Aplicación
Edalitics es un servicio de analítica en la nube que permite conectar datos, modelarlos, crear informes y cuadros de mando sin desplegar infraestructura propia y sin conocimientos técnicos. Está basado en EDA (Enterprise Data Analytics), la plataforma open source de la empresa Jortilles y se ofrece como Saas (Software as a Service), lo que reduce la complejidad técnica: el usuario accede a través de un navegador, selecciona sus fuentes y construye visualizaciones simplemente arrastrando y soltando, o bien mediante SQL.
Edalitics funciona como una plataforma de datos corporativos y públicos: puede conectarse a bases de datos y servicios web, y también admite ficheros CSV que el usuario sube para enriquecer su modelo. A partir de ahí, se crean dashboards, KPIs y alertas por correo, y se publican informes privados o públicos para distintos perfiles de decisión, con control de acceso y trazabilidad. Permite tener usuarios ilimitados, lo que la hace interesante para grandes organizaciones con muchos usuarios.
Es importante aclarar que Edalitics no incorpora datasets por defecto, sino que se integra con APIs o portales abiertos. Organismos como el Consell Comarcal del Baix Empordà han utilizado Edalitics para desplegar sus catálogos de datos abiertos.
Edalitics ofrece dos modalidades de uso:
- Versión en la nube (Cloud). La plataforma puede utilizarse directamente en la nube, con un modelo de tarifas escalonado. Esta versión es gratuita para organizaciones con un uso limitado. Las organizaciones con mayores exigencias de uso o volumen de datos pueden acceder a una versión de pago mediante una cuota mensual.
- Instalación en servidores propios (On-Premise). Para aquellas organizaciones que prefieran alojar Edalitics en su propia infraestructura, Jortilles ofrece:
- Asistencia en la instalación y configuración, adaptándose al entorno del cliente.
- Posibilidad de contratar un mantenimiento anual que incluye: soporte técnico directo del equipo desarrollador y acceso a actualizaciones y mejoras de forma proactiva, asegurando el buen funcionamiento y evolución de la plataforma.
Documentación
Los portales de datos abiertos son una fuente invaluable de información pública. Sin embargo, extraer insights significativos de estos datos puede resultar desafiante para usuarios sin conocimientos técnicos avanzados.
En este ejercicio práctico, exploraremos el desarrollo de una aplicación web que democratiza el acceso a estos datos mediante el uso de inteligencia artificial, permitiendo realizar consultas en lenguaje natural.
La aplicación, desarrollada utilizando el portal datos.gob.es como fuente de datos, integra tecnologías modernas como Streamlit para la interfaz de usuario y el modelo de lenguaje Gemini de Google para el procesamiento de lenguaje natural. La naturaleza modular permite que se pueda utilizar cualquier modelo de Inteligencia Artificial con mínimos cambios. El proyecto completo está disponible en el repositorio de Github.
Accede al repositorio del laboratorio de datos en Github.
Ejecuta el código de pre-procesamiento de datos sobre Google Colab.
En este vídeo, el autor te explica que vas a encontrar tanto en el Github como en Google Colab.
Arquitectura de la aplicación
El núcleo de la aplicación se basa en cuatro apartados principales e interconectados que trabajan para procesar las consultas de la persona usuaria:
- Generación del Contexto
- Analiza las características del dataset elegido.
- Genera una descripción detallada incluyendo dimensiones, tipos de datos y estadísticas.
- Crea una plantilla estructurada con guías específicas para la generación de código.
- Combinación de Contexto y Consulta
- Une el contexto generado con la pregunta de la persona usuaria creando el prompt que recibirá el modelo de inteligencia artificial.
- Generación de Respuesta
- Envía el prompt al modelo y obtiene el código Python que permite resolver la cuestión generada.
- Ejecución del Código
- Ejecuta de manera segura el código generado con un sistema de reintentos y correcciones automáticas.
- Captura y expone los resultados en el frontal de la aplicación.

Figura 1. Flujo de procesamiento de solicitudes
Proceso de desarrollo
El primer paso es establecer una forma de acceder a los datos públicos. El portal datos.gob.es ofrece vía API los datasets. Se han desarrollado funciones para navegar por el catálogo y descargar estos archivos de forma eficiente.
Figura 2. API de datos.gob
El segundo paso aborda la cuestión: ¿cómo convertir preguntas en lenguaje natural en análisis de datos útiles? Aquí es donde entra Gemini, el modelo de lenguaje de Google. Sin embargo, no basta con simplemente conectar el modelo; es necesario enseñarle a entender el contexto específico de cada dataset.
Se ha desarrollado un sistema en tres capas:
- Una función que analiza el dataset y genera una "ficha técnica" detallada.
- Otra que combina esta ficha con la pregunta del usuario.
- Y una tercera que traduce todo esto en código Python ejecutable.
Se puede ver en la imagen inferior como se desarrolla este proceso y, posteriormente, se muestran los resultados del código generado ya ejecutado.

Figura 3. Visualización del procesamiento de respuesta de la aplicación
Por último, con Streamlit, se ha construido una interfaz web que muestra el proceso y sus resultados al usuario. La interfaz es tan simple como elegir un dataset y hacer una pregunta, pero también lo suficientemente potente como para mostrar visualizaciones complejas y permitir la exploración de datos.
El resultado final es una aplicación que permite a cualquier persona, independientemente de sus conocimientos técnicos, realizar análisis de datos y aprender sobre el código ejecutado por el modelo. Por ejemplo, un funcionario municipal puede preguntar "¿Cuál es la edad media de la flota de vehículos?" y obtener una visualización clara de la distribución de edades.

Figura 4. Caso de uso completo. Visualizar la distribución de los años de matriculación de la flota automovilística del ayuntamiento de Almendralejo en 2018
¿Qué puedes aprender?
Este ejercicio práctico te permite aprender:
- Integración de IA en Aplicaciones Web:
- Cómo comunicarse efectivamente con modelos de lenguaje como Gemini.
- Técnicas para estructurar prompts que generen código preciso.
- Estrategias para manejar y ejecutar código generado por IA de forma segura.
- Desarrollo Web con Streamlit:
- Creación de interfaces interactivas en Python.
- Manejo de estado y sesiones en aplicaciones web.
- Implementación de componentes visuales para datos.
- Trabajo con Datos Abiertos:
- Conexión y consumo de APIs de datos públicos.
- Procesamiento de archivos Excel y DataFrames.
- Técnicas de visualización de datos.
- Buenas Prácticas de Desarrollo:
- Estructuración modular de código Python.
- Manejo de errores y reintentos.
- Implementación de sistemas de feedback visual.
- Despliegue de aplicaciones web usando ngrok.
Conclusiones y futuro
Este ejercicio demuestra el extraordinario potencial de la inteligencia artificial como puente entre los datos públicos y los usuarios finales. A través del caso práctico desarrollado, hemos podido observar cómo la combinación de modelos de lenguaje avanzados con interfaces intuitivas permite democratizar el acceso al análisis de datos, transformando consultas en lenguaje natural en análisis significativos y visualizaciones informativas.
Para aquellas personas interesadas en expandir las capacidades del sistema, existen múltiples direcciones prometedoras para su evolución:
- Incorporación de modelos de lenguaje más avanzados que permitan análisis más sofisticados.
- Implementación de sistemas de aprendizaje que mejoren las respuestas basándose en el feedback del usuario.
- Integración con más fuentes de datos abiertos y formatos diversos.
- Desarrollo de capacidades de análisis predictivo y prescriptivo.
En resumen, este ejercicio no solo demuestra la viabilidad de democratizar el análisis de datos mediante la inteligencia artificial, sino que también señala un camino prometedor hacia un futuro donde el acceso y análisis de datos públicos sea verdaderamente universal. La combinación de tecnologías modernas como Streamlit, modelos de lenguaje y técnicas de visualización abre un abanico de posibilidades para que organizaciones y ciudadanos aprovechen al máximo el valor de los datos abiertos.
Documentación
Los portales de datos abiertos juegan un papel fundamental en el acceso y reutilización de la información pública. Un aspecto clave en estos entornos es el etiquetado de los conjuntos de datos, que facilita su organización y recuperación.
Los word embeddings representan una tecnología transformadora en el campo del procesamiento del lenguaje natural, permitiendo representar palabras como vectores en un espacio multidimensional donde las relaciones semánticas se preservan matemáticamente. En este ejercicio se explora su aplicación práctica en un sistema de recomendación de etiquetas, utilizando como caso de estudio el portal de datos abiertos datos.gob.es.
El ejercicio se desarrolla en un notebook que integra la configuración del entorno, la adquisición de datos y el procesamiento del sistema de recomendación, todo ello implementado en Python. El proyecto completo se encuentra disponible en el repositorio de Github.
Accede al repositorio del laboratorio de datos en Github.
Ejecuta el código de pre-procesamiento de datos sobre Google Colab.
En este vídeo, el autor te explica que vas a encontrar tanto en el Github como en Google Colab.
Entendiendo los word embeddings
Los word embeddings son representaciones numéricas de palabras que revolucionan el procesamiento del lenguaje natural al transformar el texto en un formato matemáticamente procesable. Esta técnica codifica cada palabra como un vector numérico en un espacio multidimensional, donde la posición relativa entre vectores refleja relaciones semánticas y sintácticas entre palabras. La verdadera potencia de los embeddings radica en tres aspectos fundamentales:
- Captura de contexto: a diferencia de técnicas tradicionales como one-hot encoding, los embeddings aprenden del contexto en el que aparecen las palabras, permitiendo capturar matices de significado.
- Algebra semántica: los vectores resultantes permiten operaciones matemáticas que preservan relaciones semánticas. Por ejemplo, vector('Madrid') - vector('España') + vector('Francia') ≈ vector('París'), demostrando la captura de relaciones capital-país.
- Similitud cuantificable: la similitud entre palabras se puede medir mediante métricas, permitiendo identificar no solo sinónimos exactos sino también términos relacionados en diferentes grados y generalizar estas relaciones a nuevas combinaciones de palabras.
En este ejercicio se han utilizado embeddings pre-entrenados GloVe (Global Vectors for Word Representation), un modelo desarrollado por Stanford que destaca por su capacidad de capturar relaciones semánticas globales en el texto. En nuestro caso, empleamos vectores de 50 dimensiones, un equilibrio entre complejidad computacional y riqueza semántica. Para evaluar exhaustivamente su capacidad de representar el lenguaje castellano, se han realizado múltiples pruebas:
- Se ha analizado la similitud entre palabras mediante la similitud coseno, una métrica que evalúa el ángulo entre los vectores de dos palabras. Esta medida resulta en valores entre -1 y 1, donde valores cercanos a 1 indican alta similitud semántica, mientras que valores cercanos a 0 indican poca o ninguna relación. Se evaluaron términos como "amor", "trabajo" y "familia" para verificar que el modelo identificara correctamente palabras semánticamente relacionadas.
- Se ha probado la capacidad del modelo para resolver analogías lingüísticas, por ejemplo, "hombre es a mujer lo que rey es a reina", confirmando su habilidad para capturar relaciones semánticas complejas.
- Se han realizado operaciones vectoriales (como "rey - hombre + mujer") para comprobar si los resultados mantenían coherencia semántica.
- Finalmente, se han aplicado técnicas de reducción de dimensionalidad sobre una muestra representativa de 40 palabras en español, permitiendo visualizar las relaciones semánticas en un espacio bidimensional. Los resultados revelaron patrones de agrupación natural entre términos semánticamente relacionados, como se observa en la figura:
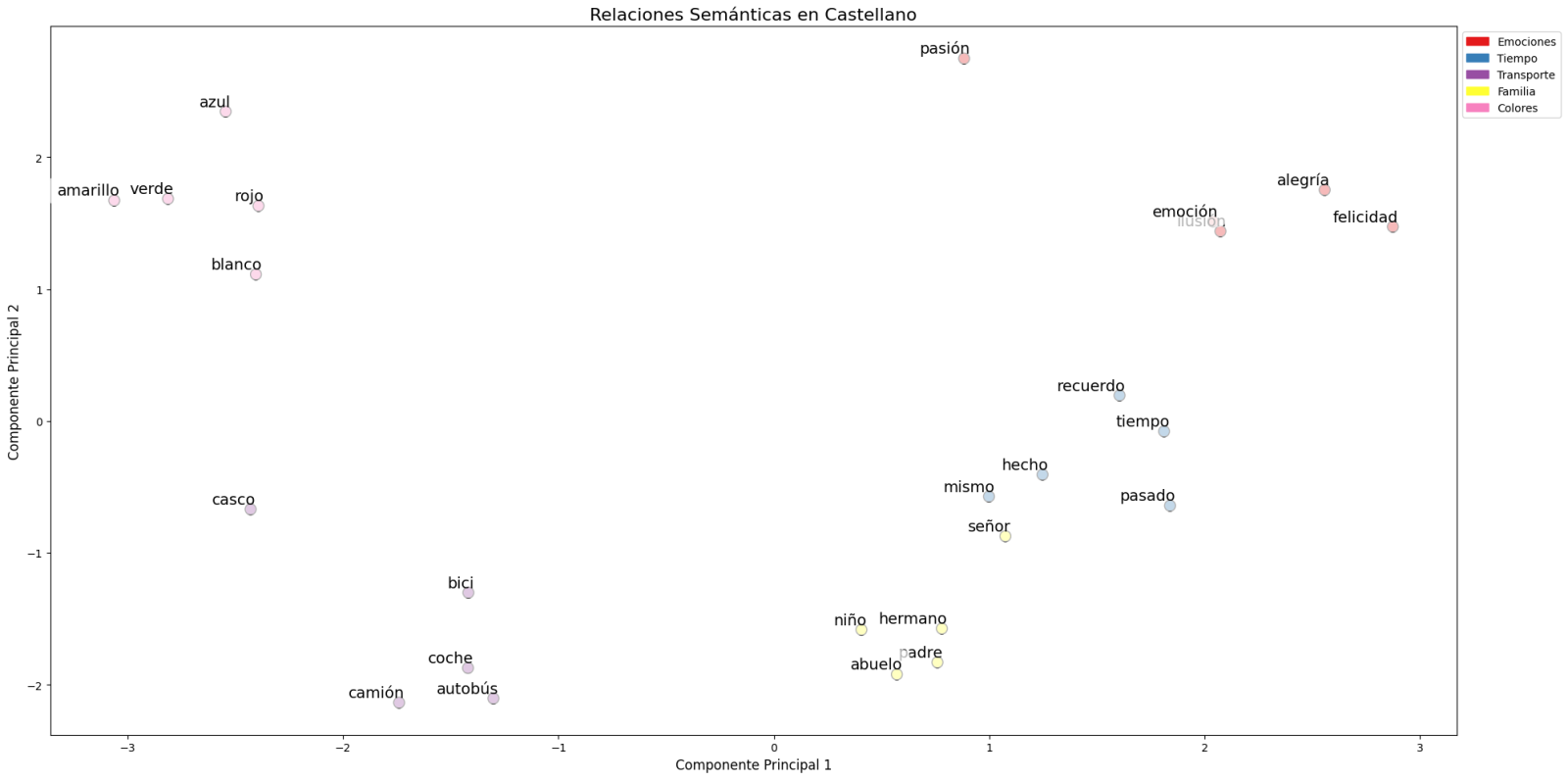
Figura 1. Análisis de Componentes principales sobre 50 dimensiones (embeddings) con un porcentaje de variabilidad explicada por los dos componentes de 0.46
- Los términos relacionados con familia (padre, hermano, abuelo) se concentran en la parte inferior.
- Los medios de transporte (coche, autobús, camión) forman un grupo distintivo.
- Los colores (azul, verde, rojo) aparecen próximos entre sí.
Para sistematizar este proceso de evaluación, se ha desarrollado una función unificada que encapsula todas las pruebas descritas anteriormente. Esta arquitectura modular permite evaluar de manera automática y reproducible diferentes modelos de embeddings pre-entrenados, facilitando así la comparación objetiva de su rendimiento en el procesamiento del lenguaje castellano. La estandarización de estas pruebas no solo optimiza el proceso de evaluación, sino que también establece un marco consistente para futuras comparaciones y validaciones de nuevos modelos por parte del público.
La buena capacidad para capturar relaciones semánticas en el lenguaje castellano es la que aprovechamos en nuestro sistema de recomendación de etiquetas.
Sistema de recomendación basado en embeddings
Aprovechando las propiedades de los embeddings, desarrollamos un sistema de recomendación de etiquetas que sigue un proceso de tres fases:
- Generación de embeddings: para cada conjunto de datos del portal, generamos una representación vectorial combinando el título y la descripción. Esto nos permite comparar datasets por su similitud semántica.
- Identificación de datasets similares: utilizando la similitud coseno entre los vectores, identificamos los conjuntos de datos más similares semánticamente.
- Extracción y estandarización de etiquetas: a partir de los conjuntos similares, extraemos sus etiquetas asociadas y las mapeamos con términos del tesauro Eurovoc. Este tesauro, desarrollado por la Unión Europea, es un vocabulario controlado multilingüe que proporciona una terminología estandarizada para la catalogación de documentos y datos en el ámbito de las políticas europeas. Aprovechando nuevamente la potencia de los embeddings, identificamos los términos de Eurovoc semánticamente más cercanos a nuestras etiquetas, garantizando así una estandarización coherente y una mejor interoperabilidad entre sistemas de información europeos.
Los resultados muestran que el sistema es capaz de generar recomendaciones de etiquetas coherentes y estandarizadas. Para ilustrar el funcionamiento del sistema, tomemos el caso del conjunto de datos “Agenda de Actividades Ciudad de Tarragona”:
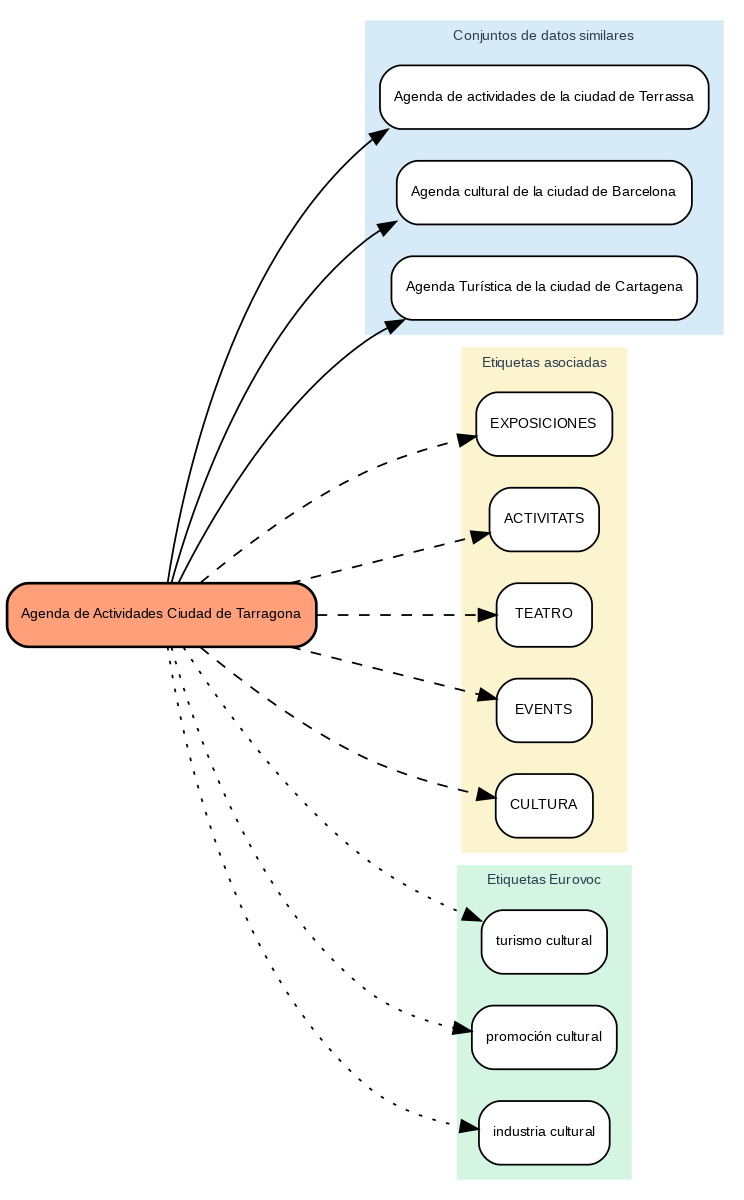
Figura 2. Agenda de Actividades Ciudad de Tarragona
El sistema:
- Encuentra conjuntos de datos similares como "Agenda de actividades de Terrassa" y "Agenda cultural de Barcelona".
- Identifica etiquetas comunes de estos conjuntos de datos, como "EXPOSICIONES", "TEATRO" y "CULTURA".
- Sugiere términos Eurovoc relacionados: "turismo cultural", "promoción cultural" e "industria cultural".
Ventajas del enfoque
Este enfoque ofrece ventajas significativas:
- Recomendaciones Contextuales: el sistema sugiere etiquetas basándose en el significado real del contenido, no solo en coincidencias textuales.
- Estandarización Automática: la integración con Eurovoc garantiza un vocabulario controlado y coherente.
- Mejora Continua: el sistema aprende y mejora sus recomendaciones a medida que se añaden nuevos datasets.
- Interoperabilidad: el uso de Eurovoc facilita la integración con otros sistemas europeos.
Conclusiones
Este ejercicio demuestra el gran potencial de los embeddings como herramienta para la asociación de textos en función de su naturaleza semántica. A través del caso práctico analizado, se ha podido observar cómo, mediante la identificación de títulos y descripciones similares entre datasets, es posible generar recomendaciones precisas de etiquetas o keywords. Estas etiquetas, a su vez, pueden vincularse con palabras clave de un tesauro estandarizado como Eurovoc, aplicando el mismo principio.
A pesar de los retos que pueden surgir, la implementación de este tipo de sistemas en entornos de producción presenta una valiosa oportunidad para mejorar la organización y recuperación de información. La precisión en la asignación de etiquetas puede verse influenciada por diversos factores interrelacionados del proceso:
- La especificidad de los títulos y descripciones de los datasets es fundamental, ya que de ella depende una correcta identificación de contenidos similares y, por tanto, una adecuada recomendación de etiquetas.
- La calidad y representatividad de las etiquetas existentes en los datasets similares determina directamente la relevancia de las recomendaciones generadas.
- La cobertura temática del tesauro Eurovoc, que, si bien es extensa, puede no abarcar términos específicos necesarios para describir ciertos datasets de manera precisa.
- La capacidad de los vectores para capturar fielmente las relaciones semánticas entre los contenidos, lo cual impacta directamente en la precisión de las etiquetas asignadas.
Para aquellos que deseen profundizar en el tema, existen otras aproximaciones interesantes al uso de embeddings que complementan lo visto en este ejercicio, tales como:
- Utilización de modelos de embeddings más complejos y computacionalmente costosos (como BERT, GPT, etc.).
- Entrenamiento de modelos en un corpus propio adaptado al dominio.
- Aplicación de técnicas más profundas de limpieza de datos.
En resumen, este ejercicio no solo demuestra la eficacia de los embeddings para la recomendación de etiquetas, sino que abre la puerta a que el lector explore todas las posibilidades que esta poderosa herramienta ofrece.
Blog
No hay duda de que los datos se han convertido en el activo estratégico para las organizaciones. Hoy en día, es esencial garantizar que las decisiones están fundamentadas en datos de calidad, independientemente del alineamiento que sigan: analítica de datos, inteligencia artificial o reporting. Sin embargo, asegurar repositorios de datos con altos niveles de calidad no es tarea fácil, dado que en muchos casos los datos provienen de fuentes heterogéneas donde los principios de calidad de datos no se han tenido en cuenta y no se dispone de contexto sobre el dominio.
Para paliar en la medida de lo posible esta casuística, en este artículo, exploraremos una de las bibliotecas más utilizadas en el análisis de datos: Pandas. Vamos a chequear cómo esta biblioteca de Python puede ser una herramienta eficaz para mejorar la calidad de los datos. También repasaremos la relación de alguna de sus funciones con las dimensiones y propiedades de calidad de datos incluidas en la especificación UNE 0081 de calidad de datos, y algunos ejemplos concretos de su aplicación en repositorios de datos con el objetivo de mejorar la calidad de los datos.
Utilizar de Pandas para Data Profiling
Si bien el data profiling y la evaluación de calidad de datos están estrechamente relacionados, sus enfoques son diferentes:
- Data Profiling: es el proceso de análisis exploratorio que se realiza para entender las características fundamentales de los datos, como su estructura, tipos de datos, distribución de valores, y la presencia de valores faltantes o duplicados. El objetivo es obtener una imagen clara de cómo son los datos, sin necesariamente hacer juicios sobre su calidad.
- Evaluación de calidad de datos: implica la aplicación de reglas y estándares predefinidos para determinar si los datos cumplen con ciertos requisitos de calidad, como exactitud, completitud, consistencia, credibilidad o actualidad. En este proceso, se identifican errores y se determinan acciones para corregirlos. Una guía útil para la evaluación de calidad de datos es la especificación UNE 0081.
Consiste en explorar y analizar un conjunto de datos para obtener una comprensión básica de su estructura, contenido y características, antes de realizar un análisis más profundo o una evaluación de la calidad de los datos. El objetivo principal es obtener una visión general de los datos mediante el análisis de la distribución, los tipos de datos, los valores faltantes, las relaciones entre columnas y la detección de posibles anomalías. Pandas dispone de varias funciones para realizar este perfilado de datos.
En resumen, el data profiling es un paso inicial exploratorio que ayuda a preparar el terreno para una evaluación más profunda de la calidad de los datos, proporcionando información esencial para identificar áreas problemáticas y definir las reglas de calidad adecuadas para la evaluación posterior.
¿Qué es Pandas y cómo ayuda a asegurar la calidad de los datos?
Pandas es una de las bibliotecas más populares de Python para la manipulación y análisis de datos. Su capacidad para gestionar grandes volúmenes de información estructurada hace que sea una herramienta poderosa en la detección y corrección de errores en repositorios de datos. Con Pandas, se pueden realizar operaciones complejas de forma eficiente, desde limpieza hasta validación de datos, todas ellas son esenciales para mantener los estándares de calidad. A continuación, se indican algunos ejemplos para mejorar la calidad de los datos en repositorios con Pandas:
-
Detección de valores nulos o inconsistentes: uno de los errores más comunes en los datos son los valores faltantes o inconsistentes. Pandas permite identificar estos valores fácilmente mediante funciones como isnull() o dropna(). Esto es clave para la propiedad de completitud de los registros y la dimensión de consistencia de datos, ya que los valores faltantes en campos críticos pueden distorsionar los resultados de los análisis.
# Identificar valores nulos en un dataframe
df.isnull().sum()
- Normalización y estandarización de datos: los errores en la consistencia de nombres o códigos son comunes en grandes repositorios. Por ejemplo, en un conjunto de datos que contiene códigos de productos, es posible que algunos estén mal escritos o no sigan una convención estándar. Pandas ofrece funciones como merge() para realizar una comparación con una base de datos de referencia y corregir estos valores. Esta opción es clave para mantener la dimensión y propiedad de consistencia semántica de los datos.
# Sustitución de valores incorrectos utilizando una tabla de referencia
df = df.merge(codigos_productos, left_on='codigo_producto', right_on='codigo_ref', how= ‘left’)
- Validación de requisitos de datos: Pandas permite crear reglas personalizadas para validar la conformidad de los datos con ciertas normas. Por ejemplo, si un campo de edad solo debería contener valores enteros positivos, podemos aplicar una función para identificar y corregir valores que no cumplan con esta regla. De esta forma, se puede validar cualquier regla de negocio de cualquiera de las dimensiones y propiedades de calidad de datos.
# Identificar registros con valores de edad no válidos (negativos o decimales)
errores_edad = df[(df['edad'] < 0) | (df['edad'] % 1 != 0)]
- Análisis exploratorio para identificar patrones anómalos: funciones como describe() o groupby() en Pandas permiten explorar el comportamiento general de los datos. Este tipo de análisis es fundamental para detectar patrones anómalos o fuera de rango en cualquier conjunto de datos, como, por ejemplo, valores inusualmente altos o bajos en columnas que deberían seguir ciertos rangos.
# Resumen estadístico de los datos
df.describe()
#Ordenar según categoría o propiedad
df.groupby()
- Eliminación de duplicados: los datos duplicados son un problema común en los repositorios de datos. Pandas ofrece métodos como drop_duplicates() para identificar y eliminar estos registros, asegurando que no haya redundancia en el conjunto de datos. Esta capacidad estaría relacionada con la dimensión de completitud y consistencia.
# Eliminar filas duplicadas
df = df.drop_duplicates()
Ejemplo práctico de aplicación de Pandas
Una vez presentadas las funciones anteriores que nos sirven para mejorar la calidad de los repositorios de datos, planteamos un caso para poner en práctica el proceso. Supongamos que estamos gestionando un repositorio de datos de ciudadanos y queremos asegurarnos de:
- Que los datos de edad no contengan valores no válidos (como negativos o decimales?
- Que los códigos de nacionalidad estén estandarizados.
- Que los identificadores únicos sigan un formato correcto.
- Que el lugar de residencia sea coherente.
Con Pandas, podríamos realizar las siguientes acciones:
1. Validación de edades sin valores incorrectos
# Identificar registros con edades fuera de los rangos permitidos (por ejemplo, menores de 0 o no enteros)
errores_edad = df[(df['edad'] < 0) | (df['edad'] % 1 != 0)]
2. Corrección de códigos de nacionalidad
# Uso de un dataset oficial de códigos de nacionalidad para corregir los registros incorrectos
df_corregida = df.merge(nacionalidades_ref, left_on='nacionalidad', right_on='codigo_ref', how='left')
3. Validación de indentificadores únicos
# Verificar si el formato del número de identificación sigue un patrón correcto
df['valid_id'] = df['identificacion'].str.match(r'^[A-Z0-9]{8}$')
errores_id = df[df['valid_id'] == False]
4. Verificación de coherencia en lugar de residencia
# Detectar posibles inconsistencias en la residencia (por ejemplo, un mismo ciudadano residiendo en dos lugares al mismo tiempo)
duplicados_residencia = df.groupby(['id_ciudadano', 'fecha_residencia'])['lugar_residencia'].nunique()
inconsistencias_residencia = duplicados_residencia[duplicados_residencia > 1]
Integración con diversidad de tecnologías
Pandas es una biblioteca extremadamente flexible y versátil que se integra fácilmente con muchas tecnologías y herramientas en el ecosistema de datos. Algunas de las principales tecnologías con las que Pandas tiene integración o se puede utilizar son:
-
Bases de datos SQL:
Pandas se integra muy bien con bases de datos relacionales como MySQL, PostgreSQL, SQLite, y otras que utilizan SQL. La biblioteca SQLAlchemy o directamente las bibliotecas específicas de cada base de datos (como psycopg2 para PostgreSQL o sqlite3) permiten conectar Pandas a estas bases de datos, realizar consultas y leer/escribir datos entre la base de datos y Pandas.
- Función común: pd.read_sql() para leer una consulta SQL en un DataFrame, y to_sql() para exportar los datos desde Pandas a una tabla SQL.
- APIs basadas en REST y HTTP:
Pandas se puede utilizar para procesar datos obtenidos de APIs utilizando solicitudes HTTP. Bibliotecas como requests permiten obtener datos de APIs y luego transformar esos datos en DataFrames de Pandas para su análisis.
- Big Data (Apache Spark):
Pandas se puede utilizar en combinación con PySpark, una API para Apache Spark en Python. Aunque Pandas está diseñado principalmente para trabajar con datos en memoria, Koalas, una biblioteca basada en Pandas y Spark, permite trabajar con estructuras distribuidas de Spark usando una interfaz similar a Pandas. Herramientas como Koalas ayudan a que los usuarios de Pandas puedan escalar sus scripts a entornos de datos distribuidos sin necesidad de aprender toda la sintaxis de PySpark.
- Hadoop y HDFS:
Pandas se puede utilizar junto con tecnologías de Hadoop, especialmente el sistema de archivos distribuido HDFS. Aunque Pandas no está diseñado para gestionar grandes volúmenes de datos distribuidos, puede utilizarse junto a bibliotecas como pyarrow o dask para leer o escribir datos desde y hacia HDFS en sistemas distribuidos. Por ejemplo, pyarrow se puede utilizar para leer o escribir archivos Parquet en HDFS.
- Formatos de archivos populares:
Pandas se utiliza comúnmente para leer y escribir datos en diferentes formatos de archivo, tales como:
- CSV: pd.read_csv()
- Excel: pd.read_excel() y to_excel()
- JSON: pd.read_json()
- Parquet: pd.read_parquet() para trabajar con archivos eficientes en espacio y tiempo.
- Feather: un formato de archivo rápido para intercambio entre lenguajes como Python y R (pd.read_feather()).
- Herramientas de visualización de datos:
Pandas se puede integrar fácilmente con herramientas de visualización como Matplotlib, Seaborn, y Plotly. Estas bibliotecas permiten generar gráficos directamente desde DataFrames de Pandas.
- Pandas incluye su propia integración ligera con Matplotlib para generar gráficos rápidos usando df.plot().
- Para visualizaciones más sofisticadas, es común usar Pandas junto a Seaborn o Plotly para gráficos interactivos.
- Bibliotecas de machine learning:
Pandas es ampliamente utilizado en el preprocesamiento de datos antes de aplicar modelos de machine learning. Algunas bibliotecas populares con las que Pandas se integra son:
- Scikit-learn: la mayoría de los pipelines de machine learning comienzan con la preparación de datos en Pandas antes de pasar los datos a modelos de Scikit-learn.
- TensorFlow y PyTorch: aunque estos frameworks están más orientados al manejo de matrices numéricas (Numpy), Pandas se utiliza frecuentemente para la carga y limpieza de datos antes de entrenar modelos de deep learning.
- XGBoost, LightGBM, CatBoost: Pandas es compatible con estas bibliotecas de machine learning de alto rendimiento, donde los DataFrames se utilizan como entrada para entrenar modelos.
- Jupyter Notebooks:
Pandas es fundamental en el análisis de datos interactivo dentro de los Jupyter Notebooks, que permiten ejecutar código Python y visualizar los resultados de manera inmediata, lo que facilita la exploración de datos y su visualización en conjunto con otras herramientas.
- Cloud Storage (AWS, GCP, Azure):
Pandas se puede utilizar para leer y escribir datos directamente desde servicios de almacenamiento en la nube como Amazon S3, Google Cloud Storage y Azure Blob Storage. Bibliotecas adicionales como boto3 (para AWS S3) o google-cloud-storage facilitan la integración con estos servicios. A continuación, se muestra un ejemplo para leer datos desde Amazon S3.
import pandas as pd
import boto3
#Crear un cliente de S3
s3 = boto3.client('s3')
#Obtener un objeto del bucket
obj = s3.get_object(Bucket='mi-bucket', Key='datos.csv')
#Leer el archivo CSV de un DataFrame
df = pd.read_csv(obj['Body'])
- Docker y contenedores:
Pandas se puede usar en entornos de contenedores utilizando Docker. Los contenedores son ampliamente utilizados para crear entornos aislados que aseguran la replicabilidad de los pipelines de análisis de datos.
En conclusión, el uso de Pandas es una solución eficaz para mejorar la calidad de los datos en repositorios complejos y heterogéneos. A través de funciones de limpieza, normalización, validación de reglas de negocio, y análisis exploratorio, Pandas facilita la detección y corrección de errores comunes, como valores nulos, duplicados o inconsistentes. Además, su integración con diversas tecnologías, bases de datos, entornos big data, y almacenamiento en la nube, convierte a Pandas en una herramienta extremadamente versátil para garantizar la exactitud, consistencia y completitud de los datos.
Contenido elaborado por Dr. Fernando Gualo, Profesor en UCLM y Consultor de Gobierno y Calidad de datos. El contenido y el punto de vista reflejado en esta publicación es responsabilidad exclusiva de su autor.
Documentación
Se presenta a continuación una nueva guía de Análisis Exploratorio de Datos (AED) implementada en Python, que evoluciona y complementa la versión publicada en R en el año 2021. Esta actualización responde a las necesidades de una comunidad cada vez más diversa en el ámbito de la ciencia de datos.
El Análisis Exploratorio de Datos (AED o EDA, por sus siglas en inglés) representa un paso crítico previo a cualquier análisis estadístico, ya que permite:
- Comprender exhaustivamente los datos antes de analizarlos.
- Verificar el cumplimiento de los requisitos estadísticos que garantizarán la validez de los análisis posteriores.
Para ejemplificar su importancia, tomemos el caso de la detección y tratamiento de valores atípicos, una de las tareas a realizar en un AED. Esta fase tiene un impacto significativo en estadísticos fundamentales como la media, la desviación estándar o el coeficiente de variación.
Además de explicar las distintas fases de un AED, la guía las ilustra con un caso práctico. En este sentido, se mantiene como caso práctico el análisis de datos de calidad del aire de Castilla y León. A través de explicaciones que el usuario podrá replicar, se transforman los datos públicos en información valiosa mediante el uso de bibliotecas Python fundamentales como pandas, matplotlib y seaborn, junto con herramientas modernas de análisis automatizado como ydata-profiling.
¿Por qué una nueva guía en Python?
La elección de Python como lenguaje para esta nueva guía refleja su creciente relevancia en el ecosistema de la ciencia de datos. Su sintaxis intuitiva y su extenso catálogo de bibliotecas especializadas lo han convertido en una herramienta fundamental para el análisis de datos. Al mantener el mismo conjunto de datos y estructura analítica que la versión en R, se facilita la comprensión de las diferencias entre ambos lenguajes. Esto resulta especialmente valioso en entornos donde coexisten múltiples tecnologías. Este enfoque es particularmente relevante en el contexto actual, donde numerosas organizaciones están migrando sus análisis desde lenguajes/herramientas tradicionales como R, SAS o SPSS hacia Python. La guía busca facilitar estas transiciones y garantizar la continuidad en la calidad de los análisis durante el proceso de migración.
Novedades y mejoras
Se ha enriquecido el contenido con la introducción al AED automatizado y las herramientas de perfilado de datos, respondiendo así a una de las últimas tendencias en el campo. El documento profundiza en aspectos esenciales como la interpretación de datos medioambientales, ofrece un tratamiento más riguroso de los valores atípicos y presenta un análisis más detallado de las correlaciones entre variables. Además, incorpora buenas prácticas en la escritura de código.
La aplicación práctica de estos conceptos se ilustra a través del análisis de datos de calidad del aire, donde cada técnica cobra sentido en un contexto real. Por ejemplo, al analizar las correlaciones entre contaminantes, no solo se muestra cómo calcularlas, sino que se explica cómo estos patrones reflejan procesos atmosféricos reales y qué implicaciones tienen para la gestión de la calidad del aire.
Estructura y contenidos
La guía sigue un enfoque práctico y sistemático, cubriendo las cinco etapas fundamentales del AED:
- Análisis descriptivo para obtener una visión representativa de los datos
- Ajuste de los tipos de variables para garantizar la consistencia
- Detección y tratamiento de datos ausentes
- Identificación y gestión de datos atípicos
- Análisis de correlación entre variables
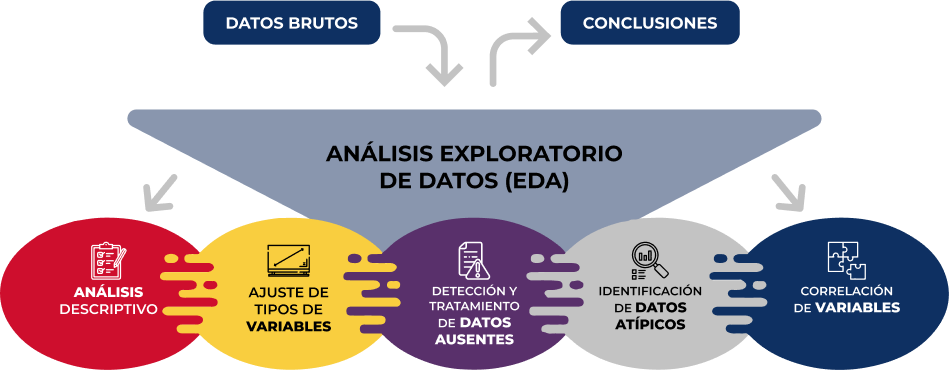
Figura 1. Fases del análisis exploratorio de datos. Fuente: elaboración propia.
Como novedad en la estructura, se incluye una sección sobre análisis exploratorio automatizado, presentando herramientas modernas que facilitan la exploración sistemática de grandes conjuntos de datos.
¿A quién va dirigida?
Esta guía está diseñada para usuarios de datos abiertos que deseen realizar análisis exploratorios y reutilizar las valiosas fuentes de información pública que se encuentran en este y otros portales de datos a nivel mundial. Si bien es recomendable tener conocimientos básicos del lenguaje, la guía incluye recursos y referencias para mejorar las competencias en Python, así como ejemplos prácticos detallados que facilitan el aprendizaje autodidacta.
El material completo, que incluye tanto la documentación como el código fuente, se encuentra disponible en el repositorio de GitHub del portal. La implementación se ha realizado utilizando herramientas de código abierto como Jupyter Notebook en Google Colab, lo que permite reproducir los ejemplos y adaptar el código según las necesidades específicas de cada proyecto.
Se invita a la comunidad a explorar esta nueva guía, experimentar con los ejemplos proporcionados y aprovechar estos recursos para desarrollar sus propios análisis de datos abiertos.
Haz click para ver la infografía completa, en versión accesible

Figura 2. Captura de la infografía. Fuente: elaboración propia.
Blog
Casi la mitad de los adultos europeos carecen de competencias digitales básicas. De acuerdo con el último informe sobre el estado de la Década Digital, en 2023, solo el 55,6% de los ciudadanos declararon tener este tipo de capacidades. Este porcentaje crece al 66,2% en el caso de España, situado por delante de la media europea.
Tener capacidades digitales básicas es esencial en la sociedad actual, porque permite acceder a una mayor cantidad de información y servicios, así como comunicarse de manera efectiva en entornos online, facilitando una mayor participación en actividades cívicas y sociales. Y también supone una gran ventaja competitiva en el mundo laboral.
En Europa, más del 90% de las funciones profesionales requieren un nivel básico de conocimientos digitales. Hace mucho tiempo que el conocimiento tecnológico dejó de ser únicamente necesario para profesiones técnicas, sino que se está extendiendo a todos los sectores, desde las empresas hasta el transporte e incluso la agricultura. En este sentido, más del 70% de las empresas han afirmado que la falta de personal con las competencias digitales adecuadas es un obstáculo para la inversión.
Por ello, un objetivo clave de la Década Digital es garantizar que al menos el 80% de las personas de entre 16 y 74 años posean al menos competencias digitales básicas de aquí a 2030
Capacidades tecnológicas básicas que todos deberíamos tener
Cuando hablamos de capacidades tecnológicas básicas nos referimos, de acuerdo con el framework DigComp, a diversas áreas, entre las que se encuentran:
- Alfabetización informacional y de datos: incluye localizar, recuperar, gestionar y organizar datos, juzgando la pertinencia de la fuente y su contenido.
- Comunicación y colaboración: supone interactuar, comunicarse y colaborar a través de las tecnologías digitales teniendo en cuenta la diversidad cultural y generacional. También incluye la gestión de la propia presencia, identidad y reputación digitales.
- Creación de contenidos digitales: se definiría como la mejora e integración de información y contenidos para generar nuevos mensajes, respetando los derechos de autor y las licencias. También implica saber dar instrucciones comprensibles para un sistema informático.
- Seguridad: se circunscribe a la protección de dispositivos, contenidos, datos personales y la intimidad en los entornos digitales, para proteger la salud física y mental.
- Resolución de problemas: permite identificar y resolver necesidades y problemas en entornos digitales. También se enfoca en el uso de herramientas digitales para innovar procesos y productos, manteniéndose al día de la evolución digital.
¿Qué puestos de trabajo relacionados con datos son los más demandados?
Una vez que tenemos claro cuáles son las competencias básicas, cabe destacar que en un mundo donde cada vez cobra más importancia la digitalización no es de extrañar que también crezca la demanda de conocimientos tecnológicos avanzados y relacionados con los datos.
De acuerdo con los datos de la plataforma de empleo LinkedIn, entre las 25 profesiones que más crecen en España en 2024 encontramos analistas de seguridad (puesto 1), analistas de desarrollo de software (2), ingenieros de datos (11) e ingenieros de inteligencia artificial (25). Datos similares ofrece el Mapa del Empleo de Fundación Telefónica, que además destaca cuatro de los perfiles más demandados relacionados con los datos:
- Analista de datos: encargados de la gestión y aprovechamiento de la información, se dedican a la recopilación, análisis y explotación de los datos, para lo cual suelen recurrir a la creación de cuadros de mando e informes.
- Diseñador/a o administrador/a de bases de datos: enfocados en diseñar, implementar y gestionar bases de datos. Así como mantener su seguridad, ejecutando procedimientos de respaldo y recuperación de datos en caso de fallos.
- Ingeniero/a de datos: responsables del diseño e implementación de arquitecturas de datos e infraestructuras para captar, almacenar, procesar y acceder a los datos, optimizando su rendimiento y garantizando su seguridad.
- Científico/a de datos: centrado en el análisis de datos y modelado predictivo, la optimización de algoritmos y la comunicación de resultados.
Todos ellos son puestos con buenos salarios y expectativas de futuro, en los que sin embargo sigue existiendo una gran brecha entre hombres y mujeres. De acuerdo con datos europeos, sólo 1 de cada 6 especialistas en TIC y 1 de cada 3 licenciados en ciencias, tecnología, ingeniería y matemáticas (STEM) son mujeres.
Para desarrollar profesiones relacionadas con los datos, se necesitan, entre otros, conocimientos de lenguajes de programación populares como Python, R o SQL, y múltiples herramientas de procesado y visualización de datos, como las detalladas en estos artículos:
- Herramientas de depuración y conversión de datos
- Herramientas de análisis de datos
- Herramientas de visualización de datos
- Librerías y APIs de visualización de datos
- Herramientas de visualización geoespacial
- Herramientas de análisis de redes
Actualmente la oferta de formaciones sobre todas estas capacidades no deja de crecer.
Perspectivas de futuro
Casi una cuarta parte de todos los puestos de trabajo (23%) cambiarán en los próximos cinco años, de acuerdo con el Informe sobre el Futuro del Empleo 2023 del Foro Económico Mundial. Los avances tecnológicos crearán nuevos empleos, transformarán los existentes y destruirán aquellos que se queden anticuados. Los conocimientos técnicos, relacionados con áreas como la inteligencia artificial o el Big Data, y el desarrollo de habilidades cognitivas, como el pensamiento analítico, supondrán grandes ventajas competitivas en el mercado laboral del futuro. En este contexto, las iniciativas políticas para impulsar la recapacitación de la sociedad, como el Plan europeo de Acción de Educación Digital (2021-2027), ayudaran a generar marcos y certificados comunes en un mundo en constante evolución.
La revolución tecnológica ha venido para quedarse y continuará cambiando nuestro mundo. Por ello, quienes antes empiecen a adquirir nuevas capacidades, tendrán una posición más ventajosa en el panorama laboral futuro.
Documentación
Antes de realizar un análisis de datos, con fines estadístico o predictivos por ejemplo a través de técnicas de machine learning, es necesario comprender la materia prima con la que vamos a trabajar. Hay que entender y evaluar la calidad de los datos para así, entre otros aspectos, detectar y tratar los datos atípicos o incorrectos, evitando posibles errores que pudieran repercutir en los resultados del análisis.
Una forma de llevar a cabo este pre-procesamiento es mediante un análisis exploratorio de datos (AED) o exploratory data analysis (EDA).
¿Qué es el análisis exploratorio de los datos?
El AED consiste en aplicar un conjunto de técnicas estadísticas dirigidas a explorar, describir y resumir la naturaleza de los datos, de tal forma que podamos garantizar su objetividad e interoperabilidad.
Gracias a ello se pueden identificar posibles errores, revelar la presencia de valores atípicos, comprobar la relación entre variables (correlaciones) y su posible redundancia, así como realizar un análisis descriptivo de los datos mediante representaciones gráficas y resúmenes de los aspectos más significativos.
En muchas ocasiones, esta exploración de los datos se descuida y no se lleva a cabo de manera correcta. Por este motivo, desde datos.gob.es hemos elaborado una guía introductoria que recoge una serie de tareas mínimas para realizar un correcto análisis exploratorios de datos, paso previo y necesario antes de llevar a cabo cualquier tipo de análisis estadístico o predictivo ligado a las técnicas de machine learning.
¿Qué incluye la guía?
La guía explica de forma sencilla cuáles son los pasos a seguir para garantizar unos datos consistentes y veraces. Para su elaboración se ha tomado como referencia el análisis exploratorio de datos descrito en el libro R for Data Science de Wickman y Grolemund (2017) disponible de forma gratuita. Estos pasos son:
Figura 1. Fases del análisis exploratorio de datos. Fuente: elaboración propia.
En la guía se explica cada uno de estos pasos y por qué son necesarios. Asimismo, se ilustran de manera práctica a través de un ejemplo. Para dicho caso práctico, se ha utilizado el dataset relativo al registro de la calidad del aire en la Comunidad Autónoma de Castilla y León incluido en nuestro catálogo de datos abiertos. El tratamiento se ha llevado a cabo con herramientas tecnológicas open source y gratuitas. En la guía se recoge el código para que los usuarios pueden replicarlo de forma autodidacta siguiendo los pasos indicados.
La guía finaliza con un apartado de recursos adicionales para aquellos que quieran seguir profundizando en la materia.
¿A quién va dirigida?
El público objetivo de la guía es el usuario reutilizador de datos abiertos. Es decir, desarrolladores, emprendedores o incluso periodistas de datos que quieran extraer todo el valor posible de la información con la que trabajan para obtener unos resultados fiables.
Es aconsejable que el usuario tenga nociones básicas del lenguaje de programación R, elegido para ilustrar los ejemplos. No obstante, en el apartado de bibliografía se incluyen recursos para adquirir mayores habilidades en este campo.
A continuación, en el apartado documentación, puedes descargarte la guía, así como una infografía-resumen que ilustra los principales pasos del análisis exploratorios de datos. También tienes disponible el código fuente del ejemplo práctico en nuestro Github.
Haz click para ver la infografía completa, en versión accesible
Figura 2. Captura de la infografía. Fuente: elaboración propia.
Infografía - Análisis de datos abiertos con herramientas open source PARTE I

Infografía - Visualización de datos abiertos con herramientas open source PARTE II

Ver infografía completa
Documentación
1. Introducción
Las visualizaciones son representaciones gráficas de datos que permiten comunicar, de manera sencilla y efectiva, la información ligada a los mismos. Las posibilidades de visualización son muy amplias, desde representaciones básicas como los gráficos de líneas, de barras o métricas relevantes, hasta visualizaciones configuradas sobre cuadros de mando interactivos.
En esta sección de “Visualizaciones paso a paso” estamos presentando periódicamente ejercicios prácticos haciendo uso de datos abiertos disponibles en datos.gob.es u otros catálogos similares. En ellos, se abordan y describen de manera sencilla las etapas necesarias para obtener los datos, realizar las transformaciones y los análisis pertinentes para, finalmente obtener unas conclusiones a modo de resumen de dicha información.
En cada ejercicio práctico se utilizan desarrollos de código documentados y herramientas de uso gratuito. Todo el material generado está disponible para su reutilización en el repositorio de GitHub de datos.gob.es.
En este ejercicio concreto, exploraremos los flujos de turistas a nivel nacional, creando visualizaciones de los turistas que se mueven entre las comunidades autónomas (CCAA) y provincias.
Accede al repositorio del laboratorio de datos en Github.
Ejecuta el código de pre-procesamiento de datos sobre Google Colab.
En este vídeo, el autor te explica que vas a encontrar tanto en el Github como en Google Colab.
2. Contexto
Analizar los flujos de turistas nacionales nos permite observar ciertos movimientos ya muy conocidos, como, por ejemplo, que la provincia de Alicante es un destino muy popular del turismo veraniego. Además, este análisis es interesante para observar tendencias en el impacto económico que el turismo pueda tener, año tras año, en ciertas CCAA o provincias. El artículo sobre experiencias para la gestión de los flujos de visitantes en destinos turísticos ilustra el impacto de los datos en el sector.
3. Objetivo
El objetivo principal del ejercicio es crear visualizaciones interactivas en Python que permitan visualizar información compleja de manera comprensible y atractiva. Se cumplirá este objetivo usando un conjunto de datos abiertos que contiene información sobre flujos de turistas nacionales, planteando varias preguntas sobre los datos y contestándolas gráficamente. Podremos responder a preguntas como las que se plantean a continuación:
- ¿En qué CCAA hay más turismo procedente de la misma CA?
- ¿Cuál es la CA que más sale de su propia CA?
- ¿Qué diferencias hay entre los flujos de turistas a lo largo del año?
- ¿Cuál es la provincia valenciana que más turistas recibe?
La comprensión de las herramientas propuestas aportará al lector la capacidad para poder modificar el código contenido en el notebook que acompaña a este ejercicio para seguir explorando los datos por su cuenta y detectar más comportamientos interesantes a partir del conjunto de datos utilizado.
Para poder crear visualizaciones interactivas y contestar a las preguntas sobre los flujos de turistas, será necesario un proceso de limpieza y reformateado de datos que está descrito en el notebook que acompaña este ejercicio.
4. Recursos
Conjunto de datos
El conjunto de datos abiertos utilizado contiene información sobre los flujos de turistas en España a nivel de CCAA y provincias, indicando también los valores totales a nivel nacional. El conjunto de datos ha sido publicado por el Instituto Nacional de Estadística, a través de varios tipos de ficheros. Para el presente ejercicio utilizamos únicamente el fichero .csv separado por “;”. Los datos datan de julio de 2019 a marzo de 2024 (a la hora de redactar este ejercicio) y se actualizan mensualmente.
Número de turistas por CCAA y provincia de destino desagregados por PROVINCIA de origen
El conjunto de datos también se encuentra disponible para su descarga en este repositorio de Github.
Herramientas analíticas
Para la limpieza de los datos y la creación de las visualizaciones se ha utilizado el lenguaje de programación Python. El código creado para este ejercicio se pone a disposición del lector a través de un notebook de Google Colab.
Las librerías de Python que utilizaremos para llevar a cabo el ejercicio son:
- pandas: es una librería que se utiliza para el análisis y manipulación de datos.
- holoviews: es una librería que permite crear visualizaciones interactivas, combinando las funcionalidades de otras librerías como Bokeh y Matplotlib.
5. Desarrollo del ejercicio
Para visualizar los datos sobre flujos de turistas interactivamente crearemos dos tipos de diagramas, los diagramas de cuerdas y los diagramas de Sankey.
Los diagramas de cuerdas son un tipo de diagrama que está compuesto por nodos y aristas, véase la figura 1. Los nodos se sitúan en un círculo y las aristas simbolizan las relaciones entre los nodos del círculo. Estos diagramas suelen utilizarse para mostrar tipos de flujos, por ejemplo, flujos migratorios o monetarios. El volumen diferente de las aristas se visualiza de manera comprensible y refleja la importancia de un flujo o de un nodo. Por su forma de círculo, el diagrama de cuerdas es una buena opción para visualizar las relaciones entre todos los nodos de nuestro análisis (relación del tipo “varios a varios”).
Figura 1. Diagrama de cuerdas (Migración global). Fuente.
Los diagramas de Sankey, igual que los diagramas de cuerdas, son un tipo de diagrama que está compuesto por nodos y aristas, véase la figura 2. Los nodos se representan en los márgenes de la visualización, estando las aristas entre los márgenes. Por esta agrupación lineal de los nodos, los diagramas de Sankey son mejores que los diagramas de cuerdas para análisis en los cuales queramos visualizar la relación entre:
- varios nodos y otros nodos (tipo varios a varios, o varios a pocos, o viceversa)
- varios nodos y un solo nodo (varios a uno, o viceversa)

Figura 2. Diagrama de Sankey (Migración interna Reino Unido). Fuente.
El ejercicio está dividido en 5 partes, siendo la parte 0 (“configuración inicial”) solo de montar el entorno de programación. A continuación, describimos las cinco partes y los pasos que se llevan a cabo.
5.1. Cargar datos
Este apartado podrás encontrarlo en el punto 1 del notebook.
En este parte cargamos el conjunto de datos para poder procesarlo en el notebook. Comprobamos el formato de los datos cargados y creamos un pandas.DataFrame que utilizaremos para el procesamiento de los datos en los siguientes pasos.
5.2. Exploración inicial de los datos
Este apartado podrás encontrarlo en el punto 2 del notebook.
En esta parte realizamos un análisis exploratorio de los datos para entender el formato del conjunto de datos que hemos cargado y para tener una idea más clara de la información que contiene. Mediante esta exploración inicial, podemos definir los pasos de limpieza que tenemos que llevar a cabo para poder crear las visualizaciones interactivas.
Si quieres aprender más sobre cómo abordar esta tarea, tienes a tu disposición esta guía introductoria sobre análisis exploratorio de datos.
5.3. Análisis del formato de los datos
Este apartado podrás encontrarlo en el punto 3 del notebook.
En esta parte resumimos las observaciones que hemos podido hacer durante la exploración inicial de los datos. Recapitulamos aquí las observaciones más importantes:
| Provincia de origen | Provincia de origen | CCAA y provincia de destino | CCAA y provincia de destino | CCAA y provincia de destino | Concepto turístico | Periodo | Total |
|---|---|---|---|---|---|---|---|
| Total Nacional | Total Nacional | Turistas | 2024M03 | 13.731.096 | |||
| Total Nacional | Ourense | Total Nacional | Andalucía | Almería | Turistas | 2024M03 | 373 |
Figura 3. Fragmento del conjunto de datos original.
Podemos observar en las columnas uno a cuatro que los orígenes de los flujos de turistas están desagregados por provincia mientras que, para los destinos, las provincias están agregadas por CCAA. Aprovecharemos el mapeado de las CCAA y de sus provincias que podemos extraer de la cuarta y quinta columna para agregar las provincias de origen por CCAA.
También podemos ver que la información contenida en la primera columna a veces es superflua, por lo cual, la combinaremos con la segunda columna. Además, hemos constatado que la quinta y sexta columna no aportan valor para nuestro análisis, por lo cual, las eliminaremos. Renombraremos algunas columnas para tener un pandas. DataFrame más comprensible.
5.4. Limpieza de los datos
Este apartado podrás encontrarlo en el punto 4 del notebook.
En esta parte llevamos a cabo los pasos necesarios para darle mejor formato a nuestros datos. Para ello aprovechamos varias funcionalidades que nos ofrece pandas, por ejemplo, para renombrar las columnas. También definimos una función reutilizable que necesitamos para concatenar los valores de la primera y segunda columna con el objetivo de no tener una columna que exclusivamente indique “Total Nacional” en todas las filas del pandas.DataFrame. Además, extraeremos de las columnas de destino un mapeado de CCAA a provincias que aplicaremos a las columnas de origen.
Queremos obtener una versión del conjunto de datos más comprimida con mayor transparencia de los nombres de las columnas y que no contenga información que no vamos a procesar. El resultado final del proceso de limpieza de datos es el siguiente:
| Origen | Provincia de origen | Destino | Provincia de destino | Periodo | Total |
|---|---|---|---|---|---|
| Total Nacional | Total Nacional | 2024M03 | 13731096.0 | ||
| Galicia | Ourense | Andalucía | Almería | 2024M03 | 373.0 |
Figura 4. Fragmento del conjunto de datos limpio.
5.5. Crear visualizaciones
Este apartado podrás encontrarlo en el punto 5 del notebook
En esta parte creamos nuestras visualizaciones interactivas utilizando la librería Holoviews. Para poder dibujar gráficos de cuerdas o de Sankey que visualicen el flujo de personas entre CCAA y CCAA y/o provincias, tenemos que estructurar la información de nuestros datos de tal forma que dispongamos de nodos y aristas. En nuestro caso, los nodos son los nombres de CCAA o provincia y las aristas, es decir, la relación entre los nodos, son el número de turistas. En el notebook definimos una función para obtener los nodos y aristas que podemos reutilizar para los diferentes diagramas que queramos realizar, cambiando el período de tiempo según la estación del año que nos interese analizar.
Vamos a crear primero un diagrama de cuerdas usando exclusivamente los datos sobre flujos de turistas de marzo de 2024. En el notebook, este diagrama de cuerdas es dinámico. Te animamos a probar su interactividad.
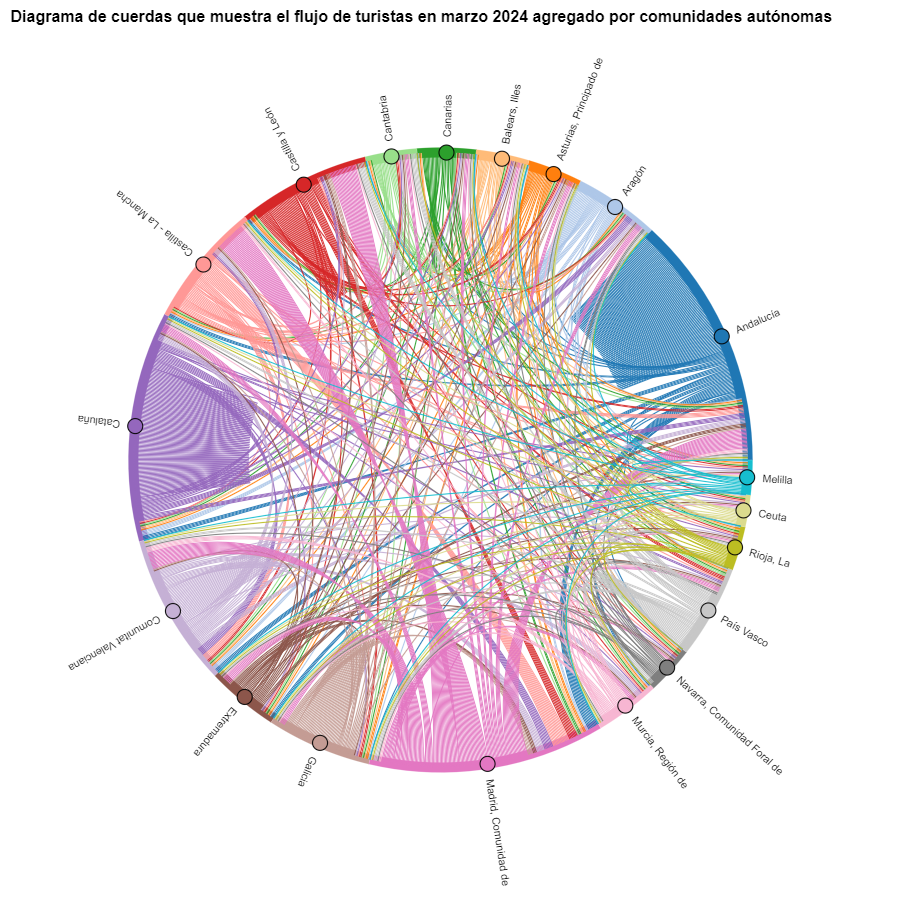
Figura 5. Diagrama de cuerdas que muestra el flujo de turistas en marzo 2024 agregado por comunidades autónomas.
En el diagrama de cuerdas se visualizan los flujos de turistas entre todas las CCAA. Cada CA tiene un color y los movimientos que hacen los turistas provenientes de esta CA se simbolizan con el mismo color. Podemos observar que los turistas de Andalucía y Cataluña viajan mucho dentro de sus propias CCAA. En cambio, los turistas de Madrid salen mucho de su propia CA.
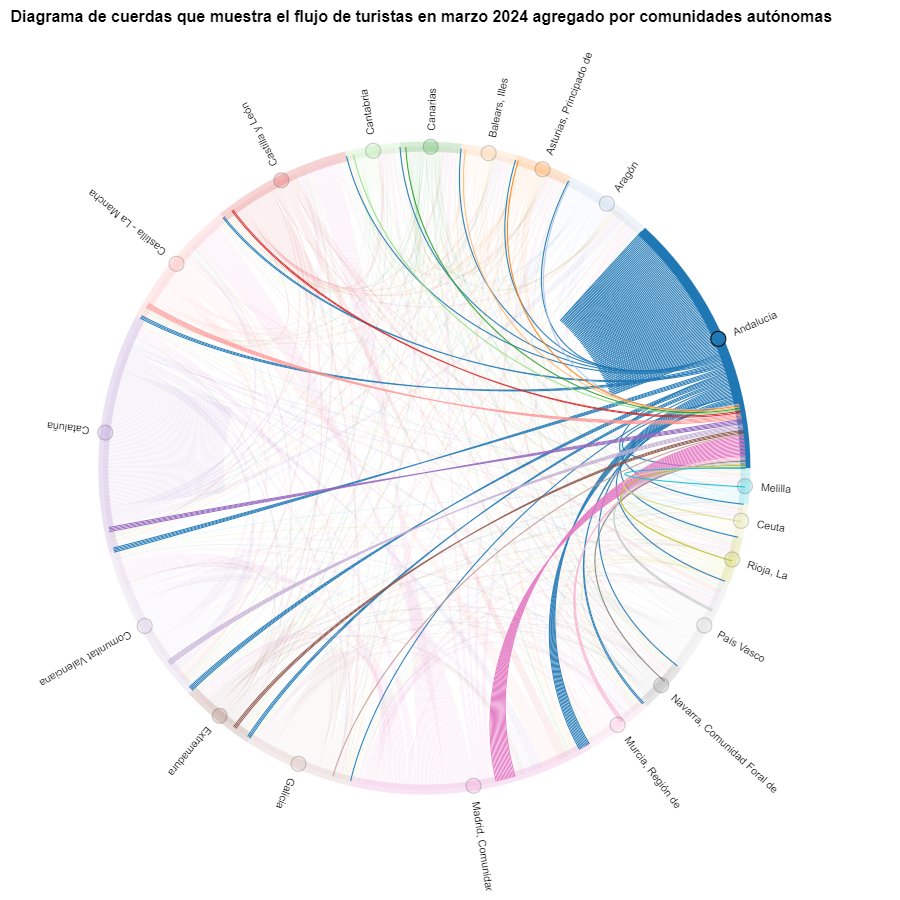
Figura 6. Diagrama de cuerdas que muestra el flujo de turistas entrando y saliendo de Andalucía en marzo 2024 agregado por comunidades autónomas.
Creamos otro diagrama de cuerdas utilizando la función que hemos creado y visualizamos los flujos de turistas en agosto de 2023.
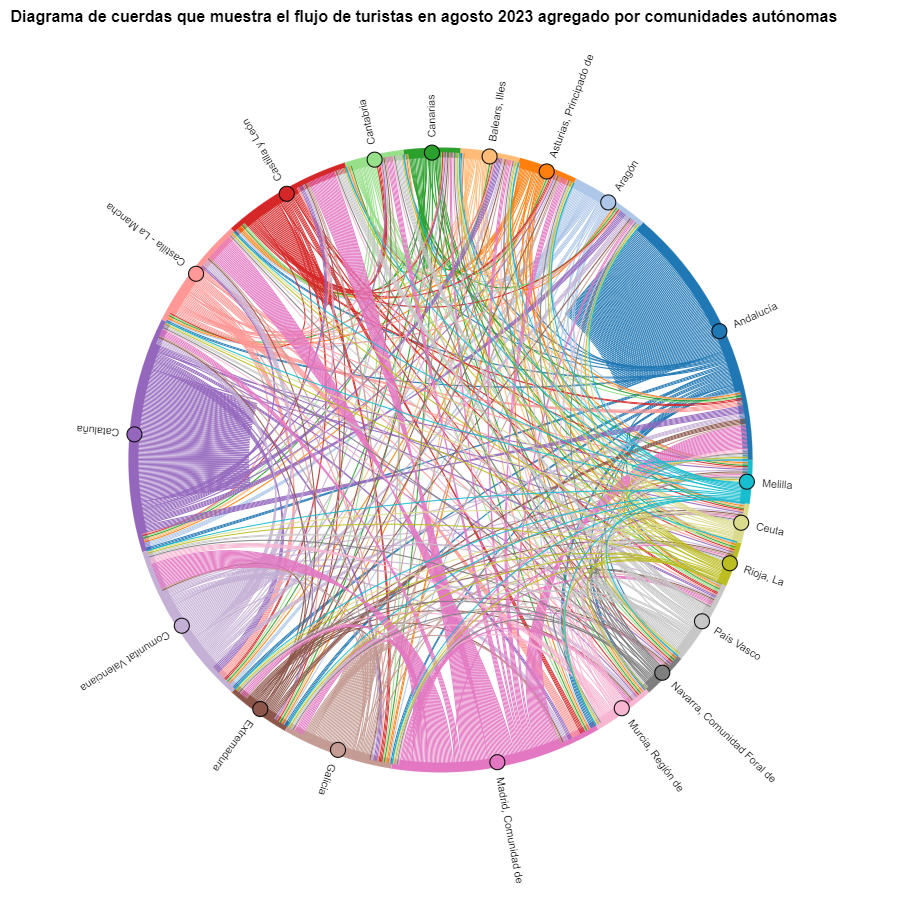
Figura 7. Diagrama de cuerdas que muestra el flujo de turistas en agosto 2023 agregado por comunidades autónomas.
Podremos observar que, a grandes rasgos, no cambian los movimientos de los turistas, solo que se intensifican los movimientos que ya hemos podido observar para marzo 2024.
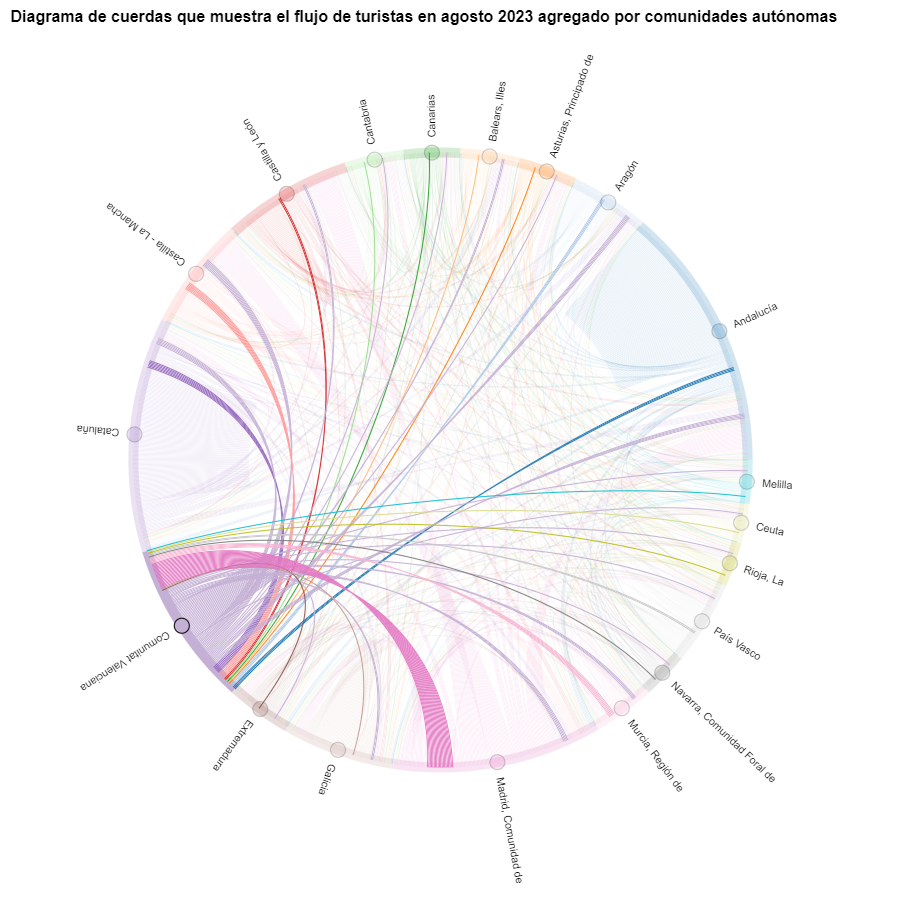
Figura 8. Diagrama de cuerdas que muestra el flujo de turistas entrando y saliendo de la Comunitat Valenciana en agosto 2023 agregado por comunidades autónomas.
El lector puede crear el mismo diagrama para otros períodos de tiempo, por ejemplo, para el verano del año 2020, con el fin de visualizar el impacto de la pandemia en el turismo veraniego, reutilizando la función que hemos creado.
Para los diagramas de Sankey nos vamos a centrar en la Comunitat Valenciana, ya que es un destino vacacional popular. Filtramos las aristas que hemos creado para el diagrama de cuerdas anterior de manera que solo contengan flujos que terminen en la Comunitat Valenciana. El mismo procedimiento se podría aplicar para estudiar cualquier otra CA o se podría invertir para analizar dónde van a veranear los valencianos. Visualizamos el diagrama de Sankey que, igual que los diagramas de cuerdas, es interactivo dentro del notebook. El aspecto visual quedaría así:
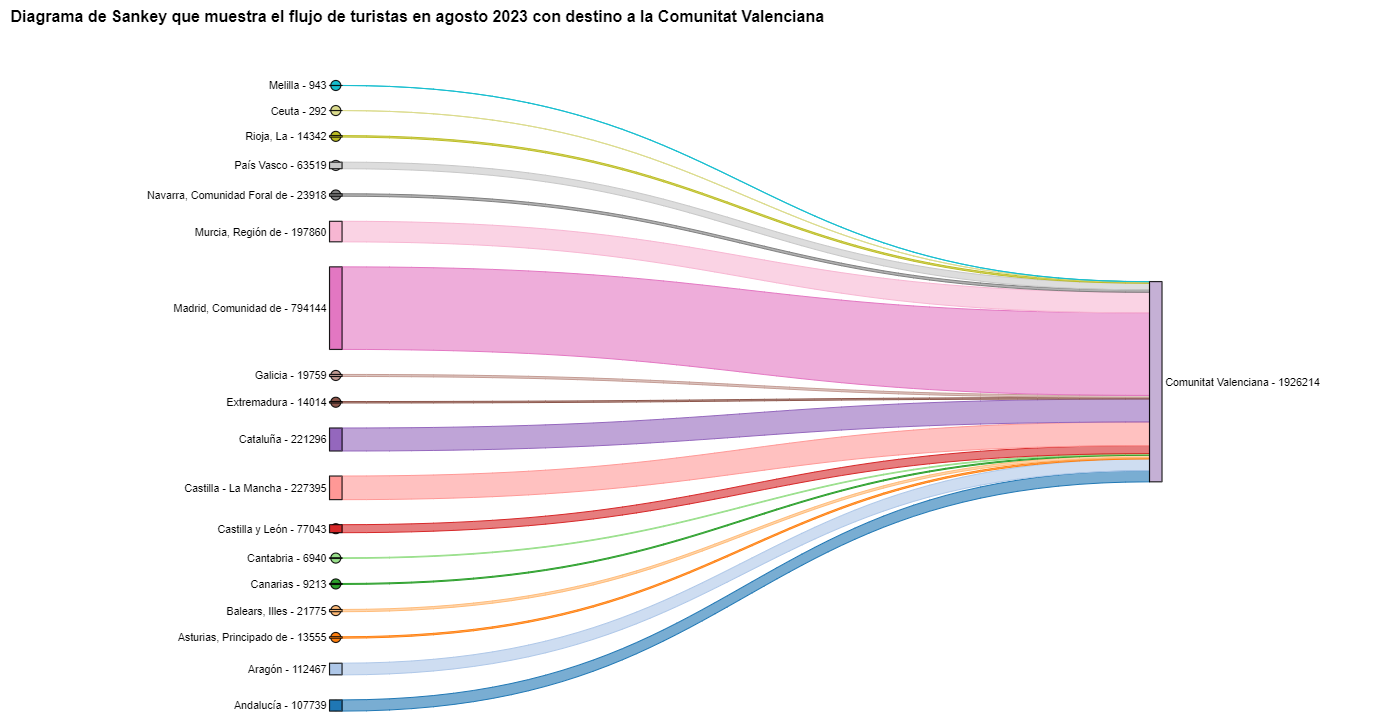
Figura 9. Diagrama de Sankey que muestra el flujo de turistas en agosto 2023 con destino a la Comunitat Valenciana.
Como ya hemos podido intuir por el diagrama de cuerdas de arriba, véase la figura 8 el mayor grupo de turistas que llegan a la Comunitat Valenciana proviene de Madrid. Vemos que también hay un elevado número de turistas que visitan la Comunitat Valenciana desde las CCAA vecinas como Murcia, Andalucía y Cataluña.
Para comprobar que estas tendencias se dan en las tres provincias de la Comunitat Valenciana, vamos a crear un diagrama de Sankey que muestre en el margen izquierdo todas las CCAA y en el margen derecho las tres provincias de la Comunitat Valenciana.
Para crear este diagrama de Sankey a nivel de provincias tenemos que filtrar nuestro pandas. DataFrame inicial para extraer de él las filas que contienen la información relevante. Los pasos en el notebook se pueden adaptar para realizar este análisis a nivel de provincias para cualquier otra CA. Aunque no estamos reutilizando la función que hemos usado anteriormente, también podemos cambiar el período de análisis.
El diagrama de Sankey que visualiza los flujos de turistas que llegaron en agosto de 2023 a las tres provincias valencianas quedaría así:
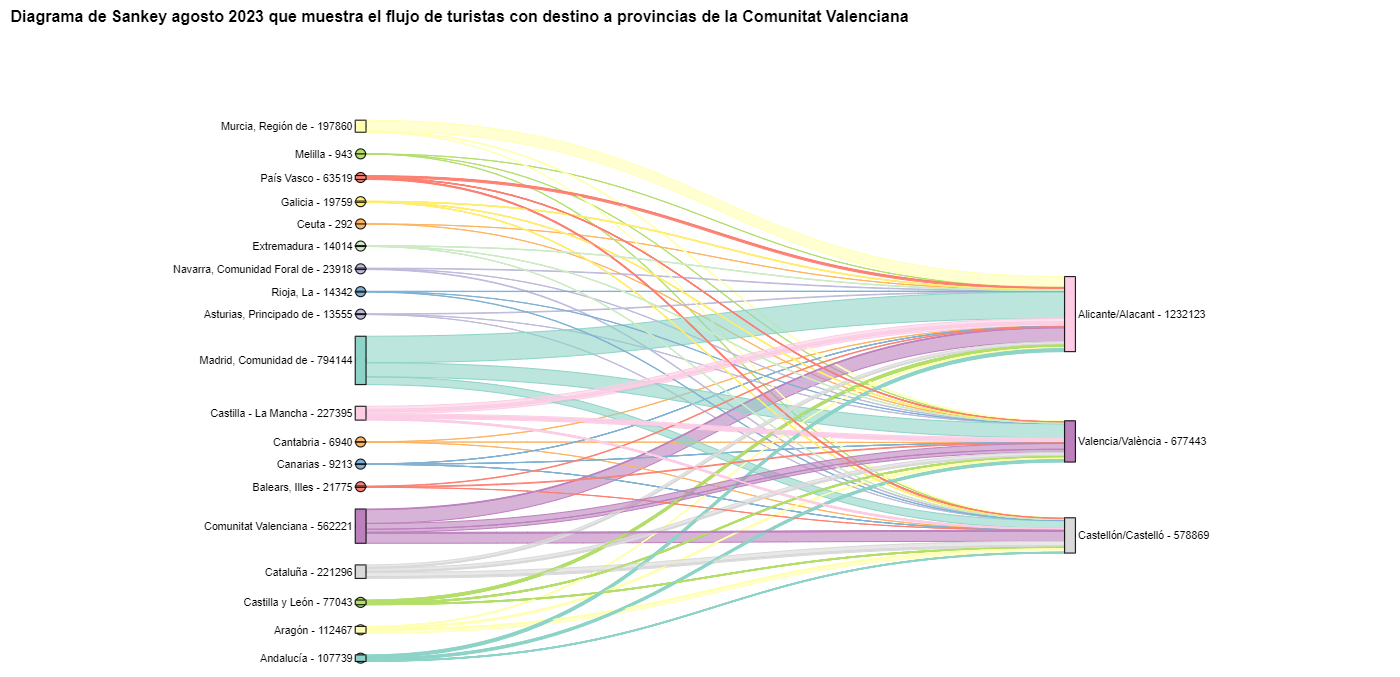
Figura 10. Diagrama de Sankey agosto 2023 que muestra el flujo de turistas con destino a provincias de la Comunitat Valenciana.
Podemos observar que, como ya suponíamos, el mayor número de turistas que llega a la Comunitat Valenciana en agosto proviene de la Comunidad de Madrid. Sin embargo, podemos comprobar que esto no es cierto para la provincia de Castellón, donde en agosto de 2023 la mayoría de los turistas fueron valencianos que se desplazaron dentro de su propia CA.
6. Conclusiones del ejercicio
Gracias a las técnicas de visualización empleadas en este ejercicio, hemos podido observar los flujos de turistas que se desplazan dentro del territorio nacional, enfocándonos en hacer comparaciones entre diversas épocas del año y tratando de identificar patrones. Tanto en los diagramas de cuerdas como en los diagramas de Sankey que hemos creado, hemos podido observar la afluencia de los turistas madrileños en las costas valencianas en verano. También hemos podido identificar las comunidades autónomas donde los turistas salen menos de su propia comunidad autónoma, como Cataluña y Andalucía.
7. ¿Quieres realizar el ejercicio?
Invitamos al lector a ejecutar el código contenido en el notebook de Google Colab que acompaña a este ejercicio para seguir con el análisis de los flujos de turistas. Dejamos aquí algunas ideas de posibles preguntas y de cómo se podrían contestar:
- El impacto de la pandemia: ya lo hemos mencionado brevemente arriba, pero una pregunta interesante sería medir el impacto que ha tenido la pandemia del coronavirus sobre el turismo. Podemos comparar los datos de los años anteriores con el 2020 y también analizar los años siguientes para detectar tendencias de estabilización. Visto que la función que hemos creado permite cambiar fácilmente el período de tiempo bajo análisis, te proponemos hacer este análisis por tu cuenta.
- Intervalos de tiempo: también es posible modificar la función que hemos estado usando de tal manera que no solo permita seleccionar un periodo de tiempo concreto, sino que también permita intervalos de tiempos.
- Análisis a nivel de provincias: igualmente, un lector avanzado con Pandas puede imponerse el reto de crear un diagrama de Sankey que visualice a qué provincias viajan los habitantes de una determinada región, por ejemplo, Ourense. Para no tener demasiadas provincias de destino que podrían hacer ilegible el diagrama de Sankey, se podrían visualizar solo las 10 más visitadas. Para obtener los datos para crear esta visualización, el lector tendría que jugar con los filtros que pone sobre el dataset y con el método de groupby de pandas, dejándose inspirar por el código ya ejecutado.
Esperamos que este ejercicio práctico te haya aportado conocimiento suficiente para desarrollar tus propias visualizaciones. Si tienes algún tema sobre ciencia de datos que quieras que tratemos próximamente, no dudes en proponer tu interés a través de nuestros canales de contacto.
Además, recuerda que tienes a tu disposición más ejercicios en el apartado sección de “Ejercicios de ciencia de datos”.
Documentación
1. Introducción
En la era de la información, la inteligencia artificial ha demostrado ser una herramienta invaluable para una variedad de aplicaciones. Una de las manifestaciones más increíbles de esta tecnología es GPT (Generative Pre-trained Transformer), desarrollado por OpenAI. GPT es un modelo de lenguaje natural que puede entender y generar texto, ofreciendo respuestas coherentes y contextualmente relevantes. Con la reciente introducción de Chat GPT-4, las capacidades de este modelo se han ampliado aún más, permitiendo una mayor personalización y adaptabilidad a diferentes temáticas.
En este post, te mostraremos cómo configurar y personalizar un asistente especializado en minerales críticos utilizando GPT-4 y fuentes de datos abiertas. Como ya mostramos en previas publicaciones, los minerales críticos son fundamentales para numerosas industrias, incluyendo la tecnología, la energía y la defensa, debido a sus propiedades únicas y su importancia estratégica. Sin embargo, la información sobre estos materiales puede ser compleja y dispersa, lo que hace que un asistente especializado sea particularmente útil.
El objetivo de este post es guiarte paso a paso desde la configuración inicial hasta la implementación de un asistente GPT que pueda ayudarte a resolver dudas y proporcionar información valiosa sobre minerales críticos en tu día a día. Además, exploraremos cómo personalizar aspectos del asistente, como el tono y el estilo de las respuestas, para que se adapte perfectamente a tus necesidades. Al final de este recorrido, tendrás una herramienta potente y personalizada que transformará la manera en que accedes y utilizas la información en abierto sobre minerales críticos.
Accede al repositorio del laboratorio de datos en Github.
En este vídeo, el autor te explica que vas a encontrar tanto en el Github como en Google Colab.
2. Contexto
La transición hacia un futuro sostenible no solo implica cambios en las fuentes de energía, sino también en los recursos materiales que utilizamos. El éxito de sectores como baterías de almacenamiento de energía, aerogeneradores, paneles solares, electrolizadores, drones, robots, redes de transmisión de datos, dispositivos electrónicos o satélites espaciales, depende enormemente del acceso a las materias primas críticas para su desarrollo. Entendemos que un mineral es crítico cuando se cumplen los siguientes factores:
- Sus reservas mundiales son escasas
- No existen materiales alternativos que puedan ejercer su función (sus propiedades son únicas o muy singulares)
- Son materiales indispensables para sectores económicos clave de futuro, y/o su cadena de suministro es de elevado riesgo
Puedes aprender más sobre los minerales críticos en el post mencionado anteriormente.
3. Objetivo
Este ejercicio se centra en mostrar al lector cómo personalizar un modelo GPT especializado para un caso de uso concreto. Adoptaremos para ello el enfoque “aprender haciendo”, de tal forma que el lector pueda comprender cómo configurar y ajustar el modelo para resolver un problema real y relevante, como el asesoramiento experto en minerales críticos. Este enfoque práctico no solo mejora la comprensión de las técnicas de personalización de modelos de lenguaje, sino que también prepara a los lectores para aplicar estos conocimientos en la resolución de problemas reales, ofreciendo una experiencia de aprendizaje rica y directamente aplicable a sus propios proyectos.
El asistente GPT especializado en minerales críticos estará diseñado para convertirse en una herramienta esencial para profesionales, investigadores y estudiantes. Su objetivo principal será facilitar el acceso a información precisa y actualizada sobre estos materiales, apoyar la toma de decisiones estratégicas y promover la educación en este campo. A continuación, se detallan los objetivos específicos que buscamos alcanzar con este asistente:
- Proporcionar información precisa y actualizada:
- El asistente debe ofrecer información detallada y precisa sobre diversos minerales críticos, incluyendo su composición, propiedades, usos industriales y disponibilidad.
- Mantenerse actualizado con las últimas investigaciones y tendencias del mercado en el ámbito de los minerales críticos.
- Asistir en la toma de decisiones:
- Proporcionar datos y análisis que puedan ayudar en la toma de decisiones estratégicas en la industria y la investigación sobre minerales críticos.
- Ofrecer comparativas y evaluaciones de diferentes minerales en función de su rendimiento, coste y disponibilidad.
- Promover la educación y la concienciación en torno a esta temática:
- Actuar como una herramienta educativa para estudiantes, investigadores y profesionales, ayudando a mejorar su conocimiento sobre los minerales críticos.
- Aumentar la conciencia sobre la importancia de estos materiales y los desafíos relacionados con su suministro y sostenibilidad.
4. Recursos
Para configurar y personalizar nuestro asistente GPT especializado en minerales críticos, es esencial disponer de una serie de recursos que faciliten la implementación y aseguren la precisión y relevancia de las respuestas del modelo. En este apartado, detallaremos los recursos necesarios que incluyen tanto las herramientas tecnológicas como las fuentes de información que serán integradas en la base de conocimiento del asistente.
Herramientas y Tecnologías
Las herramientas y tecnologías clave para desarrollar este ejercicio son:
- Cuenta de OpenAI: necesaria para acceder a la plataforma y utilizar el modelo GPT-4. En este post, utilizaremos la suscripción Plus de ChatGPT para mostrarte cómo crear y publicar un GPT personalizado. No obstante, puedes desarrollar este ejercicio de forma similar utilizando una cuenta gratuita de OpenAI y realizando el mismo conjunto de instrucciones a través de una conversación de ChatGPT estándar.
- Microsoft Excel: hemos diseñado este ejercicio de forma que cualquier persona sin conocimientos técnicos pueda desarrollarlo de principio a fin. Únicamente nos apoyaremos en herramientas ofimáticas como Microsoft Excel para realizar algunas adecuaciones de los datos descargados.
De forma complementaria, utilizaremos otro conjunto de herramientas que nos permitirán automatizar algunas acciones sin ser estrictamente necesaria su utilización:
- Google Colab: es un entorno de Python Notebooks que se ejecuta en la nube, permitiendo a los usuarios escribir y ejecutar código Python directamente en el navegador. Google Colab es especialmente útil para el aprendizaje automático, el análisis de datos y la experimentación con modelos de lenguaje, ofreciendo acceso gratuito a potentes recursos de computación y facilitando la colaboración y el intercambio de proyectos.
- Markmap: es una herramienta que visualiza mapas mentales de Markdown en tiempo real. Los usuarios escriben ideas en Markdown y la herramienta las renderiza como un mapa mental interactivo en el navegador. Markmap es útil para la planificación de proyectos, la toma de notas y la organización de información compleja visualmente. Facilita la comprensión y el intercambio de ideas en equipos y presentaciones.
Fuentes de Información
- Raw Materials Information System (RMIS): sistema de información sobre materias primas mantenido por el Joint Research Center de la Unión Europea. Proporciona datos detallados y actualizados sobre la disponibilidad, producción y consumo de materias primas en Europa.
- Catálogo de informes y datos de la Agencia Internacional de la Energía (IEA en sus siglas en inglés): ofrece un amplio catálogo de informes y datos relacionados con la energía, incluyendo estadísticas sobre producción, consumo y reservas de minerales energéticos y críticos.
- Base de datos de minerales del Instituto Geológico y Minero Español (BDMIN): contiene información detallada sobre los minerales y depósitos minerales en España, útil para obtener datos específicos sobre la producción y reservas de minerales críticos en el país.
Con estos recursos, estarás bien equipado para desarrollar un asistente GPT especializado que pueda proporcionar respuestas precisas y relevantes sobre minerales críticos, facilitando la toma de decisiones informadas en este campo.
5. Desarrollo del ejercicio
5.1. Construcción de la base de conocimiento
Para que nuestro asistente GPT especializado en minerales críticos sea verdaderamente útil y preciso, es esencial construir una base de conocimiento sólida y estructurada. Esta base de conocimiento será el conjunto de datos e información que el asistente utilizará para responder a las consultas. La calidad y relevancia de esta información determinarán la eficacia del asistente en proporcionar respuestas precisas y útiles.
Búsqueda de Fuentes de Datos
Comenzamos con la recopilación de fuentes de información que nutrirán nuestra base de conocimiento. No todas las fuentes de información son igualmente fiables. Es fundamental evaluar la calidad de las fuentes identificadas, asegurando que:
- La información esté actualizada: la relevancia de los datos puede cambiar con rapidez, especialmente en campos dinámicos como el de los minerales críticos.
- La fuente sea confiable y reconocida: es necesario utilizar fuentes de instituciones reconocidas y respetadas en el ámbito académico y profesional.
- Los datos sean completos y accesibles: es crucial que los datos sean detallados y que estén accesibles para su integración en nuestro asistente.
En nuestro caso, desarrollamos una búsqueda online en diferentes plataformas y repositorios de información tratando de seleccionar información perteneciente a diversas entidades reconocidas:
- Centros de investigación y universidades:
- Publican estudios y reportes detallados sobre la investigación y desarrollo de minerales críticos.
- Ejemplo: RMIS del Joint Research Center de la Unión Europea.
- Instituciones gubernamentales y organismos internacionales:
- Estas entidades suelen proporcionar datos exhaustivos y actualizados sobre la disponibilidad y el uso de minerales críticos.
- Ejemplo: Agencia Internacional de la Energía (IEA).
- Bases de datos especializadas:
- Contienen datos técnicos y específicos sobre depósitos y producción de minerales críticos.
- Ejemplo: Base de datos de Minerales del Instituto Geológico y Minero español (BDMIN).
Selección y preparación de la información
Nos centraremos ahora en la selección y preparación de la información existente en estas fuentes para asegurar que nuestro asistente GPT pueda acceder a datos precisos y útiles.
RMIS del Joint Research Center de la Unión Europea:
- Información seleccionada:
Seleccionamos el informe “Supply chain analysis and material demand forecast in strategic technologies and sectors in the EU – A foresight study”. Se trata de un análisis de la cadena de suministro y la demanda de minerales en tecnologías y sectores estratégicos de la UE. Presenta un estudio detallado de las cadenas de suministro de materias primas críticas y pronostica la demanda de minerales hasta 2050.
- Preparación necesaria:
El formato del documento, PDF, permite la ingesta directa de la información por parte de nuestro asistente. No obstante, como se observa en la Figura 1, existe una tabla especialmente relevante en sus páginas 238-240 donde se analiza, para cada mineral, su riesgo de suministro, tipología (estratégico, crítico o no crítico) y las tecnologías clave que lo emplean. Decidimos, por ello, extraer esta tabla a un formato estructurado (CSV), de tal forma que dispongamos de dos piezas de información que pasarán a formar parte de nuestra base de conocimiento.

Figura 1: Tabla de minerales contenida en el PDF de JRC
Para extraer de forma programática los datos contenidos en esta tabla y transformarlos en un formato más fácilmente procesable, como CSV (comma separated values o valores separados por comas), utilizaremos un script de Python que podemos utilizar a través de la plataforma Google Colab (Figura 2).

Figura 2: Script Python para la extracción de datos del PDF de JRC desarrollado en plataforma Google Colab.
A modo de resumen, este script:
- Se apoya en la librería de código abierto PyPDF2, capaz de interpretar información contenida en ficheros PDF.
- Primero, extrae en formato texto (cadena de caracteres) el contenido de las páginas del PDF donde se encuentra la tabla de minerales eliminando todo el contenido que no se corresponde con la propia tabla.
- Posteriormente, recorre, línea a línea, la cadena de caracteres convirtiendo los valores en columnas de una tabla de datos. Sabremos que un mineral es utilizado en una tecnología clave si en la columna correspondiente de dicho mineral encontramos un número 1 (en caso contrario contendrá un 0).
- Por último, exporta dicha tabla a un fichero CSV para su posterior utilización.
Agencia Internacional de la Energía (IEA):
- Información seleccionada:
Seleccionamos el informe “Global Critical Minerals Outlook 2024”. Este proporciona una visión general de los desarrollos industriales en 2023 y principios de 2024, y ofrece perspectivas a medio y largo plazo para la demanda y oferta de minerales clave para la transición energética. También evalúa los riesgos para la fiabilidad, sostenibilidad y diversidad de las cadenas de suministro de minerales críticos.
- Preparación necesaria:
El formato del documento, PDF, nos permite la ingesta directa de la información por parte de nuestro asistente virtual. No realizaremos en este caso ninguna adecuación de la información seleccionada.
Base de Datos de Minerales del Instituto Geológico y Minero Español (BDMIN)
- Información seleccionada:
En este caso, utilizamos el formulario para seleccionar los datos existentes en esta base de datos en cuanto a indicios y yacimientos del ámbito de la metalogenia, en particular seleccionamos aquellos con contenido de Litio.

Figura 3: Selección de conjunto de datos en BDMIN.
- Preparación necesaria:
Observamos cómo la herramienta web nos permite la visualización online y también la exportación de estos datos en varios formatos. Seleccionamos, por tanto, todos los datos a exportar y haciendo clic en esta opción, descargamos un fichero Excel con la información deseada.

Figura 4: Herramienta de visualización y descarga en BDMIN

Figura 5: Datos descargados BDMIN.
Todos los archivos que componen nuestra base de conocimiento se encuentran GitHub del proyecto, de tal forma que aquel lector que lo desee pueda saltarse la fase de descarga y preparación de la información.
5.2. Configuración y personalización del GPT para minerales críticos
Cuando hablamos de "crear un GPT," en realidad nos estamos refiriendo a la configuración y personalización de un modelo de lenguaje basado en GPT (Generative Pre-trained Transformer) para adaptarlo a un caso de uso específico. En este contexto, no estamos creando el modelo desde cero, sino ajustando cómo el modelo preexistente (como GPT-4 de OpenAI) interactúa y responde dentro de un dominio específico, en este caso, sobre minerales críticos.
En primer lugar, accedemos a la aplicación a través de nuestro navegador y, en caso de no tener una cuenta, seguimos el proceso de registro y login en la plataforma ChatGPT. Como indicamos con anterioridad, para realizar la creación de un GPT paso a paso será necesario disponer de una cuenta Plus. No obstante, aquellos lectores que no dispongan de dicha cuenta, podrán trabajar con una cuenta gratuita interactuando con ChatGPT a través de una conversación estándar.
Figura 6: Página de inicio de sesión y registro de ChatGPT.
Una vez iniciada la sesión, seleccionamos la opción "Explorar GPT", y posteriormente hacemos clic en "Crear" para comenzar el proceso de creación de nuestro GPT.

Figura 7: Creación de nuevo GPT.
En pantalla se nos mostrará la pantalla dividida de creación de un nuevo GPT: a la izquierda podremos conversar con el sistema para indicarle las características que debe tener nuestro GPT, mientras que a la izquierda podremos interactuar con nuestro GPT para validar que su comportamiento es el adecuado según vayamos avanzando en el proceso de configuración.

Figura 8: Pantalla de creación de nuevo GPT.
En el GitHub de este proyecto, podemos encontrar todos los prompts o instrucciones que utilizaremos para configurar y personalizar nuestro GPT y que deberemos introducir de forma secuencial en la pestaña "Crear", situada en la pestaña izquierda de nuestras pantallas, para completar los pasos que se detallan a continuación.
Los pasos que vamos a seguir para la creación del GPT son:
- En primer lugar, le indicaremos el objetivo y las consideraciones básicas a nuestro GPT para que pueda entender su modo de empleo.
Figura 9: Instrucciones básicas de nuevo GPT.
2. Posteriormente crearemos un nombre y una imagen que representen a nuestro GPT y lo hagan fácilmente identificable. En nuestro caso, lo denominaremos MateriaGuru.

Figura 10: Selección de nombre para nuevo GPT.

Figura 11: Creación de imagen para GPT.
3. A continuación, construiremos la base de conocimiento a partir de la información anteriormente seleccionada y preparada para nutrir los conocimientos de nuestro GPT.


Figura 12: Carga de información a la base de conocimiento de nuevo GPT.
4. Ahora, podemos personalizar aspectos conversacionales como su tono, el nivel de complejidad técnica de sus repuesta o si esperamos respuestas escuetas o elaboradas.
5. Por último, desde la pestaña "Configurar", podemos indicar los iniciadores de conversación deseados para que los usuarios que interactúen con nuestro GPT tengan algunas ideas para empezar la conversación de forma predefinida.

Figura 13: Pestaña Configurar GPT.
En la Figura 13 podemos también observar el resultado definitivo de nuestro entrenamiento, donde aparecen elementos clave como su imagen, nombre, instrucciones, iniciadores de conversación o documentos que forma parte de su base de conocimiento.
5.3. Validación y publicación de GPT
Antes de dar por bueno a nuestro nuevo asistente basado en GPT, procederemos a realizar una breve validación de su correcta configuración y aprendizaje respecto a la temática en torno a la que le hemos entrenado. Para ello, preparamos una batería de preguntas que le realizaremos para comprobar que responde de forma adecuada ante un escenario real de utilización.
| # | Pregunta | Respuesta |
|---|---|---|
| 1 | ¿Qué minerales críticos han experimentado una caída significativa en los precios en 2023? | Los precios de los minerales para baterías vieron particularmente grandes caídas con los precios del litio cayendo un 75% y los precios del cobalto níquel y grafito cayendo entre un 30% y un 45%. |
| 2 | ¿Qué porcentaje de la capacidad solar fotovoltaica (PV) mundial fue añadido por China en 2023? | China representó el 62% del aumento en la capacidad solar fotovoltaica global en 2023. |
| 3 | ¿Cuál es el escenario que proyecta que las ventas de autos eléctricos (EV) alcanzarán el 65% en 2030? | El escenario de emisiones netas cero (NZE) para 2050 proyecta que las ventas de autos eléctricos alcanzarán el 65% en 2030. |
| 4 | ¿Cuál fue el crecimiento de la demanda de litio en 2023? | La demanda de litio aumentó en un 30% en 2023. |
| 5 | ¿Qué país fue el mayor mercado de autos eléctricos en 2023? | China fue el mayor mercado de autos eléctricos en 2023 con 8.1 millones de ventas de autos eléctricos representando el 60% del total global. |
| 6 | ¿Cuál es el principal riesgo asociado con la concentración de mercado en la cadena de suministro de grafito para baterías? | Más del 90% del grafito de grado batería y el 77% de las tierras raras refinadas en 2030 se originan en China lo que representa un riesgo significativo para la concentración del mercado. |
| 7 | ¿Qué proporción de la capacidad mundial de producción de celdas de batería estaba en China en 2023? | China poseía el 85% de la capacidad de producción de celdas de batería en 2023. |
| 8 | ¿Cuánto aumentó la inversión en minería de minerales críticos en 2023? | La inversión en minería de minerales críticos creció un 10% en 2023. |
| 9 | ¿Qué porcentaje de la capacidad de almacenamiento de baterías en 2023 estaba compuesto por baterías de fosfato de hierro y litio (LFP)? | En 2023, las baterías LFP constituían aproximadamente el 80% del mercado total de almacenamiento de baterías. |
| 10 | ¿Cuál es el pronóstico para la demanda de cobre en un escenario de emisiones netas cero (NZE) para 2040? | En el escenario de emisiones netas cero (NZE) para 2040 se espera que la demanda de cobre tenga el mayor aumento en términos de volumen de producción. |
Figura 14: Tabla con batería de preguntas para la validación de nuestro GPT.
Valiéndonos de la parte de previsualización, situada a la derecha de nuestras pantallas, lanzamos la batería de preguntas y validamos que las respuestas se corresponden con aquellas esperadas.

Figura 15: Validación de respuestas GPT.
Por último, hacemos clic en el botón "Crear" para finalizar el proceso. Podremos seleccionar entre diferentes alternativas para restringir su utilización por parte de otros usuarios.

Figura 16: Publicación de nuestro GPT.
6. Escenarios de uso
En este apartado mostramos varios escenarios en los que podremos sacar partido a MateriaGuru en nuestro día a día. En el GitHub del proyecto podremos encontrar los prompts utilizados para replicar cada uno de ellos.
6.1. Consulta de información de minerales críticos
El escenario más típico de utilización de este tipo de GPTs es la asistencia para resolución de dudas relacionadas con la temática en cuestión, en este caso, los minerales críticos. A modo de ejemplo, hemos preparado una batería de cuestiones que el lector podrá plantear al GPT creado para comprender en mayor detalle la relevancia y situación actual de un material crítico como es el grafito a partir de los informes provistos a nuestro GPT.

Figura 17: Resolución de dudas de minerales críticos.
También podemos plantearle preguntas concretas sobre la información tabulada provista respecto a los yacimientos e indicios existentes en el territorio español.
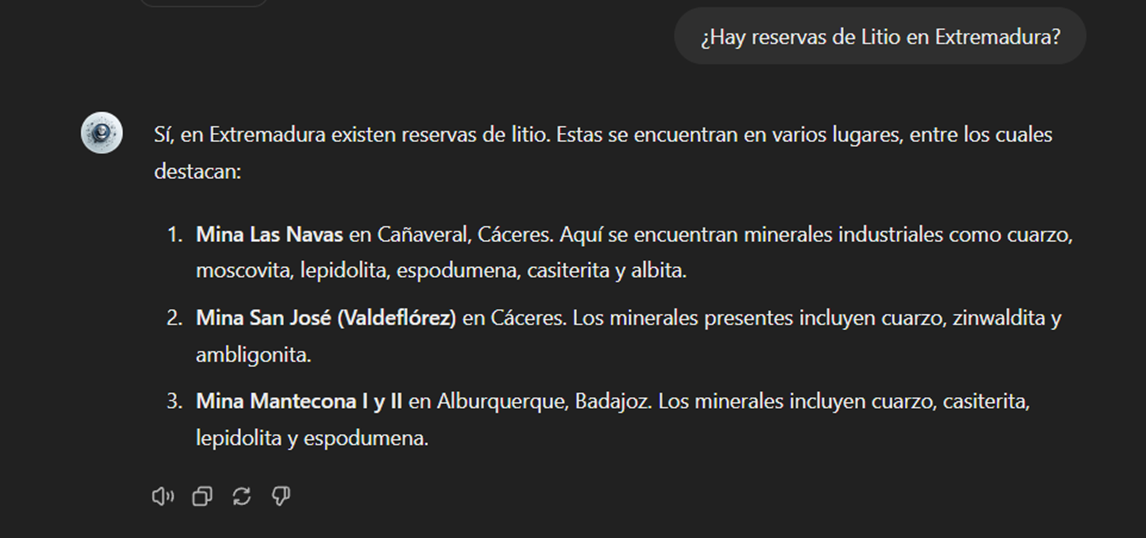
Figura 18: Reservas de litio en Extremadura.
6.2. Representación de visualizaciones de datos cuantitativos
Otro escenario común, es la necesidad de consultar información cuantitativa y realizar representaciones visuales para su mejor entendimiento. En este escenario, podemos observar cómo MateriaGuru es capaz de generar una visualización interactiva de la producción de grafito en toneladas de los principales países productores.

Figura 19: Generación de visualización interactiva con nuestro GPT.
6.3. Generación de mapas mentales para facilitar la comprensión
Por último, en línea con la búsqueda de alternativas para un mejor acceso y comprensión del conocimiento existente en nuestro GPT, plantearemos a MateriaGuru la construcción de un mapa mental que nos permita entender de una forma visual conceptos clave de los minerales críticos. Para ello, utilizamos la notación abierta Markmap (Markdown Mindmap), que nos permite definir mapas mentales utilizando notación markdown.

Figura 20: Generación de mapas mentales desde nuetro GPT.
Deberemos copiar el código generado e introducirlo en un visualizador de markmap para poder generar el mapa mental deseado. Facilitamos aquí una versión de este código generada por MateriaGuru.

Figura 21: Visualización de mapas mentales.
7. Resultados y conclusiones
En el ejercicio de construcción de un asistente experto utilizando GPT-4, hemos logrado crear un modelo especializado en minerales críticos. Este asistente proporciona información detallada y actualizada sobre minerales críticos, apoyando la toma de decisiones estratégicas y promoviendo la educación en este campo. Primero recopilamos información de fuentes confiables como el RMIS, la Agencia Internacional de la Energía (IEA), y el Instituto Geológico y Minero Español (BDMIN). Posteriormente, procesamos y estructuramos los datos adecuadamente para su integración en el modelo. Las validaciones demostraron que el asistente responde de manera precisa a preguntas relevantes del dominio, facilitando el acceso a su información.
De esta forma, el desarrollo del asistente especializado en minerales críticos ha demostrado ser una solución efectiva para centralizar y facilitar el acceso a información compleja y dispersa.
La utilización de herramientas como Google Colab y Markmap ha permitido una mejor organización y visualización de los datos, aumentando la eficiencia en la gestión del conocimiento. Este enfoque no solo mejora la comprensión y el uso de la información sobre minerales críticos, sino que también prepara a los usuarios para aplicar estos conocimientos en contextos reales.
La experiencia práctica adquirida en este ejercicio es directamente aplicable a otros proyectos que requieran la personalización de modelos de lenguaje para casos de uso específicos.
8. ¿Quieres realizar el ejercicio?
Si quieres replicar este ejercicio, accede a este repositorio donde encontrarás más información (las prompt utilizadas, el código generado por MateriaGuru, etc.)
Además, recuerda que tienes a tu disposición más ejercicios en el apartado sección de “Visualizaciones paso a paso”.
Contenido elaborado por Juan Benavente, ingeniero superior industrial y experto en Tecnologías ligadas a la economía del dato. Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Blog
¿Qué es perfilado de datos?
El perfilado de datos es el conjunto de actividades y procesos destinados a determinar los metadatos sobre un conjunto concreto de datos. Este proceso, considerado como una técnica indispensable durante el análisis exploratorio de datos, incluye la aplicación de distintos estadísticos con el principal objetivo de determinar aspectos como el número de valores nulos, la cantidad de valores distintos en una columna, los tipos de datos y/o los patrones más frecuentes de los valores de los datos. Su objetivo final es proporcionar un entendimiento claro y detallado de la estructura, contenido y calidad de los datos, lo que es esencial antes de su uso en cualquier aplicación.
Tipos de perfilado de datos
Existen distintas alternativas en cuanto a los principios estadísticos a aplicar durante un perfilado de datos, así como su tipología. Para este artículo se ha realizado una revisión de varias aproximaciones de distintos autores. En base a ello, se decide centrar el artículo sobre la tipología de técnicas de perfilado de datos en tres categorías de alto nivel: perfilado de una columna, perfilado multicolumna y perfilado de dependencias. Para cada categoría se identifican posibles técnicas y usos, como veremos a continuación.

1. Perfilado de una columna
El perfilado de una columna se centra en analizar cada columna de un conjunto de datos de manera individual. Este análisis incluye la recopilación de estadísticas descriptivas como:
-
Conteo de valores distintos, para determinar el número exacto de registros únicos de una lista y poder clasificarlos. Por ejemplo, en el caso de un conjunto de datos que recoja las subvenciones otorgadas por un organismo público, esta tarea nos permitirá saber cuántos beneficiarios distintos hay para la columna de beneficiarios, y si alguno se repite.
-
Distribución de valores (frecuencia), que se refiere al análisis de la frecuencia con la que ocurren diferentes valores dentro de una misma columna. Esto se puede representar mediante histogramas que dividen los valores en intervalos y muestran cuántos valores se encuentran en cada intervalo. Por ejemplo, en una columna de edades, podríamos encontrar que 20 personas tienen entre 25-30 años, 15 personas tienen entre 30-35 años, etc.
-
Conteo de valores nulos o faltantes, lo que implica contar la cantidad de valores nulos o vacíos en cada columna de un conjunto de datos. Ayuda a determinar la completitud de los datos y puede señalar posibles problemas de calidad. Por ejemplo, en una columna de direcciones de correo electrónico, 5 de 100 registros podrían estar vacíos, indicando un 5% de datos faltantes.
- Longitud mínima, máxima y promedio de los valores (para columnas de texto), la cual está orientada a calcular cuál es la longitud de los valores en una columna de texto. Esto es útil para identificar valores inusuales y para definir restricciones de longitud en bases de datos. Por ejemplo, en una columna de nombres, podríamos encontrar que el nombre más corto tiene 3 caracteres, el más largo 20 caracteres, y el promedio es de 8 caracteres.
En cuanto a los principales beneficios en el uso de este perfilado de datos destacan:
- Detección de anomalías: permite la identificación de valores inusuales o fuera de rango.
- Mejora de la preparación de datos: ayuda en la normalización y limpieza de datos antes de su uso en análisis más avanzados o en modelos de machine learning.
2. Perfilado multicolumna
El perfilado multicolumna analiza la relación entre dos o más columnas dentro del mismo conjunto de datos. Este tipo de perfilado puede incluir:
- Análisis de correlación, utilizado para identificar relaciones entre columnas numéricas en un conjunto de datos. Una técnica común es calcular correlaciones por pares entre todas las columnas numéricas para descubrir patrones de relación. Por ejemplo, en una tabla de investigadores, podríamos encontrar que la edad y el número de publicaciones están correlacionados, indicando que a medida que aumenta la edad de los investigadores y su categoría, también tiende a aumentar su número de publicaciones. Un coeficiente de correlación de Pearson podría cuantificar esta relación.
- Valores atípicos (outliers), lo cual implica identificar datos que se desvían significativamente de otros puntos de datos. Los outliers pueden indicar errores, variabilidad natural o puntos de datos interesantes que merecen una mayor investigación. Por ejemplo, en una columna de presupuestos para proyectos de I+D anuales, un valor de un millón de euros podría ser un outlier si la mayoría de los ingresos se encuentran entre 30.000 y 100.000 euros. Sin embargo, si se representa el importe en relación a la duración del proyecto, podría ser un valor normal si el proyecto de un millón tiene 10 veces la duración del de 100.000 euros.
- Detección de combinaciones de valores frecuentes, enfocada en encontrar conjuntos de valores que ocurren juntos con frecuencia en los datos. Se utilizan para descubrir asociaciones entre elementos, como en los datos de transacciones. Por ejemplo, en un conjunto de datos de compras, podríamos encontrar que los productos "pañales" y "leche de fórmula para bebés" se compran juntos frecuentemente. Un algoritmo de reglas de asociación podría generar la regla {pañales} → {leche de fórmula}, indicando que los clientes que compran pan también tienden a comprar mantequilla con una alta probabilidad.
En cuanto a los principales beneficios en el uso de este perfilado de datos destacan:
- Detección de tendencias: permite identificar relaciones y correlaciones significativas entre columnas, lo que puede ayudar en la detección de patrones y tendencias.
- Mejora de la consistencia de datos: permite asegurar que existe integridad referencial y que se siguen, por ejemplo, formatos similares en tipos de datos entre los datos a través de múltiples columnas.
- Reducción de dimensionalidad: permite reducir el número de columnas que contienen datos redundantes o que están altamente correlacionadas.
3. Perfilado de dependencias
El perfilado de dependencias se enfoca en descubrir y validar relaciones lógicas entre diferentes columnas, como:
-
Descubrimiento de claves ajenas, que está orientado a establecer qué valores o combinaciones de valores de un conjunto de columnas también aparecen en el otro conjunto de columnas, un requisito previo para una clave foránea. Por ejemplo, en la tabla Investigador, la columna ProyectoID contiene los valores [101, 102, 101, 103]. Para establecer ProyectoID como clave ajena, verificamos que estos valores también están presentes en la columna ProyectoID de la tabla Proyecto [101, 102, 103]. Como todos los valores coinciden, ProyectoID en Investigador puede ser una clave ajena que referencia a ProyectoID en Proyecto.
- Dependencias funcionales, que establece relaciones en la que el valor de una columna depende del valor de otra. Así mismo, se usa para la validación de reglas específicas que deben cumplirse (por ejemplo, un valor de descuento no debe exceder el valor total).
En cuanto a los principales beneficios en el uso de este perfilado de datos destacan:
- Mejora de la integridad referencial: permite asegurar que las relaciones entre tablas sean válidas y se mantengan correctas.
- Validación de consistencia entra valores: permite garantizar que los datos cumplen con determinadas restricciones o cálculos definidos por la organización.
- Optimización del repositorio de datos: permite mejorar la estructura y diseño de bases de datos mediante la validación y ajuste de dependencias.
Usos del perfilado de datos
Los estadísticos anteriormente citados pueden utilizarse en múltiples ámbitos en las organizaciones. Un caso de uso a destacar sería en iniciativas de ciencia de datos e ingeniería de datos donde permite comprender a fondo las características de un conjunto de datos antes de su análisis o modelado.
- Al generar estadísticas descriptivas, identificar valores atípicos y faltantes, descubrir patrones ocultos, identificar y corregir problemas, como valores nulos, duplicados e inconsistencias, el perfilado de datos facilita la limpieza y la preparación de datos, asegurando su calidad y consistencia.
- Además, es crucial para la detección temprana de problemas, como duplicados o errores, y para la validación de supuestos en proyectos de análisis predictivo.
- También es fundamental para la integración de datos provenientes de múltiples fuentes, garantizando su coherencia y compatibilidad.
- En el ámbito de gobierno, gestión y calidad de datos, el perfilado puede ayudar a establecer políticas y procedimientos sólidos, mientras que en el cumplimiento normativo asegura que los datos respeten con las regulaciones aplicables.
- Por último, en términos de gestión ayuda a optimizar los procesos de extracción, transformación y carga (Extract, Transform and Load o ETL en inglés), apoya la migración de datos entre sistemas y prepara conjuntos de datos para el machine learning y analíticas predictivas, mejorando la eficacia de los modelos y decisiones basadas en datos.
Diferencia entre perfilado de datos y evaluación de calidad de datos
En ocasiones, este término de perfilado de datos se confunde con la evaluación de calidad de datos.Mientras que el perfilado de datos se centra en descubrir y entender los metadatos y las características de los datos, la evaluación de calidad de datos va un paso más allá y se centra por ejemplo en analizar si los datos cumplen con ciertos requisitos o estándares de calidad predefinidos en la organización a través de las reglas de negocio. Así mismo, la evaluación de calidad de datos involucra verificar el valor de calidad para distintas características o dimensiones tales como las incluidas en la especificación UNE 0081: exactitud, completitud, consistencia o actualidad, etc., y asegurando que los datos sean aptos para su uso previsto en la organización: analítica, inteligencia artificial, inteligencia de negocio, etc.
Herramientas o soluciones para perfilado de datos
Por último, existen diversas soluciones (herramientas, librerías, o dependencias) open source destacadas para el perfilado de datos que facilitan el entendimiento de los datos. Entre ellas, destacan:
- Pandas Profiling e YData Profiling que ofrecen informes detallados y visualizaciones avanzadas en Python
- Great Expectations y Dataprep que permiten validar y preparar datos, asegurando su integridad en el ciclo de vida
- R dtables que permite la generación de informes detallados y visualizaciones para el análisis exploratorio y el perfilado de datos para el ecosistema R.
En resumen, el perfilado de datos es una parte importante en el análisis exploratorio de datos que permite obtener una comprensión detallada de la estructura, contenidos, etc. y que es recomendable tener en cuenta en iniciativas de análisis de datos. Es importante dedicar tiempo a esta actividad, contando con los recursos y herramientas necesarios, para tener un mejor conocimiento de los datos que se manejan y ser conscientes de que es una técnica más a utilizar como parte de la gestión de calidad de datos, y que puede ser utilizada como un paso previo a la evaluación de calidad de datos.
Contenido elaborado por Dr. Fernando Gualo, Profesor en UCLM y Consultor de Gobierno y Calidad de datos El contenido y el punto de vista reflejado en esta publicación es responsabilidad exclusiva de su autor.