Blog
In any data management environment (companies, public administration, consortia, research projects), having data is not enough: if you don't know what data you have, where it is, what it means, who maintains it, with what quality, when it changed or how it relates to other data, then the value is very limited. Metadata —data about data—is essential for:
-
Visibility and access: Allow users to find what data exists and can be accessed.
-
Contextualization: knowing what the data means (definitions, units, semantics).
-
Traceability/lineage: Understanding where data comes from and how it has been transformed.
-
Governance and control: knowing who is responsible, what policies apply, permissions, versions, obsolescence.
-
Quality, integrity, and consistency: Ensuring data reliability through rules, metrics, and monitoring.
-
Interoperability: ensuring that different systems or domains can share data, using a common vocabulary, shared definitions, and explicit relationships.
In short, metadata is the lever that turns "siloed" data into a governed information ecosystem. As data grows in volume, diversity, and velocity, its function goes beyond simple description: metadata adds context, allows data to be interpreted, and makes it findable, accessible, interoperable, and reusable (FAIR).
In the new context driven by artificial intelligence, this metadata layer becomes even more relevant, as it provides the provenance information needed to ensure traceability, reliability, and reproducibility of results. For this reason, some recent frameworks extend these principles to FAIR-R, where the additional "R" highlights the importance of data being AI-ready, i.e. that it meets a series of technical, structural and quality requirements that optimize its use by artificial intelligence algorithms.
Thus, we are talking about enriched metadata, capable of connecting technical, semantic and contextual information to enhance machine learning, interoperability between domains and the generation of verifiable knowledge.
From traditional metadata to "rich metadata"
Traditional metadata
In the context of this article, when we talk about metadata with a traditional use, we think of catalogs, dictionaries, glossaries, database data models, and rigid structures (tables and columns). The most common types of metadata are:
-
Technical metadata: column type, length, format, foreign keys, indexes, physical locations.
-
Business/Semantic Metadata: Field Name, Description, Value Domain, Business Rules, Business Glossary Terms.
-
Operational/execution metadata: refresh rate, last load, processing times, usage statistics.
-
Quality metadata: percentage of null values, duplicates, validations.
-
Security/access metadata: access policies, permissions, sensitivity rating.
-
Lineage metadata: Transformation tracing in data pipelines .
This metadata is usually stored in repositories or cataloguing tools, often with tabular structures or relational bases, with predefined links.
Why "rich metadata"?
Rich metadata is a layer that not only describes attributes, but also:
- They discover and infer implicit relationships, identifying links that are not expressly defined in data schemas. This allows, for example, to recognize that two variables with different names in different systems actually represent the same concept ("altitude" and "elevation"), or that certain attributes maintain a hierarchical relationship ("municipality" belongs to "province").
- They facilitate semantic queries and automated reasoning, allowing users and machines to explore relationships and patterns that are not explicitly defined in databases. Rather than simply looking for exact matches of names or structures, rich metadata allows you to ask questions based on meaning and context. For example, automatically identifying all datasets related to "coastal cities" even if the term does not appear verbatim in the metadata.
- They adapt and evolve flexibly, as they can be extended with new entity types, relationships, or domains without the need to redesign the entire catalog structure. This allows new data sources, models or standards to be easily incorporated, ensuring the long-term sustainability of the system.
- They incorporate automation into tasks that were previously manual or repetitive, such as duplication detection, automatic matching of equivalent concepts, or semantic enrichment using machine learning. They can also identify inconsistencies or anomalies, improving the quality and consistency of metadata.
- They explicitly integrate the business context, linking each data asset to its operational meaning and its role within organizational processes. To do this, they use controlled vocabularies, ontologies or taxonomies that facilitate a common understanding between technical teams, analysts and business managers.
- They promote deeper interoperability between heterogeneous domains, which goes beyond the syntactic exchange facilitated by traditional metadata. Rich metadata adds a semantic layer that allows you to understand and relate data based on its meaning, not just its format. Thus, data from different sources or sectors – for example, Geographic Information Systems (GIS), Building Information Modeling (BIM) or the Internet of Things (IoT) – can be linked in a coherent way within a shared conceptual framework. This semantic interoperability is what makes it possible to integrate knowledge and reuse information between different technical and organizational contexts.
This turns metadata into a living asset, enriched and connected to domain knowledge, not just a passive "record".
The Evolution of Metadata: Ontologies and Knowledge Graphs
The incorporation of ontologies and knowledge graphs represents a conceptual evolution in the way metadata is described, related and used, hence we speak of enriched metadata. These tools not only document the data, but connect them within a network of meaning, allowing the relationships between entities, concepts, and contexts to be explicit and computable.
In the current context, marked by the rise of artificial intelligence, this semantic structure takes on a fundamental role: it provides algorithms with the contextual knowledge necessary to interpret, learn and reason about data in a more accurate and transparent way. Ontologies and graphs allow AI systems not only to process information, but also to understand the relationships between elements and to generate grounded inferences, opening the way to more explanatory and reliable models.
This paradigm shift transforms metadata into a dynamic structure, capable of reflecting the complexity of knowledge and facilitating semantic interoperability between different domains and sources of information. To understand this evolution, it is necessary to define and relate some concepts:

Ontologies
In the world of data, an ontology is a highly organized conceptual map that clearly defines:
- What entities exist (e.g., city, river, road).
- What properties they have (e.g. a city has a name, town, zip code).
- How they relate to each other (e.g. a river runs through a city, a road connects two municipalities).
The goal is for people and machines to share the same vocabulary and understand data in the same way. Ontologies allow:
- Define concepts and relationships: for example, "a plot belongs to a municipality", "a building has geographical coordinates".
- Set rules and restrictions: such as "each building must be exactly on a cadastral plot".
- Unify vocabularies: if in one system you say "plot" and in another "cadastral unit", ontology helps to recognize that they are analogous.
- Make inferences: from simple data, discover new knowledge (if a building is on a plot and the plot in Seville, it can be inferred that the building is in Seville).
- Establish a common language: they work as a dictionary shared between different systems or domains (GIS, BIM, IoT, cadastre, urban planning).
In short: an ontology is the dictionary and the rules of the game that allow different geospatial systems (maps, cadastre, sensors, BIM, etc.) to understand each other and work in an integrated way.
Knowledge Graphs
A knowledge graph is a way of organizing information as if it were a network of concepts connected to each other.
-
Nodes represent things or entities, such as a city, a river, or a building.
-
The edges (lines) show the relationships between them, for example: "is in", "crosses" or "belongs to".
-
Unlike a simple drawing of connections, a knowledge graph also explains the meaning of those relationships: it adds semantics.
A knowledge graph combines three main elements:
-
Data: specific cases or instances, such as "Seville", "Guadalquivir River" or "Seville City Hall Building".
-
Semantics (or ontology): the rules and vocabularies that define what kinds of things exist (cities, rivers, buildings) and how they can relate to each other.
-
Reasoning: the ability to discover new connections from existing ones (for example, if a river crosses a city and that city is in Spain, the system can deduce that the river is in Spain).
In addition, knowledge graphs make it possible to connect information from different fields (e.g. data on people, places and companies) under the same common language, facilitating analysis and interoperability between disciplines.
In other words, a knowledge graph is the result of applying an ontology (the data model) to several individual datasets (spatial elements, other territory data, patient records or catalog products, etc.). Knowledge graphs are ideal for integrating heterogeneous data, because they do not require a previously complete rigid schema: they can be grown flexibly. In addition, they allow semantic queries and navigation with complex relationships. Here's an example for spatial data to understand the differences:
|
Spatial data ontology (conceptual model) |
Knowledge graph (specific examples with instances) |
|---|---|
|
|
|
|
Use Cases
To better understand the value of smart metadata and semantic catalogs, there is nothing better than looking at examples where they are already being applied. These cases show how the combination of ontologies and knowledge graphs makes it possible to connect dispersed information, improve interoperability and generate actionable knowledge in different contexts.
From emergency management to urban planning or environmental protection, different international projects have shown that semantics is not just theory, but a practical tool that transforms data into decisions.
Some relevant examples include:
- LinkedGeoData that converted OpenStreetMap data into Linked Data, linking it to other open sources.
- Virtual Singapore is a 3D digital twin that integrates geospatial, urban and real-time data for simulation and planning.
- JedAI-spatial is a tool for interconnecting 3D spatial data using semantic relationships.
- SOSA Ontology, a standard widely used in sensor and IoT projects for environmental observations with a geospatial component.
- European projects on digital building permits (e.g. ACCORD), which combine semantic catalogs, BIM models, and GIS data to automatically validate building regulations.
Conclusions
The evolution towards rich metadata, supported by ontologies, knowledge graphs and FAIR-R principles, represents a substantial change in the way data is managed, connected and understood. This new approach makes metadata an active component of the digital infrastructure, capable of providing context, traceability and meaning, and not just describing information.
Rich metadata allows you to learn from data, improve semantic interoperability between domains, and facilitate more expressive queries, where relationships and dependencies can be discovered in an automated way. In this way, they favor the integration of dispersed information and support both informed decision-making and the development of more explanatory and reliable artificial intelligence models.
In the field of open data, these advances drive the transition from descriptive repositories to ecosystems of interconnected knowledge, where data can be combined and reused in a flexible and verifiable way. The incorporation of semantic context and provenance reinforces transparency, quality and responsible reuse.
This transformation requires, however, a progressive and well-governed approach: it is essential to plan for systems migration, ensure semantic quality, and promote the participation of multidisciplinary communities.
In short, rich metadata is the basis for moving from isolated data to connected and traceable knowledge, a key element for interoperability, sustainability and trust in the data economy.
Content prepared by Mayte Toscano, Senior Consultant in Data Economy Technologies. The contents and points of view reflected in this publication are the sole responsibility of the author.
Noticia
Tourism is one of Spain's economic engines. In 2022, it accounted for 11.6% of Gross Domestic Product (GDP), exceeding €155 billion, according to the Instituto Nacional de Estadística (INE). A figure that grew to 188,000 million and 12.8% of GDP in 2023, according to Exceltur, an association of companies in the sector. In addition, Spain is a very popular destination for foreigners, ranking second in the world and growing: by 2024 it is expected to reach a record number of international visitors, reaching 95 million.
In this context, the Secretariat of State for Tourism (SETUR), in line with European policies, is developing actions aimed at creating new technological tools for the Network of Smart Tourist Destinations, through SEGITTUR (Sociedad Mercantil Estatal para la Gestión de la Innovación y las Tecnologías Turísticas), the body in charge of promoting innovation (R&D&I) in this industry. It does this by working with both the public and private sectors, promoting:
- Sustainable and more competitive management models.
- The management and creation of smart destinations.
- The export of Spanish technology to the rest of the world.
These are all activities where data - and the knowledge that can be extracted from it - play a major role. In this post, we will review some of the actions SEGITTUR is carrying out to promote data sharing and openness, as well as its reuse. The aim is to assist not only in decision-making, but also in the development of innovative products and services that will continue to position our country at the forefront of world tourism.
Dataestur, an open data portal
Dataestur is a web space that gathers in a unique environment open data on national tourism. Users can find figures from a variety of public and private information sources.
The data are structured in six categories:
- General: international tourist arrivals, tourism expenditure, resident tourism survey, world tourism barometer, broadband coverage data, etc.
- Economy: tourism revenues, contribution to GDP, tourism employment (job seekers, unemployment and contracts), etc.
- Transport: air passengers, scheduled air capacity, passenger traffic by ports, rail and road, etc.
- Accommodation: hotel occupancy, accommodation prices and profitability indicators for the hotel sector, etc.
- Sustainability: air quality, nature protection, climate values, water quality in bathing areas, etc.
- Knowledge: active listening reports, visitor behaviour and perception, scientific tourism journals, etc.
The data is available for download via API.
Dataestur is part of a more ambitious project in which data analysis is the basis for improving tourist knowledge, through actions with a wide scope, such as those we will see below.
Developing an Intelligent Destination Platform (IDP)
Within the fulfillment of the milestones set by the Next Generation funds, and corresponding to the development of the Digital Transformation Plan for Tourist Destinations, the Secretary of State for Tourism, through SEGITTUR, is developing an Intelligent Destination Platform (PID). It is a platform-node that brings together the supply of tourism services and facilitates the interoperability of public and private operators. Thanks to this platform it will be possible to provide services to integrate and link data from both public and private sources.
Some of the challenges of the Spanish tourism ecosystem to which the IDP responds are:
- Encourage the integration and development of the tourism ecosystem (academia, entrepreneurs, business, etc.) around data intelligence and ensure technological alignment, interoperability and common language.
- To promote the use of the data economy to improve the generation, aggregation and sharing of knowledge in the Spanish tourism sector, driving its digital transformation.
- To contribute to the correct management of tourist flows and tourist hotspots in the citizen space, improving the response to citizens' problems and offering real-time information for tourist management.
- Generate a notable impact on tourists, residents and companies, as well as other agents, enhancing the brand "sustainable tourism country" throughout the travel cycle (before, during and after).
- Establish a reference framework to agree on targets and metrics to drive sustainability and carbon footprint reduction in the tourism industry, promoting sustainable practices and the integration of clean technologies.

Figure 1. Objectives of the Intelligent Destination Platform (IDP).
New use cases and methodologies to implement them
To further harmonise data management, up to 25 use cases have been defined that enable different industry verticals to work in a coordinated manner. These verticals include areas such as wine tourism, thermal tourism, beach management, data provider hotels, impact indicators, cruises, sports tourism, etc.
To implement these use cases, a 5-step methodology is followed that seeks to align industry practices with a more structured approach to data:
- Identify the public problems to be solved.
- Identify what data are needed to be available to be able to solve them.
- Modelling these data to define a common nomenclature, definition and relationships.
- Define what technology needs to be deployed to be able to capture or generate such data.
- Analyse what intervention capacities, both public and private, are needed to solve the problem.
Boosting interoperability through a common ontology and data space
As a result of this definition of the 25 use cases, a ontology of tourism has been created, which they hope will serve as a global reference. The ontology is intended to have a significant impact on the tourism sector, offering a series of benefits:
- Interoperability: The ontology is essential to establish a homogeneous data structure and enable global interoperability, facilitating information integration and data exchange between platforms and countries. By providing a common language, definitions and a unified conceptual structure, data can be comparable and usable anywhere in the world. Tourism destinations and the business community can communicate more effectively and agilely, fostering closer collaboration.
- Digital transformation: By fostering the development of advanced technologies, such as artificial intelligence, tourism companies, the innovation ecosystem or academia can analyse large volumes of data more efficiently. This is mainly due to the quality of the information available and the systems' better understanding of the context in which they operate.
- Tourism competitiveness: Aligned with the previous question, the implementation of this ontology contributes to eliminating inequalities in the use and application of technology within the sector. By facilitating access to advanced digital tools, both public institutions and private companies can make more informed and strategic decisions. This not only raises the quality of the services offered, but also boosts the productivity and competitiveness of the Spanish tourism sector in an increasingly demanding global market.
- Tourist experience: Thanks to ontology, it is possible to offer recommendations tailored to the individual preferences of each traveller. This is achieved through more accurate profiling based on demographic and behavioural characteristics as well as specific motivations related to different types of tourism. By personalising offers and services, customer satisfaction before, during and after the trip is improved, and greater loyalty to tourist destinations is fostered.
- Governance: The ontology model is designed to evolve and adapt as new use cases emerge in response to changing market demands. SEGITTUR is actively working to establish a governance model that promotes effective collaboration between public and private institutions, as well as with the technology sector.
In addition, to solve complex problems that require the sharing of data from different sources, the Open Innovation Platform (PIA) has been created, a data space that facilitates collaboration between the different actors in the tourism ecosystem, both public and private. This platform enables secure and efficient data sharing, empowering data-driven decision making. The PIA promotes a collaborative environment where open and private data is shared to create joint solutions to address specific industry challenges, such as sustainability, personalisation of the tourism experience or environmental impact management.
Building consensus
SEGITTUR is also carrying out various initiatives to achieve the necessary consensus in the collection, management and analysis of tourism-related data, through collaboration between public and private actors. To this end, the Ente Promotor de la Plataforma Inteligente de Destinoswas created in 2021, which plays a fundamental role in bringing together different actors to coordinate efforts and agree on broad lines and guidelines in the field of tourism data.
In summary, Spain is making progress in the collection, management and analysis of tourism data through coordination between public and private actors, using advanced methodologies and tools such as the creation of ontologies, use cases and collaborative platforms such as PIA that ensure efficient and consensual management of the sector.
All this is not only modernising the Spanish tourism sector, but also laying the foundations for a smarter, more intelligent, connected and efficient future. With its focus on interoperability, digital transformation and personalisation of experiences, Spain is positioned as a leader in tourism innovation, ready to face the technological challenges of tomorrow.
Blog
The Hercules initiative was launched in November 2017, through an agreement between the University of Murcia and the Ministry of Economy, Industry and Competitiveness, with the aim of developing a Research Management System (RMS) based on semantic open data that offers a global view of the research data of the Spanish University System (SUE), to improve management, analysis and possible synergies between universities and the general public.
This initiative is complementary to UniversiDATA, where several Spanish universities collaborate to promote open data in the higher education sector by publishing datasets through standardised and common criteria. Specifically, a Common Core is defined with 42 dataset specifications, of which 12 have been published for version 1.0. Hercules, on the other hand, is a research-specific initiative, structured around three pillars:
- Innovative SGI prototype
- Unified knowledge graph (ASIO) 1],
- Data Enrichment and Semantic Analysis (EDMA)
The ultimate goal is the publication of a unified knowledge graph integrating all research data that participating universities wish to make public. Hercules foresees the integration of universities at different levels, depending on their willingness to replace their RMS with the Hercules RMS. In the case of external RMSs, the degree of accessibility they offer will also have an impact on the volume of data they can share through the unified network.
General organisation chart of the Hercule initiative
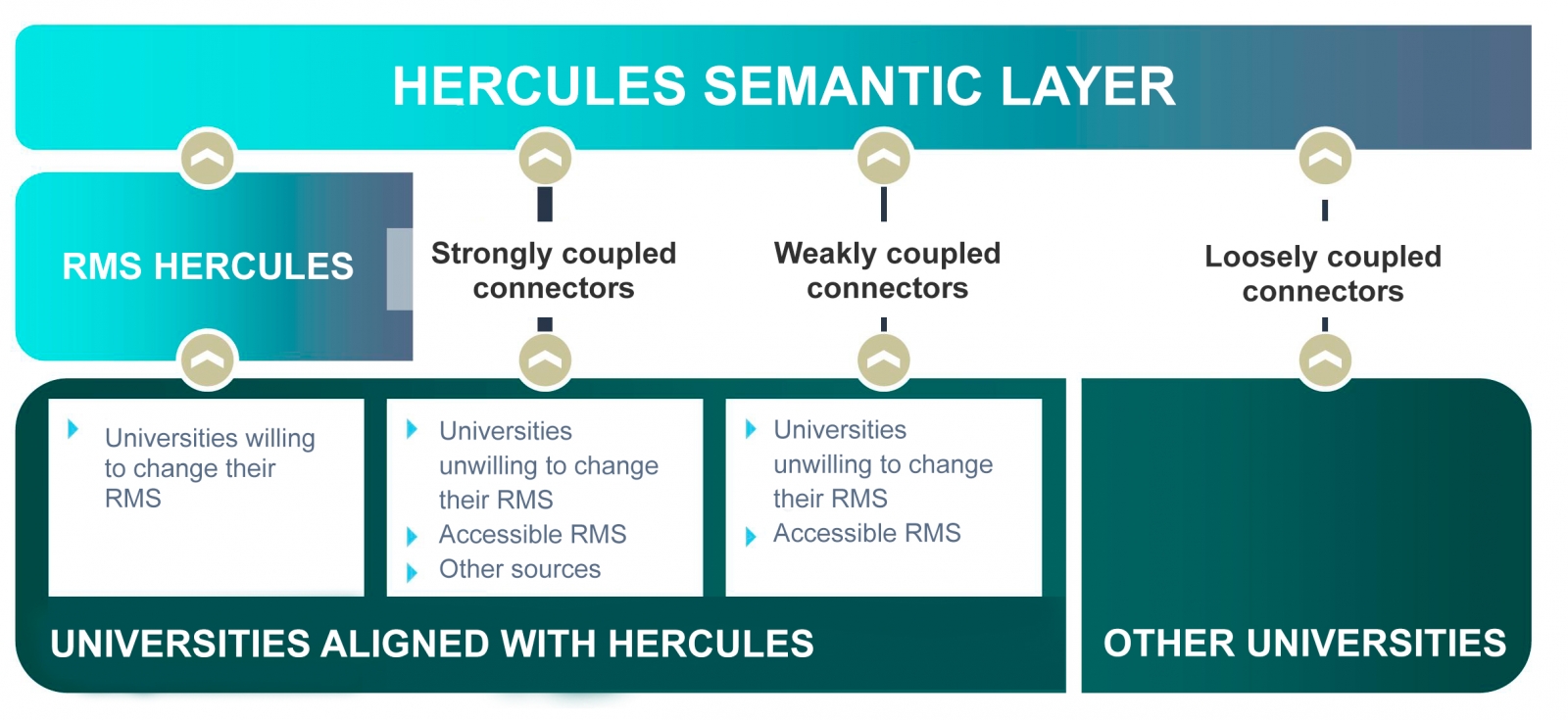
Within the Hercules initiative, the ASIO Project (Semantic Architecture and Ontology Infrastructure) is integrated. The purpose of this sub-project is to define an Ontology Network for Research Management (Ontology Infrastructure). An ontology is a formal definition that describes with fidelity and high granularity a particular domain of discussion. In this case, the research domain, which can be extrapolated to other Spanish and international universities (at the moment the pilot is being developed with the University of Murcia). In other words, the aim is to create a common data vocabulary.
Additionally, through the Semantic Data Architecture module, an efficient platform has been developed to store, manage and publish SUE research data, based on ontologies, with the capacity to synchronise instances installed in different universities, as well as the execution of distributed federated queries on key aspects of scientific production, lines of research, search for synergies, etc.
As a solution to this innovation challenge, two complementary lines have been proposed, one centralised (synchronisation in writing) and the other decentralised (synchronisation in consultation). The architecture of the decentralised solution is explained in detail in the following sections.
Domain Driven Design
The data model follows the Domain Driven Design approach, modelling common entities and vocabulary, which can be understood by both developers and domain experts. This model is independent of the database, the user interface and the development environment, resulting in a clean software architecture that can adapt to changes in the model.
This is achieved by using Shape Expressions (ShEx), a language for validating and describing RDF datasets, with human-readable syntax. From these expressions, the domain model is automatically generated and allows orchestrating a continuous integration (CI) process, as described in the following figure.
Continuous integration process using Domain Driven Design (just available in Spanish)
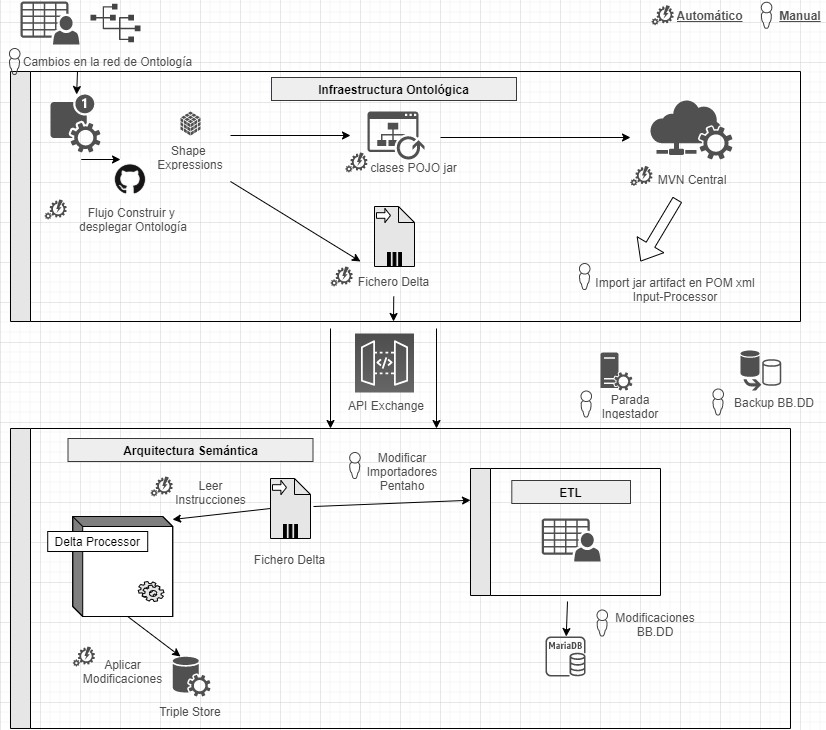
By means of a system based on version control as a central element, it offers the possibility for domain experts to build and visualise multilingual ontologies. These in turn rely on ontologies both from the research domain: VIVO, EuroCRIS/CERIF or Research Object, as well as general purpose ontologies for metadata tagging: Prov-O, DCAT, etc.
Linked Data Platform
The linked data server is the core of the architecture, in charge of rendering information about all entities. It does this by collecting HTTP requests from the outside and redirecting them to the corresponding services, applying content negotiation, which provides the best representation of a resource based on browser preferences for different media types, languages, characters and encoding.
All resources are published following a custom-designed persistent URI scheme. Each entity represented by a URI (researcher, project, university, etc.) has a series of actions to consult and update its data, following the patterns proposed by the Linked Data Platform (LDP) and the 5-star model.
This system also ensures compliance with the FAIR (Findable, Accessible, Interoperable, Reusable) principles and automatically publishes the results of applying these metrics to the data repository.
Open data publication
The data processing system is responsible for the conversion, integration and validation of third-party data, as well as the detection of duplicates, equivalences and relationships between entities. The data comes from various sources, mainly the Hercules unified RMS, but also from alternative RMSs, or from other sources offering data in FECYT/CVN (Standardised Curriculum Vitae), EuroCRIS/CERIF and other possible formats.
The import system converts all these sources to RDF format and registers them in a specific purpose repository for linked data, called Triple Store, because of its capacity to store subject-predicate-object triples.
Once imported, they are organised into a knowledge graph, easily accessible, allowing advanced searches and inferences to be made, enhanced by the relationships between concepts.
Example of a knowledge network describing the ASIO project
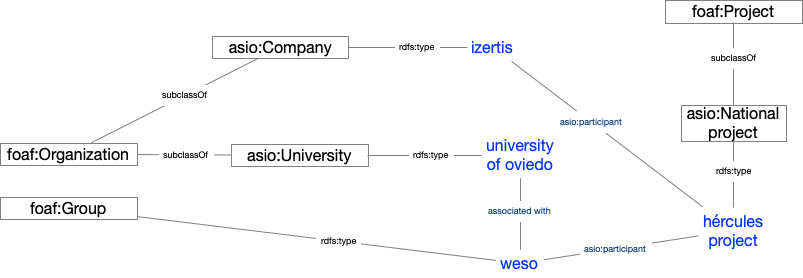
Results and conclusions
The final system not only allows to offer a graphical interface for interactive and visual querying of research data, but also to design SPARQL queries, such as the one shown below, even with the possibility to run the query in a federated way on all nodes of the Hercules network, and to display results dynamically in different types of graphs and maps.
In this example, a query is shown (with limited test data) of all available research projects grouped graphically by year:
PREFIX xsd: <http://www.w3.org/2001/XMLSchema#>
SELECT ?year (COUNT(?x) as ?cuenta)
WHERE {
?x <http://www.w3.org/1999/02/22-rdf-syntax-nes#type> <https://ldpld1test.um.es/um/es-ES/rec/Project> .
?x <https://ldpld1test.um.es/um/es-ES/rec/startDate> ?d BIND(SUBSTR(?d, 1, 4) as ?year) .
} GROUP BY ?year LIMIT 20
LIMIT 20
Ejemplo de consulta SPARQL con resultado gráfico
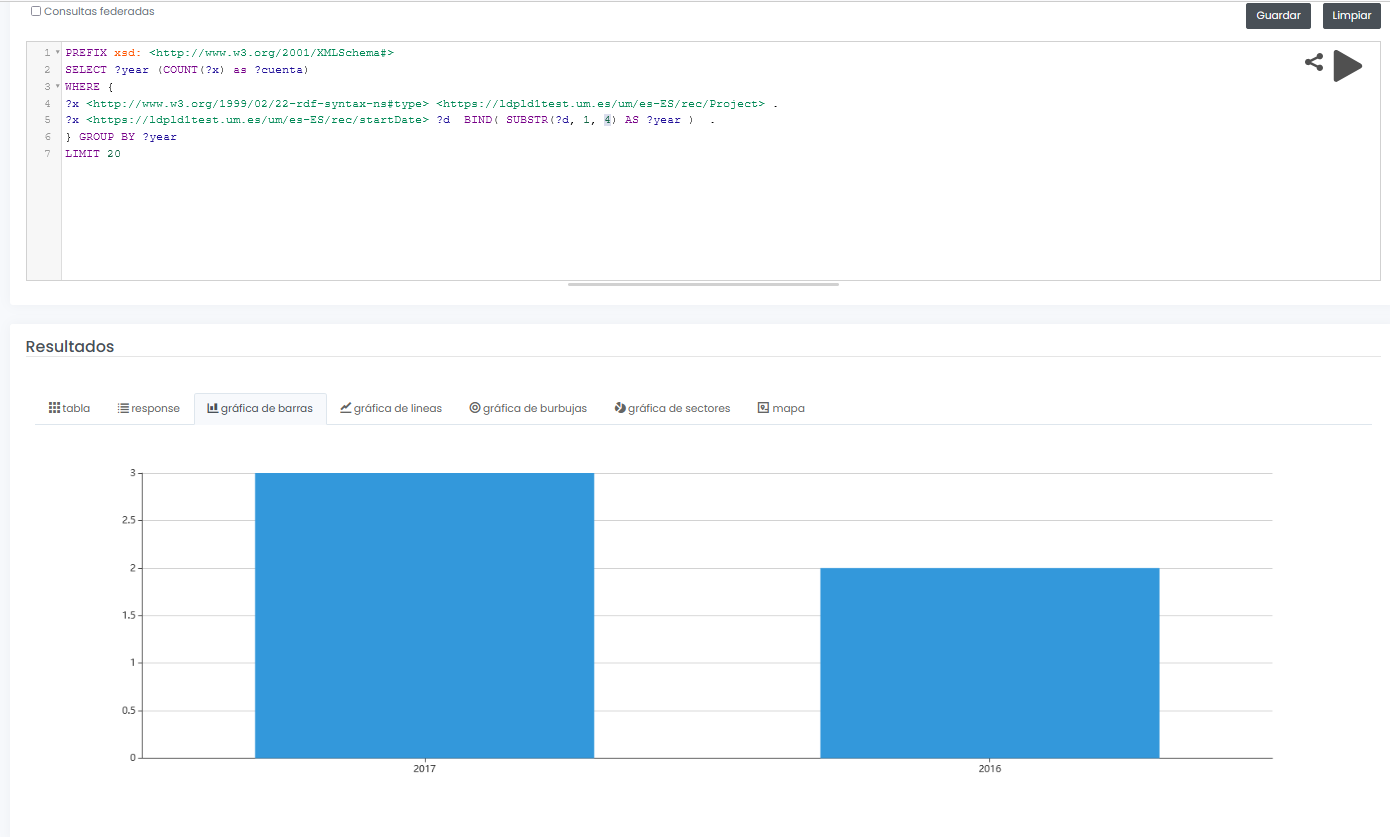
In short, ASIO offers a common framework for publishing linked open data, offered as open source and easily adaptable to other domains. For such adaptation, it would be enough to design a specific domain model, including the ontology and the import and validation processes discussed in this article.
Currently the project, in its two variants (centralised and decentralised), is in the process of being put into pre-production within the infrastructure of the University of Murcia, and will soon be publicly accessible.
[1 Graphs are a form of knowledge representation that allow concepts to be related through the integration of data sets, using semantic web techniques. In this way, the context of the data can be better understood, which facilitates the discovery of new knowledge.
Content prepared by Jose Barranquero, expert in Data Science and Quantum Computing.
The contents and views expressed in this publication are the sole responsibility of the author.
Blog
The increasing concern of European authorities for the management of digital skills among the working population, especially young people, is a growing reality whose management does not seem to have an easy solution.
“The internet and digital technologies are transforming our world. But existing barriers online mean citizens miss out on goods and services, internet companies and start-ups have their horizons limited, and businesses and governments cannot fully benefit from digital tools.” This strong affirmation opens the European Commission (EC) web section dedicated to digital single market. The digital single market is one of the strategic priorities of the EC and, within it, one of the action lines is the development of digital skills among the employed population of Europe - especially young people.
When classifying digital skills, we have the same problem as classifying emerging technologies. Most efforts in this area focus on the establishment of a hierarchical classification of skills / technologies, which rarely go deeper than two or three levels.
The EC establishes a classification of digital competences in 5 categories (always in the Internet domain):
- Information processing
- Content creation
- Communication
- Problem resolution
- Security
In each of these categories, the Commission proposes a framework whit three levels of user competence (basic, independent, expert). For each level of competence, standard statements are proposed to help users to perform a self-assessment to establish their digital competence level.
Now, the question that arises in various forums is how to take a step beyond the simple self-assessment of competencies. Questions as “how to perform a search for terms related to digital skills?” are not trivial to answer.
When the skills classification has one or two levels of depth, it is enough to perform a "literal search" of the term to be searched. But what happens if the term tree related to digital skills has thousands of terms hierarchically organized?
For example, imagine that a company needs a very specific profile for a new position in an R&D project. The required profile is a professional with advanced knowledge in MLib Apache Spark library and more than 2 years of experience in streaming Big Data. In addition to these skills - called hard skills - the professional needs to have a series of social skills or soft skills such as public communication ability and teamwork.
How can we find such a profile in a database of 400,000 employees around the world?
A possible solution to these and other issues may be the creation of a digital skills ontology in Europe.
An ontology provides a hierarchical organization of terms (taxonomy) and a set of relationships between them, which facilitates the search - both literal and inferred - of complex terms and expressions. This is already very useful by itself, but if you also combine the formal structure of an ontology with its technical implementation, using a technological tool, you get a powerful technological product. A technical implementation of this ontology would allow, among others, perform the following complex search in an efficient and unambiguous way:
Find a person WITH MLib technical skills that also HAS more than 2 years of experience in streaming Big Data and also HAS the soft skills of teamwork and communication skills at the intermediate level.
With an underlying ontology, in the previous example, all the underlined terms would have a unique identifier, as well as their relations (uppercase). The semantic search engine would be able to identify the previous query, extract the key terms, understand the relationships (WITH, HAS, more, etc.) and execute a search against the employees database, extracting those results that fit with the search.
A good example of using an ontology to perform complex searches in immense databases is SNOMED-CT. It is a standard vocabulary to search clinical terms in patient databases. The clinical domain is especially indicated for the development of ontologies due to the complex structure inherent to the clinical terms and their relationships.
Although there are classic tools and methods of organizing information based on traditional databases and relational models, ontologies and their technological implementations offer higher flexibility, scalability and level of personalization to different subfields.
Precisely the characteristics of flexibility and high scalability become fundamental as open data repositories become increasingly bigger and diverse. The European Open Data portal contains more than 12,000 datasets classified by topics. For its part, the website specializing in data science, Kaggle, hosts 9000 datasets and, annually, they organize competitions to reward those professionals who best analyse and extract useful information from these data. In short, the volume of data available to society is increasing year after year and ontologies are importance as a powerful tool for managing information hidden under that blanket of raw data.
Content prepared by Alejandro Alija, expert in Digital Transformation and innovation.
Contents and points of view expressed in this publication are the exclusive responsibility of its author.
Blog
Health is one of the priority development fields in this century. Most analysts agree that health management - from all possible perspectives - will change radically in the coming years. The analysis of health data will set the way forward in the coming days.
The life expectancy of developed countries increases as the century advances. In the last twenty years, the life expectancy of many developed countries has overcome the barrier of 80 years on average. Japan, Spain, Switzerland, Singapore, among others, are already above 83 years of life expectancy and the trend continues with a constant growth rate.
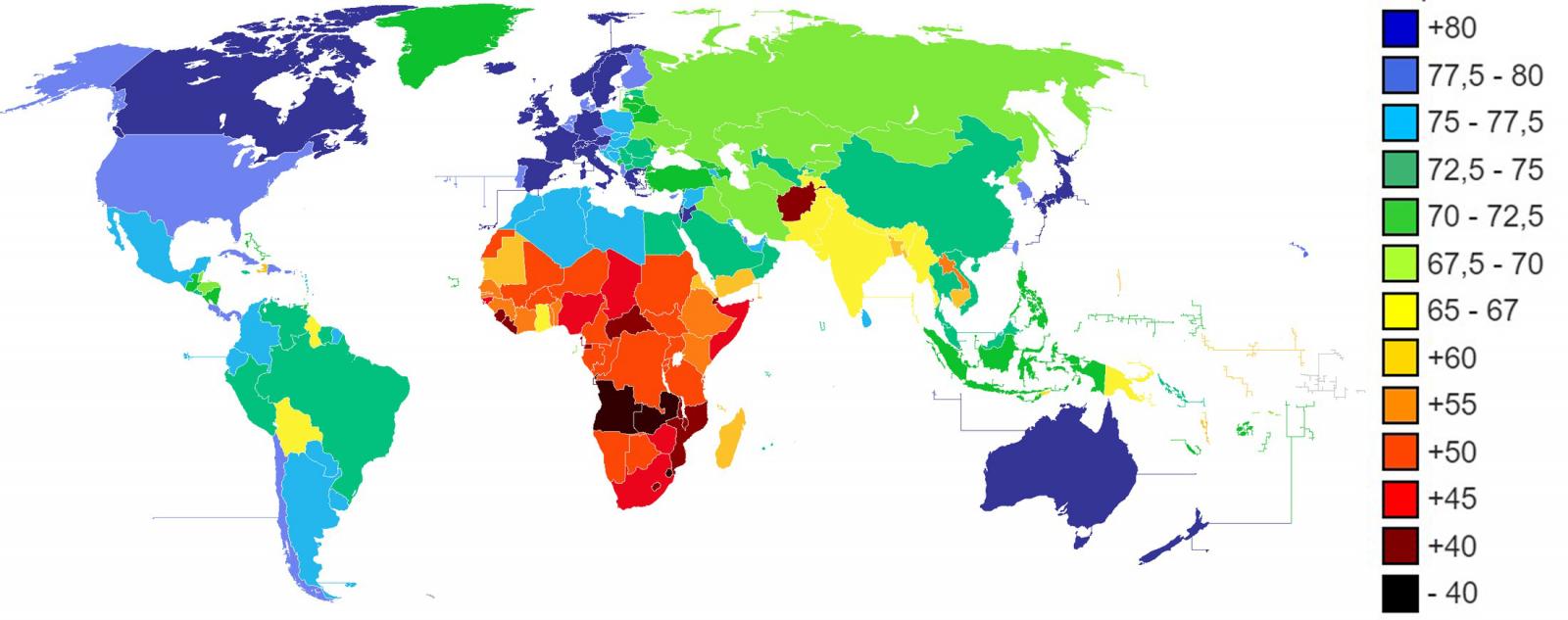
Figure 1. Life expectancy in years according to CIA World Factbook 2013.
Take this introduction on life expectancy to motivate the central theme of this article. As we get older, the diseases that affect us evolve. A longer life expectancy does not necessarily mean a better quality of life in the adult and old age. To live longer, it is necessary to develop better health care. Modern societies need to make a successful transition from treatment to prevention. That is: Prevent rather than cure.
But, to improve prevention, we need to know better the risks and anticipate future complications. The analysis of the data related to our health is vital to face this transition. There are many tasks and necessary actions before going on to establish continuous health data analysis strategies.
By nature, data related to health are sensitive data. Personal health data have a direct impact on our work and personal relationships and can have a very noticeable impact on our economy -on both personal and society level-. Among others, The challenges of health data analysis are:
- Generation of public datasets.
- Standard mechanisms for health data anonymization.
- In real time Health data collection tools.
- Health data models agreed by the scientific community.
- Health data analysis tools prepared for high data volumes.
- Specialist profiles, both health experts and data scientists specialized in this field (semi-structured data and semantic technologies).
Digital transformation of health sector
The digital transformation of health sector represents one of the greatest challenges for public and private health institutions and systems. Many hospital in developed countries have begun to digitize some of the most important data related to our health. Especially, those data recorded in the face-to-face visits to doctors. The Electronic Health Records (EHR) and the diagnostic tests (for example, medical image or clinical analysis) are the registers with a higher digitalization degree. While it is true that the digitization degree of these examples can be high, the way they have been considered is different by countries and systems. Transforming historical and analogical clinical records into digital information adds very little value compared to the effort and investment needed. However, tackling the digitalization of clinical records with the focus on the subsequent intelligent analysis of the data can mean a revolution with an incalculable impact. For example, the implementation of ontologies specially designed for the medical domain such as SNOMED-CT radically changes the future exploitation of medical data and enables a superior intelligence layer supported by the future Artificial Intelligence as an assistant to the doctors and nurses of the future.
Some public repositories
There are different repositories where you can find open data sets related to health. Most available data are statistics related to health indicators. However, there are more specialized repositories where it is possible to find data sets to perform advanced data analysis.
For example, the health systems of the United States and the United Kingdom, respectively, publish their health data in the following repositories:
Other multi-country organizations, such as the World Health Organization (WHO) or UNICEF NGO also have open data repositories:
- UNICEF offers statistics on the situation of women and children worldwide.
- World Health Organization offers world hunger, health, and disease statistics.
Beyond statistical data, Kaggle, a specialized data science website, regularly holds open competitions for teams to solve data-based challenges. For example, in one of the Kaggle competitions, the challenge was to predict hospital readmissions for diabetes. To solve the challenge, they offer a data set (duly anonymized) composed of 65 records of patients with diabetes and 50 fields that include information on: gender, age, weight, etc.

Figure 2. Excerpt from the data set available for the diabetes challenge.
In summary, the systematic analysis of health data opens the doors to predictive medicine. To enable technologies that assist health professionals of the future, it is necessary to build sustainable, scalable and long-lasting data strategies. Collecting, storing, modeling and analyzing health data is the key to a future where healthcare is something more than a mere contact with patients.
Content prepared by Alejandro Alija, expert in Digital Transformation and innovation.
Contents and points of view expressed in this publication are the exclusive responsibility of its author.
Noticia
The Open Data initiative of the Government of Aragon was created by an agreement in 2012 with the aim of creating economic value in the ICT Sector through the reuse of public information, the increase of transparency and the promotion of innovation. All this, in order to boost the development of information society and data interoperability in the Administration. Thanks to this agreement, open data is incorporated into the strategies of the Government of Aragon, who is committed to the effective opening of public data that they hold, understanding as public all data not subject to restrictions of privacy, security or property.
In this context, in 2013, the open data web portal of the Government of Aragon was launched. Since then, Aragón Open Data underwent an exponential growth, driven by the unit responsible for its management, the current General Directorate of Electronic Administration and Information Society, and, of course, by the different data providers: public units, mostly from the Autonomous government. These providers offer their information under open data philosophy from a single access point.
Since the creation of the portal, more services have been developed, such as Aragopedia, Budget or Open Analytics Data. All of them are related to open data reuse and disposition through services that facilitate its use and interpretation. In this line, Aragón Open Data offers diverse applications and training materials, as well as APIs and services that add value to data. Due to these projects, the initiative was selected as the only Spanish experience in the Open Data Leader's Network, held in London in 2016.
The most downloaded resources of the portal include: Cartographic download service e: 1/1000 by municipality, Government of Aragon Contracts, list of municipalities of Aragon or annual holiday calendars of the Autonomous Community and its provinces.
In this wide and diverse framework, in 2016, Aragón Open Data also began a work of identification and integration of the diversity of data generated by the Government of Aragon, in order to facilitate its disposition and opening. The first step was to create an ontology, the Interoperable Information Structure of Aragón EI2A, with the collaboration of the units that possess, create and manage data, participating different areas of the Government of Aragon such as agriculture, finance, culture, geographic information or environment, among others.
The Interoperable Information Structure of Aragón (EI2A) homogenizes structures, vocabularies and characteristics within the framework of Aragón Open Data to mostly resolve the problem of data diversity and heterogeneity in the Administration. A heterogeneity that is a real reflection of the reality and competences of the Administration, but which hinders its opening and reuse.
The EI2A describes the conceptual and logical data model generated by the Government of Aragon, representing entities, properties and relationships. The structure is intended to support data interoperability through its standardization. The Interoperable Information Structure of Aragon aims to relate the content and elements of the different data sets so that data can be standardized and exploited jointly in the Government of Aragon, by combining, simplifying and homogenizing them, regardless of the origin, purpose, model, entities and relationships.
It is in 2017 and 2018 when the EI2A becomes a reality due to Aragón Open Data Pool project. Aragón Open Data Pool is a pilot and innovative project that demonstrates the importance of centralizing and publish data to drive its use and exploitation. Open Data Pool is available since December 2018, based on EI2A.
As a result: more than 140 sources of well-differentiated organisms and purposes, which were previously open in Aragon Open Data (API GA_OD_Core), have been standardized according to the EI2A to be exploited together and offered in a simple way, from a single point of access and with the same query criteria.
This project data are aligned with the semantic web standards for its exploitation, consultation and use (SPARQL endpoint), which is its real potential. This makes data consulting and use possible, regardless of their characteristics and vocabularies. It even allows federating data from portals of different administrations such as Aragón Open Data (under EI2A) and Open Data Euskadi (under ELI).
Another noteworthy aspect is that it is oriented to a non-technical user, by allowing a intuitive and simple navigation using data relationships, putting interoperability into practice through the relation of diverse data using a normal navigation web.
This project has helped to better understand the reality of data incorporated into Aragón Open Data Pool under the EI2A, and confirm the need of data normalization in the production-point, to latter, open and offer them in Aragón Open Data, facilitating their use and reuse, both inside and outside the Administration. But we need a change, sought by data interoperability and reuse guidelines, to open a unique data access point in the Government of Aragon, which today corresponds to a regulatory project. Among its axes of action, this project aim to better identify data, improve its quality at source, and internally support the process from the creation of the data by the different production units, until its publication in Aragón Open Data. In this way, they seek to continue growing, improving and orienting theirselves so that any interested party, institutions, developers or infomediary company can use the information, data and services available for any of their interests, thus contributing to the development of the information society.
Entrevista
qMe-Aporta, third prize winner at Desafío Aporta 2017, is a prototype for the intuitive construction of queries, in guided natural language, based on datos.gob.es knowledge. It is a system that guides the user in the construction of the question, showing multiple alternatives to start and continue the question. It not only uses the system terms (metadata), but also the data and its synonyms. These questions can be asked in several languages.
We have spoken with Mariano Rico Almodóvar, researcher at the Polytechnic University of Madrid (UPM) and responsible for this initiative, to tell us how he is carrying out this project.
Currently, at what of qMe-Aporta development are you?
We are waiting for funding. It is a pity that a system so useful, from our point of view, for the reuse of data from public administrations is stopped, but it is. We made the effort, at zero cost, to analyze the application of Dylan-Q system (the core of qMe-Aporta) to the datasets related to Desafío Aporta (datos.gob.es) but we have not yet been able to create the system.
I'm applying Dylan-Q to a European project called SlideWiki, and that's where we hope to achieve the visibility needed for private funding. We also trust that the UPM Technologies Catalog (Dylan-Q technology is part of it), will give us enough visibility to attract customers or investors.
What information sources, public or private, is your project based on?
Dylan-Q technology is applied to RDF datasets, the standard semantic data format. In the case of Desafío Aporta, we focus on RDF datasets from datos.gob.es, where there is all kinds of data: trade, demography, education, etcetera. Most of the 2018 datasets that were available on the date of the contest were not RDF datasets. But it should be noted that we have tools to convert RDF datasets (files and databases) in any format.
Semantic technologies allow us to integrate information much more easily than with traditional techniques. If we add to this the lexicalization of the ontologies and a bit of magic (we have a positive patent report of the Dylan-Q technology), we achieve systems that allow guided consultations in natural language related to any RDF data set.
Do you think that initiatives such as the Desafio Aporta 2017 can help companies and entrepreneurs launch their open data reuse projects? What other initiatives of this kind do you think should be put into practice?
The visibility that these awards give us is very important, but other elements are necessary to be able to materialize these projects. It is common for companies to be interested in projects they know through awards like this one, but they usually demand the development at zero cost of a prototype (what in the jargon is called "proof of concept"). In addition, although the results of the prototype are good, the full implementation of the project is not guaranteed. It is also common for potential investors to demand exclusive dedication without pay for a period of up to two years. There is a tendency to think of innovation as a lottery in which it is known that one in ten start-ups will be successful and will considerably multiply their investment, but, in general, long-term investment criteria are not followed and the objective is just to make the investment profitable within a typical period of two years. In these conditions it is very difficult to undertake.
In countries such as Germany or the United States, the idea of a non-repayable investment is more widespread among companies. They understand that you have to take risks to win, and are willing to assume the cost of risk. There is no fear of "failure", which is seen as something natural in innovation processes. On the contrary, it is very widespread in the companies of our country that the risk should be assumed by the Administration or, as our case, the researchers. A century after the sentence of Unamuno " Let them do the inventing", The situation seems not to have changed. And I do not believe that it is a matter of higher or lesser economy, or of major or minor economic crisis, traditional excuses to condition the investment in R & D, but of a higher culture of innovation investment. In fact, we have known for a long time that investment in R + D + I is what makes countries more or less prosperous, and not vice versa.
But do not lose heart. We continue attending all meetings that organizations request. We dream of a company that is willing to risk a small amount, say 30 thousand euros, for us to make a prototype adapted to their business and a sample of their data, for 6 months. If that prototype convinces them, we would make a new project using all data and the entire business model. Who wants to be the first?
But in spite of all that has been said, I must insist that initiatives as Aporta or those promoted by the Technological Innovation Support Center (CAIT) of the UPM are excellent for bringing together technologists and companies. There should be meetings of this type more frequently.
As a user of open data, what challenges have you found when reusing public information? How have you solved those challenges?
The main challenge has been, and still is, to find the dataset that best suits our needs. Sometimes it is a single dataset, but most of the time we want several datasets initially unrelated. I think it is illustrated with the phrase "in a sea of data, we fish with a rod". We need more powerful tools to be able to fish more efficiently.
The search for information is a difficult problem when the volume of data increases, not so much by the number of data of a given type, but by the number of data categories and the relationships between them. Semantic technologies allow us to relate categories of data and give them meaning, so we can address this problem with more chances of success.
What actions do you consider that Spain should prioritize in terms of data provision?
I think you have to clearly divide the tasks. On the one hand, local administrations must collect the data. On the other hand, the General Administration must provide the necessary tools so that the local administrations incorporate in a simple and efficient way the collected data. The initiative datos.gob.es works in this line, but you can still go further. For example, it is necessary to integrate the data collected by local administrations, that is, link data categories. It could be facilitated through the use of semantic technologies. Once the information is integrated, the Administration could offer new services to users, such as the one provided by QMe-Aporta, and many others that we still cannot imagine.
Finally, what are your future plans? Are you immersed or have any other open data reuse project in mind?
In our research group we have several projects that use open data, in what has been called "citizen science", such as Farolapp (http://farolapp.linkeddata.es), or Stars4All (http://stars4all.eu), but perhaps our main contribution is the Spanish DBpedia (es.dbpedia.org). We have a project with the Spanish multinational TAIGER to increase the quality of Spanish DBpedia data, and we have developed several techniques with very good results. In June (2018) we organized the first international congress of knowledge graphs applied to tourism and travel, where we have confirmed the importance of this sector, which represents 14% of Spanish GDP and 10% worldwide. We think that the information stored in the Spanish DBpedia can be very useful for this economic sector. You have to know that 40% of the DBpedia data in Spanish is only found in our DBpedia.
Most of the techniques we have applied to DBpedia can be applied to other data sets, so that open data can benefit from these techniques.
Fortunately, we continue to research and develop projects where we apply our knowledge on semantic technologies, natural language processing and machine learning. I would like to take this opportunity to thank those responsible for the research group, Asunción Gómez Pérez and Oscar Corcho, for the trust they have placed in us, and the time they have allowed us to spend in this contest.
Noticia
In order to organize (classify, describe, index) knowledge, several knowledge organization tools exist. Below is a summary of them, organized from the simplest (the least formalized and with fewer rules) to the more complex (more formalized and with more rules):
- Controlled vocabularies
- Taxonomies
- Thesauri
- Ontologies
A controlled vocabulary is a simple list of the terms that are assigned a specific meaning, they are arranged a priori and are used to describe knowledge.
For example, the provinces of the Spanish territory – (Asturias, Illes Balears, Valladolid) with which any document can be labelled and which are described in Annex V of Document BOE-A-2013-2380 on “Technical Interoperability Standard for the Reuse of Information Resources”.
A taxonomy is a controlled vocabulary, where the terms are organized in a hierarchical way (with a tree structure), from the most general to the most specific terms, including those that are related.
An example would be the taxonomy of primary sectors and the areas related to each one (for example, primary sector “Environment” that includes the areas “Meteorology”, “Geography”, “Conservation of fauna and flora”). The defined primary sectors are used to describe a set of data in the data catalog of datos.gob.es. This taxonomy is defined in Annex IV of Document BOE-A-2013-2380 on “Technical Interoperability Standard for the Reuse of Information Resources”.
A thesaurus is a taxonomy with some “extra” relationships:
- Synchronicity or preference relationships: among the preferred term (PT) or descriptor and the non-preferred term (NPT).
- Whole-part or class-subclass hierarchical relationships: that is, among the broader terms (BT) and the narrower terms (NT).
- Associative relationships: among related terms (RT) in a pragmatic way, that is, not in a hierarchical or synonymous way.
AGROVOC is a thesaurus that organizes concepts related to the fields of interest of FAO, such as agriculture (mainly), food, nutrition, fisheries, forestry or the environment. For example, the concept “Fish farms” is within a broader concept “Land” (whose synonym is “farm”, which also has other relationships).
An ontology, the next step in the organization of knowledge, is the formal definition of types, properties and relationships among concepts in a particular domain of discussion. And we understand a formal decision as that which encodes knowledge based on formal logic, as a collection of assertions (thus being able to be processed by a machine that would be in a position to make inference of new knowledge).
An example of ontology would be FOAF (Friend Of A Friend), which serves to describe people, their activities and their relationships with other people and objects (“Ana meets Águeda”, “Ana’s email is <ana@example.org>” …)
There is no golden rule for selecting which tool to use, instead in each case we have to choose the one whose level of complexity is most appropriate, always trying to choose the simplest option, following the KISS principle (Keep It Simple, Stupid!) that tells us that simplicity should be a key design objective, and avoiding any unnecessary complexity. It is worth remembering that the first step before creating a new knowledge organization tool is to search and see if there is already one that is available for the proposed task and that can be reused.
Noticia
The Semantic Sensor Network Ontology (SSN) is an ontology that describes sensors and observations, that is, the physical data measured by devices. This vocabulary is intended to play a crucial role in the application of semantic technologies in application areas related to Smart Cities and the Internet of Things (IoT) and, therefore, has potential uses in many domains, for example, for environmental control issues (air and water quality), precision agriculture, traffic management, integration of health control processes, etc.
The SSN ontology is an OWL vocabulary developed by the W3C in collaboration with the Open Geospatial Consortium (OGC) to define a general standard for describing sensor networks aligned with Semantic Web technologies and the Linked Data paradigm. It is currently in the ‘Working Draft’ phase, as of the 4th of May, 2017. Given the multitude of scenarios and use cases of this ontology, its design is based on a modular architecture (horizontal and vertical) that allows it to be organically extended on the basis of a minimal common vocabulary. This vocabulary has been designated SOSA, according to its main concepts:
1. Sensor: devices that measure one or more physical magnitudes: for example, accelerometers, gyroscopes, barometers, etc.
2. Observation: the actual or estimated value of a physical magnitude.
3. Sample: representative samples of a given magnitude.
4. Actuator: a device that modifies physical quantities based on instructions, such as a fan or door operator.
The following diagram illustrates this modular design of the SS ontology:

Source: SOA and SSN ontologies with their respective modules. W3C
One of the most noteworthy aspects of this SSN ontology is, as has been mentioned, the participation of the OGC as an integral part of the process. This means that the final version of the document will be a joint standard of the two organisations: W3C and OGC. Furthermore, work has been done on the compatibility of SSN with existing OGC standards for the annotation of sensors and observations. Namely, with:
· OGC Observations and Measurements standard. XML vocabulary for the description of the conceptual model of Observations and Measurements (O&M) for the publication of environmental observations, published jointly by the OGC and the ISO (in this case as ISO/DIS 19156).
· OGC Sensor Model Language (SensorML). XML vocabulary to describe sensors, actuators, as well as the procedures to measure and transform observations.
In the coming months, contributions and revisions of this first definition of the standard are expected at the international level, as well as reference implementations that will enable the next phase of the vocabulary standardisation process. In particular, broad participation is expected from the realm of open data and especially from projects linked to the development of the Smart Cities concept.