Blog
En el sector médico, el acceso a la información puede transformar vidas. Este es uno de los principales motivos por los que las comunidades de compartición y apertura de datos o la ciencia abierta ligada a la investigación médica se han convertido en un recurso muy valioso. Los grupos de investigación médica que abogan por el uso y reutilización de datos dirigen esta transformación, impulsando la innovación, mejorando la colaboración y acelerando el avance de la ciencia.
Como vimos en el caso de la Fundación FISABIO los datos abiertos en el sector salud fomentan la colaboración entre investigadores, aceleran el proceso de validación de resultados en estudios y, en definitiva, ayudan a salvar vidas. Esta tendencia no solo facilita descubrimientos más rápidos, sino que también ayuda a crear soluciones más eficaces. En España, el Consejo Superior de Investigación Científicas (CSIC) apuesta por la apertura de datos y algunos reconocidos hospitales también comparten los resultados de sus investigaciones protegiendo los datos sensibles de sus pacientes.
En este post, exploraremos cómo los grupos de investigación y comunidades de salud están compartiendo y reutilizando datos para impulsar investigaciones pioneras y expondremos casos de uso más inspiradores. Desde el desarrollo de nuevos tratamientos hasta la identificación de tendencias en salud pública, los datos están redefiniendo el panorama de la investigación médica y abriendo nuevas oportunidades para mejorar la salud global.
Grupos de investigación médica que apuestan el trabajo con datos compartidos
En España, existen diversos grupos de investigación y comunidades que comparten sus descubrimientos de manera más libre a través de plataformas y bases de datos que facilitan la colaboración global y la reutilización de datos en el campo de la salud. A continuación, destacamos algunos de los casos más influyentes, demostrando cómo el acceso a la información puede acelerar el progreso científico y mejorar los resultados en salud.
-
H2O – Health Outcomes Observatory: repositorio de datos clínicos
H2O es una asociación estratégica entre el sector público y privado para crear un sólido modelo de infraestructura y gobernanza de datos que permita recopilar e incorporar los resultados de los pacientes a escala en la toma de decisiones sanitarias a nivel individual y poblacional. El enfoque de H2O otorga a los pacientes el control definitivo de sus y garantiza que solo ellos ejerzan ese control. En este consorcio participan hospitales de todo el mundo, entre los que se encuentran los españoles Hospital Universitario Fundación Jiménez Díaz o el Hospital Vall d’Hebron. La Unidad de investigación de España recoge los resultados de salud que reportan los pacientes y otros datos clínicos para construir un observatorio que mejore la atención al paciente.
-
Instituto de Salud Carlos III: IMPaCT: proyectos de investigación de ciencia abierta
En el marco de la infraestructura IMPaCT se desarrollan diferentes proyectos aprobados en las ayudas para Proyectos de Investigación de Medicina Personalizada de Precisión de la Acción en Salud:
- Programa COHORTE – Medicina predictiva
- Programa DATA: Ciencia de datos
- Programa GENÓMICA - Medicina genómica
La información, datos, metadatos y productos científicos generados en IMPaCT son de acceso abierto, para hacer la ciencia más accesible, eficiente, democrática y transparente. En este proyecto, participan hospitales e institutos de investigación de toda España.
-
Datos POP Salud: proyecto de investigación médica del Instituto de Salud Carlos III (ISCIII) y la Plataforma de Organizaciones de Pacientes (POP)
Es un proyecto de datos desarrollado colaborativamente entre ISCIII y POP para mejorar el conocimiento y evidencia sobre la realidad clínica, laboral y social de los pacientes crónicos, sin duda algo crucial para nosotros. En esta iniciativa participan 36 organizaciones nacionales de pacientes, 16 sociedades científicas y 3 administraciones públicas, entre los que destacan el Ministerio de Derechos Sociales y Agenda 2030, el Instituto de Salud Carlos III y la Agencia Española de Medicamentos y Productos Sanitarios.
-
Iniciativa Europea de Imagen de Cáncer: proyecto europeo para obtener imágenes oncológicas y apoyar en la investigación contra el cáncer.
Uno de los objetivos del Plan Europeo de Lucha contra el Cáncer es aprovechar al máximo el potencial de los datos y las tecnologías digitales como la inteligencia artificial (IA) o la informática de alto rendimiento (HPC). La piedra angular de la iniciativa será una infraestructura europea federada para datos de imágenes de cáncer, desarrollada por la Federación Europea de IMages CAncer (EUCAIM). El proyecto comienza con 21 centros clínicos de 12 países entre los que se encuentran 4 centros españoles situados en Valencia, Barcelona, Sevilla y Madrid.
-
4CE: Consorcio de investigación
Es un consorcio internacional para el estudio de la pandemia de COVID-19 a partir de los datos de la historia clínica electrónica (HCE). El objetivo del proyecto -dirigido por el grupo internacional de usuarios académicos i2b2 -es informar a médicos, epidemiólogos y al público en general sobre los pacientes de COVID-19 con datos adquiridos a través del proceso de atención sanitaria. La plataforma ofrece datos agregados que están disponibles en la propia web del proyecto divididos entre datos de adultos y datos pediátricos. En ambos casos, los datos deben de ser utilizados con fines académicos y de investigación; el proyecto no permite el uso de los datos para orientación médica o diagnóstico clínico.
En conclusión, la apuesta por la compartición y reutilización de datos en la investigación médica está demostrando ser un catalizador fundamental para el avance científico y la mejora de la salud pública. A través de iniciativas como H2O, IMPaCT, y la Iniciativa Europea de Imagen de Cáncer, vemos cómo la accesibilidad en la gestión de datos está redefiniendo la forma en que abordamos la investigación y el tratamiento de enfermedades.
La integración de prácticas de análisis de datos promete un futuro donde la innovación en salud se logre de manera más rápida, equitativa y eficiente, ofreciendo así mejores resultados para los pacientes a nivel global.
Noticia
Navarra ha sido la sede escogida para reunir, por primera vez, a representantes de Oficinas del Dato de las comunidades autónomas en torno la centralidad del dato en la gestión pública. El encuentro, impulsado por la Secretaría de Estado de Digitalización e Inteligencia Artificial (SEDIA) y el Gobierno de Navarra, ha tenido como objetivo poner en común los avances en el mundo de los datos a nivel autonómico, así como la asunción de compromisos para sentar las bases de un futuro digital ligado a los datos y a su poder transformador.
Foco en el poder transformador del dato
El consejero de Universidad, Innovación y Transformación Digital del Gobierno de Navarra, Juan Cruz Cigudosa García fue el encargado de la apertura de la jornada haciendo hincapié en la necesidad de fortalecer la respuesta a los desafíos sociales y estimular la innovación y el desarrollo económico a través de los datos, resaltando el ineludible compromiso con la innovación mediante el uso de tecnologías disruptivas como la Inteligencia Artificial, siempre bajo un prisma ético y de respeto a los valores y principios europeos. En esta última línea de acción, se anunció la puesta en marcha de un Comité de Ética para la Oficina del Dato de Navarra. Este comité, enmarcado la Estrategia España Digital![]() y la Estrategia Digital Navarra 2030
y la Estrategia Digital Navarra 2030![]() , se encuentra alineado con las políticas activas y el liderazgo nacional e internacional de la SEDIA, reflejada en su carta de derechos digitales.
, se encuentra alineado con las políticas activas y el liderazgo nacional e internacional de la SEDIA, reflejada en su carta de derechos digitales.
A continuación, el Chief Data Officer del Gobierno de España, Alberto Palomo, resaltó la estrategia que se había diseñado a nivel europeo en relación con el dato y su gestión soberana. También señaló el poder transformador del dato, un elemento clave en la transformación digital y en la entrada de tecnologías como la inteligencia artificial. Asimismo, informó del reciente comunicado publicado a raíz de la actual Presidencia Española del Consejo de la Unión Europea, que se firmó a inicios del mes de noviembre durante el encuentro Gaia-X Summit bajo el nombre “The Trinity of Trusted Cloud, Data and AI as Gateway to EU´s competitiveness". Este documento constituye una declaración que pone de manifiesto el compromiso de los participantes en dicho encuentro para impulsar los espacios de datos en Europa a través de la autonomía estratégica en la nube, los datos y la inteligencia artificial. En él se acuerda, entre otros puntos, ampliar y mejorar la coordinación en el desarrollo de las iniciativas europeas de nube y datos, propugnando la interoperabilidad como elemento vertebrador y abogando por el desarrollo de una Inteligencia Artificial basada en datos de alta calidad y con una sólida gobernanza. También resalta la necesidad de homogeneizar las fuentes de datos para modelar mejor las relaciones, optimizar los procesos e innovar y crear nuevos modelos de negocio.
La jornada se desarrolló como un foro de comunicación, en el que, a modo de ejemplo, se pudieran compartir experiencias directas de los participantes, creando así un espacio para la reflexión y el diálogo. La jornada se estructuró a través de tres bloques temáticos, acerca del quién, el cómo y el para qué, siendo contextualizado cada bloque, antes de las presentaciones específicas, por la Oficina del Dato de la SEDIA y aterrizado en la práctica por el Gobierno de Navarra.
-
El primer bloque temático fue “El ecosistema del dato: quién”. En él se abordaron algunas de las estrategias en torno al dato desde la Generalitat de Cataluña y desde el Gobierno Vasco.
-
A continuación, se realizaron presentaciones en un segundo bloque titulado “Modelo de gobernanza, ética y cultura: cómo”. Los gobiernos de Aragón, Andalucía, Canarias, Valencia y la Federación Española de Municipios y Provincias hicieron presentaciones de sus casos de éxito en la materia.
-
En un último bloque titulado “Servicio al ciudadano, innovación y espacios de datos: para qué” se expusieron presentaciones por parte de Andalucía, el Instituto Nacional de Estadística, Castilla-la Mancha y la Secretaría General de Administración Digital, y Red.es, esta última presentando los servicios que desde la plataforma datos.gob.es se ofrece a las comunidades autónomas.
Siete principios clave para impulsar la economía del dato
El encuentro culminó con la presentación de siete principios para avanzar en la formulación conjunta de estrategias y políticas relacionadas con el manejo de los datos y el futuro digital. Estos son:
-
Establecer un gobierno efectivo del dato fijando políticas, normas y procedimientos para la gestión, explotación y compartición efectiva de los datos, implementado a su vez controles y evaluaciones para asegurar su cumplimiento.
-
Realizar un tratamiento ético del dato, debiéndose evaluar la licitud y legitimidad de toda práctica alrededor del dato, buscando minimizar cualquier impacto adverso en las personas y la sociedad.
-
Primar la tramitación administrativa confiable centrada en el dato, priorizando la transición del documento al dato, capaz de habilitar y catalizar el uso de tecnologías y herramientas avanzadas de analítica descriptiva, predictiva y prescriptiva (BI, big data, machine learning, deep learning), algoritmos generativos (LLM, GPT) y automatización de procesos (RPA).
-
Despliegue de la compartición soberna del dato por ser un recurso cuyo valor aumenta con su difusión, fijando quién puede acceder a qué datos y en qué condiciones de uso, seguridad y confianza.
-
Favorecer la difusión abierta de la información, impulsando su reutilización efectiva y publicación acorde a los principios FAIR, esto es, asegurar que los datos son encontrables, accesibles, interoperables y reutilizables.
-
Diseñar y analizar políticas públicas basadas en las evidencias, para así tomar decisiones informadas que deriven en servicios eficaces y en innovación pública.
-
Fomento de la cultura del dato, impulsando la creación de nuevos perfiles, puestos y responsabilidades relativos al trabajo con el dato, sin descuidar la formación y transmisión de conocimiento alrededor del dato.
El éxito de participación, las intervenciones y reflexiones planteadas evidencian el consenso acerca de avanzar en la consecución de una Administración orientada al dato, capaz de sacar partido, mediante el uso de medios tecnológicos innovadores, del potencial del dato, habilitando el diseño, ejecución y evaluación de políticas públicas centradas en el ciudadano, generadoras de una economía orientada al dato, sostenible, inclusiva y generadora de valor social.
El Foro se constituye así en punto de encuentro y generación de sinergias entre las diferentes administraciones públicas. La interoperabilidad entre los distintos organismos del sector público y entre los distintos niveles de gobierno en la elaboración y el intercambio de información impulsa la cohesión territorial y habilita el aprovechamiento efectivo de las tecnologías disponibles en la búsqueda de satisfacer el bien común.
La cumbre Gaia-X Summit 2023 culmina con un comunicado para impulsar los espacios de datos en Europa
Noticia
Bajo la Presidencia española del Consejo de la Unión Europea, el Gobierno de España ha liderado la cumbre Gaia-X Summit 2023 que se ha celebrado en Alicante durante los días 9 y 10 de noviembre. El evento tenía como objetivo repasar los últimos avances de Gaia-X en la promoción de la soberanía de datos en Europa. Tal y como presentamos en datos.gob.es, Gaia-X es una iniciativa europea del sector privado para la creación de una infraestructura de datos que sea federada, abierta, interoperable y reversible, y que sirve por tanto fomenta la soberanía digital y la disponibilidad de los datos.
La cumbre ha servido también ha servido como espacio para el intercambio de ideas entre las voces líderes de la comunidad europea de espacios de datos, y ha culminado con la presentación de un comunicado para impulsar la autonomía estratégica en la nube, los datos y la inteligencia artificial, elemento considerado crítico para la competitividad de la UE. El documento, fomentado por la Secretaría de Estado de Digitalización e Inteligencia Artificial, constituye un llamamiento conjunto para una respuesta “más coherente y coordinada” en el desarrollo de programas y proyectos, tanto europeos como a nivel de estados miembro, relacionados con los datos y las tecnologías del sector.
Para ello, el comunicado aboga por la interoperabilidad respaldada por una infraestructura sólida de servicios en la nube y por el desarrollo de una inteligencia artificial basada en datos de alta calidad, con una gobernanza sólida que cumpla con los marcos normativos europeos. En concreto, se resaltan las posibilidades que ofrecen las redes neuronales profundas (Deep Neural Networks), cuyo éxito recae en tres factores principales: algoritmos, capacidad de cálculo y acceso a grandes cantidades de datos. En este sentido, el documento resalta la necesidad de apostar por este último factor, impulsando un paradigma de red neuronal basado en datos de alta calidad, bien parametrizados y en infraestructuras compartidas, que no sólo ahorren un tiempo valioso a los investigadores, sino que también eviten la degradación medioambiental, dado que limita las necesidades de cómputo de estos sistemas al trabajar más allá del paradigma de fuerza bruta.
Por este motivo, otro de los aspectos abordados por el documento es la dinamización del acceso a fuentes de datos de diferentes dominios complementarios. Eso permitiría una economía de datos “flexible, dinámica y altamente escalable” que sirva para optimizar procesos, innovar y/o crear nuevos modelos de negocio.
El llamamiento se muestra optimista con la iniciativas y programas europeos existentes, empezando por el propio proyecto de Gaia-X. También se resaltan otros proyectos como son el IPCEI-CIS o proyecto Simpl europeo. Asimismo, subraya la necesidad de “una coordinación más amplia y efectiva para impulsar proyectos industriales, avanzar en la estandarización de etiquetas de nube y datos confiables, lo que sirve para garantizar unos niveles altos de ciberseguridad, protección de datos, transparencia algorítmica y portabilidad”.
El comunicado destaca la importancia de lograr un mercado único de datos que incluya procesos de intercambios de datos bajo un marco común de gobernanza. Así, valora el novedoso conjunto de legislación digital y de datos, como la ley de datos (Data Act), entre cuyos objetivos se encuentra el impulso de la disponibilidad de datos en el conjunto de la Unión. El comunicado está abierto a la adhesión de nuevos miembros que busquen avanzar en el fomento de una economía del dato flexible, dinámica y altamente escalable.
Blog
Aspectos tan relevantes de nuestra sociedad como la sostenibilidad medioambiental, la mitigación del cambio climático o la seguridad energética han motivado que la transición energética adquiera un papel muy relevante en el día a día de naciones, organismos privados y públicos, e incluso en nuestras vidas cotidianas como ciudadanos del mundo. La transición energética hace referencia a la transformación de nuestras formas de producción y consumo energético persiguiendo la menor dependencia de combustibles fósiles mediante fuentes de bajas emisiones o sin emisiones de carbono, como son las fuentes renovables.
Las medidas necesarias para conseguir una verdadera transición son de gran calado y, por tanto, complejas. En este proceso, las iniciativas de datos abiertos pueden contribuir enormemente facilitando la concienciación de la población, mejorando la estandarización de métricas y mecanismos para medir el impacto de medidas tomadas para mitigar el cambio climático a nivel mundial, promoviendo la transparencia de gobiernos y empresas en cuanto a reducción de emisiones de CO2, o aumentando la participación ciudadana y científica para la creación de nuevas soluciones digitales, así como el avance del conocimiento y la innovación.
¿Qué iniciativas están sirviendo de guía?
La mejor forma de comprender cómo el open data nos ayuda a percibir los efectos de las elevadas emisiones de CO2 así como el impacto de las diferentes medidas adoptadas por todo tipo de actores en favor de la transición energética es mediante la observación de ejemplos reales.
El Energy Institute (EI), entidad dedicada precisamente a la aceleración de la transición energética, publica anualmente su revisión estadística de la energía mundial, la cual incluye en su última versión hasta 80 conjuntos de datos, algunos de los cuales se remontan hasta el año 1965, que describen el comportamiento de diferentes fuentes de energía, así como el uso de minerales clave en la transición hacia la sostenibilidad. Utilizando su propia herramienta de reporting online para representar aquellas variables que queremos analizar, podemos observar cómo, a pesar del crecimiento exponencial de generación de energía renovable en los últimos años (figura 1), sigue habiendo una tendencia creciente en emisiones de CO2 (figura 2), aunque no tan drástica como en la primera década de los 2000.
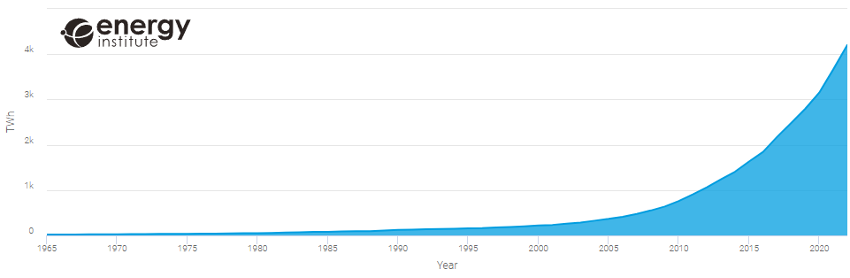
Figura 1: Evolución de la generación renovable mundial en TWh
Fuente: Energy Institute Statistical Review 2023
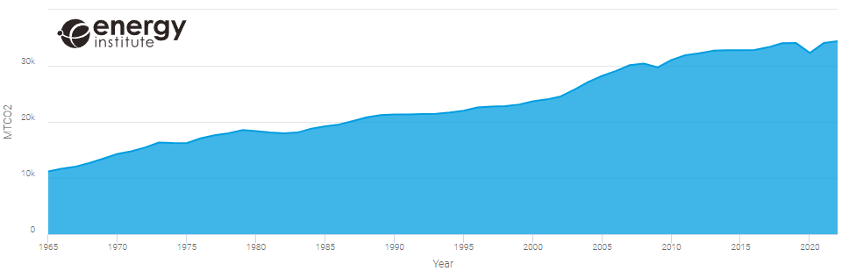
Figura 2: Evolución de las emisiones de CO2 mundiales en MTCO2
Fuente: Energy Institute Statistical Review 2023
Otra entidad internacional impulsora de la transición energética que ofrece un interesante catálogo de datos es la International Energy Agency (IEA). En este caso podemos encontrar más de 70 conjuntos de datos, no todos ellos abiertos sin subscripción, que incluyen tanto datos energéticos históricos como proyecciones futuras para poder alcanzar los objetivos Net Zero 2050. Podemos observar a continuación un ejemplo de estos datos extraído de su librería de visualizaciones gráficas, en particular, la evolución esperada de la generación energética para alcanzar los objetivos Net Zero en 2050. En la figura 3 podemos examinar cómo, para alcanzar estos objetivos, deben ocurrir principalmente dos procesos simultáneos: reducir la energía total demandada anualmente y evolucionar progresivamente a fuentes de generación con menor volumen de emisiones de CO2.
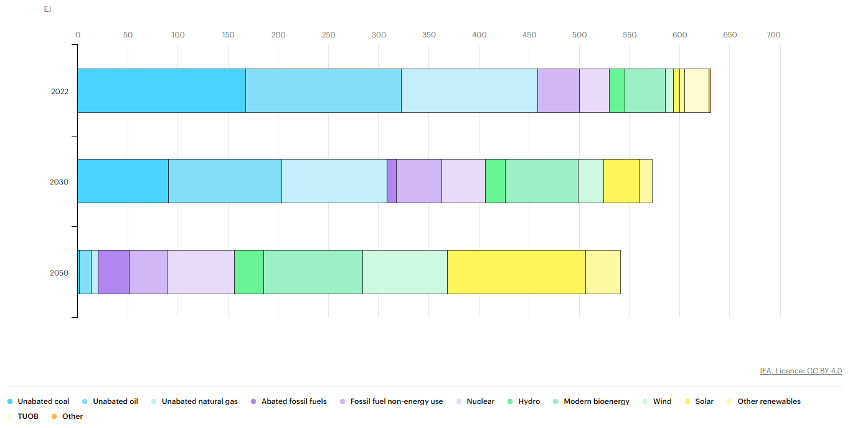
Figura 3: Generación energética 2020-2050 para alcanzar los objetivos de emisiones Net Zero en Exajulios
Fuente: IEA, Total energy supply by source in the Net Zero Scenario, 2022-2050, IEA, Paris, IEA. Licence: CC BY 4.0
Para analizar en mayor detalle cómo deben suceder estos dos procesos para alcanzar los objetivos Net Zero, IEA nos ofrece otra visualización muy relevante (figura 4). En ella, podemos observar cómo para alcanzar la reducción de la energía total demandada anualmente, es necesario avanzar aceleradamente en la década 2025-2035, gracias a medidas como electrificación, mejoras técnicas en la eficiencia de sistemas energéticos o reducción de la demanda. De esta manera, debe alcanzarse una reducción cercana a los 100EJs anuales para el año 2035, que luego debe mantenerse a lo largo del resto del período analizado. Para tratar de entender el calado de estas medidas y tomando como referencia el consumo eléctrico medio de los hogares españoles, unos 3.500kWh/año, la reducción anual deseada equivaldría a evitar el consumo de unos 7.937.000.000 hogares o, de otra manera, a evitar en un año el consumo eléctrico que todos los hogares españoles realizarían durante 418 años.
Respecto a la transición hacia fuentes de menor volumen de emisiones, podemos observar en esta figura cómo la expectativa es que la energía solar sea la líder en crecimiento, por delante de la eólica, mientras que el unabated coal (energía procedente de la quema de carbón sin utilizar sistemas de captura de CO2) sea la fuente cuyo uso más se espera reducir.
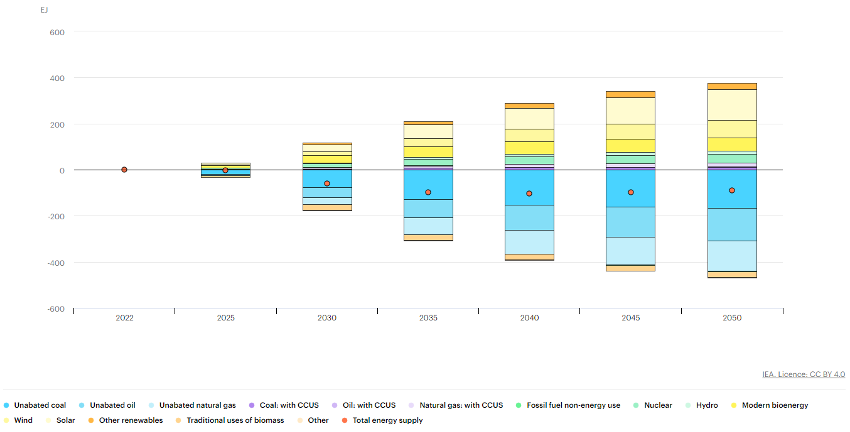
Figura 4: Cambios en la generación energética 2020-2050 para alcanzar los objetivos de emisiones Net Zero en Exajulios
Fuente: IEA, Changes in total energy supply by source in the Net Zero Scenario, 2022–2050, IEA, Paris, IEA. Licence: CC BY 4.0
Otras iniciativas de datos abiertos interesantes desde el punto de vista de la transición energética son los catálogos de la Comisión Europea (más de 1,5 millones de conjuntos de datos) y del Gobierno de España a través de datos.gob.es (más de 70 mil conjuntos de datos). Ambos aportan conjuntos de datos abiertos en temáticas como medioambiente, energía o transporte.
En ambos portales, podemos encontrar información muy variada, como consumos energéticos de ciudades y empresas, proyectos autorizados para la construcción de instalaciones de generación renovable o evolución de precios de hidrocarburos.
Por último, destaca la iniciativa REData, de Red Eléctrica Española (REE), que ofrece un área de datos con un amplio abanico de información relacionada con el sistema eléctrico español. Entre otras, información relativa a la generación eléctrica, a los mercados o al comportamiento diario del sistema.
Figura 5: Secciones de información provista desde REData
Fuente: El sistema eléctrico: Guía de uso de REData, noviembre 2022. Red Eléctrica Española.
Así mismo, la web ofrece un visualizador interactivo para la consulta y descarga de datos, como se muestra a continuación para la generación eléctrica, además de un interfaz programático (API – Application Programming Interface) para la consulta del repositorio de datos facilitado desde esta entidad.
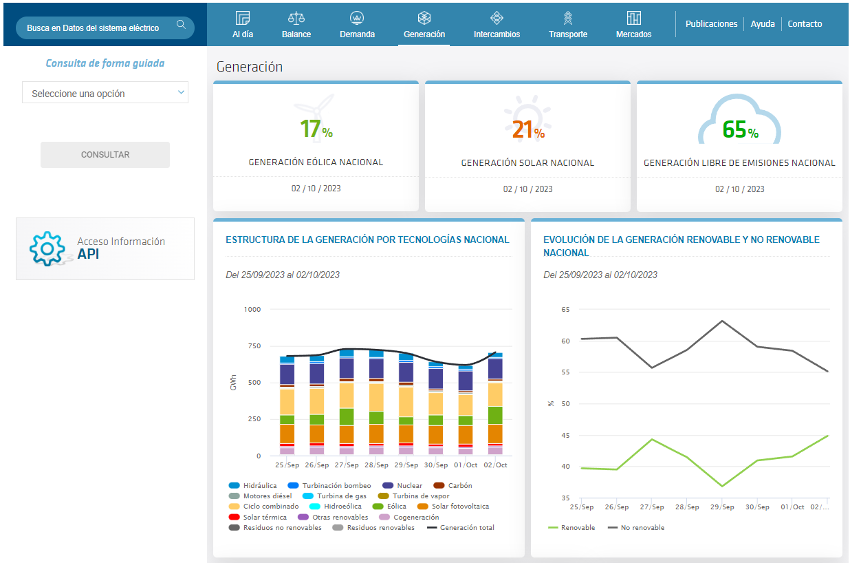
Figura 6: Plataforma REData de REE
Fuente: https://www.ree.es/es/datos/aldia
¿Qué conclusiones podemos extraer de este movimiento?
Como hemos podido observar, la enorme preocupación en torno a la transición energética ha motivado a múltiples organismos de diferente naturaleza a poner a disposición de otros organismos y de la propia ciudadanía datos de manera abierta para su análisis y explotación. Entidades tan variadas como el Energy Institute, la International Energy Agency, la Comisión Europea, el Gobierno de España o Red Eléctrica Española publican a través de sus portales de datos información muy valiosa en busca de una mayor transparencia y concienciación.
En este breve artículo hemos podido examinar cómo estos datos han sido de gran ayuda para comprender mejor la evolución histórica de las emisiones de CO2, la potencia eólica instalada o las expectativas de demanda energética para alcanzar los objetivos Net Zero. Los datos abiertos son una muy buena herramienta para mejorar la comprensión de la necesidad y calado de la transición energética, así como del avance de las medidas que progresivamente están siendo tomadas por múltiples entidades en todo el mundo, y esperamos ver cada vez un mayor número de iniciativas que sigan esta línea.
Contenido elaborado por Juan Benavente, ingeniero superior industrial y experto en tecnologías ligadas a la economía del dato. Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Blog
A medida que una mayor parte de nuestras vidas cotidianas se desarrolla online, y al mismo tiempo que la importancia y el valor de los datos personales aumenta en nuestra sociedad, las normas que protegen el derecho universal y fundamental a la privacidad, la seguridad y a la intimidad – respaldadas por marcos como la Declaración Universal de los Derechos Humanos o la Declaración Europea de Derechos Digitales – resultan cada vez de mayor importancia.
Hoy en día, nos enfrentamos también a una serie de nuevos retos en relación con nuestra privacidad y nuestros datos personales. Según el último informe de la Fundación Lloyd's Register, al menos tres de cada cuatro usuarios de internet están preocupados porque su información personal pueda ser robada o utilizada de algún modo sin su permiso. Por todo lo anterior, cada vez resulta también más urgente el poder garantizar que las personas estén en condiciones de conocer y controlar sus datos personales en todo momento.
Hoy en día, la balanza se inclina claramente hacia las grandes plataformas que son las que cuentan con los recursos necesarios para recopilar, comerciar y tomar decisiones basadas en nuestros datos personales – mientras que los individuos solo pueden aspirar a obtener cierto control sobre lo que ocurre con sus datos, generalmente previo gran esfuerzo.
Por ese motivo surgen iniciativas como MyData Global, una organización sin ánimo de lucro que lleva ya varios años promoviendo un enfoque de la gestión de datos personales centrado en el ser humano y abogando por garantizar el derecho de las personas a participar activamente en la economía del dato. El objetivo es restablecer el equilibrio y avanzar hacia una visión de los datos centrada en las personas para construir una sociedad digital más justa, sostenible y próspera cuyos pilares serían:
-
Establecer relaciones de confianza y seguridad entre las personas y las organizaciones.
-
Conseguir la autonomía en materia de datos, no sólo mediante la protección legal, sino también con medidas para compartir y distribuir el poder de los datos.
-
Maximizar los beneficios colectivos de los datos personales, compartiéndolos equitativamente entre las organizaciones, los individuos y la sociedad.
Y para poder introducir los cambios necesarios que den lugar a este nuevo enfoque más humano de los datos personales se han elaborado los siguientes principios:
1 – Control de los datos centrado en las personas
Son las personas las que deben tener el poder de decisión en la gestión de todo lo concerniente a su vida personal. Para ello deben disponer de los medios prácticos necesarios que les permitan comprender y controlar eficazmente quién tiene acceso a sus datos y cómo se utilizan y comparten.
La privacidad, la seguridad y el uso mínimo de datos deben ser prácticas habituales en el diseño de aplicaciones y las condiciones de uso de los datos personales deben ser negociadas de forma justa entre particulares y organizaciones.
2 – Las personas como punto central de integración
El valor de los datos personales crece exponencialmente con su diversidad, a la vez que crece también la potencial amenaza hacia la privacidad. Esta aparente contradicción podría resolverse si colocamos a las personas como eje central en cualquier intercambio de datos, centrándonos siempre en sus propias necesidades por encima de cualquier otra motivación.
Todo uso de los datos personales debe girar en torno al individuo a través de una profunda personalización de las herramientas y los servicios.
3 – Autonomía individual
En una sociedad impulsada por los datos, los individuos no deberían ser vistos únicamente como clientes o usuarios de servicios y aplicaciones. Deben ser considerados agentes libres y autónomos, capaces de establecer y perseguir sus propios objetivos.
Las personas deben poder gestionar con seguridad sus datos personales de la manera que prefieran, contando siempre con las herramientas, habilidades y asistencia necesarias.
4 – Portabilidad, acceso y reutilización
Permitir que las personas puedan obtener y reutilizar sus datos personales para sus propios fines y en diferentes servicios es la clave para pasar de los silos de datos aislados a los datos como recursos reutilizables.
La portabilidad de datos no debe ser un mero derecho legal, sino combinarse con medios prácticos para que las personas puedan trasladar eficazmente los datos a otros servicios o en sus dispositivos personales de forma segura y sencilla.
5 – Transparencia y responsabilidad
Las organizaciones que utilizan los datos de una persona deben ser transparentes en el uso que hacen de ellos y la finalidad que persiguen. Al mismo tiempo, deben asumir su responsabilidad sobre la gestión que hacen de esos datos, incluido cualquier incidente de seguridad.
Se deben crear canales fáciles de usar y seguros para que las personas puedan conocer y controlar lo que ocurre con sus datos en todo momento, y poder así también cuestionar las decisiones basadas únicamente en algoritmos.
6 – Interoperabilidad
Es necesario minimizar la fricción en el flujo de datos desde las fuentes de origen a los servicios que los utilizan. Para ello hay que incorporar los efectos positivos de los ecosistemas abiertos e interoperables, incluyendo protocolos, aplicaciones e infraestructura. Esto se logrará a través de la aplicación de normas y prácticas comunes y estándares técnicos.
La comunidad de MyData lleva ya años aplicando estos principios en su trabajo para conseguir difundir una visión más humana de la gestión, tratamiento y uso de los datos centrada en las personas, como está haciendo por ejemplo en la actualidad a través de su papel en el Data Spaces Support Centre, un proyecto de referencia que está llamado a definir el futuro uso y gobierno responsable de los datos en la Unión Europea.
Y para quien quiera profundizar más en el uso de los datos centrado en las personas, tendremos en breve una nueva edición de MyData Conference, que este año se centrará en mostrar casos prácticos en los que la recopilación, el procesamiento y el análisis de los datos personales sirven principalmente a las necesidades y experiencias de los seres humanos.
Contenido elaborado por Carlos Iglesias, Open data Researcher y consultor, World Wide Web Foundation.
Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Blog
Los libros son una fuente inagotable de conocimientos y de experiencias vividas por otros antes que nosotros, que podemos reutilizar para avanzar en nuestras vidas. Las bibliotecas, por tanto, son lugares donde los lectores que buscan libros, los toman prestados y una vez usados y extraído de ellos lo que necesitan, los devuelven. Resulta curioso imaginar las razones por las que un lector necesita encontrar un libro concreto que trate de un determinado tema.
En caso de que haya varios libros que cumplan con las características requeridas, cuáles pueden ser los criterios que pesen más para elegir el libro que el lector considera que mejor contribuye a su tarea. Y una vez finalizado el periodo de préstamo del libro, la labor de los bibliotecarios para hacer que todo vuelva a un estado inicial resulta casi mágica. El proceso de dejar los libros de vuelta en las estanterías se puede repetir indefinidamente.
Tanto en esas estanterías inmensas que están a disposición pública de todos los lectores en las salas, como esas otras más pequeñas, fuera de la vista de todos, donde descansan bajo custodia los libros que, debido a alguna razón no pueden estar públicamente disponibles. Este proceso lleva pasando siglos desde que el hombre empezó a escribir y a compartir su conocimiento entre coetáneos y entre generaciones.
En cierto sentido, los datos son como los libros. Y los repositorios de datos son como las bibliotecas: en nuestro día a día, tanto a nivel profesional como a nivel personal, necesitamos datos que están en las “estanterías” de numerosas “bibliotecas”. Algunos, que están abiertos, muy pocos aún, se pueden usar; otros están restringidos, y necesitamos permisos para usarlos.
En cualquier caso, contribuyen a desarrollar proyectos personales y profesionales; y por eso, estamos entendiendo que los datos son el pilar de la nueva economía del dato, lo mismo que los libros llevan siendo el pilar del conocimiento desde hace miles de años.
Los cuatro principios FAIR
Tal como ocurre con las bibliotecas, para poder elegir y usar los datos más adecuados para nuestras tareas, necesitamos que “los bibliotecarios de los datos hagan su magia” para ordenarlo todo de tal manera que sea fácil encontrar, acceder, interoperar y reutilizar los datos. Ese es el secreto de los “magos de los datos”: algo que ellos, recelosamente, llaman principios FAIR para que el resto de los humanos no podamos descubrirlos. No obstante, siempre es posible dar algunas pistas, para que podamos sacar mejor partido de su magia:

- Tiene que poder ser fácil encontrar los datos. De aquí viene la “F” de los principios FAIR, de “findable” (localizable, en español). Para ello, es importante que los datos estén suficientemente descritos mediante una colección adecuada de metadatos, de tal manera que se puedan realizar búsquedas de manera sencilla. Del mismo modo que en las bibliotecas se establece un tejuelo para etiquetar los libros, los datos necesitan su propia etiqueta. Los “magos de los datos” tienen que encontrar, por un lado, formas de escribir las etiquetas para que sea fácil localizar los libros, y por otro proporcionar herramientas (como buscadores) para que los usuarios puedan hacer búsquedas. Los usuarios, por nuestra parte, tenemos que conocer y saber interpretar lo que significan las distintas etiquetas de los libros, y saber cómo funcionan las herramientas de búsqueda (imposible no acordarse aquí de los protagonistas de “Ángeles y demonios” de Dan Brown buscando en la Biblioteca del Vaticano).
- Una vez localizados los datos que se pretenden utilizar, tiene que ser fácil poder acceder a ellos para utilizarlos. Esta es la A de “accessible” de FAIR. Lo mismo que para tomar prestado un libro de una biblioteca hay que hacerse socio y te dan un carné, con los datos pasa lo mismo: hay que conseguir una licencia para acceder a los datos. En este sentido, sería ideal poder acceder a cualquier libro sin tener ningún tipo de traba previa como ocurre con los datos abiertos licenciados por CC BY 4.0 o equivalente. Pero el hecho de ser socio de la “biblioteca de datos”, no tiene por qué conferirte acceso a toda la biblioteca. Quizás para ciertos datos que descansan en esas estanterías custodiadas fuera del alcance de todas las miradas, necesites ciertos permisos (imposible no acodarse aquí de “El nombre de la rosa” de Umberto Eco).
- No es suficiente con poder acceder a los datos, tiene que ser fácil poder interoperar con ellos, entendiendo su significado y sus descripciones. Este principio se representa con la “I” de “interoperable” en FAIR. Así, los “magos de los datos” tienen que conseguir, mediante las correspondientes técnicas, que los datos estén descritos y puedan ser entendidos para poder ser usados en el contexto de uso de los usuarios; aunque en, no pocas ocasiones, serán los usuarios los que tengan que adaptarse para poder operar con los datos (imposible no acordarse de las runas élficas de “El Señor de los Anillos” de J.R.R. Tolkien).
- Finalmente, los datos, al igual que los libros, tienen que poder ser reutilizados para ayudar una y otra vez a que otros puedan cubrir sus propias necesidades. De aquí la “R” de “reusable” en FAIR. Para ello, los “magos de los datos” tiene que establecer los mecanismos para asegurar que, tras su uso, todo puede volver a ese estado inicial, que será el punto de partida desde el que otros empezarán sus propios caminos.
A medida que nuestra sociedad va avanzando en esto de la economía digital, nuestras necesidades de datos van cambiando. Y no es que necesitemos más datos, sino que necesitamos disponer de forma distinta de los datos que se tienen, de los que se producen y de los que se ponen a disposición de los usuarios. Además, necesitamos ser más respetuosos con los datos que se generan, y con cómo usamos esos datos para no violar los derechos ni las libertades de los ciudadanos. Así que puede decirse, que nos enfrentamos a nuevos retos, lo que requiere nuevas soluciones. Esto obliga a nuestros “magos de datos” a perfeccionar sus trucos, pero siempre manteniendo la esencia de su magia, esto es, de los principios FAIR.
Hace poco, al final de febrero de 2023, tuvo lugar una Asamblea de estos magos de datos. Y estuvieron discutiendo sobre cómo revisar los principios FAIR para perfeccionar estos trucos de magia para escenarios tan relevantes como los espacios europeos de datos, los datos geoespaciales, o incluso cómo medir lo bien que se aplican los principios FAIR para estos nuevos retos. Si quieres ver de lo que hablaron, puedes ver los videos y el material en el siguiente enlace: https://www.go-peg.eu/2023/03/07/go-peg-final-workshop-28-february-20203-1030-1300-cet/
Contenido elaborado por Dr. Ismael Caballero, Profesor titular en UCLM
Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Noticia
El auge de las ciudades inteligentes, la distribución de los recursos durante la pandemia o la lucha contra los desastres naturales ha despertado el interés por los datos geográficos. Y es que, de la misma forma que los datos abiertos del ámbito sanitario contribuyen a implementar mejoras sociales relacionadas con el diagnóstico de enfermedades o la reducción de listas de espera, los Sistemas de Información Geográfica ayudan a agilizar y simplificar algunos de los retos del futuro, con el objetivo de hacer de estos una realidad más sostenible desde el punto de vista ambiental, más eficiente en términos energéticos y más habitable para los ciudadanos.
Al igual que sucede en otros ámbitos, los profesionales que se dedican a optimizar al máximo los Sistemas de Información Geográfica (GIS en adelante) también construyen sus propios grupos de trabajo, asociaciones y comunidades formativas. Las comunidades GIS son grupos de voluntarios interesados en utilizar la información geográfica para maximizar los beneficios sociales que este tipo de datos pueden aportar en términos colectivos.
Así y a través de abordar los distintos enfoques que ofrece el campo de la información geográfica, las comunidades de datos trabajan en la elaboración de aplicaciones, el análisis de información geoespacial, la generación de cartografías y la creación de contenido divulgativo, entre otros.
En las siguientes líneas, analizaremos paso a paso cuál es el compromiso y el objetivo de tres ejemplos de comunidades GIS que actualmente están en activo.
GIS and Beers
¿Qué es y cuál es su objetivo?
Gis and Beers es una asociación centrada en la difusión, el análisis y el diseño de herramientas vinculadas a la información geográfica y los datos cartográficos. Especializados en sostenibilidad y medioambiente, utilizan los datos abiertos para proponer y difundir soluciones que buscan diseñar un entorno sostenible y respetuoso con la naturaleza.
¿Qué funciones lleva a cabo?
Además de difundir contenido especializado como informes y análisis de datos, los integrantes de Gis and Beers ofrecen recursos formativos dedicados a facilitar la comprensión de los sistemas de información geográfica desde la perspectiva medioambiental. Resulta habitual leer en su web artículos centrados en nuevos datos ambientales o ver tutoriales sobre cómo acceder a las plataformas de datos abiertos especializadas en medioambiente o a las herramientas disponibles para su gestión. Igualmente, cada vez que detectan la publicación de un nuevo catálogo de datos abiertos, comparten en su web las instrucciones necesarias para descargar los datos, gestionarlos y representarlos cartográficamente.
Próximos pasos
En línea con la conciencia medioambiental que marca el proyecto, desde Gis and Beers dedican cada vez más esfuerzos a fortalecer dos pilares clave para su contenido: concienciar sobre la importancia de la ciencia ciudadana (movimiento colaborativo que aporta datos observados por la ciudadanía) y promover el acceso a datos que faciliten el modelado sin adaptarlos previamente a necesidades cartográficas de análisis.
El papel de los datos abiertos
El origen de la mayor parte de los datos abiertos que utilizan proceden de fuentes estatales como el IGN, Aemet o el INE, aunque también se nutren de otras opciones como las que ofrecen organismos Google Earth Engine y Google Public Data.
¿Cómo contactar con ellos?
Si te interesa conocer más de cerca el trabajo de esta comunidad o necesitas ponerte en contacto con Gis and Beers, puedes visitar su página web o escribirles directamente a esta cuenta de correo electrónico.
Geovoluntarios
¿Qué es y cuál es su objetivo?
Se trata de una Organización sin ánimo de lucro formada por profesionales experimentados en el uso y la aplicación en remoto de tecnología geoespacial y cuyo objetivo es cooperar con otras organizaciones que prestan su apoyo en situaciones de emergencia y en proyectos alineados con los Objetivos de Desarrollo Sostenible.
La asociación tiene como objetivos principales:
- Proporcionar ayuda a organizaciones en cualquiera de las fases de una emergencia, priorizando la ayuda a organizaciones sin ánimo de lucro, de salvamento o que apoyen al tercer sector. Algunas de ellas son Cruz Roja, Protección Civil, organizaciones humanitarias, etc.
- Fomentar el voluntariado digital entre personas con conocimientos o interés en las tecnologías geoespaciales y el trabajo con datos geolocalizados.
- Buscar formas de apoyar a organizaciones trabajando en la consecución de los Objetivos de Desarrollo Sostenible (ODS).
- Proveer de herramientas geoespaciales y datos geolocalizados a proyectos sin ánimo de lucro que de otra forma no serían técnica o económicamente viables.
¿Qué funciones lleva a cabo?
La experiencia profesional acumulada por los integrantes de geovoluntarios permite ofrecer apoyo en tareas relacionadas con el análisis de datos geográficos, el diseño de modelos o la monitorización de situaciones de especial emergencia. De este modo, las funciones más habituales que llevan a cabo como ONG pueden resumirse en:
- Capacitar y ofrecer medios a voluntarios y organizaciones en todos los aspectos necesarios para proporcionar la ayuda con garantías: sistemas de información geográfica, análisis espacial, RGPD, seguridad, etc.
- Facilitar la creación de equipos temporales de trabajo para dar respuesta a las solicitudes de ayuda recibidas y que estén acorde con los fines de la organización.
- Crear grupos de trabajo que mantengan datos que sirvan de propósito general.
- Buscar acuerdos de colaboración con otras entidades, organizar y participar en eventos y realizar campañas de promoción del voluntariado digital.
Desde un punto de vista más concreto, entre todos los proyectos en los que ha participado Geovoluntarios, cabe destacar dos iniciativas en las que los integrantes se volcaron especialmente. Por un lado, el proyecto propio datos Covid, donde se logró crear una comunidad de voluntarios digitales comprometidos con la búsqueda y el análisis de datos fiables para, así, ofrecer información de calidad sobre la situación que se estaba viviendo en cada una de las diferentes comunidades autónomas de España.
Otra de las iniciativas a destacar fue Reactiva Madrid, un evento organizado por el Ayuntamiento de Madrid y Esri España que surgió para identificar y desarrollar trabajos que, a través de la participación ciudadana, ayudasen a prevenir y/o solucionar problemas relacionados con la pandemia provocada por la COVID-19 en los ámbitos de la economía, la movilidad y la sociedad.
Próximos pasos
Tras dos años volcados en resolver parte de los problemas generados por la crisis de la Covid-19, desde Geovoluntarios siguen centrados en colaborar con organizaciones que estén comprometidas con la asistencia a las personas más vulnerables en situaciones de emergencias, sin olvidar el compromiso que les vincula a cumplir los Objetivos de Desarrollo Sostenible.
Así, uno de los proyectos propios en los que los voluntarios están más activos es la aplicación y el perfeccionamiento de GeoObs, una app para geolocalizar diferentes proyectos de observación sobre: puntos sucios, peligro de incendios, zonas peligrosas para moteros, mejorar de una ciudad, ciclismo seguro, etc.
El papel de los datos abiertos
Para una ONG como Geovoluntarios los datos abiertos son esenciales tanto para desarrollar las tareas solidarias que llevan a cabo junto a otras asociaciones, como para diseñar servicios y aplicaciones propias. De ahí que estos recursos formen parte de las nuevas funcionalidades en las que la Asociación quiere centrarse.
Tanto es así que la recogida de datos marca un punto inicial para los proyectos piloto que se pueden encontrar actualmente bajo el ámbito de Geovoluntarios. Sin ir más lejos, la aplicación mencionada anteriormente es un ejemplo que demuestra cómo generar datos por observación puede contribuir a enriquecer los catálogos de datos abiertos disponibles.
¿Cómo contactar con ellos?
Si te interesa contactar con Geovoluntarios, puedes visitar su página web o rellenar el formulario de contacto.
Comunidad SIG
¿Qué es y cuál es su objetivo?
Comunidad SIG es un colectivo virtual que reúne a profesionales del ámbito de los datos geográficos y los sistemas de información vinculados al mismo sector. Fundados en el año 2009, difunden su trabajo a través de redes sociales como Facebook, Twitter o Instagram desde donde, además, comparten noticias e información relevante sobre geotecnología, geoprocesamiento u ordenamiento territorial entre otros temas.
Su objetivo no es otro que contribuir a ampliar el conocimiento divulgativo y de interés para la comunidad de datos geográficos, un espacio virtual con escasa presencia cuando este proyecto comenzó su labor en internet.
¿Qué funciones lleva a cabo?
En línea con los objetivos mencionados anteriormente, las tareas desarrolladas por SIG están centradas en la compartición y generación de contenido relacionado con los Sistemas de Información Geográfica. Dada la diversidad de campos y sectores de actuación dentro del mismo ámbito, tratan de equilibrar el contenido de sus publicaciones para conseguir congregar tanto a quien busca información como a quien provee oportunidades. Por esta razón es posible encontrar noticias sobre eventos, capacitaciones, proyectos de investigación, noticias sobre emprendedores o literatura entre muchos otros.
Próximos pasos
Conscientes del peso que tienen como comunidad dentro del ámbito de los datos geográficos, desde SIG tienen planificado reforzar cuatro ejes que afectan directamente al trabajo del proyecto: organizar charlas y webinars, contactar con organismos e instituciones capaces de aportar financiación a proyectos del área SIG, buscar entidades que proporcionen información geoespacial abierta y, por último, conseguir que una parte del sector privado participe económicamente en la formación y capacitación de los profesionales del ámbito SIG.
El papel de los datos abiertos
Se trata de una comunidad que está estrechamente vinculada al universo de los datos abiertos, debido a que comparte contenido que puede ser utilizado, complementado y redistribuido libremente por los usuarios. De hecho, según apuntan sus propios integrantes, cada vez se aprecia más la aceptación y la preferencia por esta tendencia, logrando que los colaboradores de la comunidad y sus propios proyectos, impulsen el debate y el interés a la utilizar datos abiertos en todas las fases activas de sus tareas o actividades.
¿Cómo contactar con ellos?
Al igual que en los casos anteriores, si te interesa ponerte en contacto con Comunidad SIG puedes hacerlo a través de su página de Facebook, Twitter o Instagram o enviando un correo electrónico al siguiente email.
Comunidades como Gis and Beers, SIG o Geovoluntarios son tan solo un pequeño ejemplo del trabajo que está desarrollando el colectivo GIS en la actualidad. Si formas parte de alguna comunidad de datos de este u otro ámbito o conoces de cerca la labor de comunidades que puedan resultar de interés en datos.gob.es, no dudes en enviarnos un correo electrónico a dinamizacion@datos.gob.es.
Geo Developers
¿Qué es y cuál es su objetivo?
Geodevelopers es una comunidad cuyo objetivo es reunir a desarrolladores y topógrafos del ámbito de los datos geográficos. La función principal de esta comunidad es compartir distintas experiencias profesionales relacionadas con los datos geográficos y, para ello, organizan charlas donde todo el mundo puede compartir su experiencia y conocimiento con el resto.
A través de su canal de YouTube es posible acceder a las formaciones y charlas realizadas hasta la fecha, así como estar al tanto de las siguientes que podrán llevar a cabo.
El papel de los datos abiertos
Aunque no se trata de una comunidad centrada en la reutilización de datos abiertos como tal, estos les sirven para desarrollar algunos proyectos y extraer nuevos aprendizajes que después incorporan a los flujos de trabajo.
Próximos pasos y contacto
El principal objetivo de futuro de Geodevelopers es hacer crecer la comunidad para, así, poder seguir compartiendo experiencias y conocimiento con el resto de interesados del ámbito GIS. Si quieres ponerte en contacto y seguir la evolución de este proyecto puedes hacerlo a través de su perfil de Twitter.
Entrevista
R-Ladies es una comunidad software que tiene como objetivo visibilizar a las mujeres que trabajan o desarrollan proyectos o software utilizando R para ello. Es una rama local de R-Ladies Global, una comunidad open source que nace en 2016.
Sus organizadoras Inés Huertas, Leticia Martín-Fuertes y Elen Irazabal, nos han dedicado unos minutos para hablar de la actividad que realiza esta comunidad y de cómo impulsar la presencia de mujeres en los ámbitos tecnológicos.
Entrevista completa:
1. ¿Cómo nace R-Ladies?
R-Ladies Madrid nace a partir de una iniciativa internacional, pero también nace de una realidad local en España en aquel momento y es que se podían encontrar pocas chicas en los congresos o desarrollando paquetería en R, entonces nadie pensaba que fuera un problema hasta que en los primeros meetups comenzaron a aparecer muchas mujeres que acudían por primera vez a una comunidad y que no las veíamos en esos otros espacios por diferentes motivos. Aquello nos motivó a continuar con la comunidad, ya que en muchas ocasiones éramos la puerta de entrada a que pudieran participar en estas comunidades o congresos, etc.
2. ¿Qué ventajas y desventajas tiene R como lenguaje de programación frente a sus competidores?
R es uno de los primeros lenguajes de software libre que se utilizan en el mundo de los datos. Ha estado muy relacionado con la comunidad universitaria e investigadora que inicialmente alimentó gran parte de la paquetería que hoy en día tenemos. A día de hoy hay grandes empresas que trabajan por mejorar y mantener estos repositorios, porque el espectro de paquetería que puede encontrarse en R es muy amplio y cuenta con una potente comunidad detrás. Puedes encontrarte con desarrollos que abarcen desde paquetería de nicho de investigación como de biogenética, hasta paquetería menos específica para análisis generales.
3. El número de mujeres en ingenierías es de un 25% (mientras que el total de mujeres en el sistema universitario alcanza el 59%). En vuestra opinión, ¿cuáles son las razones detrás de esta situación?
Son diversos motivos pero si tenemos que elegir uno es la poca visibilidad a las mujeres dentro de las ingenierías. Se están haciendo actualmente grandes esfuerzos por dar visibilidad a las mujeres que desarrollan y trabajan con datos. En R-Ladies por ejemplo tenemos un directorio internacional donde puedes encontrar a mujeres para hablar en congresos a nivel mundial, pudiendo así crear modelos de referencia a otras mujeres que se animen a participar. Eso es lo que hacemos desde R-Ladies, damos visibilidad a mujeres que están trabajando con R.
De todas formas, y dada la revolución digital que estamos viviendo, lo que se está viendo es la unión entre las letras y las ciencias. Por ejemplo, en el campo de la Inteligencia Artificial, estamos viendo cómo afecta a áreas que anteriormente eran de letras, como la lingüística, el derecho, el marketing etc. Dada esta intersección, están apareciendo perfiles mixtos que, sin haber estudiado el grado de ingeniería, se dedican a aplicar aspectos técnicos al mundo no técnico. Por ejemplo, enseñar lenguaje natural a las máquinas.
El caso del derecho también es paradigmático, ya hay regulaciones que requieren de conocimientos técnicos para poder aplicarlas. De hecho, incluso el mundo técnico también puede interesarse del mundo de las letras, como por ejemplo, cómo afecta el derecho y la regulación a cómo funciona internet.
En definitiva, no hay que ver al mundo de la ciencia y de las letras como carreras laborales distintas sino que cada vez son más complementarias.
Se está viendo la unión entre las letras y las ciencias. Están apariendo perfiles mixtos que, sin haber estudiado el grado de ingeniería, se dedican a aplicar aspectos técnicos al mundo no técnico.
4. ¿Cómo ayudan Iniciativas como R-Ladies a impulsar la presencia de mujeres en el ámbito tecnológico?
Precisamente ayudando a crear Role Models. Apoyando a las mujeres para que no sufran el llamado “síndrome del impostor”. Dar una charla en tu tiempo libre sobre las cosas en las que trabajas o tienes interés es mucho más de lo que parece, para muchas de estas mujeres es un primer paso que puede ayudarlas a presentar un proyecto en su empresa o defender una propuesta ante un cliente.
5. ¿En qué proyectos están trabajando?
Actualmente con la pandemia hemos tenido que adaptarnos con un ciclo de talleres/charlas mensuales online durante 2020/2021 que no nos limita a estar físicamente en Madrid, por lo que contamos con speakers que de otra forma sería más complicado traer a Madrid. Además, hemos intentado hacer estos talleres mensuales de forma incremental, de tal forma que empezando en Septiembre hasta ahora hemos ido incrementando el nivel de la sesiones empezando desde los primeros pasos en R hasta acabar con la realización de un análisis de datos con Redes Neuronales. Además estamos alimentando con estas sesiones nuestro canal de YouTube, generando contenido en español sobre cómo utilizar R que está teniendo una gran acogida.
6. ¿Qué tipos de datos abiertos han utilizado en sus proyectos y con qué datos les gustaría trabajar?
Sobre la utilización de datos abiertos, alguno de los grupos de trabajo utiliza datos del BOE u Open Data NASA para desarrollo de proyectos. También ayudamos a montar un grupo de trabajo que trabaja con los datos del covid.
Nos gustaría poder trabajar con la jurisprudencia española. Sería muy interesante ver cómo en la historia de la democracia se han ido dictando distintas sentencias y la evolución de ellas a lo largo de todos estos años.
También nos gustaría poder trabajar con los corpus de referencia de la RAE, como el CREA, el CORDE o el CORPES XXI, que contienen textos de diversa índole, incluidos transcripciones orales, con los que se podrían hacer muchísimos análisis lingüísticos y servir como datos de entrenamiento para mejorar la presencia del español en el ámbito de la IA.
Sobre la utilización de datos abiertos, alguno de los grupos de trabajo utiliza datos del BOE u Open Data NASA para desarrollo de proyectos. También ayudamos a montar un grupo de trabajo que trabaja con los datos del covid.
7. Para terminar, ¿cómo pueden las personas interesadas seguir a R-Ladies y colaborar con vosotras?
¡Superfácil! Pueden escribirnos a madrid@rladies.org, apuntarse a nuestro Meetup o sencillamente por Twitter, en nuestra cuenta de @RladiesMad. ¡Todo el mundo es bienvenido!
Entrevista
Hackathon Lovers es una comunidad de amantes de los hackathones que realiza eventos periódicos con el foco puesto en la resolución de problemas técnicos de una manera innovadora.
En esta entrevista, Adolfo Sanz de Diego, fundador de Hackathon Lovers, nos hablan de las ventajas de este formato y del reto que ha supuesto pasar del formato presencial al online
Entrevista completa:
1. ¿Puede explicarnos de forma breve qué es Hackathon Lovers?
Hackathon Lovers empezó siendo, y es fundamentalmente, una comunidad de amantes de los hackathones, ahora también startup tecnológica que organiza sus propios hackathones y ayuda a otras empresas a organizar los suyos propios, siempre y cuando cumplan con unas condiciones no abusivas para los participantes que tenemos recogidas en nuestro código ético (https://hackathonlovers.com/#principios).
2. ¿Cuáles son las ventajas de los hackathones comparado con otro tipo de eventos?
Quizás la mayor ventaja es que con las soluciones que se desarrollan podemos ayudar a resolver problemas reales.
Se crean más lazos entre los participantes que en otros eventos, ya que estas trabajando con ellos codo con codo durante un par de días sin parar y sobre todo aprendes bastante de los compañeros.
Para los participantes que son muy juniors son un lugar donde pueden poner en práctica los conocimientos que tienen, aprender de los que ya tienen más experiencia, hacer nuevos contactos y sobre todo que salen con proyectos que pueden enseñar para encontrar trabajo.
3. Un objetivo de este tipo de eventos consiste en abordar determinados retos que pueden ser resueltos utilizando datos públicos. ¿Queréis destacar, a modo de ejemplo, alguno de éstos y comentar brevemente qué tipo de soluciones proponen los participantes?
El uso de los datos públicos en los hackathones es bastante habitual, pues esos datos públicos se pueden utilizar conjuntamente con otras APIs para desarrollar mejores productos que sin esos datos.
Por ejemplo, en el #Hack4Good se desarrolló el mapa de la evolución de la contaminación del aire de Madrid. En en #DataFestMAD, un equipo desarrolló una aplicación que mostraba la ruta óptima entre dos puntos evitando las zonas contaminación y en el #TWOC15, el equipo ganador desarrolló una aplicación que muestra la reputación de lugares (barrios) basada en datos abiertos de criminalidad, de facilidades e infraestructuras.
El uso de los datos públicos en los hackathones es bastante habitual, pues esos datos públicos se pueden utilizar conjuntamente con otras APIs para desarrollar mejores productos que sin esos datos.
4. ¿Qué tipo de perfiles acuden a vuestros encuentros?
Esta pregunta depende del reto al que se enfoque el hackathon. Normalmente las personas que asisten suelen ser del sector tecnológico y dentro de este de podemos encontrarnos perfiles de desarrollo web, de diseño, análisis de datos, blockchain… Aunque también hemos organizado otro tipo de hackathones en el que han participado gente del sector de la salud (#Searchathon), legal (#JustiApps) y energías renovables (#Renovathon) entre otros porque el reto iba más enfocado a estos sectores.
5. ¿Qué consejo darías a aquellas personas que quieren participar en un hackathon?
Que se apunten sin miedo. Para participar en un hackathon no hace falta que seas un/a supercrack. La idea es juntarse con otras personas con más/menos nivel y trabajar codo con codo para sacar adelante una solución al problema que se plantea, conocer gente del sector o de otros sectores, pasarlo bien y aprender.
6. Las restricciones ocasionadas por la pandemia han supuesto un reto para vosotros, ¿cómo lo habéis hecho frente?
Un poco porque hemos tenido que cambiar y repensar la dinámica de un hackathon para adaptarla al entorno online mediante el uso de distintas plataformas para la comunicación durante el hackathon. Entonces hemos tenido que buscar qué herramientas nos proporcionaban las funcionalidades que necesitábamos y a su vez que fueran fáciles de utilizar por los participantes, e incluso hemos tenido que hacer algún pequeño desarrollo para facilitar nuestro trabajo.
7. ¿Qué tipos de datos abiertos habéis utilizado en vuestros proyectos y con qué datos os gustaría trabajar?
Como hemos dicho antes, el uso de los datos públicos en los hackathones es bastante habitual, pues esos datos públicos se pueden utilizar conjuntamente con otras APIs, o incluso con otros datos abiertos, para desarrollar productos innovadores. Hemos utilizado datos del tiempo, de contaminación, de puntos de interés, datos estadísticos de población, de movilidad, de seguridad ciudadana… Hay tantos datos abiertos, y muy útiles…
Más que con qué datos nos gustaría trabajar, la pregunta sería qué necesitaríamos para poder usar mejor esos datos. Y pensamos que hace falta estandarización: que todos los datos tuviesen más o menos las mismas APIs de consulta o se pudiesen descargar con formatos parecidos.
8. Para terminar, ¿cómo pueden las personas interesadas seguir a Hackathon Lovers y colaborar con vosotros?
Pueden seguirnos por Twitter y apuntarse a nuestro Meetup, donde tenemos una lista de correo en la que anunciamos tanto los hackathones que organizamos nosotros como los que vemos que cumplen con nuestro código ético.
Entrevista
R Hispano es una comunidad de usuarios y desarrolladores que nació en 2011, en el seno de las III Jornadas de Usuarios de R, con el objetivo de fomentar el avance del conocimiento y el uso del lenguaje de programación en R. Desde datos.gob.es hemos hablado con Emilio López Cano, presidente de R Hispano, para que nos cuente más sobre las actividades que realizan y el papel de los datos abiertos en ellas.
Entrevista completa
1. ¿Puede explicarnos de forma breve qué es la Comunidad R-Hispano?
Se trata de una asociación creada en España cuyo objetivo es el de promover el uso de R entre un público hispano. Hay muchos usuarios de R a nivel mundial e intentamos servir como punto de encuentro entre todos aquellos cuyo idioma principal es el español. Al tener como referencia un grupo más pequeño dentro de una comunidad tan grande, es más fácil entablar relaciones y conocer a personas a las que acudir cuando se quiere aprender más o compartir lo aprendido.
2. R nace como lenguaje ligado a la explotación estadística de los datos, sin embargo, se ha ido convirtiendo en una herramienta esencial de la Ciencia de Datos, ¿por qué tanta aceptación de este lenguaje por la comunidad?
Es verdad que muchos profesionales de la ciencia e ingeniería de datos tienden a utilizar lenguajes más genéricos como Python. Sin embargo, hay varios motivos por los que R se hace imprescindible en el “Stack” de los equipos que trabajan con datos. En primer lugar, R tiene su origen en el lenguaje S, que se diseñó en los años 70 específicamente para el análisis de datos, en el seno de los laboratorios Bell. Esto permite que personas con diferente formación informática pueda participar en proyectos complejos, centrándose en los métodos de análisis. En segundo lugar, R ha envejecido muy bien, y una amplia comunidad de usuarios, desarrolladores y empresas contribuyen al proyecto con paquetes y herramientas que extienden la funcionalidad de forma rápida hacia los métodos más innovadores con (relativa) sencillez y todo el rigor.
3. R Hispano funciona a través de numerosas iniciativas locales, ¿qué ventajas conlleva esta forma de organización?
En las actividades del día a día, sobre todo cuando teníamos encuentros presenciales, hace más de un año, es más cómodo coordinar a las personas de la manera más cercana posible. No tiene sentido que una persona en Madrid organice reuniones mensuales en Málaga, Sevilla o Canarias. Lo interesante de estos eventos es asistir regularmente, ir conociendo a los asistentes, entender lo que demanda el público y lo que se puede ofrecer. Eso, aparte de mimo y dedicación, requiere estar cerca porque, si no, no hay forma de establecer ese vínculo. Por eso nos ha parecido que es desde las propias ciudades como se tiene que mantener esa relación de día a día. Por otra parte, es la forma en la que la Comunidad de R se ha organizado en todo el mundo, con el éxito que todos conocemos.
4. ¿Consideráis las iniciativas de datos abiertos una valiosa fuente de información para el desarrollo de vuestros proyectos? ¿Algún ejemplo de reutilización destacable? ¿Qué aspectos consideráis mejorables de las iniciativas actuales?
Lo primero decir que R Hispano como tal no tiene proyectos. Sin embargo, muchos socios de R Hispano trabajan con datos abiertos en su ámbito profesional, ya sea académico o empresarial. Desde luego, es una fuente de información muy valiosa, con muchísimos ejemplos, como el análisis de los datos de la pandemia que todavía sufrimos, los datos de competiciones deportivas y rendimiento de deportistas, datos medioambientales, socioeconómicos, … No podemos destacar ninguno porque hay muchos muy interesantes que lo merecerían igualmente. En cuanto a las mejoras, todavía hay muchos repositorios de datos públicos que no los publican en formato “tratable” por los analistas. Un informe en PDF puede ser datos abiertos, pero desde luego no contribuyen a su difusión, análisis, y explotación por el bien de la sociedad. Todos los datos abiertos deberían estar tabulados en formatos que permitan la rápida importación a software, como por ejemplo R.
5. ¿Puede contarnos algunas de las actividades que llevan a cabo esas Iniciativas locales?
Varios grupos locales de R, tanto en España como Latam, colaboraron recientemente con la empresa de formación en tecnologías, UTad, en el evento “Encuentros en la fase R”. Celebrado en formato online con dos días de duración. Las jornadas de usuarios de R que celebramos cada año, normalmente las organiza alguno de los grupos locales de la sede. El grupo de Córdoba está organizando las próximas, aplazadas con motivo de la pandemia y de las que esperamos poder anunciar fechas pronto.
El Grupo de Usuarios de R de Madrid comenzó a funcionar como grupo local vinculado a la Comunidad R hispano hace más de quince años. Desde su origen mantiene una periodicidad mensual de reuniones anunciadas en la red social Meetup (patrocinado por parte de RConsortium, entidad, fundada y subvencionada por grandes compañías para favorecer el uso de R). La actividad se ha visto interrumpida por las limitaciones del Covid-19, pero todo el historial de las presentaciones se ha ido recopilando en este portal.
Desde el Grupo de R Canarias se han involucrado en la conferencia TabularConf, que tuvo lugar el 30 de enero, en formato online, con una agenda de una decena de ponencias sobre data science e inteligencia artificial. En el pasado el grupo canario realizó un encuentro de usuarios de R con comunicaciones sobre varios tópicos, incluidos modelización, tratamiento de datos geográficos, así como consultas a APIs de datos públicos, como datos.gob.es, con la librería opendataes. Otras librerías presentadas en un meetup que realizaron en 2020 son istacr o inebaseR, siempre apostando por el acceso a datos públicos.
En el Grupo Local de Sevilla, durante los hackatones celebrados en los últimos años, ha comenzado a desarrollar varios paquetes totalmente vinculados a datos abiertos.
-
Aire: Para obtener datos de calidad del aire en Andalucía (funciona, pero necesita algunos ajustes)
-
Aemet: Paquete de R para interaccionar con la API de AEMET (datos climáticos). Dimos los primeros pasos en un hackaton, luego Manuel Pizarro hizo un paquete totalmente funcional.
-
Andaclima: Paquete para obtener datos climáticos de estaciones agroclimáticas de la Junta de Andalucía
-
Datos.gob.es.r: Embrión de paquete para interaccionar con http://datos.gob.es. Realmente solo una exploración de ideas, nada funcional por ahora.
Sobre COVID-19 merece la pena destacar el desarrollo por parte de la UCLM, con la colaboración en un exmiembro de la Junta Directiva de la Comunidad R Hispano, de un panel de análisis de la COVID-19, con los casos que la Junta de Comunidades de Castilla-La Mancha presenta por municipio. Consiste en una herramienta interactiva para consultar la información sobre la incidencia y tasas por 100.000 habitantes.
6. Además, también colaboran con otros grupos e iniciativas.
Sí, colaboramos con otros grupos e iniciativas centradas en datos, como la UNED (Facultad de Ciencias), que durante un largo periodo de tiempo nos acogió como sede permanente. También destacaría nuestras actuaciones con:
-
Grupo de Periodismo de Datos. Presentaciones conjuntas con el grupo de Periodismo de Datos, compartiendo las bondades de R para sus análisis.
-
Una colaboración con el Grupo Machine Learning Spain que se tradujo en una presentación común en el Google Campus de Madrid.
-
Con grupos de otros lenguajes de datos, como Python.
-
Colaboraciones con empresas. En este punto destacamos el haber participado en dos eventos de Analítica Avanzada organizadas por Microsoft, así como el haber recibido pequeñas ayudas económicas de empresas como Kabel o Kernel Analytics (recientemente adquirida por Boston Consulting Group).
Estos son algunos ejemplos de presentaciones en el grupo de Madrid basadas en datos abiertos:
Además, diferentes socios de R-Hispano, también colaboran con instituciones académicas, en las que imparten diferentes cursos relacionados al análisis de Datos, fomentando especialmente el uso y análisis de datos abiertos, como por ejemplo la Facultad de Economía de la UNED, la Facultades de Estadística y de Turismo y Comercio de la UCM, la Universidad de Castilla-La Mancha, la EOI (asignatura específica sobre datos abiertos), la Universidad Francisco de Vitoria, la Escuela Superior de Ingeniería de Telecomunicaciones, el ESIC y la escuela K-School.
Por último, nos gustaría destacar el vínculo constante que se mantiene con diferentes entidades de relevancia del ecosistema R: con R-Consortium (https://www.r-consortium.org/) y RStudio (https://rstudio.com/). Es a través del R-Consortium donde hemos conseguido el reconocimiento del Grupo de Madrid como grupo estable y del que conseguimos el patrocinio para el pago de Meetup. Dentro de RStudio mantenemos diferentes contactos que nos han permitido igualmente conseguir patrocinios que han ayudado en las Jornadas de R, así como ponentes de la talla de Javier Luraschi (autor del paquete y libro sobre “sparklyr”) o Max Kuhn ( autor de paquetes como “caret” y de su evolución “tidymodels”).
7. A través de ROpenSpain algunos socios de RHispano han colaborado en la creación de paquetes en R que facilitan el uso de datos abiertos.
ROpenSpain es una comunidad de entusiastas de R, de los datos abiertos y la reproducibilidad que se reúne y organiza para crear paquetes de R de la máxima calidad para la explotación de datos españoles de interés general. Nace, con la inspiración de ROpenSci, en febrero de 2018 como organización de GitHub y dispone de un canal de colaboración en Slack. A enero de 2021, ROpenSpain agrupa los siguientes paquetes de R:
-
opendataes: Interactúa fácilmente con la API de datos.gob.es, que proporciona datos de las administraciones públicas de toda España.
-
MicroDatosEs: Permite importar a R varios tipos de ficheros de microdatos del INE: EPA, Censo, etc.
-
caRtociudad: Consulta la API de Cartociudad, que proporciona servicios de geolocalización, rutas, mapas, etc.
-
Siane: Para representar información estadística sobre los mapas del Instituto Geográfico Nacional.
-
airqualityES: Datos de calidad del aire en España de 2011 a 2018.
-
mapSpain: Para cargar mapas de municipios, provincias y CCAA. Incluye un plugin para leaflet.
-
MorbiditySpainR: Lee y manipula datos de la Encuesta de Morbilidad Hospitalaria
-
Spanish: Para el procesamiento de cierto tipo de información española: números, geocodificación catastral, etc.
-
BOE: Para el procesamiento del Boletín Oficial del Estado y del Boletín Oficial del Registro Mercantil.
-
istacbaser: Para consultar la API del Instituto Canario de Estadística.
-
CatastRo: Consulta la API del Catastro.
Algunos de estos paquetes se han presentado en eventos organizados por la Comunidad R Hispano.
8. Para terminar, ¿cómo pueden las personas interesadas seguir a R-Hispano y colaborar con vosotros?
Un elemento importante como nexo de unión en toda la comunidad de usuarios de R en español es la lista de ayuda R-Help-es:
-
Búsqueda: https://r-help-es.r-project.narkive.com/;
-
Suscripción: https://stat.ethz.ch/mailman/listinfo/r-help-es ).
Es una de las pocas listas de ayuda sobre R, activas e independiente de la principal en inglés R-Help que ha generado más de 12.800 entradas en sus más de 12 años de historia.
Además, se mantiene un gran nivel de actividad en las redes sociales que sirven como altavoz, palanca a través de las cuales se dan a conocer futuros eventos o diferentes noticias relacionadas con datos de interés para la comunidad. Podemos destacar las siguientes iniciativas en cada una de las plataformas:
-
Twitter: Presencia de la propia asociación R-Hispano; https://twitter.com/R_Hisp y participación en el hastag #rstatsES (R en Español) de diferentes colaboradores de R del ámbito nacional.
-
LinkedIn: En esta red profesional, “R” tiene presencia a través de la página de empresa https://www.linkedin.com/company/comunidad-r-hispano/. Además, multitud de socios de R-Hispano tanto de España como de Latam forman parte de esta red compartiendo recursos en abierto.
-
Canal de Telegram: Existe un canal de Telegram dónde se difunden con cierta periodicidad noticias de interés para la comunidad https://t.me/rhispano
Por último, en la página web de la asociación, http://r-es.org, se puede encontrar información sobre la asociación, así como la forma de hacerse socio/a (la cuota es, como R, gratuita).