Blog
Web API design is a fundamental discipline for the development of applications and services, facilitating the fluid exchange of data between different systems. In the context of open data platforms, APIs are particularly important as they allow users to access the information they need automatically and efficiently, saving costs and resources.
This article explores the essential principles that should guide the creation of effective, secure and sustainable web APIs, based on the principles compiled by the Technical Architecture Group linked to the World Wide Web Consortium (W3C), following ethical and technical standards. Although these principles refer to API design, many are applicable to web development in general.
The aim is to enable developers to ensure that their APIs not only meet technical requirements, but also respect users' privacy and security, promoting a safer and more efficient web for all.
In this post, we will look at some tips for API developers and how they can be put into practice.
Prioritise user needs
When designing an API, it is crucial to follow the hierarchy of needs established by the W3C:
- First, the needs of the end-user.
- Second, the needs of web developers.
- Third, the needs of browser implementers.
- Finally, theoretical purity.
In this way we can drive a user experience that is intuitive, functional and engaging. This hierarchy should guide design decisions, while recognising that sometimes these levels are interrelated: for example, an API that is easier for developers to use often results in a better end-user experience.
Ensures security
Ensuring security when developing an API is crucial to protect both user data and the integrity of the system. An insecure API can be an entry point for attackers seeking to access sensitive information or compromise system functionality. Therefore, when adding new functionalities, we must meet the user's expectations and ensure their security.
In this sense, it is essential to consider factors related to user authentication, data encryption, input validation, request rate management (or Rate Limiting, to limit the number of requests a user can make in a given period and avoid denial of service attacks), etc. It is also necessary to continually monitor API activities and keep detailed logs to quickly detect and respond to any suspicious activity.
Develop a user interface that conveys trust and confidence
It is necessary to consider how new functionalities impact on user interfaces. Interfaces must be designed so that users can trust and verify that the information provided is genuine and has not been falsified. Aspects such as the address bar, security indicators and permission requests should make it clear who you are interacting with and how.
For example, the JavaScript alert function, which allows the display of a modal dialogue box that appears to be part of the browser, is a case history that illustrates this need. This feature, created in the early days of the web, has often been used to trick users into thinking they are interacting with the browser, when in fact they are interacting with the web page. If this functionality were proposed today, it would probably not be accepted because of these security risks.
Ask for explicit consent from users
In the context of satisfying a user need, a website may use a function that poses a threat. For example, access to the user's geolocation may be helpful in some contexts (such as a mapping application), but it also affects privacy.
In these cases, the user's consent to their use is required. To do this:
- The user must understand what he or she is accessing. If you cannot explain to a typical user what he or she is consenting to in an intelligible way, you will have to reconsider the design of the function.
- The user must be able to choose to effectively grant or refuse such permission. If a permission request is rejected, the website will not be able to do anything that the user thinks they have dismissed.
By asking for consent, we can inform the user of what capabilities the website has or does not have, reinforcing their confidence in the security of the site. However, the benefit of a new feature must justify the additional burden on the user in deciding whether or not to grant permission for a feature.
Uses identification mechanisms appropriate to the context
It is necessary to be transparent and allow individuals to control their identifiers and the information attached to them that they provide in different contexts on the web.
Functionalities that use or rely on identifiers linked to data about an individual carry privacy risks that may go beyond a single API or system. This includes passively generated data (such as your behaviour on the web) and actively collected data (e.g. through a form). In this regard, it is necessary to understand the context in which they will be used and how they will be integrated with other web functionalities, ensuring that the user can give appropriate consent.
It is advisable to design APIs that collect the minimum amount of data necessary and use short-lived temporary identifiers, unless a persistent identifier is absolutely necessary.
Creates functionalities compatible with the full range of devices and platforms
As far as possible, ensure that the web functionalities are operational on different input and output devices, screen sizes, interaction modes, platforms and media, favouring user flexibility.
For example, the 'display: block', 'display: flex' and 'display: grid' layout models in CSS, by default, place content within the available space and without overlaps. This way they work on different screen sizes and allow users to choose their own font and size without causing text overflow.
Add new capabilities with care
Adding new capabilities to the website requires consideration of existing functionality and content, to assess how it will be integrated. Do not assume that a change is possible or impossible without first verifying it.
There are many extension points that allow you to add functionality, but there are changes that cannot be made by simply adding or removing elements, because they could generate errors or affect the user experience. It is therefore necessary to verify the current situation first, as we will see in the next section.
Before removing or changing functionality, understand its current use
It is possible to remove or change functions and capabilities, but the nature and extent of their impact on existing content must first be understood. This may require investigating how current functions are used.
The obligation to understand existing use applies to any function on which the content depends. Web functions are not only defined in the specifications, but also in the way users use them.
Best practice is to prioritise compatibility of new features with existing content and user behaviour. Sometimes a significant amount of content may depend on a particular behaviour. In these situations, it is not advisable to remove or change such behaviour.
Leave the website better than you found it
The way to add new capabilities to a web platform is to improve the platform as a whole, e.g. its security, privacy or accessibility features.
The existence of a defect in a particular part of the platform should not be used as an excuse to add or extend additional functionalities in order to fix it, as this may duplicate problems and diminish the overall quality of the platform. Wherever possible, new web capabilities should be created that improve the overall quality of the platform, mitigating existing shortcomings across the board.
Minimises user data
Functionalities must be designed to be operational with the minimal amount of user input necessary to achieve their objectives. In doing so, we limit the risks of disclosure or misuse.
It is recommended to design APIs so that websites find it easier to request, collect and/or transmit a small amount of data (more granular or specific data), than to work with more generic or massive data. APIs should provide granularity and user controls, in particular if they work on personal data.
Other recommendations
The document also provides tips for API design using various programming languages. In this sense, it provides recommendations linked to HTML, CSS, JavaScript, etc. You can read the recommendations here.
In addition, if you are thinking of integrating an API into your open data platform, we recommend reading the Practical guide to publishing Open Data using APIs.
By following these guidelines, you will be able to develop consistent and useful websites for users, allowing them to achieve their objectives in an agile and resource-optimised way.
Blog
We continue with the series of posts about Chat GPT-3. The expectation raised by the conversational system more than justifies the publication of several articles about its features and applications. In this post, we take a closer look at one of the latest news published by openAI related to Chat GPT-3. In this case, we introduce its API, that is, its programming interface with which we can integrate Chat GPT-3 into our own applications.
Introduction.
In our last post about Chat GPT-3 we carried out a co-programming or assisted programming exercise in which we asked the AI to write us a simple program, in R programming language, to visualise a set of data. As we saw in the post, we used Chat GTP-3's own available interface. The interface is very minimalistic and functional, we just have to ask the AI in the text box and it answers us in the subsequent text box. As we concluded in the post, the result of the exercise was more than satisfactory. However, we also detected some points for improvement. For example, the standard interface can be a bit slow. For a long exercise, with multiple conversational interactions with the AI (a long dialogue), the interface takes quite a long time to write the answers. Several users report the same feeling and so some, like this developer, have created their own interface with the conversational assistant to improve its response speed.
But how is this possible? The reason is simple, thanks to the GPT-3 Chat API. We have talked a lot about APIs in this space in the past. Not surprisingly, APIs are the standard mechanisms in the world of digital technologies for integrating services and applications. Any app on our smartphone makes use of APIs to show us results. When we consult the weather, sports results or the public transport timetable, apps make calls to the APIs of the services to consult the information and display the results.
The GPT-3 Chat API
Like any other current service, openAI provides its users with an API with which they can invoke (call) its different services based on the trained natural language model GPT-3. To use the API, we just have to log in with our account at https://platform.openai.com/ and locate the menu (top right) View API Keys. Click on create a new secret key and we have our new access key to the service.

What do we do now? Well, to illustrate what we can do with this brand new key, let's look at some examples:
As we said in the introduction, we may want to try alternative interfaces to Chat GPT-3 such as https://www.typingmind.com/. When we access this website, the first thing we have to do is enter our API Key.
Once inside, let's do an example and see how this new interface behaves. Let's ask Chat GPT-3 What is datos.gob.es?
| Note: It is important to note that most services will not work if we do not activate a means of payment on the OpenAI website. Normally, if we have not configured a credit card, the API calls will return an error message similar to \"You exceeded your current quota, please check your plan and billing details\". |

Let's now look at another application of the GPT-3 Chat API.
Programmatic access with R to access Chat GPT-3 programmatically (in other words, with a few lines of code in R we have access to the conversational power of the GPT-3 model). This demonstration is based on the recent post published in R Bloggers. Let's access Chat GPT-3 programmatically with the following example.
| Note: Note that the API Key has been hidden for security and privacy reasons. |

En este ejemplo, utilizamos código en R para hacer una llamada HTTPs de tipo POST y le preguntamos a Chat GPT-3 ¿Qué es datos.gob.es? Vemos que estamos utilizando el modelo gpt-3.5-turbo que, tal y como se especifica en la documentación está indicado para tareas de tipo conversacional. Toda la información sobre la API y los diferentes modelos está disponible aquí. Pero, veamos el resultado:

Not bad, right? As a curious fact we can see that a few GPT-3 Chat API calls have had the following API usage:

The use of the API is priced per token (something similar to words) and the public prices can be consulted here. Specifically, the model we are using has these prices:
For small tests and examples, we can afford it. In the case of enterprise applications for production environments, there is a premium model that allows you to control costs without being so dependent on usage.
Conclusion
Naturally, Chat GPT-3 enables an API to provide programmatic access to its conversational engine. This mechanism allows the integration of applications and systems (i.e. everything that is not human) opening the door to the definitive take-off of Chat GPT-3 as a business model. Thanks to this mechanism, the Bing search engine now integrates GPT-3 Chat for conversational search responses. Similarly, Microsoft Azure has just announced the availability of GPT-3 Chat as a new public cloud service. No doubt in the coming weeks we will see communications from all kinds of applications, apps and services, known and unknown, announcing their integration with GPT-3 Chat to improve conversational interfaces with their customers. See you in the next episode, maybe with GPT-4.
Blog
Python, R, SQL, JavaScript, C++, HTML... Nowadays we can find a multitude of programming languages that allow us to develop software programmes, applications, web pages, etc. Each one has unique characteristics that differentiate it from the rest and make it more appropriate for certain tasks. But how do we know when and where to use each language? In this article we give you some clues.
Types of programming languages
Programming languages are syntactic and semantic rules that allow us to execute a series of instructions. Depending on their level of complexity, we can speak of different levels:
- Low-level languages: they use basic instructions that are directly interpreted by the machine and are difficult for humans to understand. They are custom-designed for each hardware and cannot be migrated, but they are very efficient, as they make the most of the characteristics of each machine.
- High-level languages: they use clear instructions using natural language, which is more understandable by humans. These languages emulate our way of thinking and reasoning, but must then be translated into machine language through translators/interpreters or compilers. They can be migrated and are not hardware-dependent.
Medium-level languages are sometimes also described as languages that, although they function like a low-level language, allow some abstract machine-independent handling.
The most widely used programming languages
In this article we are going to focus on the most used high-level languages in data science. To do so, we look at this survey, conducted by Anaconda in 2021, and the article by KD Nuggets.
How often are the following programming languages used?
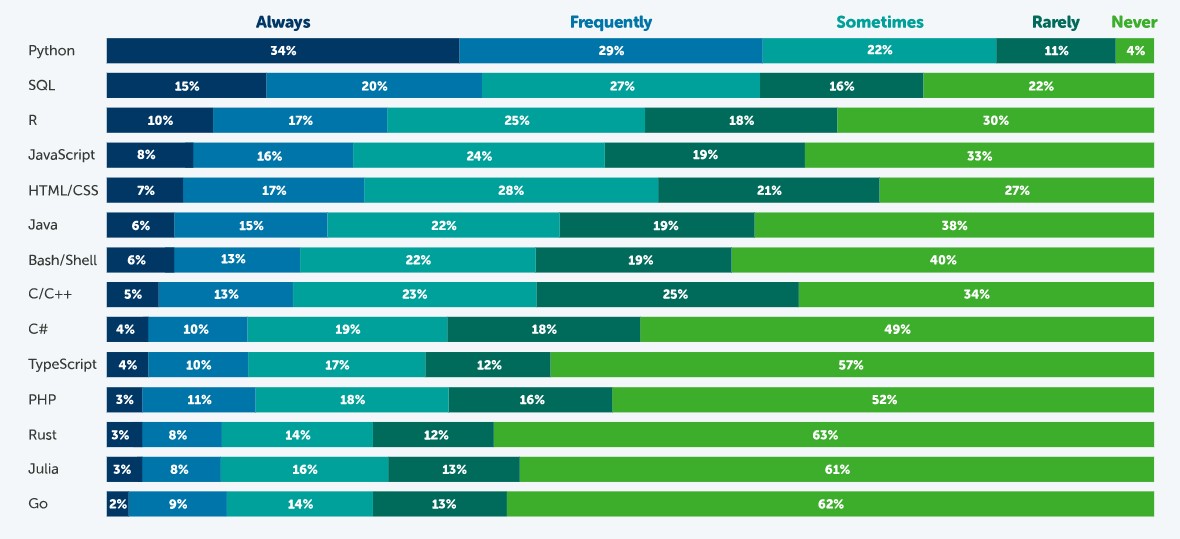
Source: State of Data Science in 2021, Anaconda.
According to this survey, the most popular language is Python. 63% of respondents - 3,104 data scientists, researchers, students and data professionals from around the world - indicated that they use Python always or frequently and only 4% indicated that they never use it. This is because it is a very versatile language, which can be used in the various tasks that exist throughout a data science project.
A data science project has different phases and tasks. Some languages can be used to perform different tasks, but with unequal performance. The following table, compiled by KD Nuggets, shows which language is most recommended for some of the most popular tasks:

Source: Data Science Programming Languages and When To Use Them, KD Nuggets, 2022.
As we can see, Python is the only language that is appropriate for all the areas analysed by KD Nuggets, although there are other options that are also very interesting, depending on the task to be carried out, as we will see below:
- Languages for data extraction and manipulation. These tasks are aimed at obtaining the data and debugging them in order to achieve a homogeneous structure, without incomplete data, free of errors and in the right format. For this purpose, it is recommended to perform an Exploratory Data Analysis. SQL is the programming language that excels the most with respect to data extraction, especially when working with relational databases. It is fast at retrieving data and has a standardised syntax, which makes it relatively simple. However, it is more limited when it comes to data manipulation. A task in which Python and R, two programs that have a large number of libraries for these tasks, give better results.
- Statistical analysis and data visualisation. This involves processing data to find patterns that are then converted into knowledge. There are different types of analysis depending on their purpose: to learn more about our environment, to make predictions or to obtain recommendations. The best language for this is R, an interpreted language that also has a programming environment, R-Studio, and a set of very flexible and versatile tools for statistical computing. Python, Java and Julia are other tools that perform well in this task, for which JavaScript can also be used. The above languages allow, in addition to performing analyses, the creation of graphical visualisations that facilitate the understanding of the information.
- Modelling/machine learning (ML). If we want to work with machine learning and build algorithms, Python, Java, Java/JavaScript, Julia and TypeScript are the best options. All of them simplify the task of writing code, although it is necessary to have extensive knowledge to be able to work with the different machine learning techniques. More experienced users can work with C/C++, a very machine-readable programming language, but with a lot of code, which can be difficult to learn. In contrast, R can be a good choice for less experienced users, although it is slower and not well suited for complex neural networks.
- Model deployment. Once a model has been created, it is necessary to deploy it, taking into account all the necessary requirements for its entry into production in a real environment. For this purpose, the most suitable languages are Python, Java, JavaScript and C#, followed by PHP, Rust, GoLang and, if we are working with basic applications, HTML/CSS.
- Automation. While not all parts of a data scientist's job can be automated, there are some tedious and repetitive tasks whose automation speeds up performance. Python, for example, has a large number of libraries for automating machine learning tasks. If we are working with mobile applications, then Java is our best option. Other options are C# (especially useful for automating model building), Bash/Shell (for data extraction and manipulation) and R (for statistical analysis and visualisations).
Ultimately, the programming language we use will depend entirely on the task at hand and our capabilities. Not all data science professionals need to know all languages, but should choose the one that is most appropriate for their daily work.
Some additional resources to learn more about these languages
At datos.gob.es we have prepared some guides and resources that may be useful for you to learn some of these languages:
- Data processing and visualization tools
- Courses to learn more about R
- Courses to learn more about Python
- Online courses to learn more about data visualization
- R and Python Communities for Developer
Content prepared by the datos.gob.es team.