Fecha publicación
11/03/2026
Comparte este contenido

Descripción
“Voy a subirte un fichero CSV. Quiero que lo analices y me resumas las conclusiones más relevantes que puedas extraer de los datos”. Hace unos años, el análisis de datos era territorio de quien sabía escribir código y utilizar entornos técnicos complejos, y una petición así habría requerido programación o habilidades avanzadas de Excel. Hoy, poder analizar en poco tiempo ficheros de datos con herramientas de IA nos aporta una gran autonomía profesional. Formular preguntas, contrastar ideas preliminares y explorar de primera mano la información cambia nuestra relación con el conocimiento, sobre todo, porque dejamos de depender de intermediarios para obtener respuestas. Ganar la capacidad de analizar datos con IA de manera independiente acelera los procesos, pero también puede provocarnos un exceso de confianza en las conclusiones.
A partir del ejemplo de un fichero de datos en bruto, vamos a revisar posibilidades, precauciones y pautas básicas para explorar la información sin asumir conclusiones demasiado rápido.
El fichero:
Para mostrar un ejemplo de análisis de datos con IA utilizaremos un fichero del Instituto Nacional de Estadística (INE) que recoge información sobre flujos turísticos en Europa, en concreto sobre ocupación en alojamientos de turismo rural. El fichero de datos contiene información desde enero de 2001 hasta diciembre de 2025. Contiene desagregaciones por sexo, edad y comunidad o ciudad autónoma, lo que permite realizar análisis comparativos a lo largo del tiempo. En el momento de escribir este artículo, la última actualización de este conjunto de datos fue el 28 de enero de 2026.

Figura 1. Información del dataset. Fuente: Instituto Nacional de Estadística (INE).
1. Exploración inicial
Para esta primera exploración vamos a utilizar una versión gratuita de Claude, el chat multitarea basado en IA desarrollado por Anthropic. Es uno de los modelos de lenguaje más avanzados en benchmarks de razonamiento y análisis, lo que lo hace especialmente adecuado para este ejercicio, y es la opción más utilizada actualmente por la comunidad para realizar tareas que requieren código.
Pensemos que nos enfrentamos al fichero de datos por primera vez. Sabemos a grandes rasgos qué contiene, pero desconocemos la estructura de la información. Nuestro primer prompt, por tanto, debería centrarse en describirla:
PROMPT: Quiero trabajar con un fichero de datos sobre ocupación en alojamientos de turismo rural. Explícame qué estructura tiene el fichero: qué variables contiene, qué mide cada una y qué posibles relaciones existen entre ellas. Señala también posibles valores ausentes o elementos que requieran aclaración.

Figura 2. Exploración inicial del fichero de datos con Claude. Fuente: Claude.
Una vez que Claude nos ha dado la idea general y la explicación de las variables, es buena práctica abrir el fichero y hacer una comprobación rápida. El objetivo es evaluar que, como mínimo, el número de filas, el número de columnas, los nombres de las variables, el período temporal y el tipo de datos coinciden con lo que nos ha dicho el modelo.
Si detectamos algún error en este punto, el LLM puede no estar leyendo correctamente los datos. Si después de intentarlo en otra conversación el error persiste, es señal de que hay algo en el fichero que dificulta su lectura automática. En este caso, lo más recomendable es no proseguir con el análisis, ya que las conclusiones serán muy aparentes, pero estarán basadas en datos mal interpretados.
2. Gestión de anomalías
En segundo lugar, si hemos descubierto anomalías, lo habitual es documentarlas y decidir cómo manejarlas antes de seguir con el análisis. Podemos pedir al modelo que nos sugiera qué hacer, pero las decisiones finales serán nuestras. Por ejemplo:
- Valores faltantes: si hay celdas vacías, tenemos que decidir si rellenarlas con un valor “promedio” de la columna o simplemente eliminar esas filas.
- Duplicados: tenemos que eliminar filas repetidas o que no aportan información nueva.
- Errores de formato o inconsistencias: debemos corregirlos para que las variables sean coherentes y comparables. Por ejemplo, fechas representadas en distintos formatos.
- Outliers: si aparece un número que no tiene sentido o es exageradamente distinto del resto, tenemos que decidir si corregirlo, ignorarlo o tratarlo tal y como está.

Figura 3. Ejemplo de análisis de valores faltantes con Claude. Fuente: Claude.
En el caso de nuestro fichero, por ejemplo, hemos detectado que en Ceuta y Melilla los valores ausentes en la variable Total son estructurales, no hay turismo rural registrado en esas ciudades, por lo que podríamos excluirlas del análisis.
Antes de tomar la decisión, una buena práctica en este punto es pedir al LLM los pros y contras de la modificación en los datos. Su respuesta puede darnos alguna pista de cuál es la mejor opción, o indicarnos algún inconveniente que no habíamos tenido en cuenta.

Figura 4. Análisis de Claude sobre la posibilidad de eliminar o no valores. Fuente: Claude.
Si decidimos seguir adelante y excluir las ciudades de Ceuta y Melilla del análisis, Claude puede ayudarnos a efectuar esta modificación directamente sobre el fichero. El prompt sería el siguiente:
PROMPT: Elimina del fichero todas las filas correspondientes a Ceuta y Melilla, de manera que el resto de los datos se mantenga intacto. Explica también los pasos que estás siguiendo para que pueda revisarlos.
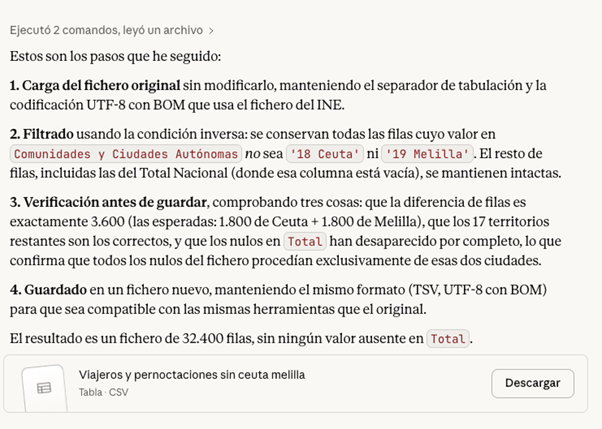
Figura 5. Paso a paso en la modificación de datos en Claude. Fuente: Claude.
En este punto, Claude nos ofrece descargar de nuevo el fichero modificado, así que una buena práctica de comprobación sería validar de forma manual que la operación se hizo bien. Por ejemplo, revisar el número de filas en un fichero y otro o cotejar algunas filas al azar con el primer fichero para asegurarnos de que los datos no se han corrompido.
3. Primeras preguntas y visualizaciones
Si el resultado hasta aquí es satisfactorio, ya podemos empezar a explorar los datos para hacernos preguntas iniciales y buscar patrones interesantes. Lo ideal al empezar la exploración es hacer preguntas grandes, claras y fáciles de responder con los datos, porque nos dan una primera visión.
PROMPT: Trabaja con el fichero sin Ceuta y Melilla a partir de ahora. ¿Cuáles han sido las cinco comunidades con más turismo rural en el período total?

Figura 6. Respuesta de Claude a las cinco comunidades con más turismo rural en el período. Fuente: Claude.
Por último, podemos pedirle a Claude que nos ayude a visualizar los datos. En lugar de hacer el esfuerzo de indicarle un tipo de gráfico concreto, le damos libertad para elegir el formato que mejor muestre la información.
PROMPT: ¿Puedes visualizar esta información en un gráfico? Elige el formato más adecuado para representar los datos.
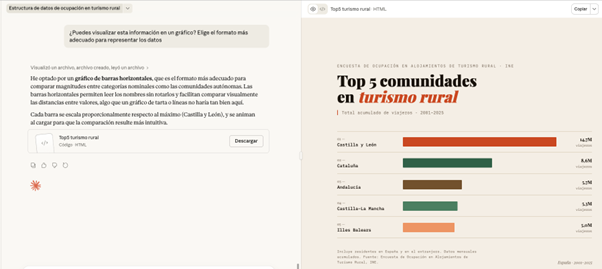
Figura 7. Gráfico elaborado por Cloude para representar la información. Fuente: Claude.
Aquí, la pantalla se desdobla: a la izquierda, podemos continuar con la conversación o descargar el fichero, mientras que a la derecha podemos visualizar el gráfico directamente. Claude ha generado una gráfica de barras horizontales muy visual y lista para usar. Los colores diferencian las comunidades y se indica correctamente el período y el tipo de datos.
¿Qué ocurre si le pedimos cambiar la paleta de color del gráfico por una inadecuada? En este caso, por ejemplo, vamos a pedirle una serie de tonos pastel que apenas se diferencian.
PROMPT: ¿Puedes cambiar la paleta de colores del gráfico por esta otra? #E8D1C5, #EDDCD2, #FFF1E6, #F0EFEB, #EEDDD3
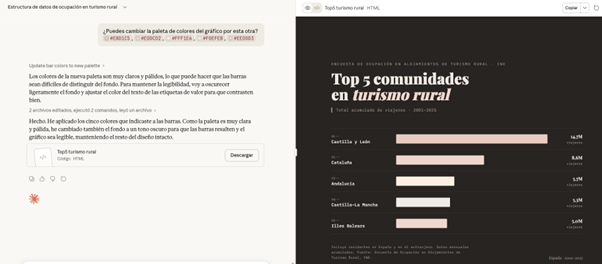
Figura 8. Ajustes realizados en el gráfico por Claude para representar la información. Fuente: Claude.
Ante el reto, Claude ajusta por sí mismo el gráfico de manera inteligente, oscurece el fondo y cambia el texto de las etiquetas para mantener legibilidad y contraste.
Todo el ejercicio anterior se ha realizado con Claude Sonnet 4.6, que no es el modelo de mayor calidad de Anthropic. Sus versiones superiores, como Claude Opus 4.6, tienen mayor capacidad de razonamiento, comprensión profunda y resultados más finos. Además, existen muchas otras herramientas para trabajar con datos y visualizaciones basadas en IA, como Julius o Quadratic. Aunque en ellas las posibilidades son casi infinitas, cuando trabajamos con datos sigue siendo fundamental mantener una metodología y un criterio propios.
Contextualizar en la vida real los datos que estamos analizando y conectarlos con otros conocimientos no es una tarea que se pueda delegar; necesitamos tener una mínima idea previa de qué queremos conseguir con el análisis para poder transmitirla al sistema. Esto nos permitirá hacer mejores preguntas, interpretar adecuadamente los resultados y por tanto hacer un prompting más eficaz.
Contenido elaborado por Carmen Torrijos, experta en IA aplicada al lenguaje y la comunicación. Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.



Comentarios