Blog
We know that the open data managed by the public sector in the exercise of its functions is an invaluable resource for promoting transparency, driving innovation and stimulating economic development. At the global level, in the last 15 years this idea has led to the creation of data portals that serve as a single point of access for public information both in a country, a region or city.
However, we sometimes find that the full exploitation of the potential of open data is limited by problems inherent in its quality. Inconsistencies, lack of standardization or interoperability, and incomplete metadata are just some of the common challenges that sometimes undermine the usefulness of open datasets and that government agencies also point to as the main obstacle to AI adoption.
When we talk about the relationship between open data and artificial intelligence, we almost always start from the same idea: open data feeds AI, that is, it is part of the fuel for models. Whether it's to train foundational models like ALIA, to specialize small language models (SLMs) versus LLMs, or to evaluate and validate their capabilities or explain their behavior (XAI), the argument revolves around the usefulness of open data for artificial intelligence, forgetting that open data was already there and has many other uses.
Therefore, we are going to reverse the perspective and explore how AI itself can become a powerful tool to improve the quality and, therefore, the value of open data itself. This approach, which was already outlined by the United Nations Economic Commission for Europe (UNECE) in its pioneering 2022 Machine Learning for Official Statistics report , has become more relevant since the explosion of generative AI. We can now use the artificial intelligence available to increase the quality of datasets that are published throughout their entire lifecycle: from capture and normalization to validation, anonymization, documentation, and follow-up in production.
With this, we can increase the public value of data, contribute to its reuse and amplify its social and economic impact. And, at the same time, to improve the quality of the next generation of artificial intelligence models.
Common challenges in open data quality
Data quality has traditionally been a Critical factor for the success of any open data initiative, which is cited in numerous reports such as that of the European Commission "Improving data publishing by open data portal managers and owners”. The most frequent challenges faced by data publishers include:
-
Inconsistencies and errors: Duplicate data, heterogeneous formats, or outliers are common in datasets. Correcting these small errors, ideally at the data source itself, was traditionally costly and greatly limited the usefulness of many datasets.
-
Lack of standardization and interoperability: Two sets that talk about the same thing may name columns differently, use non-comparable classifications, or lack persistent identifiers to link entities. Without a common minimum, combining sources becomes an artisanal work that makes it more expensive to reuse data.
- Incomplete or inaccurate metadata: The lack of clear information about the origin, collection methodology, frequency of updating or meaning of the fields, complicates the understanding and use of the data. For example, knowing with certainty if the resource can be integrated into a service, if it is up to date or if there is a point of contact to resolve doubts is very important for its reuse.
- Outdated or outdated data: In highly dynamic domains such as mobility, pricing, or environmental data, an outdated set can lead to erroneous conclusions. And if there are no versions, changelogs, or freshness indicators, it's hard to know what's changed and why. The absence of a "history" of the data complicates auditing and reduces trust.
- Inherent biases: sometimes coverage is incomplete, certain populations are underrepresented, or a management practice introduces systematic deviation. If these limits are not documented and warned, analyses can reinforce inequalities or reach unfair conclusions without anyone noticing.
Where Artificial Intelligence Can Help
Fortunately, in its current state, artificial intelligence is already in a position to provide a set of tools that can help address some of these open data quality challenges, transforming your management from a manual and error-prone process to a more automated and efficient one:
- Automated error detection and correction: Machine learning algorithms and AI models can automatically and reliably identify inconsistencies, duplicates, outliers, and typos in large volumes of data. In addition, AI can help normalize and standardize data, transforming it for example into common formats and schemas to facilitate interoperability (such as DCAT-AP), and at a fraction of the cost it was so far.
- Metadata enrichment and cataloging: Technologies associated with natural language processing (NLP), including the use of large language models (LLMs) and small language models (SLMs), can help analyze descriptions and generate more complete and accurate metadata. This includes tasks such as suggesting relevant tags, classification categories, or extracting key entities (place names, organizations, etc.) from textual descriptions to enrich metadata.
- Anonymization and privacy: When open data contains information that could affect privacy, anonymization becomes a critical, but sometimes costly, task. Artificial Intelligence can contribute to making anonymization much more robust and to minimize risks related to re-identification by combining different data sets.
Bias assessment: AI can analyze the open datasets themselves for representation or historical biases. This allows publishers to take steps to correct them or at least warn users about their presence so that they are taken into account when they are to be reused. In short, artificial intelligence should not only be seen as a "consumer" of open data, but also as a strategic ally to improve its quality. When integrated with standards, processes, and human oversight, AI helps detect and explain incidents, better document sets, and publish trust-building quality evidence. As described in the 2024 Artificial Intelligence Strategy, this synergy unlocks more public value: it facilitates innovation, enables better-informed decisions, and consolidates a more robust and reliable open data ecosystem with more useful, more reliable open data with greater social impact.
In addition, a virtuous cycle is activated: higher quality open data trains more useful and secure models; and more capable models make it easier to continue raising the quality of data. In this way, data management is no longer a static task of publication and becomes a dynamic process of continuous improvement.
Content created by Jose Luis Marín, Senior Consultant in Data, Strategy, Innovation & Digitalisation. The content and views expressed in this publication are the sole responsibility of the author.
Documentación
In the era of data, we face the challenge of a scarcity of valuable data for building new digital products and services. Although we live in a time when data is everywhere, we often struggle to access quality data that allows us to understand processes or systems from a data-driven perspective. The lack of availability, fragmentation, security, and privacy are just some of the reasons that hinder access to real data.
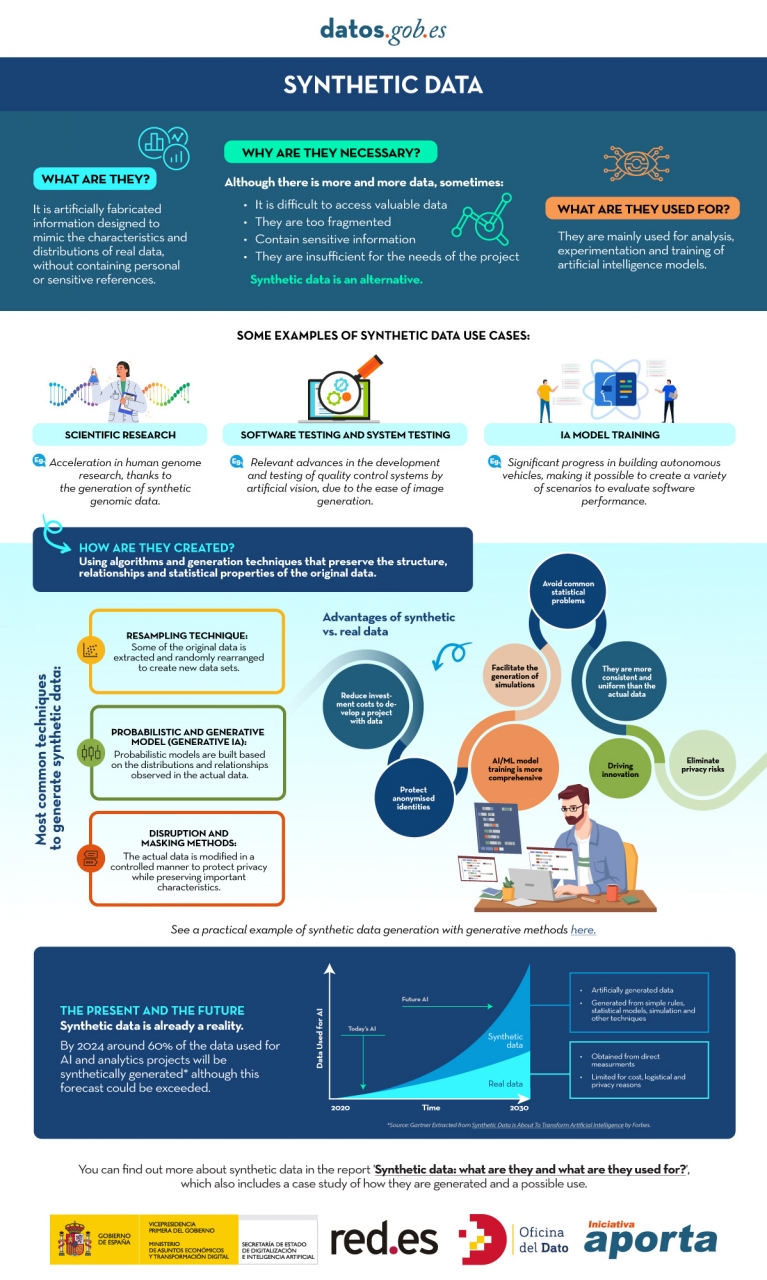
However, synthetic data has emerged as a promising solution to this problem. Synthetic data is artificially created information that mimics the characteristics and distributions of real data, without containing personal or sensitive information. This data is generated using algorithms and techniques that preserve the structure and statistical properties of the original data.
Synthetic data is useful in various situations where the availability of real data is limited or privacy needs to be protected. It has applications in scientific research, software and system testing, and training artificial intelligence models. It enables researchers to explore new approaches without accessing sensitive data, developers to test applications without exposing real data, and AI experts to train models without the need to collect all the real-world data, which is sometimes simply impossible to capture within reasonable time and cost.
There are different methods for generating synthetic data, such as resampling, probabilistic and generative modeling, and perturbation and masking methods. Each method has its advantages and challenges, but overall, synthetic data offers a secure and reliable alternative for analysis, experimentation, and AI model training.
It is important to highlight that the use of synthetic data provides a viable solution to overcome limitations in accessing real data and address privacy and security concerns. Synthetic data allows for testing, algorithm training, and application development without exposing confidential information. However, ensuring the quality and fidelity of synthetic data is crucial through rigorous evaluations and comparisons with real data.
In this report, we provide an introductory overview of the discipline of synthetic data, illustrating some valuable use cases for different types of synthetic data that can be generated. Autonomous vehicles, DNA sequencing, and quality controls in production chains are just a few of the cases detailed in this report. Furthermore, we highlight the use of the open-source software SDV (Synthetic Data Vault), developed in the academic environment of MIT, which utilizes machine learning algorithms to create tabular synthetic data that imitates the properties and distributions of real data. We present a practical example in a Google Colab environment to generate synthetic data about fictional customers hosted in a fictional hotel. We follow a workflow that involves preparing real data and metadata, training the synthesizer, and generating synthetic data based on the learned patterns. Additionally, we apply anonymization techniques to protect sensitive data and evaluate the quality of the generated synthetic data.
In summary, synthetic data is a powerful tool in the data era, as it allows us to overcome the scarcity and lack of availability of valuable data. With its ability to mimic real data without compromising privacy, synthetic data has the potential to transform the way we develop AI projects and conduct analysis. As we progress in this new era, synthetic data is likely to play an increasingly important role in generating new digital products and services.
If you want to know more about the content of this report, you can watch the interview with its author.
Below, you can download the full report, the executive summary and a presentation-summary.
Documentación
In this article we compile a series of infographics aimed at both publishers and reusers working with open data. They show standards and good practices to facilitate both the publication and the processing of data.
Interoperability: the key to working with data from various sources
 |
Published: March 2026 Interoperability operates as a four-layer system: technical, semantic, organizational, and legal. All of these layers must function properly so that we can combine data from various sources seamlessly, without misunderstandings or surprises. |
How to publish open data on datos.gob.es
 |
Published: February 2026 This infographic outlines the recommended process for an agency to publish open data in the National Open Data Catalog hosted on datos.gob.es. The process is divided into five main phases: preliminary planning, agency and user registration, cataloging, federation, and maintenance. |
Technical guide: Data version control
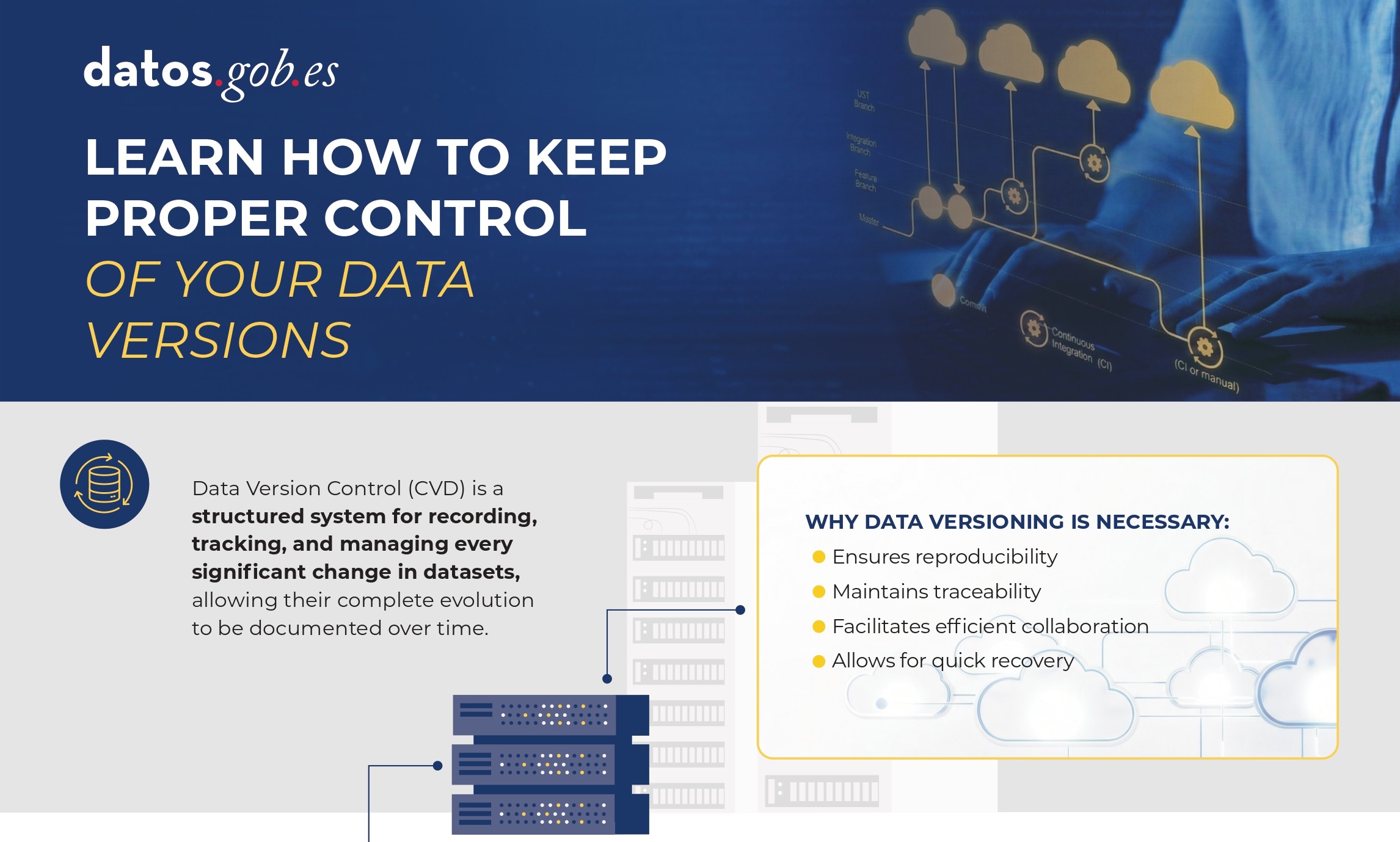 |
Published: January 2026 Data Version Control (DVC) allows you to record and document the complete evolution of a data set, facilitating collaboration, auditing, and recovery of previous versions. Without a clear system for managing these changes, it is easy to lose traceability. In this infographic, we explain how to implement DVC. |
DCAT-AP-ES: A step forward in open data interoperability
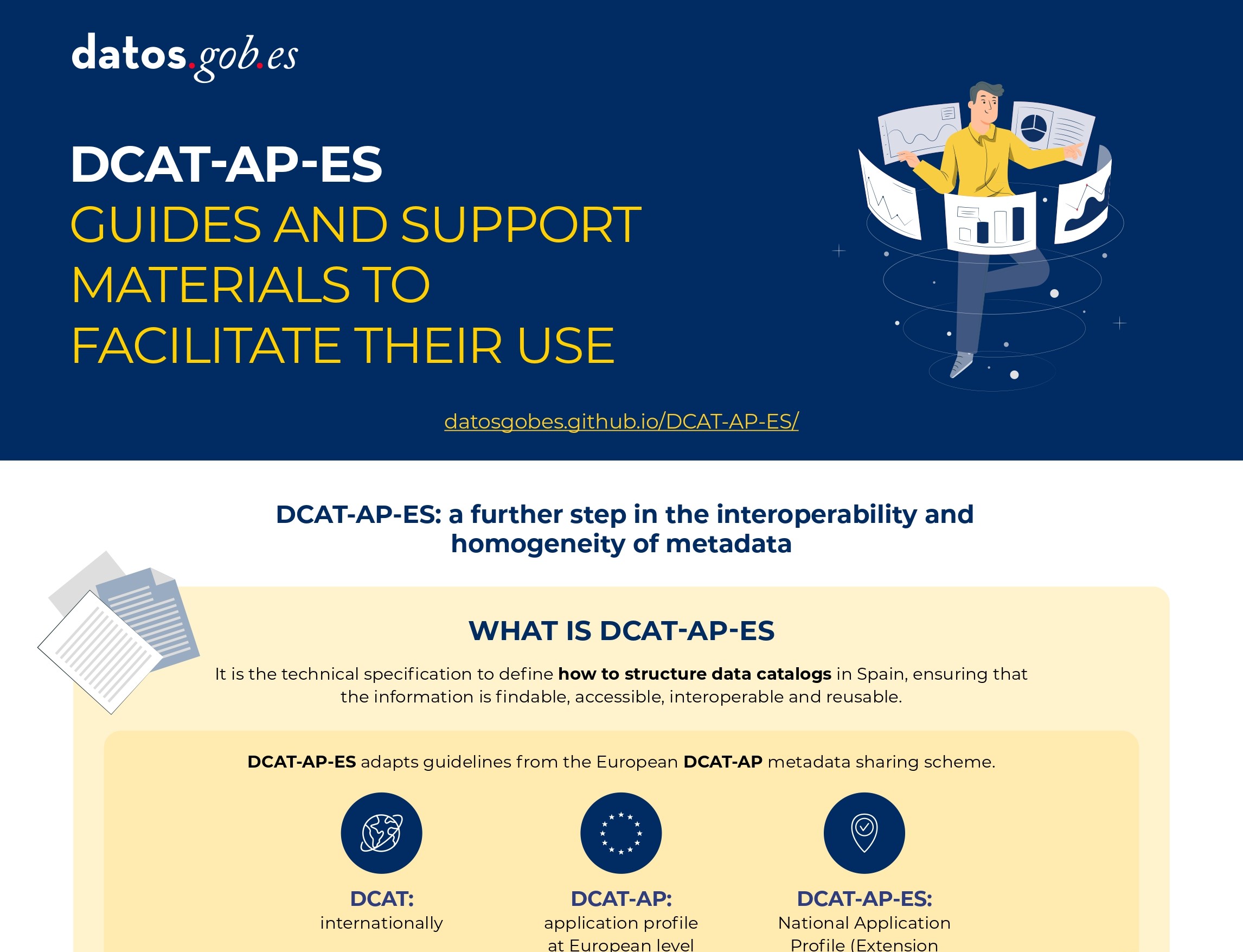 |
Published: august 2025 This new metadata model adopts the guidelines of the European metadata exchange schema DCAT-AP (Data Catalog Vocabulary-Application Profile) with some additional restrictions and adjustments.
|
Guide for the deployment of data portals. Good practices and recommendations
 |
Published: april 2025 This infographic summarizes best practices and recommendations for designing, developing and deploying open data portals at the municipal level. Specifically, it includes: strategic framework, general requirements and technical and functional guidelines. |
Data Act (DA)
 |
Published: February 2024 The Data Act is a European Union regulation to facilitate data accessibility in a horizontal way. In other words, it establishes principles and guidelines for all sectors, emphasizing fair access to data, user rights and the protection of personal data. Find out what its keys are in this infographic. A one-page version has also been created for easy printing: click here. |
Data Governance Act (DGA)
 |
Published: January 2024 The European Data Governance Act (DGA) is a horizontal instrument to regulate the reuse of data and promote its exchange under the principles and values of the European Union (EU). Find out what are its keys in this infographic. A one-page version has also been created to make printing easier: click here. |
The keys to the UNE data specifications
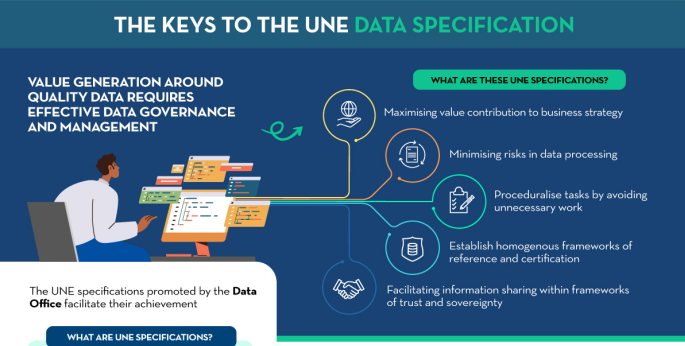 |
Published: September 2023 All types of institutions must have well-governed, managed data of adequate quality, requiring a common evaluation methodology. The following infographic summarizes the key aspects of the UNE Specifications on data and their main advantages. |
Main obligations of Law 37/2007
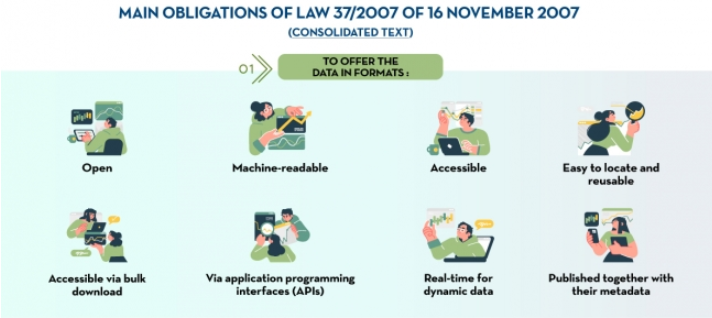 |
Published: March 2023 In accordance with the latest European Open Data Directive, Law 37/2007 has been amended to emphasize the concept of open data by design and by default. This infographic highlights the main changes in the legislation. |
How to create an action plan to drive openness and reuse of open data
 |
Published: November 2022 This infographic shows the different elements that should be included in a Plan of measures to promote openness and reuse of open data. The aim is that the units responsible for openness can draw up a feasible roadmap for open data, which also allows for its monitoring and evaluation. |
8 guides to improve data publication and processing
 |
Published: October 2022 At datos.gob.es we have prepared different guides to help publishers and reusers when preparing data for publication and/or analysis. In this infographic we summarise the content of eight of them. |
General guidelines for quality assurance of open data
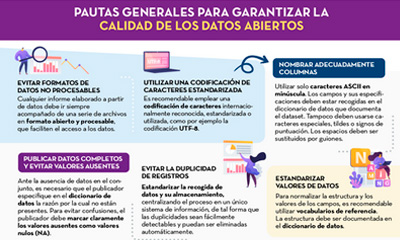 |
Published: September 2022 This infographic details general guidelines for ensuring the quality of open data, such as using standardised character encoding, avoiding duplicate records or incorporating variables with geographic information. |
Guidelines for quality assurance using specific data formats
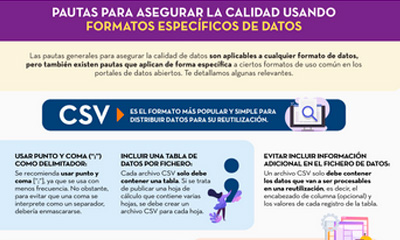 |
Published: September 2022 This infographic provides specific guidelines for ensuring the quality of open data according to the data format used. Specific guidelines have been included for CSV, XML, JSON, RDF and APIs. |
Technical standards for good data governance
 |
Published: May 2022 This infographic shows the standards to be taken into account for proper data governance, according to the Spanish Association for Standardisation (UNE). These standards are based on 4 principles: Governance, Management, Quality and Security and data privacy. |
APIs for open data access
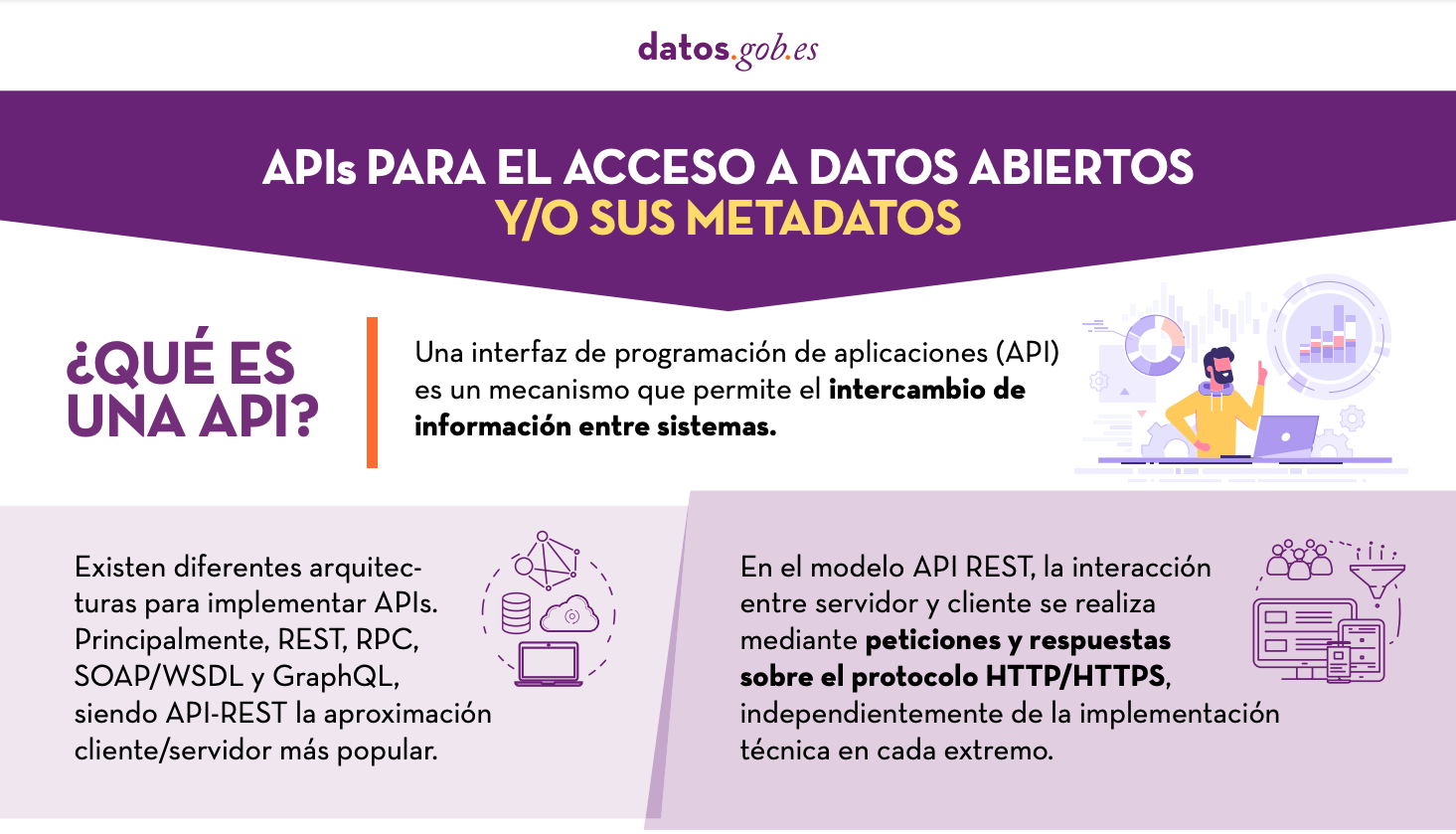 |
Published: January 2022 Many open data portals in Spain already have their own APIs to facilitate access to data and metadata. This infographic shows some examples at national, regional and local level, including information about the datos.gob.es API.. |
Documentación
When publishing open data, it is essential to ensure its quality. If data is well documented and of the required quality, it will be easier to reuse, as there will be less additional work for cleaning and processing. In addition, poor data quality can be costly for publishers, who may spend more money on fixing errors than on avoiding potential problems in advance.
To help in this task, the Aporta Initiative has developed the "Practical guide for improving the quality of open data", which provides a compendium of guidelines for acting on each of the characteristics that define quality, driving its improvement. The document takes as a reference the data.europe.eu data quality guide, published in 2021 by the Publications Office of the European Union.
Who is the guide aimed at?
The guide is aimed at open data publishers, providing them with clear guidelines on how to improve the quality of their data.
However, this collection can also provide guidance to data re-users on how to address the quality weaknesses that may be present in the datasets they work with.
What does the guide include?
The document begins by defining the characteristics, according to ISO/IEC 25012, that data must meet in order to be considered quality data, which are shown in the following image

Next, the bulk of the guide focuses on the description of recommendations and good practices to avoid the most common problems that usually arise when publishing open data, structured as follows:
- A first part where a series of general guidelines are detailed to guarantee the quality of open data, such as, for example, using a standardised character encoding, avoiding duplicity of records or incorporating variables with geographic information. For each guideline, a detailed description of the problem, the quality characteristics affected and recommendations for their resolution are provided, together with practical examples to facilitate understanding.
- A second part with specific guidelines for ensuring the quality of open data according to the data format used. Specific guidelines are included for CSV, XML, JSON, RDF and APIs.
- Finally, the guide also includes recommendations for data standardisation and enrichment, as well as for data documentation, and a list of useful tools for working on data quality.
You can download the guide here or at the bottom of the page (only available in Spanish).
Additional materials
The guide is accompanied by a series of infographics that compile the above guidelines:
- Infographic "General guidelines for quality assurance of open data".

- Infographic "Guidelines for quality assurance using specific data formats”.
