Empresa reutilizadora
Atogu is an advanced B2B data platform that helps sales and marketing teams identify, prioritise, and profile companies with a high probability of purchase.
Its database is not static: it is constantly updated to maintain fresh, actionable data that allows teams to know when a company is ready to buy and how to best personalise their sales messages.
Atogu combines multiple official and public sources to provide high-value purchase signals and variables, accelerating prospecting and improving sales results.
Blog
Digital technology and algorithms have revolutionised the way we live, work and communicate. While promising efficiency, accuracy and convenience, these technologies can exacerbate prejudice and social inequalities exacerbate prejudice and social inequalities and create new forms of exclusion and create new forms of exclusion. Thus, invisibilisation and discrimination, which have always existed, take on new forms in the age of algorithms.
Lack of interest and data leads to algorithmic invisibilisation, leading to two types of algorithmic neglect. The first of these is among the world's underserved, which includes the millions who do not have a smartphone or a bank account millions who do not have a smartphone or a bank account, and are thus on the margins of the platform economy and who are therefore on the margins of the platform economy and, for algorithms, do not exist. The second type of algorithmic abandonment includes individuals or groups who are victims of the failure of the algorithmic system, as was the case with SyRI(Systeem Risico Indicatie)SyRI(Systeem Risico Indicatie) in the Netherlands that unfairly singled out some 20,000 families from low socio-economic backgrounds for tax fraud, leading many to ruin by 2021. The algorithm, which the algorithm, which was declared illegal by a court in The Hague months later, was applied in the country's poorest neighbourhoodsthe algorithm, which was declared illegal by a court in The Hague months later, was applied in the country's poorest neighbourhoods the algorithm, which was declared illegal by a court in The Hague months later, was applied in the poorest neighbourhoods of the country and blocked many families with more than one nationality from receiving the social benefits to which they were entitled because of their socio-economic status.
Beyond the example in the Dutch public system, invisibilisation and discrimination can also originate in the private sector. One example is Amazon's amazon's job posting algorithm which showed a bias against women by learning from historical data - i.e. incomplete data because it did not include a large and representative universe - leading Amazon to abandon the project. which showed a bias against women by learning from historical data - i.e. incomplete data because it did not include a large and representative universe - leading Amazon to abandon the project. Another example is Apple Card, a credit card backed by Goldman Sachs, which was also singled out when its algorithm was found to offer more favourable credit limits to men than to women.
In general, invisibility and algorithmic discrimination, in any field, can lead to unequal access to resources and exacerbate social and economic exclusion.
Making decisions based on algorithms
Data and algorithms are interconnected components in computing and information processing. Data serve as a basis, but can be unstructured, with excessive variability and incompleteness. Algorithms are instructions or procedures designed to process and structure this data and extract meaningful information, patterns or results.
The quality and relevance of the data directly impacts the effectiveness of the algorithms, as they rely on the data inputs to generate results. Hence, the principle "rubbish in, rubbish out"which summarises the idea that if poor quality, biased or inaccurate data enters a system or process, the result will also be of poor quality or inaccurate. On the other hand, well-designed well-designed algorithms can enhance the value of data by revealing hidden relationships or making by revealing hidden relationships or making predictions.
This symbiotic relationship underscores the critical role that both data and algorithms play in driving technological advances, enabling informed decision making, and This symbiotic relationship underscores the critical role that both data and algorithms play in driving technological advances, enabling informed decision making, and fostering innovation.
Algorithmic decision making refers to the process of using predefined sets of instructions or rules to analyse data and make predictions to aid decision making. Increasingly, it is being applied to decisions that have to do with social welfare social welfare and the provision of commercial services and products through platforms. This is where invisibility or algorithmic discrimination can be found.
Increasingly, welfare systems are using data and algorithms to help make decisions on issues such as who should receive what kind of care and who is at risk. These algorithms consider different factors such as income, family or household size, expenditures, risk factors, age, sex or gender, which may include biases and omissions.
That is why the That is why the Special Rapporteur on extreme poverty and human rights, Philip Alston, warned in a report to the UN General Assembly that the uncautious adoption of these can lead to dystopian social welfare dystopian social welfare. In such a dystopian welfarestate , algorithms are used to reduce budgets, reduce the number of beneficiaries, eliminate services, introduce demanding and intrusive forms of conditionality, modify behaviour, impose sanctions and "reverse the notion that the state is accountable".
Algorithmic invisibility and discrimination: Two opposing concepts
Although data and algorithms have much in common, algorithmic invisibility and discrimination are two opposing concepts. Algorithmic invisibility refers to gaps in data sets or omissions in algorithms, which result in inattentions in the application of benefits or services. In contrast, algorithmic discrimination speaks to hotspots that highlight specific communities or biased characteristics in datasets, generating unfairness.
That is, algorithmic invisibilisation occurs when individuals or groups are absent from datasets, making it impossible to address their needs. For example, integrating data on women with disabilities into social decision-making can be vital for the inclusion of women with disabilities in society. Globally, women are more vulnerable to algorithmic invisibilisation than men, as they have less access to digital technology have less access to digital technology and leave fewer digital traces.
Opaque algorithmic systems that incorporate stereotypes can increase invisibilisation and discrimination by hiding or targeting vulnerable individuals or populations. An opaque algorithmic system is one that does not allow access to its operation.
On the other hand, aggregating or disaggregating data without careful consideration of the consequences can result in omissions or errors result in omissions or errors. This illustrates the double-edged nature of accounting; that is, the ambivalence of technology that quantifies and counts, and that can serve to improve people's lives, but also to harm them.
Discrimination can arise when algorithmic decisions are based on historical data, which usually incorporate asymmetries, stereotypes and injustices, because more inequalities existed in the past. The "rubbish in, rubbish out" effect occurs if the data is skewed, as is often the case with online content. Also, biased or incomplete databases can be incentives for algorithmic discrimination. Selection biases may arise when facial recognition data, for example, is based on the features of white men, while the users are dark-skinned women, or on online content generated by a minority of agentswhich makes generalisation difficult.
As can be seen, tackling invisibility and algorithmic discrimination is a major challenge that can only be solved through awareness-raising and collaboration between institutions, campaigning organisations, businesses and research.
Content prepared by Miren Gutiérrez, PhD and researcher at the University of Deusto, expert in data activism, data justice, data literacy and gender disinformation.
The contents and views reflected in this publication are the sole responsibility of the author.
Noticia
Public administrations (PAs) have the obligation to publish their open datasets in reusable formats, as dictated by European Directive 2019/1024 which amends Law 37/2007 of November 16, regarding the reuse of public sector information. This regulation, aligned with the European Union's Data Strategy, stipulates that PAs must have their own catalogs of open data to promote the use and reuse of public information.
One of these catalogs is the Canary Islands Open Data Portal, which contains over 7,450 open, free, and reusable datasets from up to 15 organizations within the autonomous community. The Ministry of Agriculture, Livestock, Fisheries, and Food Sovereignty (CAGPSA) of the Government of the Canary Islands is part of this list. As part of its Open Government initiative, CAGPSA has strongly promoted the opening of its data.
Through a process of analysis, refinement, and normalization of the data, CAGPSA has successfully published over 20 datasets on the portal, thus ensuring the quality of information reuse by any interested party.
Analysis, data normalization, and data opening protocol for the Government of the Canary Islands
To achieve this milestone in data management, the Ministry of Agriculture, Livestock, Fisheries, and Food Sovereignty of the Government of the Canary Islands has developed and implemented a data opening protocol, which includes tasks such as:
- Inventory creation and prioritization of data sources for publication.
- Analysis, refinement, and normalization of prioritized datasets.
- Requesting the upload of datasets to the Canary Islands Open Data Portal.
- Addressing requests related to the published datasets.
- Updating published datasets.
Data normalization has been a key factor for the Ministry, taking into account international semantic assets (including United Nations classifications and various agencies or Eurostat) and applying guidelines defined in international standards such as SDMX or those set by datos.gob.es, to ensure the quality of the published data.
CAGPSA has not only put efforts into data normalization and publication but has also provided support to the ministry's personnel in the management and maintenance of the data, offering training and awareness sessions. Furthermore, they have created a manual for data reuse, outlining guidelines based on European and national directives regarding open data and the reuse of public sector information. This manual helps address concerns of the ministry's staff regarding the publication of personal or commercial data.
As a result of this work, the Ministry has actively collaborated with the Canary Islands Open Data Portal in publishing datasets and defining the data opening protocol established for the entire Government of the Canary Islands.
Commitment to Quality and Information Reuse
CAGPSA has been particularly recognized for the publication of the Agricultural Transformation Societies (SAT) dataset, which ranked among the top 3 datasets by the Multisectorial Information Association (ASEDIE) in 2021. This initiative has been praised by the association on multiple occasions for its focus on data quality and management.
Their efforts in data normalization, support to the ministry's staff, collaboration with the open data portal, and the extensive array of datasets, position CAGPSA as a reference in this field within the Canary Islands autonomous community.
At datos.gob.es, we applaud these kinds of examples and highlight the good practices in data opening by public administrations. The initiative of the Ministry of Agriculture, Livestock, Fisheries, and Food Sovereignty of the Government of the Canary Islands is a significant step that brings us closer to the advantages that open data and its reuse offer to the citizens. The Ministry's commitment to data openness contributes to the European and national goal of achieving a data-driven administration.
Noticia
Open data can be very useful in promoting aspects such as the health and well-being of citizens or the protection of the environment, as well as the growth of economies. The opening of information encourages innovation, the creation and adaptation of companies and organizations around services and technologies capable of generating profitability and offering solutions to current problems from the reuse of data.
But, in addition, economic data contributes to many organizations being able to make better decisions. Economic statistics and indicators allow us to know how a certain market or country evolves, discover trends and act accordingly.
If you are interested in accessing this type of data, below, we collect 10 examples of repositories related to the economy at an international level:

-
Publisher: World Bank
This is a website belonging to the World Bank. This platform offers a complete range of economic data that are frequently updated and allows access to open information produced by the World Bank itself. Among the type of data it offers are international debt statistics, world development indicators or databases on household consumption patterns around the world, among many others.
Two interesting sections stand out. One is its data catalog, where you can find information on economic topics such as statistical performance indicators or data on COVID-19, for example. Another is its microdata section, which offers a collection of datasets from the World Bank and other international, regional and national organizations.
Much of this data are offered in the most popular formats (HTML, JSON, PDF, CSV, ...). In addition, it has a space for reusers, with information on APIs.
-
Publisher: IMF (Internationaly Monetary Fund)
The International Monetary Fund (IMF) is a 190-country organization that works to promote global monetary cooperation, ensure financial stability, facilitate international trade, and more.
This portal contains IMF datasets on global financial stability, regional economics, global financial statistics, economic outlook, and more. Data can be downloaded in various formats, including XLSX and XLS.
-
Publisher: OECD (Organisation for Economic Co-operation and Development)
The OCDE is an international organization of which 38 countries, including Spain, are members, whose objective is to address economic, social and governance challenges.
The OECD data catalog has a classification by sector, including the economic sector. It offers the possibility of filtering data according to whether or not they have access to the API. In addition, this portal allows queries to be made on large databases in its OECD.Stat data warehouse.
Particularly interesting are its data visualizations, such as these developed to show information about global employment rates, as well as other employment-related indicators.
-
Publisher: UNECE (United Nations Economic Commission for Europe)
Created in 1947 and composed of 56 member states, it is one of the five UN regional commissions. Its objectives include promoting pan-European economic integration and supporting countries with economies in transition.
On its public information portal, you can find various datasets, mostly economic, linked to the different countries of Europe. It also offers other datasets on population and transport and some alternative resources such as visualizations or data maps.
The data is displayed in four different forms: graphs, rankings, tables and maps. In this example, information about the global youth unemployment rate can be queried through the 4 means mentioned above. The data can be downloaded in CSV, TSV or JSON.
-
Publisher: Economic Commission for Latin America and the Caribbean (CEPAL, United Nations).
CEPALSTAT is the portal where you can find all the statistical information on the countries of Latin America and the Caribbean, collected, systematized and published by the Economic Commission for Latin America and the Caribbean (CEPAL, in spanish).
This portal brings together databases and statistical publications, as well as economic datasets for Latin America and the Caribbean, often accompanied by other resources such as data visualizations or maps. It also provides access to these data through an API to speed up and facilitate the data search process for its users. Data can be downloaded in XML, JSON or XLXS.
-
Publisher: ECB (European Central Bank)
The ECB, in collaboration with the national central banks and other national (statistical and supervisory) authorities of the European Union, offers a service for the development, collection, compilation and dissemination of statistics in open format.
The Statistical Data Warehouse provides indicators for the euro area, including in some cases national level breakdowns. Each of the statistics offered on this portal has a brief introductory description of the topics covered. All data are available for download in Excel and CSV format.
-
Publisher: World Trade Organisation (WTO).
The World Trade Organisation (WTO) is an international organisation that deals with the rules governing trade between countries. Its main objective is to help producers of goods and services, exporters and importers to conduct their activities in an optimal way.
The organisation offers access to a selection of relevant databases providing statistics and information on different trade-related measures. This information is classified in four main blocks: goods, services, intellectual property, statistics and other topics, making it easier for users to search for data.
On this page you can consult the WTO online systems (databases/websites) that are active. Some of them require registration.
UNIDO Statistics Data Portal
-
Publisher: United Nations Industrial Development Organization (UNIDO).
UNIDO is a specialised agency of the United Nations that promotes industrial development for poverty reduction, inclusive globalisation and environmental sustainability.
It publishes, among other things, datasets on industrial development, manufacturing production and investment. On its website, it has a search engine for information on indicators such as population growth or GDP growth by country. These data can be visualised through a graph that is updated with the selected information, also offering the possibility of comparing data from different countries within the same graph.
By accessing the DataBase section, each dataset can be downloaded in excel and CSV format.
UNCTADSTAT
-
Publisher: UNCTAD (United Nations Conference on Trade and Development)
UNCTAD is an organisation charged with helping developing countries harness international trade, investment, financial resources and technology to achieve sustainable and inclusive development.
On its open data portal, it collects statistical series by country and product, with a special focus on countries with developing and transition economies. Digital economy, international trade in services, maritime transport or inflation and exchange rates are just some of the topics that can be consulted on this platform.
In addition, for users who are not used to navigating this type of portal, UNCTAD provides a series of video tutorials that introduce the user to the data centre and show, among other things, how to export information from the platform (downloadable in CSV or XLSX).
-
Publisher: IDB (Inter-American Development Bank)
The Inter-American Development Bank (IDB) is an inter-national financial organisation whose main objective is to finance viable economic, social and institutional development projects and promote trade integration in Latin America and the Caribbean.
In its data section, it offers country development indicators related to the macroeconomic profile, global integration and social prospects of each country. Moreover, in this section you can find some additional resources such as graphs and visualisations that allow you to filter the information according to different indicators or courses to increase your economic knowledge based on the data.
Most of the data can be downloaded in CSV, JSON or RDF.
This has been just a small selection of data repositories related to the economic sector that may be of interest to you. Do you know of any other relevant repositories related to this field? Leave us a comment or send us an email to dinamizacion@datos.gob.es
Noticia
Open data is fundamental in the field of science. Open data facilitates scientific collaboration and enriches research by giving it greater depth. Thanks to this type of data, we can learn more about our environment and carry out more accurate analyses to support decisions.
In addition to the resources included in general data portals, we can find an increasing number of open data banks focused on specific areas of the natural sciences and the environment. In this article we bring you 10 of them.

NASA Open Data Portal
- Publisher: NASA
The data.nasa.gov portal centralizes NASA's open geospatial data generated from its rich history of planetary, lunar and terrestrial missions. It has nearly 20,000 unique monthly users and more than 40,000 datasets. A small percentage of these datasets are hosted directly on data.nasa.gov, but in most cases metadata and links to other space agency projects are provided.
data.nasa.gov includes a wide range of subject matter, from data related to rocket testing to geologic maps of Mars. The data are offered in multiple formats, depending on each publisher.
The site is part of the Open Innovation Sites project, along with api.nasa.gov, a space for sharing information about NASA APIs, and code.nasa.gov, where NASA's open source projects are collected.
Copernicus
- Publisher: Copernicus
COPERNICUS is the Earth observation program of the European Union. Led by the European Commission, with the collaboration of the member states and various European agencies and organizations, it collects, stores, combines and analyzes data obtained through satellite observation and in situ sensor systems on land, air and sea.
It provides data through 6 services: emergency, security, marine monitoring, land monitoring, climate change and atmospheric monitoring. The two main access points to Copernicus satellite data are managed by ESA: the Copernicus Open Access Platform - which has an API - and the CSCDA (Copernicus Space Component Data Access). Other access points to Copernicus satellite data are managed by Eumetsat.
Climate Data Online
- Publisher: NOAA (National Centers for Environmental Information)
Climate Data Online (CDO) from the US government agency NOAA provides free access to historical weather and climate data worldwide. Specifically, 26,000 datasets are offered, including daily, monthly, seasonal and annual measurements of parameters such as temperature, precipitation or wind, among others. Most of the data can be downloaded in CSV format.
To access the information, users can use, among other functionalities, a search tool, an API or a map viewer where a wide variety of data can be displayed in the same visualization environment, allowing variables to be related to specific locations.
AlphaFold Protein Structure Database
- Publisher: DeepMind and EMBL-EBI
AlphaFold is an artificial intelligence system developed by the company DeepMind that predicts the 3D structure of a protein from its amino acid sequence. In collaboration with the EMBL European Bioinformatics Institute (EMBL-EBI), DeepMind has created this database that provides the scientific community with free access to these predictions.
The first version covers the human proteome and the proteomes of other key organisms, but the idea is to continue to expand the database to cover a large proportion of all cataloged proteins (over 100 million). The data can be downloaded in mmCIF or PDB format, which are widely accepted by 3D structure visualization programs such as PyMOL and Chimera.
Free GIS DATA
- Publisher: Robin Wilson, expert in the GIS area.
Free GIS Data is the effort of Robin Wilson, a freelance expert in remote sensing, GIS, data science and Python. Here users can find a categorized list of links to over 500 websites offering freely available geographic datasets, all ready to be loaded into a Geographic Information System. You can find data on climate, hydrology, ecology, natural disasters, mineral resources, oil and gas, transportation and communications, or land use, among many other categories.
Users can contribute new datasets by sending them by email to robin@rtwilson.com.
GBIF (Global Biodiversity Information Facility)
- Publisher: GBIF
GBIF is an intergovernmental initiative formed by countries and international organizations that collaborate to advance free and open access to biodiversity data. Through its nodes, participating countries provide data on species records based on common standards and open source tools. In Spain, the national node is GBIF-ES, sponsored by the Spanish Ministry of Science and Innovation and managed by the Spanish National Research Council (CSIC).
The data it offers comes from many sources, from specimens held in museums and collected in the 18th and 19th centuries to geotagged photos taken with smartphones and shared by amateur naturalists. It currently has more than 1.8 billion records and 63,000 datasets of great utility for researchers conducting studies related to biodiversity and the general public. You can also access its API here.
EDI Data Portal
- Publisher:Environmental Data Initiative (EDI)
The Environmental Data Initiative (EDI) promotes the preservation and reuse of environmental data, supporting researchers to archive and publish publicly funded research data. This is done following FAIR principles and using the Ecological Metadata Language (EML) standard.
The EDI data portal contains the contributed environmental and ecological data packages, which can be accessed through a search engine or API. Users should contact the data provider before using the data in any research. These data should be properly cited when used in a publication. A Digital Object Identifier (DOI) is provided for this purpose.
PANGAEA
- Publisher: World Data Center PANGEA
The PANGAEA information system functions as an open access library for archiving, publishing and distributing georeferenced Earth system research data.
Any user can upload data related to the natural sciences. PANGAEA has a team of editors who are responsible for checking the integrity and consistency of the data and metadata. It currently includes more than 400,000 datasets from more than 650 projects. The formats in which they are available are varied: you can find from text/ASCII or tab-delimited files, to binary objects (e.g. seismic data and models, among others) or other formats following ISO standards (such as images or movies).
re3data
- Publisher: DataCite
Re3data is a worldwide registry of research data repositories covering databases from different academic disciplines available free of charge. It includes data related to the natural sciences, medicine or engineering, as well as those linked to humanities areas.
It currently offers detailed descriptions of more than 2,600 repositories. These descriptions are based on the re3data metadata schema and can be accessed through the re3data API. In this Github repository you can find examples of how to use the re3data API. These examples are implemented in R using Jupyter Notebooks.
IRIS
- Publisher: Incorporated Research Institutions for Seismology (IRIS)
IRIS is a consortium of more than 100 U.S. universities dedicated to the operation of scientific facilities for the acquisition, management and distribution of seismological data. Through this website any citizen can access a variety of resources and data related to earthquakes occurring around the world.
It collects time series data, including sensor recordings of a variety of measurements. Among the metadata available is the location of the station from which the data was obtained and its instrumentation. It also provides access to historical seismic data, including scanned seismograms and other information from pre-digital sources.
Data are available in SEED (the international standard for the exchange of digital seismic data), ASCII or SAC (Seismic Analysis Code) format.
Do you know more international repositories with data related to natural sciences and environment? Leave us a comment or send us an email to dinamizacion@datos.gob.es.
Blog
The "Support center for data exchange”(Support Center for Data Sharing or SCDS in English) was born in 2019 as part of the European strategy to promote a common data ecosystem. It is a space to investigate and report on the practices of so-called data sharing, which they themselves define as “transactions of any type of information in digital form, between different types of organizations”.
The SCDS provides practical support to public or private organizations that seek to share their data - regardless of the model chosen for it. Among other things, it disseminates good practices and success stories with the aim of inspiring others in the exchange of data. The examples, which are not limited to the geographical scope of Europe, cover different sectors, from agriculture to health to mobility.
In the report Data Sharing Practice Examples we found some of them. This report focuses primarily on third-party platforms and initiatives that can support governance and compliance in data sharing practices.
Practical examples and data sharing initiatives
One of the main challenges faced by organizations that begin to develop data exchange actions is the lack of trust that the sharing of their information can generate in the industry and the public. The use of third-party standards and technological solutions help to alleviate this challenge, also increasing efficiency by not having to dedicate time and resources to self-development.
The report divides the examples it shows into 3 categories, based on their main function:
- Data space catalysts: its objective is to create spaces for the sharing of data, addressing a specific sector or territory.
- Political / legal facilitatorsThey focus on the legal challenges of data exchange, either from a support position or offering their insight from experience.
- Technological facilitators: they are dedicated to developing technology - or advising on it - for the exchange of data in a general way, without focusing on a specific sector.
The report includes examples related to each of these categories as we will see below.
Data space catalysts: MaaS Madrid
We start with an example related to our country and the mobility sector. In Madrid there are about 70 mobility operators that offer bus, train, tram, car, bicycle and motorcycle services. Of them, 41 are public.
MaaS Madrid is a data aggregator that allows users to access real-time information from the aforementioned operators on a single integrated platform. It incorporates the information available on public transport and the adhered shared mobility services, redirecting to the applications of each of them to complete the reservation.
This is a great advantage for users, who will have all the centralized information to choose the route and the service that best meets their needs, while promoting the use of public or shared transport (with the consequent benefit for the environment).
This model also has advantages for operators, which increase their visibility and become better known among their public. In addition, it allows the collection of anonymous aggregated data in real time, very useful for decision-making and planning of mobility policies by public entities.
Political / Legal Facilitators: Technology Industries Finland
Technology Industries of Finland (TIF)is the organization in defense of electronics, electrotechnical, mechanical and metallurgical companies, engineering consulting and information technology in the Nordic country, with more than 1,600 members. After analyzing the use of data in these fields and observing the lack of established practices regarding data use rights, TIF has developed a model of conditions for the exchange of information, which they are promoting within and outside the country.
This model includes a series of standard clauses compatible with the legislation on competition and protection of personal data of the European Union. TIF recommends including these clauses as appendices to the pre-existing agreements between the parties involved in the data exchange.
Model terms are available in the webstore of Teknova.
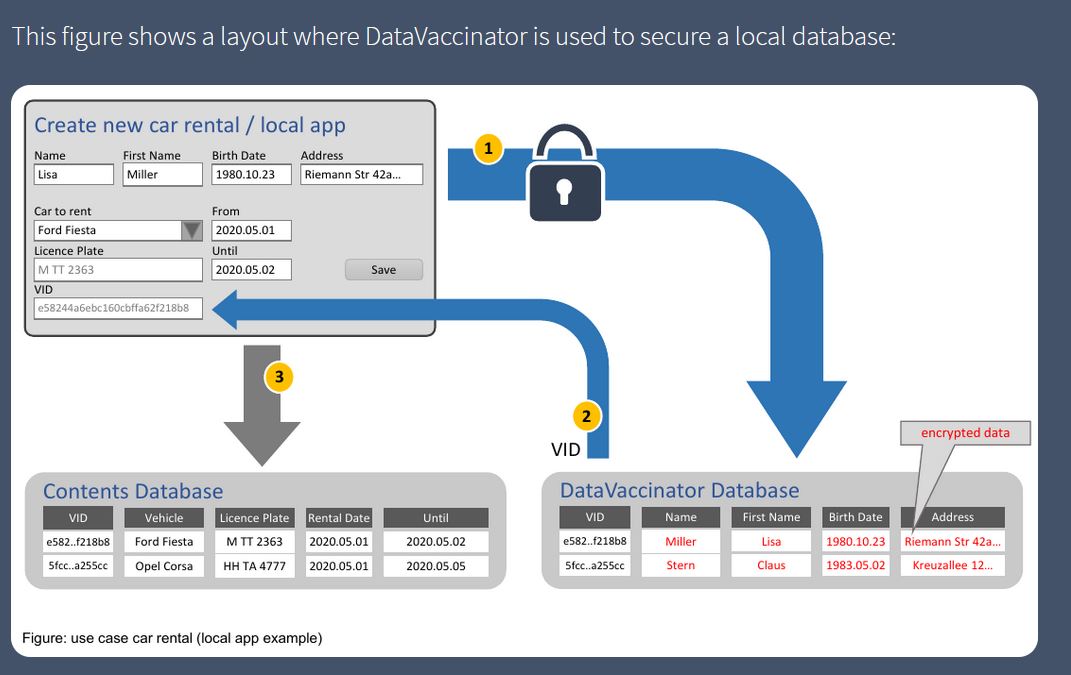
Technology Enablers: DataVaccinators
DataVaccinators focuses on the exchange of personal data in a secure way. It offers an open source software solution for the storage and protection of personal data through the use of pseudonymisation techniques applied at the time of data generation, which are separated into different databases and encrypted.
Developers can integrate other components into the database. The source code can be viewed and downloaded at GitHub (AGPL licensed), like the implementation in JavaScipt (licensed by MIT).
This solution is aimed at any type of organization, although it is especially useful for hospitals, universities, banks, insurers or manufacturers, who can take advantage of anonymized customer data to extract trends and make decisions.
Access more examples
These are just 3 examples, but the report includes many more. In addition, on the SCDS website you can find more success stories. As indicated by the SCDS itself, no model has yet emerged that has imposed itself on others, so it is important to document and be aware of the initiatives that are emerging in this area, in order to choose the one that best suits our needs. needs, although this situation has the risk of creating silos, based on the solution chosen by each operator.
The exchange of data between private organizations and with public bodies in all its forms can generate multiple benefits, mainly by providing more information to make better decisions that affect both the economic and social spheres. But to take advantage of all its advantages, it is necessary to carry out this exchange in a safe, legal and respectful way with the privacy rights of citizens.
Content prepared by the datos.gob.es team.
Application
Insight View es una solución de analítica avanzada con información de empresas y autónomos de todo el mundo para que las áreas de estrategia de negocio, finanzas, riesgos, marketing, ventas, compras y logística puedan identificar oportunidades de negocio y minimizar sus riesgos comerciales.
Insight View te permite encontrar de manera sencilla empresas con las que tienes más probabilidad de hacer negocios y te ayuda a mejorar la efectividad de tus acciones comerciales. Facilita el análisis agregado de la cartera de clientes y mejorar su ciclo de vida ayudando a tomar las mejores decisiones de negocio. También ayuda en la gestión del riesgo comercial con su valoración de empresas, acceso a RAI y Asnef Empresa.
Blog
The increasing concern of European authorities for the management of digital skills among the working population, especially young people, is a growing reality whose management does not seem to have an easy solution.
“The internet and digital technologies are transforming our world. But existing barriers online mean citizens miss out on goods and services, internet companies and start-ups have their horizons limited, and businesses and governments cannot fully benefit from digital tools.” This strong affirmation opens the European Commission (EC) web section dedicated to digital single market. The digital single market is one of the strategic priorities of the EC and, within it, one of the action lines is the development of digital skills among the employed population of Europe - especially young people.
When classifying digital skills, we have the same problem as classifying emerging technologies. Most efforts in this area focus on the establishment of a hierarchical classification of skills / technologies, which rarely go deeper than two or three levels.
The EC establishes a classification of digital competences in 5 categories (always in the Internet domain):
- Information processing
- Content creation
- Communication
- Problem resolution
- Security
In each of these categories, the Commission proposes a framework whit three levels of user competence (basic, independent, expert). For each level of competence, standard statements are proposed to help users to perform a self-assessment to establish their digital competence level.
Now, the question that arises in various forums is how to take a step beyond the simple self-assessment of competencies. Questions as “how to perform a search for terms related to digital skills?” are not trivial to answer.
When the skills classification has one or two levels of depth, it is enough to perform a "literal search" of the term to be searched. But what happens if the term tree related to digital skills has thousands of terms hierarchically organized?
For example, imagine that a company needs a very specific profile for a new position in an R&D project. The required profile is a professional with advanced knowledge in MLib Apache Spark library and more than 2 years of experience in streaming Big Data. In addition to these skills - called hard skills - the professional needs to have a series of social skills or soft skills such as public communication ability and teamwork.
How can we find such a profile in a database of 400,000 employees around the world?
A possible solution to these and other issues may be the creation of a digital skills ontology in Europe.
An ontology provides a hierarchical organization of terms (taxonomy) and a set of relationships between them, which facilitates the search - both literal and inferred - of complex terms and expressions. This is already very useful by itself, but if you also combine the formal structure of an ontology with its technical implementation, using a technological tool, you get a powerful technological product. A technical implementation of this ontology would allow, among others, perform the following complex search in an efficient and unambiguous way:
Find a person WITH MLib technical skills that also HAS more than 2 years of experience in streaming Big Data and also HAS the soft skills of teamwork and communication skills at the intermediate level.
With an underlying ontology, in the previous example, all the underlined terms would have a unique identifier, as well as their relations (uppercase). The semantic search engine would be able to identify the previous query, extract the key terms, understand the relationships (WITH, HAS, more, etc.) and execute a search against the employees database, extracting those results that fit with the search.
A good example of using an ontology to perform complex searches in immense databases is SNOMED-CT. It is a standard vocabulary to search clinical terms in patient databases. The clinical domain is especially indicated for the development of ontologies due to the complex structure inherent to the clinical terms and their relationships.
Although there are classic tools and methods of organizing information based on traditional databases and relational models, ontologies and their technological implementations offer higher flexibility, scalability and level of personalization to different subfields.
Precisely the characteristics of flexibility and high scalability become fundamental as open data repositories become increasingly bigger and diverse. The European Open Data portal contains more than 12,000 datasets classified by topics. For its part, the website specializing in data science, Kaggle, hosts 9000 datasets and, annually, they organize competitions to reward those professionals who best analyse and extract useful information from these data. In short, the volume of data available to society is increasing year after year and ontologies are importance as a powerful tool for managing information hidden under that blanket of raw data.
Content prepared by Alejandro Alija, expert in Digital Transformation and innovation.
Contents and points of view expressed in this publication are the exclusive responsibility of its author.
Empresa reutilizadora
A company dedicated to business and technology information for companies. Its main mission is to help companies around the world, with advanced analytics solutions and data integration tools, to identify business opportunities and potential risks of non-payment through business information, predictive models and propensity to buy; so that the areas of finance, risk, marketing, sales, purchasing and logistics can identify opportunities and potential risks of non-payment through business information, predictive models and propensity to buy; so that the areas of finance, risk, marketing, sales, purchasing and logistics can identify opportunities and potential risks of non-payment:
- Find new and good customers.
- Analyse the financial health of companies.
- Minimise the risk of non-payment of commercial transactions.
Iberinform is a subsidiary of Crédito y Caución, a global credit insurance operator with a presence in more than 50 countries.
Empresa reutilizadora
Axesor is a service company specialising in credit risk management, business knowledge, financial and marketing systems.
- A company of the Experian group, an international global information services company, with 17,800 people operating in 45 countries.
- Axesor has an offer adapted to all kinds of clients, with an important penetration in multinationals.
Its main objectives include:
- Maximising savings for companies by reducing their bad debts and average collection periods, optimising their resources and management times, thanks to advanced management of commercial credit risk.
- Improve companies' Marketing and Expansion Plans, through an exhaustive analysis of their environment and competition, as well as a better knowledge of clients.
- Optimising the resources of companies, taking on their procedures with the Public Administrations.