Blog
Sabemos que los datos abiertos que gestiona el sector público en el ejercicio de sus funciones constituyen un recurso de gran valor para fomentar la transparencia, impulsar la innovación y estimular el desarrollo económico. A nivel global, en los últimos 15 años esta idea ha llevado a la creación de portales de datos que sirven como punto de acceso único para la información pública tanto de un país, como de una región o ciudad.
Sin embargo, en ocasiones nos encontramos que el pleno aprovechamiento del potencial de los datos abiertos se ve limitado por problemas inherentes a su calidad. Inconsistencias, falta de estandarización o interoperabilidad y metadatos incompletos son solo algunos de los desafíos comunes que a veces merman la utilidad de los conjuntos de datos abiertos y que las agencias gubernamentales además señalan como el principal obstáculo para la adopción de la IA.
Cuando hablamos de la relación entre datos abiertos e inteligencia artificial, casi siempre partimos de la misma idea: los datos abiertos alimentan a la IA, esto es, son parte del combustible de los modelos. Ya sea para entrenar modelos fundacionales como ALIA, para especializar modelos de lenguaje pequeños (SLM) frente a LLM, o para evaluar y validar sus capacidades o explicar su comportamiento (XAI), el argumento gira en torno a la utilidad de los datos abiertos para la inteligencia artificial, olvidando que los datos abiertos ya estaban ahí y tienen muchas otras utilidades.
Por ello, vamos a invertir la perspectiva y a explorar cómo la propia IA puede convertirse en una herramienta poderosa para mejorar la calidad y, por tanto, el valor de los propios datos abiertos. Este enfoque, que ya esbozó la Comisión Económica para Europa de las Naciones Unidas (UNECE) en su pionero informe Machine Learning for Official Statistics de 2022, adquiere una mayor relevancia desde la explosión de la IA generativa. Actualmente podemos utilizar la inteligencia artificial disponible para incrementar la calidad de los conjuntos de datos que se publican a lo largo de todo su ciclo de vida: desde la captura y la normalización hasta la validación, la anonimización, la documentación y el seguimiento en producción.
Con ello, podemos aumentar el valor público del dato, contribuir a que crezca su reutilización y a amplificar su impacto social y económico. Y, al mismo tiempo, a mejorar la calidad de la siguiente generación de modelos de inteligencia artificial.
Desafíos comunes en la calidad de los datos abiertos
La calidad de los datos ha sido tradicionalmente un factor crítico para el éxito de cualquier iniciativa de datos abiertos, que aparece citado en numerosos informes como el de Comisión Europea “Improving data publishing by open data portal managers and owners”. Los desafíos más frecuentes que enfrentan los publicadores de datos incluyen:
-
Inconsistencias y errores: en los conjuntos de datos, es frecuente la presencia de datos duplicados, formatos heterogéneos o valores atípicos. La corrección de estos pequeños errores, idealmente en la propia fuente de los datos, tenía tradicionalmente un coste elevado y limitaba enormemente la utilidad de numerosos conjuntos de datos.
-
Falta de estandarización e interoperabilidad: dos conjuntos que hablan de lo mismo pueden nombrar las columnas de forma diferente, usar clasificaciones no comparables o carecer de identificadores persistentes para enlazar entidades. Sin un mínimo común, combinar fuentes se convierte en un trabajo artesanal que encarece la reutilización de los datos.
- Metadatos incompletos o inexactos: la carencia de información clara sobre el origen, la metodología de recolección, la frecuencia de actualización o el significado de los campos, complica la comprensión y el uso de los datos. Por ejemplo, saber con certeza si se puede integrar el recurso en un servicio, si está al día o si existe un punto de contacto para resolver dudas es muy importante para su reutilización.
- Datos obsoletos o desactualizados: en dominios muy dinámicos como la movilidad, los precios o los datos de medio ambiente, un conjunto desactualizado puede generar conclusiones erróneas. Y si no hay versiones, registro de cambios o indicadores de frescura, es difícil saber qué ha variado y por qué. La ausencia de un “historial” de los datos complica la auditoría y reduce la confianza.
- Sesgos inherentes: a veces la cobertura es incompleta, ciertas poblaciones quedan infrarrepresentadas o una práctica administrativa introduce una desviación sistemática. Si estos límites no se documentan y advierten, los análisis pueden reforzar desigualdades o llegar a conclusiones injustas sin que nadie lo perciba.
Dónde puede ayudar la Inteligencia Artificial
Por fortuna, en su estado actual, la inteligencia artificial ya está en disposición de proporcionar un conjunto de herramientas que pueden contribuir a abordar algunos de estos desafíos de calidad de los datos abiertos, transformando su gestión de un proceso manual y propenso a errores en uno más automatizado y eficiente:
- Detección y corrección de errores automatizada: los algoritmos de aprendizaje automático y los modelos de IA pueden identificar automáticamente y con una gran fiabilidad inconsistencias, duplicados, valores atípicos y errores tipográficos en grandes volúmenes de datos. Además, la IA puede ayudar a normalizar y estandarizar datos, transformándolos por ejemplo a formatos y esquemas comunes para facilitar la interoperabilidad (como DCAT-AP), y con una fracción del coste que suponía hasta el momento.
- Enriquecimiento de metadatos y catalogación: las tecnologías asociadas al procesamiento de lenguaje natural (PLN), incluyendo el uso de modelos de lenguaje grandes (LLM) y pequeños (SLM), puede ayudar en la tarea de analizar descripciones y generar metadatos más completos y precisos. Esto incluye tareas como sugerir etiquetas relevantes, categorías de clasificación o extraer entidades clave (nombres de lugares, organizaciones, etc.) de descripciones textuales para enriquecer los metadatos.
- Anonimización y privacidad: cuando los datos abiertos contienen información que podría afectar a la privacidad, la anonimización se convierte en una tarea crítica, pero, en ocasiones, costosa. La Inteligencia Artificial puede contribuir a que la anonimización sea mucho más robusta y a minimizar riesgos relacionados con la re-identificación al combinar diferentes conjuntos de datos.
Evaluación de sesgos: la IA puede analizar los propios conjuntos de datos abiertos para detectar sesgos de representación o históricos. Esto permite a los publicadores tomar medidas para corregirlos o, al menos, advertir a los usuarios sobre su presencia para que sean tenidos en cuenta cuando vayan a reutilizarse. En definitiva, la inteligencia artificial no debe verse solo como “consumidora” de datos abiertos, sino también como una aliada estratégica para mejorar su calidad. Cuando se integra con estándares, procesos y supervisión humana, la IA ayuda a detectar y explicar incidencias, a documentar mejor los conjuntos y a publicar evidencias de calidad que refuerzan la confianza. Tal y como se describe en la Estrategia de Inteligencia Artificial 2024, esa sinergia libera más valor público: facilita la innovación, permite decisiones mejor informadas y consolida un ecosistema de datos abiertos más robusto y fiable con unos datos abiertos más útiles, más confiables y con mayor impacto social.
Además, se activa un ciclo virtuoso: datos abiertos de mayor calidad entrenan modelos más útiles y seguros; y modelos más capaces facilitan seguir elevando la calidad de los datos. De este modo la gestión del dato deja de ser una tarea estática de publicación y se convierte en un proceso dinámico de mejora continua.
Contenido elaborado por Jose Luis Marín, Senior Consultant in Data, Strategy, Innovation & Digitalization. Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Documentación
En la era de los datos, nos enfrentamos al desafío de la escasez de datos de valor para la construcción de nuevos productos y servicios digitales. Aunque vivimos en una época en la que los datos están por todas partes, a menudo nos encontramos con dificultades para acceder a datos de calidad que nos permitan comprender procesos o sistemas desde una perspectiva basada en datos. La falta de disponibilidad, la fragmentación, la seguridad y la privacidad son solo algunas de las razones que dificultan el acceso a datos reales.
Sin embargo, los datos sintéticos han surgido como una solución prometedora a este problema. Los datos sintéticos son información fabricada artificialmente que imita las características y distribuciones de los datos reales, sin contener información personal o sensible. Estos datos se generan mediante algoritmos y técnicas que preservan la estructura y las propiedades estadísticas de los datos originales.
Los datos sintéticos son útiles en diversas situaciones donde la disponibilidad de datos reales es limitada o se requiere proteger la privacidad de las personas involucradas. Tienen aplicaciones en la investigación científica, pruebas de software y sistemas, y entrenamiento de modelos de inteligencia artificial. Permiten a los investigadores explorar nuevos enfoques sin acceder a datos sensibles, a los desarrolladores probar aplicaciones sin exponer datos reales y a los expertos en IA entrenar modelos sin la necesidad de recopilar todos los datos del mundo real que en ocasiones son, simplemente, imposibles de capturar en tiempos y costes asumibles.
Existen diferentes métodos para generar datos sintéticos, como el remuestreo, el modelado probabilístico y generativo, y los métodos de perturbación y enmascaramiento. Cada método tiene sus ventajas y desafíos, pero en general, los datos sintéticos ofrecen una alternativa segura y confiable para el análisis, la experimentación y el entrenamiento de modelos de inteligencia artificial.
Es importante destacar que el uso de datos sintéticos ofrece una solución viable para superar las limitaciones de acceso a datos reales y abordar preocupaciones de privacidad y seguridad. Los datos sintéticos permiten realizar pruebas, entrenar algoritmos y desarrollar aplicaciones sin exponer información confidencial. Sin embargo, es fundamental garantizar la calidad y la fidelidad de los datos sintéticos mediante evaluaciones rigurosas y comparaciones con los datos reales.
En este informe, abordamos de forma introductoria la disciplina de los datos sintéticos, ilustrando algunos casos de uso de valor para los diferentes tipos de datos sintéticos que se pueden generar. Los vehículos autónomos, la secuenciación de ADN o los controles de calidad en las cadenas de producción son solo algunos de los casos que detallamos en este informe. Además, hemos destacado el uso del software open-source SDV (Synthetic Data Vault), desarrollado en el entorno académico del MIT, que utiliza algoritmos de aprendizaje automático para crear datos sintéticos tabulares que imitan las propiedades y distribuciones de los datos reales. Desarrollamos un ejemplo práctico, en un entorno de Google Colab para generar datos sintéticos sobre clientes ficticios alojados en un hotel ficticio. Hemos seguido un flujo de trabajo que involucra la preparación de datos reales y metadatos, el entrenamiento del sintetizador y la generación de datos sintéticos basados en los patrones aprendidos. Además, hemos aplicado técnicas de anonimización para proteger los datos sensibles y hemos evaluado la calidad de los datos sintéticos generados.
En resumen, los datos sintéticos son una herramienta poderosa en la era de los datos, ya que nos permiten superar la escasez y la falta de disponibilidad de datos de valor. Con su capacidad para imitar los datos reales sin comprometer la privacidad, los datos sintéticos tienen el potencial de transformar la forma en que desarrollamos proyectos de inteligencia artificial y análisis. A medida que avanzamos en esta nueva era, es probable que los datos sintéticos desempeñen un papel cada vez más importante en la generación de nuevos productos y servicios digitales.
Si quieres saber más sobre el contenido de este informe, puedes ver la entrevista a su autor.
En esta infografía se resume el concepto y sus principales aplicaciones:

Puedes descargarla en PDF aquí
A continuación, puedes descargar el informe completo, el resumen ejecutivo y una presentación-resumen.
Documentación
En este artículo recopilamos una serie de infografías dirigidas tanto a publicadores como reutilizadores que trabajen con datos abiertos. En ellas se muestras normas y buenas prácticas para facilitar tanto la publicación como el tratamiento de datos.
¿Cómo publicar datos abiertos en datos.gob.es?
 |
Publicada: febrero 2026 Esta infografía describe el proceso recomendado para que un organismo publique datos abiertos en el Catálogo Nacional de Datos Abiertos albergado en datos.gob.es. El camino se divide en cinco fases principales: planificación previa, alta de organismo y usuario, catalogación, federación y mantenimiento. |
Guía técnica control de versiones de datos
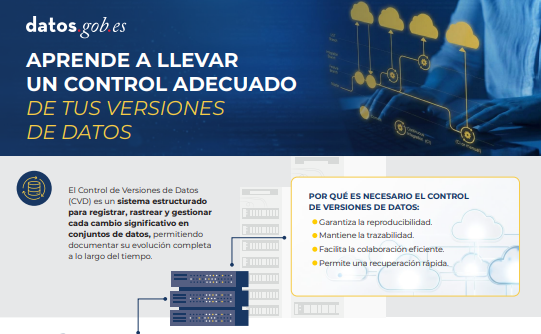 |
Publicada: enero 2026 El Control de Versiones de Datos (CVD) permite registrar y documentar la evolución completa de un conjunto de datos, facilitando la colaboración, la auditoría y la recuperación de versiones anteriores. Sin un sistema claro para gestionar esos cambios es fácil perder trazabilidad. En esta infografía te contamos cómo llevar a cabo un CVD. |
DCAT-AP-ES: Guías y materiales de apoyo para facilitar su uso
 |
Publicada: agosto 2025 Este nuevo modelo de metadatos adopta las directrices del esquema europeo de intercambio de metadatos DCAT-AP (Data Catalog Vocabulary-Aplication Profile) con algunas restricciones y ajustes adicionales. |
Guía para el despliegue de portales de datos abiertos
 |
Publicada: abril 2025 Esta infografía resume buenas prácticas y recomendaciones para diseñar, desarrollar y desplegar portales de datos abiertos en el ámbito municipal. En concreto recoge: marco estratégico, requisitos generales y pautas técnicas y funcionales. |
Ley de Datos (Data Act o DA)
 |
Publicada: febrero 2024 La Ley de Datos (Data Act) es una regulación de la Unión Europea para facilitar la accesibilidad de los datos de forma horizontal. Es decir, estableciendo principios y directrices para todos los sectores, haciendo hincapié en el acceso justo a los datos, los derechos de los usuarios y la protección de los datos personales. Descubre cuáles son sus claves en esta infografía. También se ha creado una versión a una página para facilitar su impresión: accede aquí |
Reglamento europeo de gobernanza de datos (Data Governance Act o DGA)
 |
Publicada: enero 2024 El Reglamento europeo de gobernanza de datos (Data Governance Act o DGA) es un instrumento horizontal para regular la reutilización de datos e impulsar su intercambio bajo los principios y valores de la Unión Europea (UE). Descubre cuáles son sus claves en esta infografía. También se ha creado una versión a una página para facilitar su impresión: accede aquí |
Las claves de las especificaciones UNE sobre el dato
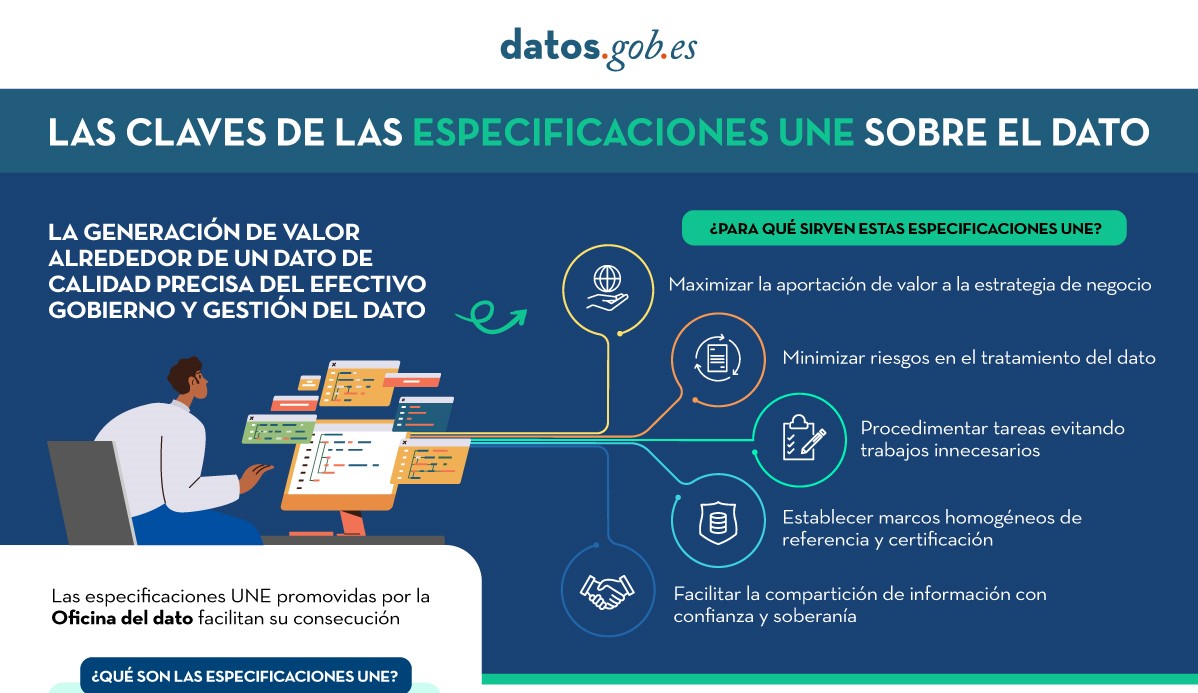 |
Publicada: septiembre 2023 Todo tipo de instituciones deben disponer de datos bien gobernados, gestionados y con niveles adecuados de calidad, siendo necesaria una metodología de evaluación común. La siguiente infografía resumen cuáles son las claves de las Especificaciones UNE sobre el dato y sus principales ventajas. |
Principales obligaciones de la Ley 37/2007
 |
Publicada: marzo 2023 En aplicación de la última Directiva europea de datos abiertos, se ha modificado la Ley 37/2007 para que incida en el concepto de los datos abiertos desde el diseño y por defecto. Esta infografía destaca los principales cambios de la normativa. |
Cómo crear un plan de medidas para impulsar la apertura y reutilización de datos abiertos
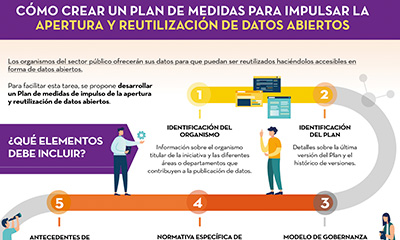 |
Publicada: noviembre 2022 Esta infografía recoge los diferentes elementos que debe contener un Plan de medidas de impulso de la apertura y reutilización de datos abiertos. El objetivo es que las unidades responsables de la apertura puedan trazar una hoja de ruta factible de apertura de datos, que además permita su seguimiento y evaluación. |
8 guías para mejorar la publicación y el tratamiento del dato
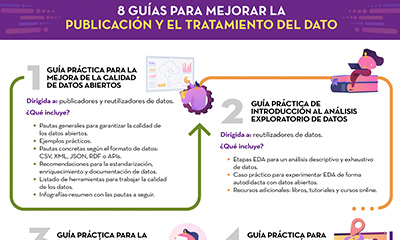 |
Publicada: octubre 2022 Desde datos.gob.es hemos elaborado diferentes guías para ayudar a publicadores y reutilizadores a la hora de preparar los datos datos para su publicación y/o análisis. En esta infografía te resumimos el contenido de ocho de ellas. |
Pautas generales para garantizar la calidad de los datos abiertos
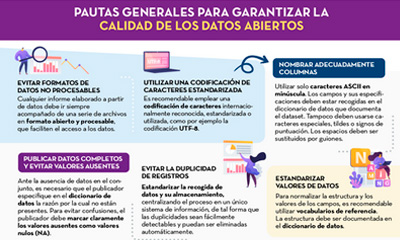 |
Publicada: septiembre 2022 Esta infografía detalla una serie pautas generales para garantizar la calidad de los datos abiertos, como, por ejemplo, utilizar una codificación de caracteres estandarizada, evitar la duplicidad de registros o incorporar variables con información geográfica. |
Pautas para asegurar la calidad usando formatos específicos de datos
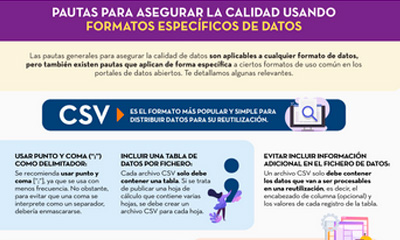 |
Publicada: septiembre 2022 Esta infografía recoge pautas concretas para asegurar la calidad de los datos abiertos según el formato de datos utilizado. Se han incluido pautas específicas para los formatos CSV, XML, JSON, RDF y APIs. |
Normas para un correcto gobierno del dato
 |
Publicada: mayo 2022 Esta infografía recoge la normas a tener en cuenta para un correcto gobierno del dato, según la Asociación Española de Normalización (UNE) . Estas normas se basan en 4 principios: Gobernanza, Gestión, Calidad y Seguridad y privacidad de datos. |
APIs para el acceso a datos abiertos
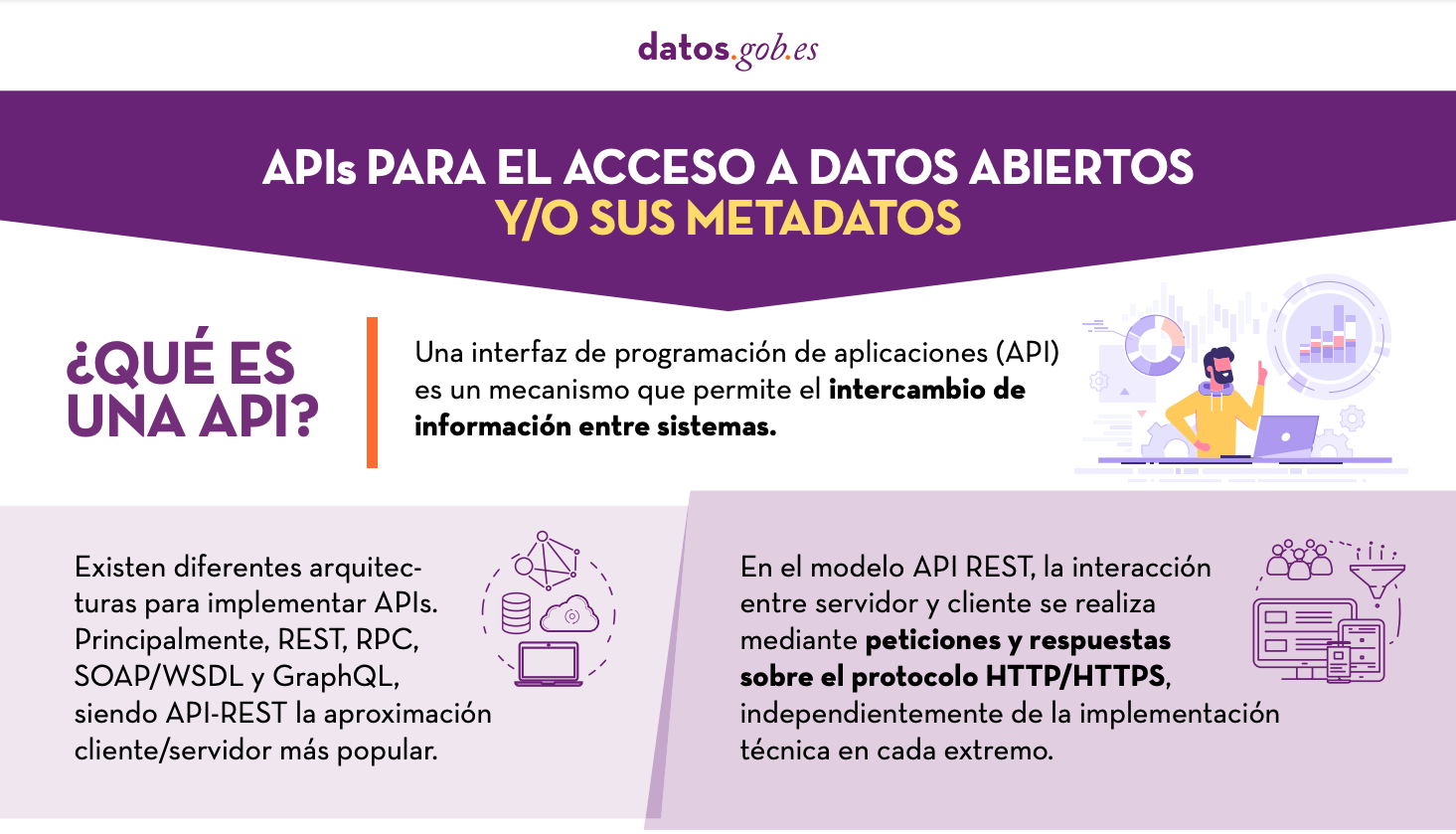 |
Publicada: enero 2022 Muchos portales de datos abiertos en España ya cuentan con sus propias APIs para facilitar el acceso a datos y metadatos. Esta infografía muestra algunos ejemplos a nivel nacional, autonómico y local, incluyendo información sobre la API de datos.gob.es. |
Documentación
A la hora de publicar datos abiertos, es fundamental garantizar su calidad. Si los datos están bien documentados y cuentan con la calidad necesaria, será más fácil su reutilización, ya que serán menores los trabajos adicionales de depuración y procesamiento. Además, la baja calidad de los datos puede suponer un coste para los publicadores, que pueden llegar a gastar más dinero en solucionar los errores que en evitar con antelación los potenciales problemas.
Para ayudar en esta tarea, en el marco de la Iniciativa Aporta se ha elaborado la “Guía práctica para la mejora de la calidad de datos abiertos”, que proporciona un compendio de directrices para actuar sobre cada una de las características que definen la calidad, impulsando su mejora. El documento toma como referente la guía para la calidad de datos de data.europe.eu, publicada en 2021 por la Oficina de Publicaciones de la Unión Europea.
¿A quién está dirigida la guía?
La guía está dirigida a publicadores de datos abiertos, a quienes proporciona una serie de pautas claras para mejorar la calidad de sus datos.
No obstante, esta recopilación también puede orientar a los reutilizadores de datos sobre cómo afrontar las debilidades de calidad que pueden presentar los conjuntos de datos con los que trabajan.
¿Qué incluye la guía?
El documento comienza definiendo las características, según la norma ISO/IEC 25012, que deben cumplir los datos para considerarse de calidad, las cuales se recogen en la siguiente imagen.

A continuación, el grueso de la guía está enfocado en la descripción de recomendaciones y buenas prácticas para evitar los problemas más habituales que suelen surgir a la hora de publicar datos abiertos, estructuradas de la siguiente manera:
- Una primera parte donde se detallan una serie pautas generales para garantizar la calidad de los datos abiertos, como, por ejemplo, utilizar una codificación de caracteres estandarizada, evitar la duplicidad de registros o incorporar variables con información geográfica. Para cada pauta se proporciona una descripción detallada del problema, las características de calidad afectadas y las recomendaciones para su resolución, junto a ejemplos prácticos que facilitan su comprensión.
- Una segunda parte con pautas concretas para asegurar la calidad de los datos abiertos según el formato de datos utilizado. Se han incluido pautas específicas para los formatos CSV, XML, JSON, RDF y APIs.
- Por último, la guía también incluye recomendaciones para la estandarización y enriquecimiento de datos, así como para su documentación, y un listado de herramientas útiles para trabajar la calidad de los datos.
Puedes descargar la guía aquí o al final de la página.
Materiales adicionales
La guía va acompañada de una serie de infografías que recopilan las pautas antes indicadas:

