Blog
The increasing adoption of artificial intelligence (AI) systems in critical areas such as public administration, financial services or healthcare has brought the need for algorithmic transparency to the forefront. The complexity of AI models used to make decisions such as granting credit or making a medical diagnosis, especially when it comes to deep learning algorithms, often gives rise to what is commonly referred to as the "black box" problem, i.e. the difficulty of interpreting and understanding how and why an AI model arrives at a certain conclusion. The LLLMs or SLMs that we use so much lately are a clear example of a black box system where not even the developers themselves are able to foresee their behaviour.
In regulated sectors, such as finance or healthcare, AI-based decisions can significantly affect people's lives and therefore it is not acceptable to raise doubts about possible bias or attribution of responsibility. As a result, governments have begun to develop regulatory frameworks such as the Artificial Intelligence Regulation that require greater explainability and oversight in the use of these systems with the additional aim of generating confidence in the advances of the digital economy.
Explainable artificial intelligence (XAI) is the discipline that has emerged in response to this challenge, proposing methods to make the decisions of AI models understandable. As in other areas related to artificial intelligence, such as LLLM training, open data is an important ally of explainable artificial intelligence to build audit and verification mechanisms for algorithms and their decisions.
What is explainable AI (XAI)?
Explainable AI refers to methods and tools that allow humans to understand and trust the results of machine learning models. According to the U.S. National Institute of Standards and Technology (NIST), the NIST is the only organisation in the U.S. that has a national standards body. The four key principles of Explainable Artificial Intelligence in the US are to ensure that AI systems are transparent, understandable and trusted by users:
- Explainability (Explainability): the AI must provide clear and understandable explanations of how it arrives at its decisions and recommendations.
- Meaningful (Meaningful): explanations must be meaningful and understandable to users.
- Accuracy (Accuracy): AI must generate accurate and reliable results, and the explanation of these results must accurately reflect its performance.
- Knowledge Limits (Knowledge Limits): AI must recognise when it does not have sufficient information or confidence in a decision and refrain from issuing responses in such cases.
Unlike traditional "black box" AI systems, which generate results without revealing their internal logic, XAI works on the traceability, interpretability and accountability of these decisions. For example, if a neural network rejects a loan application, XAI techniques can highlight the specific factors that influenced the decision. Thus, while a traditional model would simply return a numerical rating of the credit file, an XAI system could also tell us something like "Payment history (23%), job stability (38%) and current level of indebtedness (32%) were the determining factors in the loan denial". This transparency is vital not only for regulatory compliance, but also for building user confidence and improving AI systems themselves.
Key techniques in XAI
The Catalogue of trusted AI tools and metrics from the OECD's Artificial Intelligence Policy Observatory (OECD.AI) collects and shares tools and metrics designed to help AI actors develop trusted systems that respect human rights and are fair, transparent, explainable, robust, safe and reliable. For example, two widely adopted methodologies in XAI are Local Interpretable Model-agnostic Explanations (LIME) and SHapley Additive exPlanations (SHAP).
- LIME approximates complex models with simpler, interpretable versions to explain individual predictions. It is a generally useful technique for quick interpretations, but not very stable in assigning the importance of variables from one example to another.
- SHAP quantifies the exact contribution of each input to a prediction using game theory principles. This is a more precise and mathematically sound technique, but much more computationally expensive.
For example, in a medical diagnostic system, both LIME and SHAP could help us interpret that a patient's age and blood pressure were the main factors that led to a diagnosis of high risk of infarction, although SHAP would give us the exact contribution of each variable to the decision.
One of the most important challenges in XAI is to find the balance between the predictive ability of a model and its explainability. Hybrid approaches are therefore often used, integrating a posteriori explanatory methods of decision making with complex models. For example, a bank could implement a deep learning system for fraud detection, but use SHAP values to audit its decisions and ensure that no discriminatory decisions are made.
Open data in the XAI
There are at least two scenarios in which value can be generated by combining open data with explainable artificial intelligence techniques:
- The first of these is the enrichment and validation of the explanations obtained with XAI techniques. Open data makes it possible to add layers of context to many technical explanations, which is also true for the explainability of AI models. For example, if an XAI system indicates that air pollution influenced an asthma diagnosis, linking this result to open air quality datasets from patients' areas of residence would allow validation of the correctness of the result.
- Improving the performance of AI models themselves is another area where open data brings value. For example, if an XAI system identifies that the density of urban green space significantly affects cardiovascular risk diagnoses, open urban planning data could be used to improve the accuracy of the algorithm.
It would be ideal if AI model training datasets could be shared as open data, so that it would be possible to verify model training and replicate the results. What is possible, however, is the open sharing of detailed metadata on such trainings as promoted by Google's Model Cards initiative, thus facilitating post-hoc explanations of the models' decisions. In this case it is a tool more oriented towards developers than towards the end-users of the algorithms.
In Spain, in a more citizen-driven initiative, but equally aimed at fostering transparency in the use of artificial intelligence algorithms, the Open Administration of Catalonia has started to publish comprehensible factsheets for each AI algorithm applied to digital administration services. Some are already available, such as the AOC Conversational Chatbots or the Video ID for Mobile idCat.
Real examples of open data and XAI
A recent paper published in Applied Sciences by Portuguese researchers exemplifies the synergy between XAI and open data in the field of real estate price prediction in smart cities. The research highlights how the integration of open datasets covering property characteristics, urban infrastructure and transport networks, with explainable artificial intelligence techniques such as SHAP analysis, unravels the key factors influencing property values. This approach aims to support the generation of urban planning policies that respond to the evolving needs and trends of the real estate market, promoting sustainable and equitable growth of cities.
Another study by researchers at INRIA (French Institute for Research in Digital Sciences and Technologies), also on real estate data, delves into the methods and challenges associated with interpretability in machine learning based on linked open data. The article discusses both intrinsic techniques, which integrate explainability into model design, and post hoc methods that examine and explain complex systems decisions to encourage the adoption of transparent, ethical and trustworthy AI systems.
As AI continues to evolve, ethical considerations and regulatory measures play an increasingly important role in creating a more transparent and trustworthy AI ecosystem. Explainable artificial intelligence and open data are interconnected in their aim to foster transparency, trust and accountability in AI-based decision-making. While XAI provides the tools to dissect AI decision-making, open data provides the raw material not only for training, but also for testing some XAI explanations and improving model performance. As AI continues to permeate every facet of our lives, fostering this synergy will contribute to building systems that are not only smarter, but also fairer.
Content prepared by Jose Luis Marín, Senior Consultant in Data, Strategy, Innovation & Digitalization. The contents and views reflected in this publication are the sole responsibility of the author.
Blog
Language models are at the epicentre of the technological paradigm shift that has been taking place in generative artificial intelligence (AI) over the last two years. From the tools with which we interact in natural language to generate text, images or videos and which we use to create creative content, design prototypes or produce educational material, to more complex applications in research and development that have even been instrumental in winning the 2024 Nobel Prize in Chemistry, language models are proving their usefulness in a wide variety of applicationsthat we are still exploring.
Since Google's influential 2017 paper "Attention is all you need" describing the architecture of the Transformers, the technology underpinning the new capabilities that OpenAI popularised in late 2022 with the launch of ChatGPT, the evolution of language models has been more than dizzying. In just two years, we have moved from models focused solely on text generation to multimodal versions that integrate interaction and generation of text, images and audio.
This rapid evolution has given rise to two categories of language models: SLMs (Small Language Models), which are lighter and more efficient, and LLLMs (Large Language Models), which are heavier and more powerful. Far from considering them as competitors, we should analyse SLM and LLM as complementary technologies. While LLLMs offer general processing and content generation capabilities, SLMs can provide support for more agile and specialised solutions for specific needs. However, both share one essential element: they rely on large volumes of data for training and at the heart of their capabilities is open data, which is part of the fuel used to train these language models on which generative AI applications are based.
LLLM: power driven by massive data
The LLLMs are large-scale language models with billions, even trillions, of parameters. These parameters are the mathematical units that allow the model to identify and learn patterns in the training data, giving them an extraordinary ability to generate text (or other formats) that is consistent and adapted to the users' context. These models, such as the GPT family from OpenAI, Gemini from Google or Llama from Meta, are trained on immense volumes of data and are capable of performing complex tasks, some even for which they were not explicitly trained.
Thus, LLMs are able to perform tasks such as generating original content, answering questions with relevant and well-structured information or generating software code, all with a level of competence equal to or higher than humans specialised in these tasks and always maintaining complex and fluent conversations.
The LLLMs rely on massive amounts of data to achieve their current level of performance: from repositories such as Common Crawl, which collects data from millions of web pages, to structured sources such as Wikipedia or specialised sets such as PubMed Open Access in the biomedical field. Without access to these massive bodies of open data, the ability of these models to generalise and adapt to multiple tasks would be much more limited.
However, as LLMs continue to evolve, the need for open data increases to achieve specific advances such as:
- Increased linguistic and cultural diversity: although today's LLMs are multilingual, they are generally dominated by data in English and other major languages. The lack of open data in other languages limits the ability of these models to be truly inclusive and diverse. More open data in diverse languages would ensure that LLMs can be useful to all communities, while preserving the world's cultural and linguistic richness.
- Reducción de sesgos: los LLM, como cualquier modelo de IA, son propensos a reflejar los sesgos presentes en los datos con los que se entrenan. This sometimes leads to responses that perpetuate stereotypes or inequalities. Incorporating more carefully selected open data, especially from sources that promote diversity and equality, is fundamental to building models that fairly and equitably represent different social groups.
- Constant updating: Data on the web and other open resources is constantly changing. Without access to up-to-date data, the LLMs generate outdated responses very quickly. Therefore, increasing the availability of fresh and relevant open data would allow LLMs to keep in line with current events[9].
- Entrenamiento más accesible: a medida que los LLM crecen en tamaño y capacidad, también lo hace el coste de entrenarlos y afinarlos. Open data allows independent developers, universities and small businesses to train and refine their own models without the need for costly data acquisitions. This democratises access to artificial intelligence and fosters global innovation.
To address some of these challenges, the new Artificial Intelligence Strategy 2024 includes measures aimed at generating models and corpora in Spanish and co-official languages, including the development of evaluation datasets that consider ethical evaluation.
SLM: optimised efficiency with specific data
On the other hand, SLMs have emerged as an efficient and specialised alternative that uses a smaller number of parameters (usually in the millions) and are designed to be lightweight and fast. Aunque no alcanzan la versatilidad y competencia de los LLM en tareas complejas, los SLM destacan por su eficiencia computacional, rapidez de implementación y capacidad para especializarse en dominios concretos.
For this, SLMs also rely on open data, but in this case, the quality and relevance of the datasets are more important than their volume, so the challenges they face are more related to data cleaning and specialisation. These models require sets that are carefully selected and tailored to the specific domain for which they are to be used, as any errors, biases or unrepresentativeness in the data can have a much greater impact on their performance. Moreover, due to their focus on specialised tasks, the SLMs face additional challenges related to the accessibility of open data in specific fields. For example, in sectors such as medicine, engineering or law, relevant open data is often protected by legal and/or ethical restrictions, making it difficult to use it to train language models.
The SLMs are trained with carefully selected data aligned to the domain in which they will be used, allowing them to outperform LLMs in accuracy and specificity on specific tasks, such as for example:
- Text autocompletion: a SLM for Spanish autocompletion can be trained with a selection of books, educational texts or corpora such as those to be promoted in the aforementioned AI Strategy, being much more efficient than a general-purpose LLM for this task.
- Legal consultations: a SLM trained with open legal datasets can provide accurate and contextualised answers to legal questions or process contractual documents more efficiently than a LLM.
- Customised education: ein the education sector, SLM trained with open data teaching resources can generate specific explanations, personalised exercises or even automatic assessments, adapted to the level and needs of the student.
- Medical diagnosis: An SLM trained with medical datasets, such as clinical summaries or open publications, can assist physicians in tasks such as identifying preliminary diagnoses, interpreting medical images through textual descriptions or analysing clinical studies.
Ethical Challenges and Considerations
We should not forget that, despite the benefits, the use of open data in language modelling presents significant challenges. One of the main challenges is, as we have already mentioned, to ensure the quality and neutrality of the data so that they are free of biases, as these can be amplified in the models, perpetuating inequalities or prejudices.
Even if a dataset is technically open, its use in artificial intelligence models always raises some ethical implications. For example, it is necessary to avoid that personal or sensitive information is leaked or can be deduced from the results generated by the models, as this could cause damage to the privacy of individuals.
The issue of data attribution and intellectual property must also be taken into account. The use of open data in business models must address how the original creators of the data are recognised and adequately compensated so that incentives for creators continue to exist.
Open data is the engine that drives the amazing capabilities of language models, both SLM and LLM. While the SLMs stand out for their efficiency and accessibility, the LLMs open doors to advanced applications that not long ago seemed impossible. However, the path towards developing more capable, but also more sustainable and representative models depends to a large extent on how we manage and exploit open data.
Contenido elaborado por Jose Luis Marín, Senior Consultant in Data, Strategy, Innovation & Digitalization. Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Blog
In the fast-paced world of Generative Artificial Intelligence (AI), there are several concepts that have become fundamental to understanding and harnessing the potential of this technology. Today we focus on four: Small Language Models(SLM), Large Language Models(LLM), Retrieval Augmented Generation(RAG) and Fine-tuning. In this article, we will explore each of these terms, their interrelationships and how they are shaping the future of generative AI.
Let us start at the beginning. Definitions
Before diving into the details, it is important to understand briefly what each of these terms stands for:
The first two concepts (SLM and LLM) that we address are what are known as language models. A language model is an artificial intelligence system that understands and generates text in human language, as do chatbots or virtual assistants. The following two concepts (Fine Tuning and RAG) could be defined as optimisation techniques for these previous language models. Ultimately, these techniques, with their respective approaches as discussed below, improve the answers and the content returned to the questioner. Let's go into the details:
- SLM (Small Language Models): More compact and specialised language models, designed for specific tasks or domains.
- LLM (Large Language Models): Large-scale language models, trained on vast amounts of data and capable of performing a wide range of linguistic tasks.
- RAG (Retrieval-Augmented Generation): A technique that combines the retrieval of relevant information with text generation to produce more accurate and contextualised responses.
- Fine-tuning: The process of tuning a pre-trained model for a specific task or domain, improving its performance in specific applications.
Now, let's dig deeper into each concept and explore how they interrelate in the Generative AI ecosystem.
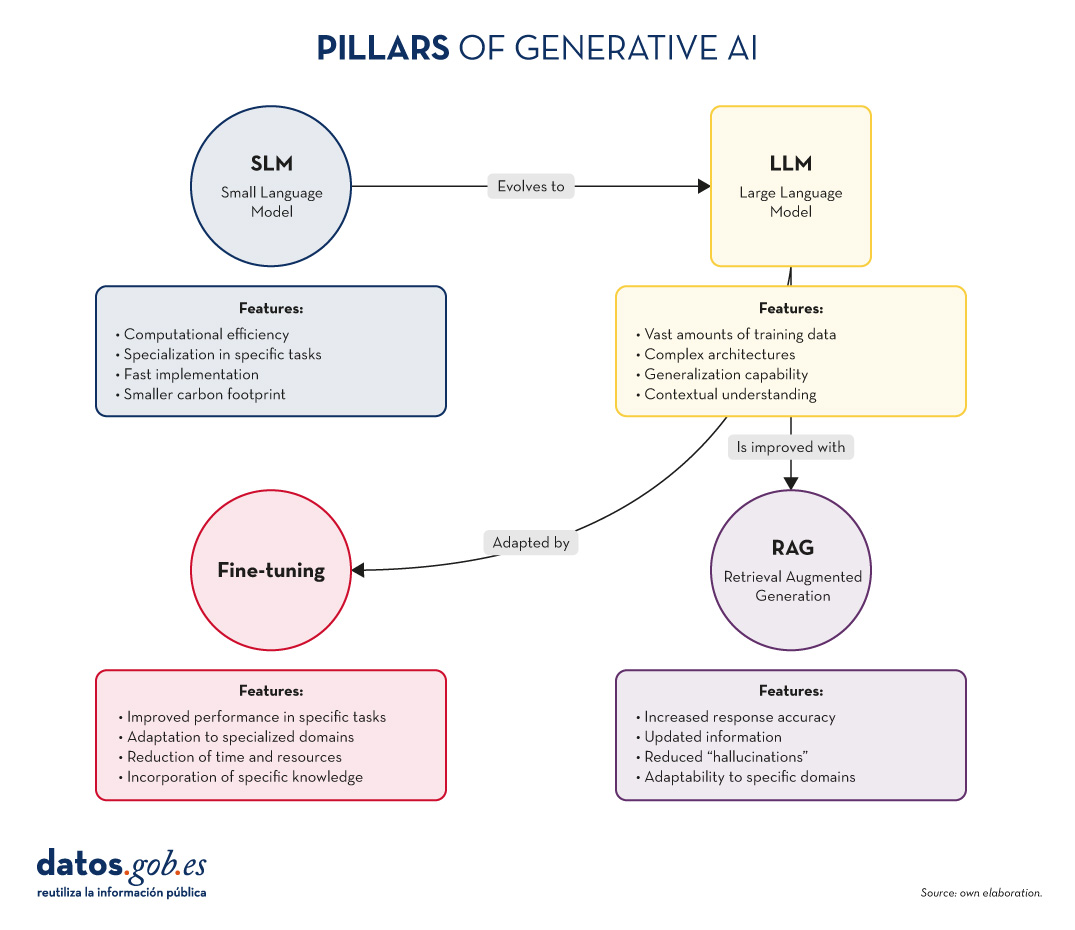
Figure 1. Pillars of Generative AI. Own elaboration.
SLM: The power of specialisation
Increased efficiency for specific tasks
Small Language Models (SLMs) are AI models designed to be lighter and more efficient than their larger counterparts. Although they have fewer parameters, they are optimised for specific tasks or domains.
Key characteristics of SLMs:
- Computational efficiency: They require fewer resources for training and implementation.
- Specialisation: They focus on specific tasks or domains, achieving high performance in specific areas.
- Rapid implementation: Ideal for resource-constrained devices or applications requiring real-time responses.
- Lower carbon footprint: Being smaller, their training and use consumes less energy.
SLM applications:
- Virtual assistants for specific tasks (e.g. booking appointments).
- Personalised recommendation systems.
- Sentiment analysis in social networks.
- Machine translation for specific language pairs.
LLM: The power of generalisation
The revolution of Large Language Models
LLMs have transformed the Generative AI landscape, offering amazing capabilities in a wide range of language tasks.
Key characteristics of LLMs:
- Vast amounts of training data: They train with huge corpuses of text, covering a variety of subjects and styles.
- Complex architectures: They use advanced architectures, such as Transformers, with billions of parameters.
- Generalisability: They can tackle a wide variety of tasks without the need for task-specific training.
- Contextual understanding: They are able to understand and generate text considering complex contexts.
LLM applications:
- Generation of creative text (stories, poetry, scripts).
- Answers to complex questions and reasoning.
- Analysis and summary of long documents.
- Advanced multilingual translation.
RAG: Boosting accuracy and relevance
The synergy between recovery and generation
As we explored in our previous article, RAG combines the power of information retrieval models with the generative capacity of LLMs. Its key aspects are:
Key features of RAG:
- Increased accuracy of responses.
- Capacity to provide up-to-date information.
- Reduction of "hallucinations" or misinformation.
- Adaptability to specific domains without the need to completely retrain the model.
RAG applications:
- Advanced customer service systems.
- Academic research assistants.
- Fact-checking tools for journalism.
- AI-assisted medical diagnostic systems.
Fine-tuning: Adaptation and specialisation
Refining models for specific tasks
Fine-tuning is the process of adjusting a pre-trained model (usually an LLM) to improve its performance in a specific task or domain. Its main elements are as follows:
Key features of fine-tuning:
- Significant improvement in performance on specific tasks.
- Adaptation to specialised or niche domains.
- Reduced time and resources required compared to training from scratch.
- Possibility of incorporating specific knowledge of the organisation or industry.
Fine-tuning applications:
- Industry-specific language models (legal, medical, financial).
- Personalised virtual assistants for companies.
- Content generation systems tailored to particular styles or brands.
- Specialised data analysis tools.
Here are a few examples
Many of you familiar with the latest news in generative AI will be familiar with these examples below.
SLM: The power of specialisation
Ejemplo: BERT for sentiment analysis
BERT (Bidirectional Encoder Representations from Transformers) is an example of SLM when used for specific tasks. Although BERT itself is a large language model, smaller, specialised versions of BERT have been developed for sentiment analysis in social networks.
For example, DistilBERT, a scaled-down version of BERT, has been used to create sentiment analysis models on X (Twitter). These models can quickly classify tweets as positive, negative or neutral, being much more efficient in terms of computational resources than larger models.
LLM: The power of generalisation
Ejemplo: OpenAI GPT-3
GPT-3 (Generative Pre-trained Transformer 3) is one of the best known and most widely used LLMs. With 175 billion parameters, GPT-3 is capable of performing a wide variety of natural language processing tasks without the need for task-specific training.
A well-known practical application of GPT-3 is ChatGPT, OpenAI's conversational chatbot. ChatGPT can hold conversations on a wide variety of topics, answer questions, help with writing and programming tasks, and even generate creative content, all using the same basic model.
Already at the end of 2020 we introduced the first post on GPT-3 as a great language model. For the more nostalgic ones, you can check the original post here.
RAG: Boosting accuracy and relevance
Ejemplo: Anthropic's virtual assistant, Claude
Claude, the virtual assistant developed by Anthropic, is an example of an application using RAGtechniques. Although the exact details of its implementation are not public, Claude is known for his ability to provide accurate and up-to-date answers, even on recent events.
In fact, most generative AI-based conversational assistants incorporate RAG techniques to improve the accuracy and context of their responses. Thus, ChatGPT, the aforementioned Claude, MS Bing and the like use RAG.
Fine-tuning: Adaptation and specialisation
Ejemplo: GPT-3 fine-tuned for GitHub Copilot
GitHub Copilot, the GitHub and OpenAI programming assistant, is an excellent example of fine-tuning applied to an LLM. Copilot is based on a GPT model (possibly a variant of GPT-3) that has been specificallyfine-tunedfor scheduling tasks.
The base model was further trained with a large amount of source code from public GitHub repositories, allowing it to generate relevant and syntactically correct code suggestions in a variety of programming languages. This is a clear example of how fine-tuning can adapt a general purpose model to a highly specialised task.
Another example: in the datos.gob.es blog, we also wrote a post about applications that used GPT-3 as a base LLM to build specific customised products.
Interrelationships and synergies
These four concepts do not operate in isolation, but intertwine and complement each other in the Generative AI ecosystem:
- SLM vs LLM: While LLMs offer versatility and generalisability, SLMs provide efficiency and specialisation. The choice between one or the other will depend on the specific needs of the project and the resources available.
- RAG and LLM: RAG empowers LLMs by providing them with access to up-to-date and relevant information. This improves the accuracy and usefulness of the answers generated.
- Fine-tuning and LLM: Fine-tuning allows generic LLMs to be adapted to specific tasks or domains, combining the power of large models with the specialisation needed for certain applications.
- RAG and Fine-tuning: These techniques can be combined to create highly specialised and accurate systems. For example, a LLM with fine-tuning for a specific domain can be used as a generative component in a RAGsystem.
- SLM and Fine-tuning: Fine-tuning can also be applied to SLM to further improve its performance on specific tasks, creating highly efficient and specialised models.
Conclusions and the future of AI
The combination of these four pillars is opening up new possibilities in the field of Generative AI:
- Hybrid systems: Combination of SLM and LLM for different aspects of the same application, optimising performance and efficiency.
- AdvancedRAG : Implementation of more sophisticated RAG systems using multiple information sources and more advanced retrieval techniques.
- Continuousfine-tuning : Development of techniques for the continuous adjustment of models in real time, adapting to new data and needs.
- Personalisation to scale: Creation of highly customised models for individuals or small groups, combining fine-tuning and RAG.
- Ethical and responsible Generative AI: Implementation of these techniques with a focus on transparency, verifiability and reduction of bias.
SLM, LLM, RAG and Fine-tuning represent the fundamental pillars on which the future of Generative AI is being built. Each of these concepts brings unique strengths:
- SLMs offer efficiency and specialisation.
- LLMs provide versatility and generalisability.
- RAG improves the accuracy and relevance of responses.
- Fine-tuning allows the adaptation and customisation of models.
The real magic happens when these elements combine in innovative ways, creating Generative AI systems that are more powerful, accurate and adaptive than ever before. As these technologies continue to evolve, we can expect to see increasingly sophisticated and useful applications in a wide range of fields, from healthcare to creative content creation.
The challenge for developers and researchers will be to find the optimal balance between these elements, considering factors such as computational efficiency, accuracy, adaptability and ethics. The future of Generative AI promises to be fascinating, and these four concepts will undoubtedly be at the heart of its development and application in the years to come.
Content prepared by Alejandro Alija, expert in Digital Transformation and Innovation. The contents and points of view reflected in this publication are the sole responsibility of its author.