Blog
La construcción del ecosistema de uso secundario de los datos de salud electrónica en el Espacio Europeo de Datos de Salud (EEDS) plantea un escenario significativo de oportunidades para la investigación española, para la innovación y el emprendimiento. Para ello, la Unión Europea está impulsando multitud de proyectos estratégicos en los que participan hospitales, fundaciones de investigación sanitaria, universidades, centros de investigación y empresas españolas. La lista de proyectos es extensa y atiende a satisfacer al menos dos objetivos: potenciar la generación de infraestructuras capaces de generar conjuntos de datos de calidad y promover condiciones para su reutilización.
El papel de España. Fortalezas en el despliegue del Espacio Europeo de Salud
España ofrece condiciones significativamente favorables no sólo para participar sino también para contribuir significativamente a las tareas de creación del EEDS:
- En primer lugar, nuestro sistema público de salud se caracteriza por un alto nivel de integración y estructuración. A diferencia de los sistemas basados en mecanismos de reembolso, en los que puede existir una atomización en el ámbito de la provisión de servicios, en nuestro sistema disponemos de un marco de referencia clara en atención primaria, especialidades médicas y servicios hospitalarios.
- Por otra parte, la experiencia desplegada por nuestros entornos de salud a partir del Reglamento General de Protección de Datos (RGPD) y, particularmente, las lecciones aprendidas a partir de la disposición adicional decimoséptima sobre tratamientos de datos de salud de la Ley Orgánica 3/2018, de 5 de diciembre, de Protección de Datos Personales y garantía de los derechos digitales (LOPDGDD) constituyen una experiencia valiosa.
- La apertura del Espacio Nacional de Datos de Salud promovido por el Gobierno de España e impulsado por el Ministerio para la Transformación Digital y de la Función Pública, el Ministerio de Sanidad y las Comunidades Autónomas permite el despliegue de una infraestructura esencial para el EEDS.
El Espacio Nacional de Datos de Salud se presentó el pasado 29 de enero. En el evento se resaltó cómo este proyecto representa un cambio de paradigma que revoluciona la gestión del dato sanitario, impulsando un modelo federado, seguro y ético que preserva la soberanía y privacidad de la información mientras facilita su uso para investigación, innovación y políticas públicas. Su funcionamiento se basa en un catálogo federado de metadatos y un riguroso proceso de acceso y análisis en entornos seguros, que busca potenciar la ciencia abierta y los avances científicos y tecnológicos, beneficiando a pacientes, investigadores, gestores e industria.
Lecciones aprendidas desde los Proyectos Europeos
El camino que arranca el Reglamento (UE) 2025/327 del Parlamento Europeo y del Consejo, de 11 de febrero de 2025, relativo al Espacio Europeo de Datos de Salud, y por el que se modifican la Directiva 2011/24/UE y el Reglamento (UE) 2024/2847 (EEDSR) plantea retos significativos que se abordan en los proyectos de investigación financiados con fondos europeos y nacionales. Las lecciones aprendidas en algunos de ellos pueden ser de extraordinaria utilidad para la comunidad investigadora y de emprendimiento en nuestro país. No podemos olvidar que partimos de fortalezas significativas.
1.-Cumplimiento desde el diseño
La existencia de una nueva normativa obliga a desplegar un análisis riguroso del estado del arte en nuestras organizaciones, no sólo para implementar su despliegue sino también para asegurar las condiciones previas de confiabilidad legal de los conjuntos de datos y de la investigación que se proponga.
2.-Accountability: responsabilidad proactiva y solidez documental
En nuestro país venimos de una larga tradición de “accountability”. El EEDSR va a imponer al solicitante de datos un conjunto de requisitos documentales relevantes, como, por ejemplo, haber previsto las garantías para prevenir cualquier uso indebido de los datos de salud electrónicos. Esta cuestión tampoco podrá descuidarse desde el punto de vista de los tenedores de datos, quienes también tendrán que cumplir algunos requisitos. Por ejemplo, demostrar que los datos son legítimos y reutilizables es una cuestión ética y jurídicamente documentable; y el procedimiento simplificado para el acceso a los datos de salud electrónicos a través de un tenedor fiable de datos de salud obliga a este a documentar la seguridad de su espacio de datos o las capacidades para evaluar las solicitudes de acceso a datos de salud.
Uno de los principales escollos a los que nos enfrentamos en este periodo intermedio de implantación del EEDS reside precisamente en la cultura organizativa para la generación de evidencias verificables. A medida que la estandarización y el conjunto de reglas comunes del EEDS escalen será necesario profundizar en la dinámica de la responsabilidad proactiva entendida como responsabilidad demostrada.
3. Entornos seguros de procesamiento
En nuestro país, los entornos de salud por su propia definición deben ser entornos seguros. El despliegue del Esquema Nacional de Seguridad (ENS) y el del RGPD, han permitido que la totalidad del sistema de salud, público o privado, haya adoptado modelos de madurez perfectamente coherentes con las condiciones de los entornos de procesamiento seguro que define el EEDSR.
Retos del sistema español
Junto a las fortalezas inherentes a nuestro sistema, es necesario considerar aquellos aspectos que se presentan como retos.
1. Anonimización y seudonimización
En el contexto nacional la citada disposición adicional decimoséptima de la Ley Orgánica 3/2018, de 5 de diciembre, de Protección de Datos Personales y garantía de los derechos digitales, define condiciones específicas para la seudonimización. Estas consisten en la separación funcional entre los equipos que seudonimizan y los que reutilizan los datos, y en la definición de un entorno seguro que prevenga cualquier intento de reidentificación. A ello se suman garantías jurídicas en términos de compromisos individuales de no reidentificación, despliegue de la herramienta de la evaluación de impacto relativa a la protección de datos y supervisión por comités de ética. El reto de la anonimización se muestra más exigente, ya que implica la imposibilidad de vincular bajo ninguna condición los datos de salud con los del paciente original.
2. Reeskilling de los equipos
El Espacio Europeo de Datos de Salud (EEDS) planteará un desafío formativo sin precedentes que atravesará todos los sectores implicados en el ecosistema de datos sanitarios. Los comités de ética de investigación deberán familiarizarse no solo con los usos secundarios admisibles de los datos de salud, sino también con la integración del Reglamento de Inteligencia Artificial y con los principios éticos del marco ALTAI (Assessment List for Trustworthy Artificial Intelligence). Esta necesidad de reeskilling se extenderá igualmente a los sistemas de salud y la administración sanitaria, donde los organismos de acceso a datos (Health Data Access Bodies) requerirán personal altamente cualificado en estos nuevos marcos éticos y regulatorios, al igual que los tenedores fiables de datos que custodiarán la información sensible. El personal de desarrollo y los equipos de tecnologías de la información también deberán adquirir nuevas competencias en ámbitos técnicos críticos, como la catalogación, validación y curación de datos, así como en los estándares de interoperabilidad que permitan la comunicación efectiva entre sistemas. Quizás el reto de capacitación más delicado recaerá sobre los nuevos operadores, que podrán aprovechar las oportunidades de acceso a conjuntos de datos para usos secundarios innovadores. Esto concierne especialmente a las startups tecnológicas del sector salud. Para enfrentar un marco normativo muy exigente, (RGPD, Regalmento de IA, EEDSR), los recursos y capacidades para el cumplimiento legal (compliance) en las pymes españolas es notablemente limitado. Por ello será necesario construir desde el inicio una cultura sólida de protección de datos y desarrollo ético de sistemas de inteligencia artificial confiables.
3. Catalogación de datos: el desafío de la calidad y la estandarización
En el contexto del Espacio Europeo de Datos de Salud, profundizar en la estandarización de los datos mediante las metodologías más funcionales —como OMOP CDM para datos clínicos observacionales, HL7 FHIR para el intercambio dinámico de información, DICOM para imágenes médicas, o terminologías de referencia como SNOMED CT, LOINC y RxNorm— se presenta como un elemento estratégico fundamental para la creación y reutilización de conjuntos de datos de alta calidad. Sin embargo, la adopción de estos estándares no es suficiente por sí sola: los procesos de validación, anotación semántica y enriquecimiento de datos requieren de recursos humanos altamente cualificados capaces de garantizar la coherencia, completitud y precisión de la información, convirtiéndose esta capacitación en una auténtica precondición para la participación efectiva en el ecosistema europeo de datos de salud. El alineamiento con la catalogación estandarizada de conjuntos de datos siguiendo el estándar HealthDCAT-AP (Health Data Catalog Application Profile), que permite describir de manera homogénea los metadatos descriptivos de los recursos de datos sanitarios, se presenta como uno de los retos inmediatos, junto con la implementación de los trabajos que se vienen desplegando en relación con el data utility quality label, una etiqueta de calidad que evalúa la utilidad real de los datos para usos secundarios y que se está convirtiendo en un sello de confianza para usuarios e investigadores.
Si anteriormente en este artículo se subrayaron las altísimas capacidades del sistema sanitario español para generar datos de salud de manera sistemática y en volúmenes significativos, estos aspectos de catalogación, estandarización y certificación de calidad ocuparán un lugar absolutamente central para diseñar condiciones óptimas de competitividad europea en su reutilización, transformando la abundancia de datos en una verdadera ventaja estratégica que permita a España posicionarse como un actor relevante en el panorama de la investigación y la innovación con datos de salud electrónicos.
La experiencia del proyecto EUCAIM (Cancer Image EU)
El Reglamento del Espacio Europeo de Datos de Salud tiene por objeto permitir el uso secundario de los datos sanitarios electrónicos en toda Europa mediante normas armonizadas en un ecosistema federado. En el ámbito del cáncer, el acceso fragmentado a conjuntos de datos de alta calidad ralentiza la investigación, limita la reproducibilidad y socava la capacidad de Europa para desarrollar y validar herramientas de IA fiables para la oncología.
EUCAIM demuestra la viabilidad de un ecosistema para el uso secundario del cáncer a través de un modelo federado que permite el acceso transfronterizo bajo normas armonizadas garantizando un control adecuado de los recursos a nivel local. Y ello se despliega mediante un conjunto de componentes habilitadores:
1) Un entorno de procesamiento seguro (SPE) federado a nivel europeo
EUCAIM está creando un SPE federado para hacer cumplir las condiciones de acceso a los datos, controlar el procesamiento y apoyar el análisis transfronterizo seguro bajo las restricciones del EEDS. Este SPE se ajusta plenamente a los requisitos y medidas que establece el artículo 73 EEDSR en materia de entornos seguros.
2) Superación de la «barrera de la anonimización»
EUCAIM promueve una estrategia de anonimización por capas que combina procesos de anonimización local autónoma por el tenedor de datos con controles de la plataforma para permitir que los conjuntos de datos sigan siendo útiles para la investigación y el desarrollo de la IA. La importancia de este enfoque radica en que pretende conciliar la protección de la privacidad con la necesidad práctica de disponer de conjuntos con grandes volúmenes de datos caracterizados por su diversidad.
3) Catalogación y estandarización de datos
EUCAIM alinea la catalogación con los principios HealthDCAT-AP cuyo objetivo principal es aplicar los principios FAIR, esto es asegurar que los datos sean encontrables, accesibles, interoperables y reutilizables.
4) Reducción de costes legales
EUCAIM ha desplegado un marco de cumplimiento propio orientado al Reglamento General de Protección de Datos y el Reglamento de Inteligencia Artificial. Para ello, se dispone de un marco sólido de cumplimiento a nivel de una plataforma que se despliega en ecosistemas complejos de datos. Este se basa en evaluaciones de impacto en la protección de datos (incluidas en el RGPD) con especial atención a los derechos fundamentales. También incorpora la formación y el reciclaje profesional de los usuarios como requisito funcional, de modo que la capacidad de cumplimiento se convierta en una característica esencial.
5) Apoyo a los usuarios de datos
EUCAIM ofrece ventajas significativas a los usuarios de datos, incluidos los investigadores y los desarrolladores de IA, al establecer un entorno transparente y bien gobernado para el acceso a los datos. La adopción de criterios de gobernanza transparentes, obligaciones claramente definidas y su aplicación técnica por la plataforma, proporcionan a los usuarios de datos la garantía de que su acceso es adecuado y lícito, totalmente auditable y se mantiene estable a lo largo del tiempo. El diseño de la plataforma garantiza que los usuarios puedan aprovechar datos de gran utilidad para análisis avanzados, incluido el procesamiento federado en un entorno seguro. A través de la formación obligatoria y la implementación de procedimientos estandarizados, los equipos se benefician de una menor incertidumbre y están mejor equipados para alinearse con los requisitos de cumplimiento establecidos por el EEDSR, el RGPD y los marcos de gobernanza de la IA.
6) Garantía de los derechos de los pacientes
El enfoque de EUCAIM se basa en la protección de datos desde el diseño y por defecto que une las salvaguardias organizativas con controles técnicos sólidos. Este marco se ha construido expresamente para minimizar el riesgo de uso indebido de los datos, al tiempo que apoya la investigación y la innovación transfronterizas seguras y eficaces en materia de cáncer. El resultado es un sistema en el que la protección de la privacidad no es un obstáculo sino un elemento fundamental que permite el uso responsable de los datos en beneficio de la sociedad y la ciencia. El modelo refuerza la responsabilidad por el uso secundario de los datos sanitarios mediante la combinación de una sólida supervisión de la gobernanza, un registro exhaustivo de las acciones y obligaciones estrictas y exigibles para todas las entidades participantes. Todas las acciones realizadas con los datos de los pacientes se registran y se someten a revisión, lo que garantiza que todos los usos sean totalmente auditables. Esta trazabilidad garantiza que el tratamiento de los datos se mantenga dentro de los límites del uso permitido y que cualquier desviación pueda identificarse y abordarse rápidamente.
Gobernanza multinivel: la clave del éxito sostenible
La lección aprendida más relevante en EUCAIM se refiere a la necesidad imperiosa de una gobernanza multinivel articulada, coherente y operativa. En sentido amplio, resulta indispensable proporcionar herramientas y marcos de gobierno efectivos sobre tres dimensiones fundamentales:
- En primer lugar, sobre los procesos de generación de conjuntos de datos y sus condiciones de compartición, estableciendo criterios claros sobre qué datos se generan, cómo se estandarizan, quién ostenta derechos sobre ellos y bajo qué licencias y restricciones pueden ser compartidos con terceros.
- En segundo lugar, sobre los procesos de solicitud de acceso a datos, definiendo procedimientos transparentes y eficientes para que investigadores, innovadores y responsables de políticas públicas puedan identificar, solicitar y obtener acceso a los datos necesarios para sus proyectos, minimizando las cargas administrativas sin comprometer las garantías éticas y legales.
- En tercer lugar, sobre los procesos de validación de la corrección de los conjuntos de datos y de adhesión al sistema, así como los procedimientos de autorización de acceso a datos, asegurando que solo datos de calidad certificada alimenten la infraestructura y que únicamente usuarios autorizados y con propósitos legítimos accedan a información sensible.
Esta gobernanza procedimental no puede funcionar sin decisiones estratégicas y operativas en relación con la definición de roles y funciones en materia de recursos humanos. Para ello, es necesario contar con perfiles profesionales necesarios como gestores de datos, expertos en ética de la investigación, especialistas en ciberseguridad, curadores de datos y responsables de calidad. En segundo lugar, será fundamental la definición de los entornos seguros de procesamiento donde se ejecutan análisis sobre datos sensibles, garantizando que estos espacios cumplan con los más altos estándares técnicos de seguridad, trazabilidad, auditoría y preservación de la privacidad, y que estén diseñados para operar bajo el principio de confianza cero (zero trust) adaptado al contexto sanitario. Solo mediante esta arquitectura de gobernanza multinivel, que integre dimensiones técnicas, organizativas, éticas y legales en todos los niveles de decisión —desde el diseño de políticas nacionales hasta la gestión operativa diaria de las plataformas—, será posible construir infraestructuras de datos de salud verdaderamente sostenibles, confiables y capaces de generar valor social, científico y económico a largo plazo, posicionando al sistema sanitario español como un actor estratégico en el ecosistema europeo de innovación en salud.
Contenido elaborado por Ricard Martínez Martínez, Director de la Cátedra de Privacidad y Transformación Digital, Departamento de Derecho Constitucional de la Universitat de València. Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Blog
En la era de la Inteligencia Artificial (IA), los datos han dejado de ser simples registros para convertirse en el combustible esencial de la innovación. Sin embargo, para que ese combustible impulse realmente nuevos servicios, políticas públicas más eficaces o modelos de IA avanzados, no basta con disponer de grandes volúmenes de información: los datos deben ser variados, de calidad y, sobre todo, accesibles.
En este contexto cobra protagonismo el data pooling o agrupación de datos, una práctica que consiste en poner datos en común para generar mayor valor a partir de su uso conjunto. Lejos de ser una idea abstracta, el data pooling se perfila como uno de los mecanismos clave para transformar la economía del dato en Europa y acaba de recibir un nuevo impulso con la propuesta del Digital Omnibus, orientada a simplificar y reforzar el marco europeo de compartición de datos.
Como ya analizamos en nuestro reciente post sobre la Estrategia de la Unión de Datos, la Unión Europea aspira a construir un mercado único de datos en el que la información pueda fluir de forma segura y con garantías. El data pooling es, precisamente, la herramienta operativa que permite hacer tangible esa visión, conectando datos hoy dispersos entre administraciones, empresas y sectores.
Pero ¿qué significa exactamente “data pooling”? ¿Por qué se habla cada vez más de este concepto en el contexto de la estrategia europea de datos y del nuevo Digital Omnibus? Y, sobre todo, ¿qué oportunidades abre para las administraciones públicas, las empresas y los reutilizadores de datos? en este artículo tratamos de responder estas preguntas.
¿Qué es el data pooling, cómo funciona y para qué sirve?
Para entender qué es el data pooling, puede resultar útil pensar en una cooperativa agrícola tradicional. En ella, pequeños productores que, de forma individual, tienen recursos limitados deciden poner en común su producción y sus medios. Al hacerlo, ganan escala, acceden a mejores herramientas y pueden competir en mercados a los que no llegarían por separado.
En el ámbito digital, el data pooling funciona de manera muy similar. Consiste en combinar o agrupar conjuntos de datos procedentes de distintas organizaciones o fuentes para analizarlos o reutilizarlos con un objetivo compartido. Al crear este “depósito común” de información —físico o lógico— se habilitan análisis más complejos y valiosos que difícilmente podrían realizarse desde una única fuente aislada.
Este “poner datos en común” puede adoptar distintas formas, en función de las necesidades técnicas y organizativas de cada iniciativa:
- Repositorios compartidos, en los que varias organizaciones aportan datos a una misma plataforma.
- Accesos conjuntos o federados, donde los datos permanecen en sus sistemas de origen, pero pueden analizarse de forma coordinada.
- Acuerdos de gobernanza, que establecen reglas claras sobre quién puede acceder a los datos, con qué finalidad y bajo qué condiciones.
En todos los casos, la idea central es la misma: cada participante contribuye con sus datos y, a cambio, todos se benefician de un mayor volumen, diversidad y riqueza de información, siempre bajo normas previamente acordadas.
¿Para qué sirve poner los datos en común?
El creciente interés por el data pooling no es casual. Compartir datos de forma estructurada permite, entre otras cosas:
- Detectar patrones que no son visibles con datos aislados, especialmente en ámbitos complejos como la movilidad, la salud, la energía o el medio ambiente.
- Mejorar el desarrollo de la inteligencia artificial, que necesita datos diversos, de calidad y a escala para generar resultados fiables.
- Evitar duplicidades, reduciendo costes y esfuerzos tanto en el sector público como en el privado.
- Impulsar la innovación, facilitando nuevos servicios, estudios comparativos o análisis predictivos.
- Reforzar la toma de decisiones basada en evidencias, un aspecto especialmente relevante en el diseño de políticas públicas.
En otras palabras, el data pooling multiplica el valor de los datos existentes sin necesidad de generar siempre nuevos conjuntos de información.
Distintos tipos de data pooling y su valor
No todos los data pools son iguales. Dependiendo del contexto y del objetivo perseguido, pueden identificarse distintos modelos de agrupación de datos:
- Data pooling M2M (Machine-to-Machine), muy habitual en el Internet de las Cosas (IoT). Por ejemplo, cuando fabricantes de sensores industriales agrupan datos de miles de máquinas para anticipar fallos o mejorar el mantenimiento.
- Data pooling transversal o intersectorial, que combina datos de sectores distintos —como transporte y energía— para optimizar servicios, por ejemplo, la gestión de la recarga de vehículos eléctricos en ciudades inteligentes.
- Data pooling para investigación, especialmente relevante en el ámbito de la salud, donde hospitales o centros de investigación comparten datos anonimizados para entrenar algoritmos capaces de detectar enfermedades poco frecuentes o mejorar diagnósticos.
Estos ejemplos muestran que el data pooling no es una solución única, sino un conjunto de prácticas adaptables, capaces de generar valor económico, social y científico cuando se aplican con las garantías adecuadas.
Del potencial a la práctica: garantías, reglas claras y nuevas oportunidades para el data pooling
Hablar de poner datos en común no significa hacerlo sin límites. Para que el data pooling genere confianza y valor sostenible, es imprescindible abordar cómo compartir datos de forma responsable. Este ha sido, de hecho, uno de los grandes retos que han condicionado su adopción en los últimos años.
Entre las principales preocupaciones destacan la protección de los datos personales, garantizando el cumplimiento del Reglamento General de Protección de Datos (RGPD) y minimizando riesgos de reidentificación; la confidencialidad y la protección de los secretos comerciales, especialmente cuando participan empresas; así como la calidad e interoperabilidad de los datos, ya que combinar información inconsistente puede conducir a conclusiones erróneas. A todo ello se suma un elemento transversal: la confianza entre las partes, sin la cual ningún mecanismo de compartición puede funcionar.
Por este motivo, el data pooling no es solo una cuestión técnica. Requiere marcos legales claros, modelos de gobernanza sólidos y mecanismos de confianza, que den seguridad tanto a quienes comparten los datos como a quienes los reutilizan.
El papel de Europa: de compartir datos a crear ecosistemas
Consciente de estos retos, la Unión Europea lleva años trabajando para construir un mercado único de datos, en el que compartir información sea más sencillo, seguro y beneficioso para todos los actores implicados. En este contexto han surgido iniciativas clave como los espacios europeos de datos, organizados por sectores estratégicos (salud, movilidad, industria, energía, agricultura), el impulso a estándares e interoperabilidad, y la aparición de intermediarios de datos como terceros de confianza que facilitan la compartición.
El data pooling encaja plenamente en esta visión: es uno de los mecanismos prácticos que permiten que estos espacios de datos funcionen y generen valor real. Al facilitar la agregación y el uso conjunto de datos, el pooling actúa como el “motor” que hace operativos muchos de estos ecosistemas.
Todo ello se enmarca en la Estrategia de la Unión de Datos, que busca conectar políticas, infraestructuras y normas para que los datos puedan circular de forma segura y eficiente en toda Europa.
El gran freno: la fragmentación normativa
Hasta hace poco, este potencial se encontraba con un obstáculo importante: la complejidad del marco legal europeo en materia de datos. Una organización que quisiera participar en un data pool transfronterizo debía navegar entre múltiples normas —RGPD, Data Governance Act, Data Act, Directiva de Datos Abiertos y regulaciones sectoriales o nacionales— con definiciones, obligaciones y autoridades competentes no siempre alineadas. Esta fragmentación generaba inseguridad jurídica: dudas sobre responsabilidades, miedo a sanciones, o incertidumbre sobre la protección real de los secretos comerciales. En la práctica, este “laberinto normativo” ha frenado durante años el desarrollo de muchos espacios comunes de datos y ha limitado la adopción del data pooling, especialmente entre pymes y empresas medianas con menos capacidad jurídica y técnica.
El Digital Omnibus: simplificar para que el data pooling escale
Es en este punto donde entra en juego el Digital Omnibus, la propuesta de la Comisión Europea para simplificar y armonizar el marco jurídico digital. Lejos de añadir nuevas capas regulatorias, el objetivo del Omnibus es ordenar, consolidar y reducir cargas administrativas, facilitando que compartir datos sea viable en la práctica.
Desde la perspectiva del data pooling, el mensaje es claro: menos fragmentación, más claridad y mayor confianza. El Omnibus busca concentrar las reglas en un marco más coherente, evitar duplicidades y eliminar barreras innecesarias que hasta ahora desincentivaban la colaboración basada en datos, especialmente en proyectos transfronterizos.
Además, se refuerza el papel de los servicios de intermediación de datos, actores clave para organizar el pooling de forma neutral y confiable. Al clarificar su rol y reducir determinadas cargas, se favorece la aparición de nuevos modelos —incluidas startups tecnológicas— capaces de actuar como “árbitros” del intercambio de datos entre múltiples participantes.
Otro elemento especialmente relevante es el refuerzo de la protección de los secretos comerciales, permitiendo a los poseedores de datos limitar o denegar el acceso cuando exista un riesgo real de uso indebido o transferencia a entornos sin garantías adecuadas. Este punto resulta clave para sectores industriales y estratégicos, donde la confianza es condición indispensable para compartir datos.
Nuevas oportunidades del data pooling: sector público, empresas y reutilización de datos
La simplificación normativa y el refuerzo de la confianza que introduce el Digital Omnibus no son un fin en sí mismos. Su verdadero valor reside en las oportunidades concretas que abre el data pooling para distintos actores del ecosistema del dato, especialmente para el sector público, las empresas y los reutilizadores de información.
En el caso de las administraciones públicas, el data pooling ofrece un potencial especialmente relevante. Permite combinar datos procedentes de distintas fuentes y niveles administrativos para mejorar el diseño y la evaluación de las políticas públicas, avanzar hacia una toma de decisiones basada en evidencias y ofrecer servicios más eficaces y personalizados a la ciudadanía. Al mismo tiempo, facilita la ruptura de silos de información, la reutilización de datos ya disponibles y la reducción de duplicidades, con el consiguiente ahorro de costes y esfuerzos.
Además, el data pooling refuerza la colaboración entre el sector público, el ámbito investigador y el sector privado, siempre bajo marcos seguros y transparentes. En este contexto, no compite con los datos abiertos, sino que los complementa, permitiendo conectar conjuntos de datos que hoy se publican de forma fragmentada y habilitando análisis más avanzados que amplían su valor social y económico.
Desde el punto de vista empresarial, el Digital Omnibus introduce una novedad significativa al ampliar el foco más allá de las pymes tradicionales. Las denominadas small mid-caps, empresas de mediana capitalización que también sufren el impacto de la burocracia, pasan a beneficiarse de la simplificación normativa. Esto incrementa de forma notable la base de organizaciones capaces de participar en esquemas de data pooling y amplía el volumen y la diversidad de datos disponibles en sectores estratégicos como la industria, la automoción o la química.
El impacto económico de este nuevo escenario es también relevante. La Comisión Europea estima importantes ahorros de costes administrativos y operativos, tanto para empresas como para administraciones públicas. Pero más allá de las cifras, estos ahorros representan capacidad liberada para innovar, invertir en nuevos servicios digitales y desarrollar modelos de inteligencia artificial más avanzados, alimentados por datos que ahora pueden compartirse con mayor seguridad.
En definitiva, el data pooling se consolida como una palanca clave para pasar de la compartición puntual de datos a la generación sistemática de valor, sentando las bases de una economía del dato más colaborativa, eficiente y competitiva en Europa.
Conclusión: cooperar para competir
La propuesta del data pooling en el Digital Omnibus marca un antes y un después en la forma en que entendemos la propiedad de la información. Europa ha entendido que, en la economía global del dato, la soberanía no se defiende cerrando fronteras, sino creando entornos seguros donde la colaboración sea la opción más sencilla y rentable.
El data pooling es el corazón de esta transformación. Al reducir la burocracia, simplificar las notificaciones y proteger los secretos comerciales, el Omnibus está quitando las piedras del camino para que empresas y ciudadanos puedan disfrutar de los beneficios de una verdadera Unión de Datos.
En definitiva, se trata de pasar de una economía de silos aislados a una de redes conectadas. Porque, en el mundo de los datos, compartir no es perder el control, es ganar escala.
Contenido elaborado por Dr. Fernando Gualo, Profesor en UCLM y Consultor de Gobierno y Calidad de datos El contenido y el punto de vista reflejado en esta publicación es responsabilidad exclusiva de su autor.
Blog
La convergencia entre datos abiertos, inteligencia artificial y sostenibilidad medioambiental plantea uno de los principales desafíos para el modelo de transformación digital que se está impulsando a nivel europeo. Esta interacción se concreta principalmente en tres manifestaciones destacadas:
-
La apertura de datos de alto valor directamente relacionados con la sostenibilidad, que pueden ayudar al desarrollo de soluciones de inteligencia artificial orientadas a la mitigación del cambio climático y la eficiencia de recursos.
-
El impulso de los denominados algoritmos verdes en la reducción del impacto ambiental de la IA, que se ha de concretar tanto en el uso eficiente de la infraestructura digital como en la toma de decisiones sostenibles.
-
La apuesta por espacios de datos medioambientales, generando ecosistemas digitales donde se comparten datos que provienen de fuentes diversas para facilitar el desarrollo de proyectos y soluciones interoperables con impacto relevante desde la perspectiva medioambiental.
A continuación, profundizaremos en cada uno de estos puntos.
Datos de alto valor para la sostenibilidad
La Directiva (UE) 2019/1024 sobre datos abiertos y reutilización de la información del sector público introdujo por primera vez el concepto de conjuntos de datos de alto valor, definidos como aquellos con un potencial excepcional para generar beneficios sociales, económicos y medioambientales. Estos conjuntos deben publicarse de forma gratuita, en formatos legibles por máquina, mediante interfaces de programación de aplicaciones (API) y, cuando proceda, se han de poder descargar de forma masiva. A tal efecto se han identificado una serie de categorías prioritarias, entre los que se encuentran los datos medioambientales y relativos a la observación de la Tierra.
Se trata de una categoría especialmente relevante, ya que abarca tanto datos sobre clima, ecosistemas o calidad ambiental, así como los vinculados a la Directiva INSPIRE, que hacen referencia a áreas ciertamente diversas como hidrografía, lugares protegidos, recursos energéticos, uso del suelo, recursos minerales o, entre otros, los relativos a zonas de riesgos naturales, incluyendo también ortoimágenes.
Estos datos tienen una singular relevancia a la hora de monitorizar las variables relacionadas con el cambio climático, como puede ser el uso del suelo, la gestión de la biodiversidad teniendo en cuenta la distribución de especies, hábitats y lugares protegidos, el seguimiento de las especies invasoras o la evaluación de los riesgos naturales. Los datos sobre calidad del aire y contaminación son cruciales para la salud pública y ambiental, de manera que el acceso a los mismos permite llevar a cabo análisis exhaustivos sin duda relevantes para la adopción de políticas públicas orientadas a su mejora. La gestión de recursos hídricos también se puede optimizar mediante datos de hidrografía y monitoreo ambiental, de manera que su tratamiento masivo y automatizado constituye una premisa inexcusable para hacer frente al reto de la digitalización de la gestión del ciclo del agua.
La combinación con otros datos medioambientales de calidad facilita el desarrollo de soluciones de IA orientadas a desafíos climáticos específicos. En concreto, permiten entrenar modelos predictivos para anticipar fenómenos extremos (olas de calor, sequías, inundaciones), optimizar la gestión de recursos naturales o monitorizar en tiempo real indicadores ambientales críticos. También permite impulsar proyectos económicos de gran impacto, como puede ser el caso de la utilización de algoritmos de IA para implementar soluciones tecnológicas en el ámbito de la agricultura de precisión, posibilitando el ajuste inteligente de los sistemas de riego, la detección temprana de plagas o la optimización del uso de fertilizantes.
Algoritmos verdes y responsabilidad digital: hacia una IA sostenible
El entrenamiento y despliegue de sistemas de inteligencia artificial, particularmente de modelos de propósito general y grandes modelos de lenguaje, conlleva un consumo energético significativo. Según estimaciones de la Agencia Internacional de la Energía, los centros de datos representaron alrededor del 1,5 % del consumo mundial de electricidad en 2024. Esta cifra supone un crecimiento de alrededor de un 12 % anual desde 2017, más de cuatro veces más rápido que la tasa de consumo eléctrico total. Está previsto que el consumo eléctrico de los centros de datos se duplique hasta alcanzar unos 945 TWh en 2030.
Ante este panorama, los algoritmos verdes constituyen una alternativa que necesariamente ha de tenerse en cuenta a la hora de minimizar el impacto ambiental que plantea la implantación de la tecnología digital y, en concreto, la IA. De hecho, tanto la Estrategia Europea de Datos como el Pacto Verde Europeo integran explícitamente la sostenibilidad digital como pilar estratégico. Por su parte, España ha puesto en marcha un Programa Nacional de Algoritmos Verdes, enmarcado en la Agenda Digital 2026 y con una medida específica en la Estrategia Nacional de Inteligencia Artificial.
Uno de los principales objetivos del Programa consiste en fomentar el desarrollo de algoritmos que minimicen su impacto ambiental desde la concepción —enfoque green by design—, por lo que la exigencia de una documentación exhaustiva de los conjuntos de datos utilizados para entrenar modelos de IA —incluyendo origen, procesamiento, condiciones de uso y huella ambiental— resulta fundamental para dar cumplimiento a esta aspiración. A este respecto, la Comisión ha publicado una plantilla para ayudar a los proveedores de inteligencia artificial de propósito general a resumir los datos utilizados para el entrenamiento de sus modelos, de manera que se pueda exigir mayor transparencia que, por lo que ahora interesa, también facilitaría la trazabilidad y gobernanza responsable desde la perspectiva ambiental, así como la realización de ecoauditorías.
El Espacio de Datos del Pacto Verde Europeo (Green Deal)
Se trata de uno de los espacios de datos comunes europeos contemplados en la Estrategia Europea de Datos que se encuentra en un estado más avanzado, tal y como demuestran las numerosas iniciativas y eventos de divulgación que se han impulsado en torno al mismo. Tradicionalmente el acceso a la información ambiental ha sido uno de los ámbitos con una regulación más favorable, de manera que con el impulso de los datos de alto valor y la decida apuesta que supone la creación de un espacio europeo en esta materia se ha producido un avance cualitativo muy destacable que refuerza una tendencia ya consolidada en este ámbito.
En concreto, el modelo de los espacios de datos facilita la interoperabilidad entre datos abiertos públicos y privados, reduciendo barreras de entrada para startups y pymes en sectores como la gestión forestal inteligente, la agricultura de precisión o, entre otros muchos ejemplos, la optimización energética. Al mismo tiempo, refuerza la calidad de los datos disponibles para que las Administraciones Públicas lleven a cabo sus políticas públicas, ya que sus propias fuentes pueden contrastarse y compararse con otros conjuntos de datos. Finalmente, el acceso compartido a datos y herramientas de IA puede fomentar iniciativas y proyectos de innovación colaborativa, acelerando el desarrollo de soluciones interoperables y escalables.
Ahora bien, el ecosistema jurídico propio de los espacios de datos conlleva una complejidad inherente a su propia configuración institucional, ya que en el mismo confluyen varios sujetos y, por tanto, diversos intereses y regímenes jurídicos aplicables:
-
Por una parte, las entidades públicas, a las que en este ámbito les corresponde un papel de liderazgo especialmente reforzado.
-
Por otra las entidades privadas y la ciudanía, que no sólo pueden aportar sus propios conjuntos de datos, sino asimismo ofrecer desarrollos y herramientas digitales que pongan en valor los datos a través de servicios innovadores.
-
Y, finalmente, los proveedores de la infraestructura necesaria para la interacción en el seno del espacio.
En consecuencia, son imprescindibles modelos de gobernanza avanzados que hagan frente a esta complejidad reforzada por la innovación tecnológica y de manera especial la IA, ya que los planteamientos tradicionales propios de la legislación que regula el acceso a la información ambiental son ciertamente limitados para esta finalidad.
Hacia una convergencia estratégica
La convergencia de datos abiertos de alto valor, algoritmos verdes responsables y espacios de datos medioambientales está configurando un nuevo paradigma digital imprescindible para afrontar los retos climáticos y ecológicos en Europa que requiere un enfoque jurídico robusto y, al mismo tiempo flexible. Este singular ecosistema no solo permite impulsar la innovación y eficiencia en sectores clave como la agricultura de precisión o la gestión energética, sino que también refuerza la transparencia y la calidad de la información ambiental disponible para la formulación de políticas públicas más efectivas.
Más allá del marco normativo vigente resulta imprescindible diseñar modelos de gobernanza que ayuden a interpretar y aplicar de manera coherente regímenes legales diversos, que protejan la soberanía de los datos y, en definitiva, garanticen la transparencia y la responsabilidad en el acceso y reutilización de la información medioambiental. Desde la perspectiva de la contratación pública sostenible, es esencial promover procesos de adquisición por parte de las entidades públicas que prioricen soluciones tecnológicas y servicios interoperables basados en datos abiertos y algoritmos verdes, fomentando la elección de proveedores comprometidos con la responsabilidad ambiental y la transparencia en las huellas de carbono de sus productos y servicios digitales.
Solo partiendo de este enfoque se puede aspirar a que la innovación digital sea tecnológicamente avanzada y ambientalmente sostenible, alineando así los objetivos del Pacto Verde, la Estrategia Europea de Datos y el enfoque europeo en materia de IA
Contenido elaborado por Julián Valero, catedrático de la Universidad de Murcia y Coordinador del Grupo de Investigación “Innovación, Derecho y Tecnología” (iDerTec). Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Blog
Los datos abiertos de salud son uno de los activos más valiosos de nuestra sociedad. Bien gestionados y compartidos de forma responsable, pueden salvar vidas, impulsar descubrimientos médicos o incluso optimizar recursos hospitalarios. Sin embargo, durante décadas, estos datos han permanecido fragmentados en silos institucionales, con formatos incompatibles y barreras técnicas y legales que dificultaban su reutilización. Ahora, la Unión Europea está cambiando radicalmente el panorama con una estrategia ambiciosa que combina dos enfoques complementarios:
- Facilitar el acceso abierto a estadísticas y datos agregados no sensibles.
- Crear infraestructuras seguras para compartir datos personales de salud bajo estrictas garantías de privacidad.
En España, esta transformación ya está en marcha a través del Espacio Nacional de Datos de Salud o grupos de investigación que están a la vanguardia en el uso innovador de datos de salud. Iniciativas como IMPACT-Data, que integra datos médicos para impulsar la medicina de precisión, demuestran el potencial de trabajar con datos de salud de manera estructurada y segura. Y para facilitar que todos estos datos sean fáciles de encontrar y reutilizar se implementan estándares como HealthDCAT-AP.
Todo ello está perfectamente alineado con la estrategia europea del Reglamento del Espacio Europeo de Datos de Salud (EHDS), publicado oficialmente en marzo de 2025 que se integra también con la Directiva de Datos Abiertos (ODD), en vigor desde 2019. Aunque ambos marcos regulatorios tienen alcances distintos, su interacción ofrece oportunidades extraordinarias para la innovación, la investigación y la mejora de la atención sanitaria en toda Europa.
Un reciente informe elaborado por Capgemini Invent para data.europa.eu analiza estas sinergias. En este post, exploramos las principales conclusiones de este trabajo y reflexionamos sobre su relevancia para el ecosistema español de datos abiertos.
Dos marcos complementarios para un objetivo común
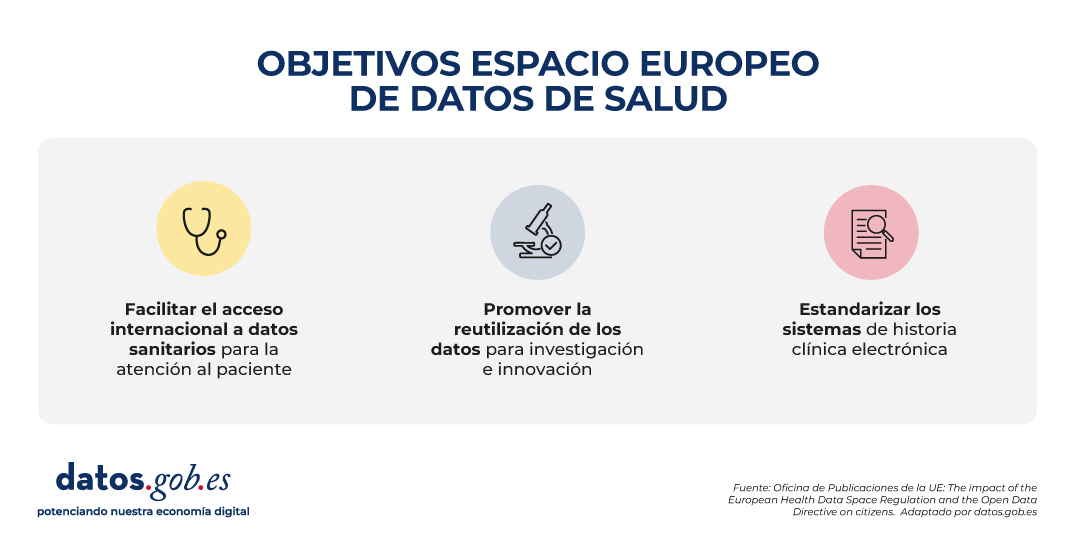
Por un lado, el Espacio Europeo de Datos de Salud se centra específicamente en datos de salud y persigue tres objetivos fundamentales:
- Facilitar el acceso internacional a datos sanitarios para la atención al paciente (uso primario).
- Promover la reutilización de estos datos para investigación, políticas públicas e innovación (uso secundario).
- Estandarizar técnicamente los sistemas de historia clínica electrónica (HCE) para mejorar la interoperabilidad transfronteriza.
Por su parte, la Directiva de Datos Abiertos tiene un alcance más amplio: promueve que el sector público ponga a disposición de cualquier usuario datos gubernamentales para su reutilización libre. Esto incluye los conjuntos de datos de alto valor (High-Value Datasets) que deben publicarse gratuitamente, en formatos legibles por máquina y a través de API en seis categorías entre las que no se encontraba “salud” originalmente. Sin embargo, en la propuesta de ampliación de las nuevas categorías que publicó la UE sí aparece la categoría de salud.
La complementariedad entre ambos marcos regulatorios es evidente: mientras la ODD facilita el acceso abierto a estadísticas sanitarias agregadas y no sensibles, el EHDS regula el acceso controlado a datos individuales de salud bajo condiciones estrictas de seguridad, consentimiento y gobernanza. Juntos, conforman un sistema escalonado de compartición de datos que maximiza su valor social sin comprometer la privacidad, en total cumplimiento con el Reglamento General de Protección de Datos (RGPD).
Principales beneficios ordenador por grupos de usuarios
El informe analiza cuatro grupos de usuarios principales y examina tanto los beneficios potenciales como los desafíos que enfrentan al combinar datos del EHDS con datos abiertos.
-
Pacientes: empoderamiento informado con barreras prácticas
Los pacientes europeos obtendrán acceso más rápido y seguro a sus propias historias clínicas electrónicas, especialmente en contextos transfronterizos gracias a infraestructuras como MyHealth@EU. Este proyecto resulta especialmente útil para ciudadanos europeos que se encuentren desplazados en otro país europeo. .
Otro proyecto interesante que informa a la ciudadanía es PatientsLikeMe que reúne a más 850.000 pacientes con enfermedades raras o crónicas en una comunidad online que comparte información de interés sobre tratamientos y otras cuestiones.
-
Profesionales de la salud potencial subordinado a la integración
Por otro lado, los profesionales sanitarios podrán acceder antes y de manera más sencilla a datos clínicos de pacientes, incluso a través de fronteras, mejorando la continuidad asistencial y la calidad del diagnóstico y tratamiento.
La combinación con datos abiertos podría amplificar estos beneficios si se desarrollan herramientas que integren ambas fuentes de información directamente en los sistemas de historia clínica electrónica.
3. Responsables políticos: datos para mejores decisiones
Los cargos públicos son beneficiarios naturales de la convergencia entre EHDS y datos abiertos. La posibilidad de combinar datos salud detallados (previa solicitud y autorización a través de los Organismos de Acceso a Datos Sanitarios que cada Estado miembro debe establecer) con información estadística y contextual abierta permitiría desarrollar políticas basadas en evidencia mucho más sólida.
El informe menciona casos de uso como la combinación de datos de salud con información medioambiental para evaluar impactos sanitarios. Un ejemplo real es el proyecto francés Green Data for Health, que cruza datos abiertos sobre contaminación acústica con información sobre prescripciones de medicamentos para el sueño de más de 10 millones de habitantes, investigando correlaciones entre ruido ambiental y trastornos del sueño.
4. Investigadores y reutilizadores: los principales beneficiarios inmediatos
Los investigadores, académicos e innovadores constituyen el grupo que más directamente se beneficiará de la sinergia EHDS-ODD ya que disponen de las habilidades y herramientas necesarias para localizar, acceder, combinar y analizar datos de múltiples fuentes. Además, su trabajo ya implica habitualmente la integración de diversos conjuntos de datos.
Un estudio reciente publicado en PLOS Digital Health sobre el caso de Andalucía demuestra cómo los datos abiertos en salud pueden democratizar la investigación en IA sanitaria y mejorar la equidad en el tratamiento.
El desarrollo del EHDS está siendo apoyado por programas europeos como EU4Health, Horizon Europe y proyectos específicos como TEHDAS2, que ayudan a definir estándares técnicos y pilotar aplicaciones reales.
Recomendaciones para maximizar el impacto
El informe concluye con cuatro recomendaciones clave que resultan particularmente relevantes para el ecosistema español de datos abiertos:
- Estimular la investigación en la intersección EHDS-datos abiertos mediante financiación específica. Es fundamental incentivar que los investigadores que combinan estas fuentes traduzcan sus hallazgos en aplicaciones prácticas: protocolos clínicos mejorados, herramientas de decisión, estándares de calidad actualizados.
- Evaluar y facilitar el uso directo por profesionales y pacientes. Promover la alfabetización en datos y desarrollar aplicaciones intuitivas integradas en los sistemas existentes (como las historias clínicas electrónicas) podría cambiar esta situación.
- Fortalecer la gobernanza mediante educación y marcos regulatorios claros. A medida que se vayan operativizando las entidades técnicas del EHDS , será esencial contar con una regulación clara que defina unos marcos regulatorios comunes..
- Monitorizar, evaluar y adaptar. El período 2025-2031 verá la entrada en vigor gradual de los distintos requisitos del EHDS. Se recomienda realizar evaluaciones periódicas para valorar cómo se está utilizando realmente el EHDS, qué combinaciones con datos abiertos están generando más valor, y qué ajustes son necesarios.
Además, para que todo esto funcione, el informe sugiere que portales como data.europa.eu (y por extensión, datos.gob.es) deberían destacar ejemplos prácticos que demuestren cómo se complementan los datos abiertos con los datos protegidos de espacios sectoriales, inspirando así nuevas aplicaciones.
En general, el papel de los portales de datos abiertos será fundamental en este ecosistema emergente: no solo como proveedores de conjuntos de datos de calidad, sino también como facilitadores de conocimiento, espacios de encuentro entre comunidades y catalizadores de innovación. El futuro de la sanidad europea se está escribiendo ahora, y los datos abiertos tienen un papel protagonista en esa historia.
Evento
El pasado mes de septiembre se lanzó oficialmente la primera edición de los European Data Spaces Awards, una iniciativa impulsada por el Data Spaces Support Centre (DSSC) en colaboración con la Comisión Europea. Estos premios nacen con el objetivo de promover las mejores iniciativas de intercambio de datos, reconociendo sus logros y aumentando su visibilidad. Con ello se busca fomentar buenas prácticas que pueden servir de guía para otros actores del ecosistema de datos europeo. La idea es que los premios se otorguen de manera anual, lo cual ayudará a la comunidad a crecer y mejorar.
¿Por qué son importantes estos premios?
Los datos son uno de los activos económicos más valiosos de Europa, y su aprovechamiento estratégico es fundamental para el desarrollo de tecnologías como la inteligencia artificial (IA). Por ello, la estrategia europea pasa por establecer un mercado único de datos que permita impulsar la innovación de forma efectiva. Sin embargo, en la actualidad, los datos todavía están ampliamente distribuidos entre numerosos agentes del ecosistema europeo.
Los European Data Spaces Awards son especialmente relevantes porque reconocen y promueven iniciativas que ayudan a superar esta problemática: los espacios de datos. Se trata de entornos organizativos y técnicos donde múltiples actores —públicos y privados— comparten datos de forma segura, soberana, controlada y conforme a normas comunes que promueven su interoperabilidad. Esto permite que los datos fluyan entre sectores y fronteras impulsando la innovación.
En España también se está impulsando el desarrollo de espacios de datos a través de iniciativas específicas como el Plan de Impulso de los Espacios de Datos Sectoriales.
Dos categorías de premios
En este contexto, se han creado dos categorías de premios:
- Excelencia en la implicación de usuarios finales y sostenibilidad financiera: reconoce espacios de datos con un fuerte enfoque en el usuario y con modelos financieros viables a largo plazo.
- Espacio de datos emergente más innovador: premia iniciativas nuevas que aportan ideas frescas e innovadoras con alto impacto en el ecosistema europeo.
¿Quién puede participar?
Los European Data Spaces Awards están abiertos a cualquier espacio de datos que cumpla con estos criterios:
- Su autoridad de gobernanza está registrada en la Unión Europea.
- Opera total o parcialmente dentro del territorio europeo.
- Está siendo utilizado activamente para el intercambio de datos.
- Incluye datos restringidos, más allá de los datos abiertos.
Los espacios en fase de implementación también pueden presentar su candidatura, siempre que compartan datos en entornos piloto o preoperativos. En estos casos, el coordinador del proyecto puede actuar en nombre del proyecto.
La evaluación de la elegibilidad se basará en la autoevaluación del solicitante, lo que facilita una participación amplia y representativa del ecosistema europeo de datos.
Un mismo espacio de datos puede presentar su candidatura a ambas categorías, aunque deberá hacer dos solicitudes distintas.
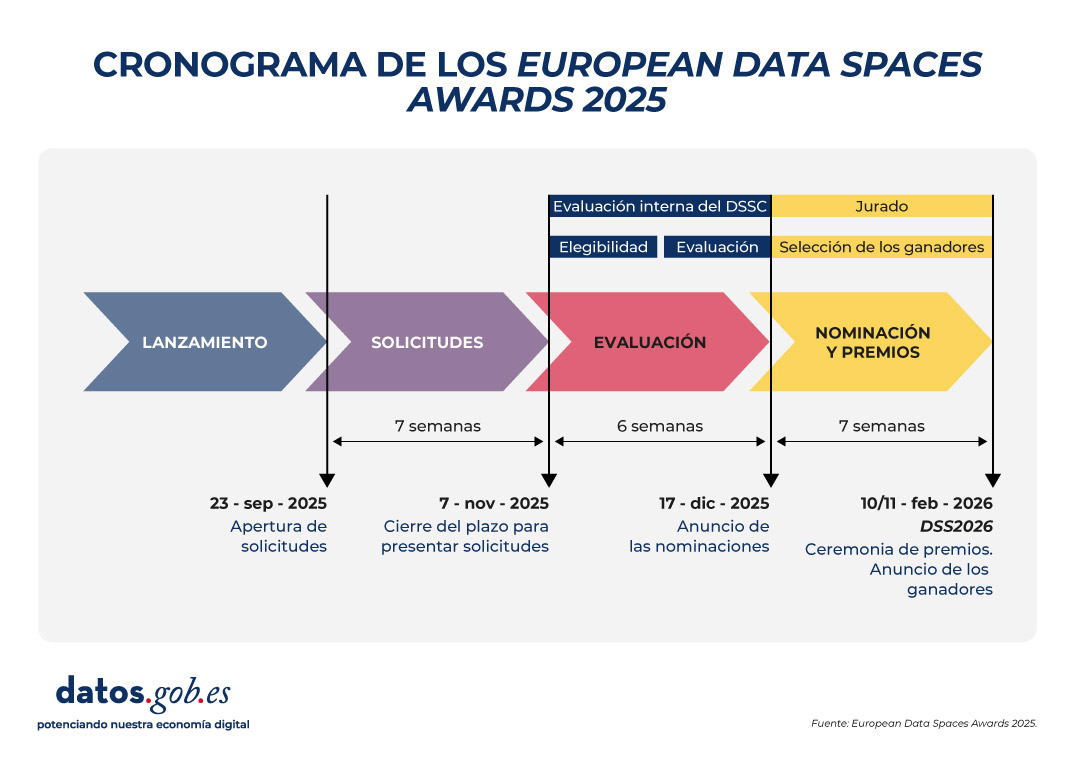
Cronograma: inscripciones abiertas hasta el 7 de noviembre
La competición está estructurada en cuatro fases clave que marcan el ritmo del proceso de participación y evaluación:
- El 23 de septiembre de 2025 se celebró el evento de lanzamiento y se abrió oficialmente el periodo de presentación de candidaturas.
- La fase de envío de solicitudes se extenderá durante 7 semanas, hasta el 7 de noviembre, permitiendo a los espacios de datos preparar y registrar sus propuestas.
- A continuación, se iniciará la fase de evaluación, que comenzará el 17 de diciembre y durará 6 semanas. Durante este tiempo, el Data Spaces Support Centre (DSSC) realizará una revisión interna de elegibilidad y el jurado selecciona a los ganadores.
- Finalmente, los premios se anunciarán y entregarán durante el evento Data Space Symposium (DSS2026), los días 10 y 11 de febrero de 2026 en Madrid. Todos los nominados serán invitados a subir al escenario durante la ceremonia, por lo que obtendrán una gran visibilidad y reconocimiento. Los galardonados no recibirán ninguna compensación monetaria.
Para inscribirse, los participantes deben acceder al formulario online disponible en la página oficial de los premios. Esta página ofrece todos los recursos necesarios para preparar la candidatura, incluidos documentos de referencia, plantillas y actualizaciones sobre el proceso.
El formulario incluye tres elementos obligatorios:
- Preguntas básicas sobre el solicitante y el espacio de datos.
- La autoevaluación de elegibilidad con cuatro preguntas obligatorias.
- Un espacio para subir el Awards Application Document, un documento en formato PDF y cuya plantilla está disponible en la plataforma. (máximo 8 páginas). EL documento, que sigue una estructura alineada con el Maturity Model v2.0, detalla los objetivos y criterios de evaluación por sección.
Además, los participantes cuentan con un espacio para proporcionar, de manera opcional, enlaces a recursos adicionales que ayuden a dar contexto a su propuesta.
Para cualquier duda que pueda surgir durante el proceso, se ha habilitado una plataforma de soporte.
Los European Data Spaces Awards 2025 no solo reconocen la excelencia, sino que visibilizan el impacto de proyectos que están transformando el futuro de los datos en Europa. Si estás interesado en participar, te invitamos a leer las bases completas de la competición en su página web.
Blog
Para alcanzar sus objetivos de sostenibilidad medioambiental, Europa necesita información precisa, accesible y actualizada que permita tomar decisiones basadas en evidencias. El Espacio de Datos del Pacto Verde (Green Deal Data Space o GDDS) facilitará esta transformación al integrar diversas fuentes de datos en una infraestructura digital común, interoperable y abierta.
Desde Europa, se está trabajando en su desarrollo a través de diversos proyectos, que han permitido obtener recomendaciones y buenas prácticas para su implementación. ¡Descúbrelas en este artículo!
¿Qué es el Green Deal Data Space?
El Green Deal Data Space (GDDS) es una iniciativa de la Comisión Europea para crear un ecosistema digital que reúna datos de múltiples sectores. Su fin es apoyar y acelerar los objetivos del Pacto Verde: la hoja de ruta de la Unión Europea para lograr una economía sostenible, climáticamente neutra y justa. Los pilares del Pacto Verde incluyen:
- Una transición energética que reduzca las emisiones y mejore la eficiencia.
- El fomento de la economía circular, promoviendo el reciclaje, la reutilización y la reparación de productos para minimizar residuos.
- El impulso de prácticas agrícolas más sostenibles.
- La restauración de la naturaleza y la biodiversidad, protegiendo hábitats naturales y reduciendo la contaminación de aire, agua y suelo.
- La garantía de la justicia social, a través de una transición que facilite que ningún país o comunidad quede atrás.
A través de esta estrategia integral, la UE aspira a convertirse en la primera economía del mundo competitiva y eficiente en el uso de los recursos, logrando emisiones netas de gases de efecto invernadero cero para 2050. El Espacio de Datos del Pacto Verde se posiciona como una herramienta clave para alcanzar estos objetivos. Integrados en la Estrategia Europea del Dato, los espacios de datos son entornos digitales que permite el intercambio fiable de datos, al tiempo que se mantiene la soberanía y se garantiza la confianza y la seguridad en virtud de un conjunto de normas acordadas mutuamente.
En este caso concreto, el GDDS integrará datos de gran valor sobre biodiversidad, contaminación cero, economía circular, cambio climático, servicios forestales, movilidad inteligente y cumplimiento medioambiental. Estos datos serán fáciles de localizar, interoperables, accesibles y reutilizables bajo los principios FAIR (Findability, Accessibility, Interoperability, Reusability).
El GDDS se implementará a través del proyecto SAGE (Espacio de datos para una Europa verde y sostenible) y se basará en los resultados de la iniciativa GREAT (Gobernanza de la innovación responsable).
Un informe con recomendaciones para el GDDS
Como vimos en un artículo anterior, cuatro proyectos pioneros están sentando las bases de este ecosistema: AD4GD, B-Cubed, FAIRiCUBE y USAGE. Estos proyectos, financiados en el marco de la convocatoria HORIZON, han analizado y documentado durante varios años los requisitos necesarios para garantizar que el GDDS siga los principios FAIR. Fruto de ese trabajo, se ha elaborado el informe “Policy Brief: Unlocking The Full Potential Of The Green Deal Data Space”. Se trata de un conjunto de recomendaciones que buscan servir de guía para la implementación exitosa del Espacio de Datos del Pacto Verde.
El informe destaca cinco grandes áreas en las que se concentran los desafíos de la construcción del GDDS:
1. Armonización de datos
Los datos ambientales son heterogéneos, ya que provienen de distintas fuentes: satélites, sensores, estaciones meteorológicas, registros de biodiversidad, empresas privadas, institutos de investigación, etc. Cada proveedor utiliza sus propios formatos, escalas y metodologías. Esto provoca incompatibilidades que dificultan la comparación y la combinación de datos. Para solucionarlo, es esencial:
- Adoptar estándares y vocabularios internacionales ya existentes, como INSPIRE, que abracan múltiples ámbitos temáticos.
- Evitar formatos propietarios, primando aquellos abiertos y bien documentados.
- Invertir en herramientas que permitan transformar datos de un formato a otro de forma sencilla.
2. Interoperabilidad semántica
Garantizar la interoperabilidad semántica es crucial para que los datos puedan entenderse y reutilizarse en diferentes contextos y disciplinas, algo fundamental cuando se comparten datos entre comunidades tan diversas como las que participan en los objetivos del Pacto Verde. A ello hay que sumar que la Ley de Datos (Data Act) obliga a que los participantes en espacios de datos ofrezcan descripciones legibles por máquinas de los datasets, garantizando así su localización, acceso y reutilización. Además, exige que los vocabularios, taxonomías y listas de códigos empleados estén documentados de forma pública y coherente. Para lograrlo es necesario:
- Usar datos enlazados (linked data) y metadatos que ofrezcan conceptos claros y compartidos, a través de vocabularios, ontologías y estándares como los desarrollados por el OGC o las normas ISO.
- Usar los estándares que ya existen para organizar y describir los datos, y solo crear extensiones nuevas cuando sea realmente necesario.
- Mejorar los vocabularios internacionales ya aceptados, dándoles más precisión y aprovechando que las comunidades científicas ya los utilizan ampliamente.
3. Metadatos y curación de datos
Los datos solo alcanzan su máximo valor si están acompañados de metadatos claros que expliquen su origen, calidad, restricciones de uso y condiciones de acceso. Sin embargo, la gestión deficiente de metadatos sigue siendo una barrera importante. En muchos casos, los metadatos son inexistentes, están incompletos o mal estructurados, y a menudo se pierden al traducirse entre estándares no interoperables. Para mejorar esta situación se debe:
- Ampliar los estándares de metadatos existentes para incluir elementos críticos como observaciones, mediciones, trazabilidad de origen, etc.
- Fomentar la interoperabilidad entre estándares de metadatos en uso, mediante herramientas de mapeo y transformación que respondan tanto a las necesidades de datos comerciales como abiertos.
- Reconocer y financiar la creación y mantenimiento de metadatos en proyectos europeos, incorporando la obligación de generar un catálogo estandarizado desde el inicio en los planes de gestión de datos.
4. Intercambio de datos y provisión federada
El GDDS no busca solo centralizar toda la información en un solo repositorio, sino permitir que múltiples actores compartan datos de manera federada y segura. Por tanto, es necesario conseguir un equilibrio entre el acceso abierto y la protección de derechos y privacidad. Para ello se requiere:
- Adoptar y promover tecnologías abiertas y fáciles de usar, que permitan la integración entre datos abiertos y protegidos, cumpliendo con el Reglamento General de Protección de Datos (RGPD).
- Garantizar la integración de diversas API utilizadas por los proveedores de datos y las comunidades de usuarios, acompañadas de demostradores y directrices claras. No obstante, es necesario impulsar el uso de API estandarizadas para facilitar una implantación más fluida, como por ejemplo, las API de OGC (Open Geospatial Consortium) para activos geoespaciales.
- Ofrecer herramientas de conversión y especificaciones claras para permitir la interoperabilidad entre API y formatos de datos.
En paralelo al desarrollo del Eclipse Dataspace Connectors (una tecnología de código abierto para facilitar la creación de espacios de datos), se propone explorar alternativas como catálogos en blockchain o certificados digitales, siguiendo ejemplos como el sistema FACTS (Federated Agile Collaborative Trusted System).
5. Gobernanza inclusiva y sostenible
El éxito del GDDS dependerá de establecer un marco de gobernanza sólido que garantice transparencia, participación y sostenibilidad a largo plazo. No se trata solo de normas técnicas, sino también de reglas justas y representativas. Para avanzar en ello es clave:
- Usar exclusivamente nubes europeas para asegurar la soberanía de los datos, reforzar la seguridad y cumplir con la normativa de la UE, algo que cobra especial importancia ante los desafíos globales actuales.
- Integrar plataformas abiertas como Copernicus, el Portal Europeo de Datos e INSPIRE en el GDDS fortalece la interoperabilidad y facilita el acceso a datos públicos. En este sentido, es necesario diseñar estrategias eficaces para atraer proveedores de datos abiertos y evitar que el GDDS se convierta en un entorno comercial o restringido.
- Obligar a citar los datos en publicaciones académicas financiadas con fondos públicos aumenta su visibilidad y apoyar iniciativas de estandarización fortalece la visibilidad de los datos y asegura su mantenimiento a largo plazo.
- Ofrecer formación integral y promover el uso cruzado de herramientas de armonización evita la creación de nuevos silos de datos y mejora la colaboración entre dominios.
La siguiente imagen resume la relación entre estos bloques:
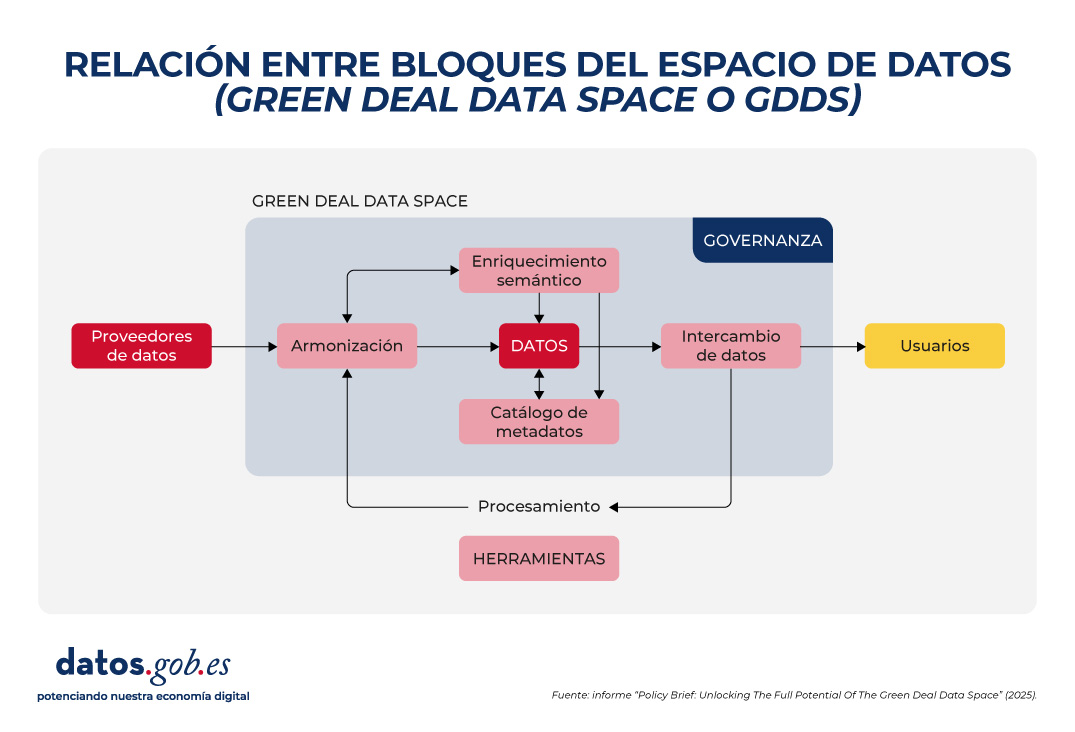
Conclusión
Todas estas recomendaciones inciden en una idea central: construir un Espacio de Datos del Pacto Verde que cumpla con los principios FAIR no solo es una cuestión técnica, sino también estratégica y ética. Requiere colaboración entre sectores, compromiso político, inversión en capacidades y una gobernanza inclusiva que garantice la equidad y la sostenibilidad. Si Europa logra consolidar este ecosistema digital, estará mejor preparada para afrontar los desafíos medioambientales con decisiones informadas, transparentes y orientadas al bien común.
Noticia
La normativa UNE 0087 define por primera vez en España los principios y requisitos clave para crear y operar en espacios de datos
El pasado día 17 de julio se publicó oficialmente la Especificación UNE 0087 “Definición y caracterización de los Espacios de Datos”, la primera norma española que establece un marco común para estos entornos digitales.
Este hito ha sido posible gracias a la colaboración del Centro de Referencia de Espacios de Datos (CRED), con la Asociación Española de Normalización (UNE). Dicha normativa, que fue aprobada el 20 de junio de 2025 define tres pilares claves en la adhesión a los espacios de datos: interoperabilidad, gobernanza y creación de valor, con el objetivo de ofrecer seguridad jurídica, confianza y un lenguaje técnico común en la economía del dato.
Para su creación, se han formado tres grupos de trabajo con más de 50 participantes de entidades tanto públicas como privadas que han aportado su conocimiento para definir los principios y características clave de estos sistemas colaborativos. Estos grupos de trabajo se han coordinado de la siguiente manera:
- GT1: Definición de Espacios de Datos y Modelo de Madurez.
- GT2: Interoperabilidad Técnica y Semántica.
- GT3: Interoperabilidad legal y organizativa.
La publicación de esta normativa supone, por tanto, un documento de referencia para la creación de espacios de datos seguros y confiables, aplicable en todos los sectores productivos y que sirve de base para futuros documentos guía.
De este modo, para ofrecer unas directrices que faciliten la implementación y desarrollo de los espacios de datos, nace la especificación UNE 0087:2025 para crear un marco inclusivo de referencia que oriente a las organizaciones y que estas se puedan aprovechar de toda la información en un entorno de cumplimiento normativo y soberanía digital. La publicación de esta normativa tiene una serie de beneficios:
- Acelerar el despliegue de los espacios de datos en todos los sectores de la economía.
- Favorecer la sostenibilidad y el escalado / crecimiento de los ecosistemas de compartición de datos.
- Fomentar la colaboración pública /privada, asegurando la convergencia con Europa.
- Avanzar hacia la autonomía tecnológica y la soberanía de los datos en los ecosistemas.
- Promover el descubrimiento de nuevas oportunidades de negocio innovadoras fomentando la colaboración y creación de alianzas estratégicas.
Dentro de la especificación se definen qué son los espacios de datos, de establecen sus características clave de interoperabilidad, gobernanza y generación de valor y se determinan cuáles con los beneficios de su adhesión. La especificación está publicada aquí y es importante añadir que, aunque aparezca un coste de descarga, tiene carácter gratuito, gracias al patrocinio de la Dirección General del Dato.
Con esta herramienta, España da un paso firme en la consolidación de espacios de datos cohesivos, seguros y alineados con el marco europeo, facilitando la implantación de proyectos transversales en diferentes sectores.
Noticia
España da un paso clave hacia la economía del dato con el lanzamiento del Kit Espacios de Datos, un programa de ayudas que subvencionará la integración de entidades públicas y privadas en espacios de datos sectoriales.
Los espacios de datos son ecosistemas seguros en los que organizaciones, tanto públicas como privadas, comparten información de forma interoperable, bajo reglas comunes y con garantías de privacidad. Éstos permiten desarrollar nuevos productos, mejorar la toma de decisiones y aumentar la eficiencia operativa, en sectores como la salud, la movilidad o la agroalimentación, entre otros.
Hoy, el Ministerio para la Transformación Digital y de la Función Pública, a través de la Secretaría de Estado de Digitalización e Inteligencia Artificial ha publicado en el BOE las bases que regulan la concesión de ayudas a entidades interesadas en incorporarse de forma efectiva a un espacio de datos.
Este programa, que recibe el nombre de “Kit Espacios de Datos”, estará gestionado por Red.es y subvencionará los costes en los que hayan incurrido las entidades beneficiarias para conseguir su incorporación a un espacio de datos elegible, es decir, que cumpla los requisitos fijados en las bases, a contar desde el día de la publicación de estas.
Destinatarios y financiación
Este plan de ayudas está dirigido a entidades tanto públicas como privadas, así como Administraciones Públicas. Dentro de los beneficiarios de estas ayudas se encuentran los participantes, que son aquellas entidades que buscan integrase en estos ecosistemas para compartir y aprovechar datos y servicios.
Para la ejecución de este plan, el Gobierno ha lanzado una ayuda de hasta 60 millones de euros que se repartirán, según el tipo de entidad o el nivel de integración de la siguiente manera:
- Entidades privadas y públicas con actividad económica tendrán una ayuda de hasta 15.000€ en régimen de incorporación efectiva o de hasta 30.000€ si se incorpora como proveedor.
- Por otro lado, las Administraciones Públicas tendrán financiación de hasta 25.000€ si se incorporan de manera efectiva, o de hasta 50.000€ si lo hacen como proveedor.
La incorporación de empresas de diferentes sectores en los espacios de datos generará beneficios tanto a nivel empresarial como para la economía nacional como el aumento de la capacidad de innovación de las empresas beneficiarias, la creación de nuevos productos y servicios basados en el análisis de los datos y la mejora de la eficiencia operativa y toma de decisiones.
Se prevé que la convocatoria se publique durante el cuarto trimestre de 2025. Las subvenciones se solicitarán en régimen de concurrencia no competitiva, por orden de llegada y hasta agotar los fondos disponibles.
Con la publicación en el BOE de estas bases reguladoras se pretende dinamizar el ecosistema de datos en España, fortalecer la competitividad de la economía en el ámbito global y consolidar la sostenibilidad financiera de modelos de negocio innovadores.
Más información:
Bases reguladoras en el BOE.
Página de LinkedIn del Centro de Referencia de Espacios de Datos.
Blog
Hace tan solo unos días, la Dirección General de Tráfico publicó el nuevo Programa Marco para Prueba de Vehículos Automatizados que, entre otras medidas, contempla “la entrega obligatoria de informes, tanto periódicos y finales como en caso de incidentes, que permitirán a la DGT evaluar la seguridad de las pruebas y publicar información básica […] garantizando la transparencia y la confianza pública”.
El avance de la tecnología digital está facilitando que el sector del transporte se enfrente a una revolución sin precedentes respecto a la conducción de vehículos autónomos, ofreciendo mejorar significativamente la seguridad vial, la eficiencia energética y la accesibilidad de la movilidad.
El despliegue definitivo de estos vehículos depende en gran medida de la disponibilidad, calidad y accesibilidad de grandes volúmenes de datos, así como de un marco jurídico adecuado que asegure la protección de los diversos bienes jurídicos implicados (datos personales, secreto empresarial, confidencialidad…), la seguridad del tráfico y la transparencia. En este contexto, los datos abiertos y la reutilización de la información del sector público se manifiestan como elementos esenciales para el desarrollo responsable de la movilidad autónoma, en particular a la hora de garantizar unos adecuados niveles de seguridad en el tráfico.
La dependencia de los datos en los vehículos autónomos
La tecnología que da soporte a los vehículos autónomos se sustenta en la integración de una compleja red de sensores avanzados, sistemas de inteligencia artificial y algoritmos de procesamiento en tiempo real, lo que les permite identificar obstáculos, interpretar las señales de tráfico, predecir el comportamiento de otros usuarios de la vía y, de una forma colaborativa, planificar rutas de forma completamente autónoma.
En el ecosistema de vehículos autónomos, la disponibilidad de datos abiertos de calidad resulta estratégica para:
- Mejorar la seguridad vial, de manera que puedan utilizarse datos de tráfico en tiempo real que permitan anticipar peligros, evitar accidentes y optimizar rutas seguras a partir del análisis masivo de datos.
- Optimizar la eficiencia operativa, ya que el acceso a información actualizada sobre el estado de las vías, obras, incidencias y condiciones de tráfico permite una planificación más eficiente de los desplazamientos.
- Impulsar la innovación sectorial, facilitando la creación de nuevas herramientas digitales que facilitan la movilidad.
En concreto, para garantizar un funcionamiento seguro y eficiente de este modelo de movilidad se requiere el acceso continuo a dos categorías fundamentales de datos:
- Datos variables o dinámicos, que ofrecen información en constante cambio como la posición, velocidad y comportamiento de otros vehículos, peatones, ciclistas o las condiciones meteorológicas en tiempo real.
- Datos estáticos, que comprenden información relativamente permanente como la localización exacta de señales de tráfico, semáforos, carriles, límites de velocidad o las principales características de la infraestructura viaria.
El protagonismo de los datos suministrados por las entidades públicas
Las fuentes de las que provienen tales datos son ciertamente diversas. Esto resulta de gran relevancia por lo que se refiere a las condiciones en que dichos datos estarán disponibles. En concreto, algunos de los datos son proporcionados por entidades públicas, mientras que en otros casos el origen proviene de empresas privadas (fabricantes de vehículos, proveedoras de servicios de telecomunicaciones, desarrolladoras de herramientas digitales…) con sus propios intereses o, incluso, de las personas que utilizan los espacios públicos, los dispositivos y las aplicaciones digitales.
Esta diversidad exige un diferente planteamiento a la hora de facilitar la disponibilidad de los datos en condiciones adecuadas, en concreto por las dificultades que pueden plantearse desde el punto de vista jurídico. Con relación a las Administraciones Públicas, la Directiva (UE) 2019/1024 relativa a datos abiertos y reutilización de información del sector público establece obligaciones claras que serían de aplicación, por ejemplo, a la Dirección General de Tráfico, las Administraciones titulares de las vías públicas o los municipios en el caso de los entornos urbanos. Asimismo, el Reglamento (UE) 2022/868 sobre gobernanza europea de datos refuerza este marco normativo, en particular por lo que se refiere a la garantía de los derechos de terceros y, en concreto, la protección de datos personales.
Más aún, algunos conjuntos de datos deberían proporcionarse en las condiciones establecidas para los datos dinámicos, esto es, aquellos “sujetos a actualizaciones frecuentes o en tiempo real, debido, en particular, a su volatilidad o rápida obsolescencia”, que habrán de estar disponibles “para su reutilización inmediatamente después de su recopilación, a través de las API adecuadas y, cuando proceda, en forma de descarga masiva”.
Incluso, cabría pensar que la categoría de datos de alto valor presenta un especial interés en el contexto de los vehículos autónomos dado su potencial para facilitar la movilidad, en concreto si tenemos en cuenta su potencial para:
- Impulsar la innovación tecnológica, ya que facilitarían a fabricantes, desarrolladores y operadores acceder a información fiable y actualizada, esencial para el desarrollo, validación y mejora continua de sistemas de conducción autónoma.
- Facilitar la supervisión y evaluación desde la perspectiva de la seguridad, ya que la transparencia y accesibilidad de estos datos son presupuestos esenciales desde esta perspectiva.
- Dinamizar el desarrollo de servicios avanzados, puesto que los datos sobre infraestructura vial, señalización, tráfico e, incluso, los resultados de pruebas realizadas en el contexto del citado Programa Marco constituyen la base para nuevas aplicaciones y servicios de movilidad que benefician al conjunto de la sociedad.
Sin embargo, esta condición no aparece expresamente recogida para los datos vinculados al tráfico en la definición realizada a nivel europeo, por lo que, al menos de momento, no cabría exigir a las entidades públicas la difusión de los datos que aplican a los vehículos autónomos en las singulares condiciones establecidas para los datos de alto valor. No obstante, en este momento de transición para el despliegue de los vehículos autónomos, resulta fundamental que las Administraciones públicas publiquen y mantengan actualizados en condiciones adecuadas para su tratamiento automatizado, algunos conjuntos de datos, como los relativos a:
- Señales viales y elementos de señalización vertical.
- Estados de semáforos y sistemas de control de tráfico.
- Configuración y características de carriles.
- Información sobre obras y alteraciones temporales de tráfico.
- Elementos de infraestructura vial críticos para la navegación autónoma.
La reciente actualización del catálogo oficial de señales de tráfico, que entra en vigor el 1 de julio de 2025 incorpora señalizaciones adaptadas a nuevas realidades, como es el caso de la movilidad personal. Sin embargo, requiere de una mayor concreción por lo que se refiere a la disponibilidad de los datos relativos a las señales en las referidas condiciones. Para ello será necesaria la intervención de las autoridades responsables de la señalización de las vías.
La disponibilidad de los datos en el contexto del espacio europeo de movilidad
Partiendo de estos condicionamientos y de la necesidad de disponer de los datos de movilidad generados por empresas privadas y particulares, los espacios de datos aparecen como el entorno jurídico y de gobernanza óptimo para facilitar su accesibilidad en condiciones adecuadas.
En este sentido, las iniciativas para el despliegue del espacio de datos europeo de movilidad, creado en 2023, constituyen una oportunidad para integrar en su diseño y configuración medidas que den soporte a la necesidad de acceso a los datos que exigen los vehículos autónomos. Así pues, en el marco de esta iniciativa sería posible liberar el potencial de los datos de movilidad y, en concreto:
- Facilitar la disponibilidad de los datos en condiciones específicas para las necesidades de los vehículos autónomos.
- Promover la interconexión de diversas fuentes de datos vinculadas a los medios de transporte ya existentes, pero también de los emergentes.
- Acelerar la transformación digital que suponen los vehículos autónomos.
- Reforzar la soberanía digital de la industria automovilística europea, reduciendo la dependencia de grandes corporaciones tecnológicas extranjeras.
En definitiva, los vehículos autónomos pueden suponer una transformación fundamental en la movilidad tal y como hasta ahora se ha concebido, pero su desarrollo depende entre otros factores de la disponibilidad, calidad y accesibilidad de datos suficientes y adecuados. El Proyecto de Ley de Movilidad Sostenible que actualmente se encuentra en tramitación en las Cortes Generales constituye una magnífica oportunidad para reforzar el papel de los datos a la hora de facilitar la innovación en este ámbito, lo que sin duda favorecería el desarrollo de los vehículos autónomos. Para ello será imprescindible, de una parte, contar con un entorno de compartición de datos que haga compatible el acceso a los datos con las adecuadas garantías para los derechos fundamentales y la seguridad de la información; y, de otra, diseñar un modelo de gobernanza que, como se enfatiza en el Programa impulsado por la Dirección General de Tráfico, facilite la participación colaborativa de “fabricantes, desarrolladores, importadores y operadores de flotas establecidos en España o en la Unión Europea”, lo que plantea importantes desafíos en la disponibilidad de los datos.
Contenido elaborado por Julián Valero, catedrático de la Universidad de Murcia y Coordinador del Grupo de Investigación “Innovación, Derecho y Tecnología” (iDerTec). Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Blog
Los datos son un recurso fundamental para mejorar nuestra calidad de vida porque permiten mejorar los procesos de toma de decisiones para crear productos y servicios personalizados, tanto en el sector público como en el privado. En contextos como la salud, la movilidad, la energía o la educación, el uso de datos facilita soluciones más eficientes y adaptadas a las necesidades reales de las personas. No obstante, en el trabajo con datos, la privacidad juega un papel clave. En este post, analizaremos cómo los espacios de datos, el paradigma de computación federada y el aprendizaje federado, una de sus aplicaciones más potentes, plantean una solución equilibrada para aprovechar el potencial de los datos sin poner en riesgo la privacidad. Además, resaltaremos cómo el aprendizaje federado también puede usarse con datos abiertos para mejorar su reutilización de forma colaborativa, incremental y eficiente.
La privacidad, clave en la gestión de datos
Como se ha mencionado anteriormente, el uso intensivo de datos exige una creciente atención a la privacidad. Por ejemplo, en salud digital, un mal uso secundario de datos de historias clínicas electrónicas podría vulnerar derechos fundamentales de pacientes. Una forma eficaz de preservar la privacidad es mediante ecosistemas de datos que prioricen la soberanía de los datos, como es el caso de los espacios de datos. Un espacio de datos es un sistema de gestión federada de datos que permite su intercambio de manera confiable entre proveedores y consumidores. Además, el espacio de datos garantiza la interoperabilidad de los datos para crear productos y servicios que generen valor. En un espacio de datos, cada proveedor mantiene sus propias normas de gobernanza, conservando el control sobre sus datos (es decir, la soberanía sobre sus datos), a la vez que se posibilita su reutilización por consumidores. Esto implica que cada proveedor debe poder decidir qué datos comparte, con quién y bajo qué condiciones, garantizando el cumplimiento de sus intereses y obligaciones legales.
Computación federada y espacios de datos
Los espacios de datos representan una evolución en la gestión de datos, relacionada con un paradigma denominado computación federada (federated computing), donde los datos se reutilizan sin necesidad de que haya un trasiego de datos desde los proveedores de datos hacia los consumidores. En la computación federada, los proveedores transforman sus datos en resultados intermedios que preservan la privacidad con el fin de poder ser enviados a los consumidores de datos. Además, esto posibilita que puedan aplicarse otras técnicas de mejora de la privacidad de datos (Privacy-Enhancing Technologies). La computación federada se alinea perfectamente con arquitecturas de referencia como Gaia-X y su Trust Framework, que establece los principios y requisitos para garantizar un intercambio de datos seguro, transparente y conforme a reglas comunes entre proveedores y consumidores de datos.
Aprendizaje federado
Una de las aplicaciones más potentes de la computación federada es el aprendizaje automático federado (federated learning), una técnica de inteligencia artificial que permite entrenar modelos sin necesidad de centralizar los datos. Es decir, en lugar de enviar los datos a un servidor central para procesarlos, lo que se envía son los modelos entrenados localmente por cada participante.
Estos modelos se combinan posteriormente de manera centralizada para crear un modelo global. A modo de ejemplo, imaginemos un consorcio de hospitales que quiere desarrollar un modelo predictivo para detectar una enfermedad rara. Cada hospital posee datos sensibles de sus pacientes, y compartirlos abiertamente no es viable por cuestiones de privacidad (incluso otras cuestiones legales o éticas). Con el aprendizaje federado, cada hospital entrena localmente el modelo con sus propios datos, y solo comparte los parámetros del modelo (resultados del entrenamiento) de manera centralizada. Así, el modelo final aprovecha la diversidad de datos de todos los hospitales sin comprometer la privacidad individual y las reglas de gobernanza de datos de cada hospital.
El entrenamiento en el aprendizaje federado suele seguir un ciclo iterativo:
- Un servidor central inicia un modelo base y lo envía a cada uno de los nodos distribuidos participantes.
- Cada nodo entrena el modelo localmente con sus datos.
- Los nodos devuelven solo los parámetros del modelo actualizado, no los datos (es decir, se evita el trasiego de datos).
- El servidor central agrega las actualizaciones en los parámetros, resultados del entrenamiento en cada nodo y actualiza el modelo global.
- El ciclo se repite hasta alcanzar un modelo suficientemente preciso.
Figura 1. Visual que representa el proceso de entrenamiento del aprendizaje federados. Elaboración propia
Este enfoque es compatible con diversos algoritmos de aprendizaje automático, incluyendo redes neuronales profundas, modelos de regresión, clasificadores, etc.
Beneficios y desafíos del aprendizaje federado
El aprendizaje federado ofrece múltiples beneficios al evitar el trasiego de datos. Destacamos los siguientes:
- Privacidad y cumplimiento normativo: al permanecer en su origen, se reducen significativamente los riesgos de exposición de los datos y se facilita el cumplimiento de regulaciones como el Reglamento General de Protección de Datos (RGPD).
- Soberanía de los datos: cada entidad mantiene el control total sobre sus datos, lo que evita conflictos de competitividad.
- Eficiencia: evita los costes y la complejidad de intercambiar grandes volúmenes de datos, lo que acelera los tiempos de procesamiento y desarrollo.
- Confianza: facilita la colaboración entre organizaciones sin fricciones.
Existen diversos casos de uso en los cuales el aprendizaje federado es necesario, por ejemplo:
- Salud: hospitales y centros de investigación pueden colaborar en modelos predictivos sin compartir datos de pacientes.
- Finanzas: bancos y aseguradoras pueden construir modelos de detección de fraude o análisis de riesgo compartido, respetando la confidencialidad de sus clientes.
- Turismo inteligente: los destinos turísticos pueden analizar flujos de visitantes o patrones de consumo sin necesidad de unificar las bases de datos de sus actores (tanto públicos como privados).
- Industria: empresas del mismo sector pueden entrenar modelos para mantenimiento predictivo o eficiencia operativa sin revelar datos competitivos.
Aunque sus beneficios son claros en diversidad de casos de uso, el aprendizaje federado también presenta retos técnicos y organizativos:
- Heterogeneidad de datos: los datos locales pueden tener diferentes formatos o estructuras, lo que dificulta el entrenamiento. Además, el esquema de estos datos puede cambiar con el tiempo, lo que representa una dificultad añadida.
- Datos desbalanceados: algunos nodos pueden tener más datos o de mayor calidad que otros, lo que puede sesgar el modelo global.
- Costes computacionales locales: cada nodo necesita recursos suficientes para entrenar el modelo localmente.
- Sincronización: el ciclo de entrenamiento requiere buena coordinación entre nodos para evitar latencias o errores.
Más allá del aprendizaje federado
Aunque la aplicación más destacada de la computación federada es el aprendizaje federado, están surgiendo muchas otras aplicaciones adicionales en la gestión de datos como, por ejemplo, el análisis de datos federado (federated analytics). El análisis de datos federado permite realizar análisis estadísticos y descriptivos sobre datos distribuidos sin necesidad de moverlos a los consumidores, sino que cada proveedor realiza localmente los cálculos estadísticos requeridos y solo comparte con el consumidor los resultados agregados según sus requisitos y permisos. En la siguiente tabla se muestran las diferencias entre aprendizaje federado y análisis de datos federado.
|
Criterio |
Aprendizaje federado |
Análisis de datos federado |
|
Objetivo |
Predicción y entrenamiento de modelos de aprendizaje automático. | Análisis descriptivo y cálculo de estadísticas. |
| Tipo de tarea | Tareas predictivas (por ejemplo, clasificación o regresión). | Tareas descriptivas (por ejemplo, medias o correlaciones). |
| Ejemplo | Entrenar modelos de diagnóstico de enfermedades a través de imágenes médicas procedentes de diversos hospitales. | Cálculo de indicadores sanitarios de un área de salud sin mover los datos entre hospitales. |
| Salida esperada | Modelo global entrenado. | Resultados estadísticos agregados. |
| Naturaleza | Iterativa. | Directa. |
| Complejidad computacional | Alta. | Media. |
| Algoritmos | Aprendizaje automático. | Algoritmos estadísticos. |
Figura 1. Tabla comparativa. Fuente: elaboración propia
Aprendizaje federado y datos abiertos: una simbiosis por explorar
En principio, los datos abiertos resuelven los problemas de privacidad antes de su publicación, por lo que se podría pensar que no es preciso hacer uso de técnicas de aprendizaje federado. Nada más lejos de la realidad. El uso de técnicas de aprendizaje federado puede aportar ventajas significativas en la gestión y explotación de los datos abiertos. De hecho, el primer aspecto a resaltar es que los portales de datos abiertos como datos.gob.es o data.europa.eu son entornos federados. Por ello, en estos portales, la aplicación de aprendizaje federado sobre conjuntos de datos de gran tamaño permitiría entrenar modelos directamente en origen, evitando costes de transferencia y procesamiento. Por otro lado, el aprendizaje federado facilitaría la combinación de datos abiertos con otros datos sensibles sin comprometer la privacidad de estos últimos. Finalmente, la naturaleza de una gran variedad de tipos de datos abiertos es muy dinámica (como los datos de tráfico), por lo que el aprendizaje federado habilitaría un entrenamiento incremental, considerando automáticamente nuevas actualizaciones de conjuntos de datos abiertos a medida que se publican, sin necesidad de reiniciar costosos procesos de entrenamiento.
Aprendizaje federado, base para una IA respetuosa con la privacidad
El aprendizaje automático federado representa una evolución necesaria en la forma en que desarrollamos servicios de inteligencia artificial, especialmente en contextos donde los datos son sensibles o están distribuidos entre varios proveedores. Su alineación natural con el concepto de espacio de datos lo convierte en una tecnología clave para impulsar la innovación basada en la compartición de datos, teniendo en cuenta la privacidad y manteniendo la soberanía de los datos.
A medida que la regulación (como el Reglamento relativo al Espacio Europeo de Datos de Salud) y las infraestructuras de espacios de datos evolucionen, el aprendizaje federado, y otros tipos de computación federada, jugarán un papel cada vez más importante en la compartición de datos, maximizando el valor de los datos, pero sin comprometer la privacidad. Finalmente, cabe destacar que, lejos de ser innecesario, el aprendizaje federado puede convertirse en un aliado estratégico para mejorar la eficiencia, gobernanza e impacto de los ecosistemas de datos abiertos.
Jose Norberto Mazón, Catedrático de Lenguajes y Sistemas Informáticos de la Universidad de Alicante. Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.