Blog
En todo entorno de gestión de datos (empresas, Administración pública, consorcios, proyectos de investigación), disponer de datos no basta: si no sabes qué datos tienes, dónde están, qué significan, quién los mantiene, con qué calidad, cuándo cambiaron o cómo se relacionan con otros datos, entonces el valor es muy limitado. Los metadatos —datos sobre los datos— son esenciales para:
-
Visibilidad y acceso: permitir que usuarios encuentren qué datos existen y puedan acceder.
-
Contextualización: saber qué significan los datos (definiciones, unidades, semántica).
-
Trazabilidad / linaje: entender de dónde vienen los datos y cómo han sido transformados.
-
Gobierno y control: conocer quién es responsable, qué políticas aplican, permisos, versiones, obsolescencia.
-
Calidad, integridad y consistencia: asegurar la fiabilidad de los datos mediante reglas, métricas y monitoreo.
-
Interoperabilidad: garantizar que diferentes sistemas o dominios puedan compartir datos, utilizando un vocabulario común, definiciones compartidas y relaciones explícitas.
En resumen, los metadatos son la palanca que convierte los datos “aislados” en un ecosistema de información gobernada. A medida que los datos crecen en volumen, diversidad y velocidad, su función va más allá de la simple descripción: los metadatos añaden contexto, permiten interpretar los datos y facilitan que puedan ser encontrados, accesibles, interoperables y reutilizables (FAIR).
En el nuevo contexto impulsado por la inteligencia artificial, esta capa de metadatos adquiere una relevancia aún mayor, ya que proporciona la información de procedencia (provenance) necesaria para garantizar la trazabilidad, la fiabilidad y la reproducibilidad de los resultados. Por ello, algunos marcos recientes amplían estos principios hacia FAIR-R, donde la “R” adicional resalta la importancia de que los datos estén listos para la IA (AI-ready), es decir, que cumplen una serie de requisitos técnicos, estructurales y de calidad que optimizan su aprovechamiento por parte de los algoritmos de inteligencia artificial.
Así, hablamos de metadatos enriquecidos, capaces de conectar información técnica, semántica y contextual para potenciar el aprendizaje automático, la interoperabilidad entre dominios y la generación de conocimiento verificable.
De los metadatos tradicionales a los “metadatos enriquecidos”
Metadatos tradicionales
En el contexto de este artículo, cuando hablamos de metadatos con un uso tradicional, pensamos en catálogos, diccionarios, glosarios, modelos de datos de base de datos, y estructuras rígidas (tablas y columnas). Los tipos de metadatos más comunes son:
-
Metadatos técnicos: tipo de columna, longitud, formato, claves foráneas, índices, ubicaciones físicas.
-
Metadatos de negocio / semánticos: nombre de campo, descripción, dominio de valores, reglas de negocio, términos del glosario empresarial.
-
Metadatos operativos / de ejecución: frecuencia de actualización, última carga, tiempos de procesamiento, estadísticas de uso.
-
Metadatos de calidad: porcentaje de valores nulos, duplicados, validaciones.
-
Metadatos de seguridad / acceso: políticas de acceso, permisos, clasificación de sensibilidad.
-
Metadatos de linaje: rastreo de transformación en los pipelines de datos.
Estos metadatos se almacenan usualmente en repositorios o herramientas de catalogación, muchas veces con estructuras tabulares o en bases relacionales, con vínculos predefinidos.
¿Por qué metadatos enriquecidos?
Los metadatos enriquecidos son aquella capa que no solo describe atributos, sino que:
- Descubren e infieren relaciones implícitas, identificando vínculos que no están expresamente definidos en los esquemas de datos. Esto permite, por ejemplo, reconocer que dos variables con nombres diferentes en sistemas distintos representan en realidad el mismo concepto (“altitud” y “elevación”), o que ciertos atributos mantienen una relación jerárquica (“municipio” pertenece a “provincia”).
- Facilitan consultas semánticas y razonamiento automatizado, permitiendo que los usuarios y las máquinas exploren relaciones y patrones que no están explícitamente definidos en las bases de datos. En lugar de limitarse a buscar coincidencias exactas de nombres o estructuras, los metadatos enriquecidos permiten formular preguntas basadas en significado y contexto. Por ejemplo, identificar automáticamente todos los conjuntos de datos relacionados con “ciudades costeras” aunque el término no aparezca literalmente en los metadatos.
- Se adaptan y evolucionan de manera flexible, ya que pueden ampliarse con nuevos tipos de entidades, relaciones o dominios sin necesidad de rediseñar toda la estructura del catálogo. Esto permite incorporar fácilmente nuevas fuentes de datos, modelos o estándares, garantizando la sostenibilidad del sistema a largo plazo.
- Incorporan automatización en tareas que antes eran manuales o repetitivas, como la detección de duplicidades, el emparejamiento automático de conceptos equivalentes o el enriquecimiento semántico mediante aprendizaje automático. También pueden identificar incoherencias o anomalías, mejorando la calidad y la coherencia de los metadatos.
- Integran de forma explícita el contexto de negocio, enlazando cada activo de datos con su significado operativo y su rol dentro de los procesos organizativos. Para ello utilizan vocabularios controlados, ontologías o taxonomías que facilitan un entendimiento común entre equipos técnicos, analistas y responsables de negocio.
- Favorecen una interoperabilidad más profunda entre dominios heterogéneos, que va más allá del intercambio sintáctico facilitado por los metadatos tradicionales. Los metadatos enriquecidos añaden una capa semántica que permite comprender y relacionar los datos en función de su significado, no solo de su formato. Así, datos procedentes de diferentes fuentes o sectores —por ejemplo, Sistemas de información Geográfica (GIS en inglés), Building Information Modeling (BIM) o Internet de las Cosas (IoT)— pueden vincularse de manera coherente dentro de un marco conceptual compartido. Esta interoperabilidad semántica es la que posibilita integrar conocimiento y reutilizar información entre contextos técnicos y organizativos diversos.
Esto convierte los metadatos en un activo vivo, enriquecido y conectado con el conocimiento del dominio, no solo un “registro” pasivo.

La evolución de los metadatos: ontologías y grafos de conocimiento
La incorporación de ontologías y grafos de conocimiento representa una evolución conceptual en la manera de describir, relacionar y aprovechar los metadatos, de ahí que hablemos de metadatos enriquecidos. Estas herramientas no solo documentan los datos, sino que los conectan dentro de una red de significado, permitiendo que las relaciones entre entidades, conceptos y contextos sean explícitas y computables.
En el contexto actual, marcado por el auge de la inteligencia artificial, esta estructura semántica adquiere un papel fundamental: proporciona a los algoritmos el conocimiento contextual necesario para interpretar, aprender y razonar sobre los datos de forma más precisa y transparente. Ontologías y grafos permiten que los sistemas de IA no solo procesen información, sino que entiendan las relaciones entre los elementos y puedan generar inferencias fundamentadas, abriendo el camino hacia modelos más explicativos y confiables.
Este cambio de paradigma transforma los metadatos en una estructura dinámica, capaz de reflejar la complejidad del conocimiento y de facilitar la interoperabilidad semántica entre distintos dominios y fuentes de información. Para comprender esta evolución conviene definir y relacionar algunos conceptos:
Ontologías
En el mundo de los datos, una ontología es un mapa conceptual muy organizado que define claramente:
- Qué entidades existen (ej. ciudad, río, carretera).
- Qué propiedades tienen (ej. una ciudad tiene nombre, población, código postal).
- Cómo se relacionan entre sí (ej. un río atraviesa una ciudad, una carretera conecta dos municipios).
El objetivo es que personas y máquinas compartan un mismo vocabulario y entiendan los datos de la misma manera. Las ontologías permiten:
- Definir conceptos y relaciones: por ejemplo, “una parcela pertenece a un municipio”, “un edificio tiene coordenadas geográficas”.
- Poner reglas y restricciones: como “cada edificio debe estar exactamente en una parcela catastral”.
- Unificar vocabularios: si en un sistema se dice “parcela” y en otro “unidad catastral”, la ontología ayuda a reconocer que son análogos.
- Hacer inferencias: a partir de datos simples, descubrir nuevo conocimiento (si un edificio está en una parcela y la parcela en Sevilla, se puede inferir que el edificio está en Sevilla).
- Establecer un lenguaje común: funcionan como un diccionario compartido entre distintos sistemas o dominios (GIS, BIM, IoT, catastro, urbanismo).
En resumen: una ontología es el diccionario y las reglas del juego que permiten que diferentes sistemas geoespaciales (mapas, catastro, sensores, BIM, etc.) se entiendan entre sí y puedan trabajar de manera integrada.
Grafos de conocimiento (Knowledge Graphs)
Un grafo de conocimiento es una forma de organizar información como si fuera una red de conceptos conectados entre sí.
-
Los nodos representan cosas o entidades, como una ciudad, un río o un edificio.
-
Las aristas (líneas) muestran las relaciones entre ellas, por ejemplo: “está en”, “atraviesa” o “pertenece a”.
-
A diferencia de un simple dibujo de conexiones, un grafo de conocimiento también explica el significado de esas relaciones: añade semántica.
Un grafo de conocimiento combina tres elementos principales:
-
Datos: los casos concretos o instancias, como “Sevilla”, “Río Guadalquivir” o “Edificio Ayuntamiento de Sevilla”.
-
Semántica (u ontología): las reglas y vocabularios que definen qué tipos de cosas existen (ciudades, ríos, edificios) y cómo pueden relacionarse entre sí.
-
Razonamiento: la capacidad de descubrir nuevas conexiones a partir de las existentes (por ejemplo, si un río atraviesa una ciudad y esa ciudad está en España, el sistema puede deducir que el río está en España).
Además, los grafos de conocimiento permiten conectar información de distintos ámbitos (por ejemplo, datos sobre personas, lugares y empresas) bajo un mismo lenguaje común, facilitando el análisis y la interoperabilidad entre disciplinas.
En otras palabras, un knowledge graph es el resultado de aplicar una ontología (el modelo de datos) a varios conjuntos de datos individuales (elementos espaciales, otros datos del territorio, registros de pacientes o productos de catálogo, etc.). Los grafos de conocimiento son ideales para integrar datos heterogéneos, porque no requieren un esquema rígido previamente completo: se pueden ir creciendo de forma flexible. Además, permiten consultas semánticas y navegación con relaciones complejas. A continuación, se pone un ejemplo para datos espaciales con los que entender las diferencias:
|
Ontología de datos espaciales (modelo conceptual) |
Grafo de conocimiento (ejemplos concretos con instancias) |
|---|---|
|
|
|
|
Casos de uso
Para entender mejor el valor de los metadatos inteligentes y los catálogos semánticos, nada mejor que mirar ejemplos donde ya se están aplicando. Estos casos muestran cómo la combinación de ontologías y grafos de conocimiento permite conectar información dispersa, mejorar la interoperabilidad y generar conocimiento accionable en distintos contextos.
Desde la gestión de emergencias hasta la planificación urbana o la protección del medio ambiente, diferentes proyectos internacionales han demostrado que la semántica no es solo teoría, sino una herramienta práctica que transforma datos en decisiones.
Algunos ejemplos relevantes incluyen:
- LinkedGeoData que convirtió datos de OpenStreetMap en Linked Data, enlazándolos con otras fuentes abiertas.
- Virtual Singapore un gemelo digital 3D que integra datos geoespaciales, urbanos y en tiempo real para simulación y planificación.
- JedAI-spatial una herramienta para interconectar datos espaciales en 3D mediante relaciones semánticas.
- SOSA Ontology, estándar ampliamente usado en proyectos de sensores e IoT para observaciones ambientales con componente geoespacial.
- Proyectos europeos de permisos digitales de construcción (ej. ACCORD), que combinan catálogos semánticos, modelos BIM y datos GIS para validar automáticamente normativas de construcción.
Conclusiones
La evolución hacia metadatos enriquecidos, apoyados en ontologías, grafos de conocimiento y principios FAIR-R, representa un cambio sustancial en la manera de gestionar, conectar y comprender los datos. Este nuevo enfoque convierte los metadatos en un componente activo de la infraestructura digital, capaz de aportar contexto, trazabilidad y significado, y no solo de describir información.
Los metadatos enriquecidos permiten aprender de los datos, mejorar la interoperabilidad semántica entre dominios y facilitar consultas más expresivas, donde las relaciones y dependencias pueden descubrirse de forma automatizada. De este modo, favorecen la integración de información dispersa y apoyan tanto la toma de decisiones informadas como el desarrollo de modelos de inteligencia artificial más explicativos y confiables.
En el ámbito de los datos abiertos, estos avances impulsan la transición desde repositorios descriptivos hacia ecosistemas de conocimiento interconectado, donde los datos pueden combinarse y reutilizarse de manera flexible y verificable. La incorporación de contexto semántico y procedencia (provenance) refuerza la transparencia, la calidad y la reutilización responsable.
Esta transformación requiere, sin embargo, un enfoque progresivo y bien gobernado: es fundamental planificar la migración de sistemas, garantizar la calidad semántica, y promover la participación de comunidades multidisciplinares.
En definitiva, los metadatos enriquecidos son la base para pasar de datos aislados a conocimiento conectado y trazable, elemento clave para la interoperabilidad, la sostenibilidad y la confianza en la economía de los datos.
Contenido elaborado por Mayte Toscano, Senior Consultant en Tecnologías ligadas a la economía del dato. Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autora
Noticia
El turismo es uno de los motores económicos de España. En 2022, supuso el 11,6% del Producto Interior Bruto (PIB), superando los 155.000 millones de euros, de acuerdo con el Instituto Nacional de Estadística (INE). Una cifra que creció hasta los 188.000 millones y el 12,8% del PIB en 2023, según Exceltur, asociación de empresas del sector. Además, España es un destino muy popular entre los extranjeros, situándose en el segundo puesto mundial y creciendo: este 2024 se espera alcanzar récord de visitantes internacionales, llegando a los 95 millones.
En este contexto, la Secretaría de Estado de Turismo (SETUR), alineada con las políticas europeas, está desarrollando actuaciones que pretenden crear nuevas herramientas tecnológicas para la Red de Destinos Turísticos Inteligentes, a través de SEGITTUR (Sociedad Mercantil Estatal parala Gestión de la Innovación y las Tecnologías Turísticas), ente encargado de impulsar la innovación (I+D+i) en esta industria. Para ello trabaja tanto con el sector público como con el privado, impulsando:
- Modelos de gestión sostenible y más competitivos.
- La gestión y creación de destinos inteligentes.
- La exportación de tecnología española al resto del mundo.
Todas ellas son actividades donde los datos -y el conocimiento que se puede extraer de ellos- tienen un gran papel. En este post, vamos a repasar algunas de las acciones que SEGITTUR lleva a cabo para impulsar la compartición y apertura de datos, así como su reutilización. El objetivo es ayudar no solo a la toma de decisiones, sino también al desarrollo de productos y servicios innovadores que continúen posicionando a nuestro país en los primeros puestos del turismo mundial.
Dataestur, un portal de datos abiertos
Dataestur es un espacio web que recoge en un único entorno datos abiertos del turismo nacional. Los usuarios pueden encontrar cifras procedentes de distintas fuentes de información, públicas y privadas.
Los datos están estructurados en seis categorías:
- General: llegadas de turistas internacionales, gasto turístico, encuesta de turismo de residentes, barómetro del turismo mundial, datos de cobertura banda ancha, etc.
- Economía: ingresos por turismo, aportación al PIB, empleo turístico (demandantes de empleo, paro y contratos), etc.
- Transporte: pasajeros aéreos, capacidad aérea programada, tráfico de pasajeros por puertos, trenes y carreteras, etc.
- Alojamientos: ocupación hotelera, precio de alojamientos e indicadores de rentabilidad del sector hotelero, etc.
- Sostenibilidad: calidad del aire, protección de la naturaleza, valores climatológicos, calidad del agua en las zonas de baño, etc.
- Conocimiento: informes de escucha activa, comportamiento y percepción del visitante, revistas científicas de turismo, etc.
Los datos están disponibles para su descarga vía API.
Dataestur forma parte de un proyecto más ambicioso en el que el análisis de los datos constituye la base para mejorar el conocimiento del turista, a través de acciones con un amplio alcance, como las que veremos a continuación.
Desarrollo de una Plataforma Inteligente de Destinos (PID)
Dentro del cumplimiento de los hitos marcados por los fondos Next Generation, y correspondiente al desarrollo del Plan de Transformación Digital de Destinos Turísticos, la Secretaría de Estado de Turismo, a través de SEGITTUR, está desarrollando una Plataforma Inteligente de Destinos (PID). Se trata de una plataforma-nodo que recoge la oferta de servicios turísticos y facilita la interoperabilidad de operadores públicos y privados. Gracias a esta plataforma se podrá proveer de servicios para integrar y relacionar datos de ambas fuentes, públicas y privadas.
Algunos de los retos del ecosistema turístico español a los que da respuesta la PID son:
- Potenciar la integración y desarrollo del ecosistema turístico (academia, emprendedores, empresa, etc.) en torno a la inteligencia del dato y garantizar el alineamiento tecnológico, la interoperabilidad y el lenguaje común.
- Promover el uso de la economía del dato para mejorar la generación, agregación y compartición de conocimiento en el sector turístico español, impulsando su transformación digital.
- Contribuir a una correcta gestión de los flujos turísticos y de los puntos de afluencia turística del espacio ciudadano, mejorando la respuesta a los problemas de la ciudadanía y ofreciendo información en tiempo real para la gestión turística.
- Generar un impacto notable en el turista, residentes y empresa, además del resto de agentes, potenciando la marca “país turismo sostenible” durante todo el ciclo de viaje (antes, durante y después).
- Establecer un marco de referencia para consensuar objetivos y métricas que impulsen la sostenibilidad y la reducción de la huella de carbono en la industria turística, fomentando prácticas sostenibles y la integración de tecnologías limpias.

Figura 1. Objetivos de la Plataforma Inteligente de Destinos (PID).
Nuevos casos de uso y metodologías para implementarlos
Para avanzar en la armonización de la gestión de datos, se han definido hasta 25 casos de uso que permiten a los distintos verticales del sector trabajar de manera coordinada. Estos verticales incluyen áreas como enoturismo, turismo termal, gestión de playas, hoteles proveedores de datos, indicadores de impacto, cruceros, turismo deportivo, etc.
Para implementar estos casos de uso, se sigue una metodología de 5 pasos que busca alinear las prácticas del sector con un enfoque más estructurado en torno a los datos:
- Identificar los problemas públicos a resolver.
- Identificar qué datos son necesarios disponer para poder resolverlos.
- Modelizar esos datos para definir una nomenclatura, definición y relaciones comunes.
- Definir qué tecnología hay que desplegar para poder capturar o generar dichos datos.
- Analizar qué capacidades de intervención, tanto públicas como privadas, se necesitan para resolver el problema.
Impulso de la interoperabilidad a través de una ontología común y un espacio de datos
Como resultado de esa definición de los 25 casos de uso se ha creado una ontología del turismo que esperan sirva como referencia mundial. La ontología tiene la vocación de generar un impacto significativo en el sector turístico, ofreciendo una serie de beneficios:
- Interoperabilidad: la ontología es esencial para establecer una estructura de datos homogénea y permitir una interoperabilidad global, lo que facilita la integración de información y el intercambio de datos entre plataformas y países. Al proporcionar un lenguaje común, definiciones y una estructura conceptual unificada, los datos pueden ser comparables y utilizables en cualquier parte del mundo. Los destinos turísticos y el tejido empresarial pueden comunicarse de manera más efectiva y ágil, impulsando una colaboración más estrecha.
- Transformación digital: al fomentar el desarrollo de tecnologías avanzadas, como la inteligencia artificial, las empresas turísticas, el ecosistema innovador o académico pueden analizar grandes volúmenes de datos de manera más eficiente. Esto es debido principalmente a la calidad de la información disponible y a que los sistemas comprenden mejor el contexto en el que operan.
- Competitividad turística: alineado con la cuestión anterior, la implementación de esta ontología contribuye a eliminar desigualdades en el uso y aplicación de la tecnología dentro del sector. Al facilitar el acceso a herramientas digitales avanzadas, tanto las instituciones públicas como las empresas privadas pueden tomar decisiones más informadas y estratégicas. Esto no solo eleva la calidad de los servicios ofrecidos, sino que también impulsa la productividad y competitividad del sector turístico español en un mercado global cada vez más exigente.
- Experiencia turística: gracias a la ontología, es posible ofrecer recomendaciones adaptadas a las preferencias individuales de cada viajero. Esto se logra mediante un perfilado más preciso basado en características demográficas y comportamentales, así como en las motivaciones específicas relacionadas con diferentes tipos de turismo. Al personalizar las ofertas y servicios, se mejora la satisfacción del cliente antes, durante y tras el viaje, y se fomenta una mayor fidelidad hacia los destinos turísticos.
- Gobernanza: el modelo ontológico está diseñado para evolucionar y adaptarse a medida que surgen nuevos casos de uso ante las demandas cambiantes del mercado. SEGITTUR está trabajando activamente en establecer un modelo de gobernanza que promueva la colaboración efectiva entre instituciones públicas y privadas, así como con el sector tecnológico.
Además, para resolver problemas complejos que requieren compartición de datos de diferentes fuentes, se ha creado la Plataforma de Innovación Abierta (PIA), un espacio de datos que facilita la colaboración entre los diferentes actores del ecosistema turístico, tanto públicos como privados. Esta plataforma permite compartir datos de manera segura y eficiente, potenciando la toma de decisiones basadas en datos. El PIA promueve un entorno colaborativo donde se comparten datos abiertos y privados para crear soluciones conjuntas que aborden desafíos específicos del sector, como la sostenibilidad, la personalización de la experiencia turístico o la gestión del impacto ambiental.
Impulso del consenso
Desde SEGITTUR también se están llevando a cabo diversas iniciativas para lograr el consenso necesario en la recopilación, gestión y análisis de datos relacionados con el turismo, a través de la colaboración entre actores públicos y privados. Para ello, en 2021 se creó el Ente Promotor de la Plataforma Inteligente de Destinos, que juega un papel fundamental al aglutinar a diversos actores para coordinar esfuerzos y acordar grandes líneas y directrices en el ámbito de los datos turísticos.
En resumen, España está avanzando en la recopilación, gestión y análisis de datos turísticos mediante la coordinación entre los actores públicos y privados, utilizando metodologías y herramientas avanzadas como la creación de ontologías, casos de uso y plataformas colaborativas como la PIA que aseguran una gestión eficiente y consensuada del sector.
Todo ello no solo está modernizando el sector turístico español, sino que también está sentando las bases para un futuro más inteligente, conectado y eficiente. Con su enfoque en la interoperabilidad, la transformación digital y la personalización de experiencias, España se posiciona como líder en innovación turística, lista para afrontar los desafíos tecnológicos del mañana.
Blog
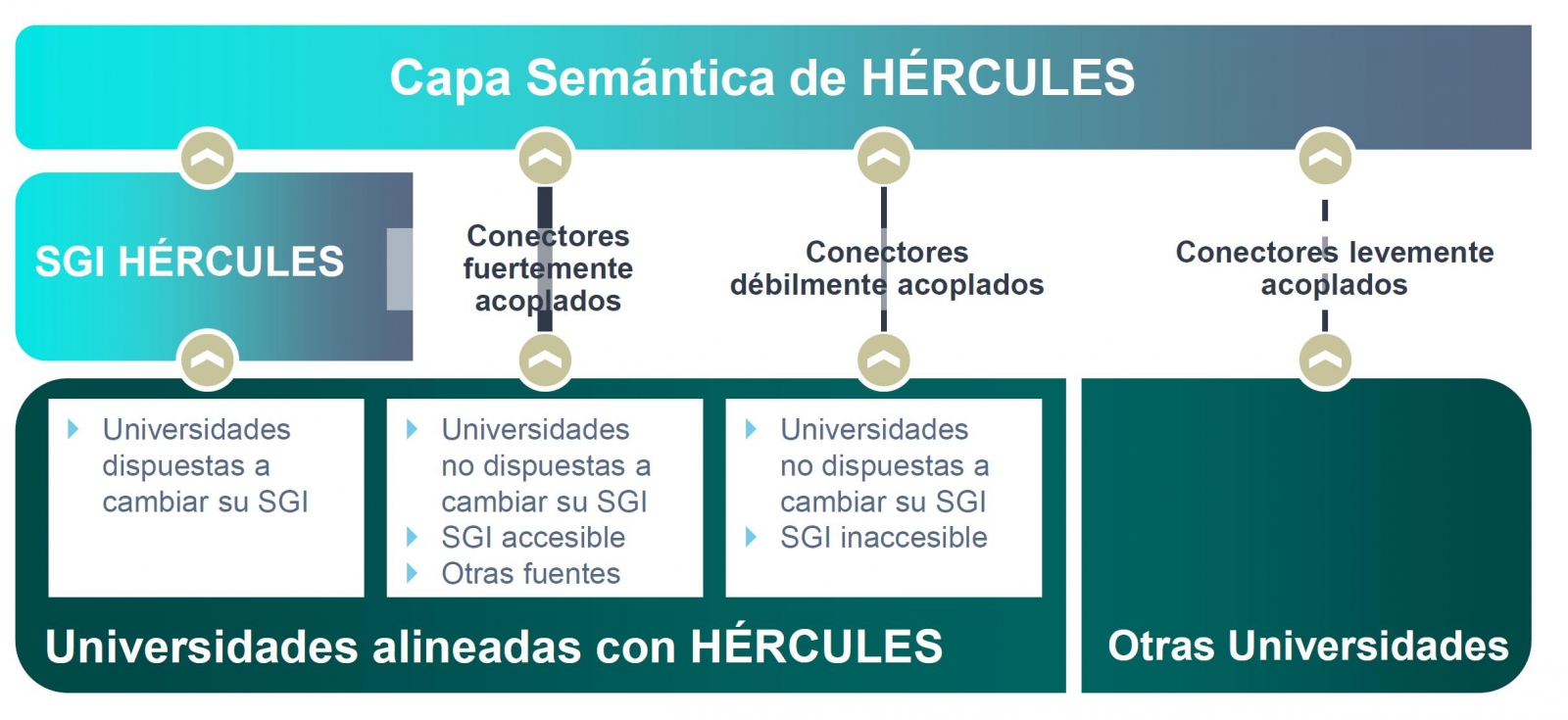
La iniciativa Hércules se inicia en noviembre de 2017, mediante un convenio entre la Universidad de Murcia y el Ministerio de Economía, Industria y Competitividad, con el objetivo de desarrollar un Sistema de Gestión de Investigación (SGI) basado en datos abiertos semánticos que ofrezca una visión global de los datos de investigación del Sistema Universitario Español (SUE), para mejorar la gestión, el análisis y las posibles sinergias entre universidades y el gran público.
Esta iniciativa es complementaria a UniversiDATA, donde varias universidades españolas colaboran para fomentar los datos abiertos en el sector de la educación superior mediante la publicación de conjuntos de datos a través de criterios estandarizados y comunes. En concreto se define un Núcleo Común con 42 especificaciones de datasets, de los cuales se han publicado 12 para la versión 1.0. Hércules, en cambio es una iniciativa específica del ámbito de investigación, estructurada en torno a tres pilares:
- Prototipo innovador de SGI
- Grafo unificado de conocimiento (ASIO) 1],
- Enriquecimiento de datos y análisis semántico (EDMA)
El objetivo final es la publicación de un grafo unificado de conocimiento donde queden integrados todos los datos de investigación que deseen hacer públicos las universidades participantes. Hércules prevé la integración de universidades a diferentes niveles, dependiendo de su disposición a reemplazar su SGI por el SGI de Hércules. En el caso de SGIs externos, el grado de accesibilidad que ofrezcan también tendrá implicación en el volumen de datos que puedan compartir a través del grafo unificado.
Organigrama general de la iniciativa Hércules
Dentro de la iniciativa Hércules, se integra el Proyecto ASIO (Arquitectura Semántica e Infraestructura Ontológica). El propósito de este sub-proyecto es definir una Red de Ontologías para la Gestión de la Investigación (Infraestructura Ontológica). Una ontología es una definición formal que describe con fidelidad y alta granularidad un dominio de discusión concreto. En este caso, el dominio de la investigación, que puede ser extrapolable a otras universidades españolas e internacionales (de momento el piloto se está desarrollando con la Universidad de Murcia). Es decir, se trata de crear un vocabulario de datos común.
Adicionalmente, a través del módulo de Arquitectura Semántica de Datos se ha desarrollado una plataforma eficiente para almacenar, gestionar y publicar datos de investigación del SUE, basándose en ontologías, con la capacidad de sincronizar instancias instaladas en diferentes universidades, así como la ejecución de consultas federadas distribuidas sobre aspectos clave de producción científica, líneas de investigación, búsqueda de sinergias, etc.
Como solución a este reto de innovación se han propuesto dos líneas complementarias, una centralizada (sincronización en escritura) y otra descentralizada (sincronización en consulta). En las próximas secciones se explica en detalle la arquitectura de la solución descentralizada.
Domain Driven Design
El modelo de datos sigue el enfoque Domain Driven Design, modelando entidades y vocabulario común, que pueda ser comprendido tanto por desarrolladores como expertos del dominio. Este modelo es independiente de la base de datos, del interfaz de usuario y del entorno de desarrollo, obteniendo una arquitectura de software limpia que permite adaptarse a los cambios del modelo.
Para ello se hace uso de Shape Expressions (ShEx), un lenguaje para validar y describir conjuntos de datos RDF, con sintaxis legible por humanos. A partir de estas expresiones se genera el modelo de dominio automáticamente y permite orquestar un proceso de integración continua (CI), tal y como se describe en la siguiente figura.
Proceso de integración continua mediante Domain Driven Design
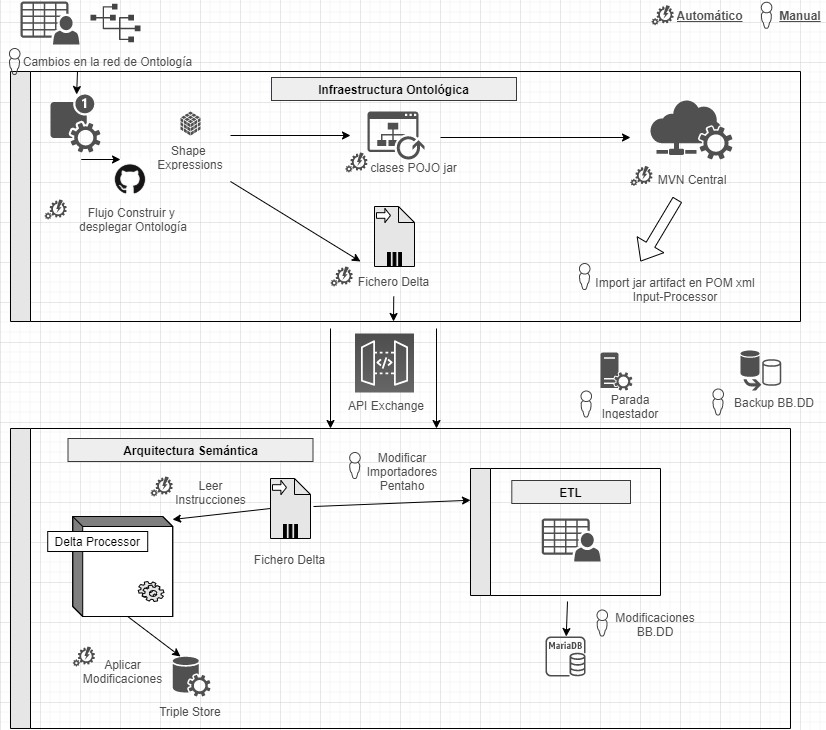
Mediante un sistema basado en de control de versiones como elemento central, se ofrece la posibilidad de que los expertos de dominio construyan y visualicen las ontologías multilingües. Estas a su vez se apoyan en ontologías tanto del ámbito de la investigación: VIVO, EuroCRIS/CERIF o Research Object, como ontologías de propósito general para la etiquetación de metadatos: Prov-O, DCAT, etc.
Linked Data Platform
El servidor de datos enlazados es el núcleo de la arquitectura, encargándose de renderizar la información sobre todas las entidades. Para ello recoge peticiones HTTP del exterior y las redirecciona a los servicios correspondientes, aplicando negociación de contenidos, la cual ofrece la mejor representación de un recurso basado en las preferencias del navegador para los distintos tipos de medios, idiomas, caracteres y codificación.
Todos los recursos se publican siguiendo un esquema de URIs persistentes diseñado a medida. Cada entidad representada mediante una URI (investigador, proyecto, universidad, etc) dispone de una serie de acciones para consultar y actualizar sus datos, siguiendo los patrones propuestos por Linked Data Platform (LDP) y el modelo de 5 estrellas.
Este sistema garantiza además el cumplimiento con los principios FAIR (Findable, Accesible, Interoperable, Reusable) y publica automáticamente los resultados de aplicar dichas métricas sobre el repositorio de datos.
Publicación de datos abiertos
El sistema de procesamiento de datos se encarga de la conversión, integración y validación de datos de terceras partes, así como la detección de duplicados, equivalencias y relaciones entre entidades. Los datos surgen de varias fuentes, principalmente el SGI unificado de Hércules, pero también de SGIs alternativos, o de otras fuentes que ofrecen datos en formato FECYT/CVN (Curriculum Vitae Normalizado), EuroCRIS/CERIF y otros posibles.
El sistema de importación convierte todas estas fuentes a formato RDF y los registra en un repositorio de propósito específico para datos enlazados, denominado Triple Store, por su capacidad para almacenar tripletas de tipo sujeto-predicado-objeto.
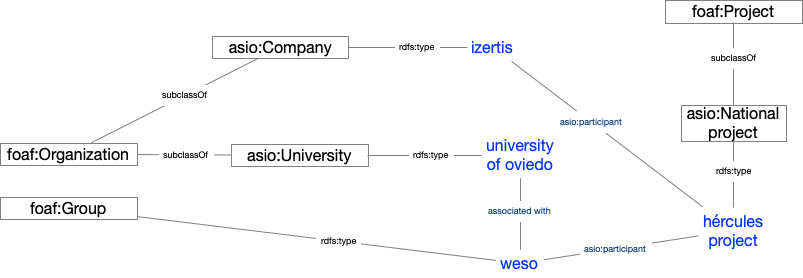
Una vez importados, se organizan formando un grafo de conocimiento, fácilmente accesible, permitiendo realizar inferencias y búsquedas avanzadas potenciadas por las relaciones entre conceptos.
Ejemplo de grafo de conocimiento describiendo el proyecto ASIO
Resultados y conclusiones
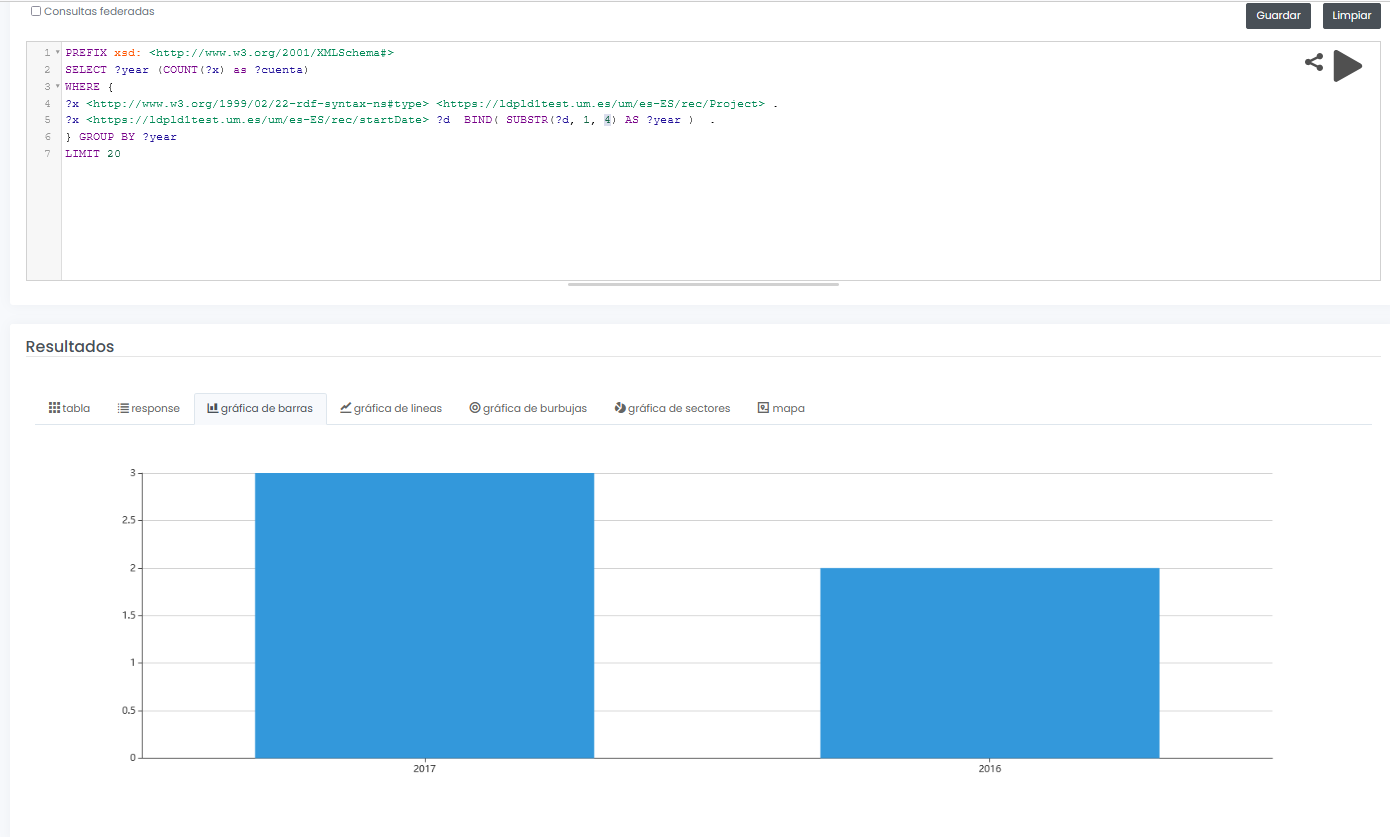
El sistema final no sólo permite ofrecer un interfaz gráfico para consulta interactiva y visual de datos de investigación, sino que además permite diseñar consultas SPARQL, como la que se muestra a continuación, incluso con la posibilidad de ejecutar la consulta de forma federada sobre todos los nodos de la red Hércules, y mostrar resultados de forma dinámica en diferentes tipos de gráficos y mapas.
En este ejemplo, se muestra una consulta (con datos limitados de prueba) de todos proyectos de investigación disponibles agrupados gráficamente por año:
PREFIX xsd: <http://www.w3.org/2001/XMLSchema#>
SELECT ?year (COUNT(?x) as ?cuenta)
WHERE {
?x <http://www.w3.org/1999/02/22-rdf-syntax-nes#type> <https://ldpld1test.um.es/um/es-ES/rec/Project> .
?x <https://ldpld1test.um.es/um/es-ES/rec/startDate> ?d BIND(SUBSTR(?d, 1, 4) as ?year) .
} GROUP BY ?year LIMIT 20
LIMIT 20
Ejemplo de consulta SPARQL con resultado gráfico
En definitiva, ASIO ofrece un marco común de publicación de datos abiertos enlazados, ofrecido como código libre y fácilmente adaptable a otros dominios. Para dicha adaptación, bastaría con diseñar un modelo de dominio específico, incluyendo la ontología y los procesos de importación y validación comentados en este artículo.
Actualmente el proyecto, en sus dos variantes (centralizada y descentralizada), se encuentra en proceso de puesta en pre-producción dentro de la infraestructura de la Universidad de Murcia, y en breve será accesible públicamente.
[1 Los grafos son una forma de representación del conocimiento que permiten relacionar conceptos a través de la integración de conjuntos de datos, utilizando técnicas de web semántica. De esta forma se puede conocer mejor el contexto de los datos, lo que facilita el descubrimiento de nuevo conocimiento.
Contenido elaborado por Jose Barranquero, experto en Ciencia de datos y computación cuántica.
Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Blog
La creciente preocupación de las autoridades europeas por la gestión de las habilidades digitales entre la población activa, especialmente los jóvenes, es una realidad que se acelera y cuya gestión no parece tener una solución fácil.
“Internet y las tecnologías digitales están cambiando el mundo. Pero los obstáculos existentes en internet hacen que los ciudadanos pierdan bienes y servicios, que las empresas de internet y las emergentes tengan su horizonte limitado, y que las empresas y las administraciones no puedan beneficiarse plenamente de las herramientas digitales”. Con esta contundente afirmación abre la Comisión Europea (CE) la sección web dedicada al mercado único digital. El mercado único digital es una de las prioridades estratégicas de la CE y, dentro de ella, una de las líneas de actuación es el desarrollo de las habilidades digitales entre la población europea en activo - en especial los jóvenes -.
A la hora de clasificar las habilidades digitales aparece el mismo problema que con la clasificación de las tecnologías emergentes. La mayoría de los esfuerzos en esta materia se centra en el establecimiento de una clasificación jerárquica de habilidades/tecnologías, que raramente es capaz de profundizar más allá de dos o tres niveles de profundidad.
La CE establece una clasificación de las competencias digitales en 5 categorías (siempre en el dominio de Internet):
-
Procesado de información
-
Creación de contenido
-
Comunicación
-
Resolución de problemas
-
Seguridad
En cada una de estas categorías, la Comisión propone un marco de trabajo donde asigna tres niveles de competencia de usuario (básico, independiente, experto). Para cada nivel de competencia se proponen afirmaciones estándar que ayuden al usuario a realizar una autoevaluación y ser capaz de establecer su nivel de competencia digital.
La cuestión que se plantea ahora en diversos foros es cómo dar un paso más allá de la pura autoevaluación de las competencias. Cuestiones del tipo "¿cómo realizar una búsqueda de términos relacionados con las habilidades digitales?" no son triviales de responder.
Cuando la clasificación de habilidades tiene uno o dos niveles de profundidad, basta con realizar una “búsqueda literal” del término a buscar. Pero, ¿qué ocurre si el árbol de términos relacionado con las habilidades digitales tiene miles de términos organizados de forma jerárquica?
Por ejemplo, supongamos que una empresa necesita de un perfil muy específico para una nueva posición en un proyecto de I+D. El perfil requerido es una persona que tenga conocimientos avanzados en la librería MLib Apache Spark. Se requiere que tenga más de 2 años de experiencia en el campo de Big data en streaming. Además de estas -las denominadas habilidades duras (hard skills)- se requiere que la persona disponga de una serie de habilidades sociales o habilidades blandas como capacidad de comunicar en público y trabajo en equipo.
¿Cómo localizamos a un perfil así en una base de datos de 400.000 empleados en todo el mundo?
Una posible solución a estas y otras cuestiones puede ser la construcción de una ontología de habilidades digitales en Europa.
Una ontología proporciona una organización jerarquizada de términos (taxonomía) y un conjunto de relaciones entre ellos, lo cual facilita la búsqueda - tanto literal como inferida- de términos y expresiones complejas. Esto es ya muy útil en sí mismo, pero si además se combina la estructura formal de una ontología con su implementación técnica en una herramienta tecnológica, se obtiene un potente producto tecnológico. Una implementación técnica de esta ontología permitiría, entre otros, realizar la siguiente búsqueda compleja de forma eficiente e inequívoca:
Localizar a una persona CON habilidades técnicas de MLib que además TENGA más de 2 años de experiencia en Big Data EN streaming y que además TENGA las habilidades blandas DE trabajo en equipo y capacidad de comunicación a nivel intermedio.
En caso de existir una ontología subyacente, en el ejemplo anterior, todos los términos subrayados tendrían un identificador único, así como las relaciones (mayúsculas). El motor de búsqueda semántico sería capaz de identificar la consulta anterior, extraer los términos clave, comprender las relaciones (CON, TENGA, más, DE, etc.) y ejecutar la búsqueda contra la base de datos de empleados, extrayendo aquellos resultados que encajasen con la búsqueda.
Un ejemplo muy claro de utilización de una ontología para realizar búsquedas complejas en bases de datos inmensas es SNOMED-CT. Se trata de un vocabulario estándar para buscar términos clínicos en bases de datos de pacientes. El dominio clínico es especialmente indicado para el desarrollo de ontologías por la compleja estructura inherente a los términos clínicos y sus relaciones.
Si bien existen herramientas y métodos clásicos de organización de la información basados en bases de datos tradicionales y modelos relacionales, las ontologías y sus implementaciones tecnológicas ofrecen mayor flexibilidad, escalabilidad y nivel de personalización a diferentes subcampos.
Precisamente las características de flexibilidad y alta escalabilidad se vuelven fundamentales a medida que los repositorios de datos abiertos (opendata) se vuelven cada vez mayores y diversos. El portal europeo para los datos abiertos contiene más de 12.000 conjuntos de datos clasificados por temas. Por su parte, la web especializada en ciencia de datos, Kaggle, alberga 9000 conjuntos de datos sobre los que, anualmente, se organizan concursos que premian a aquellos que mejor analicen y extraigan información útil de estos conjuntos. En definitiva, el volumen de datos a disposición de la sociedad no hace más que aumentar año tras año y las ontologías cobran fuerza como una potente herramienta para la gestión de la información oculta bajo ese manto de datos en crudo.
Contenido elaborado por Alejandro Alija,experto en Transformación Digital e Innovación.
Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Blog
La salud es uno de los campos de desarrollo prioritario en este siglo. La mayoría de los analistas coinciden en que la gestión de la salud - desde todas las ópticas posibles - cambiará de forma radical en los próximos años. El análisis de los datos de salud marcará el camino a seguir en las épocas venideras.
La esperanza de vida de los países desarrollados aumenta a medida que avanza el siglo. En los últimos veinte años, la esperanza de vida (EV) de muchos países desarrollados ha superado la barrera de los 80 años de media. Japón, España, Suiza, Singapur, entre otros, se sitúan ya por encima de los 83 años de esperanza de vida y la tendencia continúa con una tasa de crecimiento continuado.
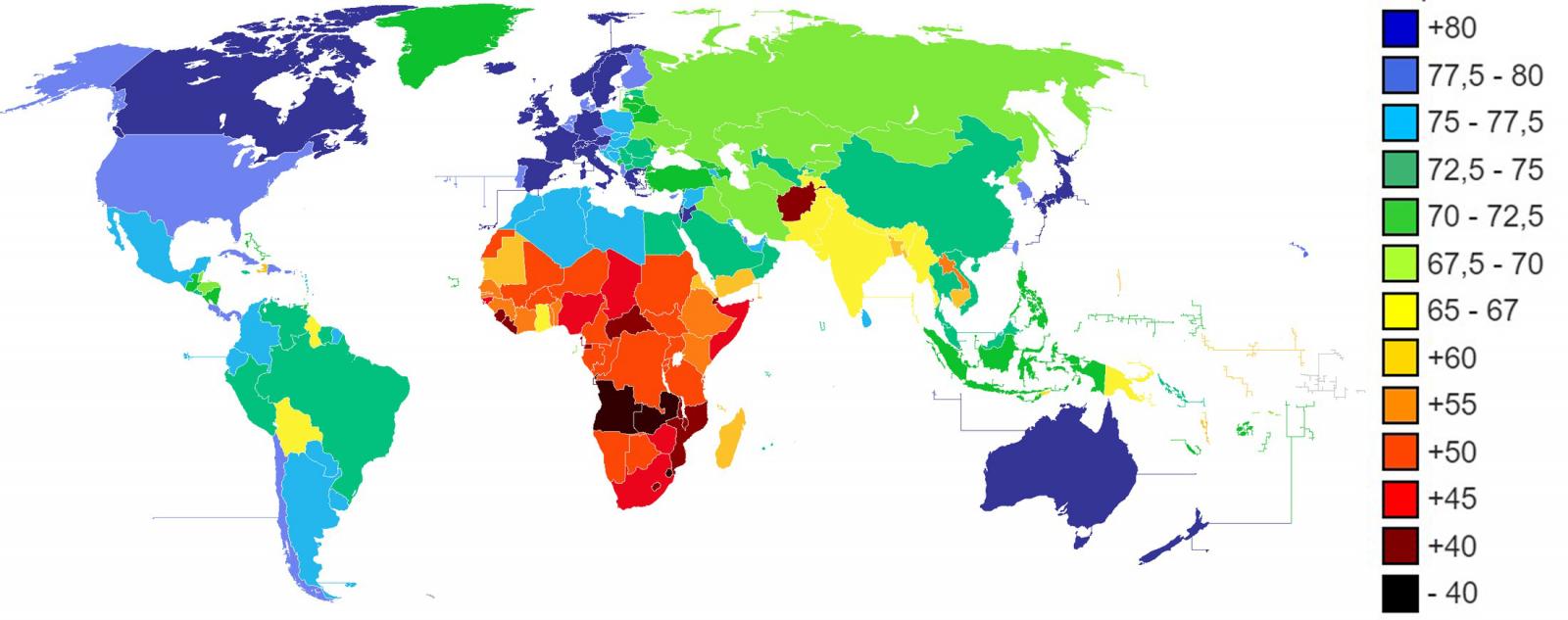
Figura 1. Esperanza de vida en años según el CIA World Factbook 2013.
Valga esta introducción sobre la esperanza de vida para motivar el tema central de este artículo. A medida que envejecemos, las enfermedades que nos afectan van evolucionando. Una mayor esperanza de vida no significa necesariamente una mejor calidad de vida en la etapa adulta y anciana. Para vivir más años es necesario desarrollar un mejor cuidado de la salud. Las sociedades modernas necesitan realizar una transición satisfactoria desde el tratamiento a la prevención. Es decir: Prevenir antes que curar.
Pero prevenir pasa, necesariamente, por conocer mejor los riesgos y anticiparse a futuras complicaciones. El análisis de los datos relacionados con nuestra salud es de capital importancia para afrontar esta transición. No son pocas las tareas y acciones necesarias antes de llegar a establecer estrategias continuadas de análisis de datos de salud.
Los datos relacionados con la salud son, por naturaleza, datos de carácter sensible. Los datos personales de salud, tienen implicaciones directas sobre nuestras relaciones laborales y personales y pueden llegar a impactar de forma muy notoria sobre nuestra economía -a nivel personal como de sociedad-. Los desafíos a los que se enfrenta el análisis de datos de salud son, entre otros:
-
Generación de conjuntos de datos (datasets) públicos.
-
Mecanismos estándar de anonimización de datos de salud.
-
Herramientas de recolección de datos de salud en tiempo real.
-
Modelos de datos de salud consensuados por la comunidad científica.
-
Herramientas de análisis de datos de salud preparadas para grandes ingestas y altos volúmenes de datos.
-
Perfiles especialistas, tanto conocedores del dominio de la salud como científicos de datos especializados en este campo (datos semi-estructurados y tecnologías semánticas).
Transformación digital del sector salud
La transformación digital del sector salud representa uno de los mayores desafíos para instituciones y sistemas de salud tanto públicos como privados. Buena parte de los centros hospitalarios de países desarrollados han comenzado a digitalizar parte de los datos más importantes en relación a nuestra salud. Especialmente, aquellos datos registrados en las visitas presenciales a centros de salud y hospitales. La historia clínica digital o EHR por sus siglas en inglés (Electronic Health Records) así como las pruebas diagnósticas (por ejemplo, imágen médica o análisis clínicos) son los registros con mayor grado de digitalización. Si bien es cierto que el grado de digitalización de estos ejemplos puede llegar a ser alto, la forma en la que se ha planteado es diferente por países y sistemas. Convertir en información digital las históricas clínicas analógicas añade muy poco valor comparado con el esfuerzo y la inversión necesaria. Sin embargo, afrontar la digitalización de las historias clínicas con el foco puesto en el posterior análisis inteligente de los datos puede suponer una revolución con un impacto incalculable. Por ejemplo, la implementación de ontología especialmente diseñada para el dominio médico como SNOMED-CT cambia de forma radical la explotación futura de los datos médicos y habilita una capa superior de inteligencia apoyada en la futura Inteligencia Artificial como asistente de los médicos y enfermeras del futuro.
Algunos repositorios públicos
Existen diferentes repositorios donde encontrar conjuntos de datos abiertos con caracter de salud. La mayor parte de datos disponibles consistente en estadísticas relacionadas con indicadores de salud. Sin embargo, existen repositorios más especializados donde es posible encontrar conjuntos de datos sobre los cuales realizar analítica de datos avanzada.
Por ejemplo, los sistemas de salud de EEUU y Reino Unido respectivamente, publican sus datos de salud en los repositorios:
Otras organizaciones multi-país, como la Organización Mundial de la salud (OMS) o la ONG Unicef también disponen de repositorios de datos abiertos:
-
UNICEF ofrece estadísticas sobre la situación de las mujeres y los niños en todo el mundo.
-
World Health Organization ofrece estadísticas mundiales sobre el hambre, la salud y las enfermedades.
Más allá de los datos estadísticos, el sitio web especializado en ciencia de datos Kaggle convoca periódicamente competiciones abiertas en las que los equipos pueden participar para resolver desafíos basados en datos. Por ejemplo, en una de las competiciones de Kaggle, el desafío consistía en predecir reingresos hospitalarios por diabetes. Para resolver el desafío, se disponía de un conjunto de datos (debidamente anonimizado) compuesto por 65 registros de pacientes con diabetes y 50 campos que incluyen información de: género, edad, peso, etc.

Figura 2. Extracto del conjunto de datos disponible para el desafío de diabetes.
En resumen, el análisis sistemático de datos de salud abre las puertas de la medicina predictiva. Para habilitar tecnologías que asistan a los profesionales sanitarios del futuro es necesario construir estrategias de datos sostenibles, escalables y duraderas. Recolectar, almacenar, modelar y analizar (RAMA) datos de salud es la clave para un futuro en el que el cuidado de la salud sea algo más que un mero contacto asistencial con los pacientes.
Contenido elaborado por Alejandro Alija,experto en Transformación Digital e Innovación.
Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Noticia
La iniciativa de datos abiertos del Gobierno de Aragón surgió mediante acuerdo en 2012 con el objetivo de crear valor económico en el Sector TIC a través de la reutilización de la información pública, el aumento de la transparencia y el fomento de la innovación. Todo ello para favorecer el desarrollo de la sociedad de la información y la interoperabilidad de datos en la Administración. Gracias a este acuerdo los datos abiertos se incorporan dentro de las estrategias del Gobierno de Aragón, quien se compromete a la efectiva apertura de datos públicos que obran en su poder, entendiendo como públicos todos aquellos datos no sujetos a restricciones de privacidad, seguridad o propiedad.
En este contexto, en el año 2013, se pone en marcha el portal web de datos abiertos del Gobierno de Aragón. Desde entonces, Aragón Open Data ha tenido un crecimiento exponencial, impulsado por la unidad responsable de su gestión, actual Dirección General de Administración Electrónica y Sociedad de la Información, y cómo no, por los diferentes proveedores de datos: unidades públicas en su mayoría del Gobierno autonómico. Estos proveedores han hecho posible que sus datos se ofrezcan bajo la filosofía de los datos abiertos desde un único punto de acceso.
Desde la creación del portal se han desarrollado más servicios, como por ejemplo la Aragopedia, Presupuesto u Open Analytics Data. Todos ellos giran en torno a la reutilización y disposición de datos abiertos mediante servicios que facilitan su uso e interpretación. En esta línea, Aragón Open Data ofrece diversas aplicaciones de uso y explotación de sus medios, junto con materiales de formación, sin olvidar la promoción de APIs y servicios que den valor añadido a los propios datos. Por estos trabajos la iniciativa fue seleccionada como única experiencia española en la Open Data Leader's Network celebrada en Londres en 2016.
Entre los recursos más descargados del portal destacan: Servicio de descarga cartográfica e:1/1000 por municipio, Contratos Gobierno de Aragón, listado de los Municipios de Aragón o los calendarios anuales de festivos de la Comunidad Autónoma y sus provincias.
En este amplio y diverso marco, Aragón Open Data también inició en 2016 un trabajo de identificación e integración de la diversidad de datos generados por el Gobierno de Aragón para facilitar su disposición y apertura. El primer paso fue generar una ontología, la Estructura de Información Interoperable de Aragón EI2A. Para ello contaron con la colaboración de las unidades que disponen, crean y gestionan datos, participando diferentes áreas del Gobierno de Aragón como por ejemplo agricultura, hacienda, cultura, información de datos geográficos o medio ambiente, entre otras.
La Estructura de Información Interoperable de Aragón (EI2A) homogeniza estructuras, vocabularios y características dentro del marco de Aragón Open Data para resolver, en buena parte, la problemática de la diversidad y heterogeneidad de datos existentes en la Administración. Una heterogeneidad que es fiel reflejo de la realidad y competencias de la Administración, pero que dificulta su apertura y reutilización.
El EI2A describe el modelo conceptual y lógico de los datos generados por el Gobierno de Aragón representando entidades, propiedades y relaciones. La estructura está destinada a apoyar la interoperabilidad de los datos bajo su dominio mediante su estandarización. La Estructura de Información Interoperable de Aragón tiene como objetivo relacionar el contenido y elementos de los diferentes conjuntos de datos para que puedan ser normalizados y explotados de manera conjunta en el Gobierno de Aragón, al aunar, simplificar y dar homogeneidad a los mismos, independientemente de su procedencia, finalidad, modelo, entidades y relaciones que los componen.
Es en el 2017 y 2018 cuando el EI2A se convierte en una realidad al ponerse en práctica con algunos de los datos de Aragón Open Data, surgiendo el proyecto Aragón Open Data Pool. Aragón Open Data Pool es un proyecto piloto e innovador que demuestra la importancia de centralizar datos y servirlos para favorecer su uso y explotación. Open Data Pool está disponible desde diciembre de 2018 siendo su base el EI2A.
Como resultado: más de 140 fuentes de datos de organismos y finalidades bien diferenciadas, que estaban abiertas previamente en Aragón Open Data (API GA_OD_Core), se han normalizado conforme al EI2A, para así, desde un único punto y con los mismos criterios de consulta, poder ser explotados en conjunto y ofrecidos de manera sencilla.
Los datos de este proyecto cuentan con los estándares de la web semántica para su explotación, consulta y uso (SPARQL endpoint), que es su verdadero potencial. Ello permite poder consultar y explotar datos independientemente de sus características y vocabularios e incluso también permite federar datos de portales de diferentes administraciones como Aragón Open Data (bajo el EI2A) y Open Data Euskadi ( bajo ELI).
Otro de los aspectos destacables es que se ha orientado su uso a un usuario no técnico, al permitir una navegación más intuitiva y sencilla a través de las relaciones entre datos, poniendo en práctica la interoperabilidad mediante la relación de datos diversos a través de una navegación web corriente.
Con este proyecto, que ha contribuido a conocer mejor la realidad de los datos incorporados a Aragón Open Data Pool bajo el EI2A, se confirma la necesidad de la normalización de los datos en origen, para abrirlos y ofrecerlos en Aragón Open Data, facilitando su uso y reutilización a nivel interno de la Administración y hacia fuera de esta. Y es aquí donde entra en juego el cambio necesario que buscan las directrices de interoperabilidad y reutilización de datos para su apertura en el punto de acceso de datos abiertos del Gobierno de Aragón, que a día de hoy corresponde a un proyecto normativo. Entre sus ejes de acción, este proyecto consiste en identificar mejor los datos, mejorar su calidad en origen, y respaldar el proceso desde la creación de los datos por las diferentes unidades productoras, a nivel interno, hasta su apertura en Aragón Open Data. De esta forma se busca seguir creciendo, mejorando y orientarse a que cualquier interesado, instituciones, desarrolladores o el sector infomediario puedan utilizar la información, los datos y los servicios disponibles para cualquiera de sus intereses, contribuyendo así al desarrollo de la sociedad de la información.
Entrevista
qMe-Aporta, tercer premiado en el Desafío Aporta 2017, es un prototipo para la construcción intuitiva de consultas, en lenguaje natural guiado, sobre la base de conocimiento de datos.gob.es. Se trata de un sistema que guía al usuario en la construcción de la pregunta, mostrando múltiples alternativas para iniciar y continuar la pregunta. No sólo utiliza términos del sistema (metadatos), también los datos y sus sinónimos. Estas preguntas se pueden hacer en varios idiomas.
Hablamos con Mariano Rico Almodóvar, investigador de la Universidad Politécnica de Madrid (UPM) y responsable de esta iniciativa, para que nos cuente cómo está llevando a cabo este proyecto.
¿En qué punto del desarrollo de qMe-Aporta te encuentras actualmente?
Estamos a la espera de financiación. Es una lástima que un sistema tan útil desde nuestro punto de vista para la reutilización de los datos de las administraciones públicas esté parado, pero así es. Hicimos el esfuerzo, a coste cero, de analizar la aplicación del sistema Dylan-Q (el núcleo de qMe-Aporta) a los datasets del Desafío Aporta (datos.gob.es) pero aún no hemos podido crear el sistema.
Estoy aplicando Dylan-Q a un proyecto europeo llamado SlideWiki, y por ahí esperamos lograr la visibilidad necesaria para lograr financiación privada. También confiamos en que el Catálogo de Tecnologías UPM, del que forma parte la tecnología Dylan-Q, nos dé suficiente visibilidad como para atraer clientes o inversores.
¿En qué fuentes de información, públicas o privadas, se basa su proyecto?
La tecnología Dylan-Q se aplica a datasets RDF, el formato estándar de datos semánticos. En el caso del Desafío Aporta nos centramos en los datasets RDF que hay en datos.gob.es, donde hay datos de todo tipo: comercio, demografía, educación, y un largo etcétera. De los 2018 datasets que había disponibles en la fecha del concurso, la mayoría no eran datasets RDF. Pero conviene destacar que disponemos de herramientas para convertir a RDF datasets (ficheros y bases de datos) en cualquier formato.
Las tecnologías semánticas nos permiten una integración de información mucho más sencilla que con las técnicas tradicionales. Si unimos a esto la lexicalización de las ontologías y un poco de magia (tenemos un informe positivo de patente de la tecnología Dylan-Q), logramos sistemas que permiten hacer consultas guiadas en lenguaje natural sobre cualquier conjunto de datos RDF.
¿Cree que iniciativas como el Desafío Aporta 2017 pueden ayudar a empresas y emprendedores a poner en marcha sus proyectos de reutilización de datos abiertos? ¿Qué otras iniciativas de este tipo cree que deberían ponerse en práctica?
La visibilidad que nos proporcionan estos premios es muy importante, pero son necesarios otros elementos para poder materializar estos proyectos. Es frecuente que las empresas se interesen por proyectos que conocen a través de premios como éste, pero suelen exigir el desarrollo a coste cero de un prototipo (lo que en la jerga se denomina, “prueba de concepto”). Además, aunque los resultados del prototipo sean buenos, no se garantiza la implementación completa del proyecto. También es habitual que los potenciales inversores exijan dedicación exclusiva y sin sueldo por un periodo de hasta dos años. Se tiende a concebir la innovación como una lotería en la que se sabe que una de cada diez start-ups tendrá éxito y permitirá multiplicar considerablemente su inversión, pero, por lo general, no se siguen criterios de inversión a largo plazo y solo se pretende rentabilizar la inversión en un plazo típico de dos años. En estas condiciones es muy difícil emprender.
En países como Alemania o Estados Unidos está más extendida entre las empresas la idea de inversión a fondo perdido. Entienden que para ganar hay que arriesgar, y están dispuestas a asumir el coste del riesgo. No hay miedo al “fracaso”, que se ve como algo natural en los procesos de innovación. Por el contrario, está muy extendido en las empresas de nuestro país que el riesgo lo debe asumir la Administración o, como es nuestro caso, los investigadores. Un siglo después de la frase de Unamuno “¡Qué inventen ellos!”, la situación parece no haber cambiado. Y no creo que sea una cuestión de mayor o menor economía, o de mayor o menor crisis económica, excusas tradicionales para condicionar la inversión en I+D+i, sino de una mayor cultura de inversión en innovación. De hecho, sabemos desde hace tiempo que es la inversión en I+D+i lo que hace que los países sean más o menos prósperos, y no al revés.
Pero no desfallecemos. Seguimos presentándonos a todas las reuniones que nos solicitan. Soñamos con una empresa que esté dispuesta a arriesgar una pequeña cantidad, digamos 30 mil euros, para que le hagamos un prototipo adaptado a su negocio y a una muestra de sus datos, durante 6 meses. Si ese prototipo le convence, haríamos un nuevo proyecto usando todos sus datos y todo su modelo de negocio. ¿Quién quiere ser el primero?.
Pero pese a todo lo dicho, debo insistir en que Iniciativas como Aporta, o como las que promueve el Centro de Apoyo a la Innovación Tecnológica (CAIT) de la UPM, son excelentes para acercar a tecnólogos y empresas. Debería haber encuentros de este tipo con más frecuencia.
Como usuario de datos abiertos, ¿qué retos se ha encontrado a la hora de reutilizar la información pública? ¿Cómo los ha solucionado?
El reto principal ha sido, y sigue siendo, encontrar el dataset más adecuado a nuestras necesidades. A veces es un único dataset, pero la mayoría de las veces queremos varios datasets inicialmente no relacionados entre sí. Creo que se ilustra con la frase “en un mar de datos, pescamos con una caña”. Necesitamos herramientas más potentes para poder pescar de forma más eficiente.
La búsqueda de información es un problema difícil cuando el volumen de datos aumenta, no tanto por el número de datos de un tipo dado como por el número de tipos de datos y las relaciones que hay entre ellos. Las tecnologías semánticas nos permiten relacionar los tipos de datos y dotarles de significado, por lo que podemos abordar este problema con más probabilidades de éxito.
¿Qué actuaciones considera que España debe priorizar en materia de disposición de datos?
Creo que hay que repartir claramente las tareas. Por una parte, las administraciones locales deben recopilar los datos. Por otra, la Administración general debe proporcionar las herramientas necesarias para que las administraciones locales incorporen de forma sencilla y eficiente los datos recopilados. La iniciativa datos.gob.es trabaja en esta línea, pero aún se puede ir más allá. Por ejemplo, es necesaria la integración de los datos recopilados por las administraciones locales, esto es, relacionar los tipos de datos con otros tipos de datos de otros datasets. Podría facilitarse mediante el uso de las tecnologías semánticas. Una vez integrada la información, la Administración podría ofrecer nuevos servicios a los usuarios, como el que proporcionaría qMe-Aporta, y muchos otros que todavía no imaginamos.
Para terminar, ¿cuáles son sus planes de futuro? ¿Están inmersos o tienen en mente algún otro proyecto de reutilización de datos abiertos?
En nuestro grupo de investigación tenemos varios proyectos que utilizan datos abiertos, en lo que se ha denominado “ciencia ciudadana”, como Farolapp (http://farolapp.linkeddata.es), o Stars4All (http://stars4all.eu), pero quizás nuestra principal contribución es la DBpedia del español (es.dbpedia.org). Tenemos un proyecto con la multinacional española TAIGER para aumentar la calidad de los datos de la DBpedia del español, y hemos desarrollado varias técnicas con muy buenos resultados. En junio (2018) hemos organizado el primer congreso internacional de grafos de conocimiento aplicados a turismo y viajes, donde hemos constatado la importancia que tiene este sector que representa el 14% del PIB español y el 10% mundial. Pensamos que la información almacenada en la DBpedia del español puede ser de mucha utilidad para este sector económico. Hay que saber que el 40% de los datos de la DBpedia del español sólo se encuentran en nuestra DBpedia.
La mayor parte de las técnicas que hemos aplicado sobre la DBpedia se pueden aplicar a otros conjuntos de datos, por lo que los datos abiertos se pueden beneficiar de estas técnicas.
Afortunadamente, seguimos investigando y desarrollando proyectos donde aplicar nuestros conocimientos sobre tecnologías semánticas, procesamiento de lenguaje natural y aprendizaje automático (machine learning). Querría aprovechar para agradecer a los responsables del grupo de investigación, Asunción Gómez Pérez y Oscar Corcho, la confianza que han depositado en nosotros, y el tiempo que nos han permitido dedicar a este concurso.
Noticia
Para organizar (clasificar, describir, indexar) el conocimiento, existen varias herramientas documentales de organización. Un extracto de ellas, ordenadas de las más simple (el menos formalizado y con menos reglas) a la más compleja (más formalizado y con más reglas) el siguiente:
- Vocabularios controlados
- Taxonomías
- Tesauros
- Ontologías.
Un vocabulario controlado es una simple lista de términos que tienen asignado un significado concreto y que se disponen a priori y que se usan para describir el conocimiento.
Por ejemplo, las provincias del territorio español - (Asturias, Illes Balears, Valladolid) con las que puede etiquetar cualquier documento y que está descritas en el Anexo V del Documento BOE-A-2013-2380 sobre “Norma Técnica de Interoperabilidad de Reutilización de recursos de la información”.
Una taxonomía es un vocabulario controlado, donde los términos se organizan de manera jerárquica (con una estructura de árbol), desde los términos más generales a los más específicos, incluyendo los relacionados.
Un ejemplo sería la taxonomía de sectores primarios y los temas relacionados de cada uno (por ejemplo, sector primario “Medio ambiente” que incluye los temas “Meteorología”, “Geografía”, “Conservación fauna y flora”). Los sectores primarios definidos sirven para describir un conjunto de datos en el catálogo de datos de datos.gob.es. Esta taxonomía está definida en el Anexo IV del Documento BOE-A-2013-2380 sobre “Norma Técnica de Interoperabilidad de Reutilización de recursos de la información”.
Un tesauro es una taxonomía con algunas relaciones “extra”:
- Relaciones de sinonimia o preferencia: entre el término preferido (TP/USE) o descriptor y el término no preferido (TNP/UF).
- Relaciones jerárquicas de tipo todo-parte o clase-subclase: es decir, entre los términos más amplios (TA/BT) y los términos más específicos (TE/NT)
- Relaciones asociativas: entre términos relacionados (TR/RT) de forma pragmática, es decir, no de forma jerárquica ni de sinonimia
AGROVOC es un tesauro que organiza conceptos relacionados con los ámbitos de interés de la FAO, como son la agricultura (principalmente), la alimentación, la nutrición, la pesca, las ciencias forestales o el medio ambiente. Por ejemplo, el concepto “Explotaciones piscícolas” está dentro de un concepto más amplio “Explotaciones agrarias” (cuyo sinónimo es “granja”, que además tiene otras relaciones.
Una ontología, siguiente escalón de organización del conocimiento, es la definición formal de tipos, propiedades, y relaciones entre conceptos de un dominio de discusión concreto. Y entendemos como definición formal, aquella que codifica el conocimiento basándose en lógica formal, como una colección de asertos (pudiendo así ser procesado por una máquina que estaría en disposición de realizar inferencia de nuevo conocimiento).
Un ejemplo de ontología sería FOAF (Friend Of A Friend, literalmente "Amigo de un Amigo"), que sirve para describir a las personas, sus actividades y sus relaciones con otras personas y objetos (“Ana conoce a Águeda”, “El correo de Ana es <ana@example.org>” …)
No hay una regla de oro para seleccionar la herramienta a utilizar, sino que para cada caso habrá que elegir aquella cuyo nivel de complejidad sea el más adecuado, siempre intentando elegir las opciones más sencillas, siguiendo el principio KISS (Keep it Simple, Stupid!) que nos dice que la simplicidad debe ser un objetivo clave del diseño, y evitar cualquier complejidad innecesaria. Conviene recordar que el primer paso, antes de crear una nueva herramienta documental de organización, es realizar una búsqueda, por si ya existiera alguna disponible para el cometido planteado y que pueda ser reutilizada.
Noticia
La Semantic Sensor Network Ontology (SSN) es una ontología para describir sensores y sus observaciones, es decir, los datos físicos que miden los dispositivos. Este vocabulario está destinado a desempeñar un rol crucial en la aplicación de las tecnologías semánticas en ámbitos de aplicación relacionados con las Smart Cities y el Internet of Things (IoT), y, por tanto, tiene potenciales usos en multitud de dominios, por ejemplo, para cuestiones de control medioambiental (calidad del aire y del agua), agricultura de precisión, gestión del tráfico, integración de procesos de control sanitarios, etc.
La ontología SSN es un vocabulario OWL elaborado por el W3C, en colaboración con Open Geospatial Consortium (OGC), para definir un estándar general de descripción de redes de sensores alineado con las tecnologías de la Web Semántica y el paradigma Linked Data. Actualmente se encuentra en fase de “Working Darft”, desde el 4 de mayo de 2017. Dada la multitud de escenarios y casos de uso de esta ontología, su diseño está basado en una arquitectura modular (horizontal y vertical) que permita su extensión de forma natural a partir de un vocabulario mínimo común. Este vocabulario se ha denominado SOSA, de acuerdo a sus conceptos principales:
-
Sensor (sensores): dispositivos que miden una o variables magnitudes físicas: por ejemplo, acelerómetros, giroscopios, barómetros, etc.
-
Observation (observaciones): el valor real o estimado de una magnitud física.
-
Sample (muestras): ejemplos representativos de una determinada magnitud.
-
Actuator (actuadores): dispositivo que modifican magnitudes físicas a partir de instrucciones: por ejemplo, un ventilador o el automatismo de una puerta.
El siguiente diagrama ilustra este diseño modular de la ontología SS:

Fuente: Ontologías SOA y SSN con sus respectivos módulos. W3C
Uno de los aspectos más destacables de esta ontología SSN es, como se ha comentado, la participación del OGC como parte integrante del proceso. Esto significa que la versión final del documento será un estándar conjunto de las dos organizaciones: W3C y OGC. Por otro lado, se ha trabajado en la compatibilidad de SSN con los estándares OGC existentes para la anotación de sensores y observaciones. En concreto con:
-
OGC Observations and Measurements standard. Vocabulario XML para la descripción del modelo conceptual de Observations and Measurements (O&M) para la publicación de observaciones ambientales, publicado conjuntamente por el OGC y la organización ISO (en este caso como estándar ISO/DIS 19156).
-
OGC Sensor Model Language (SensorML). Vocabulario XML para describir sensores, actuadores, así como los procesos de medición y transformación de observaciones.
En los próximos meses se esperan contribuciones y revisiones de esta primera definición del estándar a nivel internacional, así como implementaciones de referencia que permitan pasar a la siguiente fase en el proceso de estandarización del vocabulario. En concreto se espera una amplia participación desde el universo de datos abiertos, y especialmente de proyectos ligados al desarrollo del concepto de las Smart Cities.
Entrevista
Asunción Gómez-Pérez es ingeniera informática, máster en Ingeniería del Conocimiento, doctorado en Informática y máster en Dirección y Administración de Empresas.
Ha publicado más de 150 artículos y es autora y coautora de varios libros sobre Ingeniería Ontológica e Ingeniería del Conocimiento. Ha sido directora del comité de programa de ASWC'09, ESWC'05 y EKAW'02 y coorganizadora de numerosos talleres en ontologías.
En la actualidad, dirige el Departamento de Inteligencia Artificial y el Ontology Engineer Group (Grupo de Ingeniería Ontológica) de la Universidad Politécnica de Madrid (UPM).
Participa, también, en iniciativas de Datos enlazados (Linked Data) de instituciones como la Biblioteca Nacional de España.
--
Oscar Corcho, por su parte, es Profesor Titular de Universidad en el citado Departamento de Inteligencia Artificial y miembro, también, del Grupo de Ingeniería Ontológica.
Ha trabajado como investigador Marie Curie en la Universidad de Manchester y como gestor de investigación en la empresa iSOCO. Es licenciado en informática, Máster en Ingeniería del Software y Doctor en Ciencias de la Computación e Inteligencia Artificial por la UPM.
Sus actividades de investigación se centran en la e-Ciencia Semántica, la Web Semántica y la Ingeniería Ontológica. Entre otros numerosos proyectos de relieve, ha participado en el International Classification for Patient Safety (ICPS), financiado por la Organización Mundial de la Salud.
Ha publicado más de 100 artículos en revistas, conferencias y workshops y es autor de varios libros, entre ellos el manual de referencia “Ontological Engineering".
¿Cómo definiríais el papel que desarrolla el Ontology Engineering Group respecto de la información del sector público?
Nuestro grupo de investigación ha sido pionero en España en la generación y publicación de Linked Data de calidad de varios conjuntos de datos del sector público estatal. Concretamente, somos responsables de la publicación de Linked Data de conjuntos de datos del Instituto Geográfico Nacional (a través de la Web), la Biblioteca Nacional y la Agencia Estatal de Meteorología.
En todos estos casos, hemos trabajado con miembros de estas organizaciones durante el proceso de generación de vocabularios, generación de datos en RDF y publicación de los datos como Linked Data.
También hemos participado en iniciativas trasnacionales, como la del observatorio Otalex con Portugal. En todas estas iniciativas se han utilizado vocabularios consensuados por las comunidades implicadas, tecnologías propuestas por el W3C, y un mismo enfoque metodológico.
Se destaca la inclusión de contenidos de “provenance” y licencias de uso en todas ellas.
Asimismo, somos miembros activos del grupo de trabajo del W3C sobre Linked Data gubernamental y hemos propuesto, entre otros, un documento de buenas prácticas sobre la generación de Linked Data en el sector público.
Igualmente, hemos participado en otros grupos de trabajo que de forma indirecta son de utilidad para el sector público. A modo de ejemplo, hemos participado en el Semantic Sensor Network Incubator Group que ha desarrollado una ontología de sensores que es de gran utilidad para representar datos dinámicos como pueden ser datos metereológicos, tráfico en ciudades, niveles de polución, etc. Además, ha participado en el Library Linked Data incubator group proporcionando soluciones para Bibliotecas.
Finalmente, el grupo lidera la Red temática española de Linked Data para la que uno de los objetivos primordiales es dar a conocer iniciativas de publicación de Linked Data de los sectores público y privado.
… hemos propuesto, entre otros, un documento de buenas prácticas sobre la generación de Linked data en el sector público…"
¿Qué valores encarna, en vuestra opinión y desde el punto de vista de la investigación, la actividad de apertura de datos?
En el contexto de la investigación, la apertura de datos nos permite en muchos casos poder llevar a cabo investigaciones o evaluaciones sobre nuestras investigaciones que no serían posibles o serían más costosas si no dispusiéramos de estos datos.
Por ejemplo, en nuestro grupo hemos utilizado datos públicos para estudiar el grado de reutilización de vocabularios en la nube, técnicas y métodos que permitan mejorar la calidad de los datos, para proponer técnicas para el acceso a datos dinámicos procedentes de redes sociales y sensores, mecanismos de consultas a datos distribuidos, desarrollar nuevos procesos en los que los especialistas de dominio participan en la apertura (como ocurrió en la transformación de los datos de la Biblioteca Nacional), etc.
… nos permite llevar a cabo investigaciones… que no serían posibles o serían más costosas si no dispusiéramos de estos datos".
¿Cómo surgió el interés por los datos públicos?
En primer lugar, nuestro interés surgió desde la perspectiva tecnológica y desde el punto de vista de los vocabularios que se pueden utilizar para representar y compartir mejor estos datos. Tratándose de un grupo de investigación que lleva trabajando en el área de los vocabularios (ontologías) desde el 1995, nos resulta muy interesante trabajar para conseguir que las distintas administraciones acuerden los vocabularios a utilizar para compartir sus datos. Asimismo, también podemos proporcionar los vocabularios en varios idiomas utilizando técnicas automáticas, evaluar y explotar nuestra experiencia en las tecnologías semánticas y de la Web de datos.
… nos resulta muy interesante trabajar para que las administraciones acuerden vocabularios para compartir sus datos…"
¿Cuáles son los actores, niveles o fases con los que identificaríais el sector?
Hay muchos tipos de actores involucrados en este sector. Desde las administraciones públicas, responsables de los datos en última instancia, hasta los usuarios finales, pasando por los agentes reutilizadores y los facilitadores tecnológicos. Nuestra experiencia nos dice que todos ellos son importantes.
Sobre las fases para generar y publicar Linked Data de calidad, hemos propuesto guías de buenas prácticas que se pueden seguir para llevar a cabo este proceso de manera sistemática (https://dvcs.w3.org/hg/gld/raw-file/default/bp/index.html).
Hemos propuesto guías de buenas prácticas para llevar a cabo este proceso de manera sistematica..."
¿Qué escenario ideal imaginaríais a partir de la información del sector público?
El sector público debe proveer los datos en tiempo, forma y con la calidad adecuada. Un escenario en el que los datos que se publican son ampliamente reutilizados para fines que no se habían previsto inicialmente, y que redundan de nuevo en la mejora de la calidad de los datos originales, y por tanto son útiles también para la propia administración pública.
… datos reutilizados para fines no previstos inicialmente y que redundan en la mejora de los datos originales… y son útiles para la propia administración… "
¿Qué acciones inmediatas tomaríais para fomentar esta actividad?
La creación de un instituto como el Open Data Institute del Reino Unido podría ser una muy buena iniciativa a tener en cuenta para aglutinar y fomentar la sostenibilidad de este modelo de publicación de datos.
La creación de un Plan Estratégico que refleje cuál será la estrategia a seguir por la Administración en los próximos años. Dicho plan debería incluir:
- La creación de una metodología común para todas las administraciones públicas (nacional, autonómica y local). De la misma forma que se construyó Métrica para el desarrollo de software en la Administración, debiera crearse una metodología específica que sistematice los procesos a seguir en la apertura de datos y su exposición como datos enlazados.
- Acordar los modelos a utilizar por las administraciones públicas para representar: personas, organismos, estructuras organizativas, información estadística, geográfica, documental, licencias, `datos de “provenance”, etc.
- Analizar los vocabularios que otras iniciativas europeas están utilizando con el fin de preparar las bases para un futuro intercambio de datos entre administraciones e instituciones europeas y de otros países.
- Cursos de Capacitación en sus distintas modalidades de presencia para la Administración General del Estado, autonomías y ayuntamientos sobre: aspectos legales, estándares y de normativa del W3C, procesos de liberación de datos, tecnologías semánticas relacionadas con la Web de Datos, etc.
- Cursos de formación en apertura de datos y tecnologías semánticas dentro de los estudios de Informática.
- La creación de un Observatorio que monitorice el impacto de la apertura de datos en el mercado y su creación de valor, así como la calidad de las diferentes iniciativas.
Como profesionales pero, también, como usuarios, ¿qué responsabilidad tiene el conjunto de la sociedad en esta materia Open Data?
La sociedad tiene tanta responsabilidad como las administraciones públicas en este proceso. Los ciudadanos no son sólo los usuarios finales potenciales de esta actividad de generación y publicación de Linked Data, sino también responsables de mejorar su calidad en caso de que esto sea posible.
Los ciudadanos no son sólo los usuarios finales… sino también responsables…"
Si fuera una administración pública, ¿qué información entendéis que debería ser abierta?
En general, debería ser abierta toda la información que esté disponible en la administración y que no afecte a la Seguridad Nacional o a la Privacidad de las personas físicas o jurídicas.
La Administración pública debe proporcionar mecanismos para proporcionar datos en diferentes formatos estandarizados que fomenten la interoperabilidad, incluyendo en todos ellos el “provenance” del dato y las licencias de uso.
Y si fuera una empresa, ¿qué datos esperaríais y para qué aplicación concreta?
Estamos seguros de que cualquier fuente de datos puede ser reutilizada incluso aunque a priori la administración pública correspondiente no pensara que pudiera ser reutilizada.
En nuestra opinión, lo mejor es disponer de estos datos de manera abierta, para que las empresas puedan dedicarse a obtener el máximo valor añadido de los mismos. Incluso las propias administraciones pueden ser las primeras beneficiarias de estos datos abiertos.
¿Cómo veis ahora mismo el estado del Open Data en el ámbito estatal y en el conjunto de España?
A pesar de que existen iniciativas como datos.gob.es y también iniciativas puntuales autonómicas y locales bastante importantes, queda mucho camino por realizar en España para conseguir estar a la altura de los procesos de apertura de datos de otros países de nuestro entorno, como por ejemplo el Reino Unido.
Los pasos que se están dando son adecuados, aunque muy lentos e insuficientes. Se echa en falta directrices más detalladas que vayan más allá de reales decretos y normativas y una voluntad expresa de muchas instituciones de publicar datos de mayor utilidad.
Los pasos que se están dando son adecuados, aunque muy lentos e insuficientes…"