Blog
En 2010, tras el devastador terremoto de Haití, cientos de organizaciones humanitarias llegaron al país dispuestas a ayudar. Se encontraron con un obstáculo inesperado: no había mapas actualizados. Sin información geográfica fiable, coordinar recursos, localizar comunidades aisladas o planificar rutas seguras era casi imposible.
Ese vacío marcó un antes y un después: fue el momento en que la comunidad global de OpenStreetMap (OSM) demostró su enorme potencial humanitario. Más de 600 voluntarios de todo el mundo se organizaron y comenzaron a mapear Haití en tiempo récord. Este hecho impulsó el proyecto Humanitarian OpenStreetMap Team.
¿Qué es Humanitarian OpenStreetMap Team?
Humanitarian OpenStreetMap Team, conocida por el acrónimo HOT, es una organización internacional sin ánimo de lucro dedicada a mejorar la vida de las personas mediante datos geográficos precisos y accesibles. Su labor está inspirada en los principios de OSM, el proyecto colaborativo que busca crear un mapa digital abierto, gratuito y editable por cualquiera.
La diferencia con OSM es que HOT se orienta específicamente a contextos donde la falta de datos afecta de manera directa a la vida de las personas: se trata de aportar datos y herramientas que permitan tomar decisiones más informadas en situaciones críticas. Es decir, aplica los principios del software y datos abiertos al mapeo colaborativo con impacto social y humanitario.
En este sentido, el equipo de HOT no sólo produce mapas: también facilita las herramientas, las capacidades técnicas e impulsa nuevas formas de trabajo para distintos actores que necesitan datos espaciales precisos. Su labor va desde la respuesta inmediata cuando ocurre un desastre hasta programas estructurales que fortalecen la resiliencia local ante desafíos como el cambio climático o la expansión urbana.
Cuatro zonas geográficas prioritarias
Aunque HOT no se limita a un único país o región, sí ha establecido áreas prioritarias donde sus esfuerzos de mapeo tienen un mayor impacto debido a la existencia de brechas significativas en los datos o a necesidades humanitarias urgentes. Actualmente trabaja en más de 90 países y organiza sus actividades a través de cuatro Hubs de Mapeo Abierto (centros regionales) que coordinan iniciativas según las necesidades locales:
- Asia-Pacífico: los desafíos incluyen desde desastres naturales frecuentes (como tifones y terremotos) hasta el acceso a zonas rurales remotas con poca cobertura cartográfica.
- África Oriental y Meridional: esta región enfrenta múltiples crisis entrelazadas (sequías, movimientos migratorios, deficiencias en infraestructura básica) por lo que contar con mapas actualizados es clave para la planificación sanitaria, la gestión de recursos y la respuesta a emergencias.
- África Occidental y Norte de África: en esta zona, HOT impulsa actividades que combinan el fortalecimiento de capacidades locales con proyectos tecnológicos, promoviendo la participación activa de comunidades en la creación de mapas útiles para su entorno.
- América Latina y el Caribe: con frecuencia afectada por huracanes, terremotos y riesgos volcánicos, esta región ha visto una adopción creciente de mapeo colaborativo tanto en respuesta a emergencias como en iniciativas de desarrollo urbano y resiliencia climática.
La elección de estas zonas prioritarias no es arbitraria: responde a contextos en los que la falta de datos abiertos puede limitar respuestas rápidas y efectivas, así como la capacidad de gobiernos y comunidades para planificar su futuro con información fiable.
Herramientas de código abierto desarrolladas por HOT
Una parte esencial del impacto de HOT reside en las herramientas y plataformas de código abierto que facilitan el mapeo colaborativo y el uso de datos espaciales en escenarios reales. Para ello se desarrolló una Cadena de Valor de Mapeo E2E, la cual es la metodología central que permite a las comunidades pasar de la captura de imágenes y el mapeo al impacto. Esta cadena de valor respalda todos sus programas, garantizando que el mapeo sea un proceso transformador, basado en datos abiertos, educación y poder comunitario.
Estas herramientas no sólo apoyan el trabajo de HOT, sino que están disponibles para que cualquier persona o comunidad las utilice, adapte o amplíe. En concreto se han desarrollado herramientas para crear, acceder, gestionar, analizar y compartir datos de mapas abiertos. Puedes explorarlas en el Centro de Aprendizaje, un espacio de formación que ofrece desarrollo de capacidades, fortalecimiento de habilidades y un proceso de acreditación para personas y organizaciones interesadas. A continuación se describen estas herramientas:
Permite planificar vuelos de drones para obtener imágenes aéreas actualizadas de alta resolución, algo fundamental cuando las imágenes comerciales son demasiado costosas. De esta forma, cualquier persona con acceso a un dron -incluidos modelos de bajo coste y de uso común-, puede contribuir a un repositorio global de imágenes libres y abiertas, lo que democratiza el acceso a datos geoespaciales críticos para la respuesta ante desastres, la resiliencia comunitaria y la planificación local.
La plataforma coordina a múltiples operadores y genera planes de vuelo automatizados para cubrir áreas de interés, lo que facilita la captura de imágenes 2D y 3D con precisión y eficiencia. Además, incluye planes de formación y promueve la seguridad y el cumplimiento de regulaciones locales, apoyando la gestión de proyectos, la visualización de datos y el intercambio colaborativo entre pilotos y organizaciones.

Figura 1. Captura Drone Tasking Manager (DroneTM). Fuente: Equipo Humanitario de OpenStreetMap (HOT).
Es una plataforma de código abierto que ofrece acceso a una biblioteca comunitaria de imágenes aéreas con licencia abierta, obtenidas desde satélites, drones u otras aeronaves. Cuenta con una interfaz sencilla donde se puede hacer zoom sobre un mapa para buscar imágenes disponibles. OAM permite tanto descargar como contribuir con nuevas imágenes, ampliando así un repositorio global de datos visuales que cualquiera puede usar y trazar en OpenStreetMap.
Todas las imágenes alojadas en OpenAerialMap están licenciadas bajo CC-BY 4.0, lo que significa que son de acceso público y pueden ser reutilizadas con atribución, facilitando su integración en aplicaciones de análisis geoespacial, proyectos de respuesta ante emergencias o iniciativas de planificación local. OAM se apoya en la Open Imagery Network (OIN) para estructurar y servir estas imágenes.
Facilita el mapeo colaborativo en OpenStreetMap. Su propósito principal es coordinar a miles de voluntarios de todo el mundo para añadir datos geográficos de forma organizada y eficiente. Para ello, divide un proyecto de mapeo grande en pequeñas “tareas” que pueden completarse rápidamente por personas que trabajan de forma remota.
El funcionamiento es sencillo: los proyectos se subdividen en cuadrículas, cada una asignable a un voluntario para que trace elementos como calles, edificios o puntos de interés en OSM. Cada tarea es validada por mappers experimentados para asegurar la calidad de los datos. La plataforma muestra claramente qué zonas aún necesitan mapeo o revisión, evitando duplicaciones y mejorando la eficiencia del trabajo colaborativo.

Figura 2. Captura Tasking Manager. Fuente: Equipo Humanitario de OpenStreetMap (HOT).
Utiliza inteligencia artificial para asistir el proceso de mapeo en OpenStreetMap con fines humanitarios. A través de modelos de computer vision, fAIr analiza imágenes satelitales o aéreas y sugiere la detección de elementos geográficos como edificios, caminos, cursos de agua o vegetación a partir de imágenes libres como las de OpenAerialMap. La idea es que los voluntarios puedan usar estas predicciones como asistencia para mapear más rápido y con mayor precisión, sin realizar importaciones masivas automatizadas, integrando siempre el juicio humano en la validación de cada elemento.
Una de las características más destacadas de fAIr es que la creación y entrenamiento de los modelos de IA está en manos de las propias comunidades mapeadoras: los usuarios pueden generar sus propios conjuntos de entrenamiento ajustados a su región o contexto, lo que ayuda a reducir sesgos de los modelos estándar y hace que las predicciones sean más relevantes para las necesidades locales.
Es una aplicación móvil y web que facilita la coordinación de campañas de mapeo directamente en el terreno. Field-TM se usa junto con OpenDataKit (ODK), una plataforma de recolección de datos en Android que permite introducir información sobre el terreno usando los propios dispositivos móviles. Gracias a ella, los voluntarios pueden introducir información geoespacial verificada por observación local, como la finalidad de cada edificio (si es una tienda, un hospital, etc.).
La aplicación proporciona una interfaz para asignar tareas, seguir el avance y asegurar la consistencia de los datos. Su propósito principal es mejorar la eficiencia, organización y calidad del trabajo de campo al enriquecerlo con información local, así como reducir duplicidades, evitar zonas no cubiertas y permitir un seguimiento claro del progreso de cada colaborador en una campaña de mapeo.
Transforma conversaciones de aplicaciones de mensajería instantánea (como WhatsApp) en mapas interactivos. En muchas comunidades, especialmente en zonas propensas a desastres o con poca alfabetización tecnológica, las personas ya utilizan apps de chat para comunicarse y compartir su ubicación. ChatMap aprovecha esos mensajes exportados, extrae datos de ubicación junto con textos, fotos y videos, y los representa automáticamente sobre un mapa, sin necesidad de instalaciones complejas o conocimientos técnicos avanzados.
Esta solución funciona incluso en condiciones de conectividad limitada o sin conexión, basándose en la señal GPS del teléfono para registrar ubicaciones y almacenarlas hasta que se pueda subir la información.

Figura 3. Captura de ChatMap. Fuente: Equipo Humanitario de OpenStreetMap (HOT).
Facilitar el acceso y descarga de datos geoespaciales actualizados de OpenStreetMap en formatos útiles para análisis y proyectos. A través de esta plataforma web se puede seleccionar un área de interés en el mapa, elegir qué datos se quieren (como carreteras, edificios o servicios) y descargar esos datos en múltiples formatos, como GeoJSON, Shapefile, GeoPackage, KML o CSV. Esto permite usar la información en un software SIG (Sistemas de Información Geográfica) o integrarla directamente en aplicaciones personalizadas. También se pueden exportar todos los datos de una zona o descargar datos asociados a un proyecto concreto del Tasking Manager.
La herramienta está diseñada para ser accesible tanto a analistas técnicos como a personas que no son expertas en SIG: en cuestión de minutos se pueden generar extractos personalizados de OSM sin necesidad de instalar software especializado. También ofrece una API y métricas de calidad de datos.
Es una plataforma de creación de mapas interactivos de código abierto que permite a cualquier persona visualizar, personalizar y compartir datos geoespaciales fácilmente. Sobre una base de mapas de OpenStreetMap, uMap deja añadir capas personalizadas, marcadores, líneas y polígonos, administrar colores e íconos, importar datos en formatos comunes (como GeoJSON, GPX o KML) y elegir licencias para los datos, sin necesidad de instalar software especializado. Los mapas creados pueden incrustarse en sitios web o compartirse mediante enlaces.
La herramienta ofrece plantillas y opciones de integración con otras herramientas de HOT, como ChatMap y OpenAerialMap, para enriquecer los datos en el mapa.
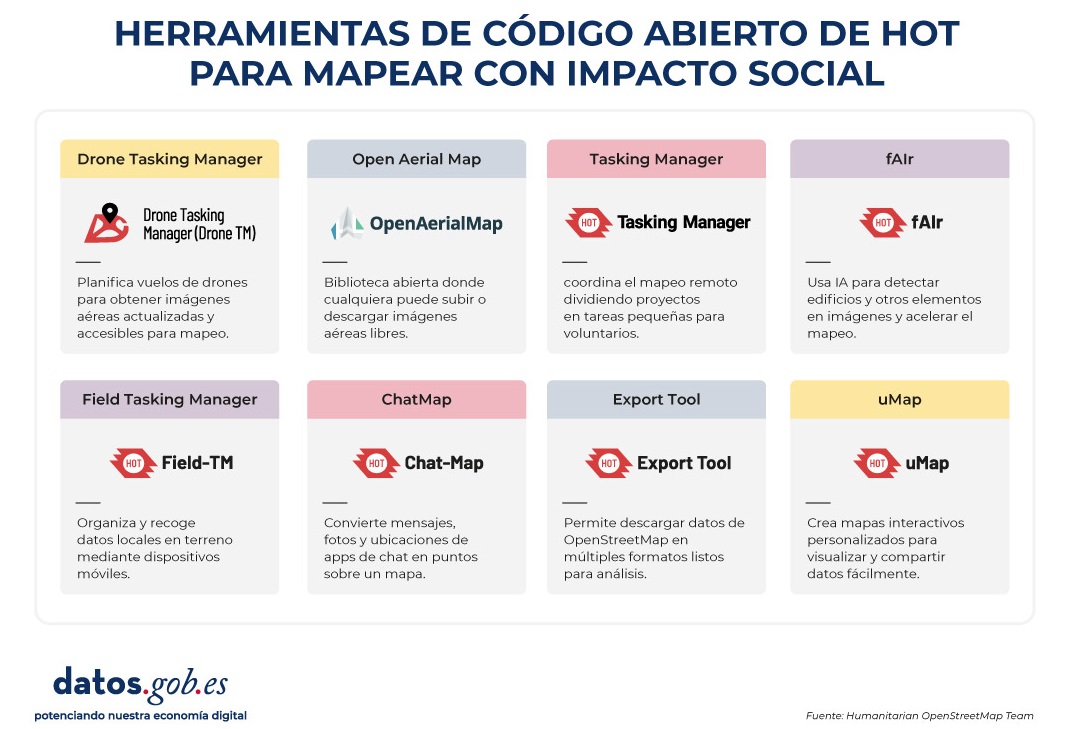
Figura 4. Herramientas de código abierto de HOT para mapear con impacto social. Fuente: Equipo Humanitario de OpenStreetMap (HOT).
Todas estas herramientas están a disposición de las comunidades locales de todo el mundo. Desde HOT también se ofrece formación para fomentar su uso y mejorar el impacto de los datos abiertos en las respuestas humanitarias.
¿Cómo puedes sumarte al impacto de HOT?
HOT se construye junto a una comunidad global que impulsa el uso de datos abiertos para fortalecer la toma de decisiones y salvar vidas. Si representas a una organización, universidad, colectivo, agencia pública o iniciativa comunitaria y tienes una idea de proyecto o interés en una alianza, el equipo de HOT está abierto a explorar colaboraciones. Puedes escribirles a partnerships@hotosm.org.
Cuando las comunidades tienen acceso a datos precisos, herramientas abiertas y el conocimiento para generar información geoespacial de forma continua, se convierten en agentes informados, listos para tomar decisiones en cualquier situación. Están mejor preparadas para identificar riesgos climáticos, responder ante emergencias, resolver problemas locales y movilizar apoyo. El mapeo abierto, por tanto, no solo representa territorios: empodera a las personas para transformar su realidad con datos que pueden salvan vidas.
Blog
Cada vez gana más terreno la idea de concebir la inteligencia artificial (IA) como un servicio de consumo inmediato o utility, bajo la premisa de que basta con “comprar una aplicación y empezar a utilizarla”. Sin embargo, subirse a la IA no es como comprar software convencional y ponerlo en marcha al instante. A diferencia de otras tecnologías de la información, la IA difícilmente se podrá utilizar con la filosofía del plug and play. Existe un conjunto de tareas imprescindibles que los usuarios de estos sistemas deberían emprender, no solo por razones de seguridad y cumplimiento legal, sino sobre todo para obtener resultados eficientes y confiables.
El Reglamento de inteligencia artificial (RIA)[1]
El RIA define marcos de referencia que deberían ser tenidos en cuenta por los proveedores[2] y responsables de desplegar[3] la IA. Esta es una norma muy compleja cuya orientación es doble. En primer lugar, en una aproximación que podríamos definir como de alto nivel, la norma establece un conjunto de líneas rojas que nunca podrán ser traspasadas. La Unión Europea aborda la IA desde un enfoque centrado en el ser humano y al servicio de las personas. Por ello, cualquier desarrollo deberá garantizar ante todo que no se vulneren derechos fundamentales ni se cause ningún daño a la seguridad e integridad de las personas. Adicionalmente, no se admitirá ninguna IA que pudiera generar riesgos sistémicos para la democracia y el estado de derecho. Para que estos objetivos se materialicen, el RIA despliega un conjunto de procesos mediante un enfoque orientado a producto. Esto permite clasificar los sistemas de IA en función de su nivel de riesgo, -bajo, medio, alto- así como los modelos de IA de uso general[4]. Y también, establecer, a partir de esta categorización, las obligaciones que cada sujeto participante deberá cumplir para garantizar los objetivos de la norma.
Habida cuenta de la extraordinaria complejidad del reglamento europeo, queremos compartir en este artículo algunos principios comunes que se deducen de su lectura y podrían inspirar buenas prácticas por parte de las organizaciones públicas y privadas. Nuestro enfoque no se centra tanto en definir una hoja de ruta para un determinado sistema de información como en destacar algunos elementos que, a nuestro juicio, pueden resultar de utilidad para garantizar que el despliegue y utilización de esta tecnología resulten seguros y eficientes, con independencia del nivel de riesgo de cada sistema de información basado en IA.
Definir un propósito claro
El despliegue de un sistema de IA es altamente dependiente de la finalidad que persigue la organización. No se trata de subirse al carro de una moda. Es cierto que la información pública disponible parece evidenciar que la integración de este tipo de tecnología forma parte importante de los procesos de transformación digital de las empresas y de la Administración, proporcionando mayor eficiencia y capacidades. Sin embargo, no puede convertirse en una moda instalar cualquiera de los Large Language Models (LLM). Se necesita una reflexión previa que tenga en cuenta cuáles son las necesidades de la organización y defina que tipo de IA va a contribuir a la mejora de nuestras capacidades. No adoptar esta estrategia podría poner en riesgo a nuestra entidad, no solo desde el punto de vista de su funcionamiento y resultados, sino incluso desde una perspectiva jurídica. Por ejemplo, introducir un LLM o un chatbot en un entorno de alto riesgo decisional podría suponer padecer impactos reputacionales o incurrir en responsabilidad civil. Insertar este LLM en un entorno médico, o utilizar un chatbot en un contexto sensible con población no preparada o en procesos de asistencia críticos, podría acabar generando situaciones de riesgo de consecuencias imprevisibles para las personas.
No hacer el mal
El principio de no maleficiencia es un elemento clave y debe inspirar de modo determinante nuestra práctica en el mundo de la IA. Por ello el RIA establece una serie de prácticas expresamente prohibidas para proteger los derechos fundamentales y la seguridad de las personas. Estas prohibiciones se centran en evitar manipulaciones, discriminaciones y usos indebidos de sistemas de IA que puedan causar daños significativos.
Categorías de prácticas prohibidas
1. Manipulación y control del comportamiento. Mediante el uso de técnicas subliminales o manipuladoras que alteren el comportamiento de personas o colectivos, impidiendo la toma de decisiones informadas y provocando daños considerables.
2. Explotación de vulnerabilidades. Derivadas de la edad, discapacidad o situación social/económica para modificar sustancialmente el comportamiento y causar perjuicio.
3. Puntuación social (Social Scoring). IA que evalúe a personas en función de su comportamiento social o características personales, generando calificaciones con efectos para los ciudadanos que resulten en tratos injustificados o desproporcionados.
4. Evaluación de riesgos penales basada en perfiles. IA utilizada para predecir la probabilidad de comisión de delitos únicamente mediante elaboración de perfiles o características personales. Aunque se admite su uso para la investigación penal cuando el delito se ha cometido efectivamente y existen hechos que analizar.
5. Reconocimiento facial y bases de datos biométricas. Sistemas para la ampliación de bases de datos de reconocimiento facial mediante la extracción no selectiva de imágenes faciales de Internet o de circuitos cerrados de televisión.
6. Inferencia de emociones en entornos sensibles. Diseñar o usar la IA para inferir emociones en el trabajo o en centros educativos, salvo por motivos médicos o de seguridad.
7. Categorización biométrica sensible. Desarrollar o utilizar una IA que clasifique a individuos según datos biométricos para deducir raza, opiniones políticas, religión, orientación sexual, etc.
8. Identificación biométrica remota en espacios públicos. Uso de sistemas de identificación biométrica remota «en tiempo real» en espacios públicos con fines policiales, salvo excepciones muy limitadas (búsqueda de víctimas, prevención de amenazas graves, localización de sospechosos de delitos graves).
Al margen de las conductas expresamente prohibidas es importante tener en cuenta que el principio de no maleficencia implica que no podemos utilizar un sistema de IA con la clara intención de causar un daño, con la conciencia de que esto podría ocurrir o, en cualquier caso, cuando la finalidad que perseguimos sea contraria a derecho.
Garantizar una adecuada gobernanza de datos
El concepto de gobernanza de datos se encuentra en el artículo 10 del RIA y aplica a los sistemas de alto riesgo. No obstante, contiene un conjunto de principios de alta rentabilidad a la hora de desplegar un sistema de cualquier nivel. Los sistemas de IA de alto riesgo que usan datos deben desarrollarse con conjuntos de entrenamiento, validación y prueba que cumplan criterios de calidad. Para ello se definen ciertas prácticas de gobernanza para asegurar:
- Diseño adecuado.
- Que la recogida y origen de los datos, y en el caso de los datos personales la finalidad perseguida, sean adecuadas y legítimas.
- Que se adopten procesos de preparación como la anotación, el etiquetado, la depuración, la actualización, el enriquecimiento y la agregación.
- Que el sistema se diseñe con casos de uso cuya información sea coherente con lo que se supone que miden y representan los datos.
- Asegurar la calidad de los datos garantizando la disponibilidad, la cantidad y la adecuación de los conjuntos de datos necesarios.
- Detectar y revisar de sesgos que puedan afectar a la salud y la seguridad de las personas, a los derechos o generar discriminación, especialmente cuando las salidas de datos influyan en las informaciones de entrada de futuras operaciones. Deben adoptarse medidas para prevenir y corregir estos sesgos.
- Identificar y resolver lagunas o deficiencias en los datos que impidan el cumplimiento del RIA, y añadiríamos que la legislación.
- Los conjuntos de datos empleados deben ser relevantes, representativos, completos y con propiedades estadísticas adecuadas para su uso previsto y deben considerar las características geográficas, contextuales o funcionales necesarias para el sistema, así como garantizar su diversidad. Además, carecerán de errores y estarán completos en vista de su finalidad prevista.
La IA es una tecnología altamente dependiente de los datos que la alimentan. Desde este punto de vista, no disponer de gobernanza de datos no solo puede afectar al funcionamiento de estas herramientas, sino que podría generar responsabilidad para el usuario.
En un futuro no lejano, la obligación de que los sistemas de alto riesgo obtengan un marcado CE emitido por un organismo notificado (es decir, designado por un Estado miembro de la Unión Europea) ofrecerá condiciones de confiabilidad al mercado. Sin embargo, para el resto de los sistemas de menor riesgo aplica la obligación de transparencia. Esto no implica en absoluto que el diseño de esta IA no deba tener en cuenta estos principios en la medida de lo posible. Por tanto, antes de realizar una contratación sería razonable verificar la información precontractual disponible tanto en relación con las características del sistema y su confiabilidad como respecto de las condiciones y recomendaciones de despliegue y uso.
Otra cuestión atañe a nuestra propia organización. Si no disponemos de las adecuadas medidas de cumplimiento normativo, organizativas, técnicas y de calidad que aseguren la confiabilidad de nuestros propios datos, difícilmente podremos utilizar herramientas de IA que se alimenten de ellos. En el contexto del RIA el usuario de un sistema también puede incurrir en responsabilidad. Es perfectamente posible que un producto de esta naturaleza haya sido desarrollado de modo adecuado por el proveedor y que en términos de reproducibilidad éste pueda garantizar que bajo las condiciones adecuadas el sistema funciona correctamente. Lo que desarrolladores y proveedores no pueden resolver son las inconsistencias en los conjuntos de datos que integre en la plataforma el usuario-cliente. No es su responsabilidad si el cliente no desplegó adecuadamente un marco de cumplimiento del Reglamento General de Protección de Datos o está utilizando el sistema para una finalidad ilícita. Tampoco será su responsabilidad que el cliente mantenga conjuntos de datos no actualizados o no confiables que al ser introducidos en la herramienta generen riesgos o contribuyan a la toma de decisiones inadecuadas o discriminatorias.
En consecuencia, la recomendación es clara: antes de implementar un sistema basado en inteligencia artificial debemos asegurarnos de que la gobernanza de datos y el cumplimiento de la legislación vigente se garanticen adecuadamente.
Garantizar la seguridad
La IA es una tecnología particularmente sensible que presenta riesgos de seguridad específicos, -los llamados efectos adversarios-, como por ejemplo la corrupción de los conjuntos de datos. No es necesario buscar ejemplos sofisticados. Como cualquier sistema de información la IA exige que las organizaciones los desplieguen y utilicen de modo seguro. En consecuencia, el despliegue de la IA en cualquier entorno exige el desarrollo previo de un análisis de riesgos que permita identificar cuáles son las medidas organizativas y técnicas que garantizan un uso seguro que la herramienta.
Formar a su personal
A diferencia del RGPD, en el que esta cuestión es implícita, el RIA expresamente establece como obligación el deber de formar. El artículo 4 del RIA es tan preciso que merece la pena su reproducción íntegra:
Los proveedores y responsables del despliegue de sistemas de IA adoptarán medidas para garantizar que, en la mayor medida posible, su personal y demás personas que se encarguen en su nombre del funcionamiento y la utilización de sistemas de IA tengan un nivel suficiente de alfabetización en materia de IA, teniendo en cuenta sus conocimientos técnicos, su experiencia, su educación y su formación, así como el contexto previsto de uso de los sistemas de IA y las personas o los colectivos de personas en que se van a utilizar dichos sistemas.
Este sin duda es un factor crítico. Las personas que utilizan la inteligencia artificial deben haber recibido una formación adecuada que les permita entender la naturaleza del sistema y ser capaces de tomar decisiones informadas. Uno de los principios nucleares de la legislación y del enfoque europeo es el de supervisión humana. Por tanto, con independencia de las garantías que ofrezca un determinado producto de mercado, la organización que lo utiliza siempre será responsable de las consecuencias. Y ello ocurrirá tanto en el caso en el que la última decisión se atribuya a una persona, como cuando en procesos altamente automatizados los responsables de su gestión no sean capaces de identificar una incidencia tomando decisiones adecuadas con supervisión humana.
La culpa in vigilando
La introducción masiva de los LLM plantea el riesgo de incurrir en la llamada culpa in vigilando: un principio jurídico que hace referencia a la responsabilidad que asume una persona por no haber ejercido la debida vigilancia sobre otra, cuando de esa falta de control se deriva un daño o un perjuicio. Si su organización ha introducido cualquiera de estos productos de mercado que integran funciones como realizar informes, evaluar información alfanumérica e incluso asistirle en la gestión del correo electrónico, será fundamental que asegure el cumplimiento de las recomendaciones que anteriormente hemos señalado. Resultará particularmente aconsejable que defina de modo muy preciso los fines para los que se implementa la herramienta, los roles y responsabilidades de cada usuario y proceda a documentar sus decisiones y a formar adecuadamente al personal.
Desgraciadamente el modelo de introducción en el mercado de los LLM ha generado por sí mismo un riesgo sistémico y grave para las organizaciones. La mayor parte de herramientas han optado por una estrategia de comercialización que no difiere en nada de la que en su día emplearon las redes sociales. Esto es, permiten el acceso en abierto y gratuito a cualquier persona. Es obvio que con ello consiguen dos resultados: reutilizar la información que se les facilita monetizando el producto y generar una cultura de uso que facilite la adopción y comercialización de la herramienta.
Imaginemos una hipótesis, por supuesto, descabellada. Un médico interno residente (MIR) ha descubierto que varias de estas herramientas han sido desarrolladas y, de hecho, se utilizan en otro país para el diagnóstico diferencial. Nuestro MIR está muy preocupado por tener que despertar al jefe de guardia médica en el hospital cada 15 minutos. Así que, diligentemente, contrata una herramienta, que no se ha previsto para ese uso en España, y toma decisiones basadas en la propuesta de diagnóstico diferencial de un LLM sin tener todavía las capacidades que lo habilitan para una supervisión humana. Evidentemente existe un riesgo significativo de acabar causando un daño a un paciente.
Situaciones como la descrita obligan a considerar cómo deben actuar las organizaciones que no utilizan IA pero que son conscientes del riesgo de que sus empleados las usen sin su conocimiento o consentimiento. En este sentido, se debería adoptar una estrategia preventiva basada en la emisión de circulares e instrucciones muy precisas respecto de la prohibición de su uso. Por otra parte, existe una situación de riesgo híbrida. El LLM se ha contratado por la organización y es utilizada por la persona empleada para fines distintos de los previstos. En tal caso la dupla seguridad-formación adquiere un valor estratégico.
Probablemente la formación y la adquisición de cultura sobre la inteligencia artificial sea un requisito esencial para el conjunto de la sociedad. De lo contrario, los problemas y riesgos sistémicos que en el pasado afectaron al despliegue de Internet volverán a suceder y quién sabe si con una intensidad difícil de gobernar.
Contenido elaborado por Ricard Martínez Martínez, Director de la Cátedra de Privacidad y Transformación Digital, Departamento de Derecho Constitucional de la Universitat de València. Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
NOTAS
[1] Reglamento (UE) 2024/1689 del Parlamento Europeo y del Consejo, de 13 de junio de 2024, por el que se establecen normas armonizadas en materia de inteligencia artificial y por el que se modifican los Reglamentos (CE) n.° 300/2008, (UE) n.° 167/2013, (UE) n.° 168/2013, (UE) 2018/858, (UE) 2018/1139 y (UE) 2019/2144 y las Directivas 2014/90/UE, (UE) 2016/797 y (UE) 2020/1828 disponible en https://eur-lex.europa.eu/legal-content/ES/TXT/?uri=OJ%3AL_202401689
[2] El RIA define como «proveedor»: una persona física o jurídica, autoridad pública, órgano u organismo que desarrolle un sistema de IA o un modelo de IA de uso general o para el que se desarrolle un sistema de IA o un modelo de IA de uso general y lo introduzca en el mercado o ponga en servicio el sistema de IA con su propio nombre o marca, previo pago o gratuitamente.
[3] EL RIA define como «responsable del despliegue»: una persona física o jurídica, o autoridad pública, órgano u organismo que utilice un sistema de IA bajo su propia autoridad, salvo cuando su uso se enmarque en una actividad personal de carácter no profesional.
[4] El RIA define como «modelo de IA de uso general»: un modelo de IA, también uno entrenado con un gran volumen de datos utilizando autosupervisión a gran escala, que presenta un grado considerable de generalidad y es capaz de realizar de manera competente una gran variedad de tareas distintas, independientemente de la manera en que el modelo se introduzca en el mercado, y que puede integrarse en diversos sistemas o aplicaciones posteriores, excepto los modelos de IA que se utilizan para actividades de investigación, desarrollo o creación de prototipos antes de su introducción en el mercado.
Blog
En un mundo cada vez más interconectado y complejo, la inteligencia geoespacial (GEOINT) se ha convertido en una herramienta esencial para la toma de decisiones en el ámbito de la defensa y la seguridad. La capacidad de recopilar, analizar e interpretar datos geoespaciales permite a las Fuerzas Armadas y a las agencias de seguridad comprender mejor el entorno operativo, anticipar amenazas y planificar operaciones con mayor eficacia.
En este contexto, los datos satelitales, clasificados pero también los abiertos, han adquirido una relevancia significativa. Programas como Copernicus de la Unión Europea proporcionan acceso gratuito y abierto a una amplia gama de datos de observación de la Tierra, lo que democratiza el acceso a información crítica y fomenta la colaboración entre diferentes actores.
Este artículo explora el papel de los datos en la inteligencia geoespacial aplicada a la defensa, destacando su importancia, aplicaciones y el liderazgo de España en este ámbito.
¿Qué es la Inteligencia Geoespacial?
La inteligencia geoespacial (GEOINT) es una disciplina que combina la recopilación, análisis e interpretación de datos geoespaciales para apoyar la toma de decisiones en diversas áreas, incluyendo la defensa, la seguridad y la gestión de emergencias. Estos datos pueden incluir imágenes satelitales, información de sensores remotos, datos de sistemas de información geográfica (SIG) y otras fuentes que proporcionan información sobre la ubicación y las características del terreno.
En el ámbito de la defensa, la GEOINT permite a los analistas y planificadores militares obtener una comprensión detallada del entorno operativo, identificar amenazas potenciales y planificar operaciones con mayor precisión. Además, facilita la coordinación entre diferentes unidades y agencias, mejorando la eficacia de las operaciones conjuntas.
Aplicaciones en el ámbito de la defensa
La integración de datos satelitales abiertos en la inteligencia geoespacial ha ampliado significativamente las capacidades de defensa. A continuación, se presentan algunas de las aplicaciones más relevantes:

Figura 1. Aplicaciones GEOINT en defensa. Fuente: elaboración propia
La inteligencia geoespacial no solo apoya a las Fuerzas Armadas en la toma de decisiones tácticas, sino que también transforma la forma en que se planifican y ejecutan operaciones militares, de vigilancia y de respuesta a emergencias. Aquí presentamos casos de uso concretos donde la GEOINT, apoyado en datos satelitales abiertos, ha tenido un impacto decisivo.
Monitoreo de movimientos militares en conflictos
Caso: Guerra de Ucrania (2022–2024)
Organizaciones como el Centro de Satélites de la UE (SatCen) y ONGs como Conflict Intelligence Team han usado imágenes Sentinel-1 y Sentinel-2 (Copernicus) para:
- Detectar concentraciones de tropas y material militar ruso.
- Analizar cambios en aeródromos, bases o rutas logísticas.
- Apoyar la verificación independiente de eventos sobre el terreno.
Esto ha sido clave para la toma de decisiones de la UE y la OTAN, sin necesidad de recurrir a datos clasificados.
Vigilancia marítima y control de fronteras
Caso: Operaciones de FRONTEX en el Mediterráneo
GEOINT alimentado por Sentinel-1 (radar) y Sentinel-3 (óptico + altímetro) permite:
- Identificar embarcaciones no autorizadas, incluso bajo nubes o de noche.
- Integrar alertas con AIS (sistema de identificación automática de buques).
- Coordinar rescates y operaciones de intercepción.
Ventaja: el radar de apertura sintética (SAR) de Sentinel-1 puede ver a través de las nubes, lo que lo hace ideal para vigilancia continua.
Apoyo a misiones de paz y ayuda humanitaria
Caso: Terremoto en Siria/Turquía (2023)
Datos abiertos (Sentinel-2, Landsat-8, PlanetScope gratuito tras catástrofe) se emplearon para:
- Detectar zonas colapsadas y evaluar daños.
- Planificar rutas de acceso seguras.
Coordinar campamentos y recursos con el apoyo de militares.
El papel de España
España ha demostrado un compromiso significativo con el desarrollo y la aplicación de la inteligencia geoespacial en defensa.
|
Centro de Satélites de la Unión Europea (SatCen) |
Proyecto Zeus del Ejército Español |
Participación en Programas Europeos | Desarrollo de capacidades nacionales |
|
Ubicado en Torrejón de Ardoz, el SatCen es una agencia de la Unión Europea que proporciona productos y servicios de inteligencia geoespacial para apoyar la toma de decisiones en materia de seguridad y defensa. España, como país anfitrión, desempeña un papel central en las operaciones del SatCen. |
El Ejército de Tierra español ha lanzado el proyecto Zeus, una iniciativa tecnológica que integra inteligencia artificial, redes 5G y datos satelitales para mejorar las capacidades operativas. Este proyecto busca crear una nube táctica de combate que permita una mayor interoperabilidad y eficacia en las operaciones militares. |
España participa activamente en programas europeos relacionados con la observación de la Tierra y la inteligencia geoespacial, como Copernicus y MUSIS. Además, colabora en iniciativas bilaterales y multilaterales para el desarrollo de capacidades satelitales y la compartición de datos. |
A nivel nacional, España ha invertido en el desarrollo de capacidades propias en inteligencia geoespacial, incluyendo la formación de personal especializado y la adquisición de tecnologías avanzadas. Estas inversiones refuerzan la autonomía estratégica del país y su capacidad para contribuir a operaciones internacionales. |
Figura 2. Tabla comparativa de la participación de España en distintos proyectos satelitales. Fuente: elaboración propia
Desafíos y oportunidades
Aunque los datos satelitales abiertos ofrecen numerosas ventajas, también presentan ciertos desafíos que deben abordarse para maximizar su utilidad en el ámbito de la defensa.
-
Calidad y resolución de los datos: si bien los datos abiertos son valiosos, a menudo tienen limitaciones en términos de resolución espacial y temporal en comparación con datos comerciales o clasificados. Esto puede afectar su aplicabilidad en ciertas operaciones que requieren información de alta precisión.
-
Integración de datos: la integración de datos de múltiples fuentes, incluyendo datos abiertos, comerciales y clasificados, requiere sistemas y procesos que garanticen la interoperabilidad y la coherencia de la información. Esto implica desafíos técnicos y organizativos que deben ser superados.
-
Seguridad y confidencialidad: el uso de datos abiertos en contextos de defensa plantea cuestiones sobre la seguridad y la confidencialidad de la información. Es esencial establecer protocolos y medidas de seguridad que protejan la información sensible y eviten su uso indebido.
- Oportunidades de colaboración: a pesar de estos desafíos, los datos satelitales abiertos ofrecen oportunidades significativas para la colaboración entre diferentes actores, incluyendo gobiernos, organizaciones internacionales, el sector privado y la sociedad civil. Esta colaboración puede mejorar la eficacia de las operaciones de defensa y contribuir a una mayor seguridad global.
Recomendaciones para fortalecer el uso de datos abiertos en defensa
Con base en el análisis anterior, pueden extraerse algunas recomendaciones clave para aprovechar mejor el potencial de los datos abiertos:
-
Refuerzo de las infraestructuras de datos abiertos: consolidar plataformas nacionales que integren datos satelitales abiertos para su uso tanto civil como militar, con especial atención a la seguridad y a la interoperabilidad.
-
Promoción de estándares abiertos geoespaciales (OGC, INSPIRE): garantizar que los sistemas de defensa integren estándares internacionales que permitan el uso combinado de fuentes abiertas y clasificadas.
-
Formación especializada: fomentar el desarrollo de capacidades en análisis GEOINT con datos abiertos, tanto en el ámbito militar como en colaboración con universidades y centros tecnológicos.
-
Cooperación civil-militar: establecer protocolos que faciliten el intercambio de datos entre agencias civiles (AEMET, IGN, Protección Civil) y actores de defensa en situaciones de crisis o emergencias.
- Apoyo a la I+D+i: impulsar proyectos de investigación que exploren el uso avanzado de datos abiertos (por ejemplo, IA aplicada a Sentinel) con aplicaciones duales (civiles y de seguridad).
Conclusión
La inteligencia geoespacial y el uso de datos satelitales abiertos han transformado la forma en que las Fuerzas Armadas y las agencias de seguridad planifican y ejecutan sus operaciones. En un contexto de amenazas multidimensionales y escenarios en constante evolución, contar con información precisa, accesible y actualizada es más que una ventaja: es una necesidad estratégica.
Los datos abiertos se han consolidado como un activo fundamental no solo por su gratuidad, sino por su capacidad de democratizar el acceso a información crítica, fomentar la transparencia y habilitar nuevas formas de colaboración entre actores militares, civiles y científicos. En particular:
- Mejoran la resiliencia de los sistemas de defensa al permitir un análisis más amplio y transversal del entorno operativo.
- Aumentan la interoperabilidad, ya que los formatos y estándares abiertos facilitan el intercambio entre países y agencias.
- Impulsan la innovación, al ofrecer a startups, centros de investigación y universidades acceso a datos de calidad que de otro modo serían inaccesibles.
En este contexto, España ha demostrado una clara apuesta por esta visión estratégica, tanto desde sus instituciones nacionales como desde su papel activo en programas europeos como Copernicus, Galileo y las misiones de defensa común.
Contenido elaborado por Mayte Toscano, Senior Consultant en Tecnologías ligadas a la economía del dato. Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Documentación
La Agencia Española de Protección de Datos ha publicado recientemente la traducción al español de la Guía sobre generación de datos sintéticos, elaborada originalmente por la Autoridad de Protección de Datos de Singapur. Este documento ofrece orientación técnica y práctica para personas responsables, encargadas y delegadas de protección de datos sobre cómo implementar esta tecnología que permite simular datos reales manteniendo sus características estadísticas sin comprometer información personal.
La guía destaca cómo los datos sintéticos pueden impulsar la economía del dato, acelerar la innovación y mitigar riesgos en brechas de seguridad. Para ello, presenta casos prácticos, recomendaciones y buenas prácticas orientadas a reducir los riesgos de reidentificación. En este post, analizamos los aspectos clave de la Guía destacando casos de uso principales y ejemplos de aplicación práctica.
¿Qué son los datos sintéticos? Concepto y beneficios
Los datos sintéticos son datos artificiales generados mediante modelos matemáticos específicamente diseñados para sistemas de inteligencia artificial (IA) o aprendizaje automático (ML). Estos datos se crean entrenando un modelo con un conjunto de datos de origen para imitar sus características y estructura, pero sin replicar exactamente los registros originales.
Los datos sintéticos de alta calidad conservan las propiedades estadísticas y los patrones de los datos originales. Por lo tanto, permiten realizar análisis que produzcan resultados similares a los que se obtendrían con los datos reales. Sin embargo, al ser artificiales, reducen significativamente los riesgos asociados con la exposición de información sensible o personal.
Para profundizar en este tema, tienes disponible este Informe monográfico sobre datos sintéticos: ¿Qué son y para qué se usan? con información detallada sobre los fundamentos teóricos, metodologías y aplicaciones prácticas de esta tecnología.
La implementación de datos sintéticos ofrece múltiples ventajas para las organizaciones, por ejemplo:
- Protección de la privacidad: permiten realizar análisis de datos manteniendo la confidencialidad de la información personal o comercialmente sensible.
- Cumplimiento normativo: facilitan el seguimiento de regulaciones de protección de datos mientras se maximiza el valor de los activos de información.
- Reducción de riesgos: minimizan las posibilidades de brechas de datos y sus consecuencias.
- Impulso a la innovación: aceleran el desarrollo de soluciones basadas en datos sin comprometer la privacidad.
- Mejora en la colaboración: posibilitan compartir información valiosa entre organizaciones y departamentos de forma segura.
Pasos para generar datos sintéticos
Para implementar correctamente esta tecnología, la Guía sobre generación de datos sintéticos recomienda seguir un enfoque estructurado en cinco pasos:
- Conocer los datos: comprender claramente el propósito de los datos sintéticos y las características de los datos de origen que deben preservarse, estableciendo objetivos precisos respecto al umbral de riesgo aceptable y la utilidad esperada.
- Preparar los datos: identificar las ideas clave que deben conservarse, seleccionar los atributos relevantes, eliminar o seudonimizar identificadores directos, y estandarizar los formatos y estructuras en un diccionario de datos bien documentado.
- Generar datos sintéticos: seleccionar los métodos más adecuados según el caso de uso, evaluar la calidad mediante comprobaciones de integridad, fidelidad y utilidad, y ajustar iterativamente el proceso para lograr el equilibrio deseado.
- Evaluar riesgos de reidentificación: aplicar técnicas basadas en ataques para determinar la posibilidad de inferir información sobre individuos o su pertenencia al conjunto original, asegurando que los niveles de riesgo sean aceptables.
- Gestionar riesgos residuales: implementar controles técnicos, de gobernanza y contractuales para mitigar los riesgos identificados, documentando adecuadamente todo el proceso.
Aplicaciones prácticas y casos de éxito
Para obtener todas estas ventajas, los datos sintéticos pueden aplicarse en diversos escenarios que responden a necesidades específicas de las organizaciones. La Guía menciona, por ejemplo:
1. Generación de conjuntos de datos para entrenar modelos de IA/ML: los datos sintéticos resuelven el problema de la escasez de datos etiquetados (es decir, que se pueden utilizar) para entrenar modelos de IA. Cuando los datos reales son limitados, los datos sintéticos pueden ser una alternativa rentable. Además, permiten simular eventos extraordinarios o incrementar la representación de grupos minoritarios en los conjuntos de entrenamiento. Una aplicación interesante para mejorar el rendimiento y la representatividad de todos los grupos sociales en los modelos de IA.
2. Análisis de datos y colaboración: este tipo de datos facilitan el intercambio de información para análisis, especialmente en sectores como la salud, donde los datos originales son particularmente sensibles. Tanto en este sector como en otros, proporcionan a las partes interesadas una muestra representativa de los datos reales sin exponer información confidencial, permitiendo evaluar la calidad y potencial de los datos antes de establecer acuerdos formales.
3. Pruebas de software: son muy útiles para el desarrollo de sistemas y la realización de pruebas de software porque permiten utilizar datos realistas, pero no reales en entornos de desarrollo, evitando así posibles brechas de datos personales en caso de comprometerse el entorno de desarrollo.
La aplicación práctica de datos sintéticos ya está demostrando resultados positivos en diversos sectores:
I. Sector financiero: detección de fraudes. J.P. Morgan ha utilizado con éxito datos sintéticos para entrenar modelos de detección de fraude, creando conjuntos de datos con un mayor porcentaje de casos fraudulentos que permitieron mejorar significativamente la capacidad de los modelos para identificar comportamientos anómalos.
II. Sector tecnológico: investigación sobre sesgos en IA. Mastercard colaboró con investigadores para desarrollar métodos de prueba de sesgos en IA mediante datos sintéticos que mantenían las relaciones reales de los datos originales, pero eran lo suficientemente privados como para compartirse con investigadores externos, permitiendo avances que no habrían sido posibles sin esta tecnología.
III. Sector salud: salvaguarda de datos de pacientes. Johnson & Johnson implementó datos sintéticos generados por IA como alternativa a las técnicas tradicionales de anonimización para procesar datos sanitarios, logrando una mejora significativa en la calidad del análisis al representar eficazmente a la población objetivo mientras se protegía la privacidad de los pacientes.
El equilibrio entre utilidad y protección
Es importante destacar que los datos sintéticos no están inherentemente libres de riesgos. La semejanza con los datos originales podría, en determinadas circunstancias, permitir la filtración de información sobre individuos o datos confidenciales. Por ello, resulta crucial encontrar un equilibrio entre la utilidad de los datos y su protección.
Este equilibrio puede lograrse mediante la implementación de buenas prácticas durante el proceso de generación de datos sintéticos, incorporando medidas de protección como:
- Preparación adecuada de los datos: eliminación de valores atípicos, seudonimización de identificadores directos y generalización de datos granulares.
- Evaluación de riesgos de reidentificación: análisis de la posibilidad de que se puedan vincular los datos sintéticos con individuos reales.
- Implementación de controles técnicos: añadir ruido a los datos, reducir la granularidad o aplicar técnicas de privacidad diferencial.
Los datos sintéticos representan una oportunidad excepcional para impulsar la innovación basada en datos mientras se respeta la privacidad y se cumple con las normativas de protección de datos. Su capacidad para generar información estadísticamente representativa pero artificial los convierte en una herramienta versátil para múltiples aplicaciones, desde el entrenamiento de modelos de IA hasta la colaboración entre organizaciones y el desarrollo de software.
Al implementar adecuadamente las buenas prácticas y controles descritos en Guía sobre generación de datos sintéticos que ha traducido la AEPD, las organizaciones pueden aprovechar los beneficios de los datos sintéticos minimizando los riesgos asociados, posicionándose a la vanguardia de la transformación digital responsable. La adopción de tecnologías de mejora de la privacidad como los datos sintéticos no solo representa una medida defensiva, sino un paso proactivo hacia una cultura organizacional que valora tanto la innovación como la protección de datos, aspectos fundamentales para el éxito en la economía digital del futuro.
Blog
Los datos satelitales se han convertido en una herramienta fundamental para comprender y monitorear nuestro planeta desde una perspectiva única. Estos datos, recopilados por satélites en órbita alrededor de la Tierra, ofrecen una visión global y detallada de diversos fenómenos terrestres, marítimos y atmosféricos que tienen aplicaciones en múltiples sectores, como el cuidado del medio ambiento o impulso de la innovación en el sector energético.
En este artículo nos vamos a centrar en un nuevo sector: el ámbito de la pesca, donde los datos satelitales han revolucionado la forma en que se monitorean y gestionan las actividades pesqueras a nivel mundial. Repasaremos cuáles son los datos satelitales sobre pesca más utilizados para monitorizar la actividad pesquera y veremos posibles usos, destacando su relevancia en la detección de actividades ilegales.
Los datos satelitales más populares relacionados con la pesca: los datos de posicionamiento
Entre los datos satelitales, encontramos gran cantidad de datos públicos y abiertos, que son gratuitos y están disponibles en formatos reutilizables, como aquellos procedentes del programa europeo Copernicus. Estos datos se pueden complementar con otros que, aunque también son públicos, pueden tener coste y restricciones de uso o acceso. Esto se debe a que la obtención y procesamiento de estos datos implica costes significativos y se requiere la compra a proveedores especializados, como ORBCOMM, exactEarth, Spire Maritime o Inmarsat. A este segundo tipo pertenecen los datos procedentes de los dos sistemas más populares para obtener datos pesqueros, que son:
- Sistema de Identificación Automática (AIS, en sus siglas en inglés): transmite la ubicación, velocidad y dirección de los barcos. Se creó para mejorar la seguridad marítima y prevenir colisiones entre embarcaciones; es decir, su objetivo era evitar accidentes al permitir que los buques comuniquen su posición y obtengan la ubicación de otros barcos en tiempo real. Sin embargo, con la liberación de los datos satelitales en la década de 2010, la academia y las autoridades se dieron cuenta de que podían mejorar el conocimiento situacional al proporcionar información sobre los barcos, incluyendo su identidad, rumbo, velocidad y otros datos de navegación. Los datos AIS pasaron a facilitar la gestión del tráfico marítimo, permitiendo a las autoridades costeras y centros de tráfico monitorear y gestionar el movimiento de embarcaciones en sus aguas. Esta tecnología ha revolucionado la navegación marítima, proporcionando una capa adicional de seguridad y eficiencia en las operaciones marítimas. Los datos están disponibles a través de sitios webs como MarineTraffic o VesselFinder, que ofrecen servicios básicos de seguimiento de forma gratuita, pero requieren una suscripción para obtener funciones avanzadas.
- Sistema de Seguimiento de Buques (VMS): diseñado específicamente para el monitoreo pesquero, proporciona datos de posición y movimiento. Se creó específicamente para el monitoreo y la gestión de la industria pesquera moderna. Su desarrollo surgió hace aproximadamente dos décadas como una respuesta a la necesidad de mejorar el seguimiento, control y vigilancia de las actividades pesqueras. El acceso a los datos del VMS varía según la jurisdicción y los acuerdos internacionales. Los datos son utilizados principalmente por organismos gubernamentales, organizaciones regionales de gestión pesquera y autoridades encargadas de la vigilancia, quienes tienen acceso restringido y deben cumplir con estrictas normativas de seguridad y confidencialidad. Por otro lado, las empresas pesqueras también emplean sistemas VMS para gestionar sus flotas y cumplir con regulaciones locales e internacionales.
Análisis de datos satelitales pesqueros
Los datos satelitales han demostrado ser particularmente útiles para observar la pesca, ya que pueden ofrecer tanto un panorama general de un área marina o una flota pesquera, como la posibilidad de conocer la vida operativa de un solo buque. Para ello se suelen seguir los siguientes pasos:
- Recopilación de datos AIS y VMS.
- Integración con otras fuentes abiertas o privadas. Por ejemplo: registros de buques, datos oceanográficos, delimitaciones de zonas económicas especiales o aguas territoriales.
- Aplicación de algoritmos de aprendizaje automático para identificar patrones de comportamiento y maniobras de pesca.
- Visualización de datos en mapas interactivos.
- Generación de alertas sobre actividades sospechosas (para el monitorio en tiempo real).
Casos de uso de los datos satélites de pesca
Los datos satelitales de pesca ofrecen opciones rentables, especialmente para que aquellos con recursos limitados para patrullar sus aguas puedan monitorear de forma continua grandes extensiones oceánicas. Entre otras actividades, estos datos hacen posible el desarrollo de sistemas que permiten:
- La Supervisión del cumplimiento de regulaciones pesqueras, ya que los satélites pueden rastrear la posición y movimientos de los barcos pesqueros. Este monitoreo se puede hacer con datos históricos, con el objeto de realizar un análisis de patrones y tendencias de actividad pesquera. De esta forma se apoyan investigaciones a largo plazo y análisis estratégicos del sector pesquero.
- La detección de pesca ilegal, utilizando tanto datos históricos como en tiempo real. Al analizar patrones de movimiento inusuales o la presencia de embarcaciones en áreas restringidas, se pueden identificar posibles actividades de pesca ilegal, no declarada y no reglamentada (llamada pesca INDNR). La pesca INDNR representa un valor de hasta 23.500 millones de dólares anuales en productos marinos.
- La evaluación del volumen pesca, con los datos de la capacidad de carga de cada nave y los trasbordos de pescado que se realizan tanto en alta mar como en puerto.
- La identificación de áreas de alta actividad pesquera y la evaluación de su impacto en ecosistemas sensibles.
Un ejemplo concreto es el trabajo realizado por el Overseas Development Institute (ODI), titulado “Pesca en aguas turbias”, que revela cómo los datos satelitales permiten identificar embarcaciones, determinar su ubicación, rumbo y velocidad, así como entrenar algoritmoss, proporcionando una visión sin precedentes de las actividades pesqueras globales. El informe está basado en dos fuentes: entrevistas con los responsables de diversas plataformas privadas y públicas que se dedican a observar la pesca INDNR, así como en recursos abiertos y gratuitos como Global Fishing Watch (GFW) –una organización que es el fruto de la colaboración entre Oceana, SkyTruth y Google— y que proporciona datos abiertos.
Desafíos, consideraciones éticas y limitaciones a la hora de monitorizar la actividad pesquera
Aunque estos datos ofrecen grandes oportunidades, es importante notar que también tienen limitaciones. El estudio "Fishing for data: The role of private data platforms in addressing illegal, unreported and unregulated fishing and overfishing", menciona los problemas de trabajar con datos satelitales para combatir la pesca ilegal, unos retos que pueden aplicar al monitoreo de la pesca en general:
- La falta de un registro universal de buques de pesca unificada. Se carece de una base de datos única de embarcaciones pesqueras, lo que dificulta la identificación de las embarcaciones y sus empresas propietarias u operadoras. La información de las embarcaciones está dispersa en múltiples fuentes, como sociedades de clasificación, registros nacionales de buques y organizaciones regionales de gestión pesquera.
- Algoritmos deficientes. Los algoritmos utilizados para identificar comportamientos de pesca son a veces incapaces de identificar con precisión la actividad pesquera, dificultando la identificación de actividades ilegales. Por ejemplo, inferir el tipo de arte de pesca utilizado, las especies objetivo o la cantidad capturada a partir de los datos satelitales puede ser complejo.
- La mayoría de estos datos no son gratuitos y pueden resultar costosos. Los datos más utilizados en este campo, es decir, aquellos procedentes de sistemas AIS y VMS, conllevan un coste considerable.
- Datos satelitales incompletos. Los sistemas de identificación automática (AIS) son obligatorios solo para embarcaciones de más de 300 toneladas brutas, lo que deja fuera a muchas embarcaciones pesqueras. Además, las embarcaciones pueden apagar sus transmisores AIS para evitar la vigilancia.
- El uso de estas herramientas para la vigilancia, el control y la aplicación de la ley conlleva riesgos, como falsos positivos y correlaciones espurias. Además, la excesiva confianza en estas herramientas puede desviar los esfuerzos de aplicación de la ley en comportamientos que no se pueden detectar.
- La colaboración y la coordinación entre diversas iniciativas privadas, como Global Fishing Watch, no es todo lo fluida que podría ser. Si unieran sus esfuerzos, podrían crear una plataforma de datos más potente, pero es difícil incentivar dicha colaboración entre organizaciones que son competidoras.
El futuro de los datos satelitales en la pesca
El campo de los datos satelitales está en constante evolución, con nuevas técnicas de captura y análisis que mejoran la precisión y utilidad de la información obtenida. Las innovaciones en la captura de datos geoespaciales incluyen el uso de drones, LiDAR (light detection and ranging) y fotogrametría de alta resolución, que complementan los datos obtenidos por satélites tradicionales. En el ámbito del análisis, el machine learning y la inteligencia artificial están desempeñando un papel crucial. Por ejemplo, Global Fishing Watch utiliza algoritmos de aprendizaje automático para procesar millones de mensajes diarios de más de 200.000 embarcaciones pesqueras, permitiendo una visión global y en tiempo real de sus actividades.
El futuro de los datos satelitales es prometedor, con avances tecnológicos que ofrecen mejorar la resolución, frecuencia, volumen, calidad y tipos de datos que se pueden recopilar. La miniaturización de satélites y el desarrollo de constelaciones de microsatélites están mejorando el acceso al espacio y a los datos que se pueden obtener desde allí.
En el contexto de la pesca, se espera que los datos satelitales desempeñen un papel cada vez más importante en la gestión sostenible de los recursos marinos. La combinación de estos datos con otras fuentes de información, como sensores in situ y modelos oceanográficos, permitirá una comprensión más holística de los ecosistemas marinos y las actividades humanas que los afectan.
Contenido elaborado por Miren Gutiérrez, Doctora e investigadora en la Universidad de Deusto, experta en activismo de datos, justicia de datos, alfabetización de datos y desinformación de género. Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor
Blog
En un mundo cada vez más expuesto a riesgos naturales y crisis humanitarias, contar con datos geoespaciales precisos y actualizados puede marcar la diferencia entre una respuesta eficaz y una reacción tardía. Las huellas de edificios, es decir, los contornos de las construcciones tal como aparecen en el terreno, son uno de los recursos más valiosos en contextos de urgencia.
En este post profundizaremos en este concepto, incluyendo dónde obtener datos abiertos de huellas de edificios, y destacaremos su importancia en uno de sus múltiples casos de uso: la gestión de emergencias.
¿Qué son las huellas de edificios?
Las huellas de edificios (en inglés, building footprints) son representaciones geoespaciales, normalmente en formato vectorial, que muestran el contorno de las estructuras construidas sobre el terreno. Es decir, indican la proyección horizontal de un edificio sobre el suelo, vista desde arriba, como si se tratara de un plano en planta.
Estas huellas pueden incluir tanto edificaciones residenciales como industriales, comerciales, institucionales o incluso construcciones rurales. Dependiendo de la fuente de datos, pueden ir acompañadas de atributos adicionales como la altura, número de plantas, uso del edificio o fecha de construcción, lo que las convierte en una fuente de información muy rica para múltiples disciplinas.
A diferencia de un plano arquitectónico que muestra detalles internos, las huellas de edificios se limitan al perímetro de la construcción en contacto con el suelo. Esta simplicidad las hace ligeras, interoperables y fácilmente combinables con otras capas de información geográfica, como redes viales, zonas de riesgo, infraestructuras críticas o datos sociodemográficos.

Figura 1. Ejemplo de huellas de edificios: cada polígono representa el controno de una construcción vista desde arriba
¿Cómo se obtienen?
Existen varias formas de generar huellas de edificios:
- A partir de imágenes satelitales o aéreas: mediante técnicas de fotointerpretación o, más recientemente, mediante inteligencia artificial y algoritmos de machine learning.
- Con datos catastrales o registros oficiales: como en el caso del Catastro en España, que mantiene bases vectoriales precisas de todas las construcciones registradas.
- Mediante mapeo colaborativo: plataformas como OpenStreetMap (OSM) permiten a usuarios voluntarios digitalizar manualmente las huellas visibles en ortofotos.
¿Para qué sirven?
Las huellas de edificios son fundamentales para:
- Análisis urbano y territorial: permiten estudiar la densidad construida, la expansión urbana o el uso del suelo.
- Gestión catastral e inmobiliaria: son clave para calcular superficies, aplicar impuestos o regular edificaciones.
- Planificación de infraestructuras y servicios públicos: ayudan a ubicar equipamientos, diseñar redes de transporte o estimar demanda energética.
- Modelización 3D y ciudades inteligentes: sirven de base para generar modelos urbanos tridimensionales.
- Gestión de riesgos y emergencias: permiten identificar zonas vulnerables, estimar población afectada o planificar evacuaciones.
En definitiva, las huellas de edificios son una pieza básica de la infraestructura de datos espaciales y, cuando se ofrecen como datos abiertos, accesibles y actualizados, multiplican su valor y utilidad para el conjunto de la sociedad.
¿Por qué son clave en situaciones de emergencia?
De entre todos los posibles casos de uso, en este artículo nos vamos a centrar en la gestión de emergencias. Durante una situación de este tipo –como un terremoto, una inundación o un incendio forestal– los equipos de intervención necesitan saber qué zonas están edificadas, cuántas personas pueden habitar esas estructuras, cómo acceder a ellas y dónde concentrar los recursos. Las huellas de edificios permiten:
- Estimar rápidamente el número de personas potencialmente afectadas.
- Priorizar zonas de intervención y rescate.
- Planificar rutas de acceso y evacuación.
- Cruzar datos con otras capas (vulnerabilidad social, zonas de riesgo, etc.).
- Coordinar la acción entre servicios de emergencia, autoridades locales y cooperación internacional.
Datos abiertos disponibles
Ante una emergencia, es fundamental saber dónde localizar datos de huellas de edificios. Uno de los avances más relevantes en el ámbito del gobierno del dato es la disponibilidad creciente de huellas de edificios como datos abiertos. Este tipo de información, que antes estaba restringida a administraciones u organismos especializados, ahora puede ser utilizada libremente por gobiernos locales, ONG, investigadores y empresas.
A continuación, se resumen algunas de las principales fuentes disponibles para la gestión de emergencias y otros fines:
- JRC – Global Human Settlement Layer (GHSL): el Centro Común de Investigación de la Comisión Europea ofrece una serie de productos derivados del análisis de imágenes satelitales:
- GHS-BUILT-S: datos raster sobre áreas construidas a nivel global.
- GHS-BUILD-V: huellas vectoriales de edificios para Europa, generadas con IA.
- Descarga de datos: https://ghsl.jrc.ec.europa.eu/download.php
- IGN y Catastro de España: las huellas de edificios oficiales en España se pueden obtener a través del Catastro y el Instituto Geográfico Nacional (IGN). Son extremadamente detalladas y actualizadas.
- Centro de descargas del IGN: https://centrodedescargas.cnig.es
- Visor del Catastro: https://www.sedecatastro.gob.es
- Copernicus Emergency Management Service: ofrece productos cartográficos generados en tiempo récord cuando se activa una emergencia (terremotos, inundaciones, incendios, etc.). Incluyen mapas de daños y huellas de edificios afectados.
- Centro de descargas: https://emergency.copernicus.eu/mapping/list-of-components/EMSR
- Importante: para descargar los datos vectoriales detallados (como las huellas), es necesario registrarse en la plataforma DIAS/Copernicus EMS o solicitar acceso según el caso.
- OpenStreetMap (OSM): plataforma colaborativa donde usuarios de todo el mundo han digitalizado huellas de edificios, especialmente en zonas no cubiertas por fuentes oficiales. Es especialmente útil para proyectos humanitarios, zonas rurales y en desarrollo, y casos donde se necesita actualización rápida o participación local.
- Descarga de datos: https://download.geofabrik.de
- Google Open Buildings: este proyecto de Google ofrece más de 2.000 millones de huellas de edificios en África, Asia y otras regiones de datos escasos, generadas con modelos de inteligencia artificial. Es especialmente útil para fines humanitarios, desarrollo urbano en países del sur global, y evaluación de exposición al riesgo en lugares donde no hay catastros oficiales.
- Acceso directo a los datos: https://sites.research.google/open-buildings/
- Microsoft Building Footprints: Microsoft ha publicado conjuntos de huellas de edificios generadas con algoritmos de aprendizaje automático aplicados a imágenes aéreas y satelitales. Cobertura: Estados Unidos, Canadá, Uganda, Tanzania, Nigeria y recientemente India. Los datos están en acceso abierto bajo licencia ODbL.
- Meta (ex Facebook) AI Buildings Footprints: Meta AI ha publicado datasets generados mediante aprendizaje profundo en colaboración con Humanitarian OpenStreetMap Team (HOT). Se centraron en países africanos y del sudeste asiático.
- Acceso directo a los datos: https://dataforgood.facebook.com/dfg/tools/buildings
Tabla comparativa de fuentes de huellas de edificios abiertas
| Fuente/Proyecto | Cobertura geográfica | Tipo de datos | Formato | Requiere registro | Utilidad principal |
|---|---|---|---|---|---|
| JRC GHSL | Global (en raster) / Europa (vector) | Raster y vector | GeoTIFF / GeoPackage / Shapefile | No | Análisis urbano, planificación europea, estudios comparativos |
| IGN + Catastro España | España | Vector oficial | GML/Shapefile/WFS/WMS | No | Datos catastrales, planificación urbana, gestión municipal |
| Copernicus EMS | Europa y global (cuando hay activación) | Vector (post-emergencia) | PDF / GeoTIFF / Shapefile | Sí (para datos vectoriales detallados) | Cartografía rápida, gestión de emergencias |
| OpenStreetMap | Global (variable por zona) | Vector colaborativo | .osm / shapefile / GeoJSON | No | Mapas base, zonas rurales, apoyo humanitario |
| Google Open Buildings | África, Asia, LatAm (zonas seleccionadas) | Vector (generado con IA) | CSV / GeoJSON | No | Evaluación de riesgos, planificación en países en desarrollo |
| Microsoft Buildings Footprints | EE. UU., Canadá, India, África | Vector (IA) | GeoJSON | No | Datos masivos, planificación urbana, zonas rurales |
| Meta AI | África, Asia (zonas específicas) | Vector (IA) | GeoJSON / CSV | No | Apoyo humanitario, complementar OSM en zonas sin cobertura |
Figura 2. Tabla comparativa de fuentes de huella de edificios abiertas
Combinación y uso integrado de datos
Una de las grandes ventajas de que estas fuentes estén abiertas y documentadas es la posibilidad de combinarlas para mejorar la cobertura, la precisión y la utilidad operativa de las huellas de edificios. Os explicamos algunos enfoques recomendados:
1. Completar zonas sin cobertura oficial
- En regiones donde el catastro no está disponible o actualizado (como muchas zonas rurales o países en desarrollo), es útil usar Google Open Buildings o OpenStreetMap como base.
- GHSL también ofrece una visión armonizada a escala continental, útil para planificación y análisis comparativos.
2. Cruzar capas oficiales y colaborativas
- Las huellas del Catastro español se pueden enriquecer con datos de OSM cuando se detectan zonas nuevas o modificadas, especialmente tras un evento como una catástrofe.
- Esta combinación es ideal para municipios pequeños que no tienen capacidad técnica propia, pero quieren mantener sus datos al día.
3. Integración con datos sociodemográficos y de riesgo
- Las huellas ganan valor cuando se integran en sistemas de información geográfica (SIG) junto a capas como:
- Población por edificio (INE, WorldPop).
- Zonas inundables (MAPAMA, Copernicus).
- Centros de salud o escuelas.
- Infraestructuras críticas (red eléctrica, agua).
Esto permite modelar escenarios de riesgo, planificar evacuaciones o incluso simular impactos potenciales de una emergencia.
4. Uso combinado de activaciones reales
Algunos ejemplos reales de usos de estos datos son:
- En casos como la erupción en La Palma, se utilizaron simultáneamente datos del Catastro, OSM y productos de Copernicus EMS para cartografiar daños, calcular población afectada y planificar ayudas.
- Durante el terremoto en Turquía en 2023, organizaciones como UNOSAT y Copernicus combinaron imágenes satelitales con algoritmos automáticos para detectar colapsos estructurales y cruzarlos con huellas existentes. Esto permitió estimar rápidamente el número de personas potencialmente atrapadas.
En situaciones de emergencia, el tiempo es un recurso crítico. La inteligencia artificial aplicada a imágenes satelitales o aéreas permite generar huellas de edificios de forma mucho más rápida y automatizada que los métodos tradicionales.
En definitiva, las distintas fuentes no son excluyentes, sino complementarias. Su integración estratégica dentro de una infraestructura de datos bien gobernada es lo que permite pasar del dato al impacto, y poner el conocimiento geoespacial al servicio de la seguridad, la planificación y el bienestar colectivo.
Gobierno de datos y coordinación
Contar con huellas de edificios de calidad es un primer paso fundamental, pero su verdadero valor solo se activa cuando estos datos están bien gobernados, coordinados entre actores y preparados para ser utilizados de forma eficiente en situaciones reales. Aquí es donde entra en juego el gobierno del dato: el conjunto de políticas, procesos y estructuras organizativas que aseguran que los datos estén disponibles, sean fiables, actualizados y utilizados de forma responsable.
¿Por qué es clave la gobernanza de datos?
En contextos de emergencia o planificación territorial, la falta de coordinación entre instituciones o la existencia de datos duplicados, incompletos o desactualizados puede tener consecuencias graves: retrasos en la toma de decisiones, duplicación de esfuerzos o, en el peor de los casos, decisiones erróneas. Una buena gobernanza de datos garantiza que:
- Los datos sean conocidos y localizables: no basta con que existan; deben estar documentados, catalogados y accesibles en plataformas donde los usuarios los puedan encontrar fácilmente.
- Haya estándares e interoperabilidad: las huellas de edificios deben seguir formatos comunes (como GeoJSON, GML, shapefile), usar sistemas de referencia consistentes, y estar alineadas con otras capas geoespaciales (redes de servicios, límites administrativos, zonas de riesgo…).
- Se mantengan actualizados: especialmente en zonas urbanas o en desarrollo, donde nuevas construcciones surgen rápidamente. Un dato de hace cinco años puede ser inservible en una crisis actual.
- Se coordinen entre niveles de gobierno: municipal, regional, nacional y europeo. La compartición eficiente evita duplicidades y facilita respuestas conjuntas, especialmente en contextos transfronterizos o internacionales.
- Se definan roles y responsabilidades claras: ¿quién produce los datos?, ¿quién los valida?, ¿quién los distribuye?, ¿quién los activa en caso de emergencia?
El valor de la colaboración
Un ecosistema sólido de gobierno del dato también debe fomentar la colaboración multisectorial. Administraciones públicas, servicios de emergencia, universidades, sector privado, organizaciones humanitarias y ciudadanía pueden beneficiarse (y contribuir) al uso y mejora de estos datos.
Por ejemplo, en muchos países, los catastros locales trabajan en colaboración con organismos como los institutos geográficos nacionales, mientras que iniciativas de ciencia ciudadana y mapeo colaborativo (como OpenStreetMap) pueden complementar o actualizar datos oficiales en zonas menos cubiertas.
Preparación para emergencias
En situaciones de crisis, la coordinación debe estar anticipada. No se trata solo de tener los datos, sino de tener planes operativos claros sobre cómo acceder a ellos, quién los activa, en qué formatos, y cómo se integran con los sistemas de respuesta (como los Centros de Coordinación de Emergencias o los SIG de protección civil).
Por ello, muchas instituciones están desarrollando protocolos de activación de datos geoespaciales en emergencias, y plataformas como Copernicus Emergency Management Service ya trabajan bajo este principio, ofreciendo productos basados en datos bien gobernados y activables en tiempo récord.
Conclusión
Las huellas de edificios no son solo un recurso técnico para urbanistas o cartógrafos: son una herramienta crítica para la gestión del riesgo, la planificación urbana sostenible y la protección de la ciudadanía. En situaciones de emergencia, donde el tiempo y la información precisa son factores determinantes, disponer de estos datos puede marcar la diferencia entre una intervención eficaz y una tragedia evitable.
El avance en tecnologías de observación de la Tierra, el uso de inteligencia artificial y el compromiso con la apertura de datos por parte de instituciones como el JRC o el IGN han democratizado el acceso a información geoespacial de altísimo valor. Hoy es posible que una administración local, una ONG o un grupo de voluntarios accedan a huellas de edificios para planificar evacuaciones, estimar población afectada o diseñar rutas logísticas en tiempo real.
Sin embargo, el reto no es solo tecnológico, sino también organizativo y cultural. Es imprescindible fortalecer el gobierno del dato: asegurar que estos conjuntos estén bien documentados, actualizados, accesibles y que su uso esté integrado en los protocolos de emergencia y planificación. También es fundamental formar a los actores clave, promover la interoperabilidad y fomentar la colaboración entre instituciones públicas, sector privado y sociedad civil.
En definitiva, las huellas de edificios representan mucho más que geometrías en un mapa: son una base sobre la que construir resiliencia, salvar vidas y mejorar la toma de decisiones en momentos críticos. Apostar por su uso responsable y abierto es apostar por una gestión pública más inteligente, coordinada y centrada en las personas.
Contenido elaborado por Mayte Toscano, Senior Consultant en Tecnologías ligadas a la economía del dato. Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Blog
La Dirección General de Tráfico (DGT) es el organismo responsable de garantizar la seguridad y fluidez en las vías de circulación de España. Entre otras actividades, se encarga de la expedición de permisos, el control del tráfico y la gestión de infracciones.
Fruto de su actividad, se genera una gran cantidad de datos, muchos de los cuales se ponen a disposición de la ciudadanía como datos abiertos. Estos datasets no solo promueven la transparencia, sino que también son una herramienta para fomentar la innovación y mejorar la seguridad vial a través de su reutilización por parte de investigadores, empresas, administraciones públicas y ciudadanos interesados.
En este artículo vamos a repasar algunos de estos conjuntos de datos, incluyendo ejemplos de aplicación.
Cómo acceder a los datasets de la DGT
Los conjuntos de datos de la DGT ofrecen información detallada y estructurada sobre diversos aspectos de la seguridad vial y la movilidad en España, incluyendo desde estadísticas de accidentes hasta información sobre vehículos y conductores. La continuidad temporal de estos conjuntos de datos, disponibles desde principios de siglo hasta la actualidad, posibilita análisis longitudinales que reflejan la evolución de los patrones de movilidad y seguridad vial en España.
Los usuarios pueden acceder a los conjuntos de datos en diferentes espacios:
- DGT en cifras. Es una sección de la Dirección General de Tráfico que ofrece un acceso centralizado a estadísticas y datos clave relacionados con la seguridad vial, los vehículos y los conductores en España. Este portal incluye información detallada sobre siniestralidad, denuncias, parque vehicular y características técnicas de los vehículos, entre otros temas. Además, proporciona análisis históricos y comparativos que permiten evaluar tendencias y diseñar estrategias para mejorar la seguridad en las carreteras.
- Punto de Acceso Nacional de Tráfico y Movilidad (National Access Point o NAP). Gestionado por la DGT, es una plataforma diseñada para centralizar y facilitar el acceso a datos viarios y de tráfico, incluidas sus actualizaciones. Este portal ha sido creado bajo el marco de la Directiva Europea 2010/40/UE y reúne información proporcionada por diversas entidades de gestión del tráfico, autoridades viarias y operadores de infraestructuras. Entre los datos disponibles se incluyen incidencias de tráfico, puntos de recarga para vehículos eléctricos, zonas de bajas emisiones y ocupación de parkings, entre otros. Su objetivo es promover la interoperabilidad y el desarrollo de soluciones inteligentes que mejoren la seguridad vial y la eficiencia en el transporte.
Mientras el NAP está enfocado en datos en tiempo real y soluciones tecnológicas, DGT en cifras se centra en proporcionar estadísticas e información histórica para análisis y toma de decisiones. Además, el NAP reúne datos no solo de la DGT, sino también de otros organismos y empresas privadas.
La mayoría de estos datos están disponibles a través de datos.gob.es.
Ejemplos de conjuntos de datos de la DGT
Algunos ejemplos de dataset que se pueden encontrar en datos.gob.es son:
- Accidentes con víctimas: incluye información detallada sobre víctimas mortales, heridos hospitalizados y leves, así como las circunstancias por tipo de vía. Estos datos ayudan a entender por qué ocurren los accidentes y quiénes están involucrados, permiten identificar situaciones de riesgo y detectar comportamientos peligrosos en la carretera. Es útil para crear mejores campañas de prevención, detectar puntos negros en las carreteras y ayudar a las autoridades a tomar decisiones más informadas. También resultan de interés para profesionales de salud pública, urbanistas y compañías de seguros que trabajan para reducir los accidentes y sus consecuencias.
- Censo de conductores: ofrece una radiografía completa de quiénes tienen permiso para conducir en España. La información resulta especialmente útil para entender la evolución del parque de conductores, identificar tendencias demográficas y analizar la penetración de los diferentes tipos de permisos por territorio y género.
- Matriculaciones de turismos por marca y cilindrada: muestra qué coches nuevos compraron los españoles, organizados por marca y potencia del motor. La información permite identificar tendencias de consumo. Estos datos son valiosos para fabricantes, concesionarios y analistas del sector automovilístico, que pueden estudiar el comportamiento del mercado en un año concreto. También resultan útiles para investigadores en movilidad, medio ambiente y economía, permitiendo analizar la evolución del parque móvil español y su impacto en términos de emisiones, consumo energético y tendencias de mercado.
Casos de uso de los datasets de la DGT
La publicación de estos datos en formato abierto permite potenciar la innovación en áreas como la prevención de accidentes, el desarrollo de infraestructuras viales más seguras, la elaboración de políticas públicas basadas en evidencia, y la creación de aplicaciones tecnológicas relacionadas con la movilidad. A continuación, se recogen algunos ejemplos:
Uso de datos por la propia DGT
La propia DGT reutiliza sus datos para crear herramientas que faciliten la visualización de la información y la acerquen de forma sencilla a la ciudadanía. Es el caso del Mapa de estado del tráfico e incidencias, que se actualiza de forma constante y automática con la información introducida 24 horas al día por la Agrupación de Tráfico de la Guardia Civil y los responsables de los Centros de Gestión de Tráfico de la DGT, la Generalitat de Catalunya y el Gobierno Vasco. Incluye información sobre las carreteras afectadas por fenómenos meteorológicos (como hielo, inundaciones, etc.) y la previsión de evolución.
Además, la DGT también aprovecha sus datos para realizar estudios que proporcionen información sobre determinados aspectos relacionados con la movilidad y la seguridad vial, de gran utilidad para la toma de decisiones y elaboración de políticas. Un ejemplo, es este estudio que analizar el comportamiento y la actividad de determinados colectivos en accidentes de tráfico para plantear medidas de manera proactiva. Otro ejemplo: este proyecto para implementar un sistema informático que identifique, mediante geolocalización, los puntos críticos de mayor siniestralidad en carreteras para su tratamiento y traslado de conclusiones.
Uso de los datos por parte de terceros
Los conjuntos de datos ofrecidos por la DGT también son reutilizados por otras administraciones públicas, investigadores, emprendedores y empresas privadas, fomentando la innovación en este campo. Gracias a ellos, encontramos apps que permiten a los usuarios acceder a información detallada sobre vehículos en España (como características técnicas e historial de inspecciones) o que informan sobre los lugares más peligrosos para los ciclistas.
Además, su combinación con tecnologías avanzadas como la inteligencia artificial permite extraer aún más valor de los datos, facilitando la identificación de patrones y ayudando a ciudadanos y autoridades a tomar medidas preventivas. Un ejemplo es la aplicación Waze, que ha implementado una funcionalidad basada en inteligencia artificial para identificar y alertar a los conductores sobre tramos de alta siniestralidad en las carreteras, es decir, los conocidos como "puntos negros". Este sistema combina datos históricos de accidentes con análisis de características de las vías, como desniveles, densidad de tráfico e intersecciones, para ofrecer alertas precisas y de alta utilidad. La aplicación notifica a los usuarios con antelación cuando se aproximan a estas zonas peligrosas, con el objetivo de reducir riesgos y mejorar la seguridad vial. Esta innovación complementa los datos proporcionados por la Dirección General de Tráfico ayudando a salvar vidas al fomentar una conducción más precavida.
Para aquellos que quieran animarse y practicar con los datos de la DGT, desde datos.gob.es tenemos a disposición de los usuarios un ejercicio paso a paso de ciencia de datos. Los usuarios podrán analizar estos conjuntos de datos y utilizar modelos predictivos que permiten realizar estimaciones respecto a la evolución del vehículo eléctrico en España. Para ello se utilizan desarrollos de código documentados y herramientas de uso gratuito. Todo el material generado está disponible para su reutilización en el repositorio de GitHub de datos.gob.es.
En resumen, los conjuntos de datos que la DGT ofrecen grandes oportunidades de reutilización, más aún si se combinan con tecnologías disruptivas. Gracias a ello se impulsa la innovación, la sostenibilidad y un transporte más seguro y conectado, que está ayudando a transformar la movilidad urbana y rural.
Blog
A medida que las organizaciones buscan aprovechar el potencial de los datos para tomar decisiones, innovar y mejorar sus servicios, surge un desafío fundamental: ¿cómo se puede equilibrar la recolección y el uso de datos con el respeto a la privacidad? Las tecnologías PET intentan dar solución a ese reto. En este post, exploraremos qué son y cómo funcionan.
¿Qué son las tecnologías PET?
Las tecnologías PET son un conjunto de medidas técnicas que utilizan diversos enfoques para la protección de la privacidad. El acrónimo PET viene de los términos en inglés “Privacy Enhancing Technologies” que se pueden traducir como “tecnologías de mejora de la privacidad”.
De acuerdo con la Agencia de la Unión Europea para la Ciberseguridad (ENISA) este tipo de sistemas protege la privacidad mediante:
- La eliminación o reducción de datos personales.
- Evitando el procesamiento innecesario y/o no deseado de datos personales.
Todo ello, sin perder la funcionalidad del sistema de información. Es decir, gracias a ellas se puede utilizar datos que de otra manera permanecerían sin explotar, ya que limita los riesgos de revelación de datos personales o protegidos, cumpliendo con la legislación vigente.
Relación entre utilidad y privacidad en datos protegidos
Para comprender la importancia de las tecnologías PET, es necesario abordar la relación que existe entre utilidad y privacidad del dato. La protección de datos de carácter personal siempre supone pérdida de utilidad, bien porque limita el uso de los datos o porque implica someterles a tantas transformaciones para evitar identificaciones que pervierte los resultados. La siguiente gráfica muestra cómo a mayor privacidad, menor es la utilidad de los datos.
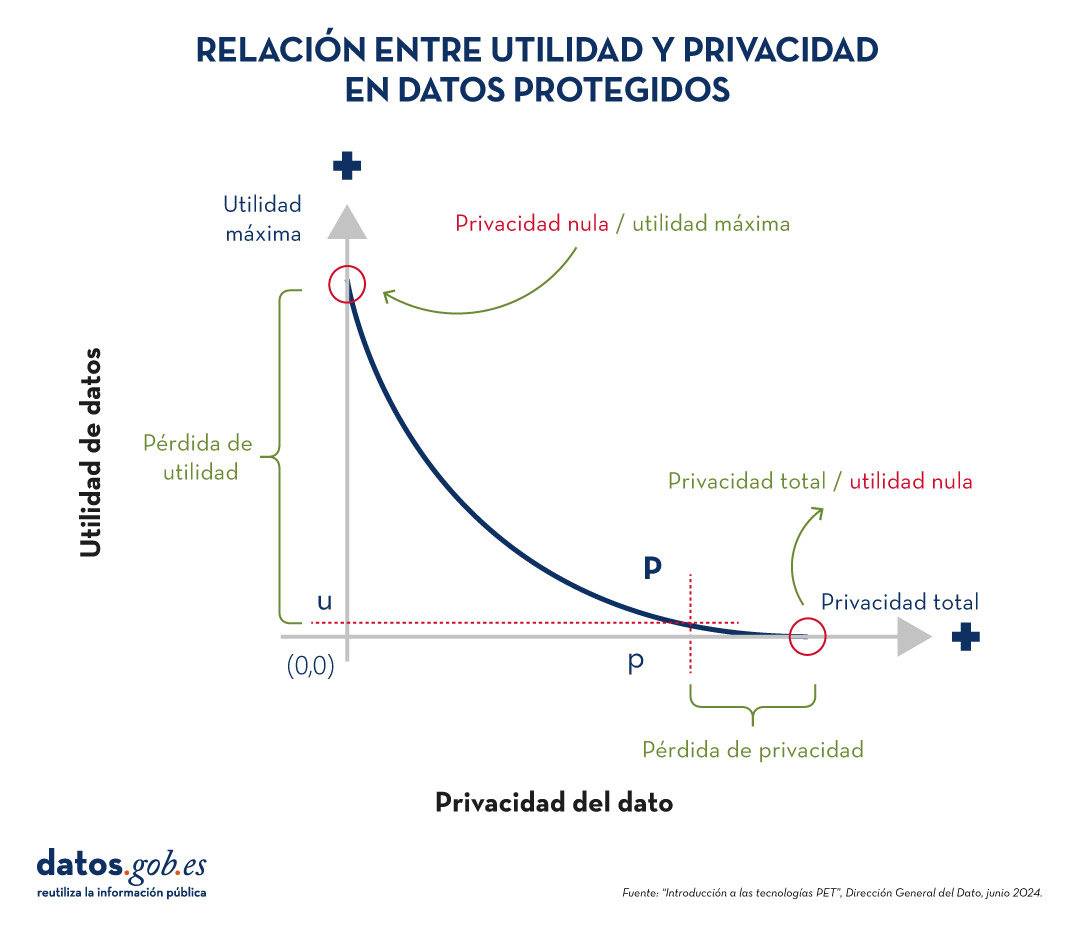
Figura 1. Relación entre utilidad y privacidad en datos protegido. Fuente: “Introducción a las tecnologías PET”, Dirección General del Dato, junio 2024.
Las técnicas PET permiten alcanzar un compromiso entre privacidad y utilidad más favorable. No obstante, hay que tener en cuenta que siempre existirá cierta limitación de la utilidad cuando explotamos datos protegidos.
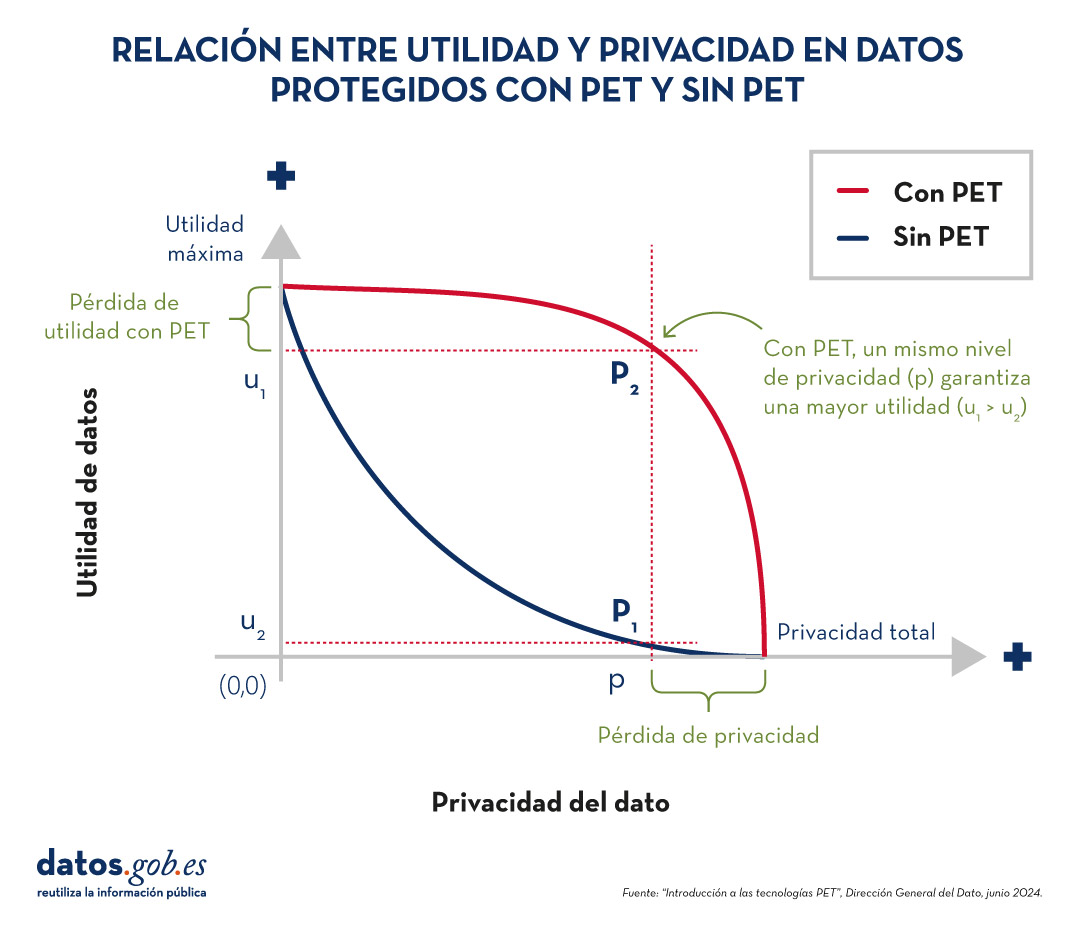
Figura 2. Relación entre utilidad y privacidad en datos protegidos con PET y sin PET. Fuente: “Introducción a las tecnologías PET”, Dirección General del Dato, junio 2024.
Técnicas PET más populares
Para aumentar la utilidad y poder explotar datos protegidos limitando los riesgos, es necesario aplicar una serie de técnicas PET. El siguiente esquema, recoge algunas de las principales:
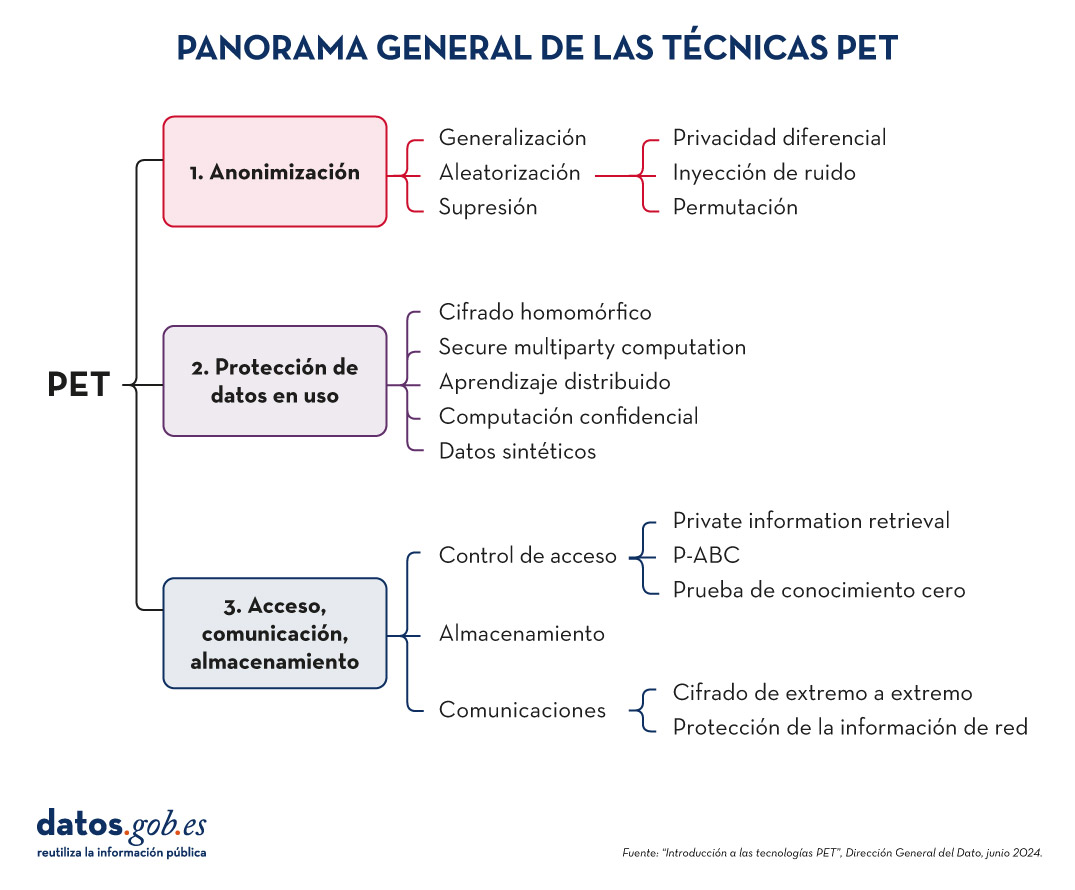
Figura 3. Panorama general de las técnicas PET. Fuente: “Introducción a las tecnologías PET”, Dirección General del Dato, junio 2024.
Como veremos a continuación, estas técnicas abordan distintas fases del ciclo de vida de los datos.
-
Antes de la explotación de los datos: anonimización
La anonimización consiste en transformar conjuntos de datos de carácter privado para que no se pueda identificar a ninguna persona. De esta forma, ya no les aplica el Reglamento General de Protección de Datos (RGPD).
Es importante garantizar que la anonimización se ha realizado de forma efectiva, evitando riesgos que permitan la reidentificación a través de técnicas como la vinculación (identificación de un individuo mediante el cruzado de datos), la inferencia (deducción de atributos adicionales en un dataset), la singularización (identificación de individuos a partir de los valores de un registro) o la composición (pérdida de privacidad acumulada debida a la aplicación reiterada de tratamientos). Para ello, es recomendable combinar varias técnicas, las cuales se pueden agrupar en tres grandes familias:
- Aleatorización: supone modificar los datos originales al introducir un elemento de azar. Esto se logra añadiendo ruido o variaciones aleatorias a los datos, de manera que se preserven patrones generales y tendencias, pero se haga más difícil la identificación de individuos.
- Generalización: consiste en reemplazar u ocultar valores específicos de un conjunto de datos por valores más amplios o menos precisos. Por ejemplo, en lugar de registrar la edad exacta de una persona, se podría utilizar un rango de edades (como 35-44 años).
- Supresión: implica eliminar completamente ciertos datos del conjunto, especialmente aquellos que pueden identificar a una persona de manera directa. Es el caso de los nombres, direcciones, números de identificación, etc.
Puedes profundizar sobre estos tres enfoques generales y las diversas técnicas que los integran en la guía práctica “Introducción a la anonimización de datos: técnicas y casos prácticos”. También recomendamos la lectura del artículo malentendidos comunes en la anonimización de datos.
2. Protección de datos en uso
En este apartado se abordan técnicas que salvaguardan la privacidad de los datos durante la aplicación de tratamientos de explotación.
-
Cifrado homomórfico: es una técnica de criptografía que permite realizar operaciones matemáticas sobre datos cifrados sin necesidad de descifrarlos primero. Por ejemplo, un cifrado será homomórfico si se cumple que, si se cifran dos números y se realiza una suma en su forma cifrada, el resultado cifrado, al ser descifrado, será igual a la suma de los números originales.
- Computación Segura Multipartita (Secure Multiparty Computation o SMPC): es un enfoque que permite que múltiples partes colaboren para realizar cálculos sobre datos privados sin revelar su información a los demás participantes. Es decir, permite que diferentes entidades realicen operaciones conjuntas y obtengan un resultado común, mientras mantienen la confidencialidad de sus datos individuales.
- Aprendizaje distribuido: tradicionalmente, los modelos de machine learning aprenden de forma centralizada, es decir, requieren reunir todos los datos de entrenamiento procedentes de múltiples fuentes en un único conjunto de datos a partir del cual un servidor central elabora el modelo que se desea. En el caso del aprendizaje distribuido, los datos no se concentran en un solo lugar, sino que permanecen en diferentes ubicaciones, dispositivos o servidores. En lugar de trasladar grandes cantidades de datos a un servidor central para su procesamiento, el aprendizaje distribuido permite que los modelos de machine learning se entrenen en cada una de estas ubicaciones, integrando y combinando los resultados parciales para obtener un modelo final.
- Computación confidencial y entornos de computación de confianza (Trusted Execution Environments o TEE): la computación confidencial se refiere a un conjunto de técnicas y tecnologías que permiten procesar datos de manera segura dentro de entornos de hardware protegidos y certificados, conocidos como entornos de computación de confianza.
- Datos sintéticos: son datos generados artificialmente que imitan las características y patrones estadísticos de datos reales sin representar a personas o situaciones específicas. Reproducen las propiedades relevantes de los datos reales, como distribución, correlaciones y tendencias, pero sin información que permita identificar a individuos o casos específicos. Puedes aprender más sobre este tipo de datos en el informe Datos sintéticos: ¿Qué son y para qué se usan?.
3. Acceso, comunicación y almacenamiento
Las técnicas PET no solo abarcan la explotación de los datos. Entre ellas también encontramos procedimientos dirigidos a asegurar el acceso a recursos, la comunicación entre entidades y el almacenamiento de datos, garantizando siempre la confidencialidad de los participantes. Algunos ejemplos son:
Técnicas de control de acceso
- Recuperación Privada de Información (Private information retrieval o PIR): es una técnica criptográfica que permite a un usuario consultar una base de datos o servidor sin que este último pueda saber qué información está buscando el usuario. Es decir, asegura que el servidor no conozca el contenido de la consulta, preservando así la privacidad del usuario.
- Credenciales Basadas en Atributos con Privacidad (Privacy-Attribute Based Credentials o P-ABC): es una tecnología de autenticación que permite a los usuarios demostrar ciertos atributos o características personales (como la mayoría de edad o la ciudadanía) sin revelar su identidad. En lugar de mostrar todos sus datos personales, el usuario presenta solo aquellos atributos necesarios para cumplir con los requisitos de la autenticación o autorización, manteniendo así su privacidad.
- Prueba de conocimiento cero (Zero-Knowledge Proof o ZKP): es un método criptográfico que permite a una parte demostrar a otra que posee cierta información o conocimiento (como una contraseña) sin revelar el propio contenido de ese conocimiento. Este concepto es fundamental en el ámbito de la criptografía y la seguridad de la información, ya que permite la verificación de información sin la necesidad de exponer datos sensibles.
Técnicas de comunicaciones
- Cifrado extremo a extremo (End to End Encryption o E2EE): esta técnica protege los datos mientras se transmiten entre dos o más dispositivos, de forma que solo los participantes autorizados en la comunicación pueden acceder a la información. Los datos se cifran en el origen y permanecen cifrados durante todo el trayecto hasta que llegan al destinatario. Esto significa que, durante el proceso, ningún individuo u organización intermediaria (como proveedores de internet, servidores de aplicaciones o proveedores de servicios en la nube) puede acceder o descifrar la información. Una vez que llegan a destino, el destinatario es capaz de descifrarlos de nuevo.
- Protección de información de Red (Proxy & Onion Routing): un proxy es un servidor intermediario entre el dispositivo de un usuario y el destino de la conexión en internet. Cuando alguien utiliza un proxy, su tráfico se dirige primero al servidor proxy, que luego reenvía las solicitudes al destino final, permitiendo el filtrado de contenidos o el cambio de direcciones IP. Por su parte, el método Onion Routing protege el tráfico en internet a través de una red distribuida de nodos. Cuando un usuario envía información usando Onion Routing, su tráfico se cifra varias veces y se envía a través de múltiples nodos, o "capas" (de ahí el nombre "onion", que significa "cebolla" en inglés).
Técnicas de almacenamiento
- Almacenamiento garante de la confidencialidad (Privacy Preserving Storage o PPS): su objetivo es proteger la confidencialidad de los datos en reposo e informar a los custodios de los datos de una posible brecha de seguridad, utilizando técnicas de cifrado, acceso controlado, auditoría y monitoreo, etc.
Estos son solo algunos ejemplos de tecnologías PET, pero hay más familias y subfamilias. Gracias a ellas, contamos con herramientas que nos permiten extraer valor de los datos de forma segura, garantizando la privacidad de los usuarios. Datos que pueden ser de gran utilidad en múltiples sectores, como la salud, el cuidado del medio ambiente o la economía.
Noticia
El pasado mes de julio comenzó la décima legislatura del Parlamento Europeo, un nuevo ciclo institucional que abarcará el periodo 2024-2029. La Presidenta de la Comisión Europea, Ursula von der Leyen, fue elegida para un segundo mandato, tras presentar al Parlamento Europeo sus Orientaciones Políticas para la próxima Comisión Europea 2024-2029.
Estas orientaciones establecen las prioridades que guiarán las políticas europeas en los próximos años. Entre los objetivos generales, encontramos que se invertirán esfuerzos en:
- Facilitar los negocios y fortalecer el mercado único.
- Descarbonizar y reducir los precios de la energía.
- Hacer que la investigación y la innovación sean los motores de la economía.
- Impulsar la productividad mediante la difusión de la tecnología digital.
- Invertir masivamente en competitividad sostenible.
- Subsanar la brecha en materia de capacidades y mano de obra.
En este artículo, nos vamos a centrar en desgranar el punto 4, centrado en combatir la insuficiente difusión de las tecnologías digitales. El desconocimiento de las posibilidades tecnológicas al alcance de la ciudadanía limita la capacidad de desarrollar nuevos servicios y modelos de negocio competitivos a nivel mundial.
Impulsar la productividad con la difusión de la tecnología digital
El mandato anterior estuvo marcado por la aprobación de nuevas regulaciones encaminadas a impulsar una economía digital justa y competitiva a través de un mercado único digital, donde la tecnología se situase al servicio de las personas. Ahora, es el momento de poner el foco en la aplicación y el cumplimiento de las leyes digitales adoptadas.
Una de las normativas de más reciente aprobación ha sido el Reglamento de Inteligencia Artificial (IA), un marco de referencia para el desarrollo de cualquier sistema IA. En esta norma, el foco estaba puesto en garantizar la seguridad y fiabilidad de la inteligencia artificial, evitando sesgos a través de diversas medidas entre las que se encontraba una gobernanza sólida de datos.
Una vez que ya contamos con este marco, ha llegado el momento de impulsar el uso de esta tecnología en pro de la innovación. Para ello, en este nuevo ciclo, se fomentarán los siguientes aspectos:
- Factorías de inteligencia artificial. Se trata de ecosistemas abiertos que ofrecen una infraestructura de servicios de supercomputación de inteligencia artificial. De esta forma se ponen grandes capacidades tecnológicas a disposición de empresas emergentes y comunidades de investigación.
- Estrategia de uso de la inteligencia artificial. Se busca impulsar usos industriales en diversos sectores, incluyendo la prestación de servicios públicos en áreas como la atención sanitaria. Para elaborar esta estrategia se contará con la visión de la industria y la sociedad civil.
- Consejo europeo de investigación sobre inteligencia artificial. Este organismo ayudará a poner en común los recursos de la Unión Europea (UE), facilitando el acceso a los mismos.
Pero para que sea posible desarrollar estas medidas, primero es necesario garantizar el acceso a datos de calidad. Estos datos no solo favorecen el entrenamiento de los sistemas IA y el desarrollo de productos y servicios tecnológicos de vanguardia, sino que también ayudan a la toma de decisiones informada y a la elaboración de estrategias políticas y económicas más certeras. Como dice el propio documento “el acceso a los datos no solo es un motor importante de la competitividad que representa casi el 4 % del PIB de la UE, sino que también es esencial para la productividad y las innovaciones sociales, desde la medicina personalizada hasta el ahorro de energía”.
Para mejorar el acceso a los datos de las empresas europeas y mejorar su capacidad competitiva con respecto a los grandes actores tecnológicos mundiales, la Unión Europea apuesta por la “mejora del acceso a los datos abiertos”, garantizando, al mismo tiempo, la más estricta protección de datos.
La revolución de los datos europea
“Europa necesita una revolución de los datos”. Así de tajante se muestra la Presidenta ante la situación actual. Por ello, una de las medidas en las que se trabajará es en una nueva Estrategia de datos de la Unión Europea. Esta estrategia se basará en las normas existentes actualmente. Es previsible que se tome como referencia la actual estrategia, entre cuyas líneas de acción se encuentra el fomento del intercambio de información a través de la creación de un mercado único de datos donde los datos puedan fluir entre países y sectores económicos de la UE.
En este marco seguirán muy presentes los avances legislativos que vimos en la última legislatura:
- Directiva (UE) 2019/1024 relativa a los datos abiertos y la reutilización de la información del sector público, que establece el marco jurídico para la reutilización de la información del sector público, puesta a disposición del público como datos abiertos, incluyendo el fomento de los datos de alto valor.
- Reglamento (UE) 2022/868 relativo a la gobernanza europea de datos (DGA en sus siglas en inglés), que regula el intercambio seguro y voluntario de conjuntos de datos que están bajo el poder de organismos públicos sobre los que concurren derechos de terceros, así como los servicios de intermediación de datos y su cesión altruista.
- Reglamento (UE) 2023/2854 sobre normas armonizadas para un acceso justo a los datos y su utilización (Data Act), que impulsa reglas armonizadas relativas al acceso y uso equitativo de los datos en el marco de la Estrategia Europea.
Con todo ello, se busca garantizar un “marco simplificado, claro y coherente para que las empresas y las administraciones compartan datos sin fisuras y a gran escala, respetando al mismo tiempo normas estrictas de privacidad y seguridad”.
Además de intensificar la inversión en tecnologías punteras, como la supercomputación, el internet de las cosas o la computación cuántica, la Unión Europea tiene entre sus planes continuar impulsando el acceso a datos de calidad que ayuden a generar un ecosistema tecnológico sostenible y solvente, capaz de competir con las grandes empresas mundiales. En este espacio iremos informando de las medidas tomadas con este fin.