Blog
The emergence of artificial intelligence (AI), and ChatGPT in particular, has become one of the main topics of debate in recent months. This tool has even eclipsed other emerging technologies that had gained prominence in a wide range of fields (legal, economic, social and cultural). This is the case, for example, of web 3.0, the metaverse, decentralised digital identity or NFTs and, in particular, cryptocurrencies.
There is an unquestionable direct relationship between this type of technology and the need for sufficient and appropriate data, and it is precisely this last qualitative dimension that justifies why open data is called upon to play a particularly important role. Although, at least for the time being, it is not possible to know how much open data provided by public sector entities is used by ChatGPT to train its model, there is no doubt that open data is a key to improving their performance.
Regulation on the use of data by AI
From a legal point of view, AI is arousing particular interest in terms of the guarantees that must be respected when it comes to its practical application. Thus, various initiatives are being promoted that seek to specifically regulate the conditions for its use, among which the proposal being processed by the European Union stands out, where data are the object of special attention.
At the state level, Law 15/2022, of 12 July, on equal treatment and non-discrimination, was approved a few months ago. This regulation requires public administrations to promote the implementation of mechanisms that include guarantees regarding the minimisation of bias, transparency and accountability, specifically with regard to the data used to train the algorithms used for decision-making.
There is a growing interest on the part of the autonomous communities in regulating the use of data by AI systems, in some cases reinforcing guarantees regarding transparency. Also, at the municipal level, protocols are being promoted for the implementation of AI in municipal services in which the guarantees applicable to the data, particularly from the perspective of their quality, are conceived as a priority requirement.
The possible collision with other rights and legal interests: the protection of personal data
Beyond regulatory initiatives, the use of data in this context has been the subject of particular attention as regards the legal conditions under which it is admissible. Thus, it may be the case that the data to be used are protected by third party rights that prevent - or at least hinder - their processing, such as intellectual property or, in particular, the protection of personal data. This concern is one of the main motivations for the European Union to promote the Data Governance Regulation, a regulation that proposes technical and organisational solutions that attempt to make the re-use of information compatible with respect for these legal rights.
Precisely, the possible collision with the right to the protection of personal data has motivated the main measures that have been adopted in Europe regarding the use of ChatGPT. In this regard, the Garante per la Protezione dei Dati Personali has ordered a precautionary measure to limit the processing of Italian citizens' data, the Spanish Data Protection Agency has initiated ex officio inspections of OpenAI as data controller and, with a supranational scope, the European Data Protection Supervisor (EDPB) has created a specific working group.
The impact of the regulation on open data and re-use
The Spanish regulation on open data and re-use of public sector information establishes some provisions that must be taken into account by IA systems. Thus, in general, re-use will be admissible if the data has been published without conditions or, in the event that conditions are set, when they comply with those established through licences or other legal instruments; although, when they are defined, the conditions must be objective, proportionate, non-discriminatory and justified by a public interest objective.
As regards the conditions for re-use of information provided by public sector bodies, the processing of such information is only allowed if the content is not altered and its meaning is not distorted, and the source of the data and the date of its most recent update must be mentioned.
On the other hand, high-value datasets are of particular interest for these AI systems characterised by the intense re-use of third-party content given the massive nature of the data processing they carry out and the immediacy of the requests for information made by users. Specifically, the conditions established by law for the provision of these high-value datasets by public bodies mean that there are very few limitations and also that their re-use is greatly facilitated by the fact that the data must be freely available, be susceptible to automated processing, be provided through APIs and be provided in the form of mass downloading, where appropriate.
In short, considering the particularities of this technology and, therefore, the very unique circumstances in which the data are processed, it seems appropriate that the licences and, in general, the conditions under which public entities allow their re-use be reviewed and, where appropriate, updated to meet the legal challenges that are beginning to arise.
Content prepared by Julián Valero, Professor at the University of Murcia and Coordinator of the "Innovation, Law and Technology" Research Group (iDerTec).
The contents and points of view reflected in this publication are the sole responsibility of the author.
Blog
We continue with the series of posts about Chat GPT-3. The expectation raised by the conversational system more than justifies the publication of several articles about its features and applications. In this post, we take a closer look at one of the latest news published by openAI related to Chat GPT-3. In this case, we introduce its API, that is, its programming interface with which we can integrate Chat GPT-3 into our own applications.
Introduction.
In our last post about Chat GPT-3 we carried out a co-programming or assisted programming exercise in which we asked the AI to write us a simple program, in R programming language, to visualise a set of data. As we saw in the post, we used Chat GTP-3's own available interface. The interface is very minimalistic and functional, we just have to ask the AI in the text box and it answers us in the subsequent text box. As we concluded in the post, the result of the exercise was more than satisfactory. However, we also detected some points for improvement. For example, the standard interface can be a bit slow. For a long exercise, with multiple conversational interactions with the AI (a long dialogue), the interface takes quite a long time to write the answers. Several users report the same feeling and so some, like this developer, have created their own interface with the conversational assistant to improve its response speed.
But how is this possible? The reason is simple, thanks to the GPT-3 Chat API. We have talked a lot about APIs in this space in the past. Not surprisingly, APIs are the standard mechanisms in the world of digital technologies for integrating services and applications. Any app on our smartphone makes use of APIs to show us results. When we consult the weather, sports results or the public transport timetable, apps make calls to the APIs of the services to consult the information and display the results.
The GPT-3 Chat API
Like any other current service, openAI provides its users with an API with which they can invoke (call) its different services based on the trained natural language model GPT-3. To use the API, we just have to log in with our account at https://platform.openai.com/ and locate the menu (top right) View API Keys. Click on create a new secret key and we have our new access key to the service.

What do we do now? Well, to illustrate what we can do with this brand new key, let's look at some examples:
As we said in the introduction, we may want to try alternative interfaces to Chat GPT-3 such as https://www.typingmind.com/. When we access this website, the first thing we have to do is enter our API Key.
Once inside, let's do an example and see how this new interface behaves. Let's ask Chat GPT-3 What is datos.gob.es?
| Note: It is important to note that most services will not work if we do not activate a means of payment on the OpenAI website. Normally, if we have not configured a credit card, the API calls will return an error message similar to \"You exceeded your current quota, please check your plan and billing details\". |

Let's now look at another application of the GPT-3 Chat API.
Programmatic access with R to access Chat GPT-3 programmatically (in other words, with a few lines of code in R we have access to the conversational power of the GPT-3 model). This demonstration is based on the recent post published in R Bloggers. Let's access Chat GPT-3 programmatically with the following example.
| Note: Note that the API Key has been hidden for security and privacy reasons. |

En este ejemplo, utilizamos código en R para hacer una llamada HTTPs de tipo POST y le preguntamos a Chat GPT-3 ¿Qué es datos.gob.es? Vemos que estamos utilizando el modelo gpt-3.5-turbo que, tal y como se especifica en la documentación está indicado para tareas de tipo conversacional. Toda la información sobre la API y los diferentes modelos está disponible aquí. Pero, veamos el resultado:

Not bad, right? As a curious fact we can see that a few GPT-3 Chat API calls have had the following API usage:

The use of the API is priced per token (something similar to words) and the public prices can be consulted here. Specifically, the model we are using has these prices:
For small tests and examples, we can afford it. In the case of enterprise applications for production environments, there is a premium model that allows you to control costs without being so dependent on usage.
Conclusion
Naturally, Chat GPT-3 enables an API to provide programmatic access to its conversational engine. This mechanism allows the integration of applications and systems (i.e. everything that is not human) opening the door to the definitive take-off of Chat GPT-3 as a business model. Thanks to this mechanism, the Bing search engine now integrates GPT-3 Chat for conversational search responses. Similarly, Microsoft Azure has just announced the availability of GPT-3 Chat as a new public cloud service. No doubt in the coming weeks we will see communications from all kinds of applications, apps and services, known and unknown, announcing their integration with GPT-3 Chat to improve conversational interfaces with their customers. See you in the next episode, maybe with GPT-4.
Blog
Generative artificial intelligence refers to machine’s ability to generate original and creative content, such as images, text or music, from a set of input data. As far as text generation is concerned, these models have been accessible, in an experimental format, for some time, but began to generate interest in mid-2020 when Open AI, an organisation dedicated to research in the field of artificial intelligence, published access to its GPT-3 language model via an API.
The GPT-3's architecture is composed of 175 billion parameters, comparing to its predecessor GPT-2 was 1.5 billion parameters, i.e. more than 100 times more. Therefore, GPT-3 represents a huge change in scale as it was also trained with a much larger corpus of data and a much larger token size, which allowed it to acquire a deeper and more complex understanding of the human language.
Although it was in 2022 when OpenAI announced the launch of chatGPT, which provides a conversational interface to a language model based on an improved version of GPT-3, it has only been in the last two months that the chat has attracted massive public attention, thanks to extensive media coverage that tries to respond to the emerging general interest.
In fact, ChatGPT is not only able to generate text from a set of characters (prompt) like GPT-3, but also it is able to respond to natural language questions in several languages including English, Spanish, French, German, Italian or Portuguese. This specific updated issue in the access interface from an API to a chatbot that has made the AI accessible to any type of user.
Maybe for this reason, more than a million people registered to use it in just five days, which has led to the multiplication of examples in which chatGPT produces software code, university-level essays, poems and even jokes. Not to mention the fact that it has been able to ace an history SAT or pass the final MBA exam at the prestigious Wharton School.
All of this has put generative AI at the centre of a new wave of technological innovation that promises to revolutionise the way we relate to the internet and the web through AI-powered searches or browsers capable of summarising the results of these searches.
Just a few days ago, we heard the news that Microsoft is working on the implementation of a conversational system within its own search engine, which has been developed based on the well-known Open AI language model and whose news has put Google in check.
As a result of this new reality in which AI is here to stay, the technological giants have gone a step further in the battle to make the most of the benefits it brings. Along these lines, Microsoft has presented a new strategy aimed at optimising the way in which we interact with the internet, introducing AI to improve the results offered by browser search engines, applications, social networks and, in short, the entire web ecosystem.
However, although the path in the development of new and future services offered by Open AI's remains to be seen, advances such as the mentioned above, offer a small hint of the browser war that is coming and that will probably change the way we create and find content on the web in the short term.
The open data
GPT-3, like other models that have been generated with the techniques described in the original GTP-3 scientific publication, is a pre-trained language model, which means that it has been trained with a large dataset, in total about 45 terabytes of text data. According to the paper, the training dataset was composed of 60% of data obtained directly from the internet containing millions of documents of all kinds, 22% from the WebText2 corpus built from Reddit, and the rest from a combination of books (16%) and Wikipedia (3%).
However, it is not known exactly how much open datasets GPT-3 uses, as OpenAI does not provide more specific details about the dataset used to train the model. What we can ask chatGPT itself are some questions that can help us draw interesting conclusions about its use of open data.
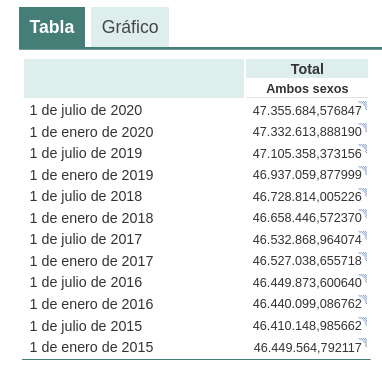
For example, if we ask chatGPT what was the population of Spain between 2015 and 2020 (we cannot ask for more recent data), we get an answer like this:

As we can see in the image above, although the question is the same, the answer may vary in both the wording and the information it contains. The variations can be even greater if we ask the question on different days or in different threads:
Small variations in the wording of the text, generating the question at different times in the conversation thread (remember that it saves the context) or in different threads or on different days may lead to slightly different results. Moreover, the answer is not completely accurate, as the tool itself warns us if we compare it with the INE's own series on the resident population in Spain, where it recommends us to consult. The data that we would ideally have expected in the response could be obtained in an open INE dataset:
Such responses suggest that open data has not been used as an authoritative source for answering factual questions, or at least that the model is not yet fully refined on this matter. Doing some basic tests with questions about other countries we have observed similar errors, so this does not seem to be a problem only with questions referring to Spain.
If we ask more specific questions, such as asking for a list of the municipalities in the province of Burgos that begin with the letter "G", we get answers that are not completely correct, as is typical of a technology that is still in its infancy.
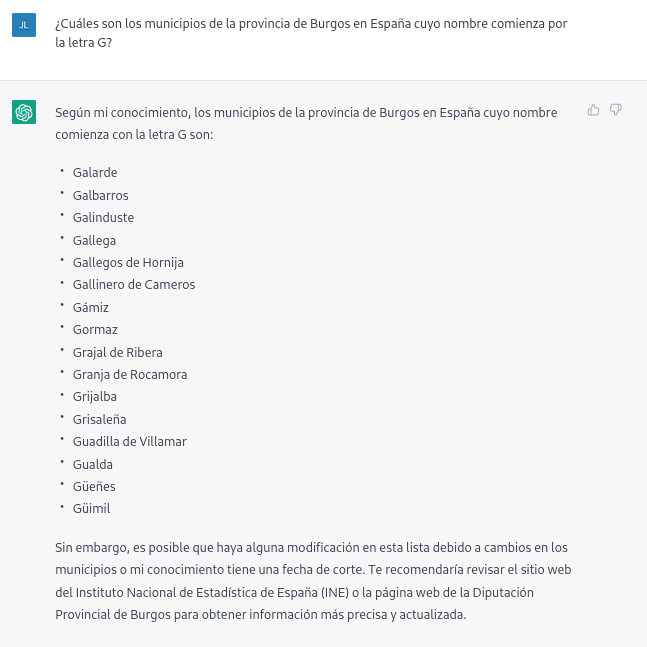
The correct answer should contain six municipalities: Galbarros, La Gallega, Grijalba, Grisaleña, Gumiel de Hizán and Gumiel del Mercado. However, the answer we have obtained only contains the first four and includes localities in the province of Guadalajara (Gualda), municipalities in the province of Valladolid (Gallegos de Hornija) or localities in the province of Burgos that are not municipalities (Galarde). In this case, we can also turn to the open dataset to get the correct answer.
Next, we ask ChatGPT for the list of municipalities beginning with the letter Z in the same province. ChatGPT tells us that there are none, reasoning the answer, when in fact there are four:
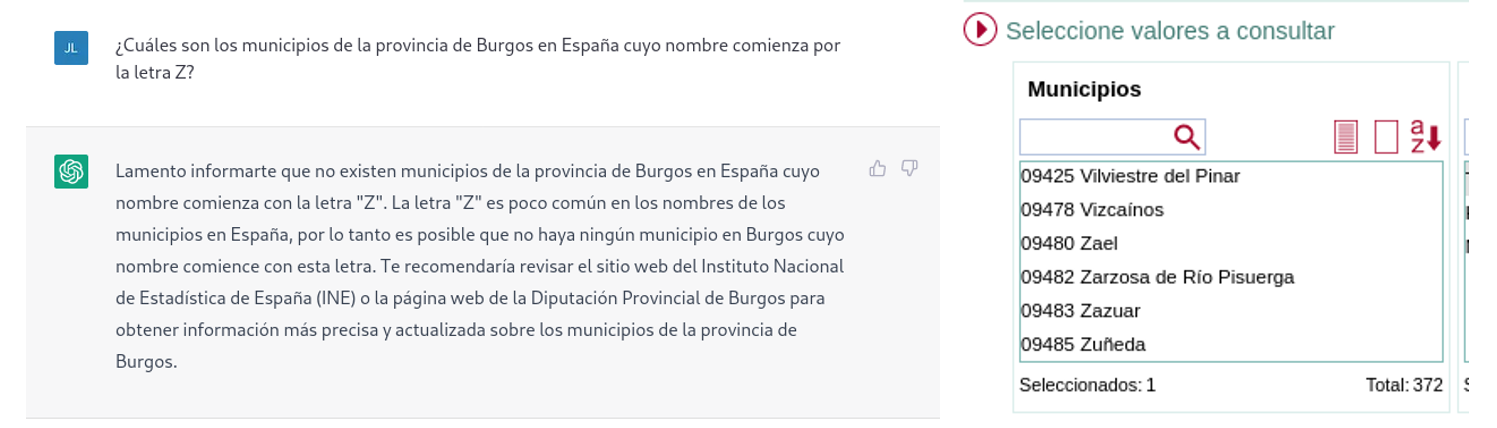
As can be seen from the examples above, we can see how open data can indeed contribute to technological evolution and thus improve the performance of Open AI's artificial intelligence. However, given its current state of maturity, it is still too early to see the optimal use of open data to answer more complex questions.
Therefore, for a generative AI model to be effective, it is necessary to have a large amount of high quality and diverse data, and open data is a valuable source of knowledge for this purpose.
In future versions of the model, we will probably be able to see how open data will acquire a much more important role in the composition of the training corpus, achieving a significant improvement in the quality of the factual answers.
Content prepared by Jose Luis Marín, Senior Consultant in Data, Strategy, Innovation & Digitalization.
The contents and views reflected in this publication are the sole responsibility of the author.
Blog
According to the latest analysis conducted by Gartner in September 2021, on Artificial Intelligence trends, Chatbots are one of the technologies that are closest to deliver effective productivity in less than 2 years. Figure 1, extracted from this report, shows that there are 4 technologies that are well past the peak of inflated expectations and are already starting to move out of the valley of disillusionment, towards states of greater maturity and stability, including chatbots, semantic search, machine vision and autonomous vehicles.
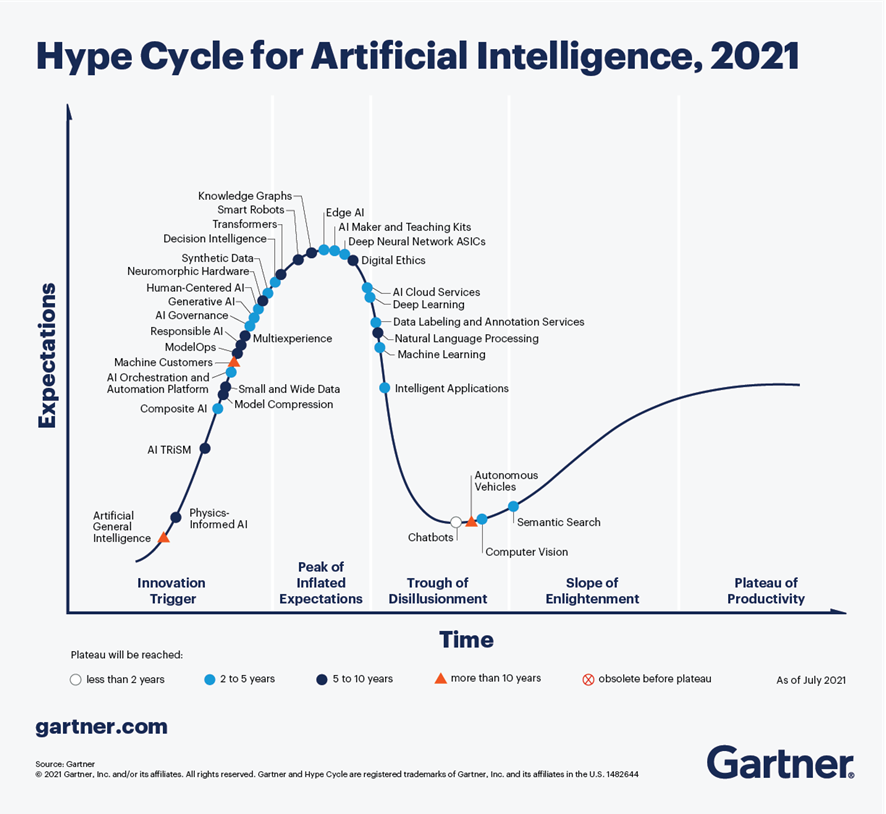
Figure 1-Trends in AI for the coming years.
In the specific case of chatbots, there are great expectations for productivity in the coming years thanks to the maturity of the different platforms available, both in Cloud Computing options and in open source projects, especially RASA or Xatkit. Currently it is relatively easy to develop a chatbot or virtual assistant without AI knowledge, using these platforms.
How does a chatbot work?
As an example, Figure 2 shows a diagram of the different components that a chatbot usually includes, in this case focused on the architecture of the RASA project.
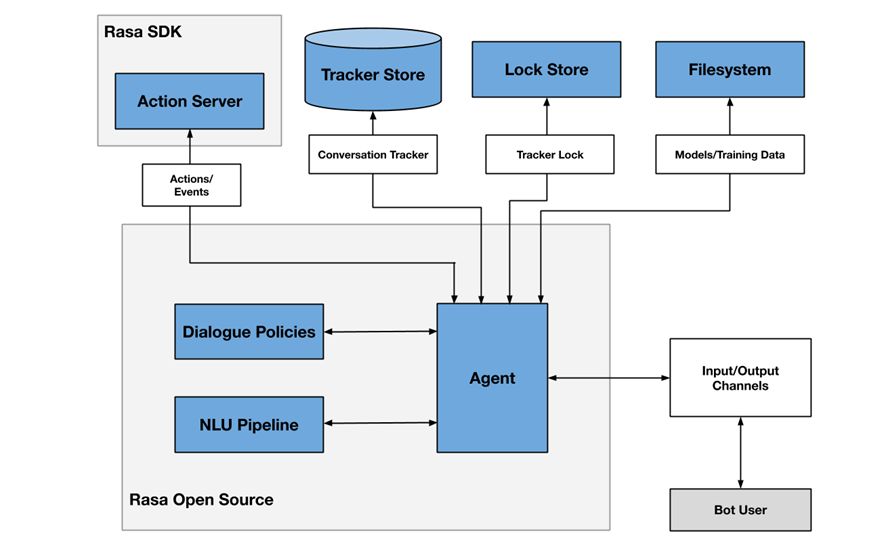
Figure 2- RASA project architecture
One of the main components is the agent module, which acts as a controller of the data flow and is normally the system interface with the different input/output channels offered to users, such as chat applications, social networks, web or mobile applications, etc.
The NLU (Natural Languge Understanding) module is responsible for identifying the user's intention (what he/she wants to consult or do), entity extraction (what he/she is talking about) and response generation. It is considered a pipeline because several processes of different complexity are involved, in many cases even through the use of pre-trained Artificial Intelligence models.
Finally, the dialogue policies module defines the next step in a conversation, based on context and message history. This module is integrated with other subsystems such as the conversation store (tracker store) or the server that processes the actions necessary to respond to the user (action server).
Chatbots in open data portals as a mechanism to locate data and access information
There are more and more initiatives to empower citizens to consult open data through the use of chatbots, using natural language interfaces, thus increasing the net value offered by such data. The use of chatbots makes it possible to automate data collection based on interaction with the user and to respond in a simple, natural and fluid way, allowing the democratization of the value of open data.
At SOM Research Lab (Universitat Oberta de Catalunya) they were pioneers in the application of chatbots to improve citizens' access to open data through the Open Data for All and BODI (Bots to interact with open data - Conversational interfaces to facilitate access to public data) projects. You can find more information about the latter project in this article.
It is also worth mentioning the Aragón Open Data chatbot, from the open data portal of the Government of Aragón, which aims to bring the large amount of data available to citizens, so that they can take advantage of its information and value, avoiding any technical or knowledge barrier between the query made and the existing open data. The domains on which it offers information are:
- General information about Aragon and its territory
- Tourism and travel in Aragon
- Transportation and agriculture
- Technical assistance or frequently asked questions about the information society.
Conclusions
These are just a few examples of the practical use of chatbots in the valorization of open data and their potential in the short term. In the coming years we will see more and more examples of virtual assistants in different scenarios, both in the field of public administrations and in private services, especially focused on improving user service in e-commerce applications and services arising from digital transformation initiatives.
Content prepared by José Barranquero, expert in Data Science and Quantum Computing.
The contents and points of view reflected in this publication are the sole responsibility of the author.