Documentación
1. Introducción
Las visualizaciones son representaciones gráficas de datos que permiten comunicar, de manera sencilla y efectiva, la información ligada a los mismos. Las posibilidades de visualización son muy amplias, desde representaciones básicas como los gráficos de líneas, de barras o métricas relevantes, hasta visualizaciones configuradas sobre cuadros de mando interactivos.
En esta sección de “Visualizaciones paso a paso” estamos presentando periódicamente ejercicios prácticos haciendo uso de datos abiertos disponibles en datos.gob.es u otros catálogos similares. En ellos se abordan y describen de manera sencilla las etapas necesarias para obtener los datos, realizar las transformaciones y los análisis pertinentes para, finalmente obtener unas conclusiones a modo de resumen de dicha información.
En cada ejercicio práctico se utilizan desarrollos de código documentados y herramientas de uso gratuito. Todo el material generado está disponible para su reutilización en el repositorio de GitHub de datos.gob.es.
En este ejercicio concreto, exploraremos la actual situación de la penetración de los vehículos eléctricos en España y las perspectivas de futuro de esta tecnología disruptiva en el transporte.
Accede al repositorio del laboratorio de datos en Github.
Ejecuta el código de pre-procesamiento de datos sobre Google Colab.
En este vídeo, el autor te explica que vas a encontrar tanto en el Github como en Google Colab.
2. Contexto: ¿Por qué es importante el vehículo eléctrico?
La transición hacia una movilidad más sostenible se ha convertido en una prioridad global, situando al vehículo eléctrico (VE) en el centro de numerosas discusiones sobre el futuro del transporte. En España, esta tendencia hacia la electrificación del parque automovilístico no solo responde a un creciente interés por parte de los consumidores en tecnologías más limpias y eficientes, sino también a un marco regulatorio y de incentivos diseñado para acelerar la adopción de estos vehículos. Con una creciente oferta de modelos eléctricos disponibles en el mercado, los vehículos eléctricos representan una pieza clave en la estrategia del país para reducir las emisiones de gases de efecto invernadero, mejorar la calidad del aire en las ciudades y fomentar la innovación tecnológica en el sector automotriz.
Sin embargo, la penetración de los vehículos eléctricos en el mercado español enfrenta una serie de desafíos, desde la infraestructura de carga hasta la percepción y el conocimiento del consumidor sobre estos vehículos. La expansión de la red de carga, junto con las políticas de apoyo y los incentivos fiscales, son fundamentales para superar las barreras existentes y estimular la demanda. A medida que España avanza hacia sus objetivos de sostenibilidad y transición energética, el análisis de la evolución del mercado de vehículos eléctricos se convierte en una herramienta esencial para entender el progreso realizado y los obstáculos que aún deben superarse.
3. Objetivo
Este ejercicio se centra en mostrar al lector técnicas para el tratamiento, visualización y análisis avanzado de datos abiertos mediante Python. Adoptaremos para ello el enfoque “aprender haciendo”, de tal forma que el lector pueda comprender la utilización de estas herramientas en el contexto de la resolución de un reto real y de actualidad como es el estudio de la penetración del VE en España. Este enfoque práctico no solo mejora la comprensión de las herramientas de ciencia de datos, sino que también prepara a los lectores para aplicar estos conocimientos en la resolución de problemas reales, ofreciendo una experiencia de aprendizaje rica y directamente aplicable a sus propios proyectos.
Las preguntas a las que trataremos de dar respuesta a través de nuestro análisis son:
- ¿Qué marcas de vehículos lideraron el mercado en 2023?
- ¿Qué modelos de vehículos fueron los más vendidos en el 2023?
- ¿Qué cuota de mercado absorbieron los vehículos eléctricos en el 2023?
- ¿Qué modelos de vehículos eléctricos fueron los más vendidos en el 2023?
- ¿Cómo han evolucionado las matriculaciones de vehículos a lo largo del tiempo?
- ¿Observamos algún tipo de tendencia respecto a la matriculación de vehículos eléctricos?
- ¿Cómo esperamos que evolucionen las matriculaciones de vehículos eléctricos el próximo año?
- ¿Cuál es la reducción de emisiones de CO2 que podemos esperar gracias a las matriculaciones obtenidas durante el próximo año?
4. Recursos
Para completar el desarrollo de este ejercicio requeriremos el uso de dos categorías de recursos: Herramientas Analíticas y Conjuntos de Datos.
4.1. Conjunto de datos
Para completar este ejercicio utilizaremos un conjunto de datos provisto por la Dirección General de Tráfico (DGT) a través de su portal estadístico, también disponible desde el catálogo Nacional de Datos Abiertos (datos.gob.es). El portal estadístico de la DGT es una plataforma en línea destinada a ofrecer acceso público a una amplia gama de datos y estadísticas relacionadas con el tráfico y la seguridad vial. Este portal incluye información sobre accidentes de tráfico, infracciones, matriculaciones de vehículos, permisos de conducción y otros datos relevantes que pueden ser útiles para investigadores, profesionales del sector y el público en general.
En nuestro caso, utilizaremos su conjunto de datos de matriculaciones de vehículos en España disponibles vía:
- Catálogo de Datos Abiertos del Gobierno de España.
- Portal estadístico de la DGT.
Aunque durante el desarrollo del ejercicio mostraremos al lector los mecanismos necesarios para su descarga y procesamiento, incluimos en el repositorio de GitHub asociado los datos preprocesados*, de tal forma que el lector pueda proceder directamente al análisis de los mismos en el caso de que lo desee.
*Los datos utilizados en este ejercicio fueron descargados el 04 de marzo de 2024. La licencia aplicable a este conjunto de datos puede encontrarse en https://datos.gob.es/avisolegal.
4.2. Herramientas analíticas
- Lenguaje de programación: Python – es un lenguaje de programación ampliamente utilizado en análisis de datos debido a su versatilidad y a la amplia gama de bibliotecas disponibles. Estas herramientas permiten a los usuarios limpiar, analizar y visualizar grandes conjuntos de datos de manera eficiente, lo que hace de Python una elección popular entre los científicos de datos y analistas.
- Plataforma: Jupyter Notebooks – es una aplicación web que permite crear y compartir documentos que contienen código vivo, ecuaciones, visualizaciones y texto narrativo. Se utiliza ampliamente para la ciencia de datos, análisis de datos, aprendizaje automático y educación interactiva en programación.
- Principales librerías y módulos:
- Manipulación de datos: Pandas – es una librería de código abierto que proporciona estructuras de datos de alto rendimiento y fáciles de usar, así como herramientas de análisis de datos.
- Visualización de datos:
- Matplotlib: es una librería para crear visualizaciones estáticas, animadas e interactivas en Python.
- Seaborn: es una librería basada en Matplotlib. Proporciona una interfaz de alto nivel para dibujar gráficos estadísticos atractivos e informativos.
- Estadística y algoritmia:
- Statsmodels: es una librería que proporciona clases y funciones para la estimación de muchos modelos estadísticos diferentes, así como para realizar pruebas y exploración de datos estadísticos.
- Pmdarima: es una librería especializada en la modelización automática de series temporales, facilitando la identificación, el ajuste y la validación de modelos para pronósticos complejos.
5. Desarrollo del ejercicio
Es aconsejable ir ejecutando el Notebook con el código a la vez que se realiza la lectura del post, ya que ambos recursos didácticos son complementarios en las futuras explicaciones
El ejercicio propuesto se divide en cuatro fases principales.
5.1 Configuración inicial
Este apartado podrás encontrarlo en el punto 1 del Notebook.
En este breve primer apartado, configuraremos nuestro Jupyter Notebook y nuestro entorno de trabajo para poder trabajar con el conjunto de datos seleccionado. Importaremos las librerías Python necesarias y crearemos algunos directorios donde almacenaremos los datos descargados.
5.2 Preparación de datos
Este apartado podrás encontrarlo en el punto 2 del Notebook.
Todo análisis de datos requiere una fase de acceso y tratamiento de los mismos hasta obtener los datos adecuados en el formato deseado. En esta fase, descargaremos los datos del portal estadístico y los transformaremos al formato Apache Parquet antes de proceder a su análisis.
Aquellos usuarios que quieran profundizar en esta tarea, tienen a su disposición la Guía Práctica de Introducción al Análisis Exploratorio de Datos.
5.3 Análisis de datos
Este apartado podrás encontrarlo en el punto 3 del Notebook.
5.3.1 Análisis descriptivo
En esta tercera fase, comenzaremos nuestro análisis de datos. Para ello, responderemos las primeras preguntas apoyándonos en herramientas de visualización de datos que además nos permitirán familiarizarnos con los mismos. Mostramos a continuación algunos ejemplos del análisis:
- Top 10 Vehículos matriculados en el 2023: En esta visualización representamos los diez modelos de vehículos con mayor número de matriculaciones durante el año 2023, indicando además el tipo de combustión de estos. Las principales conclusiones son:
- Los únicos vehículos de fabricación europea que aparecen en el Top 10 son el Arona y el Ibiza de la marca española SEAT. El resto son asiáticos.
- Nueve de los diez vehículos están propulsados por Gasolina.
- El único vehículo del Top 10 con un tipo de propulsión diferente es el DACIA Sandero GLP (Gas Licuado de Petróleo).
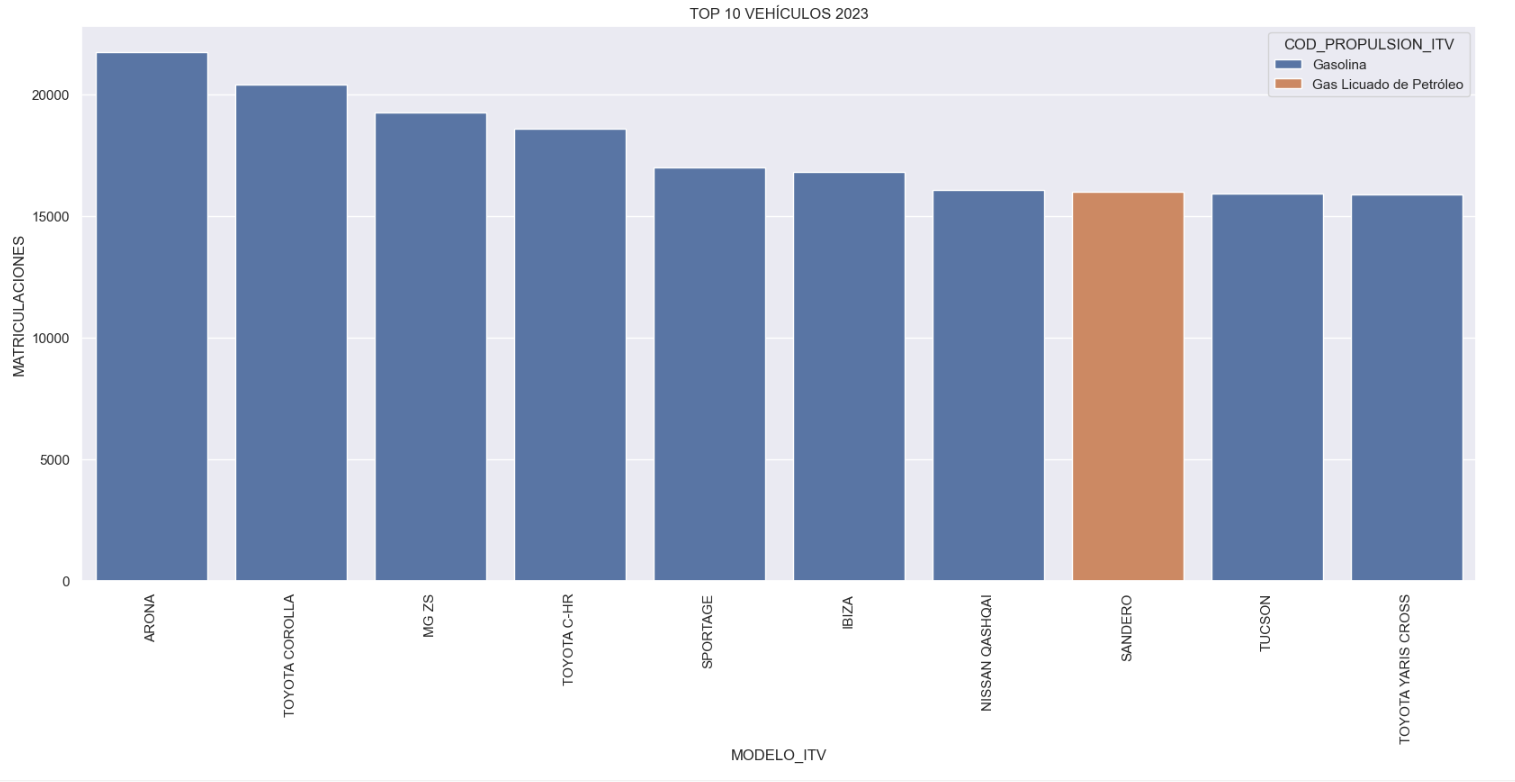
Figura 1. Gráfica "Top 10 Vehículos matriculados en el 2023"
- Cuota de mercado por tipo de propulsión: En esta visualización representamos el porcentaje de vehículos matriculado por cada tipo de propulsión (vehículos de gasolina, diésel, eléctricos u otros). Vemos cómo la inmensa mayoría del mercado (>70%) la absorbieron vehículos de gasolina, siendo los diésel la segunda opción, y como los vehículos eléctricos alcanzaron el 5.5%.
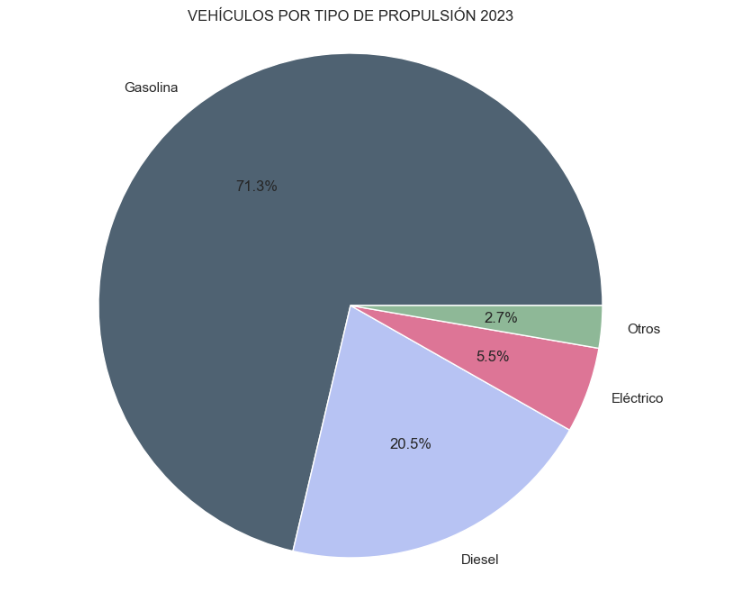
Figura 2. Gráfica "Cuota de mercado por tipo de propulsión".
- Evolución histórica de las matriculaciones: Esta visualización representa la evolución de las matriculaciones de vehículos en el tiempo. En ella se muestra el número de matriculaciones mensual entre enero de 2015 y diciembre de 2023 distinguiendo entre los tipos de propulsión de los vehículos matriculados.Podemos observar varios aspectos interesantes en este gráfico:
- Apreciamos un comportamiento estacional anual, es decir, observamos patrones o variaciones que se repiten a intervalos regulares de tiempo. Vemos cómo recurrentemente en junio/julio aparecen altos niveles de matriculación mientras que en agosto/septiembre decrecen drásticamente. Esto es muy relevante, pues el análisis de series temporales con factor estacional tiene ciertas particularidades.
- Es muy notable también la enorme caída de matriculaciones producida durante los primeros meses del COVID.
- Vemos también como los niveles de matriculación post-covid son inferiores a los previos.
- Por último, podemos observar cómo entre los años 2015 y 2023 la matriculación de vehículos eléctricos va creciendo paulatinamente.
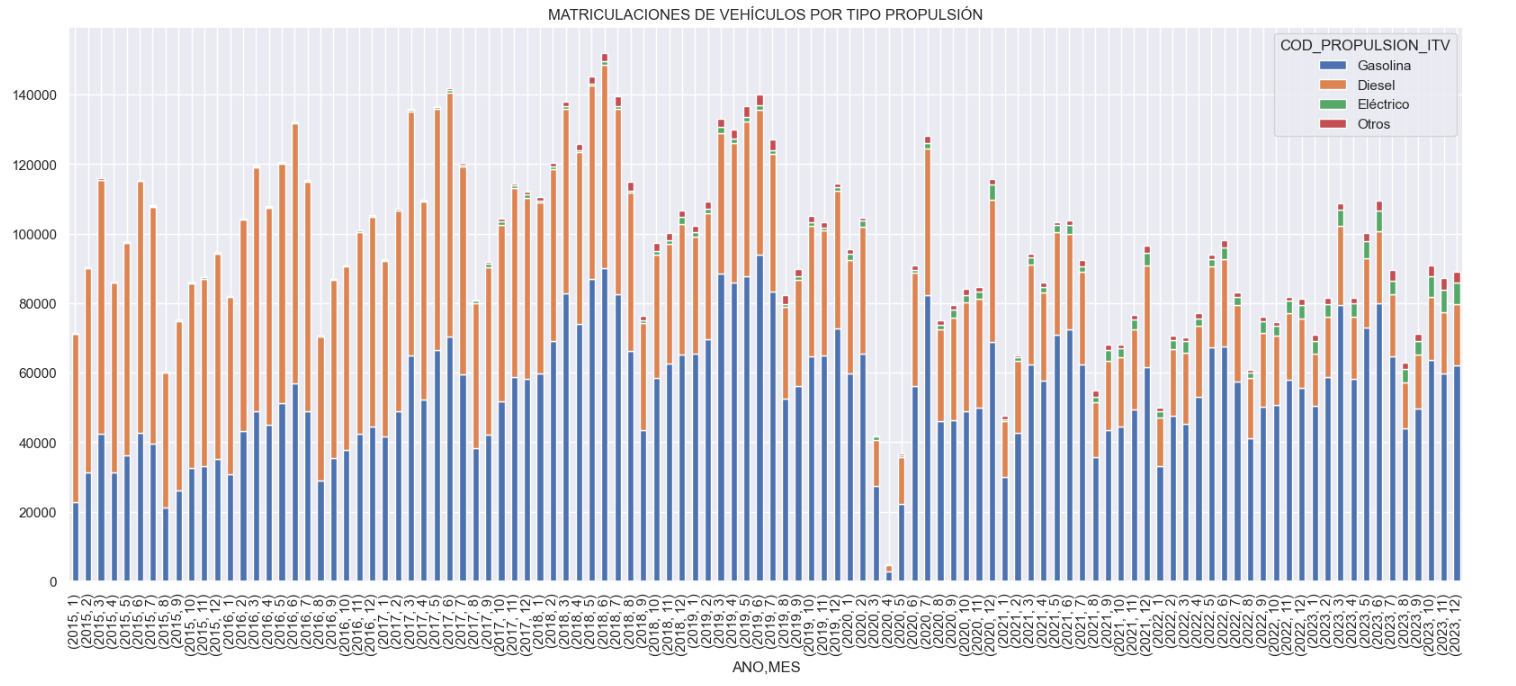
Figura 3. Gráfica "Matriculaciones de vehículos por tipo de propulsión".
- Tendencia en la matriculación de vehículos eléctricos: Analizamos ahora por separado la evolución de vehículos eléctricos y no eléctricos utilizando mapas de calor como herramienta visual. Podemos observar comportamientos muy diferenciados entre ambos gráficos. Observamos cómo el vehículo eléctrico presenta una tendencia de incremento de matriculaciones año a año y, a pesar de suponer el COVID un parón en la matriculación de vehículos, los años posteriores han mantenido la tendencia creciente.
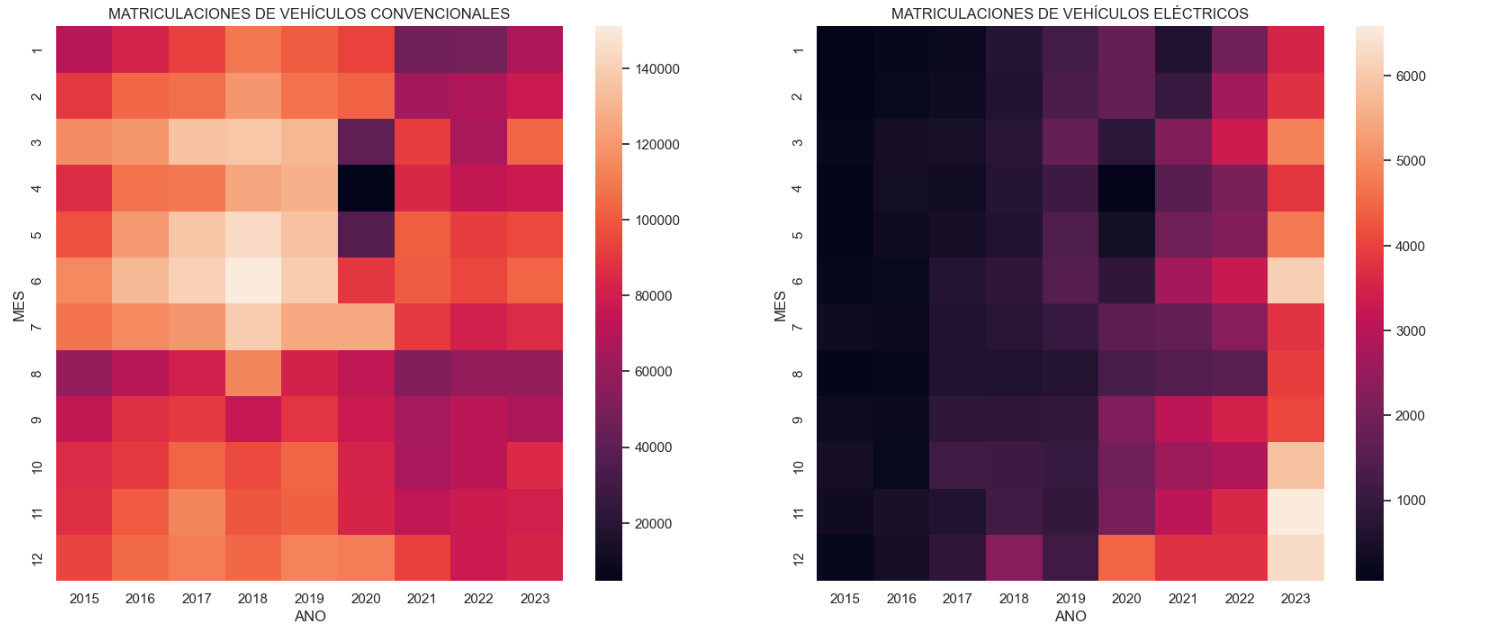
Figura 4. Gráfica "Tendencia en la matriculación de vehículos convencionales vs eléctricos".
5.3.2. Analítica predictiva
Para dar respuesta a la última de las preguntas de forma objetiva, utilizaremos modelos predictivos que nos permitan realizar estimaciones respecto a la evolución del vehículo eléctrico en España. Como podemos observar, el modelo construido nos propone una continuación del crecimiento en las matriculaciones esperadas a lo largo del año serán de 70.000, alcanzando valores cercanos a las 8.000 matriculaciones solo en el mes de diciembre del 2024.
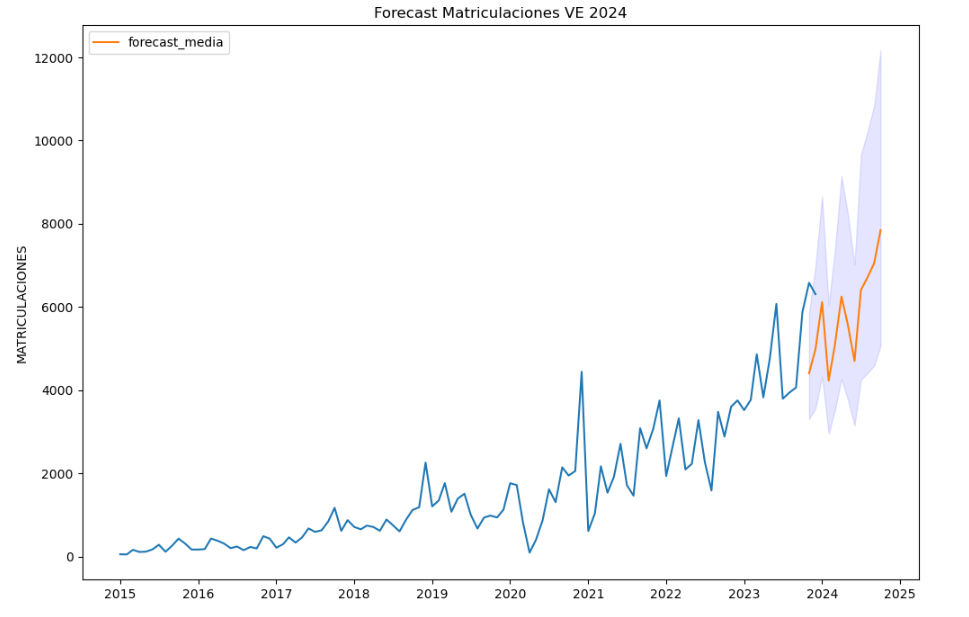
Figura 5. Gráfica "Predicción de matriculaciones de vehículos electricos".
5. Conclusiones del ejercicio
Como conclusión del ejercicio, podremos observar gracias a las técnicas de análisis empleadas como el vehículo eléctrico está penetrando cada vez a mayor velocidad en el parque móvil español aunque aún se encuentre a una distancia grande de otras alternativas como el Diésel o la Gasolina, por ahora liderado por el fabricante Tesla. Veremos en los próximos años si el ritmo crece al nivel necesario para alcanzar los objetivos de sostenibilidad fijados y si Tesla sigue siendo líder a pesar de la fuerte entrada de competidores asiáticos.
6. ¿Quieres realizar el ejercicio?
Si quieres conocer más sobre el Vehículo Eléctrico y poner a prueba tus capacidades analíticas, accede a este repositorio de código donde podrás desarrollar este ejercicio paso a paso.
Además, recuerda que tienes a tu disposición más ejercicios en el apartado sección de “Visualizaciones paso a paso”.
Contenido elaborado por Juan Benavente, ingeniero superior industrial y experto en Tecnologías ligadas a la economía del dato.Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Blog
El pasado noviembre de 2023, Crue Universidades Españolas publicó el informe TIC360 “Analítica de datos en la Universidad”. El informe es una iniciativa del grupo de trabajo de Dirección de TI Crue-Digitalización y tiene como objetivo exponer cómo la optimización en los procesos de extracción y tratamiento de los datos es clave para la generación del conocimiento en entornos de la universidad pública española. Para ello se incluyen cinco capítulos en los que se abordan determinados aspectos relacionados con la tenencia de datos y las capacidades analíticas de las universidades para generar conocimiento sobre su funcionamiento.
A continuación, presentamos un resumen de los capítulos explicando al lector qué puede encontrar en cada uno de ellos.
¿Por qué es importante la analítica de datos y cuáles son sus retos?
En la introducción, se recuerda el concepto de analítica de datos como la extracción de conocimiento a partir de datos disponible, resaltando su importancia creciente en la era actual. La analítica de datos es el instrumento adecuado para obtener la información necesaria que sirva de base para tomar decisiones en distintos campos. Entre otras cuestiones, ayuda a optimizar los procesos de gestión o mejorar la eficiencia energética de la organización, por poner algunos ejemplos. Aunque es fundamental para todos los sectores, el documento se centra en el potencial impacto de los datos en la economía y la educación, enfatizando la necesidad de un enfoque ético y responsable.
El informe explora el desarrollo acelerado de esta disciplina, impulsado por la abundancia de datos y la avanzada capacidad de cómputo; no obstante, también se alerta sobre los riesgos inherentes de unas herramientas basadas en técnicas y algoritmos que están en fase de desarrollo, y que además pueden introducir sesgos basados en edad, procedencia, sexo, estatus socioeconómico, etc. En este sentido, es importante tener en cuenta la importancia de la privacidad, la protección de datos personales, la transparencia y la explicabilidad, es decir, que cuando un algoritmo genera un resultado, debe ser posible explicar cómo se ha llegado a ese resultado.
Un buen resumen de este capítulo es la siguiente frase del autor: “El buen uso de los datos no nos llevará al paraíso, pero sí puede construir una sociedad más sostenible, justa e inclusiva. Por el contrario, su mal uso sí podría acercarnos a un infierno digital”.
¿Qué beneficio aportaría a las universidades participar en los Espacios de Datos?
El primer capítulo, partiendo de la base de que el dato es el gran protagonista y el activo vertebrador de la transformación digital, aborda el concepto de Espacio de Datos, destacando su relevancia en la estrategia de la Comisión Europea como el activo más importante de la economía del dato.
Tras resaltar los potenciales beneficios de compartir datos, el capítulo destaca cómo la economía del dato, impulsada por un mercado único de datos compartidos, puede ajustarse a los valores europeos y contribuir a una economía digital más justa e inclusiva. A ello pueden contribuir iniciativas como la Estrategia España Digital 2026, donde se destaca el papel del dato como un activo clave en la transformación digital.
La participación del mundo universitario en los espacios de datos presenta múltiples ventajas, como la compartición, el acceso y la reutilización de recursos de datos generados por otras comunidades universitarias. Esto permite avanzar más rápidamente en las investigaciones, optimizando los recursos públicos dedicados anteriormente la investigación. Una iniciativa que pone de manifiesto dichos beneficios es el Espacio Europeo de Ciencia Abierta (EOSC), que persigue establecer vínculos entre investigadores y profesionales en ciencia y tecnología en un entorno virtual con servicios abiertos y sin fisuras para el almacenamiento, gestión, análisis y reutilización de datos científicos, más allá de fronteras físicas y de disciplinas científicas. El capítulo también introduce diferentes aspectos relacionados con los espacios de datos como sus principios rectores, la legislación, los participantes y los roles a considerar. También resalta algunos aspectos relacionados con el gobierno de los espacios de datos y con las tecnologías necesarias para su despliegue.
¿En qué consiste el Espacio Europeo de Datos de Habilidades (European Skill Data Space)?
Este segundo capítulo explora la creación de un espacio común europeo de datos, enfocado en las habilidades. Este espacio busca reducir la brecha entre habilidades educativas y necesidades del mercado laboral, aumentando la productividad y competitividad gracias a un acceso transfronterizo a datos clave para la creación de aplicaciones y otros usos innovadores. En este sentido, es fundamental tener en cuenta la liberación de la versión 3.1 del European Learning Model (ELM), que pasa a consolidarse como el modelo europeo único de datos para cualquier tipo de aprendizaje (formal, no formal, informal) base para el Espacio Europeo de Datos de Habilidades.
El informe define las fases y los elementos clave para la creación e integración en el Espacio Europeo de Datos de Habilidad, destacando qué contribuciones podrían aportar y qué podrían esperar los distintos roles (proveedor de educación y capacitación, demandante de empleo, ciudadano, estudiante y empleador).
¿Cuál es el rol de la universidad española en el contexto de los Espacios Europeos de Datos?
Este capítulo se centra en el rol de las universidades españolas dentro de los espacios de datos europeos como un agente fundamental para la transformación digital del país. Para conseguir esos resultados y obtener los beneficios que aporta la analítica de datos y la interacción con espacios europeos de datos, las instituciones deben pasar de un modelo estático, basado en criterios de planificación a medio y largo plazo, a modelos flexibles más adecuados a la realidad líquida en la que vivimos, de tal forma que se puedan aprovechar los datos para mejorar la educación y la investigación.
En este contexto, es fundamental la importancia de la colaboración y el intercambio de datos a nivel europeo, pero teniendo en cuenta la legislación vigente, tanto la genérica como la específica de un dominio particular. En este sentido, estamos asistiendo a una revolución para la cual el cumplimiento normativo y el compromiso por parte de la organización universitaria es crucial. Se corre el riesgo de que organizaciones que no sean capaces de cumplir con el bloque normativo, no podrán generar conjuntos de datos de alta calidad.
Finalmente, el capítulo ofrece una serie de indicaciones sobre el tipo de plantilla que deberían tener las universidades para no verse privadas de la creación de un cuerpo de analistas y expertos en computación, vitales para el futuro.
¿Qué tipo de certificaciones existen en el ámbito de los datos?
Para poder abordar los retos introducidos en los capítulos del informe, se necesita que las universidades cuenten con: (1) datos con niveles adecuados; (2) buenas prácticas con respecto a su gobierno, gestión y calidad; y (3) profesionales suficientemente cualificados y capacitados para desempeñar las distintas tareas. Para transmitir confianza en estos elementos este capítulo justifica la importancia de tener certificaciones para los tres elementos presentados:
- Certificaciones del nivel de calidad de productos de datos como ISO/IEC 25012, ISO/IEC 25024 e ISO/IEC 25040.
- Certificaciones del nivel de madurez organizacional con respecto al gobierno del dato, gestión del dato y gestión de la calidad del dato, basadas en el modelo MAMD.
- Certificaciones de competencias personales de datos, como las referidas a conocimientos tecnológicos o las certificaciones de competencia profesionales, entre las que se incluyen las expedidas por CDMP o la Certificación CertGed.
¿En qué estado está la Universidad en la era del dato?
Aunque se ha avanzado en la materia, las universidades españolas todavía tienen un camino por delante para adaptarse y transformarse en organizaciones dirigidas por datos, y así poder obtener el máximo beneficio de las analíticas de datos. En este sentido, es necesario una actualización de la forma de operar en todas las áreas que abarca la universidad, lo cual requiere actuar y liderar los cambios necesarios para poder ser competitivos en la nueva realidad en la que estamos ya viviendo.
El objetivo es que la analítica genere impacto en la mejora de la docencia universitaria para lo que es fundamental la digitalización de los procesos de docencia y aprendizaje. Con ello se generarán beneficios también en la personalización del aprendizaje y la optimización de los procesos administrativos y de gestión.
En resumen, el análisis de datos es área de gran importancia para mejorar la eficiencia del sector universitario, pero para alcanzar todos sus beneficios es necesario continuar trabajando tanto en el desarrollo de espacios de datos, como en la capacitación del personal. Este informe busca proporcionar información para avanzar en la materia en ambos sentidos.
El documento está disponible públicamente para su lectura en: https://www.crue.org/wp-content/uploads/2023/10/TIC-360_2023_WEB.pdf
Contenido elaborado por Dr. Ismael Caballero, Profesor titular en UCLM
Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Documentación
1. Introducción
Las visualizaciones son representaciones gráficas de datos que permiten comunicar, de manera sencilla y efectiva, la información ligada a los mismos. Las posibilidades de visualización son muy amplias, desde representaciones básicas como los gráficos de líneas, de barras o métricas relevantes, hasta visualizaciones configuradas sobre cuadros de mando interactivos.
En esta sección de “Visualizaciones paso a paso” estamos presentando periódicamente ejercicios prácticos haciendo uso de datos abiertos disponibles en datos.gob.es u otros catálogos similares. En ellos se abordan y describen de manera sencilla las etapas necesarias para obtener los datos, realizar las transformaciones y los análisis que resulten pertinentes para, finalmente obtener unas conclusiones a modo de resumen de dicha información.
En cada uno de estos ejercicios prácticos, se utilizan desarrollos de código convenientemente documentados, así como herramientas de uso gratuito. Todo el material generado está disponible para su reutilización en el repositorio de GitHub de datos.gob.es.
Accede al repositorio del laboratorio de datos en Github.
Ejecuta el código de pre-procesamiento de datos sobre Google Colab.
2. Objetivo
El principal objetivo de este ejercicio es mostrar cómo realizar, de una forma didáctica, un análisis predictivo de series temporales partiendo de datos abiertos sobre el consumo de electricidad en la ciudad de Barcelona. Para ello realizaremos un análisis exploratorio de los datos, definiremos y validaremos el modelo predictivo, para por último generar las predicciones junto a sus gráficas y visualizaciones correspondientes.
Los análisis predictivos de series temporales son técnicas estadísticas y de aprendizaje automático que se utilizan para prever valores futuros en conjuntos de datos que se recopilan a lo largo del tiempo. Estas predicciones se basan en patrones y tendencias históricas identificadas en la serie temporal, siendo su objetivo principal anticipar cambios y eventos en función de datos pasados.
El conjunto de datos abiertos inicial consta de registros desde el año 2019 hasta el año 2022 ambos inclusive, por otra parte, las predicciones las realizaremos para el año 2023, del cual no tenemos datos reales.
Una vez realizado el análisis, podremos contestar a preguntas como las que se plantean a continuación:
- ¿Cuál es la predicción futura de consumo eléctrico?
- ¿Cómo de preciso ha sido el modelo con la predicción de datos ya conocidos?
- ¿Qué días tendrán un consumo máximo y mínimo según las predicciones futuras?
- ¿Qué meses tendrán un consumo medio máximo y mínimo según las predicciones futuras?
Estas y otras muchas preguntas pueden ser resueltas mediante las visualizaciones obtenidas en el análisis que mostrarán la información de una forma ordenada y sencilla de interpretar.
3. Recursos
3.1. Conjuntos de datos
Los conjuntos de datos abiertos utilizados contienen información sobre el consumo eléctrico en la ciudad de Barcelona en los últimos años. La información que aportan es el consumo en (MWh) desglosados por día, sector económico, código postal y tramo horario.
Estos conjuntos de datos abiertos son publicados por el Ayuntamiento de Barcelona en el catálogo de datos.gob.es, mediante ficheros que recogen los registros de forma anual. Cabe destacar que el publicador actualiza estos conjuntos de datos con nuevos registros con frecuencia, por lo que hemos utilizado solamente los datos proporcionados desde el 2019 hasta el 2022 ambos inclusive.
Estos conjuntos de datos también se encuentran disponibles para su descarga en el siguiente repositorio de Github.
3.2. Herramientas
Para la realización del análisis se ha utilizado el lenguaje de programación Python escrito sobre un Notebook de Jupyter alojado en el servicio en la nube de Google Colab.
"Google Colab" o, también llamado Google Colaboratory, es un servicio en la nube de Google Research que permite programar, ejecutar y compartir código escrito en Python o R sobre un Jupyter Notebook desde tu navegador, por lo que no requiere configuración. Este servicio es gratuito.
Para la creación de las visualizaciones interactivas se ha usado la herramienta Looker Studio.
"Looker Studio", antiguamente conocido como Google Data Studio, es una herramienta online que permite realizar visualizaciones interactivas que pueden insertarse en sitios web o exportarse como archivos.
Si quieres conocer más sobre herramientas que puedan ayudarte en el tratamiento y la visualización de datos, puedes recurrir al informe "Herramientas de procesado y visualización de datos".
4. Análisis predictivo de series temporales
El análisis predictivo de series temporales es una técnica que utiliza datos históricos para predecir valores futuros de una variable que cambia con el tiempo. Las series temporales son datos que se recopilan en intervalos regulares, como días, semanas, meses o años. No es el objetivo de este ejercicio explicar en detalle las características de las series temporales, ya que nos centramos en explicar brevemente el modelo de predicción. No obstante, si quieres saber más al respecto, puedes consultar el siguiente manual.
Este tipo de análisis se basa en el supuesto de que los valores futuros de una variable estarán correlacionados con los valores históricos. Utilizando técnicas estadísticas y de aprendizaje automático, se pueden identificar patrones en los datos históricos y utilizarlos para predecir valores futuros.
El análisis predictivo realizado en el ejercicio ha sido dividido en cinco fases; preparación de los datos, análisis exploratorio de los datos, entrenamiento del modelo, validación del modelo y predicción de valores futuros), las cuales se explicarán en los próximos apartados.
Los procesos que te describimos a continuación los encontrarás desarrollados y comentados en el siguiente Notebook ejecutable desde Google Colab junto al código fuente que está disponible en nuestra cuenta de Github.
Es aconsejable ir ejecutando el Notebook con el código a la vez que se realiza la lectura del post, ya que ambos recursos didácticos son complementarios en las futuras explicaciones
4.1 Preparación de los datos
Este apartado podrás encontrarlo en el punto 1 del Notebook.
En este apartado se importan los conjuntos de datos abiertos descritos en los puntos anteriores que utilizaremos en el ejercicio, prestando especial atención a su obtención y a la validación de su contenido, asegurándonos que se encuentran en el formato adecuado y consistente para su procesamiento y que no contienen errores que puedan condicionar los pasos futuros.
4.2 Análisis exploratorio de los datos (EDA)
Este apartado podrás encontrarlo en el punto 2 del Notebook.
En este apartado realizaremos un análisis exploratorio de los datos (EDA), con el fin de interpretar adecuadamente los datos de origen, detectar anomalías, datos ausentes, errores u outliers que pudieran afectar a la calidad de los procesos posteriores y resultados.
A continuación, en la siguiente visualización interactiva, podrás inspeccionar la tabla de datos con los valores de consumo históricos generada en el punto anterior pudiendo filtrar por periodo temporal concreto. De esta forma podemos comprender, de una forma visual, la principal información de la serie de datos.
Una vez inspeccionada la visualización interactiva de la serie temporal, habrás observado diversos valores que potencialmente podrían ser considerados como outliers, como se muestra en la siguiente figura. También podemos calcular de forma numérica estos outliers, como se muestra en el notebook.

Una vez evaluados los outliers, para este ejercicio se ha decidido modificar únicamente el registrado en la fecha "2022-12-05". Para ello se sustituirá el valor por la media del registrado el día anterior y el día siguiente.
La razón de no eliminar el resto de outliers es debido a que son valores registrados en días consecutivos, por lo que se presupone que son valores correctos afectados por variables externas que se escapan del alcance del ejercicio. Una vez solucionado el problema detectado con los outliers, esta será la serie temporal de datos que utilizaremos en los siguientes apartados.
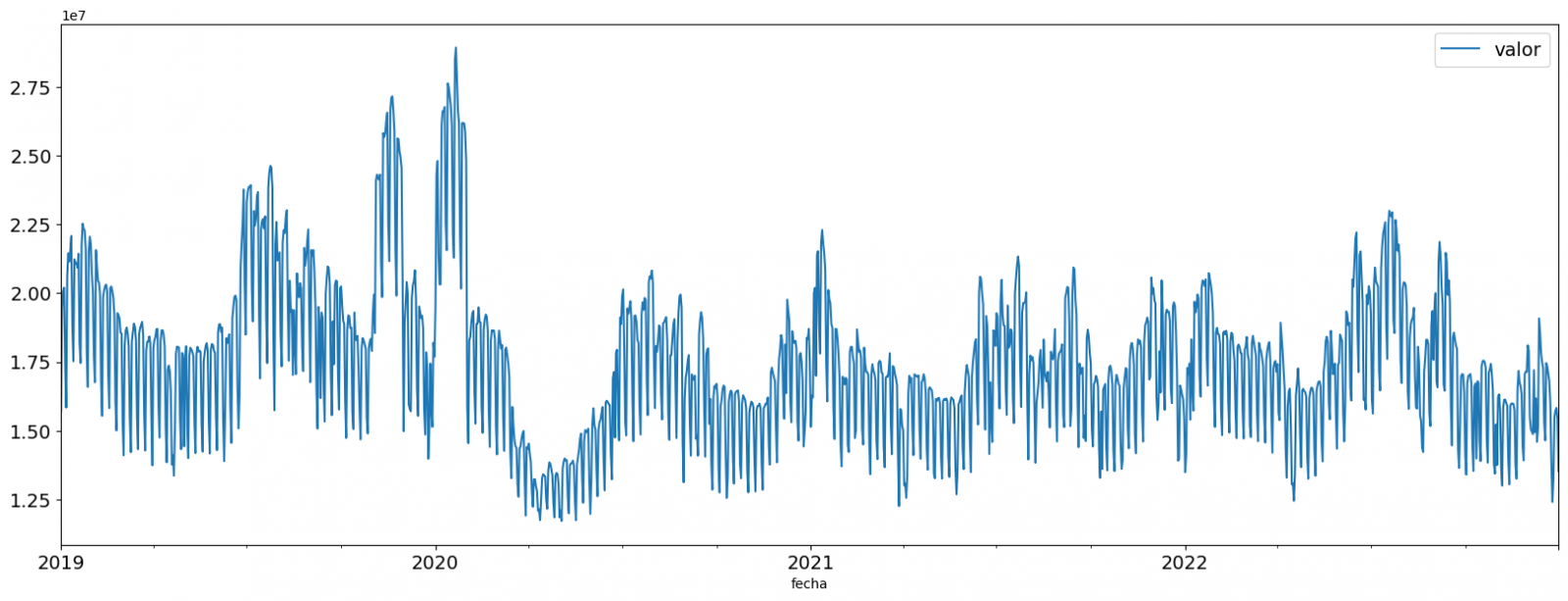
Figura 2. Serie temporal de datos históricos una vez tratados los outliers
Si quieres conocer más sobre estos procesos puedes recurrir a la Guía Práctica de Introducción al Análisis Exploratorio de Datos.
4.3 Entrenamiento del modelo
Este apartado podrás encontrarlo en el punto 3 del Notebook.
En primer lugar, creamos dentro de la tabla de datos los atributos temporales (año, mes, día de la semana y trimestre). Estos atributos son variables categóricas que ayudan a garantizar que el modelo sea capaz de capturar con precisión las características y patrones únicos de estas variables. Mediante las siguientes visualizaciones de diagramas de cajas, podemos ver su relevancia dentro de los valores de la serie temporal.
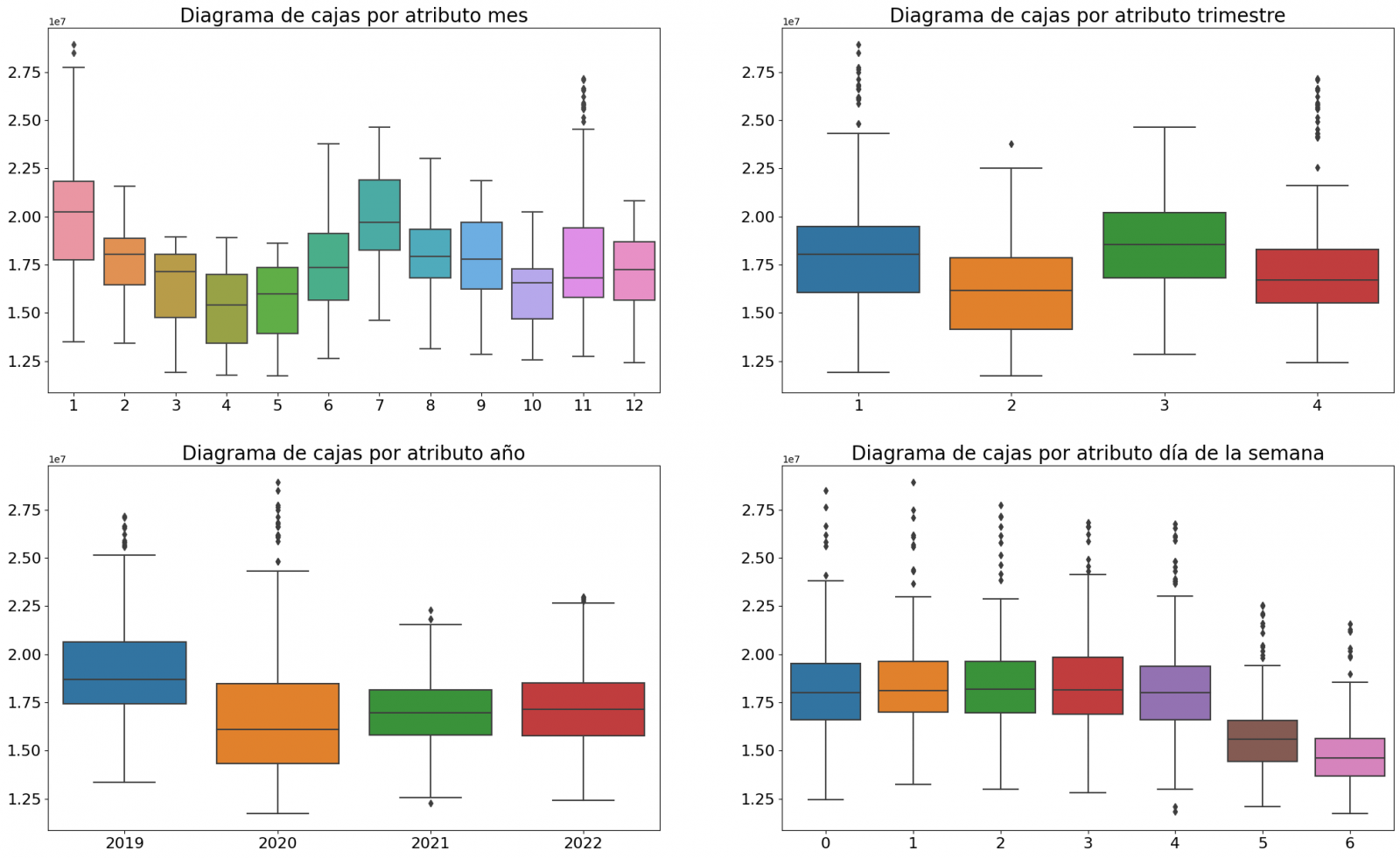
Figura 3. Diagramas de cajas de los atributos temporales generados
Podemos observar ciertos patrones en las gráficas anteriores como los siguientes:
- Los días laborales (lunes a viernes) presentan un mayor consumo que los fines de semana.
- El año que valores de consumo más bajos presenta es el 2020, esto entendemos que se debe a la reducción de actividad servicios e industrial durante la pandemia.
- El mes que mayor consumo presenta es julio, lo cual es entendible debido al uso de aparatos de aire acondicionado.
- El segundo trimestre es el que presenta valores más bajos de consumo, destacando abril como el mes con valores más bajos.
A continuación, dividimos la tabla de datos en set de entrenamiento y en set de validación. El set de entrenamiento se utiliza para entrenar el modelo, es decir, el modelo aprende a predecir el valor de la variable objetivo a partir de dicho set, mientras que el set de validación se utiliza para evaluar el rendimiento del modelo, es decir, el modelo se evalúa con los datos de dicho set para determinar su capacidad para predecir los nuevos valores.
Esta división de los datos es importante para evitar el sobreajuste siendo la proporción típica de los datos que se utilizan para el set de entrenamiento de un 70 % y el set de validación del 30% aproximadamente. Para este ejercicio hemos decidido generar el set de entrenamiento con los datos comprendidos entre el "01-01-2019" hasta el "01-10-2021", y el set de validación con los comprendidos entre el "01-10-2021" y el "31-12-2022" como podemos apreciar en la siguiente gráfica.
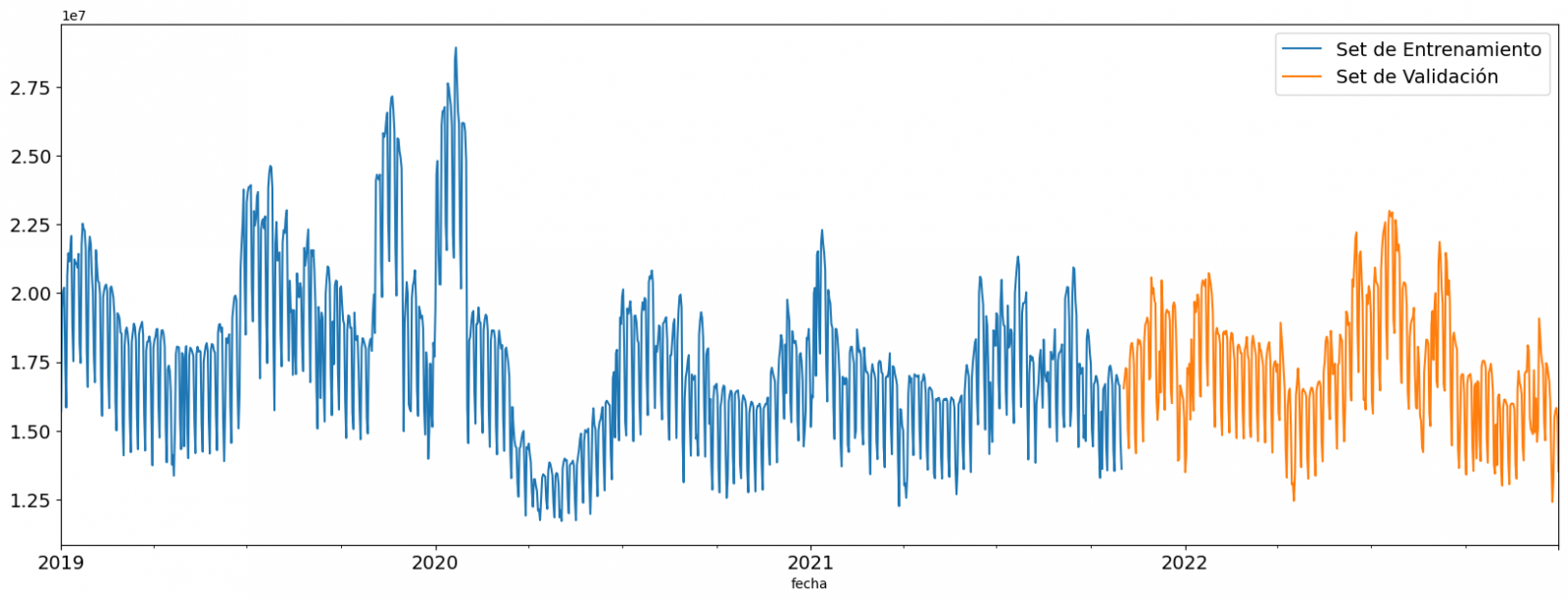
Figura 4. Serie temporal de datos históricos dividida en set de entrenamiento y set de validación
Para este tipo de ejercicio, tenemos que utilizar algún algoritmo de regresión. Existen diversos modelos y librerías que pueden utilizarse para predicción de series temporales. En este ejercicio utilizaremos el modelo “Gradient Boosting”, modelo de regresión supervisado que se trata de un algoritmo de aprendizaje automático utilizado para predecir un valor continúo basándose en el entrenamiento de un conjunto de datos que contienen valores conocidos para la variable objetivo (en nuestro ejemplo la variable “valor”) y los valores de las variables independientes (en nuestro ejercicio los atributos temporales).
Está basado en árboles de decisión y utiliza una técnica llamada "boosting" para mejorar la precisión del modelo siendo conocido por su eficiencia y capacidad para manejar una variedad de problemas de regresión y clasificación.
Sus principales ventajas son el alto grado de precisión, su robustez y flexibilidad, mientras que alguna de sus desventajas son la sensibilidad a valores atípicos y que requiere una optimización cuidadosa de los parámetros.
Utilizaremos el modelo de regresión supervisado ofrecido en la librería XGBBoost, el cuál puede ajustarse con los siguientes parámetros:
- n_estimators: parámetro que afecta al rendimiento del modelo indicando el número de árboles utilizados. Un mayor número de árboles generalmente resulta un modelo más preciso, pero también puede llevar más tiempo de entrenamiento.
- early_stopping_rounds: parámetro que controla el número de rondas de entrenamiento que se ejecutarán antes de que el modelo se detenga si el rendimiento en el conjunto de validación no mejora.
- learning_rate: controla la velocidad de aprendizaje del modelo. Un valor más alto hará que el modelo aprenda más rápido, pero puede provocar un sobreajuste.
- max_depth: controla la profundidad máxima de los árboles en el bosque. Un valor más alto puede proporcionar un modelo más preciso, pero también puede provocar un sobreajuste.
- min_child_weight: controla el peso mínimo de una hoja. Un valor más alto puede ayudar a prevenir el sobreajuste.
- gamma: controla la cantidad de reducción de la pérdida esperada que se necesita para dividir un nodo. Un valor más alto puede ayudar a prevenir el sobreajuste.
- colsample_bytree: controla la proporción de las características que se utilizan para construir cada árbol. Un valor más alto puede ayudar a prevenir el sobreajuste.
- subsample: controla la proporción de los datos que se utilizan para construir cada árbol. Un valor más alto puede ayudar a prevenir el sobreajuste.
Estos parámetros se pueden ajustar para mejorar el rendimiento del modelo en un conjunto de datos específico. Se recomienda experimentar con diferentes valores de estos parámetros para encontrar el valor que proporciona el mejor rendimiento en tu conjunto de datos.
Por último, mediante una gráfica de barras observaremos de forma visual la importancia de cada uno de los atributos durante el entrenamiento del modelo. Se puede utilizar para identificar los atributos más importantes en un conjunto de datos, lo que puede ser útil para la interpretación del modelo y la selección de características.
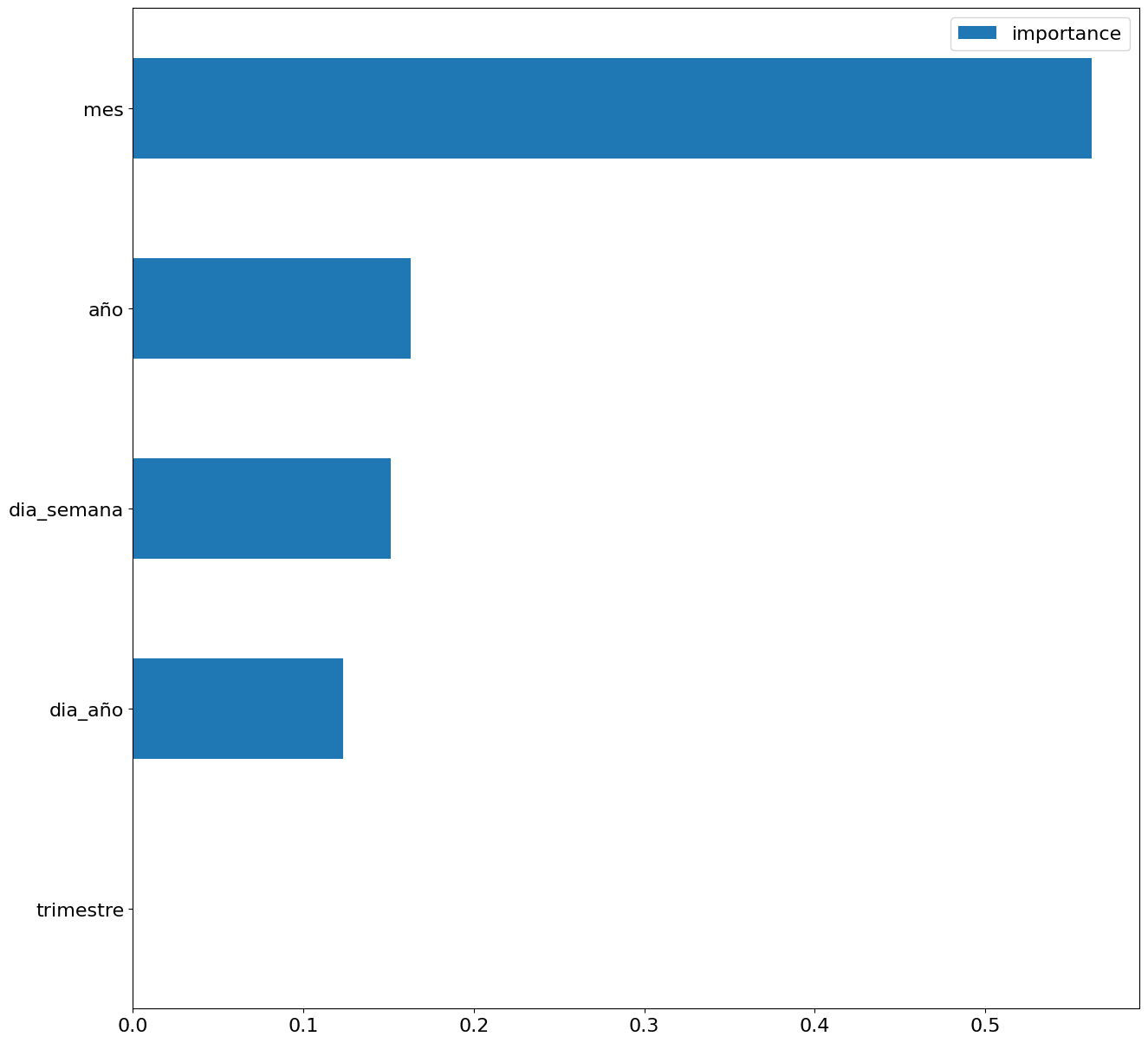
Figura 5. Gráfica de barras con importancia de los atributos temporales
4.4 Entrenamiento del modelo
Este apartado podrás encontrarlo en el punto 4 del Notebook.
Una vez entrenado el modelo, evaluaremos cómo de preciso es para los valores conocidos del set de validación.
Podemos evaluar de forma visual el modelo ploteando la serie temporal con los valores conocidos junto a las predicciones realizadas para el set de validación como se muestra en la siguiente figura.
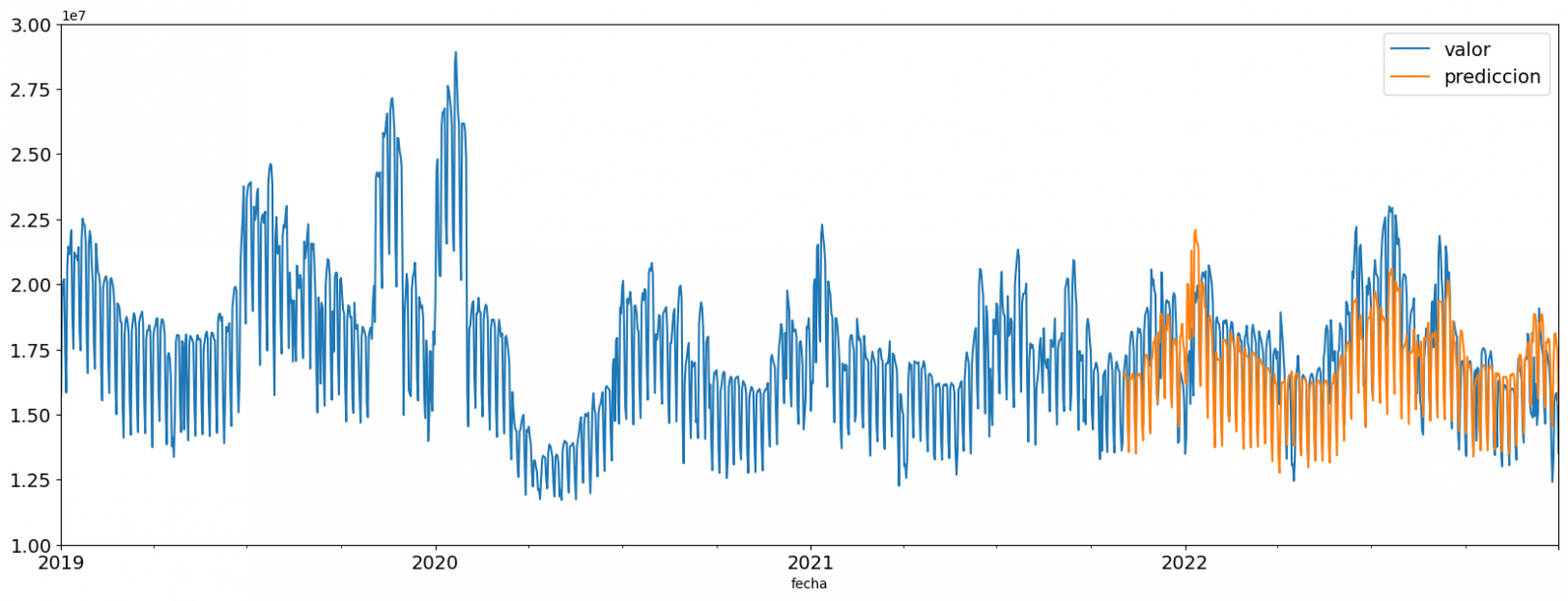
Figura 6. Serie temporal con los datos del set de validación junto a los de la predicción
También podemos evaluar de forma numérica la precisión del modelo mediante distintas métricas. En este ejercicio hemos optado por utilizar la métrica del error porcentual absoluto medio (MAPE), el cuál ha sido de un 6,58%. La precisión del modelo se considera alta o baja dependiendo del contexto y de las expectativas en dicho modelo, generalmente un MAPE se considera bajo cuando es inferior al 5%, mientras que se considera alto cuando es superior al 10%. En este ejercicio, el resultado de la validación del modelo puede ser considerado un valor aceptable.
Si quieres consultar otro tipo de métricas para evaluar la precisión de modelos aplicados a series temporales, puedes consultar el siguiente enlace.
4.5 Predicciones valores futuros
Este apartado podrás encontrarlo en el punto 5 del Notebook.
Una vez generado el modelo y evaluado su rendimiento MAPE = 6,58 %, pasamos a aplicar dicho modelo al total de datos conocidos, con la finalidad de predecir los valores de consumo eléctrico no conocidos del 2023.
En primer lugar, volvemos a entrenar el modelo con los valores conocidos hasta finales del 2022, sin dividir en set de entrenamiento y validación. Por último, calculamos los valores futuros para el año 2023.

Figura 7. Serie temporal con los datos históricos y la predicción para el 2023
En la siguiente visualización interactiva puedes observar los valores predichos para el año 2023 junto a sus principales métricas, pudiendo filtrar por periodo temporal.
Mejorar los resultados de los modelos predictivos de series temporales es un objetivo importante en la ciencia de datos y el análisis de datos. Varias estrategias que pueden ayudar a mejorar la precisión del modelo del ejercicio son el uso de variables exógenas, la utilización de más datos históricos o generación de datos sintéticos, optimización de los parámetros, …
Debido al carácter divulgativo de este ejercicio y para favorecer el entendimiento de los lectores menos especializados, nos hemos propuesto explicar de una forma lo más sencilla y didáctica posible el ejercicio. Posiblemente se te ocurrirán muchas formas de optimizar el modelo predictivo para lograr mejores resultados, ¡Te animamos a que lo hagas!
5. Conclusiones ejercicio
Una vez realizado el ejercicio, podemos apreciar distintas conclusiones como las siguientes:
- Los valores máximos para las predicciones de consumo en el 2023 se dan en la última quincena de julio superando valores de 22.500.000 MWh
- El mes con un mayor consumo según las predicciones del 2023 será julio, mientras que el mes con un menor consumo medio será noviembre, existiendo una diferencia porcentual entre ambos del 25,24%
- La predicción de consumo medio diario para el 2023 es de 17.259.844 MWh, un 1,46% inferior a la registrada entre los años 2019 y 2022.
Esperemos que este ejercicio te haya resultado útil para el aprendizaje de algunas técnicas habituales en el estudio y análisis de datos abiertos. Volveremos para mostraros nuevas reutilizaciones. ¡Hasta pronto!
Documentación
1. Introducción
Las visualizaciones son representaciones gráficas de datos que permiten comunicar de manera sencilla y efectiva la información ligada a los mismos. Las posibilidades de visualización son muy amplias, desde representaciones básicas, como los gráficos de líneas, de barras o de sectores, hasta visualizaciones configuradas sobre cuadros de mando interactivos.
En esta sección de “Visualizaciones paso a paso” estamos presentando periódicamente ejercicios prácticos de visualizaciones de datos abiertos disponibles en datos.gob.es u otros catálogos similares. En ellos se abordan y describen de manera sencilla las etapas necesarias para obtener los datos, realizar las transformaciones y los análisis que resulten pertinentes para, finalmente, posibilitar la creación de visualizaciones interactivas que nos permitan obtener unas conclusiones finales a modo de resumen de dicha información. En cada uno de estos ejercicios prácticos, se utilizan sencillos desarrollos de código convenientemente documentados, así como herramientas de uso gratuito. Todo el material generado está disponible para su reutilización en el repositorio Laboratorio de datos de GitHub.
A continuación, y como complemento a la explicación que encontrarás seguidamente, puedes acceder al código que utilizaremos en el ejercicio y que iremos explicando y desarrollando en los siguientes apartados de este post.
Accede al repositorio del laboratorio de datos en Github.
Ejecuta el código de pre-procesamiento de datos sobre Google Colab.
2. Objetivo
El objetivo principal de este ejercicio es mostrar cómo realizar un análisis de redes o de grafos partiendo de datos abiertos sobre viajes en bicicleta de alquiler en la ciudad de Madrid. Para ello, realizaremos un preprocesamiento de los datos con la finalidad de obtener las tablas que utilizaremos a continuación en la herramienta generadora de la visualización, con la que crearemos las visualizaciones del grafo.
Los análisis de redes son métodos y herramientas para el estudio y la interpretación de las relaciones y conexiones entre entidades o nodos interconectados de una red, pudiendo ser estas entidades personas, sitios, productos, u organizaciones, entre otros. Los análisis de redes buscan descubrir patrones, identificar comunidades, analizar la influencia y determinar la importancia de los nodos dentro de la red. Esto se logra mediante el uso de algoritmos y técnicas específicas para extraer información significativa de los datos de red.
Una vez analizados los datos mediante esta visualización, podremos contestar a preguntas como las que se plantean a continuación:
- ¿Cuál es la estación de la red con mayor tráfico de entrada y de salida?
- ¿Cuáles son las rutas entre estaciones más frecuentes?
- ¿Cuál es el número medio de conexiones entre estaciones para cada una de ellas?
- ¿Cuáles son las estaciones más interconectadas dentro de la red?
3. Recursos
3.1. Conjuntos de datos
Los conjuntos de datos abiertos utilizados contienen información sobre los viajes en bicicleta de préstamo realizados en la ciudad de Madrid. La información que aportan se trata de la estación de origen y de destino, el tiempo del trayecto, la hora del trayecto, el identificador de la bicicleta, …
Estos conjuntos de datos abiertos son publicados por el Ayuntamiento de Madrid, mediante ficheros que recogen los registros de forma mensual.
Estos conjuntos de datos también se encuentran disponibles para su descarga en el siguiente repositorio de Github.
3.2. Herramientas
Para la realización de las tareas de preprocesado de los datos se ha utilizado el lenguaje de programación Python escrito sobre un Notebook de Jupyter alojado en el servicio en la nube de Google Colab.
"Google Colab" o, también llamado Google Colaboratory, es un servicio en la nube de Google Research que permite programar, ejecutar y compartir código escrito en Python o R sobre un Jupyter Notebook desde tu navegador, por lo que no requiere configuración. Este servicio es gratuito.
Para la creación de la visualización interactiva se ha usado la herramienta Gephi
"Gephi" es una herramienta de visualización y análisis de redes. Permite representar y explorar relaciones entre elementos, como nodos y enlaces, con el fin de entender la estructura y patrones de la red. El programa precisa descarga y es gratuito.
Si quieres conocer más sobre herramientas que puedan ayudarte en el tratamiento y la visualización de datos, puedes recurrir al informe "Herramientas de procesado y visualización de datos".
4. Tratamiento o preparación de datos
Los procesos que te describimos a continuación los encontrarás comentados en el Notebook que también podrás ejecutar desde Google Colab.
Debido al alto volumen de viajes registrados en los conjuntos de datos, definimos los siguientes puntos de partida a la hora de analizarlos:
- Analizaremos la hora del día con mayor tráfico de viajes
- Analizaremos las estaciones con un mayor volumen de viajes
Antes de lanzarnos a analizar y construir una visualización efectiva, debemos realizar un tratamiento previo de los datos, prestando especial atención a su obtención y a la validación de su contenido, asegurándonos que se encuentran en el formato adecuado y consistente para su procesamiento y que no contienen errores.
Como primer paso del proceso, es necesario realizar un análisis exploratorio de los datos (EDA), con el fin de interpretar adecuadamente los datos de partida, detectar anomalías, datos ausentes o errores que pudieran afectar a la calidad de los procesos posteriores y resultados. Si quieres conocer más sobre este proceso puedes recurrir a la Guía Práctica de Introducción al Análisis Exploratorio de Datos.
El siguiente paso es generar la tabla de datos preprocesada que usaremos para alimentar la herramienta de análisis de redes (Gephi) que de forma visual nos ayudará a comprender la información. Para ello modificaremos, filtraremos y uniremos los datos según nuestras necesidades.
Los pasos que se siguen en este preprocesamiento de los datos, explicados en este Notebook de Google Colab, son los siguientes:
- Instalación de librerías y carga de los conjuntos de datos
- Análisis exploratorio de los datos (EDA)
- Generación de tablas preprocesadas
Podrás reproducir este análisis con el código fuente que está disponible en nuestra cuenta de GitHub. La forma de proporcionar el código es a través de un documento realizado sobre un Jupyter Notebook que, una vez cargado en el entorno de desarrollo, podrás ejecutar o modificar de manera sencilla.
Debido al carácter divulgativo de este post y para favorecer el entendimiento de los lectores no especializados, el código no pretende ser el más eficiente sino facilitar su comprensión, por lo que posiblemente se te ocurrirán muchas formas de optimizar el código propuesto para lograr fines similares. ¡Te animamos a que lo hagas!
5. Análisis de la red
5.1. Definición de la red
La red analizada se encuentra formada por los viajes entre distintas estaciones de bicicletas en la ciudad de Madrid, teniendo como principal información de cada uno de los viajes registrados la estación de origen (denominada como “source”) y la estación de destino (denominada como “target”).
La red está formada por 253 nodos (estaciones) y 3012 aristas (interacciones entre las estaciones). Se trata de un grafo dirigido, debido a que las interacciones son bidireccionales y ponderado, debido a que cada arista entre los nodos tiene asociado un valor numérico denominado "peso" que en este caso corresponde al número de viajes realizados entre ambas estaciones.
5.2. Carga de la tabla preprocesada en Gephi
Mediante la opción “importar hoja de cálculo” de la pestaña archivo, importamos en formato CSV la tabla de datos previamente preprocesada. Gephi detectará que tipo de datos se están cargando, por lo que utilizaremos los parámetros predefinidos por defecto.


5.3. Opciones de visualización de la red
5.3.1 Ventana de distribución
En primer lugar, aplicamos en la ventana de distribución, el algoritmo Force Atlas 2. Este algoritmo utiliza la técnica de repulsión de nodos en función del grado de conexión de tal forma que los nodos escasamente conectados se separan respecto a los que tiene una mayor fuerza de atracción entre sí.
Para evitar que los componentes conexos queden fuera de la vista principal, fijamos el valor del parámetro "Gravedad en Puesta a punto" a un valor de 10 y para evitar que los nodos queden amontonados, marcamos la opción “Disuadir Hubs” y “Evitar el solapamiento”.

Dentro de la ventana de distribución, también aplicamos el algoritmo de Expansión con la finalidad de que los nodos no se encuentren tan juntos entre sí mismos.

Figura 3. Ventana distribución - algoritmo de Expansión
5.3.2 Ventana de apariencia
A continuación, en la ventana de apariencia, modificamos los nodos y sus etiquetas para que su tamaño no sea igualitario, sino que dependa del valor del grado de cada nodo (nodos con un mayor grado, mayor tamaño visual). También modificaremos el color de los nodos para que los de mayor tamaño sean de un color más llamativo que los de menor tamaño. En la misma ventana de apariencia modificamos las aristas, en este caso hemos optado por un color unitario para todas ellas, ya que por defecto el tamaño va acorde al peso de cada una de ellas.
Un mayor grado en uno de los nodos implica un mayor número de estaciones conectadas con dicho nodo, mientras que un mayor peso de las aristas implica un mayor número de viajes para cada conexión.

5.3.3 Ventana de grafo
Por último, en la zona inferior de la interfaz de la ventana de grafo, tenemos diversas opciones como activar/desactivar el botón para mostrar las etiquetas de los distintos nodos, adecuar el tamaño de las aristas con la finalizad de hacer más limpia la visualización, modificar el tipo de letra de las etiquetas, …

A continuación, podemos ver la visualización del grafo que representa la red una vez aplicadas las opciones de visualización mencionadas en los puntos anteriores.

Figura 6. Visualización del grafo
Activando la opción de visualizar etiquetas y colocando el cursor sobre uno de los nodos, se mostrarán los enlaces que corresponden al nodo y el resto de los nodos que están vinculados al elegido mediante dichos enlaces.
A continuación, podemos visualizar los nodos y enlaces relativos a la estación de bicicletas “Fernando el Católico". En la visualización se distinguen con facilidad los nodos que poseen un mayor número de conexiones, ya que aparecen con un mayor tamaño y colores más llamativos, como por ejemplo "Plaza de la Cebada" o "Quevedo".

5.4 Principales medidas de red
Junto a la visualización del grafo, las siguientes medidas nos aportan la principal información de la red analizada. Estas medias, que son las métricas habituales cuando se realiza analítica de redes, podremos calcularlas en la ventana de estadísticas.

- Nodos (N): son los distintos elementos individuales que componen una red, representando entidades diversas. En este caso las distintas estaciones de bicicletas. Su valor en la red es de 243
- Enlaces (L): son las conexiones que existen entre los nodos de una red. Los enlaces representan las relaciones o interacciones entre los elementos individuales (nodos) que componen la red. Su valor en la red es de 3014
- Número máximo de enlaces (Lmax): es el máximo posible de enlaces en la red. Se calcula mediante la siguiente fórmula Lmax= N(N-1)/2. Su valor en la red es de 31878
- Grado medio (k): es una medida estadística para cuantificar la conectividad promedio de los nodos de la red. Se calcula promediando los grados de todos los nodos de la red. Su valor en la red es de 23,8
- Densidad de la red (d): indica la proporción de conexiones existentes entre los nodos de la red con respecto al total de conexiones posibles. Su valor en la red es de 0,047
- Diámetro (dmax ): es la distancia de grafo más larga entre dos nodos cualquiera de la res, es decir, cómo de lejos están los 2 nodos más alejados. Su valor en la red es de 7
- Distancia media (d): es la distancia de grafo media promedio entre los nodos de la red. Su valor en la red es de 2,68
- Coeficiente medio de clustering (C): Índica cómo los nodos están incrustados entre sus nodos vecinos. El valor medio da una indicación general de la agrupación en la red. Su valor en la red es de 0,208
- Componente conexo: grupo de nodos que están directa o indirectamente conectados entre sí, pero no están conectados con los nodos fuera de ese grupo. Su valor en la red es de 24
5.5 Interpretación de los resultados
La probabilidad de grados sigue de forma aproximada una distribución de larga cola, donde podemos observar que existen unas pocas estaciones que interactúan con un gran número de ellas mientras que la mayoría interactúa con un número bajo de estaciones.
El grado medio es de 23,8 lo que indica que cada estación interacciona de media con cerca de otras 24 estaciones (entrada y salida).
En el siguiente gráfico podemos observar que, aunque tengamos nodos con grados considerados como altos (80, 90, 100, …), se observa que el 25% de los nodos tienen grados iguales o inferiores a 8, mientras que el 75% de los nodos tienen grados inferiores o iguales a 32.

La gráfica anterior se puede desglosar en las dos siguientes correspondientes al grado medio de entrada y de salida (ya que la red es direccional). Vemos que ambas tienen distribuciones de larga cola similares, siendo su grado medio el mismo de 11,9.
Su principal diferencia es que la gráfica correspondiente al grado medio de entrada tiene una mediana de 7 mientras que la de salida es de 9, lo que significa que existe una mayoría de nodos con grados más bajos en los de entrada que los de salida.


El valor del grado medio con pesos es de 346,07 lo cual nos indica la media de viajes totales de entrada y salida de cada estación.

La densidad de red de 0,047 es considerada una densidad baja indicando que la red es dispersa, es decir, contiene pocas interacciones entre distintas estaciones en relación con las posibles. Esto se considera lógico debido a que las conexiones entre estaciones estarán limitadas a ciertas zonas debido a la dificultad de llegar a estaciones que se encuentra a largas distancias.
El coeficiente medio de clustering es de 0,208 significando que la interacción de dos estaciones con una tercera no implica necesariamente la interacción entre sí, es decir, no implica necesariamente transitividad, por lo que la probabilidad de interconexión de esas dos estaciones mediante la intervención de una tercera es baja.
Por último, la red presenta 24 componentes conexos, siendo 2 de ellos componentes conexos débiles y 22 componentes conexos fuertes.
5.6 Análisis de centralidad
Un análisis de centralidad se refiere a la evaluación de la importancia de los nodos en una red utilizando diferentes medidas. La centralidad es un concepto fundamental en el análisis de redes y se utiliza para identificar nodos clave o influyentes dentro de una red. Para realizar esta tarea se parte de las métricas calculadas en la ventana de estadísticas.
- La medida de centralidad de grado indica que cuanto más alto es el grado de un nodo, más importante es. Las cinco estaciones con valores más elevados son: 1º Plaza de la Cebada, 2º Plaza de Lavapiés, 3º Fernando el Católico, 4º Quevedo, 5º Segovia 45.

- La media de centralidad de cercanía indica que cuanto más alto sea el valor de cercanía de un nodo, más central es, ya que puede alcanzar cualquier otro nodo de la red con el menor esfuerzo posible. Las cinco estaciones que valores más elevados poseen son: 1º Fernando el Católico 2º General Pardiñas, 3º Plaza de la Cebada, 4º Plaza de Lavapiés, 5º Puerta de Madrid.

Figura 13. Distribución medida centralidad de cercanía

- La medida de centralidad de intermediación indica que cuanto mayor sea la medida de intermediación de un nodo, más importante es dado que está presente en más rutas de interacción entre nodos que el resto de los nodos de la red. Las cinco estaciones que valores más elevados poseen son: 1º Fernando el Católico, 2º Plaza de Lavapiés, 3º Plaza de la Cebada, 4º Puerta de Madrid, 5º Quevedo.
