Noticia
The Canary Islands Statistics Institute (ISTAC) has added more than 500 semantic assets and more than 2100 statistical cubes to its catalogue.
This vast amount of information represents decades of work by the ISTAC in standardisation and adaptation to leading international standards, enabling better sharing of data and metadata between national and international information producers and consumers.
The increase in datasets not only quantitatively improves the directory at datos.canarias.es and datos.gob.es, but also broadens the uses it offers due to the type of information added.
New semantic assets
Semantic resources, unlike statistical resources, do not present measurable numerical data , such as unemployment data or GDP, but provide homogeneity and reproducibility.
These assets represent a step forward in interoperability, as provided for both at national level with the National Interoperability Scheme ( Article 10, semantic assets) and at European level with the European Interoperability Framework (Article 3.4, semantic interoperability). Both documents outline the need and value of using common resources for information exchange, a maxim that is being pursued at implementing in a transversal way in the Canary Islands Government. These semantic assets are already being used in the forms of the electronic headquarters and it is expected that in the future they will be the semantic assets used by the entire Canary Islands Government.
Specifically in this data load there are 4 types of semantic assets:
- Classifications (408 loaded): Lists of codes that are used to represent the concepts associated with variables or categories that are part of standardised datasets, such as the National Classification of Economic Activities (CNAE), country classifications such as M49, or gender and age classifications.
- Concept outlines (115 uploaded): Concepts are the definitions of the variables into which the data are disaggregated and which are finally represented by one or more classifications. They can be cross-sectional such as "Age", "Place of birth" and "Business activity" or specific to each statistical operation such as "Type of household chores" or "Consumer confidence index".
- Topic outlines (2 uploaded): They incorporate lists of topics that may correspond to the thematic classification of statistical operations or to the INSPIRE topic register.
- Schemes of organisations (6 uploaded): This includes outlines of entities such as organisational units, universities, maintaining agencies or data providers.
All these types of resources are part of the international SDMX (Statistical Data and Metadata Exchange) standard, which is used for the exchange of statistical data and metadata. The SDMX provides a common format and structure to facilitate interoperability between different organisations producing, publishing and using statistical data.

The Canary Islands Statistics Institute (ISTAC) has added more than 500 semantic assets and more than 2100 statistical cubes to its catalogue.
This vast amount of information represents decades of work by the ISTAC in standardisation and adaptation to leading international standards, enabling better sharing of data and metadata between national and international information producers and consumers.
The increase in datasets not only quantitatively improves the directory at datos.canarias.es and datos.gob.es, but also broadens the uses it offers due to the type of information added.
New semantic assets
Semantic resources, unlike statistical resources, do not present measurable numerical data , such as unemployment data or GDP, but provide homogeneity and reproducibility.
These assets represent a step forward in interoperability, as provided for both at national level with the National Interoperability Scheme ( Article 10, semantic assets) and at European level with the European Interoperability Framework (Article 3.4, semantic interoperability). Both documents outline the need and value of using common resources for information exchange, a maxim that is being pursued at implementing in a transversal way in the Canary Islands Government. These semantic assets are already being used in the forms of the electronic headquarters and it is expected that in the future they will be the semantic assets used by the entire Canary Islands Government.
Specifically in this data load there are 4 types of semantic assets:
- Classifications (408 loaded): Lists of codes that are used to represent the concepts associated with variables or categories that are part of standardised datasets, such as the National Classification of Economic Activities (CNAE), country classifications such as M49, or gender and age classifications.
- Concept outlines (115 uploaded): Concepts are the definitions of the variables into which the data are disaggregated and which are finally represented by one or more classifications. They can be cross-sectional such as "Age", "Place of birth" and "Business activity" or specific to each statistical operation such as "Type of household chores" or "Consumer confidence index".
- Topic outlines (2 uploaded): They incorporate lists of topics that may correspond to the thematic classification of statistical operations or to the INSPIRE topic register.
- Schemes of organisations (6 uploaded): This includes outlines of entities such as organisational units, universities, maintaining agencies or data providers.
All these types of resources are part of the international SDMX (Statistical Data and Metadata Exchange) standard, which is used for the exchange of statistical data and metadata. The SDMX provides a common format and structure to facilitate interoperability between different organisations producing, publishing and using statistical data.
Blog
The UNESCO (United Nations Educational, Scientific and Cultural Organization) is a United Nations agency whose purpose is to contribute to peace and security in the world through education, science, culture and communication. In order to achieve its objective, this organisation usually establishes guidelines and recommendations such as the one published on 5 July 2023 entitled 'Open data for AI: what now?'
In the aftermath of the COVID-19 pandemic the UNESCO highlights a number of lessons learned:
- Policy frameworks and data governance models must be developed, supported by sufficient infrastructure, human resources and institutional capacities to address open data challenges, in order to be better prepared for pandemics and other global challenges.
- The relationship between open data and AI needs to be further specified, including what characteristics of open data are necessary to make it "AI-Ready".
- A data management, collaboration and sharing policy should be established for research, as well as for government institutions that hold or process health-related data, while ensuring data privacy through anonymisation and anonymisation data privacy should be ensured through anonymisation and anonymisation.
- Government officials who handle data that are or may become relevant to pandemics may need training to recognise the importance of such data, as well as the imperative to share them.
- As much high quality data as possible should be collected and collated. The data needs to come from a variety of credible sources, which, however, must also be ethical, i.e. it must not include data sets with biases and harmful content, and it must be collected only with consent and not in a privacy-invasive manner. In addition, pandemics are often rapidly evolving processes, so continuous updating of data is essential.
- These data characteristics are especially mandatory for improving inadequate AI diagnostic and predictive tools in the future. Efforts are needed to convert the relevant data into a machine-readable format, which implies the preservation of the collected data, i.e. cleaning and labelling.
- A wide range of pandemic-related data should be opened up, adhering to the FAIR principles.
- The target audience for pandemic-related open data includes research and academia, decision-makers in governments, the private sector for the development of relevant products, but also the public, all of whom should be informed about the available data.
- Pandemic-related open data initiatives should be institutionalised rather than ad hoc, and should therefore be put in place for future pandemic preparedness. These initiatives should also be inclusive and bring together different types of data producers and users.
- The beneficial use of pandemic-related data for AI machine learning techniques should also be regulated to prevent misuse for the development of artificial pandemics, i.e. biological weapons, with the help of AI systems.
The UNESCO builds on these lessons learned to establish Recommendations on Open Science by facilitating data sharing, improving reproducibility and transparency, promoting data interoperability and standards, supporting data preservation and long-term access.
As we increasingly recognise the role of Artificial Intelligence (AI), the availability and accessibility of data is more crucial than ever, which is why UNESCO is conducting research in the field of AI to provide knowledge and practical solutions to foster digital transformation and build inclusive knowledge societies.
Open data is the main focus of these recommendations, as it is seen as a prerequisite for planning, decision-making and informed interventions. The report therefore argues that Member States must share data and information, ensuring transparency and accountability, as well as opportunities for anyone to make use of the data.
UNESCO provides a guide that aims to raise awareness of the value of open data and specifies concrete steps that Member States can take to open their data. These are practical, but high-level steps on how to open data, based on existing guidelines. Three phases are distinguished: preparation, data opening and follow-up for re-use and sustainability, and four steps are presented for each phase.
It is important to note that several of the steps can be carried out simultaneously, i.e. not necessarily consecutively.

Step 1: Preparation
- Develop a data management and sharing policy: A data management and sharing policy is an important prerequisite for opening up data, as such a policy defines the governments' commitment to share data. The Open Data Institute suggests the following elements of an open data policy:
- A definition of open data, a general statement of principles, an outline of the types of data and references to any relevant legislation, policy or other guidance.
- Governments are encouraged to adhere to the principle "as open as possible, as closed as necessary". If data cannot be opened for legal, privacy or other reasons, e.g. personal or sensitive data, this should be clearly explained.
In addition, governments should also encourage researchers and the private sector in their countries to develop data management and sharing policies that adhere to the same principles.
- Collect and collate high quality data: Existing data should be collected and stored in the same repository, e.g. from various government departments where it may have been stored in silos. Data must be accurate and not out of date. Furthermore, data should be comprehensive and should not, for example, neglect minorities or the informal economy. Data on individuals should be disaggregated where relevant, including by income, sex, age, race, ethnicity, migration status, disability and geographic location.
- Develop open data capabilities: These capacities address two groups:
- For civil servants, it includes understanding the benefits of open data by empowering and enabling the work that comes with open data.
- For potential users, it includes demonstrating the opportunities of open data, such as its re-use, and how to make informed decisions.
- Prepare data for AI: If data is not only to be used by humans, but can also feed AI systems, it must meet a few more criteria to be AI-ready.
- The first step in this regard is to prepare the data in a machine-readable format.
- Some formats are more conducive to readability by artificial intelligence systems than others.
- Data must also be cleaned and labelled, which is often time-consuming and therefore costly.
The success of an AI system depends on the quality of the training data, including its consistency and relevance. The required amount of training data is difficult to know in advance and must be controlled by performance checks. The data should cover all scenarios for which the AI system has been created.
Step 2: Open the data
- Select the datasets to be opened: The first step in opening the data is to decide which datasets are to be opened. The criteria in favour of openness are:
- If there have been previous requests to open these data
- Whether other governments have opened up this data and whether this has led to beneficial uses of the data.
Openness of data must not violate national laws, such as data privacy laws.
- Open the datasets legally: Before opening the datasets, the relevant government has to specify exactly under which conditions, if any, the data can be used. In publishing the data, governments may choose the license that best suits their objectives, such as the creative Commons and Open. To support the licence selection the European Commission makes available JLA - Compatibility Checkera tool that supports this decision
- Open the datasets technically: The most common way to open the data is to publish it in electronic format for download on a website, and APIs must be in place for the consumption of this data, either by the government itself or by a third party.
Data should be presented in a format that allows for localisation, accessibility, interoperability and re-use, thus complying with the FAIR principles.
In addition, the data could also be published in a data archive or repository, which should be, according to the UNESCO Recommendation, supported and maintained by a well-established academic institution, learned society, government agency or other non-profit organisation dedicated to the common good that allows for open access, unrestricted distribution, interoperability and long-term digital archiving and preservation.
- Create a culture driven by open data: Experience has shown that, in addition to legal and technical openness of data, at least two other things need to be achieved to achieve an open data culture:
- Government departments are often not used to sharing data and it has been necessary to create a mindset and educate them to this end.
- Furthermore, data should, if possible, become the exclusive basis for decision-making; in other words, decisions should be based on data.
- In addition, cultural changes are required on the part of all staff involved, encouraging proactive disclosure of data, which can ensure that data is available even before it is requested.
Step 3: Monitoring of re-use and sustainability
- Support citizen participation: Once the data is open, it must be discoverable by potential users. This requires the development of an advocacy strategy, which may include announcing the openness of the data in open data communities and relevant social media channels.
Another important activity is early consultation and engagement with potential users, who, in addition to being informed about open data, should be encouraged to use and re-use it and to stay involved.
- Supporting international engagement: International partnerships would further enhance the benefits of open data, for example through south-south and north-south collaboration. Particularly important are partnerships that support and build capacity for data reuse, whether using AI or not.
- Support beneficial AI participation: Open data offers many opportunities for AI systems. To realise the full potential of data, developers need to be empowered to make use of it and develop AI systems accordingly. At the same time, the abuse of open data for irresponsible and harmful AI applications must be avoided. A best practice is to keep a public record of what data AI systems have used and how they have used it.
- Maintain high quality data: A lot of data quickly becomes obsolete. Therefore, datasets need to be updated on a regular basis. The step "Maintain high quality data" turns this guideline into a loop, as it links to the step "Collect and collate high quality data".
Conclusions
These guidelines serve as a call to action by UNESCO on the ethics of artificial intelligence. Open data is a necessary prerequisite for monitoring and achieving sustainable development monitoring and achieving sustainable development.
Due to the magnitude of the tasks, governments must not only embrace open data, but also create favourable conditions for beneficial AI engagement that creates new insights from open data for evidence-based decision-making.
If UNESCO Member States follow these guidelines and open their data in a sustainable way, build capacity, as well as a culture driven by open data, we can achieve a world where data is not only more ethical, but where applications on this data are more accurate and beneficial to humanity.
References
https://www.unesco.org/en/articles/open-data-ai-what-now
Author : Ziesche, Soenke , ISBN : 978-92-3-100600-5
Content prepared by Mayte Toscano, Senior Consultant in Data Economy Technologies. The contents and points of view reflected in this publication are the sole responsibility of its author.
Evento
Sign up for SEMIC 2023 and discover the interoperable Europe in the era of artificial intelligence. According to the forecasts of the European Commission, by 2025, the global volume of data will have increased by 530%, and in this context, it is crucial to ensure data interoperability and reuse. Thus, the European Union is working on creating a digital model that promotes data sharing while ensuring people's privacy and data interoperability.
The European Data Strategy includes the launch of common and interoperable data spaces in strategic sectors. In this context, various initiatives have emerged to discuss the processes, standards, and tools suitable for data management and exchange, which also serve to promote a culture of information and reuse. One of these initiatives is SEMIC, the most important interoperability conference in Europe, whose 2023 edition will take place on October 18th in Madrid, organized by the European Commission in collaboration with the Spanish Presidency of the Council of the European Union.
SEMIC 2023, which can also be attended virtually, focuses on 'Interoperable Europe in the AI era.' The sessions will address data spaces, digital governance, data quality assurance, generative artificial intelligence, and code as law, among other aspects. Information about the proposal for an Interoperable Europe Law will also be presented.
Pre-Workshops
Attendees will have the opportunity to learn about specific use cases where public sector interoperability and artificial intelligence have mutually benefited. Although SEMIC 2023 will take place on October 18th, the day before, three interesting workshops will also be held, which can be attended both in-person and virtually:
- Artificial Intelligence in Policy Design for the Digital Age and in Legal Text Writing: This workshop will explore how AI-driven tools can assist policymakers in public policy formulation. Different tools, such as the Policy Analysis Prototype (SeTA) or intelligent functionalities for legal drafting (LEOS), will be discussed.
- Large Language Models in Support of Interoperability: This session will explore the methods and approaches proposed for using large language models and AI technology in the context of semantic interoperability. It will focus on the state of LLM and its application to semantic clustering, data discovery, and terminology expansion, among other applications supporting semantic interoperability.
- European Register of Public Sector Semantic Models: This workshop will define actions to create an entry point for connecting national collections of semantic assets.
Interactions Between Artificial Intelligence, Interoperability, and Semantics
The main SEMIC 2023 conference program includes roundtable discussions and various working sessions that will run in parallel. The first session will address Estonia's experience as one of the first European countries to implement AI in the public sector and its pioneering role in interoperability.
In the morning, an interesting roundtable will be held on the potential of artificial intelligence to support interoperability. Speakers from different EU Member States will present success stories and challenges related to deploying AI in the public sector.
In the second half of the morning, three parallel sessions will take place:
- Crafting Policies for the Digital Age and Code as Law: This session will identify the main challenges and opportunities in the field of AI and interoperability, focusing on 'code as law' as a paradigm. Special attention will be given to semantic annotation in legislation.
- Interconnecting Data Spaces: This session will address the main challenges and opportunities in the development of data spaces, with a special focus on interoperability solutions. It will also discuss synergies between the Data Spaces Support Center (DSSC) and the European Commission's DIGIT specifications and tools.
- Automated Public Services: This session will provide an approach to automating access to public services with the help of AI and chatbots.
In the afternoon, three more parallel sessions will be held:
- Knowledge Graphs, Semantics, and AI: This session will demonstrate how traditional semantics benefit from AI.
- Data Quality in Generative and General-Purpose AI: This session will review the main data quality issues in the EU and discuss strategies to overcome them.
- Trustworthy AI for Public Sector Interoperability: This session will discuss the opportunities for using AI for interoperability in the public sector and the transparency and reliability challenges of AI systems.
In the afternoon, there will also be a roundtable discussion on the upcoming challenges, addressing the technological, social, and political implications of advances in AI and interoperability from the perspective of policy actions. Following this panel, the closing sessions will take place.
The previous edition, held in Brussels, brought together over 1,000 professionals from 60 countries, both in-person and virtually. Therefore, SEMIC 2023 presents an excellent opportunity to learn about the latest trends in interoperability in the era of artificial intelligence.
You can register here: https://semic2023.eu/registration/
Noticia
On September 11th, a webinar was held to review Gaia-X, from its foundations, embodied by its architecture and trust model called Trust Framework, to the Federation Services that aim to facilitate and speed up access to the infrastructure, to the catalogue of services that some users (providers) will be able to make available to others (consumers).
The webinar, led by the manager of the Spanish Gaia-X Hub, was led by two experts from the Data Office, who guided the audience through their presentations towards a better understanding of the Gaia-X initiative. At the end of the session, there was a dynamic question and answer session to go into more detail. A recording of this seminar can be accessed from the Hub's official website,[Forging the Future of Federated Data Spaces in Europe | Gaia-X (gaiax.es)]
Gaia-X as a key building block for forging European Data Spaces
Gaia-X emerges as an innovative paradigm to facilitate the integration of IT resources. Based on Web 3.0 technology models, the identification and traceability of different data resources is enabled, from data sets, algorithms, different semantic or other conceptual models, to even underlying technology infrastructure (cloud resources). This serves to make the origin and functioning of these entities visible, thus facilitating transparency and compliance with European regulations and values.
More specifically, Gaia-X provides different services in charge of automatically verifying compliance with minimum interoperability rules, which then allows defining more abstract rules with a business focus, or even as a basis for defining and instantiating the Trusted Cloud and sovereign data spaces. These services will be operationalised through different Gaia-X interoperability nodes, or Gaia-X Digital Clearing Houses.
Using Gaia-X as a tool, we will be able to publish, discover and exploit a catalogue of services that will cover different services according to the user's requirements. For instance, in the case of cloud infrastructure, these offerings may include features such as residence in European territory or compliance with EU regulations (such as eIDAS or GDPR, or data intermediation rules outlined in the Data Governance Regulation). It will also enable the creation of combinable services by aggregating components from different providers (which is complex now). Moreover, specific datasets will be available for training Artificial Intelligence models, and the owner of these datasets will maintain control thanks to enabled traceability, up to the execution of algorithms and apps on the consumer's own data, always ensuring privacy preservation.
As we can see, this novel traceability capability, based on cutting-edge technologies, serves as a driver for compliance, and is therefore a fundamental building block in the deployment of interoperable data spaces at European level and the digital single market.
Blog
The INSPIRE (Infrastructure for Spatial Information in Europe) Directive sets out the general rules for the establishment of an Infrastructure for Spatial Information in the European Community based on the Infrastructures of the Member States. Adopted by the European Parliament and the Council on 14 March 2007 (Directive 2007/2/EC), it entered into force on 25 April 2007.
INSPIRE makes it easier to find, share and use spatial data from different countries. The information is available through an online portal where it can be found broken down into different formats and topics of interest.
To ensure that these data are compatible and interoperable in a Community and cross-border context, the Directive requires the adoption of common Implementing Rules specific to the following areas:
- Metadata
- Data sets
- Network services
- Data sharing and services
- Spatial data services
- Monitoring and reporting
The technical implementation of these standards is done through Technical Guidelines, technical documents based on international standards and norms.
Inspire and semantic interoperability
These rules are considered Commission decisions or regulations and are therefore binding in each EU country. The transposition of this Directive into Spanish law is developed through Law 14/2010 of 5 July, which refers to the infrastructures and geographic information services of Spain (LISIGE) and the IDEE portal, both of which are the result of the implementation of the INSPIRE Directive in Spain.
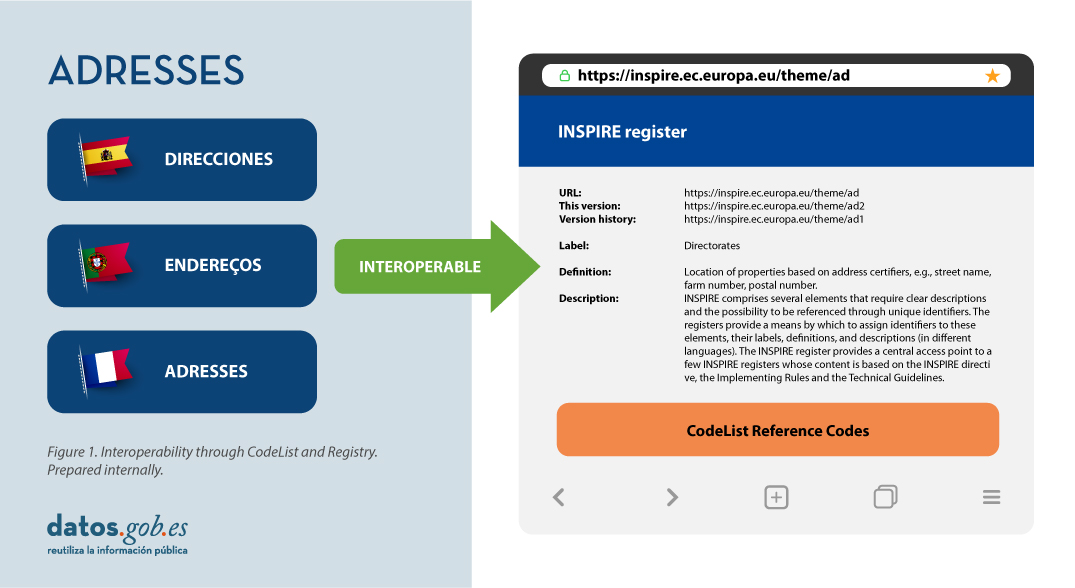
Semantic interoperability plays a decisive role in INSPIRE. Thanks to this, there is a common language in spatial data, as the integration of knowledge is only possible when a homogenisation or common understanding of the concepts that constitute a domain or area of knowledge is achieved. Thus, in INSPIRE, semantic interoperability is responsible for ensuring that the content of the information exchanged is understood in the same way by any system.
Therefore, in the implementation of spatial data models in INSPIRE, in GML exchange format, we can find codelists that are an important part of the INSPIRE data specifications and contribute substantially to interoperability.
In general, a codelist (or code list) contains several terms whose definitions are universally accepted and understood. Code lists promote data interoperability and constitute a shared vocabulary for a community. They can even be multilingual.
INSPIRE code lists are commonly managed and maintained in the central Federated INSPIRE Registry (ROR) which provides search capabilities, so that both end-users and client applications can easily access code list values for reference.
Registers are necessary because:
- They provide the codes defined in the Technical Guidelines, Regulations and Technical Specifications necessary to implement the Directive.
- They allow unambiguous references of the elements.
- Provides unique and persistent identifiers for resources.
- Enable consistent management and version control of different elements
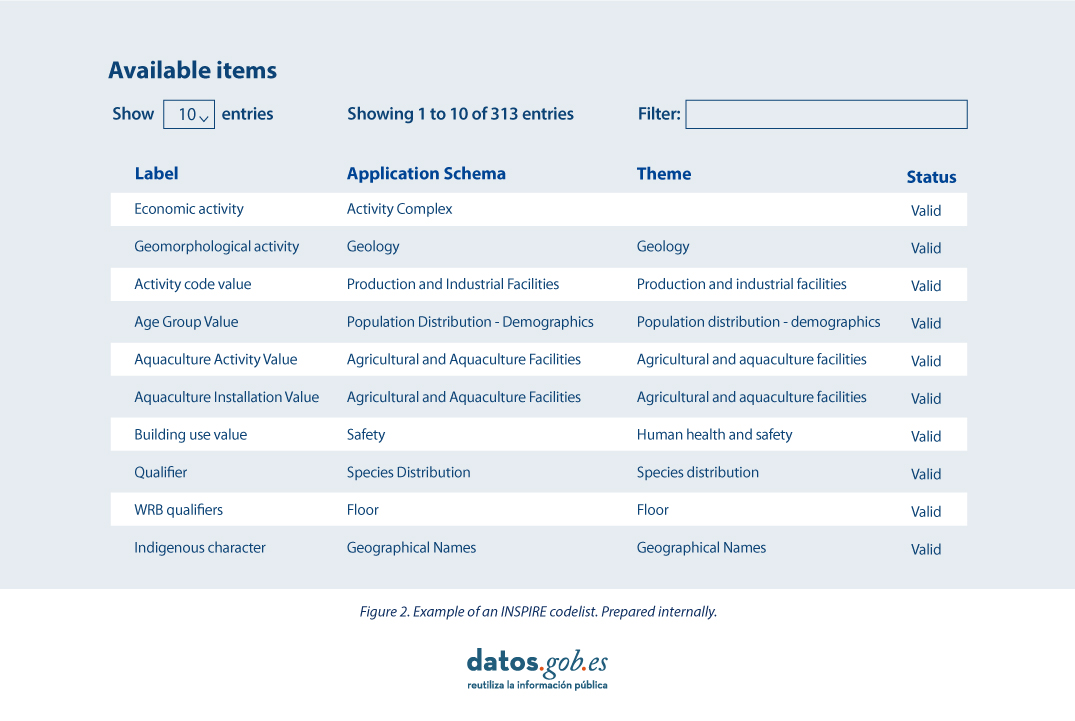
The code lists used in INSPIRE are maintained at:
- The Inspire Central Federated Registry (ROR).
- The register of code lists of a member state,
- The list registry of a recognised external third party that maintains a domain-specific code list.
To add a new code list, you will need to set up your own registry or work with the administration of one of the existing registries to publish your code list. This can be quite a complicated process, but a new tool helps us in this task.
Re3gistry is a reusable open-source solution, released under EUPL, that allows companies and organisations to manage and share \"reference codes\" through persistent URIs, ensuring that concepts are unambiguously referenced in any domain and facilitating the management of these resources graphically throughout their lifecycle.
Funded by ELISE, ISA2 is a solution recognised by the Europeans in the Interoperability Framework as a supporting tool.
Illustration 3: Image of the Re3gister interface
Re3gistry is available for both Windows and Linux and offers an easy-to-use Web Interface for adding, editing, and managing records and reference codes. In addition, it allows the management of the complete lifecycle of reference codes (based on ISO 19135: 2005 Integrated procedures for the registration of reference codes)
The editing interface also provides a flag to allow the system to expose the reference code in the format that allows its integration with RoR, so that it can eventually be imported into the INSPIRE registry federation. For this integration, Reg3gistry makes an export in a format based on the following specifications:
- The W3C Data Catalogue (DCAT) vocabulary used to model the entity registry (dcat:Catalog).
- The W3C Simple Knowledge Organisation System (SKOS) which is used to model the entity registry (skos:ConceptScheme) and the element (skos:Concept).
Other notable features of Re3gistry
- Highly flexible and customisable data models
- Multi-language content support
- Support for version control
- RESTful API with content negotiation (including OpenAPI 3 descriptor)
- Free-text search
- Supported formats: HTML, ISO 19135 XML, JSON
- Service formats can be easily added or customised (default formats): JSON and ISO 19135 XML
- Multiple authentication options
- Externally governed elements referenced through URIs
- INSPIRE record federation format support (option to automatically create RoR format)
- Easy data export and re-indexing (SOLR)
- Guides for users, administrators, and developers
- RSS feed
Ultimately, Re3gistry provides a central access point where reference code labels and descriptions are easily accessible to both humans and machines, while fostering semantic interoperability between organisations by enabling:
- Avoid common mistakes such as misspellings, entering synonyms or filling in online forms.
- Facilitate the internationalisation of user interfaces by providing multilingual labels.
- Ensure semantic interoperability in the exchange of data between systems and applications.
- Tracking changes over time through a well-documented version control system.
- Increase the value of reference codes if they are widely reused and referenced.
More about Re3gistry:




References
https://github.com/ec-jrc/re3gistry
https://inspire.ec.europa.eu/codelist
https://ec.europa.eu/isa2/solutions/re3gistry_en/
https://live.osgeo.org/en/quickstart/re3gistry_quickstart.html
Content prepared by Mayte Toscano, Senior Consultant in Technologies linked to the data economy.
The contents and views expressed in this publication are the sole responsibility of the author.
Blog
As more of our daily lives take place online, and as the importance and value of personal data increases in our society, standards protecting the universal and fundamental right to privacy, security and privacy - backed by frameworks such as the Universal Declaration of Human Rights or the European Declaration on Digital Rights - become increasingly important.
Today, we are also facing a number of new challenges in relation to our privacy and personal data. According to the latest Lloyd's Register Foundation report, at least three out of four internet users are concerned that their personal information could be stolen or otherwise used without their permission. It is therefore becoming increasingly urgent to ensure that people are in a position to know and control their personal data at all times.
Today, the balance is clearly tilted towards the large platforms that have the resources to collect, trade and make decisions based on our personal data - while individuals can only aspire to gain some control over what happens to their data, usually with a great deal of effort.
This is why initiatives such as MyData Global, a non-profit organisation that has been promoting a human-centred approach to personal data management for several years now and advocating for securing the right of individuals to actively participate in the data economy, are emerging. The aim is to redress the balance and move towards a people-centred view of data to build a more just, sustainable and prosperous digital society, the pillars of which would be:
- Establish relationships of trust and security between individuals and organisations.
- Achieve data empowerment, not only through legal protection, but also through measures to share and distribute the power of data.
- Maximising the collective benefits of personal data, sharing it equitably between organisations, individuals and society.
And in order to bring about the changes necessary to bring about this new, more humane approach to personal data, the following principles have been developed:
1 - People-centred control of data.
It is individuals who must have the power of decision in the management of everything that concerns their personal lives. They must have the practical means to understand and effectively control who has access to their data and how it is used and shared.
Privacy, security and minimal use of data should be standard practice in the design of applications, and the conditions of use of personal data should be fairly negotiated between individuals and organisations.
2 - People as the focal point of integration
The value of personal data grows exponentially with its diversity, while the potential threat to privacy grows at the same time. This apparent contradiction could be resolved if we place people at the centre of any data exchange, always focusing on their own needs above all other motivations.
Any use of personal data must revolve around the individual through deep personalisation of tools and services.
3 - Individual autonomy
In a data-driven society, individuals should not be seen solely as customers or users of services and applications. They should be seen as free and autonomous agents, able to set and pursue their own goals.
Individuals should be able to securely manage their personal data in the way they choose, with the necessary tools, skills and support.
4 - Portability, access and re-use
Enabling individuals to obtain and reuse their personal data for their own purposes and in different services is the key to moving from silos of isolated data to data as reusable resources.
Data portability should not merely be a legal right, but should be combined with practical means for individuals to effectively move data to other services or on their personal devices in a secure and simple way.
5 - Transparency and accountability
Organisations using an individual's data must be transparent about how they use it and for what purpose. At the same time, they must be accountable for their handling of that data, including any security incidents.
User-friendly and secure channels must be created so that individuals can know and control what happens to their data at all times, and thus also be able to challenge decisions based solely on algorithms.
6 - Interoperability
There is a need to minimise friction in the flow of data from the originating sources to the services that use it. This requires incorporating the positive effects of open and interoperable ecosystems, including protocols, applications and infrastructure. This will be achieved through the implementation of common norms and practices and technical standards.
The MyData community has been applying these principles for years in its work to spread a more human-centred vision of data management, processing and use, as it is currently doing for example through its role in the Data Spaces Support Centre, a reference project that is set to define the future responsible use and governance of data in the European Union.
And for those who want to delve deeper into people-centric data use, we will soon have a new edition of the MyData Conference, which this year will focus on showcasing case studies where the collection, processing and analysis of personal data primarily serves the needs and experiences of human beings.
Content prepared by Carlos Iglesias, Open data Researcher and consultant, World Wide Web Foundation.
The contents and views expressed in this publication are the sole responsibility of the author.
Evento
On 20 October, Madrid will host a new edition of the Data Management Summit Spain. This event is part of the Data Management Summit (DMS) 2022, which was previously held in Italy (7 July) and Latam (20 September).
The event is aimed at a technical audience: CiOs, CTOs, CDOs, CIOs, CIOs, Business Intelligence Officers and Data Scientists in charge of implementing emerging technologies in order to solve new technological challenges and align with new business opportunities.
Date and time
The conference will take place at the Nebrija University, on 20 October 2022, from 9:30 to 19:30.
The day before, a DMS prologue will take place in the same space, exclusively for representatives of public administrations, from 14:00 to 19:30.
Agenda
The agenda is made up of presentations, round tables and group dynamics between professionals, which will allow networking.
The prologue on the 19th will focus on open data and the exchange of information between administrations. Carlos Alonso, Director of the Data Office Division, will be one of the speakers. Among the different activities, there are two group dynamics that will focus on open data and interoperability, as well as two round tables, in the first of which the red.es coordinator of the datos.gob.es platform will participate:
- Round table 1: Open Data and data interoperability in public administrations.
- Round table 2: Challenges and barriers to data exchange in the public sector.
Day 20 will have a business-oriented focus. This second day will also feature expert presentations and group dynamics focusing on data governance, data quality, master data and data architecture, among other topics. There will be three round tables:
- Roundtable 1: “Data Architecture, Data Mesh or Data Fabric?” which will discuss the Data Mesh architecture pattern, with a decentralised approach, as opposed to Data Fabric, which promotes a single unified data architecture.
- Roundtable 2: “How Data Governance changes with the new paradigm of open banking” that will address the evolution towards an economy based on full interoperability and APIs, where the traceability of processes is complete.
- Roundtable 3: “How to converge the different data quality models”, focusing on how to measure data quality, how to manage quality processes automatically and how to avoid Data Lake corruption.
You can see more about the event in this video.
¿Cómo puedo asistir?
El aforo de cada sesión está limitado a 60 plazas presenciales y a 100 online.
How can I attend?
The capacity of each session is limited to 60 places in person and 100 online.
Registration for the session on the 20th can be done through this link (currently the capacity is full, but you can join the waiting list). Registration for the 19th is available, but remember that this session is exclusively for Public Administrations.
More information on the summit website.
Blog
Nowadays we can find a great deal of legislative information on the web. Countries, regions and municipalities make their regulatory and legal texts public through various spaces and official bulletins. The use of this information can be of great use in driving improvements in the sector: from facilitating the location of legal information to the development of chatbots capable of resolving citizens' legal queries.
However, locating, accessing and reusing these documents is often complex, due to differences in legal systems, languages and the different technical systems used to store and manage the data.
To address this challenge, the European Union has a standard for identifying and describing legislation called the European Legislation Identifier (ELI).
What is the European Legislation Identifier?
The ELI emerged in 2012 through Council Conclusions (2012/C 325/02) in which the European Union invited Member States to adopt a standard for the identification and description of legal documents. This initiative has been further developed and enriched by new conclusions published in 2017 (2017/C 441/05) and 2019 (2019/C 360/01).
The ELI, which is based on a voluntary agreement between EU countries, aims to facilitate access, sharing and interconnection of legal information published in national, European and global systems. This facilitates their availability as open datasets, fostering their re-use.
Specifically, the ELI allows:
- Identify legislative documents, such as regulations or legal resources, uniquely by means of a unique identifier (URI), understandable by both humans and machines.
- Define the characteristics of each document through automatically processable metadata. To this end, it uses vocabularies defined by means of ontologies agreed and recommended for each field.
Thanks to this, a series of advantages are achieved:
- It provides higher quality and reliability.
- It increases efficiency in information flows, reducing time and saving costs.
- It optimises and speeds up access to legislation from different legal systems by providing information in a uniform manner.
- It improves the interoperability of legal systems, facilitating cooperation between countries.
- Facilitates the re-use of legal data as a basis for new value-added services and products that improve the efficiency of the sector.
- It boosts transparency and accountability of Member States.
Implementation of the ELI in Spain
The ELI is a flexible system that must be adapted to the peculiarities of each territory. In the case of the Spanish legal system, there are various legal and technical aspects that condition its implementation.
One of the main conditioning factors is the plurality of issuers, with regulations at national, regional and local level, each of which has its own means of official publication. In addition, each body publishes documents in the formats it considers appropriate (pdf, html, xml, etc.) and with different metadata. To this must be added linguistic plurality, whereby each bulletin is published in the official languages concerned.
It was therefore agreed that the implementation of the ELI would be carried out in a coordinated manner by all administrations, within the framework of the Sectoral Commission for e-Government (CSAE), in two phases:
- Due to the complexity of local regulations, in the first phase, it was decided to address only the technical specification applicable to the State and the Autonomous Communities, by agreement of the CSAE of 13 March 2018.
- In February 2022, a new version was drafted to include local regulations in its application.
With this new specification, the common guidelines for the implementation of the ELI in the Spanish context are established, but respecting the particularities of each body. In other words, it only includes the minimum elements necessary to guarantee the interoperability of the legal information published at all levels of administration, but each body is still allowed to maintain its own official journals, databases, internal processes, etc.
With regard to the temporal scope, bodies have to apply these specifications in the following way:
- State regulations: apply to those published from 29/12/1978, as well as those published before if they have a consolidated version.
- Autonomous Community legislation: applies to legislation published on or after 29/12/1978.
- Local regulations: each entity may apply its own criteria.
How to implement the ELI?
The website https://www.elidata.es/ offers technical resources for the application of the identifier. It explains the contextual model and provides different templates to facilitate its implementation:
It also offers the list of common minimum metadata, among other resources.
In addition, to facilitate national coordination and the sharing of experiences, information on the implementation carried out by the different administrations can also be found on the website.
The ELI is already applied, for example, in the Official State Gazette (BOE). From its website it is possible to access all the regulations in the BOE identified with ELI, distinguishing between state and autonomous community regulations. If we take as a reference a regulation such as Royal Decree-Law 24/2021, which transposed several European directives (including the one on open data and reuse of public sector information), we can see that it includes an ELI permalink.
In short, we are faced with a very useful common mechanism to facilitate the interoperability of legal information, which can promote its reuse not only at a national level, but also at a European level, favouring the creation of the European Union's area of freedom, security and justice.
Content prepared by the datos.gob.es team.
Blog
In the current context, digitalisation has expanded exponentially, reaching beyond the boundaries of the private sector and consolidating itself as one of the great challenges in all productive sectors of society. This process has brought with it the massive generation of data from which to extract value. However, according to an IDC/EMC study, it is believed that, despite the fact that the volume of data will multiply exponentially in the short term, only 1% of the data generated is used, processed and exploited. One of the reasons for this lies in the inconsistency and inflexibility of data models, which block data integration.
In this regard, the Spanish government's Recovery, Transformation and Resilience Plan, which details Spain's strategy for channelling EU funds to repair the damage caused by the pandemic, emphasises technological reforms and investments focused on building a more sustainable future. One of the main challenges in this area is to boost data sharing, mainly in those sectors with the greatest impact on society, such as health and tourism.
To this end, smart data models play a fundamental role. But what exactly are they?
visión común que proporciona una base técnica para lograr la apertura de la innovación.
What are Smart Data Models?
A traditional data model is a representation of the elements of a dataset and their relationships and connections to each other. Smart Data Models go one step further. They are common and compatible data models, with the objective of supporting a digital marketplace of interoperable and replicable smart solutions across multiple sectors, so that the availability of data in specific domains is homogenised.
These models propose a common vision that provides a technical basis for unlocking innovation.
SDM Initiative
The FIWARE Foundation, TM Forum, IUDX and OASC have joined forces to lead a joint collaborative initiative to bring together intelligent data models by domains, making them available to organisations and any user who wants them. This is known as the SDM (Smart data models) initiative, in which all data models are public.
In this way, it responds to the new data modelling needs at the speed required by the market, reusing models that have already been tested in real scenarios.
How does it work?
The fundamental objective of SDM is that organisations can evolve their vision of data exchange towards a sharing that supports both the so-called Data Economy and the data spaces.
The Data Economy is nothing more than the set of activities and initiatives whose business model is based on the discovery and exploitation of data to identify opportunities that generate products and services.
SDM classifies information by domains or industrial sectors, creating a repository for each of them. In addition, each domain contains sub-modules with the relevant topics for that domain and, within each topic, the related data models. However, shared cross-cutting elements are also available for all domains. For each of these repositories, models can be extracted free of charge. It is also possible to contribute to the initiative by filling in a collaboration form to create new ones.
To facilitate sharing and common understanding, each model includes three elements:
- The model's technical representation that defines the data and its relationships, using JSON structures.
- The specification or manual with the functional descriptions of each of the elements contained in the model.
- Examples to ensure understanding.
In addition to its public nature and free use, it has a licence that allows users to make modifications if they consider it necessary, as well as to share these modifications with the rest of the users. To this end, a workflow is defined according to the phases of the life cycle of the data models, which presents three stages:
- Official: the data models have already been accepted and are fully available to users with the three elements described above.
- In harmonisation: the models have already been accepted, but are still in progress to complete the elements.
- In incubation: the models are being developed and supported by the organisation to achieve an official model.
Through this initiative, data models sharing at all levels will be made more dynamic. For the moment, models have already been homogenised in the domains of smart cities, the agri-food sector, water treatment, energy, environment, sensor technology, robotics, aeronautics, tourist destinations, health and manufacturing industry, as well as some transversal ones such as social media or incident monitoring, although not all to the same extent, as shown in the following image with the number of models included in each domain.
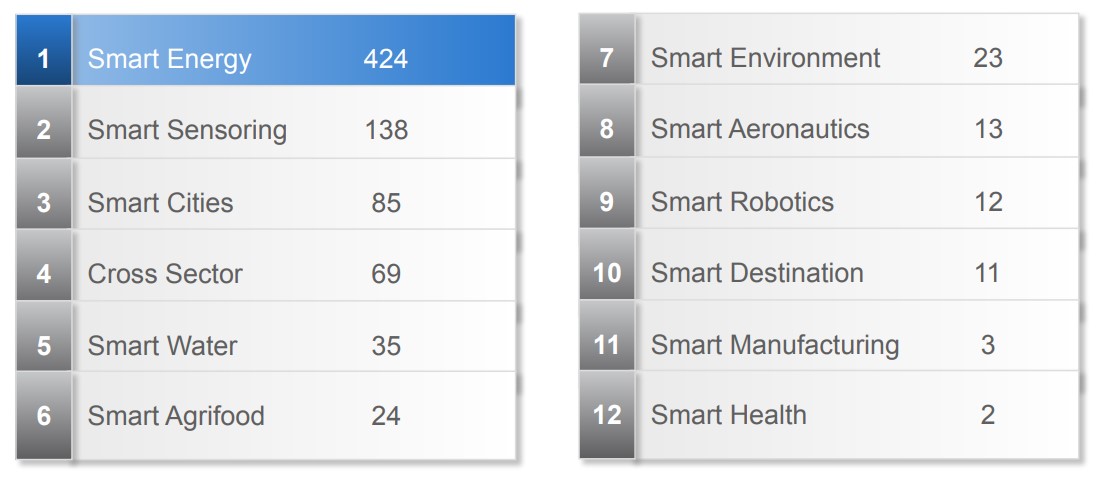
It is, without a doubt, an initiative that facilitates the path towards the data-driven transformation of products and services, providing the opening of models as the technical basis on which the adoption of reference architectures will be based. If you want to go deeper, the SDM itself contains a "Learning zone" section to facilitate learning about the initiative and encourage its use, including self-explanatory videos.
There is also a whole series of tools for those users who, although experts in their sector of activity, are not experts in the generation of data models. Under the tools menu item, there are services that allow users to generate a draft data model with an example, an assisted online data model editor, options to generate examples from existing data models, and options to incorporate the @context element that allows connection to linked data solutions.
Global initiatives such as SDM are of great importance when it comes to agreeing benchmarks to optimise citizen services. They constitute a further step in the objective of achieving common data spaces, making available contrasted data models. This milestone is a major accelerator for its transcendence, even at European level, with major initiatives already underway, such as GAIA-X.
Content prepared by Juan Mañes, expert in Data Governance, with contributions from the Data Office.
The contents and views expressed in this publication are the sole responsibility of the author.
Blog
In any project related to data, it is common to have different sources of information. Data is key for companies and public administrations, in decision making or as a basis for the implementation of projects, services or products. But if these data sources display information in a heterogeneous way, it is difficult to operate.
In the world of open data, each administration covers a different scope, be it territorial - municipal, provincial, regional or national - or jurisdictional - for example, each ministry deals with data from a specific area: ecological transition, health, mobility, etc. -. To be able to carry out projects that cover several areas, we will need interoperable data. Otherwise, the exchange and integration of data within and between organisations will be incompatible.
Why is data harmonisation important?
Today, public administrations manage large amounts of data in different formats, with different management methods. It is common to host multiple copies in many different repositories. These data are often disseminated in portals across Europe without any harmonisation in terms of content and presentation. This explains the low level of re-use of existing information on citizens and businesses. Harmonisation of information allows for consistent and coherent data in a way that is compatible and comparable, unifying formats, definitions and structures.
This shaping of data can be done individually for each project, but it entails a high cost in terms of time and resources. It is therefore necessary to promote standards that allow us to have already harmonised data. Below are several examples of initiatives that advocate the search for common requirements, which are included in this visual:

Ministry of Transport, Mobility and Urban Agenda
The Ministry of Transport, Mobility and Urban Agenda is working on a National Access Point (PAN, in its Spanish singles) where unified data on different modes of transport is collected. The creation of this portal responds to compliance with Commission Delegated Regulation (EU) 2017/1926, which establishes the obligation for authorities, operators, managers and providers of transport services to provide information on multimodal journeys in the EU, based on a series of specifications that ensure its availability and reliability. Among other issues, it indicates that the content and structure of the relevant travel and traffic data need to be adequately described using appropriate metadata.
The creation of this Single Access Point was published in the Official State Gazette (BOE) on 22 February. The text indicates that the minimum universal traffic information related to road safety will be made public, whenever possible and free of charge, with a special focus on real-time services.
At the moment, the PAN has data from the DGT, the Basque Government, the Generalitat de Catalunya, the Madrid City Council and the company Tomtom.
Spanish Federation of Municipalities and Provinces
The Spanish Federation of Municipalities and Provinces (FEMP, in its Spanish singles) has an open data group that has developed two guides to help municipalities implement open data initiatives. One of them is the proposal of 40 datasets that every administration should open to facilitate the reuse of public sector information. This guide not only seeks uniformity in the categories of data published, but also in the way they are published. A fact sheet has been created for each proposed dataset with information on update frequency, formats or recommended display form.
FEMP's future plans include reviewing the datasets published so far to assess whether to add or remove datasets and to include new practical examples.
Also in the field of cities, there is an initiative to further ground the harmonisation of a limited subset of datasets carried out in the framework of the Ciudades Abiertas project, with the collaboration of Red.es. The city councils participating in the project - A Coruña, Madrid, Santiago de Compostela and Zaragoza - have agreed on the opening of 27 harmonised datasets. Currently, common vocabularies have been developed for 16 of them and work continues on the others.
ASEDIE and its Top 3
In 2019, the Multisectoral Information Association (ASEDIE) launched an initiative for all Autonomous Communities to fully open three sets of data: the databases of cooperatives, associations and foundations. It was also proposed that they should all follow unified criteria to facilitate their reuse, such as the incorporation of the NIF of each of the entities.
The results have been very positive. To date, 15 autonomous communities have opened at least two of the three databases. The database of Associations has been opened by all 17 Autonomous Communities.
In 2020, ASEDIE proposed a new Top 3 and started to promote the opening of new databases: commercial establishments, industrial estates and SAT registers. However, due to the fact that not all Autonomous Regions have a register of commercial establishments (because it is not a regional competence), this dataset has been replaced by the Register of Energy Efficiency Certificates.
UniversiData
UniversiData is a collaborative project to promote open data linked to higher education in Spain in a harmonised way. To date, five universities have joined the project: Universidad Autónoma de Madrid, Universidad Complutense de Madrid, Universidad Rey Juan Carlos, Universidad de Valladolid and Universidad Carlos III de Madrid (UC3M).
Within the framework of the project, the "Common Core" specification has been developed, with the aim of providing answers to two questions that the universities ask themselves when opening their data: What datasets should I publish? And how should I do it? That is to say, with which fields, granularity, formats, encodings, frequency, etc. The Common Core coding has been created in accordance with the Law on Transparency, Access to Public Information and Good Governance. Two University Transparency Rankings have also been considered for its development (that of the Fundación Compromiso y Transparencia and that of Dyntra), as well as the document "Towards an Open University: Recommendations for the S.U.E.", of the Conference of Rectors of Spanish Universities (CRUE).
All these initiatives show how data harmonisation can improve the usefulness of data. If we have unified data, its reuse will be easier, as the time and cost of its analysis and management will be reduced.
Content prepared by the datos.gob.es team.