Noticia
El Centre de documentació i biblioteca del Institut Català d'Arqueologia Clàssica (ICAC) cuenta con el repositorio Open Science ICAC. Esta página web se configura como un espacio donde la ciencia se comparte de forma accesible e inclusiva. El espacio introduce recomendaciones y asesora sobre el proceso de la publicación de contenidos. También, sobre cómo poner a disposición los datos generados durante el proceso de investigación, de forma que sirvan a futuros trabajos de investigación.
La página web, además de ser un repositorio de textos de investigación científica, también es un lugar en el que encontrar herramientas y trucos a la hora de abordar el proceso de gestión de datos de investigación en cada una de sus fases: antes, durante y en el momento de la publicación.
- Antes de comenzar: recomienda crear un plan de gestión de datos para garantizar que la propuesta de investigación sea lo más sólida posible. El Plan de Gestión de Datos (PGD) es un documento metodológico que describe el ciclo de vida de los datos recogidos, generados y procesados durante un proyecto de investigación, una tesis doctoral, etc.
- Durante el proceso de investigación: en este punto señala la necesidad de unificar la nomenclatura de los documentos a generar antes de empezar a recopilar archivos o datos, para evitar una acumulación de contenido desorganizado que conducirá a datos extraviados o perdidos. Además, en este apartado se ofrece información sobre la estructura de directorios, nombres de carpetas y nombres de archivos, la creación de un archivo txt (README) que describa las nomenclaturas o el uso de nombres cortos y descriptivos como nombre del proyecto/acrónimo, fecha de creación del archivo, número de muestra o número de la versión. En la página web se pueden encontrar también recomendaciones sobre cómo estructurar cada uno de estos campos para que sean reutilizables y fácilmente buscables.
- Publicación de los datos de investigación: además de los propios resultados de la investigación en forma de tesis, tesina, paper... recomienda la publicación de los datos que se hayan ido generando con el propio proceso investigador. El propio ICAC señala que los datos de investigación siguen siendo valiosos una vez finalizado el proyecto de investigación para el que se generaron, y que compartir los datos puede abrir nuevas vías de investigación sin que los futuros investigadores tengan que recrear y recopilar datos idénticos. Por último, señala cómo, cuándo y qué tener en cuenta a la hora de publicar los datos de investigación.
Los contenidos gráficos para la mejora de la calidad de datos abiertos
Recientemente, el ICAC ha dado un paso más para incentivar unas buenas prácticas en el uso de datos abiertos. Para ello ha elaborado una serie de contenidos gráficos basándose en la “Guía práctica para la mejora de la calidad de datos abiertos”, elaborada por datos.gob.es. En concreto, el ente cultural ha elaborado cuatro infografías, en catalán e inglés, de fácil comprensión sobre buenas prácticas con datos abiertos en el trabajo con bases de datos y hojas de cálculo, textos y docs y formato CSV.
Todas las infografías surgidas de la adaptación de la guía están a disposición del público general y también del personal investigador del centro en Recercat, el repositorio de investigación de Cataluña. Próximamente también estará dentro de la web de Ciencia Abierta del Institut Català d'Arqueologia Clàssica (ICAC), Open Science ICAC.
Las infografías elaboradas por el ICAC repasan diversos aspectos. Las primeras, recogen las recomendaciones generales para garantizar la calidad de los datos abiertos, como el uso de codificación de caracteres estandarizados, tales como el UTF-8, o nombrar las columnas de forma correcta, utilizando solo letras en minúscula y evitando los espacios, siendo estos sustituidos por guiones. Entre las recomendaciones para generar datos de calidad, también recogen cómo mostrar la presencia de datos nulos o la carencia de datos o cómo gestionar la duplicidad de datos, de manera que se centralice la recogida de datos y su procesamiento en un único sistema de forma que, en caso de haber duplicidad, se puedan detectar de forma sencilla y puedan ser eliminados.
Las segundas abordan cómo establecer el formato de las cifras numéricas y de otros datos como las fechas, de manera que sigan el sistema estandarizado ISO, así como utilizar los puntos como decimales. En el caso de la información geográfica, tal y como recomienda la Guía, sus materiales también recogen la necesidad de reservar dos columnas para insertar la longitud y la latitud de los puntos geográficos utilizados.
La tercera temática de estas infografías se centra en la elaboración de buenas bases de datos u hojas de cálculo, de forma que sean fácilmente reutilizables y no generen problemas a la hora de trabajar con ellas. Entre las recomendaciones que destacan se encuentra la consistencia a la hora de generar nombres o códigos para cada ítem incluido en la recogida de datos, así como elaborar una guía de ayuda para las celdas que se encuentran codificadas, de manera que sean inteligibles para quienes necesiten reutilizarlas.
En el apartado de textos y documentos dentro de estas bases de datos, las infografías que ha elaborado el Institut Català d'Arqueologia Clàssica recogen algunas de las recomendaciones más importantes para crear textos y asegurarse de su conservación de la mejor forma posible. Entre ellas, señala la necesidad de guardar materiales adjuntos en los documentos de texto como pueden ser imágenes u hojas de cálculo de forma separada al documento de texto. De esta manera, se asegura que el documento conserva su calidad original, como la resolución de una imagen, por ejemplo.
Por último, la cuarta infografía que se ha puesto a disposición recoge las recomendaciones más importantes a la hora de trabajar con formato CSV (comma separated value) como crear un documento CSV para cada tabla y, en caso de trabajar con un documento con varias hojas de cálculo, ponerlas a disposición de forma independiente. También señala en este caso que cada fila en el documento CSV tiene el mismo número de columnas para que sean fácilmente trabajables y reutilizables, sin necesidad de realizar una limpieza posterior.
Como se mencionaba anteriormente, todas las infografías siguen las recomendaciones ya recogidas en la Guía práctica para la mejora de la calidad de datos abiertos.
La guía para la mejora de la calidad de datos abiertos
La “Guía práctica para la mejora de la calidad de datos abiertos” es un documento elaborado por datos.gob.es dentro de la Iniciativa Aporta y publicado en septiembre de 2022. El documento proporciona un compendio de directrices para actuar sobre cada una de las características que definen la calidad, impulsando su mejora. A su vez, esta guía toma como referente la guía para la calidad de datos de data.europe.eu, publicada en 2021 por la Oficina de Publicaciones de la Unión Europea y la completa para que tanto publicadores como reutilizadores de datos puedan seguir pautas que garanticen la calidad de los datos abiertos.

En resumen, la guía pretende ser un marco de referencia para todas las personas involucradas tanto en la generación como en la utilización de datos abiertos para que tengan un punto de partida que garantice la idoneidad de los datos tanto en su puesta a disposición como a la hora de evaluar si un conjunto de datos posee calidad suficiente para su reutilización en estudios, aplicaciones, servicios u otros.
Evento
Madrid acoge del 25 al 27 de septiembre la cuarta edición del Open Science Fair, un evento internacional sobre la ciencia abierta que reunirá a expertos de todo el mundo con el objetivo de identificar prácticas comunes, acercar posturas y, en definitiva, mejorar las sinergias entre las diferentes comunidades y servicios que trabajan en este ámbito.
Este evento es una iniciativa de OpenAIRE, una organización que pretende crear una comunicación académica más abierta y transparente. Esta edición del Open Science Fair está co-organizada por la Fundación Española para la Ciencia y Tecnología (FECYT), dependiente del Ministerio de Ciencia e Innovación, y es uno de los eventos auspiciados por la presidencia española del Consejo de la Unión Europea.
La situación actual de la ciencia abierta
La ciencia ha dejado de ser algo exclusivo de los científicos. Investigadores, instituciones, agencias de financiación y editores científicos forman parte de un ecosistema que lleva a cabo un trabajo con un eco creciente en la ciudadanía y un mayor impacto en la sociedad. Además, cada vez es más habitual que los grupos de investigación se abran a colaborar con instituciones de todo el mundo. Para hacer posible esta colaboración es clave poder contar con datos abiertos y disponibles para su reutilización en investigaciones.
Sin embargo, para permitir que la investigación internacional e interdisciplinaria avance, es necesario garantizar la interoperabilidad entre comunidades y servicios, manteniendo al mismo tiempo la capacidad de apoyar los diferentes flujos de trabajo y sistemas de conocimiento.
Los objetivos y el programa de Open Science Fair
En este contexto se celebra el Open Science Fair 2023, que tiene como objetivo reunir y empoderar a las comunidades y servicios de ciencia abierta; identificar prácticas comunes relacionadas con la ciencia abierta para analizar las sinergias más adecuadas y, en definitiva, compartir experiencias que se desarrollan en diferentes partes del mundo.
El evento cuenta con un interesante programa que incluye conferencias magistrales de relevantes ponentes, mesas redondas, talleres y sesiones de capacitación, así como una sesión de demostración. Los asistentes podrán compartir experiencias e intercambiar opiniones, lo que permitirá definir las maneras más eficientes para que las comunidades puedan trabajar en conjunto y trazar hojas de ruta, adaptadas a cada circunstancia, para la implementación de la ciencia abierta.
Esta tercera edición del Open Science se centrará en ‘La ciencia abierta para futuras generaciones’ y los principales temas sobre los que tratará, tal y como se destaca en la web del evento, son:
- Avance y reforma de la evaluación de la investigación y la ciencia abierta. Conexiones, barreras y camino a seguir.
- Impacto de la inteligencia artificial en la ciencia abierta e impacto de la ciencia abierta en la inteligencia artificial.
- Innovación y disrupción en la publicación académica.
- Fair data, software y hardware.
- Apertura en investigación y educación.
- Compromiso público y ciencia ciudadana.
Ciencia abierta e inteligencia artificial
La inteligencia artificial está teniendo una gran importancia en el mundo académico a través de análisis de datos. Gracias al análisis de grandes cantidades de datos, los investigadores pueden identificar patrones y correlaciones a los que sería difícil llegar a través de otros métodos. La utilización de datos abiertos en el ámbito de la ciencia abierta abre un interesante y prometedor futuro, aunque es importante garantizar que los beneficios de la inteligencia artificial estén disponibles para todos de forma justa y equitativa.
Dada su gran relevancia, en el Open Science Fair se celebrarán dos conferencias magistrales y una mesa redonda sobre ‘IA con y para la ciencia abierta’. La combinación de los beneficios de los datos abiertos y la inteligencia artificial es una de áreas con mayor potencial para lograr avances científicos significativos y, como tal, tendrá su espacio en el evento. Así, se analizará desde tres puntos de vista (ética, infraestructura y algoritmos), cómo la inteligencia artificial apoya a los investigadores y cuáles son los ingredientes clave para que las infraestructuras abiertas pueden lograr que esto suceda.
El programa del Open Science Fair 2023 incluye también la presentación de una demo de una herramienta para mapear las actividades de investigación de la Universidad Europea de Tecnología EUt+ aprovechando los datos abiertos y el procesamiento del lenguaje natural. Este proyecto incluye el desarrollo de un conjunto de herramientas basadas en datos. Los asistentes a la demo podrán ver la plataforma desarrollada que integra datos de repositorios públicos, como proyectos europeos de investigación e innovación de CORDIS, patentes de la base de datos de la Oficina Europea de Patentes y publicaciones científicas de OpenAIRE. También se han recopilado datos de proyectos nacionales y regionales de diferentes repositorios, que han sido procesados y puestos a disposición del público.
Estos son solo alguno de los eventos que se desarrollarán dentro del Open Science Fair, pero el programa completo incluye un amplio conjunto de actos para explorar el conocimiento multidisciplinar y la evaluación de las investigaciones.
Aunque la inscripción al encuentro ya está cerrada, es posible mantenerse al tanto de todo lo que se hable durante su celebración a través del hashtag #OSFAIR2023 en Twitter, LinkedIn y Facebook, así como en su página web.
Además, en la web de datos.gob.es y en nuestras redes sociales puedes mantenerte al día sobre los eventos más destacados en el ámbito de los datos abiertos, como los que tendrán lugar durante este otoño.
Blog
En la era digital, los avances tecnológicos han transformado el sector de la investigación médica. Uno de los factores que contribuyen al desarrollo tecnológico en este ámbito son los datos y, en especial, los datos abiertos. La apertura y disponibilidad de la información que se obtiene de investigaciones sanitarias aporta múltiples beneficios a la comunidad científica. Los datos abiertos en el sector salud fomentan la colaboración entre investigadores, aceleran el proceso de validación de resultados en estudios y, en definitiva, ayudan a salvar vidas.
La relevancia de este tipo de datos también se manifiesta en la intención prioritaria de constituir el proyecto de espacio europeo de datos sanitarios (EEDS), el primer espacio común de datos de la UE que surge de la Estrategia Europea de Datos y una de las prioridades de la Comisión para el período 2019-2025. Tal y como plantea la Comisión Europea en su propuesta, el EEDS este espacio contribuirá a promover un mejor intercambio y acceso a diferentes tipos de datos sanitarios, no solo para apoyar la prestación de asistencia médica sino también para la investigación sanitaria y la elaboración de políticas en el ámbito de la salud.
Sin embargo, el tratamiento de este tipo de datos debe de ser adecuado, debido a la información sensible que albergan. Los datos personales relativos a la salud están considerados como una categoría especial por la Agencia Española de Protección de Datos (AEPD) y una brecha de datos personales, especialmente, en el sector de la salud, tiene un alto impacto personal y social.
Para evitar estos riesgos, los datos médicos se pueden anonimizar garantizando el cumplimiento normativo y de los derechos fundamentales y, así, proteger la privacidad de los pacientes. La Guía básica de anonimización elaborada por la AEPD a partir de la Personal Data Protection Commission Singapore (PDPC) define los conceptos clave de un proceso de anonimización, incluyendo términos, principios metodológicos, tipos de riesgos y técnicas existentes.
Una vez se realiza ese proceso, los datos médicos pueden contribuir a la investigación sobre enfermedades, lo que se traduce en mejoras en la eficacia de tratamientos y en el desarrollo de tecnologías de asistencia médica. Además, los datos abiertos en el sector salud permiten que los científicos compartan información, resultados y hallazgos de manera rápida y accesible, fomentando así la colaboración y la replicabilidad de los estudios.
En este sentido, existen diversas instituciones que comparten sus datos anonimizados para contribuir a la investigación sanitaria y el desarrollo de la ciencia. Una de ellas es la Fundación FISABIO (Fundación para el Fomento de la Investigación Sanitaria y Biomédica de la Comunitat Valenciana) que se ha convertido en un referente en el campo de la medicina gracias a su compromiso con la apertura y compartición de datos médicos. Como parte de esta institución, ubicada en la Comunidad Valenciana, existe la Unidad Mixta de Imagen Biomédica de FISABIO y la Fundación Príncipe Felipe (FISABIO-CIPF) que se dedica, entre otras tareas, al estudio y desarrollo de técnicas avanzadas de imagen médica para mejorar el diagnóstico y tratamiento de enfermedades.
Este grupo de investigación ha desarrollado diferentes proyectos sobre análisis de imagen médica. El resultado de todo su trabajo se publica bajo licencias de código abierto: desde el resultado de sus investigaciones hasta los repositorios de datos que emplean para entrenar modelos de inteligencia artificial y machine learning.
Para proteger los datos sensibles de los pacientes, también han desarrollado sus propias técnicas de anonimización y seudonimización de imágenes e informes médicos mediante un modelo de Procesamiento del Lenguaje Natural (NLP) por el que los datos anonimizados se pueden sustituir por valores sintéticos. Siguiendo su técnica, se puede borrar la información facial de resonancias magnéticas cerebrales empleando un software libre de deep learning.
BIMCV: Banco de imágenes médicas de la Comunidad Valenciana
Uno de los mayores hitos de la Conselleria de Sanidad Universal y Salud Pública, a través de la Fundación y el hospital San Juan de Alicante, es la creación y mantenimiento del Banco de Imágenes Médicas de la Comunidad Valenciana, BIMCV (por sus siglas en inglés, Medical Imaging Databank of the Valencia Region), un repositorio de conocimiento para lograr “avances tecnológicos en imágenes médicas y proporcionar servicios de cobertura tecnológica para apoyar proyectos de I+D”, tal y como explican en su web.
BIMCV se aloja en XNAT, una plataforma que contiene imágenes de código abierto para la investigación basada en imágenes, y que es accesible bajo previo registro y/o bajo demanda. Actualmente, el Banco de Imágenes Médicas de la Comunidad Valenciana incluye datos abiertos procedentes de investigaciones realizada en diversos centros sanitarios de la región: alberga datos de más de 90.000 sujetos recogidos en más de 150.000 sesiones.
Nuevo conjunto de datos de imágenes radiológicas
Recientemente, la Unidad Mixta de Imagen Biomédica de FISABIO y la Fundación Príncipe Felipe (FISABIO-CIPF) ha publicado en abierto la tercera y última iteración de datos del proyecto BIMCV-COVID-19: iniciativa con la que liberaron datos de imagen de radiologías de tórax realizadas a pacientes con COVID-19, así como los modelos que habían entrenado para detección de diferentes patologías de Rx tórax, gracias al apoyo de la Conselleria de Innovación, la Conselleria de Sanidad y los Fondos de la Unión Europea REACT-UE. Todo ello, “para que pueda ser utilizado por empresas del sector o simplemente para investigación”, explica María de la Iglesia, directora de la Unidad. “Creemos que la reproducibilidad es de gran relevancia e importancia en el sector salud", añade. Los conjuntos de datos y el resultado de sus investigaciones se pueden consultar aquí.
Los hallazgos están mapeados en terminología estándar del Sistema Unificado de Lenguaje Médico (UMLS) (como propuesta de los resultados de la tesis doctoral de la Oncóloga e Ingeniera Informática Dra. Aurelia Bustos)y almacenados en alta resolución con etiquetas anatómicas en un formato de Estructura de Datos de Imágenes Médicas (MIDS). Entre la información almacenada, se encuentran datos demográficos del paciente, el tipo de proyección y los parámetros de adquisición del estudio de imagen, entre otros, todo ello anonimizado.
La contribución que este tipo de proyectos sobre datos abiertos aportan a la sociedad, no solo beneficia a los investigadores y profesionales de la salud, sino que también permite el desarrollo de soluciones que pueden tener un impacto relevante en la mejora de la atención médica. Una de ellas puede ser la IA generativa que proporciona interesantes resultados que los profesionales sanitarios, priorizando su criterio, pueden tomar en consideración para personalizar el diagnóstico y proponer un tratamiento más eficaz.
Por otro lado, la digitalización de los sistemas sanitarios ya es una realidad: impresión 3D, gemelos digitales aplicados a la medicina, consultas telemáticas o dispositivos médicos portátiles. En este contexto, la colaboración y compartición de datos médicos, siempre y cuando se garantice su protección, contribuye a impulsar la investigación e innovación en el sector. Es decir, las iniciativas de datos abiertos para la investigación médica estimulan este avance tecnológico en la salud.
Por todo ello, la Fundación FISABIO conjuntamente con el Centro de Investigación Príncipe Felipe en donde se ubica la plataforma que alberga BIMCV, se destaca como un ejemplo destacado al promover la apertura y compartición de datos en el campo de la medicina. A medida que avanza la era digital, es fundamental seguir fomentando la apertura de datos y promoviendo su uso responsable en la investigación médica, en beneficio de toda la sociedad.
Blog
La iniciativa Hércules se inicia en noviembre de 2017, mediante un convenio entre la Universidad de Murcia y el Ministerio de Economía, Industria y Competitividad, con el objetivo de desarrollar un Sistema de Gestión de Investigación (SGI) basado en datos abiertos semánticos que ofrezca una visión global de los datos de investigación del Sistema Universitario Español (SUE), para mejorar la gestión, el análisis y las posibles sinergias entre universidades y el gran público.
Esta iniciativa es complementaria a UniversiDATA, donde varias universidades españolas colaboran para fomentar los datos abiertos en el sector de la educación superior mediante la publicación de conjuntos de datos a través de criterios estandarizados y comunes. En concreto se define un Núcleo Común con 42 especificaciones de datasets, de los cuales se han publicado 12 para la versión 1.0. Hércules, en cambio es una iniciativa específica del ámbito de investigación, estructurada en torno a tres pilares:
- Prototipo innovador de SGI
- Grafo unificado de conocimiento (ASIO) 1],
- Enriquecimiento de datos y análisis semántico (EDMA)
El objetivo final es la publicación de un grafo unificado de conocimiento donde queden integrados todos los datos de investigación que deseen hacer públicos las universidades participantes. Hércules prevé la integración de universidades a diferentes niveles, dependiendo de su disposición a reemplazar su SGI por el SGI de Hércules. En el caso de SGIs externos, el grado de accesibilidad que ofrezcan también tendrá implicación en el volumen de datos que puedan compartir a través del grafo unificado.
Organigrama general de la iniciativa Hércules
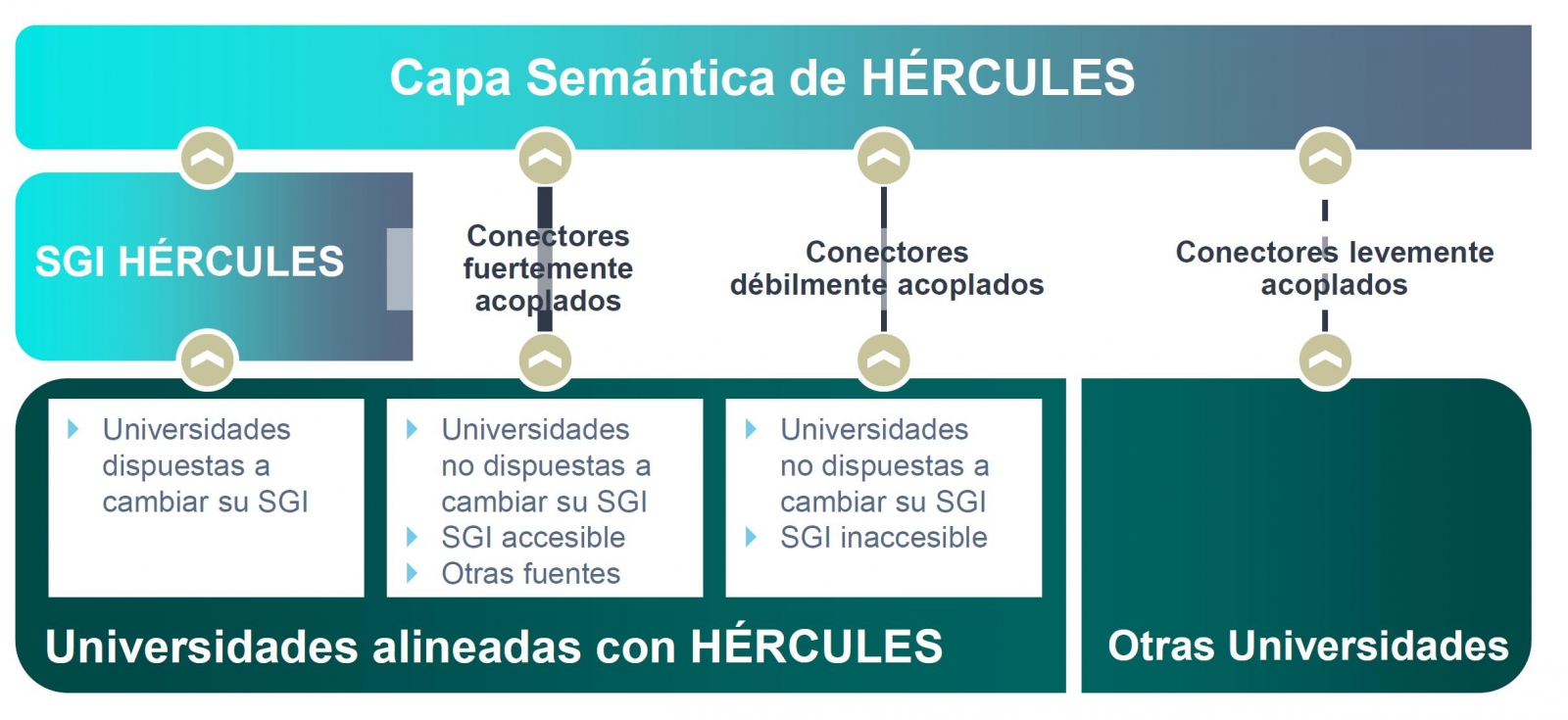
Dentro de la iniciativa Hércules, se integra el Proyecto ASIO (Arquitectura Semántica e Infraestructura Ontológica). El propósito de este sub-proyecto es definir una Red de Ontologías para la Gestión de la Investigación (Infraestructura Ontológica). Una ontología es una definición formal que describe con fidelidad y alta granularidad un dominio de discusión concreto. En este caso, el dominio de la investigación, que puede ser extrapolable a otras universidades españolas e internacionales (de momento el piloto se está desarrollando con la Universidad de Murcia). Es decir, se trata de crear un vocabulario de datos común.
Adicionalmente, a través del módulo de Arquitectura Semántica de Datos se ha desarrollado una plataforma eficiente para almacenar, gestionar y publicar datos de investigación del SUE, basándose en ontologías, con la capacidad de sincronizar instancias instaladas en diferentes universidades, así como la ejecución de consultas federadas distribuidas sobre aspectos clave de producción científica, líneas de investigación, búsqueda de sinergias, etc.
Como solución a este reto de innovación se han propuesto dos líneas complementarias, una centralizada (sincronización en escritura) y otra descentralizada (sincronización en consulta). En las próximas secciones se explica en detalle la arquitectura de la solución descentralizada.
Domain Driven Design
El modelo de datos sigue el enfoque Domain Driven Design, modelando entidades y vocabulario común, que pueda ser comprendido tanto por desarrolladores como expertos del dominio. Este modelo es independiente de la base de datos, del interfaz de usuario y del entorno de desarrollo, obteniendo una arquitectura de software limpia que permite adaptarse a los cambios del modelo.
Para ello se hace uso de Shape Expressions (ShEx), un lenguaje para validar y describir conjuntos de datos RDF, con sintaxis legible por humanos. A partir de estas expresiones se genera el modelo de dominio automáticamente y permite orquestar un proceso de integración continua (CI), tal y como se describe en la siguiente figura.
Proceso de integración continua mediante Domain Driven Design
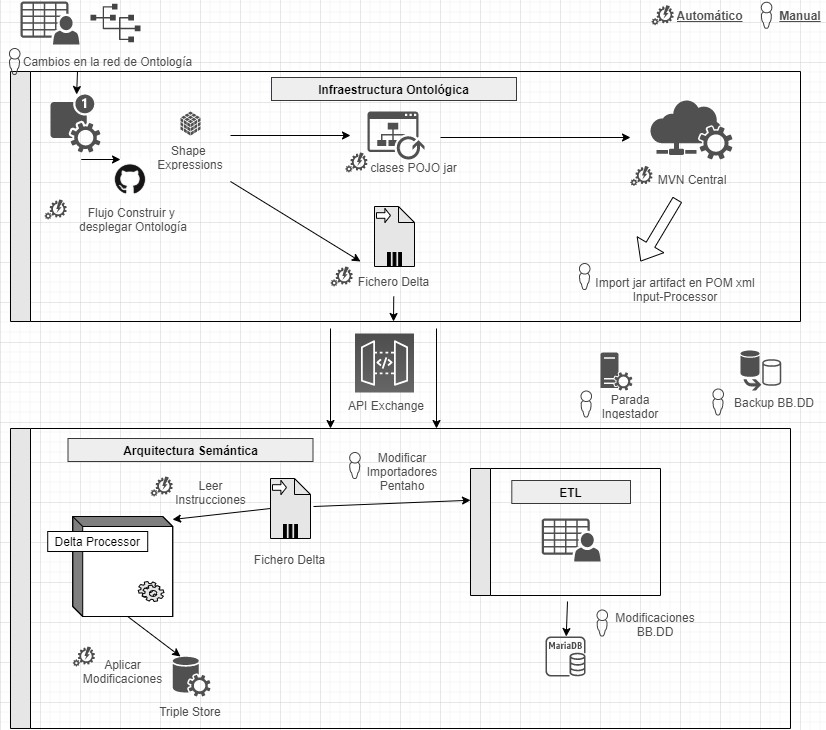
Mediante un sistema basado en de control de versiones como elemento central, se ofrece la posibilidad de que los expertos de dominio construyan y visualicen las ontologías multilingües. Estas a su vez se apoyan en ontologías tanto del ámbito de la investigación: VIVO, EuroCRIS/CERIF o Research Object, como ontologías de propósito general para la etiquetación de metadatos: Prov-O, DCAT, etc.
Linked Data Platform
El servidor de datos enlazados es el núcleo de la arquitectura, encargándose de renderizar la información sobre todas las entidades. Para ello recoge peticiones HTTP del exterior y las redirecciona a los servicios correspondientes, aplicando negociación de contenidos, la cual ofrece la mejor representación de un recurso basado en las preferencias del navegador para los distintos tipos de medios, idiomas, caracteres y codificación.
Todos los recursos se publican siguiendo un esquema de URIs persistentes diseñado a medida. Cada entidad representada mediante una URI (investigador, proyecto, universidad, etc) dispone de una serie de acciones para consultar y actualizar sus datos, siguiendo los patrones propuestos por Linked Data Platform (LDP) y el modelo de 5 estrellas.
Este sistema garantiza además el cumplimiento con los principios FAIR (Findable, Accesible, Interoperable, Reusable) y publica automáticamente los resultados de aplicar dichas métricas sobre el repositorio de datos.
Publicación de datos abiertos
El sistema de procesamiento de datos se encarga de la conversión, integración y validación de datos de terceras partes, así como la detección de duplicados, equivalencias y relaciones entre entidades. Los datos surgen de varias fuentes, principalmente el SGI unificado de Hércules, pero también de SGIs alternativos, o de otras fuentes que ofrecen datos en formato FECYT/CVN (Curriculum Vitae Normalizado), EuroCRIS/CERIF y otros posibles.
El sistema de importación convierte todas estas fuentes a formato RDF y los registra en un repositorio de propósito específico para datos enlazados, denominado Triple Store, por su capacidad para almacenar tripletas de tipo sujeto-predicado-objeto.
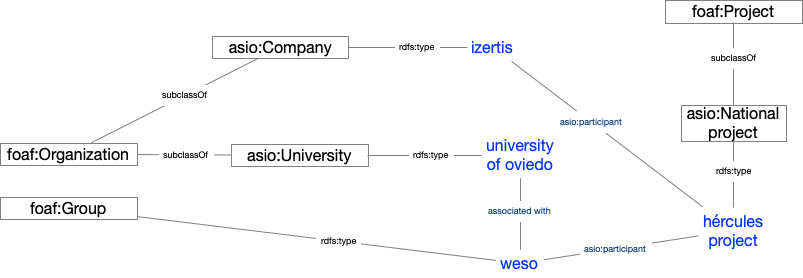
Una vez importados, se organizan formando un grafo de conocimiento, fácilmente accesible, permitiendo realizar inferencias y búsquedas avanzadas potenciadas por las relaciones entre conceptos.
Ejemplo de grafo de conocimiento describiendo el proyecto ASIO
Resultados y conclusiones
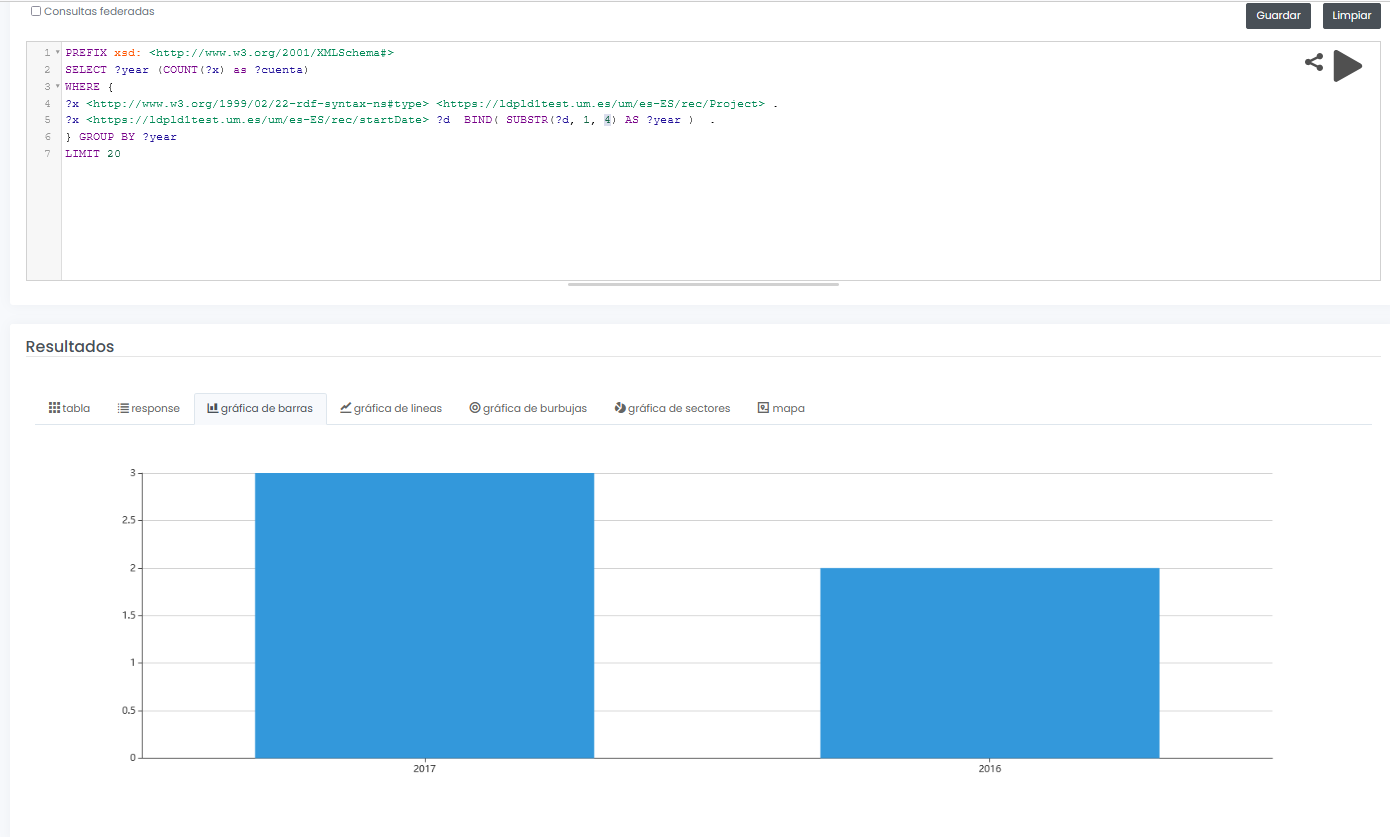
El sistema final no sólo permite ofrecer un interfaz gráfico para consulta interactiva y visual de datos de investigación, sino que además permite diseñar consultas SPARQL, como la que se muestra a continuación, incluso con la posibilidad de ejecutar la consulta de forma federada sobre todos los nodos de la red Hércules, y mostrar resultados de forma dinámica en diferentes tipos de gráficos y mapas.
En este ejemplo, se muestra una consulta (con datos limitados de prueba) de todos proyectos de investigación disponibles agrupados gráficamente por año:
PREFIX xsd: <http://www.w3.org/2001/XMLSchema#>
SELECT ?year (COUNT(?x) as ?cuenta)
WHERE {
?x <http://www.w3.org/1999/02/22-rdf-syntax-nes#type> <https://ldpld1test.um.es/um/es-ES/rec/Project> .
?x <https://ldpld1test.um.es/um/es-ES/rec/startDate> ?d BIND(SUBSTR(?d, 1, 4) as ?year) .
} GROUP BY ?year LIMIT 20
LIMIT 20
Ejemplo de consulta SPARQL con resultado gráfico
En definitiva, ASIO ofrece un marco común de publicación de datos abiertos enlazados, ofrecido como código libre y fácilmente adaptable a otros dominios. Para dicha adaptación, bastaría con diseñar un modelo de dominio específico, incluyendo la ontología y los procesos de importación y validación comentados en este artículo.
Actualmente el proyecto, en sus dos variantes (centralizada y descentralizada), se encuentra en proceso de puesta en pre-producción dentro de la infraestructura de la Universidad de Murcia, y en breve será accesible públicamente.
[1 Los grafos son una forma de representación del conocimiento que permiten relacionar conceptos a través de la integración de conjuntos de datos, utilizando técnicas de web semántica. De esta forma se puede conocer mejor el contexto de los datos, lo que facilita el descubrimiento de nuevo conocimiento.
Contenido elaborado por Jose Barranquero, experto en Ciencia de datos y computación cuántica.
Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Evento
Hoy en día los métodos de investigación (sensores, dispositivos tecnológicos, simulaciones, etc.) generan gran cantidad de datos que, en formato abierto y reutilizable, esconden un gran potencial reutilizador para otros investigadores, administraciones públicas, empresas privadas o usuarios. Por ello, el año pasado la Comisión Europea acordó en el Consejo de Competitividad un compromiso internacional por la ciencia abierta, garantizando que todos los resultados de las investigaciones realizados en la UE estén disponibles sin ningún ningún tipo de restricción técnica, legal o financiera.
No obstante, el acceso en abierto y la difusión de la información científica supone una serie de retos legales -propiedad intelectual, privacidad y protección de datos personales- que requieren de soluciones ad hoc para que el movimiento open science sea viable. En este contexto, el próximo martes 4 de abril se celebrará en el marco del plenario de la Research Data Alliance (RDA) en Barcelona la octava edición del taller OpenAIRE, dedicado a explorar las barreras legales que dificultan la apertura de los datos de investigación e identificar las posibles soluciones al respecto.
Durante la jornada se intentará familiarizar a los asistentes con aquellos aspectos normativos relacionados directamente con los datos abiertos de investigación, ofreciendo recomendaciones específicas y pragmáticas para que dichas barreras no impidan la apertura y reutilización de la información científica de mano de los expertos de OpenAIRE.
En este proyecto, financiado por la Comisión Europea, se trabaja para fomentar e impulsar la investigación abierta y optimizar el acceso a los datos científicos europeos, al mismo tiempo que ofrece una red de repositorios para el acceso libre al conocimiento y resultados de investigación en los campos de la salud, energía, medio ambiente, TIC y ciencias sociales. De forma paralela, OpenAIRE organiza diferentes talleres, como el workshop que tendrá lugar en la ciudad condal, para divulgar y sensibilizar sobre la ciencia abierta, sus oportunidades y desafíos.
Evento
“Preguntas colaborativas cuya respuesta ayudará a comprender mejor los datos abiertos”
El próximo 5 de octubre, investigadores de todo el mundo se reunirán en el segundo Simposio sobre Investigación de Datos Abiertos (ODRS); un evento previo a la Conferencia Internacional de Datos Abiertos que tendrá lugar en Madrid. Al igual que en la edición anterior, ODRS 16 ofrecerá a los asistentes la oportunidad de reflexionar de forma crítica sobre los resultados de sus investigaciones al mismo tiempo que se busca la cohesión dentro de la comunidad investigadora en torno al impacto potencial de los datos abiertos.
Aunque la presentación de propuestas para el ODRS finalizó el pasado mes de mayo, se ha ampliado el plazo para que todos los miembros del movimiento open data ayuden a dar forma al programa del evento, centrándose en aquellos aspectos más relevantes en la materia. Para ello, la organización ha creado una sección específica en la web del Simposio donde los usuarios pueden enviar preguntas para que los investigadores resuelvan sus dudas sobre los datos abiertos. Además, también es posible remitir dichas cuestiones a través de Twitter mediante el hashtag #ODSR16. El plazo estará abierto hasta el viernes 1 de julio.
Gracias a las preguntas de los usuarios, se podrán identificar los temas de mayor interés para la comunidad internacional open data, crear un borrador del programa de ODRS que garantice sesiones adaptadas a las necesidades de los participantes, construir una agenda colaborativa e informar de los esfuerzos y colaboraciones que se lleven a cabo durante el encuentro.
¿Más información sobre los eventos que acompañarán a la cita anual de los datos abiertos? No te pierdas la sección de novedades de la página web de la Conferencia Internacional de Datos Abiertos. ¡Te esperamos en Madrid!
Noticia
El Consejo Superior de Investigaciones Científicas (CSIC) y seis universidades españolas han trabajado conjuntamente para lanzar Maredata, una red temática nacional que almacena en abierto datos de investigación para su reutilización por otros sectores interesados en la información científica.
La Universidad de Barcelona es el centro encargado de coordinador este proyecto, en el que participan a su vez la Universidad Carlos III de Madrid, la Universidad de Alicante, la Universitat Oberta de Catalunya, el Instituto de Agroquímica y Tecnología de Alimentos (IATA-CSIC), Ingenio (centro del CSIC adscrito a la UPV) y UISYS, centro del CSIC vinculado a la Universidad de Valencia.
Financiada por el Ministerio de Economía y Competitividad, la red supone un acicate para la ciencia abierta en España, garantizando el acceso sin restricciones a los datos de investigación de financiación pública e impulsando la participación de la comunidad nacional en el proyecto piloto de apertura de datos de investigación financiado por Horizonte 2020. Asimismo, esta iniciativa tiene entre sus objetivos el desarrollo de nuevas líneas de investigación y colaboración entre los miembros de la comunidad de datos abiertos y open science, realizando recomendaciones que ayuden a otras instituciones a abrir sus resultados científicos.
La ciencia abierta fomenta que los resultados procedentes de investigaciones científicas y metodologías así como los datos obtenidos a partir de ellas puedan ser distribuidos, reutilizados y accesibles de forma gratuita y libre. Crear nuevos modelos de negocio, construir productos o servicios para su comercialización, desarrollar nuevas líneas de investigación o, incluso, validar la calidad de la ciencia que se está produciendo en el país son solo algunos ejemplos del potencial y beneficios que encierran los datos de investigación para todos los niveles de la ciudadanía.
Por todos estos motivos, los agentes gubernamentales han querido poner en valor esta información e impulsar la red temática Maredata. Al fin y al cabo, las universidades y centros de investigación, como entidades públicas que son, desempeñan un papel esencial en la sociedad y, así, deberían consolidarse como organismos abiertos que, gracias a los datos que custodian y generan en los diferentes ámbitos académicos (docencia, investigación…), contribuirán a ampliar el conocimiento y la participación ciudadana.
Conscientes de la importancia de los datos académicos, el ámbito universitario español ya cuenta con varias universidades que, a través de su propio portal open data, ponen a disposición de la sociedad la información del centro y difunden su plan de acción tal y como ha hecho la Universidad de Alicante, que además de participar en la red Maredata, ha publicado un libro sobre el ecosistema de datos abiertos de la entidad, el cual refleja la experiencia de la Universidad de Alicante en el proceso de implantación de su política open data.
Gracias a este tipo de iniciativas, el concepto de universidad abierta y el acceso a los datos de investigación ya son una realidad palpable; la cual no solo respalda el intercambio y reutilización de los mismos sino que, a su vez, facilita tanto la toma de decisiones basadas en la información académica como genera espacios de colaboración entre los diferentes agentes de la sociedad actual.
Aplicación
Dataverse es una aplicación web de código abierto para compartir, preservar, citar, explorar y analizar datos sobre investigación. Facilita poner a disposición de los demas los datos, y permite replicar el trabajo de otros. Investigadores, autors de datos, publicadores, distribudores de datos e instituciones afiliadas, todos reciben su correspondiente crédito.
Un repositorio Dataverse alberga múltiples dataverses. Cada dataverse contiene conjuntos de cada u otros dataverses, y cada conjunto de datos contiene metadatos descriptivos y archivos de datos (incluyendo documentación y el código que acompaña a los datos).
Más información en http://dataverse.org/about/
Noticia
Cada año, la entidad Open Data Institute (ODI) abre un programa de ayuda económica para aquellas start-ups que basan sus servicios en los datos abiertos. Esta iniciativa ha sido concebida como apoyo a emprendedores de todo el mundo para que estos puedan convertir sus proyectos en realidad y formen parte del ecosistema open data internacional.
El éxito alcanzado por este programa hasta la fecha ha contribuido a que la Unión Europea destine 14,4 millones de euros a tres iniciativas que impulsan la innovación en materia open data en todo el continente:
Incubadora europea basada en el Programa Start-Up de ODI
Bajo el marco de Horizon 2020, este programa -de 30 meses de duración- recibirá 7,8 millones de euros para apoyar a los emprendedores de datos abiertos en Europa. El programa está compuesto por siete entidades –Telefónica, Universidad de Southampton, Open Data Institute, The Guardian, Open Future Wayra, Fraunhofer, Open Knowledge Foundation- quienes reclutarán a un total de 50 start-ups para ayudarlas en sus proyectos a partir de la primavera del 2015.
Red de investigación de datos
La ODI junto a otras cinco entidades ha obtenido una financiación de 3,7 millones de euros para crear una red que aglutine a quince investigadores de toda Europa. La ayuda económica tendrá una duración de cuatro años y cada institución podrá abrir dos o tres plazas de doctorado para estudiantes que resuelvan cuestiones complejas sobre los datos en la web, la combinación de datasets con diferentes licencias de reutilización o soluciones que muestren cómo encontrar los conjuntos de datos necesarios para resolver las necesidades de los usuarios.
Nueva escuela de formación para científicos de datos
El tercer proyecto estará dedicado a la creación de EDSA, Escuela Europea de Ciencias de Datos, la cual recibirá 2,9 millones de euros de ayuda económica y formará a la futura generación de científicos de datos quienes contarán con los conocimientos y habilidades necesarias para permitir al tejido empresarial de Europa fortalecerse en la era de los datos.
EDSA combinará las últimas tecnologías de análisis de datos y e-learning para construir un panel europeo que estudie y comprenda la información industrial y cree el material educativo necesario para satisfacer la demanda actual.