Blog
La irrupción de la inteligencia artificial (IA) y, en particular ChatGPT, se ha convertido en uno de los principales temas de debate en los últimos meses. Esta herramienta ha eclipsado incluso otras tecnologías emergentes que habían adquirido un protagonismo en los más diversos ámbitos (jurídicos, económicos, sociales o culturales). Caso, por ejemplo, la web 3.0, el metaverso, la identidad digital descentralizada o los NFT y, en particular, las criptomonedas.
Resulta incuestionable la relación directa que existe entre este tipo de tecnología y la necesidad de disponer de datos suficientes y adecuados, siendo precisamente esta última dimensión cualitativa la que justifica que los datos abiertos estén llamados a desempeñar un papel de especial importancia. Aunque, al menos de momento, no es posible saber cuántos datos abiertos proporcionados por las entidades del sector público utiliza ChatGPT para entrenar su modelo, no hay duda de que los datos abiertos son una fuente especialmente significativa a la hora de mejorar su funcionamiento.
La regulación sobre el uso de los datos por la IA
Desde el punto de vista jurídico, la IA está despertando un especial interés por lo que se refiere a las garantías que deben respetarse a la hora de su aplicación práctica. Así, se están impulsando diversas iniciativas que pretenden regular específicamente las condiciones para proceder a su utilización, entre las que destaca la propuesta que está tramitando la Unión Europea, donde los datos son objeto de especial atención.
Ya en el ámbito estatal, hace unos meses se aprobó la Ley 15/2022, de 12 de julio, integral para la igualdad de trato y la no discriminación. Esta normativa exige a las Administraciones Públicas que favorezcan la implantación de mecanismos que contemplen garantías relativas a la minimización de sesgos, transparencia y rendición de cuentas, en concreto por lo que respecta a los datos utilizados para el entrenamiento de los algoritmos que se empleen para la toma de decisiones.
Por parte de las comunidades autónomas existe un creciente interés a la hora de regular el uso de los datos por parte de los sistemas de IA, reforzándose en algún caso las garantías relativas a la transparencia. También, a nivel municipal se están promoviendo protocolos para la implantación de la IA en los servicios municipales en los que las garantías aplicables a los datos, en particular desde la perspectiva de su calidad, se conciben como una exigencia prioritaria.
La posible colisión con otros derechos y bienes jurídicos: la protección de datos de carácter personal
Más allá de las iniciativas regulatorias, el uso de los datos en este contexto ha sido objeto de una especial atención por lo que se refiere a las condiciones jurídicas en que resulta admisible. Así, puede darse el caso de que los datos que se utilicen estén protegidos por derechos de terceros que impidan —o al menos dificulten— su tratamiento, tal y como sucede con la propiedad intelectual o, singularmente, la protección de datos de carácter personal. Esta inquietud constituye una de las principales motivaciones de la Unión Europea a la hora de promover el Reglamento de Gobernanza de Datos, regulación donde se plantean soluciones técnicas y organizativas que intentan compatibilizar la reutilización de la información con el respeto de tales bienes jurídicos.
Precisamente, la posible colisión con el derecho a la protección de datos de carácter personal ha motivado las principales medidas que se han adoptado en Europa respecto del uso de ChatGPT. En este sentido, el Garante per la Protezione dei Dati Personali ha acordado cautelarmente la limitación del tratamiento de datos de ciudadanos italianos, la Agencia Española de Protección de Datos ha iniciado de oficio actuaciones de inspección frente a OpenAI como responsable del tratamiento y, con una proyección supranacional, el Supervisor Europeo de Protección de Datos (EDPB) ha creado un grupo de trabajo específico.
La incidencia de la regulación sobre datos abiertos y reutilización
La regulación española sobre datos abiertos y reutilización de la información del sector público establece algunas previsiones que han de tenerse en cuenta por los sistemas de IA. Así, con carácter general, la reutilización será admisible si los datos se hubieren publicado sin sujeción a condiciones o, en el caso de que se fijen, cuando se ajuste a las establecidas a través de licencias u otros instrumentos jurídicos; si bien, cuando se definan, las condiciones han de ser objetivas, proporcionadas, no discriminatorias y estar justificadas por un objetivo de interés público.
Por lo que se refiere a las condiciones de reutilización de la información proporcionada por las entidades del sector público, su tratamiento sólo se permitirá si no se altera el contenido ni se desnaturaliza su sentido, debiéndose citar la fuente de la que se hubieren obtenido los datos y la fecha de su actualización más reciente.
Por otra parte, los conjuntos de datos de alto valor adquieren un especial interés para estos sistemas de IA caracterizados por la intensa reutilización de contenidos de terceros dado el carácter masivo de los tratamientos de datos que llevan a cabo y la inmediatez de las peticiones de información que formulan quienes las utilizan. En concreto, las condiciones establecidas legalmente para la puesta a disposición de estos conjuntos de datos de alto valor por parte de las entidades públicas determinan que existan muy pocas limitaciones y, asimismo, que se facilite enormemente su reutilización al tratarse de datos que han de estar disponibles de manera gratuita, ser susceptibles de tratamiento automatizado, suministrarse a través de API y proporcionarse en forma de descarga masiva, siempre que proceda.
En definitiva, teniendo en cuenta las particularidades de esta tecnología y, por tanto, las circunstancias tan singulares en las que tratan los datos, parece oportuno que las licencias y, en general, las condiciones en las que las entidades públicas permiten su reutilización sean revisadas y, en su caso, actualizadas para hacer frente a los retos jurídicos que se están empezando a plantear.
Contenido elaborado por Julián Valero, catedrático de la Universidad de Murcia y Coordinador del Grupo de Investigación “Innovación, Derecho y Tecnología” (iDerTec).
Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Blog
Continuamos con la serie de posts sobre Chat GPT-3. La expectación levantada por el sistema conversacional justifica con creces la publicación de varios artículos sobre sus características y aplicaciones. En este post, profundizamos sobre una de las últimas novedades publicadas por openAI relacionadas con Chat GPT-3. En este caso introducimos su API, es decir, su interfaz de programación con la que podemos integrar Chat GPT-3 en nuestras propias aplicaciones.
Introducción.
En nuestro último post sobre Chat GPT-3 realizamos un ejercicio de co-programación o programación asistida en el que le solicitamos a la IA que nos escribiera un programa sencillo, en lenguaje de programación R, para visualizar un conjunto de datos. Como vimos en el post, utilizamos la propia interfaz disponible de Chat GTP-3. La interfaz es muy minimalista y funcional, tan solo tenemos que preguntar a la IA en el cuadro de texto y ella nos contesta en el cuadro de texto posterior. Tal y como concluimos en el post, el resultado del ejercicio fue más que satisfactorio. Sin embargo, también detectamos algunos puntos de mejora. Por ejemplo, la interfaz estándar puede resultar un poco lenta. Para un ejercicio largo, con múltiples interacciones conversacionales con la IA (un diálogo largo), la interfaz tarda bastante en escribir las respuestas. Varios usuarios reportan la misma sensación y por eso algunos, como este desarrollador, han creado su propia interfaz con el asistente conversacional para mejorar su velocidad de respuesta.
Pero, ¿cómo es posible esto? La razón es sencilla, gracias al API de Chat GPT-3. En este espacio de divulgación hemos hablado mucho sobre las APIs en el pasado. No en vano, las APIs son los mecanismos estándar en el mundo de las tecnologías digitales para integrar servicios y aplicaciones. Cualquier app en nuestro smartphone hace uso de las APIs para mostrarnos los resultados. Cuando consultamos el tiempo, los resultados deportivos o el horario del transporte público, las apps hacen llamadas a las APIs de los servicios para consultar la información y mostrar los resultados.
El API de Chat GPT-3
Como cualquier otro servicio actual, openAI pone a disposición de sus usuarios una API con la que poder invocar (llamar) a sus diferentes servicios basados en el modelo entrenado de lenguaje natural GPT-3. Para usar el API, tan solo tenemos que iniciar sesión con nuestra cuenta en https://platform.openai.com y localizar el menú (superior derecha) View API Keys. Hacemos click en create a new secret key y ya tenemos nuestra nueva clave de acceso al servicio.

¿Qué hacemos ahora? Bien, para ilustrar lo que podemos hacer con esta nueva y flamante clave veamos algunos ejemplos:
Como decíamos en la introducción, podemos querer probar interfaces alternativas a Chat GPT-3 como https://www.typingmind.com/. Cuando accedemos a esta web, lo primero que debemos hacer es ingresar nuestra API Key.
Una vez dentro, hagamos un ejemplo y veamos cómo se comporta esta nueva interfaz. Preguntemos a Chat GPT-3 ¿Qué es datos.gob.es?
| Nota: Es importante notar que la mayoría de servicios no funcionarán si no activamos algún medio de pago en la web de OpenAI. Lo normal es que, si no hemos configurado una tarjeta de crédito, las llamadas al API devuelvan un mensaje de error similar a \"You exceeded your current quota, please check your plan and billing details”. |

Veamos ahora otra aplicación del API de Chat GPT-3.
Acceso programático con R para acceder a Chat GPT-3 de modo programático (o lo que es lo mismo, con algunas líneas de código en R tenemos acceso a la potencia conversacional del modelo GPT-3). Esta demostración está basada en el reciente post publicado en R Bloggers. Vamos a acceder a Chat GPT-3 de modo programático con el siguiente ejemplo.
| Nota: Notar que el API Key se ha ocultado por motivos de seguridad y privacidad |

En este ejemplo, utilizamos código en R para hacer una llamada HTTPs de tipo POST y le preguntamos a Chat GPT-3 ¿Qué es datos.gob.es? Vemos que estamos utilizando el modelo gpt-3.5-turbo que, tal y como se especifica en la documentación está indicado para tareas de tipo conversacional. Toda la información sobre la API y los diferentes modelos está disponible aquí. Pero, veamos el resultado:

¿Nada mal verdad? Como dato curioso podemos ver que unas pocas llamadas al API de Chat GPT-3 han tenido el siguiente uso del API:

El uso del API se cotiza por tokens (algo similar a las palabras) y los precios públicos pueden consultarse aquí. En concreto el modelo que estamos utilizando tiene estos precios:

Para pequeñas pruebas y ejemplos, nos lo podemos permitir. En caso de aplicaciones empresariales para entornos productivos existe un modelo premium que permite tener un control de los costes sin depender tanto del uso.
Conclusión
Como no podía ser de otra manera, Chat GPT-3 habilita un API para proporcionar acceso programático a su motor conversacional. Este mecanismo permite la integración de aplicaciones y sistemas (es decir, todo lo que no son humanos) abriendo la puerta al despegue definitivo del Chat GPT-3 como modelo de negocio. Gracias a este mecanismo, el buscador Bing ahora integra Chat GPT-3 para respuestas a las búsquedas en modo conversacional. De la misma forma, Microsoft Azure acaba de anunciar la disponibilidad de Chat GPT-3 como un nuevo servicio de la nube pública. Sin lugar a dudas, en las próximas semanas veremos comunicaciones de todo tipo de aplicaciones, apps y servicios, conocidos y desconocidos, anunciando su integración con Chat GPT-3 para mejorar las interfaces conversacionales con sus clientes. Nos vemos en el próximo episodio, quién sabe sin con GPT-4.
Contenido elaborado por Alejandro Alija, experto en Transformación Digital.
Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Blog
La inteligencia artificial generativa se refiere a la capacidad de una máquina para generar contenido original y creativo, como imágenes, texto o música, a partir de un conjunto de datos de entrada. En lo que se refiere a la generación de texto, estos modelos son accesibles, en formato experimental, desde hace un tiempo, pero comenzaron a generar interés a mediados de 2020 cuando Open AI, una organización dedicada a la investigación en el campo de la inteligencia artificial general, publicó el acceso a su modelo de lenguaje GPT-3 a través de una API.
La arquitectura de GPT-3 está compuesta por 175 mil millones de parámetros, mientras que la de su antecesor GPT-2 era de 1.500 millones de parámetros, esto es, más de 100 veces más. GPT-3 representa por tanto un cambio de escala enorme ya que además fue entrenado con un corpus de datos mucho mayor y un tamaño de los tokens mucho más grande, lo que le permitió adquirir una comprensión más profunda y compleja del lenguaje humano.
A pesar de que fue de 2022 cuando OpenAI anunció la apertura de chatGPT, que permite dotar de una interfaz conversacional a un modelo de lenguaje basado en una versión mejorada de GPT-3, no ha sido hasta los últimos dos meses cuando la noticia ha llamado masivamente la atención del público, gracias a la amplia cobertura mediática que trata de dar respuesta al incipiente interés general.
Y es que, ChatGPT no sólo es capaz de generar texto a partir de un conjunto de caracteres (prompt) como GPT-3, sino que responde a preguntas en lenguaje natural en varios idiomas que incluyen inglés, español, francés, alemán, italiano o portugués. Es precisamente este cambio en la interfaz de acceso, pasando de ser una API a un chatbot, lo que lo ha convertido a la IA en accesible para cualquier tipo de usuario.
Tanto es así que más de un millón de personas se registraron para usarlo en tan solo cinco días, lo que ha motivado la multiplicación de ejemplos en los que chatGPT produce código de software, ensayos de nivel universitario, poemas e incluso chistes. Eso sin tener en cuenta que ha sido capaz de sacar adelante un examen de selectividad de Historia o de aprobar el examen final del MBA de la prestigiosa Wharton School.
Todo esto ha puesto a la IA generativa en el centro de una nueva ola de innovación tecnológica que promete revolucionar la forma en que nos relacionamos con internet y la web a través de búsquedas vitaminadas por IA o navegadores capaces de resumir el resultado de estas búsquedas.
Hace tan solo unos días, conocíamos la noticia de que Microsoft trabaja en la implementación de un sistema conversacional dentro de su propio buscador, el cual ha sido desarrollado a partir del conocido modelo de lenguaje de Open AI y cuya noticia ha puesto en jaque a Google.
Y es que, como consecuencia de esta nueva realidad en la que la IA ha llegado para quedarse, los gigantes tecnológicos han ido un paso más allá en la batalla por aprovechar al máximo los beneficios que esta reporta. En esta línea, Microsoft ha presentado una nueva estrategia dirigida a optimizar al máximo la manera en la que nos relacionamos con internet, introduciendo la IA para mejorar los resultados ofrecidos por los buscadores de navegadores, aplicaciones, redes sociales y, en definitiva, todo el ecosistema de la web.
Sin embargo, aunque el camino en el desarrollo de los nuevos y futuros servicios ofrecidos por la IA de Open AI aún están por ver, avances como los anteriores ofrecen una pequeña pista de la guerra de navegadores que se avecina y que, probablemente, cambie en el corto plazo la manera de crear y hallar contenido en la web.
Los datos abiertos
GPT-3, al igual que otros modelos que han sido generados con las técnicas descritas en la publicación científica original de GTP-3, es un modelo de lenguaje pre-entrenado, lo que significa que ha sido entrenado con un gran conjunto de datos, en total unos 45 terabytes de datos de texto. Según este paper, el conjunto de datos de entrenamiento estaba compuesto en un 60% por datos obtenidos directamente de internet en los que están contenidos millones de documentos de todo tipo, un 22% del corpus WebText2 construido a partir de Reddit, y el resto con una combinación de libros (16%) y Wikipedia (3%).
Sin embargo, no se sabe cuántos datos abiertos utiliza GPT-3 exactamente, ya que OpenAI no proporciona detalles más específicos sobre el conjunto de datos utilizado para entrenar el modelo. Lo que sí podemos hacer son algunas preguntas al propio chatGPT que nos ayuden a extraer interesantes conclusiones sobre el uso que hace de los datos abiertos.
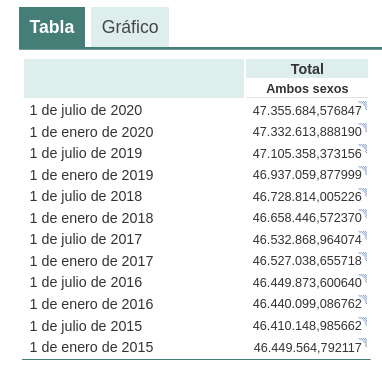
Por ejemplo, si le preguntamos a chatGPT cuál era la población de España entre 2015 y 2020 (no podemos pedirle datos más recientes), obtenemos una respuesta de este tipo:

Tal como podemos ver en la imagen superior, aunque la pregunta sea la misma, la respuesta puede variar tanto en la redacción como en la información que contiene. Las variaciones pueden ser aún mayores si realizamos la pregunta en diferentes días o hilos de conversación:
Pequeñas variaciones en la redacción del texto, generar la pregunta en diferentes momentos del hilo de conversación (recordemos que guarda el contexto) o en hilos o días diferentes puede conducir a resultados ligeramente diferentes. Además, la respuesta no es completamente precisa, tal y como nos advierte la propia herramienta si las comparamos con las series de población residente en España del propio INE, donde nos recomienda consultar. Los datos que idealmente habríamos esperado en la respuesta podrían obtenerse en un conjunto de datos abiertos del INE:
Este tipo de respuestas sugieren que los datos abiertos no se han empleado como una fuente autoritativa para responder preguntas de tipo factual, o al menos que aún no está completamente refinado el modelo en este sentido. Haciendo algunas pruebas básicas con preguntas sobre otros países hemos observado errores parecidos, por lo que no parece que se trate de un problema sólo con preguntas referentes a España.
Si hacemos preguntas algo más específicas como pedir la lista de los municipios de la provincia de Burgos que comienzan por la letra “G” obtenemos respuestas que no son completamente correctas, como es propio de una tecnología que todavía está en fase incipiente.
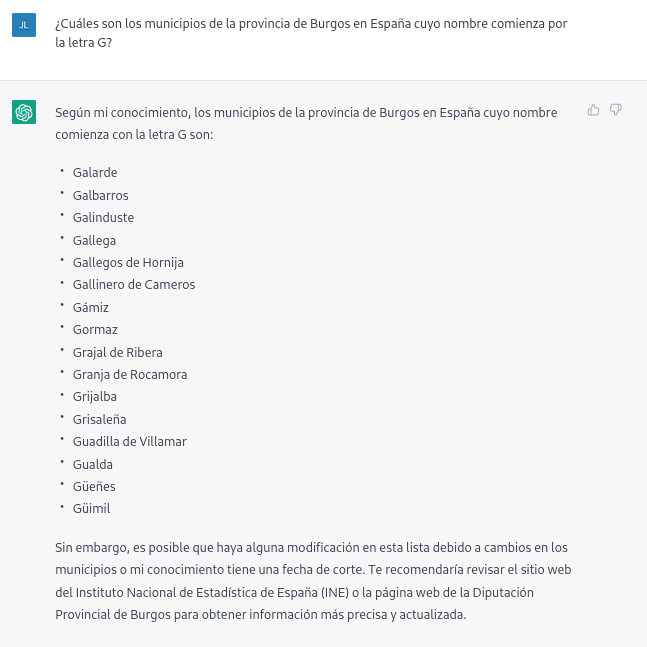
La respuesta correcta debería contener seis municipios: Galbarros, La Gallega, Grijalba, Grisaleña, Gumiel de Hizán y Gumiel del Mercado. Sin embargo, la respuesta que hemos obtenido sólo contiene los cuatro primeros e incluye localidades de la provincia de Guadalajara (Gualda), municipios de la provincia de Valladolid (Gallegos de Hornija) o localidades de la provincia de Burgos que no son municipios (Galarde). En este caso, también podemos acudir a conjunto de datos abiertos para obtener la respuesta correcta.
A continuación, le preguntamos a ChatGPT por la lista de municipios que comienzan por la letra Z en la misma provincia. ChatGPT nos dice que nos hay ninguno, razonando la respuesta, cuando en realidad hay cuatro:
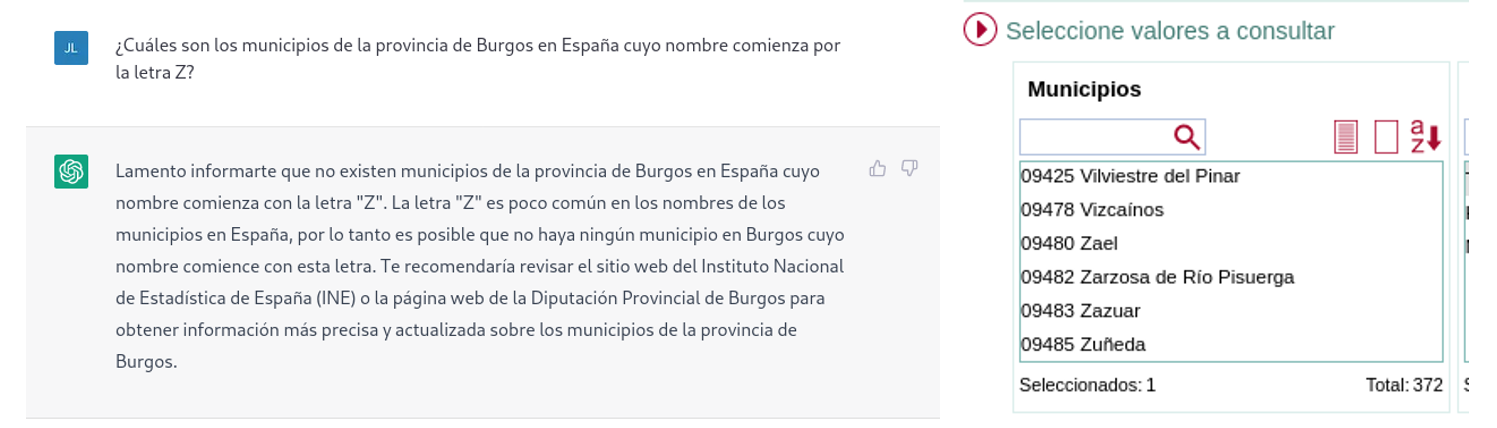
Como se deduce de los ejemplos anteriores, vemos cómo los datos abiertos sí pueden contribuir a la evolución tecnológica y, por ende, a mejorar el funcionamiento de la inteligencia artificial de Open AI. Sin embargo, dado el estado de madurez actual de la misma, aún es pronto para ver un empleo óptimo de estos, a la hora de dar respuesta a preguntas más complejas.
Por lo tanto, para que un modelo de inteligencia artificial generativa sea eficaz, es necesario que cuente con una gran cantidad de datos de alta calidad y diversidad, y los datos abiertos son una fuente de conocimiento valiosa para este fin.
Probablemente, en futuras versiones del modelo, podamos ver cómo los datos abiertos ya adquieren un peso mucho más importante en la composición del corpus de entrenamiento, logrando conseguir una mejora importante en la calidad de las respuestas de tipo factual.
Contenido elaborado por Jose Luis Marín, Senior Consultant in Data, Strategy, Innovation & Digitalization.
Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Blog
Según el último análisis realizado por Gartner en septiembre de 2021, sobre las tendencias en materia de Inteligencia Artificial, los Chatbots son una de las tecnologías más cercanas a ofrecer una productividad efectiva en menos de 2 años. En la Figura 1, extraída de dicho informe, se observa que existen 4 tecnologías que han superado ampliamente el estado de sobre-expectativa (peak of inflated expectations) y comienzan ya a salir del canal de desilusión (trough of disillisionment), hacia estados de mayor madurez y estabilidad, incluyendo chatbots, búsqueda semántica, visión artificial y vehículos autónomos.
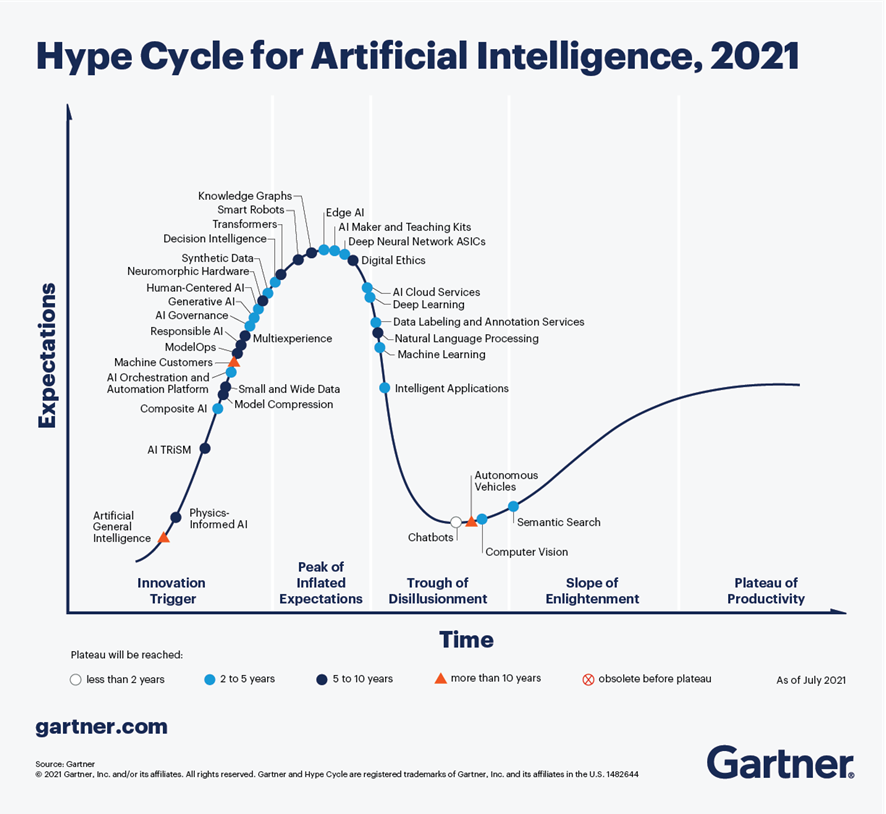
Figura 1 - Tendencias en IA para los próximos años.
En el caso concreto de los chatbots, existen grandes expectativas de productividad en los próximos años gracias a la madurez de las diferentes plataformas disponibles, tanto en opciones de Cloud Computing, como en proyectos de código abierto, es especial RASA o Xatkit. En la actualidad es relativamente sencillo desarrollar un chatbot o asistente virtual sin conocimientos de IA, mediante el uso de estas plataformas.
¿Cómo funciona un chatbot?
A modo de ejemplo, la Figura 2 muestra un diagrama de los diferentes componentes que habitualmente incluye un chatbot, en este caso enfocado en la arquitectura del proyecto RASA.
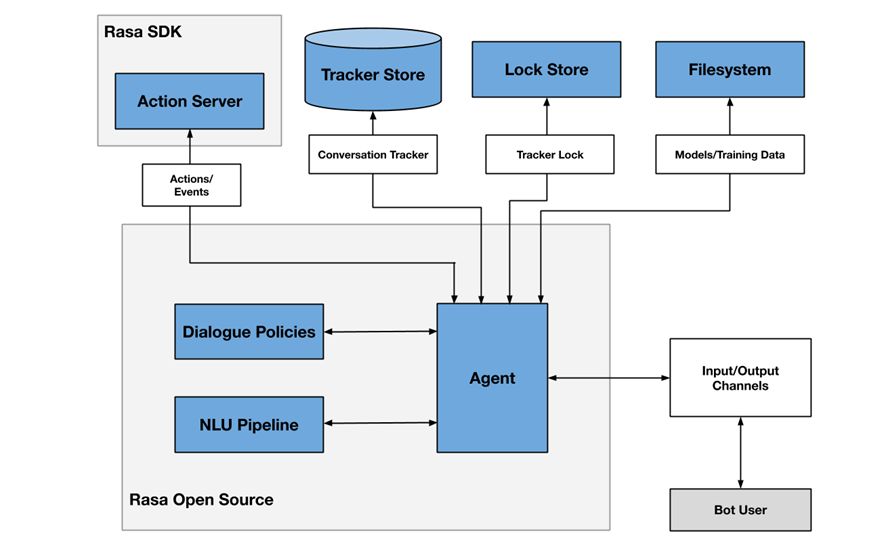
Figura 2 - Arquitectura del proyecto RASA
Uno de los componentes principales es el módulo agente (agent), que actúa a modo de controlador del flujo de datos y normalmente es la interfaz del sistema con los diferentes canales (input/output channels) ofrecidos a los usuarios, como aplicaciones de chat, redes sociales, aplicaciones web o móviles, etc.
El módulo de NLU (Natural Languge Understanding) se encarga de identificar la intención del usuario (qué quiere consultar o hacer), la extracción de entidades (de qué está hablando) y la generación de respuestas. Se considera un flujo (pipeline) porque intervienen varios procesos de diferente complejidad, en muchos casos incluso mediante el uso de modelos pre-entrenados de Inteligencia Artificial.
Finalmente, el módulo de gestión de conversaciones (dialogue policies) define cuál es el siguiente paso en una conversación, basándose en el contexto y el histórico de mensajes. Este módulo se integra con otros subsistemas como el almacén de conversaciones (tracker store) o el servidor que procesa las acciones necesarias para dar respuesta al usuario (action server).
Chatbots en portales de datos abiertos como mecanismo para localizar datos y acceder a información
Cada vez existen más iniciativas para empoderar a los ciudadanos en la consulta de datos abiertos mediante el uso de chatbots, empleando interfaces de lenguaje natural, aumentando así el valor neto que ofrecen dichos datos. El uso de chatbots permite automatizar la recopilación de datos a partir de la interacción con el usuario y responder de forma sencilla, natural y fluida, permitiendo la democratización de la puesta en valor de datos abiertos.
En el SOM Research Lab (Universitat Oberta de Catalunya) fueron pioneros en la aplicación de chatbots para mejorar el acceso de los ciudadanos a los datos abiertos a través de los proyectos Open Data for All y BODI (Bots para interactuar con datos abiertos – Interfaces conversacionales para facilitar el acceso a los datos públicos). Puedes encontrar más información sobre este último proyecto en este artículo.
También cabe destacar el chatbot de Aragón Open Data, del portal de datos abiertos del Gobierno de Aragón, cuyo objetivo es acercar la gran cantidad de datos disponibles a la ciudadanía, para que esta pueda aprovechar su información y valor, evitando cualquier barrera técnica o de conocimiento entre la consulta realizada y los datos abiertos existentes. Los dominios sobre los que ofrece información son:
- Información general sobre Aragón y su territorio
- Turismo y viajes en Aragón
- Transporte y agricultura
- Asistencia técnica o preguntas frecuentes en materia de sociedad de la información
Conclusiones
Estos son sólo algunos ejemplos del uso práctico de chatbots en la puesta en valor de datos abiertos y su potencial a corto plazo. En los próximos años veremos cada vez más ejemplos de asistentes virtuales en diferentes escenarios, tanto del ámbito de las administraciones públicas como en servicios privados, en especial enfocados a la mejora de la atención al usuario en aplicaciones de comercio electrónico y servicios surgidos de iniciativas de transformación digital.
Contenido elaborado por José Barranquero, experto en Ciencia de Datos y Computación Cuántica.
Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Aplicación
Victoria es un 'chatbot' que habla sobre cosas de Málaga utilizando interfaces conversacionales tanto en Facebook como en el Asistente de Google. Se puede iniciar desde cualquier PC, o dispositivo móvil iPhone o Android a través de Facebook, Messenger o el propio Asistente de Google.
Sus funcionalidades se encuentran en continua actualización. Entre la información que actualmente proporciona la aplicación hay:
-
Datos geolocalizados: basta con activar la geolocalización y Victoria informará al usuario de:
-
Equipamientos: la aplicación incluye la mayoría de los elementos de la ciudad que están geolocalizados en el callejero de Málaga (callejero.malaga.eu) como mercados, sedes Wifi, polígonos industriales, auditorios, bibliotecas, cines, monumentos, museos, teatros, paradas de taxi, cortes de tráfico, etc.
-
Autobuses: Victoria permite informar sobre los tiempos de espera para que un autobús llegue a una parada. Si se conoce el nombre de la parada se le puede preguntar por el tiempo de espera y nos dirá todos los autobuses que llegan a esa parada y el tiempo que falta para que lleguen. Pero si no se sabe el número de parada, también se puede consultar información sobre la Línea y mostrará todas las paradas de la misma.
-
-
Aparcamientos: se pueden realizar consultas sobre la ocupación para los 14 aparcamientos municipales en tiempo real. Para conocer las plazas disponibles se le puede preguntar por el listado de aparcamientos. Además se le podrá pedir el mapa de aparcamientos donde aparecen todas las plazas, las entradas peatonales y los espacios destinados a personas con discapacidad.
-
Restaurantes: Victoria también puede recomendar restaurantes si el usuario indica el tipo de comida que desea. El resultado generará una consulta a Google Maps que mostrará los restaurantes de ese tipo más cercanos.
-
Rutas: uno de los elementos más demandados es la obtención de rutas para llegar a distintos sitios, ya se trate de una dirección o un lugar reconocido de la ciudad, como un museo o un centro comercial. Para dar esta ayuda se crea una llamada a Google Maps con la ubicación solicitada por el usuario.
-
Otros datos de interés sobre Málaga: Victoria también aporta información sobre aspectos ligados a la ciudad como curiosidades y personajes célebres, información del tiempo y estado de las playas, cámaras de tráfico, expresiones típicas de la zona, la agenda de eventos de la ciudad e incluso un diccionario malagueño.
Para hacer posible esta información, la aplicación se basa en una recopilación de datos abiertos proporcionados por el Equipo de Datos Abiertos CEMI (https://datosabiertos.malaga.eu/).