Documentación
Blog
The year 2023 was undoubtedly the year of artificial intelligence. This has brought data, and therefore open data, back to the forefront, as it is the raw material that fuels this technology, which is key to value creation in our increasingly digital economy.
Perhaps that is why 2023 has also left us a number of new developments in terms of the drive to open data, many of which could lead to the creation of significant economic and social value through re-use. One of these developments is the obligation for public sector bodies to open in the first half of 2024 a number of high-value datasets, already specified in a regulation that was published in the last few days of 2022 in order to implement the provisions of open data directive (2019). Specifically, there are six high-value thematic categories: geospatial, earth observation and environmental, meteorology, statistics, companies and company ownership and mobility.
In order to comply with this obligation and with the rest of the obligations set out in Directive 2019/1024, in 2023, Spain has amended the Law 37/2007 on the re-use of public sector information has been amended in Spain in 2023. This amendment emphasises the duty to encourage the openness of high-value data published under an open data attribution licence (CC BY 4.0 or equivalent), in machine-readable format and accompanied by metadata describing the characteristics of the datasets.
The European Statistical System and the National Statistical Plan 2021-2024
Of the six thematic categories, number four, Statistics, is dedicated to statistical datasets, characterised by their broad definition and specification. It is based on the European Statistical System which ensures that European statistics produced in all Member States are reliable, following common criteria and definitions and treating data in an appropriate way, so that they are always comparable between EU countries. Specifically, the regulation defines 21 statistical datasets as high-value (it actually includes 22, but one of them is redundant as it is broken down into three components: population, fertility and mortality).
The National Statistical Institute] is part of the European Statistical System and is in charge of the production of the harmonised national statistics that Eurostat then compiles and analyses to provide comparable figures, so that Community policies can be defined, implemented and analysed.
In Spain, the National Statistical Plan is the main instrument that organises the statistical activity of the General State Administration, the backbone of statistics for state purposes. The current plan was published at the end of 2020, covering the 2021-2024 period.
The National Statistical Plan 2021-2024 includes new strategic lines such as the use of new sources of information, including, for example, Big Data and massive databases. It also promotes new production models, such as experimental statistics, and incorporates a special focus on the inclusion of gender, disability, age and nationality perspectives, as well as improvements in real estate market information, especially on rentals.
High-value statistical datasets
In these strategic lines, the plan does not yet contain any mention of high-value datasets. However, as the plan is developed and implemented through specific annual programmes detailing the statistical operations to be carried out, their objectives, the bodies involved, and the budget appropriations statistical operations to be carried out, their objectives, the bodies involved and the budget appropriations needed to finance them, it is possible to get an idea of which of these statistical operations are aligned with the 21 categories of high value Ssatistical datasets regulation.
The following table shows the possible equivalences:
| High-value statistical datasets | Equivalence in the Inventory of Statistical Operations (IOE) |
|---|---|
| Industrial production | IOE 30050 data sheet, Industrial Production Indices |
| Industrial producer price index breakdowns by activity | IOE 30051 data sheet , Industrial Price Indices |
| Volume of sales by activity | Partially covered by IOE 32092 data sheet Statistics on Sales, Employment and Wages in Large enterprises and SMEs and 32096 data sheet, Daily Domestic Sales. |
| EU International trade in goods statistics | There does not seem to be a clear correspondence in the plan, as the planned statistical operations on international trade are focused on services, while trade in goods is worked out in terms of trade between EU Member States. However, part of the specified data could be found in the IOE 30029 data sheet, Annual National Accounts of Spain: Main Aggregates, although perhaps at a higher level of aggregation than required. |
| Tourism flows in Europe | Many similarities with what is defined in the IOE 16028 data sheet, Statistics on Tourist Movements at Borders (FRONTUR) and 16023, Residents' Tourism Survey (ETR/FAMILITUR). |
| Harmonised Indices of consumer prices | IOE 30180 data sheet, Harmonised Index of Consumer Prices (HICP). |
| National Accounts - key indicators on GDP | IOE 30029 data sheet, Annual National Accounts of Spain: Main Aggregates. |
| National accounts - key indicators on corporations | |
| National accounts- key indicators on households | |
| Government expenditure and revenue | It is reflected in the three IOE data sheets on the settlement of budgets of the different levels of public administration: 31125 data sheet, Budget Settlement Statistics of the State and its Public Bodies, Companies and Foundations; 31030 datasheet Budgets Settlement of the Autonomous Communities (MHAC); and 31026 Budgets Settlement of Local Entities (MHAC). |
| Consolidated government gross debt | |
| Environmental accounts and statistics | It is reflected in the eight data sheet (from 30084 to 30095) of the inventory of statistical operations regarding Environmental Accounts. View listing here. |
| Population | IOE 30264 data sheet, Basic Demographic Indicators. |
| Fertility | |
| Mortality | IOE 30271 data sheet, Mortality Tables. |
| Current healthcare expenditure | IOE 54012 data sheet, Satellite Accounts of Public Health Expenditure |
| Poverty | IOE 30453 data sheet, Living Conditions Survey (LCS). |
| Inequality | |
| Employment | There are quite a few statistical operations that study the labor market, of which the IOE 0308 Labor Force Survey stands out. |
| Unemployment | |
| Potential labour force | IOE 30308 data sheet, Labor force Survey, which also contains worksheet 30309 data sheet, Community Labour Force Survey (CLFS). |
En definitiva, parece que la mayor parte de las variables clave que el reglamento europeo ha previsto para los conjuntos estadísticos de alto valor están ya produciéndose de acuerdo con el plan estadístico nacional vigente. El plan estadístico nacional, que sucederá al actualmente vigente, comenzará en 2025 y a buen seguro se publicará a lo largo de este 2024. Este año veremos en Europa un intenso trabajo para cumplir con las obligaciones del reglamento, ya que, además, la Comisión Europea ha publicado recientemente el informe "Identification of data themes for the extensions of public sector High-Value Datasets" donde se incluyen siete nuevas categorías que se estudia considerar como datos de alto valor y que previsiblemente acabarán siendo incluidas en el reglamento.
All in all, it seems that most of the key variables that the European regulation has foreseen for high value statistical datasets are already being produced according to the existing national statistical plan. The national statistical plan, which will succeed the current one, will start in 2025 and will most likely be published in the course of 2024. This year will see intense work in Europe to comply with the obligations of the regulation, as the European Commission has also recently published the report "Identification of data themes for the extensions of public sector High-Value Datasets" which includes seven new categories that are being considered as high-value datasets and are expected to be included in the regulation and which will foreseeably end up being included in the regulation.
Content prepared by Jose Luis Marín, Senior Consultant in Data, Strategy, Innovation & Digitalization. The contents and views reflected in this publication are the sole responsibility of the author.
Blog
The Implementing Regulation (EU) 2023/138 of the European Commission sets clear guidelines for public bodies on the availability of high-value datasets within 16 months. These high-value datasets are grouped into the following themes, which were already described in this post post:

This article focuses on the geospatial category, called High-Value Geospatial Datasets (HVDG).
For all HVDGs, the following shall apply Directive 2007/2/EC of the European Parliament and of the Council of 14 March 2007 establishing an infrastructure for spatial information in the European Community (INSPIRE) with the exception of agricultural and reference parcels, for which Regulation (EU) 2021/211/EEC applies Regulation (EU) No 2021/2116 of the European Parliament and of the Council of 2 December 2021.
As reflected in the table below, the regulation provides detailed information on the requirements to be considered for these HVDGs, such as scales or granularity and attributes of each dataset. These are complementary to the attributes defined in the European Regulation (No 1089/2010), which establishes the interoperability of spatial data sets and services.
| Datasets | Scales | Attributes |
|---|---|---|
| Administrative units |
Levels of generalisation available with a granularity down to the scale of 1:5 000. From municipalities to countries; maritime units. |
|
| Geographical names |
Not applicable. |
|
| Directorates | Not applicable. |
|
| Buildings | Levels of generalisation available with a granularity up to the scale of 1:5 000 |
|
| Cadastral parcels | Levels of generalisation available with a granularity up to the scale of 1:5 000 |
|
| Reference areas | Levels of generalisation available with a granularity up to the scale of 1:5 000 |
|
| Agricultural areas | Level of accuracy equivalent to 1:10 000 scale and from 2016, 1:5 000 scale |
|
To ensure the accessibility and re-use of all these valuable datasets, it is imperative to follow certain provisions to facilitate their publication. Here are the key requirements:
- Open Licence: All datasets must be made available for re-use under a licence Creative Commons BY 4.0 or any equivalent less restrictive open licence. This encourages the freedom to share and adapt information.
- Open and Machine Readable Format: Data should be presented in an open, machine-readable format and be publicly documented. This ensures that the information is easily understandable and accessible to any person or automated system.
- Application Programming Interfaces (APIs) and Mass Download: Application programming interfaces (APIs) should be provided to facilitate programmatic access to data. In addition, direct bulk downloading of datasets should be possible, allowing flexible options for users according to their needs.
- Updated version: The availability of datasets in their most up-to-date version is essential. This ensures that users have access to the latest information, promoting the relevance and accuracy of data.
- Metadata: The description of the data will also be carefully taken care of through the use of metadata. This metadata shall, as a minimum, include the elements as defined in Commission Regulation (EC) No 1205/2008 of 3 December 2008. This regulation implements Directive 2007/2/EC of the European Parliament and of the Council and sets standards for metadata associated with datasets. The use of standardised metadata provides additional information essential for understanding, interpreting and using datasets effectively. By following these standards, interoperability and consistency in reporting is facilitated, thus promoting a more complete and accurate understanding of the available data.
These provisions not only promote transparency and openness, but also facilitate collaboration and the effective use of information in a variety of contexts.
Does Spain comply with the Geospatial HVD Regulation?
The INSPIRE (Infrastructure for Spatial Information in Europe) Directive determines the general rules for the establishment of an Infrastructure for Spatial Information in the European Community based on the Infrastructures of the Member States. Adopted by the European Parliament and Council on 14 March 2007 (Directive 2007/2/EC), entered into force on 25 April 2007.
INSPIRE makes it easier to find, share and use spatial data from different countries and in each of the regions, with HVDs available in the the Commission's new catalogue of HVDs and in each of the catalogues of the Spatial Data Infrastructures of the Autonomous Communities, as well as in the Official INSPIRE Data and Services Catalogue of Spain. The information is available through an online platform whit data from different countries.

WARNING!: They are currently working on this Geoportal carrying out the tasks of data dump, therefore, there may be some temporal inconsistency with the data provided, which correspond to the Official Catalogue of INSPIRE Data and Services (CODSI).
In Spain, we can find the Law 14/2010 of 5 July 2010 on geographic information infrastructures and services in Spain (LISIGE), which transposes Directive 2007/2/EC INSPIRE. This law frames the work to make all national spatial data available and obliges the adaptation of national spatial data to the Technical Guides or Guidelines collected by the INSPIRE Directive, thus ensuring that these data are compatible and interoperable in a Community and cross-border context.
LISIGE applies to geographic data that meet these conditions:
- Refering to a geographical area of the national territory, the territorial sea, the contiguous zone, the continental shelf and the exclusive economic zone.
- Having been generated by or under the responsibility of public administrations.
- Being in electronic format.
- Their production and maintenance is the responsibility of a public sector administration or body.
- Being within the themes of Annexes I (Geographic Reference Information), II (Fundamental Thematic Data) or III (General Thematic Data) referred to in the aforementioned law
Furthermore, it is clarified that the geographic data and services regulated by the LISIGE will be available on the NSDI Geoportal and on the CODSI as well as in the rest of the catalogues of the Autonomous Communities. The National Geographic Institute (IGN) is responsible for its maintenance.
Thanks to the tireless efforts of the entire Spanish administration since the publication of LISIGE, Spain has achieved a remarkable milestone. It is currently available on the INSPIRE Geoportal a wide range of information classified as High Value Geospatial Data Set (HVDG) is now available on the INSPIRE Geoportal. This achievement reflects our country's continued commitment to transparency and access to high quality geospatial data.
As of January 2024 Spain has published in the INSPIRE Geoportal and in CODSI the following information related to the High Geospatial Value Datasets (HVD)
- 31 datasets associated with their metadata
- 34 download services (WFS, ATOM Feed, OGC Api Feature)
- 28 visualisation services (WMS, WMTS)
Analysing the sets of high geospatial value we see that, according to the thematics, they have already been published:
| HVDG Spain | Datasets | Download services | Visualisation services | Covers Spanish territory |
|---|---|---|---|---|
| Administrative units |
5 | 7 | 7 | Sí |
| Geographical names |
7 | 8 | 8 | Sí |
| Directorates | 6 | 5 | 7 | Sí |
| Buildings | 5 | 3 | 4 | Sí |
| Cadastral parcels | 3 | 3 | 3 | Sí |
| Reference areas | 3 | 0 | 3 | Sí |
| Agricultural areas | 2 | 2 | 2 | Sí |
Spain currently complies with the HVDG Regulation in all categories. Specifically, it complies with the established legislation at the level of scale or granularity, attributes, license, format, availability of the data in API or maximum download, with being the most updated version and with the metadata.
A detailed analysis of the datasets published under the HVD framework highlights several key issues:
- Comprehensive Geographic Coverage: At least one dataset covering the whole of Spain has been made available.
- Comprehensive Metadata: Metadata has been generated for all High Geospatial Value Datasets (HVDGs). These metadata are published in the Official INSPIRE Catalogue of INSPIRE Data and Services (CODSI), validated to comply with the standards of the Commission Regulation (EC) No 1205/2008.
- Viewing and Downloading Services: All HVDGs have viewing and download services. Download services can be bulk download or download APIs. Currently, they are WFS and ATOM. In the future may be OGC API Feature or API Coverage.
- Open Licences and Open Formats: All published services are licensed under Creative Commons BY 4.0, and download services use standard and open formats such as the GML format documented by the international standard ISO 19136.
- Compliance with INSPIRE Data Models: Almost all datasets comply with the INSPIRE data models, thus ensuring the consistency and quality of the attributes set out in the HVDG regulation.
- Data Updated and Maintained: Download services guarantee the availability of data in the most up-to-date version. Each public administration responsible for the data is responsible for maintaining and updating the information.
This analysis highlights the commitment and efficiency in the management of geospatial data in Spain, contributing to the transparency, accessibility and quality of the information provided to the community.
It should be noted that, in Spain, all HVDG requirements are met. Organisations such as the CNIG and the ICGC or the Government of Navarre, in addition to publishing through WFS or ATOM services, are already working on publishing these datasets with the APIs of OGC.
The INSPIRE Geoportal has become a valuable source of information, thanks to the dedication and collaboration of various governmental entities, including Spanish ones. This breakthrough not only highlights progress in the implementation of geospatial standards, but also strengthens the basis for sustainable development and informed decision-making in Spain. A significant achievement for the country in the geospatial field!
Content prepared by Mayte Toscano, Senior Consultant in Data Economy Technologies. The contents and points of view reflected in this publication are the sole responsibility of its author.
Documentación
In order to comply with Directive (EU) 2019/1024 and its subsequent implementing regulation, EU member states are working on making available so-called high-value datasets (HVD). The aim is to enable citizens and businesses to access such data under technical requirements that favour its re-use and its positive impact on society, the economy and the environment.
Opening up these datasets is a major challenge for public administrations in all EU countries. Although much of this data is already available tousers, countries need to identify it in order to be able to report on it and resolve the high heterogeneity in formats, structures and semantics. In particular, from February 2025, Member States will have to report to the Commission every two years on available high-value datasets, including links to licence conditions and APIs.
To assist in this task, the European Data Portal has published the report "Report on Data Homogenisation for High-value Datasets" where it proposes a methodological approach to facilitate the identification and homogenisation of HVD. Among other issues, the report provides examples of standards that help to achieve greater interoperability not only between data, but also between the applications that use them.
A method for identification and homogenisation
The report describes a methodological approach based on three steps:
- The identification of HVDs in existing data portals. Although there are some guidelines for HVD publication, like these for applying DCAT-AP, the naming of already published datasets is not uniform, which makes it difficult to find them. The report proposes a protocol that consists of defining keywords, based on the datasets and their associated attributes, contained in Annex I of the Implementing Regulation. The idea is to use these keywords to search the various existing data portals. The report explains how the identification protocol has been tested with datasets from the categories of business registers, statistical data and transport network data, including tables with the keywords used.
- Localisation or development of data models, ontologies, controlled vocabularies and/or common APIs. In this section, the report describes some useful resources, which are summarised in the following table:
| Resource | DESCRIPTION | Category of data in which they can help the most, according to the report |
|---|---|---|
| Inspire Directive | Characteristics that spatial information and its metadata must have. |
|
|
Inspire Directive data specifications (data specifications) |
Models, schemes and coding rules for different spatial data thematic areas.
|
|
| Inspire network services (network services) | A set of common interfaces for web services that enable the discovery, visualisation, downloading and transformation of spatial data. |
|
|
Technical guidelines for Inspire metadata (Inspire technical guidelines for metadata) |
Technical guidelines for metadata, with the minimum elements to be included as defined in Commission Regulation 1205/2008 . |
|
| Geo-DCATAP | Extension of the DCAT application profile to describe geospatial datasets. |
|
| Core Location Vocabulary | A simplified data model that includes the fundamental characteristics of a location, represented as an address or geographic name, or through geometry. |
|
| General Multilingual Environmental Thesaurus (GEMET). | Controlled vocabulary specialised in environmental information. It has a section on concepts linked to the spatial data categories included in Inspire. |
|
| Semantic Sensor Network | W3C recommendation for describing sensors and their observations. |
|
| Quantity, unit, dimension and type (QUDT). | A set of ontologies defining basic classes, properties and constraints used to model physical quantities, units of measurement and their dimensions in various measurement systems. |
|
| List of Eurostat statistical classifications | Statistical classifications maintained by Eurostat, available as Linked Open Data in XKOS, the SKOS extension for modelling statistical classifications. They are presented by classification family, categorised by statistical domain and sub-domains (e.g. NACE for economic activity, which we will describe below). |
|
| Eurostat standard code lists | Predefined and organised sets of elements presenting statistical concepts using unique codes |
|
| Statistical Data and Metadata eXchange (SDMX) | Global initiative to standardise and harmonise the exchange of statistical data and metadata. It provides technical standards (the SDMX information model), guidelines, an IT architecture, tools and a series of tutorials to assist users. |
|
| RDF Data Cube Vocabulary | Ontology for describing multidimensional data, such as statistics, which is based on the core of the SDMX 2.0 information model. |
|
| Core Business Vocabulary | Referred to by the regulation itself, it consists of a simplified data model that captures the fundamental characteristics of a legal entity, such as its legal name, activity or address. |
|
| NACE Code | Codes for the classification of economic activities in the European Union. Its NACE 2 revision was published by the European Commission in October 2022 |
|
| Organisation ontology | W3C ontology to support the publication of linked data relating to organisational information, i.e. it provides a number of ways to represent the relationship between people and organisations, together with the internal information structure of an organisation. |
|
| Global Legal Entity Identifier Foundation | Centralised database with information on legal entities participating in global financial markets. It assigns each entity a unique Legal Entity Identifier (LEI) code that is recognised worldwide. |
|
| NST Taxonomy | Classification system for goods transported by road, rail, inland waterways and sea. It takes into account the economic activity associated with the origin of the goods. |
|
| Table of authorities of "Transport service" | List of codes for different types of transport services provided by the EU Vocabularies section. |
|
Source: Report on Data Homogenisation for High-value Datasets
The report also mentions some models to be used in the field of smart cities, such as Smart Data Models and the Spanish Open Cities.
- The application of such models. The last step is the actual harmonisation of the data. Once the models to be used have been selected, it is time to apply them. In this phase, the necessary conversion processes will be carried out to provide the data in the appropriate formats and with unified quality metadata. The way in which these transformations are applied will vary depending on the intended end result. For example, it may consist of transforming tabular data (comma-separated values or CSVs, Excel, relational databases, etc.) into other data sources that are also tabular but follow the structure provided in common data models. You can also go further and transform them into tree-based representations (such as JSON) or RDF according to the ontologies and controlled vocabularies you select.
Conclusions of the report
The report ends with a series of conclusions and recommendations. There are still challenges around the identification of HVDs and the implementation of the Implementing Regulation in all European countries, especially in raising awareness and disseminating information about their importance. In HVD categories where there are large data harmonisation initiatives, such as Inspire on geospatial data or Eurostat on statistical HVD, we can find a larger amount of data available in an interoperable and harmonised way. In contrast, in categories where there is no majority initiative, such as companies and company ownership, there is still some way to go to implement the regulation.
The recommendations set out in the European Data Portal report help to shape a roadmap for publishing high-value datasets in each of the categories defined by the European Commission. A challenge that administrations will have to address during 2024 and that will facilitate the re-use of public information.
Blog
The Spanish Federation of Municipalities and Provinces (FEMP) approved at the end of 2023 two model ordinances that address progress in two key areas: transparency and data governance. Both documents will not only improve the quality of processes, but also facilitate access, management and re-use of data. In this post, we will analyse the second ordinance drafted within the FEMP's Network of Entities for Transparency and Citizen Participation in its quest to define common reference models. In particular, the ordinance on data governance.
The usefulness and good work of the Model Ordinance on Data Governance in Local Entities has been highlighted by the Multisectoral Association of Information (ASEDIE), which awarded it the prize in the category 'Promoting data literacy' at its 15th ASEDIE International Conference.
Under this premise, the document addresses all elements related to the collection, management and exploitation of data in order to approach them as a commongood, i.e. ensuring their openness, accessibility and re-use. This is a relevant objective for local administrations, as it enables them to improve their functioning, service delivery and decision-making. Data governance is the framework that guides and guarantees this process and this ordinance proposes a flexible regulatory framework that different administrations can adapt according to their specific needs.
What is data governance?
Data Governance comprehensively addresses all aspects related to the collection, management and exploitation of data, as well as its openness and re-use by society as a whole on an equal basis. Itcan therefore bedefined as an organisational function responsible for being accountable for the effective, efficient and acceptable use of databy the organisation, which is necessary to deliver the business strategy. This is described in the specifications UNE 0077:2023 on Data Governance and UNE 78:2023 on Data Management, which include standardised processes to guide organisations in the establishment of approved and validated mechanisms that provide organisational support to aspects related to the opening and publication of data, for subsequent use by citizens and other institutions.
How was the FEMP Data Governance Ordinance developed?
In order to develop the Model Ordinance on Data Governance in the Local Entity, a multidisciplinary working group was set up in 2022, which included workers from the Public Administrations, private companies, representatives of the infomediary sector, the Data Office, universities, etc. This team set out two main objectives that would mark the content of the document:
- Develop guidelines for municipalities and other public authorities defining the strategy to be followed in order to implement an open data project.
- Create a reference model of datasets common to all public administrations to facilitate the re-use of information.
With these two challenges in mind, in early 2023 the FEMP working group started to establish aspects, structure, contents and work plan. During the following months, work was carried out to draft, elaborate and reach consensus on a single draft.
In addition, a participatory process was organised on the Idea Zaragoza platform to nurture the document with contributions from experts from all over the country and FEMP partners.
The result of all the work was based on the Open Data Charter (ODC), the recommendations issued by the Spanish Government's Data Office and the existing European and national regulations on this matter.
New features and structure of the Data Governance Ordinance
The FEMP's Model Ordinance on Data Governance is in line with the context in which it has been presented, i.e. it recognises relevant aspects of the current moment we are living in. One of the document's salient features is the premise of guaranteeing and enhancing the rights of both natural and legal persons and respecting the General Data Protection Regulation. The regulation places particular emphasis on the proportionality of anonymisation to ensure the privacy of individuals.
Another novel aspect of the standard is that it brings the vision of high-value data defined by the European Commission from the perspective of local government. In addition, the Model Ordinance recognises a single regime for access and re-use of public information, in accordance with Law 19/2013 of 9 December on transparency, access to public information and good governance, and Law 37/2007 on the re-use of public sector information.
Beyond ensuring the legal and regulatory framework, the FEMP Ordinance also addresses the data associated with artificial intelligence, a cutting-edge technological synergy that every day offers great innovative solutions. For an artificial intelligence to function properly, it is necessary to have quality data to help train it. In relation to this point, the ordinance defines quality requirements (Article 18) and metrics for their assessment that are adapted to each specific context and address issues such as accuracy, portability or confidentiality, among others. The document establishes guarantees that the use of the data will be carried out in a way that respects the rights of individuals.
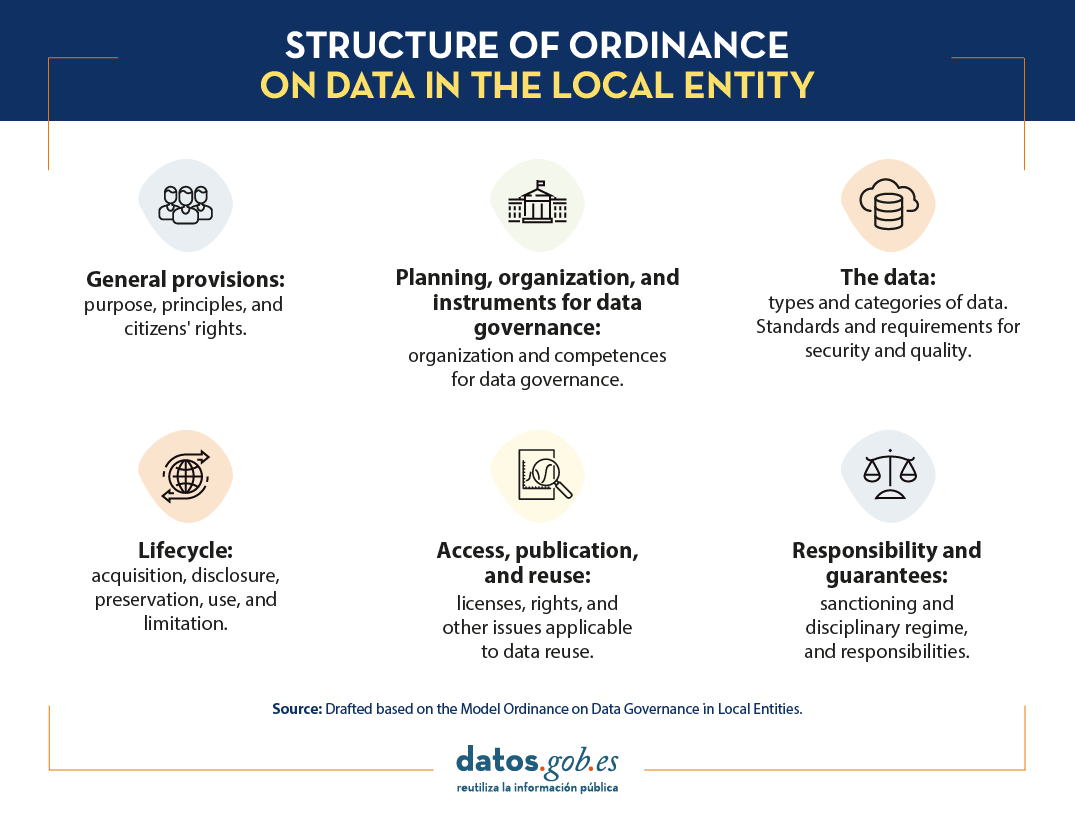
All these new aspects are part of the FEMP's Model Ordinance on Data Governance for Local Entities, which is organised in the following structure:
- General provisions: This first section presents data as the main digital asset of Public Administrations as a strategic asset, and the object, principles and right of citizenship.
- Planning, organisation and tools for data governance: Here the organisation and competencies for data governance are defined. In addition, the importance of maintaining an inventory of datasets and information sources is stressed (Article 9).
- The data: This chapter recognises the publication requirements and security standards, the importance of the use of reference vocabularies, and the categories of datasets whose openness should be prioritised, namely the 80 typologies referred to by FEMP as most relevant.
- Life cycle: This section highlights, on the one hand, the collection, opening, storage and use of data; and, on the other hand, the limits, deletion and destruction of data when these actions are required. when these actions are required.
- Access, publication and re-use: The fifth chapter deals with issues related to the exploitation of data such as the use of specific licences, exclusive rights, payment for re-use or prior request for access to certain datasets.
- Liability and guarantees: The last point describes the sanctioning and disciplinary regime and the civil and criminal liabilities of the re-user.
In short, the publication of the Ordinance on Data Governance in Local Entities provides local administrations with a flexible regulation and defines administrative structures that seek to improve management, reuse and the promotion of a data-driven society.
You can access the full document here: Standard Ordinance on Data Governance in the Local Entity
Noticia
The concept of High-Value data (High-Value datasets) was introduced by the European Parliament and the Council of the European Union 4 years ago, in Directive (EU) 2019/1024. In it, they were defined as a series of datasets with a high potential to generate "benefits for society, the environment and the economy". Therefore, member states were to push for their openness for free, in machine-readable formats, via APIs, in the form of bulk download and comprehensively described by metadata.
Initially, the directive proposed in its annex six thematic categories to be considered as high value: geospatial, earth observation and environmental, meteorological, statistical, business records and transport network data. These categories were subsequently detailed in an implementing regulation published in December 2022. In addition, to facilitate their openness, a document with guidelines on how to use DCAT-AP for publication was published in June 2023.
New categories of data to be considered of high value
These initial categories were always open to extension. In this sense, the European Commission has just published the report "Identification of data themes for the extensions of public sector High-Value Datasets" which includes seven new categories to be considered as high-value data
-
Climate loss: This refers to data related to approaches and actions needed to avoid, minimize and address damages associated with climate change. Examples of datasets in this category are economic and non-economic losses from extreme weather events or slow-onset changes such as sea level rise or desertification. It also includes data related to early warning systems for natural disasters, the impact of mitigation measures, or research data on the attribution of extreme events to climate change.
-
Energy: This category includes comprehensive statistics on the production, transport, trade and final consumption of primary and secondary energy sources, both renewable and non-renewable. Examples of data sets to consider are price and consumption indicators or information on energy security.
-
Finance: This is information on the situation of private companies and public administrations, which can be used to assess business performance or economic sustainability, as well as to define spending and investment strategies. It includes datasets on company registers, financial statements, mergers and acquisitions, as well as annual financial reports.
-
Government and public administration: This theme includes data that public services and companies collect to inform and improve the governance and administration of a specific territorial unit, be it a state, a region or a municipality. It includes data relating to government (e.g. minutes of meetings), citizens (census or registration in public services) and government infrastructures. These data are then reused to inform policy development, deliver public services, optimize resources and budget allocation, and provide actionable and transparent information to citizens and businesses.
-
Health: This concept identifies data sets covering the physical and mental well-being of the population, referring to both objective and subjective aspects of people's health. It also includes key indicators on the functioning of health care systems and occupational safety. Examples include data relating to Covid-19, health equity or the list of services provided by health centers.
-
Justice and legal affairs: Identifies datasets to strengthen the responsiveness, accountability and interoperability of EU justice systems, covering areas such as the application of justice, the legal system or public security, i.e. that which ensures the protection of citizens. The data sets on justice and legal matters include documentation of national or international jurisprudence, decisions of courts and prosecutors general, as well as legal acts and their content.
-
Linguistic data: Refers to written or spoken expressions that are at the basis of artificial intelligence, natural language processing and the development of related services. The Commission provides a fairly broad definition of this category of data, all of which are grouped under the term "multimodal linguistic data". They may include repositories of text collections, corpora of spoken languages, audio resources, or video recordings.

To make this selection, the authors of the report conducted desk research as well as consultations with public administrations, data experts and private companies through a series of workshops and surveys. In addition to this assessment, the study team mapped and analyzed the regulatory ecosystem around each category, as well as policy initiatives related to their harmonization and sharing, especially in relation to the creation of European Common Data Spaces.
Potential for SMEs and digital platforms
In addition to defining these categories, the study also provides a high-level estimate of the impact of the new categories on small and medium-sized companies, as well as on large digital platforms. One of the conclusions of the study is that the cost-benefit ratio of data openness is similar across all new topics, with those relating to the categories "Finance" and "Government and public administration" standing out in particular.
Based on the publicly available datasets, an estimate was also made of the current degree of maturity of the data belonging to the new categories, according to their territorial coverage and their degree of openness (taking into account whether they were open in machine-readable formats, with adequate metadata, etc.). To maximize the overall cost-benefit ratio, the study suggests selecting a different approach for each thematic category: based on their level of maturity, it is recommended to indicate a higher or lower number of mandatory criteria for publication, thus ensuring to avoid overlaps between new topics and existing high-value data.
You can read the full study at this link.
Noticia
Public administrations (PAs) have the obligation to publish their open datasets in reusable formats, as dictated by European Directive 2019/1024 which amends Law 37/2007 of November 16, regarding the reuse of public sector information. This regulation, aligned with the European Union's Data Strategy, stipulates that PAs must have their own catalogs of open data to promote the use and reuse of public information.
One of these catalogs is the Canary Islands Open Data Portal, which contains over 7,450 open, free, and reusable datasets from up to 15 organizations within the autonomous community. The Ministry of Agriculture, Livestock, Fisheries, and Food Sovereignty (CAGPSA) of the Government of the Canary Islands is part of this list. As part of its Open Government initiative, CAGPSA has strongly promoted the opening of its data.
Through a process of analysis, refinement, and normalization of the data, CAGPSA has successfully published over 20 datasets on the portal, thus ensuring the quality of information reuse by any interested party.
Analysis, data normalization, and data opening protocol for the Government of the Canary Islands
To achieve this milestone in data management, the Ministry of Agriculture, Livestock, Fisheries, and Food Sovereignty of the Government of the Canary Islands has developed and implemented a data opening protocol, which includes tasks such as:
- Inventory creation and prioritization of data sources for publication.
- Analysis, refinement, and normalization of prioritized datasets.
- Requesting the upload of datasets to the Canary Islands Open Data Portal.
- Addressing requests related to the published datasets.
- Updating published datasets.
Data normalization has been a key factor for the Ministry, taking into account international semantic assets (including United Nations classifications and various agencies or Eurostat) and applying guidelines defined in international standards such as SDMX or those set by datos.gob.es, to ensure the quality of the published data.
CAGPSA has not only put efforts into data normalization and publication but has also provided support to the ministry's personnel in the management and maintenance of the data, offering training and awareness sessions. Furthermore, they have created a manual for data reuse, outlining guidelines based on European and national directives regarding open data and the reuse of public sector information. This manual helps address concerns of the ministry's staff regarding the publication of personal or commercial data.
As a result of this work, the Ministry has actively collaborated with the Canary Islands Open Data Portal in publishing datasets and defining the data opening protocol established for the entire Government of the Canary Islands.
Commitment to Quality and Information Reuse
CAGPSA has been particularly recognized for the publication of the Agricultural Transformation Societies (SAT) dataset, which ranked among the top 3 datasets by the Multisectorial Information Association (ASEDIE) in 2021. This initiative has been praised by the association on multiple occasions for its focus on data quality and management.
Their efforts in data normalization, support to the ministry's staff, collaboration with the open data portal, and the extensive array of datasets, position CAGPSA as a reference in this field within the Canary Islands autonomous community.
At datos.gob.es, we applaud these kinds of examples and highlight the good practices in data opening by public administrations. The initiative of the Ministry of Agriculture, Livestock, Fisheries, and Food Sovereignty of the Government of the Canary Islands is a significant step that brings us closer to the advantages that open data and its reuse offer to the citizens. The Ministry's commitment to data openness contributes to the European and national goal of achieving a data-driven administration.
Noticia
Updated: 21/03/2024
On January 2023, the European Commission published a list of high-value datasets that public sector bodies must make available to the public within a maximum of 16 months. The main objective of establishing the list of high-value datasets was to ensure that public data with the highest socio-economic potential are made available for re-use with minimal legal and technical restriction, and at no cost. Among these public sector datasets, some, such as meteorological or air quality data, are particularly interesting for developers and creators of services such as apps or websites, which bring added value and important benefits for society, the environment or the economy.
The publication of the Regulation has been accompanied by frequently asked questions to help public bodies understand the benefit of HVDS (High Value Datasets) for society and the economy, as well as to explain some aspects of the obligatory nature of HVDS (High Value Datasets) and the support for publication.
In line with this proposal, Executive Vice-President for a Digitally Ready Europe, Margrethe Vestager, stated the following in the press release issued by the European Commission:
"Making high-value datasets available to the public will benefit both the economy and society, for example by helping to combat climate change, reducing urban air pollution and improving transport infrastructure. This is a practical step towards the success of the Digital Decade and building a more prosperous digital future".
In parallel, Internal Market Commissioner Thierry Breton also added the following words on the announcement of the list of high-value data: "Data is a cornerstone of our industrial competitiveness in the EU. With the new list of high-value datasets we are unlocking a wealth of public data for the benefit of all”. Start-ups and SMEs will be able to use this to develop new innovative products and solutions to improve the lives of citizens in the EU and around the world.
Six categories to bring together new high-value datasets
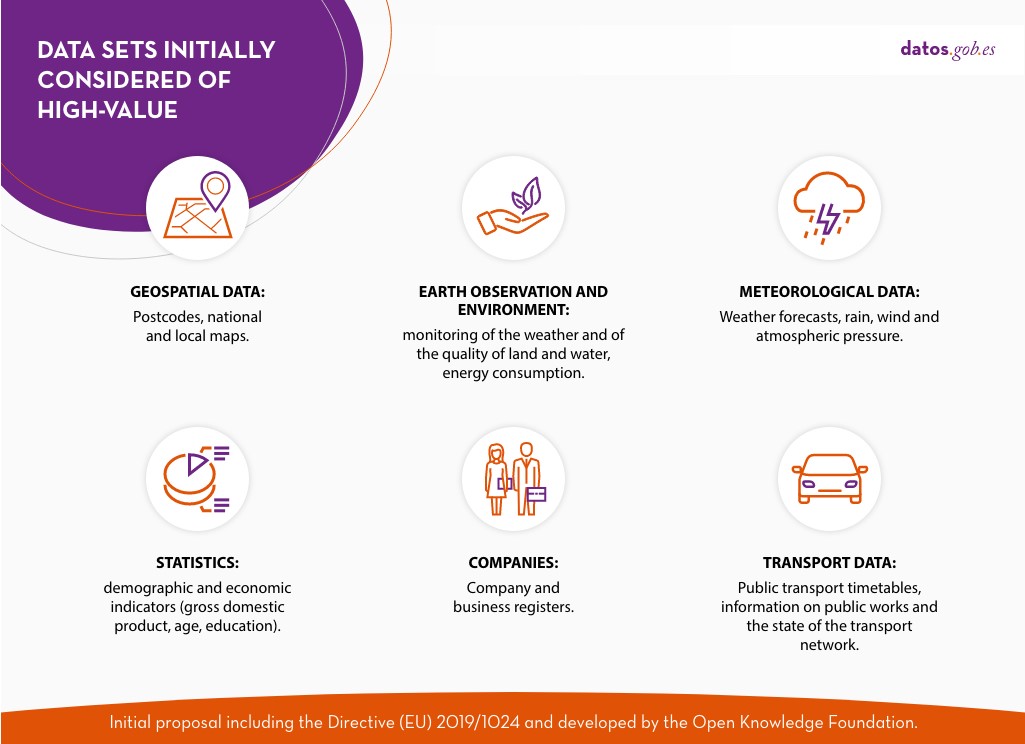
The regulation is thus created under the umbrella of the European Open Data Directive, which defines six categories to differentiate the new high-value datasets requested:
- Geospatial
- Earth observation and environmental
- Meteorological
- Statistical
- Business
- Mobility
However, as stated in the European Commission's press release, this thematic range could be extended at a later stage depending on technological and market developments. Thus, the datasets will be available in machine-readable format, via an application programming interface (API) and, if relevant, also with a bulk download option.
In addition, the reuse of datasets such as mobility or building geolocation data can expand the business opportunities available for sectors such as logistics or transport. In parallel, weather observation, radar, air quality or soil pollution data can also support research and digital innovation, as well as policy making in the fight against climate change.
Ultimately, greater availability of data, especially high-value data, has the potential to boost entrepreneurship as these datasets can be an important resource for SMEs to develop new digital products and services, which in turn can also attract new investors.
Find out more in this infographic:


Access the accessible version on two pages.
Blog
Since the publication of Directive (EU) 2019/1024 on open data and re-use of public sector information, the European Commission is undertaking a number of actions to develop the concept of high-value data that this directive introduced as an important novelty in June 2019.
We recall that high-value datasets are defined in this directive as "documents whose re-use is associated with considerable benefits for society, the environment and the economy, in particular because of their suitability for the creation of value-added services, applications and new, decent and quality jobs". The Directive further proposes a first list of six thematic categories of high-value datasets: geospatial, earth observation and environment, meteorology, statistics, corporate and company ownership, and mobility.
In the last three years, numerous initiatives have been launched with the aim of deepening the liberation of this type of datasets and moving towards realising the economic and social benefits derived from their re-use. Studies have been launched such as the “Impact Assessment study on the list of High Value Datasets” by the Commission's DG CONNECT, which presents different options identified for policy-level interventions linked to high-value datasets in the six thematic areas. Or the report “High-value datasets: understanding the perspective of data providers” published by the official European data portal, which aims to understand the perspective of data providers and contains interesting conclusions such as that the perspective is not sufficient to understand where the "high value" actually lies.
A public consultation has also been launched in 2022 to gather public opinion on its draft High-Value Data Act. This draft act already contains a list of specific high-value datasets and provisions for their publication and re-use, which will represent a very significant advance on the objectives of the directive itself. At the end of June, the draft act was also presented to the Committee on Open Data and Re-use of Public Sector Information composed of representatives from EU countries and further progress is expected in September 2022.
For their part, Member States are also carrying out their own work in parallel, as in the case of Spain, which has already started by dedicating the 2019 Aporta Meeting to the promotion of high-value data.
However, the EU's focus on high-value data as a driver of the economy is not unique in the world and there are other initiatives with different degrees of progress and impact that have similar objectives.
Datasets of national interest in Australia
In the case of Australia, a pioneer in this regard, the first National Action Plan of the Australian Open Government Partnership 2016-2018 already contained among its objectives the implementation of actions to develop and publish a framework for high-value datasets and to design how best to facilitate the sharing and use of these datasets through the legislative consultation process.
The Productivity Commission in 2018 recommended recognising a new type of data asset, national interest datasets, defined as datasets that would generate significant benefits for society and would be a special subset of high-value data. At the time, the Australian government committed to appoint a National Data Commissioner, to implement, oversee and regulate a simpler and more efficient data sharing and publishing framework.
However, in 2019 the end-of-term self-assessment report for Australia's first national open government action plan 2016-18 already acknowledged the delay in the initiative. Work was resumed by the National Data Commissioner, who building on previous work continues to conceptualise a framework for identifying high-value data, although no documentation has been released to the general public at this stage.
Aligning open data in Canada
The Canadian Open Government Working Group (COGWG) already started in its 2016-2018 action plan to work on its commitment to align datasets across the country and specifically on the development of a list of priority high-value datasets for collaborative publication across jurisdictions. The plan recognised that publishing common types of data across Canadian jurisdictions would help foster innovation and provide significant socio-economic impact.
In 2018, Canada's Open Government Working Group released an initial list of 17 high-value datasets to be prioritised for publication by federal, provincial, territorial and municipal governments across Canada. This list is part of a report providing common criteria to help identify high-value datasets and is based on work done to unify criteria across levels of government, stakeholder surveys and international standards.
The National Open Government Action Plan 2018-2020 includes a commitment to carry out a pilot project to standardise across jurisdictions five high-value datasets from the list previously identified in the previous plan.
Although the results have not been openly published, the plan's evaluation system acknowledges the delay in meeting this objective as preliminary standards could only be completed for 4 of the 5 high-value datasets. These standards are available through an intranet system to all Canadian public servants (federal, provincial, territorial and municipal), academics and students, as well as to all Canadians by invitation. However, none of the work has been made public nor is it known what datasets they are working on.
India begins work on identifying datasets
More recently, in 2022, the Indian government has published a background note on data accessibility and usage policy in India announcing the development of new policies to improve data access, quality and usage, in line with the technological needs of the next decade.
As with other initiatives in other regions of the world, it recognises the lack of common criteria for consistently identifying and maintaining high-value datasets. It therefore envisages developing a data policy framework that makes data from multiple sources (public and private) accessible through G2G, G2B, B2G and B2B channels.
The objective is also similar to other initiatives, on the one hand, to make public services more efficient, and to enable a new generation of start-ups to drive digital innovation and growth in the Indian economy.
The approaches being followed in different regions of the world to identify and release high-value datasets are very similar and include public consultations, the formation of expert committees, pilot projects and the definition of assessment frameworks. However, we see that development is much slower than expected and that some initiatives, such as those started in Canada or Australia before the EU itself, have not yet been finalised and therefore their impact is not yet known.
For the time being, it seems that the work initiated by the EU is more advanced and, more importantly, more transparent, as the results are being published openly. Let us hope that the initiative does not lose momentum as seems to have happened in Australia or Canada and that we will soon be able to enjoy high-value datasets available for re-use and discuss the impact they have had on society and the European economy.
Content written by Jose Luis Marín, Senior Consultant in Data, Strategy, Innovation & Digitalization.
The contents and views reflected in this publication are the sole responsibility of the author.
Noticia
The European Union wants to bring digital technology closer to businesses, citizens and public administrations. To this end, it launched the Digital Europe Programme, which aims to close the gap between research in digital technology and its implementation in all sectors of the economy and society. With a 6-year extension (2021-2027), the programme covers areas such as supercomputing, artificial intelligence, cybersecurity and advanced digital skills.
Given that open data has a key potential in the development of many of these disruptive technologies, it is not surprising that within the programme we also find specific grants aimed at their development. This is the case of the "Public Sector Open Data for AI and Open Data Platform" grants, included in the programme's Cloud Data and TEF call (DIGITAL-2022-CLOUD-AI-02).
The objective of these grants is to boost the availability, quality and usability of high-value public sector data, in compliance with the requirements of the Open Data Directive and the re-use of public sector information. This, in turn, is intended to boost the re-use and combination of open public data across the EU for the development of information products and services, with a special focus on Artificial Intelligence.

The importance of high-value data
According to Directive (EU) 2019/1024, high-value data is a set of datasets with a high potential to generate "benefits for society, the environment and the economy, in particular because of their suitability for the creation of value-added services, applications and new, decent and quality jobs".
Initially, the Directive listed 6 categories of data to be considered of high value: geospatial, earth observation and environmental, meteorological, statistical, company and mobility data. However, these categories will be modified in the future to respond to technological and market changes. In Spain, the role of adding new categories of high-value data falls to the Data Office with the collaboration of public and private stakeholders, as specified in Royal Decree-Law 24/2021, of 2 November, transposing several European Union directives, including Directive 2019/1024.
What is being sought?
The grants aim to support public administrations at local, regional and national level to increase semantic, technical and legal interoperability and portability of high-value data.
The datasets generated as a result of the work must meet the following conditions:
- They must be freely available through one or more open data portals of the Member States.
- They must belong to one of the 6 thematic categories indicated in Directive (EU) 2019/1024.
- Both new datasets and datasets resulting from the merging of existing, harmonised, quality-enhanced, etc. datasets are valid.
- They must be available through application programming interfaces (APIs), in a machine-readable format.
- Their publication and re-use conditions must be compatible with an open standard licence.
- They must have quality standards (attribute lists, formats, structures, semantics, documentation and terms of use) that ensure cross-border interoperability.
The proposal should propose concrete Key Performance Indicators (KPIs) to assess the benefits of the implemented solutions for citizens and/or businesses.
What does the aid cover?
The aid covers 50% of the actual costs in a number of "eligible" categories, including staff costs, communication costs, purchasing costs, etc.
To whom is the proposal addressed?
The grants are targeted at public administrations to which the obligations of Directive 2019/1024 apply. Public and private data re-users may be involved in the choice of the datasets to be prioritised.
Only legal entities, not natural persons, from EU Member States associated to the European Economic Area or the Digital Europe Programme can participate.
How to participate?
Proposals must be submitted electronically through the European Commission's Funding and Tendering Portal, using a number of forms provided in the system:
- Application Form Part A. Contains administrative information and the summary budget for the project.
- Application form Part B. Contains the technical description of the project (Max. 70 pages).
- Mandatory annexes and supporting documents
The deadline for applications is 17 May 2022.