Blog
La Agencia Española de Protección de Datos (AEPD), a través de su propia sección de Innovación y Tecnología desempeña una labor didáctica esencial al proporcionar un corpus documental que traduce las obligaciones legales del Reglamento General de Protección de Datos (RGPD) a realidades tecnológicas concretas. Su valor reside en su capacidad para ofrecer seguridad jurídica y pautas técnicas en áreas donde la normativa aún está encontrando su encaje práctico, como la inteligencia artificial o la biometría.
Se trata de guías de referencia, artículos y otros materiales didácticos orientados especialmente a pymes y personas emprendedoras. En este post presentamos algunas de las más recientes, ordenadas según sector y materia.
Las nuevas tendencias de la inteligencia artificial y su despliegue seguro
La evolución de la inteligencia artificial hacia sistemas cada vez más autónomos plantea nuevos retos en materia de protección de datos. Por ello, la Agencia Española de Protección de Datos ha desarrollado diversas guías y documentos orientados a facilitar un despliegue seguro y responsable de esta tecnología. En general, la IA es una de las áreas de mayor actividad documental de la AEPD debido a su impacto transversal. Los recursos de la Agencia cubren desde la gestión interna hasta las tecnologías de última generación.
- Guía inteligencia artificial agéntica desde la perspectiva de protección de datos: la denominada IA agéntica es aquella capaz de tomar decisiones y actuar con cierto grado de independencia. A diferencia de los modelos puramente reactivos, una IA agéntica puede llevar a cabo múltiples tareas de forma autónoma y adoptar decisiones intermedias durante procesos complejos. Esta guía analiza los riesgos de la pérdida de control humano y establece criterios para asegurar que la trazabilidad de las decisiones no se pierda en la automatización.
- Política general para el uso de la IA generativa en procesos administrativos de la AEPD: la inteligencia artificial generativa (IAG o GenAI) es un tipo de IA capaz de producir contenido nuevo, como texto, imágenes, audio o código a partir de patrones aprendidos. Este documento establece una política interna para su uso responsable en procesos administrativos.
- Anexo de implementación de la política general IAG de la AEPD: este anexo al documento anterior incluye los casos de uso permitidos, el tipo de sistemas recomendados (externos, internos o ad hoc), el nivel de riesgo asociado a cada aplicación y las obligaciones específicas de revisión, control humano, seguridad y protección de datos.
- Resumen básico de obligaciones y recomendaciones para la gestión de IA generativa: se trata de un esquema sintetizado sobre aspectos de gobernanza, diseño y desarrollo de casos de uso, tratamiento de datos personales e información sensible, transparencia y explicabilidad, y uso responsable de herramientas, entre otros.
- Informe sobre aprendizaje federado: el aprendizaje federado es un enfoque de inteligencia artificial que permite entrenar modelos de forma colaborativa sin centralizar los datos, mejorando la privacidad y alineándose con el RGPD. Esta guía explica en qué consiste, dónde puede haber un tratamiento de datos personales y cuáles son los beneficios y desafío en la protección de datos.
Para complementar esta información, los usuarios también pueden visitar el blog de la AEPD, que sirve como un observatorio de tendencias donde se analizan los riesgos visibles e invisibles de las tecnologías de consumo. Algunas de las temáticas que se trata son:
- Tratamiento de imagen y voz: se han publicado análisis sobre la transcripción de voz con IA y el uso de servicios que convierten fotografías a otros formatos (como animaciones). Estos artículos alertan sobre el tratamiento de datos biométricos y la propiedad de los datos en la nube.
- Alfabetización algorítmica: recursos como "Abordando conceptos erróneos de la IA" buscan elevar el nivel de juicio crítico de los usuarios y responsables frente a la opacidad de los algoritmos.
- Equilibrio de derechos: destaca el análisis sobre la protección del menor en el entorno digital y el diseño de contratos públicos que integren la privacidad desde el diseño.
Cartera europea de identidad digital
La evolución hacia una Europa interconectada exige estándares de identidad robustos y medidas de seguridad accesibles para todos los niveles empresariales.
La construcción de una identidad digital segura, interoperable y confiable es uno de los pilares de la transformación digital en Europa. La futura cartera europea de identidad digital es un proyecto que plantea permitir a la ciudadanía identificarse electrónicamente y compartir atributos personales de forma controlada en múltiples servicios, tanto públicos como privados.
Para analizar sus implicaciones desde el punto de vista de la privacidad, la Agencia Española de Protección de Datos ha publicado una serie de cuatro artículos monográficos a lo largo de 2025. En ellos, la Agencia desglosa la relación entre la nueva cartera de identidad digital y el RGPD.
Estos contenidos abordan cuestiones clave como:
- La minimización de datos y el principio de proporcionalidad en el intercambio de información: explica cómo el Reglamento eIDAS2 impulsa la cartera europea de identidad digital. Este reglamento establece un marco para una identificación electrónica segura, interoperable y centrada en el usuario, alineada con el RGPD para garantizar el control y la protección de los datos personales en toda la UE.
- Los riesgos asociados a la interoperabilidad entre sistemas: profundiza en cómo evitar que el uso de la Cartera Europea de Identidad Digital permita rastrear a los ciudadanos cuando presentan credenciales en distintos servicios públicos o privados, destacando la necesidad de soluciones criptográficas avanzadas.
- La necesidad de garantizar el control del usuario sobre sus credenciales: examina las amenazas de identificación en las carteras de identidad digital bajo eIDAS2, destacando que, sin garantías sólidas como seudonimización y no vinculación, incluso la revelación selectiva de datos puede permitir la identificación y el perfilado indebido de los usuarios.
- Las medidas de seguridad necesarias para evitar usos indebidos o brechas de datos: plantea las amenazas de inexactitud en las carteras de identidad digital bajo eIDAS2, destacando cómo datos desactualizados o mecanismos criptográficos vinculables pueden provocar decisiones erróneas y comprometer la privacidad. Para solucionarlo, subraya la necesidad de soluciones que garanticen tanto la fiabilidad como la negación plausible (que no exista ninguna prueba técnica que permita demostrar que una persona ha realizado una acción concreta con su cartera o credencial digital).
A través de esta serie, se ofrece una visión progresiva que ayuda a comprender tanto el potencial de la identidad digital europea como los desafíos que plantea su implementación desde una perspectiva de protección de datos.
Cifrado de protección de datos personales en las PYMES
Para muchas pequeñas y medianas empresas, garantizar la seguridad de los datos personales sigue siendo un desafío, especialmente por la falta de recursos técnicos o conocimiento especializado. En este contexto, el cifrado se presenta como una herramienta fundamental para proteger la confidencialidad e integridad de la información.
Con el objetivo de acercar este concepto a un público no experto, la Agencia Española de Protección de Datos ha publicado la Guía de cifrado para autónomos y pymes, acompañada de una infografía explicativa.
Estos recursos explican de manera clara y práctica:
- Qué es el cifrado y por qué es importante en la protección de datos.
- Qué tipos de cifrado existen y en qué casos se aplican.
- Cómo implementar medidas de cifrado en situaciones habituales, como el envío de correos electrónicos o el almacenamiento de información.
- Qué herramientas pueden utilizarse sin necesidad de conocimientos avanzados.
Investigación científica y marco legal europeo
Para los perfiles que requieren un análisis más profundo y académico, la Agencia ha impulsado la publicación de artículos científicos en diversos medios internacionales, que conectan la tecnología con la ética y el derecho. Algunos ejemplos son:
- Patrones adictivos: análisis sobre cómo el diseño de interfaces afecta al comportamiento humano.
- Neurotecnología: estudio sobre los riesgos de las interfaces cerebro-computador.
- Gobernanza algorítmica: un análisis integral que alinea el RGPD con el Reglamento europeo de inteligencia artificial (AI Act), la Ley de Servicios Digitales (DSA, Digital Services Act) y la Ley de Ciberresiliencia.
El valor didáctico de estos materiales reside en su capacidad para ofrecer una visión de 360 grados sobre el dato. Desde la investigación académica de vanguardia hasta las infografías de cifrado para una pequeña empresa, la AEPD proporciona los pilares para una innovación que no sacrifique la privacidad.
En conjunto, estos materiales que comparte la Agencia Española de Protección de datos ayudan a incorporar medidas de seguridad eficaces y a cumplir con los requisitos del Reglamento General de Protección de Datos de forma proporcionada y accesible. Todos ellos, y algunos otros, están recopilados y ordenados por temática en su apartado web, disponible aquí.
Blog
Nadie duda ya de la importancia de los datos en la sociedad y la economía actuales. Los datos están presentes hoy en día en prácticamente todos los aspectos de nuestra vida. Es por ello que cada vez más países han ido incorporando a sus políticas normativas específicas referentes a los datos: ya sean sobre datos personales, empresariales o gubernamentales, o bien para regular una serie de cuestiones, como quién puede acceder a ellos, dónde pueden almacenarse, cómo deben protegerse, etc.
Sin embargo, cuando se examinan esas políticas con más detenimiento, se pueden observar diferencias significativas entre ellas, dependiendo de los objetivos principales que establece cada país a la hora de aplicar sus políticas de datos. Así pues, todos los países reconocen el valor social y económico de los datos, pero las políticas que implementan para maximizar ese valor pueden variar ampliamente. Para algunos, los datos son principalmente un activo económico, para otros puede ser un medio de innovación y modernización, y para otros una herramienta para el desarrollo.
Un informe reciente del Centro para la Innovación a través de los Datos compara las políticas generales aplicables en varios países que han sido precisamente seleccionados por las diferencias respecto a su visión de cómo se deben gestionar los datos: China, India, Singapur, el Reino Unido y la Unión Europea. A continuación, haremos un repaso de las características principales de sus políticas de datos, centrándonos principalmente en aquellos aspectos relacionados con el fomento de la innovación a través del uso de los datos.
CHINA
Sus esfuerzos se centran en construir una economía interna de datos sólida para fortalecer la competitividad nacional y mantener el control del gobierno a través de la recopilación y uso de datos. Cuenta con dos agencias desde las que se dirigen las políticas de datos: la administración del ciberespacio (CAC) y la administración nacional de datos (NDA).
Las principales políticas que gobiernan los datos en el país son:
- El plan quinquenal nacional de informatización, publicado a finales de 2021 para incrementar la recopilación de datos en la industria nacional.
- La ley de seguridad de los datos (DSL), efectiva desde septiembre de 2021 y donde se otorga especial protección a todos los datos que se considera puedan tener un impacto en la seguridad nacional.
- La ley de ciberseguridad (CSL), efectiva desde junio de 2017 y a través de la cual se prohíbe el anonimato online y se concede también acceso a los datos por parte del gobierno cuando sea requerido por cuestiones de seguridad.
- La ley de protección de la información personal (PIPL), efectiva desde noviembre de 2021 y que establece la obligatoriedad de mantener los datos en el territorio nacional.
INDIA
Su objetivo principal es utilizar la política de datos para desbloquear un nuevo recurso económico e impulsar la modernización y el desarrollo del país. El Ministerio de Electrónica y Tecnología de la Información (MEIT por sus siglas en inglés) rige y supervisa las políticas de datos en el país, que resumimos a continuación:
- La ley de protección de datos digitales personales del 2023, cuyo objetivo es habilitar el procesamiento de datos personales de forma que se reconozca, tanto el derecho de las personas a proteger sus datos, como la necesidad de procesarlos para fines legítimos.
- La arquitectura de empoderamiento y protección de los datos (DEPA), que se puso en marcha en el 2020 y otorga a los ciudadanos un mayor control sobre sus datos personales al establecer intermediarios entre los usuarios de la información y los proveedores, además de proporcionar consentimiento a las empresas en función de un conjunto de permisos establecido por el usuario.
- El marco de gobernanza de los datos no personales, también aprobado en el 2020 y a través del cual se establece que los beneficios obtenidos a través de los datos deben repercutir también en la comunidad, y no solo en las empresas que recopilan esos datos. También indica que deben compartirse datos de gran valor y aquellos relacionados con el interés público (como por ejemplo los datos de energía, transporte, geoespaciales o sanidad).
SINGAPUR
Pretende utilizar los datos como vehículo para atraer nuevas empresas a operar dentro del país. La Autoridad de Desarrollo de Medios Infocomm (IMDA) es la entidad encargada de gestionar las políticas de datos en este caso, lo que incluye el control de la Comisión de Protección de Datos Personales (PDPC).
Entre la normativa más relevante en este caso podemos encontrar:
- La ley de Protección de Datos Personales (PDPA), actualizada por última vez en el 2021 y que se basa en el consentimiento, pero también establece algunas excepciones por interés legítimo público.
- El marco de confianza para la compartición de datos, publicado en el 2019 y donde se establecen estándares para el intercambio de datos entre empresas (incluyendo plantillas para establecer acuerdos legales de intercambio), aunque con ciertas protecciones para el secreto comercial.
- La obligatoriedad de portabilidad de datos (DPO), que será próximamente incorporada a la PDPA para establecer el derecho a la transmisión de datos personales a otro servicio (siempre que cuente con sede en el país) en un formato estándar que facilite el intercambio.
REINO UNIDO
Quiere impulsar la competitividad económica del país, al mismo tiempo que protege la privacidad de los datos de sus ciudadanos. La Oficina del Comisionado de la Información (ICO) es el organismo encargado de la protección de datos y las pautas para poder compartirlos.
En el caso del Reino Unido el marco legislativo es muy amplio:
- El núcleo de los principios de privacidad, como la portabilidad de datos o las condiciones de acceso a los datos personales, está cubierto por el Reglamento General de Protección de Datos (GDPR) del 2016, la ley de Protección de Datos (DPA) del 2018, la regulación para la Privacidad de las Comunicaciones Electrónicas del 2013 y la propuesta de ley de Protección de Datos e Información Digital todavía bajo debate.
- La ley de Economía Digital, establecida en el 2017 y donde se definen las normas para compartir datos entre administraciones públicas para el desarrollo de los servicios públicos.
- El Código para Compartir Datos, que entró en vigor en Octubre de 2021 y determina buenas prácticas que sirven de guía a las empresas a la hora de compartir datos.
- La Directiva de Servicios de Pago (PSD2), que entró en vigor inicialmente en el 2018 requiriendo a los bancos compartir sus datos en formatos estandarizados para fomentar el desarrollo de nuevos servicios.
UNIÓN EUROPEA
Utiliza un enfoque basado en los derechos humanos para la protección de datos. El objetivo es dar prioridad a la creación de un mercado único que facilite el flujo libre de datos entre los estados miembro. Los Consejos Europeos de Protección de Datos (EDPB) y de Innovación a través de los Datos son los principales organismos responsables de supervisar la protección de datos en la Unión.
Nuevamente, la normativa aplicable es muy amplia y ha continuado extendiéndose recientemente:
- El Reglamento General de Protección de Datos (GDPR), que se ha convertido en la regulación más completa y descriptiva en el mundo, y que está basada en los principios de legalidad, equidad, transparencia, contención, minimización, exactitud, almacenamiento, integridad, confidencialidad y responsabilidad.
- El programa para la Década Digital, para el fomento de un mercado digital único, interoperable, interconectado y seguro.
- La Declaración de Principios y Derechos Digitales, que amplía los derechos digitales y sobre los datos ya existentes en la norma de protección.
- La Ley de Datos y el Reglamento de Gobernanza de Datos, que facilitan la accesibilidad a los datos de forma horizontal, es decir entre sectores y dentro de los mismos, siguiendo los principios de la UE. La Ley de Datos Impulsa reglas armonizadas relativas al acceso y uso equitativo de los datos, aclarando quién puede crear valor a partir de ellos y bajo qué condiciones. Por su parte, el Reglamento de Gobernanza de datos regula el intercambio seguro de conjuntos de datos que están bajo el poder de organismos públicos sobre los que concurren derechos de terceros, así como los servicios de intermediación de datos y su cesión altruista para el beneficio de la sociedad.
Las claves para el fomento de la innovación
En general, podríamos concluir que aquellas políticas de datos que adoptan un enfoque más orientado en favor de la innovación se caracterizan por:
- Protección de datos basada en distintos niveles de riesgo, priorizando la protección de los datos personales más sensibles, como la información médica o financiera, mientras se reduce los costes regulatorios para aquellos menos sensibles.
- Marcos de compartición para datos personales y no personales, fomentando la compartición de datos por defecto tanto en el sector público como privado y eliminando barreras a la compartición voluntaria de datos.
- Facilitar el flujo de datos, respaldando una economía digital abierta y competitiva.
- Políticas de producción de datos proactivas, fomentando el uso de los datos como factor de producción mediante la recopilación de datos en varios sectores y evitando lagunas en la información.
Como hemos visto, las políticas de datos se han convertido en un aspecto estratégico para muchos países, ya que no sólo contribuyen a reforzar sus objetivos y prioridades como nación, sino que además envían señales sobre cuáles son sus prioridades e intereses en el escenario internacional. Lograr un equilibrio adecuado entre la protección de datos y el fomento de la innovación es uno de los desafíos clave. Antes de abordar sus propias políticas, se recomienda a los países invertir tiempo en analizar y comprender los distintos enfoques existentes, incluyendo sus fortalezas y debilidades, para después tomar las medidas específicas más adecuadas a la hora de diseñar sus propias estrategias.
Contenido elaborado por Carlos Iglesias, Open data Researcher y consultor, World Wide Web Foundation. Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Blog
La segmentación de imágenes es un método que divide una imagen digital en subgrupos (segmentos) para reducir la complejidad de esta y, así, poder facilitar su procesamiento o análisis. La finalidad de la segmentación es asignar etiquetas a píxeles para identificar objetos, personas u otros elementos en la imagen.
La segmentación de las imágenes es clave para las tecnologías y algoritmos de visión artificial, pero también se utiliza hoy en día para muchas aplicaciones como, por ejemplo, el análisis de imágenes médicas, la visión de los vehículos autónomos, el reconocimiento y la detección de rostros o el análisis de imágenes satelitales, entre otras.
Segmentar una imagen es un proceso lento y costoso, por eso en lugar de procesar la imagen completa, una práctica común es la segmentación de imágenes mediante el enfoque de desplazamiento medio. Este procedimiento emplea una ventana desplazable que atraviesa progresivamente la imagen, calculando el promedio de los valores de píxeles contenidos en dicha región.
Este cálculo se efectúa con el propósito de establecer los píxeles que han de ser incorporados a cada uno de los segmentos delineados. Conforme la ventana avanza a lo largo de la imagen, lleva a cabo de manera iterativa una recalibración del cálculo para garantizar la idoneidad de cada uno de los segmentos resultantes.
A la hora de segmentar una imagen los factores o características que se tienen en cuenta son principalmente:
- El color: Los diseñadores gráficos tienen la posibilidad de emplear una pantalla de tonalidad verdosa con el fin de asegurar una uniformidad cromática en el fondo de la imagen. Esta práctica posibilita la automatización de la detección y sustitución del fondo durante la etapa de postprocesamiento.
- Bordes: La segmentación basada en bordes es una técnica que identifica los bordes de varios objetos en una imagen determinada. Estos se identifican en función de las variaciones de contraste, textura, color y saturación.
- Contraste: Se procesa la imagen distinguiendo entre una figura oscura y un fondo claro basándose en valores de alto contraste.
Estos factores se aplican en distintas técnicas de segmentación:
- Umbrales: Divide los píxeles en función de su intensidad en relación con un valor o umbral determinado. Este método es el más adecuado para segmentar objetos con mayor intensidad que otros objetos o fondos.
- Regiones: Consiste en dividir una imagen en regiones con características semejantes agregando los píxeles con características similares.
- Clústeres: Los algoritmos de agrupamiento son algoritmos de clasificación no supervisados que ayudan a identificar información oculta en las imágenes. El algoritmo divide las imágenes en grupos de píxeles con características similares, separando los elementos en grupos y agrupando elementos similares en estos grupos.
- Cuencas hidrográficas: Se trata de un proceso que transforma las imágenes a escala de grises, tratándolas como mapas topográficos, donde el brillo de los píxeles determina la altura. Esta técnica sirve para detectar líneas que forman crestas y cuencas. marcando las áreas entre las líneas divisorias de aguas.
El aprendizaje automático y el aprendizaje profundo (Deep learning) han mejorado estas técnicas, como la segmentación de clústeres, pero también han generado nuevos enfoques de segmentación que utilizan el entrenamiento de modelos para mejorar la capacidad de los programas a la hora de identificar características importantes. La tecnología de redes neuronales profundas es especialmente efectiva para las tareas de segmentación de imágenes.
En la actualidad encontramos distintos tipos de segmentación de imágenes, siendo las principales:
- Segmentación Semántica: La segmentación semántica de imágenes es un proceso que permite crear regiones dentro de una imagen y atribuir significado semántico a cada una de ellas. Estos objetos o también conocidas como clases semánticas, por ejemplo: coche, autobús, persona, árbol, etc., han sido previamente definidas mediante el entrenamiento de modelos en los que se clasifican y etiquetan estos objetos. El resultado es una imagen en lo que se han clasificado los pixeles en cada objeto o clase localizado.
- Segmentación de instancias: La segmentación de instancias combina el método de segmentación semántica (interpretando los objetos de una imagen) y la detección de objetos (al localizarlos dentro de la imagen). Como resultado de esta segmentación, se localizan los objetos, para que cada uno de ellos sea singularizado por medio de una ventana delimitadora (bounding box) y una máscara binaria, las cuales determinan qué píxeles de dicha ventana pertenecen al objeto localizado.
- Segmentación panóptica: Es el tipo más actual de segmentación. Se trata de una combinación de segmentación semántica y de instancias. Este método sí puede determinar la identidad de cada objeto porque esta técnica de segmentación localiza y distingue los diferentes objetos o instancias y asigna dos etiquetas a cada píxel de la imagen: una etiqueta semántica y una ID de instancia. De esta forma cada objeto es único.

En la imagen se pueden observar los resultados de aplicar las distintas segmentaciones a una imagen satelital. La segmentación semántica devuelve una categoría por cada tipo de objeto identificado. La segmentación por instancia devuelve los objetos individualizados y la caja delimitadora y, en la segmentación panóptica, obtenemos los objetos individualizados y el contexto también diferenciado, pudiendo detectar el suelo y la región de calles.
El nuevo modelo de Meta: SAM
En abril del 2023, el departamento de investigación de Meta presentó un nuevo modelo de Inteligencia Artificial (IA) al que llamaron SAM (Segment Anything Model). Con SAM se puede realizar la segmentación de una imagen mediante tres formas:
- Seleccionando un punto en la imagen, se buscará y distinguirá el objeto que intersecta con ese punto y se buscará todos los objetos iguales encontrados en la imagen.
- Por ventana delimitadora o bounding box, sobre la imagen se dibuja un rectángulo y se identifican todos los objetos encontrados en esa área.
- Por palabras, mediante una consola se escribe una palabra y SAM puede identificar los objetos que coincidan con esa palabra u orden explícita tanto en imágenes o videos, incluso si ese dato no fue incluido en su entrenamiento.
SAM es un modelo flexible que fue entrenado con el conjunto de datos más grande hasta la fecha, llamado SA-1B y que cuenta con 11 millones de imágenes y 1.1 mil millones de máscaras en segmentación. Gracias a estos datos, SAM es capaz de detectar todo tipo de objetos sin necesidad de un entrenamiento adicional.
Por ahora, el modelo SAM y el conjunto de datos SA-1B está disponible para su uso no comercial y con fines de investigación. De este modo, los usuarios que suban sus imágenes tendrán que comprometerse a utilizarlo únicamente con fines de académicos. Para probarla, ingresa a este enlace de GitHub.
En agosto del 2023, el Grupo de Análisis de Imagen y Vídeo de la Academia China de las Ciencias, lanza una actualización de su modelo llamado FastSAM que reduce considerablemente el tiempo de procesado, se consigue una velocidad de ejecución 50 veces mayor, haciendo que el modelo sea más práctico de ejecutar que el modelo SAM original. Esta aceleración la consiguen habiendo entrenado el modelo con el 2% de los datos utilizados para entrenar SAM. FastSAM tiene menos requisitos computacionales que SAM, sin dejar de alcanzar una gran precisión.
SAMGEO: la versión que permite analizar datos geoespaciales
El paquete segment-geospatial desarrollado por Qiusheng Wu tiene como finalidad facilitar el uso de Segment Anything Model (SAM) para datos geoespaciales, para ello se he desarrollado los paquetes de Python segment-anything-py y segment-geospatial , que están disponibles en PyPI y conda-forge.
El objetivo es simplificar el proceso de aprovechamiento de SAM para el análisis de datos geoespaciales al permitir que los usuarios lo logren con un mínimo esfuerzo de codificación. A partir de estas librerías, se desarrolla el plugin de QGIS Geo-SAM y se desarrolla el uso del modelo en ArcGIS Pro.

Conclusiones
En definitiva, SAM supone una gran revolución no sólo por las posibilidades que abre a la hora de editar fotografías o extraer elementos de imágenes para collages o edición de video, sino también por las oportunidades de mejora que permiten aumentar la visión por computadora, a la hora de usar lentes de realidad aumentada o cascos de realidad virtual.
También SAM supone una revolución para la obtención de información espacial, mejorando la detención de objetos mediante imágenes satelitales y facilitando la detección de cambios en el territorio de forma rápida.
Contenido elaborado por Mayte Toscano, Senior Consultant in Tecnologías ligadas a la economía del dato.
Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Blog
La demanda de profesionales con habilidades relacionadas con la analítica de datos no deja de crecer y ya se estima que la industria solo en España necesitaría más de 90.000 profesionales en datos e inteligencia artificial para impulsar la economía. Formar profesionales que puedan llenar este hueco es un gran reto que está haciendo incluso grandes compañías tecnológicas como Google, Amazon o Microsoft estén proponiendo programas de formación especializado que en paralelo a los que propone el sistema educativo reglado. Y en este contexto los datos abiertos tienen un papel muy relevante en la formación práctica de estos profesionales, ya que con frecuencia, los datos abiertos son la única posibilidad para realizar ejercicios reales y no solo simulados.
Además, aunque aún no existe un corpus de investigación sólido al respecto, algunos trabajos ya sugieren efectos positivos derivados del uso de datos abiertos como herramienta en el proceso de enseñanza-aprendizaje de cualquier materia y no solo de las relacionadas con la analítica de datos. Algunos países europeos han reconocido ya este potencial y han desarrollado proyectos piloto para determinar la mejor forma de introducir datos abiertos en el currículo escolar.
En este sentido, los datos abiertos se pueden utilizar como una herramienta para la educación y la formación de varias maneras. Por ejemplo, los datos abiertos se pueden utilizar para desarrollar nuevos materiales de enseñanza y aprendizaje, para crear proyectos basados en datos del mundo real para estudiantes o para apoyar la investigación sobre enfoques pedagógicos efectivos. Además, los datos abiertos se pueden utilizar para crear oportunidades de colaboración entre educadores, estudiantes e investigadores con el fin de compartir mejores prácticas y colaborar en soluciones a desafíos comunes.
Proyectos basados en datos del mundo real
Una aportación clave de los datos abiertos es su autenticidad, ya que son una representación de la enorme complejidad e incluso de los defectos del mundo real a diferencia de las construcciones artificiales o los ejemplos de libros de texto que se basan en supuestos muchos más simples.
Un ejemplo interesante en este sentido es el que documentó la Universidad Simon Fraser de Canadá en su Máster en Edición donde la mayor parte de sus alumnos proceden de programas universitarios no STEM y que por tanto tenían unas capacidades limitadas en el manejo de datos. El proyecto está disponible como recurso educativo abierto en la plataforma OER Commons y su objetivo es que los estudiantes comprendan que las métricas y la medición son herramientas estratégicas importantes para comprender el mundo que nos rodea.
Al trabajar con datos del mundo real, los estudiantes pueden desarrollar habilidades de construcción de relatos e investigación, y pueden aplicar habilidades analíticas y colaborativas en el uso de datos para resolver problemas del mundo real. El caso de estudio realizado con la primera edición en la que se utilizó este OER basado en datos abiertos está documentado en el libro “Open Data as Open Educational Resources - Case studies of emerging practice”. En él se muestra que la oportunidad de trabajar con datos pertenecientes a su campo de estudio resultó esencial para mantener a los estudiantes comprometidos con el proyecto. Sin embargo, lidiar con el desorden de los datos del "mundo real" fue lo que les permitió obtener un aprendizaje valioso y nuevas habilidades prácticas.
Desarrollo de nuevos materiales de aprendizaje
Los conjuntos de datos abiertos tienen un gran potencial para ser utilizados en el desarrollo de recursos educativos abiertos (REA) que son materiales de enseñanza, aprendizaje e investigación en soporte digital de carácter gratuito, pues son publicados con una licencia abierta (Creative Commons) que permite su uso, adaptación y redistribución para usos no comerciales de acuerdo con la definición de la UNESCO.
En este contexto, si bien los datos abiertos no siempre son REA, podemos decir que se convierten en REA cuando se usan en contextos pedagógicos. Los datos abiertos cuando se utilizan como recurso educativo facilitan que los estudiantes aprendan y experimenten trabajando con los mismos conjuntos de datos que utilizan investigadores, gobiernos y sociedad civil. Son un componente clave para que los estudiantes desarrollen habilidades de análisis, estadísticas, científicas y de pensamiento crítico.
Es difícil estimar la presencia actual de los datos abiertos como parte de los REA pero no resulta difícil encontrar ejemplos interesantes dentro de las principales plataformas de recursos educativos abiertos. En la plataforma Procomún podemos encontrar interesantes ejemplos como Aprender Geografía a través de la evolución de los paisajes agrarios de España que construye sobre la plataforma ArcGIS Online de la Universidad Complutense de Madrid un Webmap para el aprendizaje de los paisajes agrarios en España. El recurso educativo emplea ejemplos concretos de distintas comunidades autónomas empleando fotografías o imágenes fijas geolocalizadas y datos propios integrados con datos abiertos. De este modo los estudiantes trabajan los conceptos no a través de una mera descripción en texto sino con recursos interactivos que favorecen además la mejora de sus competencias digitales y espaciales
En la plataforma OER Commons encontramos por ejemplo el recurso “De los datos abiertos al compromiso cívico” que está dirigido a públicos a partir de enseñanza secundaria con el objetivo de enseñar a interpretar cómo se gasta el dinero público en un área regional, local, o barrio determinado. Para ello se apoya en los conocidos proyectos para analizar presupuestos públicos “¿Dónde van mis impuestos?”, disponibles en muchas zonas del mundo como fruto de las políticas de transparencia de los poderes públicos. Este recurso que podría ser portado a España con facilidad ya que contamos con numerosos proyectos ¿Donde van mis impuestos?, como el mantenido por Fundación Civio.
Habilidades relacionadas con datos
Cuando nos referimos a la formación y educación en habilidades relacionadas con los datos, en realidad nos estamos refiriendo a un área de gran amplitud que además es muy difícil dominar en todas sus facetas. De hecho, lo habitual es que los proyectos relacionados con datos se aborden en equipos donde cada miembro desempeña un rol especializado en alguna de estas áreas. Por ejemplo, es habitual diferenciar al menos la limpieza y preparación de datos, el modelado de datos y la visualización de datos como las principales actividades que se realizan en un proyecto de ciencia datos e inteligencia artificial.
En todos los casos el uso de datos abiertos está ampliamente adoptado como recurso central de los proyectos que se proponen para la adquisición de cualquiera de estas habilidades. La muy conocida comunidad de ciencia de datos Kaggle organiza competiciones basadas en conjuntos de datos abiertos aportados a la comunidad y que constituyen un recurso esencial para el aprendizaje basado en proyectos reales de quienes quieren adquirir habilidades relacionadas con los datos. Existen otras propuestas basadas en suscripciones como Dataquest o ProjectPro pero en todos los casos utilizan para los proyectos que proponen conjuntos de datos reales obtenidos de los múltiples repositorios de datos abiertos de carácter general o repositorios específicos de un área de conocimiento.
Los datos abiertos, al igual que en otras áreas, aún no han desarrollado todo su potencial como herramienta para la educación y la formación. Sin embargo como puede verse en el programa de la última edición de la OER Conference 2022, cada vez son más los ejemplos en los que los datos abiertos tienen un papel central en la enseñanza, las nuevas prácticas educativas y la creación de nuevos recursos educativos para todo tipo de materias, conceptos y habilidades.
Contenido elaborado por Jose Luis Marín, Senior Consultant in Data, Strategy, Innovation & Digitalization.
Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Blog
Tras varios meses de pruebas y entrenamientos de distinto tipo, el primer sistema masivo de Inteligencia Artificial de la lengua española es capaz de generar sus propios textos y resumir otros ya existentes. MarIA es un proyecto que ha sido impulsado por la Secretaría de Estado de Digitalización e Inteligencia Artificial y desarrollado por el Centro Nacional de Supercomputación, a partir de los archivos web de la Biblioteca Nacional de España (BNE).
Hablamos de un avance muy importante en este ámbito, ya que se trata del primer sistema de inteligencia artificial experto en comprender y escribir en lengua española. Enmarcada dentro del Plan de Tecnologías del Lenguaje, esta herramienta pretende contribuir al desarrollo de una economía digital en español, gracias al potencial que los desarrolladores pueden encontrar en ella.
El reto de crear los asistentes del lenguaje del futuro
Los modelos de lenguaje al estilo de MarIA son la piedra angular sobre la que se sustenta el desarrollo del procesamiento del lenguaje natural, la traducción automática o los sistemas conversacionales, tan necesarios para comprender y replicar de forma automática una lengua. MarIA es un sistema de inteligencia artificial formado por redes neuronales profundas que han sido entrenadas para adquirir una comprensión de la lengua, de su léxico y de sus mecanismos para expresar el significado y escribir a nivel experto.
Gracias a este trabajo previo, los desarrolladores pueden crear herramientas relacionadas con el lenguaje y capaces de clasificar documentos, realizar correcciones o elaborar herramientas de traducción.
La primera versión de MarIA fue elaborada con RoBERTa, una tecnología que crea modelos del lenguaje del tipo “codificadores”, capaces de generar una interpretación que puede servir para categorizar documentos, encontrar similitudes semánticas en diferentes textos o detectar los sentimientos que se expresan en ellos.
Así, la última versión de MarIA ha sido desarrollada con GPT-2, una tecnología más avanzada que crea modelos generativos decodificadores y añade prestaciones al sistema. Gracias a estos modelos decodificadores, la última versión de MarIA es capaz de generar textos nuevos a partir de un ejemplo previo, lo que resulta muy útil a la hora de elaborar resúmenes, simplificar grandes cantidades de información, generar preguntas y respuestas e, incluso, mantener un diálogo.
Avances como los anteriores convierten a MarIA en una herramienta que, con entrenamientos adaptados a tareas específicas, puede ser de gran utilidad para desarrolladores, empresas y administraciones públicas. En esta línea, modelos similares que se han desarrollado en inglés son utilizados para generar sugerencias de texto en aplicaciones de escritura, resumir contratos o buscar informaciones concretas dentro de grandes bases de datos de texto para relacionarlas posteriormente con otras informaciones relevantes.
En otras palabras, además de redactar textos a partir de titulares o palabras, MarIA puede comprender no solo conceptos abstractos, sino también el contexto de los mismos.
Más de 135 mil millones de palabras al servicio de la inteligencia artificial
Para ser exactos, MarIA se ha entrenado con 135.733.450.668 de palabras procedentes de millones de páginas web que recolecta la Biblioteca Nacional y que ocupan un total de 570 Gigabytes de información. Para estos mismos entrenamientos, se ha utilizado el superordenador MareNostrum del Centro Nacional de Supercomputación de Barcelona y ha sido necesaria una potencia de cálculo de 9,7 trillones de operaciones (969 exaflops).
Teniendo en cuenta que uno de los primeros pasos para diseñar un modelo del lenguaje pasa por construir un corpus de palabras y frases que sirva como base de datos para entrenar al propio sistema, en el caso de MarIA, fue necesario realizar un cribado para eliminar todos los fragmentos de texto que no fuesen “lenguaje bien formado” (elementos numéricos, gráficos, oraciones que no terminan, codificaciones erróneas, etc.) y así entrenar correctamente a la IA.
Debido al volumen de información que maneja, MarIA se sitúa ya como el tercer sistema de inteligencia artificial experto en comprender y escribir con mayor número de modelos masivos de acceso abierto. Por delante solo están los modelos del lenguaje elaborados para el inglés y el mandarín. Esto ha sido posible principalmente por dos razones. Por un lado, debido al elevado nivel de digitalización en el que se encuentra el patrimonio de la Biblioteca Nacional y, por el otro, gracias a la existencia de un Centro de Supercomputación Nacional que cuenta con superordenadores como el MareNostrum 4.
El papel de los conjuntos de datos de la BNE
Desde que en 2014 lanzase su propio portal de datos abiertos (datos.bne.es), la BNE ha apostado por acercar los datos que están a su disposición y bajo su custodia: datos de las obras que conserva, pero también de autores, vocabularios controlados de materias y términos geográficos, entre otros.
En los últimos años, se ha desarrollado también la plataforma educativa BNEscolar, que busca ofrecer contenidos digitales del fondo documental de la Biblioteca Digital Hispánica y que pueden resultar de interés para la comunidad educativa.
Así mismo y para cumplir con los estándares internacionales de descripción e interoperabilidad, los datos de la BNE están identificados mediante URIs y modelos conceptuales enlazados, a través de tecnologías semánticas y ofrecidos en formatos abiertos y reutilizables. Además, cuentan con un alto nivel de normalización.
Próximos pasos
Así y con el objetivo de perfeccionar y ampliar las posibilidades de uso de MarIA, se pretende que la versión actual dé lugar a otras especializadas en áreas de conocimiento más concretas. Teniendo en cuenta que se trata de un sistema de inteligencia artificial dedicado a comprender y generar texto, se torna fundamental que este sea capaz de desenvolverse con soltura ante léxicos y conjuntos de información especializada.
Para ello, el PlanTL continuará expandiendo MarIA para adaptarse a los nuevos desarrollos tecnológicos en procesamiento del lenguaje natural (modelos más complejos que el GPT-2 ahora implementado, entrenados con mayor cantidad de datos) y se buscará la forma de crear espacios de trabajo para facilitar el uso de MarIA por compañías y grupos de investigación.
Contenido elaborado por el equipo de datos.gob.es.
Blog
Los portales de datos abiertos están experimentando un importante crecimiento en el número de conjuntos de datos que están siendo publicados en la categoría de transporte y movilidad. Sirva como ejemplo el portal de datos abiertos de la UE que ya cuenta con casi 48.000 conjuntos de datos en la categoría de transporte o el propio portal español datos.gob.es, que registra en torno a 2.000, si incluimos los que están dentro de la categoría de sector público. Una de las razones principales del crecimiento en la publicación de los datos relacionados con el transporte es la existencia de tres directivas que tienen entre sus objetivos maximizar la reutilización de conjuntos de datos en el área. La directiva PSI de reutilización de información del sector público en combinación con las directivas INSPIRE sobre infraestructura de información espacial e ITS sobre implantación de los sistemas de transporte inteligentes, junto con otros desarrollos legislativos, hacen que cada vez resulte más complicado justificar que los datos de transporte y movilidad permanezcan cerrados.
En este sentido, en España, la ley 37/2007 en su redacción de noviembre de 2021, añade la obligación de publicar datos abiertos a las sociedades mercantiles pertenecientes al sector público institucional que actúen como compañías aéreas. Con ello se consigue dar un paso más allá respecto a las más frecuentes obligaciones con los datos de los servicios públicos de transporte de viajeros por ferrocarril y carretera.
Además, los datos abiertos están en el corazón de las estrategias de movilidad inteligente, conectada y respetuosa con el medio ambiente, tanto en el caso de la estrategia española “es.movilidad”, como en el caso de la estrategia de movilidad sostenible propuesta por la comisión europea. En ambos casos los datos abiertos se han introducido como uno de los vectores de innovación clave en la transformación digital del sector para contribuir a la consecución de los objetivos de mejora en la calidad de vida de los ciudadanos y de protección al medio ambiente.
Sin embargo, se suele hablar mucho menos de la importancia y necesidad de los datos abiertos durante la fase de investigación, que después conduce a las innovaciones que todos disfrutamos. Y sin esta etapa en la que los investigadores trabajan para adquirir un mejor conocimiento del funcionamiento de las dinámicas de transporte y movilidad de las que todos somos parte, y en la que los datos abiertos tienen un papel fundamental, no sería posible obtener innovaciones relevantes o políticas públicas bien informadas. En este sentido vamos a revisar dos iniciativas muy relevantes en las que se están realizando esfuerzos coordinados plurinacionales en el ámbito de la investigación en movilidad y transporte.
El sistema de información y seguimiento de la investigación y la innovación en el transporte
A nivel europeo, la UE también apoya con firmeza la investigación e innovación en transporte, consciente de que necesita adaptarse a realidades globales como el cambio climático y la digitalización. La agenda estratégica de investigación e innovación en el transporte (STRIA) describe lo que está haciendo la UE para acelerar la investigación y la innovación necesarias para cambiar radicalmente el transporte apoyando prioridades como la electrificación, el transporte conectado y automatizado o la movilidad inteligente.
En este sentido, el sistema de información y seguimiento de la investigación y la innovación en el transporte (TRIMIS) es la herramienta que la Comisión Europea mantiene para proporcionar información de acceso abierto sobre la investigación y la innovación (I+i) en el transporte y que se lanzó con la misión de apoyar la formulación de las políticas públicas en el ámbito del transporte y la movilidad.
TRIMIS mantiene actualizado un cuadro de mando con el que visualizar los datos sobre investigación e innovación en transporte y ofrece una descripción general y datos detallados sobre la financiación y las organizaciones involucradas en estas investigaciones. La información puede filtrarse por las siete prioridades de STRIA y también incluye datos sobre la capacidad de innovación del sector del transporte.
Si nos fijamos en la distribución geográfica de los fondos de investigación que proporciona TRIMIS, vemos que España aparece en quinto lugar, muy lejos de Alemania y Francia. Los sistemas de transporte en los que se está haciendo un mayor esfuerzo son el transporte por carretera y aéreo, beneficiarios de más de la mitad del esfuerzo total.
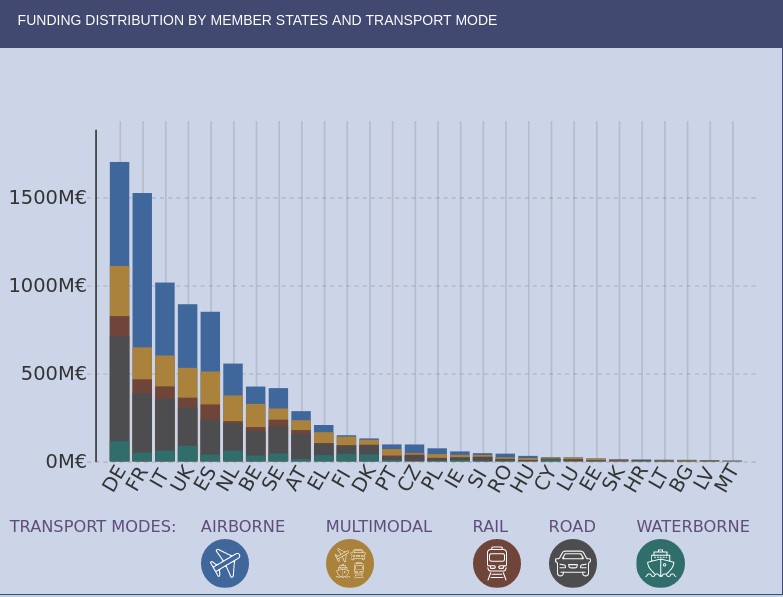
Sin embargo, encontramos que en el área estratégica de Servicios y movilidad inteligente (SMO), que se evalúan en términos de su contribución a la sostenibilidad general del sistema de energía y transporte, en España se está liderando el esfuerzo investigador al mismo nivel que Alemania. Cabe destacar además que el esfuerzo que se está realizando en España en lo que se refiere al transporte multimodal es superior al de otros países.
Como ejemplo del esfuerzo investigador que se está realizando en España tenemos el conjunto de datos piloto para implementar capacidades semánticas sobre la información de incidencias de tráfico relacionadas con la seguridad en la red estatal de carreteras españolas, excepto País Vasco y Cataluña, que publica la Dirección General de Tráfico y que utiliza una ontología para representar incidentes de tráfico que ha desarrollado a Universidad de Valencia.
El área de los sistemas y servicios de movilidad inteligente pretende contribuir a la descarbonización del sector del transporte europeo y entre sus principales prioridades están el desarrollo de sistemas que conecten los servicios de movilidad urbana y rural y promuevan el cambio modal, el uso sostenible del suelo, la suficiencia en la demanda de viajes y los modos de viaje activos y ligeros; el desarrollo de soluciones de gestión de datos de movilidad e infraestructura digital pública de acceso justo o la implantación de la intermodalidad, la interoperabilidad y el acoplamiento sectorial.
La iniciativa 100 preguntas en el ámbito de la movilidad
La Iniciativa de 100 Preguntas, lanzada por The Govlab en colaboración con Schmidt Futures, pretende identificar las 100 preguntas más importantes del mundo en una serie de dominios críticos para el futuro de la humanidad, como son el género, la migración o la calidad del aire.
Uno de estos dominios está dedicado precisamente al transporte y la movilidad urbana y tiene como objetivo identificar preguntas en las cuales los datos y la ciencia de datos tienen un gran potencial para obtener respuestas que contribuyan a impulsar importantes avances en conocimiento e innovación sobre los dilemas públicos más importantes y los problemas más graves que tienen que resolverse.
De acuerdo con la metodología utilizada, la iniciativa finalizó el 28 de julio la cuarta etapa en la que el público en general realizó la votación con la que se decidieron cuáles serían las 10 preguntas finales que deben ser abordadas. Las 48 preguntas iniciales fueron propuestas por un grupo de expertos en movilidad y científicos de datos por lo que están concebidas para que puedan ser respondidas con datos y pensadas para que, si se consiguen resolver, puedan tener un impacto transformador para las políticas de movilidad urbana.
En la próxima etapa, el grupo de trabajo de GovLab identificará cuáles son los conjuntos de datos que podrían proporcionar respuestas a las preguntas seleccionadas, algunas tan complejas como saber “¿dónde quieren ir los viajeros pero realmente no pueden y cuáles son las razones por las que no pueden alcanzar su destino con facilidad?” o “¿cómo podemos incentivar a las personas a realizar viajes en modos sostenibles, como caminar, andar en bicicleta y/o transporte público, en lugar de vehículos de motor personales?”
Otras preguntas están relacionadas con las dificultades encontradas por los reutilizadores y que han sido puestas de manifiesto con frecuencia en artículos de investigación como “Open Transport Data for maximising reuse in multimodal route”: “¿Cómo se pueden compartir los datos de transporte/movilidad recopilados con dispositivos como teléfonos inteligentes, y ponerlos a disposición de los investigadores, planificadores urbanos y legisladores?"
En algunos casos es previsible que los conjuntos de datos necesarios para responder las preguntas no estén disponibles o pertenezcan a compañías privadas por lo que también se intentará definir cuáles son los nuevos conjuntos de datos que deben generarse para ayudar a llenar los vacíos identificados. El objetivo final es proporcionar una definición clara de los requisitos de datos para responder a las preguntas y facilitar la formación de colaboraciones de datos que contribuyan a avanzar en la obtención de estas respuestas[2].
En definitiva, los cambios en el modo en que utilizamos el transporte y los estilos de vida, como el uso de teléfonos inteligentes, aplicaciones web móviles y redes sociales, junto con la tendencia a alquilar, en lugar de poseer un medio de transporte en particular, han abierto nuevos caminos hacia la movilidad sostenible y unas enormes posibilidades en el análisis e investigación de los datos capturados por estas aplicaciones.
Por ello las iniciativas globales para coordinar los esfuerzos de investigación son esenciales ya que las ciudades necesitan bases de conocimiento sólidas a las que recurrir para que las decisiones políticas sobre desarrollo urbano, transporte limpio, igualdad de acceso a oportunidades económicas y calidad de vida en los centros urbanos sean efectivas. No debemos olvidar que todo este conocimiento es además clave para que puedan establecerse adecuadamente prioridades y, de este modo, podamos aprovechar al máximo los escasos recursos públicos de los que habitualmente disponemos para afrontar los desafíos.
Contenido elaborado por Jose Luis Marín, Senior Consultant in Data, Strategy, Innovation & Digitalization.
Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Noticia
La Data Spaces Business Alliance (DSBA) nació en septiembre de 2021, fruto de la colaboración de cuatro grandes organizaciones con mucho que aportar a la economía del dato: la Big Data Value Association (BDVA), FIWARE, Gaia-X y la International Data Spaces Association (IDSA). Su objetivo: impulsar la adopción de espacios de datos en toda Europa aprovechando sinergias.
¿Cómo funciona la DSBA?
La DSBA reúne a diversos agentes para hacer realidad un futuro impulsado por los datos, donde las organizaciones públicas y privadas puedan compartirlos y así liberar todo su valor, garantizando la soberanía, interoperabilidad, seguridad y fiabilidad. Para alcanzar este objetivo, la DSBA ofrece apoyo a las organizaciones, así como herramientas, recursos y conocimientos especializados. Por ejemplo, se trabaja en el desarrollo de un framework común de bloques tecnológicos agnósticos reutilizables en diferentes dominios, con que asegurar la interoperabilidad de los diferentes espacios de datos.
Las cuatro organizaciones fundadoras, BDVA, FIWARE, Gaia-X e IDSA, cuentan con una serie de redes internacionales de "Hubs" nacionales o regionales, con más de 90 iniciativas distribuidas en 34 países. Estas iniciativas, pese a ser muy heterogéneas en foco, forma jurídica, nivel de madurez, etc., cuentan con puntos en común y con un gran potencial para colaborar, complementarse y crear impacto. Además, al operar a nivel local, regional y/o nacional, estas iniciativas proporcionan información periódica a las asociaciones europeas sobre las diferentes políticas, culturas y ecosistemas empresariales regionales dentro la UE.
Además, la postulación de la DSBA ha resultado ganadora a la convocatoria de la Comisión Europea para la creación de un Centro de Soporte, que promoverá y coordinará acciones relativas a los espacios de datos sectoriales. Este centro pondrá a disposición tecnologías, procesos, estándares y herramientas con que apoyar el despliegue de los espacios de datos comunes, permitiendo así la reutilización de datos entre sectores.
Los hubs de la DSBA
Cuando se habla de los hubs de la DSBA se hace referencia a la red global que combina las iniciativas ya existentes de BDVA, FIWARE, Gaia-X e IDSA, como recoge la siguiente figura.
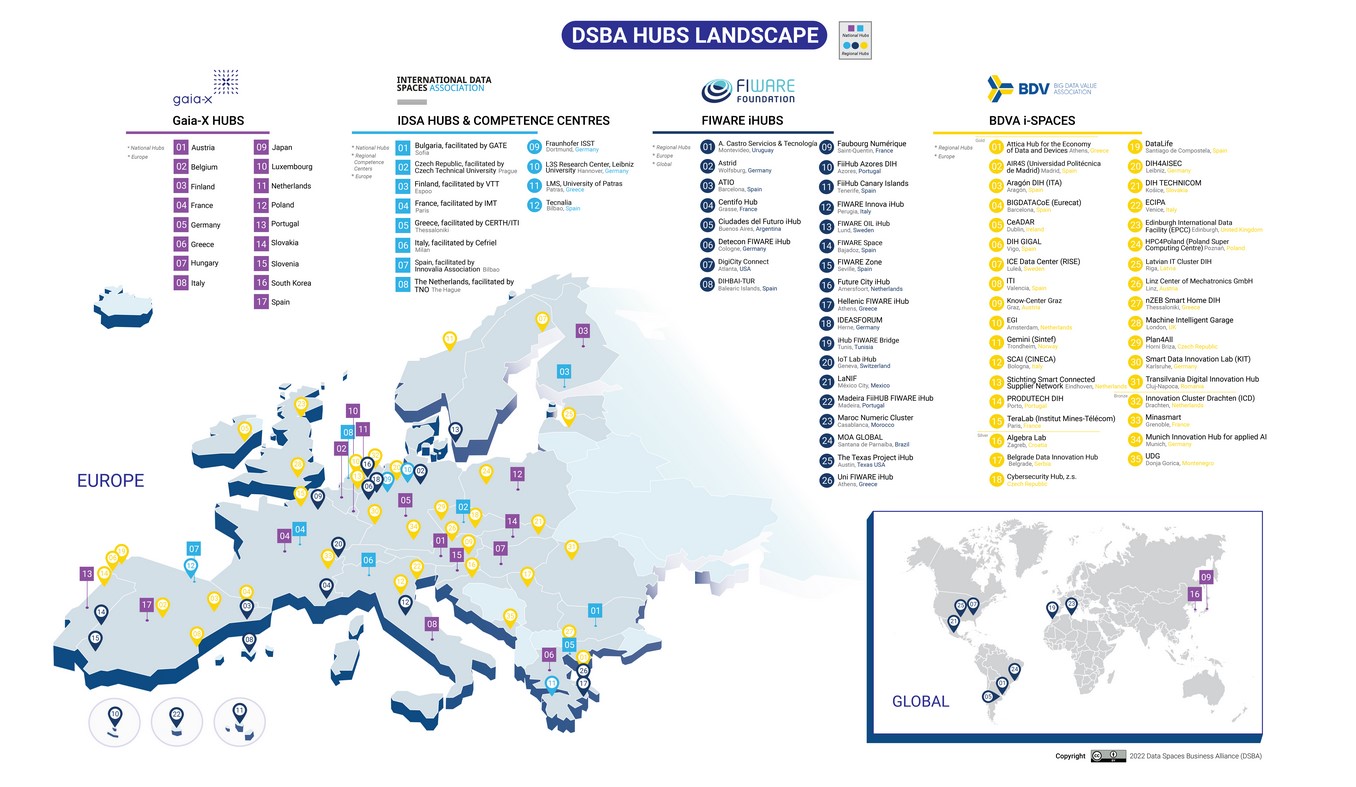
Las principales características de cada uno de estos grupos son:
BDVA i-Spaces
Los i-Spaces de BDVA son incubadoras de datos y centros de innovación intersectoriales e interorganizativos, cuyo fin es acelerar la innovación basada en datos y la inteligencia artificial en los sectores público y privado. Ofrecen entornos seguros de experimentación, que reúnen todos los aspectos técnicos y no técnicos necesarios para que las organizaciones, especialmente las PYMEs, puedan probar, pilotar y explotar rápidamente sus servicios, productos y aplicaciones.
Los i-Spaces ofrecen acceso a fuentes de datos, herramientas para gestionarlos y tecnologías de inteligencia artificial, entre otros. Alojan datos cerrados y abiertos de fuentes empresariales y públicas, como recursos lingüísticos, datos geoespaciales, datos sanitarios, estadísticas económicas, datos de transporte, datos meteorológicos, etc. Los i-spaces cuentan con su propia infraestructura Big Data con potencia de procesamiento ad hoc, almacenamiento en línea y aceleradores de última generación, todas dentro de las fronteras europeas.
Para convertirse en un i-Space las organizaciones deben pasar por un proceso de evaluación, utilizando para ello un sistema de 5 categorías, que se clasifican de acuerdo a los niveles de oro, plata y bronce. Estos hubs deben renovar sus etiquetas cada dos años, y estas certificaciones les permiten unirse a una federación pan-europea para fomentar la innovación de datos transfronterizos, a través del proyecto EUHubs4Data.
FIWARE iHubs
FIWARE es una comunidad de software abierto promovida por la industria TIC, que -con el apoyo de la Comisión Europea- proporciona herramientas y conforma un ecosistema de innovación para que emprendedores creen nuevas aplicaciones y servicios Smart. Los iHubs de FIWARE son centros de innovación enfocados a la creación de comunidades y entornos de colaboración que impulsen el avance de las empresas digitales en esta área. Estos centros proporcionan a empresas privadas, administraciones públicas, instituciones académicas y desarrolladores, acceso a conocimiento y una red mundial de proveedores e integradores de esta tecnología, que además ha sido avalada por organismos de normalización internacionales.
Existen 5 tipos de iHubs:
- iHub School: Entorno enfocado en el aprendizaje de FIWARE, desde una perspectiva empresarial y técnica, aprovechando casos de uso prácticos.
- iHub Lab: Laboratorio donde ejecutar pruebas y pilotos, así como obtener certificaciones FIWARE.
- iHub Business Mentor: Espacio para aprender a construir un modelo de negocio viable a medida.
- iHub Community Creator: Punto físico de encuentro para la comunidad local donde reunir a todas las partes interesadas, que actúa como puerta de entrada al ecosistema local y global de FIWARE.
Gaia-X Hubs
Los Gaia-X Hubs son los puntos de contacto nacionales sobre la iniciativa Gaia-X. Hay que destacar que no son parte como tal de la Gaia-X AISBL (la asociación europea sin ánimo de lucro), sino que actúan como grupos de reflexión independientes, que cooperan con la asociación en el despliegue de proyectos, tareas de comunicación, y generación de requerimientos de negocios para la definición de la arquitectura de la iniciativa (ya que los hubs tienen cercanía con los proyectos industriales de cada país).
A través de ellos se desarrollan espacios de datos específicos en base a las necesidades nacionales, así como la identificación de oportunidades de financiación para implementar los servicios y tecnología de Gaia-X. También se busca que interactúen con otras regiones para construir espacios de datos transnacionales, facilitando el intercambio de información y que los casos de uso nacionales escalen internacionalmente. Para ello, la AISBL proporciona acceso a una plataforma de colaboración, así como apoyo a los respectivos hubs en la distribución y comunicación de los casos de uso.
IDSA Hubs
Los IDSA Hubs permiten intercambiar conocimiento en torno a la arquitectura de referencia (conocida como el IDS-RAM) a nivel país. Reuniendo a las organizaciones de investigación, de promoción de la innovación, sin ánimo de lucro, y a las empresas que utilizan los conceptos y normas de IDS en la región, buscan impulsar su adopción, y -por ende- fomentar una economía del dato soberana con mayor capilaridad.
Estos centros son impulsados en cada país por una universidad, una organización de investigación, o una entidad sin ánimo de lucro, que trabajan junto a IDSA para crear conciencia sobre la soberanía en torno a los datos, transferir conocimientos, reclutar nuevos miembros y difundir casos de uso en base al IDS-RAM. Para ello, desarrollan actividades que van desde sesiones formativas hasta reuniones con responsables de las diferentes administraciones públicas. También fomentan y coordinan proyectos de investigación y desarrollo con organizaciones y empresas internacionales, así como con gobiernos y otras entidades de carácter público.
Conclusión
Como decíamos al principio, existe un gran potencial de sinergias entre estos grupos, que deben explorarse, debatirse y articularse en acciones y proyectos concretos. Nos encontramos ante una prometedora oportunidad de aunar esfuerzos y seguir avanzando en el desarrollo y expansión de los espacios de datos, para generar un impacto notable en la Economía del Dato.
Para estimular el debate inicial, desde la Data Spaces Business Alliance han elaborado el documento “Data Spaces Business Alliance Hubs: potential for synergies and impact”, donde se profundiza en la coyuntura desarrollada anteriormente.
Blog
Los datos se han convertido en un elemento fundamental para nuestras economías y sociedades cada vez más digitalizadas. Las cinco mayores compañías del índice S&P500 (Apple, Microsoft, Amazon, Facebook y Alphabet) tienen a los datos como la base principal que sustenta sus negocios y entre todas juntas suponen aproximadamente una cuarta parte de la capitalización total del índice. Esto nos da una clara idea del peso que tienen los datos en la economía actual. Así mismo, está previsto que el volumen global de datos crezca desde los 33ZB (ZettaBytes — un 1 seguido de 21 ceros) existentes en el año 2018 hasta los 175ZB en el 2025. Para entonces se espera también que hasta un 75% de la población mundial conviva con los datos a diario, con una media de una interacción a través de los datos por persona cada 18 segundos.
Por otro lado, y debido a la propagación de la pandemia de COVID-19 que comenzó el año pasado, hemos sido testigos de una transición prolongada en nuestras actividades más cotidianas desde las interacciones físicas hacia las digitales en los ámbitos educativo, empresarial, gubernamental y familiar — lo que seguramente dará lugar a que ese crecimiento previsto en el universo de los datos se afiance, pero también a que cada vez exista una mayor demanda social por servicios que hagan un uso respetuoso y responsable de los datos. Además, el plan de recuperación previsto por la Comisión Europea en respuesta a la pandemia aportará la mayor inversión económica jamás realizada hasta el momento por la Unión Europea, con cerca de 2 billones de inversión durante los próximos años. Dentro de ese plan, el paquete mas grande de inversión previsto estará destinado a fomentar la innovación y la digitalización de Europa. Esto, unido al marco estratégico y normativo que se está poniendo en marcha, no hará más que consolidar e incluso acelerar estas tendencias en nuestro continente.
Ya hace unos meses, en este contexto particular y decisivo en el que nos encontramos, el Foro Económico Mundial (WEF) nos invitaba a reflexionar sobre los nuevos paradigmas de innovación y negocio que están surgiendo en torno a la forma en la que nos relacionamos e interactuamos con la tecnología y los datos. La idea es aprovechar también esta oportunidad para replantearnos los modelos de negocio existentes en la actualidad en torno a la información con el fin de experimentar y comenzar a utilizar los datos de forma más justa y creativa.
Las nuevas áreas de innovación
Estas nuevas oportunidades que surgen se seguirían basando, principalmente, en la creación de valor a través de los datos, pero se caracterizarían también por ser mas respetuosos con los datos de los consumidores, habilitando relaciones de mayor confianza entre todos los actores implicados y en las que todos se beneficiarían del resultado final. El WEF clasifica estas oportunidades en cuatro grupos principales:
- Nuevas áreas de creación de valor: utilizando el conocimiento obtenido a través de los datos y las nuevas tecnologías que surgen en su entorno para encontrar nuevas fuentes de ingresos e incorporar nuevos productos y servicios, así como para proporcionar información más rica a una gama más amplia de partes interesadas, garantizando al mismo tiempo la privacidad y la seguridad.
Un buen ejemplo de cómo surgen estas nuevas áreas de valor es cómo Airbus ha conseguido ampliar su mercado más allá de su base tradicional de clientes gracias a los nuevos servicios de productos geoespaciales que facilita a través de su nueva filial UP42, sirviendo de intermediarios entre sus proveedores de datos geoespaciales habituales y nuevos clientes con sus propias necesidades en ese ámbito.
- Nuevos modelos de negocio: reinventándose y proponiendo modelos de colaboración que habiliten nuevos casos de uso, poniendo siempre el foco en el consumidor para poder dar respuesta a sus necesidades básicas a la vez que se genera confianza.
Un ejemplo cercano en este campo lo tenemos en la estrategia de banca basada en datos que ha puesto en marcha el BBVA. Dicha estrategia se basa en el concepto de que los datos pertenecen al cliente y es él quien decide cómo gestionarlos. Para ello han creado una plataforma a través de la cual otros colaboradores externos pueden acceder de forma segura y consentida a dichos datos y ofrecer así un rango de servicios adicionales que el banco no podría proporcionar por sí mismo.
- Experiencias enriquecidas: utilizando los datos para comprender mejor tanto a sus propios empleados como a sus socios y clientes, pudiendo así ofrecer productos y servicios mas personalizados y una experiencia mas completa y enriquecedora.
Ese es el caso de Digi.me, una plataforma donde los usuarios pueden ir recopilando de forma voluntaria sus datos personales, financieros y de salud, para luego compartirlos según sus propios intereses. Así las empresas consiguen una fuente única y fiable de datos y a cambio los usuarios reciben una contraprestación en forma de productos o servicios, a la vez que mantienen el control sobre su propia privacidad en todo momento.
- Mejoras en la toma de decisiones: identificando qué optimizaciones de los procesos empresariales pueden dar lugar a una mejor racionalización de los procesos internos para conseguir una mayor reducción en los costes operativos.
Por ejemplo, Aera Technology es una empresa que combina big data, machine learning e inteligencia artificial para desarrollar la automatización en la cadena de suministro. Ofrece datos en tiempo real de la demanda, el suministro, la producción y el rendimiento del inventario a través de una simple interfaz de búsqueda en la que se formulan directamente preguntas en lenguaje natural.
Colaborativo, respetuoso y sostenible
En este entorno de creciente dependencia respecto a los datos, el mundo se está preparando para un cambio de paradigma en su uso por parte de los negocios. Los nuevos enfoques que surjan deben ser responsables con el uso de los datos además de respetar la normativa de referencia en cuanto a su protección, persiguiendo no solo el beneficio económico sino también la creación de valor para los individuos y para la sociedad en su conjunto. Las empresas tienen en este momento la oportunidad y el imperativo de replantearse sus modelos de actuales, empezar a utilizar los datos de forma más creativa y experimentar con nuevas formas de monetización, convirtiéndose así en custodios de confianza de los datos. La clave para el éxito será la creación de ecosistemas colaborativos que permitan la participación de todas las partes interesadas y persigan un cambio en los sistemas actuales para la creación conjunta de valor a través de los datos de forma sostenible y respetuosa.
El WEF ya ha dado un primer paso en colaboración con mas de 50 empresas de 20 países a través de su reciente y pionera Iniciativa de Datos para un Propósito Común (en inglés, DCPI), enfocada al diseño de un marco de gobernanza de los datos flexible que permita explotar el beneficio social de los datos.
Contenido elaborado por Carlos Iglesias, Open data Researcher y consultor, World Wide Web Foundation. Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Blog
El próximo día 12 de septiembre concluye el plazo para que empresas y entidades que han desarrollado proyectos con datos públicos se presenten a la primera edición de los Premios Aporta 2017. Unos premios enfocados a divulgar y reconocer a profesionales que han apostado por la reutilización de datos abiertos y la innovación como motor de transformación digital y que son promovidos por la Secretaría de Estado para la Sociedad de la Información y la Agenda Digital, la Entidad Pública Empresarial Red.es y la Secretaría General de Administración Digital.
Con esta iniciativa, se pretende impulsar y visibilizar el valor de los datos generados por las administraciones públicas españolas, así como reutilización de los mismos. Los proyectos y trabajos que pueden optar a dichos premios han tenido que ser desarrollados en los dos últimos años, reutilizando datos públicos y contribuyendo a generar valor social, nuevos negocios y/o mejoras para la sociedad.
Las candidaturas serán evaluadas durante el mes de septiembre por representantes de Iniciativa Aporta. Se tendrá en cuenta la originalidad, la utilidad y el impacto de la iniciativa en términos de destinatarios beneficiados. Las dos mejores iniciativas recibirán un reconocimiento en el Encuentro Aporta que tendrá lugar a finales de octubre de 2017.
Convocamos y animamos a los profesionales del sector y empresas innovadoras para que presenten su candidatura a los Premios Aporta, a través del formulario disponible en la sede electrónica de Red.es. La fecha límite es el próximo 12 de septiembre. ¡Participa!
Toda la información en datos.gob.es y en Bases de los Premios Aporta 2017.
Evento
Por tercer año consecutivo, Correos ha puesto en marcha el reto Lehnica, un concurso de emprendimiento que busca impulsar la innovación como valor esencial del progreso empresarial. A través de este reto se seleccionarán un máximo de 5 proyectos que pasarán a formar parte de Correoslabs, el espacio de emprendimiento e innovación de Correos.
¿A quién va dirigido?
El Reto Lehnica va dirigido a empresas de reciente creación con una antigüedad máxima de tres años y que tengan fijado su domicilio social en España.
¿En qué consiste?
Las empresas interesadas tienen que apuntarse en la web de Correoslabs. Una vez registrados podrán descargar una plantilla tipo que deberán rellenar con toda la información solicitada y presentar siguiendo las normas indicadas en las bases del concurso.
Los proyectos presentados deberán estar enfocados en el desarrollo de productos o servicios innovadores en alguna de las siguientes categorías:
-
Tecnologías emergentes: proyectos destinados a transformar negocios tradicionales o crear nuevos servicios utilizando Inteligencia artificial, Blockchain, Big Data o Internet de las cosas, entre otras tecnologías.
-
Logística: proyectos que mejoren la experiencia logística, en áreas como la trazabilidad, los nuevos modelos de entrega, la economía circular o la eficiencia energética.
-
Social: proyectos que contribuyan al impulso y revitalización de los entornos rurales.
-
Servicios públicos: proyectos enfocados en la mejora de la prestación de los servicios públicos.
Tras un proceso de evaluación, se seleccionarán un máximo de 5 proyectos.
¿Qué beneficios obtienen las empresas seleccionadas?
Las empresas seleccionadas recibirán hasta 30.000 euros para poder desarrollar su proyecto. El programa se desarrollará durante un año, en base a un calendario personalizado propuesto por Correos donde se incluirán los logros a alcanzar.
Además, estas empresas tendrán a su disposición:
-
Las instalaciones de Correoslabs, un espacio de coworking completamente equipado donde intercambiar opiniones con otros emprendedores.
-
Un programa de mentoring personalizado, que incluye tutorías individuales con expertos internos de Correos que acompañarán y servirán de guía a las empresas seleccionadas.
-
Un programa de coaching con profesionales expertos en el desarrollo de negocios.
-
La posibilidad de integrarse en la comunidad emprendedora y aceleradora de los diferentes partners colaboradores con el ecosistema de Correoslabs.
¿Hasta cuándo está abierta la convocatoria?
Se pueden presentar las solicitudes hasta el viernes 13 de diciembre a las 14:00 horas.
El programa comenzará en febrero de 2020.