environment that allows users to quickly explore the model to see how it works.
Finally, we mention some of the best-known Auto ML systems and tools, such as H2O.ai, Auto-Sklearn end TPOT. It should be noted that these three systems cover the entire Machine Learning process that we saw at the beginning. However, there are more solutions and tools that partially cover some of the steps of the complete process. There are also articles comparing the effectiveness of these systems for certain machine learning problems on open and accessible datasets.
In conclusion, these tools provide valuable solutions to common data science problems and have the potential to dramatically improve the productivity of data science teams. However, data science still has a significant art component and not all problems are solved with automation tools. We encourage all algorithm alchemists and data craftsmen to continue to devote time and effort to developing new techniques and algorithms that allow us to turn data into value quickly and effectively.
The aim of this post is to explain to the general public, in a simple and accessible way, how auto ML techniques can simplify the process of advanced data analysis. Sometimes oversimplifications may be used in order not to overcomplicate the content of this post.
Content elaborated by Alejandro Alija, expert in Digital Transformation and Innovation.
Contents and points of view expressed in this publication are the exclusive responsibility of its author.
Entrevista
Now that the call for the third edition of the Aporta Challenge is open, in this occasion focused on the field of education, we have talked to the winner of the 2019 edition, Mariano Nieves, who won thanks to his Optimacis solution. Mariano explained his experience and gave us some advice for this year's participants.
Full interview:
1. What does Optimacis consist of?
Optimacis is a project for the optimisation of the fresh fish market, which seeks to balance prices against monopsony situations.
The success of the project lies in the delivery of value for the three main actors in these markets:
- the fishing companies as producers
- wholesalers and hospitality companies as mediators in the delivery to the market;
- and the fish markets themselves as primary distribution centres.
The values for each actor are specific: in the case of fishermen, by means of advance knowledge of the most advantageous prices for sale; in the case of wholesalers and restaurateurs, by means of knowledge of the supply points with the greatest capacity; and in the case of fish markets, by means of advance knowledge of the expected influx into their facilities, for the internal organisation of resources.
2. What prompted you to participate in the Aporta Challenge?
Without a doubt, the institutional support of datos.gob.es is a reference in the Public Administration, given that the project has a marked character of sustainability for a group that usually requires additional resources to the exploitation.
It was not a preconceived project that came to take advantage of the call. On the contrary, the project was developed after reading the call for proposals. In all honesty, I even asked a formal question at the Red.es website to make sure that fishing was an area covered by the 2019 Aporta Challenge.
I thought that having the recognition and dissemination of the Aporta Challenge would boost my professional career, as it has. This is a value that I want to highlight to encourage other participants in the new call: there are currently many professionals with an impressive career, who can make their CV shine with success in the Aporta Challenge.
3. How was your experience?
The challenge was impressive. For those who know the exciting world of data, I think it is important to stress the importance of handling more than 3,500 predictive models in real time (well, with a 24-hour regeneration cycle).
This is supported by various sources of ingestion, highlighting the information from Meteogalicia and the State Agency of Meteorology, the ingestion in real time from two radar systems (actually, they are called Automatic Identification Systems) located in As Pontes de García Rodríguez and Vigo, and the daily extraction of the price data published from the Galician fish markets.
Shuffling all these sources of information in record time (with seven machines working in continuous mode 24x7), ingesting and monitoring the predictive models was a major effort for me, to which I dedicated the entire summer of 2019. And the months of September and October was dedicated to geolocation and machine learning tasks.
The main advantage that the challenge has given me has been to know sources of large masses of data that are available for projects of all kinds, with the solvency of the sources of the Public Administration.
4. What is the current status of the development of the Optimacis System?
We are already in a phase of promoting the solution, in order to coordinate with public bodies that promote sustainable projects in the field of fisheries at a state, local and regional level. The balance of the market conditions is being a factor that awakens interest in local administrations.
5. What advice would you give to participants in the Aporta 2020 Challenge?
Well, only from my partition experience of course. I think that the dedication and effort were decisive in my case, because the rest of the participants had a very high level to which I could not aspire. Most of them were groups of people, while my participation was of a personal nature. However, the fact that I was able to build this whole block of predictive models and carefully review the results was decisive.
On the other hand, I think it also helped that I took meticulous care of the presentation. The fact that I carefully wrapped the content was well appreciated, as I had a fully functional model.
6. Closing and farewell.
I want to convey all the encouragement to the participants of this call, and not hesitate to include dedication and effort because it is worth it. Not every day you receive recognition from a government institution like datos.gob.es. May the best one win!
Blog
Machine learning is a branch within the field of Artificial Intelligence that provides systems with the ability to learn and improve automatically, based on experience. These systems transform data into information, and with this information, they can make decisions. A model needs to be fed with data to make predictions in a robust way. The more, the better. Fortunately, today's network is full of data sources. In many cases, data is collected by private companies for their own benefit, but there are also other initiatives, such as open data portals.
Once we have the data, we are ready to start the learning process. This process, carried out by an algorithm, tries to analyze and explore the data in search of hidden patterns. The result of this learning, sometimes, is nothing more than a function that operates on the data to calculate a certain prediction.
In this article we will see the types of machine learning that exist including some examples.
Types of machine learning
Depending on the data available and the task we want to tackle, we can choose between different types of learning. These are: supervised learning, unsupervised learning, semi-supervised learning and reinforcement learning.
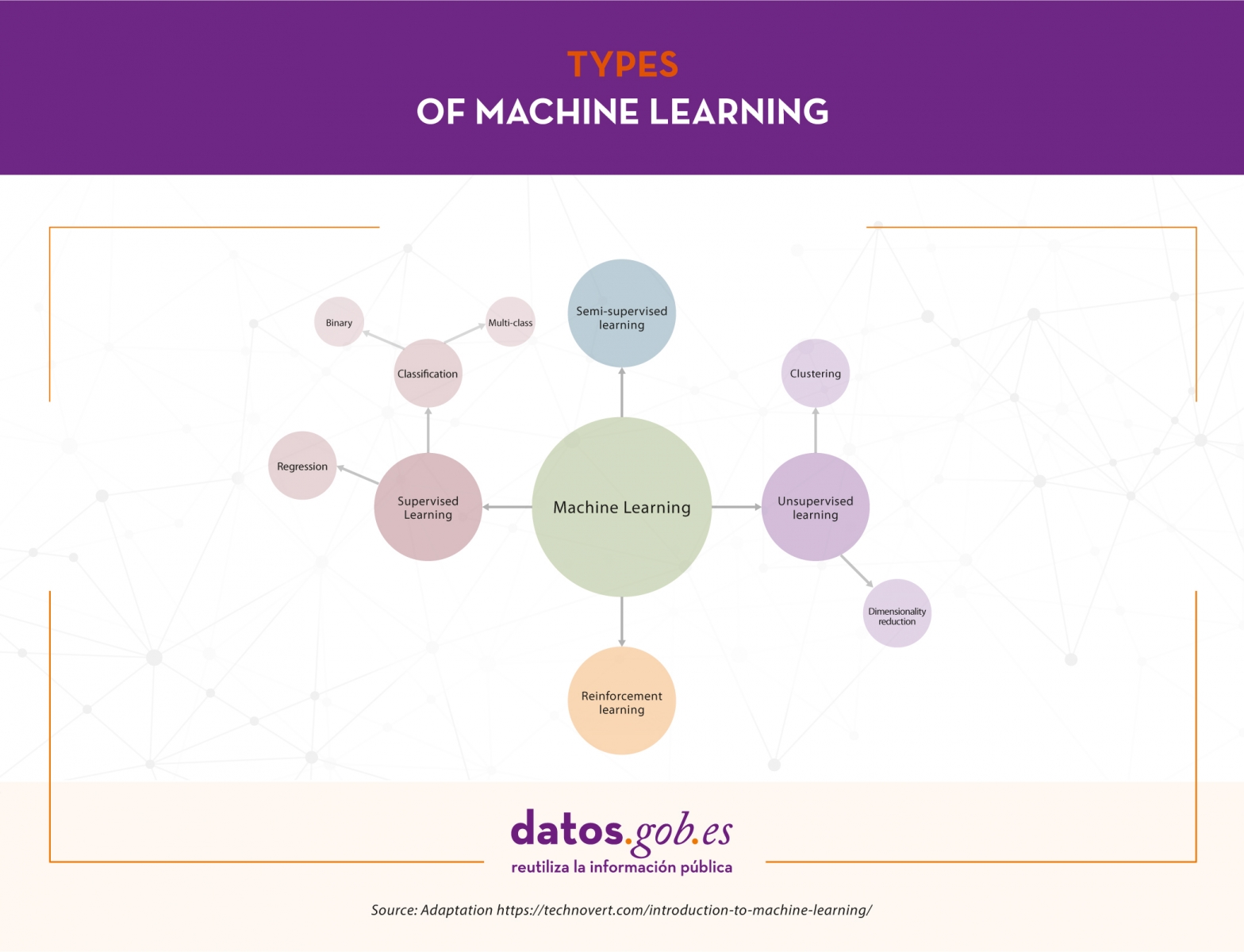
Supervised learning
Supervised learning needs labeled datasets, that is, we tell the model what we want it to learn. Suppose we have an ice cream shop and for the last few years we have been recording daily weather data, temperature, month, day of the week, etc., and we have also been doing the same with the number of ice creams sold each day. In this case, we would surely be interested in training a model that, based on the climatological data, temperature, etc. (characteristics of the model) of a specific day, tells us how many ice creams are going to be sold (the label to be predicted).
Depending on the type of label, within the supervised learning there are two types of models:
- Classification models, which produce as output a discrete label, that is, a label within a finite set of possible labels. In turn, classification models can be binary if we have to predict between two classes or labels (disease or not disease, classification of emails as "spam" or not "spam") or multiclass, when we have to classify more than two classes (classification of animal images, sentiment analysis, etc.).
- The regression models produce as output a real value, like the example we mentioned of the ice cream.
Unsupervised learning
Unsupervised learning, on the other hand, works with data that has not been labeled. We do not have a label to predict. These algorithms are mainly used in tasks where it is necessary to analyze the data to extract new knowledge or group entities by affinity.
This type of learning also has applications for reducing dimensionality or simplifying datasets. In the case of grouping data by affinity, the algorithm must define a similarity or distance metric that serves to compare the data with each other. As an example of unsupervised learning we have the clustering algorithms, which could be applied to find customers with similar characteristics to those who offer certain products or target a marketing campaign, discovery of topics or detection of anomalies, among others. On the other hand, sometimes some datasets such as those related to genomic information have large amounts of characteristics and for various reasons, such as reducing the training time of the algorithms, improving the performance of the model or facilitating the visual representation of the data, we need to reduce the dimensionality or number of columns in the dataset. Dimensionality reduction algorithms use mathematical and statistical techniques to convert the original dataset into a new one with fewer dimensions in exchange for losing some information. Examples of dimensionality reduction algorithms are PCA, t-SNE or ICA.
Semi-supervised learning
Sometimes it is very complicated to have a fully labeled dataset. Let's imagine that we are the owners of a dairy product manufacturing company and we want to study the brand image of our company through the comments that users have posted on social networks. The idea is to create a model that classifies each comment as positive, negative or neutral and then do the study. The first thing we do is dive into social networks and collect sixteen thousand messages where our company is mentioned. The problem now is that we don't have a label on the data, that is, we don't know what the feeling of each comment is. This is where semi-supervised learning comes into play. This type of learning has a little of the two previous ones. Using this approach, you start by manually tagging some of the comments. Once we have a small portion of tagged comments, we train one or more supervised learning algorithms on that small portion of tagged data and use the resulting training models to tag the remaining comments. Finally, we train a supervised learning algorithm using as labels those manually tagged plus those generated by the previous models.
Reinforcement learning
Finally, reinforcement learning is an automatic learning method based on rewarding desired behaviors and penalizing unwanted ones. Applying this method, an agent is able to perceive and to interpret the environment, to execute actions and to learn through test and error. It is a learning that sets long term objectives to obtain a maximum general reward and achieve an optimal solution. The game is one of the most used fields to test reinforcement learning. AlphaGo or Pacman are some games where this technique is applied. In these cases, the agent receives information about the rules of the game and learns to play by himself. At first, obviously, it behaves randomly, but with time it starts to learn more sophisticated movements. This type of learning is also applied in other areas as the robotics, the optimization of resources or systems of control.
Automatic learning is a very powerful tool that converts data into information and facilitates decision making. The key is to define in a clear and concise way the objective of the learning in order to, depending on the characteristics of the dataset we have, select the type of learning that best fits to give a solution that responds to the needs.
Content elaborated by Jose Antonio Sanchez, expert in Data Science and enthusiast of the Artificial Intelligence.
Contents and points of view expressed in this publication are the exclusive responsibility of its author.
Evento
We live in an era in which training has become an essential element, both to enter and to progress in an increasingly competitive labour market, as well as to be part of research projects that can lead to great improvements in our lifetime.
Summer is coming and with it, a renewed training offer that does not rest at all in the summer season, but quite the opposite. Every year, the number of courses related to data science, analytics or open data increases. The current labour market demands and requires professionals specialized in these technological fields, as reflected by the EC in its European Data Strategy, where it is highlighted that the EU will provide financing "to expand the digital talent pool with in the order of 250000 people who will be able to deploy the latest technologies in businesses throughout the EU”.
In this sense, the possibilities offered by new technologies to carry out any type of online training, from your own home with the maximum guarantees, help more professionals to use this type of course each year.
From datos.gob.es we have selected a series of online courses, both free and paid, related to data that may be of interest to you:
- We started with the Machine Learning and Data Science Course taught by the Polytechnic University of Valencia, which stands out for offering its future students the learning necessary to extract technical knowledge from the data. With a 5-week program, this course introduce R language and, among other things, different preprocessing techniques and data visualization.
- The Modern Methods in Data Analytics course is another option if you are looking to expand your data training and learn English at the same time. The University of Utrecht will begin to teach this course completely online from August 31, totally focused on the study of linear models and longitudinal data analysis, among other fields.
- Another of the English courses that will begin on June 16 is a 9-week training programme focused on Data Analytics and which is taught by the Ironhack International School. This is a recommended course for those who want to learn how to load, clean, explore and extract information from a wide range of datasets, as well as how to use Python, SQL and Tableau, among other aspects.
- Next we discover the course on Business Digitization and Big Data: Data, Information and Knowledge in Highly Competitive Markets, taught by FGUMA (General Foundation of the University of Malaga). Its duration is 25 hours and its registration deadline is June 15. If you are a professional related to business management and / or entrepreneurship, this course will surely be of interest to you.
- R for Data Science is another course offered by the FGUMA. Its main objective is to show an introductory view to the R programming language for data analysis tasks, including advanced reports and visualizations, presenting techniques typical of computer learning as an extra value. As with the previous course, the deadline for registration for this training is June 15.
- For its part, Google Cloud offers a completely online and free learning path for data professionals seeking to perfect the design, complication, analysis and optimization of macrodata solutions. Surely this Specialized program: Data Engineering, Big Data, and Machine Learning on GCP fits into the training you had planned.
In addition to these specific courses, it is worth noting the existence of online training platforms that offer courses related to new technologies on an ongoing basis. These courses are known as MOOC and are an alternative to traditional training, in areas such as Machine Learning, Data Analytics, Business Intelligence or Deep Learning, knowledge that is increasingly demanded by companies.
This is just a selection of the many courses that exist as data related training offerings. However, we would love to count on your collaboration by sending us, through the comments, other courses of interest in the field of data to complete this list in the future.
Blog
Data science is an interdisciplinary field that seeks to extract actuable knowledge from datasets, structured in databases or unstructured as texts, audios or videos. Thanks to the application of new techniques, data science is allowing for answering questions that are not easy to solve through other methods. The ultimate goal is to design improvement or correction actions based on the new knowledge.
The key concept in data science is SCIENCE, and not really data, considering that experts has even begun to speak about a fourth paradigm of science, including data-based approach together with the traditional theoretical, empirical and computational approachs.
Data science combines methods and technologies that come from mathematics, statistics and computer science. It include exploratory analysis, machine learning, deep learning, natural-language processing, data visualization and experimental design, among others.
Within Data Science, the two most talked-about technologies are Machine Learning and Deep Learning, both included in the field of artificial intelligence. In both cases, the objective is the construction of systems capable of learning to solve problems without the intervention of a human being, including from orthographic or automatic translation systems to autonomous cars or artificial vision systems applied to use cases as spectacular as the Amazon Go stores.
In both cases, the systems learn to solve problems from the datasets “we teach them” in order to train them to solve the problem, either in a supervised way - training datasets are previously labeled by humans-, or in a unsupervised way - these data sets are not labeled-.
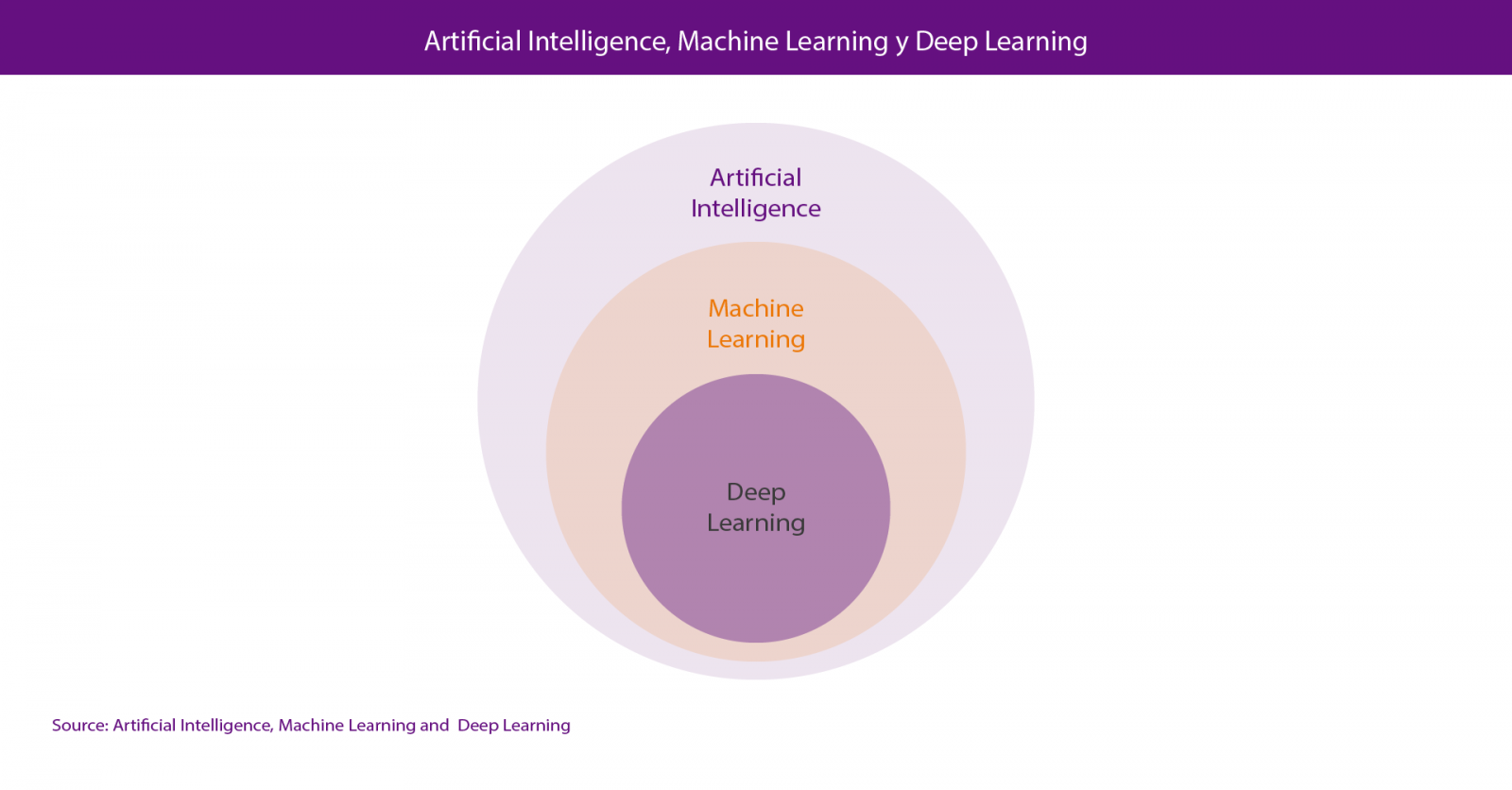
Actually, the correct point of view is to consider deep learning as a part of machine learning so, if we have to look for an attribute to differentiate both of them, we could consider their method of learning, which is completely different. Machine learning is based on algorithms (Bayesian networks, support vector machines, clusters analysis, etc.) that are able to discover patterns from the observations included in a dataset. In the case of deep learning, the approach is inspired, basically, in the functioning of human brain´s neurons and their connections; and there are also numerous approaches for different problems, such as convolutional neural networks for image recognition or recurrent neural networks for natural language processing.
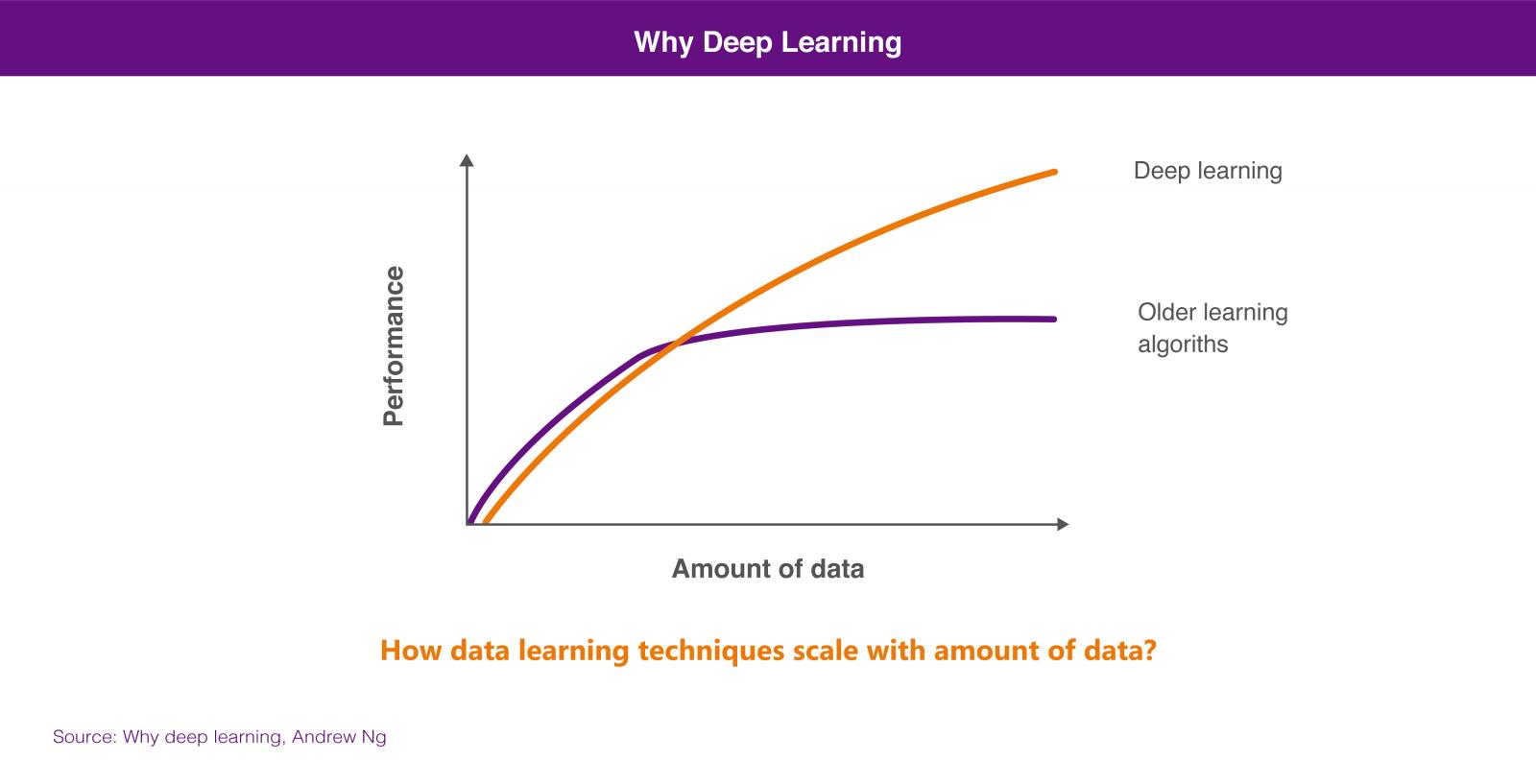
The suitability of one approach or another will rely on the amount of data we have available to train our artificial intelligence system. In general, we can affirm that, if we have a small amounts of training data, the neural network-based approach does not offer superior performance than the algorithm-based approach. The algorithm-based approach usually come to a standstill due to huge amount of data, not being able to offer greater precision although we teach more training cases. However, through deep learning we can have a better performance from this greater amount of data, because the system is usually able to solve the problem with greater precision, the more cases of training are available.
None of these technologies is new at all, considering that they have decades of theoretical development. However, in recent years new advances have greatly reduced their barriers: the opening of programming tools that allow high-level work with very complex concepts, open source software packages to run data management infrastructures, cloud tools that allow access to almost unlimited computing power and without the need to manage the infrastructure, and even free training given by some of the best specialists in the world.
All this issues are contributing to capture data on an unprecedented scale, and store and process data at acceptable costs that allow us to solve old problems with new approaches. Artificial intelligence is also available to many more people, whose collaboration in an increasingly connected world is giving rise to innovation, advancing increasingly faster in all areas: transport, medicine, services, manufacturing, etc.
For some reason, data scientist has been called the sexiest job of the 21st century.
Content prepared by Jose Luis Marín, Head of Corporate Technology Startegy en MADISON MK and Euroalert CEO.
Contents and points of view expressed in this publication are the exclusive responsibility of its author.
Blog
Not all press headlines on Artificial Intelligence are true, but do not make the mistake of underestimating the changes in the coming years thanks to the development of AI.
Artificial intelligence has not yet changed our lives, but we are experiencing a cycle of over-exposure about its results and applications in the short term. The non-specialized media and the marketing departments of companies and other organizations foster a climate of excessive optimism regarding the current achievements in the development of AI.
Undoubtedly, we can all ask our smartphone some simple questions and get reasonable answers. In our online purchases (for example on Amazon.com), we experience the recommendation of personalized products based on our profile as buyers. We can search for events in our digital photographs library hosted in an online service such as Google Photos. With just writing, "mum's birthday" we will get a list of photos of that day with a relatively high precision in seconds. However, the time has not yet come for AI modifying our daily experience when we consume digital or physical products and services. Up to now, our doctor does not use AI to support his diagnosis and our lawyer or financial advisor does not use AI to prepare a resource or better invest our money.
The hot news floods us with photorealistic infographics of a world full of autonomous cars and virtual assistants with whom we talk as if it were a person. The risk of overexploitation in the short term is that, in any development process of a disruptive and exponential technology, technology necessarily fails. This leads to a state of disappointment that entails a reduction of investments by companies and states, which in turn produces a slowdown in the development of such technology. The development of AI is not unconnected to this process and has already known two stages of slowdown. These historical stages are known as the "winters of artificial intelligence". The first winter of the AI took place in the early years of the 1970 decade. After the birth of what today we know as IA - in the decade of 1950 - at the end of the sixties, Marvin Minsky got to assure in 1967 that "... in the course of a generation... the problem of creating an artificial intelligence will be practically solved...". Only three years later, Minsky himself said: "... in three to eight years we will have achieved a machine with an artificial intelligence superior to human beings ..."
Currently, no expert would dare to specify when (if so) this could happen. The second winter of AI arrived in the early years of the nineties. After a period of overexploitation of the then known as "expert systems". Expert systems are computer programs that contain logical rules that code and parameterize the operation of simple systems. For example, a computer program that encodes the rules of the chess game belongs to the type of programs that we know as expert systems. The coding of fixed logic rules to simulate the behavior of a system is what is known as symbolic artificial intelligence and was the first type of artificial intelligence that was developed.
Between 1980 and 1985, companies had invested more than one billion US dollars each year in the development of these systems. After this period, it was demonstrated that these turned out to be extremely expensive to maintain as well as not scalable and with little results for the investment they entailed. The historical journey of t AI development from its beginnings in 1950 to the present is a highly recommended and exciting reading.
What has artificial intelligence achieved so far?
Although we say that we must be prudent with the expectations regarding AI applications in the short term, we must punctuate here what have been the main achievements of artificial intelligence from a strictly rigorous point of view. For this, we will base on the book Deep Learning with R. Manning Shelter Island (2018) by Francois Cho-llet with J.J. Allaire.
- Classification of images at an almost-human level.
- Recognition of spoken language at an almost-human level.
- Transcription of written language at an almost-human level.
- Substantial improvement in the text conversion to spoken language.
- Substantial improvement in translations.
- Autonomous driving at an almost-human level.
- Ability to answer questions in natural language.
- Players (Chess or Go) that far exceed human capabilities.
After this brief introduction of the current historical moment in regarding to AI, we are in a position to define, in a slightly more formal way, what artificial intelligence is and which fields of science and technology directly are affected by its development.
Artificial intelligence could be defined as: the field of science that studies the possibility of automating intellectual tasks that are normally performed by humans. The reality is that the scientific domain of AI is normally divided into two sub-fields of computer science and mathematics called Machine Learning and Deep Learning. The representation of this statement can be seen in Figure 1.
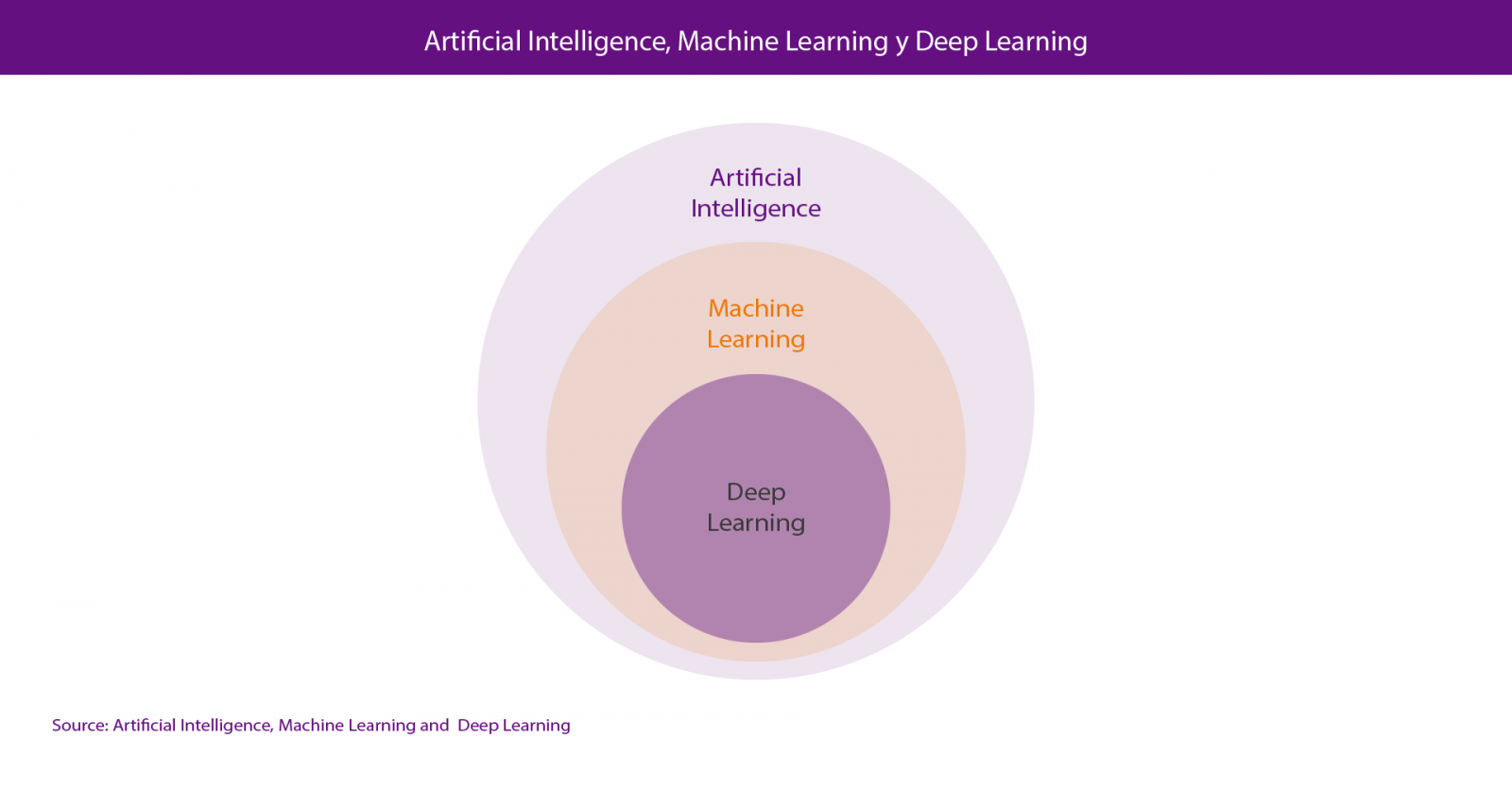
Figure 1. Artificial Intelligence and sub-fields such as Machine Learning and Deep Lear-ning.
We are not going to speak here about technical considerations about the difference between machine learning and deep learning (you can learn more about these concepts in this post). However, perhaps the most interesting is to understand the paradigm shift from the first development of AI based on logical rules to the modern conception of our days, where machines find out those rules that govern a certain process (for example, the risk of suffering a myocardial infarction) based on input data and previous experiences that have been recorded and analysed by a certain algorithm. Figure 2 represents that change of paradigm between the classic programming of logical rules and the machine learning approach.
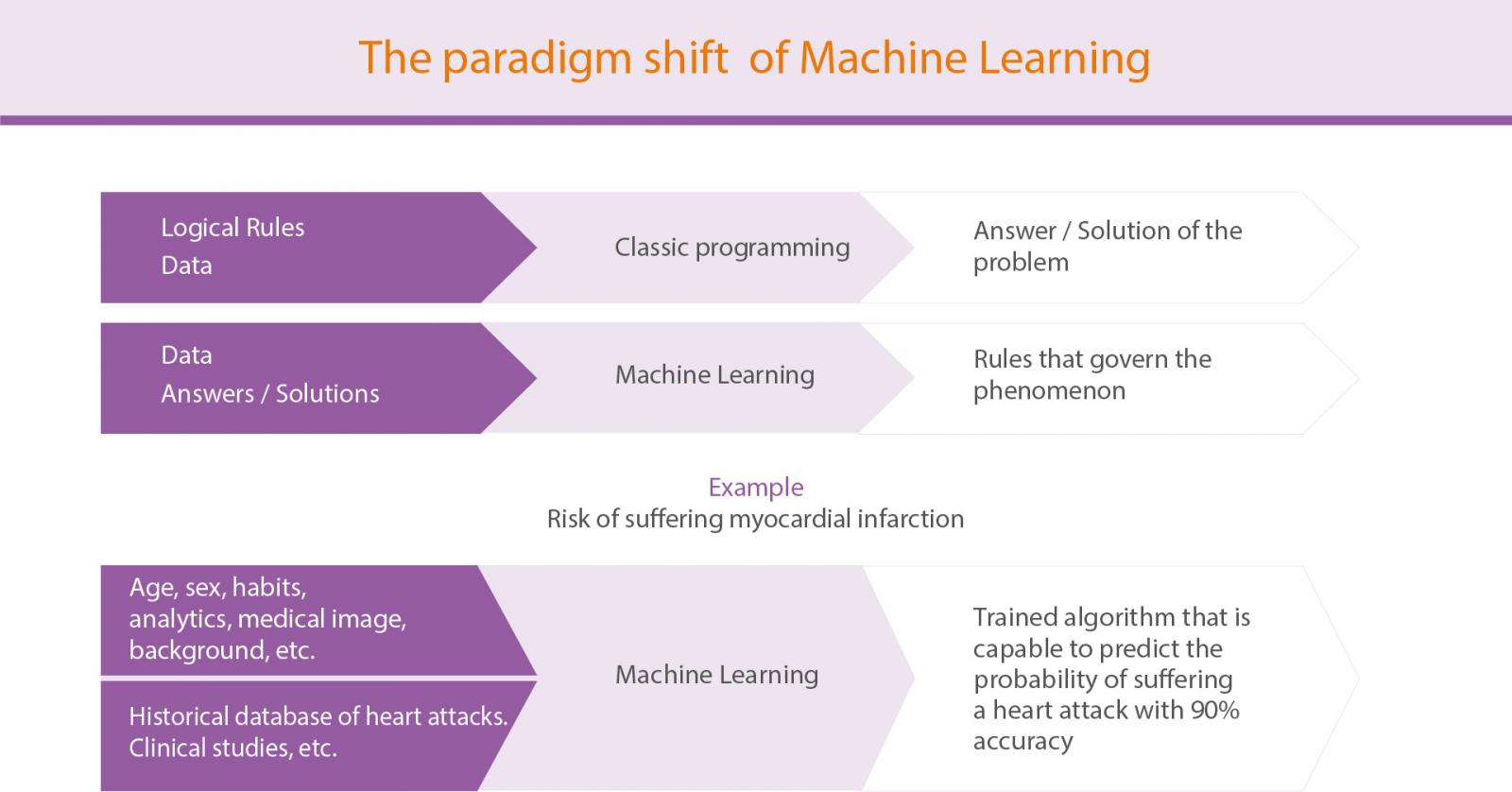
Figure 2. The paradigm shift to Machine Learning from classical programming.
The fast development of AI in our days is the result of multiple factors. However all experts agree that two of them have been and are key to enhance this third wave of artificial intelligence development: the reduction of computing cost and the explosion of available data thanks to the Internet and the connected devices.
Just as the Internet has impacted, and more than it is going to impact, in all areas of our lives - from the end consumer to the processes and operating models of the most traditional companies and industries - the IA will radically change the way in which humans use our capacities for the development of our species. There is a lot of news about the negative impact that AI will have on jobs positions in the next 10-20 years. While there is no doubt that the automation of certain processes will eliminate some jobs that still exist today, it is no less true that, precisely, the first jobs to disappear will be those jobs that make us "less human". Those jobs that employ people as machines to repeat the same actions, one after another, will be replaced by agents equipped with AI, either in the form of software or in the form of robots equipped with AI.
The iterative and predictable tasks will fall within the exclusive domain of the machines. On the contrary, those tasks that require leadership, empathy, creativity and value judgments will continue to belong only to humans. So, is it done? Do we have nothing else to do but wait for the machines to do part of the work while we do the other part? The answer is no. The reality is there is a big space in the middle of these two extremes.
The space in which the human is amplified by the AI and in return the AI is trained by humans to feed back this intermediate cycle. Paul R. Daugherty and H. James Wil-son, define in his book Human + Machine this space as "The missing middle”. In this intermediate space, AI machines increase human capabilities, make us stronger with exoskeletons capable of lifting heavy loads or restore us the capacity to walk after paralysis; they make us less vulnerable by working in potentially harmful environments such as space, the bottom of the sea or in a pipeline with deadly gases; We increase our sensory capabilities in real time with glasses that carry cameras and sensors that complement our field of vision with overlapping textual information.
With the help of machines equipped with an improved AI, it is not difficult to imagine how the processes and maintenance tasks will change in a factory, the different way in which our fields will be cultivated, how the warehouses of the future will work and the efficiency of our self-managed homes.
In conclusion, let's stop looking at the machines and AI as rivals that will dispute our jobs, and start thinking about how we will merge our most human skills with the superior capabilities of the machines regarding resistance, speed and precision.
Let's do different things now to do different things in the future.
Content prepared by Alejandro Alija, expert in Digital Transformation and innovation.
Contents and points of view expressed in this publication are the exclusive responsibility of its author.
Empresa reutilizadora
GIS4tech is a Spanish Spin-Off company founded in 2016, as a result of the research activity of the Cluster Territorial group and the Department of Urban Planning of the University of Granada. GIS4tech is dedicated to technical assistance, advice, training, research and development supported by Geographic Information Systems and related technologies. The team has more than 20 years of experience in territory studies, elaboration of cartographies and Geographic Information Systems.