Blog
In 2010, following the devastating earthquake in Haiti, hundreds of humanitarian organizations arrived in the country ready to help. They encountered an unexpected obstacle: there were no updated maps. Without reliable geographic information, coordinating resources, locating isolated communities, or planning safe routes was nearly impossible.
That gap marked a turning point: it was the moment when the global OpenStreetMap (OSM) community demonstrated its enormous humanitarian potential. More than 600 volunteers from all over the world organized themselves and began mapping Haiti in record time. This gave impetus to the Humanitarian OpenStreetMap Team project.
What is Humanitarian OpenStreetMap Team?
Humanitarian OpenStreetMap Team, known by the acronym HOT, is an international non-profit organization dedicated to improving people's lives through accurate and accessible geographic data. Their work is inspired by the principles of OSM, the collaborative project that seeks to create an open, free and editable digital map for anyone.
The difference with OSM is that HOT is specifically aimed at contexts where the lack of data directly affects people's lives: it is about providing data and tools that allow more informed decisions to be made in critical situations. That is, it applies the principles of open software and data to collaborative mapping with social and humanitarian impact.
In this sense, the HOT team not only produces maps, but also facilitates technical capacities and promotes new ways of working tools, the for different actors who need precise spatial data. Their work ranges from immediate response when a disaster strikes to structural programs that strengthen local resilience to challenges such as climate change or urban sprawl.
Four priority geographical areas
While HOT is not limited to a single country or region, it has established priority areas where its mapping efforts have the greatest impact due to significant data gaps or urgent humanitarian needs. It currently works in more than 90 countries and organizes its activities through four Open Mapping Hubs (regional centers) that coordinate initiatives according to local needs:
- Asia-Pacific: challenges range from frequent natural disasters (such as typhoons and earthquakes) to access to remote rural areas with poor map coverage.
- Eastern and Southern Africa: this region faces multiple intertwined crises (droughts, migratory movements, deficiencies in basic infrastructure) so having up-to-date maps is key for health planning, resource management and emergency response.
- West Africa and North Africa: in this area, HOT promotes activities that combine local capacity building with technological projects, promoting the active participation of communities in the creation of useful maps for their environment.
- Latin America and the Caribbean: frequently affected by hurricanes, earthquakes, and volcanic hazards, this region has seen a growing adoption of collaborative mapping in both emergency response and urban development and climate resilience initiatives.
The choice of these priority areas is not arbitrary: it responds to contexts in which the lack of open data can limit rapid and effective responses, as well as the ability of governments and communities to plan their future with reliable information.
Open source tools developed by HOT
An essential part of HOT's impact lies in the open-source tools and platforms that facilitate collaborative mapping and the use of spatial data in real-world scenarios. To this end, an E2E Value Chain Mapping was developed, which is the core methodology that enables communities to move from image capture and mapping to impact. This value chain supports all of its programs, ensuring that mapping is a transformative process based on open data, education, and community empowerment.
These tools not only support HOT's work, but are available for anyone or community to use, adapt, or expand. Specifically, tools have been developed to create, access, manage, analyse and share open map data. You can explore them in the Learning Center, a training space that offers capacity building, skills strengthening and an accreditation process for interested individuals and organisations. These tools are described below:
It allows drone flights to be planned for up-to-date, high-resolution aerial imagery, which is critical when commercial imagery is too expensive. In this way, anyone with access to a drone – including low-cost and commonly used models – can contribute to a global repository of free and open imagery, democratizing access to geospatial data critical to disaster response, community resilience, and local planning.
The platform coordinates multiple operators and generates automated flight plans to cover areas of interest, making it easy to capture 2D and 3D images accurately and efficiently. In addition, it includes training plans and promotes safety and compliance with local regulations, supporting project management, data visualization and collaborative exchange between pilots and organizations.

Figure 1. Drone Tasking Manager (DroneTM) screenshot. Source: Humanitarian OpenStreetMap Team (HOT).
It is an open-source platform that offers access to a community library of openly-licensed aerial imagery, obtained from satellites, drones, or other aircraft. It has a simple interface where you can zoom in on a map to search for available images. OAM allows you to both download and contribute new imagery, thus expanding a global repository of visual data that anyone can use and plot in OpenStreetMap.
All imagery hosted on OpenAerialMap is licensed under CC-BY 4.0, which means that they are publicly accessible and can be reused with attribution, facilitating their integration into geospatial analysis applications, emergency response projects, or local planning initiatives. OAM relies on the Open Imagery Network (OIN) to structure and serve these images.
It facilitates collaborative mapping in OpenStreetMap. Its main purpose is to coordinate thousands of volunteers from all over the world to aggregate geographic data in an organized and efficient way. To do this, it breaks down a large mapping project into small "tasks" that can be completed quickly by people working remotely.
The way it works is simple: projects are subdivided into grids, each assignable to a volunteer in order to map out elements such as streets, buildings, or points of interest in OSM. Each task is validated by experienced mappers to ensure data quality. The platform clearly shows which areas still need mapping or review, avoiding duplication and improving the efficiency of collaborative work.

Figure 2. Tasking Manager screenshot. Source: Humanitarian OpenStreetMap Team (HOT).
It uses artificial intelligence to assist the mapping process in OpenStreetMap for humanitarian purposes. Through computer vision models, fAIr analyzes satellite or aerial images and suggests the detection of geographical elements such as buildings, roads, watercourses or vegetation from free images such as those of OpenAerialMap. The idea is that volunteers can use these predictions as an aid to map faster and more accurately, without performing automated mass imports, always integrating human judgment into the validation of each element.
One of the most outstanding features of fAIr is that the creation and training of AI models is in the hands of the mapping communities themselves: users can generate their own training sets adjusted to their region or context, which helps reduce biases of standard models and makes predictions more relevant to local needs.
It is a mobile and web application that facilitates the coordination of mapping campaigns directly in the field. Field-TM is used in conjunction with OpenDataKit (ODK), a data collection platform on Android that allows information to be entered in the field using mobile devices themselves. Thanks to it, volunteers can enter geospatial information verified by local observation, such as the purpose of each building (whether it is a store, a hospital, etc.).
The app provides an interface to assign tasks, track progress, and ensure data consistency. Its main purpose is to improve the efficiency, organization and quality of fieldwork by enriching it with local information, as well as to reduce duplications, avoid uncovered areas and allow clear monitoring of the progress of each collaborator in a mapping campaign.
Transform conversations from instant messaging apps (like WhatsApp) into interactive maps. In many communities, especially in disaster-prone or low-tech literacy areas, people are already using chat apps to communicate and share their location. ChatMap leverages those exported messages, extracts location data along with texts, photos, and videos, and automatically renders them on a map, without the need for complex installations or advanced technical knowledge.
This solution works even in conditions of limited or offline connectivity, relying on the phone's GPS signal to record locations and store them until the information can be uploaded.

Figure 3. ChatMap screenshot. Source: OpenStreetMap Humanitarian Team (HOT).
Facilitate access to and download of up-to-date geospatial data from OpenStreetMap in useful formats for analysis and projects. Through this web platform, you can select an area of interest on the map, choose what data you want (such as roads, buildings, or services), and download that data in multiple formats, such as GeoJSON, Shapefile, GeoPackage, KML, or CSV. This allows the information to be used in GIS (Geographic Information Systems) software or integrated directly into custom applications. You can also export all the data for a zone or download data associated with a specific project from the Tasking Manager.
The tool is designed to be accessible to both technical analysts and non-GIS experts: in a matter of minutes, custom OSM extracts can be generated without the need to install specialized software. It also offers an API and data quality metrics.
It is an open-source interactive map creation platform that allows anyone to easily visualize, customize, and share geospatial data. Based on OpenStreetMap maps, uMap allows you to add custom layers, markers, lines and polygons, manage colors and icons, import data in common formats (such as GeoJSON, GPX or KML) and choose licenses for the data, without the need to install specialized software. The maps created can be embedded in websites or shared using links.
The tool offers templates and integration options with other HOT tools, such as ChatMap and OpenAerialMap, to enrich the data on the map.
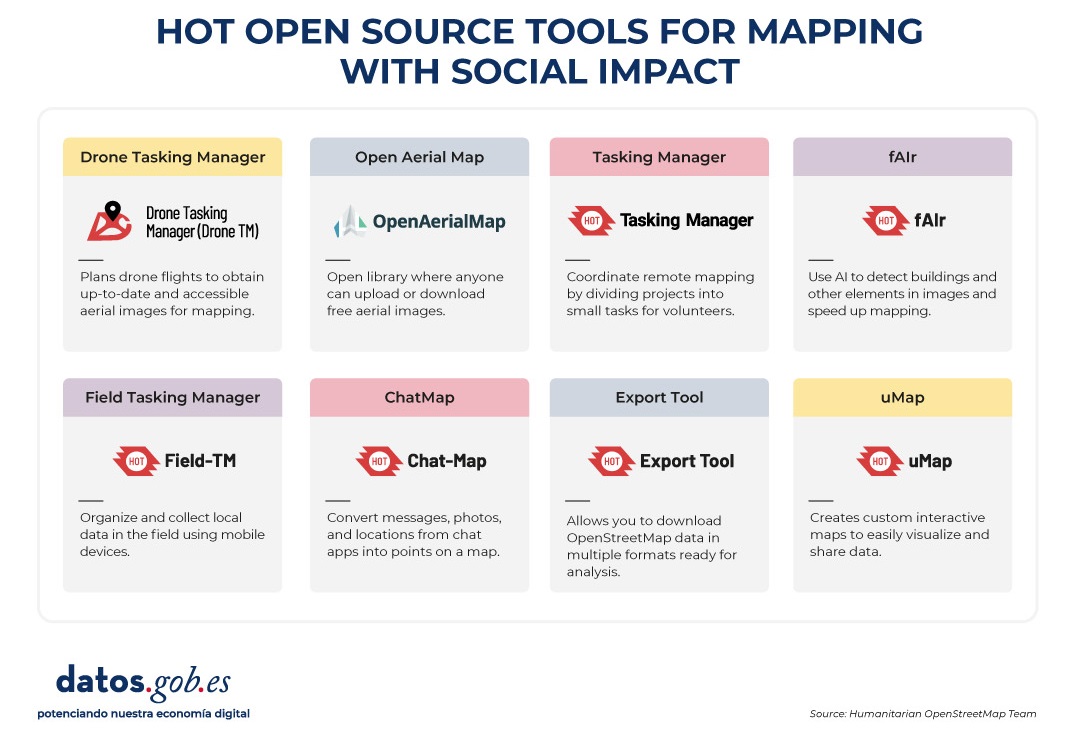
Figure 4. HOT open source tools for mapping with social impact. Source: Humanitarian OpenStreetMap Team (HOT).
All of these tools are available to local communities around the world. HOT also offers training to promote its use and improve the impact of open data in humanitarian responses.
How can you join HOT's impact?
HOT is built alongside a global community that drives the use of open data to strengthen decision-making and save lives. If you represent an organization, university, collective, public agency, or community initiative and have a project idea or interest in an alliance, the HOT team is open to exploring collaborations. You can write to partnerships@hotosm.org.
When communities have access to accurate data, open tools, and the knowledge to generate geospatial information on an ongoing basis, they become informed agents, ready to make decisions in any situation. They are better equipped to identify climate risks, respond to emergencies, solve local problems, and mobilize support. Open mapping, therefore, does not only represent territories: it empowers people to transform their reality with data that can save lives.
Blog
The idea of conceiving artificial intelligence (AI) as a service for immediate consumption or utility, under the premise that it is enough to "buy an application and start using it", is gaining more and more ground. However, getting on board with AI isn't like buying conventional software and getting it up and running instantly. Unlike other information technologies, AI will hardly be able to be used with the philosophy of plug and play. There is a set of essential tasks that users of these systems should undertake, not only for security and legal compliance reasons, but above all to obtain efficient and reliable results.
The Artificial Intelligence Regulation (RIA)[1]
The RIA defines frameworks that should be taken into account by providers[2] and those responsible for deploying[3] AI. This is a very complex rule whose orientation is twofold. Firstly, in an approach that we could define as high-level, the regulation establishes a set of red lines that can never be crossed. The European Union approaches AI from a human-centred and human-serving approach. Therefore, any development must first and foremost ensure that fundamental rights are not violated or that no harm is caused to the safety and integrity of people. In addition, no AI that could generate systemic risks to democracy and the rule of law will be admitted. For these objectives to materialize, the RIA deploys a set of processes through a product-oriented approach. This makes it possible to classify AI systems according to their level of risk, -low, medium, high- as well as general-purpose AI models[4]. And also, to establish, based on this categorization, the obligations that each participating subject must comply with to guarantee the objectives of the standard.
Given the extraordinary complexity of the European regulation, we would like to share in this article some common principles that can be deduced from reading it and could inspire good practices on the part of public and private organisations. Our approach is not so much on defining a roadmap for a given information system as on highlighting some elements that we believe can be useful in ensuring that the deployment and use of this technology are safe and efficient, regardless of the level of risk of each AI-based information system.
Define a clear purpose
The deployment of an AI system is highly dependent on the purpose pursued by the organization. It is not about jumping on the bandwagon of a fashion. It is true that the available public information seems to show that the integration of this type of technology is an important part of the digital transformation processes of companies and the Administration, providing greater efficiency and capabilities. However, it cannot become a fad to install any of the Large Language Models (LLMs). Prior reflection is needed that takes into account what the needs of the organization are and defines what type of AI will contribute to the improvement of our capabilities. Not adopting this strategy could put our bank at risk, not only from the point of view of its operation and results, but also from a legal perspective. For example, introducing an LLM or chatbot into a high-decision-making risk environment could result in reputational impacts or liability. Inserting this LLM in a medical environment, or using a chatbot in a sensitive context with an unprepared population or in critical care processes, could end up generating risk situations with unforeseeable consequences for people.
Do no evil
The principle of non-malefficiency is a key element and should decisively inspire our practice in the world of AI. For this reason, the RIA establishes a series of practices expressly prohibited to protect the fundamental rights and security of people. These prohibitions focus on preventing manipulations, discrimination, and misuse of AI systems that can cause significant harm.
Categories of Prohibited Practices
1. Manipulation and control of behavior. Through the use of subliminal or manipulative techniques that alter the behavior of individuals or groups, preventing informed decision-making and causing considerable damage.
2. Exploiting vulnerabilities. Derived from age, disability or social/economic situation to substantially modify behavior and cause harm.
3. Social Scoring. AI that evaluates people based on their social behavior or personal characteristics, generating ratings with effects for citizens that result in unjustified or disproportionate treatment.
4. Criminal risk assessment based on profiles. AI used to predict the likelihood of committing crimes solely through profiling or personal characteristics. Although its use for criminal investigation is admitted when the crime has actually been committed and there are facts to be analyzed.
5. Facial recognition and biometric databases. Systems for the expansion of facial recognition databases through the non-selective extraction of facial images from the Internet or closed circuit television.
6. Inference of emotions in sensitive environments. Designing or using AI to infer emotions at work or in schools, except for medical or safety reasons.
7. Sensitive biometric categorization. Develop or use AI that classifies individuals based on biometric data to infer race, political opinions, religion, sexual orientation, etc.
8. Remote biometric identification in public spaces. Use of "real-time" remote biometric identification systems in public spaces for police purposes, with very limited exceptions (search for victims, prevention of serious threats, location of suspects of serious crimes).
Apart from the expressly prohibited conduct, it is important to bear in mind that the principle of non-maleficence implies that we cannot use an AI system with the clear intention of causing harm, with the awareness that this could happen or, in any case, when the purpose we pursue is contrary to law.
Ensure proper data governance
The concept of data governance is found in Article 10 of the RIA and applies to high-risk systems. However, it contains a set of principles that are highly cost-effective when deploying a system at any level. High-risk AI systems that use data must be developed with training, validation, and testing suites that meet quality criteria. To this end, certain governance practices are defined to ensure:
- Proper design.
- That the collection and origin of the data, and in the case of personal data the purpose pursued, are adequate and legitimate.
- Preparation processes such as annotation, labeling, debugging, updating, enrichment, and aggregation are adopted.
- That the system is designed with use cases whose information is consistent with what the data is supposed to measure and represent.
- Ensure data quality by ensuring the availability, quantity, and adequacy of the necessary datasets.
- Detect and review biases that may affect the health and safety of people, rights or generate discrimination, especially when data outputs influence the input information of future operations. Measures should be taken to prevent and correct these biases.
- Identify and resolve gaps or deficiencies in data that impede RIA compliance, and we would add legislation.
- The datasets used should be relevant, representative, complete and with statistical properties appropriate for their intended use and should consider the geographical, contextual or functional characteristics necessary for the system, as well as ensure its diversity. In addition, they shall be error-free and complete in view of their intended purpose.
AI is a technology that is highly dependent on the data that powers it. From this point of view, not having data governance can not only affect the operation of these tools, but could also generate liability for the user.
In the not too distant future, the obligation for high-risk systems to obtain a CE marking issued by a notified body (i.e., designated by a member state of the European Union) will provide conditions of reliability to the market. However, for the rest of the lower-risk systems, the obligation of transparency applies. This does not at all imply that the design of this AI should not take these principles into account as far as possible. Therefore, before making a contract, it would be reasonable to verify the available pre-contractual information both in relation to the characteristics of the system and its reliability and with respect to the conditions and recommendations for deployment and use.
Another issue concerns our own organization. If we do not have the appropriate regulatory, organizational, technical and quality compliance measures that ensure the reliability of our own data, we will hardly be able to use AI tools that feed on it. In the context of the RIA, the user of a system may also incur liability. It is perfectly possible that a product of this nature has been properly developed by the supplier and that in terms of reproducibility the supplier can guarantee that under the right conditions the system works properly. What developers and vendors cannot solve are the inconsistencies in the datasets that the user-client integrates into the platform. It is not your responsibility if the customer failed to properly deploy a General Data Protection Regulation compliance framework or is using the system for an unlawful purpose. Nor will it be their responsibility for the client to maintain outdated or unreliable data sets that, when introduced into the tool, generate risks or contribute to inappropriate or discriminatory decision-making.
Consequently, the recommendation is clear: before implementing an AI-based system, we must ensure that data governance and compliance with current legislation are adequately guaranteed.
Ensuring Safety
AI is a particularly sensitive technology that presents specific security risks, such as the corruption of data sets. There is no need to look for fancy examples. Like any information system, AI requires organizations to deploy and use them securely. Consequently, the deployment of AI in any environment requires the prior development of a risk analysis that allows identifying which are the organizational and technical measures that guarantee a safe use of the tool.
Train your staff
Unlike the GDPR, in which this issue is implicit, the RIA expressly establishes the duty to train as an obligation. Article 4 of the RIA is so precise that it is worthwhile to reproduce it in its entirety:
Providers and those responsible for deploying AI systems shall take measures to ensure that, to the greatest extent possible, their staff and others responsible on their behalf for the operation and use of AI systems have a sufficient level of AI literacy, taking into account their technical knowledge; their experience, education and training, as well as the intended context of use of AI systems and the individuals or groups of people in whom those systems are to be used.
This is certainly a critical factor. People who use artificial intelligence must have been given adequate training that allows them to understand the nature of the system and be able to make informed decisions. One of the core principles of European legislation and approach is that of human supervision. Therefore, regardless of the guarantees offered by a given market product, the organization that uses it will always be responsible for the consequences. And this will happen both in the case where the last decision is attributed to a person, and when in highly automated processes those responsible for its management are not able to identify an incident by making appropriate decisions with human supervision.
Guilt in vigilando
The massive introduction of LLMs poses the risk of incurring the so-called culpa in vigilando: a legal principle that refers to the responsibility assumed by a person for not having exercised due vigilance over another, when that lack of control results in damage or harm. If your organization has introduced any of these marketplace products that integrate functions such as reporting, evaluating alphanumeric information, and even assisting you in email management, it will be critical that you ensure compliance with the recommendations outlined above. It is particularly advisable to define very precisely the purposes for which the tool is implemented, the roles and responsibilities of each user, and to document their decisions and to train staff appropriately.
Unfortunately, the model of introduction of LLMs into the market has itself generated a systemic and serious risk for organizations. Most tools have opted for a marketing strategy that is no different from the one used by social networks in their day. That is, they allow open and free access to anyone. It is obvious that with this they achieve two results: reuse the information provided to them by monetizing the product and generate a culture of use that facilitates the adoption and commercialization of the tool.
Let's imagine a hypothesis, of course, that is far-fetched. A resident intern (MIR) has discovered that several of these tools have been developed and, in fact, are used in another country for differential diagnosis. Our MIR is very worried about having to wake up the head of medical duty in the hospital every 15 minutes. So, diligently, he hires a tool, which has not been planned for that use in Spain, and makes decisions based on the proposal of differential diagnosis of an LLM without yet having the capabilities that enable it for human supervision. Obviously, there is a significant risk of ending up causing harm to a patient.
Situations such as the one described force us to consider how organizations that do not use AI but are aware of the risk that their employees use them without their knowledge or consent should act. In this regard, a preventive strategy should be adopted based on the issuance of very precise circulars and instructions regarding the prohibition of their use. On the other hand, there is a hybrid risk situation. The LLM has been contracted by the organization and is used by the employee for purposes other than those intended. In this case, the safety-training duo acquires a strategic value.
Training and the acquisition of culture about artificial intelligence are probably an essential requirement for society as a whole. Otherwise, the systemic problems and risks that in the past affected the deployment of the Internet will happen again and who knows if with an intensity that is difficult to govern.
Content prepared by Ricard Martínez, Director of the Chair of Privacy and Digital Transformation. Professor, Department of Constitutional Law, Universitat de València. The contents and points of view reflected in this publication are the sole responsibility of its author.
NOTES:
[1] Regulation (EU) 2024/1689 of the European Parliament and of the Council of 13 June 2024 laying down harmonised standards in the field of artificial intelligence and amending Regulations (EC) No 300/2008, (EU) No 167/2013, (EU) No 168/2013, (EU) 2018/858, (EU) 2018/1139 and (EU) 2019/2144 and Directives 2014/90/EU, (EU) 2016/797 and (EU) 2020/1828 available in https://eur-lex.europa.eu/legal-content/ES/TXT/?uri=OJ%3AL_202401689
[2] The RIA defines 'provider' as a natural or legal person, public authority, body or agency that develops an AI system or a general-purpose AI model or for which an AI system or a general-purpose AI model is developed and places it on the market or puts the AI system into service under its own name or brand; for a fee or free of charge.
[3] The RIA defines "deployment controller" as a natural or legal person, or public authority, body, office or agency that uses an AI system under its own authority, except where its use is part of a personal activity of a non-professional nature.
[4] The RIA defines a 'general-purpose AI model' as an AI model, also one trained on a large volume of data using large-scale self-monitoring, which has a considerable degree of generality and is capable of competently performing a wide variety of different tasks, regardless of how the model is introduced to the market. and that it can be integrated into various downstream systems or applications, except for AI models that are used for research, development, or prototyping activities prior to their introduction to the market.
Blog
In an increasingly interconnected and complex world, geospatial intelligence (GEOINT) has become an essential tool for defence and security decision-making . The ability to collect, analyse and interpret geospatial data enables armed forces and security agencies to better understand the operational environment, anticipate threats and plan operations more effectively.
In this context, satellite data, classified but also open data, have acquired significant relevance. Programmes such as Copernicus of the European Union provide free and open access to a wide range of Earth observation data, which democratises access to critical information and fosters collaboration between different actors.
This article explores the role of data in geospatial intelligence applied to defence, highlighting its importance, applications and Spain's leadership in this field.
Geospatial intelligence (GEOINT) is a discipline that combines the collection, analysis and interpretation of geospatial data to support decision making in a variety of areas, including defence, security and emergency management. This data may include satellite imagery, remotely sensed information, geographic information system (GIS) data and other sources that provide information on the location and characteristics of the terrain.
In the defence domain, GEOINT enables military analysts and planners to gain a detailed understanding of the operational environment, identify potential threats and plan operations with greater precision. It also facilitates coordination between different units and agencies, improving the effectiveness of joint operations.
Defence application
The integration of open satellite data into geospatial intelligence has significantly expanded defence capabilities. Some of the most relevant applications are presented below:

Figure 1. GEOINT applications in defence. Source: own elaboration
Geospatial intelligence not only supports the military in making tactical decisions, but also transforms the way military, surveillance and emergency response operations are planned and executed. Here we present concrete use cases where GEOINT, supported by open satellite data, has had a decisive impact.
Monitoring of military movements in conflicts
Case. Ukraine War (2,022-2,024)
Organisations such as the EU Satellite Centre (SatCen) and NGOs such as the Conflict Intelligence Team have used Sentinel-1 and Sentinel-2 (Copernicus) imagery for the Conflict Intelligence Team :
- Detect concentrations of Russian troops and military equipment.
- Analyse changes to airfields, bases or logistics routes.
- Support independent verification of events on the ground.
This has been key to EU and NATO decision-making, without the need to resort to classified data.
Maritime surveillance and border control
Case. FRONTEX operations in the Mediterranean
GEOINT powered by Sentinel-1 (radar) and Sentinel-3 (optical + altimeter) allows:
- Identify unauthorised vessels, even under cloud cover or at night.
- Integrate alerts with AIS (automatic ship identification system).
- Coordinate rescue and interdiction operations.
Advantage: Sentinel-1's synthetic aperture radar (SAR) can see through clouds, making it ideal for continuous surveillance.
Support to peace missions and humanitarian aid
Case. Earthquake in Syria/Turkey (2,023)
Open data (Sentinel-2, Landsat-8, PlanetScope free after catastrophe) were used for:
- Detect collapsed areas and assess damage.
- Plan safe access routes.
Coordinate camps and resources with military support.
Spain's role
Spain has demonstrated a significant commitment to the development and application of geospatial intelligence in defence.
|
European Union Satellite Centre (SatCen) |
Project Zeus of the Spanish Army |
Participation in European Programmes | National capacity building |
|
Located in Torrejón de Ardoz, SatCen is a European Union agency that provides geospatial intelligence products and services to support security and defence decision-making. Spain, as host country, plays a central role in SatCen operations. |
The Spanish Army has launched the Zeus project, a technological initiative that integrates artificial intelligence, 5G networks and satellite data to improve operational capabilities. This project aims to create a tactical combat cloud to enable greater interoperability and efficiency in military operations. |
Spain actively participates in European programmes related to Earth observation and geospatial intelligence, such as Copernicus and MUSIS. In addition, it collaborates in bilateral and multilateral initiatives for satellite capacity building and data sharing. |
At the national level, Spain has invested in the development of its own geospatial intelligence capabilities, including the training of specialised personnel and the acquisition of advanced technologies. These investments reinforce the country's strategic autonomy and its ability to contribute to international operations. |
Figure 2. Comparative table of Spain's participation in different satellite projects. Source: own elaboration
Challenges and opportunities
While open satellite data offers many advantages, it also presents certain challenges that need to be addressed to maximise its usefulness in the defence domain.
-
Data quality and resolution: While open data is valuable, it often has limitations in terms of spatial and temporal resolution compared to commercial or classified data. This may affect its applicability in certain operations requiring highly accurate information.
-
Data integration: The integration of data from multiple sources, including open, commercial and classified data, requires systems and processes to ensure interoperability and consistency of information. This involves technical and organisational challenges that must be overcome.
-
Security and confidentiality: The use of open data in defence contexts raises questions about the security and confidentiality of information. It is essential to establish security protocols and measures to protect sensitive information and prevent its misuse.
- Opportunities for collaboration: Despite these challenges, open satellite data offer significant opportunities for collaboration between different actors, including governments, international organisations, the private sector and civil society. Such collaboration can improve the effectiveness of defence operations and contribute to greater global security.
Recommendations for strengthening the use of open data in defence
Based on the above analysis, some key recommendations can be drawn to better exploit the potential of open data:
-
Strengthening open data infrastructures: consolidate national platforms integrating open satellite data for both civilian and military use, with a focus on security and interoperability.
-
Promotion of open geospatial standards (OGC, INSPIRE): Ensure that defence systems integrate international standards that allow the combined use of open and classified sources.
-
Specialised training: foster the development of capabilities in GEOINT analysis with open data, both in the military domain and in collaboration with universities and technology centres.
-
Civil-military cooperation: establish protocols to facilitate the exchange of data between civilian agencies (AEMET, IGN, Civil Protection) and defence actors in crisis or emergency situations.
- Support to R&D&I: to foster research projects exploring the advanced use of open data (e.g. AI applied to Sentinel) with dual applications (civilian and security).
Conclusion
Geospatial intelligence and the use of open satellite data have transformed the way armed forces and security agencies plan and execute their operations. In a context of multidimensional threats and constantly evolving scenarios, having accurate, accessible and up-to-date information is more than an advantage: it is a strategic necessity.
Open data has established itself as a fundamental asset not only because it is free of charge, but also because of its ability to democratise access to critical information, foster transparency and enable new forms of collaboration between military, civilian and scientific actors. In particular:
- Improve the resilience of defence systems by enabling broader, cross-cutting analysis of the operating environment.
- Increase interoperability, as open formats and standards facilitate exchange between countries and agencies.
- They drive innovationby providing startups, research centres and universities with access to quality data that would otherwise be inaccessible.
In this context, Spain has demonstrated a clear commitment to this strategic vision, both through its national institutions and its active role in European programmes such as Copernicus, Galileo and the common defence missions.
Content prepared by Mayte Toscano, Senior Consultant in Data Economy Technologies. The contents and points of view reflected in this publication are the sole responsibility of the author.
Documentación
The Spanish Data Protection Agency has recently published the Spanish translation of the Guide on Synthetic Data Generation, originally produced by the Data Protection Authority of Singapore. This document provides technical and practical guidance for data protection officers, managers and data protection officers on how to implement this technology that allows simulating real data while maintaining their statistical characteristics without compromising personal information.
The guide highlights how synthetic data can drive the data economy, accelerate innovation and mitigate risks in security breaches. To this end, it presents case studies, recommendations and best practices aimed at reducing the risks of re-identification. In this post, we analyse the key aspects of the Guide highlighting main use cases and examples of practical application.
What are synthetic data? Concept and benefits
Synthetic data is artificial data generated using mathematical models specifically designed for artificial intelligence (AI) or machine learning (ML) systems. This data is created by training a model on a source dataset to imitate its characteristics and structure, but without exactly replicating the original records.
High-quality synthetic data retain the statistical properties and patterns of the original data. They therefore allow for analyses that produce results similar to those that would be obtained with real data. However, being artificial, they significantly reduce the risks associated with the exposure of sensitive or personal information.
For more information on this topic, you can read this Monographic report on synthetic data:. What are they and what are they used for? with detailed information on the theoretical foundations, methodologies and practical applications of this technology.
The implementation of synthetic data offers multiple advantages for organisations, for example:
- Privacy protection: allow data analysis while maintaining the confidentiality of personal or commercially sensitive information.
- Regulatory compliance: make it easier to follow data protection regulations while maximising the value of information assets.
- Risk reduction: minimise the chances of data breaches and their consequences.
- Driving innovation: accelerate the development of data-driven solutions without compromising privacy.
- Enhanced collaboration: Enable valuable information to be shared securely across organisations and departments.
Steps to generate synthetic data
To properly implement this technology, the Guide on Synthetic Data Generation recommends following a structured five-step approach:
- Know the data: cClearly understand the purpose of the synthetic data and the characteristics of the source data to be preserved, setting precise targets for the threshold of acceptable risk and expected utility.
- Prepare the data: iidentify key insights to be retained, select relevant attributes, remove or pseudonymise direct identifiers, and standardise formats and structures in a well-documented data dictionary .
- Generate synthetic data: sselect the most appropriate methods according to the use case, assess quality through completeness, fidelity and usability checks, and iteratively adjust the process to achieve the desired balance.
- Assess re-identification risks: aApply attack-based techniques to determine the possibility of inferring information about individuals or their membership of the original set, ensuring that risk levels are acceptable.
- Manage residual risks: iImplement technical, governance and contractual controls to mitigate identified risks, properly documenting the entire process.
Practical applications and success stories
To realise all these benefits, synthetic data can be applied in a variety of scenarios that respond to specific organisational needs. The Guide mentions, for example:
1 Generation of datasets for training AI/ML models: lSynthetic data solves the problem of the scarcity of labelled (i.e. usable) data for training AI models. Where real data are limited, synthetic data can be a cost-effective alternative. In addition, they allow to simulate extraordinary events or to increase the representation of minority groups in training sets. An interesting application to improve the performance and representativeness of all social groups in AI models.
2 Data analysis and collaboration: eThis type of data facilitates the exchange of information for analysis, especially in sectors such as health, where the original data is particularly sensitive. In this sector as in others, they provide stakeholders with a representative sample of actual data without exposing confidential information, allowing them to assess the quality and potential of the data before formal agreements are made.
3 Software testing: sis very useful for system development and software testing because it allows the use of realistic, but not real data in development environments, thus avoiding possible personal data breaches in case of compromise of the development environment..
The practical application of synthetic data is already showing positive results in various sectors:
I. Financial sector: fraud detection. J.P. Morgan has successfully used synthetic data to train fraud detection models, creating datasets with a higher percentage of fraudulent cases that significantly improved the models' ability to identify anomalous behaviour.
II. Technology sector: research on AI bias. Mastercard collaborated with researchers to develop methods to test for bias in AI using synthetic data that maintained the true relationships of the original data, but were private enough to be shared with outside researchers, enabling advances that would not have been possible without this technology.
III. Health sector: safeguarding patient data. Johnson & Johnson implemented AI-generated synthetic data as an alternative to traditional anonymisation techniques to process healthcare data, achieving a significant improvement in the quality of analysis by effectively representing the target population while protecting patients' privacy.
The balance between utility and protection
It is important to note that synthetic data are not inherently risk-free. The similarity to the original data could, in certain circumstances, allow information about individuals or sensitive data to be leaked. It is therefore crucial to strike a balance between data utility and data protection.
This balance can be achieved by implementing good practices during the process of generating synthetic data, incorporating protective measures such as:
- Adequate data preparation: removal of outliers, pseudonymisation of direct identifiers and generalisation of granular data.
- Re-identification risk assessment: analysis of the possibility that synthetic data can be linked to real individuals.
- Implementation of technical controls: adding noise to data, reducing granularity or applying differential privacy techniques.
Synthetic data represents a exceptional opportunity to drive data-driven innovation while respecting privacy and complying with data protection regulations. Their ability to generate statistically representative but artificial information makes them a versatile tool for multiple applications, from AI model training to inter-organisational collaboration and software development.
By properly implementing the best practices and controls described in Guide on synthetic data generation translated by the AEPD, organisations can reap the benefits of synthetic data while minimising the associated risks, positioning themselves at the forefront of responsible digital transformation. The adoption of privacy-enhancing technologies such as synthetic data is not only a defensive measure, but a proactive step towards an organisational culture that values both innovation and data protection, which are critical to success in the digital economy of the future.
Blog
Satellite data has become a fundamental tool for understanding and monitoring our planet from a unique perspective. This data, collected by satellites in orbit around the Earth, provides a global and detailed view of various terrestrial, maritime and atmospheric phenomena that have applications in multiple sectors, such as environmental care or driving innovation in the energy sector.
In this article we will focus on a new sector: the field of fisheries, where satellite data have revolutionised the way fisheries are monitored and managed worldwide. We will review which fisheries satellite data are most commonly used to monitor fishing activity and look at possible uses, highlighting their relevance in detecting illegal activities.
The most popular fisheries-related satellite data: positioning data
Among the satellite data, we find a large amount ofpublic and open data , which are free and available in reusable formats, such as those coming from the European Copernicus programme. This data can be complemented with other data which, although also public, may have costs and restrictions on use or access. This is because obtaining and processing this data involves significant costs and requires purchasing from specialised suppliers such as ORBCOMM, exactEarth, Spire Maritime or Inmarsat. To this second type belong the data from the two most popular systems for obtaining fisheries data, namely:
- Automatic Identification System (AIS): transmits the location, speed and direction of vessels. It was created to improve maritime safety and prevent collisions between vessels, i.e. its aim was to prevent accidents by allowing vessels to communicate their position and obtain the location of other ships in real time. However, with the release of satellite data in the 2010s, academia and authorities realised that they could improve situational awareness by providing information about ships, including their identity, course, speed and other navigational data. AIS data went on to facilitate maritime traffic management, enabling coastal authorities and traffic centres to monitor and manage the movement of vessels in their waters. This technology has revolutionised maritime navigation, providing an additional layer of safety and efficiency in maritime operations. Data is available through websites such as MarineTraffic or VesselFinder, which offer basic tracking services for free, but require a subscription for advanced features..
- Vessel Monitoring System (VMS): designed specifically for fisheries monitoring, it provides position and movement data. It was created specifically for the monitoring and management of the modern fishing industry. Its development emerged about two decades ago as a response to the need for improved monitoring, control and surveillance of fishing activities. Access to VMS data varies according to jurisdiction and international agreements. The data are mainly used by government agencies, regional fisheries management organisations and surveillance authorities, who have restricted access and must comply with strict security and confidentiality regulations.The data are used mainly by government agencies, regional fisheries management organisations and surveillance authorities, who have restricted access and must comply with strict security and confidentiality regulations.. On the other hand, fishing companies also use VMS systems to manage their fleets and comply with local and international regulations.
Analysis of fisheries satellite data
Satellite data has proven to be particularly useful for fisheries observation, as it can provide both an overview of a marine area or fishing fleet, as well as the possibility of knowing the operational life of a single vessel. The following steps are usually followed:
- AIS and VMS data collection.
- Integration with other open or private sources. For example: ship registers, oceanographic data, delimitations of special economic zones or territorial waters.
- Application of machine learning algorithms to identify behavioural patterns and fishing manoeuvres.
- Visualisation of data on interactive maps.
- Generation of alerts on suspicious activity (for real-time monitoring).
Use cases of fisheries satellite data
Satellite fisheries data offer cost-effective options, especially for those with limited resources to patrol their waters to continuously monitor large expanses of ocean. Among other activities, these data make possible the development of systems that allow:
- Monitoring of compliance with fishing regulations, as satellites can track the position and movements of fishing vessels. This monitoring can be done with historical data, in order to perform an analysis of fishing activity patterns and trends. This supports long-term research and strategic analysis of the fisheries sector.
- The detection of illegal fishing, using both historical and real-time data. By analysing unusual movement patterns or the presence of vessels in restricted areas, possible illegal, unreported and unregulated (IUU) fishing activities can be identified. IUU fishing is worth up to US$23.5 billionper year in seafood products.
- The assessment of the fishing volume, with data on the carrying capacity of each vessel and the fish transhipments that take place both at sea and in port.
- The identification of areas of high fishing activity and the assessment of their impact on sensitive ecosystems.
A concrete example is work by the Overseas Development Institute (ODI), entitled "Turbid Water Fishing", which reveals how satellite data can identify vessels, determine their location, course and speed, and train algorithms, providing unprecedented insight into global fishing activities. The report is based on two sources: interviews with the heads of various private and public platforms dedicated to monitoring IUU fishing, as well as free and open resources such as Global Fishing Watch (GFW) - an organisation that is a collaboration between Oceana, SkyTruth and Google - which provides open data.
Challenges, ethical considerations and constraints in monitoring fishing activity
While these data offer great opportunities, it is important to note that they also have limitations. The study "Fishing for data: The role of private data platforms in addressing illegal, unreported and unregulated fishing and overfishing", mentions the problems of working with satellite data to combat illegal fishing, challenges that can be applied to fisheries monitoring in general:
- The lack of a unified universal fishing vessel register. There is a lack of a single database of fishing vessels, which makes it difficult to identify vessels and their owners or operators. Vessel information is scattered across multiple sources such as classification societies, national vessel registers and regional fisheries management organisations.
- Deficient algorithms. Algorithms used to identify fishing behaviour are sometimes unable to accurately identify fishing activity, making it difficult to identify illegal activities. For example, inferring the type of fishing gear used, target species or quantity caught from satellite data can be complex.
- Most of this data is not free and can be costly. The most commonly used data in this field, i.e. data from AIS and VMS systems, are of considerable cost.
- Incomplete satellite data. Automatic Identification Systems (AIS) are mandatory only for vessels over 300 gross tonnes, which leaves out many fishing vessels. In addition, vessels can turn off their AIS transmitters to avoid surveillance.
- The use of these tools for surveillance, monitoring and law enforcement carries risks, such as false positives and spurious correlations. In addition, over-reliance on these tools can divert enforcement efforts away from undetectable behaviour.
- Collaboration and coordination between various private initiatives, such as Global Fishing Watch, is not as smooth as it could be. If they joined forces, they could create a more powerful data platform, but it is difficult to incentivise such collaboration between competing organisations.
The future of satellite data in fisheries
The field of satellite data is in constant evolution, with new techniques for capture and analysis improving the accuracy and utility of the information obtained. Innovations in geospatial data capture include the use of drones, LiDAR (light detection and ranging) and high-resolution photogrammetry, which complement traditional satellite data. In the field of analytics, machine learning and artificial intelligence are playing a crucial role. For example, Global Fishing Watch uses machine learning algorithms to process millions of daily messages from more than 200,000 fishing vessels, allowing a global, real-time view of their activities.
The future of satellite data is promising, with technological advances offering improvements in the resolution, frequency, volume, quality and types of data that can be collected. The miniaturisation of satellites and the development of microsatellite constellations are improving access to space and the data that can be obtained from it.
In the context of fisheries, satellite data are expected to play an increasingly important role in the sustainable management of marine resources. Combining these data with other sources of information, such as in situ sensors and oceanographic models, will allow a more holistic understanding of marine ecosystems and the human activities that affect them.
Content prepared by Miren Gutiérrez, PhD and researcher at the University of Deusto, expert in data activism, data justice, data literacy and gender disinformation. The contents and views reflected in this publication are the sole responsibility of the author.
Blog
In a world increasingly exposed to natural hazards and humanitarian crises, accurate and up-to-date geospatial data can make the difference between effective response and delayed reaction. The building footprints, i.e. the contours of buildings as they appear on the ground, are one of the most valuable resources in emergency contexts.
In this post we will delve deeper into this concept, including where to obtain open building footprint data, and highlight its importance in one of its many use cases: emergency management.
What are buildings footprints
The building footprints are geospatial representations, usually in vector format, showing the outline of structures built on the ground. That is, they indicate the horizontal projection of a building on the ground, viewed from above, as if it were a floor plan.
These footprints can include residential buildings as well as industrial, commercial, institutional or even rural buildings. Depending on the data source, they may be accompanied by additional attributes such as height, number of floors, building use or date of construction, making them a rich source of information for multiple disciplines.
Unlike an architectural plan showing internal details, building footprints are limited to the perimeter of the building in contact with the ground. This simplicity makes them lightweight, interoperable and easily combined with other geographic information layers, such as road networks, risk areas, critical infrastructures or socio-demographic data.

Figure 1. Example of building footprints: each polygon represents the outline of a building as seen from above.
How are they obtained?
There are several ways to generate building footprints:
- From satellite or aerial imagery: using photo-interpretation techniques or, more recently, artificial intelligence and machine learning algorithms.
- With cadastral data or official registers: as in the case of the Cadastre in Spain, which maintains precise vector bases of all registered constructions.
- By collaborative mapping: platforms such as OpenStreetMap (OSM) allow volunteer users to manually digitise visible footprints on orthophotos.
What are they for?
Building footprints are essential for:
- Urban and territorial analysis: allow the study of built density, urban sprawl or land use.
- Cadastral and real estate management: are key to calculating surface areas, applying taxes or regulating buildings.
- Planning of infrastructures and public services: they help to locate facilities, design transport networks or estimate energy demand.
- 3D modelling and smart cities: serve as a basis for generating three-dimensional urban models.
- Risk and emergency management: to identify vulnerable areas, estimate affected populations or plan evacuations.
In short, building footprints are a basic piece of the spatial data infrastructure and, when offered as open, accessible and up-to-date data, they multiply their value and usefulness for society as a whole.
Why are they key in emergency situations?
Of all the possible use cases, in this article we will focus on emergency management. During such a situation - such as an earthquake, flood or wildfire - responders need to know which areas are built-up, how many people can inhabit those structures, how to access them and where to concentrate resources. The building footprints allow:
- Rapidly estimate the number of people potentially affected.
- Prioritise intervention and rescue areas.
- Plan access and evacuation routes.
- Cross-reference data with other layers (social vulnerability, risk areas, etc.).
- Coordinate action between emergency services, local authorities and international cooperation.
Open data available
In an emergency, it is essential to know where to locate building footprint data. One of the most relevant developments in the field of data governance is the increasing availability of building footprints as open data. This type of information, previously restricted to administrations or specialised agencies, can now be freely used by local governments, NGOs, researchers and businesses.
Some of the main sources available for emergency management and other purposes are summarised below:
- JRC - Global Human Settlement Layer (GHSL): the Joint Research Centre of the European Commission offers a number of products derived from satellite imagery analysis:
- GHS-BUILT-S: raster data on global built-up areas.
- GHS-BUILD-V: AI-generated vector building footprints for Europe.
- Downloading data: https://ghsl.jrc.ec.europa.eu/download.php
- IGN and Cadastre of Spain: the footprints of official buildings in Spain can be obtained through the Cadastre and the Instituto Geográfico Nacional (IGN).. They are extremely detailed and up-to-date.
- Download centre of the IGN: https://centrodedescargas.cnig.es
- Cadastral Surveyor: https://www.sedecatastro.gob.es.
- Copernicus Emergency Management Service: provides mapping products generated in record time when an emergency (earthquakes, floods, fires, etc.) is triggered.. They include damage maps and footprints of affected buildings.
- Download centre: https://emergency.copernicus.eu/mapping/list-of-components/EMSR
- Important: to download detailed vector data (such as footprints), you need to register on the platform DIAS/Copernicus EMS or request access on a case-by-case basis.
- OpenStreetMap (OSM): collaborative platform where users from all over the world have digitised building footprints, especially in areas not covered by official sources. It is especially useful for humanitarian projects, rural and developing areas, and cases where rapid updating or local involvement is needed.
- Downloading data: https://download.geofabrik.de
- Google Open Buildings: this Google project offers more than 2 billion building footprints in Africa, Asia and other data-scarce regions, generated with artificial intelligence models. It is especially useful for humanitarian purposes, urban development in countries of the global south, and risk exposure assessment in places where there are no official cadastres.
- Direct access to the data: https://sites.research.google/open-buildings/
- Microsoft Building Footprints: Microsoft has published sets of building footprints generated with machine learning algorithms applied to aerial and satellite imagery. Coverage: United States, Canada, Uganda, Tanzania, Nigeria and recently India. The data is open access under the ODbL licence.
- Meta (ex Facebook) AI Buildings Footprints: Meta AI has published datasets generated through deep learning in collaboration with the Humanitarian OpenStreetMap Team (HOT). They focused on African and Southeast Asian countries.
- Direct access to the data: https://dataforgood.facebook.com/dfg/tools/buildings.
Comparative table of open building footprints sources
| Source/Project | Geographic coverage | Data type | Format | Requires registration | Main use |
|---|---|---|---|---|---|
| JRC GHSL | Global (raster) / Europe (vector) | Raster and vector | GeoTIFF / GeoPackage / Shapefile | No | Urban analysis, European planning, comparative studies |
| IGN + Cadastre Spain | Spain | Official vector | GML/Shapefile/WFS/WMS | No | Cadastral data, urban planning, municipal management |
| Copernicus EMS | Europe and global (upon activation) | Vector (post-emergency) | PDF / GeoTIFF / Shapefile | Yes (for detailed vector data) | Rapid mapping, emergency management |
| OpenStreetMap | Global (varies by area) | Collaborative vector | .osm / shapefile / GeoJSON | No | Base maps, rural areas, humanitarian aid |
| Google Open Buildings | Africa, Asia, LatAm (selected areas) | Vector (AI-generated) | CSV / GeoJSON | No | Risk assessment, planning in developing countries |
| Microsoft Buildings Footprints | USA, Canada, India, Africa | Vector (AI) | GeoJSON | No | Massive data, urban planning, rural areas |
| Meta AI | Africa, Asia (specific areas) | Vector (AI) | GeoJSON / CSV | No | Humanitarian aid, complementing OSM in uncovered areas |
Figure 2. Comparative table of open building footprint sources.
Combination and integrated use of data
One of the great advantages of these sources being open and documented is the possibility of combining them to improve the coverage, accuracy and operational utility of building footprints. Here are some recommended approaches:
1. Complementing areas without official coverage
- In regions where cadastre is not available or up to date (such as many rural areas or developing countries), it is useful to use Google Open Buildings or OpenStreetMap as a basis.
- GHSL also provides a harmonised view on a continental scale, useful for planning and comparative analysis.
2. Cross official and collaborative layers
- The Spanish cadastre footprints can be enriched with OSM data when new or modified areas are detected, especially after an event such as a catastrophe.
- This combination is ideal for small municipalities that do not have their own technical capacity, but want to keep their data up to date.
3. Integration with socio-demographic and risk data
- Footprints gain value when integrated into geographic information systems (GIS) alongside layers such as:
- Population per building (INE, WorldPop).
- Flood zones (MAPAMA, Copernicus).
- Health centres or schools.
- Critical infrastructure (electricity grid, water).
This allows modelling risk scenarios, planning evacuations or even simulating potential impacts of an emergency.
4. Combined use in actual activations
Some real-world examples of uses of this data include:
- In cases such as the eruption on La Palma, data from the Cadastre, OSM and Copernicus EMS products were used simultaneously to map damage, estimate the affected population and plan assistance.
- During the earthquake in Turkey in 2023, organisations such as UNOSAT and Copernicus combined satellite imagery with automatic algorithms to detect structural collapses and cross-reference them with existing footprints. This made it possible to quickly estimate the number of people potentially trapped.
In emergency situations, time is a critical resource. Artificial intelligence applied to satellite or aerial imagery makes it possible to generate building footprints much faster and more automated than traditional methods.
In short, the different sources are not exclusive, but complementary. Its strategic integration within a well-governed data infrastructure is what allows moving from data to impact, and putting geospatial knowledge at the service of security, planning and collective well-being.
Data governance and coordination
Having quality building footprints is an essential first step, but their true value is only activated when these data are well governed, coordinated between actors and prepared to be used efficiently in real-world situations. This is where data governancecomes into play: the set of policies, processes and organisational structures that ensure that data is available, reliable, up-to-date and used responsibly.
Why is data governance key?
In emergency or territorial planning contexts, the lack of coordination between institutions or the existence of duplicated, incomplete or outdated data can have serious consequences: delays in decision-making, duplication of efforts or, in the worst case, erroneous decisions. Good data governance ensures that:
- Data must be known and findable: It is not enough that it exists; it must be documented, catalogued and accessible on platforms where users can easily find it.
- Have standards and interoperability: building footprints should follow common formats (such as GeoJSON, GML, shapefile), use consistent reference systems, and be aligned with other geospatial layers (utility networks, administrative boundaries, risk zones...).
- Keep up to date: especially in urban or developing areas, where new construction is rapidly emerging. Data from five years ago may be useless in a current crisis.
- Coordination between levels of government: municipal, regional, national and European. Efficient sharing avoids duplication and facilitates joint responses, especially in cross-border or international contexts.
- Clear roles and responsibilities are defined: who produces the data, who validates it, who distributes it, who activates it in case of emergency?
The value of collaboration
A robust data governance ecosystem must also foster multi-sector collaboration. Public administrations, emergency services, universities, the private sector, humanitarian organisations and citizens can benefit from (and contribute to) the use and improvement of this data.
For example, in many countries, local cadastres work in collaboration with agencies such as national geographic institutes, while citizen science and collaborative mapping initiatives (such as OpenStreetMap) can complement or update official data in less covered areas.
Emergency preparedness
In crisis situations, coordination must be anticipated. It is not just about having the data, but about having clear operational plans on how to access it, who activates it, in what formats, and how it integrates with response systems (such as Emergency Coordination Centres or civil protection GIS).
Therefore, many institutions are developing protocols for activating geospatial data in emergencies, and platforms such as Copernicus Emergency Management Service already work on this principle, offering products based on well-governed data that can be activated in record time.
Conclusion
Building footprints are not just a technical resource for urban planners or cartographers: they are a critical tool for risk management, sustainable urban planning and citizen protection. In emergency situations, where time and accurate information are critical factors, having this data can make the difference between an effective intervention and an avoidable tragedy.
Advances in Earth observation technologies, the use of artificial intelligence and the commitment to open data by institutions such as the JRC and the IGN have democratised access to highly valuable geospatial information. Today it is possible for a local administration, an NGO or a group of volunteers to access building footprints to plan evacuations, estimate affected populations or design logistical routes in real time.
However, the challenge is not only technological, but also organisational and cultural. It is imperative to strengthen data governance: to ensure that these sets are well documented, updated, accessible and that their use is integrated into emergency and planning protocols. It is also essential to train key actors, promote interoperability and foster collaboration between public institutions, the private sector and civil society.
Ultimately, building footprints represent much more than geometries on a map: they are a foundation on which to build resilience, save lives and improve decision-making at critical moments. Betting for its responsible and open use means betting for a smarter, more coordinated and people-centred public management.
Content prepared by Mayte Toscano, Senior Consultant in Data Economy Technologies. The contents and points of view reflected in this publication are the sole responsibility of the author.
Blog
The General direction of traffic (DGT in its Spanish acronym) is the body responsible for ensuring safety and fluidity on the roads in Spain. Among other activities, it is responsible for the issuing of permits, traffic control and the management of infringements.
As a result of its activity, a large amount of data is generated, much of which is made available to the public as open data. These datasets not only promote transparency but are also a tool to encourage innovation and improve road safety through their re-use by researchers, companies, public administrations and interested citizens.
In this article we will review some of these datasets, including application examples.
How to access the DGT's datasets
DGT datasets provide detailed and structured information on various aspects of road safety and mobility in Spain, ranging from accident statistics to vehicle and driver information. The temporal continuity of these datasets, available from the beginning of the century to the present day, enables longitudinal analyses that reflect the evolution of mobility and road safety patterns in Spain.
Users can access datasets in different spaces:
- DGT en cifras. It is a section of the General direction of traffic that offers a centralised access to statistics and key data related to road safety, vehicles and drivers in Spain. This portal includes detailed information on accidents, complaints, vehicle fleet and technical characteristics of vehicles, among other topics. It also provides historical and comparative analyses to assess trends and design strategies to improve road safety.
- National Access Point (NAP). Managed by the DGT, it is a platform designed to centralise and facilitate access to road and traffic data, including updates. This portal has been created under the framework of the European Directive 2010/40/EU and brings together information provided by various traffic management bodies, road authorities and infrastructure operators. Available data includes traffic incidents, electric vehicle charging points, low-emission zones and car park occupancy, among others. It aims to promote interoperability and the development of intelligent solutions that improve road safety and transport efficiency.
While the NAP is focused on real-time data and technological solutions, DGT en cifras focuses on providing statistics and historical information for analysis and decision making. In addition, the NAP collects data not only from the DGT, but also from other agencies and private companies.
Most of these data are available through datos.gob.es.
Examples of DGT datasets
Some examples of datasets that can be found in datos.gob.es are:
- Accidents with casualties: includes detailed information on fatalities, hospitalised and minor injuries, as well as circumstances by road type. This data helps to understand why accidents happen and who is involved, to identify risky situations and to detect dangerous behaviour on the road. It is useful for creating better prevention campaigns, detecting black spots on the roads and helping authorities to make more informed decisions. They are also of interest to public health professionals, urban planners and insurance companies working to reduce accidents and their consequences.
- Census of drivers: provides a complete x-ray of who has a driving licence in Spain. The information is particularly useful for understanding the evolution of the driver fleet, identifying demographic trends and analysing the penetration of different types of licences by territory and gender.
- Car registrations by make and engine capacity: shows which new cars Spaniards bought, organised by brand and engine power. The information allows consumer trends to be identified. This data is valuable for manufacturers, dealers and automotive analysts, who can study the market performance in a given year. They are also useful for researchers in mobility, environment and economics, allowing to analyse the evolution of the Spanish vehicle fleet and its impact in terms of emissions, energy consumption and market trends.
Use cases of DGT datasets
The publication of this data in an open format enables innovation in areas such as accident prevention, the development of safer road infrastructure, the development of evidence-based public policies, and the creation of mobility-related technology applications. Some examples are given below:
DGT's own use of data
The DGT itself reuses its data to create tools that facilitate the visualisation of the information and bring it closer to citizens in a simple way. This is the case of the Traffic status and incident map, which is constantly and automatically updated with the information entered 24 hours a day by the Civil Guard Traffic Group and the heads of the Traffic Management Centres of the DGT, the Generalitat de Catalunya and the Basque Government. Includes information on roads affected by weather phenomena (e.g. ice, floods, etc.) and forecast developments.
In addition, the DGT also uses its data to carry out studies that provide information on certain aspects related to mobility and road safety, which are very useful for decision-making and policy-making. One example is this study which analyses the behaviour and activity of certain groups in traffic accidents in order to propose proactive measures. Another example: this project to implement a computer system that identifies, through geolocation, the critical points with the highest accident rates on roads for their treatment and transfer of conclusions.
Use of data by third parties
The datasets provided by the DGT are also reused by other public administrations, researchers, entrepreneurs and private companies, fostering innovation in this field. Thanks to them, we find apps that allow users to access detailed information about vehicles in Spain (such as technical characteristics and inspection history and other data) or that provide information about the most dangerous places for cyclists.
In addition, its combination with advanced technologies such as artificial intelligence allows extracting even more value from the data, facilitating the identification of patterns and helping citizens and authorities to take preventive measures. One example is the Waze application, which has implemented an artificial intelligence-based functionality to identify and alert drivers to high-crashstretches of road, known as "black spots". This system combines historical accident data with analysis of road characteristics, such as gradients, traffic density and intersections, to provide accurate and highly useful alerts. The application notifies users in advance when they are approaching these dangerous areas, with the aim of reducing risks and improving road safety. This innovation complements the data provided by the DGT, helping to save lives by encouraging more cautious driving.
For those who would like to get a taste and practice with DGT data, from datos.gob.es we have a step-by-step data science exercise. Users will be able to analyse these datasets and use predictive models to estimate the evolution of the electric vehicle in Spain. Documented code development and free-to-use tools are used for this purpose. All the material generated is available for reuse in the GitHub repository of datos.gob.es.
In short, the DGT's data sets offer great opportunities for reuse, even more so when combined with disruptive technologies. This is driving innovation, sustainability and safer, more connected transport, which is helping to transform urban and rural mobility.
Blog
As organisations seek to harness the potential of data to make decisions, innovate and improve their services, a fundamental challenge arises: how can data collection and use be balanced with respect for privacy? PET technologies attempt to address this challenge. In this post, we will explore what they are and how they work.
What are PET technologies?
PET technologies are a set of technical measures that use various approaches to privacy protection. The acronym PET stands for "Privacy Enhancing Technologies" which can be translated as "privacy enhancing technologies".
According to the European Union Agency for Cibersecurity this type of system protects privacy by:
- The deletion or reduction of personal data.
- Avoiding unnecessary and/or unwanted processing of personal data.
All this, without losing the functionality of the information system. In other words, they make it possible to use data that would otherwise remain unexploited, as they limit the risks of disclosure of personal or protected data, in compliance with current legislation.
Relationship between utility and privacy in protected data
To understand the importance of PET technologies, it is necessary to address the relationship between data utility and data privacy. The protection of personal data always entails a loss of usefulness, either because it limits the use of the data or because it involves subjecting them to so many transformations to avoid identification that it perverts the results. The following graph shows how the higher the privacy, the lower the usefulness of the data.

Figure 1. Relationship between utility and privacy in protected data. Source: "Introduction to PET technologies", Directorate-General for Data, June 2024.
PET techniques allow a more favourable privacy-utility trade-off to be achieved. However, it should be borne in mind that there will always be some limitation of usability when exploiting protected data.
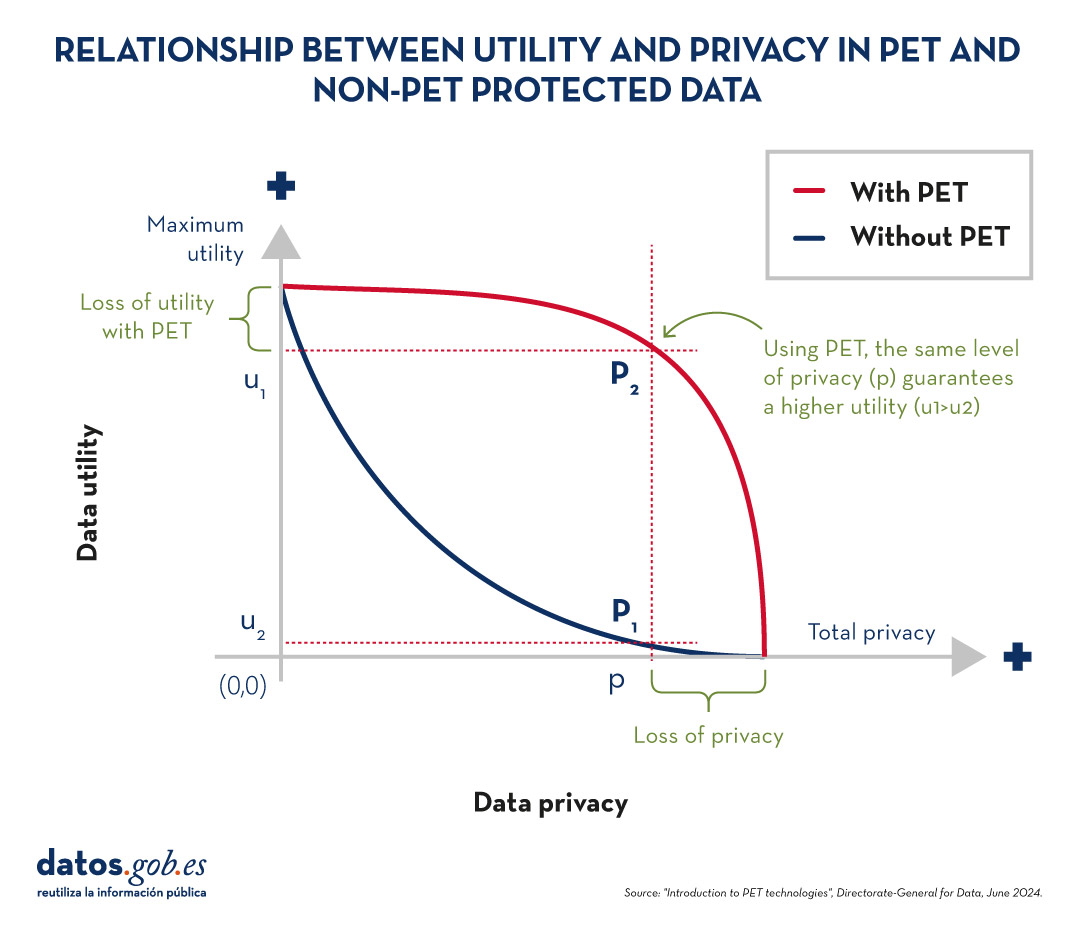
Figure 2. Relationship between utility and privacy in PET and non-PET protected data. Source: "Introduction to PET technologies", Directorate-General for Data, June 2024.
Most popular PET techniques
In order to increase usability and to be able to exploit protected data while limiting risks, a number of PET techniques need to be applied. The following diagram shows some of the main ones:
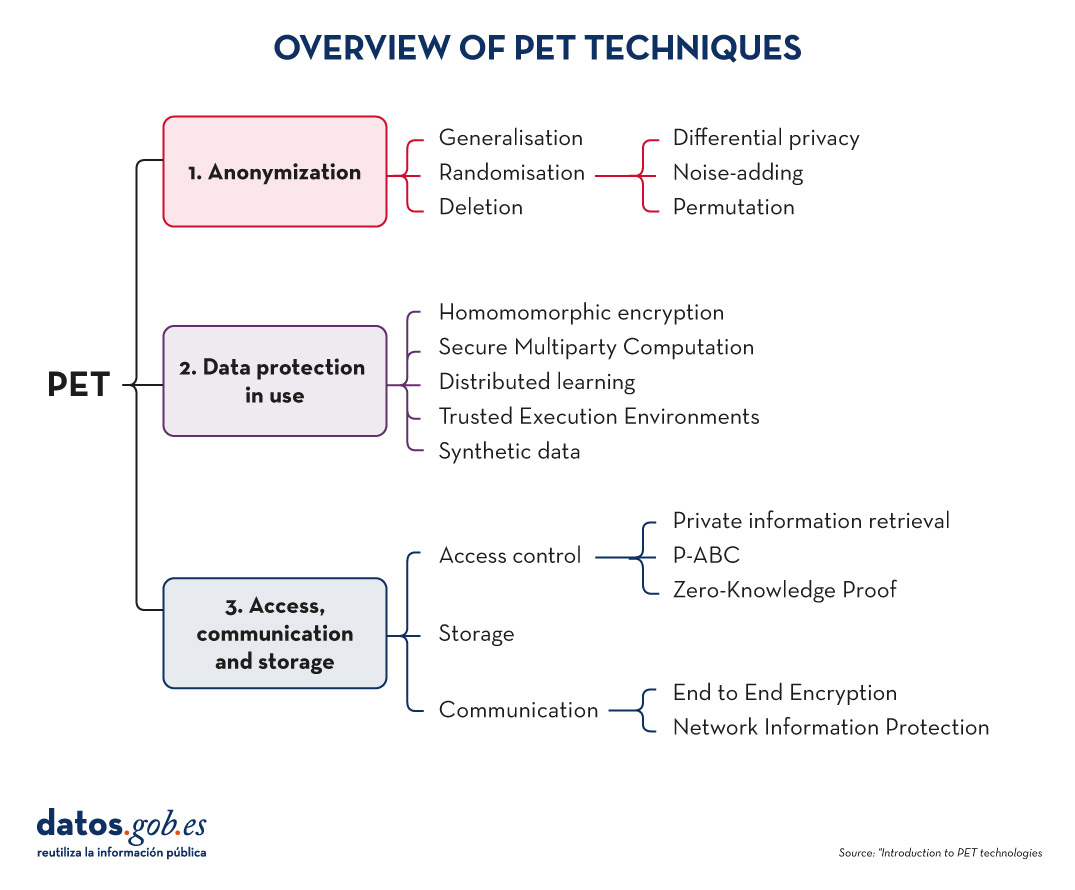
Figure 3. Overview of PET techniques. Source: "Introduction to PET technologies", Directorate-General for Data, June 2024.
As we will see below, these techniques address different phases of the data lifecycle.
Before data mining: anonymisation
Anonymisation is the transformation of private data sets so that no individual can be identified. Thus, the General Data Protection Regulation (GDPR) no longer applies to them.
It is important to ensure that anonymisation has been done effectively, avoiding risks that allow re-identification through techniques such as linkage (identification of an individual by cross-referencing data), inference (deduction of additional attributes in a dataset), singularisation (identification of individuals from the values of a record) or compounding (cumulative loss of privacy due to repeated application of treatments). For this purpose, it is advisable to combine several techniques, which can be grouped into three main families:
- Randomisation: involves modifying the original data by introducing an element of chance. This is achieved by adding noise or random variations to the data, so that general patterns and trends are preserved, but identification of individuals is made more difficult.
- Generalisation: is the replacement or hiding of specific values in a data set with broader or less precise values. For example, instead of recording the exact age of a person, a range of ages (such as 35-44 years) could be used.
- Deletion: implies the complete removal of certain data from the set, especially those that can identify a person directly. This is the case for names, addresses, identification numbers, etc.
You can learn more about these three general approaches and the various techniques involved in the practical guide "Introduction to data anonymisation: techniques and practical cases". We also recommend reading the article Common misunderstandings in data anonymisation.
Data protection in use
This section deals with techniques that safeguard data privacy during the implementation of operational processing.
-
Homomomorphic encryption: is a cryptographic technique which allows mathematical operations to be performed on encrypted data without first decrypting it. For example, a cipher will be homomorphic if it is true that, if two numbers are encrypted and a sum is performed in their encrypted form, the encrypted result, when decrypted, will be equal to the sum of the original numbers.
- Secure Multiparty Computation or SMPC: is an approach that allows multiple parties to collaborate to perform computations on private data without revealing their information to the other participants. In other words, it allows different entities to perform joint operations and obtain a common result, while maintaining the confidentiality of their individual data.
- Distributed learning: traditionally, machine learning models learn centrally, i.e., they require gathering all training data from multiple sources into a single dataset from which a central server builds the desired model. In el distributed learning, data is not concentrated in one place, but remains in different locations, devices or servers. Instead of moving large amounts of data to a central server for processing, distributed learning allows machine learning models to be trained at each of these locations, integrating and combining the partial results to obtain a final model.
- Trusted Execution Environments or TEE: trusted computing refers to a set of techniques and technologies that allow data to be processed securely within protected and certified hardware environments known as trusted computing environments.
- Synthetic data: is artificially generated data that mimics the characteristics and statistical patterns of real data without representing specific people or situations. They reproduce the relevant properties of real data, such as distribution, correlations and trends, but without information to identify specific individuals or cases. You can learn more about this type of data in the report Synthetic data:. What are they and what are they used for?
3. Access, communication and storage
PET techniques do not only cover data mining. These also include procedures aimed at ensuring access to resources, communication between entities and data storage, while guaranteeing the confidentiality of the participants. Some examples are:
Access control techniques
-
Private information retrieval or PIR: is a cryptographic technique that allows a user to query a database or server without the latter being able to know what information the user is looking for. That is, it ensures that the server does not know the content of the query, thus preserving the user's privacy.
-
Privacy-Attribute Based Credentials or P-ABC: is an authentication technology that allows users to demonstrate certain personal attributes or characteristics (such as age of majority or citizenship) without revealing their identity. Instead of displaying all his personal data, the user presents only those attributes necessary to meet the authentication or authorisation requirements, thus maintaining his privacy.
- Zero-Knowledge Proof or ZKP: is a cryptographic method that allows one party to prove to another that it possesses certain information or knowledge (such as a password) without revealing the content of that knowledge itself. This concept is fundamental in the field of cryptography and information security, as it allows the verification of information without the need to expose sensitive data.
Communication techniques
-
End to End Encryption or E2EE: This technique protects data while it is being transmitted between two or more devices, so that only authorised participants in the communication can access the information. Data is encrypted at the origin and remains encrypted all the way to the recipient. This means that, during the process, no intermediary individual or organisation (such as internet providers, application servers or cloud service providers) can access or decrypt the information. Once they reach their destination, the addressee is able to decrypt them again.
- Network Information Protection (Proxy & Onion Routing): a proxy is an intermediary server between a user's device and the connection destination on the Internet. When someone uses a proxy, their traffic is first directed to the proxy server, which then forwards the requests to the final destination, allowing content filtering or IP address change. The Onion Routing method protects internet traffic over a distributed network of nodes. When a user sends information using Onion Routing, their traffic is encrypted multiple times and sent through multiple nodes, or "layers" (hence the name "onion", meaning "onion").
Storage techniques
- Privacy Preserving Storage (PPS): its objective is to protect the confidentiality of data at rest and to inform data custodians of a possible security breach, using encryption techniques, controlled access, auditing and monitoring, etc.
These are just a few examples of PET technologies, but there are more families and subfamilies. Thanks to them, we have tools that allow us to extract value from data in a secure way, guaranteeing users' privacy. Data that can be of great use in many sectors, such as health, environmental care or the economy.
Noticia
The European Parliament's tenth parliamentary term started on July, a new institutional cycle that will run from 2024-2029. The President of the European Commission, Ursula von der Leyen, was elected for a second term, after presenting to the European Parliament her Political Guidelines for the next European Commission 2024-2029.
These guidelines set out the priorities that will guide European policies in the coming years. Among the general objectives, we find that efforts will be invested in:
- Facilitating business and strengthening the single market.
- Decarbonise and reduce energy prices.
- Make research and innovation the engines of the economy.
- Boost productivity through the diffusion of digital technology.
- Invest massively in sustainable competitiveness.
- Closing the skills and manpower gap.
In this article, we will explain point 4, which focuses on combating the insufficient diffusion of digital technologies. Ignorance of the technological possibilities available to citizens limits the capacity to develop new services and business models that are competitive on a global level.
Boosting productivity with the spread of digital technology
The previous mandate was marked by the approval of new regulations aimed at fostering a fair and competitive digital economy through a digital single market, where technology is placed at the service of people. Now is the time to focus on the implementation and enforcement of adopted digital laws.
One of the most recently approved regulations is the Artificial Intelligence (AI) Regulation, a reference framework for the development of any AI system. In this standard, the focus was on ensuring the safety and reliability of artificial intelligence, avoiding bias through various measures including robust data governance.
Now that this framework is in place, it is time to push forward the use of this technology for innovation. To this end, the following aspects will be promoted in this new cycle:
- Artificial intelligence factories. These are open ecosystems that provide an infrastructure for artificial intelligence supercomputing services. In this way, large technological capabilities are made available to start-up companies and research communities.
- Strategy for the use of artificial intelligence. It seeks to boost industrial uses in a variety of sectors, including the provision of public services in areas such as healthcare. Industry and civil society will be involved in the development of this strategy.
- European Research Council on Artificial Intelligence. This body will help pool EU resources, facilitating access to them.
But for these measures to be developed, it is first necessary to ensure access to quality data. This data not only supports the training of AI systems and the development of cutting-edge technology products and services, but also helps informed decision-making and the development of more accurate political and economic strategies. As the document itself states " Access to data is not only a major driver for competitiveness, accounting for almost 4% of EU GDP, but also essential for productivity and societal innovations, from personalised medicine to energy savings”.
To improve access to data for European companies and improve their competitiveness vis-à-vis major global technology players, the European Union is committed to "improving open access to data", while ensuring the strictest data protection.
The European data revolution
"Europe needs a data revolution. This is how blunt the President is about the current situation. Therefore, one of the measures that will be worked on is a new EU Data Strategy. This strategy will build on existing standards. It is expected to build on the existing strategy, whose action lines include the promotion of information exchange through the creation of a single data market where data can flow between countries and economic sectors in the EU.
In this framework, the legislative progress we saw in the last legislature will continue to be very much in evidence:
- Directive (EU) 2019/1024 on open data and re-use of public sector information, which establishes the legal framework for the re-use of public sector information, made available to the public as open data, including the promotion of high-value data.
- Regulation (EU) 2022/868 on European Data Governance (EDG), which regulates the secure and voluntary exchange of data sets held by public bodies over which third party rights concur, as well as data brokering services and the altruistic transfer of data.
- Regulation (EU) 2023/2854 on harmonised rules for fair access to and use of data (Data Act), which promotes harmonised rules on fair access and use of data in the framework of the European Strategy.
The aim is to ensure a "simplified, clear and coherent legal framework for businesses and administrations to share data seamlessly and at scale, while respecting high privacy and security standards".
In addition to stepping up investment in cutting-edge technologies, such as supercomputing, the internet of things and quantum computing, the EU plans to continue promoting access to quality data to help create a sustainable and solvent technological ecosystem capable of competing with large global companies. In this space we will keep you informed of the measures taken to this end.