Blog
In the first part of this article, the concept of data strategy was introduced as the organisation's effort to put the necessary data at the service of its business strategy. In this second part, we will explore some aspects related to the materialisation of such a strategy as part of the design or maintenance - if it already exists - of a data governance system.
For the materialisation of the data strategy, a development environment will have to be addressed, as described in a founding act that includes some aspects such as the identification of the main people responsible for the implementation, the expected results, the available resources and the timeframe established to achieve the objectives. In addition, it will contain a portfolio of data governance programmes including individual projects or specific related projects to address the achievement of the strategic objectives of the data.
It is important to mention that the implementation of a data strategy has an impact on the development and maintenance of the different components of a data governance system:
- Manager
- Organisational structures
- Principles, policies and frameworks
- For Information
- Culture, ethics and behaviour
- People, skills and competences
- Services, infrastructures and applications.
In this sense, it can be said that each of the projects included in the data government's programme aims to contribute to developing or maintaining one or more of these components.
It should be noted that the final design of this data governance system is achieved in an iterative and incremental manner over time, depending on the constraints and possibilities of the organisation and its current operating context. Consequently, the prioritisation, selection and sequencing of projects within the data governance programme to implement the strategic objectives of data also has an iterative and incremental nature[1].
The three biggest data risks commonly encountered in organisations are:
- Not knowing who has to take responsibility for implementing the data strategy,
- Not having adequate knowledge of data in quantity and quality, and
- Failure to exercise adequate control over the data, e.g. by at least complying with current legislation.
Therefore, as far as possible, projects should be approached in the following way:
- Firstly, to address those projects related to the identification, selection or maintenance of organisational structures ("strategic alignment" type objective), also known as governance framework.
- Next, undertake projects related to the knowledge of the business processes and the data used (a "strategic alignment" type objective aimed at the description of data through the corresponding metadata, including data lifecycle metadata).
- And finally, proceed to the definition of policies and derived controls for different policy areas (which may be of the "strategic alignment", "risk optimisation" or "value for money" type).
The artefact-based approach and the process approach
In approaching the definition of these data governance programmes, some organisations with a project understanding more oriented to the generation and deployment of technological products follow an artefact-based approach. That is, they approach the projects that are part of the data governance programme as the achievement of certain artefacts. Thus, it is possible to find organisations whose first concern when implementing data governance is to acquire and install a specific tool that supports, for example, a glossary of terms, a data dictionary, or a data lake. Moreover, as for various reasons some companies do not adequately differentiate between data governance and data management, this approach is often sufficient. However, the artefact approach introduces the risk of "the tool without the instruction manual the artefact approach introduces the risk of "the tool without the instruction manual": the tool is purchased - probably after a proof of concept by the vendor - and deployed according to the needs of the organisation, but what it is used for and when it is used is unknown, leaving the artefact often as an isolated resource. This, unless the organisation promotes a profound change, may end up being a waste of resources in the long run as the use of the artefacts generated is abandoned.
A better alternative, as has been widely demonstrated in the software development sector, is the execution of the data governance programme with a process approach. This process approach allows not only to develop the necessary artefacts, but also to model the way the organisation works with respect to some area of performance, and contextualises the rationale and use of the artefacts within the process, specifying who should use the artefact, for what, when, what should be obtained by using the artefact, etc.
This process approach is an ideal instrument to capture and model the knowledge that the organisation already has regarding the tasks covered by the process, and to make this knowledge the reference for new operations to be carried out in the future. In addition, the definition of the process also allows for the particularisation of chains of responsibility and accountability and the establishment of communication plans, so that each worker knows what to do, what artefacts to use, who to ask for or receive resources from to carry out their work, who to communicate their results to, or who to escalate potential problems to.
This way of working provides some advantages, such as predictable behaviour of the organisation with respect to the process; the possibility to use these processes as building blocks for the execution of data projects; the option to easily replace a human resource; or the possibility to efficiently measure the performance of a process. But undoubtedly, one of the greatest advantages of this process approach is that it allows organisations to adopt the good practices contained in any of the process reference models for data governance, data management and quality management that exist in the current panorama, such as the UNE 0077 specifications (for data governance), UNE 0078 (for data management) and UNE 0079 (for data quality management).
This adoption enables the possibility of using frameworks for process assessment and improvement, such as the one described in UNE 0080, which includes the Alarcos Data Maturity Model, in which the concept of organisational maturity of data governance, data management and data quality management is introduced as an indicator of the organisation's potential to face the achievement of strategic objectives with certain guarantees of success. In fact, it is common for many organisations adopting the process approach to pre-include specific data objectives ("strategic alignment" type objectives) aimed at preparing the organisation - by increasing the level of maturity - to better support the execution of the data governance programme. These "preparatory" objectives are mainly manifested in the implementation of data governance, data management and data quality management processes to close the gap between the current initial state of maturity (AS_IS) and the required final state of maturity of the organisation (TO_BE).
If the process approach is chosen, the different projects contained in the data programme will generate controlled and targeted increments in each of the components of the data governance system, which will enable the transformation of the organisation to meet the organisation's strategic business objectives.
Ultimately, the implementation of a data strategy manifests itself in the development or maintenance of a data governance system, which ensures that the organisation's data is put at the service of strategic business objectives. The instrument to achieve this objective is the data governance programme, which should ideally be implemented through a process approach in order to benefit from all the advantages it brings.
______________________________________________
Content developed by Dr. Ismael Caballero, Associate Professor at UCLM, and Dr. Fernando Gualo, PhD in Computer Science, and Chief Executive Officer and Data Quality and Data Governance Consultant.
The content and viewpoints reflected in this publication are the sole responsibility of the authors.
[1] We recommend reading the article https://hdl.handle.net/11705/JISBD/2019/083
Blog
More and more organisations are deciding to govern their data to ensure that it is relevant, adequate and sufficient for its intended uses, i.e. that it has a certain organisational value.
Although the scenarios are often very diverse, a close look at needs and intentions reveals that many of these organisations had already started to govern their data some time ago but did not know it. Perhaps the only thing they are doing as a result of this decision is to state it explicitly. This is often the case when they become aware of the need to contextualise and justify such initiatives, for example, to address a particular organisational change - such as a long-awaited digital transformation - or to address a particular technological challenge such as the implementation of a data lake to better support data analytics projects.
A business strategy may be to reduce the costs required to produce a certain product, to define new lines of business, to better understand customer behaviour patterns, or to develop policies that address specific societal problems. To implement a business strategy you need data, but not just any data, but data that is relevant and useful for the objectives included in the business strategy. In other words, data that can be used as a basis for contributing to the achievement of these objectives. Therefore, it can be said that when an organisation recognises that it needs to govern its data, it is really expressing its need to put certain data at the service of the business strategy. And this is the real mission of data governance.
Having the right data for the business strategy requires a data strategy. It is a necessary condition that the data strategy is derived from and aligned with a business strategy. For this reason, it is possible to affirm that the projects that are being developed (especially those that seek to develop some technological artefact), or those that are to be developed in the organisation, need a justification determined by a data strategy[1] and, therefore, will be part of data governance.
Strategic objectives of the data
A data strategy is composed of a set of strategic data objectives, which may be one or a necessary combination of the following four generic types:
- Benefits realisation: ensuring that all data producers have the appropriate mechanisms in place to produce the data sources that support the business strategy, and that data consumers have the necessary data to be able to perform the tasks required to achieve the strategic objectives of the business. Examples of such objectives could be:
- the definition of the organisation's reporting processes;
- the identification of the most relevant data architecture to service all data needs in a timely manner;
- the creation of data service layers;
- the acquisition of data from third party sources to meet certain data demands; or
- the implementation of information technologies supporting data provisioning and consumption
- Strategic alignment: the objective is to align the data with basic principles or behavioural guidelines that the organisation has defined, should have defined, or will define as part of the strategy. This alignment seeks to homogenise the way of working with the organisation's data. Examples of this type of objective include:
- establish organisational structures to support chains of responsibility and accountability;
- homogenise, reconcile and unify the description of data in different types of metadata repositories;
- define and implement the organisation's best practices with respect to data governance, data management and data quality management[2];
- readapt or enrich (what in DAMA terminology is known as operationalising data governance) the organisation's data procedures in order to align them with the good practices implemented by the organisation in the different processes;
- or define data policies in any of the areas of data management[3] and ensure compliance with them, including security, master data management, historical data management, etc.
- Resource optimisation: this consists of establishing guidelines to ensure that the generation, use and exploitation of data makes the most appropriate and efficient use of the organisation's resources. Examples of such targets could include:
- the decrease of data storage and processing costs to much more efficient and effective storage systems, such as migrations of data storage and processing layers to the cloud[4];
- improving response times of certain applications by removing historical data; improving data quality;
- improving the skills and knowledge of the different actors involved in the exploitation and use of data;
- the redesign of business plans to make them more efficient; or
- the redefinition of roles to simplify the allocation and delegation of responsibilities.
- Risk optimisation: the fundamental objective is to analyse the possible risks related to data that may undermine the achievement of the different business objectives of the organisation, or even jeopardise its viability as an entity, and to develop the appropriate data processing mechanisms. Some examples of this type of target would be:
- the definition or implementation of security and data protection mechanisms;
- the establishment of the necessary ethical parameters; or
- securing sufficiently qualified human resources to cope with functional turnover.
A close reading of the proposed examples might lead one to think that some of these strategic data objectives could be understood as being of different types simultaneously. For example, ensuring the quality of data to be used in certain business processes may seek, in some way, to ensure that the data is not only used ('benefit realisation' and 'risk optimisation'), but also helps to ensure that the organisation has a serious and responsible brand image with data ('strategic alignment') that avoids having to perform frequent data cleansing actions, with the consequent waste of resources ('value for money' and 'risk optimisation').
Typically, the process of selecting one or more strategic data objectives should not only take into account the context of the organisation and the scope of these objectives in functional, geographic or dataterms, but also consider the dependency between the objectives and the way in which they should be sequenced. It may be common for the same strategic objective to cover data used in different departments or even to apply to different data. For example, the strategic objective of the types "benefit realisation" and "risk optimisation", called "ensuring the level of access to personal data repositories", would cover personal data that can be used in the commercial and operational departments.
Taking into account typical data governance responsibilities (evaluate, manage, monitor), the use of the SMART (specific, measurable, achievable, realistic, time-bound) technique is recommended for the selection of strategic objectives. Thus, these strategic objectives should:
- be specific,
- the level of achievement can be measured and monitored,
- that are achievable and realistic within the context of the strategy and the company, and finally,
- that their achievement is limited in time.
Once the strategic data objectives have been identified, and the backing and financial support of the organisation's management is in place, their implementation must be addressed, taking into account the dimensions discussed above (context, functional aspects and dependencies between objectives), by defining a specific data governance programme. It is interesting to note that behind the concept of "programme" is the idea of "a set of interrelated projects contributing to a specific objective".
In short, a data strategy is the way in which an organisation puts the necessary data at the service of the organisation's business strategy. This data strategy is composed of a series of strategic objectives that can be of one of the four types outlined above or a combination of them. Finally, the implementation of this data strategy will be done through the design and execution of a data governance programme, aspects that we will address in a future post.
______________________________________________
Content developed by Dr. Ismael Caballero, Associate Professor at UCLM, and Dr. Fernando Gualo, PhD in Computer Science, and Chief Executive Officer and Data Quality and Data Governance Consultant.
The content and viewpoints reflected in this publication are the sole responsibility of the authors.
______________________________________________
[1] It is easy to find digital transformation projects where the only thing that is changed is the core technology to a more modern sounding one, but still doing the same thing.
[2] In this example of a strategic objective for data it is essential to consider the UNE 0077, UNE 0078 and UNE 0079 specifications because they provide an adequate definition of the different processes of data governance, data management and data quality management respectively.
[3] Meaning security, quality, master data management, historical data management, metadata management, integration management…
[4] Examples of such initiatives are migrations of data storage and processing layers to the cloud.
Application
Insight View es una solución de analítica avanzada con información de empresas y autónomos de todo el mundo para que las áreas de estrategia de negocio, finanzas, riesgos, marketing, ventas, compras y logística puedan identificar oportunidades de negocio y minimizar sus riesgos comerciales.
Insight View te permite encontrar de manera sencilla empresas con las que tienes más probabilidad de hacer negocios y te ayuda a mejorar la efectividad de tus acciones comerciales. Facilita el análisis agregado de la cartera de clientes y mejorar su ciclo de vida ayudando a tomar las mejores decisiones de negocio. También ayuda en la gestión del riesgo comercial con su valoración de empresas, acceso a RAI y Asnef Empresa.
Blog
The commercial adoption of any new technology and, therefore, its incorporation into the business value chain follows a cycle that can be moulded in different ways. One of the best known models is the Gartner hype cycle. With regard to artificial intelligence and data science, the current discussion focuses on whether the peak of inflated expectations has already been reached or, on the contrary, we will continue to see how the promises of new and revolutionary innovations increase.
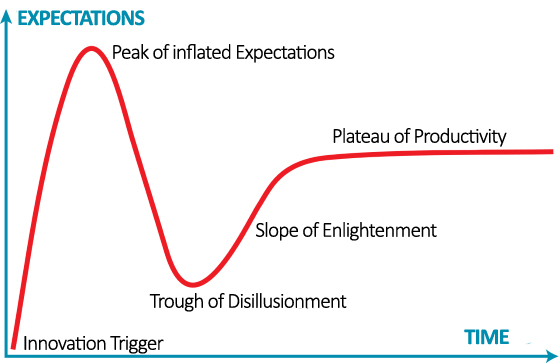
As we advance in this cycle, it is usual to find new advances in technology (new algorithms, in the case of Artificial Intelligence) or a great knowledge about their possibilities of commercial application (new products or products with better price or functionalities). And, of course, the more industries and sectors are affected, the higher expectations are generated.
However, the new discoveries do not only remain on the technological level, but it usually also go deeper into the study and understanding of the economic, social, legal or ethical impact derived from the innovations that are arriving on the market. For any business, it is essential to detect and understand as soon as possible the impact that a new technology will have on its value chain. This way, the company will be able to incorporate the technology into its capabilities before its competitors and generate competitive advantages.
One of the most interesting thesis recently published to model and understand the economic impact of Artificial Intelligence is the one proposed by Professor Ajay Agrawal with Joshua Gans and Avi Goldfarb in his book "Prediction Machines: The Simple Economics of Artificial Intelligence”. The premise is very simple: at the beginning, it establish that the purpose of artificial intelligence, from a merely economic point of view, is to reduce the cost of predictions.
When the cost of a raw material or technology is reduced, it is usual for the industry to increase their use, first applying this technology to the products or services it was designed for, and later, to other product or services that were manufactured in another way. Sometimes it even affects the value of substitute products (that fall) and complementary products (that rise), or other elements of the value chain.
Although these technologies are very complex, the authors were able to establish a surprisingly simple economic framework to understand the AI. But let's see a concrete case, familiar to all of us, in which the increase of the accuracy of the predictions, taken to the extreme, could mean not only to automate a series of tasks, but also to completely change the rules of a business .
As we all know, Amazon uses Artificial Intelligence for the purchase recommendation system that offers suggestions for new products. As mentioned by the authors in his book, the accuracy of this system is around 5%. This means that users acquire 1 out of every 20 products that Amazon suggests, which is not bad.
If Amazon is able to increase the accuracy of these predictions, let's say to 20%, that is, if users acquire 1 out of every 5 suggested products, Amazon would increase its profits enormously and the value of the company would skyrocket even more. But if we imagine a system capable of having a precision of 90% in the purchase predictions, Amazon could consider radically changing its business model and send us products before we decide to buy them, because we would only return 1 out of every 10. AI would not just automate tasks or improve our shopping experience, it would also radically change the way we understand the retail industry.
Given that the main substitute for AI predictions are human predictions, it seems clear that our value as a predictive tool will continue decreasing. The advance of the wave of automations based on artificial intelligence and data science already allows us to see the beginning of this trend.
On the contrary, company data would become an increasingly valuable asset, since they are the main complementary product necessary to generate correct predictions. Likewise, the public data necessary to enrich the companies data, and thus make possible new use cases, would also increase its value.
Following this line of reasoning, we could dare to establish metrics to measure the value of public data where they were used. We would only have to answer this question: how much improves the accuracy of a certain prediction if we enrich the training with determined open data? These improvements would have a concrete value that could give us an idea of the economic value of a public dataset in a specific scenario.
The repeated mantra "data is the new oil" is changing from being a political or marketing affirmation to being supported by economic science, because data are the necessary and indispensable raw material to make good and valuable predictions. And it seems clear that, to continue reducing the predictions cost, the data value should increase. Simple economy.
Content prepared by Jose Luis Marín, Head of Corporate Technology Startegy en MADISON MK and Euroalert CEO.
Contents and points of view expressed in this publication are the exclusive responsibility of its author.
Noticia
Open data is an ideal raw material to launch a business. The information that is offered openly by different public agencies covers the most diverse topics and sectors, from health and education to tourism and the economy, as well as urban infrastructures or rural environment, so the opportunities are almost overwhelming. In addition, such information is usually free (or with a marginal cost), which limits the risks when starting a business from zero. That is why an increasing number of companies are betting on launching businesses based on open data.
How do data-based businesses evolve in Spain?
The economic potential of the reuse of open data in our country was evident in the latest edition of the ASEDIE annual report, which analyzes the situation of the infomediate sector in Spain. According to the report, revenues from sales and service provision of companies that "use public and private data to create value-added products and services for society" was 1,720 million euros in 2016, which means a 2% growth in comparison with the previous year. The most reused data were geographical and economic-financial information.
These figures show this is an established sector in our country. Almost a third of the infomediary companies are more than 20 years old. These are solid businesses with an important numbers of employees that contribute to the economic growth of the regions where they are located. But it is also a sector that increasingly attracts more entrepreneurs. Specifically, 23% of the infomediary companies have been founded in the last 5 years.
Many of these new companies seek to take advantage of market niches, joining open data with new technologies such as Big Data, artificial intelligence - and machine learning and Deep Learning - or virtual reality, among others. However, to achieve success in these fields they also have to overcome a series of challenges. According to the ASEDIE report, the main barriers that the infomediary sector has to face are the incomplete information, access difficulty data and the inadequate formats.
How do public administrations help reuse companies?
Public administrations are aware of this situation, and for this reason the promotion of open data and reuse economy is one of its objectives. To solve the aforementioned challenges and help to further strengthen this sector, numerous initiatives have been launched to boost the reuse of open data in Spain, some of which are listed below:
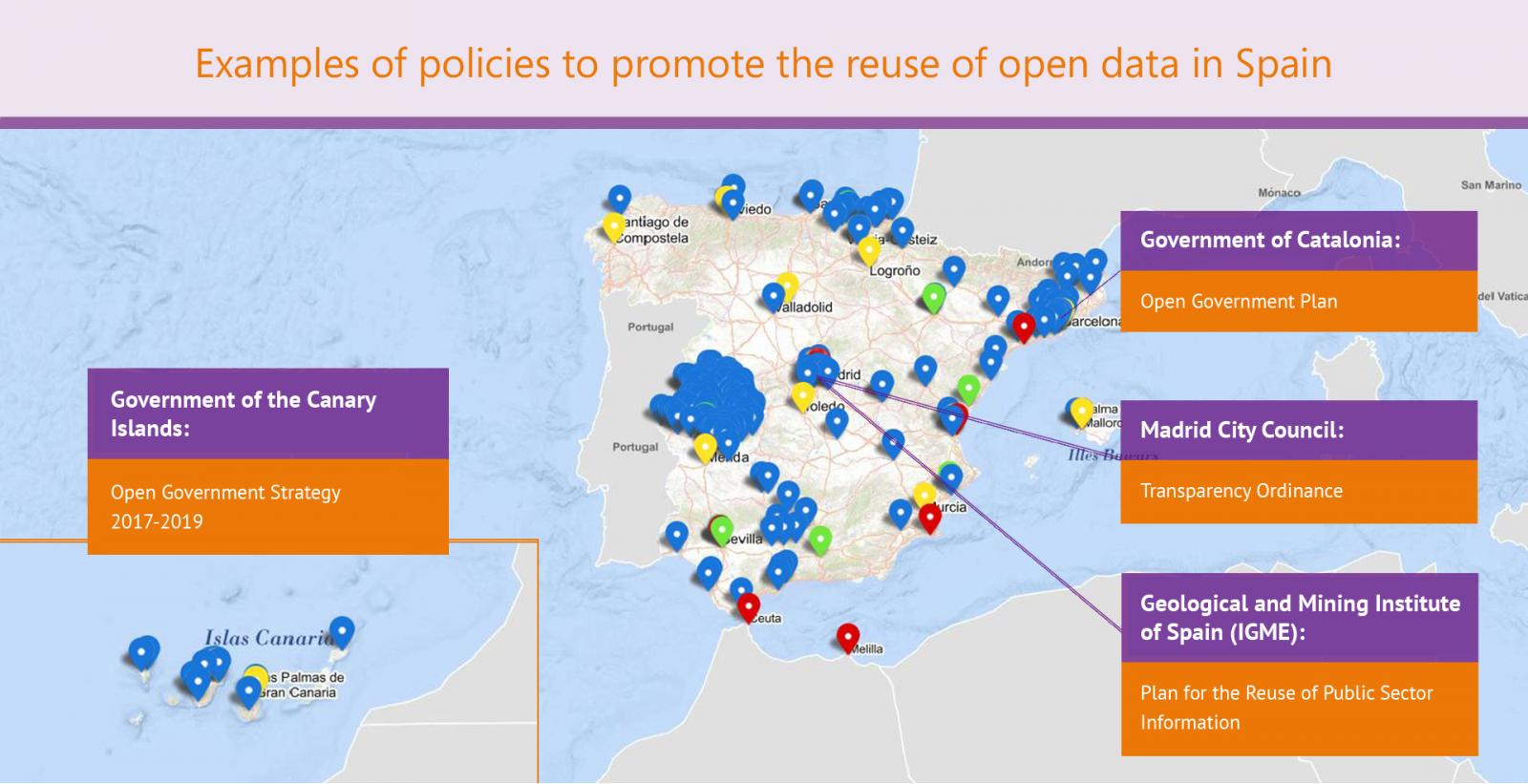
- The Government of Catalonia has approved the Open Government Plan aimed at promoting the generation of social value linked to open data use. This plan includes 15 specific actions aimed at improving public data opening, encouraging their use. The actions include the creation of an open data dictionary, the migration of public data to a new platform or the creation of an "online enquiry” section to identify specific open data demands.
- The Government of the Canary Islands, within its Open Government Strategy 2017-2019, includes actions linked to improve its data catalog, as well as training actions and sharing of experiences through public awareness campaigns on open data. Some of the suggested actions are the "Identification and opening of data with high democratic, social and economic value" or the "implementation of technical guidelines to ensure the reuse, consistency, uniformity, accessibility, quality and interoperability of public information in Internet".
- The Transparency Ordinance of the Madrid City, which entered into force on August 27, 2017, regulates the reuse of local information without prior authorization and free of charge, encouraging the use of "standard, free-use and open formats".
- In February 2018, the Plan for the Reuse of Public Sector Information elaborated by the Geological and Mining Institute of Spain (IGME) was approved. Thanks to this plan, the IGME has made available to users more than 2,200 datasets under favorable conditions for reuse. These data are also available at datos.gob.es.
These examples are just a sample, but there are many others. More and more public organizations are aware of the economic value of open data for citizenship, and therefore do not only seek to share the information, but also publish data in the appropriate formats to favor its reuse. Sharing unique, up-to-date data with open standards can help new data-based businesses emerge, which can help boost our country's economic growth.
Noticia
The COTEC Foundation, a private non-profit organization that promotes innovation as a driving force for economic and social development in Spain, recently published its report "The Reuse of Open Data: an opportunity for Spain". In this study, led by the experts Alberto Abella, María Ortiz de Urbina and Carmen de Pablos, different diagnostic exercises have been carried out to draw a scenario that seeks to show current knowledge about the reuse of open data, in order to identify guidelines and recommendations that help promote the use of data in the generation of business.
The realization of the study has followed a methodology that mainly includes three research areas:
- Study of 103 operational national portals included in the map of initiatives of datos.gob.es, and of their maturity according to a simplified version of the model established by the pan-European data portal.
- Study of the published datasets, on a total of 20,026 identified datasets, after the necessary filtering to avoid duplication as a result of federations among portals.
- Study of the reuse of the published data through a survey carried out to the responsible for the open data portals in Spain.
After the corresponding analysis, a SWOT analysis has been carried out, which has highlighte a series of evidences and reflections that are summarized in the following graph:

Thus, according to the report, aspects such as the lack of homogeneity and quality of published data are presented as great barriers to the creation of innovative businesses. In fact, despite the fact that 87% of the services generated from open data are geolocated and are in real time by 67%, 52% of the published data does not contain any geographical reference and only 5% is updated at least once a week.
In parallel, this study identifies a set of strategic barriers and key techniques. As regards strategic barriers, the lack of mechanisms for internal governance of data to control and manage how data moves within the organization and mechanisms of publication and systematic updating. Regarding technical barriers, the scarce use of adequate tools for the publication of data stands out, which limits the automation of access, the systematic publication, the notification of new features or the adequate understanding of information due to the lack of visualizations about the published data.
Finally, and based on the diagnosis made, the report concludes with a series of key measures to overcome the identified barriers, many of which have in commeon the need for coordination, the importance of a strategy in service generation organizations based on data and measurement actions of use and impact.
The publication of data is not an exercise in transparency, but the sowing of resources that must bear fruit in other entities (re-users). The field where this reuse occurs must be taken care of. - Alberto Abella, 2017-
Application
Iberinform is the information subsidiary of Atradius Crédito y Caución, a leading company in the world of credit insurance with a direct presence in over 50 countries.
We help companies identify business opportunities and potential delinquency risks. Our advanced analytics solutions and predictive algorithms facilitate commercial decision-making, providing practical and useful information for marketing, finance, and sales departments.
They transform business data into information and knowledge through tools that facilitate business processes and decisions. Primarily, their sources of information include 500,000 interviews per year with companies, the commercial register, and other public sources. Their business information service allows access to reports on 322 million companies in 72 countries and provides access to the largest files of Spanish banking delinquency, such as RAI and ASNEF Empresas.
This platform offers databases that help identify new clients and tools that facilitate risk management, analysis, and monitoring of clients, suppliers, or sectors. In addition to providing its online services, Iberinform also has twelve offices in different locations in Spain and Portugal.