Blog
La creciente adopción de sistemas de inteligencia artificial (IA) en ámbitos críticos como la administración pública, los servicios financieros o la atención sanitaria ha puesto en primer plano la necesidad de transparencia algorítmica. La complejidad de los modelos de IA que se utilizan para tomar decisiones como la concesión de un crédito o la realización de un diagnóstico médico, especialmente en lo que se refiere a algoritmos de aprendizaje profundo, a menudo da lugar a lo que comúnmente se conoce como el problema de la "caja negra", esto es, la dificultad de interpretar y comprender cómo y por qué un modelo de IA llega a una determinada conclusión. Los LLM o SLM que tanto utilizamos últimamente son un claro ejemplo de un sistema de caja negra donde ni los propios desarrolladores son capaces de prever sus comportamientos.
En sectores regulados, como el financiero o el sanitario, las decisiones basadas en IA pueden afectar significativamente la vida de las personas y, por tanto, no es admisible que generan dudas sobre su posible sesgo o atribución de responsabilidades. Por ello, los gobiernos han comenzado a desarrollar marcos normativos como el Reglamento de Inteligencia Artificial que exigen mayor explicabilidad y supervisión en el uso de estos sistemas con el fin adicional de generar confianza en los avances de la economía digital.
La inteligencia artificial explicable (conocida como XAI, del inglés explainable artificial intelligence) es la disciplina que surge como respuesta a este desafío, proponiendo métodos para hacer comprensibles las decisiones de los modelos de IA. Al igual que en otras áreas relacionados con la inteligencia artificial, como el entrenamiento de los LLM, los datos abiertos son un aliado importante de la inteligencia artificial explicable para construir mecanismos de auditoría y verificación de los algoritmos y sus decisiones.
¿Qué es la IA explicable (XAI)?
La IA explicable se refiere a métodos y herramientas que permiten a los humanos comprender y confiar en los resultados de los modelos de aprendizaje automático. Según el Instituto Nacional de Estándares y Tecnología (NIST) de EE. UU. son cuatro los principios clave de la Inteligencia Artificial Explicable de forma que se pueda garantizar que los sistemas de IA sean transparentes, comprensibles y confiables para los usuarios:
- Explicabilidad (Explainability): la IA debe proporcionar explicaciones claras y comprensibles sobre cómo llega a sus decisiones y recomendaciones.
- Justificabilidad (Meaningful): las explicaciones deben ser significativas y comprensibles para los usuarios.
- Precisión (Accuracy): la IA debe generar resultados precisos y confiables, y la explicación de estos resultados debe reflejar fielmente su desempeño.
- Límites del conocimiento (Knowledge Limits): la IA debe reconocer cuándo no tiene suficiente información o confianza en una decisión y abstenerse de emitir respuestas en esos casos.
A diferencia de los sistemas de IA tradicionales de "caja negra", que generan resultados sin revelar su lógica interna, XAI trabaja sobre la trazabilidad, interpretabilidad y responsabilidad de estas decisiones. Por ejemplo, si una red neuronal rechaza una solicitud de préstamo, las técnicas de XAI pueden destacar los factores específicos que influyeron en la decisión. De este modo, mientras un modelo tradicional simplemente devolvería una calificación numérica del expediente de crédito, un sistema XAI podría decirnos además algo como que "El historial de pagos (23%), la estabilidad laboral (38%) y el nivel de endeudamiento actual (32%) fueron los factores determinantes en la denegación del préstamo”. Esta transparencia es vital no solo para el cumplimiento normativo, sino también para fomentar la confianza del usuario y la mejora de los propios sistemas de IA.
Técnicas clave en XAI
El Catálogo de herramientas y métricas IA confiable del Observatorio de Políticas de Inteligencia Artificial de la OCDE (OECD.AI) recopila y comparte herramientas y métricas diseñadas para ayudar a los actores de la IA a desarrollar sistemas confiables que respeten los derechos humanos y sean justos, transparentes, explicables, robustos, seguros y confiables. Por ejemplo, dos metodologías ampliamente adoptadas en XAI son Local Interpretable Model-agnostic Explanations (LIME) y SHapley Additive exPlanations (SHAP).
- LIME aproxima modelos complejos con versiones más simples e interpretables para explicar predicciones individuales. Es una técnica en general útil para interpretaciones rápidas, pero no muy estable en la asignación de la importancia de las variables entre unos ejemplos y otros.
- SHAP cuantifica la contribución exacta de cada variable de entrada a una predicción utilizando principios de teoría de juegos. Se trata de una técnica más precisa y matemáticamente sólida, pero mucho más costosa computacionalmente.
Por ejemplo, en un sistema de diagnóstico médico, tanto LIME como SHAP podrían ayudarnos a interpretar que la edad y la presión arterial de un paciente fueron los principales factores que concluyeron en un diagnóstico de alto riesgo de infarto, aunque SHAP nos daría la contribución exacta de cada variable a la decisión.
Uno de los desafíos más importantes en XAI es encontrar el equilibrio entre la capacidad predictiva de un modelo y su explicabilidad. Por ello suelen utilizarse enfoques híbridos que integren métodos de explicación a posteriori de las decisiones tomadas con modelos complejos. Por ejemplo, un banco podría implementar un sistema de aprendizaje profundo para la detección de fraude, pero usar valores SHAP para auditar sus decisiones y garantizar que no se toman decisiones discriminatorias.
Los datos abiertos en la XAI
Existen, al menos, dos escenarios en los que se puede generar valor combinando datos abiertos con técnicas de inteligencia artificial explicable:
- El primero de ellos es el enriquecimiento y validación de las explicaciones obtenidas con técnicas XAI. Los datos abiertos permiten añadir capas de contexto a muchas explicaciones técnicas, algo que también es válido para la explicabilidad de los modelos de IA. Por ejemplo, si un sistema XAI indica que la contaminación atmosférica influyó en un diagnóstico de asma, vincular este resultado con conjuntos de datos abiertos de calidad del aire de las áreas de residencia de los pacientes permitiría validar si el resultado es correcto.
- La mejora del rendimiento de los propios modelos de IA es otra área en el que los datos abiertos aportan valor. Por ejemplo, si un sistema XAI identifica que la densidad de espacios verdes urbanos afecta significativamente los diagnósticos de riesgo cardiovascular, se podrían utilizar datos abiertos de urbanismo para mejorar la precisión del algoritmo.
Sería ideal que se pudiesen compartir como datos abiertos los conjuntos de datos de entrenamiento de los modelos de IA, de forma que fuese posible verificar el entrenamiento del modelo y replicar los resultados. En todo caso, lo que sí es posible es compartir de forma abierta son metadatos detallados sobre dichos entrenamientos como promueve la iniciativa Model Cards de Google, facilitando así explicaciones post-hoc de las decisiones de los modelos. En este caso se trata de un instrumento más orientado a los desarrolladores que a los usuarios finales de los algoritmos.
En España, en una iniciativa más dirigida a los ciudadanos, pero igualmente destinada a fomentar la transparencia en el uso de algoritmos de inteligencia artificial, la Administración Abierta de Cataluña ha comenzado a publicar fichas comprensibles para cada algoritmo de IA aplicado a los servicios de administración digital. Ya están disponibles algunas, como, por ejemplo, la de los Chatbots conversacionales de la AOC o la de la Videoidentificación para obtener el idCat Móvil.
Ejemplos reales de datos abiertos y XAI
Un artículo reciente publicado en Applied Sciences por investigadores portugueses ejemplifica la sinergia entre XAI y datos abiertos en el ámbito de la predicción de precios inmobiliarios en ciudades inteligentes. La investigación destaca cómo la integración de conjuntos de datos abiertos que abarcan características de propiedades, infraestructuras urbanas y redes de transporte, con técnicas de inteligencia artificial explicable, como el análisis SHAP, permite desentrañar los factores clave que influyen en los valores de las propiedades. Este enfoque pretende apoyar la generación de políticas de planificación urbana que respondan a las necesidades y tendencias evolutivas del mercado inmobiliario, promoviendo un crecimiento sostenible y equitativo de las ciudades.
Otro estudio realizado por investigadores de INRIA (Instituto francés de investigación en ciencias y tecnologías digitales), también sobre datos inmobiliarios, profundiza en los métodos y desafíos asociados a la interpretabilidad en el aprendizaje automático apoyándose en datos abiertos enlazados. El artículo analiza tanto técnicas intrínsecas, que integran la explicabilidad en el diseño del modelo, como métodos post hoc que permiten examinar y explicar las decisiones de sistemas complejos para fomentar la adopción de sistemas de IA transparentes, éticos y confiables.
A medida que la IA continúa evolucionando, las consideraciones éticas y las medidas regulatorias tienen un papel cada vez más relevante en la creación de un ecosistema de IA más transparente y confiable. La inteligencia artificial explicable y los datos abiertos están interconectados en su objetivo de fomentar la transparencia, la confianza y la responsabilidad en la toma de decisiones basadas en IA. Mientras que la XAI ofrece las herramientas para diseccionar la toma de decisiones de la IA, los datos abiertos proporcionan la materia prima no solo para el entrenamiento, sino para comprobar algunas explicaciones de la XAI y mejorar los rendimientos de los modelos. A medida que la IA continúa permeando en cada faceta de nuestras vidas, fomentar esta sinergia contribuirá a construir sistemas que no solo sean más inteligentes, sino también más justos.
Contenido elaborado por Jose Luis Marín, Senior Consultant in Data, Strategy, Innovation & Digitalization. Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Blog
Los modelos de lenguaje se encuentran en el epicentro del cambio de paradigma tecnológico que está protagonizando la inteligencia artificial (IA) generativa en los últimos dos años. Desde las herramientas con las que interaccionamos en lenguaje natural para generar texto, imágenes o vídeos y que utilizamos para crear contenido creativo, diseñar prototipos o producir material educativo, hasta aplicaciones más complejas en investigación y desarrollo que incluso han contribuido de forma decisiva a la consecución del Premio Nobel de Química de 2024, los modelos de lenguaje están demostrando su utilidad en una gran variedad de aplicaciones, que por otra parte, aún estamos explorando.
Desde que en 2017 Google publicó el influyente artículo "Attention is all you need", donde se describió la arquitectura de los Transformers, tecnología que sustenta las nuevas capacidades que OpenAI popularizó a finales de 2022 con el lanzamiento de ChatGPT, la evolución de los modelos de lenguaje ha sido más que vertiginosa. En apenas dos años, hemos pasado de modelos centrados únicamente en la generación de texto a versiones multimodales que integran la interacción y generación de texto, imágenes y audio.
Esta rápida evolución ha dado lugar a dos categorías de modelos de lenguaje: los SLM (Small Language Models), más ligeros y eficientes, y los LLM (Large Language Models), más pesados y potentes. Lejos de considerarlos competidores, debemos analizar los SLM y LLM como tecnologías complementarias. Mientras los LLM ofrecen capacidades generales de procesamiento y generación de contenido, los SLM pueden proporcionar soporte a soluciones más ágiles y especializadas para necesidades concretas. Sin embargo, ambos comparten un elemento esencial: dependen de grandes volúmenes de datos para su entrenamiento y en el corazón de sus capacidades están los datos abiertos, que son parte del combustible que se utiliza para entrenar estos modelos de lenguaje en los que se basan las aplicaciones de IA generativa.
LLM: potencia impulsada por datos masivos
Los LLM son modelos de lenguaje a gran escala que cuentan con miles de millones, e incluso billones, de parámetros. Estos parámetros son las unidades matemáticas que permiten al modelo identificar y aprender patrones en los datos de entrenamiento, lo que les proporciona una extraordinaria capacidad para generar texto (u otros formatos) coherente y adaptado al contexto de los usuarios. Estos modelos, como la familia GPT de OpenAI, Gemini de Google o Llama de Meta, se entrenan con inmensos volúmenes de datos y son capaces de realizar tareas complejas, algunas incluso para las que no fueron explícitamente entrenados.
De este modo, los LLM son capaces de realizar tareas como la generación de contenido original, la respuesta a preguntas con información relevante y bien estructurada o la generación de código de software, todas ellas con un nivel de competencia igual o superior al de los humanos especializados en dichas tareas y siempre manteniendo conversaciones complejas y fluidas.
Los LLM se basan en cantidades masivas de datos para alcanzar su nivel de desempeño actual: desde repositorios como Common Crawl, que recopila datos de millones de páginas web, hasta fuentes estructuradas como Wikipedia o conjuntos especializados como PubMed Open Access en el campo biomédico. Sin acceso a estos corpus masivos de datos abiertos, la capacidad de estos modelos para generalizar y adaptarse a múltiples tareas sería mucho más limitada.
Sin embargo, a medida que los LLM continúan evolucionando, la necesidad de datos abiertos aumenta para conseguir progresos específicos como:
- Mayor diversidad lingüística y cultural: aunque los LLM actuales manejan múltiples idiomas, en general están dominados por datos en inglés y otros idiomas mayoritarios. La falta de datos abiertos en otras lenguas limita la capacidad de estos modelos para ser verdaderamente inclusivos y diversos. Más datos abiertos en idiomas diversos garantizarían que los LLM puedan ser útiles para todas las comunidades, preservando al mismo tiempo la riqueza cultural y lingüística del mundo.
- Reducción de sesgos: los LLM, como cualquier modelo de IA, son propensos a reflejar los sesgos presentes en los datos con los que se entrenan. Esto, en ocasiones, genera respuestas que perpetúan estereotipos o desigualdades. Incorporar más datos abiertos cuidadosamente seleccionados, especialmente de fuentes que promuevan la diversidad y la igualdad, es fundamental para construir modelos que representen de manera justa y equitativa a diferentes grupos sociales.
- Actualización constante: los datos en la web y en otros recursos abiertos cambian constantemente. Sin acceso a datos actualizados, los LLM generan respuestas obsoletas muy rápidamente. Por ello, incrementar la disponibilidad de datos abiertos frescos y relevantes permitiría a los LLM mantenerse alineados con la actualidad.
- Entrenamiento más accesible: a medida que los LLM crecen en tamaño y capacidad, también lo hace el coste de entrenarlos y afinarlos. Los datos abiertos permiten que desarrolladores independientes, universidades y pequeñas empresas entrenen y afinen sus propios modelos sin necesidad de costosas adquisiciones de datos. De este modo se democratiza el acceso a la inteligencia artificial y se fomenta la innovación global.
Para solucionar algunos de estos retos, en la nueva Estrategia de Inteligencia Artificial 2024 se han incluido medidas destinadas a generar modelos y corpus en castellano y lenguas cooficiales, incluyendo también el desarrollo de conjuntos de datos de evaluación que consideran la evaluación ética.
SLM: eficiencia optimizada con datos específicos
Por otra parte, los SLM han emergido como una alternativa eficiente y especializada que utiliza un número más reducido de parámetros (generalmente en millones) y que están diseñados para ser ligeros y rápidos. Aunque no alcanzan la versatilidad y competencia de los LLM en tareas complejas, los SLM destacan por su eficiencia computacional, rapidez de implementación y capacidad para especializarse en dominios concretos.
Para ello, los SLM también dependen de datos abiertos, pero en este caso, la calidad y relevancia de los conjuntos de datos son más importantes que su volumen, por ello los retos que les afectan están más relacionados con la limpieza y especialización de los datos. Estos modelos requieren conjuntos que estén cuidadosamente seleccionados y adaptados al dominio específico para el que se van a utilizar, ya que cualquier error, sesgo o falta de representatividad en los datos puede tener un impacto mucho mayor en su desempeño. Además, debido a su enfoque en tareas especializadas, los SLM enfrentan desafíos adicionales relacionados con la accesibilidad de datos abiertos en campos específicos. Por ejemplo, en sectores como la medicina, la ingeniería o el derecho, los datos abiertos relevantes suelen estar protegidos por restricciones legales y/o éticas, lo que dificulta su uso para entrenar modelos de lenguaje.
Los SLM se entrenan con datos cuidadosamente seleccionados y alineados con el dominio en el que se utilizarán, lo que les permite superar a los LLM en precisión y especificidad en tareas concretas, como por ejemplo:
- Autocompletado de textos: un SLM para autocompletado en español puede entrenarse con una selección de libros, textos educativos o corpus como los que se impulsarán en la ya mencionada Estrategia de IA, siendo mucho más eficiente que un LLM de propósito general para esta tarea.
- Consultas jurídicas: un SLM entrenado con conjuntos de datos jurídicos abiertos pueden proporcionar respuestas precisas y contextualizadas a preguntas legales o procesar documentos contractuales de forma más eficaz que un LLM.
- Educación personalizada: en el sector educativo, SLM entrenados con datos abiertos de recursos didácticos pueden generar explicaciones específicas, ejercicios personalizados o incluso evaluaciones automáticas, adaptadas al nivel y las necesidades del estudiante.
- Diagnóstico médico: un SLM entrenado con conjuntos de datos médicos, como resúmenes clínicos o publicaciones abiertas, puede asistir a médicos en tareas como la identificación de diagnósticos preliminares, la interpretación de imágenes médicas mediante descripciones textuales o el análisis de estudios clínicos.
Desafíos y consideraciones éticas
No debemos olvidar que, a pesar de los beneficios, el uso de datos abiertos en modelos de lenguaje presenta desafíos significativos. Uno de los principales retos es, como ya hemos mencionado, garantizar la calidad y neutralidad de los datos para que estén libres de sesgos, ya que estos pueden amplificarse en los modelos, perpetuando desigualdades o prejuicios.
Aunque un conjunto de datos sea técnicamente abierto, su utilización en modelos de inteligencia artificial siempre plantea algunas implicaciones éticas. Por ejemplo, es necesario evitar que información personal o sensible se filtre o pueda deducirse de los resultados generados por los modelos, ya que esto podría causar daños a la privacidad de las personas.
También debe tenerse en cuenta la cuestión de la atribución y propiedad intelectual de los datos. El uso de datos abiertos en modelos comerciales debe abordar cómo se reconoce y compensa adecuadamente a los creadores originales de los datos para que sigan existiendo incentivos a los creadores.
Los datos abiertos son el motor que impulsa las asombrosas capacidades de los modelos de lenguaje, tanto en el caso de los SLM como de los LLM. Mientras que los SLM destacan por su eficiencia y accesibilidad, los LLM abren puertas a aplicaciones avanzadas que no hace mucho nos parecían imposibles. Sin embargo, el camino hacia el desarrollo de modelos más capaces, pero también más sostenibles y representativos, depende en gran medida de cómo gestionemos y aprovechemos los datos abiertos.
Contenido elaborado por Jose Luis Marín, Senior Consultant in Data, Strategy, Innovation & Digitalization. Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Blog
En el vertiginoso mundo de la Inteligencia Artificial (IA) Generativa, encontramos diversos conceptos que se han convertido en fundamentales para comprender y aprovechar el potencial de esta tecnología. Hoy nos centramos en cuatro: los Modelos de Lenguaje Pequeños (SLM, por sus siglas en inglés), los Modelos de Lenguaje Grandes (LLM), la Generación Aumentada por Recuperación (RAG) y el Fine-tuning. En este artículo, exploraremos cada uno de estos términos, sus interrelaciones y cómo están moldeando el futuro de la IA generativa.
Empecemos por el principio. Definiciones.
Antes de sumergirnos en los detalles, es importante entender brevemente qué representa cada uno de estos términos. Los dos primeros conceptos (SLM y LLM) que abordamos, son lo que se conoce cómo modelos del lenguaje. Un modelo de lenguaje es un sistema de inteligencia artificial que entiende y genera texto en lenguaje humano, como lo hacen los chatbots o los asistentes virtuales. Los siguientes dos conceptos (Fine Tuning y RAG), podríamos definirlos cómo técnicas de optimización de estos modelos del lenguaje previos. En definitiva, estás técnicas, con sus respectivos enfoques, que veremos más adelante, mejoran las respuestas y el contenido que devuelven al que pregunta. Vamos a por los detalles:
- SLM (Small Language Models): Modelos de lenguaje más compactos y especializados, diseñados para tareas específicas o dominios concretos.
- LLM (Large Language Models): Modelos de lenguaje de gran escala, entrenados con vastas cantidades de datos y capaces de realizar una amplia gama de tareas lingüísticas.
- RAG (Retrieval-Augmented Generation): Una técnica que combina la recuperación de información relevante con la generación de texto para producir respuestas más precisas y contextualizadas.
- Fine-tuning: El proceso de ajustar un modelo pre-entrenado para una tarea o dominio específico, mejorando su rendimiento en aplicaciones concretas.
Ahora, profundicemos en cada concepto y exploremos cómo se interrelacionan en el ecosistema de la IA Generativa.
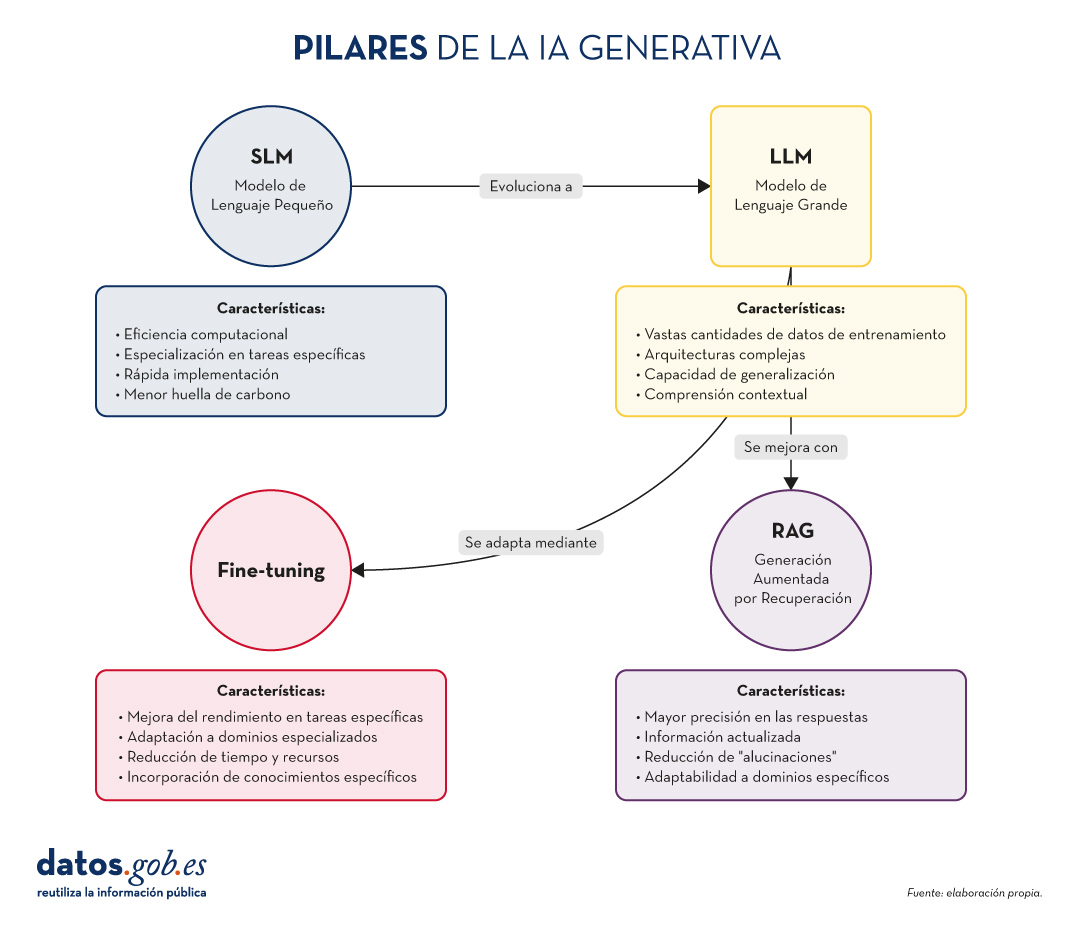
Figura 1. Pilares de la IA genrativa. Elaboración propia.
SLM: La potencia en la especialización
Mayor eficiencia para tareas concretas
Los Modelos de Lenguaje Pequeños (SLM) son modelos de IA diseñados para ser más ligeros y eficientes que sus contrapartes más grandes. Aunque tienen menos parámetros, están optimizados para tareas específicas o dominios concretos.
Características clave de los SLM:
- Eficiencia computacional: requieren menos recursos para su entrenamiento y ejecución.
- Especialización: se centran en tareas o dominios específicos, logrando un alto rendimiento en áreas concretas.
- Rápida implementación: ideal para dispositivos con recursos limitados o aplicaciones que requieren respuestas en tiempo real.
- Menor huella de carbono: al ser más pequeños, su entrenamiento y uso consumen menos energía.
Aplicaciones de los SLM:
- Asistentes virtuales para tareas específicas (por ejemplo, reserva de citas).
- Sistemas de recomendación personalizados.
- Análisis de sentimientos en redes sociales.
- Traducción automática para pares de idiomas específicos.
LLM: El poder de la generalización
La revolución de los Modelos de Lenguaje Grandes
Los LLM han transformado el panorama de la IA Generativa, ofreciendo capacidades sorprendentes en una amplia gama de tareas lingüísticas.
Características clave de los LLM:
- Vastas cantidades de datos de entrenamiento: se entrenan con enormes corpus de texto, abarcando diversos temas y estilos.
- Arquitecturas complejas: utilizan arquitecturas avanzadas, como Transformers, con miles de millones de parámetros.
- Capacidad de generalización: pueden abordar una amplia variedad de tareas sin necesidad de entrenamiento específico para cada una.
- Comprensión contextual: son capaces de entender y generar texto considerando contextos complejos.
Aplicaciones de los LLM:
- Generación de texto creativo (historias, poesía, guiones).
- Respuesta a preguntas complejas y razonamientos.
- Análisis y resumen de documentos extensos.
- Traducción multilingüe avanzada.
RAG: Potenciando la precisión y relevancia
La sinergia entre recuperación y generación
Como ya exploramos en nuestro artículo anterior, RAG combina la potencia de los modelos de recuperación de información con la capacidad generativa de los LLM. Sus aspectos fundamentales son:
Características clave de RAG:
- Mayor precisión en las respuestas.
- Capacidad de proporcionar información actualizada.
- Reducción de "alucinaciones" o información incorrecta.
- Adaptabilidad a dominios específicos sin necesidad de reentrenar completamente el modelo.
Aplicaciones de RAG:
- Sistemas de atención al cliente avanzados.
- Asistentes de investigación académica.
- Herramientas de fact-checking para periodismo.
- Sistemas de diagnóstico médico asistido por IA.
Fine-tuning: Adaptación y especialización
Perfeccionando modelos para tareas específicas
El fine-tuning es el proceso de ajustar un modelo pre-entrenado (generalmente un LLM) para mejorar su rendimiento en una tarea o dominio específico. Sus elementos principales son los siguientes:
Características clave del fine-tuning:
- Mejora significativa del rendimiento en tareas específicas.
- Adaptación a dominios especializados o nichos.
- Reducción del tiempo y recursos necesarios en comparación con el entrenamiento desde cero.
- Posibilidad de incorporar conocimientos específicos de la organización o industria.
Aplicaciones del fine-tuning:
- Modelos de lenguaje específicos para industrias (legal, médica, financiera).
- Asistentes virtuales personalizados para empresas.
- Sistemas de generación de contenido adaptados a estilos o marcas particulares.
- Herramientas de análisis de datos especializadas.
Pongamos algunos ejemplos
A muchos de los que estéis familiarizados con las últimas noticias en IA generativa os sonarán estos ejemplos que citamos a continuación.
SLM: La potencia en la especialización
Ejemplo: BERT para análisis de sentimientos
BERT (Bidirectional Encoder Representations from Transformers) es un ejemplo de SLM cuando se utiliza para tareas específicas. Aunque BERT en sí es un modelo de lenguaje grande, versiones más pequeñas y especializadas de BERT se han desarrollado para análisis de sentimientos en redes sociales.
Por ejemplo, DistilBERT, una versión reducida de BERT, se ha utilizado para crear modelos de análisis de sentimientos en X (Twitter). Estos modelos pueden clasificar rápidamente tweets como positivos, negativos o neutros, siendo mucho más eficientes en términos de recursos computacionales que modelos más grandes.
LLM: El poder de la generalización
Ejemplo: GPT-3 de OpenAI
GPT-3 (Generative Pre-trained Transformer 3) es uno de los LLM más conocidos y utilizados. Con 175 mil millones de parámetros, GPT-3 es capaz de realizar una amplia variedad de tareas de procesamiento de lenguaje natural sin necesidad de un entrenamiento específico para cada tarea.
Una aplicación práctica y conocida de GPT-3 es ChatGPT, el chatbot conversacional de OpenAI. ChatGPT puede mantener conversaciones sobre una gran variedad de temas, responder preguntas, ayudar con tareas de escritura y programación, e incluso generar contenido creativo, todo ello utilizando el mismo modelo base.
Ya a finales de 2020 introducimos en este espacio el primer post sobre GPT-3 como gran modelo del lenguaje. Para los más nostálgicos, podéis consultar el post original aquí.
RAG: Potenciando la precisión y relevancia
Ejemplo: El asistente virtual de Anthropic, Claude
Claude, el asistente virtual desarrollado por Anthropic, es un ejemplo de aplicación que utiliza técnicas RAG. Aunque los detalles exactos de su implementación no son públicos, Claude es conocido por su capacidad para proporcionar respuestas precisas y actualizadas, incluso sobre eventos recientes.
De hecho, la mayoría de asistentes conversacionales basados en IA generativa incorporan técnicas RAG para mejorar la precisión y el contexto de sus respuestas. Así, ChatGPT, la citada Claude, MS Bing y otras similares usan RAG.
Fine-tuning: Adaptación y especialización
Ejemplo: GPT-3 fine-tuned para GitHub Copilot
GitHub Copilot, el asistente de programación de GitHub y OpenAI, es un excelente ejemplo de fine-tuning aplicado a un LLM. Copilot está basado en un modelo GPT (posiblemente una variante de GPT-3) que ha sido específicamente ajustado (fine-tuned) para tareas de programación.
El modelo base se entrenó adicionalmente con una gran cantidad de código fuente de repositorios públicos de GitHub, lo que le permite generar sugerencias de código relevantes y sintácticamente correctas en una variedad de lenguajes de programación. Este es un claro ejemplo de cómo el fine-tuning puede adaptar un modelo de propósito general a una tarea altamente especializada.
Otro ejemplo: en el blog de datos.gob.es, también escribimos un post sobre aplicaciones que utilizaban GPT-3 como LLM base para construir productos concretos ajustados específicamente.
Interrelaciones y sinergias
Estos cuatro conceptos no operan de forma aislada, sino que se entrelazan y complementan en el ecosistema de la IA Generativa:
- SLM y LLM: Mientras que los LLM ofrecen versatilidad y capacidad de generalización, los SLM proporcionan eficiencia y especialización. La elección entre uno u otro dependerá de las necesidades específicas del proyecto y los recursos disponibles.
- RAG y LLM: RAG potencia las capacidades de los LLM al proporcionarles acceso a información actualizada y relevante. Esto mejora la precisión y utilidad de las respuestas generadas.
- Fine-tuning y LLM: El fine-tuning permite adaptar LLM genéricos a tareas o dominios específicos, combinando la potencia de los modelos grandes con la especialización necesaria para ciertas aplicaciones.
- RAG y Fine-tuning: Estas técnicas pueden combinarse para crear sistemas altamente especializados y precisos. Por ejemplo, un LLM con fine-tuning para un dominio específico puede utilizarse como componente generativo en un sistema RAG.
- SLM y Fine-tuning: El fine-tuning también puede aplicarse a SLM para mejorar aún más su rendimiento en tareas específicas, creando modelos altamente eficientes y especializados.
Conclusiones y futuro de la IA
La combinación de estos cuatro pilares está abriendo nuevas posibilidades en el campo de la IA Generativa:
- Sistemas híbridos: combinación de SLM y LLM para diferentes aspectos de una misma aplicación, optimizando rendimiento y eficiencia.
- RAG avanzado: implementación de sistemas RAG más sofisticados que utilicen múltiples fuentes de información y técnicas de recuperación más avanzadas.
- Fine-tuning continuo: desarrollo de técnicas para el ajuste continuo de modelos en tiempo real, adaptándose a nuevos datos y necesidades.
- Personalización a escala: creación de modelos altamente personalizados para individuos o pequeños grupos, combinando fine-tuning y RAG.
- IA Generativa ética y responsable: implementación de estas técnicas con un enfoque en la transparencia, la verificabilidad y la reducción de sesgos.
SLM, LLM, RAG y Fine-tuning representan los pilares fundamentales sobre los que se está construyendo el futuro de la IA Generativa. Cada uno de estos conceptos aporta fortalezas únicas:
- Los SLM ofrecen eficiencia y especialización.
- Los LLM proporcionan versatilidad y capacidad de generalización.
- RAG mejora la precisión y relevancia de las respuestas.
- El Fine-tuning permite la adaptación y personalización de modelos.
La verdadera magia ocurre cuando estos elementos se combinan de formas innovadoras, creando sistemas de IA Generativa más potentes, precisos y adaptables que nunca. A medida que estas tecnologías continúen evolucionando, podemos esperar ver aplicaciones cada vez más sofisticadas y útiles en una amplia gama de campos, desde la atención médica hasta la creación de contenido creativo.
El desafío para los desarrolladores e investigadores será encontrar el equilibrio óptimo entre estos elementos, considerando factores como la eficiencia computacional, la precisión, la adaptabilidad y la ética. El futuro de la IA Generativa promete ser fascinante, y estos cuatro conceptos estarán sin duda en el centro de su desarrollo y aplicación en los años venideros.
Contenido elaborado por Alejandro Alija,experto en Transformación Digital e Innovación. Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.