Blog
En el vertiginoso mundo de la Inteligencia Artificial (IA) Generativa, encontramos diversos conceptos que se han convertido en fundamentales para comprender y aprovechar el potencial de esta tecnología. Hoy nos centramos en cuatro: los Modelos de Lenguaje Pequeños (SLM, por sus siglas en inglés), los Modelos de Lenguaje Grandes (LLM), la Generación Aumentada por Recuperación (RAG) y el Fine-tuning. En este artículo, exploraremos cada uno de estos términos, sus interrelaciones y cómo están moldeando el futuro de la IA generativa.
Empecemos por el principio. Definiciones.
Antes de sumergirnos en los detalles, es importante entender brevemente qué representa cada uno de estos términos. Los dos primeros conceptos (SLM y LLM) que abordamos, son lo que se conoce cómo modelos del lenguaje. Un modelo de lenguaje es un sistema de inteligencia artificial que entiende y genera texto en lenguaje humano, como lo hacen los chatbots o los asistentes virtuales. Los siguientes dos conceptos (Fine Tuning y RAG), podríamos definirlos cómo técnicas de optimización de estos modelos del lenguaje previos. En definitiva, estás técnicas, con sus respectivos enfoques, que veremos más adelante, mejoran las respuestas y el contenido que devuelven al que pregunta. Vamos a por los detalles:
- SLM (Small Language Models): Modelos de lenguaje más compactos y especializados, diseñados para tareas específicas o dominios concretos.
- LLM (Large Language Models): Modelos de lenguaje de gran escala, entrenados con vastas cantidades de datos y capaces de realizar una amplia gama de tareas lingüísticas.
- RAG (Retrieval-Augmented Generation): Una técnica que combina la recuperación de información relevante con la generación de texto para producir respuestas más precisas y contextualizadas.
- Fine-tuning: El proceso de ajustar un modelo pre-entrenado para una tarea o dominio específico, mejorando su rendimiento en aplicaciones concretas.
Ahora, profundicemos en cada concepto y exploremos cómo se interrelacionan en el ecosistema de la IA Generativa.
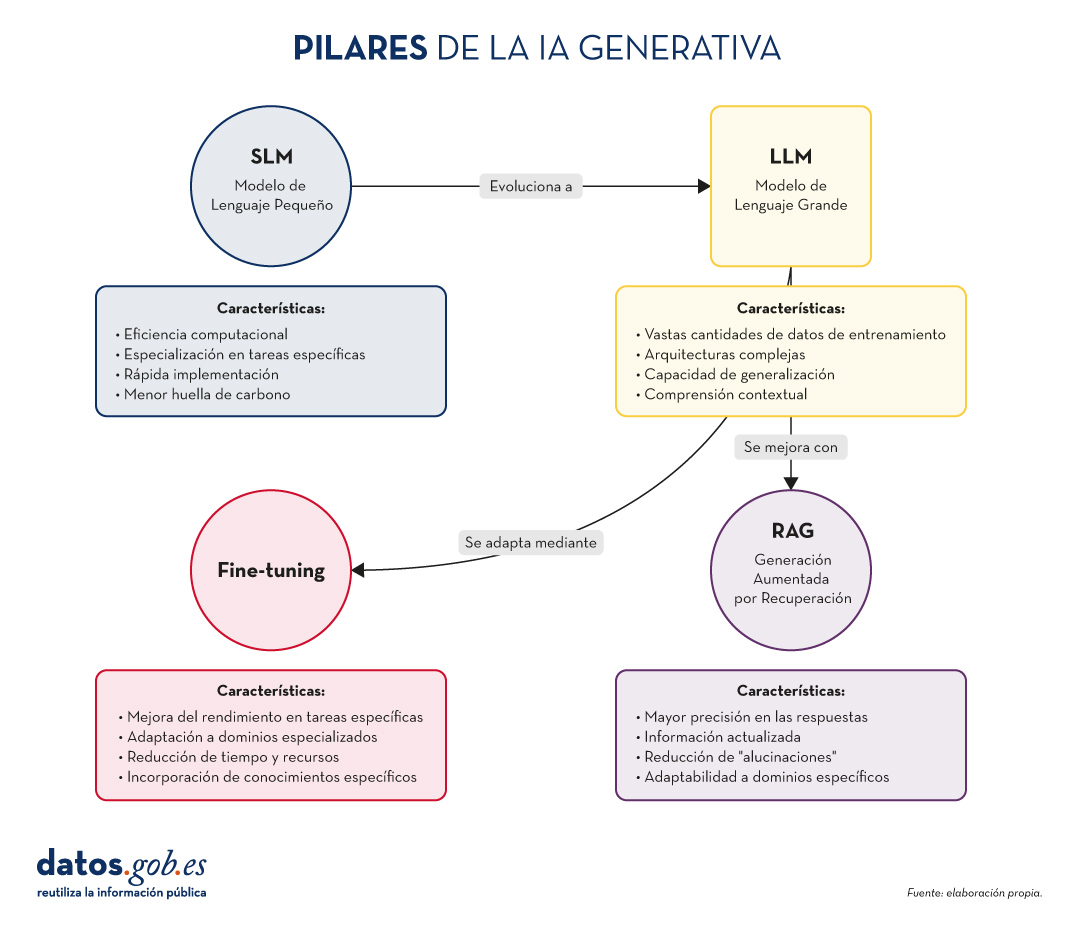
Figura 1. Pilares de la IA genrativa. Elaboración propia.
SLM: La potencia en la especialización
Mayor eficiencia para tareas concretas
Los Modelos de Lenguaje Pequeños (SLM) son modelos de IA diseñados para ser más ligeros y eficientes que sus contrapartes más grandes. Aunque tienen menos parámetros, están optimizados para tareas específicas o dominios concretos.
Características clave de los SLM:
- Eficiencia computacional: requieren menos recursos para su entrenamiento y ejecución.
- Especialización: se centran en tareas o dominios específicos, logrando un alto rendimiento en áreas concretas.
- Rápida implementación: ideal para dispositivos con recursos limitados o aplicaciones que requieren respuestas en tiempo real.
- Menor huella de carbono: al ser más pequeños, su entrenamiento y uso consumen menos energía.
Aplicaciones de los SLM:
- Asistentes virtuales para tareas específicas (por ejemplo, reserva de citas).
- Sistemas de recomendación personalizados.
- Análisis de sentimientos en redes sociales.
- Traducción automática para pares de idiomas específicos.
LLM: El poder de la generalización
La revolución de los Modelos de Lenguaje Grandes
Los LLM han transformado el panorama de la IA Generativa, ofreciendo capacidades sorprendentes en una amplia gama de tareas lingüísticas.
Características clave de los LLM:
- Vastas cantidades de datos de entrenamiento: se entrenan con enormes corpus de texto, abarcando diversos temas y estilos.
- Arquitecturas complejas: utilizan arquitecturas avanzadas, como Transformers, con miles de millones de parámetros.
- Capacidad de generalización: pueden abordar una amplia variedad de tareas sin necesidad de entrenamiento específico para cada una.
- Comprensión contextual: son capaces de entender y generar texto considerando contextos complejos.
Aplicaciones de los LLM:
- Generación de texto creativo (historias, poesía, guiones).
- Respuesta a preguntas complejas y razonamientos.
- Análisis y resumen de documentos extensos.
- Traducción multilingüe avanzada.
RAG: Potenciando la precisión y relevancia
La sinergia entre recuperación y generación
Como ya exploramos en nuestro artículo anterior, RAG combina la potencia de los modelos de recuperación de información con la capacidad generativa de los LLM. Sus aspectos fundamentales son:
Características clave de RAG:
- Mayor precisión en las respuestas.
- Capacidad de proporcionar información actualizada.
- Reducción de "alucinaciones" o información incorrecta.
- Adaptabilidad a dominios específicos sin necesidad de reentrenar completamente el modelo.
Aplicaciones de RAG:
- Sistemas de atención al cliente avanzados.
- Asistentes de investigación académica.
- Herramientas de fact-checking para periodismo.
- Sistemas de diagnóstico médico asistido por IA.
Fine-tuning: Adaptación y especialización
Perfeccionando modelos para tareas específicas
El fine-tuning es el proceso de ajustar un modelo pre-entrenado (generalmente un LLM) para mejorar su rendimiento en una tarea o dominio específico. Sus elementos principales son los siguientes:
Características clave del fine-tuning:
- Mejora significativa del rendimiento en tareas específicas.
- Adaptación a dominios especializados o nichos.
- Reducción del tiempo y recursos necesarios en comparación con el entrenamiento desde cero.
- Posibilidad de incorporar conocimientos específicos de la organización o industria.
Aplicaciones del fine-tuning:
- Modelos de lenguaje específicos para industrias (legal, médica, financiera).
- Asistentes virtuales personalizados para empresas.
- Sistemas de generación de contenido adaptados a estilos o marcas particulares.
- Herramientas de análisis de datos especializadas.
Pongamos algunos ejemplos
A muchos de los que estéis familiarizados con las últimas noticias en IA generativa os sonarán estos ejemplos que citamos a continuación.
SLM: La potencia en la especialización
Ejemplo: BERT para análisis de sentimientos
BERT (Bidirectional Encoder Representations from Transformers) es un ejemplo de SLM cuando se utiliza para tareas específicas. Aunque BERT en sí es un modelo de lenguaje grande, versiones más pequeñas y especializadas de BERT se han desarrollado para análisis de sentimientos en redes sociales.
Por ejemplo, DistilBERT, una versión reducida de BERT, se ha utilizado para crear modelos de análisis de sentimientos en X (Twitter). Estos modelos pueden clasificar rápidamente tweets como positivos, negativos o neutros, siendo mucho más eficientes en términos de recursos computacionales que modelos más grandes.
LLM: El poder de la generalización
Ejemplo: GPT-3 de OpenAI
GPT-3 (Generative Pre-trained Transformer 3) es uno de los LLM más conocidos y utilizados. Con 175 mil millones de parámetros, GPT-3 es capaz de realizar una amplia variedad de tareas de procesamiento de lenguaje natural sin necesidad de un entrenamiento específico para cada tarea.
Una aplicación práctica y conocida de GPT-3 es ChatGPT, el chatbot conversacional de OpenAI. ChatGPT puede mantener conversaciones sobre una gran variedad de temas, responder preguntas, ayudar con tareas de escritura y programación, e incluso generar contenido creativo, todo ello utilizando el mismo modelo base.
Ya a finales de 2020 introducimos en este espacio el primer post sobre GPT-3 como gran modelo del lenguaje. Para los más nostálgicos, podéis consultar el post original aquí.
RAG: Potenciando la precisión y relevancia
Ejemplo: El asistente virtual de Anthropic, Claude
Claude, el asistente virtual desarrollado por Anthropic, es un ejemplo de aplicación que utiliza técnicas RAG. Aunque los detalles exactos de su implementación no son públicos, Claude es conocido por su capacidad para proporcionar respuestas precisas y actualizadas, incluso sobre eventos recientes.
De hecho, la mayoría de asistentes conversacionales basados en IA generativa incorporan técnicas RAG para mejorar la precisión y el contexto de sus respuestas. Así, ChatGPT, la citada Claude, MS Bing y otras similares usan RAG.
Fine-tuning: Adaptación y especialización
Ejemplo: GPT-3 fine-tuned para GitHub Copilot
GitHub Copilot, el asistente de programación de GitHub y OpenAI, es un excelente ejemplo de fine-tuning aplicado a un LLM. Copilot está basado en un modelo GPT (posiblemente una variante de GPT-3) que ha sido específicamente ajustado (fine-tuned) para tareas de programación.
El modelo base se entrenó adicionalmente con una gran cantidad de código fuente de repositorios públicos de GitHub, lo que le permite generar sugerencias de código relevantes y sintácticamente correctas en una variedad de lenguajes de programación. Este es un claro ejemplo de cómo el fine-tuning puede adaptar un modelo de propósito general a una tarea altamente especializada.
Otro ejemplo: en el blog de datos.gob.es, también escribimos un post sobre aplicaciones que utilizaban GPT-3 como LLM base para construir productos concretos ajustados específicamente.
Interrelaciones y sinergias
Estos cuatro conceptos no operan de forma aislada, sino que se entrelazan y complementan en el ecosistema de la IA Generativa:
- SLM y LLM: Mientras que los LLM ofrecen versatilidad y capacidad de generalización, los SLM proporcionan eficiencia y especialización. La elección entre uno u otro dependerá de las necesidades específicas del proyecto y los recursos disponibles.
- RAG y LLM: RAG potencia las capacidades de los LLM al proporcionarles acceso a información actualizada y relevante. Esto mejora la precisión y utilidad de las respuestas generadas.
- Fine-tuning y LLM: El fine-tuning permite adaptar LLM genéricos a tareas o dominios específicos, combinando la potencia de los modelos grandes con la especialización necesaria para ciertas aplicaciones.
- RAG y Fine-tuning: Estas técnicas pueden combinarse para crear sistemas altamente especializados y precisos. Por ejemplo, un LLM con fine-tuning para un dominio específico puede utilizarse como componente generativo en un sistema RAG.
- SLM y Fine-tuning: El fine-tuning también puede aplicarse a SLM para mejorar aún más su rendimiento en tareas específicas, creando modelos altamente eficientes y especializados.
Conclusiones y futuro de la IA
La combinación de estos cuatro pilares está abriendo nuevas posibilidades en el campo de la IA Generativa:
- Sistemas híbridos: combinación de SLM y LLM para diferentes aspectos de una misma aplicación, optimizando rendimiento y eficiencia.
- RAG avanzado: implementación de sistemas RAG más sofisticados que utilicen múltiples fuentes de información y técnicas de recuperación más avanzadas.
- Fine-tuning continuo: desarrollo de técnicas para el ajuste continuo de modelos en tiempo real, adaptándose a nuevos datos y necesidades.
- Personalización a escala: creación de modelos altamente personalizados para individuos o pequeños grupos, combinando fine-tuning y RAG.
- IA Generativa ética y responsable: implementación de estas técnicas con un enfoque en la transparencia, la verificabilidad y la reducción de sesgos.
SLM, LLM, RAG y Fine-tuning representan los pilares fundamentales sobre los que se está construyendo el futuro de la IA Generativa. Cada uno de estos conceptos aporta fortalezas únicas:
- Los SLM ofrecen eficiencia y especialización.
- Los LLM proporcionan versatilidad y capacidad de generalización.
- RAG mejora la precisión y relevancia de las respuestas.
- El Fine-tuning permite la adaptación y personalización de modelos.
La verdadera magia ocurre cuando estos elementos se combinan de formas innovadoras, creando sistemas de IA Generativa más potentes, precisos y adaptables que nunca. A medida que estas tecnologías continúen evolucionando, podemos esperar ver aplicaciones cada vez más sofisticadas y útiles en una amplia gama de campos, desde la atención médica hasta la creación de contenido creativo.
El desafío para los desarrolladores e investigadores será encontrar el equilibrio óptimo entre estos elementos, considerando factores como la eficiencia computacional, la precisión, la adaptabilidad y la ética. El futuro de la IA Generativa promete ser fascinante, y estos cuatro conceptos estarán sin duda en el centro de su desarrollo y aplicación en los años venideros.
Contenido elaborado por Alejandro Alija,experto en Transformación Digital e Innovación. Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Blog
En los últimos meses hemos visto cómo los grandes modelos del lenguaje (LLM en sus siglas en inglés) que habilitan las aplicaciones de Inteligencia artificial generativa (GenAI) han ido mejorando en cuanto a su precisión y confiabilidad. Las técnicas de RAG (Retrieval Augmented Generation) nos han permitido utilizar toda la potencia de la comunicación en lenguaje natural (NLP) con las máquinas para explorar bases de conocimiento propias y extraer información procesada en forma de respuestas a nuestras preguntas. En este artículo profundizamos en las técnicas RAG con el objetivo de conocer mejor su funcionamiento y todas las posibilidades que nos ofrecen en el contexto de la IA generativa.
¿Qué son las técnicas RAG?
No es la primera vez que hablamos de las técnicas RAG. En este artículo ya introdujimos el tema, explicando de forma sencilla en qué consisten, cuáles son sus principales ventajas y qué beneficios aporta en el uso de la IA Generativa.
Recordemos por un momento sus principales claves. RAG, del inglés, Retrieval Augmented Generation, viene a traducirse cómo Generación Aumentada por Recuperación (de información). Es decir, RAG consiste en lo siguiente: cuando un usuario realiza una pregunta -normalmente en un interfaz conversacional-, la Inteligencia Artificial (IA), antes de proporcionar la respuesta directa -que podría dar haciendo uso de la base de conocimiento (fijo) con la que ha sido entrenada-, realiza un proceso de búsqueda y procesamiento de información en una base de datos específica proporcionada previamente, complementaria a la del entrenamiento. Cuando hablamos de una base de datos nos referimos a una base de conocimiento previamente preparada a partir de un conjunto de documentos que el sistema utilizará para proporcionar respuestas más precisas. De esta forma, cuando hacen uso de las técnicas RAG, las interfaces conversacionales producen respuestas más precisas y adaptadas a un contexto concreto.
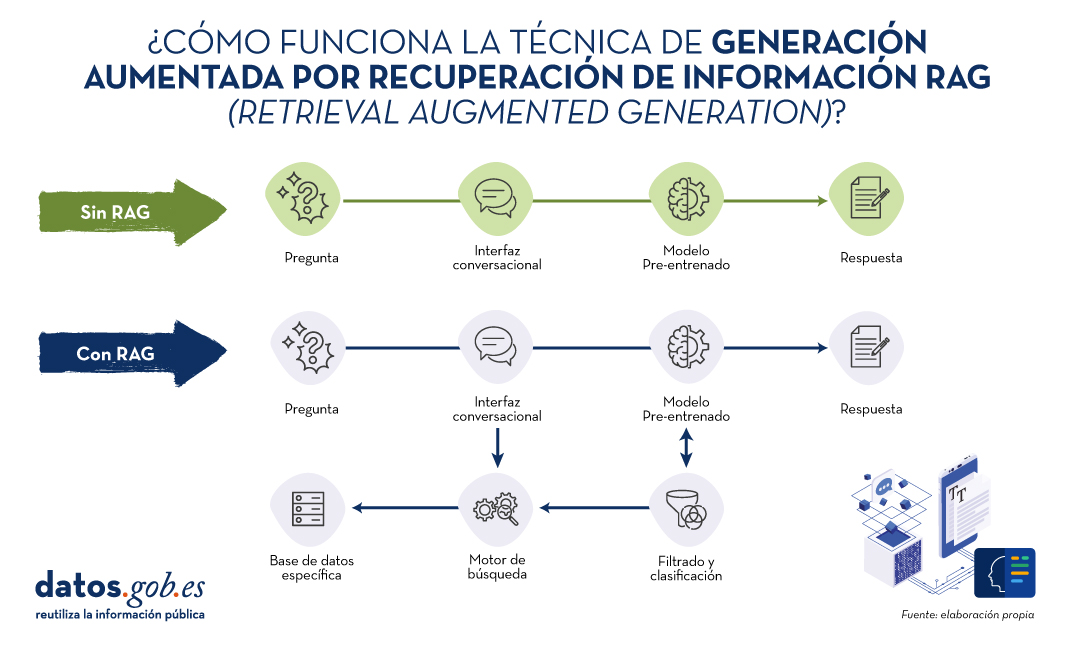
Fuente: Elaboración propia
Diagrama conceptual del funcionamiento de un asistente o interfaz conversacional sin hacer uso de RAG (arriba) y haciendo uso de RAG (abajo).
Haciendo un símil con el ámbito médico, podríamos decir que el uso de RAG es como si un médico, con amplia experiencia y, por lo tanto, altamente entrenado, además de los conocimientos adquiridos durante su formación académica y años de experiencia, tuviera acceso rápido y sin esfuerzo a los últimos estudios, análisis y bases de datos médicas al instante, antes de proporcionar un diagnóstico. La formación académica y los años de experiencia equivalen al entrenamiento del modelo grande del lenguaje (LLM) y el “mágico” acceso a los últimos estudios y bases de datos específicas pueden asimilarse a lo que proporciona las técnicas RAG.
Evidentemente, en el ejemplo que acabamos de poner, la buena práctica médica hace indispensables ambos elementos que el cerebro humano sabe combinar de forma natural, aunque no sin esfuerzo y tiempo, incluso disponiendo de las herramientas digitales actuales, que hacen más sencilla e inmediata la búsqueda de información.
RAG en detalle
Fundamentos de RAG
RAG combina dos fases para conseguir su objetivo: la recuperación y la generación. En la primera, se buscan documentos relevantes en una base de datos que contiene información pertinente a la pregunta planteada (por ejemplo, una base de datos clínicos o una base de conocimiento de preguntas y respuestas más habituales). En la segunda, se utiliza un LLM para generar una respuesta basada en los documentos recuperados. Este enfoque asegura que las respuestas no solo sean coherentes sino también precisas y respaldadas por datos verificables.
Componentes del Sistema RAG
A continuación, vamos a describir los componentes que utiliza un algoritmo de RAG para cumplir con su función. Para ello, en cada componente, vamos a explicar qué función cumple, qué tecnologías se utilizan para cumplir esta función y un ejemplo de la parte del proceso RAG en el que interviene ese componente.
1. Modelo de Recuperación:
- Función: Identifica y recupera documentos relevantes de una base de datos grande en respuesta a una consulta.
- Tecnología: Generalmente utiliza técnicas de recuperación de información (Information Retrieval en inglés o IR) como BM25 o modelos de recuperación basados en embeddings como Dense Passage Retrieval (DPR).
- Proceso: Dada una pregunta, el modelo de recuperación busca en una base de datos para encontrar los documentos más relevantes y los presenta como contexto para la generación de la respuesta.
2. Modelo de Generación:
- Función: Generar respuestas coherentes y contextualmente relevantes utilizando los documentos recuperados.
- Tecnología: Basado en algunos de los principales grandes modelos de Lenguaje (LLM) como GPT-3.5, T5, o BERT, Llama.
- Proceso: El modelo de generación toma la consulta del usuario y los documentos recuperados y utiliza esta información combinada para producir una respuesta precisa.
Proceso Detallado de RAG1
En detalle, un algoritmo RAG realiza las siguientes etapas:
1. Recepción de la pregunta. El sistema recibe una pregunta del usuario. Esta pregunta se procesa para extraer las palabras clave y entender la intención.
2. Recuperación de documentos. La pregunta se envía al modelo de recuperación.
- Ejemplo de Recuperación basada en embeddings:
- La pregunta se convierte en un vector de embeddings utilizando un modelo pre-entrenado.
- Este vector se compara con los vectores de documentos en la base de datos.
- Se seleccionan los documentos con mayor similitud.
- Ejemplo de BM25:
- Se tokeniza la pregunta y se comparan las palabras clave con los índices invertidos de la base de datos.
- Se recuperan los documentos más relevantes según una puntuación de relevancia.
3. Filtrado y clasificación. Los documentos recuperados se filtran para eliminar redundancias y clasificarlos según su relevancia. Pueden aplicarse técnicas adicionales como reranking utilizando modelos más sofisticados.
4. Generación de la respuesta. Los documentos filtrados se concatenan con la pregunta del usuario y se introducen en el modelo de generación. El LLM utiliza la información combinada para generar una respuesta que es coherente y directamente relevante a la pregunta. Por ejemplo, si utilizamos GPT-3.5 como LLM, la entrada al modelo incluye tanto la pregunta del usuario como fragmentos de los documentos recuperados. Finalmente, el modelo genera texto utilizando su capacidad para comprender el contexto de la información proporcionada.
En la siguiente sección vamos a ver algunas aplicaciones en las que la Inteligencia Artificial y los modelos grandes del lenguaje juegan un papel diferenciador y, en concreto, vamos a analizar cómo se benefician estos casos de usos de la aplicación de las técnicas RAG.
Ejemplos de casos de uso que se benefician sustancialmente de usar RAG frente a no usar RAG
1. Atención al Cliente en eCommerce
- Sin RAG:
- Un chatbot básico puede dar respuestas genéricas y potencialmente incorrectas sobre políticas de devolución.
- Ejemplo: Por favor, revise nuestra política de devoluciones en el sitio web.
- Con RAG:
- El chatbot accede a la base de datos de políticas actualizadas y proporciona una respuesta específica y precisa.
- Ejemplo: Puede devolver los productos dentro de 30 días desde la compra, siempre que estén en su embalaje original. Consulte más detalles [aquí].
2. Diagnóstico Médico
- Sin RAG:
- Un asistente virtual de salud podría ofrecer recomendaciones basadas solo en su entrenamiento previo, sin acceso a la información médica más reciente.
- Ejemplo: Es posible que tenga gripe. Consulte a su médico
- Con RAG:
- El asistente puede recuperar información de bases de datos médicas recientes y proporcionar un diagnóstico más preciso y actualizado.
- Ejemplo: Según los síntomas y los estudios recientes publicados en PubMed, podría estar enfrentando una infección viral. Consulte a su médico para un diagnóstico preciso.
3. Asistencia en Investigación Académica
- Sin RAG:
- Un investigador recibe respuestas limitadas a lo que el modelo ya sabe, lo que puede no ser suficiente para temas altamente especializados.
- Ejemplo: Los modelos de crecimiento económico son importantes para entender la economía.
- Con RAG:
- El asistente recupera y analiza artículos académicos relevantes, proporcionando información detallada y precisa.
- Ejemplo: Según el estudio de 2023 en 'Journal of Economic Growth', el modelo XYZ ha mostrado un 20% más de precisión en la predicción de tendencias económicas en mercados emergentes.
4. Periodismo
- Sin RAG:
- Un periodista recibe información genérica que puede no estar actualizada ni ser precisa.
- Ejemplo: La inteligencia artificial está cambiando muchas industrias.
- Con RAG:
- El asistente recupera datos específicos de estudios y artículos recientes, ofreciendo una base sólida para el artículo.
- Ejemplo: Según un informe de 2024 de 'TechCrunch', la adopción de IA en el sector financiero ha aumentado en un 35% en el último año, mejorando la eficiencia operativa y reduciendo costos.
Por supuesto, para la mayoría de los usuarios que hemos experimentado los interfaces conversacionales más accesibles, como ChatGPT, Gemini o Bing, podemos constatar que las respuestas suelen ser completas y bastante precisas cuando se trata de preguntas de ámbito general. Esto es porque estos agentes hacen uso de métodos RAG y otras técnicas avanzadas para proporcionar las respuestas. Sin embargo, no hay que remontarse mucho tiempo atrás en el que los asistentes conversacionales, como Alexa, Siri u OK Google, proporcionaban respuestas extremadamente simples y muy similares a las que explicamos en los ejemplos anteriores cuando no se hace uso de RAG.
Conclusiones
Las técnicas de Generación Aumentada por Recuperación (RAG) mejora la precisión y relevancia de las respuestas de los modelos de lenguaje al combinar recuperación de documentos y generación de texto. Utilizando métodos de recuperación como BM25 o DPR y modelos avanzados de lenguaje, RAG proporciona respuestas más contextualizadas, actualizadas y precisas. En la actualidad, RAG es la clave para el desarrollo exponencial de la IA en el ámbito de los datos privados de empresas y organizaciones. En los próximos meses se espera una adopción masiva de RAG en diversas industrias, optimizando la atención al cliente, diagnósticos médicos, investigación académica y periodismo, gracias a su capacidad para integrar información relevante y actual en tiempo real.
1. Para entender mejor esta sección, recomendamos al lector la lectura de este trabajo previo en el que explicamos de forma didáctica los fundamentos del procesamiento del lenguaje natural y cómo enseñamos a leer a las máquinas.
Contenido elaborado por Alejandro Alija,experto en Transformación Digital e Innovación. Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Blog
En estos momentos nos encontramos en medio de una carrera sin precedentes por dominar las innovaciones en Inteligencia Artificial. Durante el último año, la estrella ha sido la Inteligencia Artificial Generativa (GenAI), es decir, aquella capaz de generar contenido original y creativo como imágenes, texto o música. Pero los avances no dejan de sucederse, y últimamente comienzan a llegar noticias en las que se sugiere que la utopía de la Inteligencia Artificial General (AGI) podría no estar tan lejos como pensábamos. Estamos hablando de máquinas capaces de comprender, aprender y realizar tareas intelectuales con resultados similares al cerebro humano.
Sea esto cierto o simplemente una predicción muy optimista, consecuencia de los asombrosos avances conseguido en un espacio muy corto de tiempo, lo cierto es que la Inteligencia Artificial parece ya capaz de revolucionar prácticamente todas las facetas de nuestra sociedad a partir de la cada vez mayor cantidad de datos que se utilizan para su entrenamiento.
Y es que si, como argumentaba Andrew Ng ya en 2017, la inteligencia artificial es la nueva electricidad, los datos abiertos serían el combustible que alimenta su motor, al menos en un buen número de aplicaciones cuya fuente principal y más valiosa es la información pública que se encuentra accesible para ser reutilizada. En este artículo vamos a repasar un campo en el que previsiblemente veremos grandes avances en los próximos años gracias a la combinación de inteligencia artificial y datos abiertos: la creación artística.
Creación Generativa basada en Datos Culturales Abiertos
La capacidad de la inteligencia artificial para generar nuevos contenidos podría llevarnos a una nueva revolución en la creación artística, impulsada por el acceso a datos culturales abiertos y a una nueva generación de artistas capaces de aprovechar estos avances para crear nuevas formas de pintura, música o literatura, trascendiendo barreras culturales y temporales.
Música
El mundo de la música, con su diversidad de estilos y tradiciones, representa un campo lleno de posibilidades para la aplicación de la inteligencia artificial generativa. Los conjuntos de datos abiertos en este ámbito incluyen grabaciones de música folclórica, clásica, moderna y experimental de todo el mundo y de todas las épocas, partituras digitalizadas, e incluso información sobre teorías musicales documentadas. Desde el archi-conocido MusicBrainz, la enciclopedia de la música abierta, hasta conjuntos de datos que abren los propios dominadores de la industria del streaming como Spotify o proyectos como Open Music Europe, son algunos ejemplos de recursos que están en la base del progreso en esta área. A partir del análisis de todos estos datos, los modelos de inteligencia artificial pueden identificar patrones y estilos únicos de diferentes culturas y épocas, fusionándolos para crear composiciones musicales inéditas con herramientas y modelos como MuseNet de OpenAI o Music LM de Google.
Literatura y pintura
En el ámbito de la literatura, la Inteligencia artificial también tiene potencial para hacer más productiva no solo la creación de contenidos en internet, sino para producir formas más elaboradas y complejas de contar historias. El acceso a bibliotecas digitales que albergan obras literarias desde la antigüedad hasta el momento actual hará posible explorar y experimentar con estilos literarios, temas y arquetipos de narración de diversas culturas a lo largo de la historia, con el fin de crear nuevas obras en colaboración con la propia creatividad humana. Incluso se podrá generar una literatura de carácter más personalizado a los gustos de grupos de lectores más minoritarios. La disponibilidad de datos abiertos como el Proyecto Guttemberg con más de 70.000 libros o los catálogos digitales abiertos de museos e instituciones que han publicado manuscritos, periódicos y otros recursos escritos producidos por la humanidad, son un recurso de gran valor para alimentar el aprendizaje de la inteligencia artificial.
Los recursos de la Digital Public Library of America (DPLA) en Estados Unidos o de Europeana en la Unión Europea son sólo algunos ejemplos. Estos catálogos no sólo incluyen texto escrito, sino que incluyen también vastas colecciones de obras de arte visuales, digitalizadas a partir de las colecciones de museos e instituciones, que en muchos casos ni tan siquiera pueden admirarse porque las organizaciones que las conservan no disponen de espacio suficiente para exponerlas al público. Los algoritmos de inteligencia artificial, al analizar estas obras, descubren patrones y aprenden sobre técnicas, estilos y temas artísticos de diferentes culturas y períodos históricos. Esto posibilita que herramientas como DALL-E2 o Midjourney puedan crear obras visuales a partir de unas sencillas instrucciones de texto con estética de pintura renacentista, impresionista o una mezcla de ambas.
Sin embargo, estas fascinantes posibilidades están acompañadas de una controversia aún no resuelta acerca de los derechos de autor que está siendo debatida en los ámbitos académicos, legales y jurídicos y que plantea nuevos desafíos en la definición de autoría y propiedad intelectual. Por una parte, está la cuestión sobre la propiedad de los derechos sobre las creaciones producidas por inteligencia artificial. Y por otra parte encontramos el uso de conjuntos de datos que contienen obras sujetas a derechos de propiedad intelectual y que se han utilizado en el entrenamiento de los modelos sin el consentimiento de los autores. En ambas cuestiones existen numerosas disputas judiciales en todo el mundo y solicitudes de retirada explícita de contenido de los principales conjuntos de datos de entrenamiento.
En definitiva, nos encontramos ante un campo donde el avance de la inteligencia artificial parece imparable, pero habrá que tener muy presente no solo las oportunidades, sino también los riesgos que supone.
Contenido elaborado por Jose Luis Marín, Senior Consultant in Data, Strategy, Innovation & Digitalization. Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Blog
La inteligencia artificial generativa se refiere a la capacidad de una máquina para generar contenido original y creativo, como imágenes, texto o música, a partir de un conjunto de datos de entrada. En lo que se refiere a la generación de texto, estos modelos son accesibles, en formato experimental, desde hace un tiempo, pero comenzaron a generar interés a mediados de 2020 cuando Open AI, una organización dedicada a la investigación en el campo de la inteligencia artificial general, publicó el acceso a su modelo de lenguaje GPT-3 a través de una API.
La arquitectura de GPT-3 está compuesta por 175 mil millones de parámetros, mientras que la de su antecesor GPT-2 era de 1.500 millones de parámetros, esto es, más de 100 veces más. GPT-3 representa por tanto un cambio de escala enorme ya que además fue entrenado con un corpus de datos mucho mayor y un tamaño de los tokens mucho más grande, lo que le permitió adquirir una comprensión más profunda y compleja del lenguaje humano.
A pesar de que fue de 2022 cuando OpenAI anunció la apertura de chatGPT, que permite dotar de una interfaz conversacional a un modelo de lenguaje basado en una versión mejorada de GPT-3, no ha sido hasta los últimos dos meses cuando la noticia ha llamado masivamente la atención del público, gracias a la amplia cobertura mediática que trata de dar respuesta al incipiente interés general.
Y es que, ChatGPT no sólo es capaz de generar texto a partir de un conjunto de caracteres (prompt) como GPT-3, sino que responde a preguntas en lenguaje natural en varios idiomas que incluyen inglés, español, francés, alemán, italiano o portugués. Es precisamente este cambio en la interfaz de acceso, pasando de ser una API a un chatbot, lo que lo ha convertido a la IA en accesible para cualquier tipo de usuario.
Tanto es así que más de un millón de personas se registraron para usarlo en tan solo cinco días, lo que ha motivado la multiplicación de ejemplos en los que chatGPT produce código de software, ensayos de nivel universitario, poemas e incluso chistes. Eso sin tener en cuenta que ha sido capaz de sacar adelante un examen de selectividad de Historia o de aprobar el examen final del MBA de la prestigiosa Wharton School.
Todo esto ha puesto a la IA generativa en el centro de una nueva ola de innovación tecnológica que promete revolucionar la forma en que nos relacionamos con internet y la web a través de búsquedas vitaminadas por IA o navegadores capaces de resumir el resultado de estas búsquedas.
Hace tan solo unos días, conocíamos la noticia de que Microsoft trabaja en la implementación de un sistema conversacional dentro de su propio buscador, el cual ha sido desarrollado a partir del conocido modelo de lenguaje de Open AI y cuya noticia ha puesto en jaque a Google.
Y es que, como consecuencia de esta nueva realidad en la que la IA ha llegado para quedarse, los gigantes tecnológicos han ido un paso más allá en la batalla por aprovechar al máximo los beneficios que esta reporta. En esta línea, Microsoft ha presentado una nueva estrategia dirigida a optimizar al máximo la manera en la que nos relacionamos con internet, introduciendo la IA para mejorar los resultados ofrecidos por los buscadores de navegadores, aplicaciones, redes sociales y, en definitiva, todo el ecosistema de la web.
Sin embargo, aunque el camino en el desarrollo de los nuevos y futuros servicios ofrecidos por la IA de Open AI aún están por ver, avances como los anteriores ofrecen una pequeña pista de la guerra de navegadores que se avecina y que, probablemente, cambie en el corto plazo la manera de crear y hallar contenido en la web.
Los datos abiertos
GPT-3, al igual que otros modelos que han sido generados con las técnicas descritas en la publicación científica original de GTP-3, es un modelo de lenguaje pre-entrenado, lo que significa que ha sido entrenado con un gran conjunto de datos, en total unos 45 terabytes de datos de texto. Según este paper, el conjunto de datos de entrenamiento estaba compuesto en un 60% por datos obtenidos directamente de internet en los que están contenidos millones de documentos de todo tipo, un 22% del corpus WebText2 construido a partir de Reddit, y el resto con una combinación de libros (16%) y Wikipedia (3%).
Sin embargo, no se sabe cuántos datos abiertos utiliza GPT-3 exactamente, ya que OpenAI no proporciona detalles más específicos sobre el conjunto de datos utilizado para entrenar el modelo. Lo que sí podemos hacer son algunas preguntas al propio chatGPT que nos ayuden a extraer interesantes conclusiones sobre el uso que hace de los datos abiertos.
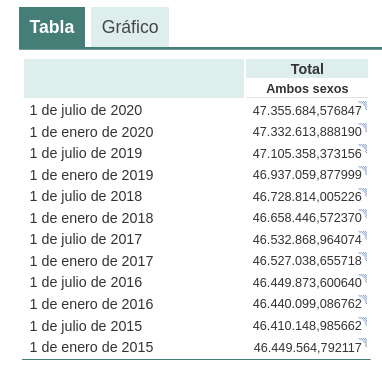
Por ejemplo, si le preguntamos a chatGPT cuál era la población de España entre 2015 y 2020 (no podemos pedirle datos más recientes), obtenemos una respuesta de este tipo:

Tal como podemos ver en la imagen superior, aunque la pregunta sea la misma, la respuesta puede variar tanto en la redacción como en la información que contiene. Las variaciones pueden ser aún mayores si realizamos la pregunta en diferentes días o hilos de conversación:
Pequeñas variaciones en la redacción del texto, generar la pregunta en diferentes momentos del hilo de conversación (recordemos que guarda el contexto) o en hilos o días diferentes puede conducir a resultados ligeramente diferentes. Además, la respuesta no es completamente precisa, tal y como nos advierte la propia herramienta si las comparamos con las series de población residente en España del propio INE, donde nos recomienda consultar. Los datos que idealmente habríamos esperado en la respuesta podrían obtenerse en un conjunto de datos abiertos del INE:
Este tipo de respuestas sugieren que los datos abiertos no se han empleado como una fuente autoritativa para responder preguntas de tipo factual, o al menos que aún no está completamente refinado el modelo en este sentido. Haciendo algunas pruebas básicas con preguntas sobre otros países hemos observado errores parecidos, por lo que no parece que se trate de un problema sólo con preguntas referentes a España.
Si hacemos preguntas algo más específicas como pedir la lista de los municipios de la provincia de Burgos que comienzan por la letra “G” obtenemos respuestas que no son completamente correctas, como es propio de una tecnología que todavía está en fase incipiente.
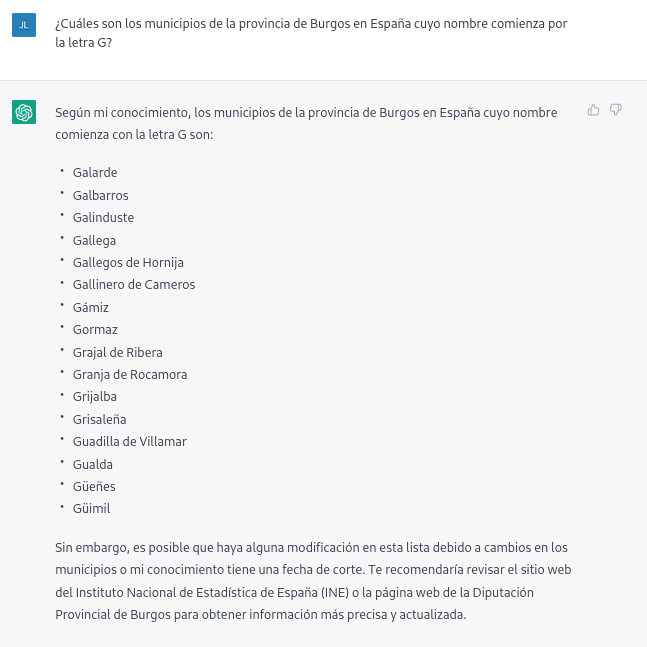
La respuesta correcta debería contener seis municipios: Galbarros, La Gallega, Grijalba, Grisaleña, Gumiel de Hizán y Gumiel del Mercado. Sin embargo, la respuesta que hemos obtenido sólo contiene los cuatro primeros e incluye localidades de la provincia de Guadalajara (Gualda), municipios de la provincia de Valladolid (Gallegos de Hornija) o localidades de la provincia de Burgos que no son municipios (Galarde). En este caso, también podemos acudir a conjunto de datos abiertos para obtener la respuesta correcta.
A continuación, le preguntamos a ChatGPT por la lista de municipios que comienzan por la letra Z en la misma provincia. ChatGPT nos dice que nos hay ninguno, razonando la respuesta, cuando en realidad hay cuatro:
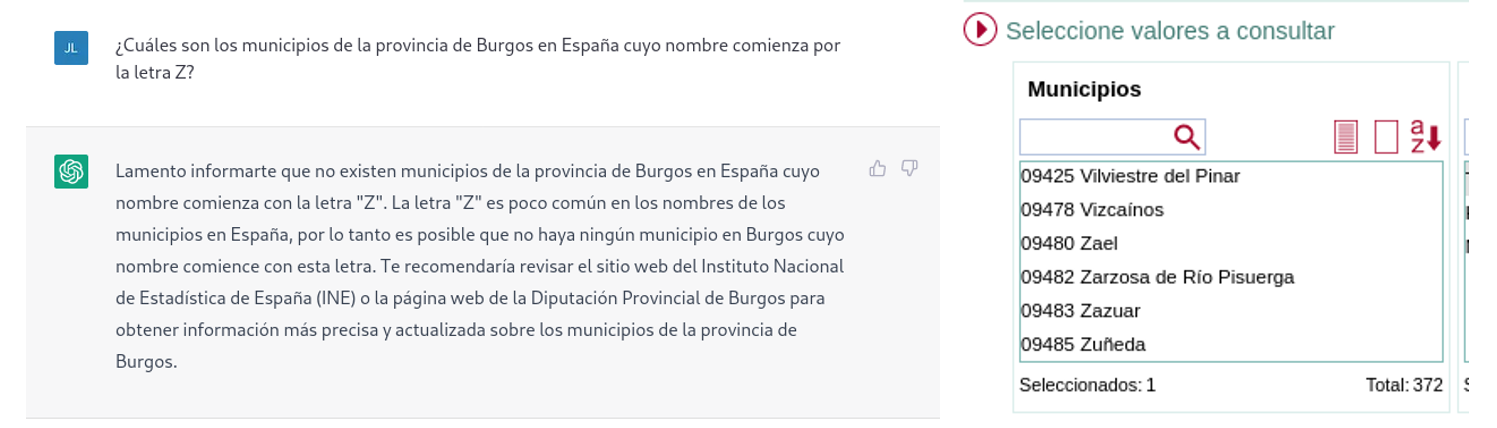
Como se deduce de los ejemplos anteriores, vemos cómo los datos abiertos sí pueden contribuir a la evolución tecnológica y, por ende, a mejorar el funcionamiento de la inteligencia artificial de Open AI. Sin embargo, dado el estado de madurez actual de la misma, aún es pronto para ver un empleo óptimo de estos, a la hora de dar respuesta a preguntas más complejas.
Por lo tanto, para que un modelo de inteligencia artificial generativa sea eficaz, es necesario que cuente con una gran cantidad de datos de alta calidad y diversidad, y los datos abiertos son una fuente de conocimiento valiosa para este fin.
Probablemente, en futuras versiones del modelo, podamos ver cómo los datos abiertos ya adquieren un peso mucho más importante en la composición del corpus de entrenamiento, logrando conseguir una mejora importante en la calidad de las respuestas de tipo factual.
Contenido elaborado por Jose Luis Marín, Senior Consultant in Data, Strategy, Innovation & Digitalization.
Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Blog
En este post describimos paso a paso un ejercicio de ciencia de datos en el que tratamos de entrenar un modelo de deep learning con el objetivo de clasificar automáticamente imágenes médicas de personas sanas y enfermas.
El diagnóstico por radio-imagen existe desde hace muchos años en los hospitales de los países desarrollados, sin embargo, siempre ha existido una fuerte dependencia de personal altamente especializado. Desde el técnico que opera los instrumentos hasta el médico radiólogo que interpreta las imágenes. Con nuestras capacidades analíticas actuales, somos capaces de extraer medidas numéricas como el volumen, la dimensión, la forma y la tasa de crecimiento (entre otras) a partir del análisis de imagen. A lo largo de este post trataremos de explicarte, mediante un sencillo ejemplo, la potencia de los modelos de inteligencia artificial para ampliar las capacidades humanas en el campo de la medicina.
Este post explica el ejercicio práctico (sección Action) asociado al informe “Tecnologías emergentes y datos abiertos: introducción a la ciencia de datos aplicada al análisis de imagen”. Dicho informe introduce los conceptos fundamentales que permiten comprender cómo funciona el análisis de imagen, detallando los principales casos de aplicación en diversos sectores y resaltando el papel de los datos abiertos en su ejecución.
Proyectos previos
No podríamos haber preparado este ejercicio sin el trabajo y el esfuerzo previo de otros entusiastas de la ciencia de datos. A continuación, te dejamos una pequeña nota y las referencias a estos trabajos previos.
- Este ejercicio es una adaptación del proyecto original de Michael Blum sobre el desafío STOIC2021 - dissease-19 AI challenge. El proyecto original de Michael, partía de un conjunto de imágenes de pacientes con patología Covid-19, junto con otros pacientes sanos para hacer contraste.
- En una segunda aproximación, Olivier Gimenez utilizó un conjunto de datos similar al del proyecto original publicado en una competición de Kaggle. Este nuevo dataset (250 MB) era considerablemente más manejable que el original (280GB). El nuevo dataset contenía algo más de 1000 imágenes de pacientes sanos y enfermos. El código del proyecto de Olivier puede encontrarse en el siguiente repositorio.
Conjuntos de datos
En nuestro caso, inspirándonos en estos dos fantásticos proyectos previos, hemos construido un ejercicio didáctico apoyándonos en una serie de herramientas que facilitan la ejecución del código y la posibilidad de examinar los resultados de forma sencilla. El conjunto de datos original (de rayos-x de tórax) comprende 112.120 imágenes de rayos-X (vista frontal) de 30.805 pacientes únicos. Las imágenes se acompañan con las etiquetas asociadas de catorce enfermedades (donde cada imagen puede tener múltiples etiquetas), extraídas de los informes radiológicos asociados utilizando procesamiento de lenguaje natural (NLP). Partiendo del conjunto de imágenes médicas original hemos extraído (utilizando algunos scripts) una muestra más pequeña y acotada (tan solo personas sanas frente a personas con una sola patología) para facilitar este ejercicio. En particular, la patología escogida es el neumotórax.
Si quieres ampliar la información sobre el campo de procesamiento del lenguaje natural puedes consultar el siguiente informe que ya publicamos en su momento. Además, en el post 10 repositorios de datos públicos relacionados con la salud y el bienestar se cita al NIH como un ejemplo de fuente de datos sanitarios de calidad. En particular, nuestro conjunto de datos está disponible públicamente aquí.
Herramientas
Para la realización del tratamiento previo de los datos (entorno de trabajo, programación y redacción del mismo) se ha utilizado R (versión 4.1.2) y RStudio (2022-02-3). Los pequeños scripts de ayuda a la descarga y ordenación de ficheros se han escrito en Python 3.
Acompañando a este post, hemos creado un cuaderno de Jupyter con el que poder experimentar de forma interactiva a través de los diferentes fragmentos de código que van desarrollando nuestro ejemplo. El objetivo de este ejercicio es entrenar a un algoritmo para que sea capaz de clasificar automáticamente una imagen de una radiografía de pecho en dos categorías (persona enferma vs persona no-enferma). Para facilitar la ejecución del ejercicio por parte de los lectores que así lo deseen, hemos preparado el cuaderno de Jupyter en el entorno de Google Colab que contiene todos los elementos necesarios para reproducir el ejercicio paso a paso. Google Colab o Collaboratory es una herramienta gratuita de Google que te permite programar y ejecutar código en Python (y también en R) sin necesidad de instalar ningún software adicional. Es un servicio online y para usarlo tan solo necesitas tener una cuenta de Google.
Flujo lógico del análisis de datos
Nuestro cuaderno de Jupyter, realiza las siguientes actividades diferenciadas que podrás seguir en el propio documento interactivo cuándo lo vayas ejecutando sobre Google Colab.
- Instalación y carga de dependencias.
- Configuración del entorno de trabajo
- Descarga, carga y pre-procesamiento de datos necesarios (imágenes médicas) en el entorno de trabajo.
- Pre-visualización de las imágenes cargadas.
- Preparación de los datos para entrenamiento del algoritmo.
- Entrenamiento del modelo y resultados.
- Conclusiones del ejercicio.
A continuación, hacemos un repaso didáctico del ejercicio, enfocando nuestras explicaciones en aquellas actividades que son más relevantes respecto al ejercicio de análisis de datos:
- Descripción del análisis de datos y entrenamiento del modelo
- Modelización: creación del conjunto de imágenes de entrenamiento y entrenamiento del modelo
- Analisis del resultado del entrenamiento
- Conclusiones
Descripción del análisis de datos y entrenamiento del modelo
Los primeros pasos que encontraremos recorriendo el cuaderno de Jupyter son las actividades previas al análisis de imágenes propiamente dicho. Como en todos los procesos de análisis de datos, es necesario preparar el entorno de trabajo y cargar las librerías necesarias (dependencias) para ejecutar las diferentes funciones de análisis. El paquete de R más representativo de este conjunto de dependencias es Keras. En este artículo ya comentamos sobre el uso de Keras como framework de Deep Learning. Adicionalmente también son necesarios los siguientes paquetes: httr; tidyverse; reshape2;patchwork.
A continuación, debemos descargar a nuestro entorno el conjunto de imágenes (datos) con el que vamos a trabajar. Como hemos comentado previamente, las imágenes se encuentran en un almacenamiento remoto y solo las descargamos en Colab en el momento de analizarlas. Tras ejecutar las secciones de código que descargan y descomprimen los ficheros de trabajo que contienen las imágenes médicas encontraremos dos carpetas (No-finding y Pneumothorax) que contienen los datos de trabajo.

Una vez que disponemos de los datos de trabajo en Colab, debemos cargarlas en la memoria del entorno de ejecución. Para ello hemos creado una función que verás en el cuaderno denominada process_pix(). Esta función, va a buscar las imágenes a las carpetas anteriores y las carga en memoria, además de pasarlas a escala de grises y normalizarlas todas a un tamaño de 100x100 pixels. Para no exceder los recursos que nos proporciona de forma gratuita Google Colab, limitamos la cantidad de imágenes que cargamos en memoria a 1000 unidades. Es decir, el algoritmo va a ser entrenado con 1000 imágenes, entre las que va usar para entrenamiento y las que va a usar para la validación posterior.
Una vez tenemos las imágenes perfectamente clasificadas, formateadas y cargadas en memoria hacemos una visualización rápida para verificar que son correctas.Obtenemos los siguientes resultados:

Obviamente, a ojos de un observador no experto no se ven diferencias significativas que nos permitan extraer ninguna conclusión. En los siguientes pasos veremos cómo el modelo de inteligencia artificial sí que tiene mejor ojo clínico que nosotros.
Modelización
Creación del conjunto de imágenes de entrenamiento
Como comentamos en los pasos previos, disponemos de un conjunto de 1000 imágenes de partida cargadas en el entorno de trabajo. Hasta este momento, tenemos clasificadas (por un especialista en rayos-x) aquellas imágenes de pacientes que presentan indicios de neumotórax (en la ruta "./data/Pneumothorax") y aquellos pacientes sanos (en la ruta "./data/No-Finding")
El objetivo de este ejercicio es, justamente, demostrar la capacidad de un algoritmo de asistir al especialista en la clasificación (o detección de signos de enfermedad en la imagen de rayos-x). Para esto, tenemos que mezclar las imágenes, para conseguir un conjunto homogéneo que el algoritmo tendrá que analizar y clasificar valiéndose solo de sus características. El siguiente fragmento de código, asocia un identificador (1 para personas enfermas y 0 para personas sanas) para, posteriormente, tras el proceso de clasificación del algoritmo, poder verificar aquellas que el modelo ha clasificado de forma correcta o incorrecta.

Bien, ahora tenemos un conjunto “df” uniforme de 1000 imágenes mezcladas con pacientes sanos y enfermos. A continuación, dividimos en dos este conjunto original. El 80% del conjunto original, lo vamos a utilizar para entrenar el modelo. Esto es, el algoritmo utilizará las características de las imágenes para crear un modelo que permita concluir si una imagen se corresponde con el identificador 1 o 0. Por otro lado, el 20% restante de la mezcla homogénea la vamos a utilizar para comprobar si el modelo, una vez entrenado, es capaz de tomar una imagen cualquiera y asignarle el 1 o el 0 (enfermo, no enfermo).

Entrenamiento del modelo
Listo, solo nos queda configurar el modelo y entrenar con el anterior conjunto de datos.
Antes de entrenar, veréis unos fragmentos de código que sirven para configurar el modelo que vamos a entrenar. El modelo que vamos a entrenar es de tipo clasificador binario. Esto significa que es un modelo que es capaz de clasificar los datos (en nuestro caso imágenes) en dos categorías (en nuestro caso sano o enfermo). El modelo escogido se denomina CNN o Convolutional Neural Network. Su propio nombre ya nos indica que es un modelo de redes neuronales y por lo tanto cae dentro de la disciplina de Deep Learning o aprendizaje profundo. Estos modelos se basan en capas de características de los datos que se van haciendo más profundas a medida que la complejidad del modelo aumenta. Os recordamos que el término deep hace referencia, justamente, a la profundidad del número de capas mediante las cuales estos modelos aprenden.
Nota: los siguientes fragmentos de código son los más técnicos del post. La documentación introductoria se puede encontrar aquí, mientras que toda la documentación técnica sobre las funciones del modelo está accesible aquí.
Finalmente, tras la configuración del modelo, estamos en disposición de entrenar el modelo. Como comentamos, entrenamos con el 80% de las imágenes y validamos el resultado con el 20% restante.

Resultado del entrenamiento
Bien, ya hemos entrenado nuestro modelo. ¿Y ahora qué? Las siguientes gráficas nos proporcionan una visualización rápida sobre cómo se comporta el modelo sobre las imágenes que hemos reservado para validar. Básicamente, estas figuras vienen a representar (la del panel inferior) la capacidad del modelo de predecir la presencia (identificador 1) o ausencia (identificador 0) de enfermedad (en nuestro caso neumotórax). La conclusión es que cuando el modelo entrenado con las imágenes de entrenamiento (aquellas de las que se sabe el resultado 1 o 0) se aplica al 20% de las imágenes de las cuales no se sabe el resultado, el modelo acierta aproximadamente en el 85% (0.87309) de las ocasiones.

En efecto, cuando solicitamos la evaluación del modelo para saber qué tan bien clasifica enfermedades el resultado nos indica la capacidad de nuestro modelo recién entrenado para clasificar de forma correcta el 0.87309 de las imágenes de validación.
Hacemos ahora algunas predicciones sobre imágenes de pacientes. Es decir, una vez entrenado y validado el modelo, nos preguntamos cómo va a clasificar las imágenes que le vamos a dar ahora. Como sabemos "la verdad" (lo que se denomina el ground truth) sobre las imágenes, comparamos el resultado de la predicción con la verdad. Para comprobar los resultados de la predicción (que variarán en función del número de imágenes que se usen en el entrenamiento) se utiliza lo que en ciencia de datos se denomina la matriz de confusión. La matriz de confusión:
- coloca en la posición (1,1) los casos que SÍ tenían enfermedad y el modelo clasifica como "con enfermedad"
- coloca en la posición (2,2), los casos que NO tenían enfermedad y el modelo clasifica como "sin enfermedad"
Es decir, estas son las posiciones en las que el modelo "acierta" en su clasificación.
En las posiciones contrarias, es decir, la (1,2) y la (2,1) son las posiciones en las que el modelo se "equivoca". Así, la posición (1,2) son los resultados que el modelo clasifica como CON enfermedad y la realidad es que eran pacientes sanos. La posición (2,1), justo lo contrario.
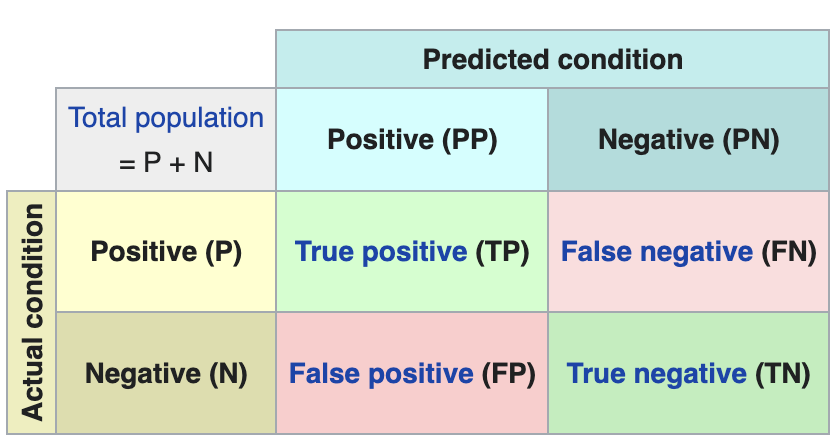
Ejemplo explicativo sobre cómo funciona la matriz de confusión. Fuente: wikipedia https://en.wikipedia.org/wiki/Confusion_matrix
En nuestro ejercicio, el modelo nos proporciona los siguientes resultados:


Es decir, 81 pacientes tenían esta enfermedad y el modelo los clasifica de forma correcta. De la misma forma, 91 pacientes estaban sanos y el modelo los clasifica, igualmente, de forma correcta. Sin embargo, el modelo clasifica cómo enfermos, 13 pacientes que estaban sanos. Y al contrario, el modelo clasifica cómo sanos a 12 pacientes que en realidad estaban enfermos. Cuando sumamos los aciertos del modelo 81+91 y lo dividimos sobre la muestra de validación total obtenemos el 87% de precisión del modelo.
Conclusiones
En este post te hemos guiado a través de un ejercicio didáctico que consiste en entrenar un modelo de inteligencia artificial para realizar clasificaciones de imágenes de radiografías de pecho con el objetivo de determinar automáticamente si una persona está enferma o sana. Por sencillez, hemos escogido pacientes sanos y pacientes que presentan un neumotórax (solo dos categorías) previamente diagnosticados por un médico. El viaje que hemos realizado nos ofrece una idea de las actividades y las tecnologías involucradas en el análisis automatizado de imágenes mediante inteligencia artificial. El resultado del entrenamiento nos ofrece un sistema de clasificación razonable para el screening automático con un 87% de precisión en sus resultados. Los algoritmos y las tecnologías avanzadas de análisis de imagen son y cada vez más serán, un complemento indispensable en múltiples ámbitos y sectores como, por ejemplo, la medicina. En los próximos años veremos cómo se consolidan los sistemas que, de forma natural, combinan habilidades de humanos y máquinas en procesos costosos, complejos o peligrosos. Los médicos y otros trabajadores verán aumentadas y reforzadas sus capacidades gracias a la inteligencia artificial. La combinación de fuerzas entre máquinas y humanos nos permitirá alcanzar cotas de precisión y eficiencia nunca vistas hasta la fecha. Esperamos que con este ejercicio os hayamos ayudado a entender un poco más cómo funcionan estas tecnologías. No olvides completar tu aprendizaje con el resto de materiales que acompañan este post.
Contenido elaborado por Alejandro Alija, experto en Transformación Digital. Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Blog
La ciencia de datos es un campo interdisciplinar que busca extraer conocimiento actuable a partir de conjuntos de datos, estructurados en bases de datos o no estructurados como textos, audios o vídeos. Gracias a la aplicación de nuevas técnicas, la ciencia de datos nos está permitiendo responder preguntas que no son fáciles de resolver a través de otros métodos. El fin último es diseñar acciones de mejora o corrección a partir del nuevo conocimiento que obtenemos.
El concepto clave en ciencia de datos es CIENCIA, y no tanto datos, ya que incluso se ha comenzado a hablar de un cuarto paradigma de la ciencia, añadiendo el enfoque basado en datos a los tradicionales teórico, empírico y computacional.
La ciencia de datos combina métodos y tecnologías que provienen de las matemáticas, la estadística y la informática, y entre las que encontramos el análisis exploratorio, el aprendizaje automático (machine learning), el aprendizaje profundo (deep learning), el procesamiento del lenguaje natural, la visualización de datos y el diseño experimental.
Dentro de la Ciencia de Datos, las dos tecnologías de las que más se está hablando son el Aprendizaje Automático (Machine Learning) y el Aprendizaje profundo (Deep Learning), ambas englobadas en el campo de la inteligencia artificial. En los dos casos se busca la construcción de sistemas que sean capaces de aprender a resolver problemas sin la intervención de un humano y que van desde los sistemas de predicción ortográfica o traducción automática hasta los coches autónomos o los sistemas de visión artificial aplicados a casos de uso tan espectaculares como las tiendas de Amazon Go.
En los dos casos los sistemas aprenden a resolver los problemas a partir de los conjuntos de datos que les enseñamos para entrenarlos en la resolución del problema, bien de forma supervisada cuando los conjuntos de datos de entrenamiento están previamente etiquetados por humanos, o bien de forma no supervisada cuando estos conjuntos de datos no están etiquetados.
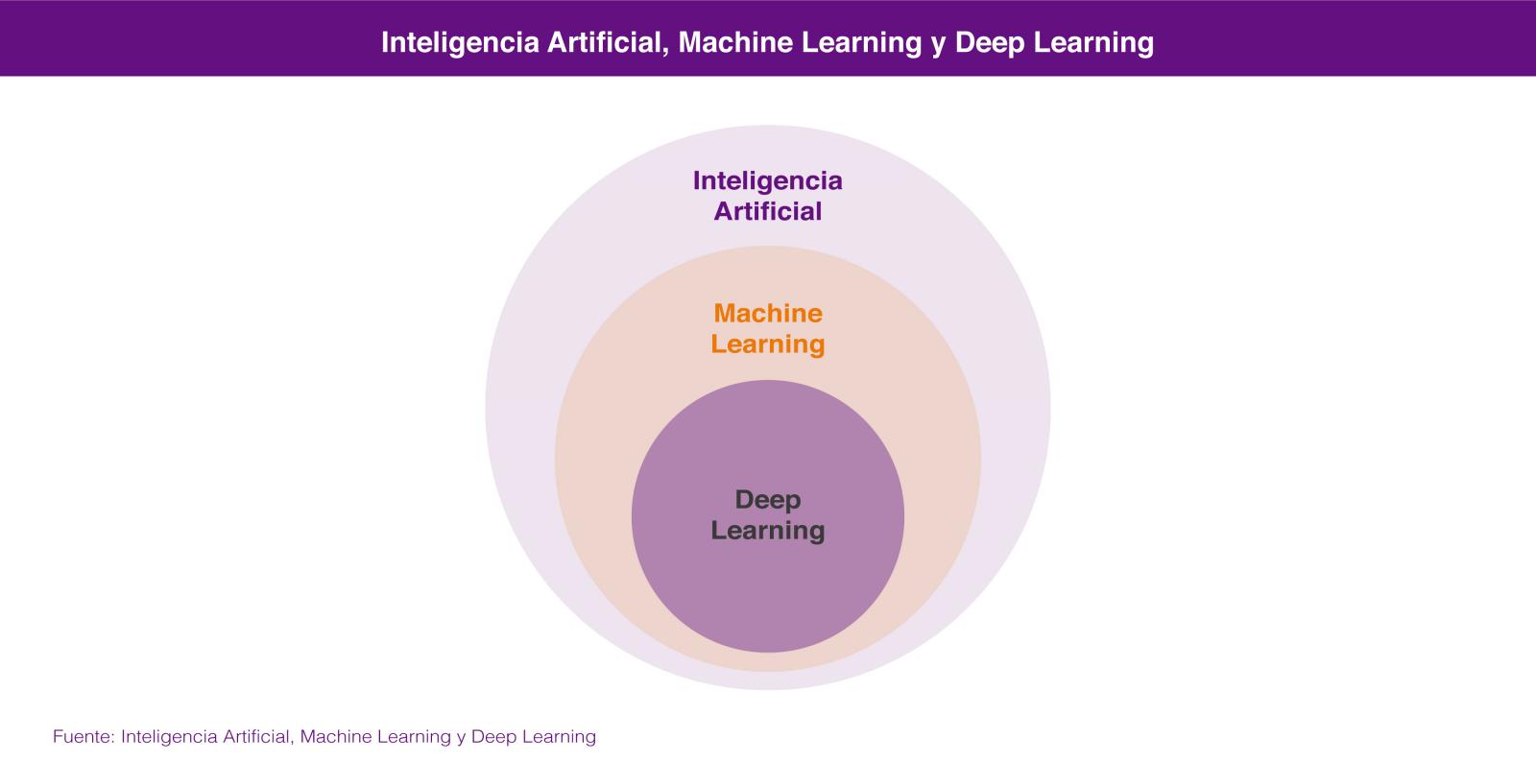
En realidad lo correcto es considerar el aprendizaje profundo como una parte del aprendizaje automático por lo que, si tenemos que buscar un atributo que nos permita diferenciarlas, éste sería su forma de aprender, que es completamente diferente. El aprendizaje automático se basa en algoritmos (redes bayesianas, máquinas de vectores de soporte, análisis de clusters, etc) que son capaces de descubrir patrones a partir de las observaciones incluidas en un conjunto de datos. En el caso del aprendizaje profundo se emplea un enfoque que está inspirado, salvando las distancias, en el funcionamiento de las conexiones de las neuronas del cerebro humano y existen también numerosas aproximaciones para diferentes problemas, como por ejemplo las redes neuronales convolucionales para reconocimiento de imágenes o las redes neuronales recurrentes para procesamiento del lenguaje natural.
La idoneidad de un enfoque u otro la marcará la cantidad de datos que tengamos disponibles para entrenar nuestro sistema de inteligencia artificial. En general podemos decir que para pequeñas cantidades de datos de entrenamiento, el enfoque basado en redes neuronales no ofrece un rendimiento superior al enfoque basado en algoritmos. El enfoque basado en algoritmos se suele estancar a partir de una cierta cantidad de datos, no siendo capaz de ofrecer una mayor precisión aunque le enseñemos más casos de entrenamiento. Sin embargo, a través del aprendizaje profundo podemos extraer un mejor rendimiento a partir de esa mayor disponibilidad de datos, ya que el sistema suele ser capaz de resolver el problema con una mayor precisión, cuanto más casos de entrenamiento tenga a su disposición.

Ninguna de estas tecnologías es nuevas en absoluto, ya que llevan décadas de desarrollo teórico. Sin embargo en los últimos años se han producido avances que han rebajado enormemente la barrera para trabajar con ellas: liberación de herramientas de programación que permiten trabajar a alto nivel con conceptos muy complejos, paquetes de software open source para administrar infraestructuras de gestión de datos, herramientas en la nube que permiten acceder a una potencia de computación casi sin límites y sin necesidad de administrar la infraestructura, e incluso formación gratuita impartida por algunos de los mejores especialistas del mundo.
Todo ello está contribuyendo a que capturemos datos a una escala sin precedentes y los almacenemos y procesemos a unos costes aceptables que permiten resolver problemas antiguos con enfoques novedosos. La inteligencia artificial está además al alcance de muchas más personas, cuya colaboración en un mundo cada vez más conectado están dando lugar a innovaciones que avanzan a un ritmo cada vez más veloz en todos los ámbitos: el transporte, la medicina, los servicios, la industria, etc.
Por algo el trabajo de científico de datos ha sido denominado el trabajo más sexy del siglo 21.
Contenido elaborado por Jose Luis Marín, Head of corporate Technology Strategy en MADISON MK y CEO de Euroalert.
Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.