Blog
La UNESCO (Organización de las Naciones Unidas para la Educación, la Ciencia y la Cultura) es un organismo de las Naciones Unidas cuyo objeto es el de contribuir a la paz y a la seguridad en el mundo mediante la educación, la ciencia, la cultura y las comunicaciones. Para cumplir con su objetivo esta organización suele establecer guías y recomendaciones como la que ha publicado este 5 de Julio del 2023 titulado ‘Open data for AI: what now?’
Tras la pandemia del COVID-19 la UNESCO destaca una serie de lecciones aprendidas:
- Deben desarrollarse marcos normativos y modelos de gobernanza de datos, respaldados por infraestructuras, recursos humanos y capacidades institucionales suficientes para abordar los retos relacionados con los datos abiertos, con el fin de estar mejor preparados para las pandemias y otros retos mundiales.
- Es necesario especificar más la relación entre los datos abiertos y la IA, incluyendo qué características de los datos abiertos son necesarias para que sean "AI-Ready".
- Debe establecerse una política de gestión, colaboración e intercambio de datos para la investigación, así como para las instituciones gubernamentales que posean o procesen datos relacionados con la salud, al tiempo que se debe garantizar la privacidad de los datos mediante la anonimización.
- Los funcionarios públicos que manejan datos que son o pueden llegar a ser de utilidad para las pandemias pueden necesitar formación para reconocer la importancia de dichos datos, así como el imperativo de compartirlos.
- Deben recopilarse y recogerse tantos datos de alta calidad como sea posible. Los datos tienen que proceder de una variedad de fuentes creíbles, que, sin embargo, también deben ser éticas, es decir, no deben incluir conjuntos de datos con sesgos y contenido perjudicial, y tienen que recopilarse únicamente con consentimiento y no de forma invasiva para la privacidad. Además, las pandemias suelen ser procesos que evolucionan rápidamente, por lo que la actualización continua de los datos es esencial.
- Estas características de los datos son especialmente obligatorias para mejorar en el futuro las inadecuadas herramientas de diagnóstico y predicción de la IA. Es necesario realizar un esfuerzo para convertir los datos pertinentes en un formato legible por máquina, lo que implica la conservación de los datos recopilados, es decir, su limpieza y etiquetado.
- Debe abrirse una amplia gama de datos relacionados con las pandemias, adhiriéndose a los principios FAIR.
- El público objetivo de los datos abiertos relacionados con la pandemia incluye la investigación y el mundo académico, los responsables de la toma de decisiones en los gobiernos, el sector privado para el desarrollo de productos relevantes, pero también el público, todos los cuales deben ser informados sobre los datos disponibles.
- Las iniciativas de datos abiertos relacionadas con pandemias deberían institucionalizarse en lugar de formarse ad hoc, y por tanto deberían ponerse en marcha para la preparación ante futuras pandemias. Estas iniciativas también deberían ser integradoras y reunir a distintos tipos de productores y usuarios de datos.
- Asimismo, debería regularse el uso beneficioso de los datos relacionados con pandemias para las técnicas de aprendizaje automático de IA con el objetivo de evitar el uso indebido para el desarrollo de pandemias artificiales, es decir, armas biológicas, con la ayuda de sistemas de IA.
La UNESCO se basa en estas lecciones aprendidas para establecer unas Recomendaciones sobre la Ciencia Abierta facilitando el intercambio de datos, mejorando la reproducibilidad y la transparencia, promoviendo la interoperabilidad de los datos y las normas, apoyando la preservación de los datos y el acceso a largo plazo.
A medida que reconocemos cada vez más el papel de la Inteligencia Artificial (IA), la disponibilidad y el acceso a los datos son más cruciales que nunca, por ello la UNESCO lleva a cabo investigaciones en el ámbito de la IA para proporcionar conocimientos y soluciones prácticas que fomenten la transformación digital y construyan sociedades del conocimiento inclusivas.
Los datos abiertos son el principal objetivo de estas recomendaciones, ya que se consideran un requisito previo para la elaboración de planes, la toma de decisiones y las intervenciones con conocimiento de causa. Por ello, el informe afirma que los Estados miembros deben compartir los datos y la información, garantizando la transparencia y la rendición de cuentas, así como las oportunidades para que cualquiera pueda hacer uso de los datos.
La UNESCO ofrece una guía en la que pretende dar a conocer el valor de los datos abiertos y especifican los pasos concretos que los Estados miembros pueden dar para abrir sus datos. Son pasos prácticos, pero de alto nivel sobre cómo abrir datos, basándose en las directrices existentes. Se distinguen tres fases: preparación, apertura de los datos y seguimiento para su reutilización y sostenibilidad, y se presentan cuatro pasos para cada fase.
Es importante señalar que varios de los pasos pueden realizarse simultáneamente, es decir, no necesariamente de forma consecutiva.

Paso 1: Preparación
- Elaborar una política de gestión y puesta en común de datos: Una política de gestión y puesta en común de datos es un requisito importante previo a la apertura de los datos, ya que dicha política define el compromiso de los gobiernos de compartir los datos. El Instituto de Datos Abiertos sugiere los siguientes elementos de una política de datos abiertos:
- Una definición de datos abiertos, una declaración general de principios, un esquema de los tipos de datos y referencias a cualquier legislación, política u otra orientación pertinente.
- Se anima a los gobiernos a adherirse al principio "tan abierto como sea posible, tan cerrado como sea necesario". Si los datos no pueden abrirse por motivos legales, de privacidad o de otro tipo, por ejemplo, datos personales o sensibles, debe explicarse claramente.
Además, los gobiernos también deberían animar a los investigadores y al sector privado de sus países a desarrollar políticas de gestión e intercambio de datos que se adhieran a los mismos principios.
- Reunir y recopilar datos de alta calidad: Los datos existentes deben recopilarse y almacenarse en el mismo repositorio, por ejemplo, de varios departamentos gubernamentales donde pueden haber estado almacenados en silos. Los datos deben ser precisos y no estar desfasados. Además, los datos deben ser exhaustivos y no deben, por ejemplo, descuidar a las minorías o la economía informal. Los datos sobre las personas deben desglosarse cuando sea pertinente, incluso por ingresos, sexo, edad, raza, origen étnico, situación migratoria, discapacidad y ubicación geográfica.
- Desarrollar capacidades de datos abiertos: Estas capacidades se dirigen a dos grupos:
- Para los funcionarios públicos, incluye la comprensión de los beneficios de los datos abiertos potenciando y propiciando el trabajo que conlleva la apertura de los datos.
- Para los usuarios potenciales, incluye la demostración de las oportunidades de los datos abiertos, como su reutilización, y cómo tomar decisiones informadas.
- Preparar los datos para la IA: Si los datos no van a ser utilizados únicamente por humanos, sino que también pueden alimentar sistemas de IA, deben cumplir algunos criterios más para estar preparados para la IA.
- El primer paso en este sentido es preparar los datos en un formato legible por máquinas.
- Algunos formatos favorecen más que otros la legibilidad por parte de los sistemas de inteligencia artificial.
- Los datos también deben limpiarse y etiquetarse, lo que a menudo lleva mucho tiempo y, por tanto, es costoso.
- El éxito de un sistema de IA depende de la calidad de los datos de entrenamiento, incluida su coherencia y pertinencia. La cantidad necesaria de datos de entrenamiento es difícil de conocer de antemano y debe controlarse mediante comprobaciones de rendimiento. Los datos deben abarcar todos los escenarios para los que se ha creado el sistema de IA.
Paso 2: Abrir los datos
- Seleccionar los conjuntos de datos que se van a abrir: El primer paso para abrir los datos es decidir qué conjuntos de datos se van a abrir. Los criterios a favor de la apertura son:
- Si ha habido solicitudes previas de apertura de estos datos
- Si otros gobiernos han abierto estos datos y si ello ha dado lugar a usos beneficiosos de los datos.
La apertura de los datos no debe violar las leyes nacionales, como las leyes de privacidad de datos.
- Abrir los conjuntos de datos legalmente: Antes de abrir los conjuntos de datos, el gobierno correspondiente tiene que especificar exactamente en qué condiciones, en su caso, se pueden utilizar los datos. A la hora de publicar los datos, los gobiernos podrán optar por la licencia que mejor se adapte a sus objetivos, como son por ejemplo las licencias Creative Commons y Open. Para dar soporte a la selección de licencia la comisión europea pone a disposición JLA - Compatibility Checker, una herramienta que da apoyo para esta decisión
- Abrir los conjuntos de datos técnicamente: La forma más habitual de abrir los datos es publicarlos en formato electrónico para su descarga en un sitio web, además se debe contar con APIs para el consumo de estos datos, ya sea el del propio Gobierno o el de un tercero.
Los datos deben presentarse en un formato que permita su localización, accesibilidad, interoperabilidad y reutilización, cumpliendo así los principios FAIR.
Además, los datos también podrían publicarse en un archivo o repositorio de datos, que debería ser, según la Recomendación de la UNESCO, apoyado y mantenido por una institución académica, una sociedad académica, una agencia gubernamental u otra organización sin ánimo de lucro bien establecida y dedicada al bien común que permita el acceso abierto, la distribución sin restricciones, la interoperabilidad y la preservación y el archivo digital a largo plazo.
- Crear una cultura impulsada por los datos abiertos: La experiencia ha demostrado que, además de la apertura legal y técnica de los datos, hay que lograr al menos dos cosas más para alcanzar una cultura de datos abiertos:
- A menudo los departamentos gubernamentales no están acostumbrados a compartir datos y ha sido necesario crear una mentalidad y educarles en esta finalidad.
- Además, los datos deben convertirse, si es posible, en la base exclusiva para la toma de decisiones; en otras palabras, las decisiones deben estar basadas en los datos.
- Además se requieren cambios culturales por parte de todo el personal implicado, fomentando la divulgación proactiva de datos, lo que puede asegurar que los datos estén disponibles incluso antes de que se soliciten.
Paso 3: Seguimiento de la reutilización y la sostenibilidad
- Apoyar la participación ciudadana: Una vez abiertos los datos, deben ser descubiertos por los usuarios potenciales. Para ello hay que desarrollar una estrategia de promoción, que puede comprender anunciar la apertura de los datos en comunidades de datos abiertos y los canales de medios sociales pertinentes.
Otra actividad importante es la consulta y el compromiso tempranos con los usuarios potenciales, a los que, además de informar sobre los datos abiertos, se debe animar a utilizarlos y reutilizarlos y a seguir participando.
- Apoyar el compromiso internacional: Las asociaciones internacionales aumentarían aún más los beneficios de los datos abiertos, por ejemplo, mediante la colaboración sur-sur y norte-sur. Especialmente importantes son las asociaciones que apoyan y crean capacidades para la reutilización de los datos, ya sea mediante el uso de IA o sin ella.
- Apoyar la participación beneficiosa de la IA: Los datos abiertos ofrecen muchas oportunidades a los sistemas de IA. Para aprovechar todo el potencial de los datos, es necesario potenciar que los desarrolladores hagan uso de ellos y desarrollen sistemas de IA en consecuencia. Al mismo tiempo, hay que evitar el abuso de los datos abiertos para aplicaciones de IA irresponsables y perjudiciales. Una práctica recomendada es mantener un registro público de qué datos han utilizado los sistemas de IA y cómo lo han hecho.
- Mantener datos de alta calidad: Muchos datos quedan obsoletos rápidamente. Por lo tanto, los conjuntos de datos deben actualizarse con regularidad. El paso "Mantener datos de alta calidad" convierte esta directriz en un bucle, ya que enlaza con el paso "Reunir y recopilar datos de alta calidad".
Conclusiones
Estas directrices sirven como una llamada a la acción por parte de la UNESCO sobre la ética de la inteligencia artificial. Los datos abiertos son un requisito previo y necesario para el seguimiento y la consecución del desarrollo sostenible.
Debido a la magnitud de las tareas, los gobiernos no sólo deben adoptar la apertura de los datos, sino también crear condiciones favorables para una participación beneficiosa de la IA que cree nuevos conocimientos a partir de los datos abiertos, para una toma de decisiones basada en pruebas.
Si los Estados Miembros de la UNESCO siguen estas directrices y abren sus datos de manera sostenible, crean capacidades, así como una cultura impulsada por los datos abiertos, podremos conseguir un mundo en el que los datos no sólo sean más éticos, sino que las aplicaciones sobre estos datos sean más certeras y beneficiosas para la humanidad.
Referencias
https://www.unesco.org/en/articles/open-data-ai-what-now
Autor : Ziesche, Soenke , ISBN : 978-92-3-100600-5
Contenido elaborado por Mayte Toscano, Senior Consultant in Tecnologías ligadas a la economía del dato. Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Evento
Según las previsiones de la Comisión Europea, en 2025 el volumen global de datos se habrá incrementado en un 530% y en ese contexto es clave garantizar la interoperabilidad y la reutilización de los datos. Así, la Unión Europea trabaja en la creación de un modelo digital que fomente el intercambio de datos y en el que se garantice la privacidad de las personas y la interoperabilidad de los datos.
La Estrategia Europea de Datos recoge la puesta en marcha de espacios de datos comunes e interoperables en sectores estratégicos. En este contexto, han surgido diferentes iniciativas en las que se debaten los procesos, estándares y herramientas adecuadas para la gestión e intercambio de datos, que sirven además para promover una cultura de información y reutilización. Una de estas iniciativas es SEMIC, la conferencia más importante sobre interoperabilidad a nivel europeo cuya edición de 2023 se celebra el próximo 18 de octubre en Madrid. Organizada por la Comisión Europea, esta edición cuenta con la colaboración de la Presidencia española del Consejo de la Unión Europea.
SEMIC 2023, que también se podrá seguir de manera virtual, se centra en ‘La Europa interoperable en la era de la IA’. Las sesiones abordarán los espacios de datos, la gobernanza digital, la garantía de calidad de los datos, la inteligencia artificial generativa y de propósito general o el derecho como código, entre otros aspectos. Además, se dará a conocer información sobre la propuesta de una Ley de Europa interoperable.
Talleres previos
Los asistentes tendrán la oportunidad de conocer casos de uso concretos en los que la interoperabilidad del sector público y la inteligencia artificial se han beneficiado mutuamente. Aunque SEMIC 2023 se celebrará el 18 de octubre, el día anterior se desarrollarán tres interesantes talleres a los que también se podrá asistir tanto de manera presencial como virtual.
- Inteligencia artificial en el diseño de políticas para la era digital y en la redacción de textos jurídicos. Este taller explorará cómo las herramientas impulsadas por la IA pueden ayudar a los responsables de la formulación de políticas públicas. Se abordarán diferentes herramientas, como el prototipo de análisis de políticas (SeTA) o las funcionalidades inteligentes para la redacción jurídica (LEOS).
- Grandes modelos lingüísticos en apoyo de la interoperabilidad. En esta sesión se explorarán los métodos y enfoques propuestos para el uso de grandes modelos lingüísticos y tecnología de IA en el contexto de la interoperabilidad semántica. Se centrará en el estado de LLM y su aplicación a la agrupación semántica, el descubrimiento de datos y la expansión de la terminología, entre otras aplicaciones que apoyan la interoperabilidad semántica.
- Registro europeo de modelos semánticos del sector público. En este taller se definirán acciones que permitan crear un punto de entrada para conectar las colecciones nacionales de activos semánticos.
Interacciones entre inteligencia artificial, interoperabilidad y semántica
El programa de la conferencia principal de SEMIC 2023 incluye mesas redondas y varias sesiones de trabajo que se desarrollarán de manera paralela. La primera sesión abordará la experiencia de Estonia, uno de los primeros países europeos que ha aplicado la IA en el sector público y pionero en interoperabilidad.
Por la mañana, se celebrará una interesante mesa redonda sobre el potencial de la inteligencia artificial para apoyar la interoperabilidad, en la que ponentes de diferentes Estados miembro de la Unión Europea presentarán casos de éxito y retos en relación con el despliegue de la IA en el sector público.
En la segunda mitad de la mañana se desarrollarán tres sesiones de manera paralela:
- Elaboración de políticas para la era digital y el derecho cómo código. En esta sesión se identificarán los principales retos y oportunidades en el ámbito de la IA y la interoperabilidad, teniendo como paradigma ‘el derecho como código’ y se prestará especial atención a la anotación semántica en la legislación.
- Interconexión de los espacios de datos. En este caso, se abordarán los principales retos y oportunidades en el desarrollo de los espacios de datos, prestando especial atención en las soluciones en materia de interoperabilidad. Igualmente, se tratarán las sinergias entre el Centro de apoyo a los espacios de datos (DSSC) y las especificaciones y herramientas DIGIT de la Comisión Europea.
- Servicios públicos automatizados. En esta sesión se hará una aproximación a la automatización del acceso a los servicios públicos con la ayuda de la IA y los chatbots.
Durante la tarde habrá tres nuevas sesiones paralelas:
- Grafos de conocimiento, semántica e IA. Se mostrará cómo la semántica tradicional se aprovecha de la IA.
- Calidad de los datos en la IA generativa y de propósito general. En esta sesión se hará un repaso de los principales problemas de calidad de los datos en la UE y se debatirá sobre las estrategias para superarlos.
- IA confiable para la interoperabilidad en el sector público. En este caso, se hablará sobre las oportunidades de utilizar la IA con fines de interoperabilidad en el sector público y los retos de transparencia y fiabilidad de los sistemas de IA.
También por la tarde tendrá lugar una mesa redonda sobre los próximos retos, en la que se abordarán las implicaciones tecnológicas, sociales y políticas de los avances en IA e interoperabilidad desde el punto de vista de las actuaciones políticas. Tras este panel, se celebrarán las conferencias de clausura.
La edición anterior, que tuvo lugar en Bruselas, congregó a más de 1.000 profesionales de 60 países tanto de manera presencial como virtual, por lo que SEMIC 2023 se presenta como una excelente oportunidad para conocer las últimas tendencias en interoperabilidad en la era de la inteligencia artificial.
Puedes apuntarte aquí: https://semic2023.eu/registration/
Noticia
El pasado 11 de septiembre se celebró un webinar en el que se llevó a cabo un repaso sobre Gaia-X, desde sus fundamentos, encarnados por su arquitectura y modelo de confianza denominado Trust Framework, pasando por los Servicios de Federación con los que se trata de facilitar y agilizar el acceso a la infraestructura, hasta el catálogo de servicios que unos usuarios (proveedores) podrán poner a disposición de otros (consumidores).
El webinar dirigido por la gerente del Hub español de Gaia-X, estuvo protagonizado por dos de los expertos de la Oficina del Dato, que a través de sus ponencias guiaron a la audiencia hacia un mayor conocimiento de los que es la iniciativa Gaia-X. Al final de la sesión. se contó con una dinámica de preguntas y respuestas en la que se pudo profundizar en detalle. Se puede acceder a la grabación de este seminario desde la página oficial del Hub: [Forjando el Futuro de los Espacios de Datos Federados en Europa | Gaia-X (gaiax.es)
Gaia-X como pieza clave para forjar los Espacios de Datos europeos
Gaia-X surge como un innovador paradigma con el que facilitar la integración de los recursos informáticos. En base a modelos tecnológicos de la Web 3.0, se habilita la identificación y trazabilidad de diferentes recursos de datos, desde conjuntos de datos, algoritmos, diferentes modelos semánticos o de otra índole conceptual, a incluso infraestructura tecnológica subyacente (recursos de nube). Esto sirve para visibilizar el origen y el funcionamiento de estas entidades, lo que permite facilitar la transparencia y el cumplimiento de normativas y los valores europeos.
Más concretamente, Gaia-X proporciona diferentes servicios encargados de verificar automáticamente el cumplimiento de unas reglas mínimas de interoperabilidad, lo que permite después definir reglas más abstractas con un foco de negocio, o incluso como base para definir e instanciar la Nube Confiable y los espacios soberanos de datos. Estos servicios se operacionalizarán mediante diferentes nodos de interoperabilidad de Gaia-X, o Gaia-X Digital Clearing Houses.
Con Gaia-X como herramienta podremos publicar, encontrar y explotar un catálogo de servicios que cubrirá diferentes servicios según los requerimientos del usuario. Por ejemplo, para infraestructura cloud estos pueden ser características como la residencia en territorio europeo o el cumplimiento de normativas UE (como el eIDAS o el RGPD, o las normas de intermediación de datos presentes en el Reglamento de Gobernanza de Datos), y también crear servicios combinables, agregando piezas de diferentes proveedores (algo complejo en estos momentos). También se encontrarán conjuntos de datos específicos con los que entrenar modelos de Inteligencia Artificial, y sobre los cuales su propietario tendrá control gracias a la trazabilidad habilitada, hasta la ejecución de algoritmos y apps sobre datos propios del consumidor, de forma que se preserve en todo momento la privacidad de los mismos.
Como vemos, esta novedosa capacidad de trazabilidad, basada en tecnologías punteras, sirve como acicate del Compliance, y por ello es una pieza fundamental en el despliegue de los espacios de datos interoperables a nivel europeo y el mercado único digital.
Blog
La Directiva INSPIRE (Infrastructure for Spatial Information in Europe) establece las reglas generales para el establecimiento de una Infraestructura de Información espacial en la Comunidad Europea basada en las Infraestructuras de los Estados miembro. Aprobada por el Parlamento Europeo y el Consejo el 14 de marzo de 2007 (Directiva 2007/2/CE), esta entró en vigor el 25 de abril de 2007.
INSPIRE permite encontrar, compartir y utilizar con más facilidad los datos espaciales de diferentes países. La información está disponible a través de un portal online desde el que se pueden encontrar desglosados en distintos formatos y temáticas de interés.
Para asegurar que estos datos sean compatibles e interoperables en un contexto comunitario y transfronterizo, la Directiva exige que se adopten Normas de Ejecución comunes (Implementing Rules) específicas para las siguientes áreas:
- Metadatos
- Conjuntos de datos
- Servicios de red
- Uso compartido de datos y servicios
- Servicios de datos espaciales
- Monitoreo e informes
La implementación técnica de estas normas se realiza mediante las Guías Técnicas o Directrices (Technical Guidelines), documentos técnicos basados en estándares y normas internacionales.
Inspire e interoperabilidad semántica
Estas normas se consideran decisiones o reglamentos de la Comisión y, por lo tanto, son de obligado cumplimiento en cada uno de los países de la Unión. La transposición de esta Directiva al ordenamiento jurídico español se desarrolla a través de la Ley 14/2010 de 5 de julio, la cual hace referencia a las infraestructuras y los servicios de información geográfica de España (LISIGE) y el portal IDEE, ambos son el resultado de la implementación de la Directiva INSPIRE en España.
En INSPIRE juega un papel decisivo la interoperabilidad semántica. Gracias a esta, existe un lenguaje común en los datos espaciales, pues la integración del conocimiento solo es posible cuando se logra una homogenización o entendimiento común de los conceptos que constituyen un dominio o área de conocimiento. Así, en INSPIRE, la interoperabilidad semántica es la encargada de asegurar que el contenido de la información intercambiada sea entendido de la misma manera por cualquier sistema.
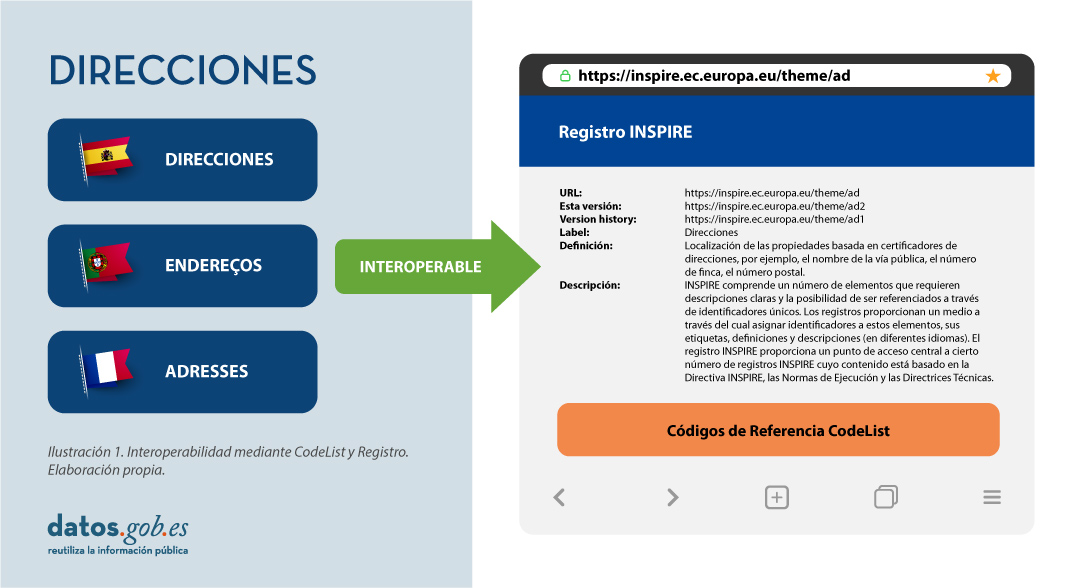
Por ello, en la implementación de los modelos de datos espaciales en INSPIRE, en formato de intercambio GML, podemos encontrar los codelist que son una parte importante de las especificaciones de datos de INSPIRE y contribuyen sustancialmente a la interoperabilidad.
En general, una codelist o lista de códigos contiene varios términos cuyas definiciones son universalmente aceptadas y comprendidas. Las listas de códigos favorecen la interoperabilidad de los datos y constituyen un vocabulario compartido por una comunidad. Incluso pueden ser multilingües.
Las listas de códigos INSPIRE se administran y mantienen comúnmente en Registro Inspire Central Federado (ROR) que proporciona capacidades de búsqueda, de modo que tanto los usuarios finales como las aplicaciones cliente pueden acceder fácilmente a los valores de la lista de códigos como referencia.
Los registros son necesarios porque:
- Proporcionan los códigos definidos en las Directrices Técnicas (Guidelines), Reglamentos y Especificaciones técnicas necesarios para implementar la Directiva
- Permiten referencias inequívocas de los elementos
- Proporcionna identificadores únicos y persistentes para los recursos
- Permiten una gestión y control de versiones coherentes de los diferentes elementos
Las listas de códigos utilizados en INSPIRE se mantienen en:
- El Registro Inspire Central Federado (ROR)
- El registro de listas de códigos de un estado miembro
- El registro de listas de un tercero externo reconocido que mantiene una lista de códigos específica de dominio.
Para agregar una nueva lista de códigos, tendrá que configurar su propio registro o trabajar con la administración de uno de los registros existentes para publicar su lista de códigos. Este puede ser un proceso bastante complicado pero una nueva herramienta nos ayuda en esta labor.
Re3gistry es una solución de código abierto reutilizable y publicado bajo licencia EUPL, que permite a las empresas y organizaciones administrar y compartir \"códigos de referencia\" a través de URI persistentes, asegurando que los conceptos se referencian inequívocamente en cualquier dominio y facilitando la gestión de estos recursos gráficamente durante todo su ciclo de vida.
Financiado por ELISE, ISA2 es una solución reconocida por los europeos en el Marco de interoperabilidad como una herramienta de apoyo.Ilustración 3 Imagen de la interface de Re3gister.
Ilustración 3: Imagen de la interface de Re3gister
Re3gistry está disponible tanto para Windows como para Linux y ofrece una Interfaz Web fácil de usar para agregar, editar y administrar los registros y códigos de referencia. Además, permite la gestión del ciclo de vida completo de los códigos de referencia (basado en la norma ISO 19135: 2005 Procedimientos integrados para el registro de códigos de referencia)
La interfaz de edición también proporciona un indicador para permitir que el sistema exponga el código de referencia en el formato que permite su integración con RoR, de esta manera, eventualmente se puede importar en la federación de registro INSPIRE. Para esta integración, Reg3gistry hace una exportación en un formato basado en las siguientes especificaciones:
- El vocabulario del Catálogo de datos del W3C (DCAT) que se utiliza para modelar el registro de entidades (dcat:Catalog).
- El Sistema de Organización Simple del Conocimiento (SKOS) del W3C que se utiliza para modelar el registro de entidades (skos:ConceptScheme) y el elemento (skos:Concept).
Otras características destacables de Re3gistry
- Modelos de datos altamente flexibles y personalizables
- Soporte de contenido en varios idiomas
- Soporte para el control de versiones
- API RESTful con negociación de contenido (incluido el descriptor OpenAPI 3)
- Búsqueda de texto-libre
- Formatos soportados: HTML, ISO 19135 XML, JSON
- Los formatos de servicio se pueden agregar o personalizar fácilmente (formatos predeterminados: JSON e ISO 19135 XML)
- Múltiples opciones de autentificación
- Elementos gobernados externamente a los que se hace referencia a través de URIs
- Soporte de formato de federación de registro INSPIRE (opción para crear automáticamente el formato RoR)
- Fácil exportación y reindexación de datos (SOLR)
- Guías para usuarios, administradores y desarrolladores
- Fuente RSS
En definitiva, Re3gistry proporciona un punto de acceso central donde las etiquetas y descripciones de los códigos de referencia son fácilmente accesibles tanto para humanos como para máquinas, al tiempo que fomenta la interoperabilidad semántica entre organizaciones ya que permite:
- Evitar errores comunes como faltas de ortografía, ingresar sinónimos o completar formularios en línea.
- Facilitar la internacionalización de las interfaces de usuario proporcionando etiquetas multilingües.
- Garantizar la interoperabilidad semántica en el intercambio de datos entre sistemas y aplicaciones.
- El rastreo de los cambios a lo largo del tiempo a través de un sistema de control de versiones bien documentado.
- Aumentar el valor de los códigos de referencia, si se reutilizan y referencian ampliamente.
Más acerca de Re3gistry:
|
|
Soporte | https://github.com/ec-jrc/re3gistry |
|
|
Manual de usuario | https://github.com/ec-jrc/re3gistry/blob/master/documentation/user-manual.md |
|
|
Manual de administrador | https://github.com/ec-jrc/re3gistry/blob/master/documentation/administrator-manual.md |
|
|
Manual de desarrollador |
https://github.com/ec-jrc/re3gistry/blob/master/documentation/developer-manual.md
|




Referencias
https://github.com/ec-jrc/re3gistry
https://inspire.ec.europa.eu/codelist
https://ec.europa.eu/isa2/solutions/re3gistry_en/
https://live.osgeo.org/en/quickstart/re3gistry_quickstart.html
Contenido elaborado por Mayte Toscano, Senior Consultant in Tecnologías ligadas a la economía del dato.
Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Blog
A medida que una mayor parte de nuestras vidas cotidianas se desarrolla online, y al mismo tiempo que la importancia y el valor de los datos personales aumenta en nuestra sociedad, las normas que protegen el derecho universal y fundamental a la privacidad, la seguridad y a la intimidad – respaldadas por marcos como la Declaración Universal de los Derechos Humanos o la Declaración Europea de Derechos Digitales – resultan cada vez de mayor importancia.
Hoy en día, nos enfrentamos también a una serie de nuevos retos en relación con nuestra privacidad y nuestros datos personales. Según el último informe de la Fundación Lloyd's Register, al menos tres de cada cuatro usuarios de internet están preocupados porque su información personal pueda ser robada o utilizada de algún modo sin su permiso. Por todo lo anterior, cada vez resulta también más urgente el poder garantizar que las personas estén en condiciones de conocer y controlar sus datos personales en todo momento.
Hoy en día, la balanza se inclina claramente hacia las grandes plataformas que son las que cuentan con los recursos necesarios para recopilar, comerciar y tomar decisiones basadas en nuestros datos personales – mientras que los individuos solo pueden aspirar a obtener cierto control sobre lo que ocurre con sus datos, generalmente previo gran esfuerzo.
Por ese motivo surgen iniciativas como MyData Global, una organización sin ánimo de lucro que lleva ya varios años promoviendo un enfoque de la gestión de datos personales centrado en el ser humano y abogando por garantizar el derecho de las personas a participar activamente en la economía del dato. El objetivo es restablecer el equilibrio y avanzar hacia una visión de los datos centrada en las personas para construir una sociedad digital más justa, sostenible y próspera cuyos pilares serían:
-
Establecer relaciones de confianza y seguridad entre las personas y las organizaciones.
-
Conseguir la autonomía en materia de datos, no sólo mediante la protección legal, sino también con medidas para compartir y distribuir el poder de los datos.
-
Maximizar los beneficios colectivos de los datos personales, compartiéndolos equitativamente entre las organizaciones, los individuos y la sociedad.
Y para poder introducir los cambios necesarios que den lugar a este nuevo enfoque más humano de los datos personales se han elaborado los siguientes principios:
1 – Control de los datos centrado en las personas
Son las personas las que deben tener el poder de decisión en la gestión de todo lo concerniente a su vida personal. Para ello deben disponer de los medios prácticos necesarios que les permitan comprender y controlar eficazmente quién tiene acceso a sus datos y cómo se utilizan y comparten.
La privacidad, la seguridad y el uso mínimo de datos deben ser prácticas habituales en el diseño de aplicaciones y las condiciones de uso de los datos personales deben ser negociadas de forma justa entre particulares y organizaciones.
2 – Las personas como punto central de integración
El valor de los datos personales crece exponencialmente con su diversidad, a la vez que crece también la potencial amenaza hacia la privacidad. Esta aparente contradicción podría resolverse si colocamos a las personas como eje central en cualquier intercambio de datos, centrándonos siempre en sus propias necesidades por encima de cualquier otra motivación.
Todo uso de los datos personales debe girar en torno al individuo a través de una profunda personalización de las herramientas y los servicios.
3 – Autonomía individual
En una sociedad impulsada por los datos, los individuos no deberían ser vistos únicamente como clientes o usuarios de servicios y aplicaciones. Deben ser considerados agentes libres y autónomos, capaces de establecer y perseguir sus propios objetivos.
Las personas deben poder gestionar con seguridad sus datos personales de la manera que prefieran, contando siempre con las herramientas, habilidades y asistencia necesarias.
4 – Portabilidad, acceso y reutilización
Permitir que las personas puedan obtener y reutilizar sus datos personales para sus propios fines y en diferentes servicios es la clave para pasar de los silos de datos aislados a los datos como recursos reutilizables.
La portabilidad de datos no debe ser un mero derecho legal, sino combinarse con medios prácticos para que las personas puedan trasladar eficazmente los datos a otros servicios o en sus dispositivos personales de forma segura y sencilla.
5 – Transparencia y responsabilidad
Las organizaciones que utilizan los datos de una persona deben ser transparentes en el uso que hacen de ellos y la finalidad que persiguen. Al mismo tiempo, deben asumir su responsabilidad sobre la gestión que hacen de esos datos, incluido cualquier incidente de seguridad.
Se deben crear canales fáciles de usar y seguros para que las personas puedan conocer y controlar lo que ocurre con sus datos en todo momento, y poder así también cuestionar las decisiones basadas únicamente en algoritmos.
6 – Interoperabilidad
Es necesario minimizar la fricción en el flujo de datos desde las fuentes de origen a los servicios que los utilizan. Para ello hay que incorporar los efectos positivos de los ecosistemas abiertos e interoperables, incluyendo protocolos, aplicaciones e infraestructura. Esto se logrará a través de la aplicación de normas y prácticas comunes y estándares técnicos.
La comunidad de MyData lleva ya años aplicando estos principios en su trabajo para conseguir difundir una visión más humana de la gestión, tratamiento y uso de los datos centrada en las personas, como está haciendo por ejemplo en la actualidad a través de su papel en el Data Spaces Support Centre, un proyecto de referencia que está llamado a definir el futuro uso y gobierno responsable de los datos en la Unión Europea.
Y para quien quiera profundizar más en el uso de los datos centrado en las personas, tendremos en breve una nueva edición de MyData Conference, que este año se centrará en mostrar casos prácticos en los que la recopilación, el procesamiento y el análisis de los datos personales sirven principalmente a las necesidades y experiencias de los seres humanos.
Contenido elaborado por Carlos Iglesias, Open data Researcher y consultor, World Wide Web Foundation.
Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Evento
El próximo 20 de octubre, Madrid acogerá una nueva edición del Data Management Summit Spain. Esta cita forma parte del Data Management Summit (DMS) 2022, que ya contó con dos jornadas previas en Italia (7 de julio) y Latam (20 de septiembre).
El evento está dirigido a una audiencia técnica: CiOs, CTOs, CDOs, Directores de Sistemas, Responsables de Inteligencia de Negocio y Científicos de Datos encargados de implementar tecnologías emergentes con el fin de resolver nuevos retos tecnológicos y alinearse con nuevas oportunidades de negocio.
Fecha y hora
La jornada tendrá lugar en la Universidad Nebrija, el día 20 de octubre de 2022, en horario de de 9:30 a 19:30.
El día anterior tendrá lugar, en el mismo espacio, un prólogo del DMS solo para representantes de administraciones públicas, con horario de 14:00 a 19:30.
Agenda
La agenda está integrada por ponencias, mesas redondas y dinámicas de grupo entre profesionales, las cuales permitirán potenciar el networking.
El prólogo del día 19 estará focalizada en los datos abiertos y el intercambio de información entre administraciones. Carlos Alonso, Director de la División Oficina del Dato, será uno de los ponentes. Entre las distintas actividades, encontramos dos dinámicas de grupos que girarán en torno a los datos abiertos y la interoperabilidad, así como dos mesas redondas, en la primera de las cuales participará la coordinadora en red.es de la plataforma datos.gob.es:
- Mesa redonda 1: "Open Data y la interoperabilidad de datos en las AAPP".
- Mesa redonda 2: "Desafíos y barreras para el intercambio de datos en el sector público".
Por su parte, el día 20 contará con un enfoque más empresarial. Este segundo día también contará con ponencias de expertos y dinámicas de grupo centradas en la gobernanza de datos, su calidad, los datos maestros y la arquitectura de datos, entre otros temas. Las mesas redondas serán tres:
- Mesa redonda 1: "Arquitectura de datos, ¿malla de datos o tejido de datos?", donde se hablará del patrón de arquitectura Data Mesh (malla de datos), con un enfoque descentralizado, en contraposición a Data Fabric (tejido de datos), que promueve una única arquitectura de datos unificada.
- Mesa redonda 2: "Cómo cambia el Gobierno del Dato con el nuevo paradigma de la banca abierta", donde se abordará la evolución hacia una economía basada en la interoperabilidad total y las API, donde la trazabilidad de los procesos sea completa.
- Mesa redonda 3: "¿Cómo converger los diferentes modelos de calidad de datos?", enfocada en cómo medir la calidad de los datos, cómo administrar los procesos de calidad automáticamente y cómo evitar la corrupción de Data Lake.
Puedes ver más sobre cómo será la jornada en este vídeo.
¿Cómo puedo asistir?
El aforo de cada sesión está limitado a 60 plazas presenciales y a 100 online.
La inscripción para la jornada del día 20 se realiza a través de este enlace (actualmente el aforo está completo, pero puedes apuntarte a la lista de espera). Sí está disponible el registro para el día 19, pero recuerda que dicha sesión es exclusiva para Administraciones Públicas.
Más información en la página web de la cumbre.
Blog
Hoy en día podemos encontrar gran cantidad de información legislativa en la red. Países, regiones y municipios hacen públicos sus textos normativos y jurídicos a través de diversos espacios y boletines oficiales. El uso de esa información puede ser de gran utilidad para impulsar mejoras en el sector: desde facilitar la localización de información jurídica hasta el desarrollo de chatbots capaces de resolver dudas legales de los ciudadanos.
Sin embargo, localizar, acceder y reutilizar estos documentos suele resultar complejo, debido a las diferencias en los ordenamientos jurídicos, los diversos idiomas o los distintos sistemas técnicos utilizados para almacenar y gestionar los datos.
Para resolver este reto, la Unión Europea cuenta con un estándar de identificación y descripción de las normas denominado Identificador Europeo de Legislación, conocido como ELI por sus siglas en inglés (European Legislation Identifier).
¿Qué es el Identificador Europeo de Legislación?
El ELI surgió en 2012 a través de unas Conclusiones del Consejo (2012/C 325/02) en las que la Unión Europea invitaba a los Estados miembros a adoptar un estándar de identificación y descripción de las normas jurídicas. Esta iniciativa ha ido evolucionando y enriqueciéndose gracias a nuevas conclusiones publicadas en 2017 (2017/C 441/05) y 2019 (2019/C 360/01).
El ELI, que se basa en un acuerdo voluntario entre los países de la UE, busca facilitar el acceso, intercambio e interconexión de la información jurídica publicada en los sistemas nacionales, europeos y mundiales. De esta forma se facilita su disponibilidad como conjuntos de datos abiertos, impulsando su reutilización.
En concreto, el ELI permite:
- Identificar documentos legislativos, como normas o recursos legales, de forma univoca mediante un identificador único (URI), comprensible tanto por personas como por máquinas.
- Definir las características de cada documento a través de metadatos procesables automáticamente. Para ello utiliza vocabularios definidos mediante ontologías consensuadas y recomendadas para cada ámbito.
Gracias a ello, se consiguen una serie de ventajas:
- Aporta mayor calidad y fiabilidad.
- Aumenta la eficacia en los flujos de información, reduciendo tiempos y ahorrando costes.
- Optimiza y agiliza el acceso a la legislación de distintos sistemas jurídicos al proporcionar la información de manera uniforme.
- Mejora de la interoperabilidad de los sistemas jurídicos, facilitando la cooperación entre países.
- Facilita la reutilización de datos jurídicos como base de nuevos servicios y productos de valor añadido que mejoran la eficiencia del sector.
- Impulsa la transparencia y la rendición de cuentas de los Estados Miembros.
Aplicación del ELI en España
El ELI es un sistema flexible que debe ser adaptado a las peculiaridades de cada territorio. En el caso del ordenamiento español, existen diversos aspectos jurídicos y técnicos que condicionan su implementación.
Uno de los principales condicionantes es la pluralidad de emisores, con normas a nivel nacional, autonómico y local, cada una de las cuales cuenta con su propio medio de publicación oficial. Además, cada organismo publica los documentos en los formatos que considera adecuados (pdf, html, xml, etc.) y con distintos metadatos. A ello hay que sumar la pluralidad lingüística, por la cual cada boletín se publica en las lenguas oficiales correspondientes.
Por ello, se acordó que la implementación del ELI se realizaría de forma coordinada por todas las administraciones, en el marco de la Comisión Sectorial de Administración Electrónica (CSAE), a través de dos fases:
- Debido a la complejidad de la normativa local, en la primera fase, se decidió abordar únicamente la especificación técnica aplicable al Estado y las Comunidades Autónomas, mediante acuerdo de la CSAE de 13 de marzo de 2018.
- En febrero de 2022, se ha elaborado una nueva versión para incluir en su aplicación a la normativa local.
Con esta nueva especificación, quedan establecidas las directrices comunes para la implementación del ELI en el contexto español, pero respetando las particularidades de cada organismo. Es decir, recoge únicamente los elementos mínimos necesarios para garantizar la interoperabilidad de la información legal publicada en todos los niveles de administración, pero se sigue permitiendo que cada organismo mantenga sus propios diarios oficiales, bases de datos, procesos internos, etc.
Con respecto al ámbito temporal, los organismos tienen que aplicar estas especificaciones de la siguiente manera:
- Normativa estatal: aplica a aquella publicada a partir del 29/12/1978, así como la publicada antes si cuenta con versión consolidada.
- Normativa autonómica: aplica a aquella publicada a partir del 29/12/1978.
- Normativa local: cada entidad podrá aplicar su propio criterio.
¿Cómo implementar el ELI?
En la página web https://www.elidata.es/ se ofrecen recursos técnicos para la aplicación del identificador. En ella se explica el modelo contextual y se ofrecen distintas plantillas para facilitar su aplicación:
También ofrece la relación de metadatos mínimos comunes, entre otros recursos.
Además, para facilitar la coordinación nacional y la compartición de experiencias, en la web también se puede encontrar información sobre la implementación efectuada por las distintas administraciones.
El ELI ya se aplica, por ejemplo, en el Boletín Oficial del Estado (BOE). Desde su página web se puede acceder a todas las normas del BOE identificadas con ELI, distinguiendo entre las normas estatales y autonómicas. Si tomamos como referencia una norma como el Real Decreto-ley 24/2021, donde se procedía a la transposición de varias directivas europeas (incluida la de datos abiertos y reutilización de la información del sector público), vemos que se incluye un incluye un permalink ELI.
En definitiva, nos encontramos ante un mecanismo común de gran utilidad para facilitar la interoperabilidad de la información jurídica, lo cual puede impulsar su reutilización no solo a nivel nacional, sino también europeo, favoreciendo la creación del espacio de libertad, seguridad y justicia de la Unión Europea.
Contenido elaborado por el equipo de datos.gob.es.
Blog
En el contexto actual, la digitalización se ha expandido de forma exponencial, llegando a traspasar las fronteras del sector privado y consolidándose como uno de los grandes retos en todos los sectores productivos de la sociedad. Este proceso ha traído consigo la generación masiva de datos de los que extraer valor. Sin embargo, según un estudio de IDC/EMC se cree que, pese a que el volumen de datos se multiplicará exponencialmente en el corto plazo, únicamente el 1% de los datos generados se utiliza, se procesa y se aprovecha. Una de las razones la encontramos en la incoherencia y poca flexibilidad de los modelos de datos, que bloquean la integración de los mismos.
En este sentido, en el Plan de Recuperación, Transformación y Resiliencia del Gobierno de España, que detalla la estrategia española para canalizar los fondos destinados por la Unión Europea a reparar los daños provocados por la pandemia, hace hincapié en las reformas tecnológicas e inversiones enfocadas a construir un futuro más sostenible. Uno de los principales retos en este ámbito es dinamizar la compartición de datos, principalmente en aquellos sectores con más impacto en la sociedad, como la salud y el turismo.
Para ello, los modelos de datos inteligentes o smart data models juegan un papel fundamental. Pero, ¿qué son exactamente?
¿Qué son los Smart Data Models?
Un modelo de datos tradicional es la representación de los elementos de un conjunto de datos y de sus relaciones y conexiones entre sí. Los modelos de datos inteligentes van un paso más allá. Son modelos de datos comunes y compatibles, con el objetivo de sustentar un mercado digital de soluciones inteligentes interoperables y replicables en múltiples sectores, de forma que se homogenice la disponibilidad de datos en ámbitos determinados.
Estos modelos proponen una visión común que proporciona una base técnica para lograr la apertura de la innovación.
Iniciativa SDM
La Fundación FIWARE, TM Forum, IUDX y OASC se han unido para liderar una iniciativa de colaboración conjunta que permita agrupar los modelos de datos inteligentes por dominios, poniéndolos a disposición de las organizaciones y de cualquier usuario que lo desee. Es lo que se conoce como iniciativa SDM (Smart data models) y, en ella, todos los modelos de datos son de carácter público.
De esta manera, se da respuesta a las nuevas necesidades de modelado de datos a la velocidad que requiere el mercado, reaprovechando modelos ya probados en escenarios reales.
¿Cómo funciona?
El objetivo fundamental de SDM se basa en que las organizaciones puedan evolucionar su visión de intercambio de datos hacia una compartición que dé soporte tanto a la llamada Economía del Dato como a los espacios de datos. La Economía del Dato, no es más que el conjunto de actividades e iniciativas cuyo modelo de negocio se basa en el descubrimiento y explotación de los datos, para la identificación de oportunidades que generen productos y servicios.
SDM clasifica la información por dominios o sectores industriales, creando un repositorio para cada uno de ellos. Además, cada dominio contiene submódulos con los temas relevantes para ese dominio y, dentro de cada tema, los modelos de datos relacionados. No obstante, también se dispone de elementos transversales compartidos para todos los dominios. Para cada uno de estos repositorios, se pueden extraer los modelos de forma gratuita. También se puede contribuir con la iniciativa mediante la cumplimentación de un formulario de colaboración que permita crear nuevos.
Para facilitar la compartición y el entendimiento común, cada modelo incluye tres elementos:
- La representación técnica propia del modelo que define los datos y sus relaciones, mediante estructuras JSON.
- La especificación o manual con las descripciones funcionales de cada uno de los elementos contenidos.
- Ejemplos que aseguren su comprensión.
Además de su carácter público y uso gratuito, cuenta con una licencia que permite a los usuarios realizar modificaciones en caso que lo consideren necesario, así como compartir dichas modificaciones con el resto de usuarios. Con esa finalidad, se define un flujo de trabajo de acuerdo a las fases del ciclo de vida de los modelos de datos, que presenta tres etapas:
- Oficial: los modelos de datos ya han sido aceptados y están totalmente a disposición de los usuarios con los tres elementos descritos anteriormente.
- En armonización: los modelos ya han sido aceptados, pero todavía se encuentran en progreso para completar los elementos.
- En incubación: los modelos están siendo elaborados y cuentan con el apoyo de la organización para lograr un modelo oficial.
Gracias a esta iniciativa, se pretende dinamizar la compartición de modelos de datos en todos los ámbitos. Por el momento, ya se han conseguido homogeneizar modelos en los dominios de ciudades inteligentes, sector agroalimentario, tratamiento del agua, energía, medio ambiente, sensórica, robótica, aeronáutica, destinos turísticos, salud e industria manufacturera, además de algunos transversales como puedan ser redes sociales o monitorización de incidencias, aunque no todos en la misma medida, tal y como muestra la siguiente imagen con el número de modelos incluidos en cada dominio.
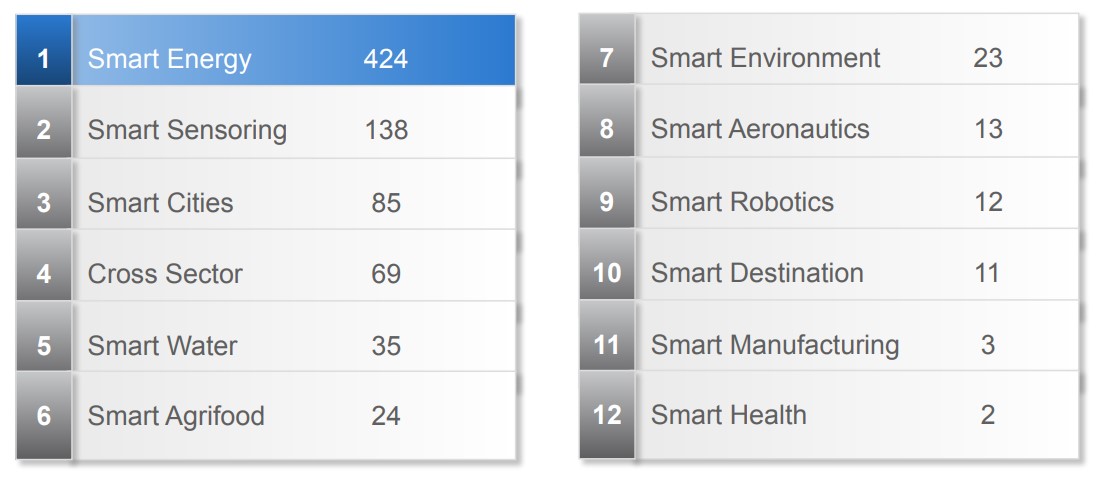
Se trata, sin duda, de una iniciativa que facilita el camino hacia la transformación data driven de productos y servicios, proporcionando la apertura de modelos como la base técnica sobre la que se sustentará la adopción de arquitecturas de referencia. Si quieres profundizar más, la propia SDM contiene un apartado de “Learning zone” para facilitar el aprendizaje sobre la iniciativa y fomentar su uso, incluyendo videos auto explicativos.
También hay toda una serie de herramientas para aquellos usuarios que, siendo expertos en su sector de actividad, no lo son en la generación de modelos de datos. Bajo el elemento de menú tools, se encuentran servicios que permiten desde generar un borrador de un modelo de datos con un ejemplo, un editor de modelso de datos asistido y en línea, opciones para generar ejemplos desde modelos de datos existentes, y otras para incorporar el elemento @context que permite la conexión con soluciones linked data.
Iniciativas globales como la de SDM adquieren gran importancia a la hora de acordar referencias que permitan optimizar los servicios al ciudadano. Constituyen un paso más en el objetivo de conseguir espacios de datos comunes, poniendo a disposición modelos de datos contrastados. Este hito, supone un gran acelerador por su trascendencia, incluso a nivel europeo, con grandes iniciativas ya en curso como la de GAIA-X.
Contenido elaborado por Juan Mañes, experto en Data Governance.
Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Blog
En cualquier proyecto relacionado con datos, es habitual contar con distintas fuentes de información. Los datos son clave para empresas y administraciones públicas, en la toma de decisiones o como base para la puesta en marcha de proyectos, servicios o productos. Pero si dichas fuentes de datos muestran la información de forma heterogénea, es complicado operar.
En el mundo de los datos abiertos, cada administración cubre un ámbito distinto, bien sea territorial – municipal, provincial, autonómico o estatal – o competencial -por ejemplo, cada ministerio aborda datos de un área concreta: transición ecológica, sanidad, movilidad, etc.-. Para poder realizar proyectos que cubran varios ámbitos, necesitaremos datos interoperables. Si no, el intercambio e integración de datos dentro de una organización y entre organizaciones será incompatible.
¿Por qué es importante la armonización de los datos?
En la actualidad, las administraciones públicas gestionan grandes cantidades de datos en distintos formatos, con diferentes métodos de gestión. Lo habitual es alojar múltiples copias en muchos repositorios diferentes. Estos datos se divulgan, a menudo, en portales por toda Europa sin ninguna armonización en términos de contenido y presentación. Este hecho explica el bajo nivel de reutilización de la información existente sobre ciudadanos y empresas. La armonización de la información permite logra datos consistentes y coherentes de manera que sean compatibles y comparables, unificando formatos, definiciones y estructuras.
Esta conformación de los datos se puede hacer de manera individual para cada proyecto, pero supone un gran coste en tiempo y recursos. Por ello es necesario impulsar estándares que nos permitan contar con unos datos ya armonizados. A continuación, se recogen varios ejemplos de iniciativas que abogan por buscar requisitos comunes, los cuales están recogidos en este visual:

El Ministerio de Transporte, Movilidad y Agenda Urbana
El Ministerio de Transporte, Movilidad y Agenda Urbana trabaja en un Punto de Acceso Nacional (PAN) en el que se recogen datos unificados de los diferentes medios de transporte. La creación de este portal responde al cumplimiento del Reglamento Delegado (UE) 2017/1926 de la Comisión, que establece la obligatoriedad para las autoridades, operadores, gestores y proveedores de servicios de transporte de suministrar información sobre desplazamientos multimodales en la UE, en base a una serie de especificaciones que aseguren su disponibilidad y fiabilidad. Entre otras cuestiones, indica que es necesario describir adecuadamente el contenido y la estructura de los datos de desplazamientos y tráfico pertinentes utilizando los metadatos apropiados.
La creación de este Punto de Acceso Único fue recogida por el BOE el pasado 22 de febrero. El texto indica que se hará pública, siempre que sea posible y de forma gratuita, la información mínima universal sobre el tráfico en relación con la seguridad vial, prestando especial atención a los servicios en tiempo real.
En este momento el PAN cuenta con datos de la DGT, el Gobierno Vasco, la Generalitat de Catalunya, el Ayuntamiento de Madrid y la empresa Tomtom.
Federación de Municipios y Provincias de España
La Federación de Municipios y Provincias de España (FEMP) cuenta con un grupo de datos abiertos que ha elaborado dos guías para ayudar a los ayuntamientos a poner en marcha iniciativas de datos abiertos. Una de ellas es la propuesta de 40 conjuntos de datos que toda administración debería abrir para facilitar la reutilización de la información del sector público. Esta guía no solo busca uniformidad en las categorías de datos publicadas, sino también en la forma en que se publican. Se ha creado una ficha para cada conjunto de datos propuesto con información acerca de la frecuencia de actualización, los formatos o la forma de visualización recomendada.
Entre los planes de futuro de la FEMP está revisar los conjuntos publicados hasta la fecha para valorar si añadir o quitar conjuntos de datos e incluir nuevos ejemplos prácticos.
También en el ámbito de las ciudades, destaca una iniciativa para aterrizar aún más la armonización de un subconjunto acotado de datasets realizada en el marco del proyecto de Ciudades Abiertas, que cuenta con la colaboración de Red.es. Los ayuntamientos participantes en el proyecto – A Coruña, Madrid, Santiago de Compostela y Zaragoza- han consensuado la apertura de 27 conjuntos de datos armonizados. Actualmente se han desarrollado vocabularios comunes para 16 de ellos y se sigue trabajando en los demás.
ASEDIE y su Top 3
En 2019, la Asociación Multisectorial de la Información (ASEDIE) puso en marcha una iniciativa para que todas las Comunidades Autónomas abriesen de manera completa tres conjuntos de datos: las bases de datos de cooperativas, asociaciones y fundaciones. Se proponía, además, que todas siguieran unos criterios unificados que facilitasen su reutilización, como la incorporación del NIF de cada una de las entidades.
Los resultados han sido muy positivos. A día de hoy, 15 comunidades autónomas tienen abiertas al menos dos de las tres bases de datos. Destaca la base de datos de Asociaciones que ha sido abierta por las 17 CC.AA.
En 2020, ASEDIE propuso un nuevo Top 3 y comenzó a impulsar la apertura de nuevas bases de datos: establecimientos comerciales, polígonos industriales y registros SAT. No obstante, debido a que no todas las CC.AA. cuentan con registro de establecimientos comerciales (debido a que no es una competencia autonómica), este conjunto de datos se ha sustituido por el Registro de Certificados de Eficiencia Energética.
UniversiData
UniversiData es un proyecto colaborativo para impulsar los datos abiertos ligados a la educación superior en España de una forma armonizada. A día de hoy, son cinco las universidades que se han unido al proyecto: la Universidad Autónoma de Madrid, la Universidad Complutense de Madrid, la Universidad Rey Juan Carlos, la Universidad de Valladolid y la Universidad Carlos III de Madrid (UC3M).
En el marco del proyecto se ha desarrollado la especificación "Núcleo Común", con el objetivo de dar respuesta a dos preguntas que las Universidades se plantean a la hora de abrir sus datos: ¿Qué datasets debo publicar? ¿Y cómo debo hacerlo? Es decir, con que campos, granularidad, formatos, codificaciones, frecuencia, etc. La codificación Núcleo Común se ha creado atendiendo a o la Ley de transparencia, acceso a la información pública y buen gobierno. Para su desarrolla también se ha tenido en cuenta dos Ránkings de Transparencia de Universidades (el de la Fundación Compromiso y Transparencia y el de Dyntra), así como el documento “Hacia una Universidad abierta: Recomendaciones para el S.U.E.”, de la Conferencia de Rectores de las Universidades Españolas (CRUE).
Todas estas iniciativas ponen de manifiesto como la armonización de datos puede mejora la utilidad de los datos. Si contamos con datos unificados, será más sencilla su reutilización, al disminuir el tiempo y el coste de su análisis y gestión.
Contenido elaborado por el equipo de datos.gob.es.
Noticia
La iniciativa de datos abiertos del Gobierno de Aragón surgió mediante acuerdo en 2012 con el objetivo de crear valor económico en el Sector TIC a través de la reutilización de la información pública, el aumento de la transparencia y el fomento de la innovación. Todo ello para favorecer el desarrollo de la sociedad de la información y la interoperabilidad de datos en la Administración. Gracias a este acuerdo los datos abiertos se incorporan dentro de las estrategias del Gobierno de Aragón, quien se compromete a la efectiva apertura de datos públicos que obran en su poder, entendiendo como públicos todos aquellos datos no sujetos a restricciones de privacidad, seguridad o propiedad.
En este contexto, en el año 2013, se pone en marcha el portal web de datos abiertos del Gobierno de Aragón. Desde entonces, Aragón Open Data ha tenido un crecimiento exponencial, impulsado por la unidad responsable de su gestión, actual Dirección General de Administración Electrónica y Sociedad de la Información, y cómo no, por los diferentes proveedores de datos: unidades públicas en su mayoría del Gobierno autonómico. Estos proveedores han hecho posible que sus datos se ofrezcan bajo la filosofía de los datos abiertos desde un único punto de acceso.
Desde la creación del portal se han desarrollado más servicios, como por ejemplo la Aragopedia, Presupuesto u Open Analytics Data. Todos ellos giran en torno a la reutilización y disposición de datos abiertos mediante servicios que facilitan su uso e interpretación. En esta línea, Aragón Open Data ofrece diversas aplicaciones de uso y explotación de sus medios, junto con materiales de formación, sin olvidar la promoción de APIs y servicios que den valor añadido a los propios datos. Por estos trabajos la iniciativa fue seleccionada como única experiencia española en la Open Data Leader's Network celebrada en Londres en 2016.
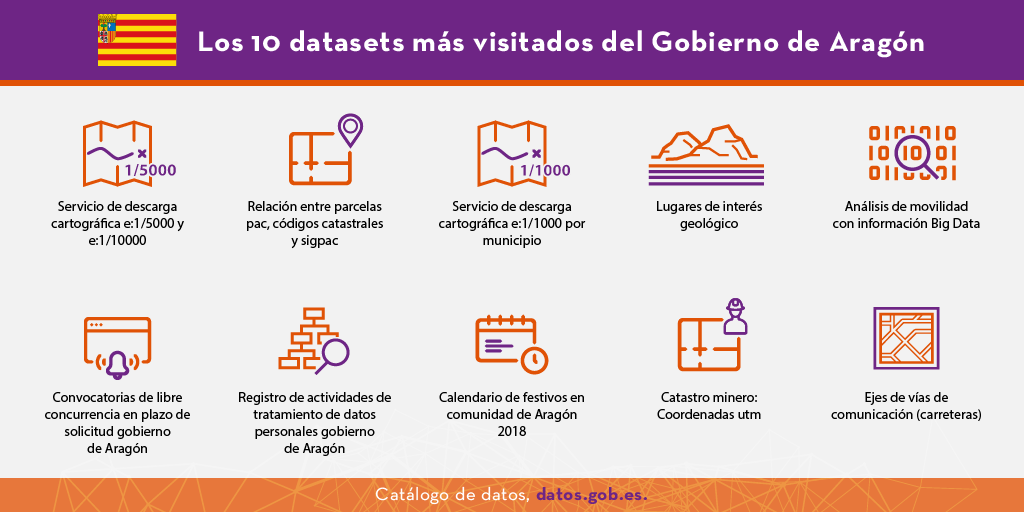
Entre los recursos más descargados del portal destacan: Servicio de descarga cartográfica e:1/1000 por municipio, Contratos Gobierno de Aragón, listado de los Municipios de Aragón o los calendarios anuales de festivos de la Comunidad Autónoma y sus provincias.
En este amplio y diverso marco, Aragón Open Data también inició en 2016 un trabajo de identificación e integración de la diversidad de datos generados por el Gobierno de Aragón para facilitar su disposición y apertura. El primer paso fue generar una ontología, la Estructura de Información Interoperable de Aragón EI2A. Para ello contaron con la colaboración de las unidades que disponen, crean y gestionan datos, participando diferentes áreas del Gobierno de Aragón como por ejemplo agricultura, hacienda, cultura, información de datos geográficos o medio ambiente, entre otras.
La Estructura de Información Interoperable de Aragón (EI2A) homogeniza estructuras, vocabularios y características dentro del marco de Aragón Open Data para resolver, en buena parte, la problemática de la diversidad y heterogeneidad de datos existentes en la Administración. Una heterogeneidad que es fiel reflejo de la realidad y competencias de la Administración, pero que dificulta su apertura y reutilización.
El EI2A describe el modelo conceptual y lógico de los datos generados por el Gobierno de Aragón representando entidades, propiedades y relaciones. La estructura está destinada a apoyar la interoperabilidad de los datos bajo su dominio mediante su estandarización. La Estructura de Información Interoperable de Aragón tiene como objetivo relacionar el contenido y elementos de los diferentes conjuntos de datos para que puedan ser normalizados y explotados de manera conjunta en el Gobierno de Aragón, al aunar, simplificar y dar homogeneidad a los mismos, independientemente de su procedencia, finalidad, modelo, entidades y relaciones que los componen.
Es en el 2017 y 2018 cuando el EI2A se convierte en una realidad al ponerse en práctica con algunos de los datos de Aragón Open Data, surgiendo el proyecto Aragón Open Data Pool. Aragón Open Data Pool es un proyecto piloto e innovador que demuestra la importancia de centralizar datos y servirlos para favorecer su uso y explotación. Open Data Pool está disponible desde diciembre de 2018 siendo su base el EI2A.
Como resultado: más de 140 fuentes de datos de organismos y finalidades bien diferenciadas, que estaban abiertas previamente en Aragón Open Data (API GA_OD_Core), se han normalizado conforme al EI2A, para así, desde un único punto y con los mismos criterios de consulta, poder ser explotados en conjunto y ofrecidos de manera sencilla.
Los datos de este proyecto cuentan con los estándares de la web semántica para su explotación, consulta y uso (SPARQL endpoint), que es su verdadero potencial. Ello permite poder consultar y explotar datos independientemente de sus características y vocabularios e incluso también permite federar datos de portales de diferentes administraciones como Aragón Open Data (bajo el EI2A) y Open Data Euskadi ( bajo ELI).
Otro de los aspectos destacables es que se ha orientado su uso a un usuario no técnico, al permitir una navegación más intuitiva y sencilla a través de las relaciones entre datos, poniendo en práctica la interoperabilidad mediante la relación de datos diversos a través de una navegación web corriente.
Con este proyecto, que ha contribuido a conocer mejor la realidad de los datos incorporados a Aragón Open Data Pool bajo el EI2A, se confirma la necesidad de la normalización de los datos en origen, para abrirlos y ofrecerlos en Aragón Open Data, facilitando su uso y reutilización a nivel interno de la Administración y hacia fuera de esta. Y es aquí donde entra en juego el cambio necesario que buscan las directrices de interoperabilidad y reutilización de datos para su apertura en el punto de acceso de datos abiertos del Gobierno de Aragón, que a día de hoy corresponde a un proyecto normativo. Entre sus ejes de acción, este proyecto consiste en identificar mejor los datos, mejorar su calidad en origen, y respaldar el proceso desde la creación de los datos por las diferentes unidades productoras, a nivel interno, hasta su apertura en Aragón Open Data. De esta forma se busca seguir creciendo, mejorando y orientarse a que cualquier interesado, instituciones, desarrolladores o el sector infomediario puedan utilizar la información, los datos y los servicios disponibles para cualquiera de sus intereses, contribuyendo así al desarrollo de la sociedad de la información.