Blog
España fue el segundo país del mundo que más turistas recibió durante 2019, con 83,8 millones de visitantes. La actividad turística supuso ese año el 12,4% del PIB, empleando a más de 2,2 millones de personas (12,7% del total). Se trata por tanto de un sector fundamental para nuestra economía.
Estas cifras se han visto reducidas debido a la pandemia, pero se espera que el sector se vaya recuperando en los próximos meses. A ello pueden ayudar los datos abiertos. Contar con información actualizada puede generar beneficios a todos los actores implicados en esta industria:
- Turistas: El open data ayuda a los turistas a planificar sus viajes, dotándoles de la información necesaria para elegir donde alojarse o qué actividades realizar. La información actualizada que pueden proporcionar los datos abiertos cobra especial importancia en tiempos de COVID. Existen distintos portales que recogen información y visualizaciones de las restricciones de viaje, como Humanitarian Data Exchange, de las Naciones Unidas. Esta web alberga un mapa interactivo actualizado diariamente con las restricciones de viaje por país y compañía aérea.
- Empresas. Las empresas pueden generar distintas aplicaciones dirigidas a los viajeros, con información de utilidad. Además, analizando los datos, los establecimientos turísticos pueden detectar mercados y destinos sin explotar. También pueden personalizar sus ofertas e incluso crear sistemas de recomendaciones que ayuden a la promoción de diversas actividades, con un impacto positivo en la experiencia de los viajeros.
- Administraciones Públicas. Cada vez más gobiernos están implementando soluciones para captar y analizar datos de distintas fuentes en tiempo real, con el fin de conocer mejor el comportamiento de sus visitantes. Ejemplo de ello son Segovia, Mallorca y Gran Canaria. Gracias a estas herramientas podrán definir estrategias y tomar decisiones informadas, por ejemplo, dirigidas a evitar masificaciones. En este sentido, herramientas como Affluences permiten informar de la ocupación de museos, piscinas y tiendas en tiempo real, y obtener predicciones para las sucesivas franjas horarias.
Los beneficios de contar con datos de calidad relacionados con el turismo es tal que no es de extrañar que el Gobierno de España haya elegido este sector como prioritario a la hora de crear espacios de datos que permitan la compartición voluntaria de datos entre organizaciones. De esta forma se podrán cruzar datos de distintas fuentes, enriqueciendo los diversos casos de uso.
Los datos utilizados en este ámbito son muy diversos: datos sobre consumo, transporte, actividades culturales, tendencias económicas o incluso sobre la predicción meteorológica. Pero para poder aprovechar bien estos datos altamente dinámicos es necesarios que estén a disposición de los usuarios en formatos adecuados, actualizados y que el acceso se pueda automatizar a través de interfaces de programación de aplicaciones (APIs).
Ya son muchas las organizaciones que ofrecen datos a través de APIs. En esta infografía puedes ver varios ejemplos ligados a nuestro país a nivel nacional, autonómico y local. Pero además de portales de datos generalistas, también encontramos APIs en plataformas de datos abiertos ligadas exclusivamente al sector turismo. En la siguiente infografía puedes ver varios ejemplos:

Haz clic aquí para ver la infografía en tamaño completo y en su versión accesible
¿Conoces más ejemplos de APIs u otros recursos que faciliten el acceso a los datos abiertos relacionados con el turismo? ¡Déjanos un comentario o escribe a datos.gob.es!
Contenido elaborado por el equipo de datos.gob.es.
Blog
El pasado diciembre el Congreso de los Diputados aprobó el Real Decreto-ley 24/2021, que incluía la transposición de la Directiva (UE) 2019/1024, relativa a los datos abiertos y la reutilización de la información del sector público. Con este Real Decreto se modifica la Ley 37/2007 sobre reutilización de la información del sector público, incluyendo nuevos requisitos para los organismos públicos, entre los que se encuentra el facilitar el acceso a los datos de alto valor.
Los datos de alto valor son aquellos cuya reutilización está asociada a considerables beneficios para la sociedad, el medio ambiente y la economía. Inicialmente, la Comisión Europea destacó como datos de alto valor aquellos pertenecientes a las categorías de datos geoespaciales, ambientales, meteorológicos, estadísticos, relativos a sociedades y de movilidad, aunque estas clases pueden ser ampliadas tanto por, la Comisión como por el Ministerio de Asuntos Económicos y Transformación Digital a través de la Oficina del Dato. De acuerdo con la Directiva, este tipo de datos “se pondrán a disposición para su reutilización en un formato legible por máquina, a través de interfaces de programación de aplicaciones adecuadas y, cuando proceda, en forma de descarga masiva”. Es decir, entre otras cuestiones, se hace necesario el contar con una API.
¿Qué es una API?
Una interfaz de programación de aplicaciones o API (la abreviatura en inglés de Application Programming Interfaces) es un conjunto de definiciones y protocolos que permite el intercambio de información entre sistemas. Cabe destacar que existen distintos tipos de APIs en base a su arquitectura, protocolos de comunicación y sistemas operativos.
Las APIs suponen una serie de ventajas para los desarrolladores, ya que permiten automatizar el consumo de datos y metadatos, facilitan la descarga masiva y optimizan la recuperación de información al admitir funcionalidades de filtrado, ordenación y paginación. Todo ello repercute en un ahorro tanto económico como de tiempo.
En este sentido, muchos portales de datos abiertos de nuestro país ya cuentan con sus propias APIs para facilitar el acceso a datos y metadatos. En la siguiente infografía puedes ver algunos ejemplos a nivel nacional, autonómico y local, incluyendo información sobre la API de datos.gob.es. La infografía también incluye información breve sobre qué es una API y qué se necesita para poder utilizarlas.

Haz clic aquí para ver la infografía en tamaño completo y en su versión accesible
Estos ejemplos ponen de manifiesto el esfuerzo que los organismos públicos de nuestro país están haciendo para facilitar el acceso a la información que custodian de forma más eficiente y automatizada, con el fin de impulsar la reutilización de sus datos abiertos.
En datos.gob.es contamos con una Guía práctica para la publicación de datos abiertos usando APIs donde se detallan una serie de pautas y buenas prácticas para definir e implementar este mecanismo en un portal open data.
Contenido elaborado por el equipo de datos.gob.es.
Documentación
En una plataforma como datos.gob.es, donde la frecuencia de actualización de los conjuntos de datos es constante, es necesario contar con mecanismos que faciliten la realización de consultas de forma masiva y automática.
En datos.gob.es contamos con una API y un punto SPARQL para facilitar esta tarea. Ambas herramientas permiten consultar los metadatos asociados a los conjuntos de datos del Catálogo Nacional de datos abiertos en base a las definiciones incluidas en la Norma Técnica de Interoperabilidad de Reutilización de recursos de información (NTI-RISP). En concreto, la base de datos semántica de datos.gob.es contiene dos grafos, uno que contiene todo el Catálogo de datos y otro con las URIs correspondientes a la taxonomía de sectores primarios y a la identificación de cobertura geográfica en base a la NTI.
Para ayudar a los reutilizadores a realizar sus búsquedas a través de estas funcionalidades, ponemos a disposición de los usuarios dos vídeos que muestran de manera sencilla los pasos a seguir para sacar el máximo partido a ambas herramientas.
Vídeo 1: ¿Cómo realizar consultas al catálogo de datos.gob.es a través de una API?
Una interfaz de programación de aplicaciones o API es un mecanismo que permite la comunicación e intercambio de información entre sistemas. Gracias a la API de datos.gob.es puedes consultar de forma automática los conjuntos de datos de un publicador, los datasets que pertenecen a una temática determinada o los que están disponibles en un formato concreto, entre otras muchas consultas.
El vídeo muestra:
- Cómo usar la API de datos.gob.es
- Qué tipos de consultas se pueden realizar utilizando dicha API
- Un ejemplo para aprender a listar los datasets que hay en el catálogo
- Qué otras Iniciativas de Datos Abiertos están publicando APIs
- Cómo se pueden consultar otras API disponibles
También tienes a tu disposición con una infografía con ejemplos de APIs para el acceso a datos abiertos.
Vídeo 2: ¿Cómo realizar consultas al catálogo de datos.gob.es a través del punto SPARQL?
Un punto SPARQL es una forma alternativa de consultar los metadatos del catálogo de datos.gob.es utilizando un servicio que permite realizar consultas sobre grafos RDF utilizando el lenguaje SPARQL.
Con este vídeo, podrás ver:
- Cómo usar el punto SPARQL de datos.gob.es
- Qué consultas se pueden realizar utilizando el punto SPARQL
- Qué métodos existen para consultar el punto SPARQL
- Ejemplos sobre cómo realizar una consulta para conocer qué conjuntos de datos están disponibles en el catálogo o cómo obtener la lista de todos los organismos que publican datos en el catálogo
- Incluye además ejemplos de puntos SPARQL en diferentes iniciativas del ámbito nacional
Estos vídeos están dirigidos principalmente a reutilizadores de datos. Desde datos.gob.es también hemos preparado una serie de vídeo para publicadores donde se explican las diversas funcionalidades que tienen a su disposición en la plataforma.
Blog
La vida ocurre en tiempo real y buena parte de nuestra vida, hoy, discurre en el mundo digital. Los datos, nuestros datos, son la representación de cómo vivimos experiencias híbridas entre lo físico y lo virtual. Si queremos saber lo que ocurre a nuestro alrededor, debemos de analizar los datos en tiempo real. En este post, te explicamos cómo.
Introducción
Imaginemos la siguiente situación: entramos en nuestra tienda online favorita, buscamos un producto que queremos y nos sale un mensaje en la pantalla que dice que el precio del producto mostrado es de hace una semana y no tenemos información del precio actual del mismo. Alguien encargado de los procesos de datos de esa tienda online, podría decir que este es el comportamiento esperado puesto que las cargas de la base de datos de precios desde el sistema central hacia los e-commerce son semanales. Afortunadamente, esta experiencia online es impensable hoy en día en una e-commerce, pero lejos de lo que podría pensarse, es una situación habitual en muchos otros procesos de las empresas y organizaciones. A todos nos habrá pasado que estando dados de alta en alguna base de datos de algún comercio, cuándo acudimos a una tienda diferente a nuestra tienda habitual, opps!, resulta que no figuramos cómo clientes. De nuevo, esto se debe a que el procesamiento de los datos (en este caso la base de datos de clientes) se encuentra centralizada y las cargas hacia sistemas periféricos (servicio post-venta, distribuidores, canal comercial) se hacen en modo por lotes o batch. Esto, en la práctica, significa que la actualización de datos puede tardar días o incluso semanas.
En el ejemplo anterior, el pensamiento en modo por lotes o batch de los datos, puede arruinar, sin saberlo, la experiencia de un cliente o un usuario. El pensamiento en batch puede ocasionar graves consecuencias cómo: la pérdida de un cliente, el empeoramiento de la imagen de marca o la fuga de los mejores empleados.
Beneficios de usar datos en tiempo real
Existen situaciones en las que simplemente, los datos son en tiempo real o no lo son. Un ejemplo muy reconocible es el caso de las transacciones, bancarias o de cualquier otro tipo. No podemos imaginarnos que el pago en un comercio no se produzca en tiempo real (aunque a veces los terminales de pago se queden sin cobertura y esto origine molestas situaciones en los comercios físicos). Tampoco puede (o debe) ocurrir, que al paso por un peaje en una autopista, la barrera no se abra a tiempo (aunque probablemente todos hayamos vivido alguna situación rocambolesca en este contexto).
Sin embargo, en muchos procesos y situaciones puede ser razón de debate y discusión si implementar una estrategia de datos en tiempo real o simplemente seguir aproximaciones convencionales, intentando tener un decalaje en los tiempos de análisis (de datos) y respuesta lo más bajos posible. A continuación, listamos algunos de los beneficios más importantes de implementar estrategias de datos en tiempo real:
- Reacción inmediata ante un error. Los errores ocurren y con los datos no es diferente. Si disponemos de un sistema de monitorización y alertas en tiempo real, reaccionaremos antes de que sea demasiado tarde ante un error.
- Mejora drástica de la calidad del servicio. Cómo hemos comentado, no disponer de la información adecuada en el momento en que se necesita, puede arruinar la experiencia de nuestro servicio y con ello la pérdida de clientes o potenciales clientes. Si nuestro servicio falla, debemos de conocerlo inmediatamente para poder enmendarlo y solucionarlo. Esto es lo que marca la diferencia entre las organizaciones que se han adaptado a la transformación digital y las que no.
- Incrementar las ventas. No disponer de los datos en tiempo real, puede hacerte perder mucho dinero y rentabilidad. Imaginemos el siguiente ejemplo, que veremos con más detalle en la sección práctica. Si tenemos un negocio en el que el servicio que prestamos depende de una capacidad limitada (una cadena de restaurantes, hoteles o un parking, por ejemplo) nos interesa disponer de nuestros datos de ocupación en tiempo real, puesto que eso implica que podamos vender de forma más dinámica nuestra capacidad de servicio disponible.
La parte tecnológica del tiempo real.
Durante años, los análisis de datos se plantearon desde el origen en modo batch. Cargas de datos históricos, cada cierto tiempo, en procesos que se ejecutan solo bajo ciertos condicionantes. La razón es que existe cierta complejidad tecnológica debajo de la posibilidad de capturar y consumir datos en el mismo momento en el que estos se generan. Los almacenamientos de datos tradicionales, las bases de datos (relacionales), por ejemplo, tienen ciertas limitaciones para trabajar con transacciones rápidas y para ejecutar operaciones sobre los datos en tiempo real. Existe una cantidad ingente de documentación a este respecto y sobre cómo las soluciones tecnológicas han ido incorporando tecnología para superar estas barreras. No es el objetivo de este post entrar en los detalles técnicos de las tecnologías para alcanzar el objetivo de capturar y analizar datos en tiempo real. Sin embargo, comentaremos que existen dos paradigmas claros para construir soluciones de tiempo real que no tienen por qué ser excluyentes.
- Las soluciones basadas en mecanismos y flujos clásicos de captura, almacenamiento (persistencia) y exposición de datos a canales de consumo concretos (cómo una página web o un API).
- Las soluciones basadas en mecanismos de disponibilización de eventos, en los que el dato, se genera y se publica con independencia de quién y cómo lo vaya a consumir.
Un ejemplo práctico
Cómo acostumbramos a hacer en este tipo de posts, tratamos de ilustrar el tema del post con un ejemplo práctico con el que el lector pueda interactuar. En este caso, vamos a utilizar un conjunto de datos abiertos del catálogo de datos.gob.es. En particular, vamos a utilizar un conjunto de datos que contiene información sobre la ocupación de plazas de aparcamientos públicos en el centro de la ciudad de Málaga. El conjunto de datos se encuentra disponible en este enlace y se puede explorar en profundidad a través de este enlace. Los datos son accesibles a través de este API. En la descripción del conjunto de datos se indica que la frecuencia de actualización es cada 2 minutos. Cómo hemos comentado anteriormente, este es un buen ejemplo en el que disponer de los datos en tiempo real[1] tiene importantes ventajas tanto para el prestador del servicio cómo para los usuarios del mismo. No hace muchos años era difícil pensar en disponer de esta información en tiempo real y nos conformábamos con información agregada a final de semana o mes sobre la evolución de la ocupación de las plazas de aparcamiento.
A partir del conjunto de datos hemos construido una app interactiva donde el usuario puede observar en tiempo real el nivel de ocupación mediante unas visualizaciones gráficas. El lector tiene a su disposición el código del ejemplo para reproducirlo en cualquier momento.
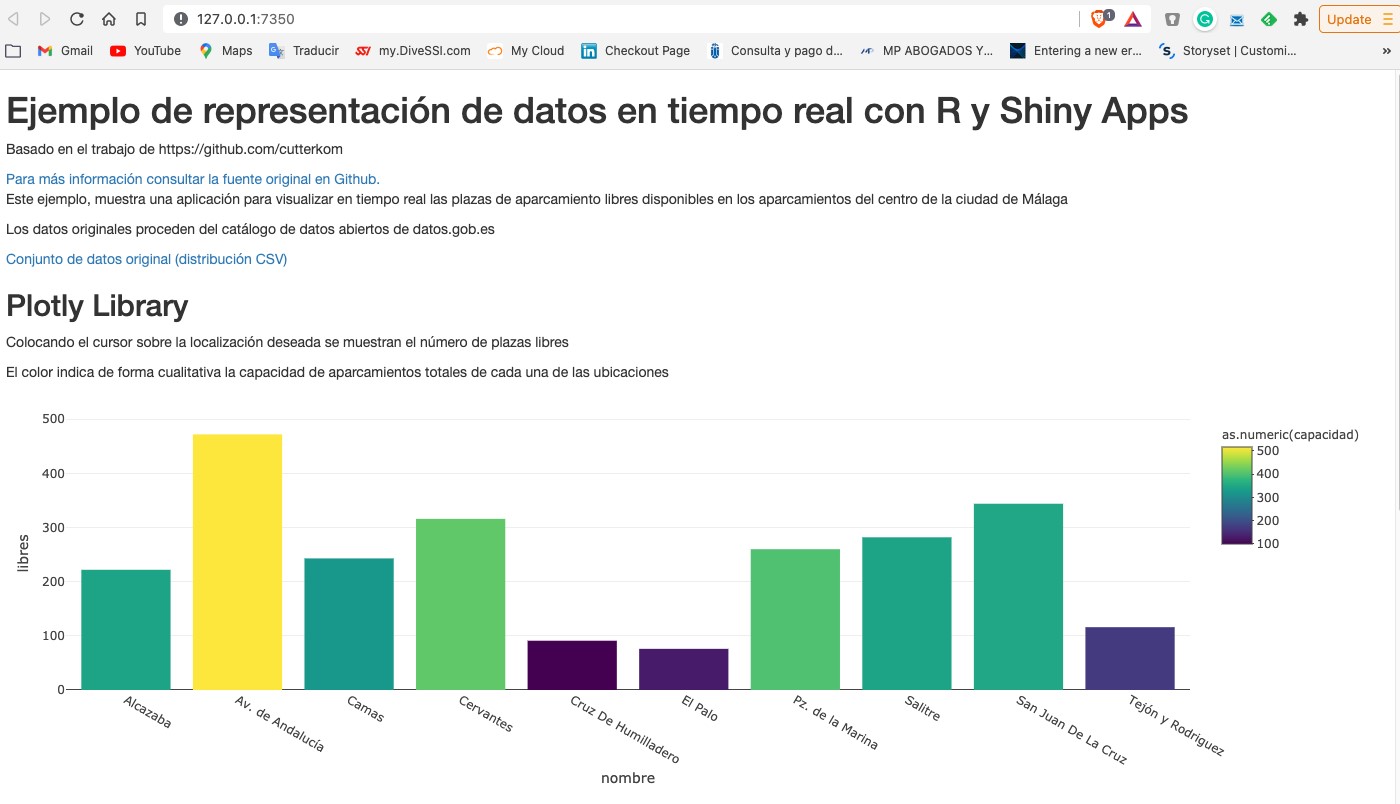
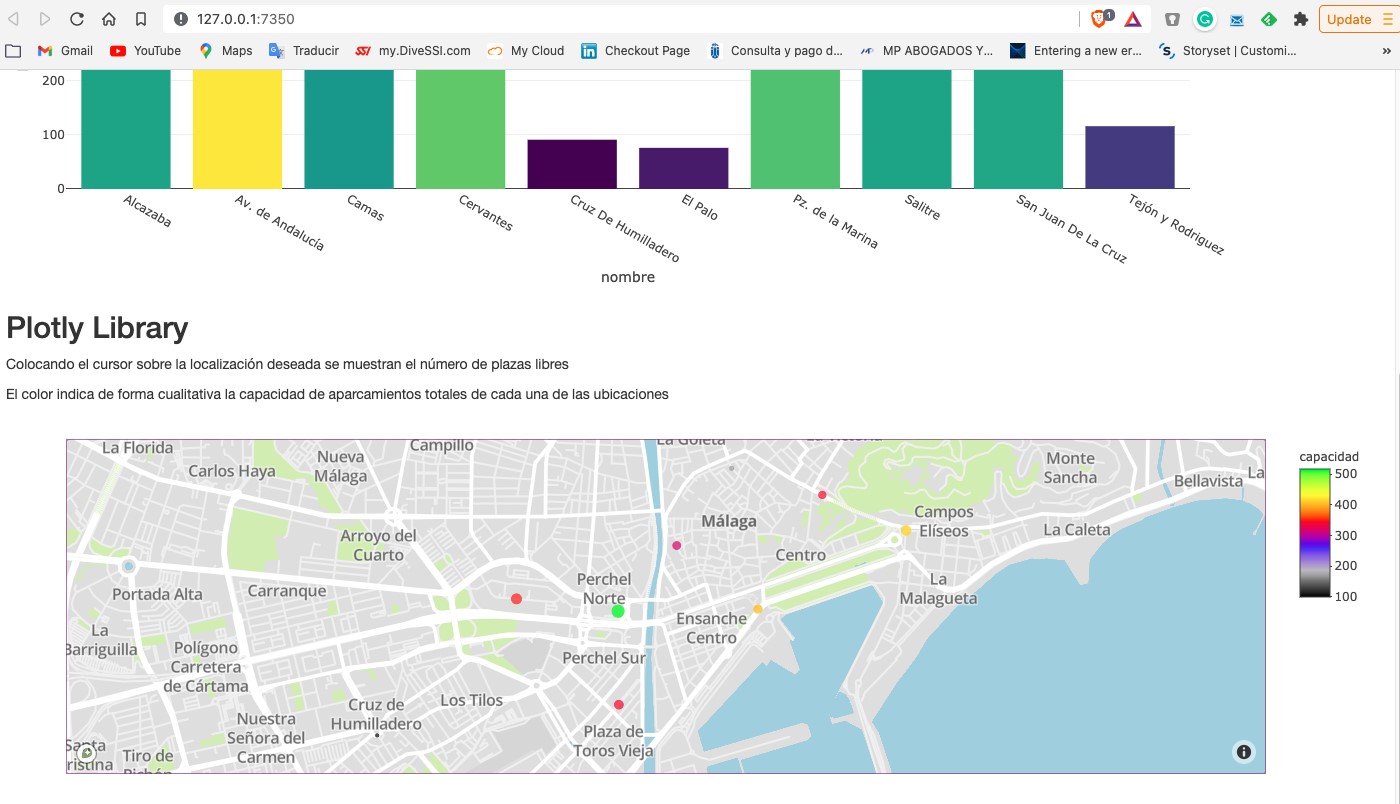
En este ejemplo, hemos visto cómo, desde el momento en que los sensores de ocupación comunican su estado (libre u ocupado) hasta que nosotros consumimos los datos en una aplicación web, estos mismos datos han pasado por varios sistemas e incluso han tenido que ser convertidos a un fichero de texto para exponerlos al público. Un sistema mucho más eficiente sería publicar los datos en un broker de eventos al que poder suscribirse con tecnologías de tiempo real. En cualquier caso, a través de esta API somos capaces de capturar estos datos en tiempo real y representarlos en una aplicación web lista para su consumo y todo esto con menos de 150 líneas de código. ¿Te animas a probarlo?
Concluyendo, la importancia de los datos en tiempo real es fundamental ya en la mayoría de procesos, no solo la gestión de espacios o el comercio online. A medida que el volumen de datos en tiempo real aumenta, es necesario modificar nuestra forma de pensar desde una perspectiva batch o por lotes hacia un mindset real-time first. Es decir, pensemos directamente que los datos han de estar disponibles para su consumo en tiempo real desde el momento en el que se generan intentando minimizar el número de operaciones que hacemos con ellos antes de poder consumirlos.
[1] El término tiempo real puede ser ambiguo en determinados casos. En el contexto de este post, podemos considerar que tiempo real es el tiempo de actualización de datos característico que sea relevante en el dominio particular en el que estemos trabajando. Por ejemplo, en este caso de uso una frecuencia de actualización de 2 min es suficiente y puede considerarse tiempo real. Si estuviéramos analizando un caso de uso de cotizaciones de bolsa el concepto de tiempo real sería del orden de segundos.
Contenido elaborado por Alejandro Alija,experto en Transformación Digital e Innovación.
Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Blog
Hace un par de semanas, comentamos a través de este artículo la importancia de las herramientas de análisis de datos para generar representaciones que permitan comprender mejor la información y tomar decisiones más acertadas. En dicho artículo dividimos estas herramientas en 2 categorías: herramientas de visualización de datos genéricas - como son Kibana, Tableau Public, SpagoBI (actual Knowage) y Grafana - y las librerías y APIs de visualización. Este nuevo post se lo vamos a dedicar a las segundas.
Las librerías y APIs de visualización son más versátiles que las herramientas de visualización genéricas, pero para poder trabajar con ellas es necesario que el usuario conozca del lenguaje de programación donde se implemente la librería.
Existe una amplia gama de librerías y APIs para diferentes lenguajes de programación o plataformas, que implementan funcionalidades relacionadas con la visualización de datos. A continuación, os mostraremos una selección tomando como criterio fundamental la popularidad que les otorga la Comunidad de usuarios.
Google Chart Tools
Funcionalidad:
Google Chart Tools es la API de Google para la creación de visualizaciones interactivas. Permite la creación de dashboards utilizando diferentes tipos de widgets, como selectores de categoría, rangos temporales o autocompletadores, entre otros.
Principales ventajas:
Se trata de una herramienta muy fácil de usar e intuitiva, que permite la interacción con datos en tiempo real. Además, las visualizaciones generadas pueden ser integradas en portales webs utilizando tecnología HTML5/SVG.
¿Quieres saber más?
-
Materiales de ayuda: En Youtube encontramos diversos tutoriales elaborados por usuarios de la API.
-
Repositorio: En Github podemos acceder a una biblioteca común para los paquetes de gráficos, así como conocer los tipos de gráficos compatibles y ejemplos de cómo personalizar los componentes de cada gráfico, entre otros.
-
Comunidad de usuarios: Los usuarios de Google Chart Tools pueden plantear sus dudas en la comunidad de Google, en el espacio habilitado para ello.
JavaScript InfoVis Toolkit
Funcionalidad:
JavaScript InfoVis Toolkit es la librería de JavaScript que proporciona funciones para la creación de múltiples visualizaciones interactivas como mapas, árboles jerárquicos o gráficos de líneas.
Principales ventajas:
Es eficiente en el manejo de estructuras de datos complejas y dispone de una gran diversidad de opciones de visualización, por lo que se adapta a cualquier necesidad del desarrollador.
¿Quieres saber más?
-
Materiales de ayuda: Este manual de usuario explica las principales opciones de visualización y cómo trabajar con la librería. También hay disponibles demos para la creación de diferentes tipos de gráficos.
-
Repositorio: Los usuarios deben descargar el proyecto de http://thejit.org, aunque también tienen disponible un repositorio en Github donde, entre otras cosas, pueden descargar extras.
-
Comunidad de usuarios: Tanto en la comunidad de usuarios de Google como en Stackoverflow encontramos espacios dedicados a JavaScript InfoVis Tookit para que los usuarios compartan dudas y experiencias.
Data-Driven Documents (D3.js)
Funcionalidad:
Data-Driven Documents (D3.js) es la librería de Javascript que permite la creación de gráficos interactivos y visualizaciones complejas. Gracias a ella se pueden manipular documentos basados en datos usando estándares abiertos de la web (HTML. SVG y CSS), de forma que los navegadores puedan interpretarlos para crear visualizaciones independientemente del software propietario.
Principales ventajas:
Esta librería permite la manipulación de un DOM (Modelo en Objetos para la Representación de Documentos) aplicando las transformaciones necesarias a la estructura en función de los datos vinculados a un documento HTML o XML. Esto proporciona una versatilidad prácticamente ilimitada.
¿Quieres saber más?
-
Materiales de ayuda: En Github puedes encontrar numerosos tutoriales, aunque principalmente dedicados a las versiones antiguas (actualmente están en proceso de actualizar esta sección de la wiki y escribir nuevos tutoriales sobre la versión 4.0 de D3).
-
Repositorio: También en Github encontramos hasta 53 repositorios, que abarcan distintos materiales para gestionar miles de animaciones simultáneas, agrupar puntos bidimensionales en bandejas hexagonales o trabajar con el módulo d3-color, entre otros. En esta galería puedes ver algunos de los trabajos realizados.
-
Comunidad de usuarios: Existen espacios de discusión sobre D3 en la Comunidad de Google, Stackoverflow, Gitter y Slack.
-
Redes sociales: En la cuenta de Twitter @d3js_org se comparten experiencias, novedades y casos de uso. También existe un grupo en LinkedIn.
Matplotlib
Funcionalidad:
Matplotlib es una de las librerías más populares en Python para la creación de visualizaciones y gráficos de alta calidad. Se caracteriza por presentar una organización jerárquica que va desde el nivel más general, como puede ser el contorno de una matriz 2D, hasta un nivel muy específico, como puede ser colorear un pixel determinado.
Principales ventajas:
Matplotlib soporta texto y etiquetas en formato LaTeX. Además, los usuarios pueden personalizar su funcionalidad a través de paquetes diseñados por terceros (Cartopy, Ridge Map, holoviews, entre otros).
¿Quieres saber más?
-
Materiales de ayuda: En su propia web encontramos una guía de usuario que incluye información sobre la instalación y el uso de las diversas funcionalidades. También hay disponibles tutoriales para usuarios tanto principiantes, como intermedios o avanzados.
-
Repositorio: En este repositorio Github están los materiales que necesitas para su instalación. En la web puedes ver una galería con ejemplos de trabajos para tu inspiración.
-
Comunidad de usuarios: La web oficial dispone de una sección de comunidad, aunque también puedes encontrar grupos de usuarios que te ayuden con tus dudas en Stackoverflow y Gitter.
-
Redes sociales: En el perfil de Twitter @matplotlib también se comparten ejemplos de visualizaciones y trabajos de usuarios, así como información sobre las últimas novedades de la herramienta.
Bokeh
Funcionalidad:
Bokeh es la librería de Python orientada a la creación de gráficas interactivas basadas en HTML/JS. Tiene la capacidad de generar visualizaciones interactivas con características como, texto flotante, zoom, filtros o selecciones, entre otros.
Principales ventajas:
Su principal ventaja es la simplicidad en la implementación: con pocas líneas de código se pueden crear visualizaciones interactivas complejas. Además, permite embeber código JavaScript para implementar funcionalidades específicas.
¿Quieres saber más?
-
Materiales de ayuda: Esta guía del usuario proporciona descripciones detalladas y ejemplos que describen muchas tareas comunes que se puede realizar con Bokeh. En la web de Bokeh también encontramos este tutorial y ejemplos de aplicaciones construidas con esta herramienta.
-
Repositorio: En este repositorio Github están los materiales e instrucciones para su instalación, así como ejemplos de uso. También hay ejemplos disponibles en esta galería.
-
Comunidad de usuarios: La comunidad oficial se encuentra en la propia web de Bokeh, aunque los usuarios de esta herramienta también se reúnen en Stackoverflow.
-
Redes sociales: Para estar al día de las novedades, puedes seguir la cuenta de Twitter @bokeh o su perfil en LinkedIn.
La siguiente tabla muestra un resumen de las herramientas mencionadas anteriormente:
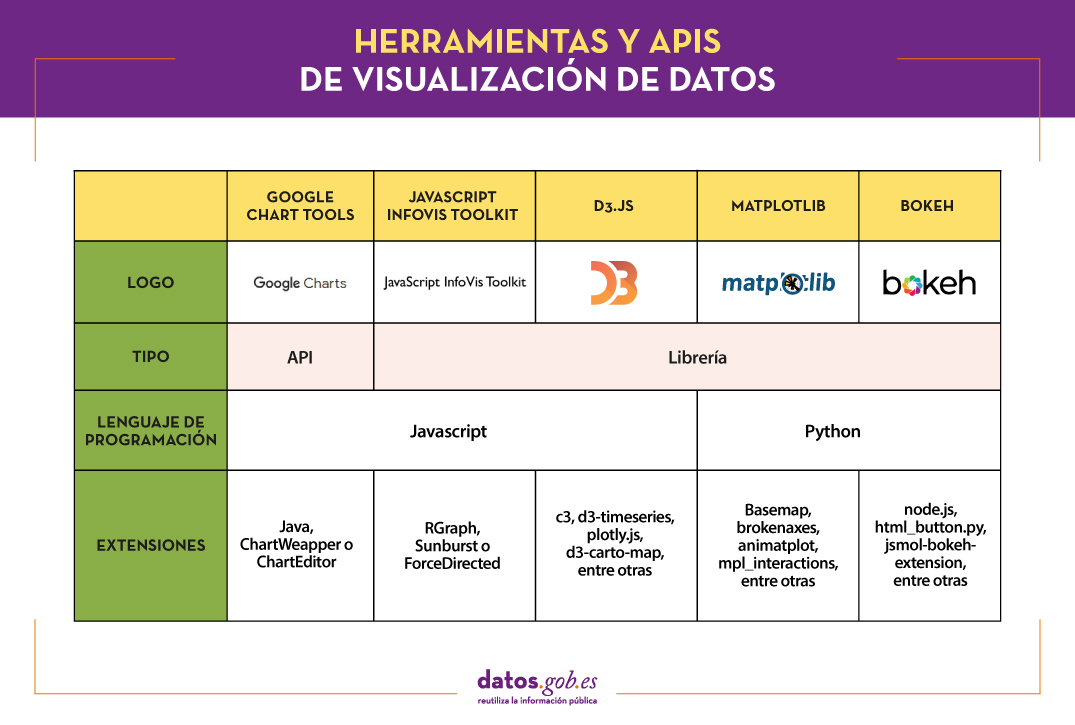
¿Estás de acuerdo con nuestra selección? Te invitamos a compartir tu experiencia con estas u otras herramientas en la sección de comentarios.
Si estás buscando herramientas para ayudarte en el procesamiento de datos, desde datos.gob.es ponemos a tu disposición el informe “Herramientas de procesado y visualización de datos”, recientemente actualizado, así como los siguientes artículos monográficos:
- Las herramientas de análisis de datos más populares
- Las herramientas de depuración y conversión de datos más populares
- Las herramientas de visualización de datos más populares
- Las herramientas de visualización geoespacial más populares
- Las herramientas de análisis de redes más populares
Contenido elaborado por el equipo de datos.gob.es.
Blog
Cuando hablamos de infraestructuras, la base de nuestra civilización moderna se basa en hormigón y acero. Miremos donde miremos, las grandes estructuras cómo carreteras, edificios, coches, trenes y aviones están hechas de hormigón y metal. En el mundo digital, todo está hecho de datos y APIs. Desde que nos levantamos por la mañana y miramos nuestro móvil interactuamos con datos y APIs.
Introducción
Cuando revisamos nuestro email, nos preguntamos el tiempo que va a hacer o comprobamos nuestra ruta en coche, lo hacemos a través de aplicaciones (móviles, web o de escritorio) que hacen uso de las APIs para devolvernos los datos que solicitamos. Ya hemos hablado con anterioridad, largo y tendido de las APIs, a través de diversos contenidos donde hemos explicado, por ejemplo, cómo publicar datos abiertos utilizando este mecanismo o cómo garantizar que las Apis cumplen con determinadas especificaciones.
Las APIs son las interfaces mediante las cuales los programas informáticos hablan entre sí e intercambian información. El actual estándar absoluto de las APIs es la tecnología REST. Hace tiempo que REST sustituyó a SOAP como tecnología preferente para comunicar unas aplicaciones con otras a través de Internet. REST utiliza el protocolo HTTPs cómo medio de transporte para hacer preguntas y obtener respuestas. Por ejemplo, la app de AEMET, ejecuta una consulta vía REST utilizando HTTPs a través de Internet hacia los servidores de AEMET. Cuando los servidores de AEMET (lo que se conoce cómo la API de AEMET) recibe la consulta concreta, devuelve la información a nuestro móvil tal y cómo esté programado. Todo esto suele ocurrir muy rápido (en menos de un segundo habitualmente) y es inapreciable para nosotros.
Sin lugar a dudas la mayoría de los productos digitales se basan en API REST para su funcionamiento. Los productos de datos no son una excepción y la gran mayoría adoptan este estándar para su funcionamiento. Sin embargo, pese a la gran aceptación y flexibilidad de REST, éste, no es perfecto, y algunas de sus limitaciones impactan negativamente en el desarrollo de productos muy orientados a datos. Algunas de sus limitaciones más evidentes son:
- REST es todo o nada. Cuando se hace una consulta se obtiene el resultado íntegro que está programado. Por ejemplo, si se quiere consultar un usuario en una base de datos, normalmente se hace una llamada (al endpoint) de usuarios y se obtiene la lista completa de usuarios.
- REST, a menudo, requiere varias llamadas para obtener los datos deseados. Siguiendo con el ejemplo anterior, si se desea consultar el saldo de una cuenta bancaria de un usuario, es habitual, tener que realizar la llamada a la lista de usuarios, luego llamar a la lista de cuentas bancarias, cruzar estos dos resultados y, finalmente, llamar a la consulta de saldos con el usuario y su cuenta bancaria cómo parámetros de la consulta final.
- REST no está diseñado para gestionar fácilmente relaciones. En el ejemplo anterior veíamos cómo para obtener el resultado de una consulta relacionada hemos de hacer varios pasos secuenciales intermediando consultas parciales.
Para entender de forma sencilla la diferencia entre un una aplicación de IT orientada a servicios y otra orientada a datos, pongamos un ejemplo: cuándo se desarrolla una aplicación moderna con diferente funcionalidad, se suele hablar de un patrón de diseño orientado a servicios (service-oriented IT). Bajo este patrón, un servicio que permita a los usuarios iniciar sesión en el sistema, es un caso típico de integración entre servicios. Esta funcionalidad, típicamente, utiliza API REST cómo mecanismo de integración. Un ejemplo concreto son aquellas aplicaciones que nos permiten iniciar sesión en su servicio utilizando una cuenta de email o una red social. El caso de un servicio orientado a datos, es aquel en que el la aplicación, realiza una consulta al sistema con el objetivo principal de intercambiar datos. Por ejemplo, cuando solicitamos el tiempo promedio que un usuario ha estado navegando por una parte concreta de nuestra aplicación o web.
GraphQL
Cómo alternativa a REST y para superar estas limitaciones, en 2012 Facebook crea GraphQL. Por aquel entonces, Facebook lo usa de manera interna para sus propias consultas sobre la red social, pero en 2015, la compañía decide publicar el código fuente de este proyecto convirtiéndolo en un software Open Source.
La gran ventaja de GraphQL es la posibilidad de solicitar datos concretos, con independencia de cómo se organizan los datos en su origen. Los datos de origen pueden estar organizados (y almacenados) en una base de datos relacional, en un API REST en una base de datos NoSQL o en un objeto diseñado de forma específica, por ejemplo, el resultado de un algoritmo.
El aspecto que tiene una consulta en el lenguaje de GraphQL es de esta forma:
{
Bicicletas_Barcelona(district:1, type:”electric”){
Bike,
Street
}
Barcelona(district:1){
Bus,
Stop,
Lat,
Long
}
}
En el ejemplo anterior, partiendo de un conjunto de datos abiertos disponible en datos.gob.es, con GraphQL, seríamos capaces de combinar (en una sola consulta) los resultados de la localización de un parking urbano de bicicletas eléctricas en Barcelona junto con la posición de una parada de autobús cercana. El objetivo sería poder construir un producto de datos que sea capaz de planificar desplazamientos urbanos en medios de transporte sostenibles[1]. De la misma forma podríamos combinar múltiples fuentes de datos, por ejemplo, los datos abiertos sobre autobuses y movilidad del resto de ciudades de España. Tan solo tendríamos que incorporar estas nuevas fuentes de datos puesto que el modelo subyacente que devuelve las consultas sería muy similar.
Cómo se ve en la consulta, GraphQL es de naturaleza declarativa. Se utiliza el formato JSON para declarar de forma muy sencilla y clara qué es lo que se está solicitando al sistema.
Un ejemplo de GraphQL
Supongamos que tenemos una base de datos para gestionar un curso formativo. Es fácil pensar que en esa base de datos tengamos varias tablas con el registro de los alumnos, las asignaturas, las calificaciones, etc. Cuándo apificamos con REST esta base de datos, crearemos varios endpoints para consultar, los estudiantes, las asignaturas y las calificaciones. Cuándo queramos consultar los alumnos que son aptos en una asignatura concreta deberemos hacer varias llamadas consecutivas y nuestra aplicación deberá de encargarse de hacer los filtros correspondientes. El flujo lógico sería algo tal que así:
- Solicitamos la lista de alumnos.
- Solicitamos la lista de asignaturas.
- Cruzamos ambas listas y filtramos para la asignatura que deseamos comprobar.
- Solicitamos la lista de calificaciones para esa asignatura.
- Filtramos los alumnos por encima de una determinada calificación.
Cada una de estas llamadas tendrá un endpoint diferente del tipo:
Sin embargo, en GraphQL podemos realizar esta consulta en una sola llamada puesto que GraphQL permite consultar datos relacionados en una misma llamada.
En conclusión, GraphQL es una tecnología a tener muy en cuenta hoy en día cómo herramienta de integración con los sistemas de información. De forma general, se acepta que las APIs REST están más orientadas a la integración entre servicios de internet (por ejemplo un servicio de autenticación de un usuario) mientras que GraphQL está más orientada a la integración entre productos de datos (por ejemplo un comparador de precios en Internet). Todo apunta en este interesante debate entre integración de productos de TI versus los productos de datos, ambas tecnologías coexistirán en el futuro cercano.
[1] Esta consulta ha sido adaptada de su fuente original. Gracias a Ángel Garrido Román por su explicación detallada en su TFG 2018.
Contenido elaborado por Alejandro Alija,experto en Transformación Digital e Innovación.
Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Blog
Mucha gente no lo sabe, pero estamos rodeados de APIs. Las APIs son el mecanismo mediante el cual se comunican los servicios en Internet. Las APIs son las que hacen posible que iniciemos sesión en nuestro correo electrónico o que realicemos una compra por Internet.
API significa Application Programming Interface, que para la mayoría de usuarios en Internet no significa nada. Sin embargo, la realidad es que gracias a las APIs hoy podemos hacer todas esas cosas fantásticas que tanto nos gustan del mundo digital. Desde iniciar sesión en cualquier servicio de Internet, realizar una compra en Amazon o reservar una habitación de hotel en Booking. Todos estos servicios son posibles gracias a las APIs.
Una forma sencilla de explicar para qué sirve una API es la siguiente: un mecanismo mediante el cual dos programas de software pueden “hablar” e intercambiar los datos que necesiten para cumplir con la funcionalidad para la que han sido diseñados. Por ejemplo, para iniciar sesión en nuestro proveedor de correo electrónico, existe un programa encargado de validar que disponemos de un usuario y contraseña correctos. Sin embargo, este programa debe de recibir ese usuario y contraseña de una persona que interactúa con un navegador web o una aplicación móvil. Para que la aplicación móvil sepa enviarle a ese programa el usuario y la contraseña de la persona que quiere acceder al servicio, utiliza una API cómo lenguaje de intercambio. Esta API define la forma en la que la app móvil envía esos datos y la forma en la que el programa de validación los consume. Así, cuándo una nueva aplicación móvil requiera de ese mismo proceso de validación, bastará con seguir la misma API para comprobar las credenciales del usuario.
La importancia de las APIs en la creación de productos de datos
En este nuevo post, ponemos el foco en el ámbito de las APIs cómo base tecnológica clave para la creación de productos de datos. La disrupción digital tiene como característica fundamental el papel de los datos cómo principal elemento transformador de las organizaciones y la sociedad. Es por esto que los productos de datos son cada vez más habituales y valiosos. Los productos de datos son aplicaciones y servicios digitales creados con la componente de datos integrada desde su diseño. La componente de datos no tiene por qué ser la única característica del producto o servicio, pero sí juega un papel fundamental en el funcionamiento del producto (físico o digital) o servicio. Pensemos, por ejemplo, en una aplicación móvil de mapas. Su principal funcionalidad puede ser mostrarnos un mapa y ubicar físicamente nuestra posición actual. Sin embargo, la aplicación puede entenderse cómo un producto de datos donde, además de nuestra posición actual, encontramos servicios cercanos cómo restaurantes, gasolineras, bibliotecas, etc. Además, podemos sobre-impresionar información meteorológica o el estado del tráfico actual. Una aplicación de este tipo no puede entenderse sin un ecosistema de APIs que permitan la intercomunicación de los diferentes servicios (meteorología, tráfico, puntos de interés, etc.) con la aplicación en sí misma.
Cómo gestionar las APIs en los productos de datos: el ejemplo de API Friendliness Checker
Una vez entendida con claridad la importancia de las APIs en los productos de datos, pasemos ahora a analizar la complejidad de gestionar una o varias APIs extensas en un producto de datos. Crear buenas APIs es un trabajo complicado. Es necesario determinar qué datos va a proporcionar y aceptar nuestra API. Hay que estimar el volumen de peticiones que vamos a tener que asumir. Debemos de pensar en los mecanismos de actualización así como en la monitorización del uso que está teniendo la API. Por no hablar de la seguridad y la privacidad de los datos que va a manejar la API.
Por estas y otras muchas razones, el Support Centre for Data Sharing (en español, el Centro de apoyo para la puesta en común de datos) ha creado la herramienta API Friendliness Checker. El Support Centre for Data Sharing (SCDS) es un proyecto europeo liderado por un consorcio de tres empresas: Capgemini Invent, Fraunhofer Fokus y Timelex.
La herramienta API Friendliness Checker permite a los desarrolladores de APIs analizar si sus APIs cumplen con la especificación OpenAPI: un estándar establecido y ampliamente reconocido para desarrollar APIs. La especificación OpenAPI se desarrolló teniendo en cuenta criterios de accesibilidad. El objetivo es que los servicios y las aplicaciones que la implementan puedan ser entendidos por humanos y máquinas por igual, sin necesidad de acceder al código de programación o la documentación. Es decir, una API desarrollada bajo especificación OpenAPI es autocontenida y puede usarse desde el primer momento sin necesidad de documentación ni código adicional.
Cuando utilizamos la herramienta, el validador de compatibilidad de la API permite al desarrollador comparar su API contra los criterios esenciales de calidad y usabilidad definidos por la especificación de OpenAPI. La herramienta permite copiar la url de especificación de nuestra API para evaluar la compatibilidad de ésta. También es posible copiar y pegar la descripción de nuestra API en el editor de la herramienta. Con tan solo presionar el botón validar, el verificador de compatibilidad evaluará la API y mostrará cualquier comentario para mejorarla.
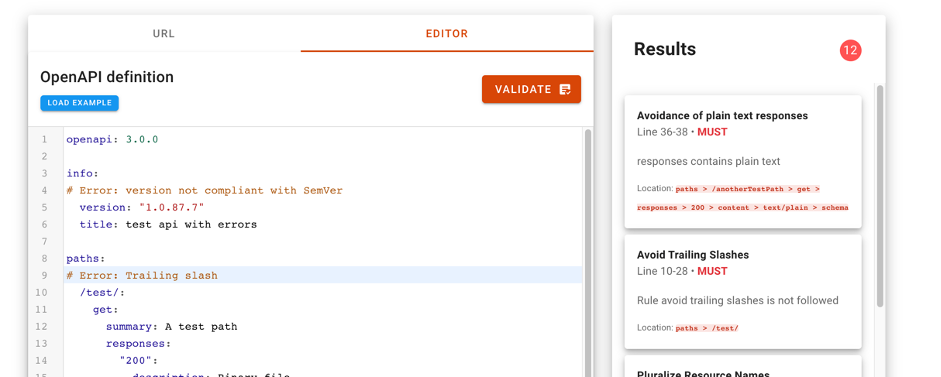
Para más información sobre las características técnicas de esta herramienta de validación se puede consultar toda la información en la página web del SCDS https://eudatasharing.eu/es/node/578.
Si estáis pensando en crear un nuevo producto de datos, estamos seguros que esta herramienta para validar vuestra API antes de ponerla en producción será de gran ayuda. Por último, si vuestro producto digital se basa en datos en tiempo real, seguro que os resulta de interés explorar estos otros conceptos cómo los sistemas orientados a eventos y las APIs asíncronas.
¿Quieres saber más sobre las APIs?
Como hemos visto las APIS son un elemento fundamental dentro del mundo de los datos. Tanto si eres un publicador como un reutilizador de datos abiertos, en datos.gob.es tienes a tu disposición algunos materiales que te pueden ayudar:
- Informe “Cómo generar valor a partir de los datos: formatos, técnicas y herramientas para analizar datos abiertos”. Dirigido a reutilizadores, en él se discute con más detalle el mundo de las APIs incluyendo ejemplos prácticos sobre su uso en Internet.
- “Guía práctica para la publicación de Datos Abiertos usando APIs”. Dirigida a aquellos portales de datos que todavía no cuenten con una API, esta guía ofrece pautas para definir y poner en marcha este mecanismo de acceso a los datos.
Contenido elaborado por Alejandro Alija,experto en Transformación Digital e Innovación.
Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Documentación
Una interfaz de programación de aplicaciones o API es un mecanismo que permite la comunicación e intercambio de información entre sistemas. Las plataformas de datos abiertos, como datos.gob.es, cuentan con este tipo de herramientas para interactuar con el sistema de información y consultar los datos sin necesidad de un conocimiento de la estructura interna o de la tecnología utilizada en su desarrollo. Gracias a las APIs, los reutilizadores pueden acceder más fácilmente la información que necesitan de forma automática, siendo posible ajustar la descarga exclusivamente a los datos requeridos.
Cada vez son más los organismos que apuesta por este tipo de mecanismos, sobre todo para publicar datos con alta frecuencia de actualización como los datos en tiempo real. La propia directiva europea de sobre datos abiertos y reutilización de la información del sector público refiere la necesidad de contar con este tipo de mecanismos para la publicación de datos dinámicos y de alto valor. Es habitual usar APIs para acceder a datos meteorológicos, de transporte público o los producidos por sensores de monitorización urbanos, aunque cabe destacar que las APIs son adecuadas para consumir todo tipo de datos.
Con el objetivo de ayudar a aquellos portales de datos abiertos que todavía no cuenten con una API, desde datos.gob.es hemos preparado un guía con las principales pautas a seguir a la hora de definir y poner en marcha este mecanismo de acceso a los datos.
¿Qué puede encontrar el lector en esta guía?
La guía comienza con un primer apartado dedicado a entender qué son las APIS y cuál es su valor. En él se explica cómo funcionan y se implementan. Para aquellos que quieran ampliar la información, se recomienda realizar la unidad formativa ”Buenas prácticas en el diseño de APIs y Linked Data”.
A continuación, la guía se centra en las pautas de diseño e implementación de APIs. Entre otros aspectos, se aborda cómo usar URIs para identificar recursos o cómo evitar rupturas de servicio.
La guía acaba con una serie de apartados más específicos centrados en la implementación de APIs en catálogos de Datos Abiertos, para el acceso a datos enlazados y a servicios web geográficos.
¿Cuáles son las principales novedades de la actualización realizada en 2025?
La guía ha sido revisada en el 2025 para actualizar el contenido con nuevos enlaces y ejemplos, además de ampliar el contenido sobre FIWARE con un enfoque práctico así como en profundizar más detalle para la sección OpenAPI.
Un nuevo volumen en la colección
Esta guía forma parte a una colección de documentos elaborados desde la Iniciativa Aporta para ayudar a los publicadores de datos a la hora de facilitar el acceso e impulsar el uso de la información publicada. En concreto, la colección busca dar a conocer cuáles son los mejores formatos para la reutilización, y facilitar una serie de pautas claras y sencillas que los organismos puedan seguir a la hora de abrir sus dataset, garantizando así la calidad de los mismos.
La “Guía práctica para la publicación de Datos Abiertos usando APIs” es el segundo número de la serie, que comenzó en el mes de marzo con la publicación de un primer volumen dedicado a la publicación de datos tabulares en archivos CSV. En los próximos meses continuaremos publicando contenidos en nuestro afán por facilitar la apertura de datos y su reutilización.
Documentación
En el mundo digital, los datos se convierten en un activo fundamental para las empresas. Gracias a ellos, pueden conocer mejor su entorno, negocio y competencia, y tomar decisiones oportunas en el momento adecuado.
En este contexto, no es de extrañar que cada vez más compañías busquen perfiles profesionales con capacidades digitales avanzadas. Trabajadores que sean capaces de buscar, encontrar, procesar y comunicar historias apasionantes sustentadas en los datos.
El informe "Cómo generar valor a partir de los datos: formatos, técnicas y herramientas para analizar datos abiertos" tiene como objetivo orientar a aquellos profesionales que deseen mejorar las competencias digitales destacadas anteriormente. En él se exploran diferentes técnicas para la extracción y el análisis descriptivo de los datos contenidos en los repositorios de datos abiertos.
El documento se estructura de la siguiente manera:
-
Formatos de datos. Explicación sobre los formatos de datos más habituales que se pueden encontrar en un repositorio de datos abiertos, prestando especial atención al csv y json.
-
Mecanismos de intercambio de datos a través de La Web. Recopilación de ejemplos prácticos que ilustran cómo extraer datos de interés de algunos de los repositorios con más populares de Internet.
-
Principales licencias. Se explican los factores que hay que tener en cuenta al trabajar con distintos tipos de licencias, orientando al lector hacia su identificación y reconocimiento.
-
Herramientas y tecnologías para el análisis de datos. Esta sección se vuelve ligeramente más técnica. En ella, se muestran diferentes ejemplos de extracción de información útil de los repositorios de datos abiertos, haciendo uso de algunos fragmentos cortos de código en diferentes lenguajes de programación.
-
Conclusiones. Se ofrece una visión tecnológica de futuro, con la mirada puesta en los más jóvenes, quienes constituirán la fuerza de trabajo del futuro.
El informe está orientado hacia un público general no especialista, aunque aquellos lectores familiarizados con el tratamiento e intercambio de datos en el mundo web se encontrarán con una lectura familiar y reconocible.
A continuación puedes descargar el texto completo, así como el resumen ejecutivo y una presentación resumen.
Nota: El código publicado pretende ser una guía para el lector, pero puede requerir de dependencias externas o configuraciones específicas para cada usuario que desee ejecutarlo.
Aplicación
El servicio API JSON INE (Java Script Object Notation) permite acceder mediante peticiones URL a toda la información disponible en la base de datos de difusión del Instituto Nacional de Estadística: Tempus3.