Application
This application is a map in which about 70% of the fatal cyclist hit-and-runs on Spanish roads in the last fifteen years are geolocated. Each point on the map represents a fatal hit-and-run and contains the following information: cyclists killed, date and time, road, circumstances of the driver, link to Google Street View and to the source of information.
The dataset used is made up of accident data from the Dirección General de Tráfico and information obtained from the consultation of more than 300 news items on hit-and-runs in the digital version of different media.
From the data obtained, the application shows in which provinces there have been a greater number of accidents or in which time slot and day of the week they are more frequent.
The open data sources are:
-
DGT: https://www.dgt.es/menusecundario/dgt-en-cifras/dgt-en-cifras-resultado…
-
Information has also been extracted from more than 300 news items on road accidents.
Blog
Trust, as a key factor in unlocking the potential of data in the digital economy, is an increasingly central element in all data regulations. The European General Data Protection Regulation, in 2016 already recognised that if individuals have more control over their own personal data, this will improve trust and contribute to the positive impact on the development of the digital economy. The European Commission's European Data Law 2022 European Commission proposal puts even greater emphasis on the targets themselves, stating that "low trust prevents the full potential of data-driven innovation from being realised".
Among the findings of the World Data Regulation Survey published by the World Bank in 2021, highlights the need to strengthen regulatory frameworks around the world to build greater citizen trust. This would contribute to more effective effectiveness of government initiatives that use data and that aim, in many cases, to generate value forsociety. As an example, he cites the limited impact of contact-tracking applications around the world during the COVID-19 pandemic, largely due to a lack of public confidence in the potential use of the data provided.
If we really believe that trust in data is so critical to creating value for society and the economy, we need to pay close attention both to the mechanisms we have at our disposal to enhance that trustworthiness, and to the strategies for building and maintaining that trust, beyond the regulatory frameworks themselves.
Quality and transparency
Trust in data starts with quality and transparency. When users understand how data are collected, processed and maintained, they are more likely to trust them to use them use it, and even be more willing to contribute their own data.
A fundamental mechanism for ensuring quality and transparency is the implementation of rigorous standards, such as the UNE specifications for Data Governance UNE 0077:2023, Data Management UNE 0078:2023, and Data Quality Management UNE 0079:2023 at each stage of the data lifecycle. On the one hand, quality is enhanced through the deployment of robust validation and verification practices that ensure the accuracy and integrity of the data, and on the other hand, transparency is improved through, for example, descriptive metadata that provide detailed information about the data, including its origin, collection methodology and any transformation it has undergone.
European Data Spaces
The European Data Spaces is an ambitious EU initiative aimed at building trust and facilitating the exchange and use of data between countries and sectors in a secure and regulated environment. The central idea behind the European Data Spaces is to create environments in which the availability, accessibility and interoperability of data are maximised, while the risks associated with data handling are minimised. Initially the European data strategy initially envisaged 10 data spaces in strategic areas such as health, energy or public administration. Since then this number has grown and other data spaces have been launched in important areas such as media and cultural heritage, or in strategic sectors for Spain such as tourism.
In order to bet on the leadership in data spaces in strategic sectors for Spain, the government is promoting the Gaia-X Spanish Hub the Spanish government is promoting a new initiative, comprised of companies of all sizes, aimed at deploying a solid ecosystem in the field of industrial data sharing
Improving cyber security
The increasing number of cyber security incidents media headlines, some of which have even brought private companies and public bodies to a standstill, has made cyber security a primary concern for users and organisations in the digital age.
Robust cyber security involves organisations deploying advanced technologies and best practices to protect systems and data from unauthorised access and malicious manipulation through measures such as firewalls, two-factor authentication, and real-time threat monitoring and detection, encryption two-factor authentication, and real-time threat monitoring and detection. However, improving users' education and cybersecurity awareness is also vital to help them recognise and avoid potential threats.
European digital identity
The European Digital Identity is being developed in the framework of the European Union with the aim of providing citizens and businesses with a secure and unified way of accessing services, public and private, online and offline, across the EU. The idea is that, with a European digital identity, people would be able to identify themselves or confirm data in services such as banking, education or health, among others, in a secure and frictionless way, providing a high level of security and privacy protection.
This deepens the framework of trust and confidence created by the EIDAS Regulation on electronic identification and trust services for electronic transactions in the internal market, which already contributes significantly to increasing consumer confidence phishing or improving confidence in the origin of documents.
Building a culture of trust and responsibility in the handling of data and digital infrastructures is the focus of the actions of EU governments, including Spain. In this context, the intersection between data quality and transparency, robust cybersecurity that reduces cybercrime, European Data Spaces, and European digital identity stand out as key mechanisms to cultivate this trust and propose a route towards greater innovation that ultimately generates social and economic value through data.
Contenido elaborado por Jose Luis Marín, Senior Consultant in Data, Strategy, Innovation & Digitalization. Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Documentación
The digitalization in the public sector in Spain has also reached the judicial field. The first regulation to establish a legal framework in this regard was the reform that took place through Law 18/2011, of July 5th (LUTICAJ). Since then, there have been advances in the technological modernization of the Administration of Justice. Last year, the Council of Ministers approved a new legislative package to definitively address the digital transformation of the public justice service, the Digital Efficiency Bill.
This project incorporates various measures specifically aimed at promoting data-driven management, in line with the overall approach formulated through the so-called Data Manifesto promoted by the Data Office.
Once the decision to embrace data-driven management has been made, it must be approached taking into account the requirements and implications of Open Government, so that not only the possibilities for improvement in the internal management of judicial activity are strengthened, but also the possibilities for reuse of the information generated as a result of the development of said public service (RISP).
Open data: a premise for the digital transformation of justice
To address the challenge of the digital transformation of justice, data openness is a fundamental requirement. In this regard, open data requires conditions that allow their automated integration in the judicial field. First, an improvement in the accessibility conditions of the data sets must be carried out, which should be in interoperable and reusable formats. In fact, there is a need to promote an institutional model based on interoperability and the establishment of homogeneous conditions that, through standardization adapted to the singularities of the judicial field, facilitate their automated integration.
In order to deepen the synergy between open data and justice, the report prepared by expert Julián Valero identifies the keys to digital transformation in the judicial field, as well as a series of valuable open data sources in the sector.
If you want to learn more about the content of this report, you can watch the interview with its author.
Below, you can download the full report, the executive summary, and a summary presentation.
Blog
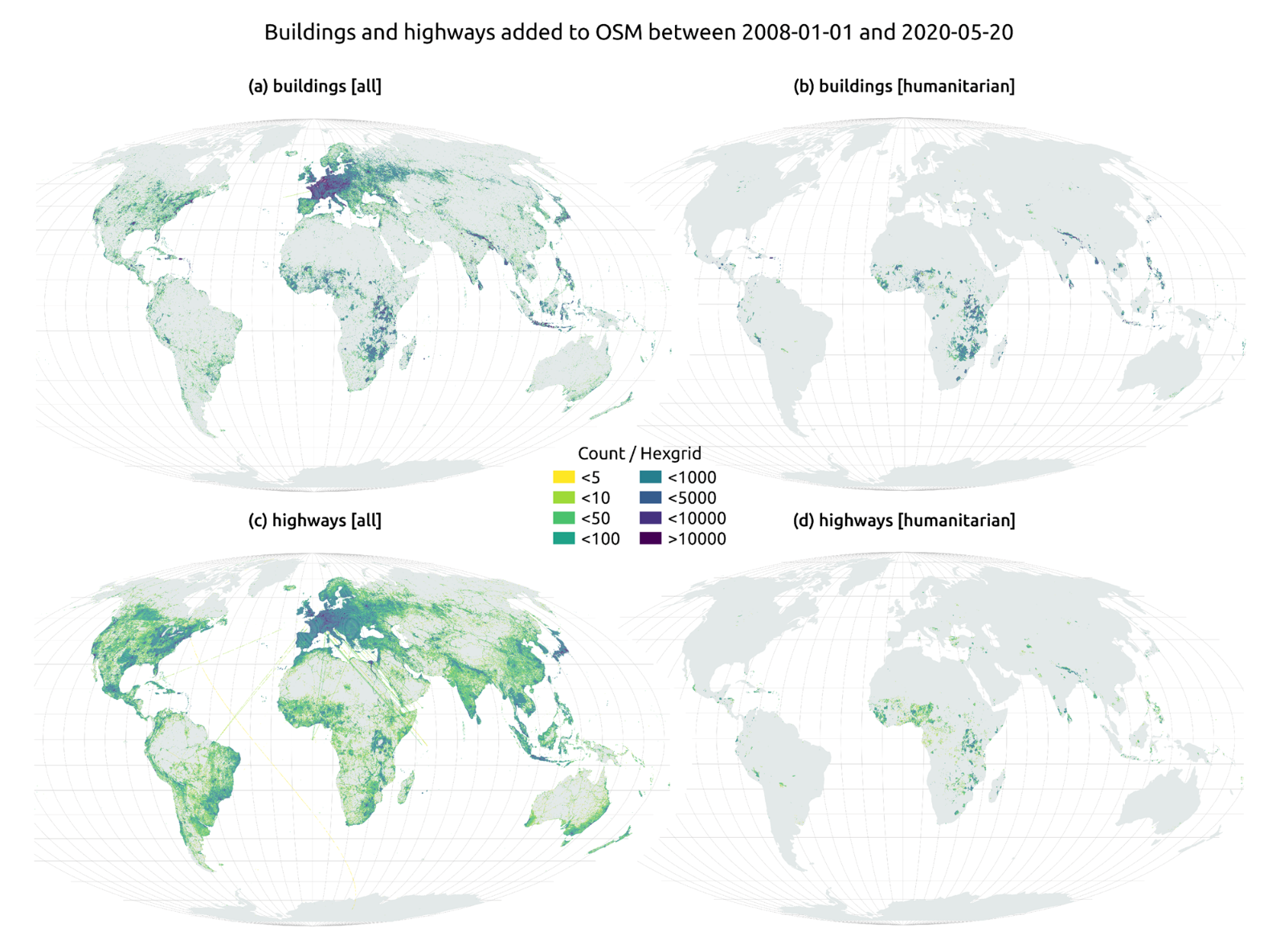
The humanitarian crisis following the earthquake in Haiti in 2010 was the starting point for a voluntary initiative to create maps to identify the level of damage and vulnerability by areas, and thus to coordinate emergency teams. Since then, the collaborative mapping project known as Hot OSM (OpenStreetMap) has played a key role in crisis situations and natural disasters.
Now, the organisation has evolved into a global network of volunteers who contribute their online mapping skills to help in crisis situations around the world. The initiative is an example of data-driven collaboration to solve societal problems, a theme we explore in this data.gob.es report.
Hot OSM works to accelerate data-driven collaboration with humanitarian and governmental organisations, as well as local communities and volunteers around the world, to provide accurate and detailed maps of areas affected by natural disasters or humanitarian crises. These maps are used to help coordinate emergency response, identify needs and plan for recovery.
In its work, Hot OSM prioritises collaboration and empowerment of local communities. The organisation works to ensure that people living in affected areas have a voice and power in the mapping process. This means that Hot OSM works closely with local communities to ensure that areas important to them are mapped. In this way, the needs of communities are considered when planning emergency response and recovery.
Hot OSM's educational work
In addition to its work in crisis situations, Hot OSM is dedicated to promoting access to free and open geospatial data, and works in collaboration with other organisations to build tools and technologies that enable communities around the world to harness the power of collaborative mapping.
Through its online platform, Hot OSM provides free access to a wide range of tools and resources to help volunteers learn and participate in collaborative mapping. The organisation also offers training for those interested in contributing to its work.
One example of a HOT project is the work the organisation carried out in the context of Ebola in West Africa. In 2014, an Ebola outbreak affected several West African countries, including Sierra Leone, Liberia and Guinea. The lack of accurate and detailed maps in these areas made it difficult to coordinate the emergency response.
In response to this need, HOT initiated a collaborative mapping project involving more than 3,000 volunteers worldwide. Volunteers used online tools to map Ebola-affected areas, including roads, villages and treatment centres.
This mapping allowed humanitarian workers to better coordinate the emergency response, identify high-risk areas and prioritize resource allocation. In addition, the project also helped local communities to better understand the situation and participate in the emergency response.
This case in West Africa is just one example of HOT's work around the world to assist in humanitarian crisis situations. The organisation has worked in a variety of contexts, including earthquakes, floods and armed conflict, and has helped provide accurate and detailed maps for emergency response in each of these contexts.
On the other hand, the platform is also involved in areas where there is no map coverage, such as in many African countries. In these areas, humanitarian aid projects are often very challenging in the early stages, as it is very difficult to quantify what population is living in an area and where they are located. Having the location of these people and showing access routes "puts them on the map" and allows them to gain access to resources.
In this article The evolution of humanitarian mapping within the OpenStreetMap community by Nature, we can see graphically some of the achievements of the platform.
How to collaborate
It is easy to start collaborating with Hot OSM, just go to https://tasks.hotosm.org/explore and see the open projects that need collaboration.
This screen allows us a lot of options when searching for projects, selected by level of difficulty, organisation, location or interests among others.
To participate, simply click on the Register button.
Give a name and an e-mail adress on the next screen:

It will ask us if we have already created an account in Open Street Maps or if we want to create one.
If we want to see the process in more detail, this website makes it very easy.
Once the user has been created, on the learning page we find help on how to participate in the project.
It is important to note that the contributions of the volunteers are reviewed and validated and there is a second level of volunteers, the validators, who validate the work of the beginners. During the development of the tool, the HOT team has taken great care to make it a user-friendly application so as not to limit its use to people with computer skills.
In addition, organisations such as the Red Cross and the United Nations regularly organise mapathons to bring together groups of people for specific projects or to teach new volunteers how to use the tool. These meetings serve, above all, to remove the new users' fear of "breaking something" and to allow them to see how their voluntary work serves concrete purposes and helps other people.
Another of the project's great strengths is that it is based on free software and allows for its reuse. In the MissingMaps project's Github repository we can find the code and if we want to create a community based on the software, the Missing Maps organisation facilitates the process and gives visibility to our group.
In short, Hot OSM is a citizen science and data altruism project that contributes to bringing benefits to society through the development of collaborative maps that are very useful in emergency situations. This type of initiative is aligned with the European concept of data governance that seeks to encourage altruism to voluntarily facilitate the use of data for the common good.
Content by Santiago Mota, senior data scientist.
The contents and views reflected in this publication are the sole responsibility of the author.
Documentación
Data anonymization defines the methodology and set of best practices and techniques that reduce the risk of identifying individuals, the irreversibility of the anonymization process, and the auditing of the exploitation of anonymized data by monitoring who, when, and for what purpose they are used.
This process is essential, both when we talk about open data and general data, to protect people's privacy, guarantee regulatory compliance, and fundamental rights.
The report "Introduction to Data Anonymization: Techniques and Practical Cases," prepared by Jose Barranquero, defines the key concepts of an anonymization process, including terms, methodological principles, types of risks, and existing techniques.
The objective of the report is to provide a sufficient and concise introduction, mainly aimed at data publishers who need to ensure the privacy of their data. It is not intended to be a comprehensive guide but rather a first approach to understand the risks and available techniques, as well as the inherent complexity of any data anonymization process.
What techniques are included in the report?
After an introduction where the most relevant terms and basic anonymization principles are defined, the report focuses on discussing three general approaches to data anonymization, each of which is further integrated by various techniques:
- Randomization: data treatment, eliminating correlation with the individual, through the addition of noise, permutation, or Differential Privacy.
- Generalization: alteration of scales or orders of magnitude through aggregation-based techniques such as K-Anonymity, L-Diversity, or T-Closeness.
- Pseudonymization: replacement of values with encrypted versions or tokens, usually through HASH algorithms, which prevent direct identification of the individual unless combined with additional data, which must be adequately safeguarded.
The document describes each of these techniques, as well as the risks they entail, providing recommendations to avoid them. However, the final decision on which technique or set of techniques is most suitable depends on each particular case.
The report concludes with a set of simple practical examples that demonstrate the application of K-Anonymity and pseudonymization techniques through encryption with key erasure. To simplify the execution of the case, users are provided with the code and data used in the exercise, available on GitHub. To follow the exercise, it is recommended to have minimal knowledge of the Python language.
You can now download the complete report, as well as the executive summary and a summary presentation.
Blog
On 24 February Europe entered a scenario that not even the data could have predicted: Russia invaded Ukraine, unleashing the first war on European soil so far in the 21st century.
Almost five months later, on 26 September, the United Nations (UN) published its official figures: 4,889 dead and 6,263 wounded. According to the official UN data, month after month, the reality of the Ukrainian victims was as follows:
| Date | Deceased | Injured |
|---|---|---|
| 24-28 February | 336 | 461 |
| March | 3028 | 2384 |
| April | 660 | 1253 |
| May | 453 | 1012 |
| Jun | 361 | 1029 |
| 1-3 july | 51 | 124 |
According to data extracted by the mission that the UN High Commissioner for Human Rights has been carrying out in Ukraine since Russia invaded Crimea in 2014, the total number of civilians displaced as a result of the conflict is more than 7 million people.
However, as in other areas, the data serve not only to develop solutions, but also to gain an in-depth understanding of aspects of reality that would otherwise not be possible. In the case of the war in Ukraine, the collection, monitoring and analysis of data on the territory allows organisations such as the United Nations to draw their own conclusions.
With the aim of making visible how data can be used to achieve peace, we will now analyse the role of data in relation to the following tasks:
Prediction
In this area, data are used to try to anticipate situations and plan an appropriate response to the anticipated risk. Whereas before the outbreak of war, data was used to assess the risk of future conflict, it is now being used to establish control and anticipate escalation.
For example, satellite images provided by applications such as Google Maps have made it possible to monitor the advance of Russian troops. Similarly, visualisers such as Subnational Surge Tracker identify peaks of violence at different administrative levels: states, provinces or municipalities.
Information
It is just as important to know the facts in order to prevent violence as it is to use them to limit misinformation and communicate the facts objectively, truthfully and in line with official figures. To achieve this, fact-checking applications have begun to be used, capable of responding to fake news with official data.
Among them is Newsguard, a verification entity that has developed a tracker that gathers all the websites that share disinformation about the conflict, placing special emphasis on the most popular false narratives circulating on the web. It even catalogues this type of content according to the language in which it is promoted.
Material damage
The data can also be used to locate material damage and track the occurrence of new damage. Over the past months, the Russian offensive has damaged the Ukrainian public infrastructure network, rendering roads, bridges, water and electricity supplies, and even hospitals unusable.
Data on this reality is very useful for organising a response aimed at reconstructing these areas and sending humanitarian assistance to civilians who have been left without services.
In this sense, we highlight the following use cases:
- The United Nations Development Programme''s (UNDP) machine learning algorithm has been developed and improved to identify and classify war-damaged infrastructure.
- In parallel, the HALO Trust uses social media mining capable of capturing information from social media, satellite imagery and even geographic data to help identify areas with ''explosive remnants''. Thanks to this finding, organisations deployed across the Ukrainian terrain can move more safely to organise a coordinated humanitarian response.
- The light information captured by NASA satellites is also being used to build a database to help identify areas of active conflict in Ukraine. As in the previous examples, this data can be used to track and send aid to where it is most needed.
Human rights violations and abuses
Unfortunately, in such conflicts, violations of the human rights of the civilian population are the order of the day. In fact, according to experience on the ground and information gathered by the UN High Commissioner for Human Rights, such violations have been documented throughout the entire period of war in Ukraine.
In order to understand what is happening to Ukrainian civilians, monitoring and human rights officers collect data, public information and first-person accounts of the war in Ukraine. From this, they develop a mosaic map that facilitates decision-making and the search for just solutions for the population.
Another very interesting work developed with open data is carried out by Conflict Observatory. Thanks to the collaboration of analysts and developers, and the use of geospatial information and artificial intelligence, it has been possible to discover and map war crimes that might otherwise remain invisible.
Migratory movements
Since the outbreak of war last February, more than 7 million Ukrainians have fled the war and thus their own country. As in previous cases, data on migration flows can be used to bolster humanitarian efforts for refugees and IDPs.
Some of the initiatives where open data contributes include the following:
The Displacement Tracking Matrix is a project developed by the International Organization for Migration and aimed at obtaining data on migration flows within Ukraine. Based on the information provided by approximately 2,000 respondents through telephone interviews, a database was created and used to ensure the effective distribution of humanitarian actions according to the needs of each area of the country
Humanitarian response
Similar to the analysis carried out to monitor migratory movements, the data collected on the conflict also serves to design humanitarian response actions and track the aid provided.
In this line, one of the most active actors in recent months has been the United Nations Population Fund (UNFPA), which created a dataset containing updated projections by gender, age and Ukrainian region. In other words, thanks to this updated mapping of the Ukrainian population, it is much easier to think about what needs each area has in terms of medical supplies, food or even mental health support.
Another initiative that is also providing support in this area is the Ukraine Data Explorer, an open source project developed on the Humanitarian Data Exchange (HDX) platform that provides collaboratively collected information on refugees, victims and funding needs for humanitarian efforts.
Finally, the data collected and subsequently analysed by Premise provides visibility on areas with food and fuel shortages. Monitoring this information is really useful for locating the areas of the country with the least resources for people who have migrated internally and, in turn, for signalling to humanitarian organisations which areas are most in need of assistance.
Innovation and the development of tools capable of collecting data and drawing conclusions from it is undoubtedly a major step towards reducing the impact of armed conflict. Thanks to this type of forecasting and data analysis, it is possible to respond quickly and in a coordinated manner to the needs of civil society in the most affected areas, without neglecting the refugees who are displaced thousands of kilometres from their homes.
We are facing a humanitarian crisis that has generated more than 12.6 million cross-border movements. Specifically, our country has attended to more than 145,600 people since the beginning of the invasion and more than 142,190 applications for temporary protection have been granted, 35% of them to minors. These figures make Spain the fifth Member State with the highest number of favourable temporary protection decisions. Likewise, more than 63,500 displaced persons have been registered in the National Health System and with the start of the academic year, there are 30,919 displaced Ukrainian students enrolled in school, of whom 28,060 are minors..
Content prepared by the datos.gob.es team.
Blog
The imminent application of the recent GDPR (May 25th) modifies the European panorama in terms of security and privacy of personal data. Overall, the GDPR could be considered a "Digital Declaration of Rights". As we saw earlier, this Regulation lists the detailed requirements that any institution or individual that processes personal data from citizens of the 28 member countries must comply with, regardless of where that company is located.
GDPR increases citizens’ rights and puts limits to the power of “digital states” such as software platforms and those that make use of them. However, it also assumes centralized models of storage and transmission of digital data. Under the new decentralized blockchain paradigm, new challenges are opened to be resolved under the common framework of GDPR.
The use of blockchain technology brings us closer than ever to digital identity models, where the user is the main owner of their data. Currently there are many different implementations of blockchain. Not all of these implementations follow the original model of the Bitcoin network as a public and pseudo-anonymous network. Many blockchain technologies are specially designed to build private networks where there is a similar figure to the central authority, which grants identity certificates to operate in the network. It would be something similar to a special participant who is responsible for issuing digital IDs to the rest of the participants. In other words, many of the applications that use blockchain continue to operate using the centralized authority model. EU GDPR was designed for this model.
In the medium term applications aimed at end users will begin to proliferate, with the objective of complying with GDPR framework and data security and privacy using partial or total implementations of blockchain technology. For example, providers of data storage software products begin to emerge. On the one hand, this product will store user data in their database systems according to GDPR and, on the other hand, they will use blockchain technology to protect the metadata associated with the stored data.
In this same line, the Blockcerts standard pursues the development of an open source technology, which allows the exchange of user certificates (academic diplomas, criminal records, work certificates, letters of recommendation, etc.) through a blockchain. Under this standard, a user requests his work life certificate through a mobile app. The corresponding authority issues the corresponding certificate and the transaction is entered in the blockchain. Then the user can share his certificate with the hiring company. This company can verify the authenticity and validity of the certificate by its hash.
Therefore, Blockchain joins other technologies that can help companies facilitating compliance with GDPR, such as data tracking tools or security solutions that allow threats detection in real time. Thanks to GDPR compliance, organizations have the opportunity to optimize their information processes, making them safer and more transparent for citizens.
Content prepared by Alejandro Alija, expert in Digital Transformation and innovation.
Contents and points of view expressed in this publication are the exclusive responsibility of its author.
Noticia
The recent and important security and privacy problems of a big company like Facebook, which manages the personal data of billions of people, have at least served to finally raise conscience and awareness of privacy in many people. Unfortunately, these cases can no longer be considered an exception. Therefore, we must ask ourselves, do we really know what extent the problem is and how are our personal data currently exposed?
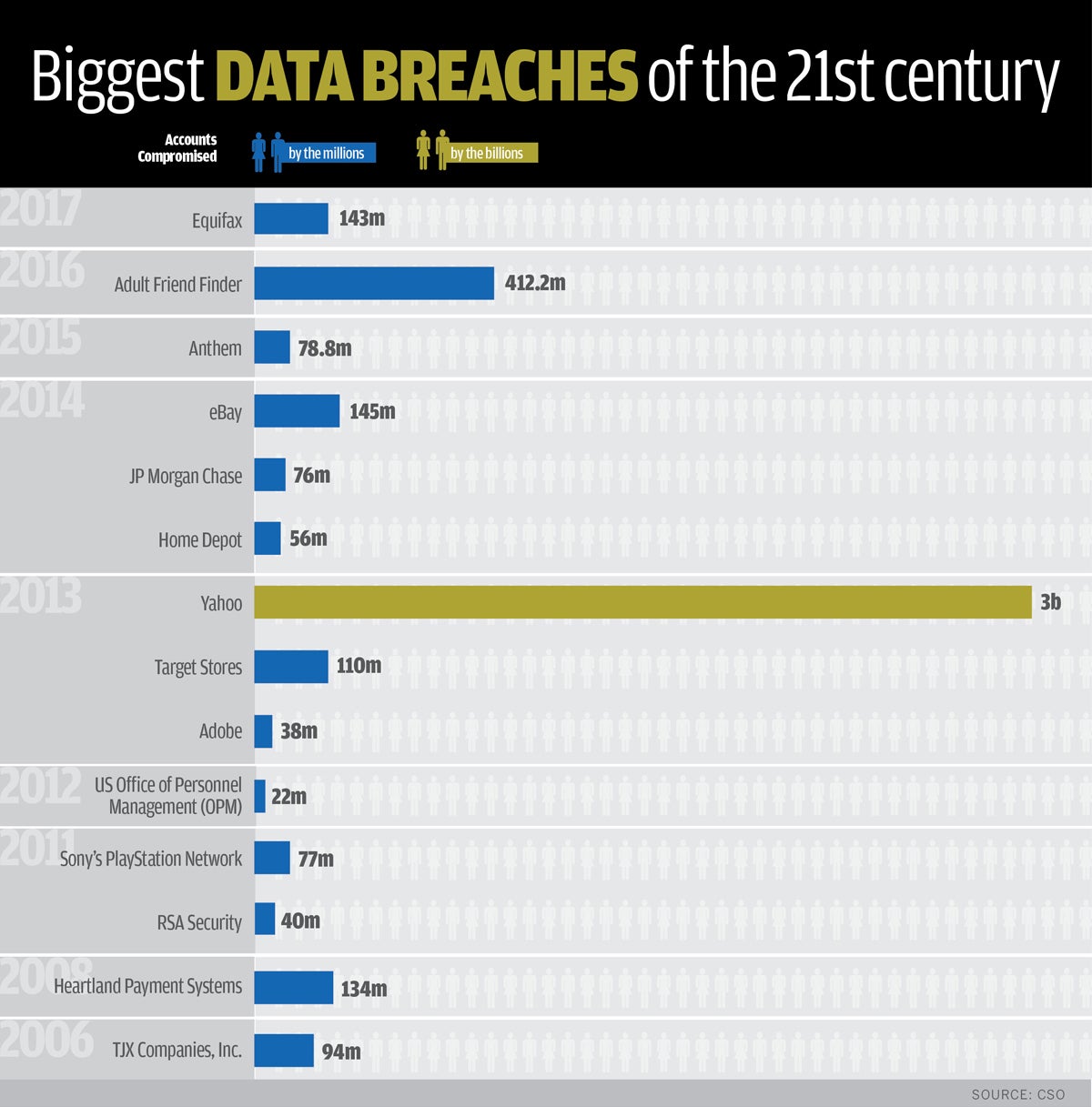{kind=link}
As an example, a controversial artistic exhibition in China, which precisely aimed to draw attention to how unprotected our data are, showed personal information of almost 350,000 people (including names, gender, phone numbers, purchasing records, vehicle registration numbers, etc.) that had been easily acquired by the artist for just over 700 euros (5 people per cent).
We might think that it is an isolated case in a country with a laxer personal data protection rules, and we would have a higher protection in Europe, especially after the recent entry into force of the new General Data Protection Regulation (known as GDPR). However, how much do we really know about the privacy and data protection policies of the services we daily use? Are our data really protected? What do we know about the data they are using and their specific use? Can our personal data also be considered as open data? To what extent would we be willing to negotiate with our privacy? To what extent are we already consciously or unconsciously?
The answer to all these questions is relatively simple. Basically the companies are using all those personal data we have given consent in a more or less explicit way, always depending on the applicable legislation in each country - something that, on the other hand, is becoming more diffuse due to the ubiquity of these cloud services and the difficulty to sometimes determine our online citizenship.
In any case, a good personal exercise to be aware of what data we are giving is taking a look at the information that the most popular services know about us. For example, both Google and Facebook allow us, in a few simple steps, to access all the data they have stored on our personal profiles. Reviewing the results is very likely to be a cause of surprise because, in a large number of cases, in addition to our photos or videos, we can also find unexpected contents such as the detail of all our conversations through these platforms, information about our credit cards, our complete telephone book, the websites and advertisements that we have visited, our approximate location or the exact place where we have made each of our videos and Photos. It is also more than likely that we feel quite uncomfortable to see how an increasing number of websites follow each of our activities while we are surfing, being able to reconstruct each and every steps and even collecting sensitive information during that process.
And then, what could these companies do with all the personal data we have given them? This is the key question and also the one with the most difficult answer. Basically, everything that we have allowed. The key in this case are the famous terms and conditions of use that we must accept when we want to start using these services. Unfortunately the reality is a little more frustrating, because "most people read at a rate of 200 words per minute. A medium terms of use agreement contains almost 12,000 words. This means that to read the conditions before accepting them would take about 60 minutes on average", which in practice means that the vast majority of people accept these conditions directly and without reading, and, therefore, without knowing which the final use of the data will be.
It is difficult for this type of behavior to change in the short term, but fortunately we also have more and more services and tools that help us in this difficult task of deciphering the use conditions of the websites, such as those offered by Polisis and Usable Privacy, among others, that alert us in real time when we use sites that are potentially harmful to our privacy, as Didn’t Read services. Other tools, such as Ghostery, will also help us to easily identify what kind of services are following our online activity in each website we visit and for what purpose, while offering the option to block them, something very useful until more transparent policies are defined, such as those that we are beginning to see in some cases.
Open personal data? In fact, it is possible and in some fields, such as clinical trials, the opening of certain personal data could even be very useful, but always only and exclusively under our control and explicit and informed consent.
Regardless of this, we hope that the new European regulation will be consolidated as a useful tool to offer higher protection and its obligations are quickly adopted also by other countries.
Content prepared by Carlos Iglesias, Open data Researcher and consultan, World Wide Web Foundation.
Contents and points of view expressed in this publication are the exclusive responsibility of its author.
Noticia
Next May 25th, the period of two years that the European Union provided to companies and Public Administrations to comply with the new General Data Protection Regulation (GDPR) ends. This Regulation affects any company or organization that manages personal data of EU citizens, regardless of its origin.
In a previous post, we already saw how GDPR influences the opening of personal data. Now is the time to focus on how GDPR affects those administrations and companies that capture and process personal data, whether they are going to publish data or not.
GDPR enhances citizens' rights, which increases responsibilities of the organizations, as we will see next.
Enhancement of citizens' rights
New rights are added to the traditional ones (access, rectification or cancellation). This new rights are related to new technologies or automated information processing. Some examples of these rights are:
- Right to be forgotten. It can be defined as the right of cancellation applied to the internet: it grants the right to prevent the dissemination of personal data if those data do not comply with the adequacy requirements included in the Regulation.
- Right to data portability. A citizen can request copies of their stored information, in a structured, automated and commonly used format, in order to use it for another purpose.
In addition, now, the age of consent for data processing is 13 years old.
Increase of responsibilities of organizations
GDPR includes the concept of accountability, which establishes the obligation to adopt the appropriate technical and organizational measures to ensure European citizens’ rights. The Regulation is not very extensive in terms of process and technology requirements, but it does define a series of "principles" that companies must comply with. Some of this principles are listed below:
- Need to obtain clear and distinguishable consent. This implies the obligation to explain future personal data use and processing in a simple and univocal way.
- Carry out Privacy Impact Assessments before data processing in those cases where it “is likely to result in a high risk to the rights and freedoms of persons”.
- Organizations with more than 250 employees or where processing is not occasional should establish a records of data processing activities.
- Guarantee data privacy by design and by default, which implies that public administrations and companies must review and design their processes, taking into account the security at the beginning and providing high level protection by default. In addition, they must ensure that data collected should be adequate, relevant and limited to what is necessary in relation to the purposes for which they are processes.
- Take into account the state of the art. In case of security breach, the organization must justify why they implemented or not certain technologies, based on a state of the art assessment in the terms of context, cost and risk level.
- Notify security breaches to the supervisory authorities, not later than 72 hours after having become aware of it.
- Data Protection Officer becomes a mandatory role for public organizations and companies that engage in large scale systematic monitoring, or process sensitive data (such as ethnic origin, political opinions, religious beliefs or sexual orentation, among others). Teir duties are monitoring, informing and advise, among others.
- The fines for non-compliance reach up to 20 million euros, or 4% of the worldwide annual revenue of the prior financial year – it is not clear how fines will be applied to the Public Administrations -.
Although GDPR includes some additional requirements related to citizens’ rights, as well as new figures and procedures, it should not be considered as a revolution, but as an evolution of the current Data Protection Law, and this is the approach selected by our country uthorities. Government is working on a new Data Protection Organic Law that adapts GDPR changes to Spanish legislation. Regardless of this situation, GDPR will be directly applicable whether or not there is a new national law on May 25th.
For the moment, to help Spanish organizations to understand the changes, the Spanish Agency for Data Protection has published several guides and free tools, both for companies and Public Administrations, which help to make easier the journey towards a better and more efficient data government. An example is the following infographic (the resources are in Spanish).
