Empresa reutilizadora
Atogu es una plataforma de datos B2B avanzada que ayuda a equipos comerciales y de marketing a identificar, priorizar y perfilar empresas con alta probabilidad de compra.
Su base de datos no es estática: se actualiza constantemente para mantener datos frescos y accionables que permiten a los equipos saber cuándo una empresa está lista para comprar y cómo personalizar mejor sus mensajes comerciales.
Atogu combina múltiples fuentes oficiales y públicas para ofrecer señales de compra y variables de alto valor, lo que acelera la prospección y mejora los resultados de ventas.
Blog
La tecnología digital y los algoritmos han revolucionado la forma en que vivimos, trabajamos y nos comunicamos. Si bien prometen eficiencia, precisión y conveniencia, estas tecnologías pueden exacerbar los prejuicios y las desigualdades sociales y crear nuevas formas de exclusión. Así, la invisibilización y la discriminación, que siempre han existido, cobran nuevas formas en la era de los algoritmos.
La falta de interés y de datos lleva a la invisibilización algorítmica, motivando que existan dos tipos de abandono algorítmico. El primero de ellos ocurre entre las personas desatendidas en el mundo, que incluye a los millones que no tienen un teléfono inteligente ni una cuenta bancaria y que, por ende, se encuentran al margen de la economía de plataformas y, para los algoritmos, no existen. El segundo tipo de abandono algorítimico incluye a individuos o grupos que son víctimas del fracaso del sistema algorítmico, como sucedió con SyRI (Systeem Risico Indicatie) en Países Bajos que señaló injustamente a unas 20.000 familias de origen socioeconómico bajo de cometer fraude fiscal, llevando a muchas a la ruina en 2021. El algoritmo, que fue declarado ilegal por un tribunal de La Haya meses más tarde, se aplicó en los barrios más pobres del país y bloqueó la posibilidad de muchas familias con más de una nacionalidad de percibir los beneficios sociales a los que tenían derecho por su condición socioeconómica.
Más allá del ejemplo en el sistema público neerlandés, la invisibilización y la discriminación también pueden originarse en el sector privado. Un ejemplo es el algoritmo de ofertas de trabajo de Amazon que mostró un sesgo contra las mujeres al aprender de datos históricos –es decir, datos incompletos al no incluir un universo amplio y representativo—, lo que llevó a Amazon a abandonar el proyecto. Otro ejemplo Apple Card, una tarjeta de crédito respaldada por Goldman Sachs, que también fue señalada cuando se descubrió que su algoritmo ofrecía límites de crédito más favorables a los hombres que a las mujeres.
En general, la invisibilidad y la discriminación algorítmica, en cualquier ámbito, puede derivar en un acceso desigual a los recursos y en una exacerbación de la exclusión social y económica.
Tomar decisiones basadas en algoritmos
Los datos y los algoritmos son componentes interconectados en el ámbito de la informática y el procesamiento de la información. Los datos sirven de base, pero pueden ser desestructurados, con excesiva variabilidad e incompletos. Los algoritmos son instrucciones o procedimientos diseñados para procesar y estructurar estos datos y extraer información, patrones o resultados significativos.
La calidad y relevancia de los datos impacta directamente en la efectividad de los algoritmos, ya que estos dependen de las entradas de datos para generar resultados. De ahí, el principio “basura entra basura sale”, que resume la idea de que, si entran datos de mala calidad, sesgados o inexactos en un sistema o proceso, el resultado también será de mala calidad o impreciso. Por su lado, los algoritmos bien diseñados pueden mejorar el valor de los datos al revelar relaciones ocultas o hacer predicciones.
Esta relación simbiótica subraya el papel fundamental que desempeñan tanto los datos como los algoritmos a la hora de impulsar los avances tecnológicos, permitir la toma de decisiones informadas y favorecer innovaciones.
La toma de decisiones algorítmica se refiere al proceso de utilizar conjuntos predefinidos de instrucciones o reglas para analizar datos y emitir predicciones que ayuden a decidir. Cada vez más, se aplica a decisiones que tienen que ver con el bienestar social y la oferta de servicios y productos comerciales a través de plataformas. Es ahí donde se puede encontrar la invisibilidad o la discriminación algorítmica.
Cada vez con más frecuencia, los sistemas de bienestar utilizan datos y algoritmos para ayudar en la toma de decisiones sobre asuntos como quién debe recibir asistencia y de qué tipo o quién presenta riesgos. Estos algoritmos consideran diferentes factores como ingresos, tamaño de la familia o de la vivienda, gastos, factores de riesgo, edad, sexo o género, que pueden incluir sesgos y omisiones.
Por eso el Relator Especial sobre la extrema pobreza y los derechos humanos, Philip Alston, advertía en un informe ante la Asamblea General de Naciones Unidas que la adopción sin cautelas de estos puede llevar a un bienestar social distópico. En dicho estado de bienestar distópico, los algoritmos se utilizan para reducir presupuestos, disminuir el número de personas beneficiarias, eliminar servicios, introducir formas exigentes e intrusivas de condicionalidad, modificar comportamientos, imponer sanciones y “revertir la noción de que el Estado debe rendir cuentas”.
Invisibilidad y discriminación algorítmicas: Dos conceptos opuestos
Aunque los datos y los algoritmos tienen mucho en común, la invisibilidad y la discriminación algorítmicas son dos conceptos opuestos. La invisibilidad algorítmica se refiere a lagunas en conjuntos de datos u omisiones en los algoritmos, que resultan en desatenciones en la aplicación de beneficios o servicios. Por el contrario, la discriminación algorítmica habla de puntos críticos que resaltan comunidades específicas o características sesgadas en conjuntos de datos, generando injusticia.
Es decir, la invisibilización algorítmica ocurre cuando individuos o grupos están ausentes en los conjuntos de datos, lo que hace imposible abordar sus necesidades. Por ejemplo, integrar en la toma de decisiones social datos sobre mujeres con discapacidad puede ser vital para la inclusión. A nivel mundial, las mujeres son más vulnerables a la invisibilización algorítmica que los hombres, ya que tienen menos acceso a la tecnología digital y dejan menos trazas digitales.
Los sistemas algorítmicos opacos que incorporan estereotipos pueden aumentar la invisibilización y la discriminación al ocultar, o bien apuntar, a personas o poblaciones vulnerables. Un sistema algorítmico opaco es aquel no permite el acceso a su funcionamiento.
Por otro lado, agregar o desagregar datos sin estudiar las consecuencias cuidadosamente puede resultar en omisiones u errores. Esto ilustra el doble filo de la contabilidad; es decir, la ambivalencia de la tecnología que cuantifica y cuenta, y que puede servir para mejorar la vida de las personas, pero también para perjudicarlas.
La discriminación puede surgir cuando las decisiones algorítmicas se basan en datos históricos, que normalmente incorporan asimetrías, estereotipos e injusticias, porque en el pasado existieron más desigualdades. El efecto de “basura entra basura sale” se produce si los datos están sesgados, como suele pasar con el contenido en línea. Asimismo, las bases de datos con sesgos o incompletas pueden ser incentivos de la discriminación algorítmica. Pueden aparecer sesgos de selección cuando los datos de reconocimiento facial, por ejemplo, se basan en rasgos de hombres blancos, mientras que las usuarias son mujeres de piel oscura, o en contenido en línea generado por una minoría de agentes, lo que dificulta la generalización.
Como se ve, abordar la invisibilidad y la discriminación algorítmica es un reto de primera magnitud que solo se podrá resolver con la concienciación y la colaboración de instituciones, organizaciones de campaña, empresas, e investigación.
Contenido elaborado por Miren Gutiérrez, Doctora e investigadora en la Universidad de Deusto, experta en activismo de datos, justicia de datos, alfabetización de datos y desinformación de género.
Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor
Noticia
Las administraciones públicas (AA.PP.) tienen el deber de publicar sus conjuntos de datos abiertos en formatos reutilizables, tal y como dicta la Directiva Europea 2019/1024 que modifica la Ley 37/2007 de 16 de noviembre, sobre reutilización de la información del sector público. Esta regulación, alineada con la Estrategia de datos de la Unión Europea, determina que las AA.PP. dispongan de catálogos propios de datos abiertos para fomentar el uso y la reutilización de la información pública.
Uno de estos catálogos es el Portal de Datos Abiertos de Canarias que cuenta con más de 7.450 conjuntos de datos abiertos, gratuitos y reutilizables de hasta 15 organizaciones de la comunidad autónoma. La Consejería de Agricultura, Ganadería, Pesca y Soberanía Alimentaria (CAGPSA) del Gobierno de Canarias forma parte de esta lista. Dentro de su eje de trabajo de Gobierno Abierto, la CAGPSA ha impulsado con decisión la apertura de sus datos.
A través de un proceso de análisis, depuración y normalización de los datos, la CAGPSA ha conseguido publicar más de 20 conjuntos de datos en el portal, garantizando así la calidad en la reutilización de la información por parte de cualquier persona interesada.
Análisis, normalización de los datos y protocolo de apertura de datos para el Gobierno de Canarias
Para lograr este hito en la gestión de los datos, la Consejería de Agricultura, Ganadería, Pesca y Soberanía Alimentaria del Gobierno de Canarias ha llevado a cabo la definición y ejecución de un protocolo de apertura de datos, en el que se incluyen tareas tales como:
- Elaboración de inventario y priorización de fuentes de datos a publicar.
- Análisis, depuración y normalización de conjuntos de datos priorizados.
- Solicitud de carga de conjuntos de datos en el Portal de Datos Abiertos de Canarias.
- Atención a peticiones derivadas de los conjuntos de datos publicados.
- Actualización de conjuntos de datos publicados.
La normalización de los datos ha sido un factor clave para la Consejería, y en este sentido, ha tenido en cuenta activos semánticos internacionales (entre ellos clasificaciones de las Naciones Unidas y sus diversas agencias o Eurostat) y ha aplicado pautas definidas en estándares internacionales, como lo es SDMX o las marcadas por datos.gob.es, para garantizar la calidad de los datos publicados.
La CAGPSA no solo ha volcado esfuerzos en la normalización y publicación de los datos, sino que también ha proporcionado soporte al personal de la Consejería en la gestión y mantenimiento de los mismos, impartiendo sesiones de formación y concienciación. Por otra parte, ha elaborado un manual para la reutilización de los datos donde se contemplan las pautas a tener en cuenta en el momento de valorar qué datos se pueden publicar, basadas en las directivas europeas y estatales relativas a los datos abiertos y reutilización de información del sector público. De este modo, ha dado respuesta a las inquietudes del personal de la Consejería frente a la publicación de datos de carácter personal o comercial.
Como fruto de este trabajo, la Consejería ha colaborado activamente con el Portal de Datos Abiertos de Canarias para la publicación de los conjuntos de datos y para la definición del protocolo de apertura de datos establecido para todo el Gobierno de Canarias.
Compromiso por la calidad y la reutilización de la información
La CAGPSA ha sido especialmente destacada por la publicación del conjunto de datos de Sociedades Agrarias de Transformación (SAT), que se encuentra dentro del top 3 de la Asociación Multisectorial de la Información (ASEDIE) en 2021. Esta iniciativa ha sido valorada por esta Asociación en diversas ocasiones por su enfoque en la calidad de los datos y su gestión.
Su labor en la normalización de los datos y el soporte al personal de la Consejería, así como la colaboración con el portal de datos abiertos y la amplia oferta de conjuntos de datos, sitúan a la CAGPSA como referente en este ámbito en la comunidad autónoma de Canarias.
Desde datos.gob.es, aplaudimos este tipo de ejemplos y destacamos las buenas prácticas sobre apertura de datos por parte de las administraciones públicas. La iniciativa de la Consejería de Agricultura, Ganadería, Pesca y Soberanía Alimentaria del Gobierno de Canarias es un paso relevante que nos acerca a las ventajas que los datos abiertos y su reutilización aportan a la ciudadanía. El compromiso de la Consejería por la apertura de datos contribuye al objetivo europeo y nacional de lograr una administración orientada al dato.
Aplicación
Portal web con diversos cuadros de mandos interactivos de acceso libre dedicado a la gobernanza climática.
La aplicación agrupa ocho conjuntos de datos del portal de datos del Gobierno de Canarias, MITECO, ITC, ISTAC y GRAFCAN:
1. Inventario de emisiones
2. Huella de carbono
3. Contaminantes emitidos a la atmósfera
4. Incendios forestales
5. Proyecciones climáticas
6. PIMA
7. Producción de energía en Canarias
8. Producción neta de electricidad
Noticia
Los datos abiertos pueden ser de gran utilidad a la hora de fomentar aspectos como la salud y el bienestar de la ciudadanía o la protección del medio ambiente, así como el crecimiento de las economías. La apertura de información fomenta la innovación, la creación y la adaptación de empresas y organismos en torno a servicios y tecnologías capaces de generar rentabilidad y ofrecer soluciones a problemas actuales a partir de la reutilización de datos.
Pero, además, los datos de carácter económicos contribuyen a que muchas organizaciones puedan realizar una mejor toma de decisiones. Las estadísticas e indicadores económicos nos permiten conocer cómo evoluciona un determinado mercado o país, descubrir tendencias y actuar en consecuencia.
Si estas interesado en acceder a este tipo de datos, a continuación, recogemos 10 ejemplos de repositorios relacionados con la economía a nivel internacional:

-
Publicador: World Bank
Se trata de un sitio web que pertenece al World Bank. Esta plataforma cuenta con una completa oferta de datos económicos que se actualiza con frecuencia y permite el acceso a información abierta que elabora el propio Banco Mundial. Entre el tipo de datos que ofrece se encuentran estadísticas de deuda internacional, indicadores del desarrollo mundial o bases de datos sobre los patrones de consumo en los hogares de todo el mundo, entre muchos otros.
Destacan dos secciones interesantes. Una es su catálogo de datos, donde se puede encontrar información acerca de temas económicos como indicadores de desempeño estadístico o datos sobre la COVID-19, por ejemplo. Otra es su sección de microdatos, que ofrece una colección de conjuntos de datos del Banco Mundial y otras organizaciones internacionales, regionales y nacionales.
Gran parte de estos datos se ofrecen en los formatos más populares (HTML, JSON, PDF, CSV, …). Además, cuenta con un espacio para reutilizadores, con información sobre APIs.
-
Publicador: IMF (Internationaly Monetary Fund)
El Fondo Monetario Internacional (FMI) es una organización integrada por 190 países que trabaja para fomentar la cooperación monetaria mundial, asegurar la estabilidad financiera o facilitar el comercio internacional, entre otros aspectos.
Este portal contiene conjuntos de datos del FMI (IMF por sus siglas en inglés) acerca de la estabilidad financiera mundial, la economía regional, las estadísticas financieras mundiales y las perspectivas económicas, entre otras. Los datos se pueden descargar en distintos formatos, incluyendo XLSX y XLS.
-
Publicador: OCDE (Organización para la Cooperación y el Desarrollo Económicos)
La OCDE es una organización internacional de la que forman parte 38 países, entre ellos España, cuyo objetivo es hacer frente a los desafíos económicos, sociales y de buen gobierno.
El catálogo de datos de la OCDE dispone de una clasificación por sectores, entre los que se encuentra el económico. Ofrece la posibilidad de filtrar los datos según cuenten o no con acceso a la API. Además, este portal permite realizar consultas en grandes bases de datos en su almacén de datos OECD.Stat.
Especialmente interesantes son sus visualizaciones de datos, como estas desarrolladas para mostrar información acerca de las tasas de empleo a nivel mundial, así como otros indicadores relacionados con el empleo.
-
Publicador: UNECE (Comisión Económica de las Naciones Unidas para Europa)
Creada en 1947 y compuesta por 56 Estados miembros, se trata de una de las 5 comisiones regionales de la ONU. Entre sus objetivos se encuentra promover la integración económica paneuropea y apoyar a los países con economías en transición.
En su portal de información pública, se pueden encontrar diversos conjuntos de datos, en su mayoría económicos, ligados a los distintos países de Europa. Ofrece también otros conjuntos de datos sobre población y transporte y algunos recursos alternativos como visualizaciones o mapas de datos.
Los datos se muestran en cuatro formas diferentes: gráficos, clasificaciones, tablas y mapas. En este ejemplo se puede consultar información acerca de la tasa de desempleo juvenil a nivel mundial a través de los 4 medios anteriormente citados. Los datos se pueden descargar en CSV, TSV o JSON.
-
Publicador: Comisión Económica para América Latina y el Caribe (CEPAL, Naciones Unidas)
CEPALSTAT es el portal donde se encuentra toda la información estadística de los países de América Latina y el Caribe, recolectada, sistematizada y publicada por la Comisión Económica para América Latina (CEPAL).
Este portal recoge bases de datos y publicaciones estadísticas, así como conjuntos de datos económicos de América Latina y el Caribe, a menudo acompañados por otros recursos como visualizaciones de datos o mapas. Además, permite acceder a estos datos a través de una API para agilizar y facilitar el proceso de búsqueda de datos a sus usuarios. Los datos se pueden descargar en XML, JSON o XLXS.
-
Publicador: BCE (Banco Central Europeo)
El BCE, en colaboración con los bancos centrales nacionales y otras autoridades nacionales (estadísticas y de supervisión) de la Unión Europea, ofrece un servicio de desarrollo, recopilación, compilación y difusión de estadísticas en formato abierto.
El Statistical Data Warehouse ofrece indicadores de la zona del euro, incluyendo en algunos casos desgloses a nivel nacional. Cada una de las estadísticas ofrecidas en este portal cuenta con una breve descripción introductoria a los temas que tratan. Todos los datos están disponibles para su descarga en formato Excel y CSV.
-
Publicador: Organización Mundial del Comercio (OMC)
La Organización Mundial del Comercio (OMC) es una organización internacional que se ocupa de las normas que rigen el comercio entre los países. Su principal objetivo reside en ayudar a los productores de bienes y servicios, los exportadores y los importadores a llevar a cabo sus actividades de manera óptima.
Esta organización ofrece el acceso a una selección de bases de datos de relevancia que ofrecen estadísticas e información sobre diferentes medidas relacionadas con el comercio. Esta información se encuentra clasificada en cuatro grandes bloques: mercancías, servicios, propiedad intelectual, estadísticas y otras temáticas, facilitando así la búsqueda de datos a los usuarios.
En esta página puedes consultar los sistemas en línea de la OMC (bases de datos/sitios web) que se encuentran activos. Algunos de ellos necesitan registro.
-
Publicador: Organización de las Naciones Unidas para el Desarrollo Industrial (UNIDO)
La ONUDI (UNIDO por sus siglas en inglés) es un organismo especializado de las Naciones Unidas que se encarga de promover el desarrollo industrial para reducir la pobreza, promover la globalización inclusiva y la sostenibilidad ambiental.
Este organismo publica, ente otros, conjuntos de datos sobre desarrollo industrial, producción manufacturera e inversiones. En su portal, cuenta con un buscador de información sobre indicadores como el crecimiento de la población o del PIB por países. Estos datos pueden visualizarse a través de un gráfico que se actualiza con la información seleccionada, ofreciendo también la posibilidad de comparar datos de diferentes países dentro del mismo.
Al acceder a la sección DataBase, se puede descargar cada conjunto de datos en formato excel y CSV.
-
Publicador: UNCTAD (Conferencia de las Naciones Unidas sobre el Comercio y Desarrollo)
La UNCTAD (por sus siglas en inglés) es una organización encargada de ayudar a los países en desarrollo a aprovechar el comercio internacional, la inversión, los recursos financieros y la tecnología para alcanzar un desarrollo sostenible e inclusivo.
En su portal de datos en abierto, recoge series estadísticas por países y productos, poniendo especialmente el foco en países con una economía en desarrollo y en transición. Economía digital, comercio internacional de servicios, transporte marítimo o inflación y tipos de cambio son solo algunas de las temáticas que se pueden consultar en esta plataforma.
Además, para usuarios que no estén acostumbrados a navegar en este tipo de portales, UNCTAD pone a su disposición una serie de tutoriales en vídeo que introducen al usuario en el centro de datos y le enseñan, entre otros aspectos, cómo exportar la información de esta plataforma (se pueden descargar en CSV o XLSX).
-
Publicador: BID (Banco Interamericano de Desarrollo)
El Banco Interamericano de Desarrollo (IDB por sus siglas en inglés) es una organización financiera internacional cuyo principal objetivo consiste en la financiación de proyectos viables de desarrollo económico, social e institucional, además de promover la integración comercial en América Latina y el Caribe.
En su sección dedicada a los datos, ofrece indicadores de desarrollo por país relacionados con su perfil macroeconómico, su integración global y sus perspectivas sociales. Además, en esta sección se pueden encontrar algunos recursos adicionales como gráficos y visualizaciones que permiten filtrar la información de acuerdo a diferentes indicadores o cursos para aumentar el conocimiento en materia económica a partir de los datos.
La mayoría de los datos se pueden descargar en CSV, JSON o RDF.
Esta ha sido tan solo una pequeña selección de repositorios de datos relacionados con el sector económico que pueden ser de tu interés. ¿Conoces alguno más de relevancia relacionado con este campo? Déjanos un comentario o envíanos un correo electrónico a dinamizacion@datos.gob.es
Noticia
La apertura de datos es fundamental en el campo de la ciencia. Los datos abiertos facilitan la colaboración científica y enriquecen las investigaciones dotándolas de una mayor profundidad. Gracias a este tipo de datos podemos conocer mejor nuestro entorno y llevar a cabo análisis más certeros para fundamentar las decisiones.
Además de los recursos incluidos en portales de datos generalistas, cada vez son más los bancos de datos abiertos que podemos encontrar centrados en ámbitos concretos de las ciencias naturales y el medio ambiente. En este artículo te acercamos 10 de ellos.

NASA Open Data Portal
- Publicador: NASA
El portal data.nasa.gov centraliza datos abiertos geoespaciales de la NASA, generados fruto de su rico historial de misiones planetarias, lunares y terrestres. Cuenta con casi 20.000 usuarios únicos mensuales y más de 40.000 conjuntos de datos. Un pequeño porcentaje de estos conjuntos de datos está alojado directamente en data.nasa.gov, pero en la mayoría de los casos se ofrecen metadatos y los enlaces a otros proyectos de la agencia espacial.
data.nasa.gov incluye gran cantidad de temáticas, desde datos relacionados con pruebas de cohetes hasta mapas geológicos de Marte. Los datos se ofrecen en múltiples formatos, dependiendo de cada publicador.
El sitio se enmarca en el proyecto Open Innovation Sites, junto con api.nasa.gov, un espacio para el intercambio de información sobre las API de la NASA, y code.nasa.gov, donde se recopilan los proyectos de código abierto de la NASA.
Copernicus
- Publicador: Copernicus
COPERNICUS es el programa de observación de la Tierra de la Unión Europea. Liderado por la Comisión Europea, con la colaboración de los estados miembros y diversas agencias y organizaciones europeas, recopila, almacena, combina y analiza datos obtenidos a través de la observación por satélite y por sistemas de sensores in situ terrestres, aéreos y marítimos.
Ofrece datos a través de 6 servicios: emergencias, seguridad, vigilancia marina, vigilancia terrestre, cambio climático y vigilancia atmosférica. Los dos puntos principales de acceso a los datos satelitales de Copernicus están gestionados por la ESA: la Plataforma de acceso abierto de Copernicus -que cuenta con una API- y el CSCDA (acceso a los datos del componente espacial de Copernicus). Otros puntos de acceso a los datos satelitales de Copernicus están gestionados por la Eumetsat.
Climate Data Online
- Publicador: NOAA (National Centers for Environmental Information)
Climate Data Online (CDO) de la agencia del gobierno americana NOAA proporciona acceso gratuito a datos meteorológicos y climáticos históricos a nivel mundial. En concreto, se ofrecen 26.000 conjuntos de datos, que incluyen mediciones diarias, mensuales, estacionales y anuales de parámetros como la temperatura, las precipitaciones o el viento, entre otros. La mayoría de los datos se pueden descargar en formato CSV.
Para acceder a la información, los usuarios pueden utilizar, entre otras funcionalidades, una herramienta de búsqueda, una API o un visor de mapas donde se pueden mostrar una gran variedad de datos en el mismo entorno de visualización, lo que permite relacionar variables con ubicaciones específicas.
AlphaFold Protein Structure Database
- Publicador: DeepMind y EMBL-EBI
AlphaFold es un sistema de inteligencia artificial desarrollado por la compañía DeepMind que predice la estructura 3D de una proteína a partir de su secuencia de aminoácidos. En colaboración con el Instituto Europeo de Bioinformática del EMBL (EMBL-EBI), DeepMind ha creado esta base de datos que facilita el acceso gratuito de la comunidad científica a dichas predicciones.
La primera versión cubre el proteoma humano y los proteomas de otros organismos clave, pero la idea es seguir ampliando la base de datos para que cubra una gran proporción de todas las proteínas catalogadas (más de 100 millones). Los datos pueden descargarse en formato mmCIF o PDB, ampliamente aceptados por los programas de visualización de estructuras 3D, como PyMOL y Chimera.
Free GIS DATA
- Publicador: Robin Wilson, experto en el área GIS.
Free GIS Data recoge el esfuerzo de Robin Wilson, freelance experto en teledetección, GIS, ciencia de los datos y Python. En ella los usuarios pueden encontrar una lista clasificada de enlaces a más de 500 sitios web que ofrecen conjuntos de datos geográficos de libre acceso, todos ellos listos para ser cargados en un Sistema de Información Geográfica. Puedes encontrar datos sobre clima, hidrología, ecología, desastres naturales, recursos minerales, gas y petróleo, transportes y comunicaciones o usos de la tierra, entre otras muchas categorías.
Aquellos usuarios que lo deseen pueden contribuir con nuevos datasets, enviándolos por email a robin@rtwilson.com.
GBIF (Global Biodiversity Information Facility)
- Publicador: GBIF
GBIF es una iniciativa intergubernamental formada por países y organizaciones internacionales, que colaboran en el avance del acceso libre y abierto a los datos sobre biodiversidad. A través de sus nodos, los países participantes proporcionan datos sobre registros de especies en base a normas comunes y herramientas de código abierto. En España, el nodo nacional es GBIF-ES, patrocinado por el Ministerio Español de Ciencia e Innovación y gestionado por el Consejo Superior de Investigaciones Científicas (CSIC).
Los datos que ofrece proceden de muchas fuentes, desde los especímenes que se encuentran en los museos y que fueron recogidos en los siglos XVIII y XIX hasta las fotos geoetiquetadas realizadas con teléfonos inteligentes y compartidas por naturalistas aficionados. Actualmente cuenta con más de 1.800 millones de registro y 63.000 datasets de gran utilidad para investigadores que estén realizando estudios ligados al ámbito de la biodiversidad y público en general. También puedes acceder a su API aquí.
EDI Data Portal
- Publicador: Environmental Data Initiative (EDI)
La Environmental Data Initiative (EDI) promueve la conservación y reutilización de datos medioambientales, dando soporte a investigadores para que archiven y publiquen los datos de investigaciones financiadas con fondos públicos. Todo ello siguiendo los principios FAIR y utilizando el estándar Ecological Metadata Language (EML).
El portal de datos EDI contiene los paquetes de datos medioambientales y ecológicos aportados, a los que se puede acceder mediante un buscador o una API. Los usuarios deben ponerse en contacto con el proveedor de los datos antes de utilizarlos en cualquier investigación. Estos datos deben citarse adecuadamente cuando se utilicen en una publicación. Para ello se proporciona un identificador de objeto digital (DOI, en inglés).
PANGAEA
- Publicador: World Data Center PANGEA
El sistema de información PANGAEA funciona como una biblioteca de acceso abierto destinada a archivar, publicar y distribuir datos georreferenciados procedentes de investigaciones sobre el sistema terrestre.
Cualquier usuario puede dar de alta datos ligados a las ciencias naturales. PANGAEA cuenta con un equipo de editores que se encargan de comprobar la integridad y coherencia de los datos y metadatos. Actualmente incluye más de 400.000 conjuntos de datos pertenecientes a más de 650 proyectos. Los formatos en los que están disponibles son variados: puedes encontrar desde archivos de texto/ASCII o delimitados por tabulaciones, hasta objetos binarios (por ejemplo, datos sísmicos y modelos, entre otros) u otros formatos que siguen las normas ISO (como imágenes o películas).
re3data
- Publicador: DataCite
Re3data es un registro mundial de repositorios de datos de investigación que abarca bases de datos de diferentes disciplinas académicas disponibles de forma gratuita. Incluye desde datos relacionados con las ciencias naturales, la medicina o la ingeniería, hasta aquellos ligados con áreas de humanidades.
Actualmente ofrece descripciones detalladas de más de 2.600 repositorios. Estas descripciones se basan en el esquema de metadatos de re3data y se puede acceder a ellas a través de la API de re3data. En este repositorio de Github puedes encontrar ejemplos para utilizar la API de re3data. Dichos ejemplos se implementan en R utilizando Jupyter Notebooks.
IRIS
- Publicador: Incorporated Research Institutions for Seismology (IRIS)
IRIS es un consorcio de más de 100 universidades estadounidenses dedicado a la explotación de instalaciones científicas para la adquisición, gestión y distribución de datos sismológicos. A través de esta web cualquier ciudadano puede acceder a diversos recursos y datos relacionados con los terremotos que tienen lugar en todo el mundo.
Recoge datos de series temporales, incluyendo grabaciones de sensores de una variedad de mediciones. Entre los metadatos disponibles está la ubicación de la estación de la que se han obtenido los datos y su instrumentación. Además, permite el acceso a datos sísmicos históricos, incluidos los sismogramas escaneados y otra información procedente de fuentes pre-digitales.
Los datos están disponibles en formato SEED (el estándar internacional para el intercambio de datos sismológicos digitales), ASCII o SAC (Seismic Analysis Code).
¿Conoces más repositorios internacionales con datos relacionados con las ciencias naturales y el medio ambiente? Déjanos un comentario o mándanos un email a dinamizacion@datos.gob.es.
Noticia
Una de las líneas de acción de la Comisión Europea para los próximos meses, es la creación de un espacio europeo de datos sanitarios. Siguiendo los pasos de Europa, el Gobierno español también tiene entre sus planes poner en marcha un data lake sanitario con una gran cantidad de datos en bruto a disposición de los investigadores y administraciones, entre otros colectivos.
El interés de los gobiernos por promover la apertura de datos en este sector no es casual. Los datos sobre salud y bienestar son fundamentales para mejorar la asistencia médica, la investigación y la elaboración de políticas sanitarias. Además, el acceso a este tipo de datos permite poner en marcha soluciones basadas en tecnologías innovadoras, como la inteligencia artificial, que transformen los sistemas sanitarios, impulsando mejoras en la salud y calidad de vida de toda la ciudadanía.
Aunque en los repositorios generalistas es común encontrar datos de este tipo (por ejemplo, en datos.gob.es hay actualmente disponibles más de 16.000 conjuntos de datos en las categorías salud y bienestar), cada vez surgen más iniciativas, tanto privadas como públicas, especializadas en la publicación de datos de investigación, resultados médicos o estadísticas sobre salud. Este tipo de datos se comparten de forma anonimizada y garantizando la privacidad de los pacientes. A continuación, recogemos 10 ejemplos a nivel internacional.

CDC Wonder
- Publicador: Centro de Control y Prevención de Enfermedades de EE.UU.
Los usuarios pueden acceder a datos de investigación estadística publicados o alojados por el Centro de Control y Prevención de Enfermedades a través de un sistema de consultas ad-hoc. También ofrece materiales de referencia, informes y directrices sobre temas relacionados con la salud y la investigación epidemiológica.
Entre otros, se pueden consultar conjuntos de datos de uso público sobre mortalidad, incidencia del cáncer, VIH y SIDA, tuberculosis, vacunas, natalidad, datos censales, etc. Los datos solicitados se resumen y muestra fácilmente, con estadísticas, gráficos y mapas calculados dinámicamente. Estos datos están disponibles para su descarga. CDC Wonder también cuenta con una API para las consultas de datos automatizadas en formato XML.
Organización Mundial de la Salud
- Publicador: Organización Mundial de la Salud
La Organización Mundial de la Salud (OMS) tiene entre sus objetivos impulsar que los estados recopilen, gestionen, analicen y utilicen datos sanitarios tanto de la población (encuestas de hogares, sistemas de registro civil de acontecimientos vitales, etc.) como institucionales (actividades administrativas y operativas de las instituciones, como los centros sanitarios). En este sentido ofrece una serie de herramientas de recolección y análisis de datos, como SCORE, un paquete de herramientas, recursos, metodologías e intervenciones armonizadas para reforzar los datos sanitarios de cada país.
En su web, la OMS ofrece acceso centralizado a diversas colecciones de datos sobre enfermedades como la tuberculosis, o temas relacionados como la seguridad alimentaria, que se pueden descargar en formato CSV. También ofrece visualizaciones y una serie de cuadros de mando para acercar de forma sencilla a la ciudanía datos sobre coronavirus, el seguimiento de la labor de la OMS o las diferencias entre países respecto a la mortalidad.
HealthData.gov
- Publicador: Gobierno de EE.UU.
En el portal de datos de Salud del Gobierno de EE.UU. podemos encontrar conjuntos de datos sobre una amplia gama de temas, como la salud ambiental, los dispositivos médicos, la atención médica, los servicios sociales, la salud mental o el abuso de sustancias.
Los datos se recogen y suministran desde agencias del Departamento de Salud y Servicios Sociales de los Estados Unidos, así como desde centros y agencias especializadas. Se pueden descargar en formato CSV (algunos también están disponibles en RDF) o usando consultas SoQL.
Broad Institute
- Publicador: Broad Institute
Los investigadores del Broad Institute generan del orden de 20 terabytes de secuencias de datos cada día. En su web ofrecen resultados de investigaciones científicas y de salud relacionadas con la biología humana, la salud y las enfermedades. También ofrecen herramientas open source para trabajar con los datos.
Navegando a través de sus diversos programas podemos encontrar y descargar datos relacionados con el cáncer -aquí se descargan- o el epigenoma, entre otros.
GDC Data Portal
- Publicador: National Cancer Institute
Esta web permite la búsqueda dirigida de una amplia variedad de conjuntos de datos disponibles públicamente relacionados con el cáncer. Incluye más de 600.000 archivos relativos a 85.000 casos, con información sobre genes y mutaciones.
En la web se pueden explorar los datos, ver visualizaciones y analizar la información a través de diversas herramientas. Los usuarios pueden descargar la información en formato JSON y TSV o acceder a ellos a través de una API.
PhysioNet
- Publicador: Physionet
PhysioBank contiene más de 36.000 grabaciones de señales fisiológicas y series temporales anotadas y digitalizadas. Muchos de los datos son libres y se pueden descargar en CSV, pero otros tienen un uso restringido.
Un factor diferencial de PhysioNet es que colabora en la organización y difusión de retos donde los participantes deben abordar cuestiones de interés clínico no resueltas utilizando los datos.
También ofrece una colección de programas informáticos para la visualización, el análisis y la modelización de señales fisiológicas y las series temporales. Se trata de una serie de programas de código abierto que pueden estudiarse, verificarse y modificarse para adaptarlos a las necesidades específicas de cada usuario. En su web pueden encontrar varios tutoriales para saber cómo trabajar con Physionet y sus herramientas asociadas.
NHS Digital
- Publicador: UK National Health Services.
NHS Digital alberga los conjuntos de datos relacionados con salud y bienestar del Reino Unido, y algunos a nivel mundial. Incluye datos sobre gastos, tiempo de espera, enfermedades o hábitos de vida (como el consumo de alcohol y drogas, o la obesidad). Es necesario registrarse para poder acceder a la información.
También ofrece cuadros de mando interactivos sobre temas de interés como la medicina general o la salud mental en Inglaterra. En su web cuenta con un área para desarrolladores con información sobre su API.
Global Health Data Exchange (GHDx)
- Publicador: Institute for Health Metrics and Evaluation (IHME)
El Institute for Health Metrics and Evaluation (IHME), un centro independiente de investigación en salud global de la Universidad de Washington, proporciona mediciones comparables de los problemas de salud más importantes del mundo y evalúa las estrategias utilizadas para abordarlos. Esa información se comparte en abierto a través del portal GHDx, donde los usuarios pueden encontrar conjuntos de datos de encuestas, censos, estadísticas vitales, etc.
Los datos pueden ser utilizados, compartidos, modificados o desarrollados por usuarios con fines no comerciales a través de la licencia de atribución Open Data Commons.
OpenNeuro
- Publicador: cualquier investigador que quiera abrir los datos de su investigación.
OpenNeuro es una plataforma pensada para compartir datos de resonancias magnéticas, magnetoencefalografía (MEG), electroencefalogramas, etc. El nuevo material es agregado a medida que los investigadores abren sus propios datos.
Actualmente hay más de 600 datasets. Los conjuntos de datos están disponibles públicamente para fomentar la investigación y conseguir mejores diagnósticos en formato Brain Imaging Data Structure (BIDS) y bajo una licencia Creative Commons CC0.
Cabe destacar que OpenNeuro ha integrado los datos de OpenfMRI.
CMS.gob
- Publicador: U.S. Centers for Medicare & Medicaid Services.
CMS.gob es un buscador que ofrece acceso a conjuntos de datos relacionados con los servicios proporcionados por las instituciones que aceptan Medicare. Medicare es un programa de cobertura de seguridad social administrado por el gobierno de EE.UU., el cual provee atención médica a todas las personas mayores de 65 años o de cualquier edad con alguna discapacidad o enfermedad grave.
A través de este repositorio se comparten datos sobre doctores, hospitales, instalaciones que ofrecen determinados servicios como la diálisis o rehabilitación, asistencia a domicilio, etc. Los datos se pueden descargar en formato CSV o a través de su API.
Gracias a los datos de todos estos repositorios, se pueden llevar a cabo análisis e investigaciones que sirvan para predecir y detectar enfermedades, así como mejorar la atención proporcionada a los pacientes.
¿Conoces más repositorios internacionales con datos de salud? Déjanos un comentario o mándanos un email a dinamizacion@datos.gob.es.
Blog
El “Centro de soporte para el intercambio de datos” (Support Centre for Data Sharing o SCDS en inglés) nació en 2019 como parte de la estrategia europea para impulsar un ecosistema de datos común. Se trata de un espacio para investigar e informar sobre las prácticas del llamado data sharing (intercambio de datos), que ellos mismos definen como “transacciones de cualquier tipo de información en forma digital, entre diferentes tipos de organizaciones”.
El SCDS proporciona soporte práctico a organismos públicos o privados que busquen compartir sus datos -independientemente del modelo elegido para ello-. Entre otras cuestiones, difunde buenas prácticas y casos de éxito con el objetivo de inspirar a otros en el intercambio de datos. Los ejemplos, que no se limitan al ámbito geográfico de Europa, abarcan diferentes sectores, desde la agricultura hasta la sanidad o la movilidad.
En el informe Data Sharing Practice Examples encontramos algunos de ellos. Este documento se centra principalmente en plataformas e iniciativas de terceros que pueden servir de apoyo a la gobernanza y el cumplimiento normativo en las prácticas de intercambio de datos.
Ejemplos prácticos e iniciativas de intercambio de datos
Uno de los principales retos que se encuentran las organizan que empiezan a desarrollar acciones de intercambio de datos es la falta de confianza que puede generar en la industria y la ciudadanía la compartición de su información. El uso de estándares y soluciones tecnológicas de terceros ayudan a paliar este reto, aumentando también la eficiencia al no tener que dedicar tiempo y recursos al desarrollo propio.
El informe divide los ejemplos que muestra en 3 categorías, en base a su función principal:
-
Catalizadores de espacios de datos: su objetivo es crear espacios para la puesta en común de datos, abordando un sector o territorio específico.
-
Facilitadores políticos/legales: se centran en los retos legales del intercambio de datos, bien desde una posición de soporte u ofreciendo su visión desde la experiencia.
-
Facilitadores tecnológicos: se dedican a desarrollar tecnología - o asesorar sobre ella - para el intercambio de datos de manera general, sin centrarse en un sector específico.
El informe incluye ejemplos relativos a cada una de estas categorías como veremos a continuación.
Catalizadores de espacios de datos: MaaS Madrid y Mobility 360
Empezamos con un ejemplo relativo a nuestro país y al sector de la movilidad. En Madrid conviven operadores públicos y privados de transporte que ofrecen servicios de autobuses, trenes, tranvías, coches, bicicletas y motos.
MaaS Madrid nació como un agregador de datos que permite a los usuarios acceder a la información en tiempo real de los citados operadores en una única plataforma integrada, incorporando la información disponible del transporte público y de los servicios de movilidad compartida adheridos - como coches compartidos, patinetes o bicicletas-. MaaS Madrid fue una primera aproximación, que ha dado paso a Mobility 360, presentada recientemente en una fecha posterior al informe y por ello no incluida en el mismo.
Mobility 360 ofrece “una experiencia de movilidad inteligente, es decir, digital e innovadora que proporciona al usuario alternativas eficientes para realizar sus desplazamientos de forma fácil y fluida”. Esto supone una gran ventaja para los usuarios, que disponen de toda la información centralizada para elegir la ruta y el servicio que mejor responda a sus necesidades, a la vez que se fomenta el uso del transporte público o compartido (con el consiguiente beneficio para el medio ambiente).
Este modelo también tiene ventajas para los operadores, que amplían su visibilidad y se hacen más conocidos entre su público. Además, permite recopilar datos anónimos agregados en tiempo real, muy útiles para la toma de decisiones y la planificación de políticas de movilidad por parte de los entes públicos.
Facilitadores políticos/legales: Technology Industries Finland
Technology Industries of Finland (TIF) es la organización en defensa de las empresas de electrónica, electrotécnica, mecánica y metalúrgica, consultoría de ingeniería y tecnología de la información en el país nórdico, con más de 1.600 miembros. Tras analizar el uso de los datos en estos campos y observar la falta de prácticas establecidas relativas a los derechos de uso de los datos, TIF ha elaborado un modelo de condiciones para el intercambio de información, que están promoviendo dentro y fuera del país.
Este modelo incluye una serie de cláusulas estándar compatibles con la legislación sobre competencia y protección de datos personales de la Unión Europea. TIF recomienda incluir estas cláusulas como apéndices a los acuerdos preexistente entre las partes implicadas en el intercambio de datos.
Los términos del modelo están disponibles en la tienda web de Teknova.
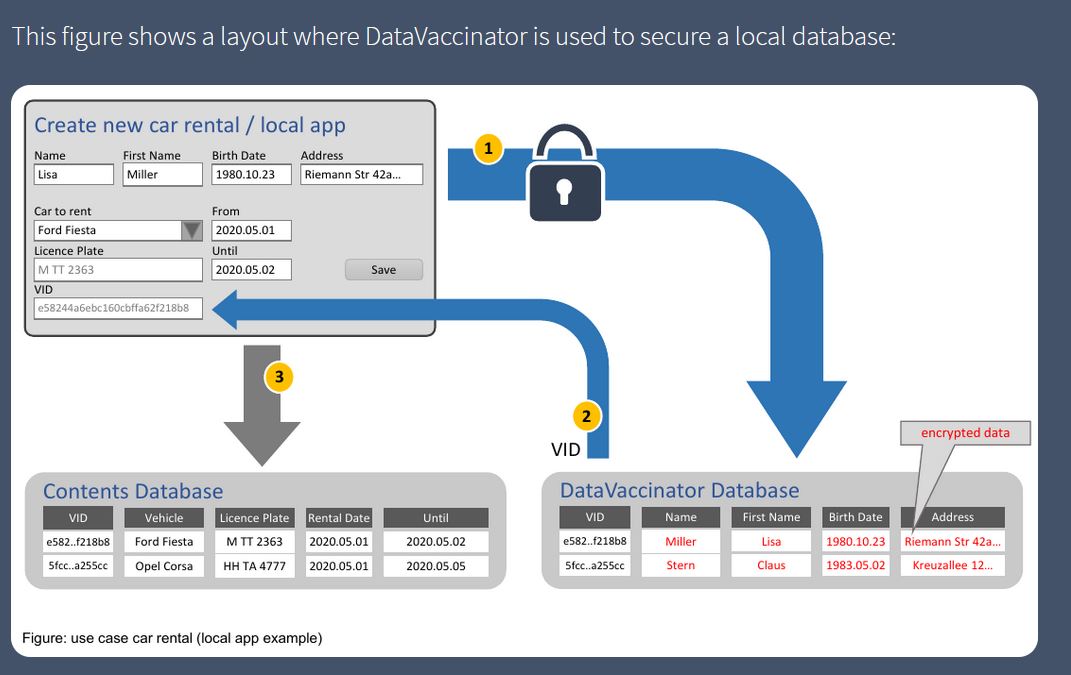
Facilitadores tecnológicos: DataVaccinators
DataVaccinators se centra en el intercambio de datos personales de forma segura. Ofrece una solución de software de código abierto para el almacenamiento y la protección de datos personales mediante el uso de técnicas de seudonimización aplicadas en el momento de generación de los datos, que son separados en distintas bases de datos y cifrados.
DataVaccinators se puede integrar en cualquier aplicación. Los desarrolladores pueden integrar otros componentes en la base de datos. El código fuente puede verse y descargarse en GitHub (con licencia AGPL), al igual que la implementación en JavaScipt (con licencia MIT).
Esta solución está dirigida a cualquier tipo de organización, aunque es especialmente útil para hospitales, universidades, bancos, aseguradoras o fabricantes, que pueden aprovechar los datos anonimizados de los clientes para extraer tendencias y tomar decisiones.
Accede a más ejemplos
Estos son solo 3 ejemplos, pero el informe incluye muchos más. Además, en la web del SCDS puedes encontrar más casos de éxito. Como bien indican desde el propio SCDS, todavía no ha surgido ningún modelo que se haya impuesto a los demás, por ello es importante documentar y tener constancia de las iniciativas que van surgiendo en este ámbito, para poder elegir la que más se adapte a nuestras necesidades, aunque esta situación tiene el riego de crear silos, en base a la solución elegida por cada operador.
El intercambio de datos entre organizaciones privadas y con organismos públicos en todas sus modalidades puede generar múltiples beneficios, principalmente al proporcionar una mayor información para tomar mejores decisiones que afecten tanto al ámbito económico como social. Pero para aprovecharse de todas sus ventajas es necesario llevar a cabo este intercambio de manera segura, legal y respetuosa con los derechos de privacidad de los ciudadanos. La Unión Europea es consciente de ello y ya está dando pasos en este sentido. Uno de ellos es el Reglamento sobre gobernanza de los datos en el ámbito europeo, dirigido a “ampliar la disponibilidad de datos con miras a su utilización”, a través de mecanismos como los proveedores de servicios de intercambio de datos o el punto único de información.
Contenido elaborado por el equipo de datos.gob.es.
Aplicación
Insight View es una solución de analítica avanzada que proporciona información de empresas y trabajadores autónomos en 73 países. Se centra en las áreas de marketing, ventas, finanzas, compras, logística y riesgos. Su valor añadido reside en la toma de las mejores decisiones de negocio en la búsqueda de nuevas oportunidades comerciales, así como minimizar riesgos de impagos.
- Bases de datos actualizadas
Posibilidad de elaborar bases de datos propias a través de 25 filtros en 11 países de Europa, directivos, datos generales, etc. Descarga el Top 500 compañías por facturación de una región, actividad CNAE. También puedes recibir alertas diarias de empresas (constituidas, disueltas o en concurso). Mejora el rendimiento de las campañas de Marketing directo y Telemarketing.
- Situación financiera de empresas
Informes dinámicos sobre los principales indicadores financieros, empresariales y comerciales de un sector empresarial o grupo de empresas. Otra de las características es la posibilidad de comparar 5 sociedades para elegir el mejor acuerdo comercial.
- Disminuye el riesgo de impagos comerciales
Acceso a RAI y ASNEF (solo en España). Información sobre el límite de crédito y el Rating de Morosidad realizando una simulación por importe de venta.
Tags: bases de datos empresas, ASNEF empresas, ratios financieros empresas
Blog
La creciente preocupación de las autoridades europeas por la gestión de las habilidades digitales entre la población activa, especialmente los jóvenes, es una realidad que se acelera y cuya gestión no parece tener una solución fácil.
“Internet y las tecnologías digitales están cambiando el mundo. Pero los obstáculos existentes en internet hacen que los ciudadanos pierdan bienes y servicios, que las empresas de internet y las emergentes tengan su horizonte limitado, y que las empresas y las administraciones no puedan beneficiarse plenamente de las herramientas digitales”. Con esta contundente afirmación abre la Comisión Europea (CE) la sección web dedicada al mercado único digital. El mercado único digital es una de las prioridades estratégicas de la CE y, dentro de ella, una de las líneas de actuación es el desarrollo de las habilidades digitales entre la población europea en activo - en especial los jóvenes -.
A la hora de clasificar las habilidades digitales aparece el mismo problema que con la clasificación de las tecnologías emergentes. La mayoría de los esfuerzos en esta materia se centra en el establecimiento de una clasificación jerárquica de habilidades/tecnologías, que raramente es capaz de profundizar más allá de dos o tres niveles de profundidad.
La CE establece una clasificación de las competencias digitales en 5 categorías (siempre en el dominio de Internet):
-
Procesado de información
-
Creación de contenido
-
Comunicación
-
Resolución de problemas
-
Seguridad
En cada una de estas categorías, la Comisión propone un marco de trabajo donde asigna tres niveles de competencia de usuario (básico, independiente, experto). Para cada nivel de competencia se proponen afirmaciones estándar que ayuden al usuario a realizar una autoevaluación y ser capaz de establecer su nivel de competencia digital.
La cuestión que se plantea ahora en diversos foros es cómo dar un paso más allá de la pura autoevaluación de las competencias. Cuestiones del tipo "¿cómo realizar una búsqueda de términos relacionados con las habilidades digitales?" no son triviales de responder.
Cuando la clasificación de habilidades tiene uno o dos niveles de profundidad, basta con realizar una “búsqueda literal” del término a buscar. Pero, ¿qué ocurre si el árbol de términos relacionado con las habilidades digitales tiene miles de términos organizados de forma jerárquica?
Por ejemplo, supongamos que una empresa necesita de un perfil muy específico para una nueva posición en un proyecto de I+D. El perfil requerido es una persona que tenga conocimientos avanzados en la librería MLib Apache Spark. Se requiere que tenga más de 2 años de experiencia en el campo de Big data en streaming. Además de estas -las denominadas habilidades duras (hard skills)- se requiere que la persona disponga de una serie de habilidades sociales o habilidades blandas como capacidad de comunicar en público y trabajo en equipo.
¿Cómo localizamos a un perfil así en una base de datos de 400.000 empleados en todo el mundo?
Una posible solución a estas y otras cuestiones puede ser la construcción de una ontología de habilidades digitales en Europa.
Una ontología proporciona una organización jerarquizada de términos (taxonomía) y un conjunto de relaciones entre ellos, lo cual facilita la búsqueda - tanto literal como inferida- de términos y expresiones complejas. Esto es ya muy útil en sí mismo, pero si además se combina la estructura formal de una ontología con su implementación técnica en una herramienta tecnológica, se obtiene un potente producto tecnológico. Una implementación técnica de esta ontología permitiría, entre otros, realizar la siguiente búsqueda compleja de forma eficiente e inequívoca:
Localizar a una persona CON habilidades técnicas de MLib que además TENGA más de 2 años de experiencia en Big Data EN streaming y que además TENGA las habilidades blandas DE trabajo en equipo y capacidad de comunicación a nivel intermedio.
En caso de existir una ontología subyacente, en el ejemplo anterior, todos los términos subrayados tendrían un identificador único, así como las relaciones (mayúsculas). El motor de búsqueda semántico sería capaz de identificar la consulta anterior, extraer los términos clave, comprender las relaciones (CON, TENGA, más, DE, etc.) y ejecutar la búsqueda contra la base de datos de empleados, extrayendo aquellos resultados que encajasen con la búsqueda.
Un ejemplo muy claro de utilización de una ontología para realizar búsquedas complejas en bases de datos inmensas es SNOMED-CT. Se trata de un vocabulario estándar para buscar términos clínicos en bases de datos de pacientes. El dominio clínico es especialmente indicado para el desarrollo de ontologías por la compleja estructura inherente a los términos clínicos y sus relaciones.
Si bien existen herramientas y métodos clásicos de organización de la información basados en bases de datos tradicionales y modelos relacionales, las ontologías y sus implementaciones tecnológicas ofrecen mayor flexibilidad, escalabilidad y nivel de personalización a diferentes subcampos.
Precisamente las características de flexibilidad y alta escalabilidad se vuelven fundamentales a medida que los repositorios de datos abiertos (opendata) se vuelven cada vez mayores y diversos. El portal europeo para los datos abiertos contiene más de 12.000 conjuntos de datos clasificados por temas. Por su parte, la web especializada en ciencia de datos, Kaggle, alberga 9000 conjuntos de datos sobre los que, anualmente, se organizan concursos que premian a aquellos que mejor analicen y extraigan información útil de estos conjuntos. En definitiva, el volumen de datos a disposición de la sociedad no hace más que aumentar año tras año y las ontologías cobran fuerza como una potente herramienta para la gestión de la información oculta bajo ese manto de datos en crudo.
Contenido elaborado por Alejandro Alija,experto en Transformación Digital e Innovación.
Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.