Noticia
The Centre de documentació i biblioteca del Institut Català d'Arqueologia Clàssica (ICAC) has the repository Open Science ICAC. This website is a space where science is shared in an accessible and inclusive way. The space introduces recommendations and advises on the process of publishing content. Also, on how to make the data generated during the research process available for future research work.
The website, in addition to being a repository of scientific research texts, is also a place to find tools and tips on how to approach the research data management process in each of its phases: before, during and at the time of publication.
- Before you begin: create a data management plan to ensure that your research proposal is as robust as possible. The Data Management Plan (DMP) is a methodological document that describes the life cycle of the data collected, generated and processed during a research project, a doctoral thesis, etc.
- During the research process: at this point it points out the need to unify the nomenclature of the documents to be generated before starting to collect files or data, in order to avoid an accumulation of disorganised content that will lead to lost or misplaced data. In addition, this section provides information on directory structure, folder names and file names, the creation of a txt file (README) describing the nomenclatures or the use of short, descriptive names such as project name/acronym, file creation date, sample number or version number. Recommendations on how to structure each of these fields so that they are reusable and easily searchable can also be found on the website.
- Publication of research data: in addition to the results of the research itself in the form of a thesis, dissertation, paper, etc., it recommends the publication of the data generated by the research process itself. The ICAC itself points out that research data remains valuable after the research project for which it was generated has ended, and that sharing data can open up new avenues of research without future researchers having to recreate and collect identical data. Finally, it outlines how, when and what to consider when publishing research data.
Graphical content for improving the quality of open data
Recently, the ICAC has taken a further step to encourage good practice in the use of open data. To this end, it has developed a series of graphic contents based on the "Practical guide for the improvement of the quality of open data"produced by datos.gob.es. Specifically, the cultural body has produced four easy-to-understand infographics, in Catalan and English, on good practices with open data in working with databases and spreadsheets, texts and docs and CSV format.
All the infographics resulting from the adaptation of the guide are available to the general public and also to the centre's research staff at Recercat, Catalonia's research repository. Soon it will also be available on the Open Science website of the Institut Català d'Arqueologia Clàssica (ICAC)open Science ICAC.
The infographics produced by the ICAC review various aspects. The first ones contain general recommendations to ensure the quality of open data, such as the use of standardised character encoding, such as UTF-8, or naming columns correctly, using only lowercase letters and avoiding spaces, which are replaced by hyphens. Among the recommendations for generating quality data, they also include how to show the presence of null or missing data or how to manage data duplication, so that data collection and processing is centralised in a single system so that, in case of duplication, it can be easily detected and eliminated.
The latter deal with how to set the format of thenumerical figures and other data such as dates, so that they follow the ISO standardised system, as well as how to use dots as decimals. In the case of geographic information, as recommended by the Guide, its materials also include the need to reserve two columns for inserting the longitude and latitude of the geographic points used.
The third theme of these infographics focuses on the development of good databases or spreadsheets databases or spreadsheetsso that they are easily reusable and do not generate problems when working with them. Among the recommendations that stand out are consistency in generating names or codes for each item included in the data collection, as well as developing a help guide for the cells that are coded, so that they are intelligible to those who need to reuse them.
In the section on texts and documents within these databases, the infographics produced by the Institut Català d'Arqueologia Clàssica include some of the most important recommendations for creating texts and ensuring that they are preserved in the best possible way. Among them, it points to the need to save attachments to text documents such as images or spreadsheets separately from the text document. This ensures that the document retains its original quality, such as the resolution of an image, for example.
Finally, the fourth infographic that has been made available contains the most important recommendations for working with CSV format working with CSV format (comma separated value) format, such as creating a CSV document for each table and, in the case of working with a document with several spreadsheets, making them available independently. It also notes in this case that each row in the CSV document has the same number of columns so that they are easily workable and reusable, without the need for further clean-up.
As mentioned above, all infographics follow the recommendations already included in the Practical guide for improving the quality of open data.
The guide to improving open data quality
The "Practical guide for improving the quality of open data" is a document produced by datos.gob.es as part of the Aporta Initiative and published in September 2022. The document provides a compendium of guidelines for action on each of the defining characteristics of quality, driving quality improvement. In turn, this guide takes the data.europe.eu data quality guide, published in 2021 by the Publications Office of the European Union, as a reference and complements it so that both publishers and re-users of data can follow guidelines to ensure the quality of open data.

In summary, the guide aims to be a reference framework for all those involved in both the generation and use of open data so that they have a starting point to ensure the suitability of data both in making it available and in assessing whether a dataset is of sufficient quality to be reused in studies, applications, services or other.
Evento
From September 25th to 27th , Madrid will be hosting the fourth edition of the Open Science Fair, an international event on open science that will bring together experts from all over the world with the aim of identifying common practices, bringing positions closer together and, in short, improving synergies between the different communities and services working in this field.
This event is an initiative of OpenAIRE, an organisation that aims to create more open and transparent academic communication. This edition of the Open Science Fair is co-organised by the Spanish Foundation for Science and Technology (FECYT), which depends on the Ministry of Science and Innovation, and is one of the events sponsored by the Spanish Presidency of the spanish Presidency of the Council of the European Union.
The current state of open science
Science is no longer the preserve of scientists. Researchers, institutions, funding agencies and scientific publishers are part of an ecosystem that carries out work with a growing resonance with the public and a greater impact on society. In addition, it is becoming increasingly common for research groups to open up to collaborations with institutions around the world. Key to making this collaboration possible is the availability of data that is open and available for reuse in research.
However, to enable international and interdisciplinary research to move forward, it is necessary to ensure interoperability between communities and services, while maintaining the capacity to support different workflows and knowledge systems.
The objectives and programme of the Open Science Fair
In this context, the Open Science Fair 2023 is being held, with the aim of bringing together and empowering open science communities and services, identifying common practices related to open science to analyse the most suitable synergies and, ultimately sharing experiences that are developed in different parts of the world.
The event has an interesting programme that includes keynote speeches from relevant speakers, round tables, workshops, and training sessions, as well as a demonstration session. Attendees will be able to share experiences and exchange views, which will help define the most efficient ways for communities to work together and draw up tailor-made roadmaps for the implementation of open science.
This third edition of Open Science will focus on 'Open Science for Future Generations' and the main themes it will address, as highlighted on the the event's website, are:
- Progress and reform of research evaluation and open science. Connections, barriers and the way forward.
- Impact of artificial intelligence on open science and impact of open science on artificial intelligence.
- Innovation and disruption in academic publishing.
- Fair data, software and hardware.
- Openness in research and education.
- Public engagement and citizen science.
Open science and artificial intelligence
The artificial intelligence is gaining momentum in academia through data analysis. By analysing large amounts of data, researchers can identify patterns and correlations that would be difficult to reach through other methods. The use of open data in open science opens up an exciting and promising future, but it is important to ensure that the benefits of artificial intelligence are available to all in a fair and equitable way.
Given its high relevance, the Open Science Fair will host two keynote lectures and a panel discussion on 'AI with and for open science'. The combination of the benefits of open data and artificial intelligence is one of the areas with the greatest potential for significant scientific breakthroughs and, as such, will have its place at the event is one of the areas with the greatest potential for significant scientific breakthroughs and, as such, will have its place at the event. It will look from three perspectives (ethics, infrastructure and algorithms) at how artificial intelligence supports researchers and what the key ingredients are for open infrastructures to make this happen.
The programme of the Open Science Fair 2023 also includes the presentation of a demo of a tool for mapping the research activities of the European University of Technology EUt+ by leveraging open data and natural language processing. This project includes the development of a set of data-driven tools. Demo attendees will be able to see the developed platform that integrates data from public repositories, such as European research and innovation projects from CORDIS, patents from the European Patent Office database and scientific publications from OpenAIRE. National and regional project data have also been collected from different repositories, processed and made publicly available.
These are just some of the events that will take place within the Open Science Fair, but the full programme includes a wide range of events to explore multidisciplinary knowledge and research evaluation.
Although registration for the event is now closed, you can keep up to date with all the latest news through the hashtag #OSFAIR2023 on Twitter, LinkedIn and Facebook, as well as on the event's website website.
In addition, on the website of datos.gob.es and on our social networks you can keep up to date on the most important events in the field of open data, such as those that will take place during this autumn.
Blog
In the digital age, technological advancements have transformed the field of medical research. One of the factors contributing to technological development in this area is data, particularly open data. The openness and availability of information obtained from health research provide multiple benefits to the scientific community. Open data in the healthcare sector promotes collaboration among researchers, accelerates the validation process of study results, and ultimately helps save lives.
The significance of this type of data is also evident in the prioritized intention to establish the European Health Data Space (EHDS), the first common EU data space emerging from the European Data Strategy and one of the priorities of the Commission for the 2019-2025 period. As proposed by the European Commission, the EHDS will contribute to promoting better sharing and access to different types of health data, not only to support healthcare delivery but also for health research and policymaking.
However, the handling of this type of data must be appropriate due to the sensitive information it contains. Personal data related to health is considered a special category by the Spanish Data Protection Agency (AEPD), and a personal data breach, especially in the healthcare sector, has a high personal and social impact.
To avoid these risks, medical data can be anonymized, ensuring compliance with regulations and fundamental rights, thereby protecting patient privacy. The Basic Anonymization Guide developed by the AEPD based on the Personal Data Protection Commission Singapore (PDPC) defines key concepts of an anonymization process, including terms, methodological principles, types of risks, and existing techniques.
Once this process is carried out, medical data can contribute to research on diseases, resulting in improvements in treatment effectiveness and the development of medical assistance technologies. Additionally, open data in the healthcare sector enables scientists to share information, results, and findings quickly and accessibly, thus fostering collaboration and study replicability.
In this regard, various institutions share their anonymized data to contribute to health research and scientific development. One of them is the FISABIO Foundation (Foundation for the Promotion of Health and Biomedical Research of the Valencian Community), which has become a reference in the field of medicine thanks to its commitment to open data sharing. As part of this institution, located in the Valencian Community, there is the FISABIO-CIPF Biomedical Imaging Unit, which is dedicated, among other tasks, to the study and development of advanced medical imaging techniques to improve disease diagnosis and treatment.
This research group has developed different projects on medical image analysis. The outcome of all their work is published under open-source licenses: from the results of their research to the data repositories they use to train artificial intelligence and machine learning models.
To protect sensitive patient data, they have also developed their own techniques for anonymizing and pseudonymizing images and medical reports using a Natural Language Processing (NLP) model, whereby anonymized data can be replaced by synthetic values. Following their technique, facial information from brain MRIs can be erased using open-source deep learning software.
BIMCV: Medical Imaging Bank of the Valencian Community
One of the major milestones of the Regional Ministry of Universal Health and Public Health, through the Foundation and the San Juan de Alicante Hospital, is the creation and maintenance of the Medical Imaging Bank of the Valencian Community, BIMCV (Medical Imaging Databank of the Valencia Region in English), a repository of knowledge aimed at achieving "technological advances in medical imaging and providing technological coverage services to support R&D projects," as explained on their website.
BIMCV is hosted on XNAT, a platform that contains open-source images for image-based research and is accessible by prior registration and/or on-demand. Currently, the Medical Imaging Bank of the Valencian Community includes open data from research conducted in various healthcare centers in the region, housing data from over 90,000 subjects collected in more than 150,000 sessions.
New Dataset of Radiological Images
Recently, the FISABIO-CIPF Biomedical Imaging Unit and the Prince Felipe Research Center (FISABIO-CIPF) released in open access the third and final iteration of data from the BIMCV-COVID-19 project. They released image data of chest radiographs taken from patients with and without COVID-19, as well as the models they had trained for the detection of different chest X-ray pathologies, thanks to the support of the Regional Ministry of Innovation, the Regional Ministry of Health and the European Union REACT-EU Funds. All of this was made available "for use by companies in the sector or simply for research purposes," explains María de la Iglesia, director of the unit. "We believe that reproducibility is of great relevance and importance in the healthcare sector," she adds. The datasets and the results of their research can be accessed here.
The findings are mapped using the standard terminology of the Unified Medical Language System (UMLS), as proposed by the results of Dr. Aurelia Bustos' doctoral thesis, an oncologist and computer engineer. They are stored in high resolution with anatomical labels in a Medical Image Data Structure (MIDS) format. Among the stored information are patient demographic data, projection type, and imaging study acquisition parameters, among others, all anonymized.
The contribution that such open data projects make to society not only benefits researchers and healthcare professionals but also enables the development of solutions that can have a significant impact on improving healthcare. One of these solutions can be generative AI, which provides interesting results that healthcare professionals can consider in personalized diagnosis and propose more effective treatment, prioritizing their own judgment.
On the other hand, the digitization of healthcare systems is already a reality, including 3D printing, digital twins applied to medicine, telemedicine consultations, or portable medical devices. In this context, the collaboration and sharing of medical data, provided their protection is ensured, contribute to promoting research and innovation in the sector. In other words, open data initiatives for medical research stimulate technological advancements in healthcare.
Therefore, the FISABIO Foundation, together with the Prince Felipe Research Center, where the platform hosting BIMCV is located, stands out as an exemplary case in promoting the openness and sharing of data in the field of medicine. As the digital age progresses, it is crucial to continue promoting data openness and encouraging its responsible use in medical research, for the benefit of society.
Blog
The Hercules initiative was launched in November 2017, through an agreement between the University of Murcia and the Ministry of Economy, Industry and Competitiveness, with the aim of developing a Research Management System (RMS) based on semantic open data that offers a global view of the research data of the Spanish University System (SUE), to improve management, analysis and possible synergies between universities and the general public.
This initiative is complementary to UniversiDATA, where several Spanish universities collaborate to promote open data in the higher education sector by publishing datasets through standardised and common criteria. Specifically, a Common Core is defined with 42 dataset specifications, of which 12 have been published for version 1.0. Hercules, on the other hand, is a research-specific initiative, structured around three pillars:
- Innovative SGI prototype
- Unified knowledge graph (ASIO) 1],
- Data Enrichment and Semantic Analysis (EDMA)
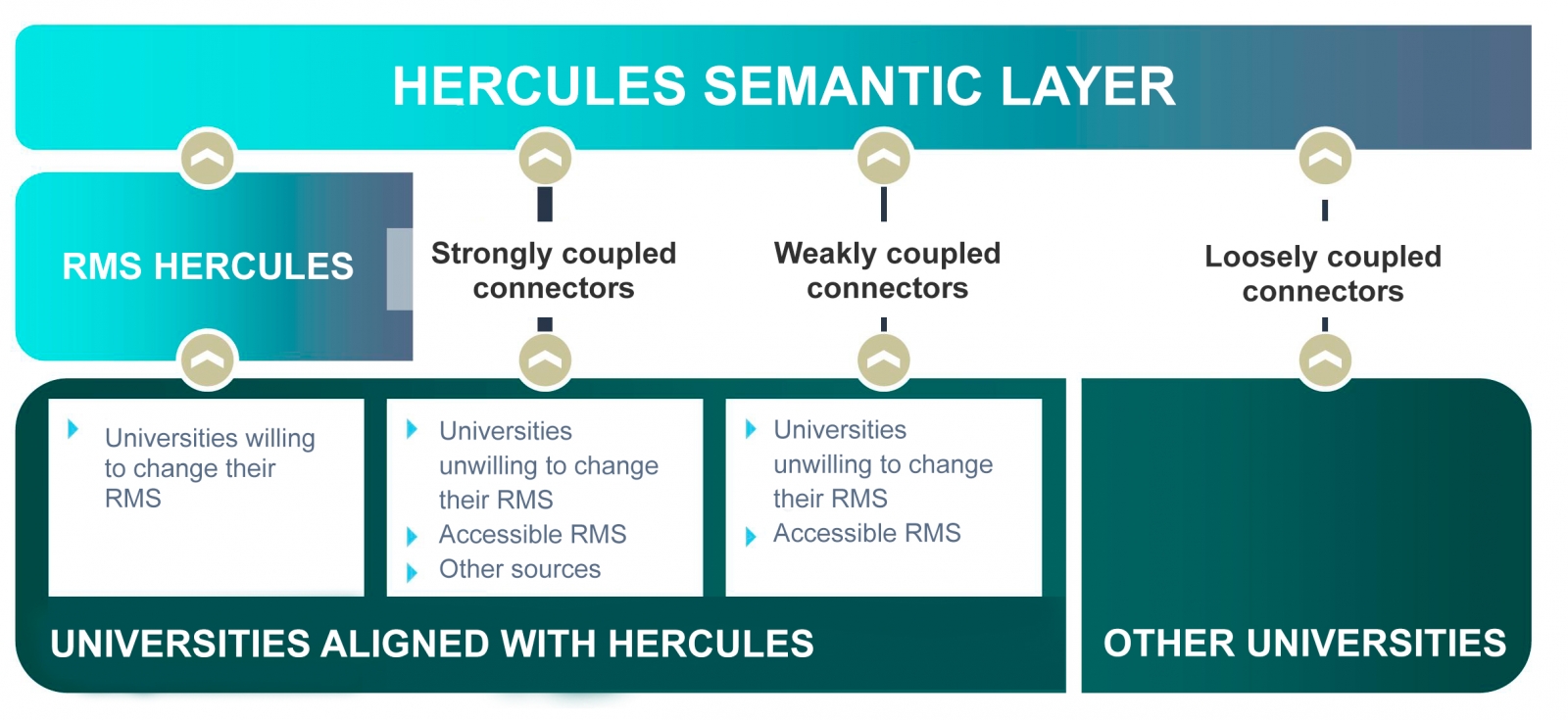
The ultimate goal is the publication of a unified knowledge graph integrating all research data that participating universities wish to make public. Hercules foresees the integration of universities at different levels, depending on their willingness to replace their RMS with the Hercules RMS. In the case of external RMSs, the degree of accessibility they offer will also have an impact on the volume of data they can share through the unified network.
General organisation chart of the Hercule initiative
Within the Hercules initiative, the ASIO Project (Semantic Architecture and Ontology Infrastructure) is integrated. The purpose of this sub-project is to define an Ontology Network for Research Management (Ontology Infrastructure). An ontology is a formal definition that describes with fidelity and high granularity a particular domain of discussion. In this case, the research domain, which can be extrapolated to other Spanish and international universities (at the moment the pilot is being developed with the University of Murcia). In other words, the aim is to create a common data vocabulary.
Additionally, through the Semantic Data Architecture module, an efficient platform has been developed to store, manage and publish SUE research data, based on ontologies, with the capacity to synchronise instances installed in different universities, as well as the execution of distributed federated queries on key aspects of scientific production, lines of research, search for synergies, etc.
As a solution to this innovation challenge, two complementary lines have been proposed, one centralised (synchronisation in writing) and the other decentralised (synchronisation in consultation). The architecture of the decentralised solution is explained in detail in the following sections.
Domain Driven Design
The data model follows the Domain Driven Design approach, modelling common entities and vocabulary, which can be understood by both developers and domain experts. This model is independent of the database, the user interface and the development environment, resulting in a clean software architecture that can adapt to changes in the model.
This is achieved by using Shape Expressions (ShEx), a language for validating and describing RDF datasets, with human-readable syntax. From these expressions, the domain model is automatically generated and allows orchestrating a continuous integration (CI) process, as described in the following figure.
Continuous integration process using Domain Driven Design (just available in Spanish)
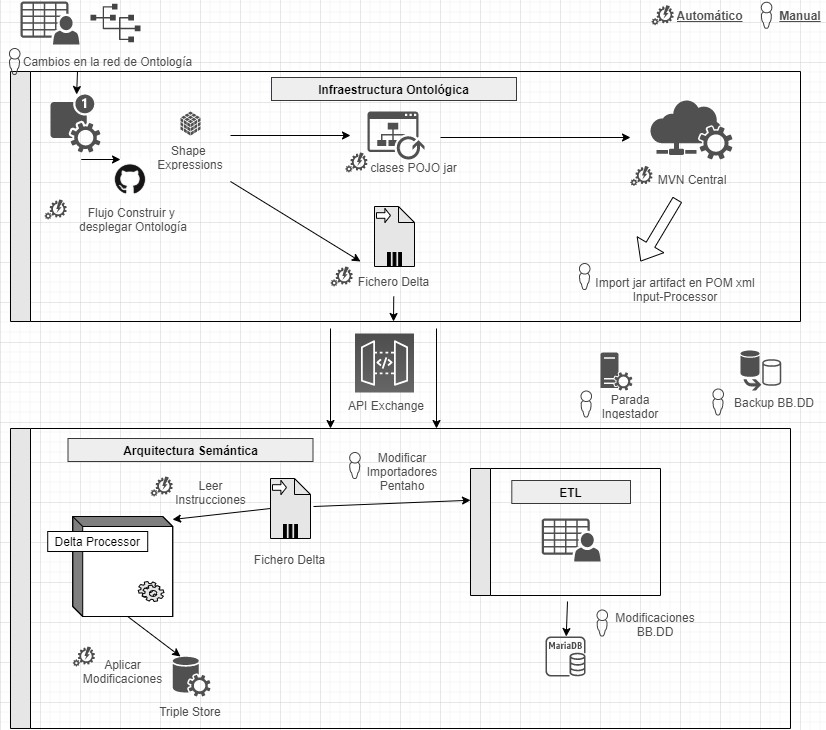
By means of a system based on version control as a central element, it offers the possibility for domain experts to build and visualise multilingual ontologies. These in turn rely on ontologies both from the research domain: VIVO, EuroCRIS/CERIF or Research Object, as well as general purpose ontologies for metadata tagging: Prov-O, DCAT, etc.
Linked Data Platform
The linked data server is the core of the architecture, in charge of rendering information about all entities. It does this by collecting HTTP requests from the outside and redirecting them to the corresponding services, applying content negotiation, which provides the best representation of a resource based on browser preferences for different media types, languages, characters and encoding.
All resources are published following a custom-designed persistent URI scheme. Each entity represented by a URI (researcher, project, university, etc.) has a series of actions to consult and update its data, following the patterns proposed by the Linked Data Platform (LDP) and the 5-star model.
This system also ensures compliance with the FAIR (Findable, Accessible, Interoperable, Reusable) principles and automatically publishes the results of applying these metrics to the data repository.
Open data publication
The data processing system is responsible for the conversion, integration and validation of third-party data, as well as the detection of duplicates, equivalences and relationships between entities. The data comes from various sources, mainly the Hercules unified RMS, but also from alternative RMSs, or from other sources offering data in FECYT/CVN (Standardised Curriculum Vitae), EuroCRIS/CERIF and other possible formats.
The import system converts all these sources to RDF format and registers them in a specific purpose repository for linked data, called Triple Store, because of its capacity to store subject-predicate-object triples.
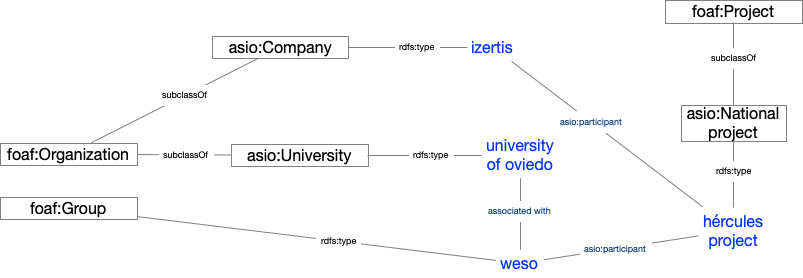
Once imported, they are organised into a knowledge graph, easily accessible, allowing advanced searches and inferences to be made, enhanced by the relationships between concepts.
Example of a knowledge network describing the ASIO project
Results and conclusions
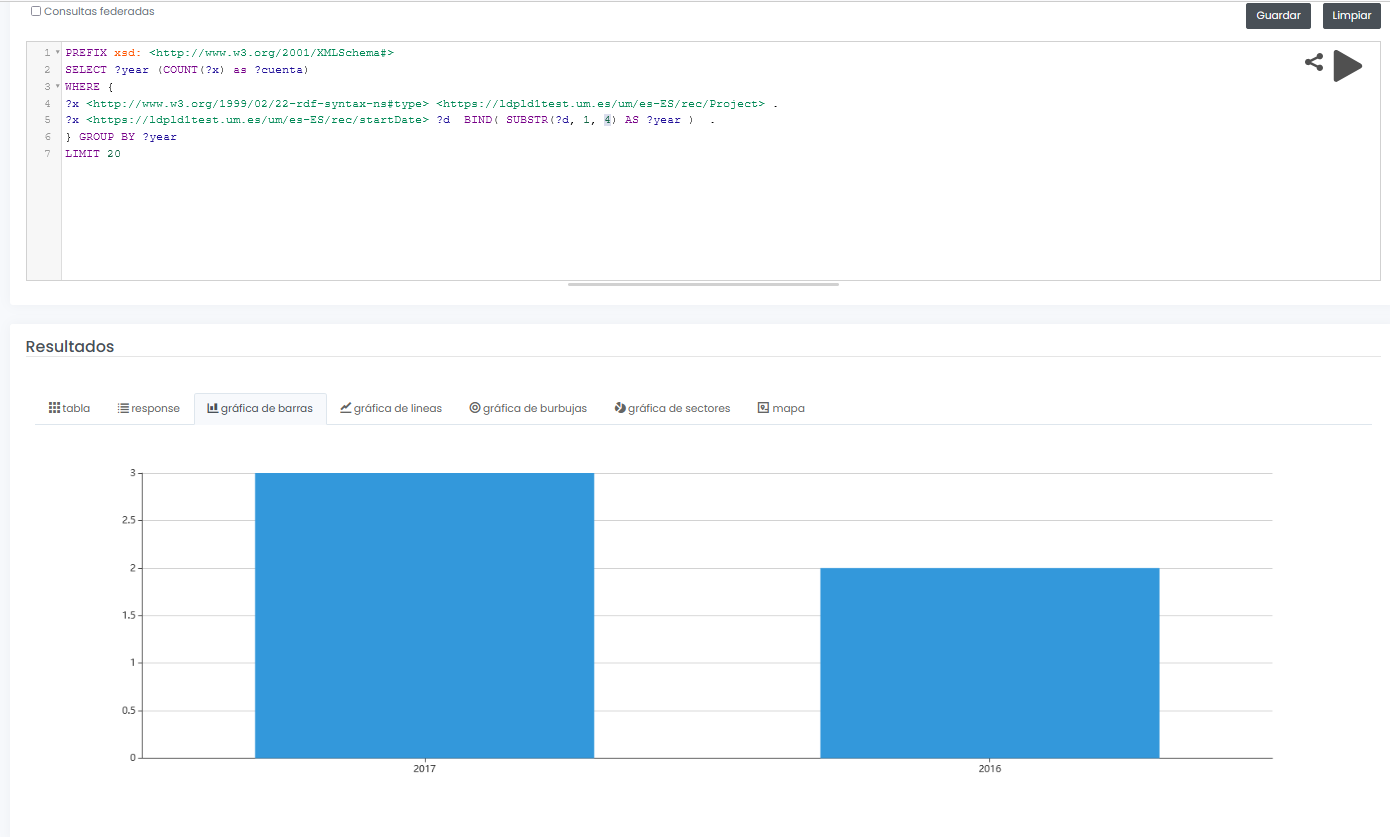
The final system not only allows to offer a graphical interface for interactive and visual querying of research data, but also to design SPARQL queries, such as the one shown below, even with the possibility to run the query in a federated way on all nodes of the Hercules network, and to display results dynamically in different types of graphs and maps.
In this example, a query is shown (with limited test data) of all available research projects grouped graphically by year:
PREFIX xsd: <http://www.w3.org/2001/XMLSchema#>
SELECT ?year (COUNT(?x) as ?cuenta)
WHERE {
?x <http://www.w3.org/1999/02/22-rdf-syntax-nes#type> <https://ldpld1test.um.es/um/es-ES/rec/Project> .
?x <https://ldpld1test.um.es/um/es-ES/rec/startDate> ?d BIND(SUBSTR(?d, 1, 4) as ?year) .
} GROUP BY ?year LIMIT 20
LIMIT 20
Ejemplo de consulta SPARQL con resultado gráfico
In short, ASIO offers a common framework for publishing linked open data, offered as open source and easily adaptable to other domains. For such adaptation, it would be enough to design a specific domain model, including the ontology and the import and validation processes discussed in this article.
Currently the project, in its two variants (centralised and decentralised), is in the process of being put into pre-production within the infrastructure of the University of Murcia, and will soon be publicly accessible.
[1 Graphs are a form of knowledge representation that allow concepts to be related through the integration of data sets, using semantic web techniques. In this way, the context of the data can be better understood, which facilitates the discovery of new knowledge.
Content prepared by Jose Barranquero, expert in Data Science and Quantum Computing.
The contents and views expressed in this publication are the sole responsibility of the author.
Evento
Nowadays, research methods (sensors, technological devices, simulations, etc.) generate a large amount of data that, in open and reusable format, conceals a great re-use potential for other researchers, public administrations, private companies or users. That is why last year the European Commission agreed on an international commitment to promote open science during the Competitiveness Council, ensuring that all results of EU research are available without any technical, legal or financial constraints.
Nevertheless, open access and the dissemination of scientific information involves a series of legal challenges - intellectual property, privacy and personal data protection - that require ad hoc solutions to make the open science movement viable. In this context, the eighth edition of the OpenAIRE workshop will be held on Tuesday 4 April in the framework of the Research Data Alliance (RDA) plenary in Barcelona, dedicated to exploring the legal barriers that hinder the open research data and identifying possible solutions.
During the event attendees will be familiarized with those normative aspects directly related to the open research data, providing specific and pragmatic recommendations so such barriers do not hinder the opennes and re-use of scientific information by the experts of OpenAIRE.
In this project, funded by the European Commission, work is done to encourage and promote open research and optimize the access to European scientific data, while offering a network of repositories for free access to knowledge and research results on health, energy, environment, ICT and social sciences. At the same time, OpenAIRE organizes different workshops, such as the event that will take place in the city of Barcelona, to raise awareness about open science, its opportunities and challenges.
Evento
“Crowd-sourcing questions that if answered could radically increase our understanding of open data”
On October 5th, international researchers will gather at the second Open Data Research Symposium (ODRS); a pre-event to the International Open Data Conference to be held in Madrid. As in the previous edition, ODRS 16 will offer attendees the opportunity to reflect critically on the results of their investigations while cohesion is sought within the research community about the potential impacts of open data.
Though the ODRS call for proposals ended last May, the deadline has been extended to all members of the open data movement to help shape the program of the event, focusing on the most relevant aspects in the field. To do this, the organization has created a specific section on the Symposium website where users can submit questions for researchers to resolve their doubts about open data. Moreover, it is also possible to send the questions via Twitter using the hashtag #ODSR16. The deadline is July 1st.
Thanks to user’s questions, it will be possible to identify the topics of interest to the international open data community, draft the ODRS program to ensure sessions are tailored to the needs of the participants, build a collaborative agenda and report efforts and collaborations that take place during the meeting.
More information about the pre-events to the annual open data meeting? Stay tuned to the website of the International Open Data Conference. See you in Madrid!
Noticia
The Superior Council for Scientific Research (CSIC) and six Spanish universities have worked together to launch Maredata, a national thematic network which stores open research data for being reused by other stakeholders interested in scientific information.
The University of Barcelona is the centre responsible for coordinating this project, in which the following academic institutions take part: the Carlos III University, the University of Alicante, the Open University of Catalonia, the Institute of Agricultural Chemistry and Food Technology (IATA-CSIC), Ingenio and UISYS, CSIC entities attached to the University of Valencia.
Financed by the Ministry of Economy and Competitiveness, the network boosts open science in Spain, guaranteeing unrestricted access to research data from public funding and promoting the participation of the national community in the Pilot Project on Open Research Data sponsored by Horizon 2020. Moreover, two of the goals of this initiative are the development of new research areas and the collaboration between open data and open science communities, making recommendations to help other institutions open their scientific results.
Open science makes the results from scientific research and methodologies as well as data obtained from them be distributed, reused and accessible for free. Creating new business models, building products or services, developing new investigation lines or even validating the quality of science produced in the country are just a few examples of the potential and benefits that research data provide for all levels of citizenship.
For these reasons, government agents want to value this information and promote Maredata thematic network. After all, universities and research centers are public entities and play an essential role in society; so they should be consolidated as open bodies which, thanks to the data stored and produced in different academic fields (teaching, research ...), will help increase awareness and public participation.
Aware of the relevance of academic data, the Spanish university has already several institutions which, through their own open data sites, make accessible their information to the society and publish their action plan as the University of Alicante has done, which, apart from participating in Maredata network, has published a book about its open data ecosystem that shows the experience of the University of Alicante in the process of implementing its open data policy.
Thanks to these initiatives, the open university and the access to research data are already a reality; which not only supports the sharing and reuse of information but facilitates making decisions based on academic information and generates opportunities for collaboration among the different society actors.