
Description
For years, the debate on data reuse has focused mainly on publishing processes, i.e. how to expose more and better datasets from provider entities. On the other hand, support for those who must identify, understand, combine and convert them into value-added products or services has often taken a back seat.
With the emergence of artificial intelligence (AI), this view began to change. The question was no longer just how much data exists, but how to transform dispersed, heterogeneous and subject to different rules data into useful raw material for innovation (using, among others, advanced analytics and AI techniques). In this context, the European Union has begun to outline data labs as a key part of its Strategy for a Data Union: an initiative aimed at increasing the availability of quality data for AI, simplifying the applicable rules and better connecting existing data sources (data spaces, open data portals, statistical portals, etc.) with innovation ecosystems.
Data labs, the new concept that brings together services for the reuse of data
And what exactly are data labs? The European Union describes them as specialized operational centers that will give companies and researchers access to diverse datasets and offer services related to the application of AI techniques on that data.
This represents a relevant change of approach because the focus, in addition to helping the provider to publish the data, is on accompanying the consumer so that they can find, prepare and reuse the data more easily. In this sense, one of the most interesting contributions of data labs is that they shift the focus from the simple accumulation of data to its quality, preparation and effective reuse.
In data science and AI projects, a version of the Pareto rule has been repeated for years, stating that around 80% of the time is spent locating, cleaning, integrating, documenting, and preparing data, while only the remaining 20% is reserved for analyzing or training models. It is not a mathematical law, but it is a reality that recent studies continue to place in the same order of magnitude.
And that's precisely where data labs can make a difference, turning these percentages around, as they help discover relevant sources, improve metadata, harmonize formats, solve access problems, and advance curation tasks that turn raw data into a truly usable asset. In other words, it's not just about having more data, it's about having better data.
Scope and added value of data labs
The EU places data labs in a very specific context: increasing access to quality data for AI, simplifying the regulatory framework and strengthening Europe's position in the global data economy. Seen from the perspective of reuse, this translates into three very recognizable needs: finding and accessing the right data, operating with legal certainty and trust, and preparing the data with sufficient quality to generate impact. Specifically, the scope of data labs encompasses six areas:
- Infrastructure and technical tools: they provide secure environments and tools to manage data (from anonymization to synthetic data generation).
- Data pooling: they pool heterogeneous data from various sources, combining them according to the applicable rules.
- Curation and labeling: Help enrich datasets to make them more representative and useful to AI.
- Regulatory guidance and training: Provide practical guidance on how to comply with European regulations applicable to data and AI.
- Connection between data spaces and AI ecosystems: they act as a bridge between European data spaces and those who develop AI solutions.
- Facilitating access to data: they help locate relevant datasets and overcome technical, legal, or administrative barriers to using them.
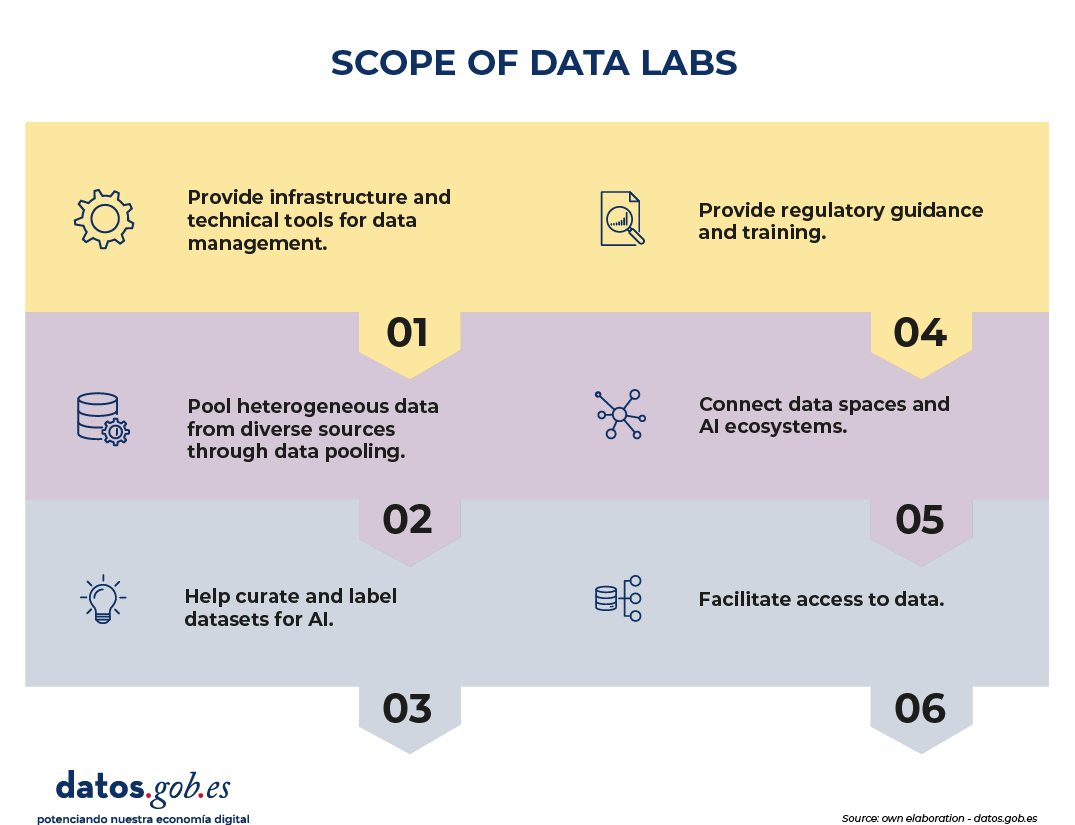
Figure 1. Scope of datalabs. Source: own elaboration - datos.gob.es
For all these reasons, the value of the data labs It is not in "giving access" to the data (in fact, this is already done by data spaces or open data portals), but in making the data operational. The data labs will be able to offer services such as data set cleansing and enrichment, normalization, anonymization, synthetic data generation, and data pooling compatible with competition regulations. Therefore, they offer less friction to move from raw data to data ready to train, test or deploy AI solutions.
Data labs' relationship with open data and data spaces
In the European framework, open data remains the most accessible layer of the ecosystem, especially when it comes from the public sector. The concept of high-value datasets (HVDs) stands out because the European regulations themselves underline that these sets are key sources for the development of AI. In fact, the Strategy for a Data Union plans to expand the list of high-value data to areas such as legal, judicial and administrative data by 2026, as well as make 30 million digitised cultural objects available for AI training through Europeana. Therefore, data labs add an additional layer to open data portals, responsible for the search and combination of data (between open datasets from different sources, but also between open datasets and data from other sources), as well as its preparation.
Data labs do not replace open data initiatives or data space initiatives, but rather complement them.
Moreover, the EU explicitly defines that data labs should act as the bridge between data spaces and the AI ecosystem. It could be said, in a simplified way, that data spaces bring order to the availability of data while data labs turn that availability into a usable resource to innovate through the use of AI. That is, data spaces have adequate infrastructure and governance to share and reuse data and data labs convert that data availability into effective use, helping to locate, gather, organize, curate, label and prepare that data for AI and advanced analytics use cases.
By bringing together both scenarios (open data and data spaces), data labs could be used to detect which new public sector datasets would deserve to be opened or strengthened from the datasets available in a data space.
Data labs and AI factories: the perfect pairing
AI factories are conceived as ecosystems that bring together computing power, data, and talent to develop AI models and advanced applications. Data labs will be deployed precisely in that environment, as a kind of data services layer for those factories. The complementarity is clear: an AI factory without quality data runs the risk of being left with underutilized computing capacity, while a data lab without access to AI infrastructures has a harder time closing the loop from data to model.
What is not a data lab?
It is also worth clarifying a possible confusion regarding the term data lab. We are not talking here about "safe rooms" or controlled environments for access to protected data for research purposes, such as ES_Datalab, which includes data from the INE or the Bank of Spain. These environments are intended for controlled access to microdata and other sensitive information for research purposes, while preserving confidentiality and privacy.
European data labs have a distinct and broader scope, as they are an instrument for connecting public and private data (including data spaces) and AI innovation through access, preparation, curation, and regulatory support services. They may incorporate protective techniques, but they do not equate to a safe room.
In conclusion, the European commitment of data labs consists of moving from talking only about data publication to talking about activating data for innovation based on its reuse. This is very useful for different profiles:
- For technical profiles, data labs promise more prepared and better documented data.
- For companies in the infomediary industry, they open up opportunities in discovery, quality, metadata, labeling, integration, or compliance services.
- For the public administration, they can become a very useful mechanism to guide what to publish in open access, with what quality and for what uses.
- For the research community, they offer the possibility of bringing closer access to data, governance and computing infrastructure.
Therefore, data labs do not compete with open data or data spaces, they simply help both generate more value in practice.
Jose Norberto Mazón, Professor of Computer Languages and Systems at the University of Alicante. The content and views expressed in this publication are the sole responsibility of the author.


