Noticia
Between 2 April and 16 May, applications for the call on aid for the digital transformation of strategic productive sectors may be submitted at the electronic headquarters of the Ministry for Digital Transformation and Civil Service. Order TDF/1461/2023, of 29 December, modified by Order TDF/294/2024, regulates grants totalling 150 million euros for the creation of demonstrators and use cases, as part of a more general initiative of Sectoral Data Spaces Program, promoted by the State Secretary for Digitalisation and Artificial Intelligence and framed within the Recovery, Transformation and Resilience Plan (PRTR). The objective is to finance the development of data spaces and the promotion of disruptive innovation in strategic sectors of the economy, in line with the strategic lines set out in the Digital Spain Agenda 2026.
Lines, sectors and beneficiaries
The current call includes funding lines for experimental development projects in two complementary areas of action: the creation of demonstration centres (development of technological platforms for data spaces); and the promotion of specific use cases of these spaces. This call is addressed to all sectors except tourism, which has its own call. Beneficiaries may be single entities with their own legal personality, tax domicile in the European Union, and an establishment or branch located in Spain. In the case of the line for demonstration centres, they must also be associative or representative of the value chains of the productive sectors in territorial areas, or with scientific or technological domains.
Infographic-summary
The following infographics show the key information on this call for proposals:


Would you like more information?
- Access to the grant portal for application proposals in the following link. On the portal you will find the regulatory bases and the call for applications, a summary of its content, documentation and informative material with presentations and videos, as well as a complete list of questions and answers. In the mailbox espaciosdedatos@digital.gob.es you will get help about the call and the application procedure. From this portal you can access the electronic office for the application.
- Quick guide to the call for proposals in pdf + downloadable Infographics (on the Sectoral Data Program and Technical Information)
- Link to other documents of interest:
- Additional information on the data space concept
Blog
Data has become the great transforming power of society. Beyond the more mercantilist view, its capacity to generate knowledge, drive innovation and empower individuals and communities is undeniable. Indeed, it is a resource with which to address, from an innovative perspective, major environmental, social and health challenges, enabling collaboration between actors, driving innovation and improving accountability.
Following European guidelines such as the European Data Strategy, the challenge now is to promote the circulation of data for the benefit of all, by pooling data in key sectors with the creation of common and interoperabledata spaces. A data space is an ecosystem where the voluntary sharing of its participants' data takes place within an environment of sovereignty, trust and security, established through integrated governance, organisational, regulatory and technical mechanisms. Data spaces are key to the development of the data economy, enabling access, exchange and legitimate re-use, positioning data as a non-rivalrous resource, whose utility grows as its use becomes more widespread, in a clear example of the network effect.
What are the Coordinated Support Actions (CSA)?
In order to foster the development of data spaces, the European Commission's Digital Europe Programme (DIGITAL) is funding a series of Coordinated Support Actions (CSA) to foster their development. Most of these actions have a funding of around one million euros per project and a duration of approximately one year, with an expected completion date in the fourth quarter of 2023. Their results should contribute to the objectives of the DIGITAL programme, which aims to bridge the gap between research and deployment of digital technologies, and to facilitate the transfer of research results to the market, to the benefit of European citizens and businesses, especially small and medium-sized ones.
Each concrete action focuses on a particular sector of economic activity seeking, based on a mapping of the data landscape of each sector concerned, to contact and connect relevant stakeholders, seeking to collaboratively develop a shared strategic roadmap. This shared roadmap ultimately aims to eventually build up the corresponding sectoral data spacesin subsequent phases. During the process, clear objectives and key results are defined to inspire, support and motivate all stakeholders to contribute and use high quality sectoral data as a basis for innovation and value generation.
In order to carry out this roadmap, a comprehensive inventory of existing platforms that already share relevant data has been drawn up. In addition, each CSA project has focused, through different working groups and stakeholder workshops, on developing recommendations on governance models for data spaces and digital business models for their sector. The aim is to identify key success factors and outline how a data space can create value and benefits not only for the sector in question but also for other sectors with which it is interlinked. In addition, plans to address the technical and organisational challenges that drive the use of interoperability standards are made in the different projects in close collaboration with the Data Spatial Support Centre (DSSC) in order to align with the European Technological Framework for Data Spaces.
Where can I find up-to-date information on CSAs?
Concrete information on the state of play of the different coordination and support actions can be found on their websites through the following links:
 |
DATES (Tourism) |
 |
Tourism Data Space (Tourism) |
 |
DS4SKills (Skills) |
 |
PrepDSpace4Mobility (Mobility) |
 |
AgriDataSpace (Agri-food) |
 |
Great (Environmental) |
 |
DataSp4ce (Industrial) |
 |
DS4SSCC (Smarts Cities) |
The outcome of these coordinated support actions will provide the information and the basis for the correct execution of the projects for the development and implementation (\"deployments\") of the Common European Data Spaces, which will be supported by different European programmes. This will catalyse the creation of a single data market, based on reliable and quality data, which will enable the digitisation of industries' value chains. Moreover, its effective development will support the European Union's objectives of achieving a green transition and a digital transformation, and of strengthening its resilience and strategic autonomy.
Noticia
Under the Spanish Presidency of the Council of the European Union, the Government of Spain has led the Gaia-X Summit 2023, held in Alicante on November 9 and 10. The event aimed to review the latest advances of Gaia-X in promoting data sovereignty in Europe. As presented on datos.gob.es, Gaia-X is a European private sector initiative for the creation of a federated, open, interoperable, and reversible data infrastructure, fostering digital sovereignty and data availability.
The summit has also served as a space for the exchange of ideas among the leading voices in the European data spaces community, culminating in the presentation of a statement to boost strategic autonomy in cloud computing, data, and artificial intelligence—considered crucial for EU competitiveness. The document, promoted by the State Secretariat for Digitization and Artificial Intelligence, constitutes a joint call for a "more coherent and coordinated" response in the development of programs and projects, both at the European and member state levels, related to data and sector technologies.
To achieve this, the statement advocates for interoperability supported by a robust cloud services infrastructure and the development of high-quality data-based artificial intelligence with a robust governance framework in compliance with European regulatory frameworks. Specifically, it highlights the possibilities offered by Deep Neural Networks, where success relies on three main factors: algorithms, computing capacity, and access to large amounts of data. In this regard, the document emphasizes the need to invest in the latter factor, promoting a neural network paradigm based on high-quality, well-parameterized data in shared infrastructures, not only saving valuable time for researchers but also mitigating environmental degradation by reducing computing needs beyond the brute force paradigm.
For this reason, another aspect addressed in the document is the stimulation of access to data sources from different complementary domains. This would enable a "flexible, dynamic, and highly scalable" data economy to optimize processes, innovate, and/or create new business models.
The call is optimistic about existing European initiatives and programs, starting with the Gaia-X project itself. Other projects highlighted include IPCEI-CIS or the Simpl European project. It also emphasizes the need for "broader and more effective coordination to drive industrial projects, advance the standardization of cloud and reliable data tags, ensuring high levels of cybersecurity, data protection, algorithmic transparency, and portability."
The statement underscores the importance of achieving a single data market that includes data exchange processes under a common governance framework. It values the innovative set of digital and data legislation, such as the Data Act, with the goal of promoting data availability across the Union. The statement is open to new members seeking to advance the promotion of a flexible, dynamic, and highly scalable data economy.
You can read the full document here: The Trinity of Trusted Cloud Data and AI as a Gateway to EU's Competitiveness
Documentación
In the era of data, we face the challenge of a scarcity of valuable data for building new digital products and services. Although we live in a time when data is everywhere, we often struggle to access quality data that allows us to understand processes or systems from a data-driven perspective. The lack of availability, fragmentation, security, and privacy are just some of the reasons that hinder access to real data.
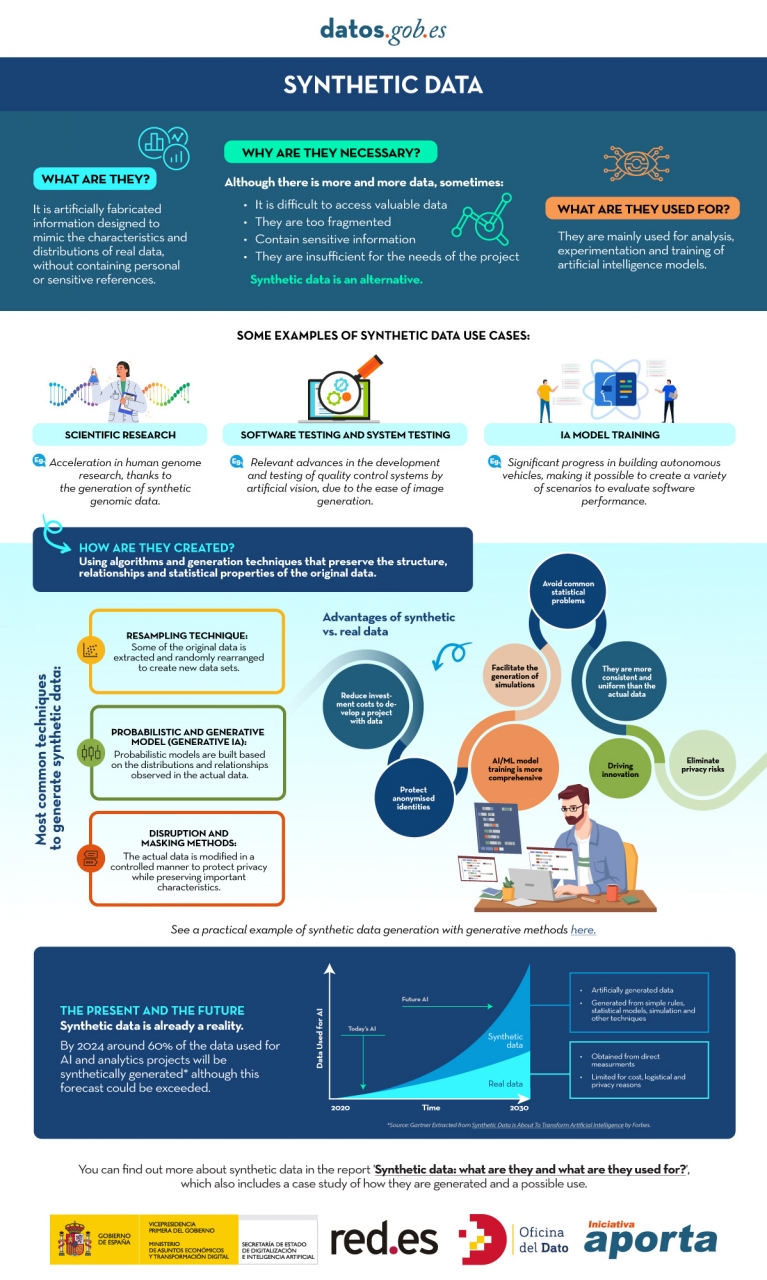
However, synthetic data has emerged as a promising solution to this problem. Synthetic data is artificially created information that mimics the characteristics and distributions of real data, without containing personal or sensitive information. This data is generated using algorithms and techniques that preserve the structure and statistical properties of the original data.
Synthetic data is useful in various situations where the availability of real data is limited or privacy needs to be protected. It has applications in scientific research, software and system testing, and training artificial intelligence models. It enables researchers to explore new approaches without accessing sensitive data, developers to test applications without exposing real data, and AI experts to train models without the need to collect all the real-world data, which is sometimes simply impossible to capture within reasonable time and cost.
There are different methods for generating synthetic data, such as resampling, probabilistic and generative modeling, and perturbation and masking methods. Each method has its advantages and challenges, but overall, synthetic data offers a secure and reliable alternative for analysis, experimentation, and AI model training.
It is important to highlight that the use of synthetic data provides a viable solution to overcome limitations in accessing real data and address privacy and security concerns. Synthetic data allows for testing, algorithm training, and application development without exposing confidential information. However, ensuring the quality and fidelity of synthetic data is crucial through rigorous evaluations and comparisons with real data.
In this report, we provide an introductory overview of the discipline of synthetic data, illustrating some valuable use cases for different types of synthetic data that can be generated. Autonomous vehicles, DNA sequencing, and quality controls in production chains are just a few of the cases detailed in this report. Furthermore, we highlight the use of the open-source software SDV (Synthetic Data Vault), developed in the academic environment of MIT, which utilizes machine learning algorithms to create tabular synthetic data that imitates the properties and distributions of real data. We present a practical example in a Google Colab environment to generate synthetic data about fictional customers hosted in a fictional hotel. We follow a workflow that involves preparing real data and metadata, training the synthesizer, and generating synthetic data based on the learned patterns. Additionally, we apply anonymization techniques to protect sensitive data and evaluate the quality of the generated synthetic data.
In summary, synthetic data is a powerful tool in the data era, as it allows us to overcome the scarcity and lack of availability of valuable data. With its ability to mimic real data without compromising privacy, synthetic data has the potential to transform the way we develop AI projects and conduct analysis. As we progress in this new era, synthetic data is likely to play an increasingly important role in generating new digital products and services.
If you want to know more about the content of this report, you can watch the interview with its author.
Below, you can download the full report, the executive summary and a presentation-summary.
Blog
We live in a constantly evolving environment in which data is growing exponentially and is also a fundamental component of the digital economy. In this context, it is necessary to unlock its potential to maximize its value by creating opportunities for its reuse. However, it is important to bear in mind that this increase in speed, scale and variety of data means that ensuring its quality is more complicated.
In this scenario, the need arises to establish common processes applicable to the data assets of all organizations throughout their lifecycle. All types of institutions must have well-governed, well-managed data with adequate levels of quality, and a common evaluation methodology is needed that can help to continuously improve these processes and allow the maturity of an organization to be evaluated in a standardized way.
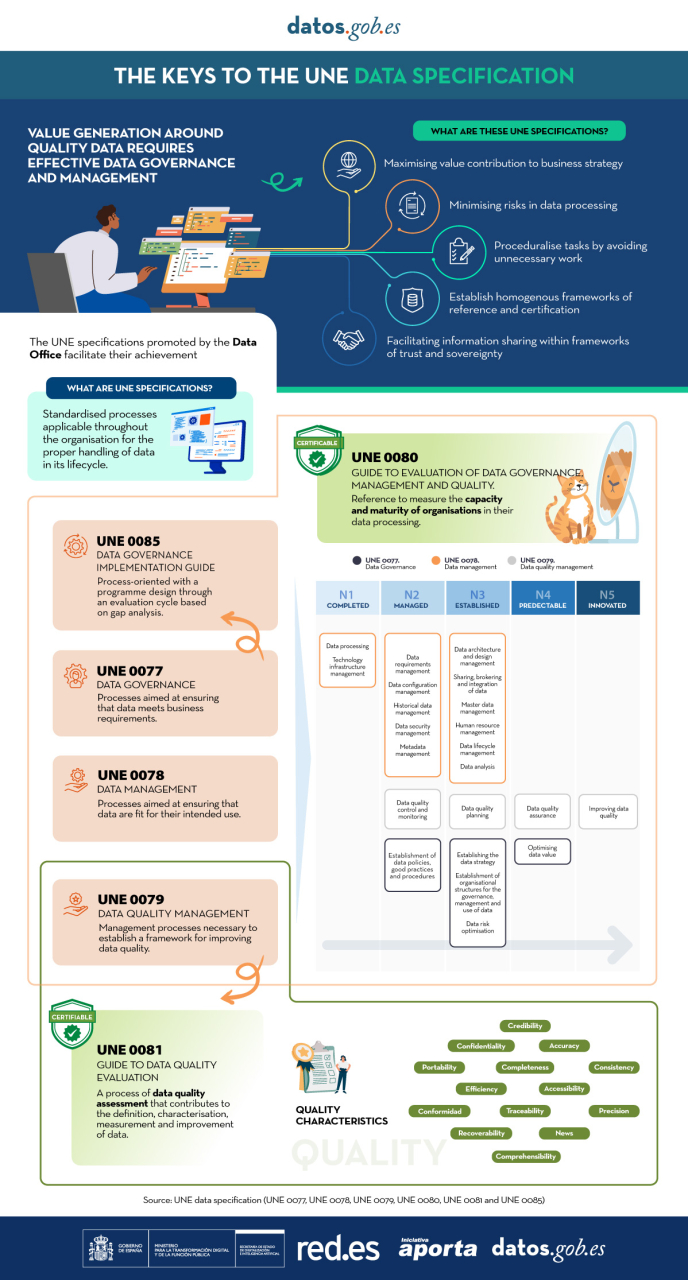
The Data Office has sponsored, promoted and participated in the generation of the UNE specifications, normative resources that allow the implementation of common processes in data management and that also provide a reference framework to establish an organizational data culture.
On the one hand, we find the specifications UNE 0077:2023 Data Governance, UNE 0078:2023 Data Management and UNE 0079:2023 Data Quality Management, which are designed to be applied jointly, enabling a solid reference framework that encourages the adoption of sustainable and effective practices around data.
In addition, a common assessment methodology is needed to enable continuous improvement of data governance, management and data quality management processes, as well as the measurement of the maturity of organizations in a standardized way. The UNE 0080 specification has been developed for the development of a homogeneous framework for the evaluation of an organization's treatment of data.
With the aim of offering a process based on international standards that helps organizations to use a quality model and to define appropriate quality characteristics and metrics, the UNE 0081 Data Quality Assessment specification has been generated, which complements the UNE 0079 Data Quality Management.
The following infographic summarizes the key points of the UNE Specifications on data and the main advantages of their application (click on the image to access the infographic).
Noticia
On September 11th, a webinar was held to review Gaia-X, from its foundations, embodied by its architecture and trust model called Trust Framework, to the Federation Services that aim to facilitate and speed up access to the infrastructure, to the catalogue of services that some users (providers) will be able to make available to others (consumers).
The webinar, led by the manager of the Spanish Gaia-X Hub, was led by two experts from the Data Office, who guided the audience through their presentations towards a better understanding of the Gaia-X initiative. At the end of the session, there was a dynamic question and answer session to go into more detail. A recording of this seminar can be accessed from the Hub's official website,[Forging the Future of Federated Data Spaces in Europe | Gaia-X (gaiax.es)]
Gaia-X as a key building block for forging European Data Spaces
Gaia-X emerges as an innovative paradigm to facilitate the integration of IT resources. Based on Web 3.0 technology models, the identification and traceability of different data resources is enabled, from data sets, algorithms, different semantic or other conceptual models, to even underlying technology infrastructure (cloud resources). This serves to make the origin and functioning of these entities visible, thus facilitating transparency and compliance with European regulations and values.
More specifically, Gaia-X provides different services in charge of automatically verifying compliance with minimum interoperability rules, which then allows defining more abstract rules with a business focus, or even as a basis for defining and instantiating the Trusted Cloud and sovereign data spaces. These services will be operationalised through different Gaia-X interoperability nodes, or Gaia-X Digital Clearing Houses.
Using Gaia-X as a tool, we will be able to publish, discover and exploit a catalogue of services that will cover different services according to the user's requirements. For instance, in the case of cloud infrastructure, these offerings may include features such as residence in European territory or compliance with EU regulations (such as eIDAS or GDPR, or data intermediation rules outlined in the Data Governance Regulation). It will also enable the creation of combinable services by aggregating components from different providers (which is complex now). Moreover, specific datasets will be available for training Artificial Intelligence models, and the owner of these datasets will maintain control thanks to enabled traceability, up to the execution of algorithms and apps on the consumer's own data, always ensuring privacy preservation.
As we can see, this novel traceability capability, based on cutting-edge technologies, serves as a driver for compliance, and is therefore a fundamental building block in the deployment of interoperable data spaces at European level and the digital single market.
Noticia
Last March 13th, a session of the Mobility Working Group of the Gaia-X Spain Hub was held, addressing the main challenges of the sector regarding projects related to data sharing and exploitation. The session, which took place at the Technical School of Civil Engineers of the Polytechnic University of Madrid, allowed attendees to learn firsthand about the main challenges of the sector, as well as some of the cutting-edge data projects in the mobility industry. The event was also a meeting point where ideas and reflections were shared among key actors in the sector.
The session began with a presentation from the Ministry of Transport, Mobility, and Urban Agenda, which highlighted the great importance of the National Access Point for Multimodal Transport, a European project that allows all information on passenger transport services in the country to be centralized in a single national point, with the aim of providing the foundation for driving the development of future mobility services.
Next, the Data Office of the State Secretariat for Artificial Intelligence (SEDIA) provided their vision of the Data Spaces development model and the design principles of such spaces aligned with European values. The importance of business networks based on data ecosystems, the intersectoral nature of the Mobility industry, and the significant role of open data in the sector's data spaces were highlighted.
Next, use cases were presented by Vicomtech, Amadeus, i2CAT, and the Alcobendas City Council, which allowed attendees to learn firsthand about some examples of technology use for data sharing projects (both data spaces and data lakes).
Finally, an initial study by the i2CAT Foundation, FACTUAL Consulting, and EIT Urban Mobility on the basic components of future mobility data spaces in Spain was presented. The study, which can be downloaded here in Spanish, addresses the potential of mobility data spaces for the Spanish market. Although it focuses on Spain, it takes a national and international research approach, framed in the European context to establish standards, develop the technical components that enable data spaces, the first flagship projects, and address common challenges to achieve milestones in sustainable mobility in Europe.
The presentations used in the session are available at this link.
Noticia
Gaia-X represents an innovative paradigm for linking data more closely to the technological infrastructure underneath, so as to ensure the transparency, origin and functioning of these resources. This model allows us to deploy a sovereign and transparent data economy, which respects European fundamental rights, and which in Spain will take shape around the sectoral data spaces (C12.I1 and C14.I2 of the Recovery, Transformation and Resilience Plan). These data spaces will be aligned with the European regulatory framework, as well as with governance and instruments designed to ensure interoperability, and on which to articulate the sought-after single data market.
In this sense, Gaia-X interoperability nodes, or Gaia-X Digital Clearing House (GXDCH), aim to offer automatic validation services of interoperability rules to developers and participants of data spaces. The creation of such nodes was announced at the Gaia-X Summit 2022 in Paris last November. The Gaia-X architecture, promoted by the Gaia-X European Association for Data & Cloud AISBL, has established itself as a promising technological alternative for the creation of open and transparent ecosystems of data sets and services.
These ecosystems, federated by nature, will serve to develop the data economy at scale. But in order to do so, a set of minimum rules must be complied with to ensure interoperability between participants. Compliance with these rules is precisely the function of the GXDCH, serving as an "anchor" to deploy certified market services. Therefore, the creation of such a node in Spain is a crucial element for the deployment of federated data spaces at national level, which will stimulate development and innovation around data in an environment of respect for data sovereignty, privacy, transparency and fair competition.
The GXDCH is defined as a node where operational services of an ecosystem compliant with the Gaia-X interoperability rules are provided. Operational services" should be understood as services that are necessary for the operation of a data space, but are not in themselves data sharing services, data exploitation applications or cloud infrastructures. Gaia-X defines six operational services, of which at least two must be part of the mandatory nodes hosting the GXDCHs:
Mandatory services
- Gaia-X Registry: Defined as an immutable, non-repudiable, distributed database with code execution capabilities. Typically it would be a blockchain infrastructure supporting a decentralised identity service ('Self Sovereign Identity') in which, among others, the list of Trust Anchors or other data necessary for the operation of identity management in Gaia-X is stored.
- Gaia-X Compliance Service or Gaia-X Compliance Service: Belongs to the so-called Gaia-X Federation Services and its function is to verify compliance with the minimum interoperability rules defined by the Gaia-X Association (e.g. the Trust Framework).
Optional services
- Self-Descriptions (SDs) or Wizard Edition Service: SDs are verifiable credentials according to the standard defined by the W3C by means of which both the participants of a Gaia-X ecosystem and the products made available by the providers describe themselves. The aforementioned compliance service consists of validating that the SDs comply with the interoperability standards. The Wizard is a convenience service for the creation of Self-Descriptions according to pre-defined schemas.
- Catalogue: Storage service of the service offer available in the ecosystem for consultation.
- e-Wallet: For the management of verifiable credentials (SDs) by participants in a system based on distributed identities.
- Notary Service: Service for issuing verifiable credentials signed by accreditation authorities (Trust Anchors).
What is the Gaia-X Compliance Service (i.e. Compliance Service)?
The Gaia-X Compliance Service belongs to the so-called Gaia-X Federation Services and its function is to verify compliance with the minimum interoperability rules defined by the Gaia-X Association. Gaia-X calls these minimum interoperability rules (Trust Framework). It should be noted that the establishment of the Trust Framework is one of the differentiating contributions of the Gaia-X technology framework compared to other solutions on the market. But the objective is not just to establish interoperability standards, but to create a service that is operable and, as far as possible, automated, that validates compliance with the Trust Framework. This service is the Gaia-X Compliance Service.
The key element of these rules are the so-called "Self-Descriptions" (SDs). SDs are verifiable credentials according to the standard defined by the W3C by which both the participants of a data space and the products made available by the providers describe themselves. The Gaia-X Compliance service validates compliance with the Trust Framework by checking the SDs from the following points of view:
- Format and syntax of the SDs
- Validation of the SDs schemas (vocabulary and ontology)
- Validation of the cryptography of the signatures of the issuers of the SDs
- Attribute consistency
- Attribute value veracity.
Once the Self-Descriptions have been validated, the compliance service operator issues a verifiable credential that attests to compliance with interoperability standards, providing confidence to ecosystem participants. Gaia-X AISBL provides the necessary code to implement the Compliance Service and authorises the provision of the service to trusted entities, but does not directly operate the service and therefore requires the existence of partners to carry out this task.

Blog
The Spanish Hub of Gaia-X (Gaia-X Hub Spain), a non-profit association whose aim is to accelerate Europe's capacity in data sharing and digital sovereignty, seeks to create a community around data for different sectors of the economy, thus promoting an environment conducive to the creation of sectoral data spaces. Framed within the Spain Digital 2026 strategy and with the Recovery, Transformation and Resilience Plan as a roadmap for Spain's digital transformation, the objective of the hub is to promote the development of innovative solutions based on data and artificial intelligence, while contributing to boosting the competitiveness of our country's companies.
The hub is organized into different working groups, with a specific one dedicated to analyzing the challenges and opportunities of data sharing and exploitation spaces in the tourism sector. Tourism is one of the key productive sectors in the Spanish economy, reaching a volume of 12.2% of the national GDP.
Tourism, given its ecosystem of public and private participants of different sizes and levels of technological maturity, constitutes an optimal environment to contrast the benefits of these federated data ecosystems. Thanks to them, the extraction of value from non-traditional data sources is facilitated, with high scalability, and ensuring robust conditions of security, privacy, and thus data sovereignty.
Thus, with the aim of producing the first X-ray of this dataspace in Spain, the Data Office, in collaboration with the Spanish Hub of Gaia-X, has developed the report 'X-ray of the Tourism Dataspace in Spain', a document that seeks to summarize and highlight the current status of the design of this dataspace, the different opportunities for the sector, and the main challenges that must be overcome to achieve its deployment, offering a roadmap for its construction and deployment.
Why is a tourism data space necessary?
If something became clear after the outbreak of the COVID-19 pandemic, it is that tourism is an interdependent activity with other industries, so when it was paused, sectors such as mobility, logistics, health, agriculture, automotive, or food, among others, were also affected.
Situations like the one mentioned above highlight the possibilities offered by data sharing between sectors, as they can help improve decision-making. However, achieving this in the tourism sector is not an easy task since deploying a data space for this sector requires coordinated efforts among the different parts of society involved.
Thus, the objective and challenge is to create intelligent "spaces" capable of providing a context of security and trust that promotes the exchange and combination of data. In this way, and based on the added value generated by data, it would be possible to solve some of the existing problems in the sector and create new strategies focused on better understanding the tourist and, therefore, improving their travel experience.
The creation of these data sharing and exploitation spaces will bring significant benefits to the sector, as it will facilitate the creation of more personalized offers, products, and services that provide an enhanced and tailored experience to meet the needs of customers, thus improving the capacity to attract tourists. In addition, it will promote a better understanding of the sector and informed decision-making by both public and private organizations, which can more easily detect new business opportunities.
Challenges of security and data governance to take advantage of digital tourism market opportunities
One of the main obstacles to developing a sectoral data space is the lack of trust in data sharing, the absence of shared data models, or the insufficient interoperability standards for efficient data exchange between different existing platforms and actors in the value chain.
Moving to more specific challenges, the tourism sector also faces the need to combine B2B data spaces (sharing between private companies and organizations) with C2B and G2B spaces (sharing between users and companies, and between the public sector and companies, respectively). If we add to this the ideal need to land the tourism sector's datasets at the national, regional, and local levels, the challenge becomes even greater.
To design a sector data space, it is also important to take into account the differences in data quality among the aforementioned actors. Due to the lack of specific standards, there are differences in the level of granularity and quality of data, semantics, as well as disparity in formats and licenses, resulting in a disconnected data landscape.
Furthermore, it is essential to understand the demands of the different actors in the industry, which can only be achieved by listening and taking notes on the needs present at the different levels of the industry. Therefore, it is important to remember that tourism is a social activity whose focus should not be solely on the destination. The success of a tourism data space will also rely on the ability to better understand the customer and, consequently, offer services tailored to their demands to improve their experience and incentivize them to continue traveling.
Thus, as stated in the report prepared by the Data Office, in collaboration with the Spanish hub of Gaia-X, it is interesting to redirect the focus and shift it from the destination to the tourist, in line with the discovery and generation of use cases by SEGITTUR. While it is true that focusing on the destination has helped develop digital platforms that have driven competitiveness, efficiency, and tourism strategy, a strategy that pays the same attention to the tourist would allow for expanding and improving the available data catalogs.
Measuring the factors that condition tourists' experience during their visit to our country allows for optimizing their satisfaction throughout the entire travel circuit, while also contributing to creating increasingly personalized marketing campaigns, based on the analysis of the interests of different market segments.
Current status of the construction of the Spanish Tourism data space and next steps
The lack of maturity of the market in the creation of data spaces as a solution makes an experimental approach necessary, both for the consolidation of the technological components and for the validation of the different facets (soft infrastructure) present in the data spaces.
Currently, the Tourism Working Group of the Spanish Gaia-X Hub is working on the definition of the key elements of the tourism data space, based on use cases aligned with the sector's challenges. The objective is to answer some key questions, using existing knowledge in the field of data spaces:
- What are the key characteristics of the tourism environment and what business problems can be addressed?
- What data-oriented models can be worked on in different use cases?
- What requirements exist and what governance model is necessary? What types of participants should be considered?
- What business, legal, operational, functional, and technological components are necessary?
- What reference technology architecture can be used?
- What development, integration, testing, and technology deployment processes can be employed?
Noticia
Updated: 21/03/2024
On January 2023, the European Commission published a list of high-value datasets that public sector bodies must make available to the public within a maximum of 16 months. The main objective of establishing the list of high-value datasets was to ensure that public data with the highest socio-economic potential are made available for re-use with minimal legal and technical restriction, and at no cost. Among these public sector datasets, some, such as meteorological or air quality data, are particularly interesting for developers and creators of services such as apps or websites, which bring added value and important benefits for society, the environment or the economy.
The publication of the Regulation has been accompanied by frequently asked questions to help public bodies understand the benefit of HVDS (High Value Datasets) for society and the economy, as well as to explain some aspects of the obligatory nature of HVDS (High Value Datasets) and the support for publication.
In line with this proposal, Executive Vice-President for a Digitally Ready Europe, Margrethe Vestager, stated the following in the press release issued by the European Commission:
"Making high-value datasets available to the public will benefit both the economy and society, for example by helping to combat climate change, reducing urban air pollution and improving transport infrastructure. This is a practical step towards the success of the Digital Decade and building a more prosperous digital future".
In parallel, Internal Market Commissioner Thierry Breton also added the following words on the announcement of the list of high-value data: "Data is a cornerstone of our industrial competitiveness in the EU. With the new list of high-value datasets we are unlocking a wealth of public data for the benefit of all”. Start-ups and SMEs will be able to use this to develop new innovative products and solutions to improve the lives of citizens in the EU and around the world.
Six categories to bring together new high-value datasets
The regulation is thus created under the umbrella of the European Open Data Directive, which defines six categories to differentiate the new high-value datasets requested:
- Geospatial
- Earth observation and environmental
- Meteorological
- Statistical
- Business
- Mobility
However, as stated in the European Commission's press release, this thematic range could be extended at a later stage depending on technological and market developments. Thus, the datasets will be available in machine-readable format, via an application programming interface (API) and, if relevant, also with a bulk download option.
In addition, the reuse of datasets such as mobility or building geolocation data can expand the business opportunities available for sectors such as logistics or transport. In parallel, weather observation, radar, air quality or soil pollution data can also support research and digital innovation, as well as policy making in the fight against climate change.
Ultimately, greater availability of data, especially high-value data, has the potential to boost entrepreneurship as these datasets can be an important resource for SMEs to develop new digital products and services, which in turn can also attract new investors.
Find out more in this infographic:

