Blog
For years, the debate on data reuse has focused mainly on publishing processes, i.e. how to expose more and better datasets from provider entities. On the other hand, support for those who must identify, understand, combine and convert them into value-added products or services has often taken a back seat.
With the emergence of artificial intelligence (AI), this view began to change. The question was no longer just how much data exists, but how to transform dispersed, heterogeneous and subject to different rules data into useful raw material for innovation (using, among others, advanced analytics and AI techniques). In this context, the European Union has begun to outline data labs as a key part of its Strategy for a Data Union: an initiative aimed at increasing the availability of quality data for AI, simplifying the applicable rules and better connecting existing data sources (data spaces, open data portals, statistical portals, etc.) with innovation ecosystems.
Data labs, the new concept that brings together services for the reuse of data
And what exactly are data labs? The European Union describes them as specialized operational centers that will give companies and researchers access to diverse datasets and offer services related to the application of AI techniques on that data.
This represents a relevant change of approach because the focus, in addition to helping the provider to publish the data, is on accompanying the consumer so that they can find, prepare and reuse the data more easily. In this sense, one of the most interesting contributions of data labs is that they shift the focus from the simple accumulation of data to its quality, preparation and effective reuse.
In data science and AI projects, a version of the Pareto rule has been repeated for years, stating that around 80% of the time is spent locating, cleaning, integrating, documenting, and preparing data, while only the remaining 20% is reserved for analyzing or training models. It is not a mathematical law, but it is a reality that recent studies continue to place in the same order of magnitude.
And that's precisely where data labs can make a difference, turning these percentages around, as they help discover relevant sources, improve metadata, harmonize formats, solve access problems, and advance curation tasks that turn raw data into a truly usable asset. In other words, it's not just about having more data, it's about having better data.
Scope and added value of data labs
The EU places data labs in a very specific context: increasing access to quality data for AI, simplifying the regulatory framework and strengthening Europe's position in the global data economy. Seen from the perspective of reuse, this translates into three very recognizable needs: finding and accessing the right data, operating with legal certainty and trust, and preparing the data with sufficient quality to generate impact. Specifically, the scope of data labs encompasses six areas:
- Infrastructure and technical tools: they provide secure environments and tools to manage data (from anonymization to synthetic data generation).
- Data pooling: they pool heterogeneous data from various sources, combining them according to the applicable rules.
- Curation and labeling: Help enrich datasets to make them more representative and useful to AI.
- Regulatory guidance and training: Provide practical guidance on how to comply with European regulations applicable to data and AI.
- Connection between data spaces and AI ecosystems: they act as a bridge between European data spaces and those who develop AI solutions.
- Facilitating access to data: they help locate relevant datasets and overcome technical, legal, or administrative barriers to using them.
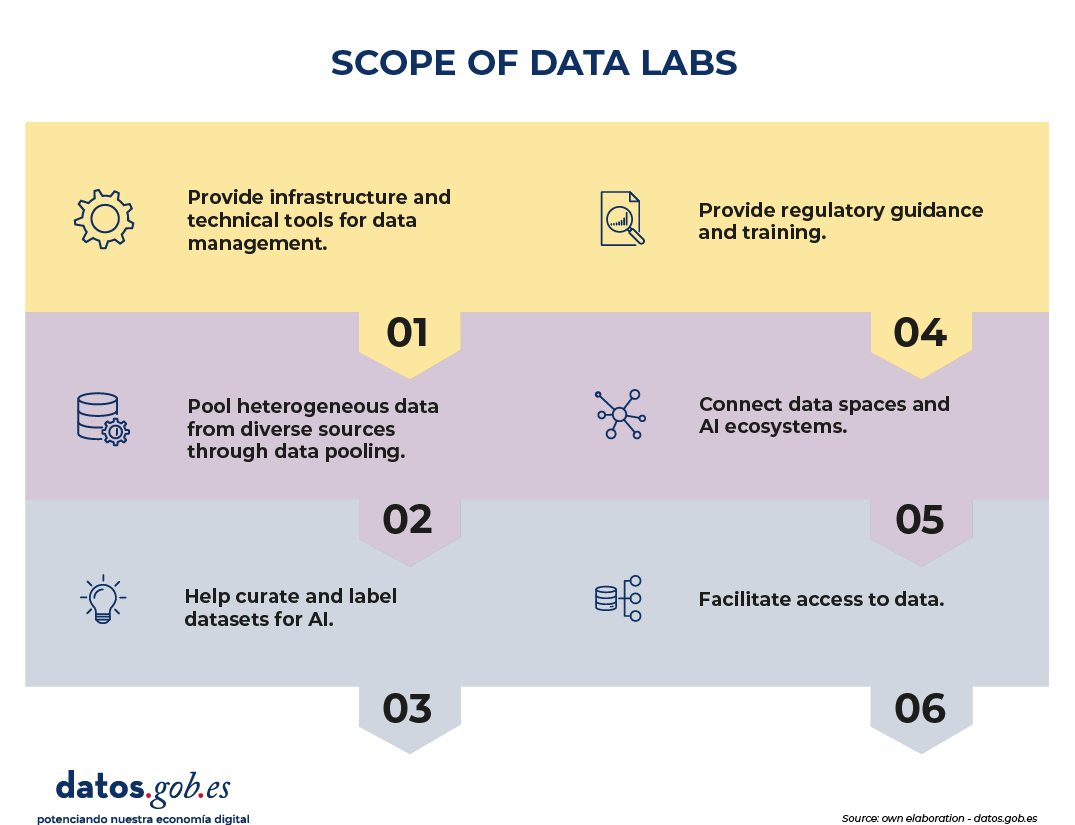
Figure 1. Scope of datalabs. Source: own elaboration - datos.gob.es
For all these reasons, the value of the data labs It is not in "giving access" to the data (in fact, this is already done by data spaces or open data portals), but in making the data operational. The data labs will be able to offer services such as data set cleansing and enrichment, normalization, anonymization, synthetic data generation, and data pooling compatible with competition regulations. Therefore, they offer less friction to move from raw data to data ready to train, test or deploy AI solutions.
Data labs' relationship with open data and data spaces
In the European framework, open data remains the most accessible layer of the ecosystem, especially when it comes from the public sector. The concept of high-value datasets (HVDs) stands out because the European regulations themselves underline that these sets are key sources for the development of AI. In fact, the Strategy for a Data Union plans to expand the list of high-value data to areas such as legal, judicial and administrative data by 2026, as well as make 30 million digitised cultural objects available for AI training through Europeana. Therefore, data labs add an additional layer to open data portals, responsible for the search and combination of data (between open datasets from different sources, but also between open datasets and data from other sources), as well as its preparation.
Data labs do not replace open data initiatives or data space initiatives, but rather complement them.
Moreover, the EU explicitly defines that data labs should act as the bridge between data spaces and the AI ecosystem. It could be said, in a simplified way, that data spaces bring order to the availability of data while data labs turn that availability into a usable resource to innovate through the use of AI. That is, data spaces have adequate infrastructure and governance to share and reuse data and data labs convert that data availability into effective use, helping to locate, gather, organize, curate, label and prepare that data for AI and advanced analytics use cases.
By bringing together both scenarios (open data and data spaces), data labs could be used to detect which new public sector datasets would deserve to be opened or strengthened from the datasets available in a data space.
Data labs and AI factories: the perfect pairing
AI factories are conceived as ecosystems that bring together computing power, data, and talent to develop AI models and advanced applications. Data labs will be deployed precisely in that environment, as a kind of data services layer for those factories. The complementarity is clear: an AI factory without quality data runs the risk of being left with underutilized computing capacity, while a data lab without access to AI infrastructures has a harder time closing the loop from data to model.
What is not a data lab?
It is also worth clarifying a possible confusion regarding the term data lab. We are not talking here about "safe rooms" or controlled environments for access to protected data for research purposes, such as ES_Datalab, which includes data from the INE or the Bank of Spain. These environments are intended for controlled access to microdata and other sensitive information for research purposes, while preserving confidentiality and privacy.
European data labs have a distinct and broader scope, as they are an instrument for connecting public and private data (including data spaces) and AI innovation through access, preparation, curation, and regulatory support services. They may incorporate protective techniques, but they do not equate to a safe room.
In conclusion, the European commitment of data labs consists of moving from talking only about data publication to talking about activating data for innovation based on its reuse. This is very useful for different profiles:
- For technical profiles, data labs promise more prepared and better documented data.
- For companies in the infomediary industry, they open up opportunities in discovery, quality, metadata, labeling, integration, or compliance services.
- For the public administration, they can become a very useful mechanism to guide what to publish in open access, with what quality and for what uses.
- For the research community, they offer the possibility of bringing closer access to data, governance and computing infrastructure.
Therefore, data labs do not compete with open data or data spaces, they simply help both generate more value in practice.
Jose Norberto Mazón, Professor of Computer Languages and Systems at the University of Alicante. The content and views expressed in this publication are the sole responsibility of the author.
Blog
The construction of the ecosystem for the secondary use of e-health data in the European Health Data Space (EHDS) poses a significant scenario of opportunities for Spanish research, innovation and entrepreneurship. To this end, the European Union is promoting a multitude of strategic projects in which hospitals, health research foundations, universities, research centres and Spanish companies participate. The list of projects is extensive and aims to satisfy at least two objectives: to promote the generation of infrastructures capable of generating quality datasets and to promote conditions for their reuse.
The role of Spain. Strengths in the deployment of the European Health Area
Spain offers significantly favourable conditions not only to participate but also to contribute significantly to the tasks of creating the EHDS
- First, our public health system is characterized by a high level of integration and structuring. Unlike systems based on reimbursement mechanisms, in which there may be an atomisation in the field of service provision, in our system we have a clear frame of reference in primary care, medical specialities and hospital services.
- On the other hand, the experience deployed by our health environments from the General Data Protection Regulation (GDPR) and, particularly, the lessons learned from the seventeenth additional provision on health data processing of Organic Law 3/2018, of 5 December, on the Protection of Personal Data and guarantee of digital rights (LOPDGDD) they constitute a valuable experience.
- The opening of the National Health Data Space promoted by the Government of Spain and promoted by the Ministry for Digital Transformation and Public Function, the Ministry of Health and the Autonomous Communities allows the deployment of an essential infrastructure for the EHDS.
The National Health Data space was presented on January 29. The event highlighted how this project represents a paradigm shift that revolutionizes the management of health data, promoting a federated, secure and ethical model that preserves the sovereignty and privacy of information while facilitating its use for research, innovation and public policies. Its operation is based on a federated catalog of metadata and a rigorous process of access and analysis in secure environments, which seeks to promote open science and scientific and technological advances, benefiting patients, researchers, managers and industry.
Lessons learned from European Projects
The path taken by Regulation (EU) 2025/327 of the European Parliament and of the Council of 11 February 2025 on the European Health Data Space, amending Directive 2011/24/EU and Regulation (EU) 2024/2847 (EEDSR), poses significant challenges that are addressed in research projects funded by European and national funds. The lessons learned in some of them can be extraordinarily useful for the research and entrepreneurship community in our country. We cannot forget that we start from significant strengths.
1.-Compliance by design
The existence of a new regulation requires a rigorous analysis of the state of the art in our organizations, not only to implement its deployment but also to ensure the preconditions of legal reliability of the datasets and the research that is proposed.
2.-Accountability: proactive responsibility and documentary strength
In our country we come from a long tradition of accountability. The EEDSR will impose on the data requester a set of relevant documentary requirements, such as, for example, having provided safeguards to prevent any misuse of electronic health data. This issue cannot be neglected from the point of view of data holders, who will also have to meet certain requirements. For example, proving that data is legitimate and reusable is an ethical and legally documentable issue; and the simplified procedure for accessing electronic health data through a trusted health data holder requires the latter to document the security of its data space or capabilities to evaluate requests for access to health data.
One of the main obstacles we face in this intermediate period of implementation of the EHDS lies precisely in the organizational culture for the generation of verifiable evidence. As standardization and the set of common rules of the EEDS scale, it will be necessary to deepen the dynamics of proactive responsibility understood as demonstrated responsibility.
3. Secure processing environments
In our country, health environments by their very definition must be safe environments. The deployment of the National Security Scheme (ENS) and the GDPR have allowed the entire health system, public or private, to adopt maturity models that are perfectly consistent with the conditions of the secure processing environments defined by the EEDSR.
Challenges of the Spanish system
Along with the inherent strengths of our system, it is necessary to consider those aspects that present themselves as challenges.
1. Anonymisation and pseudonymisation
In the national context, the aforementioned seventeenth additional provision of Organic Law 3/2018, of 5 December, on the Protection of Personal Data and guarantee of digital rights, defines specific conditions for pseudonymisation. These consist of the functional separation between the teams that pseudonymize and those that reuse data, and the definition of a secure environment that prevents any attempt at re-identification. In addition, there are legal guarantees in terms of individual commitments not to re-identify, deployment of the impact assessment tool related to data protection and supervision by ethics committees. The challenge of anonymization is more demanding, since it implies the impossibility of linking health data with those of the original patient under any conditions.
2. Reeskilling of teams
The European Health Data Space (EHDS) will pose an unprecedented training challenge that will cut across all sectors involved in the health data ecosystem. Research ethics committees should familiarise themselves not only with the permissible secondary uses of health data, but also with the integration of the Artificial Intelligence Regulation and with the ethical principles of the ALTAI (Assessment List for Trustworthy Artificial Intelligence) framework. This need for reeskilling will also extend to health systems and health administration, where Health Data Access Bodies will require highly qualified personnel in these new ethical and regulatory frameworks, as well as reliable data holders who will safeguard sensitive information. Development staff and IT teams will also need to acquire new skills in critical technical areas, such as cataloguing, validation, and curation of data, as well as in interoperability standards that enable effective communication between systems. Perhaps the most sensitive training challenge will fall on new entrants, who will be able to take advantage of opportunities to access datasets for innovative secondary uses. This especially concerns technology startups in the health sector. To face a very demanding regulatory framework (GDPR, Regalmento de AI, EEDSR), the resources and capabilities for legal compliance in Spanish SMEs is notably limited. For this reason, it will be necessary to build a solid culture of data protection and ethical development of reliable artificial intelligence systems from the beginning.
3. Data cataloguing: the challenge of quality and standardization
In the context of the European Health Data Space, deepen the standardization of data through the most functional methodologies – such as OMOP CDM for observational clinical data, HL7 FHIR for dynamic information exchange, DICOM for medical imaging, or reference terminologies such as SNOMED CT, LOINC and RxNorm— is presented as a key strategic element for the creation and re-use of high-quality datasets. However, the adoption of these standards is not enough on its own: the processes of validation, semantic annotation and data enrichment require highly qualified human resources capable of ensuring the coherence, completeness and accuracy of the information, making this training a real precondition for effective participation in the European health data ecosystem. Alignment with the standardized cataloguing of datasets following the HealthDCAT-AP (Health Data Catalog Application Profile) standard, which allows the descriptive metadata of health data resources to be described in a homogeneous way, is presented as one of the immediate challenges, along with the implementation of the work that has been deployed in relation to the data utility quality label, a quality label that assesses the real usefulness of data for secondary uses and is becoming a seal of trust for users and researchers.
If previously in this article the very high capacities of the Spanish health system to generate health data in a systematic way and in significant volumes were highlighted, these aspects of cataloguing, standardization and quality certification will occupy an absolutely central place in designing optimal conditions of European competitiveness in their reuse, transforming the abundance of data into a real strategic advantage that allows Spain to position itself as a relevant player in the research and innovation landscape with electronic health data.
The experience of the EUCAIM project (Cancer Image EU)
The European Health Data Space Regulation aims to enable the secondary use of electronic health data across Europe through harmonised rules in a federated ecosystem. In the cancer arena, fragmented access to high-quality datasets slows down research, limits reproducibility and undermines Europe's ability to develop and validate reliable AI tools for oncology.
EUCAIM demonstrates the viability of an ecosystem for the secondary use of cancer through a federated model that allows cross-border access under harmonized rules guaranteeing adequate control of resources at the local level. And this is deployed through a set of enabling components:
1) A Secure Processing Environment (SPE) federated at European level
EUCAIM is creating a federated PES to enforce data access conditions, control processing, and support secure cross-border analysis under EEDS restrictions. This PES is fully in line with the requirements and measures laid down in Article 73 EEDSR for safe environments.
2) Overcoming the "anonymisation barrier"
EUCAIM promotes a layered anonymization strategy that combines dataholder-autonomous local anonymization processes with platform controls to enable datasets to remain useful for AI research and development. The importance of this approach lies in the fact that it aims to reconcile the protection of privacy with the practical need to have sets with large volumes of data characterized by their diversity.
3) Data cataloguing and standardization
EUCAIM aligns cataloguing with the HealthDCAT-AP principles whose main objective is to apply the FAIR principles, that is, to ensure that data is findable, accessible, interoperable and reusable.
4) Reduction of legal costs
EUCAIM has deployed its own compliance framework aimed at the General Data Protection Regulation and the Artificial Intelligence Regulation. To do this, a robust compliance framework is in place at the platform level that is deployed across complex data ecosystems. This is based on data protection impact assessments (included in the GDPR) with a particular focus on fundamental rights. It also incorporates training and professional retraining of users as a functional requirement, so that compliance capability becomes an essential feature.
5) Support for data users
EUCAIM offers significant advantages to data users, including researchers and AI developers, by establishing a transparent and well-governed environment for data access. The adoption of transparent governance criteria, clearly defined obligations and their technical application by the platform, provide data users with the guarantee that their access is adequate and lawful, fully auditable and remains stable over time. The platform's design ensures that users can leverage powerful data for advanced analytics, including federated processing in a secure environment. Through mandatory training and implementation of standardized procedures, teams benefit from less uncertainty and are better equipped to align with compliance requirements set forth by the EEDSR, GDPR, and AI governance frameworks.
6) Guarantee of patients' rights
EUCAIM's approach is based on data protection by design and by default that unites organisational safeguards with robust technical controls. This framework has been purpose-built to minimise the risk of data misuse, while supporting safe and effective cross-border cancer research and innovation. The result is a system in which the protection of privacy is not an obstacle but a fundamental element that allows the responsible use of data for the benefit of society and science. The model reinforces accountability for the secondary use of health data by combining strong governance oversight, a comprehensive record of actions, and strict and enforceable obligations for all participating entities. All actions taken with patient data are recorded and reviewed, ensuring that all uses are fully auditable. This traceability ensures that the processing of data is kept within the limits of the permitted use and that any deviations can be identified and addressed quickly.
Multi-level governance: the key to sustainable success
The most relevant lesson learned at EUCAIM concerns the imperative need for articulated, coherent and operational multilevel governance. In a broad sense, it is essential to provide effective governance tools and frameworks on three fundamental dimensions:
- Firstly, on the processes for generating datasets and their sharing conditions, establishing clear criteria on what data is generated, how it is standardised, who holds rights over it and under what licences and restrictions it can be shared with third parties.
- Second, on data access request processes, defining transparent and efficient procedures so that researchers, innovators, and policymakers can identify, request, and obtain access to the data needed for their projects, minimizing administrative burdens without compromising ethical and legal guarantees.
- Thirdly, on the processes of validating the correctness of the datasets and adherence to the system, as well as the procedures for authorising access to data, ensuring that only data of certified quality feed the infrastructure and that only authorised users with legitimate purposes access sensitive information.
This procedural governance cannot function without strategic and operational decisions regarding the definition of human resources roles and functions. To do this, it is necessary to have the necessary professional profiles such as data managers, experts in research ethics, cybersecurity specialists, data curators and quality managers. Secondly, it will be essential to define the secure processing environments where analyses are carried out on sensitive data, ensuring that these spaces comply with the highest technical standards of security, traceability, auditing and privacy preservation, and that they are designed to operate under the principle of zero trust) adapted to the health context. Only through this multi-level governance architecture, which integrates technical, organizational, ethical and legal dimensions at all levels of decision-making – from the design of national policies to the day-to-day operational management of platforms – will it be possible to build health data infrastructures that are truly sustainable, reliable and capable of generating long-term social, scientific and economic value. positioning the Spanish healthcare system as a strategic player in the European healthcare innovation ecosystem.
Content prepared by Ricard Martínez Martínez, Director of the Chair of Privacy and Digital Transformation, Department of Constitutional Law, University of Valencia. The contents and views expressed in this publication are the sole responsibility of the author.
Blog
In the era of Artificial Intelligence (AI), data has ceased to be simple records and has become the essential fuel of innovation. However, for this fuel to really drive new services, more effective public policies or advanced AI models, it is not enough to have large volumes of information: the data must be varied, of quality and, above all, accessible.
In this context, the data pooling or Data Clustering, a practice that consists of Pooling data to generate greater value from their joint use. Far from being an abstract idea, the data pooling is emerging as one of the key mechanisms for transforming the data economy in Europe and has just received a new impetus with the proposal of the Digital Omnibus, aimed at simplifying and strengthening the European data-sharing framework.
As we already analyzed in our recent post on the Data Union Strategy, the European Union aspires to build a Single Data Market in which information can flow safely and with guarantees. The data pooling it is, precisely, the Operational tool which makes this vision tangible, connecting data that is now dispersed between administrations, companies and sectors.
But what exactly does "data pooling" mean? Why is this concept being talked about more and more in the context of the European data strategy and the new Digital Omnibus? And, above all, what opportunities does it open up for public administrations, companies and data reusers? In this article we try to answer these questions.
What is data pooling, how does it work and what is it for?
To understand what data pooling is, it can be helpful to think about a traditional agricultural cooperative. In it, small producers who, individually, have limited resources decide to pool their production and their means. By doing so, they gain scale, access better tools, and can compete in markets they wouldn't reach separately.
In the digital realm, data pooling works in a very similar way. It consists of combining or grouping datasets from different organizations or sources to analyze or reuse them with a shared goal. Creating this "common repository" of information—physical or logical—enables more complex and valuable analyses that could hardly be performed from a single isolated source.
This "pooling of data" can take different forms, depending on the technical and organizational needs of each initiative:
- Shared repositories, where multiple organizations contribute data to the same platform.
- Joint or federated access, where data remains in its source systems, but can be analyzed in a coordinated way.
- Governance agreements, which set out clear rules about who can access data, for what purpose, and under what conditions.
In all cases, the central idea is the same: each participant contributes their data and, in return, everyone benefits from a greater volume, diversity and richness of information, always under previously agreed rules.
What is the purpose of sharing data?
The growing interest in data pooling is no coincidence. Sharing data in a structured way allows, among other things:
- Detect patterns that are not visible with isolated data, especially in complex areas such as mobility, health, energy or the environment.
- Enhance the development of artificial intelligence, which needs diverse, quality data at scale to generate reliable results.
- Avoiding duplication, reducing costs and efforts in both the public and private sectors.
- To promote innovation, facilitating new services, comparative studies or predictive analysis.
- Strengthen evidence-based decision-making, a particularly relevant aspect in the design of public policies.
In other words, data pooling multiplies the value of existing data without the need to always generate new sets of information.
Different types of data pooling and their value
Not all data pools are created equal. Depending on the context and the objective pursued, different models of data grouping can be identified:
- M2M (Machine-to-Machine) data pooling, very common in the Internet of Things (IoT). For example, when industrial sensor manufacturers pool data from thousands of machines to anticipate failures or improve maintenance.
- Cross-sector or cross-sector data pooling, which combines data from different sectors – such as transport and energy – to optimise services, for example, the management of electric vehicle charging in smart cities.
- Data pooling for research, especially relevant in the field of health, where hospitals or research centers share anonymized data to train algorithms capable of detecting rare diseases or improving diagnoses.
These examples show that data pooling is not a single solution, but a set of adaptable practices, capable of generating economic, social and scientific value when applied with the appropriate guarantees.
From potential to practice: guarantees, clear rules and new opportunities for data pooling
Talking about sharing data does not mean doing it without limits. For data pooling to build trust and sustainable value, it is imperative to address how to share data responsibly. This has been, in fact, one of the great challenges that have conditioned its adoption in recent years.
Among the main concerns are the Protection of personal data, ensuring compliance with the General Data Protection Regulation (GDPR) and minimizing risks of re-identification; the confidentiality and the protection of trade secrets, especially when companies are involved; as well as the Quality and interoperability of the data, as combining inconsistent information can lead to erroneous conclusions. To all this is added a transversal element: the Trust between the parties, without which no sharing mechanism can function.
For this reason, data pooling is not just a technical issue. It requires clear legal frameworks, strong governance models, and trust mechanisms, which provide security to both those who share the data and those who reuse it.
Europe's role: from sharing data to creating ecosystems
Aware of these challenges, the European Union has been working for years to build a Single Data Market, where sharing information is simpler, safer and more beneficial for all actors involved. In this context, key initiatives have emerged, such as the European Data Spaces, organized by strategic sectors (health, mobility, industry, energy, agriculture), the promotion of Standards and Interoperability, and the appearance of Data Brokers as trusted third parties who facilitate sharing.
Data pooling fits fully into this vision: it is one of the practical mechanisms that allow these data spaces to work and generate real value. By facilitating the aggregation and joint use of data, pooling acts as the "engine" that makes many of these ecosystems operational.
All this is part of the Data Union Strategy, which seeks to connect policies, infrastructures and standards so that data can flow safely and efficiently throughout Europe.
The big brake: regulatory fragmentation
Until recently, this potential was met with a major hurdle: the Complexity of the European legal framework on data. An organization that would like to participate in a data pool cross-border had to navigate between multiple rules – GDPR, Data Governance Act, Data Act, Open Data Directive and sectoral or national regulations—with definitions, obligations, and competent authorities that are not always aligned. This fragmentation generated legal uncertainty: doubts about responsibilities, fear of sanctions, or uncertainty about the real protection of trade secrets. In practice, this "normative labyrinth" has for years held back the development of many common data spaces and limited the adoption of the data pooling, especially among SMEs and medium-sized companies with less legal and technical capacity.
The Digital Omnibus: Simplifying for Data Pooling to Scale
This is where the Digital Omnibus, the European Commission's proposal to simplify and harmonise the digital legal framework, comes into play. Far from adding new regulatory layers, the objective of the Omnibus is to organize, consolidate and reduce administrative burdens, making it easier to share data in practice.
From a data pooling perspective, the message is clear: less fragmentation, more clarity, and greater trust. The Omnibus seeks to concentrate the rules in a more coherent framework, avoid duplication and remove unnecessary barriers that until now discouraged data-driven collaboration, especially in cross-border projects.
In addition, the role of data intermediation services, key actors in organizing pooling in a neutral and reliable way, is reinforced. By clarifying their role and reducing certain burdens, it favors the emergence of new models – including technology startups – capable of acting as "arbiters" of data exchange between multiple participants.
Another particularly relevant element is the strengthening of the protection of trade secrets, allowing data holders to limit or deny access when there is a real risk of misuse or transfer to environments without adequate guarantees. This point is key for industrial and strategic sectors, where trust is an essential condition for sharing data.
New opportunities for data pooling: public sector, companies and data reuse
The regulatory simplification and confidence-building introduced by the Digital Omnibus is not an end in itself. Its true value lies in the concrete opportunities that data pooling opens up for different actors in the data ecosystem, especially for the public sector, companies and information reusers.
In the case of public administrations, data pooling offers particularly relevant potential. It allows data from different sources and administrative levels to be combined to improve the design and evaluation of public policies, move towards evidence-based decision-making and offer more effective and personalised services to citizens. At the same time, it facilitates the breaking down of information silos, the reuse of already available data and the reduction of duplications, with the consequent savings in costs and efforts.
In addition, data pooling reinforces collaboration between the public sector, the research field and the private sector, always under secure and transparent frameworks. In this context, it does not compete with open data, but complements it, making it possible to connect datasets that are currently published in a fragmented way and enabling more advanced analyses that expand their social and economic value.
From a business point of view, the Digital Omnibus introduces a significant novelty by expanding the focus beyond traditional SMEs. The so-called small mid-caps, mid-cap companies that also suffer the impact of bureaucracy, are now benefiting from regulatory simplification. This significantly increases the base of organizations capable of participating in data pooling schemes and expands the volume and diversity of data available in strategic sectors such as industry, automotive or chemicals.
The economic impact of this new scenario is also relevant. The European Commission estimates significant savings in administrative and operational costs, both for companies and public administrations. But beyond the numbers, these savings represent freed up capacity to innovate, invest in new digital services, and develop more advanced AI models, fueled by data that can now be shared more securely.
In short, data pooling is consolidated as a key lever to move from the punctual sharing of data to the systematic generation of value, laying the foundations for a more collaborative, efficient and competitive data economy in Europe.
Conclusion: Cooperate to compete
The proposal of data pooling in the Digital Omnibus marks a before and after in the way we understand the ownership of information. Europe has understood that, in the global data economy, sovereignty is not defended by closing borders, but by creating secure environments where collaboration is the simplest and most profitable option.
Data pooling is at the heart of this transformation. By cutting red tape, simplifying notifications, and protecting trade secrets, the Omnibus is taking the stones out of the way so that businesses and citizens can enjoy the benefits of a true Data Union.
In short, it is a question of moving from an economy of isolated silos to one of connected networks. Because, in the world of data, sharing is not losing control, it is gaining scale.
Content created by Dr. Fernando Gualo, Professor at UCLM and Government and Data Quality Consultant. The content and views expressed in this publication are the sole responsibility of the author.
Blog
The convergence between open data, artificial intelligence and environmental sustainability poses one of the main challenges for the digital transformation model that is being promoted at European level. This interaction is mainly materialized in three outstanding manifestations:
-
The opening of high-value data directly related to sustainability, which can help the development of artificial intelligence solutions aimed at climate change mitigation and resource efficiency.
-
The promotion of the so-called green algorithms in the reduction of the environmental impact of AI, which must be materialized both in the efficient use of digital infrastructure and in sustainable decision-making.
-
The commitment to environmental data spaces, generating digital ecosystems where data from different sources is shared to facilitate the development of interoperable projects and solutions with a relevant impact from an environmental perspective.
Below, we will delve into each of these points.
High-value data for sustainability
Directive (EU) 2019/1024 on open data and re-use of public sector information introduced for the first time the concept of high-value datasets, defined as those with exceptional potential to generate social, economic and environmental benefits. These sets should be published free of charge, in machine-readable formats, using application programming interfaces (APIs) and, where appropriate, be available for bulk download. A number of priority categories have been identified for this purpose, including environmental and Earth observation data.
This is a particularly relevant category, as it covers both data on climate, ecosystems or environmental quality, as well as those linked to the INSPIRE Directive, which refer to certainly diverse areas such as hydrography, protected sites, energy resources, land use, mineral resources or, among others, those related to areas of natural hazards, including orthoimages.
These data are particularly relevant when it comes to monitoring variables related to climate change, such as land use, biodiversity management taking into account the distribution of species, habitats and protected sites, monitoring of invasive species or the assessment of natural risks. Data on air quality and pollution are crucial for public and environmental health, so access to them allows exhaustive analyses to be carried out, which are undoubtedly relevant for the adoption of public policies aimed at improving them. The management of water resources can also be optimized through hydrography data and environmental monitoring, so that its massive and automated treatment is an inexcusable premise to face the challenge of the digitalization of water cycle management.
Combining it with other quality environmental data facilitates the development of AI solutions geared towards specific climate challenges. Specifically, they allow predictive models to be trained to anticipate extreme phenomena (heat waves, droughts, floods), optimize the management of natural resources or monitor critical environmental indicators in real time. It also makes it possible to promote high-impact economic projects, such as the use of AI algorithms to implement technological solutions in the field of precision agriculture, enabling the intelligent adjustment of irrigation systems, the early detection of pests or the optimization of the use of fertilizers.
Green algorithms and digital responsibility: towards sustainable AI
Training and deploying AI systems, particularly general-purpose models and large language models, involves significant energy consumption. According to estimates by the International Energy Agency, data centers accounted for around 1.5% of global electricity consumption in 2024. This represents a growth of around 12% per year since 2017, more than four times faster than the rate of total electricity consumption. Data center power consumption is expected to double to around 945 TWh by 2030.
Against this backdrop, green algorithms are an alternative that must necessarily be taken into account when it comes to minimising the environmental impact posed by the implementation of digital technology and, specifically, AI. In fact, both the European Data Strategy and the European Green Deal explicitly integrate digital sustainability as a strategic pillar. For its part, Spain has launched a National Green Algorithm Programme, framed in the 2026 Digital Agenda and with a specific measure in the National Artificial Intelligence Strategy.
One of the main objectives of the Programme is to promote the development of algorithms that minimise their environmental impact from conception ( green by design), so the requirement of exhaustive documentation of the datasets used to train AI models – including origin, processing, conditions of use and environmental footprint – is essential to fulfil this aspiration. In this regard, the Commission has published a template to help general-purpose AI providers summarise the data used for the training of their models, so that greater transparency can be demanded, which, for the purposes of the present case, would also facilitate traceability and responsible governance from an environmental perspective. as well as the performance of eco-audits.
The European Green Deal Data Space
It is one of the common European data spaces contemplated in the European Data Strategy that is at a more advanced stage, as demonstrated by the numerous initiatives and dissemination events that have been promoted around it. Traditionally, access to environmental information has been one of the areas with the most favourable regulation, so that with the promotion of high-value data and the firm commitment to the creation of a European area in this area, there has been a very remarkable qualitative advance that reinforces an already consolidated trend in this area.
Specifically, the data spaces model facilitates interoperability between public and private open data, reducing barriers to entry for startups and SMEs in sectors such as smart forest management, precision agriculture or, among many other examples, energy optimization. At the same time, it reinforces the quality of the data available for Public Administrations to carry out their public policies, since their own sources can be contrasted and compared with other data sets. Finally, shared access to data and AI tools can foster collaborative innovation initiatives and projects, accelerating the development of interoperable and scalable solutions.
However, the legal ecosystem of data spaces entails a complexity inherent in its own institutional configuration, since it brings together several subjects and, therefore, various interests and applicable legal regimes:
-
On the one hand, public entities, which have a particularly reinforced leadership role in this area.
-
On the other hand, private entities and citizens, who can not only contribute their own datasets, but also offer digital developments and tools that value data through innovative services.
-
And, finally, the providers of the infrastructure necessary for interaction within the space.
Consequently, advanced governance models are essential to deal with this complexity, reinforced by technological innovation and especially AI, since the traditional approaches of legislation regulating access to environmental information are certainly limited for this purpose.
Towards strategic convergence
The convergence of high-value open data, responsible green algorithms and environmental data spaces is shaping a new digital paradigm that is essential to address climate and ecological challenges in Europe that requires a robust and, at the same time, flexible legal approach. This unique ecosystem not only allows innovation and efficiency to be promoted in key sectors such as precision agriculture or energy management, but also reinforces the transparency and quality of the environmental information available for the formulation of more effective public policies.
Beyond the current regulatory framework, it is essential to design governance models that help to interpret and apply diverse legal regimes in a coherent manner, that protect data sovereignty and, ultimately, guarantee transparency and responsibility in the access and reuse of environmental information. From the perspective of sustainable public procurement, it is essential to promote procurement processes by public entities that prioritise technological solutions and interoperable services based on open data and green algorithms, encouraging the choice of suppliers committed to environmental responsibility and transparency in the carbon footprints of their digital products and services.
Only on the basis of this approach can we aspire to make digital innovation technologically advanced and environmentally sustainable, thus aligning the objectives of the Green Deal, the European Data Strategy and the European approach to AI.
Content prepared by Julián Valero, professor at the University of Murcia and coordinator of the Innovation, Law and Technology Research Group (iDerTec). The content and views expressed in this publication are the sole responsibility of the author.
Blog
Open health data is one of the most valuable assets of our society. Well managed and shared responsibly, they can save lives, drive medical discoveries, or even optimize hospital resources. However, for decades, this data has remained fragmented in institutional silos, with incompatible formats and technical and legal barriers that made it difficult to reuse. Now, the European Union is radically changing the landscape with an ambitious strategy that combines two complementary approaches:
- Facilitate open access to statistics and non-sensitive aggregated data.
- Create secure infrastructures to share personal health data under strict privacy guarantees.
In Spain, this transformation is already underway through the National Health Data Space or research groups that are at the forefront of the innovative use of health data. Initiatives such as IMPACT-Data, which integrates medical data to drive precision medicine, demonstrate the potential of working with health data in a structured and secure way. And to make it easier for all this data to be easy to find and reuse, standards such as HealthDCAT-AP are implemented.
All this is perfectly aligned with the European strategy of the European Health Data Space Regulation (EHDS), officially published in March 2025, which is also integrated with the Open Data Directive (ODD), in force since 2019. Although the two regulatory frameworks have different scopes, their interaction offers extraordinary opportunities for innovation, research and the improvement of healthcare across Europe.
A recent report prepared by Capgemini Invent for data.europa.eu analyzes these synergies. In this post, we explore the main conclusions of this work and reflect on its relevance for the Spanish open data ecosystem.
-
Two complementary frameworks for a common goal
On the one hand, the European Health Data Space focuses specifically on health data and pursues three fundamental objectives:
- Facilitate international access to health data for patient care (primary use).
- Promote the reuse of this data for research, public policy, and innovation (secondary use).
- Technically standardize electronic health record (EHR) systems to improve cross-border interoperability.

For its part, the Open Data Directive has a broader scope: it encourages the public sector to make government data available to any user for free reuse. This includes High-Value Datasets that must be published for free, in machine-readable formats, and via APIs in six categories that did not originally include "health." However, in the proposal to expand the new categories published by the EU, the health category does appear.
The complementarity between the two regulatory frameworks is evident: while the ODD facilitates open access to aggregated and non-sensitive health statistics, the EHDS regulates controlled access to individual health data under strict conditions of security, consent and governance. Together, they form a tiered data sharing system that maximizes its social value without compromising privacy, in full compliance with the General Data Protection Regulation (GDPR).
Main benefits computer by user groups
The report looks at four main user groups and examines both the potential benefits and challenges they face in combining EHDS data with open data.
-
Patients: Informed Empowerment with Practical Barriers
European patients will gain faster and more secure access to their own electronic health records, especially in cross-border contexts thanks to infrastructures such as MyHealth@EU. This project is particularly useful for European citizens who are displaced in another European country. .
Another interesting project that informs the public is PatientsLikeMe, which brings together more than 850,000 patients with rare or chronic diseases in an online community that shares information of interest about treatments and other issues.
-
Potential health professionals subordinate to integration
On the other hand, healthcare professionals will be able to access clinical patient data earlier and more easily, even across borders, improving continuity of care and the quality of diagnosis and treatment.
The combination with open data could amplify these benefits if tools are developed that integrate both sources of information directly into electronic health record systems.
3. Policymakers: data for better decisions
Public officials are natural beneficiaries of the convergence between EHDS and open data. The possibility of combining detailed health data (upon request and authorisation through the Health Data Access Bodies that each Member State must establish) with open statistical and contextual information would allow for much more robust evidence-based policies to be developed.
The report mentions use cases such as combining health data with environmental information to assess health impacts. A real example is the French Green Data for Health project, which crosses open data on noise pollution with information on prescriptions for sleep medications from more than 10 million inhabitants, investigating correlations between environmental noise and sleep disorders.
4. Researchers and reusers: the main immediate beneficiaries
Researchers, academics and innovators are the group that will most directly benefit from the EHDS-ODD synergy as they have the skills and tools to locate, access, combine and analyse data from multiple sources. In addition, their work already routinely involves the integration of various data sets.
A recent study published in PLOS Digital Health on the case of Andalusia demonstrates how open data in health can democratize research in health AI and improve equity in treatment.
The development of EHDS is being supported by European programmes such as EU4Health, Horizon Europe and specific projects such as TEHDAS2, which help to define technical standards and pilot real applications.
-
Recommendations to maximize impact
The report concludes with four key recommendations that are particularly relevant to the Spanish open data ecosystem:
- Stimulate research at the EHDS-open data intersection through dedicated funding. It is essential to encourage researchers who combine these sources to translate their findings into practical applications: improved clinical protocols, decision tools, updated quality standards.
- Evaluate and facilitate direct use by professionals and patients. Promoting data literacy and developing intuitive applications integrated into existing systems (such as electronic health records) could change this.
- Strengthen governance through education and clear regulatory frameworks. As EHDS technical entities become operationalized, clear regulation defining common regulatory frameworks will be essential.
- Monitor, evaluate and adapt. The period 2025-2031 will see the gradual entry into force of the various EHDS requirements. Regular evaluations are recommended to assess how EHDS is actually being used, which combinations with open data are generating the most value, and what adjustments are needed.
Moreover, for all this to work, the report suggests that portals such as data.europa.eu (and by extension, datos.gob.es) should highlight practical examples that demonstrate how open data complements protected data from sectoral spaces, thus inspiring new applications.
Overall, the role of open data portals will be fundamental in this emerging ecosystem: not only as providers of quality datasets, but also as facilitators of knowledge, meeting spaces between communities and catalysts for innovation. The future of European healthcare is now being written, and open data plays a leading role in that story.
Evento
Last September, the first edition of the European Data Spaces Awards was officially launched, an initiative promoted by the Data Spaces Support Centre (DSSC) in collaboration with the European Commission. These awards were created with the aim of promoting the best data exchange initiatives, recognizing their achievements and increasing their visibility. This seeks to promote good practices that can serve as a guide for other actors in the European data ecosystem. The idea is that the awards will be awarded annually, which will help the community grow and improve.
Why are these awards important?
Data is one of Europe's most valuable economic assets, and its strategic harnessing is critical for the development of technologies such as artificial intelligence (AI). Therefore, the European strategy It involves establishing a single market for data that allows innovation to be promoted effectively. However, at present, the data is still widely distributed among many actors in the European ecosystem.
The European Data Spaces Awards are especially relevant because they recognise and promote initiatives that help to overcome this problem: data spaces. These are organisational and technical environments where multiple actors – public and private – share data in a secure, sovereign, controlled way and in accordance with common standards that promote their interoperability. This allows data to flow across sectors and borders, driving innovation.
In Spain, the development of data spaces is also being promoted through specific initiatives such as the Plan to Promote Sectoral Data Spaces.
Two award categories
In this context, two categories of awards have been created:
- Excellence in end-user engagement and financial sustainability: Recognizes data spaces with a strong user focus and viable long-term financial models.
- Most innovative emerging data space: rewards new initiatives that bring fresh and innovative ideas with high impact on the European ecosystem.

Who can participate?
The European Data Spaces Awards are open to any data space that meets these criteria:
- Its governance authority is registered in the European Union.
- It operates wholly or partially within European territory.
- It is being actively used for data exchange.
- It includes restricted data, beyond open data.
Spaces in the implementation phase can also apply, as long as they share data in pilot or pre-operational environments. In these cases, the project coordinator can act on behalf of the project.
The assessment of eligibility will be based on the applicant's self-assessment, facilitating broad and representative participation of the European data ecosystem.
The same data space can apply for both categories, although you must make two different applications.
Schedule: registration open until November 7
The competition is structured in four key phases that set the pace of the participation and evaluation process:
- On 23 September 2025, the launch event was held and the application period was officially opened.
- The application submission phase will run for 7 weeks, until November 7, allowing data spaces to prepare and register their proposals.
- This will be followed by the evaluation phase, which will begin on December 17 and last 6 weeks. During this time, the Data Spaces Support Centre (DSSC) will conduct an internal eligibility review and the jury selects the winners.
- Finally, the awards will be announced and presented during the Data Space Symposium (DSS2026) event, on February 10 and 11, 2026 in Madrid. All nominees will be invited to take the stage during the ceremony, so they will get great visibility and recognition. The winners will not receive any monetary compensation.
How to participate?
To register, participants must access the online form available on the official website of the awards. This page provides all the resources needed to prepare for your application, including reference documents, templates, and updates on the process.
The form includes three required elements:
- Basic questions about the requester and the data space.
- The eligibility self-assessment with four mandatory questions.
- A space to upload the Awards Application Document, a document in PDF format and whose template is available on the platform. (maximum 8 pages). The document, which follows a structure aligned with the Maturity Model v2.0, details the objectives and evaluation criteria by section.
In addition, participants have a space to provide, optionally, links to additional resources that help give context to their proposal.
For any questions that may arise during the process, a support platform has been set up.
The European Data Spaces Awards 2025 not only recognise excellence, but also highlight the impact of projects that are transforming the future of data in Europe. If you are interested in participating, we invite you to read the complete rules of the competition on their website.
Blog
To achieve its environmental sustainability goals, Europe needs accurate, accessible and up-to-date information that enables evidence-based decision-making. The Green Deal Data Space (GDDS) will facilitate this transformation by integrating diverse data sources into a common, interoperable and open digital infrastructure.
In Europe, work is being done on its development through various projects, which have made it possible to obtain recommendations and good practices for its implementation. Discover them in this article!
What is the Green Deal Data Space?
The Green Deal Data Space (GDDS) is an initiative of the European Commission to create a digital ecosystem that brings together data from multiple sectors. It aims to support and accelerate the objectives of the Green Deal: the European Union's roadmap for a sustainable, climate-neutral and fair economy. The pillars of the Green Deal include:
- An energy transition that reduces emissions and improves efficiency.
- The promotion of the circular economy, promoting the recycling, reuse and repair of products to minimise waste.
- The promotion of more sustainable agricultural practices.
- Restoring nature and biodiversity, protecting natural habitats and reducing air, water and soil pollution.
- The guarantee of social justice, through a transition that makes it easier for no country or community to be left behind.
Through this comprehensive strategy, the EU aims to become the world's first competitive and resource-efficient economy, achieving net-zero greenhouse gas emissions by 2050. The Green Deal Data Space is positioned as a key tool to achieve these objectives. Integrated into the European Data Strategy, data spaces are digital environments that enable the reliable exchange of data, while maintaining sovereignty and ensuring trust and security under a set of mutually agreed rules.
In this specific case, the GDDS will integrate valuable data on biodiversity, zero pollution, circular economy, climate change, forest services, smart mobility and environmental compliance. This data will be easy to locate, interoperable, accessible and reusable under the FAIR (Findability, Accessibility, Interoperability, Reusability) principles.
The GDDS will be implemented through the SAGE (Dataspace for a Green and Sustainable Europe) project and will be based on the results of the GREAT (Governance of Responsible Innovation) initiative.
A report with recommendations for the GDDS
How we saw in a previous article, four pioneering projects are laying the foundations for this ecosystem: AD4GD, B-Cubed, FAIRiCUBE and USAGE. These projects, funded under the HORIZON call, have analysed and documented for several years the requirements necessary to ensure that the GDDS follows the FAIR principles. As a result of this work, the report "Policy Brief: Unlocking The Full Potential Of The Green Deal Data Space”. It is a set of recommendations that seek to serve as a guide to the successful implementation of the Green Deal Data Space.
The report highlights five major areas in which the challenges of GDDS construction are concentrated:
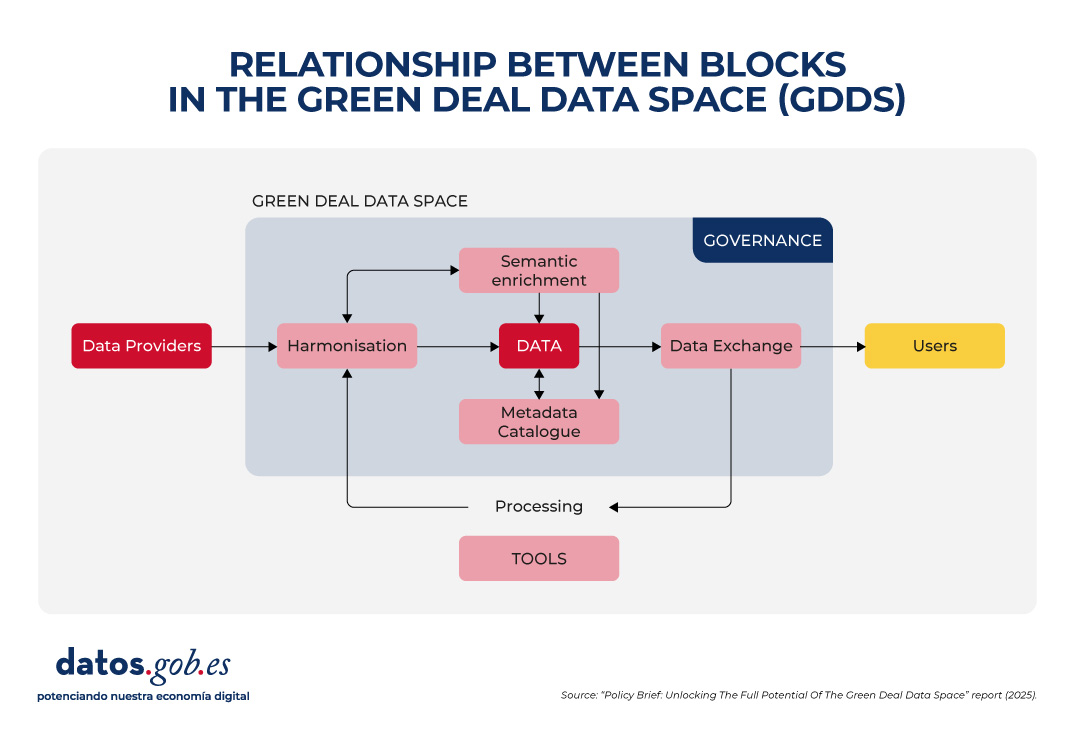
1. Data harmonization
Environmental data is heterogeneous, as it comes from different sources: satellites, sensors, weather stations, biodiversity registers, private companies, research institutes, etc. Each provider uses its own formats, scales, and methodologies. This causes incompatibilities that make it difficult to compare and combine data. To fix this, it is essential to:
- Adopt existing international standards and vocabularies, such as INSPIRE, that span multiple subject areas.
- Avoid proprietary formats, prioritizing those that are open and well documented.
- Invest in tools that allow data to be easily transformed from one format to another.
2. Semantic interoperability
Ensuring semantic interoperability is crucial so that data can be understood and reused across different contexts and disciplines, which is critical when sharing data between communities as diverse as those participating in the Green Deal objectives. In addition, the Data Act requires participants in data spaces to provide machine-readable descriptions of datasets, thus ensuring their location, access, and reuse. In addition, it requires that the vocabularies, taxonomies and lists of codes used be documented in a public and coherent manner. To achieve this, it is necessary to:
- Use linked data and metadata that offer clear and shared concepts, through vocabularies, ontologies and standards such as those developed by the OGC or ISO standards.
- Use existing standards to organize and describe data and only create new extensions when really necessary.
- Improve the already accepted international vocabularies, giving them more precision and taking advantage of the fact that they are already widely used by scientific communities.
3. Metadata and data curation
Data only reaches its maximum value if it is accompanied by clear metadata explaining its origin, quality, restrictions on use and access conditions. However, poor metadata management remains a major barrier. In many cases, metadata is non-existent, incomplete, or poorly structured, and is often lost when translated between non-interoperable standards. To improve this situation, it is necessary to:
- Extend existing metadata standards to include critical elements such as observations, measurements, source traceability, etc.
- Foster interoperability between metadata standards in use, through mapping and transformation tools that respond to both commercial and open data needs.
- Recognize and finance the creation and maintenance of metadata in European projects, incorporating the obligation to generate a standardized catalogue from the outset in data management plans.
4. Data Exchange and Federated Provisioning
The GDDS does not only seek to centralize all the information in a single repository, but also to allow multiple actors to share data in a federated and secure way. Therefore, it is necessary to strike a balance between open access and the protection of rights and privacy. This requires:
- Adopt and promote open and easy-to-use technologies that allow the integration between open and protected data, complying with the General Data Protection Regulation (GDPR).
- Ensure the integration of various APIs used by data providers and user communities, accompanied by clear demonstrators and guidelines. However, the use of standardized APIs needs to be promoted to facilitate a smoother implementation, such as OGC (Open Geospatial Consortium) APIs for geospatial assets.
- Offer clear specification and conversion tools to enable interoperability between APIs and data formats.
In parallel to the development of the Eclipse Dataspace Connectors (an open-source technology to facilitate the creation of data spaces), it is proposed to explore alternatives such as blockchain catalogs or digital certificates, following examples such as the FACTS (Federated Agile Collaborative Trusted System).
5. Inclusive and sustainable governance
The success of the GDDS will depend on establishing a robust governance framework that ensures transparency, participation, and long-term sustainability. It is not only about technical standards, but also about fair and representative rules. To make progress in this regard, it is key to:
- Use only European clouds to ensure data sovereignty, strengthen security and comply with EU regulations, something that is especially important in the face of today's global challenges.
- Integrating open platforms such as Copernicus, the European Data Portal and INSPIRE into the GDDS strengthens interoperability and facilitates access to public data. In this regard, it is necessary to design effective strategies to attract open data providers and prevent GDDS from becoming a commercial or restricted environment.
- Mandating data in publicly funded academic journals increases its visibility, and supporting standardization initiatives strengthens the visibility of data and ensures its long-term maintenance.
- Providing comprehensive training and promoting cross-use of harmonization tools prevents the creation of new data silos and improves cross-domain collaboration.
The following image summarizes the relationship between these blocks:
Conclusion
All these recommendations have an impact on a central idea: building a Green Deal Data Space that complies with the FAIR principles is not only a technical issue, but also a strategic and ethical one. It requires cross-sector collaboration, political commitment, investment in capacities, and inclusive governance that ensures equity and sustainability. If Europe succeeds in consolidating this digital ecosystem, it will be better prepared to meet environmental challenges with informed, transparent and common good-oriented decisions.
Noticia
The UNE 0087 standard defines for the first time in Spain the key principles and requirements for creating and operating in data spaces
On 17 July, the UNE 0087 Specification "Definition and Characterisation of Data Spaces" was officially published, the first Spanish standard to establish a common framework for these digital environments.
This milestone has been possible thanks to the collaboration of the Data Space Reference Centre (CRED) with the Spanish Association for Standardisation (UNE). This regulation, which was approved on June 20, 2025, defines three key pillars in adherence to data spaces: interoperability, governance and value creation, with the aim of offering legal certainty, trust and a common technical language in the data economy.
For its creation, three working groups have been formed with more than 50 participants from both public and private entities who have contributed their knowledge to define the principles and key characteristics of these collaborative systems. These working groups have been coordinated as follows:
- WG1: Definition of Data Spaces and Maturity Model.
- WG2: Technical and Semantic Interoperability.
- WG3: Legal and organisational interoperability.
The publication of this regulation is, therefore, a reference document for the creation of secure and reliable data spaces, applicable in all productive sectors and which serves as a basis for future guide documents.
In this way, to offer guidelines that facilitate the implementation and development of data spaces, the UNE 0087:2025 specification was created to create an inclusive framework of reference that guides organizations so that they can take advantage of all the information in an environment of regulatory compliance and digital sovereignty. The publication of this regulation has a number of benefits:
- Accelerate the deployment of data spaces across all sectors of the economy.
- Supporting sustainability and scaling/growth of data-sharing ecosystems.
- Promoting public/private collaboration, ensuring convergence with Europe.
- Move towards technological autonomy and data sovereignty in ecosystems.
- Promote the discovery of new innovative business opportunities by fostering collaboration and the creation of strategic alliances.
Within the specification, data spaces are defined, their key characteristics of interoperability, governance and value generation are established and the benefits of their adhesion are determined. The specification is published here and it is important to add that, although there is a download cost, it is free of charge, thanks to the sponsorship of the General Directorate of Data.
With this tool, Spain takes a firm step in the consolidation of cohesive, secure data spaces aligned with the European framework, facilitating the implementation of cross-cutting projects in different sectors.
Noticia
Spain is taking a key step towards the data economy with the launch of the Data Spaces Kit, an aid programme that will subsidise the integration of public and private entities in sectoral data spaces.
Data spaces are secure ecosystems in which organizations, both public and private, share information in an interoperable way, under common rules and with privacy guarantees. These allow new products to be developed, decision-making to be improved and operational efficiency to be increased, in sectors such as health, mobility or agri-food, among others.
Today, the Ministry for Digital Transformation and Public Function, through the Secretary of State for Digitalisation and Artificial Intelligence, has published in the Official State Gazette the rules governing the granting of aid to entities interested in effectively joining a data space.
This programme, which is called the "Data Spaces Kit", will be managed by Red.es and will subsidise the costs incurred by the beneficiary entities to achieve their incorporation into an eligible data space, i.e. one that meets the requirements set out in the bases, from the day of their publication.
Recipients and Funding
This aid plan is aimed at both public and private entities, as well as Public Administrations. Among the beneficiaries of these grants are the participants, which are those entities that seek to integrate into these ecosystems to share and take advantage of data and services.
For the execution of this plan, the Government has launched aid of up to 60 million euros that will be distributed, depending on the type of entity or the level of integration as follows:
- Private and public entities with economic activity will have an aid of up to €15,000 under the effective incorporation regime or up to €30,000 if they join as a supplier.
- On the other hand, Public Administrations will have funding of up to €25,000 if they are effectively incorporated, or up to €50,000 if they do so as a supplier.
The incorporation of companies from different sectors in the data spaces will generate benefits both at the business level and for the national economy, such as increasing the innovation capacity of the beneficiary companies, the creation of new products and services based on data analysis and the improvement of operational efficiency and decision-making.
The call is expected to be published during the fourth quarter of 2025. The subsidies will be applied for on a non-competitive basis, on a first-come, first-served basis and until the available funds are exhausted.
The publication of these regulatory bases in the Official State Gazette (BOE) aims to boost the data ecosystem in Spain, strengthen the competitiveness of the economy at the global level and consolidate the financial sustainability of innovative business models.
More information:
Regulatory bases in the BOE.
Data Space Reference Center LinkedIn page.
Blog
Just a few days ago, the Directorate General of Traffic published the new Framework Programme for the Testing of Automated Vehicles which, among other measures, contemplates "the mandatory delivery of reports, both periodic and final and in the event of incidents, which will allow the DGT to assess the safety of the tests and publish basic information [...] guaranteeing transparency and public trust."
The advancement of digital technology is making it easier for the transport sector to face an unprecedented revolution in autonomous vehicle driving, offering significant improvements in road safety, energy efficiency and mobility accessibility.
The final deployment of these vehicles depends to a large extent on the availability, quality and accessibility of large volumes of data, as well as on an appropriate legal framework that ensures the protection of the various legal assets involved (personal data, trade secrets, confidentiality, etc.), traffic security and transparency. In this context, open data and the reuse of public sector information are essential elements for the responsible development of autonomous mobility, in particular when it comes to ensuring adequate levels of traffic safety.
Data Dependency on Autonomous Vehicles
The technology that supports autonomous vehicles is based on the integration of a complex network of advanced sensors, artificial intelligence systems and real-time processing algorithms, which allows them to identify obstacles, interpret traffic signs, predict the behavior of other road users and, in a collaborative way, plan routes completely autonomously.
In the autonomous vehicle ecosystem, the availability of quality open data is strategic for:
- Improve road safety, so that real-time traffic data can be used to anticipate dangers, avoid accidents and optimise safe routes based on massive data analysis.
- Optimise operational efficiency, as access to up-to-date information on the state of roads, works, incidents and traffic conditions allows for more efficient planning of journeys.
- To promote sectoral innovation, facilitating the creation of new digital tools that facilitate mobility.
Specifically, ensuring the safe and efficient operation of this mobility model requires continuous access to two key categories of data:
- Variable or dynamic data, which offers constantly changing information such as the position, speed and behaviour of other vehicles, pedestrians, cyclists or weather conditions in real time.
- Static data, which includes relatively permanent information such as the exact location of traffic signs, traffic lights, lanes, speed limits or the main characteristics of the road infrastructure.
The prominence of the data provided by public entities
The sources from which such data come are certainly diverse. This is of great relevance as regards the conditions under which such data will be available. Specifically, some of the data are provided by public entities, while in other cases the origin comes from private companies (vehicle manufacturers, telecommunications service providers, developers of digital tools...) with their own interests or even from people who use public spaces, devices and digital applications.
This diversity requires a different approach to facilitating the availability of data under appropriate conditions, in particular because of the difficulties that may arise from a legal point of view. In relation to Public Administrations, Directive (EU) 2019/1024 on open data and the reuse of public sector information establishes clear obligations that would apply, for example, to the Directorate General of Traffic, the Administrations owning public roads or municipalities in the case of urban environments. Likewise, Regulation (EU) 2022/868 on European data governance reinforces this regulatory framework, in particular with regard to the guarantee of the rights of third parties and, in particular, the protection of personal data.
Moreover, some datasets should be provided under the conditions established for dynamic data, i.e. those "subject to frequent or real-time updates, due in particular to their volatility or rapid obsolescence", which should be available "for re-use immediately after collection, through appropriate APIs and, where appropriate, in the form of a mass discharge."
One might even think that the high-value data category is of particular interest in the context of autonomous vehicles given its potential to facilitate mobility, particularly considering its potential to:
- To promote technological innovation, as they would make it easier for manufacturers, developers and operators to access reliable and up-to-date information, essential for the development, validation and continuous improvement of autonomous driving systems.
- Facilitate monitoring and evaluation from a security perspective, as transparency and accessibility of such data are essential prerequisites from this perspective.
- To boost the development of advanced services, since data on road infrastructure, signage, traffic and even the results of tests carried out in the context of the aforementioned Framework Programme constitute the basis for new mobility applications and services that benefit society as a whole.
However, this condition is not expressly included for traffic-related data in the definition made at European level, so that, at least for the time being, public entities should not be required to disseminate the data that apply to autonomous vehicles under the unique conditions established for high-value data. However, at this time of transition for the deployment of autonomous vehicles, it is essential that public administrations publish and keep updated under appropriate conditions for their automated processing, some datasets, such as those relating to:
- Road signs and vertical signage elements.
- Traffic light states and traffic control systems.
- Lane configuration and characteristics.
- Information on works and temporary traffic alterations.
- Road infrastructure elements critical for autonomous navigation.
The recent update of the official catalogue of traffic signs, which comes into force on 1 July 2025, incorporates signs adapted to new realities, such as personal mobility. However, it requires greater specificity with regard to the availability of data relating to signals under these conditions. This will require the intervention of the authorities responsible for road signage.
The availability of data in the context of the European Mobility Area
Based on these conditions and the need to have mobility data generated by private companies and individuals, data spaces appear as the optimal legal and governance environment to facilitate their accessibility under appropriate conditions.
In this regard, the initiatives for the deployment of the European Mobility Data Space, created in 2023, constitute an opportunity to integrate into its design and configuration measures that support the need for access to data required by autonomous vehicles. Thus, within the framework of this initiative, it would be possible to unlock the potential of mobility data , and in particular:
- Facilitate the availability of data under conditions specific to the needs of autonomous vehicles.
- Promote the interconnection of various data sources linked to existing means of transport, but also emerging ones.
- Accelerate the digital transformation of autonomous vehicles.
- Strengthen the digital sovereignty of the European automotive industry, reducing dependence on large foreign technology corporations.
In short, autonomous vehicles can represent a fundamental transformation in mobility as it has been conceived until now, but their development depends, among other factors, on the availability, quality and accessibility of sufficient and adequate data. The Sustainable Mobility Bill currently being processed in Parliament is a great opportunity to strengthen the role of data in facilitating innovation in this area, which would undoubtedly favour the development of autonomous vehicles. To this end, it will be essential, on the one hand, to have a data sharing environment that makes access to data compatible with the appropriate guarantees for fundamental rights and information security; and, on the other hand, to design a governance model that, as emphasised in the Programme promoted by the Directorate-General for Traffic, facilitates the collaborative participation of "manufacturers, developers, importers and fleet operators established in Spain or the European Union", which poses significant challenges in the availability of data.
Content prepared by Julián Valero, Professor at the University of Murcia and Coordinator of the Research Group "Innovation, Law and Technology" (iDerTec). The contents and points of view reflected in this publication are the sole responsibility of its author.