Blog
In the fast-paced world of Generative Artificial Intelligence (AI), there are several concepts that have become fundamental to understanding and harnessing the potential of this technology. Today we focus on four: Small Language Models(SLM), Large Language Models(LLM), Retrieval Augmented Generation(RAG) and Fine-tuning. In this article, we will explore each of these terms, their interrelationships and how they are shaping the future of generative AI.
Let us start at the beginning. Definitions
Before diving into the details, it is important to understand briefly what each of these terms stands for:
The first two concepts (SLM and LLM) that we address are what are known as language models. A language model is an artificial intelligence system that understands and generates text in human language, as do chatbots or virtual assistants. The following two concepts (Fine Tuning and RAG) could be defined as optimisation techniques for these previous language models. Ultimately, these techniques, with their respective approaches as discussed below, improve the answers and the content returned to the questioner. Let's go into the details:
- SLM (Small Language Models): More compact and specialised language models, designed for specific tasks or domains.
- LLM (Large Language Models): Large-scale language models, trained on vast amounts of data and capable of performing a wide range of linguistic tasks.
- RAG (Retrieval-Augmented Generation): A technique that combines the retrieval of relevant information with text generation to produce more accurate and contextualised responses.
- Fine-tuning: The process of tuning a pre-trained model for a specific task or domain, improving its performance in specific applications.
Now, let's dig deeper into each concept and explore how they interrelate in the Generative AI ecosystem.
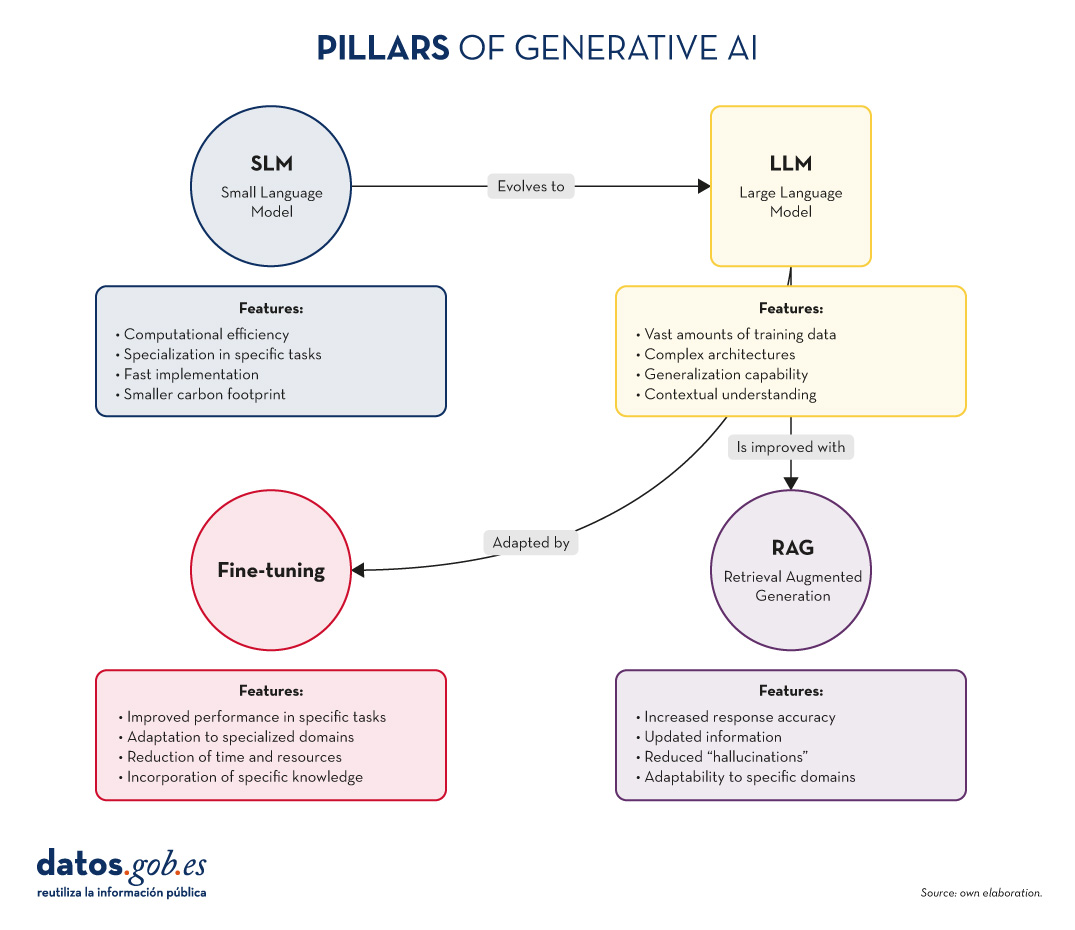
Figure 1. Pillars of Generative AI. Own elaboration.
SLM: The power of specialisation
Increased efficiency for specific tasks
Small Language Models (SLMs) are AI models designed to be lighter and more efficient than their larger counterparts. Although they have fewer parameters, they are optimised for specific tasks or domains.
Key characteristics of SLMs:
- Computational efficiency: They require fewer resources for training and implementation.
- Specialisation: They focus on specific tasks or domains, achieving high performance in specific areas.
- Rapid implementation: Ideal for resource-constrained devices or applications requiring real-time responses.
- Lower carbon footprint: Being smaller, their training and use consumes less energy.
SLM applications:
- Virtual assistants for specific tasks (e.g. booking appointments).
- Personalised recommendation systems.
- Sentiment analysis in social networks.
- Machine translation for specific language pairs.
LLM: The power of generalisation
The revolution of Large Language Models
LLMs have transformed the Generative AI landscape, offering amazing capabilities in a wide range of language tasks.
Key characteristics of LLMs:
- Vast amounts of training data: They train with huge corpuses of text, covering a variety of subjects and styles.
- Complex architectures: They use advanced architectures, such as Transformers, with billions of parameters.
- Generalisability: They can tackle a wide variety of tasks without the need for task-specific training.
- Contextual understanding: They are able to understand and generate text considering complex contexts.
LLM applications:
- Generation of creative text (stories, poetry, scripts).
- Answers to complex questions and reasoning.
- Analysis and summary of long documents.
- Advanced multilingual translation.
RAG: Boosting accuracy and relevance
The synergy between recovery and generation
As we explored in our previous article, RAG combines the power of information retrieval models with the generative capacity of LLMs. Its key aspects are:
Key features of RAG:
- Increased accuracy of responses.
- Capacity to provide up-to-date information.
- Reduction of "hallucinations" or misinformation.
- Adaptability to specific domains without the need to completely retrain the model.
RAG applications:
- Advanced customer service systems.
- Academic research assistants.
- Fact-checking tools for journalism.
- AI-assisted medical diagnostic systems.
Fine-tuning: Adaptation and specialisation
Refining models for specific tasks
Fine-tuning is the process of adjusting a pre-trained model (usually an LLM) to improve its performance in a specific task or domain. Its main elements are as follows:
Key features of fine-tuning:
- Significant improvement in performance on specific tasks.
- Adaptation to specialised or niche domains.
- Reduced time and resources required compared to training from scratch.
- Possibility of incorporating specific knowledge of the organisation or industry.
Fine-tuning applications:
- Industry-specific language models (legal, medical, financial).
- Personalised virtual assistants for companies.
- Content generation systems tailored to particular styles or brands.
- Specialised data analysis tools.
Here are a few examples
Many of you familiar with the latest news in generative AI will be familiar with these examples below.
SLM: The power of specialisation
Ejemplo: BERT for sentiment analysis
BERT (Bidirectional Encoder Representations from Transformers) is an example of SLM when used for specific tasks. Although BERT itself is a large language model, smaller, specialised versions of BERT have been developed for sentiment analysis in social networks.
For example, DistilBERT, a scaled-down version of BERT, has been used to create sentiment analysis models on X (Twitter). These models can quickly classify tweets as positive, negative or neutral, being much more efficient in terms of computational resources than larger models.
LLM: The power of generalisation
Ejemplo: OpenAI GPT-3
GPT-3 (Generative Pre-trained Transformer 3) is one of the best known and most widely used LLMs. With 175 billion parameters, GPT-3 is capable of performing a wide variety of natural language processing tasks without the need for task-specific training.
A well-known practical application of GPT-3 is ChatGPT, OpenAI's conversational chatbot. ChatGPT can hold conversations on a wide variety of topics, answer questions, help with writing and programming tasks, and even generate creative content, all using the same basic model.
Already at the end of 2020 we introduced the first post on GPT-3 as a great language model. For the more nostalgic ones, you can check the original post here.
RAG: Boosting accuracy and relevance
Ejemplo: Anthropic's virtual assistant, Claude
Claude, the virtual assistant developed by Anthropic, is an example of an application using RAGtechniques. Although the exact details of its implementation are not public, Claude is known for his ability to provide accurate and up-to-date answers, even on recent events.
In fact, most generative AI-based conversational assistants incorporate RAG techniques to improve the accuracy and context of their responses. Thus, ChatGPT, the aforementioned Claude, MS Bing and the like use RAG.
Fine-tuning: Adaptation and specialisation
Ejemplo: GPT-3 fine-tuned for GitHub Copilot
GitHub Copilot, the GitHub and OpenAI programming assistant, is an excellent example of fine-tuning applied to an LLM. Copilot is based on a GPT model (possibly a variant of GPT-3) that has been specificallyfine-tunedfor scheduling tasks.
The base model was further trained with a large amount of source code from public GitHub repositories, allowing it to generate relevant and syntactically correct code suggestions in a variety of programming languages. This is a clear example of how fine-tuning can adapt a general purpose model to a highly specialised task.
Another example: in the datos.gob.es blog, we also wrote a post about applications that used GPT-3 as a base LLM to build specific customised products.
Interrelationships and synergies
These four concepts do not operate in isolation, but intertwine and complement each other in the Generative AI ecosystem:
- SLM vs LLM: While LLMs offer versatility and generalisability, SLMs provide efficiency and specialisation. The choice between one or the other will depend on the specific needs of the project and the resources available.
- RAG and LLM: RAG empowers LLMs by providing them with access to up-to-date and relevant information. This improves the accuracy and usefulness of the answers generated.
- Fine-tuning and LLM: Fine-tuning allows generic LLMs to be adapted to specific tasks or domains, combining the power of large models with the specialisation needed for certain applications.
- RAG and Fine-tuning: These techniques can be combined to create highly specialised and accurate systems. For example, a LLM with fine-tuning for a specific domain can be used as a generative component in a RAGsystem.
- SLM and Fine-tuning: Fine-tuning can also be applied to SLM to further improve its performance on specific tasks, creating highly efficient and specialised models.
Conclusions and the future of AI
The combination of these four pillars is opening up new possibilities in the field of Generative AI:
- Hybrid systems: Combination of SLM and LLM for different aspects of the same application, optimising performance and efficiency.
- AdvancedRAG : Implementation of more sophisticated RAG systems using multiple information sources and more advanced retrieval techniques.
- Continuousfine-tuning : Development of techniques for the continuous adjustment of models in real time, adapting to new data and needs.
- Personalisation to scale: Creation of highly customised models for individuals or small groups, combining fine-tuning and RAG.
- Ethical and responsible Generative AI: Implementation of these techniques with a focus on transparency, verifiability and reduction of bias.
SLM, LLM, RAG and Fine-tuning represent the fundamental pillars on which the future of Generative AI is being built. Each of these concepts brings unique strengths:
- SLMs offer efficiency and specialisation.
- LLMs provide versatility and generalisability.
- RAG improves the accuracy and relevance of responses.
- Fine-tuning allows the adaptation and customisation of models.
The real magic happens when these elements combine in innovative ways, creating Generative AI systems that are more powerful, accurate and adaptive than ever before. As these technologies continue to evolve, we can expect to see increasingly sophisticated and useful applications in a wide range of fields, from healthcare to creative content creation.
The challenge for developers and researchers will be to find the optimal balance between these elements, considering factors such as computational efficiency, accuracy, adaptability and ethics. The future of Generative AI promises to be fascinating, and these four concepts will undoubtedly be at the heart of its development and application in the years to come.
Content prepared by Alejandro Alija, expert in Digital Transformation and Innovation. The contents and points of view reflected in this publication are the sole responsibility of its author.
Blog
In recent months we have seen how the large language models (LLMs ) that enable Generative Artificial Intelligence (GenAI) applications have been improving in terms of accuracy and reliability. RAG (Retrieval Augmented Generation) techniques have allowed us to use the full power of natural language communication (NLP) with machines to explore our own knowledge bases and extract processed information in the form of answers to our questions. In this article we take a closer look at RAG techniques in order to learn more about how they work and all the possibilities they offer in the context of generative AI.
What are RAG techniques?
This is not the first time we have talked about RAG techniques. In this article we have already introduced the subject, explaining in a simple way what they are, what their main advantages are and what benefits they bring in the use of Generative AI.
Let us recall for a moment its main keys. RAG is translated as Retrieval Augmented Generation . In other words, RAG consists of the following: when a user asks a question -usually in a conversational interface-, the Artificial Intelligence (AI), before providing a direct answer -which it could give using the (fixed) knowledge base with which it has been trained-, carries out a process of searching and processing information in a specific database previously provided, complementary to that of the training. When we talk about a database, we refer to a knowledge base previously prepared from a set of documents that the system will use to provide more accurate answers. Thus, when using RAGtechniques, conversational interfaces produce more accurate and context-specific responses.
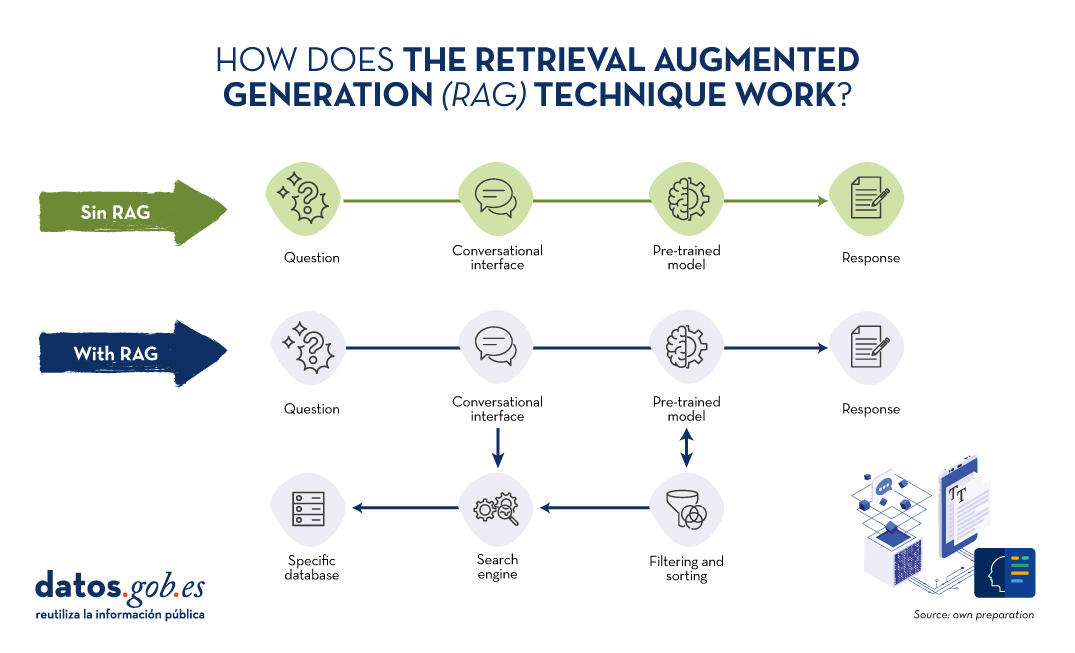
Source: Own preparation.
Conceptual diagram of the operation of a conversational interface or assistant without using RAG (top) and using RAG (bottom).
Drawing a comparison with the medical field, we could say that the use of RAG is as if a doctor, with extensive experience and therefore highly trained, in addition to the knowledge acquired during his academic training and years of experience, has quick and effortless access to the latest studies, analyses and medical databases instantly, before providing a diagnosis. Academic training and years of experience are equivalent to large language model (LLM) training and the "magic" access to the latest studies and specific databases can be assimilated to what RAG techniques provide.
Evidently, in the example we have just given, good medical practice makes both elements indispensable, and the human brain knows how to combine them naturally, although not without effort and time, even with today's digital tools, which make the search for information easier and more immediate.
RAG in detail
RAG Fundamentals
RAG combines two phases to achieve its objective: recovery and generation. In the first, relevant documents are searched for in a database containing information relevant to the question posed (e.g. a clinical database or a knowledge base of commonly asked questions and answers). In the second, an LLM is used to generate a response based on the retrieved documents. This approach ensures that responses are not only consistent but also accurate and supported by verifiable data.
Components of the RAG System
In the following, we will describe the components that a RAG algorithm uses to fulfil its function. For this purpose, for each component, we will explain what function it fulfils, which technologies are used to fulfil this function and an example of the part of the RAG process in which that component is involved.
- Recovery Model:
- Function: Identifies and retrieves relevant documents from a large database in response to a query.
- Technology: It generally uses Information Retrieval (IR) techniques such as BM25 or embedding-based retrieval models such as Dense Passage Retrieval (DPR).
- Process: Given a question, the retrieval model searches a database to find the most relevant documents and presents them as context for answer generation.
- Generation Model:
- Function: Generate coherent and contextually relevant answers using the retrieved documents.
- Technology: Based on some of the major Large Language Models (LLM) such as GPT-3.5, T5, or BERT, Llama.
- Process: The generation model takes the user's query and the retrieved documents and uses this combined information to produce an accurate response.
Detailed RAG Process
For a better understanding of this section, we recommend the reader to read this previous work in which we explain in a didactic way the basics of natural language processing and how we teach machines to read. In detail, a RAG algorithm performs the following steps:
- Reception of the question. The system receives a question from the user. This question is processed to extract keywords and understand the intention.
- Document retrieval. The question is sent to the recovery model.
- Example of Retrieval based on embeddings:
- The question is converted into a vector of embeddings using a pre-trained model.
- This vector is compared with the document vectors in the database.
- The documents with the highest similarity are selected.
- Example of BM25:
- The question is tokenised and the keywords are compared with the inverted indexes in the database.
- The most relevant documents are retrieved according to a relevance score.
- Example of Retrieval based on embeddings:
- Filtering and sorting. The retrieved documents are filtered to eliminate redundancies and to classify them according to their relevance. Additional techniques such as reranking can be applied using more sophisticated models.
- Response generation. The filtered documents are concatenated with the user's question and fed into the generation model. The LLM uses the combined information to generate an answer that is coherent and directly relevant to the question. For example, if we use GPT-3.5 as LLM, the input to the model includes both the user's question and fragments of the retrieved documents. Finally, the model generates text using its ability to understand the context of the information provided.
In the following section we will look at some applications where Artificial Intelligence and large language models play a differentiating role and, in particular, we will analyse how these use cases benefit from the application of RAGtechniques.
Examples of use cases that benefit substantially from using RAG vs. not using RAG
1. ECommerceCustomer Service
- No RAG:
- A basic chatbot can give generic and potentially incorrect answers about return policies.
- Example: Please review our returns policy on the website.
- With RAG:
- The chatbot accesses the database of updated policies and provides a specific and accurate response.
- Example: You may return products within 30 days of purchase, provided they are in their original packaging. See more details [here].
2. Medical Diagnosis
- No RAG:
- A virtual health assistant could offer recommendations based only on their previous training, without access to the latest medical information.
- Example: You may have the flu. Consult your doctor
- With RAG:
- The wizard can retrieve information from recent medical databases and provide a more accurate and up-to-date diagnosis.
- Example: Based on your symptoms and recent studies published in PubMed, you could be dealing with a viral infection. Consult your doctor for an accurate diagnosis.
3. Academic Research Assistance
- No RAG:
- A researcher receives answers limited to what the model already knows, which may not be sufficient for highly specialised topics.
- Example: Economic growth models are important for understanding the economy.
- With RAG:
- The wizard retrieves and analyses relevant academic articles, providing detailed and accurate information.
- Example: According to the 2023 study in the Journal of Economic Growth, the XYZ model has been shown to be 20% more accurate in predicting economic trends in emerging markets.
4. Journalism
- No RAG:
- A journalist receives generic information that may not be up to date or accurate.
- Example Artificial intelligence is changing many industries.
- With RAG:
- The wizard retrieves specific data from recent studies and articles, providing a solid basis for the article.
- Example: According to a 2024 report by 'TechCrunch', AI adoption in the financial sector has increased by 35% in the last year, improving operational efficiency and reducing costs.
Of course, for most of us who have experienced the more accessible conversational interfaces, such as ChatGPT, Gemini o Bing we can see that the answers are usually complete and quite precise when it comes to general questions. This is because these agents make use of AGN methods and other advanced techniques to provide the answers. However, it is not long before conversational assistants, such as Alexa, Siri u OK Google provided extremely simple answers and very similar to those explained in the previous examples when not making use of RAG.
Conclusions
Retrieval Augmented Generation (RAG) techniques improve the accuracy and relevance of language model answers by combining document retrieval and text generation. Using retrieval methods such as BM25 or DPR and advanced language models, RAG provides more contextualised, up-to-date and accurate responses.Today, RAG is the key to the exponential development of AI in the private data domain of companies and organisations. In the coming months, RAG is expected to see massive adoption in a variety of industries, optimising customer care, medical diagnostics, academic research and journalism, thanks to its ability to integrate relevant and current information in real time.
Content prepared by Alejandro Alija, expert in Digital Transformation and Innovation. The contents and points of view reflected in this publication are the sole responsibility of its author.
Blog
We are currently in the midst of an unprecedented race to master innovations in Artificial Intelligence. Over the past year, the star of the show has been Generative Artificial Intelligence (GenAI), i.e., that which is capable of generating original and creative content such as images, text or music. But advances continue to come and go, and lately news is beginning to arrive suggesting that the utopia of Artificial General Intelligence (AGI) may not be as far away as we thought. We are talking about machines capable of understanding, learning and performing intellectual tasks with results similar to those of the human brain.
Whether this is true or simply a very optimistic prediction, a consequence of the amazing advances achieved in a very short space of time, what is certain is that Artificial Intelligence already seems capable of revolutionizing practically all facets of our society based on the ever-increasing amount of data used to train it.
And the fact is that if, as Andrew Ng argued back in 2017, artificial intelligence is the new electricity, open data would be the fuel that powers its engine, at least in a good number of applications whose main and most valuable source is public information that is accessible for reuse. In this article we will review a field in which we are likely to see great advances in the coming years thanks to the combination of artificial intelligence and open data: artistic creation.
Generative Creation Based on Open Cultural Data
The ability of artificial intelligence to generate new content could lead us to a new revolution in artistic creation, driven by access to open cultural data and a new generation of artists capable of harnessing these advances to create new forms of painting, music or literature, transcending cultural and temporal barriers.
Music
The world of music, with its diversity of styles and traditions, represents a field full of possibilities for the application of generative artificial intelligence. Open datasets in this field include recordings of folk, classical, modern and experimental music from all over the world and from all eras, digitized scores, and even information on documented music theories. From the arch-renowned MusicBrainz, the open music encyclopedia, to datasets opened by streaming industry dominators such as Spotify or projects such as Open Music Europe, these are some examples of resources that are at the basis of progress in this area. From the analysis of all this data, artificial intelligence models can identify unique patterns and styles from different cultures and eras, fusing them to create unpublished musical compositions with tools and models such as OpenAI's MuseNet or Google's Music LM.
Literature and painting
In the realm of literature, Artificial Intelligence also has the potential to make not only the creation of content on the Internet more productive, but to produce more elaborate and complex forms of storytelling. Access to digital libraries that house literary works from antiquity to the present day will make it possible to explore and experiment with literary styles, themes and storytelling archetypes from diverse cultures throughout history, in order to create new works in collaboration with human creativity itself. It will even be possible to generate literature of a more personalized nature to the tastes of more minority groups of readers. The availability of open data such as the Guttemberg Project with more than 70,000 books or the open digital catalogs of museums and institutions that have published manuscripts, newspapers and other written resources produced by mankind, are a valuable resource to feed the learning of artificial intelligence.
The resources of the Digital Public Library of America1 (DPLA) in the United States or Europeana in the European Union are just a few examples. These catalogs not only include written text, but also vast collections of visual works of art, digitized from the collections of museums and institutions, which in many cases cannot even be admired because the organizations that preserve them do not have enough space to exhibit them to the public. Artificial intelligence algorithms, by analyzing these works, discover patterns and learn about artistic techniques, styles and themes from different cultures and historical periods. This makes it possible for tools such as DALL-E2 or Midjourney to create visual works from simple text instructions with aesthetics of Renaissance painting, Impressionist painting or a mixture of both.
However, these fascinating possibilities are accompanied by a still unresolved controversy about copyright that is being debated in academic, legal and juridical circles and that poses new challenges to the definition of authorship and intellectual property. On the one hand, there is the question of the ownership of rights over creations produced by artificial intelligence. On the other hand, there is the use of datasets containing copyrighted works that have been used in the training of models without the consent of the authors. On both issues there are numerous legal disputes around the world and requests for explicit removal of content from the main training datasets.
In short, we are facing a field where the advance of artificial intelligence seems unstoppable, but we must be very aware not only of the opportunities, but also of the risks involved.
Content prepared by Jose Luis Marín, Senior Consultant in Data, Strategy, Innovation & Digitalization. The contents and points of view reflected in this publication are the sole responsibility of its author.
Blog
Generative artificial intelligence refers to machine’s ability to generate original and creative content, such as images, text or music, from a set of input data. As far as text generation is concerned, these models have been accessible, in an experimental format, for some time, but began to generate interest in mid-2020 when Open AI, an organisation dedicated to research in the field of artificial intelligence, published access to its GPT-3 language model via an API.
The GPT-3's architecture is composed of 175 billion parameters, comparing to its predecessor GPT-2 was 1.5 billion parameters, i.e. more than 100 times more. Therefore, GPT-3 represents a huge change in scale as it was also trained with a much larger corpus of data and a much larger token size, which allowed it to acquire a deeper and more complex understanding of the human language.
Although it was in 2022 when OpenAI announced the launch of chatGPT, which provides a conversational interface to a language model based on an improved version of GPT-3, it has only been in the last two months that the chat has attracted massive public attention, thanks to extensive media coverage that tries to respond to the emerging general interest.
In fact, ChatGPT is not only able to generate text from a set of characters (prompt) like GPT-3, but also it is able to respond to natural language questions in several languages including English, Spanish, French, German, Italian or Portuguese. This specific updated issue in the access interface from an API to a chatbot that has made the AI accessible to any type of user.
Maybe for this reason, more than a million people registered to use it in just five days, which has led to the multiplication of examples in which chatGPT produces software code, university-level essays, poems and even jokes. Not to mention the fact that it has been able to ace an history SAT or pass the final MBA exam at the prestigious Wharton School.
All of this has put generative AI at the centre of a new wave of technological innovation that promises to revolutionise the way we relate to the internet and the web through AI-powered searches or browsers capable of summarising the results of these searches.
Just a few days ago, we heard the news that Microsoft is working on the implementation of a conversational system within its own search engine, which has been developed based on the well-known Open AI language model and whose news has put Google in check.
As a result of this new reality in which AI is here to stay, the technological giants have gone a step further in the battle to make the most of the benefits it brings. Along these lines, Microsoft has presented a new strategy aimed at optimising the way in which we interact with the internet, introducing AI to improve the results offered by browser search engines, applications, social networks and, in short, the entire web ecosystem.
However, although the path in the development of new and future services offered by Open AI's remains to be seen, advances such as the mentioned above, offer a small hint of the browser war that is coming and that will probably change the way we create and find content on the web in the short term.
The open data
GPT-3, like other models that have been generated with the techniques described in the original GTP-3 scientific publication, is a pre-trained language model, which means that it has been trained with a large dataset, in total about 45 terabytes of text data. According to the paper, the training dataset was composed of 60% of data obtained directly from the internet containing millions of documents of all kinds, 22% from the WebText2 corpus built from Reddit, and the rest from a combination of books (16%) and Wikipedia (3%).
However, it is not known exactly how much open datasets GPT-3 uses, as OpenAI does not provide more specific details about the dataset used to train the model. What we can ask chatGPT itself are some questions that can help us draw interesting conclusions about its use of open data.
For example, if we ask chatGPT what was the population of Spain between 2015 and 2020 (we cannot ask for more recent data), we get an answer like this:

As we can see in the image above, although the question is the same, the answer may vary in both the wording and the information it contains. The variations can be even greater if we ask the question on different days or in different threads:
Small variations in the wording of the text, generating the question at different times in the conversation thread (remember that it saves the context) or in different threads or on different days may lead to slightly different results. Moreover, the answer is not completely accurate, as the tool itself warns us if we compare it with the INE's own series on the resident population in Spain, where it recommends us to consult. The data that we would ideally have expected in the response could be obtained in an open INE dataset:
Such responses suggest that open data has not been used as an authoritative source for answering factual questions, or at least that the model is not yet fully refined on this matter. Doing some basic tests with questions about other countries we have observed similar errors, so this does not seem to be a problem only with questions referring to Spain.
If we ask more specific questions, such as asking for a list of the municipalities in the province of Burgos that begin with the letter "G", we get answers that are not completely correct, as is typical of a technology that is still in its infancy.
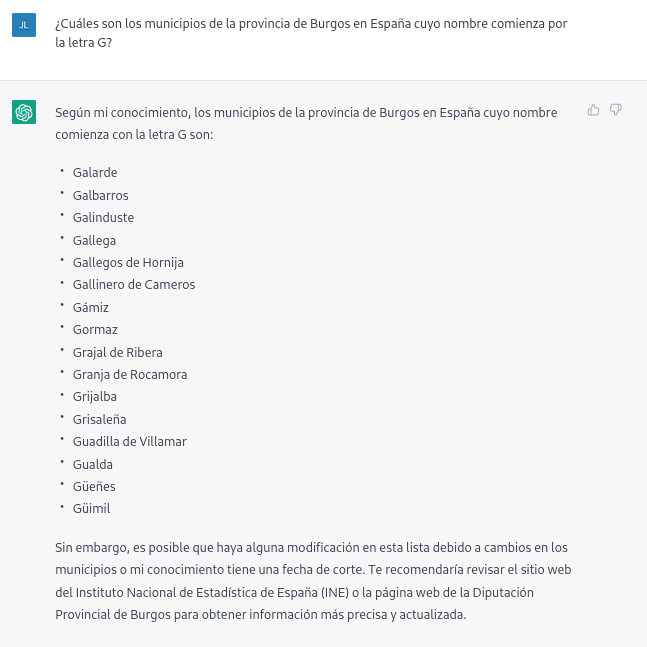
The correct answer should contain six municipalities: Galbarros, La Gallega, Grijalba, Grisaleña, Gumiel de Hizán and Gumiel del Mercado. However, the answer we have obtained only contains the first four and includes localities in the province of Guadalajara (Gualda), municipalities in the province of Valladolid (Gallegos de Hornija) or localities in the province of Burgos that are not municipalities (Galarde). In this case, we can also turn to the open dataset to get the correct answer.
Next, we ask ChatGPT for the list of municipalities beginning with the letter Z in the same province. ChatGPT tells us that there are none, reasoning the answer, when in fact there are four:
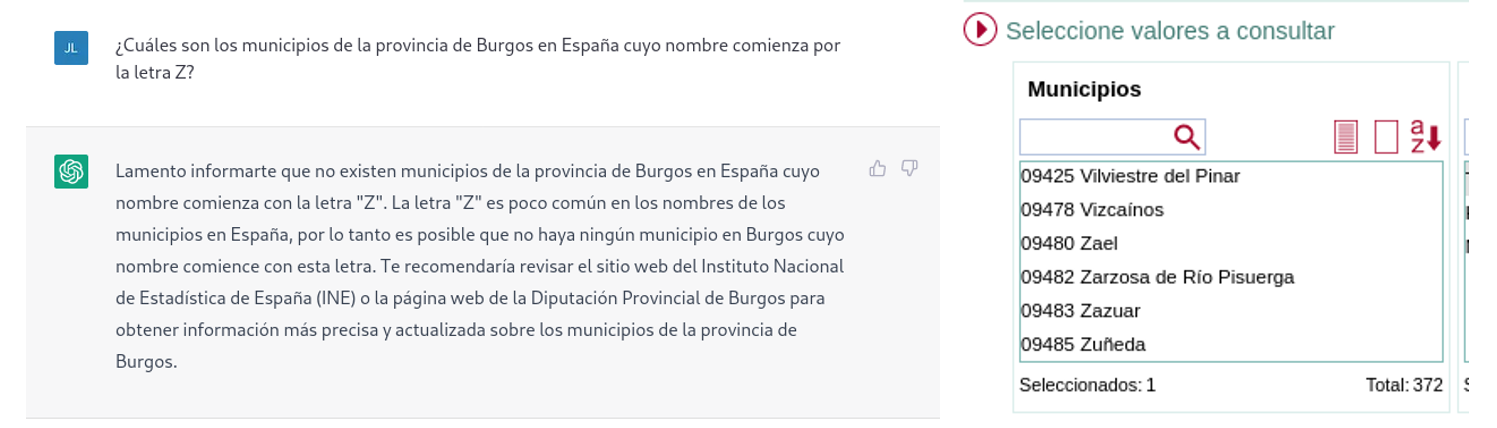
As can be seen from the examples above, we can see how open data can indeed contribute to technological evolution and thus improve the performance of Open AI's artificial intelligence. However, given its current state of maturity, it is still too early to see the optimal use of open data to answer more complex questions.
Therefore, for a generative AI model to be effective, it is necessary to have a large amount of high quality and diverse data, and open data is a valuable source of knowledge for this purpose.
In future versions of the model, we will probably be able to see how open data will acquire a much more important role in the composition of the training corpus, achieving a significant improvement in the quality of the factual answers.
Content prepared by Jose Luis Marín, Senior Consultant in Data, Strategy, Innovation & Digitalization.
The contents and views reflected in this publication are the sole responsibility of the author.
Blog
In this post we have described step-by-step a data science exercise in which we try to train a deep learning model with a view to automatically classifying medical images of healthy and sick people.
Diagnostic imaging has been around for many years in the hospitals of developed countries; however, there has always been a strong dependence on highly specialised personnel. From the technician who operates the instruments to the radiologist who interprets the images. With our current analytical capabilities, we are able to extract numerical measures such as volume, dimension, shape and growth rate (inter alia) from image analysis. Throughout this post we will try to explain, through a simple example, the power of artificial intelligence models to expand human capabilities in the field of medicine.
This post explains the practical exercise (Action section) associated with the report “Emerging technologies and open data: introduction to data science applied to image analysis”. Said report introduces the fundamental concepts that allow us to understand how image analysis works, detailing the main application cases in various sectors and highlighting the role of open data in their implementation.
Previous projects
However, we could not have prepared this exercise without the prior work and effort of other data science lovers. Below we have provided you with a short note and the references to these previous works.
- This exercise is an adaptation of the original project by Michael Blum on the STOIC2021 - disease-19 AI challenge. Michael's original project was based on a set of images of patients with Covid-19 pathology, along with other healthy patients to serve as a comparison.
- In a second approach, Olivier Gimenez used a data set similar to that of the original project published in a competition of Kaggle. This new dataset (250 MB) was considerably more manageable than the original one (280GB). The new dataset contained just over 1,000 images of healthy and sick patients. Olivier's project code can be found at the following repository.
Datasets
In our case, inspired by these two amazing previous projects, we have built an educational exercise based on a series of tools that facilitate the execution of the code and the possibility of examining the results in a simple way. The original data set (chest x-ray) comprises 112,120 x-ray images (front view) from 30,805 unique patients. The images are accompanied by the associated labels of fourteen diseases (where each image can have multiple labels), extracted from associated radiological reports using natural language processing (NLP). From the original set of medical images we have extracted (using some scripts) a smaller, delimited sample (only healthy people compared with people with just one pathology) to facilitate this exercise. In particular, the chosen pathology is pneumothorax.
If you want further information about the field of natural language processing, you can consult the following report which we already published at the time. Also, in the post 10 public data repositories related to health and wellness the NIH is referred to as an example of a source of quality health data. In particular, our data set is publicly available here.
Tools
To carry out the prior processing of the data (work environment, programming and drafting thereof), R (version 4.1.2) and RStudio (2022-02-3) was used. The small scripts to help download and sort files have been written in Python 3.
Accompanying this post, we have created a Jupyter notebook with which to experiment interactively through the different code snippets that our example develops. The purpose of this exercise is to train an algorithm to be able to automatically classify a chest X-ray image into two categories (sick person vs. non-sick person). To facilitate the carrying out of the exercise by readers who so wish, we have prepared the Jupyter notebook in the Google Colab environment which contains all the necessary elements to reproduce the exercise step-by-step. Google Colab or Collaboratory is a free Google tool that allows you to programme and run code on python (and also in R) without the need to install any additional software. It is an online service and to use it you only need to have a Google account.
Logical flow of data analysis
Our Jupyter Notebook carries out the following differentiated activities which you can follow in the interactive document itself when you run it on Google Colab.
- Installing and loading dependencies.
- Setting up the work environment
- Downloading, uploading and pre-processing of the necessary data (medical images) in the work environment.
- Pre-visualisation of the loaded images.
- Data preparation for algorithm training.
- Model training and results.
- Conclusions of the exercise.
Then we carry out didactic review of the exercise, focusing our explanations on those activities that are most relevant to the data analysis exercise:
- Description of data analysis and model training
- Modelling: creating the set of training images and model training
- Analysis of the training result
- Conclusions
Description of data analysis and model training
The first steps that we will find going through the Jupyter notebook are the activities prior to the image analysis itself. As in all data analysis processes, it is necessary to prepare the work environment and load the necessary libraries (dependencies) to execute the different analysis functions. The most representative R package of this set of dependencies is Keras. In this article we have already commented on the use of Keras as a Deep Learning framework. Additionally, the following packages are also required: htr; tidyverse; reshape2; patchwork.
Then we have to download to our environment the set of images (data) we are going to work with. As we have previously commented, the images are in remote storage and we only download them to Colab at the time we analyse them. After executing the code sections that download and unzip the work files containing the medical images, we will find two folders (No-finding and Pneumothorax) that contain the work data.

Once we have the work data in Colab, we must load them into the memory of the execution environment. To this end, we have created a function that you will see in the notebook called process_pix(). This function will search for the images in the previous folders and load them into the memory, in addition to converting them to grayscale and normalising them all to a size of 100x100 pixels. In order not to exceed the resources that Google Colab provides us with for free, we limit the number of images that we load into memory to 1000 units. In other words, the algorithm will be trained with 1000 images, including those that it will use for training and those that it will use for subsequent validation.
Once we have the images perfectly classified, formatted and loaded into memory, we carry out a quick visualisation to verify that they are correct. We obtain the following results:

Self-evidently, in the eyes of a non-expert observer, there are no significant differences that allow us to draw any conclusions. In the steps below we will see how the artificial intelligence model actually has a better clinical eye than we do.
Modelling
Creating the training image set
As we mentioned in the previous steps, we have a set of 1000 starting images loaded in the work environment. Until now, we have had classified (by an x-ray specialist) those images of patients with signs of pneumothorax (on the path "./data/Pneumothorax") and those patients who are healthy (on the path "./data/No -Finding")
The aim of this exercise is precisely to demonstrate the capacity of an algorithm to assist the specialist in the classification (or detection of signs of disease in the x-ray image). With this in mind, we have to mix the images to achieve a homogeneous set that the algorithm will have to analyse and classify using only their characteristics. The following code snippet associates an identifier (1 for sick people and 0 for healthy people) so that, later, after the algorithm's classification process, it is possible to verify those that the model has classified correctly or incorrectly.

So, now we have a uniform “df” set of 1000 images mixed with healthy and sick patients. Next, we split this original set into two. We are going to use 80% of the original set to train the model. In other words, the algorithm will use the characteristics of the images to create a model that allows us to conclude whether an image matches the identifier 1 or 0. On the other hand, we are going to use the remaining 20% of the homogeneous mixture to check whether the model, once trained, is capable of taking any image and assigning it 1 or 0 (sick, not sick).

Model training
Right, now all we have left to do is to configure the model and train with the previous data set.
Before training, you will see some code snippets which are used to configure the model that we are going to train. The model we are going to train is of the binary classifier type. This means that it is a model that is capable of classifying the data (in our case, images) into two categories (in our case, healthy or sick). The model selected is called CNN or Convolutional Neural Network. Its very name already tells us that it is a neural networks model and thus falls under the Deep Learning discipline. These models are based on layers of data features that get deeper as the complexity of the model increases. We would remind you that the term deep refers precisely to the depth of the number of layers through which these models learn.
Note: the following code snippets are the most technical in the post. Introductory documentation can be found here, whilst all the technical documentation on the model's functions is accessible here.
Finally, after configuring the model, we are ready to train the model. As we mentioned, we train with 80% of the images and validate the result with the remaining 20%.

Training result
Well, now we have trained our model. So what's next? The graphs below provide us with a quick visualisation of how the model behaves on the images that we have reserved for validation. Basically, these figures actually represent (the one in the lower panel) the capability of the model to predict the presence (identifier 1) or absence (identifier 0) of disease (in our case pneumothorax). The conclusion is that when the model trained with the training images (those for which the result 1 or 0 is known) is applied to 20% of the images for which the result is not known, the model is correct approximately 85% (0.87309) of times.

Indeed, when we request the evaluation of the model to know how well it classifies diseases, the result indicates the capability of our newly trained model to correctly classify 0.87309 of the validation images.
Now let’s make some predictions about patient images. In other words, once the model has been trained and validated, we wonder how it is going to classify the images that we are going to give it now. As we know "the truth" (what is called the ground truth) about the images, we compare the result of the prediction with the truth. To check the results of the prediction (which will vary depending on the number of images used in the training) we use that which in data science is called the confusion matrix. The confusion matrix:
- Places in position (1,1) the cases that DID have disease and the model classifies as "with disease"
- Places in position (2,2), the cases that did NOT have disease and the model classifies as "without disease"
In other words, these are the positions in which the model "hits" its classification.
In the opposite positions, in other words, (1,2) and (2,1) are the positions in which the model is "wrong". So, position (1,2) are the results that the model classifies as WITH disease and the reality is that they were healthy patients. Position (2,1), the very opposite.
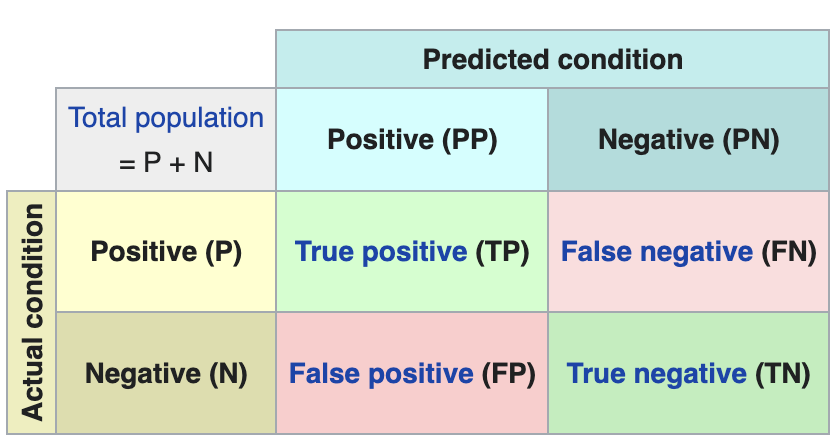
Explanatory example of how the confusion matrix works. Source: Wikipedia https://en.wikipedia.org/wiki/Confusion_matrix
In our exercise, the model gives us the following results:


In other words, 81 patients had this disease and the model classifies them correctly. Similarly, 91 patients were healthy and the model also classifies them correctly. However, the model classifies as sick 13 patients who were healthy. Conversely, the model classifies 12 patients who were actually sick as healthy. When we add the hits of the 81+91 model and divide it by the total validation sample, we obtain 87% accuracy of the model.
Conclusions
In this post we have guided you through a didactic exercise consisting of training an artificial intelligence model to carry out chest x-ray imaging classifications with the aim of determining automatically whether someone is sick or healthy. For the sake of simplicity, we have chosen healthy patients and patients with pneumothorax (only two categories) previously diagnosed by a doctor. The journey we have taken gives us an insight into the activities and technologies involved in automated image analysis using artificial intelligence. The result of the training affords us a reasonable classification system for automatic screening with 87% accuracy in its results. Algorithms and advanced image analysis technologies are, and will increasingly be, an indispensable complement in multiple fields and sectors, such as medicine. In the coming years, we will see the consolidation of systems which naturally combine the skills of humans and machines in expensive, complex or dangerous processes. Doctors and other workers will see their capabilities increased and strengthened thanks to artificial intelligence. The joining of forces between machines and humans will allow us to reach levels of precision and efficiency never seen before. We hope that through this exercise we have helped you to understand a little more about how these technologies work. Don't forget to complete your learning with the rest of the materials that accompany this post.
Content prepared by Alejandro Alija, an expert in Digital Transformation.The contents and points of view reflected in this publication are the sole responsibility of its author.
Blog
Data science is an interdisciplinary field that seeks to extract actuable knowledge from datasets, structured in databases or unstructured as texts, audios or videos. Thanks to the application of new techniques, data science is allowing for answering questions that are not easy to solve through other methods. The ultimate goal is to design improvement or correction actions based on the new knowledge.
The key concept in data science is SCIENCE, and not really data, considering that experts has even begun to speak about a fourth paradigm of science, including data-based approach together with the traditional theoretical, empirical and computational approachs.
Data science combines methods and technologies that come from mathematics, statistics and computer science. It include exploratory analysis, machine learning, deep learning, natural-language processing, data visualization and experimental design, among others.
Within Data Science, the two most talked-about technologies are Machine Learning and Deep Learning, both included in the field of artificial intelligence. In both cases, the objective is the construction of systems capable of learning to solve problems without the intervention of a human being, including from orthographic or automatic translation systems to autonomous cars or artificial vision systems applied to use cases as spectacular as the Amazon Go stores.
In both cases, the systems learn to solve problems from the datasets “we teach them” in order to train them to solve the problem, either in a supervised way - training datasets are previously labeled by humans-, or in a unsupervised way - these data sets are not labeled-.
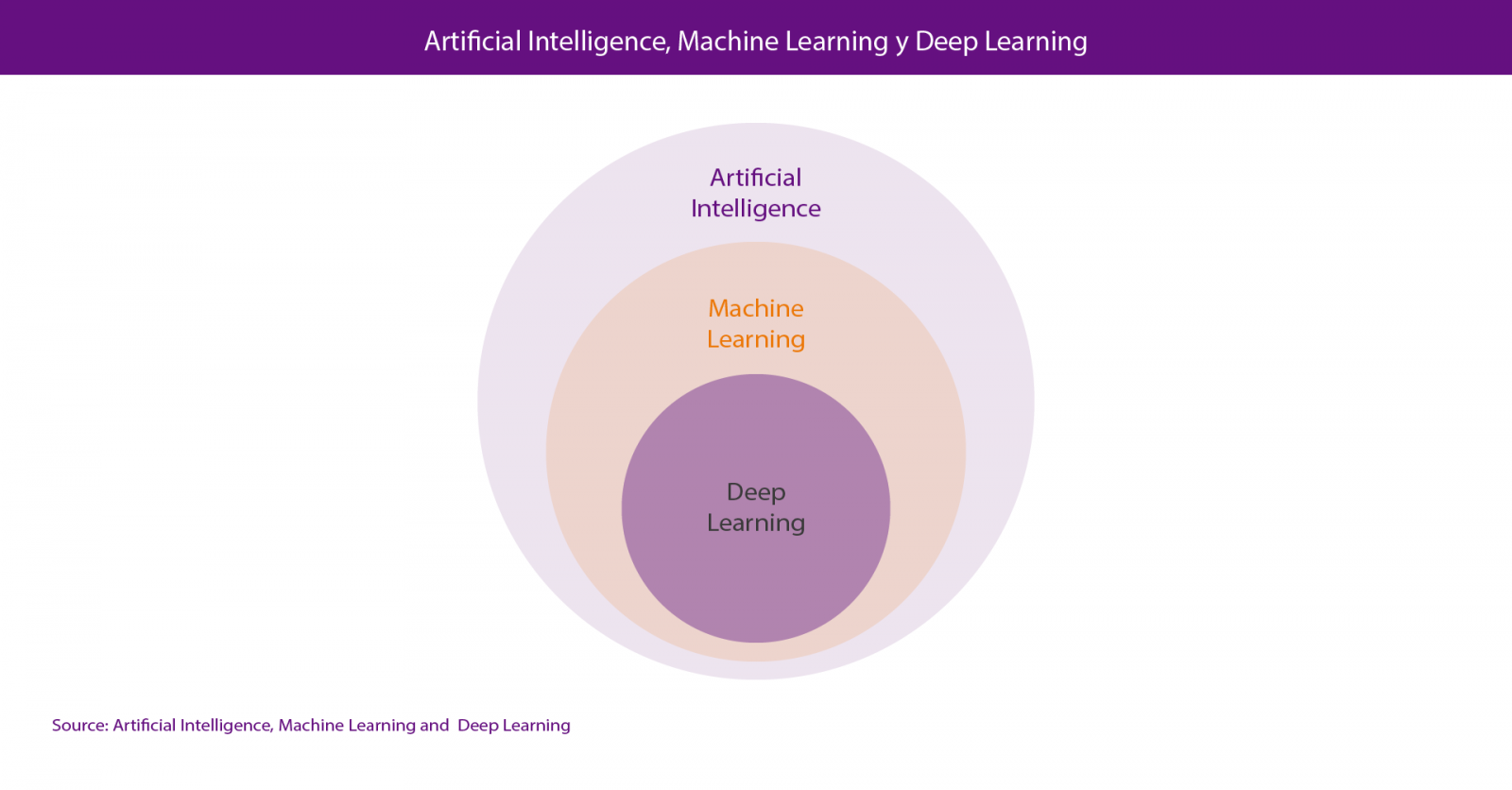
Actually, the correct point of view is to consider deep learning as a part of machine learning so, if we have to look for an attribute to differentiate both of them, we could consider their method of learning, which is completely different. Machine learning is based on algorithms (Bayesian networks, support vector machines, clusters analysis, etc.) that are able to discover patterns from the observations included in a dataset. In the case of deep learning, the approach is inspired, basically, in the functioning of human brain´s neurons and their connections; and there are also numerous approaches for different problems, such as convolutional neural networks for image recognition or recurrent neural networks for natural language processing.
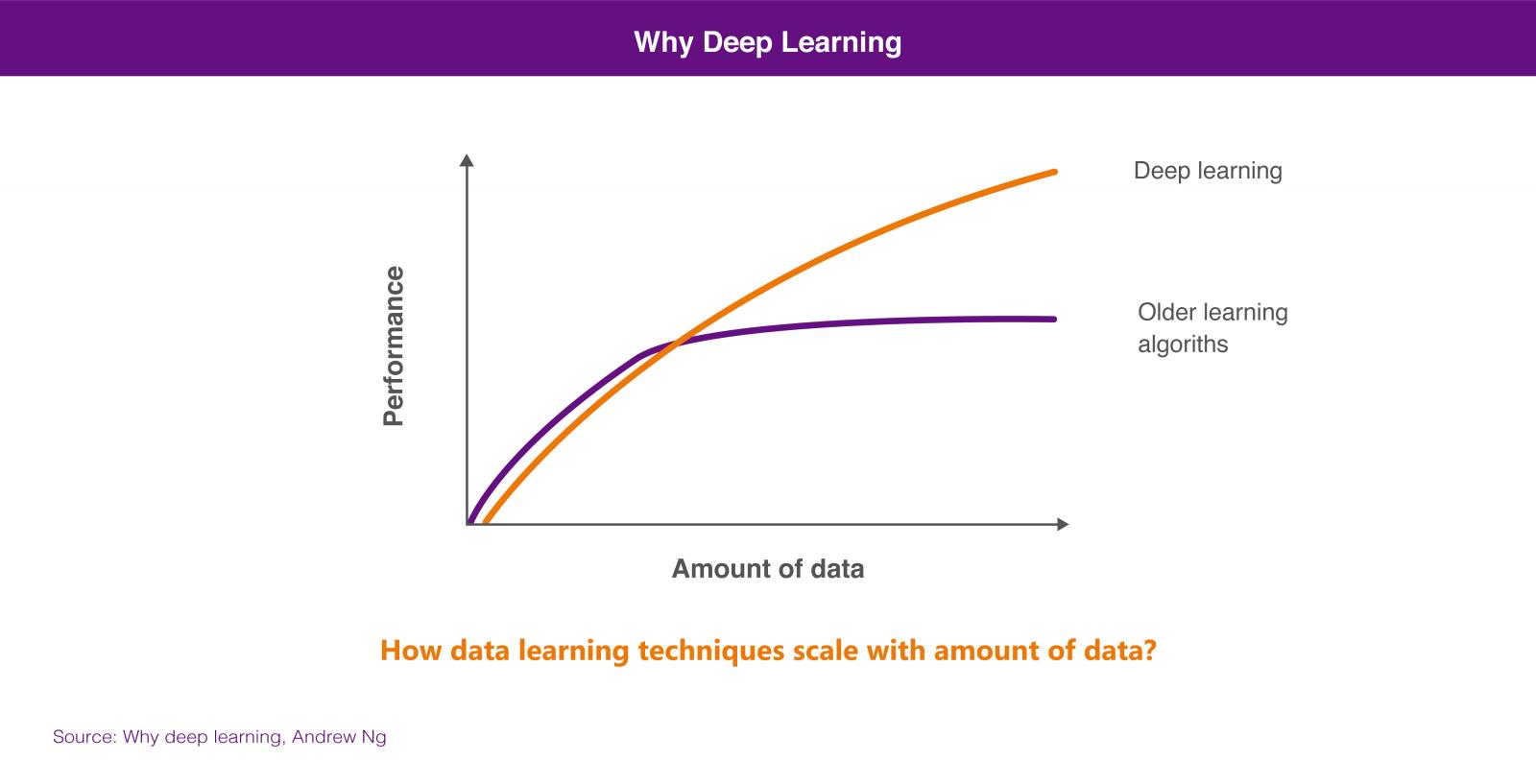
The suitability of one approach or another will rely on the amount of data we have available to train our artificial intelligence system. In general, we can affirm that, if we have a small amounts of training data, the neural network-based approach does not offer superior performance than the algorithm-based approach. The algorithm-based approach usually come to a standstill due to huge amount of data, not being able to offer greater precision although we teach more training cases. However, through deep learning we can have a better performance from this greater amount of data, because the system is usually able to solve the problem with greater precision, the more cases of training are available.
None of these technologies is new at all, considering that they have decades of theoretical development. However, in recent years new advances have greatly reduced their barriers: the opening of programming tools that allow high-level work with very complex concepts, open source software packages to run data management infrastructures, cloud tools that allow access to almost unlimited computing power and without the need to manage the infrastructure, and even free training given by some of the best specialists in the world.
All this issues are contributing to capture data on an unprecedented scale, and store and process data at acceptable costs that allow us to solve old problems with new approaches. Artificial intelligence is also available to many more people, whose collaboration in an increasingly connected world is giving rise to innovation, advancing increasingly faster in all areas: transport, medicine, services, manufacturing, etc.
For some reason, data scientist has been called the sexiest job of the 21st century.
Content prepared by Jose Luis Marín, Head of Corporate Technology Startegy en MADISON MK and Euroalert CEO.
Contents and points of view expressed in this publication are the exclusive responsibility of its author.