Blog
Las imágenes sintéticas son representaciones visuales generadas de forma artificial mediante algoritmos y técnicas computacionales, en lugar de capturarse directamente de la realidad con cámaras o sensores. Se producen a partir de distintos métodos, entre los que destacan las redes generativas antagónicas (Generative Adversarial Networks, GAN), los modelos de difusión, y las técnicas de renderizado 3D. Todas ellas permiten crear imágenes de apariencia realista que en muchos casos resultan indistinguibles de una fotografía auténtica.
Cuando se traslada este concepto al campo de la observación de la Tierra, hablamos de imágenes satelitales sintéticas. Estas no se obtienen a partir de un sensor espacial que capta radiación electromagnética real, sino que se generan digitalmente para simular lo que vería un satélite desde la órbita. En otras palabras, en vez de reflejar directamente el estado físico del terreno o la atmósfera en un momento concreto, son construcciones computacionales capaces de imitar el aspecto de una imagen satelital real.
El desarrollo de este tipo de imágenes responde a necesidades prácticas. Los sistemas de inteligencia artificial que procesan datos de teledetección requieren conjuntos muy amplios y variados de imágenes. Las imágenes sintéticas permiten, por ejemplo, recrear zonas de la Tierra poco observadas, simular desastres naturales -como incendios forestales, inundaciones o sequías- o generar condiciones específicas que son difíciles o costosas de capturar en la práctica. De este modo, constituyen un recurso valioso para entrenar algoritmos de detección y predicción en agricultura, gestión de emergencias, urbanismo o monitorización ambiental.
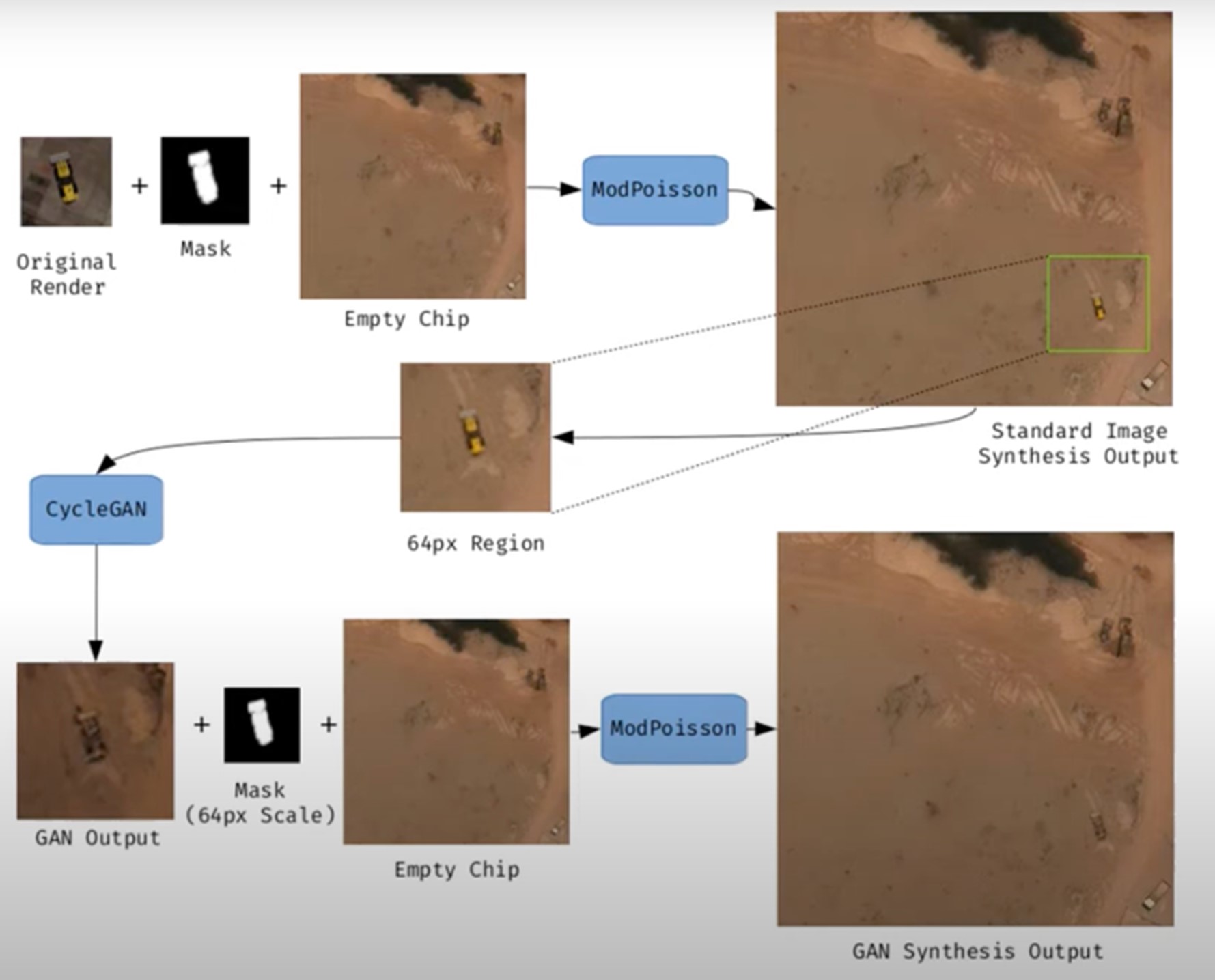
Figura 1. Ejemplo de generación de una imagen satelital sintética.
Su valor no se limita al entrenamiento de modelos. Allí donde no existen imágenes de alta resolución —por limitaciones técnicas, restricciones de acceso o motivos económicos—, la síntesis permite rellenar huecos de información y facilitar estudios preliminares. Por ejemplo, los investigadores pueden trabajar con imágenes sintéticas aproximadas para diseñar modelos de riesgo o simulaciones antes de disponer de datos reales.
Sin embargo, las imágenes satelitales sintéticas también plantean riesgos importantes. La posibilidad de generar escenas muy realistas abre la puerta a la manipulación y a la desinformación. En un contexto geopolítico, una imagen que muestre tropas inexistentes o infraestructuras destruidas podría influir en decisiones estratégicas o en la opinión pública internacional. En el terreno ambiental, se podrían difundir imágenes manipuladas para exagerar o minimizar impactos de fenómenos como la deforestación o el deshielo, con efectos directos en políticas y mercados.
Por ello, conviene diferenciar dos usos muy distintos. El primero es el uso como apoyo, cuando las imágenes sintéticas complementan a las reales para entrenar modelos o realizar simulaciones. El segundo es el uso como falsificación, cuando se presentan deliberadamente como imágenes auténticas con el fin de engañar. Mientras el primer uso impulsa la innovación, el segundo amenaza la confianza en los datos satelitales y plantea un reto urgente de autenticidad y gobernanza.
Riesgos de las imágenes satelitales aplicada a la observación de la Tierra
Las imágenes satelitales sintéticas plantean riesgos significativos cuando se utilizan en vez de imágenes captadas por sensores reales. A continuación, se detallan ejemplos que lo demuestran.
Un nuevo frente de desinformación: “deepfake geography”
El término deepfake geography ya se ha consolidado en la literatura académica y divulgativa para describir imágenes satelitales ficticias, manipuladas con IA, que parecen auténticas, pero no reflejan ninguna realidad existente. Una investigación de la Universidad de Washington, liderada por Bo Zhao, utilizó algoritmos como CycleGAN para modificar imágenes de ciudades reales -por ejemplo, alterando la apariencia de Seattle con edificios inexistentes o transformando Beijing en zonas verdes- lo que pone en evidencia el potencial para generar paisajes falsos convincentes.
Un artículo de la plataforma OnGeo Intelligence (OGC) subraya que estas imágenes no son puramente teóricas, sino amenazas reales que afectan a la seguridad nacional, el periodismo y el trabajo humanitario. Por su parte, el OGC advierte que ya se han observado imágenes satelitales fabricadas, modelos urbanos generados por IA y redes de carreteras sintéticas, y que representan desafíos reales a la confianza pública y operativa.
Implicaciones estratégicas y políticas
Las imágenes satelitales son consideradas "ojos imparciales" sobre el planeta, usadas por gobiernos, medios y organizaciones. Cuando estas imágenes se falsifican, sus consecuencias pueden ser graves:
- Seguridad nacional y defensa: si se presentan infraestructuras falsas o se ocultan otras reales, se pueden desviar análisis estratégicos o inducir decisiones militares equivocadas.
- Desinformación en conflictos o crisis humanitarias: una imagen alterada que muestre incendios, inundaciones o movimientos de tropas falsos puede alterar la respuesta internacional, los flujos de ayuda o la percepción de los ciudadanos, especialmente si se difunde por redes sociales o medios sin verificación.
- Manipulación de imágenes realistas de lugares: no solo las imágenes generales están en juego. Nguyen y colaboradores (2024) demostraron que es posible generar imágenes satelitales sintéticas altamente realistas de instalaciones muy específicas como plantas nucleares.
Crisis de confianza y erosión de la verdad
Durante décadas, las imágenes satelitales han sido percibidas como una de las fuentes más objetivas y fiables de información sobre nuestro planeta. Eran la prueba gráfica que permitía confirmar fenómenos ambientales, seguir conflictos armados o evaluar el impacto de desastres naturales. En muchos casos, estas imágenes se utilizaban como “evidencia imparcial”, difíciles de manipular y fáciles de validar. Sin embargo, la irrupción de las imágenes sintéticas generadas por inteligencia artificial ha empezado a poner en cuestión esa confianza casi inquebrantable.
Hoy en día, cuando una imagen satelital puede ser falsificada con gran realismo, surge un riesgo profundo: la erosión de la verdad y la aparición de una crisis de confianza en los datos espaciales.
La quiebra de la confianza pública
Cuando los ciudadanos ya no pueden distinguir entre una imagen real y una fabricada, se resquebraja la confianza en las fuentes de información. La consecuencia es doble:
- Desconfianza hacia las instituciones: si circulan imágenes falsas de un incendio, una catástrofe o un despliegue militar y luego resultan ser sintéticas, la ciudadanía puede empezar a dudar también de las imágenes auténticas publicadas por agencias espaciales o medios de comunicación. Este efecto “que viene el lobo” genera escepticismo incluso frente a pruebas legítimas.
- Efecto en el periodismo: los medios tradicionales, que han usado históricamente las imágenes satelitales como fuente visual incuestionable, corren el riesgo de perder credibilidad si publican imágenes adulteradas sin verificación. Al mismo tiempo, la abundancia de imágenes falsas en redes sociales erosiona la capacidad de distinguir qué es real y qué no.
- Confusión deliberada: en contextos de desinformación, la mera sospecha de que una imagen pueda ser falsa ya puede bastar para generar duda y sembrar confusión, aunque la imagen original sea completamente auténtica.
A continuación, se resumen los posibles casos de manipulación y riesgo en imágenes satelitales:
| Ámbito | Tipo de manipulación | Riesgo principal | Ejemplo documentado |
|---|---|---|---|
| Conflictos armados | Inserción o eliminación de infraestructuras militares. | Desinformación estratégica; decisiones militares erróneas; pérdida de credibilidad en observación internacional. | Alteraciones demostradas en estudios de deepfake geography donde se añadían carreteras, puentes o edificios ficticios en imágenes satelitales. |
| Cambio climático y medio ambiente | Alteración de glaciares, deforestación o emisiones. | Manipulación de políticas ambientales; retraso en medidas contra el cambio climático; negacionismo. | Estudios han mostrado la capacidad de generar paisajes modificados (bosques en zonas urbanas, cambios en el hielo) mediante GAN. |
| Gestión de emergencias | Creación de desastres inexistentes (incendios, inundaciones). | Mal uso de recursos en emergencias; caos en evacuaciones; pérdida de confianza en agencias. | Investigaciones han demostrado la facilidad de insertar humo, fuego o agua en imágenes satelitales. |
| Mercados y seguros | Falsificación de daños en infraestructuras o cultivos. | Impacto financiero; fraude masivo; litigios legales complejos. | Uso potencial de imágenes falsas para exagerar daños tras desastres y reclamar indemnizaciones o seguros. |
| Derechos humanos y justicia internacional | Alteración de pruebas visuales sobre crímenes de guerra. | Deslegitimación de tribunales internacionales; manipulación de la opinión pública. | Riesgo identificado en informes de inteligencia: imágenes adulteradas podrían usarse para acusar o exonerar a actores en conflictos. |
| Geopolítica y diplomacia | Creación de ciudades ficticias o cambios fronterizos. | Tensiones diplomáticas; cuestionamiento de tratados; propaganda estatal. | Ejemplos de deepfake maps que transforman rasgos geográficos de ciudades como Seattle o Tacoma. |
Figura 2. Tabla con los posibles casos de manipulación y riesgo en imágenes satelitales
Impacto en la toma de decisiones y políticas públicas
Las consecuencias de basarse en imágenes adulteradas van mucho más allá del terreno mediático:
- Urbanismo y planificación: decisiones sobre dónde construir infraestructuras o cómo planificar zonas urbanas podrían tomarse sobre imágenes manipuladas, generando errores costosos y de difícil reversión.
- Gestión de emergencias: si una inundación o un incendio se representan en imágenes falsas, los equipos de emergencia pueden destinar recursos a lugares equivocados, mientras descuidan zonas realmente afectadas.
- Cambio climático y medio ambiente: imágenes adulteradas de glaciares, deforestación o emisiones contaminantes podrían manipular debates políticos y retrasar la implementación de medidas urgentes.
- Mercados y seguros: aseguradoras y empresas financieras que confían en imágenes satelitales para evaluar daños podrían ser engañadas, con consecuencias económicas significativas.
En todos estos casos, lo que está en juego no es solo la calidad de la información, sino la eficacia y legitimidad de las políticas públicas basadas en esos datos.
El juego del gato y el ratón tecnológico
La dinámica de generación y detección de falsificaciones ya se conoce en otros ámbitos, como los deepfakes de vídeo o audio: cada vez que surge un método de generación más realista, se desarrolla un algoritmo de detección más avanzado, y viceversa. En el ámbito de las imágenes satelitales, esta carrera tecnológica tiene particularidades:
- Generadores cada vez más sofisticados: los modelos de difusión actuales pueden crear escenas de gran realismo, integrando texturas de suelo, sombras y geometrías urbanas que engañan incluso a expertos humanos.
- Limitaciones de la detección: aunque se desarrollan algoritmos para identificar falsificaciones (analizando patrones de píxeles, inconsistencias en sombras o metadatos), estos métodos no siempre son fiables cuando se enfrentan a generadores de última generación.
- Coste de la verificación: verificar de forma independiente una imagen satelital requiere acceso a fuentes alternativas o sensores distintos, algo que no siempre está al alcance de periodistas, ONG o ciudadanos.
- Armas de doble filo: las mismas técnicas usadas para detectar falsificaciones pueden ser aprovechadas por quienes las generan, perfeccionando aún más las imágenes sintéticas y haciendo más difícil diferenciarlas.
De la prueba visual a la prueba cuestionada
El impacto más profundo es cultural y epistemológico: lo que antes se asumía como una prueba objetiva ahora se convierte en un elemento sujeto a duda. Si las imágenes satelitales dejan de ser percibidas como evidencia fiable, se debilitan narrativas fundamentales en torno a la verdad científica, la justicia internacional y la rendición de cuentas política.
- En conflictos armados, una imagen de satélite que muestre posibles crímenes de guerra puede ser descartada bajo la acusación de ser un deepfake.
- En tribunales internacionales, pruebas basadas en observación satelital podrían perder peso frente a la sospecha de manipulación.
- En el debate público, el relativismo de “todo puede ser falso” puede usarse como arma retórica para deslegitimar incluso la evidencia más sólida.
Estrategias para garantizar autenticidad
La crisis de confianza en las imágenes satelitales no es un problema aislado del sector geoespacial, sino que forma parte de un fenómeno más amplio: la desinformación digital en la era de la inteligencia artificial. Así como los deepfakes de vídeo han puesto en cuestión la validez de pruebas audiovisuales, la proliferación de imágenes satelitales sintéticas amenaza con debilitar la última frontera de datos percibidos como objetivos: la mirada imparcial desde el espacio.
Garantizar la autenticidad de estas imágenes exige una combinación de soluciones técnicas y mecanismos de gobernanza, capaces de reforzar la trazabilidad, la transparencia y la responsabilidad en toda la cadena de valor de los datos espaciales. A continuación, se describen las principales estrategias en desarrollo.
Metadatos robustos: registrar el origen y la cadena de custodia
Los metadatos constituyen la primera línea de defensa frente a la manipulación. En imágenes satelitales, deben incluir información detallada sobre:
- El sensor utilizado (tipo, resolución, órbita).
- El momento exacto de la adquisición (fecha y hora, con precisión temporal).
- La localización geográfica precisa (sistemas de referencia oficiales).
- La cadena de procesado aplicada (correcciones atmosféricas, calibraciones, reproyecciones).
Registrar estos metadatos en repositorios seguros permite reconstruir la cadena de custodia, es decir, el historial de quién, cómo y cuándo ha manipulado una imagen. Sin esta trazabilidad, resulta imposible distinguir entre imágenes auténticas y falsificadas.
EJEMPLO: el programa Copernicus de la Unión Europea ya implementa metadatos estandarizados y abiertos para todas sus imágenes Sentinel, lo que facilita auditorías posteriores y confianza en el origen.
Firmas digitales y blockchain: garantizar la integridad
Las firmas digitales permiten verificar que una imagen no ha sido alterada desde su captura. Funcionan como un sello criptográfico que se aplica en el momento de adquisición y se valida en cada uso posterior.
La tecnología blockchain ofrece un nivel adicional de garantía: almacenar los registros de adquisición y modificación en una cadena inmutable de bloques. De esta manera, cualquier cambio en la imagen o en sus metadatos quedaría registrado y sería fácilmente detectable.
EJEMPLO: el proyecto ESA – Trusted Data Framework explora el uso de blockchain para proteger la integridad de datos de observación de la Tierra y reforzar la confianza en aplicaciones críticas como cambio climático y seguridad alimentaria.
Marcas de agua invisible: señales ocultas en la imagen
El marcado de agua digital consiste en incrustar señales imperceptibles en la propia imagen satelital, de modo que cualquier alteración posterior se pueda detectar automáticamente.
- Puede hacerse a nivel de píxel, modificando ligeramente patrones de color o luminancia.
- Se combina con técnicas criptográficas para reforzar su validez.
- Permite validar imágenes incluso si han sido recortadas, comprimidas o reprocesadas.
EJEMPLO: en el sector audiovisual, las marcas de agua se usa desde hace años en la protección de contenidos digitales. Su adaptación a imágenes satelitales está en fase experimental, pero podría convertirse en una herramienta estándar de verificación.
Estándares abiertos (OGC, ISO): confianza mediante interoperabilidad
La estandarización es clave para garantizar que las soluciones técnicas se apliquen de forma coordinada y global.
- OGC (Open Geospatial Consortium) trabaja en estándares para la gestión de metadatos, la trazabilidad de datos geoespaciales y la interoperabilidad entre sistemas. Su trabajo en API geoespaciales y metadatos FAIR (Findable, Accessible, Interoperable, Reusable) es esencial para establecer prácticas comunes de confianza.
- ISO desarrolla normas sobre gestión de la información y autenticidad de registros digitales que también pueden aplicarse a imágenes satelitales.
EJEMPLO: el OGC Testbed-19 incluyó experimentos específicos sobre autenticidad de datos geoespaciales, probando enfoques como firmas digitales y certificados de procedencia.
Verificación cruzada: combinar múltiples fuentes
Un principio básico para detectar falsificaciones es contrastar fuentes. En el caso de imágenes satelitales, esto implica:
- Comparar imágenes de diferentes satélites (ej. Sentinel-2 vs. Landsat-9).
- Usar distintos tipos de sensores (ópticos, radar SAR, hiperespectrales).
- Analizar series temporales para verificar la consistencia en el tiempo.
EJEMPLO: la verificación de daños en Ucrania tras el inicio de la invasión rusa en 2022 se realizó mediante la comparación de imágenes de varios proveedores (Maxar, Planet, Sentinel), asegurando que los hallazgos no se basaban en una sola fuente.
IA contra IA: detección automática de falsificaciones
La misma inteligencia artificial que permite crear imágenes sintéticas se puede utilizar para detectarlas. Las técnicas incluyen:
- Análisis forense de píxeles: identificar patrones generados por GAN o modelos de difusión.
- Redes neuronales entrenadas para distinguir entre imágenes reales y sintéticas en función de texturas o distribuciones espectrales.
- Modelos de inconsistencias geométricas: detectar sombras imposibles, incoherencias topográficas o patrones repetitivos.
EJEMPLO: investigadores de la Universidad de Washington y otros grupos han demostrado que algoritmos específicos pueden detectar falsificaciones satelitales con una precisión superior al 90% en condiciones controladas.
Experiencias actuales: iniciativas globales
Varios proyectos internacionales ya trabajan en mecanismos para reforzar la autenticidad:
- Coalition for Content Provenance and Authenticity (C2PA): una alianza entre Adobe, Microsoft, BBC, Intel y otras organizaciones para desarrollar un estándar abierto de procedencia y autenticidad de contenidos digitales, incluyendo imágenes. Su modelo se puede aplicar directamente al sector satelital.
- Trabajo del OGC: la organización impulsa el debate sobre confianza en datos geoespaciales y ha destacado la importancia de garantizar la trazabilidad de imágenes satelitales sintéticas y reales (OGC Blog).
- NGA (National Geospatial-Intelligence Agency) en EE. UU. ha reconocido públicamente la amenaza de imágenes sintéticas en defensa y está impulsando colaboraciones con academia e industria para desarrollar sistemas de detección.
Hacia un ecosistema de confianza
Las estrategias descritas no deben entenderse como alternativas, sino como capas complementarias en un ecosistema de confianza:
|
Id |
Capas |
¿Qué aportan? |
|---|---|---|
| 1 | Metadatos robustos (origen, sensor, cadena de custodia) |
Garantizan trazabilidad |
| 2 | Firmas digitales y blockchain (integridad de datos) |
Aseguran integridad |
| 3 | Marcas de agua invisible (señales ocultas) |
Añade un nivel oculto de protección |
| 4 | Verificación cruzada (múltiples satélites y sensores) |
Valida con independencia |
| 5 | IA contra IA (detector de falsificaciones) |
Responde a amenazas emergentes |
| 6 | Gobernanza internacional (responsabilidad, marcos legales) |
Articula reglas claras de responsabilidad |
Figura 3. Capas para garantizar la confianza en las imágenes sintéticas satelitales
El éxito dependerá de que estos mecanismos se integren de manera conjunta, bajo marcos abiertos y colaborativos, y con la implicación activa de agencias espaciales, gobiernos, sector privado y comunidad científica.
Conclusiones
Las imágenes sintéticas, lejos de ser únicamente una amenaza, representan una herramienta poderosa que, bien utilizada, puede aportar un valor significativo en ámbitos como la simulación, el entrenamiento de algoritmos o la innovación en servicios digitales. El problema surge cuando estas imágenes se presentan como reales sin la debida transparencia, alimentando la desinformación o manipulando la percepción pública.
El reto, por tanto, es doble: aprovechar las oportunidades que ofrece la síntesis de datos visuales para avanzar en ciencia, tecnología y gestión, y minimizar los riesgos asociados al mal uso de estas capacidades, especialmente en forma de deepfakes o falsificaciones deliberadas.
En el caso particular de las imágenes satelitales, la confianza adquiere una dimensión estratégica. De ellas dependen decisiones críticas en seguridad nacional, respuesta a desastres, políticas ambientales y justicia internacional. Si la autenticidad de estas imágenes se pone en duda, se compromete no solo la fiabilidad de los datos, sino también la legitimidad de las decisiones basadas en ellos.
El futuro de la observación de la Tierra estará condicionado por nuestra capacidad de garantizar la autenticidad, transparencia y trazabilidad en toda la cadena de valor: desde la adquisición de los datos hasta su difusión y uso final. Las soluciones técnicas (metadatos robustos, firmas digitales, blockchain, marcas de agua, verificación cruzada e IA para detección de falsificaciones), combinadas con marcos de gobernanza y cooperación internacional, serán la clave para construir un ecosistema de confianza.
En definitiva, debemos asumir un principio rector sencillo pero contundente:
“Si no podemos confiar en lo que vemos desde el espacio, ponemos en riesgo nuestras decisiones en la Tierra.”
Contenido elaborado por Mayte Toscano, Senior Consultant en Tecnologías ligadas a la economía del dato. Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Blog
Los datos son un recurso fundamental para mejorar nuestra calidad de vida porque permiten mejorar los procesos de toma de decisiones para crear productos y servicios personalizados, tanto en el sector público como en el privado. En contextos como la salud, la movilidad, la energía o la educación, el uso de datos facilita soluciones más eficientes y adaptadas a las necesidades reales de las personas. No obstante, en el trabajo con datos, la privacidad juega un papel clave. En este post, analizaremos cómo los espacios de datos, el paradigma de computación federada y el aprendizaje federado, una de sus aplicaciones más potentes, plantean una solución equilibrada para aprovechar el potencial de los datos sin poner en riesgo la privacidad. Además, resaltaremos cómo el aprendizaje federado también puede usarse con datos abiertos para mejorar su reutilización de forma colaborativa, incremental y eficiente.
La privacidad, clave en la gestión de datos
Como se ha mencionado anteriormente, el uso intensivo de datos exige una creciente atención a la privacidad. Por ejemplo, en salud digital, un mal uso secundario de datos de historias clínicas electrónicas podría vulnerar derechos fundamentales de pacientes. Una forma eficaz de preservar la privacidad es mediante ecosistemas de datos que prioricen la soberanía de los datos, como es el caso de los espacios de datos. Un espacio de datos es un sistema de gestión federada de datos que permite su intercambio de manera confiable entre proveedores y consumidores. Además, el espacio de datos garantiza la interoperabilidad de los datos para crear productos y servicios que generen valor. En un espacio de datos, cada proveedor mantiene sus propias normas de gobernanza, conservando el control sobre sus datos (es decir, la soberanía sobre sus datos), a la vez que se posibilita su reutilización por consumidores. Esto implica que cada proveedor debe poder decidir qué datos comparte, con quién y bajo qué condiciones, garantizando el cumplimiento de sus intereses y obligaciones legales.
Computación federada y espacios de datos
Los espacios de datos representan una evolución en la gestión de datos, relacionada con un paradigma denominado computación federada (federated computing), donde los datos se reutilizan sin necesidad de que haya un trasiego de datos desde los proveedores de datos hacia los consumidores. En la computación federada, los proveedores transforman sus datos en resultados intermedios que preservan la privacidad con el fin de poder ser enviados a los consumidores de datos. Además, esto posibilita que puedan aplicarse otras técnicas de mejora de la privacidad de datos (Privacy-Enhancing Technologies). La computación federada se alinea perfectamente con arquitecturas de referencia como Gaia-X y su Trust Framework, que establece los principios y requisitos para garantizar un intercambio de datos seguro, transparente y conforme a reglas comunes entre proveedores y consumidores de datos.
Aprendizaje federado
Una de las aplicaciones más potentes de la computación federada es el aprendizaje automático federado (federated learning), una técnica de inteligencia artificial que permite entrenar modelos sin necesidad de centralizar los datos. Es decir, en lugar de enviar los datos a un servidor central para procesarlos, lo que se envía son los modelos entrenados localmente por cada participante.
Estos modelos se combinan posteriormente de manera centralizada para crear un modelo global. A modo de ejemplo, imaginemos un consorcio de hospitales que quiere desarrollar un modelo predictivo para detectar una enfermedad rara. Cada hospital posee datos sensibles de sus pacientes, y compartirlos abiertamente no es viable por cuestiones de privacidad (incluso otras cuestiones legales o éticas). Con el aprendizaje federado, cada hospital entrena localmente el modelo con sus propios datos, y solo comparte los parámetros del modelo (resultados del entrenamiento) de manera centralizada. Así, el modelo final aprovecha la diversidad de datos de todos los hospitales sin comprometer la privacidad individual y las reglas de gobernanza de datos de cada hospital.
El entrenamiento en el aprendizaje federado suele seguir un ciclo iterativo:
- Un servidor central inicia un modelo base y lo envía a cada uno de los nodos distribuidos participantes.
- Cada nodo entrena el modelo localmente con sus datos.
- Los nodos devuelven solo los parámetros del modelo actualizado, no los datos (es decir, se evita el trasiego de datos).
- El servidor central agrega las actualizaciones en los parámetros, resultados del entrenamiento en cada nodo y actualiza el modelo global.
- El ciclo se repite hasta alcanzar un modelo suficientemente preciso.
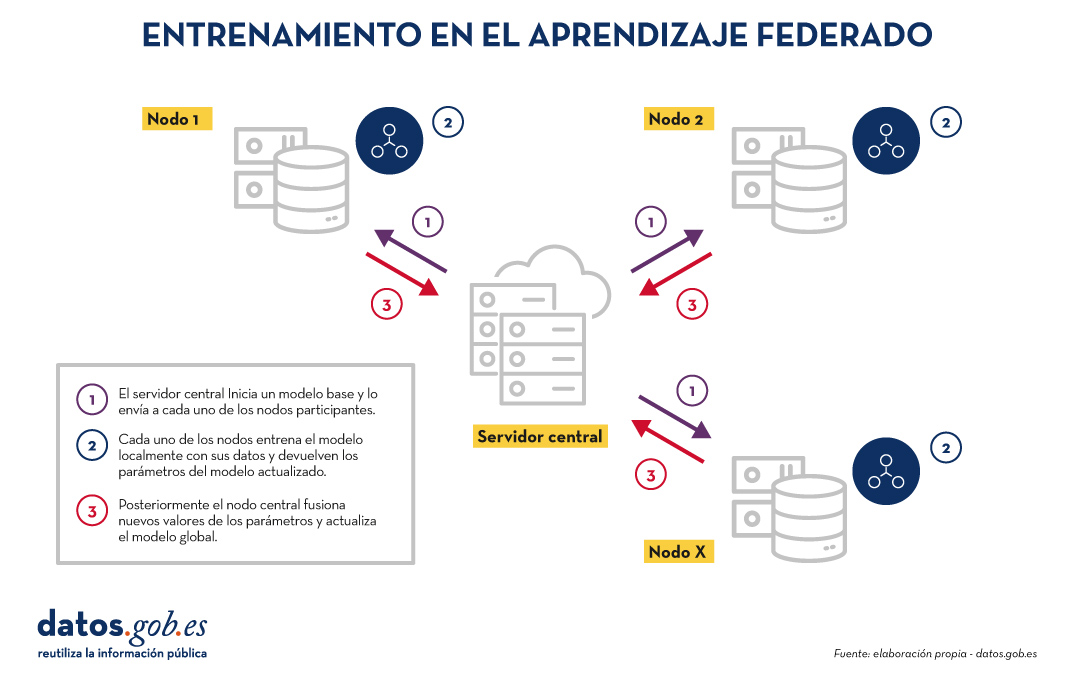
Figura 1. Visual que representa el proceso de entrenamiento del aprendizaje federados. Elaboración propia
Este enfoque es compatible con diversos algoritmos de aprendizaje automático, incluyendo redes neuronales profundas, modelos de regresión, clasificadores, etc.
Beneficios y desafíos del aprendizaje federado
El aprendizaje federado ofrece múltiples beneficios al evitar el trasiego de datos. Destacamos los siguientes:
- Privacidad y cumplimiento normativo: al permanecer en su origen, se reducen significativamente los riesgos de exposición de los datos y se facilita el cumplimiento de regulaciones como el Reglamento General de Protección de Datos (RGPD).
- Soberanía de los datos: cada entidad mantiene el control total sobre sus datos, lo que evita conflictos de competitividad.
- Eficiencia: evita los costes y la complejidad de intercambiar grandes volúmenes de datos, lo que acelera los tiempos de procesamiento y desarrollo.
- Confianza: facilita la colaboración entre organizaciones sin fricciones.
Existen diversos casos de uso en los cuales el aprendizaje federado es necesario, por ejemplo:
- Salud: hospitales y centros de investigación pueden colaborar en modelos predictivos sin compartir datos de pacientes.
- Finanzas: bancos y aseguradoras pueden construir modelos de detección de fraude o análisis de riesgo compartido, respetando la confidencialidad de sus clientes.
- Turismo inteligente: los destinos turísticos pueden analizar flujos de visitantes o patrones de consumo sin necesidad de unificar las bases de datos de sus actores (tanto públicos como privados).
- Industria: empresas del mismo sector pueden entrenar modelos para mantenimiento predictivo o eficiencia operativa sin revelar datos competitivos.
Aunque sus beneficios son claros en diversidad de casos de uso, el aprendizaje federado también presenta retos técnicos y organizativos:
- Heterogeneidad de datos: los datos locales pueden tener diferentes formatos o estructuras, lo que dificulta el entrenamiento. Además, el esquema de estos datos puede cambiar con el tiempo, lo que representa una dificultad añadida.
- Datos desbalanceados: algunos nodos pueden tener más datos o de mayor calidad que otros, lo que puede sesgar el modelo global.
- Costes computacionales locales: cada nodo necesita recursos suficientes para entrenar el modelo localmente.
- Sincronización: el ciclo de entrenamiento requiere buena coordinación entre nodos para evitar latencias o errores.
Más allá del aprendizaje federado
Aunque la aplicación más destacada de la computación federada es el aprendizaje federado, están surgiendo muchas otras aplicaciones adicionales en la gestión de datos como, por ejemplo, el análisis de datos federado (federated analytics). El análisis de datos federado permite realizar análisis estadísticos y descriptivos sobre datos distribuidos sin necesidad de moverlos a los consumidores, sino que cada proveedor realiza localmente los cálculos estadísticos requeridos y solo comparte con el consumidor los resultados agregados según sus requisitos y permisos. En la siguiente tabla se muestran las diferencias entre aprendizaje federado y análisis de datos federado.
|
Criterio |
Aprendizaje federado |
Análisis de datos federado |
|
Objetivo |
Predicción y entrenamiento de modelos de aprendizaje automático. | Análisis descriptivo y cálculo de estadísticas. |
| Tipo de tarea | Tareas predictivas (por ejemplo, clasificación o regresión). | Tareas descriptivas (por ejemplo, medias o correlaciones). |
| Ejemplo | Entrenar modelos de diagnóstico de enfermedades a través de imágenes médicas procedentes de diversos hospitales. | Cálculo de indicadores sanitarios de un área de salud sin mover los datos entre hospitales. |
| Salida esperada | Modelo global entrenado. | Resultados estadísticos agregados. |
| Naturaleza | Iterativa. | Directa. |
| Complejidad computacional | Alta. | Media. |
| Algoritmos | Aprendizaje automático. | Algoritmos estadísticos. |
Figura 1. Tabla comparativa. Fuente: elaboración propia
Aprendizaje federado y datos abiertos: una simbiosis por explorar
En principio, los datos abiertos resuelven los problemas de privacidad antes de su publicación, por lo que se podría pensar que no es preciso hacer uso de técnicas de aprendizaje federado. Nada más lejos de la realidad. El uso de técnicas de aprendizaje federado puede aportar ventajas significativas en la gestión y explotación de los datos abiertos. De hecho, el primer aspecto a resaltar es que los portales de datos abiertos como datos.gob.es o data.europa.eu son entornos federados. Por ello, en estos portales, la aplicación de aprendizaje federado sobre conjuntos de datos de gran tamaño permitiría entrenar modelos directamente en origen, evitando costes de transferencia y procesamiento. Por otro lado, el aprendizaje federado facilitaría la combinación de datos abiertos con otros datos sensibles sin comprometer la privacidad de estos últimos. Finalmente, la naturaleza de una gran variedad de tipos de datos abiertos es muy dinámica (como los datos de tráfico), por lo que el aprendizaje federado habilitaría un entrenamiento incremental, considerando automáticamente nuevas actualizaciones de conjuntos de datos abiertos a medida que se publican, sin necesidad de reiniciar costosos procesos de entrenamiento.
Aprendizaje federado, base para una IA respetuosa con la privacidad
El aprendizaje automático federado representa una evolución necesaria en la forma en que desarrollamos servicios de inteligencia artificial, especialmente en contextos donde los datos son sensibles o están distribuidos entre varios proveedores. Su alineación natural con el concepto de espacio de datos lo convierte en una tecnología clave para impulsar la innovación basada en la compartición de datos, teniendo en cuenta la privacidad y manteniendo la soberanía de los datos.
A medida que la regulación (como el Reglamento relativo al Espacio Europeo de Datos de Salud) y las infraestructuras de espacios de datos evolucionen, el aprendizaje federado, y otros tipos de computación federada, jugarán un papel cada vez más importante en la compartición de datos, maximizando el valor de los datos, pero sin comprometer la privacidad. Finalmente, cabe destacar que, lejos de ser innecesario, el aprendizaje federado puede convertirse en un aliado estratégico para mejorar la eficiencia, gobernanza e impacto de los ecosistemas de datos abiertos.
Jose Norberto Mazón, Catedrático de Lenguajes y Sistemas Informáticos de la Universidad de Alicante. Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Blog
La Inteligencia Artificial (IA) ha dejado de ser un concepto futurista y se ha convertido en una herramienta clave en nuestra vida diaria. Desde las recomendaciones de películas o series en plataformas de streaming hasta los asistentes virtuales como Alexa o Google Assistant en nuestros dispositivos, la IA está en todas partes. Pero, ¿cómo se construye un modelo de IA? A pesar de lo que podría parecer, el proceso es menos intimidante si lo desglosamos en pasos claros y comprensibles.
Paso 1: definir el problema
Antes de empezar, necesitamos tener muy claro qué queremos resolver. La IA no es una varita mágica: diferentes modelos funcionarán mejor en diferentes aplicaciones y contextos por lo que es importante definir la tarea específica que deseamos ejecutar. Por ejemplo, ¿queremos predecir las ventas de un producto? ¿Clasificar correos como spam o no spam? Tener una definición clara del problema nos ayudará a estructurar el resto del proceso.
Además, debemos plantearnos qué tipo de datos tenemos y cuáles son las expectativas. Esto incluye determinar el nivel de precisión deseado y las limitaciones de tiempo o recursos disponibles.
Paso 2: recopilar los datos
La calidad de un modelo de IA depende directamente de la calidad de los datos utilizados para entrenarlo. Este paso consiste en recopilar y organizar los datos relevantes para nuestro problema. Por ejemplo, si queremos predecir ventas, necesitaremos datos históricos como precios, promociones o patrones de compra.
La recopilación de datos comienza identificando las fuentes relevantes, que pueden ser bases de datos internas, sensores, encuestas… Además de los datos propios de cada empresa, existe un amplio ecosistema de datos, tanto abiertos como propietarios, a los que podemos recurrir en busca de la construcción de modelos más potentes. Por ejemplo, el Gobierno de España habilita a través del portal datos.gob.es múltiples conjuntos de datos abiertos publicados por instituciones públicas. Por otro lado, la empresa Amazon Web Services (AWS) a través de su portal AWS Data Exchange permite el acceso y suscripción a miles de conjuntos de datos propietarios publicados y mantenidos por diferentes empresas y organizaciones.
En este punto también se debe considerar la cantidad de datos necesaria. Los modelos de IA suelen necesitar grandes volúmenes de información para aprender de manera efectiva. También es crucial que los datos sean representativos y no contengan sesgos que puedan afectar los resultados. Por ejemplo, si entrenamos un modelo para predecir patrones de consumo y solo usamos datos de un grupo limitado de personas, es probable que las predicciones no sean válidas para otros grupos con comportamientos diferentes.
Paso 3: preparar y explorar los datos
Una vez recopilados los datos, es hora de limpiarlos y normalizarlos. En muchas ocasiones, los datos en bruto pueden contener problemas como errores, duplicidades, valores faltantes, inconsistencias o formatos no estandarizados. Por ejemplo, podríamos encontrarnos con celdas vacías en un conjunto de datos de ventas o con fechas que no siguen un formato coherente. Antes de alimentar el modelo con estos datos, es fundamental adecuarlos para garantizar que el análisis sea preciso y confiable. Este paso no solo mejora la calidad de los resultados, sino que también asegura que el modelo pueda interpretar correctamente la información.
Una vez tenemos los datos limpios es fundamental realizar la ingeniería de características (feature engineering), un proceso creativo que puede marcar la diferencia entre un modelo básico y uno excelente. Esta fase consiste en crear nuevas variables que capturen mejor la naturaleza del problema que queremos resolver. Por ejemplo, si estamos analizando ventas online, además de usar el precio directo del producto, podríamos crear nuevas características como el ratio precio/media_categoría, los días desde la última promoción, o variables que capturen la estacionalidad de las ventas. La experiencia demuestra que contar con características bien diseñadas suele ser más determinante para el éxito del modelo que la elección del algoritmo en sí mismo.
En esta fase, también realizaremos un primer análisis exploratorio de los datos, buscando familiarizarnos con ellos y detectar posibles patrones, tendencias o irregularidades que puedan influir en el modelo. En esta guía podemos encontrar mayor detalle sobre cómo realizar un análisis exploratorio de datos.
Otra actividad típica de esta etapa es dividir los datos en conjuntos de entrenamiento, validación y prueba. Por ejemplo, si tenemos 10.000 registros, podríamos usar el 70% para entrenamiento, el 20% para validación y el 10% para pruebas. Esto permite que el modelo aprenda sin sobreajustarse a un conjunto de datos específico.
Para garantizar que nuestra evaluación sea robusta, especialmente cuando trabajamos con conjuntos de datos limitados, es recomendable implementar técnicas de validación cruzada (cross-validation). Esta metodología divide los datos en múltiples subconjuntos y realiza varias iteraciones de entrenamiento y validación. Por ejemplo, en una validación cruzada de 5 pliegues, dividimos los datos en 5 partes y entrenamos 5 veces, usando cada vez una parte diferente como conjunto de validación. Esto nos proporciona una estimación más fiable del rendimiento real del modelo y nos ayuda a detectar problemas de sobreajuste o variabilidad en los resultados.
Paso 4: seleccionar un modelo
Existen múltiples tipos de modelos de IA, y la elección depende del problema que deseemos resolver. Algunos ejemplos comunes son regresión, modelos de árboles de decisión, modelos de agrupamiento, modelos de series temporales o redes neuronales. En general, existen modelos supervisados, modelos no supervisados y modelos de aprendizaje por refuerzo. Podemos encontrar un mayor detalle en este post sobre cómo las maquinas aprenden.
A la hora de seleccionar un modelo, es importante tener en cuenta factores como la naturaleza de los datos, la complejidad del problema y el objetivo final. Por ejemplo, un modelo simple como la regresión lineal puede ser suficiente para problemas sencillos y bien estructurados, mientras que redes neuronales o modelos avanzados podrían ser necesarios para tareas como reconocimiento de imágenes o procesamiento del lenguaje natural. Además, también se debe considerar el balance entre precisión, tiempo de entrenamiento y recursos computacionales. Un modelo más preciso generalmente requiere configuraciones más complejas, como más datos, redes neuronales más profundas o parámetros optimizados. Aumentar la complejidad del modelo o trabajar con conjuntos de datos grandes puede alargar significativamente el tiempo necesario para entrenarlo. Esto puede ser un problema en entornos donde las decisiones deben tomarse rápidamente o los recursos son limitados y requerir hardware especializado, como GPUs o TPUs, y mayores cantidades de memoria y almacenamiento.
Hoy en día, muchas bibliotecas de código abiertas facilitan la implementación de estos modelos, como TensorFlow, PyTorch o scikit-learn.
Paso 5: entrenar el modelo
El entrenamiento es el corazón del proceso. Durante esta etapa, alimentamos el modelo con los datos de entrenamiento para que aprenda a realizar su tarea. Esto se logra ajustando los parámetros del modelo para minimizar el error entre sus predicciones y los resultados reales.
Aquí es clave evaluar constantemente el rendimiento del modelo con el conjunto de validación y realizar ajustes si es necesario. Por ejemplo, en un modelo de tipo red neuronal podríamos probar diferentes configuraciones de hiperparámetros como tasa de aprendizaje, número de capas ocultas y neuronas, tamaño del lote, número de épocas, o función de activación, entre otros.
Paso 6: evaluar el modelo
Una vez entrenado, es momento de poner a prueba el modelo utilizando el conjunto de datos de prueba que apartamos durante la fase de entrenamiento. Este paso es crucial para medir cómo se desempeña con datos que para el modelo son nuevos y garantiza que no esté “sobreentrenado”, es decir, que no solo funcione bien con los datos de entrenamiento, sino que sea capaz de aplicar el aprendizaje sobre nuevos datos que puedan generarse en el día a día.
Al evaluar un modelo, además de la precisión, también es común considerar:
- Confianza en las predicciones: evaluar cuán seguras son las predicciones realizadas.
- Velocidad de respuesta: tiempo que toma el modelo en procesar y generar una predicción.
- Eficiencia en recursos: medir cuánto uso de memoria y cómputo requiere el modelo.
- Adaptabilidad: cuán bien puede ajustarse el modelo a nuevos datos o condiciones sin necesidad de un reentrenamiento completo.
Paso 7: desplegar y mantener el modelo
Cuando el modelo cumple con nuestras expectativas, está listo para ser desplegado en un entorno real. Esto podría implicar integrar el modelo en una aplicación, automatizar tareas o generar informes.
Sin embargo, el trabajo no termina aquí. La IA necesita mantenimiento continuo para adaptarse a los cambios en los datos o en las condiciones del mundo real. Por ejemplo, si los patrones de compra cambian por una nueva tendencia, el modelo deberá ser actualizado.
Construir modelos de IA no es una ciencia exacta, es el resultado de un proceso estructurado que combina lógica, creatividad y perseverancia. Esto se debe a que intervienen múltiples factores, como la calidad de los datos, las elecciones en el diseño del modelo y las decisiones humanas durante la optimización. Aunque existen metodologías claras y herramientas avanzadas, la construcción de modelos requiere experimentación, ajustes y, a menudo, un enfoque iterativo para obtener resultados satisfactorios. Aunque cada paso requiere atención al detalle, las herramientas y tecnologías disponibles hoy en día hacen que este desafío sea accesible para cualquier persona interesada en explorar el mundo de la IA.
ANEXO I – Definiciones tipos de modelos
-
Regresión: técnicas supervisadas que modelan la relación entre una variable dependiente (resultado) y una o más variables independientes (predictores). La regresión se utiliza para predecir valores continuos, como ventas futuras o temperaturas, y puede incluir enfoques como la regresión lineal, logística o polinómica, dependiendo de la complejidad del problema y la relación entre las variables.
-
Modelos de árboles de decisión: métodos supervisados que representan decisiones y sus posibles consecuencias en forma de árbol. En cada nodo, se toma una decisión basada en una característica de los datos, dividiendo el conjunto en subconjuntos más pequeños. Estos modelos son intuitivos y útiles para clasificación y predicción, ya que generan reglas claras que explican el razonamiento detrás de cada decisión.
-
Modelos de agrupamiento: técnicas no supervisadas que agrupan datos en subconjuntos llamados clústeres, basándose en similitudes o proximidad entre los datos. Por ejemplo, se pueden agrupar clientes con hábitos de compra similares para personalizar estrategias de marketing. Modelos como k-means o DBSCAN permiten identificar patrones útiles sin necesidad de datos etiquetados.
-
Modelos de series temporales: diseñados para trabajar con datos ordenados cronológicamente, estos modelos analizan patrones temporales y realizan predicciones basadas en el historial. Se utilizan en casos como predicción de demanda, análisis financiero o meteorología. Incorporan tendencias, estacionalidad y relaciones entre los datos pasados y futuros.
-
Redes neuronales: modelos inspirados en el funcionamiento del cerebro humano, donde capas de neuronas artificiales procesan información y detectan patrones complejos. Son especialmente útiles en tareas como reconocimiento de imágenes, procesamiento de lenguaje natural y juegos. Las redes neuronales pueden ser simples o muy profundas (deep learning), dependiendo del problema y la cantidad de datos.
-
Modelos supervisados: estos modelos aprenden de datos etiquetados, es decir, conjuntos en los que cada entrada tiene un resultado conocido. El objetivo es que el modelo generalice para predecir resultados en datos nuevos. Ejemplos incluyen clasificación de correos en spam o no spam y predicciones de precios.
-
Modelos no supervisados: trabajan con datos sin etiquetas, buscando patrones ocultos, estructuras o relaciones dentro de los datos. Son ideales para tareas exploratorias donde no se conoce de antemano el resultado esperado, como segmentación de mercados o reducción de dimensionalidad.
- Modelo de aprendizaje por refuerzo: en este enfoque, un agente aprende interactuando con un entorno, tomando decisiones y recibiendo recompensas o penalizaciones según su desempeño. Este tipo de aprendizaje es útil en problemas donde las decisiones afectan un objetivo a largo plazo, como entrenar robots, jugar videojuegos o desarrollar estrategias de inversión.
Contenido elaborado por Juan Benavente, ingeniero superior industrial y experto en tecnologías ligadas a la economía del dato. Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Blog
La creciente complejidad de los modelos de aprendizaje automático y la necesidad de optimizar su rendimiento lleva años impulsando el desarrollo del AutoML (Automated Machine Learning). Esta disciplina busca automatizar tareas clave en el ciclo de vida del desarrollo de modelos, como la selección de algoritmos, el procesamiento de datos y la optimización de hiperparámetros.
El AutoML permite a los usuarios desarrollar modelos de manera más sencilla y rápida. Se trata de un enfoque que facilita el acceso a la disciplina, haciéndola accesible a los profesionales con menos experiencia en programación y acelerando los procesos para aquellos que cuentan con más experiencia. Así, para un usuario con conocimientos profundos de programación, el AutoML también puede ser interesante. Gracias al auto machine learning, este usuario podría aplicar automáticamente las configuraciones técnicas necesarias, como definir variables o interpretar los resultados de manera más ágil.
En este post, abordaremos las claves de estos procesos de automatización y recopilaremos una serie de herramientas de código abierto gratuitas y/o con modelo freemium, que te pueden servir para profundizar en el AutoML.
Aprende a crear tu propio modelado de aprendizaje automático
Como se indicaba anteriormente, gracias a la automatización, el proceso de entrenamiento y evaluación de modelos en base a herramientas de AutoML es más rápido que en un proceso de machine learning (ML) habitual, si bien las etapas para la creación de modelos son similares.
En general, los componentes clave del AutoML son:
- Preprocesamiento de datos: automatiza tareas como la limpieza, transformación y selección de características de los datos.
- Selección de modelos: examina una variedad de algoritmos de machine learning y elige el más adecuado para la tarea específica.
- Optimización de hiperparámetros: ajusta automáticamente los parámetros de los modelos para mejorar su rendimiento.
- Evaluación de modelos: proporciona métricas de rendimiento y valida modelos utilizando técnicas como la validación cruzada.
- Implementación y mantenimiento: facilita la implementación de modelos en producción y, en algunos casos, su actualización.
Todos estos elementos ofrecen, en su conjunto, una serie de ventajas como las que vemos en la imagen
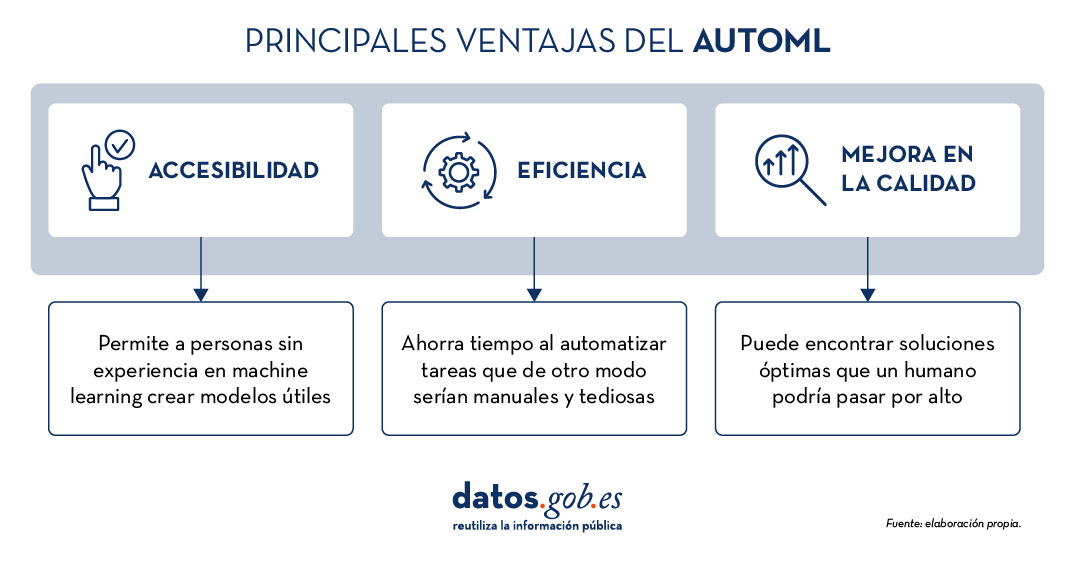
Figura 1. Fuente: elaboración propia.
Ejemplos de herramientas de AutoML
A pesar que el AutoML puede llegar a ser muy útil, es importante destacar algunas de sus limitaciones como el riesgo de overfitting (cuando el modelo se ajusta demasiado a los datos de entrenamiento y no generaliza bien el conocimiento), la pérdida de control sobre el proceso de modelado o la interpretabilidad de ciertos resultados.
No obstante, a medida que el AutoML continúa ganando terreno en el ámbito del aprendizaje automático, diversas herramientas han surgido para facilitar su implementación y uso. A continuación, exploraremos algunas de las herramientas de AutoML de código abierto más destacadas:
H2O.ai, versátil y escalable, ideal para empresas
H2O.ai es una plataforma de AutoML que incluye modelos de deep learning y machine learning como XGBoost (biblioteca de machine learning diseñada para mejorar la eficiencia de los modelos) y una interfaz de usuario gráfica. Esta herramienta se utiliza en proyectos a gran escala y permite un alto nivel de personalización. H2O.ai incluye opciones para modelos de clasificación, regresión y series temporales, y se destaca por su capacidad para manejar grandes volúmenes de datos.
Aunque H2O facilita el acceso al machine learning a no expertos, sí son necesarios algunos conocimientos y experiencia en ciencia de datos para sacarle el máximo partido a la herramienta. Además, permite realizar un gran número de tareas relacionadas con el modelado que normalmente requerirían muchas líneas de código, facilitando la tarea del analista de datos. H2O ofrece un modelo freemium y también cuenta con una versión comunitaria de código abierto.
TPOT, basado en algoritmos genéticos, buena opción para experimentar
TPOT (Tree-based Pipeline Optimization Tool) es una herramienta gratuita y de código abierto para el aprendizaje automático con Python que optimiza los procesos mediante programación genética.
Esta solución busca la mejor combinación de preprocesamiento de datos y modelos de aprendizaje automático para un conjunto de datos específico. Para ello, utiliza algoritmos genéticos que le permiten explorar y optimizar diferentes pipelines, transformación de datos y modelos. Se trata de una opción más experimental que puede resultar menos intuitiva, pero ofrece soluciones innovadoras.
Además, TPOT está construido sobre la popular biblioteca scikit-learn, así que los modelos generados por TPOT se pueden utilizar y ajustar con las mismas técnicas que se usarían en scikit-learn.
Auto-sklearn, accesible para usuarios de scikit-learn y eficiente en problemas estructurados
Como TPOT, Auto-sklearn está basada en scikit-learn y sirve para automatizar la selección de algoritmos y la optimización de hiperparámetros en modelos de aprendizaje automático en Python.
Además de ser una opción gratuita y de código abierto, incluye técnicas para manejar datos ausentes, una funcionalidad muy útil a la hora de trabajar con conjuntos de datos del mundo real. Por otro lado, Auto-sklearn ofrece una API sencilla y fácil de usar, lo que permite a los usuarios iniciar el proceso de modelado con pocas líneas de código.
BigML, integración mediante API REST y modelos de precios flexibles
BigML es una plataforma de aprendizaje automático consumible, programable y escalable que, como el resto de herramientas mencionadas, facilita la resolución y automatización de tareas de clasificación, regresión, pronóstico de series de tiempo, análisis de clústeres, detección de anomalías, descubrimiento de asociaciones y modelado de temas. Cuenta con una interfaz intuitiva y un enfoque hacia la visualización que facilita la creación y gestión de modelos de ML, incluso para usuarios con pocas nociones de programación.
Además, BigML tiene una API REST que posibilita la integración con diversas aplicaciones y lenguajes, y es escalable para manejar grandes volúmenes de datos. Por otro lado, ofrece un modelo de precios flexible basado en el uso, y cuenta con una comunidad activa que actualiza regularmente los recursos didácticos disponibles.
La siguiente tabla muestra una comparativa entre estas herramientas:
| H2O.ai | TPOT | Auto-sklearn | BigML | |
|---|---|---|---|---|
| Uso | Para proyectos a gran escala. | Para experimentar con algoritmos genéticos y optimizar pipelines. | Para usuarios de scikit-learn que desean automatizar el proceso de selección de modelos y para tareas estructuradas. | Para crear y desplegar modelos de ML de forma accesible y sencilla. |
| Dificultad de configuración | Sencilla, con opciones avanzadas. | Dificultad media. Una opción más técnica por los algoritmos genéticos. | Dificultad media. Precisa una configuración técnica, pero es fácil para usuarios de scikit-learn. | Sencilla. Interfaz intuitiva con opciones de personalización. |
| Facilidad de uso | Fácil de usar con los lenguajes de programación más habituales. Tiene interfaz gráfica y APIs para R y Python. | Fácil de usar, pero requiere conocimientos de Python. | Fácil de usar, pero requiere conocimientos previos. Opción sencilla para usuarios de scikit-learn. | Fácil de usar, enfocada a la visualización, no requiere grandes conocimientos de programación. |
| Escalabilidad | Escalable a grandes volúmenes de datos. | Enfocada en conjuntos de datos pequeños y medianos. Menos eficiente en datasets grandes. | Efectivo en conjuntos de datos tamaño pequeño y medio. | Escalable para diferentes tamaños de datasets. |
| Interoperabilidad | Compatible con varias bibliotecas y lenguajes, como Java, Scala, Python y R. | Basado en Python. | Basado en Python integrando scikit-learn. | Compatible con API REST y varios lenguajes. |
| Comunidad | Amplia y activa que comparte documentación de referencia. | Menos extensa, pero en proceso de crecimiento. | Cuenta con el soporte de la comunidad scikit-learn. | Comunidad activa y soporte disponible. |
| Desventajas | Aunque es versátil, su personalización avanzada podría ser desafiante para principiantes sin experiencia técnica. | Puede ser menos eficiente en grandes conjuntos de datos debido a la naturaleza intensiva de los algoritmos genéticos. | Su rendimiento está optimizado para tareas estructuradas (datos estructurados), lo que podría limitar su uso en otros tipos de problemas. | Su personalización avanzada podría ser desafiante para principiantes sin experiencia técnica. |
Figura 2. Tabla comparativa de herramientas de autoML. Fuente:elaboración propia.
Cada herramienta tiene su propia propuesta de valor, y la elección dependerá de las necesidades específicas y del entorno en el que trabaje el usuario.
Estos son algunos ejemplos de herramientas gratuitas y de código abierto que puedes explorar para adentrarte en el AutoML. Te invitamos a compartir tu experiencia con estas u otras herramientas en la sección de comentarios.
Si estás buscando herramientas para ayudarte en el procesamiento de datos, desde datos.gob.es ponemos a tu disposición el informe “Herramientas de procesado y visualización de datos”, así como los siguientes artículos monográficos:
Blog
En el proceso de análisis de datos y entrenamiento de modelos de aprendizaje automático, es fundamental contar con un conjunto de datos adecuado. Por lo tanto, surgen las preguntas: ¿cómo se deben preparar los conjuntos de datos para el aprendizaje automático y el análisis? ¿Cómo se puede confiar en que los datos conducirán a conclusiones sólidas y predicciones precisas?
Lo primero que hay que tener en cuenta al preparar los datos es saber el tipo de problema que se intenta resolver. Por ejemplo, si tu intención es crear un modelo de aprendizaje automático capaz de reconocer el estado emocional de alguien a partir de sus expresiones faciales, necesitarás un conjunto de datos con imágenes o vídeos de caras de personas. O, tal vez, el objetivo es crear un modelo que identifique los correos electrónicos no deseados. Para ello, se necesitarán datos en formato texto de correos electrónicos.
Además, los datos que se precisan también dependen del tipo de algoritmo que quieras utilizar. Los algoritmos de aprendizaje supervisado, como la regresión lineal o los árboles de decisión, requieren un campo que contenga el valor verdadero de un resultado para que el modelo aprenda de él. Además de este valor verdadero, denominado objetivo, requieren campos que contengan información sobre las observaciones, algo que se conoce como características. En cambio, los algoritmos de aprendizaje no supervisado, como la agrupación k-means o los sistemas de recomendación basados en el filtrado colaborativo, por lo general sólo necesitan características.
Sin embargo, encontrar los datos es sólo la mitad del trabajo. Los conjuntos de datos del mundo real pueden contener todo tipo de errores que pueden hacer que todo el trabajo resulte inútil si no se detectan y corrigen antes de empezar. En este post, vamos a presentar algunos de los principales obstáculos que puede haber en los conjuntos de datos para el aprendizaje automático y el análisis, así como conocer algunas maneras en que la plataforma de ciencia de datos colaborativa, Datalore, puede ayudar a detectarlos rápidamente y ponerles remedio.
¿Los datos son representativos de aquello que se quiere medir?
La mayoría de los conjuntos de datos para proyectos o análisis de aprendizaje automático no están diseñados específicamente para ese fin. A falta de un diccionario de metadatos o de una explicación sobre lo qué significan los campos del conjunto de datos, es posible que el usuario tenga que resolver la incógnita basándose en la información de la que dispone.
Una forma de determinar lo que miden las características de un conjunto de datos es comprobar sus relaciones con otras características. Si se supone que dos campos miden cosas similares, es de esperar que estén muy relacionados. Por el contrario, si dos campos miden cosas muy diferentes, es de esperar que no estén relacionados. Estas ideas se conocen como validez convergente y discriminante, respectivamente.
Otra cosa importante que hay que comprobar es si alguno de los rasgos está demasiado relacionado con el público objetivo. Si esto ocurre, puede indicar que este rasgo está accediendo a la misma información que el objetivo a predecir. Este fenómeno se conoce como “feature leakage” (fuga de características). Si se emplean estos datos, existe el riesgo de inflar artificialmente el rendimiento del modelo.
En este sentido, Datalore permite escanear rápidamente la relación entre variables continúas mediate el gráfico de correlación en la pestaña Visualizar para un DataFrame. Otra manera de comprobar estas relaciones es utilizando gráficos de barras o tabulaciones cruzadas, o medidas del tamaño del efecto como el coeficiente de determinación o la V de Cramér.
¿El conjunto de datos está correctamente filtrado y limpio?
Los conjuntos de datos pueden contener todo tipo de inconsistencias que pueden afectar negativamente a nuestros modelos o análisis. Algunos de los indicadores más importantes de datos sucios son:
- Valores inverosímiles: Esto incluye valores que están fuera de rango, como los negativos en una variable de recuento o frecuencias que son mucho más altas o más bajas de lo esperado para un campo en particular.
- Valores atípicos: Se trata de valores extremos, que pueden representar cualquier cosa, desde errores de codificación que se produjeron en el momento en que se escribieron los datos, hasta valores raros pero reales que se sitúan fuera del grueso de las demás observaciones.
- Valores perdidos: El patrón y la cantidad de datos que faltan determinan el impacto que tendrán, siendo los más graves los que están relacionados con el objetivo o las características.
Los datos sucios pueden mermar la calidad de sus análisis y modelos, en gran medida porque distorsionan las conclusiones o porque conducen a un rendimiento deficiente del modelo. La pestaña Estadísticas de Datalore permite comprobar fácilmente estos problemas, ya que muestra de un vistazo la distribución, el número de valores perdidos y la presencia de valores atípicos para cada campo. Datalore también facilita la exploración de los datos en bruto y permite realizar operaciones básicas de filtrado, ordenación y selección de columnas directamente en un DataFrame, exportando el código Python correspondiente a cada acción a una nueva celda.
¿Las variables están equilibradas?
Los datos desequilibrados se producen cuando los campos categóricos tienen una distribución desigual de observaciones entre todas las clases. Esta situación puede causar problemas importantes para los modelos y los análisis. Cuando se tiene un objetivo muy desequilibrado, se pueden crear modelos perezosos que aún pueden lograr un buen rendimiento simplemente prediciendo por defecto la clase mayoritaria. Pongamos un ejemplo extremo: tenemos un conjunto de datos en el que el 90% de las observaciones corresponden a una de las clases objetivo y el 10% a la otra. Si siempre predijéramos la clase mayoritaria para este conjunto de datos, seguiríamos obteniendo una precisión del 90%, lo que demuestra que, en estos casos, un modelo que no aprende nada de las características puede tener un rendimiento excelente.
Las características también se ven afectadas por el desequilibrio de clases. Los modelos funcionan aprendiendo patrones, y cuando las clases son demasiado pequeñas, es difícil para los modelos hacer predicciones para estos grupos. Estos efectos pueden agravarse cuando se tienen varias características desequilibradas, lo que lleva a situaciones en las que una combinación concreta de clases poco comunes sólo puede darse en un puñado de observaciones.
Los datos desequilibrados pueden rectificarse mediante diversas técnicas de muestreo. El submuestreo (undersampling, en inglés) consiste en reducir el número de observaciones en las clases más grandes para igualar la distribución de los datos, y el sobremuestreo (oversampling) consiste en crear más datos en las clases más pequeñas. Hay muchas formas de hacerlo. Algunos ejemplos incluyen el uso de paquetes Python como imbalanced-learn o servicios como Gretel. Las características desequilibradas también pueden corregirse mediante la ingeniería de características, cuyo objetivo es combinar clases dentro de un campo sin perder información.
En definitiva, ¿es representativo el conjunto de datos?
A la hora de crear un conjunto de datos, se tiene en mente un grupo objetivo o target para el cual deseas que tu modelo o análisis funcione. Por ejemplo, un modelo para predecir la probabilidad de que los hombres estadounidenses interesados en la moda compren una determinada marca. Este grupo objetivo es la población sobre la que se quiere poder hacer generalizaciones. Sin embargo, como no suele ser práctico recopilar información sobre todos los individuos que constituyen esta parte de la población, en su lugar se emplea un subconjunto denominado muestra.
A veces surgen problemas que hacen que los datos de la muestra para el modelo de aprendizaje automático y el análisis no representen correctamente el comportamiento de la población. Esto se denomina sesgo de los datos. Por ejemplo, es posible que la muestra no capte todos los subgrupos de la población, un tipo de sesgo denominado sesgo de selección.
Una forma de comprobar el sesgo es inspeccionar la distribución de los campos de sus datos y comprobar que tienen sentido basándose en lo que uno sabe sobre ese grupo de la población. El uso de la pestaña Estadísticas de Datalore permite escanear la distribución de las variables continuas y categóricas de un DataFrame.
¿Se está midiendo el rendimiento real de los modelos?
Una última cuestión que puede ponerle en un aprieto es la medición del rendimiento de sus modelos. Muchos modelos son propensos a un problema llamado sobreajuste que es cuando el modelo se ajusta tan bien a los datos de entrenamiento que no se generaliza bien a los nuevos datos. El signo revelador del sobreajuste es un modelo que funciona extremadamente bien con los datos de entrenamiento y su rendimiento es inferior con nuevos datos. La forma de tener esto en cuenta es dividir el conjunto de datos en varios conjuntos: un conjunto de entrenamiento para entrenar el modelo, un conjunto de validación para comparar el rendimiento de diferentes modelos y un conjunto de prueba final para comprobar cómo funcionará el modelo en el mundo real.
Sin embargo, crear una división limpia de entrenamiento-validación-prueba puede ser complicado. Un problema importante es la fuga de datos, por la que la información de los otros dos conjuntos de datos se filtra en el conjunto de entrenamiento. Esto puede dar lugar a problemas que van desde los obvios, como las observaciones duplicadas que terminan en los tres conjuntos de datos, a otros más sutiles, como el uso de información de todo el conjunto de datos para realizar el preprocesamiento de características antes de dividir los datos. Además, es importante que los tres conjuntos de datos tengan la misma distribución de objetivos y características, para que cada uno sea una muestra representativa de la población.
Para evitar cualquier problema, se debe dividir el conjunto de datos en conjuntos de entrenamiento, validación y prueba al principio de su trabajo, antes de realizar cualquier exploración o procesamiento. Para asegurarse de que cada conjunto de datos tiene la misma distribución de cada campo, se puede utilizar un método como train_test_split de scikit-learn, diseñado específicamente para crear divisiones representativas de los datos. Por último, es recomendable comparar las estadísticas descriptivas de cada conjunto de datos para comprobar si hay signos de fuga de datos o divisiones desiguales, lo que se hace fácilmente utilizando la pestaña Estadísticas de Datalore.
En definitiva, existen varios problemas que pueden ocurrir cuando se preparan los datos para el aprendizaje automático y el análisis y es importante saber cómo mitigarlos. Si bien esto puede ser una parte que consume mucho tiempo del proceso de trabajo, existen herramientas que pueden hacer que sea más rápido y fácil detectar problemas en una etapa temprana.
Contenido elaborado a partir del post de Jodie Burchell How to prepare your dataset for machine learning and analysis publicado en The JetBrains Datalore Blog
Blog
La crisis humanitaria que se originó tras el terremoto de Haití en 2010 fue el punto de partida de una iniciativa voluntaria para crear mapas que identificaran el nivel de daño y vulnerabilidad por zonas, y así, poder coordinar los equipos de emergencia. Desde entonces, el proyecto de mapeo colaborativo conocido como Hot OSM (OpenStreetMap) realiza una labor clave en situaciones de crisis y desastres naturales.
Ahora, la organización ha evolucionado hasta convertirse en una red global de voluntarios que aportan sus habilidades de creación de mapas en línea para ayudar en situaciones de crisis por todo el mundo. La iniciativa es un ejemplo de colaboración en torno a los datos para resolver problemas de la sociedad, tema que desarrollamos en este informe de datos.gob.es.
Hot OSM trabaja para acelerar la colaboración con organizaciones humanitarias y gubernamentales en torno a los datos, así como con comunidades locales y voluntarios de todo el mundo, para proporcionar mapas precisos y detallados de áreas afectadas por desastres naturales o crisis humanitarias. Estos mapas se utilizan para ayudar a coordinar la respuesta de emergencia, identificar necesidades y planificar la recuperación.
En su trabajo, Hot OSM prioriza la colaboración y el empoderamiento de las comunidades locales. La organización trabaja para garantizar que las personas que viven en las áreas afectadas tengan voz y poder en el proceso de mapeo. Esto significa que Hot OSM trabaja en estrecha colaboración con las comunidades locales para asegurarse de que se mapeen áreas importantes para ellos. De esta manera, se tienen en cuenta las necesidades de las comunidades a la hora de planificar respuesta de emergencia y la recuperación.
Labor didáctica de Hot OSM
Además de su trabajo en situaciones de crisis, Hot OSM dedica esfuerzos a la promoción del acceso a datos geoespaciales abiertos y libres, y trabaja en colaboración con otras organizaciones para construir herramientas y tecnologías que permitan a las comunidades de todo el mundo aprovechar el poder del mapeo colaborativo.
A través de su plataforma en línea, Hot OSM proporciona acceso gratuito a una amplia gama de herramientas y recursos para ayudar a los voluntarios a aprender y participar en la creación de mapas colaborativos. La organización también ofrece capacitación para aquellos interesados en contribuir a su trabajo.
Un ejemplo de proyecto de HOT es el trabajo que la organización realizó en el contexto del ébola en África Occidental. En 2014, un brote de ébola afectó a varios países de África Occidental, incluidos Sierra Leona, Liberia y Guinea. La falta de mapas precisos y detallados en estas áreas dificultó la coordinación de la respuesta de emergencia.
En respuesta a esta necesidad, HOT inició un proyecto de mapeo colaborativo que involucró a más de 3.000 voluntarios en todo el mundo. Los voluntarios utilizaron herramientas en línea para mapear áreas afectadas por el ébola, incluidas carreteras, pueblos y centros de tratamiento.
Este mapeo permitió a los trabajadores humanitarios coordinar mejor la respuesta de emergencia, identificar áreas de alto riesgo y priorizar la asignación de recursos. Además, el proyecto también ayudó a las comunidades locales a comprender mejor la situación y a participar en la respuesta de emergencia.
Este caso en África Occidental es solo un ejemplo del trabajo que HOT realiza en todo el mundo para ayudar en situaciones de crisis humanitarias. La organización ha trabajado en una variedad de contextos, incluidos terremotos, inundaciones y conflictos armados, y ha ayudado a proporcionar mapas precisos y detallados para la respuesta de emergencia en cada uno de estos contextos.
Por otro lado, la plataforma también está involucrada en zonas en las que no hay cobertura de mapas, como en muchos países africanos. En estas zonas los proyectos de ayuda humanitaria muchas veces tienen un gran reto en las primeras fases, ya que es muy difícil cuantificar qué población vive en una zona y donde está emplazada. Poder tener la ubicación esas personas y que muestre vías de acceso las “pone en el mapa” y permite que puedan llegar a acceder a los recursos.
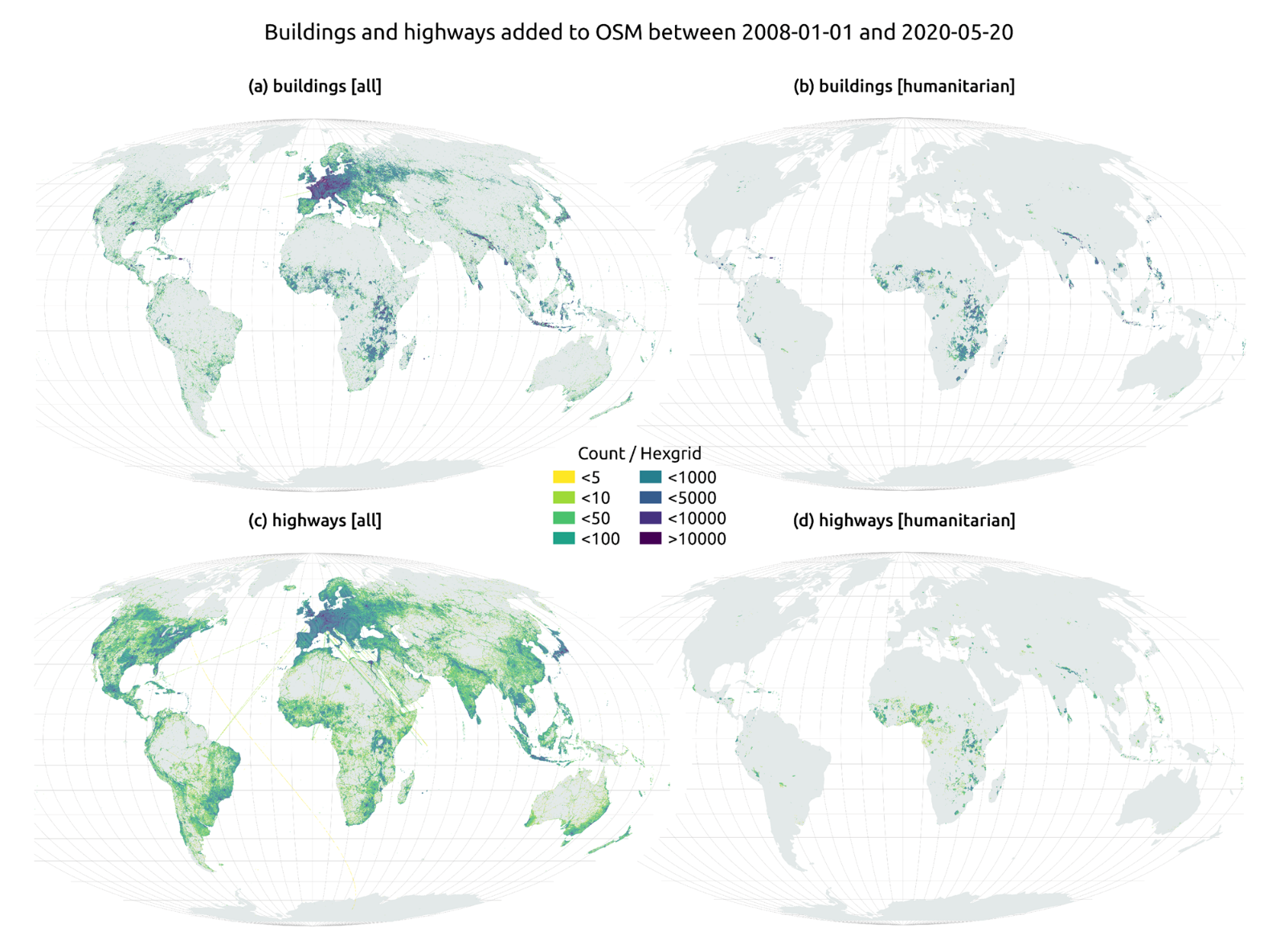
En el artículo The evolution of humanitarian mapping within the OpenStreetMap community de Nature, podemos ver gráficamente algunos de los logros de la plataforma.
Como colaborar
Empezar a colaborar con Hot OSM es fácil, basta con ir a la página https://tasks.hotosm.org/explore y ver los proyectos abiertos que necesitan colaboración.
Esta pantalla nos permite una gran cantidad de opciones a la hora de buscar los proyectos, seleccionado por nivel de dificultad, organización, ubicación o intereses entre otros.
Para participar, basta con pulsar el botón Registrese.
Dar un nombre y un e-mail y en la siguiente pantalla:

Nos preguntará si tenemos creada una cuenta en Open Street Maps o queremos crear una.
Si queremos ver más en detalle el proceso, esta página nos lo pone muy fácil.
Una vez creado el usuario, en la página aprender encontramos ayuda de cómo participar en el proyecto.
Es importante destacar que las contribuciones de los voluntarios se revisan y validan y existe un segundo nivel de voluntarios, los validadores, que dan por bueno el trabajo de los principiantes. Durante el desarrollo de la herramienta, el equipo de HOT ha cuidado mucho que sea una aplicación sencilla de utilizar para no limitar su uso a personas con conocimientos informáticos.
Además, organizaciones como Cruz Roja o Naciones unidas organizan regularmente mapatones con el objetivo de reunir grupos de personas para proyectos específicos o enseñar a nuevos voluntarios el uso de la herramienta. Estas reuniones sirven, sobre todo, para quitar el miedo de los nuevos usuarios a “romper algo” y para que puedan ver cómo su labor de voluntariado sirve para cosas concretas y ayuda a otras personas.
Otra de las grandes fortalezas del proyecto es que está basado en software libre y permite la reutilización del mismo. En el repositorio Github del proyecto MissingMaps podemos encontrar el código y si queremos crear una comunidad basada en el software, la organización Missing Maps nos facilita el proceso y dará visibilidad a nuestro grupo.
En definitiva, Hot OSM es un proyecto de ciencia ciudadana y altruismo de datos que contribuye a aportar beneficios a la sociedad mediante la elaboración de mapas colaborativos muy útiles en situaciones de emergencia. Este tipo de iniciativas están alineadas con el concepto europeo de gobernanza de datos que busca impulsar el altruismo para facilitar voluntariamente el uso de los datos para el bien común.
Contenido elaborado por Santiago Mota, senior data scientist.
Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Blog
Detrás de un asistente virtual de voz, la recomendación de una película en una plataforma de streaming o el desarrollo de algunas vacunas contra el covid-19 existen modelos de machine learning. Esta rama de la inteligencia artificial permite que los sistemas aprendan y mejoren su funcionamiento.
El machine learning (ML) o aprendizaje automático es uno de los campos que impulsa el avance tecnológico del presente y sus aplicaciones crecen cada día. Como ejemplos de soluciones desarrolladas con machine learning podemos mencionar DALL-E, el conjunto de modelos del lenguaje en español MarIA o incluso Chat GPT-3, herramienta de IA generativa que es capaz de crear contenido de todo tipo, como, por ejemplo, código para programar visualizaciones con datos del catálogo datos.gob.es.
Todas estas soluciones funcionan gracias a grandes repositorios de datos que hacen posible el aprendizaje de los sistemas. Entre estos, los datos abiertos juegan un papel fundamental para el desarrollo de la inteligencia artificial ya que pueden servir de entrenamiento para los modelos de aprendizaje automático.
Bajo esta premisa, sumado al esfuerzo permanente de las administraciones por la apertura de datos, existen organizaciones no gubernamentales y asociaciones que contribuyen desarrollando aplicaciones que usan técnicas de machine learning dirigidas a mejorar la vida de la ciudadanía. Destacamos tres de ellas:
ML Commons impulsa un sistema de aprendizaje automático mejor para todos
Esta iniciativa pretende mejorar el impacto positivo del aprendizaje automático en la sociedad y acelerar la innovación ofreciendo herramientas como conjuntos de datos, mejores prácticas y algoritmos abiertos. Entre sus miembros fundadores se encuentran empresas como Google, Microsoft, DELL, Intel AI, Facebook AI, entre otras.
Según ML Commons, en torno al 80% de las investigaciones realizadas en el ámbito del machine learning se basan en datos abiertos. Por lo tanto, los datos abiertos son vitales para acelerar la innovación en esta materia. Sin embargo, hoy en día, “la mayoría de los ficheros de datos públicos disponibles son pequeños, estáticos, tienen restricciones legales y no son redistribuibles”, tal y como asegura David Kanter, director de ML Commons.
En esta línea, las tecnologías innovadoras de ML necesitan grandes conjuntos de datos con licencias que permitan su reutilización, que puedan ser redistribuibles y que estén en continua mejora. Por ello, la misión de ML Commons es contribuir a mitigar esa brecha y para así impulsar la innovación en machine learning.
El principal objetivo de esta organización es crear una comunidad de datos abiertos para el desarrollo de aplicaciones machine learning. Su estrategia se basa en tres pilares:
En primer lugar, crear y mantener conjuntos de datos abiertos completos. Entre otros: The People’s Speech, con más de 30.000 horas de discurso en inglés para entrenar modelos de procesamiento del lenguaje natural (PLN), Multilingual Spoken Words, con más de 23 millones de expresiones en 50 idiomas diferentes o Dollar Street, con más de 38.000 imágenes de hogares de todo el mundo en situaciones socioeconómicas variadas. El segundo pilar consiste en impulsar buenas prácticas que faciliten la estandarización. Ejemplo de ello es el proyecto MLCube que propone estandarizar el proceso de contenedores para modelos ML para facilitar su uso compartido. Y, por último, realizar benchmarking en grupos de estudios para definir puntos de referencia para la comunidad desarrolladora e investigadora.
Aprovechar las ventajas y formar parte de la comunidad ML Commons es gratuito para las instituciones académicas y las empresas pequeñas (menos de diez trabajadores).
Datacommons sintetiza diferentes fuentes de datos abiertos en un único portal
Datacommons busca potenciar los flujos democráticos de datos dentro de la economía cooperativa y solidaria y tiene como objetivo principal ofrecer datos depurados, normalizados e interoperables.
La variedad de formato e información que ofrecen los portales públicos de datos abiertos puede llegar a ser un obstáculo para la investigación. El objetivo de Datacommons es compilar datos abiertos en una web enciclopédica que ordena todos los dataset mediante nodos. De esta manera, el usuario puede acceder a la fuente que más le interesa.
Esta plataforma, que fue diseñada con fines educativos y de investigación periodística, funciona como herramienta de referencia para navegar entre distintas fuentes de datos. El equipo de colaboradores trabaja para mantener la información actualizada e interactúa con la comunidad a través de su e-mail (support@datacommons.org) o foro de GitHub.
Papers with Code: el repositorio de materiales en abierto para alimentar modelos machine learning
Se trata de un portal que ofrece código, informes, datos, métodos y tablas de evaluación en formato abierto y gratuito. Todo el contenido de la web está bajo licencia CC-BY-SA, es decir, permite copiar, distribuir, exhibir y modificar la obra incluso con fines comerciales compartiendo las contribuciones realizadas con la misma licencia original.
Cualquier usuario puede contribuir aportando contenido e, incluso, participar en el canal de Slack de la comunidad que está moderado por responsables que protegen la política de inclusión definida por la plataforma.
A día de hoy, Papers with Code aloja 7806 conjuntos de datos que se pueden filtrar según formato (gráfico, texto, imagen, tabular etc.), tarea (detección de objeto, consultas, clasificación de imágenes etc.) o idioma. El equipo que mantiene Papers with Code pertenece al instituto de investigación de Meta.
El objetivo de ML Commons, Data Commons y Papers with Code es mantener y hacer crecer comunidades de datos abiertos que contribuyan al desarrollo de tecnologías innovadoras. Entre ellas, la inteligencia artificial (machine learning, deep learning etc.) con todas las posibilidades que su desarrollo puede llegar a ofrecer a la sociedad.
Como parte de este proceso, las tres organizaciones desarrollan un papel fundamental: ofrecen repositorios de datos en formato estándar y redistribuible para entrenar modelos machine learning. Son recursos útiles para realizar ejercicios académicos, impulsar la investigación y, al fin y al cabo, facilitar la innovación de tecnologías que cada día están más presentes en nuestra sociedad.
Blog
Tras varios meses de pruebas y entrenamientos de distinto tipo, el primer sistema masivo de Inteligencia Artificial de la lengua española es capaz de generar sus propios textos y resumir otros ya existentes. MarIA es un proyecto que ha sido impulsado por la Secretaría de Estado de Digitalización e Inteligencia Artificial y desarrollado por el Centro Nacional de Supercomputación, a partir de los archivos web de la Biblioteca Nacional de España (BNE).
Hablamos de un avance muy importante en este ámbito, ya que se trata del primer sistema de inteligencia artificial experto en comprender y escribir en lengua española. Enmarcada dentro del Plan de Tecnologías del Lenguaje, esta herramienta pretende contribuir al desarrollo de una economía digital en español, gracias al potencial que los desarrolladores pueden encontrar en ella.
El reto de crear los asistentes del lenguaje del futuro
Los modelos de lenguaje al estilo de MarIA son la piedra angular sobre la que se sustenta el desarrollo del procesamiento del lenguaje natural, la traducción automática o los sistemas conversacionales, tan necesarios para comprender y replicar de forma automática una lengua. MarIA es un sistema de inteligencia artificial formado por redes neuronales profundas que han sido entrenadas para adquirir una comprensión de la lengua, de su léxico y de sus mecanismos para expresar el significado y escribir a nivel experto.
Gracias a este trabajo previo, los desarrolladores pueden crear herramientas relacionadas con el lenguaje y capaces de clasificar documentos, realizar correcciones o elaborar herramientas de traducción.
La primera versión de MarIA fue elaborada con RoBERTa, una tecnología que crea modelos del lenguaje del tipo “codificadores”, capaces de generar una interpretación que puede servir para categorizar documentos, encontrar similitudes semánticas en diferentes textos o detectar los sentimientos que se expresan en ellos.
Así, la última versión de MarIA ha sido desarrollada con GPT-2, una tecnología más avanzada que crea modelos generativos decodificadores y añade prestaciones al sistema. Gracias a estos modelos decodificadores, la última versión de MarIA es capaz de generar textos nuevos a partir de un ejemplo previo, lo que resulta muy útil a la hora de elaborar resúmenes, simplificar grandes cantidades de información, generar preguntas y respuestas e, incluso, mantener un diálogo.
Avances como los anteriores convierten a MarIA en una herramienta que, con entrenamientos adaptados a tareas específicas, puede ser de gran utilidad para desarrolladores, empresas y administraciones públicas. En esta línea, modelos similares que se han desarrollado en inglés son utilizados para generar sugerencias de texto en aplicaciones de escritura, resumir contratos o buscar informaciones concretas dentro de grandes bases de datos de texto para relacionarlas posteriormente con otras informaciones relevantes.
En otras palabras, además de redactar textos a partir de titulares o palabras, MarIA puede comprender no solo conceptos abstractos, sino también el contexto de los mismos.
Más de 135 mil millones de palabras al servicio de la inteligencia artificial
Para ser exactos, MarIA se ha entrenado con 135.733.450.668 de palabras procedentes de millones de páginas web que recolecta la Biblioteca Nacional y que ocupan un total de 570 Gigabytes de información. Para estos mismos entrenamientos, se ha utilizado el superordenador MareNostrum del Centro Nacional de Supercomputación de Barcelona y ha sido necesaria una potencia de cálculo de 9,7 trillones de operaciones (969 exaflops).
Teniendo en cuenta que uno de los primeros pasos para diseñar un modelo del lenguaje pasa por construir un corpus de palabras y frases que sirva como base de datos para entrenar al propio sistema, en el caso de MarIA, fue necesario realizar un cribado para eliminar todos los fragmentos de texto que no fuesen “lenguaje bien formado” (elementos numéricos, gráficos, oraciones que no terminan, codificaciones erróneas, etc.) y así entrenar correctamente a la IA.
Debido al volumen de información que maneja, MarIA se sitúa ya como el tercer sistema de inteligencia artificial experto en comprender y escribir con mayor número de modelos masivos de acceso abierto. Por delante solo están los modelos del lenguaje elaborados para el inglés y el mandarín. Esto ha sido posible principalmente por dos razones. Por un lado, debido al elevado nivel de digitalización en el que se encuentra el patrimonio de la Biblioteca Nacional y, por el otro, gracias a la existencia de un Centro de Supercomputación Nacional que cuenta con superordenadores como el MareNostrum 4.
El papel de los conjuntos de datos de la BNE
Desde que en 2014 lanzase su propio portal de datos abiertos (datos.bne.es), la BNE ha apostado por acercar los datos que están a su disposición y bajo su custodia: datos de las obras que conserva, pero también de autores, vocabularios controlados de materias y términos geográficos, entre otros.
En los últimos años, se ha desarrollado también la plataforma educativa BNEscolar, que busca ofrecer contenidos digitales del fondo documental de la Biblioteca Digital Hispánica y que pueden resultar de interés para la comunidad educativa.
Así mismo y para cumplir con los estándares internacionales de descripción e interoperabilidad, los datos de la BNE están identificados mediante URIs y modelos conceptuales enlazados, a través de tecnologías semánticas y ofrecidos en formatos abiertos y reutilizables. Además, cuentan con un alto nivel de normalización.
Próximos pasos
Así y con el objetivo de perfeccionar y ampliar las posibilidades de uso de MarIA, se pretende que la versión actual dé lugar a otras especializadas en áreas de conocimiento más concretas. Teniendo en cuenta que se trata de un sistema de inteligencia artificial dedicado a comprender y generar texto, se torna fundamental que este sea capaz de desenvolverse con soltura ante léxicos y conjuntos de información especializada.
Para ello, el PlanTL continuará expandiendo MarIA para adaptarse a los nuevos desarrollos tecnológicos en procesamiento del lenguaje natural (modelos más complejos que el GPT-2 ahora implementado, entrenados con mayor cantidad de datos) y se buscará la forma de crear espacios de trabajo para facilitar el uso de MarIA por compañías y grupos de investigación.
Contenido elaborado por el equipo de datos.gob.es.
Blog
Python, R, SQL, JavaScript, C++, HTML... Hoy en día podemos encontrar multitud de lenguajes de programación que nos permiten desarrollar programas de software, aplicaciones, páginas webs, etc. Cada uno tiene características únicas que lo diferencian del resto y que lo hacen más apropiado para determinadas tareas. Pero, ¿cómo sabemos cuándo y dónde utilizar cada lenguaje? En este artículo te damos algunas pistas.
Tipos de lenguajes de programación
Los lenguajes de programación son reglas sintácticas y semánticas que nos permiten ejecutar una serie de instrucciones. Según su nivel de complejidad, podemos hablar de distintos niveles:
- Lenguajes de bajo nivel: utilizan instrucciones básicas que la máquina interpreta directamente y que son difíciles de entender por las personas. Están diseñados a medida de cada hardware y no se pueden migrar, pero son muy eficaces, ya que aprovechan al máximo las características de cada máquina.
- Lenguajes de alto nivel: utilizan instrucciones claras usando un lenguaje natural, más entendible por los humanos. Estos lenguajes emulan nuestra forma de pensar y razonar, pero después deben ser traducidos a lenguaje máquina a través de traductores/intérpretes o compiladores. Se pueden migrar y no dependen del hardware.
En ocasiones también se habla de lenguajes de nivel medio para aquellos que, aunque funcionan como un lenguaje de bajo nivel, permiten cierto manejo abstracto independiente de la máquina.
Los lenguajes de programación más utilizados
En este artículo nos vamos a centrar en los lenguajes de alto nivel más utilizados en la ciencia de datos. Para ello nos vamos a fijar en esta encuesta, realizada por Anaconda en 2021, y en el artículo elaborado por KD Nuggets.
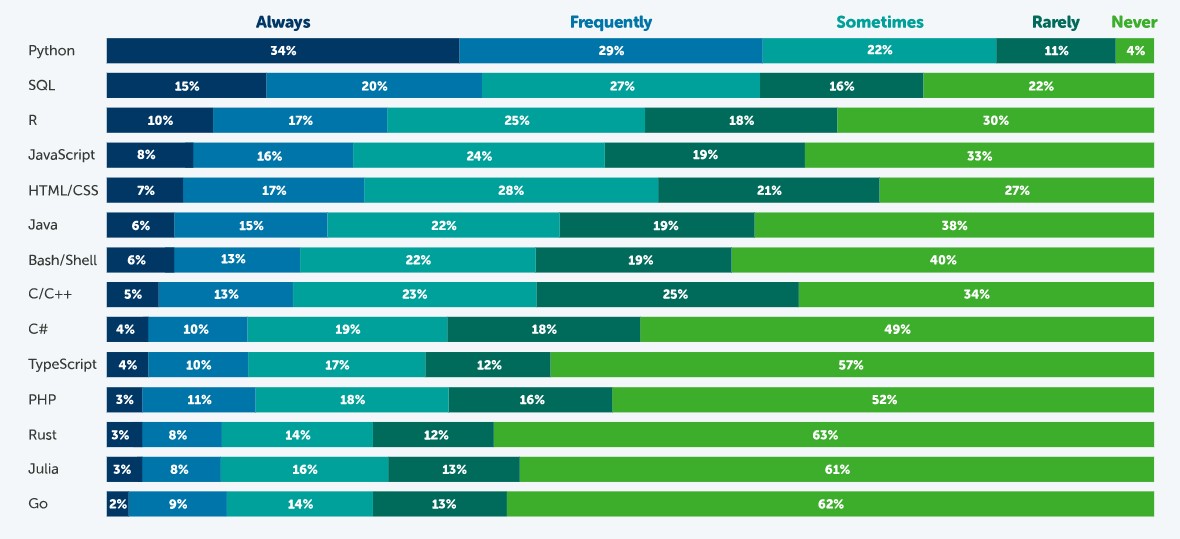
Fuente: Estado de la Ciencia de Datos en 2021, Anaconda.
Según esta encuesta, el lenguaje más popular es Python. El 63% de los encuestados – 3.104 científicos de datos, investigadores, estudiantes y profesionales del dato de todo el mundo- indicó que utiliza Python siempre o frecuentemente y solo un 4% indicó que nunca. Esto se debe a que es un lenguaje muy versátil, que se puede utilizar en las distintas tareas que existen a lo largo de un proyecto de ciencia de datos.
Un proyecto de ciencia de datos cuenta con distintas fases y tareas. Algunos lenguajes pueden ser utilizados para ejecutar distintas labores, pero con desigual rendimiento. La siguiente tabla, elaborada por KD Nuggets, muestra qué lenguaje es más recomendado para algunas de las tareas más populares:

Como vemos Python es el único lenguaje que resulta apropiado para todas las áreas analizadas por KD Nuggets, aunque existen otras opciones que también son muy interesantes, según la tarea a realizar, como veremos a continuación:
- Extracción y manipulación de datos. Estas tareas están dirigidas a obtener los datos y depurarlos con el fin de conseguir una estructura homogénea, sin datos incompletos, libre de errores y en el formato adecuado. Para ello se recomienda realizar un Análisis Exploratorio de Datos. SQL es el lenguaje de programación que más destaca con respecto a la extracción de datos, sobre todo cuando se trabaja con bases de datos relacionales. Es rápido en la recuperación de datos y cuenta con una sintaxis estandarizada, lo cual lo hace relativamente sencillo. Sin embargo, es más limitado a la hora de manipular datos. Una tarea en la que dan mejores resultados Python y R, dos programas que cuentan con una gran cantidad de librerías para estas tareas.
- Análisis estadístico y visualización de datos. Supone el tratamiento de los datos para encontrar patrones que luego se convierten en conocimiento. Existen distintos tipo de análisis según su propósito: conocer mejor nuestro entorno, realizar predicciones u obtener recomendaciones. El mejor lenguaje para ello es R, un lenguaje interpretado que además dispone de un entorno de programación, R-Studio y un conjunto de herramientas muy flexibles y versátiles para la computación estadística. Python, Java y Julia son otras herramientas que dan un buen rendimiento en esta tarea, para la cual también se puede utilizar JavaScript. Los lenguajes anteriores permiten, además de realizar análisis, elaborar visualizaciones gráficas que facilitan la comprensión de la información.
- Modelización/aprendizaje automático (ML). Si queremos trabajar con machine learning y construir algoritmos, Python, Java, Java/JavaScript, Julia y TypeScript son las mejores opciones. Todas ellas simplifican la tarea de escribir código, aunque es necesario tener conocimientos amplios para poder trabajar con las diferentes técnicas de aprendizaje automático. Aquellos usuarios más expertos pueden trabajar con C/C++, un lenguaje de programación muy fácil de leer por máquinas, pero con mucho código, que puede ser difícil de aprender. Por el contrario, R puede ser una buena opción para aquellos menos expertos, aunque es más lento y poco apropiado para redes neuronales complejas.
- Despliegue de modelos. Una vez creado un modelo, es necesario su despliegue, teniendo en cuenta todos los requisitos necesarios para su entrada en producción en un entorno real. Para ello, los lenguajes más adecuados son Python, Java, JavaScript y C#, seguido de PHP, Rust, GoLang y, si trabajamos con aplicaciones básicas, HTML/CSS.
- Automatización. Aunque no todas las partes del trabajo de un científico de datos pueden automatizarse, hay algunas tareas tediosas y repetitivas cuya automatización agiliza el rendimiento. Python, por ejemplo, cuenta con una gran cantidad de librerías para la automatización de tareas de machine learning. Si trabajamos con aplicaciones móviles, entonces nuestra mejor opción será Java. Otras opciones son C# (especialmente útil para automatizar la construcción de modelos), Bash/Shell (para extracción y manipulación de datos) y R (para análisis estadísticos y visualizaciones).
En definitiva, el lenguaje de programación que utilicemos dependerá completamente de la tarea a realizar y de nuestras capacidades. No todos los profesionales de la ciencia de datos necesitan saber de todos los lenguajes, sino que deberán optar por profundizar en aquel más adecuado en base a su trabajo diario.
Algunos recursos adicionales para aprender más sobre estos lenguajes
En datos.gob.es hemos elaborado algunas guías y recursos que pueden ser de tu utilidad para aprender algunos de estos lenguajes:
- Informe sobre Herramientas de procesado y visualización de datos
- Cursos para aprender más sobre R
- Cursos para aprender más sobre Python
- Cursos online para aprender más sobre visualización de datos
- Comunidades de desarrolladores en R y Python
Contenido elaborado por el equipo de datos.gob.es.
Blog
Las librerías de programación hacen referencia a los conjuntos de archivos de código que han sido creados para desarrollar software de manera sencilla. Gracias a ellas, los desarrolladores pueden evitar la duplicidad de código y minimizar errores con mayor agilidad y menor coste. Existen multitud de librerías, enfocadas en distintas actividades. Hace unas semanas vimos algunos ejemplos de librerías para la creación de visualizaciones, y en esta ocasión nos vamos a centrar en librerías de utilidad para tareas de aprendizaje automático (Machine Learning).
Estas librerías son altamente prácticas a la hora de implementar flujos de Machine Learning. Esta disciplina, perteneciente al campo de la Inteligencia Artificial, utiliza algoritmos que ofrecen, por ejemplo, la capacidad de identificar patrones de datos masivos o la capacidad de ayudar a elaborar análisis predictivos.
A continuación, te mostramos algunas de las librerías de análisis de datos y Machine Learning más populares que existen en la actualidad para los principales lenguajes de programación, como Python o R:
Librerías para Python
NumPy
- Descripción:
Esta librería de Python está especializada en el cálculo matemático y en el análisis de grandes volúmenes de datos. Permite trabajar con arrays que permiten representar colecciones de datos de un mismo tipo en varias dimensiones, además de funciones muy eficientes para su manipulación.
- Materiales de apoyo:
Aquí encontramos la Guía para principiantes, con conceptos básicos y tutoriales, la Guía del usuario, con información sobre las características generales, o la Guía del colaborador, para contribuir al mantenimiento y desarrollo del código o en la redacción de documentación técnica. NumPy también cuenta con una Guía de referencia que detalla funciones, módulos y objetos incluidos en esta librería, así como una serie de tutoriales para aprender a utilizarla de forma sencilla.
Pandas
- Descripción:
Se trata de una de las librerías más utilizadas para el tratamiento de datos en Python. Esta herramienta de análisis y manipulación de datos se caracteriza, entre otros aspectos, por definir nuevas funcionalidades de datos basadas en los arrays de la librería NumPy. Permite leer y escribir fácilmente ficheros en formato CSV, Excel y especificar consultas a bases de datos SQL.
- Materiales de apoyo:
Su web cuenta con diferentes documentos como la Guía del usuario, con información básica detallada y explicaciones útiles, la Guía del desarrollador, que detalla los pasos a seguir ante la identificación de errores o sugerencia de mejoras en las funcionalidades, así como la Guía de referencia, con descripción detallada de su API. Además, ofrece una serie de tutoriales aportados por la comunidad y referencias sobre operaciones equivalentes en otros softwares y lenguajes como SAS, SQL o R.
Scikit-learn
- Descripción:
Scikit-Learn es una librería que implementa una gran cantidad de algoritmos de Machine Learning para tareas de clasificación, regresión, clustering y reducción de dimensionalidad. Además, es compatible con otras librerías de Python como NumPy, SciPy y Matplotlib (Matpotlib es una librería de visualización de datos y como tal está incluida en el artículo anterior).
- Materiales de apoyo:
Esta librería cuenta con diferentes documentos de ayuda como un Manual de instalación, una Guía del Usuario o un Glosario de términos comunes y elementos de su API. Además, ofrece una sección con diferentes ejemplos que ilustran las características de la librería, así como otras secciones de interés con tutoriales, preguntas frecuentes o acceso a su GitHub.
Scipy
- Descripción:
Esta librería presenta una colección de algoritmos matemáticos y funciones construidas sobre la extensión de NumPy. Incluye módulos de extensión para Python sobre estadística, optimización, integración, álgebra lineal o procesamiento de imágenes, entre otros.
- Materiales de apoyo:
Al igual que los ejemplos anteriores, esta librería también cuenta con materiales como Guías de instalación, Guías para usuarios, para desarrolladores o un documento con descripciones detalladas sobre su API. Además, ofrece información sobre act, una herramienta para ejecutar acciones de GitHub de forma local.
Librerías para R
mlr
- Descripción:
Esta librería ofrece componentes fundamentales para desarrollar tareas de aprendizaje automático, entre otros, preprocesamiento, pipelining, selección de características, visualización e implementación de técnicas supervisadas y no supervisadas utilizando un amplio abanico de algoritmos.
- Materiales de apoyo:
En su web cuenta con múltiples recursos para usuarios y desarrolladores, entre los que destaca un tutorial de referencia que presenta un extenso recorrido que abarca los aspectos básicos sobre tareas, predicciones o preprocesamiento de datos hasta la implementación de proyectos complejos utilizando funciones avanzadas.
Además, cuenta con un apartado que redirige a GitHub en el que ofrece charlas, vídeos y talleres de interés sobre el funcionamiento y los usos de esta librería.
Tidyverse
- Descripción:
Esta librería ofrece una colección de paquetes de R diseñados para la ciencia de datos que aporta funcionalidades muy útiles para importar, transformar, visualizar, modelar y comunicar información a partir de datos. Todos ellos comparten una misma filosofía de diseño, gramática y estructuras de datos subyacentes. Los principales paquetes que lo componen son: dplyr, ggplot2, forcats, tibble, readr, stringr, tidyr y purrr.
- Materiales de apoyo:
Tidyverse cuenta con un blog en el que podrás encontrar posts sobre programación, paquetes o trucos y técnicas para trabajar con esta librería. Además, cuenta con una sección que recomienda libros y workshops para aprender a utilizar esta librería de una manera más sencilla y amena.
Caret
- Descripción:
Esta popular librería contiene una interfaz que unifica bajo un único marco de trabajo cientos de funciones para entrenar clasificadores y regresores, facilitando en gran medida todas las etapas de preprocesado, entrenamiento, optimización y validación de modelos predictivos.
- Materiales de apoyo:
La web del proyecto contine exhaustiva información que facilita al usuario abordar tareas mencionadas. También se puede encontrar referencias en CRAN y el proyecto está alojado en GitHub. Algunos recursos de interés para el manejo de esta librería se pueden encontrar a través de libros como Applied Predictive Modeling, artículos, seminarios o tutoriales, entre otros.
Librerías para abordar tareas de Big Data
TensorFlow
- Descripción:
Además de Python y R, esta librería también es compatible con otros lenguajes como JavaScript, C++ o Julia. TensorFlow ofrece la posibilidad de compilar y entrenar modelos de ML utilizando APIs. La API más destacada es Keras, que permite construir y entrenar modelos de aprendizaje profundo (Deep Learning).
- Materiales de apoyo:
En su web se pueden encontrar recursos como modelos y conjuntos de datos previamente establecidos y desarrollados, herramientas, bibliotecas y extensiones, programas de certificación, conocimientos sobre aprendizaje automático o recursos y herramientas para integrar las prácticas de IA responsable. Puedes acceder a su página de GitHub aquí.
Dmlc XGBoost
- Descripción:
Librería de "Gradient Boosting" (GBM, GBRT, GBDT) escalable, portátil y distribuida es compatible con los lenguajes de programación C++, Python, R, Java, Scala, Perl y Julia. Esta librería permite resolver muchos problemas de ciencia de datos de una manera rápida y precisa y se puede integrar con Flink, Spark y otros sistemas de flujo de datos en la nube para abordar tareas Big Data.
- Materiales de apoyo:
En su web cuenta con un blog con temáticas relacionadas como actualizaciones de algoritmos o integraciones, además de una sección de documentación que cuenta con guías de instalación, tutoriales, preguntas frecuentes, foro de usuarios o paquetes para los distintos lenguajes de programación. Puedes acceder a su página de GitHub a través de este enlace.
H20
- Descripción:
Esta librería combina los principales algoritmos de Machine Learning y aprendizaje estadístico con Big Data, además de ser capaz de trabajar con millones de registros. H20 está escrita en Java, y sigue el paradigma Key/Value para almacenar datos y Map/Reduce para implementar algoritmos. Gracias a su API, se puede acceder desde R, Python o Scala.
- Materiales de apoyo:
Cuenta con una serie de vídeos en forma de tutorial para enseñar y facilitar su uso a los usuarios. En su página de GitHub podrás encontrar recursos adicionales como blogs, proyectos, recursos, trabajos de investigación, cursos o libros sobre H20.
En este artículo hemos ofrecido una muestra de algunas de las librerías más populares que ofrecen funcionalidades versátiles para abordar tareas típicas de ciencia de datos y aprendizaje automático, aunque hay muchas otras. Este tipo de librerías está en constante evolución gracias a la posibilidad que ofrece a sus usuarios de participar en su mejora a través de acciones como la contribución a la escritura de código, la generación de nueva documentación o el reporte de errores. Todo ello permite enriquecer y perfeccionar sus resultados continuamente.
Si sabes de alguna otra librería de interés que quieras recomendarnos, puedes dejarnos un mensaje en comentarios o envíanos un correo electrónico a dinamizacion@datos.gob.es
Contenido elaborado por el equipo de datos.gob.es.