Publication date
21/04/2022
Update date
23/10/2024

Description
Have you ever wondered how Alexa is able to recognise our voice and understand what we are saying (sometimes better than others)? Have you ever stopped to think about how Google is able to search for images similar to the one we are providing it with? You probably know that these techniques belong to the field of artificial intelligence. But don't be fooled, building these sophisticated models is only within the reach of a few. In this post we tell you why and what we ordinary mortals can do to train artificial intelligence models.
Introduction
In recent years we have witnessed incredible and surprising advances in the field of training Deep Learning models. On previous occasions we have cited the most relevant examples such as GPT-3 or Megatron-Turing NLG. These models, optimised for natural language processing (NLP), are capable of writing complete articles (practically indistinguishable from those written by a human) or making coherent summaries of classic works, hundreds of pages long, synthesising the content in just a few paragraphs. Impressive, isn't it?
However, these achievements are far from cheap. That is, the complexity of these models is such that thousands of gigabytes of pre-processed information - what we call annotated datasets - are needed, which have been previously analysed (labelled) by a human expert in the field. For example, the latest training of the Megatron-Turing NLG model, created in collaboration between Microsoft and NVIDIA, used 270 billion tokens (small pieces of text that can be words or sub-words that form the basis for training these natural language models). In addition to the information needed to be able to train these models, there is the fact of the special computational needs that these trainings require. To execute training tasks for these models, the most advanced machines (computers) in the world are needed, and training times are counted in weeks. Although there is no official data, some sources quote the cost of training the latest models such as GPT-3 or Megatron-Turing in the tens of millions of dollars. So how can we use and train models if we do not have access to the most powerful computing clusters in the world?
The answer: Transfer Learning
When working on a machine learning or deep learning project and we do not have access to large datasets ready for training, we can start from pre-trained models to create a new model adjusted or tuned to our specific use case. In other words, we load a previously trained model with a very large set of training data and re-train its final layers to fit our particular data set. This is known as Transfer Learning.
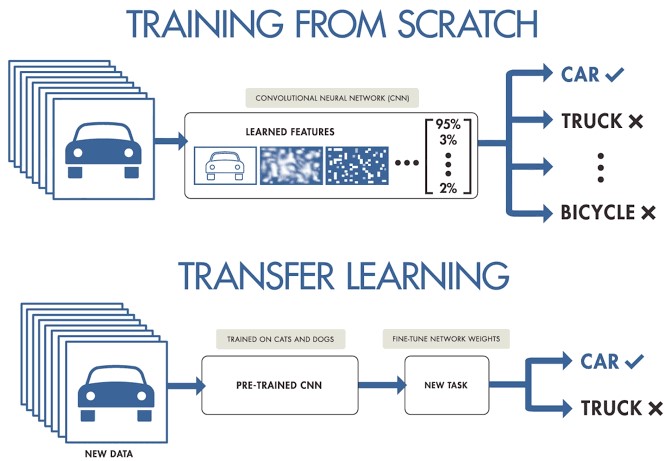
Original source: Transfer Learning in Deep Learning: Beyond our models. Post by Josu Alonso on Medium.
Simplifying a lot, we could say that traditional Machine Learning applies to isolated learning tasks, where it is not necessary to retain the acquired knowledge, while in a Transfer Learning project the learning is the result of previous tasks, achieving good precision in less time and with less data. This brings many opportunities, but also some challenges, such as the new domain inheriting biases from the previous domain.
Let's look at a concrete example. Suppose we have a new Deep Learning challenge and we want to make an automatic dog breed classifier. In this case, we can apply the transfer learning technique starting from a general image classification model, and then fit it to a specific set of dog breed photographs. Most of the pre-trained models are based on a subset of the ImageNet database, which we have already discussed on several occasions. The neural network (from ImageNet), which is the base type of algorithm used in these image classification models, has been trained on 1.2 million images of over 1000 different object categories such as keyboards, coffee cups, pencils and many animals. By using a pre-trained network to apply Transfer Learning, we get much faster and easier results than if we had to train a network from scratch.
For example, this code snippet shows the process of starting from a pre-trained model with ImageNet and re-training or adding new layers to achieve fine adjustments to the original model.
# we create the basis of the pre-trained model starting from ImageNET
base_model <- application_inception_v3(weights = 'imagenet', include_top = FALSE)
# We add additional layers to our neural network
predictions <- base_model$output %>%
layer_global_average_pooling_2d() %>%
layer_dense(units = 1024, activation = 'relu') %>%
layer_dense(units = 200, activation = 'softmax')
# we create a new model for training
model <- keras_model(inputs = base_model$input, outputs = predictions)
# We make sure to train only our new layers so as not to destroy previous training
freeze_weights(base_model)
# we compile the model
model %>% compile(optimizer = 'rmsprop', loss = 'categorical_crossentropy')
# we train the model
model %>% fit_generator(...)
Conclusions
Training a general-purpose deep learning model is not within everyone's reach. There are several barriers, from the difficulty of accessing quality training data in sufficient volume, to the computational capacity needed to process billions of images or texts. For more limited use cases, where we only require a refinement of generalist models, applying the Transfer Learning technique allows us to achieve fantastic results in terms of accuracy and training time, at a cost that is affordable for most data scientists. Transfer Learning applications are very numerous and specialised websites are full of application examples. In line with this trend, Style Transfer Learning, which consists of reconstructing images based on the style of a previous image, has recently become very popular. We will continue to discuss this topic in future posts.

Example of Style Transfer Learning in Kaggle
[1] It is not the purpose of this post to explain in detail each of the sections of this code snippet.
Content prepared by Alejandro Alija, expert in Digital Transformation and Innovation.
The contents and views expressed in this publication are the sole responsibility of the author.
Comments