Publication date
17/02/2022
Update date
22/10/2024

Description
Today, Artificial Intelligence (AI) applications are present in many areas of everyday life, from smart TVs and speakers that are able to understand what we ask them to do, to recommendation systems that offer us services and products adapted to our preferences.
These AIs "learn" thanks to various techniques, including supervised, unsupervised and reinforcement learning. In this article we will focus on reinforcement learning, which focuses mainly on trial and error, similar to how humans and animals in general learn.
The key to this type of system is to correctly set long-term goals in order to find an optimal global solution, without focusing too much on immediate rewards, which do not allow for an adequate exploration of the set of possible solutions.
Simulation environments as a complement to open data sets.
Unlike other types of learning, where learning is usually based on historical datasets, this type of technique requires simulation environments that allow training a virtual agent through its interaction with an environment, where it receives rewards or penalties depending on the state and actions it performs. This cycle between agent and environment can be seen in the following diagram:
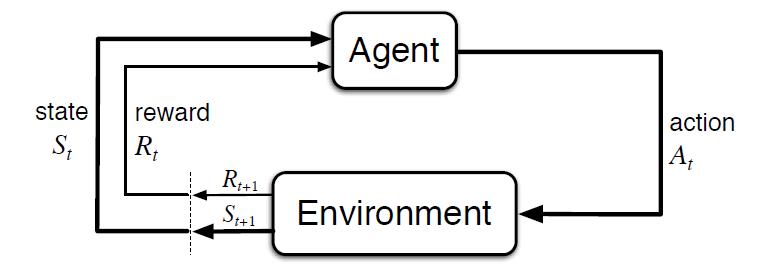
Figure 1 - Scheme of learning by reinforcement [Sutton & Barto, 2015]
That is, starting from a simulated environment, with an initial state, the agent performs an action that generates a new state and a possible reward or penalty, which depends on the previous states and the action performed. The agent learns the best strategy in this simulated environment from experience, exploring the set of states, and being able to recommend the best action policy if configured appropriately.
The best-known example worldwide was the success achieved by AlphaGo, beating 18-time world champion Lee Sedol in 2016. Go is an ancient game, considered one of the 4 basic arts in Chinese culture, along with music, painting and calligraphy. Unlike chess, the number of possible game combinations is greater than the number of atoms in the Universe, being a problem impossible to solve by traditional algorithms.
Curiously, the technological breakthrough demonstrated by AlphaGo in solving a problem that was claimed to be beyond the reach of an AI, was eclipsed a year later by its successor AlphaGo Zero. In this version, its creators chose not to use historical data or heuristic rules. AlphaGo Zero only uses the board positions and learns by trial and error by playing against itself.
Following this innovative learning strategy, in 3 days of execution he managed to beat AlphaGo, and after 40 days he became the best Go player, accumulating thousands of years of knowledge in a matter of days, and even discovering previously unknown strategies.
The impact of this technological milestone covers countless areas, and AI solutions that learn to solve complex problems from experience can be counted on. From resource management, strategy planning, or the calibration and optimization of dynamic systems.
The development of solutions in this area is especially limited by the need for appropriate simulation environments, being the most complex component to build. However, there are multiple repositories to obtain open simulation environments that allow us to test this type of solutions.
The best known reference is Open AI Gym, which includes an extensive set of libraries and open simulation environments for the development and validation of reinforcement learning algorithms. Among others, it includes simulators for the basic control of mechanical elements, robotics applications and physics simulators, two-dimensional ATARI video games, and even the landing of a lunar module. In addition, it allows to integrate and publish new open simulators for the development of our own simulators adapted to our needs that can be shared with the community:

Figure 2 - Examples of visual simulation environments offered by Open AI Gym
Another interesting reference is Unity ML Agents, where we also find multiple libraries and several simulation environments, also offering the possibility of integrating our own simulator:

Figure 3 - Examples of visual simulation environments offered by Unity ML Agents
Potential applications of reinforcement learning in public administrations
This type of learning is used especially in areas such as robotics, resource optimization or control systems, allowing the definition of optimal policies or strategies for action in specific environments.
One of the best-known practical examples is the DeepMind algorithm used by Google to reduce by 40% the energy consumption required to cool its data centers in 2016, achieving a significant reduction in energy consumption during use, as can be seen in the following graph (taken from the previous article):
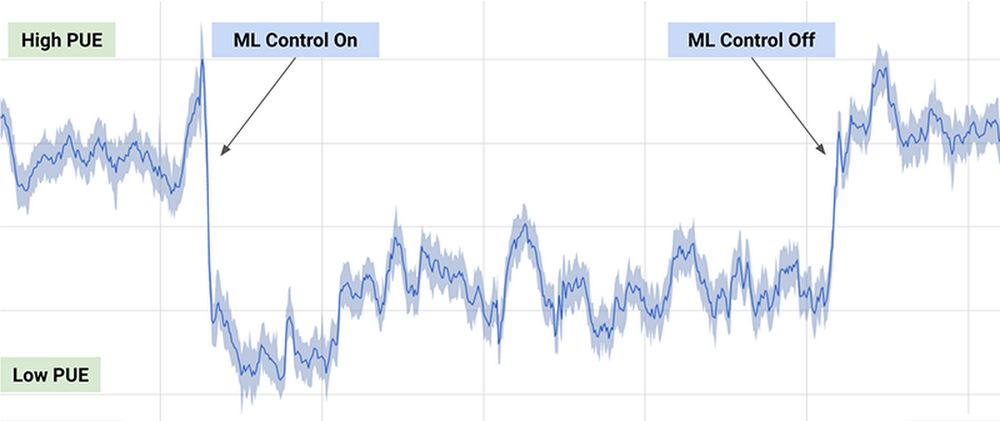
Figure 4 - Results of the DeepMind algorithm on the energy consumption of Google's data centers.
The algorithm employed uses a combination of deep learning and reinforcement learning techniques, together with a general purpose simulator to understand complex dynamic systems that could be applied in multiple environments such as transformation between energy types, water consumption or resource optimization in general.
Other possible applications in the public domain include the search and recommendation of open datasets through chatbots, or the optimization of public policies, as is the case of the European project Policy Cloud, applied for example in the analysis of future strategies of the different designations of origin of wines from Aragon.
In general, the application of this type of techniques could optimize the use of public resources by planning action policies that result in more sustainable consumption, reducing pollution, waste and public spending.
Content prepared by Jose Barranquero, expert in Data Science and Quantum Computing.
The contents and views expressed in this publication are the sole responsibility of the author.
Comments