Blog
2023 fue un año cargado de novedades en materia de inteligencia artificial, algoritmos y tecnologías relacionadas con los datos. Por ello, estas fiestas navideñas se configuran como un buen momento para aprovechar la llegada de los Reyes Magos y pedirles un libro para disfrutar de su lectura en los días de fiesta, el descanso merecido y la vuelta a la rutina tras el periodo vacacional.
Tanto si estás buscando una lectura que haga mejorar tu perfil profesional, conocer novedades y aplicaciones tecnológicas ligadas al mundo de los datos y la inteligencia artificial, como si quieres ofrecer a tus seres más queridos un regalo didáctico e interesante, desde datos.gob.es queremos proponerte algunos ejemplos. Para la elaboración de la lista hemos contado con la opinión de expertos en la materia.
¡Coge papel y lápiz porque todavía estás a tiempo de incluirlos en tu carta a los Reyes Magos!
1. Inteligencia Artificial: Ficción, Realidad y... sueños, Nuria Oliver, Real Academia de Ingeniería GTT (2023)
¿De qué trata?: El libro tiene su origen en el discurso de ingreso en la Real Academia de Ingeniería de la autora. En él, explora la historia de la IA, sus implicaciones y desarrollo, describe su impacto actual y plantea diversas perspectivas.
¿A quién va dirigido?: Está pensado para personas con interés en introducirse en el mundo de la Inteligencia Artificial, conocer su historia y aplicaciones prácticas. También se dirige a aquellas personas que quieren adentrarse en el mundo de la IA ética y aprender cómo utilizarla para un bien social.
2. A Data-Driven Company. 21 Claves para crear valor a través de los datos y de la Inteligencia Artificial, Richard Benjamins, Lid Editorial (2022)
¿De qué trata?: A Data-Driven Company analiza 21 decisiones clave a las que tienen que hacer frente las compañías para convertirse en una empresa orientada hacia los datos y la IA. En él se abordan las típicas decisiones organizativas, tecnológicas, empresariales, de personal y éticas que las organizaciones deben afrontar para empezar a tomar decisiones basadas en datos, incluyendo cómo financiar su estrategia de datos, organizar equipos, medir los resultados y escalar.
¿A quién va dirigido?: Sirve tanto para profesionales que empiezan a trabajar con datos, como para aquellos que ya tienen experiencia, pero necesitan adaptarse para trabajar con big data, analítica o inteligencia artificial.
3. Digital Empires: The Global Battle to Regulate Technology, Anu Bradford, OUP USA (2023)
¿De qué trata?: Ante los avances tecnológicos en todo el mundo y la llegada de gigantes empresariales repartidos en las potencias internacionales, Bradford examina tres enfoques regulatorios que compiten entre sí: el modelo estadounidense donde lo que prima es el mercado, el modelo chino condicionado por el Estado y el modelo regulatorio europeo, centrado en los derechos. A través de sus páginas, se analiza cómo los gobiernos y las empresas tecnológicas navegan por los inevitables conflictos que surgen cuando estos enfoques regulatorios chocan en el ámbito internacional.
¿A quién va dirigido?: Es un libro pensado para quienes desean conocer más sobre el enfoque regulador de las tecnologías alrededor del mundo y cómo afecta al ámbito empresarial. Está redactado de manera clara y comprensible, a pesar de la complejidad del tema. Sin embargo, el lector deberá saber inglés, porque aún no se ha traducido a nuestro idioma.
4. El mito del algoritmo, Richard Benjamins e Idoia Salazar, Anaya Multimedia (2020)
¿De qué trata?: La inteligencia artificial y su uso exponencial en múltiples disciplinas está provocando un cambio social sin precedentes. Con ello, empiezan a surgir pensamientos filosóficos tan profundos como la existencia del alma o debates relacionados con la posibilidad de que las máquinas tengan sentimientos. Se trata de un libro para conocer los desafíos, retos y oportunidades de esta tecnología.
¿A quién va dirigido?: Está dirigido a personas con interés en la filosofía de la tecnología y el desarrollo de avances tecnológicos. Al usar un lenguaje sencillo y esclarecedor, es un libro al alcance de un público generalista.
5. ¿Cómo sobrevivir a la incertidumbre?, de Anabel Forte Deltell, Next Door Publishers
¿De qué trata?: Explica de forma sencilla y con ejemplos cómo la estadística y la probabilidad están más presentes en la vida diaria. El libro parte de la actualidad, en la que datos, números, porcentajes y gráficos se han adueñado del día a día y se han convertido en indispensables para tomar decisiones o para comprender el mundo que nos rodea.
¿A quién va dirigido?: A un público general que quiere entender cómo el análisis de los datos, la estadística y la probabilidad van configurando buena parte de las decisiones políticas, sociales, económicas...
6. Análisis espacial con R: Usa R como un Sistema de Información Geográfica, Jean François Mas, European Scientific Institute
¿De qué trata?: Se trata de un libro más técnico, en el que se realiza una breve introducción de los principales conceptos para el manejo del lenguaje y entorno de programación R (tipos de objetos y operaciones básicas) para posteriormente acercar al lector al uso de la librería o paquete sf, para datos espaciales en formato vector a través de sus principales funciones para lectura, escritura y análisis. El libro aborda, desde una perspectiva práctica y aplicativa con un lenguaje de fácil entendimiento, los primeros pasos para iniciarse con el manejo de R en aplicaciones de análisis espacial; para ello, es necesario que los usuarios tengan conocimientos básicos de Sistemas de Información Geográfica.
¿A quién va dirigido?: A un público con algún conocimiento en R y conocimientos básicos de GIS que desean introducirse en el mundo de las aplicaciones de análisis espacial.
Esta es solo una pequeña muestra de la gran variedad de literatura existente relacionada con el mundo de los datos. Seguro que nos dejamos algún libro interesante sin incluir por lo que, si tienes alguna recomendación extra que quieres hacer, no dudes en dejarnos tu título favorito en comentarios. Quienes formamos el equipo de datos.gob.es estaremos encantados de leer vuestras recomendaciones.
Blog
En estos momentos nos encontramos en medio de una carrera sin precedentes por dominar las innovaciones en Inteligencia Artificial. Durante el último año, la estrella ha sido la Inteligencia Artificial Generativa (GenAI), es decir, aquella capaz de generar contenido original y creativo como imágenes, texto o música. Pero los avances no dejan de sucederse, y últimamente comienzan a llegar noticias en las que se sugiere que la utopía de la Inteligencia Artificial General (AGI) podría no estar tan lejos como pensábamos. Estamos hablando de máquinas capaces de comprender, aprender y realizar tareas intelectuales con resultados similares al cerebro humano.
Sea esto cierto o simplemente una predicción muy optimista, consecuencia de los asombrosos avances conseguido en un espacio muy corto de tiempo, lo cierto es que la Inteligencia Artificial parece ya capaz de revolucionar prácticamente todas las facetas de nuestra sociedad a partir de la cada vez mayor cantidad de datos que se utilizan para su entrenamiento.
Y es que si, como argumentaba Andrew Ng ya en 2017, la inteligencia artificial es la nueva electricidad, los datos abiertos serían el combustible que alimenta su motor, al menos en un buen número de aplicaciones cuya fuente principal y más valiosa es la información pública que se encuentra accesible para ser reutilizada. En este artículo vamos a repasar un campo en el que previsiblemente veremos grandes avances en los próximos años gracias a la combinación de inteligencia artificial y datos abiertos: la creación artística.
Creación Generativa basada en Datos Culturales Abiertos
La capacidad de la inteligencia artificial para generar nuevos contenidos podría llevarnos a una nueva revolución en la creación artística, impulsada por el acceso a datos culturales abiertos y a una nueva generación de artistas capaces de aprovechar estos avances para crear nuevas formas de pintura, música o literatura, trascendiendo barreras culturales y temporales.
Música
El mundo de la música, con su diversidad de estilos y tradiciones, representa un campo lleno de posibilidades para la aplicación de la inteligencia artificial generativa. Los conjuntos de datos abiertos en este ámbito incluyen grabaciones de música folclórica, clásica, moderna y experimental de todo el mundo y de todas las épocas, partituras digitalizadas, e incluso información sobre teorías musicales documentadas. Desde el archi-conocido MusicBrainz, la enciclopedia de la música abierta, hasta conjuntos de datos que abren los propios dominadores de la industria del streaming como Spotify o proyectos como Open Music Europe, son algunos ejemplos de recursos que están en la base del progreso en esta área. A partir del análisis de todos estos datos, los modelos de inteligencia artificial pueden identificar patrones y estilos únicos de diferentes culturas y épocas, fusionándolos para crear composiciones musicales inéditas con herramientas y modelos como MuseNet de OpenAI o Music LM de Google.
Literatura y pintura
En el ámbito de la literatura, la Inteligencia artificial también tiene potencial para hacer más productiva no solo la creación de contenidos en internet, sino para producir formas más elaboradas y complejas de contar historias. El acceso a bibliotecas digitales que albergan obras literarias desde la antigüedad hasta el momento actual hará posible explorar y experimentar con estilos literarios, temas y arquetipos de narración de diversas culturas a lo largo de la historia, con el fin de crear nuevas obras en colaboración con la propia creatividad humana. Incluso se podrá generar una literatura de carácter más personalizado a los gustos de grupos de lectores más minoritarios. La disponibilidad de datos abiertos como el Proyecto Guttemberg con más de 70.000 libros o los catálogos digitales abiertos de museos e instituciones que han publicado manuscritos, periódicos y otros recursos escritos producidos por la humanidad, son un recurso de gran valor para alimentar el aprendizaje de la inteligencia artificial.
Los recursos de la Digital Public Library of America (DPLA) en Estados Unidos o de Europeana en la Unión Europea son sólo algunos ejemplos. Estos catálogos no sólo incluyen texto escrito, sino que incluyen también vastas colecciones de obras de arte visuales, digitalizadas a partir de las colecciones de museos e instituciones, que en muchos casos ni tan siquiera pueden admirarse porque las organizaciones que las conservan no disponen de espacio suficiente para exponerlas al público. Los algoritmos de inteligencia artificial, al analizar estas obras, descubren patrones y aprenden sobre técnicas, estilos y temas artísticos de diferentes culturas y períodos históricos. Esto posibilita que herramientas como DALL-E2 o Midjourney puedan crear obras visuales a partir de unas sencillas instrucciones de texto con estética de pintura renacentista, impresionista o una mezcla de ambas.
Sin embargo, estas fascinantes posibilidades están acompañadas de una controversia aún no resuelta acerca de los derechos de autor que está siendo debatida en los ámbitos académicos, legales y jurídicos y que plantea nuevos desafíos en la definición de autoría y propiedad intelectual. Por una parte, está la cuestión sobre la propiedad de los derechos sobre las creaciones producidas por inteligencia artificial. Y por otra parte encontramos el uso de conjuntos de datos que contienen obras sujetas a derechos de propiedad intelectual y que se han utilizado en el entrenamiento de los modelos sin el consentimiento de los autores. En ambas cuestiones existen numerosas disputas judiciales en todo el mundo y solicitudes de retirada explícita de contenido de los principales conjuntos de datos de entrenamiento.
En definitiva, nos encontramos ante un campo donde el avance de la inteligencia artificial parece imparable, pero habrá que tener muy presente no solo las oportunidades, sino también los riesgos que supone.
Contenido elaborado por Jose Luis Marín, Senior Consultant in Data, Strategy, Innovation & Digitalization. Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Noticia
Apúntatelos en el calendario, toma nota en tu agenda o establece recordatorios en tu móvil para no olvidarte de esta lista de eventos sobre datos y gobierno abierto que se celebrará este otoño. Esta época del año viene cargada de oportunidades para aprender sobre innovación tecnológica y debatir acerca del poder transformador de los datos abiertos en la sociedad.
Desde talleres prácticos hasta congresos y conferencias magistrales. En este post, te presentamos algunos de los eventos más destacados que se celebraran durante octubre y noviembre. ¡Apúntate antes de que se agoten las plazas!
Espacios de datos en la UE: sinergias entre la protección de datos y los espacios de datos
A principios del décimo mes del año, la Agencia Española de Protección de Datos (AEPD) y la Agencia Europea de Ciberseguridad (ENISA) celebrarán un evento en inglés para abordar los desafíos y oportunidades de implementar las disposiciones del Reglamento General de Protección de Datos (GDPR) en los espacios de datos de la UE.
Durante la conferencia, se repasarán buenas prácticas de los espacios de datos existentes en la UE, se analizará la interacción entre la legislación y las políticas de la UE sobre intercambio de datos y se presentará la ingeniería de protección de datos como un elemento integral en la estructura de los espacios de datos, así como sus implicaciones jurídicas.
- ¿A quién va dirigido? Este evento promete ser una plataforma de conocimiento y colaboración de interés para toda persona interesada en el futuro de los datos en la región.
- ¿Cuándo y dónde es? El 2 de octubre en Madrid de 9:30 a 18:00 y en streaming con registro previo hasta las 14:45.
- Inscripción:(enlace ya no disponible)
Conferencia SEMIC ‘Europa interoperable en la época de la IA’
También en octubre regresa la conferencia anual SEMIC organizada por la Comisión Europea en colaboración con la Presidencia Española del Consejo de la Unión Europea. Este año el evento se celebra en Madrid y explorará cómo la interoperabilidad en el sector público y la inteligencia artificial pueden beneficiarse mutuamente a través de casos de usos concretos y proyectos exitosos.
Las sesiones abordarán las últimas tendencias en espacios de datos, gobernanza digital, garantía de calidad de los datos e inteligencia artificial generativa, entre otros. Además, se presentará una propuesta para una Ley sobre Europa Interoperable.
- ¿A quién va dirigido? Profesionales del sector público o privado que trabajen con datos, gobernanza y/o tecnología. La edición del año pasado atrajo a más de 1.000 profesionales de 60 países.
- ¿Cuándo y dónde es? El 18 de octubre se celebra la conferencia en el Hotel Riu Plaza de Madrid, también se podrá seguir online. El 17 de octubre tendrán lugar los talleres previos a la conferencia en el Instituto Nacional de Administración Pública.
- Inscripción: https://semic2023.eu/registration/

Data e IA en acción: impacto sostenible y realidades futuras
Del 25 al 27 de octubre se celebra en Valencia un evento sobre el valor de los datos en la inteligencia artificial que cuenta con la colaboración de la Comisión Europea y la Presidencia Española del Consejo de la Unión Europea, entre otros.
A lo largo de las tres jornadas, se presentarán ponencias de una hora aproximadamente sobre temáticas variadas como espacios de datos sectoriales, economía del dato o ciberseguridad.
- ¿A quién va dirigido? Los miembros del European Big Data Value Forum recibirán un descuento a la entrada y los miembros asociados cuentan con tres tickets por organización. El precio de la entrada varía de 120 a 370 euros.
- ¿Cuándo y dónde es? El 25, 26 y 27 de octubre en Valencia.
- Inscripción: bipeek
Webinars europeos: datos abiertos para investigación, crecimiento regional con datos abiertos y espacios de datos
El portal europeo de datos abiertos organiza de manera periódica seminarios online sobre proyectos y tecnologías relacionadas con datos abiertos. En datos.gob.es nos hacemos eco de ello en publicaciones resumen sobre cada sesión o en redes sociales. Además, una vez concluido el evento, se publican los materiales que se han utilizado para llevar a cabo la sesión didáctica. Ya está disponible el calendario de eventos de octubre en la web del portal. Inscríbete para recibir un recordatorio del webinar y, posteriormente los materiales utilizados.
-
Espacios de datos: Descubriendo la arquitectura de bloques
-
¿Cuándo? El 6 de octubre de 10:00 a 11:30 horas
-
Inscripción: data.europa academy 'Data spaces: Discovering the building blocks' (clickmeeting.com)
-
-
¿Cómo utilizar datos abiertos en tu investigación?
-
¿Cuándo? El 19 de octubre de 10:00 a 11:30
-
Inscripción: How to use open data for your research (clickmeeting.com)
-
-
Open Data Maturity Report: La dimensión de impacto en profundidad
-
¿Cuándo? El 27 de octubre de 10:00 a 11.30
-
Inscripción: data.europa academy 'Open Data Maturity 2022: Diving deeper into the impact dimension' (clickmeeting.com)
-
ODI SUMMIT 2023: Cambios en los datos
El mes de noviembre empieza con un evento del Instituto Open Data (ODI, por sus siglas en inglés) que plantea la siguiente pregunta a modo de presentación: ¿Cómo impactan los datos en el desarrollo tecnológico para abordar desafíos globales? Para que la sociedad pueda beneficiarse de tecnologías tan innovadoras como la inteligencia artificial, hacen falta datos.
En esta edición, ODI SUMMIT cuenta con ponentes del calibre del fundador de la World Wide Web, Tim Berners-Lee, la cofundadora de Women Income Network, Alicia Mbalire o la CEO de ODI Louise Burke. Es un evento gratuito previo registro.
- ¿A quién va dirigido? Profesores, estudiantes, profesionales del sector o investigadores son bienvenidos al evento.
- ¿Cuándo y dónde es? El 7 de noviembre Online
- Inscripción: Form (hsforms.com)
Estos son algunos de los eventos que están agendados para este otoño. De todas formas, no olvides seguirnos en redes sociales para no perderte ninguna novedad sobre innovación y datos abiertos. Estamos en Twitter y LinkedIn, también nos puedes escribir a dinamizacion@datos.gob.es si quieres que incluyamos algún otro evento a la lista o si necesitas información extra.
Documentación
1. Introducción
Las visualizaciones son representaciones gráficas de datos que permiten comunicar de manera sencilla y efectiva la información ligada a los mismos. Las posibilidades de visualización son muy amplias, desde representaciones básicas, como los gráficos de líneas, de barras o de sectores, hasta visualizaciones configuradas sobre cuadros de mando interactivos.
En esta sección de “Visualizaciones paso a paso” estamos presentando periódicamente ejercicios prácticos de visualizaciones de datos abiertos disponibles en datos.gob.es u otros catálogos similares. En ellos se abordan y describen de manera sencilla las etapas necesarias para obtener los datos, realizar las transformaciones y los análisis que resulten pertinentes para, finalmente, posibilitar la creación de visualizaciones interactivas que nos permitan obtener unas conclusiones finales a modo de resumen de dicha información. En cada uno de estos ejercicios prácticos, se utilizan sencillos desarrollos de código convenientemente documentados, así como herramientas de uso gratuito. Todo el material generado está disponible para su reutilización en el repositorio Laboratorio de datos de GitHub.
A continuación, y como complemento a la explicación que encontrarás seguidamente, puedes acceder al código que utilizaremos en el ejercicio y que iremos explicando y desarrollando en los siguientes apartados de este post.
Accede al repositorio del laboratorio de datos en Github.
Ejecuta el código de pre-procesamiento de datos sobre Google Colab.
2. Objetivo
El objetivo principal de este ejercicio es mostrar cómo realizar un análisis de redes o de grafos partiendo de datos abiertos sobre viajes en bicicleta de alquiler en la ciudad de Madrid. Para ello, realizaremos un preprocesamiento de los datos con la finalidad de obtener las tablas que utilizaremos a continuación en la herramienta generadora de la visualización, con la que crearemos las visualizaciones del grafo.
Los análisis de redes son métodos y herramientas para el estudio y la interpretación de las relaciones y conexiones entre entidades o nodos interconectados de una red, pudiendo ser estas entidades personas, sitios, productos, u organizaciones, entre otros. Los análisis de redes buscan descubrir patrones, identificar comunidades, analizar la influencia y determinar la importancia de los nodos dentro de la red. Esto se logra mediante el uso de algoritmos y técnicas específicas para extraer información significativa de los datos de red.
Una vez analizados los datos mediante esta visualización, podremos contestar a preguntas como las que se plantean a continuación:
- ¿Cuál es la estación de la red con mayor tráfico de entrada y de salida?
- ¿Cuáles son las rutas entre estaciones más frecuentes?
- ¿Cuál es el número medio de conexiones entre estaciones para cada una de ellas?
- ¿Cuáles son las estaciones más interconectadas dentro de la red?
3. Recursos
3.1. Conjuntos de datos
Los conjuntos de datos abiertos utilizados contienen información sobre los viajes en bicicleta de préstamo realizados en la ciudad de Madrid. La información que aportan se trata de la estación de origen y de destino, el tiempo del trayecto, la hora del trayecto, el identificador de la bicicleta, …
Estos conjuntos de datos abiertos son publicados por el Ayuntamiento de Madrid, mediante ficheros que recogen los registros de forma mensual.
Estos conjuntos de datos también se encuentran disponibles para su descarga en el siguiente repositorio de Github.
3.2. Herramientas
Para la realización de las tareas de preprocesado de los datos se ha utilizado el lenguaje de programación Python escrito sobre un Notebook de Jupyter alojado en el servicio en la nube de Google Colab.
"Google Colab" o, también llamado Google Colaboratory, es un servicio en la nube de Google Research que permite programar, ejecutar y compartir código escrito en Python o R sobre un Jupyter Notebook desde tu navegador, por lo que no requiere configuración. Este servicio es gratuito.
Para la creación de la visualización interactiva se ha usado la herramienta Gephi
"Gephi" es una herramienta de visualización y análisis de redes. Permite representar y explorar relaciones entre elementos, como nodos y enlaces, con el fin de entender la estructura y patrones de la red. El programa precisa descarga y es gratuito.
Si quieres conocer más sobre herramientas que puedan ayudarte en el tratamiento y la visualización de datos, puedes recurrir al informe "Herramientas de procesado y visualización de datos".
4. Tratamiento o preparación de datos
Los procesos que te describimos a continuación los encontrarás comentados en el Notebook que también podrás ejecutar desde Google Colab.
Debido al alto volumen de viajes registrados en los conjuntos de datos, definimos los siguientes puntos de partida a la hora de analizarlos:
- Analizaremos la hora del día con mayor tráfico de viajes
- Analizaremos las estaciones con un mayor volumen de viajes
Antes de lanzarnos a analizar y construir una visualización efectiva, debemos realizar un tratamiento previo de los datos, prestando especial atención a su obtención y a la validación de su contenido, asegurándonos que se encuentran en el formato adecuado y consistente para su procesamiento y que no contienen errores.
Como primer paso del proceso, es necesario realizar un análisis exploratorio de los datos (EDA), con el fin de interpretar adecuadamente los datos de partida, detectar anomalías, datos ausentes o errores que pudieran afectar a la calidad de los procesos posteriores y resultados. Si quieres conocer más sobre este proceso puedes recurrir a la Guía Práctica de Introducción al Análisis Exploratorio de Datos.
El siguiente paso es generar la tabla de datos preprocesada que usaremos para alimentar la herramienta de análisis de redes (Gephi) que de forma visual nos ayudará a comprender la información. Para ello modificaremos, filtraremos y uniremos los datos según nuestras necesidades.
Los pasos que se siguen en este preprocesamiento de los datos, explicados en este Notebook de Google Colab, son los siguientes:
- Instalación de librerías y carga de los conjuntos de datos
- Análisis exploratorio de los datos (EDA)
- Generación de tablas preprocesadas
Podrás reproducir este análisis con el código fuente que está disponible en nuestra cuenta de GitHub. La forma de proporcionar el código es a través de un documento realizado sobre un Jupyter Notebook que, una vez cargado en el entorno de desarrollo, podrás ejecutar o modificar de manera sencilla.
Debido al carácter divulgativo de este post y para favorecer el entendimiento de los lectores no especializados, el código no pretende ser el más eficiente sino facilitar su comprensión, por lo que posiblemente se te ocurrirán muchas formas de optimizar el código propuesto para lograr fines similares. ¡Te animamos a que lo hagas!
5. Análisis de la red
5.1. Definición de la red
La red analizada se encuentra formada por los viajes entre distintas estaciones de bicicletas en la ciudad de Madrid, teniendo como principal información de cada uno de los viajes registrados la estación de origen (denominada como “source”) y la estación de destino (denominada como “target”).
La red está formada por 253 nodos (estaciones) y 3012 aristas (interacciones entre las estaciones). Se trata de un grafo dirigido, debido a que las interacciones son bidireccionales y ponderado, debido a que cada arista entre los nodos tiene asociado un valor numérico denominado "peso" que en este caso corresponde al número de viajes realizados entre ambas estaciones.
5.2. Carga de la tabla preprocesada en Gephi
Mediante la opción “importar hoja de cálculo” de la pestaña archivo, importamos en formato CSV la tabla de datos previamente preprocesada. Gephi detectará que tipo de datos se están cargando, por lo que utilizaremos los parámetros predefinidos por defecto.


5.3. Opciones de visualización de la red
5.3.1 Ventana de distribución
En primer lugar, aplicamos en la ventana de distribución, el algoritmo Force Atlas 2. Este algoritmo utiliza la técnica de repulsión de nodos en función del grado de conexión de tal forma que los nodos escasamente conectados se separan respecto a los que tiene una mayor fuerza de atracción entre sí.
Para evitar que los componentes conexos queden fuera de la vista principal, fijamos el valor del parámetro "Gravedad en Puesta a punto" a un valor de 10 y para evitar que los nodos queden amontonados, marcamos la opción “Disuadir Hubs” y “Evitar el solapamiento”.

Dentro de la ventana de distribución, también aplicamos el algoritmo de Expansión con la finalidad de que los nodos no se encuentren tan juntos entre sí mismos.

Figura 3. Ventana distribución - algoritmo de Expansión
5.3.2 Ventana de apariencia
A continuación, en la ventana de apariencia, modificamos los nodos y sus etiquetas para que su tamaño no sea igualitario, sino que dependa del valor del grado de cada nodo (nodos con un mayor grado, mayor tamaño visual). También modificaremos el color de los nodos para que los de mayor tamaño sean de un color más llamativo que los de menor tamaño. En la misma ventana de apariencia modificamos las aristas, en este caso hemos optado por un color unitario para todas ellas, ya que por defecto el tamaño va acorde al peso de cada una de ellas.
Un mayor grado en uno de los nodos implica un mayor número de estaciones conectadas con dicho nodo, mientras que un mayor peso de las aristas implica un mayor número de viajes para cada conexión.

5.3.3 Ventana de grafo
Por último, en la zona inferior de la interfaz de la ventana de grafo, tenemos diversas opciones como activar/desactivar el botón para mostrar las etiquetas de los distintos nodos, adecuar el tamaño de las aristas con la finalizad de hacer más limpia la visualización, modificar el tipo de letra de las etiquetas, …

A continuación, podemos ver la visualización del grafo que representa la red una vez aplicadas las opciones de visualización mencionadas en los puntos anteriores.

Figura 6. Visualización del grafo
Activando la opción de visualizar etiquetas y colocando el cursor sobre uno de los nodos, se mostrarán los enlaces que corresponden al nodo y el resto de los nodos que están vinculados al elegido mediante dichos enlaces.
A continuación, podemos visualizar los nodos y enlaces relativos a la estación de bicicletas “Fernando el Católico". En la visualización se distinguen con facilidad los nodos que poseen un mayor número de conexiones, ya que aparecen con un mayor tamaño y colores más llamativos, como por ejemplo "Plaza de la Cebada" o "Quevedo".

5.4 Principales medidas de red
Junto a la visualización del grafo, las siguientes medidas nos aportan la principal información de la red analizada. Estas medias, que son las métricas habituales cuando se realiza analítica de redes, podremos calcularlas en la ventana de estadísticas.

- Nodos (N): son los distintos elementos individuales que componen una red, representando entidades diversas. En este caso las distintas estaciones de bicicletas. Su valor en la red es de 243
- Enlaces (L): son las conexiones que existen entre los nodos de una red. Los enlaces representan las relaciones o interacciones entre los elementos individuales (nodos) que componen la red. Su valor en la red es de 3014
- Número máximo de enlaces (Lmax): es el máximo posible de enlaces en la red. Se calcula mediante la siguiente fórmula Lmax= N(N-1)/2. Su valor en la red es de 31878
- Grado medio (k): es una medida estadística para cuantificar la conectividad promedio de los nodos de la red. Se calcula promediando los grados de todos los nodos de la red. Su valor en la red es de 23,8
- Densidad de la red (d): indica la proporción de conexiones existentes entre los nodos de la red con respecto al total de conexiones posibles. Su valor en la red es de 0,047
- Diámetro (dmax ): es la distancia de grafo más larga entre dos nodos cualquiera de la res, es decir, cómo de lejos están los 2 nodos más alejados. Su valor en la red es de 7
- Distancia media (d): es la distancia de grafo media promedio entre los nodos de la red. Su valor en la red es de 2,68
- Coeficiente medio de clustering (C): Índica cómo los nodos están incrustados entre sus nodos vecinos. El valor medio da una indicación general de la agrupación en la red. Su valor en la red es de 0,208
- Componente conexo: grupo de nodos que están directa o indirectamente conectados entre sí, pero no están conectados con los nodos fuera de ese grupo. Su valor en la red es de 24
5.5 Interpretación de los resultados
La probabilidad de grados sigue de forma aproximada una distribución de larga cola, donde podemos observar que existen unas pocas estaciones que interactúan con un gran número de ellas mientras que la mayoría interactúa con un número bajo de estaciones.
El grado medio es de 23,8 lo que indica que cada estación interacciona de media con cerca de otras 24 estaciones (entrada y salida).
En el siguiente gráfico podemos observar que, aunque tengamos nodos con grados considerados como altos (80, 90, 100, …), se observa que el 25% de los nodos tienen grados iguales o inferiores a 8, mientras que el 75% de los nodos tienen grados inferiores o iguales a 32.

La gráfica anterior se puede desglosar en las dos siguientes correspondientes al grado medio de entrada y de salida (ya que la red es direccional). Vemos que ambas tienen distribuciones de larga cola similares, siendo su grado medio el mismo de 11,9.
Su principal diferencia es que la gráfica correspondiente al grado medio de entrada tiene una mediana de 7 mientras que la de salida es de 9, lo que significa que existe una mayoría de nodos con grados más bajos en los de entrada que los de salida.


El valor del grado medio con pesos es de 346,07 lo cual nos indica la media de viajes totales de entrada y salida de cada estación.

La densidad de red de 0,047 es considerada una densidad baja indicando que la red es dispersa, es decir, contiene pocas interacciones entre distintas estaciones en relación con las posibles. Esto se considera lógico debido a que las conexiones entre estaciones estarán limitadas a ciertas zonas debido a la dificultad de llegar a estaciones que se encuentra a largas distancias.
El coeficiente medio de clustering es de 0,208 significando que la interacción de dos estaciones con una tercera no implica necesariamente la interacción entre sí, es decir, no implica necesariamente transitividad, por lo que la probabilidad de interconexión de esas dos estaciones mediante la intervención de una tercera es baja.
Por último, la red presenta 24 componentes conexos, siendo 2 de ellos componentes conexos débiles y 22 componentes conexos fuertes.
5.6 Análisis de centralidad
Un análisis de centralidad se refiere a la evaluación de la importancia de los nodos en una red utilizando diferentes medidas. La centralidad es un concepto fundamental en el análisis de redes y se utiliza para identificar nodos clave o influyentes dentro de una red. Para realizar esta tarea se parte de las métricas calculadas en la ventana de estadísticas.
- La medida de centralidad de grado indica que cuanto más alto es el grado de un nodo, más importante es. Las cinco estaciones con valores más elevados son: 1º Plaza de la Cebada, 2º Plaza de Lavapiés, 3º Fernando el Católico, 4º Quevedo, 5º Segovia 45.

- La media de centralidad de cercanía indica que cuanto más alto sea el valor de cercanía de un nodo, más central es, ya que puede alcanzar cualquier otro nodo de la red con el menor esfuerzo posible. Las cinco estaciones que valores más elevados poseen son: 1º Fernando el Católico 2º General Pardiñas, 3º Plaza de la Cebada, 4º Plaza de Lavapiés, 5º Puerta de Madrid.

Figura 13. Distribución medida centralidad de cercanía

- La medida de centralidad de intermediación indica que cuanto mayor sea la medida de intermediación de un nodo, más importante es dado que está presente en más rutas de interacción entre nodos que el resto de los nodos de la red. Las cinco estaciones que valores más elevados poseen son: 1º Fernando el Católico, 2º Plaza de Lavapiés, 3º Plaza de la Cebada, 4º Puerta de Madrid, 5º Quevedo.

 FIgura 16. Visualización grafo centralidad de intermediación
FIgura 16. Visualización grafo centralidad de intermediación
Con la herramienta Gephi se pueden calcular gran cantidad de métricas y parámetros que no se reflejan en este estudio ,como por ejemplo, la medida de vector propio o distribucción de centralidad "eigenvector".
5.7 Filtros
Mediante la ventana de filtrado, podemos seleccionar ciertos parámetros que simplifiquen las visualizaciones con la finalidad de mostrar información relevante del análisis de redes de una forma más clara visualmente.

A continuación, mostraremos varios filtrados realizados:
- Filtrado de rango (grado), en el que se muestran los nodos con un rango superior a 50, suponiendo un 13,44% (34 nodos) y un 15,41% (464 aristas)

- Filtrado de aristas (peso de la arista), en el que se muestran las aristas con un peso superior a 100, suponiendo un 0,7% (20 aristas)

Figura 19. VIsualización grafo filtrado de arista (peso)
Dentro de la ventana de filtros, existen muchas otras opciones de filtrado sobre atributos, rangos, tamaños de particiones, las aristas, … con los que puedes probar a realizar nuevas visualizaciones para extraer información del grafo. Si quieres conocer más sobre el uso de Gephi, puedes consultar los siguientes cursos y formaciones sobre la herramienta.
6. Conclusiones del ejercicio
Una vez realizado el ejercicio, podemos apreciar las siguientes conclusiones:
- Las tres estaciones más interconectadas con otras estaciones son Plaza de la Cebada (133), Plaza de Lavapiés (126) y Fernando el Católico (114).
- La estación que tiene un mayor número de conexiones de entrada es la Plaza de la Cebada (78), mientras que la que tiene un mayor número de conexiones de salida es la Plaza de Lavapiés con el mismo número que Fernando el Católico (57)
- Las tres estaciones con un mayor número de viajes totales son Plaza de la Cebada (4524), Plaza de Lavapiés (4237) y Fernando el Católico (3526).
- Existen 20 rutas con más de 100 viajes. Siendo las 3 rutas con un mayor número de ellos: Puerta de Toledo – Plaza Conde Suchil (141), Quintana Fuente del Berro – Quintana (137), Camino Vinateros – Miguel Moya (134).
- Teniendo en cuenta el número de conexiones entre estaciones y de viajes, las estaciones de mayor importancia dentro de la red son: Plaza la Cebada, Plaza de Lavapiés y Fernando el Católico.
Esperemos que esta visualización paso a paso te haya resultado útil para el aprendizaje de algunas técnicas muy habituales en el tratamiento y representación de datos abiertos. Volveremos para mostraros nuevas reutilizaciones. ¡Hasta pronto!
Aplicación
Se trata de una aplicación colaborativa desarrollada para la captura y el envío de datos de cobertura de acceso a internet dentro de la Comunidad de Aragón. La ciudadanía puede participar y aportar información para ayudar a conocer la calidad de acceso a internet en sus municipios. Su principal objetivo es el de conocer la calidad en el acceso a internet en Aragón.
En definitiva, esta app obtiene y ofrece los datos de cobertura a internet de todos los municipios de Aragón a través de un trabajo de campo inicial unido a los datos aportados de forma anónima por los usuarios. Su finalidad es la de procesar los datos obtenidos y ofrecerlos abiertamente y de forma pública a través de un mapa. Para ello utiliza los sistemas y servicios cartográficos del Gobierno de Aragón los del Instituto Geográfico de Aragón.
Aplicación
Play4CYL es una aplicación web desarrollada por Daniel Heras y Carlos Montero para el VI Concurso de Datos Abiertos de Castilla y León. Esta iniciativa recibió el ‘Premio estudiantes’ (dotado con 1.500€) en la categoría ‘Productos y Servicios’, que reconoce aquellos proyectos que proporcionan estudios, servicios, sitios web o aplicaciones para dispositivos móviles que utilizan la información del Portal de Datos Abiertos de la Junta de Castilla y León para su desarrollo.
Se trata de una aplicación web que presenta un mapa interactivo para localizar zonas recreativas en espacios naturales, así como árboles singulares y miradores de la comunidad autónoma. Además, presenta otras secciones con información acerca de la población total y los juegos tradicionales típicos de cada zona.
Blog
En el proceso de análisis de datos y entrenamiento de modelos de aprendizaje automático, es fundamental contar con un conjunto de datos adecuado. Por lo tanto, surgen las preguntas: ¿cómo se deben preparar los conjuntos de datos para el aprendizaje automático y el análisis? ¿Cómo se puede confiar en que los datos conducirán a conclusiones sólidas y predicciones precisas?
Lo primero que hay que tener en cuenta al preparar los datos es saber el tipo de problema que se intenta resolver. Por ejemplo, si tu intención es crear un modelo de aprendizaje automático capaz de reconocer el estado emocional de alguien a partir de sus expresiones faciales, necesitarás un conjunto de datos con imágenes o vídeos de caras de personas. O, tal vez, el objetivo es crear un modelo que identifique los correos electrónicos no deseados. Para ello, se necesitarán datos en formato texto de correos electrónicos.
Además, los datos que se precisan también dependen del tipo de algoritmo que quieras utilizar. Los algoritmos de aprendizaje supervisado, como la regresión lineal o los árboles de decisión, requieren un campo que contenga el valor verdadero de un resultado para que el modelo aprenda de él. Además de este valor verdadero, denominado objetivo, requieren campos que contengan información sobre las observaciones, algo que se conoce como características. En cambio, los algoritmos de aprendizaje no supervisado, como la agrupación k-means o los sistemas de recomendación basados en el filtrado colaborativo, por lo general sólo necesitan características.
Sin embargo, encontrar los datos es sólo la mitad del trabajo. Los conjuntos de datos del mundo real pueden contener todo tipo de errores que pueden hacer que todo el trabajo resulte inútil si no se detectan y corrigen antes de empezar. En este post, vamos a presentar algunos de los principales obstáculos que puede haber en los conjuntos de datos para el aprendizaje automático y el análisis, así como conocer algunas maneras en que la plataforma de ciencia de datos colaborativa, Datalore, puede ayudar a detectarlos rápidamente y ponerles remedio.
¿Los datos son representativos de aquello que se quiere medir?
La mayoría de los conjuntos de datos para proyectos o análisis de aprendizaje automático no están diseñados específicamente para ese fin. A falta de un diccionario de metadatos o de una explicación sobre lo qué significan los campos del conjunto de datos, es posible que el usuario tenga que resolver la incógnita basándose en la información de la que dispone.
Una forma de determinar lo que miden las características de un conjunto de datos es comprobar sus relaciones con otras características. Si se supone que dos campos miden cosas similares, es de esperar que estén muy relacionados. Por el contrario, si dos campos miden cosas muy diferentes, es de esperar que no estén relacionados. Estas ideas se conocen como validez convergente y discriminante, respectivamente.
Otra cosa importante que hay que comprobar es si alguno de los rasgos está demasiado relacionado con el público objetivo. Si esto ocurre, puede indicar que este rasgo está accediendo a la misma información que el objetivo a predecir. Este fenómeno se conoce como “feature leakage” (fuga de características). Si se emplean estos datos, existe el riesgo de inflar artificialmente el rendimiento del modelo.
En este sentido, Datalore permite escanear rápidamente la relación entre variables continúas mediate el gráfico de correlación en la pestaña Visualizar para un DataFrame. Otra manera de comprobar estas relaciones es utilizando gráficos de barras o tabulaciones cruzadas, o medidas del tamaño del efecto como el coeficiente de determinación o la V de Cramér.
¿El conjunto de datos está correctamente filtrado y limpio?
Los conjuntos de datos pueden contener todo tipo de inconsistencias que pueden afectar negativamente a nuestros modelos o análisis. Algunos de los indicadores más importantes de datos sucios son:
- Valores inverosímiles: Esto incluye valores que están fuera de rango, como los negativos en una variable de recuento o frecuencias que son mucho más altas o más bajas de lo esperado para un campo en particular.
- Valores atípicos: Se trata de valores extremos, que pueden representar cualquier cosa, desde errores de codificación que se produjeron en el momento en que se escribieron los datos, hasta valores raros pero reales que se sitúan fuera del grueso de las demás observaciones.
- Valores perdidos: El patrón y la cantidad de datos que faltan determinan el impacto que tendrán, siendo los más graves los que están relacionados con el objetivo o las características.
Los datos sucios pueden mermar la calidad de sus análisis y modelos, en gran medida porque distorsionan las conclusiones o porque conducen a un rendimiento deficiente del modelo. La pestaña Estadísticas de Datalore permite comprobar fácilmente estos problemas, ya que muestra de un vistazo la distribución, el número de valores perdidos y la presencia de valores atípicos para cada campo. Datalore también facilita la exploración de los datos en bruto y permite realizar operaciones básicas de filtrado, ordenación y selección de columnas directamente en un DataFrame, exportando el código Python correspondiente a cada acción a una nueva celda.
¿Las variables están equilibradas?
Los datos desequilibrados se producen cuando los campos categóricos tienen una distribución desigual de observaciones entre todas las clases. Esta situación puede causar problemas importantes para los modelos y los análisis. Cuando se tiene un objetivo muy desequilibrado, se pueden crear modelos perezosos que aún pueden lograr un buen rendimiento simplemente prediciendo por defecto la clase mayoritaria. Pongamos un ejemplo extremo: tenemos un conjunto de datos en el que el 90% de las observaciones corresponden a una de las clases objetivo y el 10% a la otra. Si siempre predijéramos la clase mayoritaria para este conjunto de datos, seguiríamos obteniendo una precisión del 90%, lo que demuestra que, en estos casos, un modelo que no aprende nada de las características puede tener un rendimiento excelente.
Las características también se ven afectadas por el desequilibrio de clases. Los modelos funcionan aprendiendo patrones, y cuando las clases son demasiado pequeñas, es difícil para los modelos hacer predicciones para estos grupos. Estos efectos pueden agravarse cuando se tienen varias características desequilibradas, lo que lleva a situaciones en las que una combinación concreta de clases poco comunes sólo puede darse en un puñado de observaciones.
Los datos desequilibrados pueden rectificarse mediante diversas técnicas de muestreo. El submuestreo (undersampling, en inglés) consiste en reducir el número de observaciones en las clases más grandes para igualar la distribución de los datos, y el sobremuestreo (oversampling) consiste en crear más datos en las clases más pequeñas. Hay muchas formas de hacerlo. Algunos ejemplos incluyen el uso de paquetes Python como imbalanced-learn o servicios como Gretel. Las características desequilibradas también pueden corregirse mediante la ingeniería de características, cuyo objetivo es combinar clases dentro de un campo sin perder información.
En definitiva, ¿es representativo el conjunto de datos?
A la hora de crear un conjunto de datos, se tiene en mente un grupo objetivo o target para el cual deseas que tu modelo o análisis funcione. Por ejemplo, un modelo para predecir la probabilidad de que los hombres estadounidenses interesados en la moda compren una determinada marca. Este grupo objetivo es la población sobre la que se quiere poder hacer generalizaciones. Sin embargo, como no suele ser práctico recopilar información sobre todos los individuos que constituyen esta parte de la población, en su lugar se emplea un subconjunto denominado muestra.
A veces surgen problemas que hacen que los datos de la muestra para el modelo de aprendizaje automático y el análisis no representen correctamente el comportamiento de la población. Esto se denomina sesgo de los datos. Por ejemplo, es posible que la muestra no capte todos los subgrupos de la población, un tipo de sesgo denominado sesgo de selección.
Una forma de comprobar el sesgo es inspeccionar la distribución de los campos de sus datos y comprobar que tienen sentido basándose en lo que uno sabe sobre ese grupo de la población. El uso de la pestaña Estadísticas de Datalore permite escanear la distribución de las variables continuas y categóricas de un DataFrame.
¿Se está midiendo el rendimiento real de los modelos?
Una última cuestión que puede ponerle en un aprieto es la medición del rendimiento de sus modelos. Muchos modelos son propensos a un problema llamado sobreajuste que es cuando el modelo se ajusta tan bien a los datos de entrenamiento que no se generaliza bien a los nuevos datos. El signo revelador del sobreajuste es un modelo que funciona extremadamente bien con los datos de entrenamiento y su rendimiento es inferior con nuevos datos. La forma de tener esto en cuenta es dividir el conjunto de datos en varios conjuntos: un conjunto de entrenamiento para entrenar el modelo, un conjunto de validación para comparar el rendimiento de diferentes modelos y un conjunto de prueba final para comprobar cómo funcionará el modelo en el mundo real.
Sin embargo, crear una división limpia de entrenamiento-validación-prueba puede ser complicado. Un problema importante es la fuga de datos, por la que la información de los otros dos conjuntos de datos se filtra en el conjunto de entrenamiento. Esto puede dar lugar a problemas que van desde los obvios, como las observaciones duplicadas que terminan en los tres conjuntos de datos, a otros más sutiles, como el uso de información de todo el conjunto de datos para realizar el preprocesamiento de características antes de dividir los datos. Además, es importante que los tres conjuntos de datos tengan la misma distribución de objetivos y características, para que cada uno sea una muestra representativa de la población.
Para evitar cualquier problema, se debe dividir el conjunto de datos en conjuntos de entrenamiento, validación y prueba al principio de su trabajo, antes de realizar cualquier exploración o procesamiento. Para asegurarse de que cada conjunto de datos tiene la misma distribución de cada campo, se puede utilizar un método como train_test_split de scikit-learn, diseñado específicamente para crear divisiones representativas de los datos. Por último, es recomendable comparar las estadísticas descriptivas de cada conjunto de datos para comprobar si hay signos de fuga de datos o divisiones desiguales, lo que se hace fácilmente utilizando la pestaña Estadísticas de Datalore.
En definitiva, existen varios problemas que pueden ocurrir cuando se preparan los datos para el aprendizaje automático y el análisis y es importante saber cómo mitigarlos. Si bien esto puede ser una parte que consume mucho tiempo del proceso de trabajo, existen herramientas que pueden hacer que sea más rápido y fácil detectar problemas en una etapa temprana.
Contenido elaborado a partir del post de Jodie Burchell How to prepare your dataset for machine learning and analysis publicado en The JetBrains Datalore Blog
Aplicación
Hablando en data es el primer proyecto de visualización de datos de la Biblioteca y Centro de Documentación del Museo Reina Sofía, en colaboración con la Facultad de Ciencias Sociales de la Universidad de Salamanca. Su objetivo es analizar y visualizar la presencia de mujeres artistas, críticas de arte, comisarias, escritoras y autoras que integran su catálogo bibliográfico. El proyecto busca conectar y recopilar la información disponible sobre estas creadoras en otras bases de datos y dar acceso a estos resultados a través de su página web. Toda la información recopilada está disponible para su consulta, uso o descarga, dejando abierta la posibilidad a otros enfoques y visualizaciones.
Financiado con fondos del Plan de Recuperación, Transformación y Resiliencia de la UE
Blog
Continuamos con la serie de posts sobre Chat GPT-3. La expectación levantada por el sistema conversacional justifica con creces la publicación de varios artículos sobre sus características y aplicaciones. En este post, profundizamos sobre una de las últimas novedades publicadas por openAI relacionadas con Chat GPT-3. En este caso introducimos su API, es decir, su interfaz de programación con la que podemos integrar Chat GPT-3 en nuestras propias aplicaciones.
Introducción.
En nuestro último post sobre Chat GPT-3 realizamos un ejercicio de co-programación o programación asistida en el que le solicitamos a la IA que nos escribiera un programa sencillo, en lenguaje de programación R, para visualizar un conjunto de datos. Como vimos en el post, utilizamos la propia interfaz disponible de Chat GTP-3. La interfaz es muy minimalista y funcional, tan solo tenemos que preguntar a la IA en el cuadro de texto y ella nos contesta en el cuadro de texto posterior. Tal y como concluimos en el post, el resultado del ejercicio fue más que satisfactorio. Sin embargo, también detectamos algunos puntos de mejora. Por ejemplo, la interfaz estándar puede resultar un poco lenta. Para un ejercicio largo, con múltiples interacciones conversacionales con la IA (un diálogo largo), la interfaz tarda bastante en escribir las respuestas. Varios usuarios reportan la misma sensación y por eso algunos, como este desarrollador, han creado su propia interfaz con el asistente conversacional para mejorar su velocidad de respuesta.
Pero, ¿cómo es posible esto? La razón es sencilla, gracias al API de Chat GPT-3. En este espacio de divulgación hemos hablado mucho sobre las APIs en el pasado. No en vano, las APIs son los mecanismos estándar en el mundo de las tecnologías digitales para integrar servicios y aplicaciones. Cualquier app en nuestro smartphone hace uso de las APIs para mostrarnos los resultados. Cuando consultamos el tiempo, los resultados deportivos o el horario del transporte público, las apps hacen llamadas a las APIs de los servicios para consultar la información y mostrar los resultados.
El API de Chat GPT-3
Como cualquier otro servicio actual, openAI pone a disposición de sus usuarios una API con la que poder invocar (llamar) a sus diferentes servicios basados en el modelo entrenado de lenguaje natural GPT-3. Para usar el API, tan solo tenemos que iniciar sesión con nuestra cuenta en https://platform.openai.com y localizar el menú (superior derecha) View API Keys. Hacemos click en create a new secret key y ya tenemos nuestra nueva clave de acceso al servicio.

¿Qué hacemos ahora? Bien, para ilustrar lo que podemos hacer con esta nueva y flamante clave veamos algunos ejemplos:
Como decíamos en la introducción, podemos querer probar interfaces alternativas a Chat GPT-3 como https://www.typingmind.com/. Cuando accedemos a esta web, lo primero que debemos hacer es ingresar nuestra API Key.
Una vez dentro, hagamos un ejemplo y veamos cómo se comporta esta nueva interfaz. Preguntemos a Chat GPT-3 ¿Qué es datos.gob.es?
| Nota: Es importante notar que la mayoría de servicios no funcionarán si no activamos algún medio de pago en la web de OpenAI. Lo normal es que, si no hemos configurado una tarjeta de crédito, las llamadas al API devuelvan un mensaje de error similar a \"You exceeded your current quota, please check your plan and billing details”. |

Veamos ahora otra aplicación del API de Chat GPT-3.
Acceso programático con R para acceder a Chat GPT-3 de modo programático (o lo que es lo mismo, con algunas líneas de código en R tenemos acceso a la potencia conversacional del modelo GPT-3). Esta demostración está basada en el reciente post publicado en R Bloggers. Vamos a acceder a Chat GPT-3 de modo programático con el siguiente ejemplo.
| Nota: Notar que el API Key se ha ocultado por motivos de seguridad y privacidad |

En este ejemplo, utilizamos código en R para hacer una llamada HTTPs de tipo POST y le preguntamos a Chat GPT-3 ¿Qué es datos.gob.es? Vemos que estamos utilizando el modelo gpt-3.5-turbo que, tal y como se especifica en la documentación está indicado para tareas de tipo conversacional. Toda la información sobre la API y los diferentes modelos está disponible aquí. Pero, veamos el resultado:

¿Nada mal verdad? Como dato curioso podemos ver que unas pocas llamadas al API de Chat GPT-3 han tenido el siguiente uso del API:

El uso del API se cotiza por tokens (algo similar a las palabras) y los precios públicos pueden consultarse aquí. En concreto el modelo que estamos utilizando tiene estos precios:

Para pequeñas pruebas y ejemplos, nos lo podemos permitir. En caso de aplicaciones empresariales para entornos productivos existe un modelo premium que permite tener un control de los costes sin depender tanto del uso.
Conclusión
Como no podía ser de otra manera, Chat GPT-3 habilita un API para proporcionar acceso programático a su motor conversacional. Este mecanismo permite la integración de aplicaciones y sistemas (es decir, todo lo que no son humanos) abriendo la puerta al despegue definitivo del Chat GPT-3 como modelo de negocio. Gracias a este mecanismo, el buscador Bing ahora integra Chat GPT-3 para respuestas a las búsquedas en modo conversacional. De la misma forma, Microsoft Azure acaba de anunciar la disponibilidad de Chat GPT-3 como un nuevo servicio de la nube pública. Sin lugar a dudas, en las próximas semanas veremos comunicaciones de todo tipo de aplicaciones, apps y servicios, conocidos y desconocidos, anunciando su integración con Chat GPT-3 para mejorar las interfaces conversacionales con sus clientes. Nos vemos en el próximo episodio, quién sabe sin con GPT-4.
Contenido elaborado por Alejandro Alija, experto en Transformación Digital.
Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Documentación
1. Introducción
Las visualizaciones son representaciones gráficas de datos que permiten comunicar de manera sencilla y efectiva la información ligada a los mismos. Las posibilidades de visualización son muy amplias, desde representaciones básicas, como puede ser un gráfico de líneas, barras o sectores, hasta visualizaciones configuradas sobre cuadros de mando o dashboards interactivos.
En esta sección de “Visualizaciones paso a paso” estamos presentando periódicamente ejercicios prácticos de visualizaciones de datos abiertos disponibles en datos.gob.es u otros catálogos similares. En ellos se abordan y describen de manera sencilla las etapas necesarias para obtener los datos, realizar las transformaciones y análisis que resulten pertinentes para, finalmente, la creación de visualizaciones interactivas, de las que podemos extraer información resumida en unas conclusiones finales. En cada uno de estos ejercicios prácticos, se utilizan sencillos desarrollos de código convenientemente documentados, así como herramientas de uso gratuito. Todo el material generado está disponible para su reutilización en el repositorio de GitHub.
En este ejercicio práctico, hemos realizado un sencillo desarrollo de código que está convenientemente documentado apoyandonos en herramientas de uso gratuito.
Accede al repositorio del laboratorio de datos en Github.
Ejecuta el código de pre-procesamiento de datos sobre Google Colab.
2. Objetivo
El objetivo principal de este post es mostrar cómo generar un mapa personalizado de Google Maps mediante la herramienta "My Maps" partiendo de datos abiertos. Este tipo de mapas son altamente populares en páginas, blogs y aplicaciones del sector turístico, no obstante, la información útil proporcionada al usuario suele ser escasa.
En este ejercicio, utilizaremos el potencial de los datos abiertos para ampliar la información a mostrar en nuestro mapa y hacerlo de una forma automática. También mostraremos como realizar un enriquecimiento de los datos abiertos para añadir información de contexto que mejore significativamente la experiencia de usuario.
Desde un punto de vista funcional, el objetivo del ejercicio es la creación de un mapa personalizado para planificar rutas turísticas por los espacios naturales de la Comunidad Autónoma de Castilla y León. Para ello se han utilizado conjuntos de datos abiertos publicados por la Junta de Castilla y León, que hemos preprocesado y adaptado a nuestras necesidades de cara a generar el mapa personalizado.
3. Recursos
3.1. Conjuntos de datos
Los conjuntos de datos contienen distinta información turística de interés geolocalizada. Dentro del catálogo de datos abiertos de la Junta de Castilla y León, encontramos el “diccionario de entidades” (sección información adicional), documento de vital importancia, ya que nos define la terminología utilizada en los distintos conjuntos de datos.
Estos conjuntos de datos también se encuentran disponibles en el repositorio de Github
3.2. Herramientas
Para la realización de las tareas de preprocesado de los datos se ha utilizado el lenguaje de programación Python escrito sobre un Notebook de Jupyter alojado en el servicio en la nube de Google Colab.
"Google Colab" o también llamado "Google Colaboratory", es un servicio gratuito en la nube de Google Research que permite programar, ejecutar y compartir código escrito en Python o R desde tu navegador, por lo que no requiere la instalación de ninguna herramienta o configuración.
Para la creación de la visualización interactiva se ha usado la herramienta Google My Maps.
"Google My Maps" es una herramienta online que permite crear mapas interactivos que pueden ser incrustados en sitios web o exportarse como archivos. Esta herramienta es gratuita, sencilla de usar y permite múltiples opciones de personalización.
Si quieres conocer más sobre herramientas que puedan ayudarte en el tratamiento y la visualización de datos, puedes recurrir al informe "Herramientas de procesado y visualización de datos".
4. Tratamiento o preparación de los datos
Los procesos que te describimos a continuación los encontrarás comentados en el Notebook que podrás ejecutar desde Google Colab.
Antes de lanzarnos a construir una visualización efectiva, debemos realizar un tratamiento previo de los datos, prestando especial atención a la obtención de los mismos y validando su contenido, asegurando que se encuentran en el formato adecuado y consistente para su procesamiento y que no contienen errores.
Como primer paso del proceso es necesario realizar un análisis exploratorio de los datos (EDA) con el fin de interpretar adecuadamente los datos de partida, detectar anomalías, datos ausentes o errores que pudieran afectar a la calidad de los procesos posteriores y resultados. Si quieres conocer más sobre este proceso puedes recurrir a la Guía Práctica de Introducción al Análisis Exploratorio de Datos.
El siguiente paso a dar es generar las tablas de datos preprocesados que usaremos para alimentar el mapa. Para ello, transformaremos los sistemas de coordenadas, modificaremos y filtraremos la información según nuestras necesidades.
Los pasos que se siguen en este preprocesamiento de los datos, explicados en el Notebook, son los siguientes:
- Instalación y carga de librerías
- Carga de los conjuntos de datos
- Análisis exploratorio de datos (EDA)
- Preprocesamiento de los conjuntos de datos
- Transformación de coordenadas
- Filtrado de la información
- Representación gráfica de los conjuntos de datos
- Almacenamiento de las nuevas tablas de datos transformadas
Durante el preprocesado de las tablas de datos, hay que hacer un cambio de sistema de coordenadas ya que en los conjuntos de datos de origen el sistema en el que se encuentran es ESTR89 (sistema estándar que se usa en la Unión Europea), mientras que las necesitaremos en el sistema WGS84 (sistema usado por Google My Maps entre otras aplicaciones geográficas). La forma de realizar este cambio de coordenadas se encuentra explicado en el Notebook. Si quieres saber más sobre tipos y sistemas de coordenadas, puedes recurrir a la “Guía de datos espaciales”
Una vez terminado el preprocesamiento, obtendremos las tablas de datos "recreativas_parques_naturales.csv", "alojamientos_rurales_2estrellas.csv", "refugios_parques_naturales.csv", "observatorios_parques_naturales.csv", "miradores_parques_naturales.csv", "casas_del_parque.csv", "arboles_parques_naturales.csv" las cuales incluyen campos de información genéricos y comunes como: nombre, observaciones, geoposición, … junto a campos de información específicos, los cuales se definen en detalle en el apartado 6.2 Personalización de la información a mostrar en el mapa.
Podrás reproducir este análisis, ya que el código fuente está disponible en nuestra cuenta de GitHub. La forma de proporcionar el código es a través de un documento realizado sobre un Jupyter Notebook que una vez cargado en el entorno de desarrollo podrás ejecutar o modificar de manera sencilla. Debido al carácter divulgativo de este post y para favorecer el entendimiento de los lectores no especializados, el código no pretende ser el más eficiente, sino facilitar su comprensión por lo que posiblemente se te ocurrirán muchas formas de optimizar el código propuesto para lograr fines similares. ¡Te animamos a que lo hagas!
5. Enriquecimiento de los datos
Con la finalidad de aportar mayor información relacionada, se realiza un proceso de enriquecimiento de datos sobre el conjunto de datos “registro de alojamientos hoteleros” explicado a continuación. Con este paso vamos a lograr añadir de forma automática información complementaria que no está inicialmente incluida. Con ello, conseguiremos mejorar la experiencia del usuario durante su uso del mapa al proporcionar información de contexto relacionada con cada punto de interés.
Para ello vamos a utilizar una herramienta útil para este tipo de tarea, OpenRefine. Esta herramienta de código abierto permite realizar múltiples acciones de preprocesamiento de datos, aunque en esta ocasión la usaremos para llevar a cabo un enriquecimiento de nuestros datos mediante la incorporación de contexto enlazando automáticamente información que reside en el popular repositorio de conocimiento Wikidata.
Una vez instalada la herramienta en nuestro ordenador, al ejecutarse se abrirá una aplicación web en el navegador.
A continuación, se detallan los pasos a seguir.
Paso 1
Carga del CSV en el sistema (Figura 1). En esta caso, el conjunto de datos “Registro de alojamientos hoteleros”.
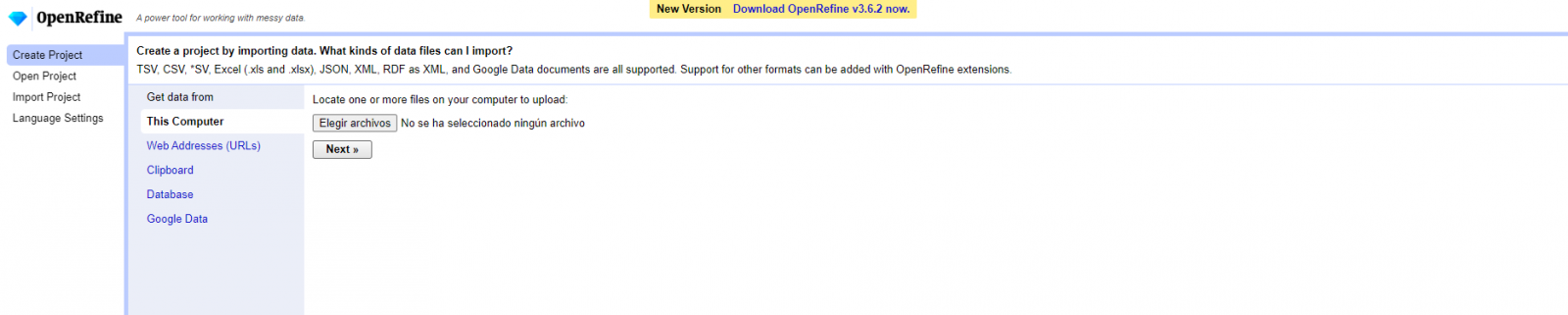
Figura 1. Carga de archivo CSV en OpenRefine
Paso 2
Creación del proyecto a partir del CSV cargado (Figura 2). OpenRefine se gestiona mediante proyectos (cada CSV subido será un proyecto), que se guardan en el ordenador dónde se esté ejecutando OpenRefine para un posible uso posterior. En este paso debemos dar un nombre al proyecto y algunos otros datos, como el separador de columnas, aunque lo más habitual es que estos últimos ajustes se rellenen automáticamente.
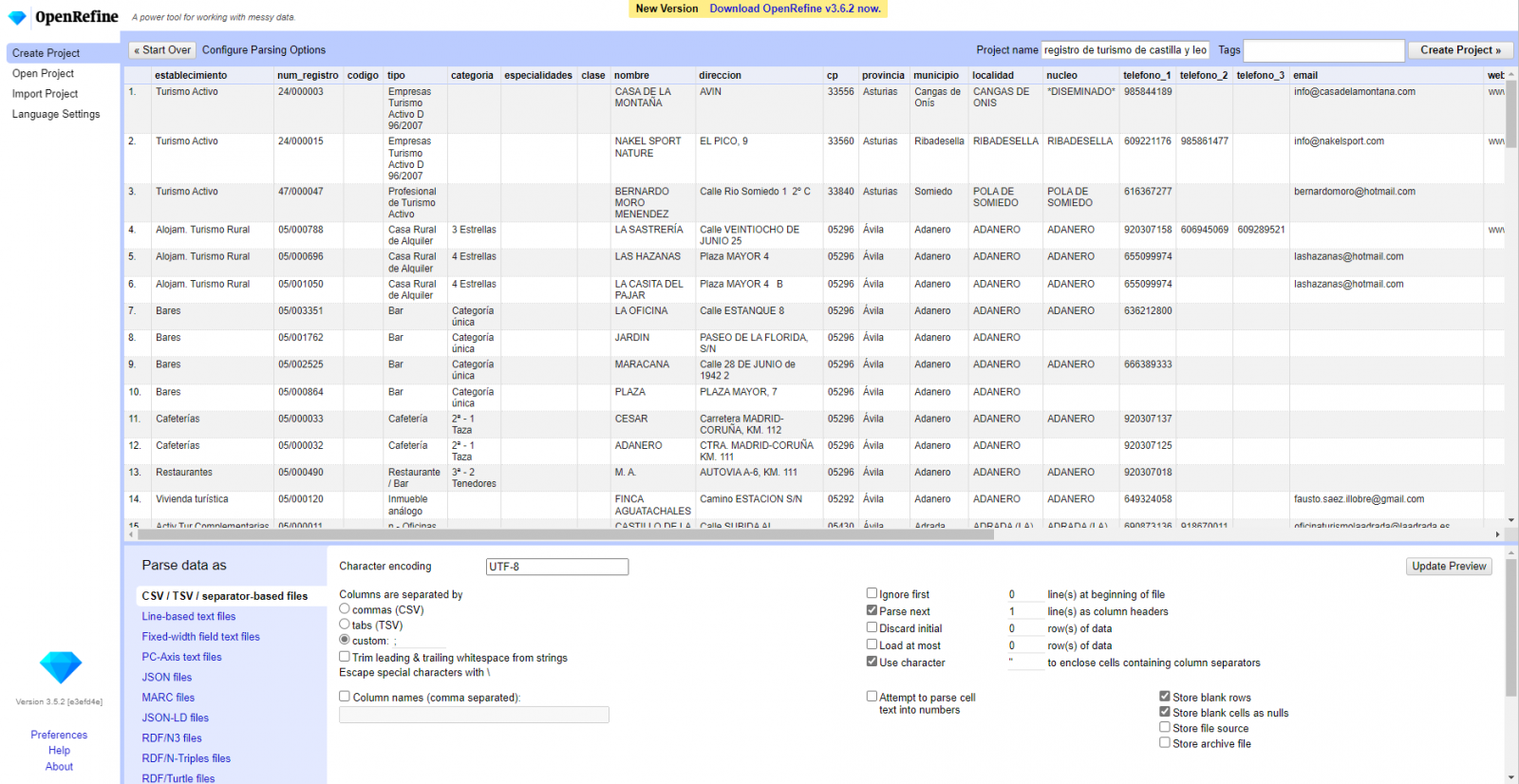
Figura 2. Creación de un proyecto en OpenRefine
Paso 3
Enlazado (o reconciliación, usando la nomenclatura de OpenRefine) con fuentes externas. OpenRefine nos permite enlazar recursos que tengamos en nuestro CSV con fuentes externas como Wikidata. Para ello se deben realizar las siguientes acciones:
- Identificación de las columnas a enlazar. Habitualmente este paso suele estar basado en la experiencia del analista y su conocimiento de los datos que se representan en Wikidata. Como consejo, de forma genérica se podrán reconciliar o enlazar aquellas columnas que contengan información de carácter más global o general como nombres de países, calles, distritos, etc., y no se podrán enlazar aquellas columnas como coordenadas geográficas, valores numéricos o taxonomías cerradas (tipos de calles, por ejemplo). En este ejemplo, disponemos de la columna “municipios” que contiene el nombre de los municipios españoles.
- Comienzo de la reconciliación. (Figura 3) Comenzamos la reconciliación y seleccionamos la fuente por defecto que estará disponible: Wikidata(en). Después de hacer clic en Start Reconciling, automáticamente comenzará a buscar la clase del vocabulario de Wikidata que más se adecue basado en los valores de nuestra columna.
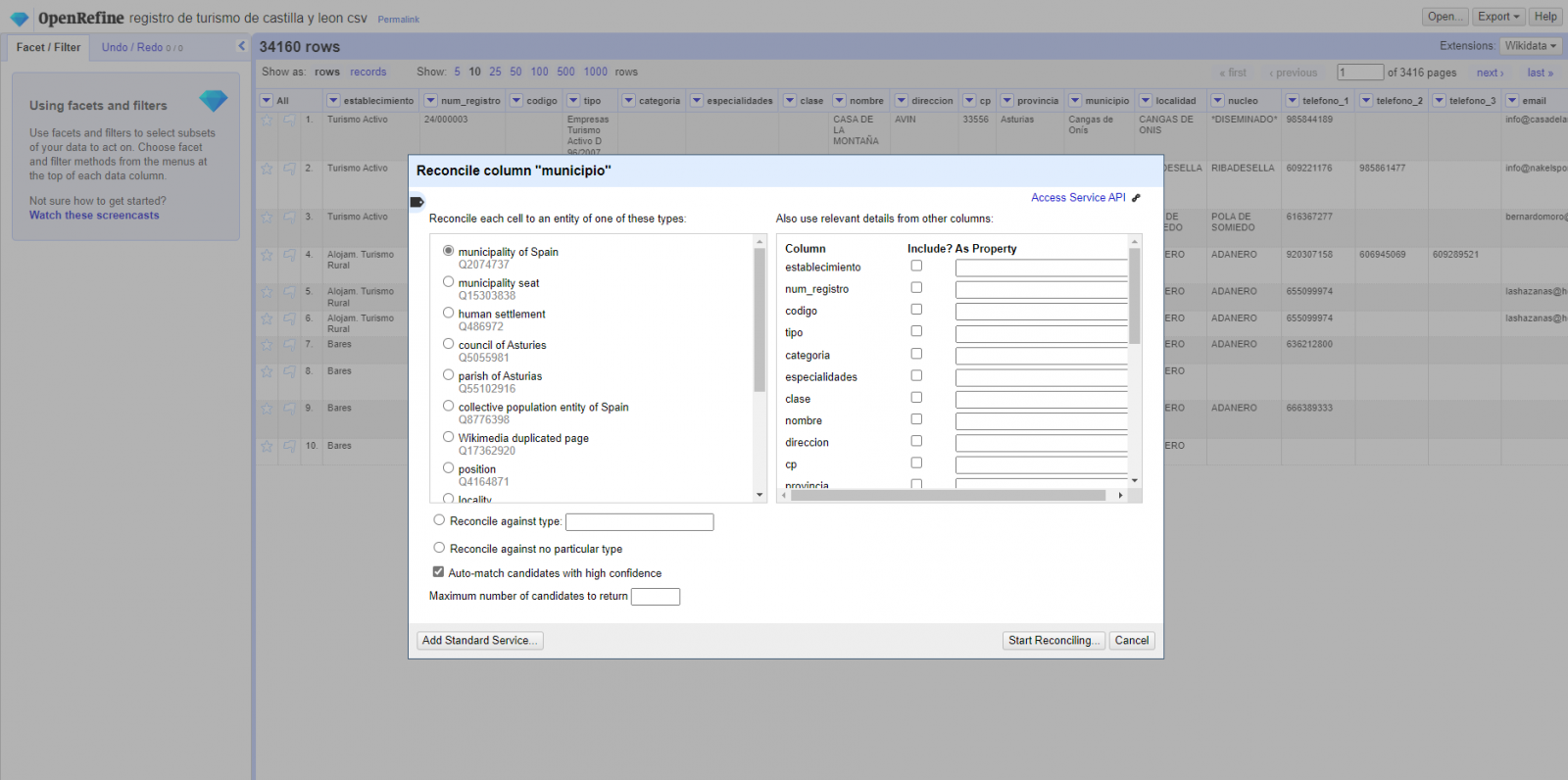
Figura 3. Selección de la clase que mejor representa los valores de la columna "municipio"
- Obtención de los valores de la reconciliación. OpenRefine nos ofrece la posibilidad de mejorar el proceso de reconciliación agregando algunas características que permitan orientar el enriquecimiento de la información con mayor precisión.
Paso 4
Generar una nueva columna con los valores reconciliados o enlazados. (Figura 4) Para ello debemos pulsar en la columna “municipio” e ir a “Edit Column → Add column based in this column”, dónde se mostrará un texto en la que tendremos que indicar el nombre de la nueva columna (en este ejemplo podría ser “wikidata”). En la caja de expresión deberemos indicar: “http://www.wikidata.org/entity/”+cell.recon.match.id y los valores aparecen como se previsualiza en la Figura. “http://www.wikidata.org/entity/” se trata de una cadena de texto fija para representar las entidades de Wikidata, mientras el valor reconciliado de cada uno de los valores lo obtenemos a través de la instrucción cell.recon.match.id, es decir, cell.recon.match.id(“Adanero”) = Q1404668
Mediante la operación anterior, se generará una nueva columna con dichos valores. Con el fin de comprobar que se ha realizado correctamente, haciendo clic en una de las celdas de la nueva columna, está debería conducir a una página web de Wikidata con información del valor reconciliado.
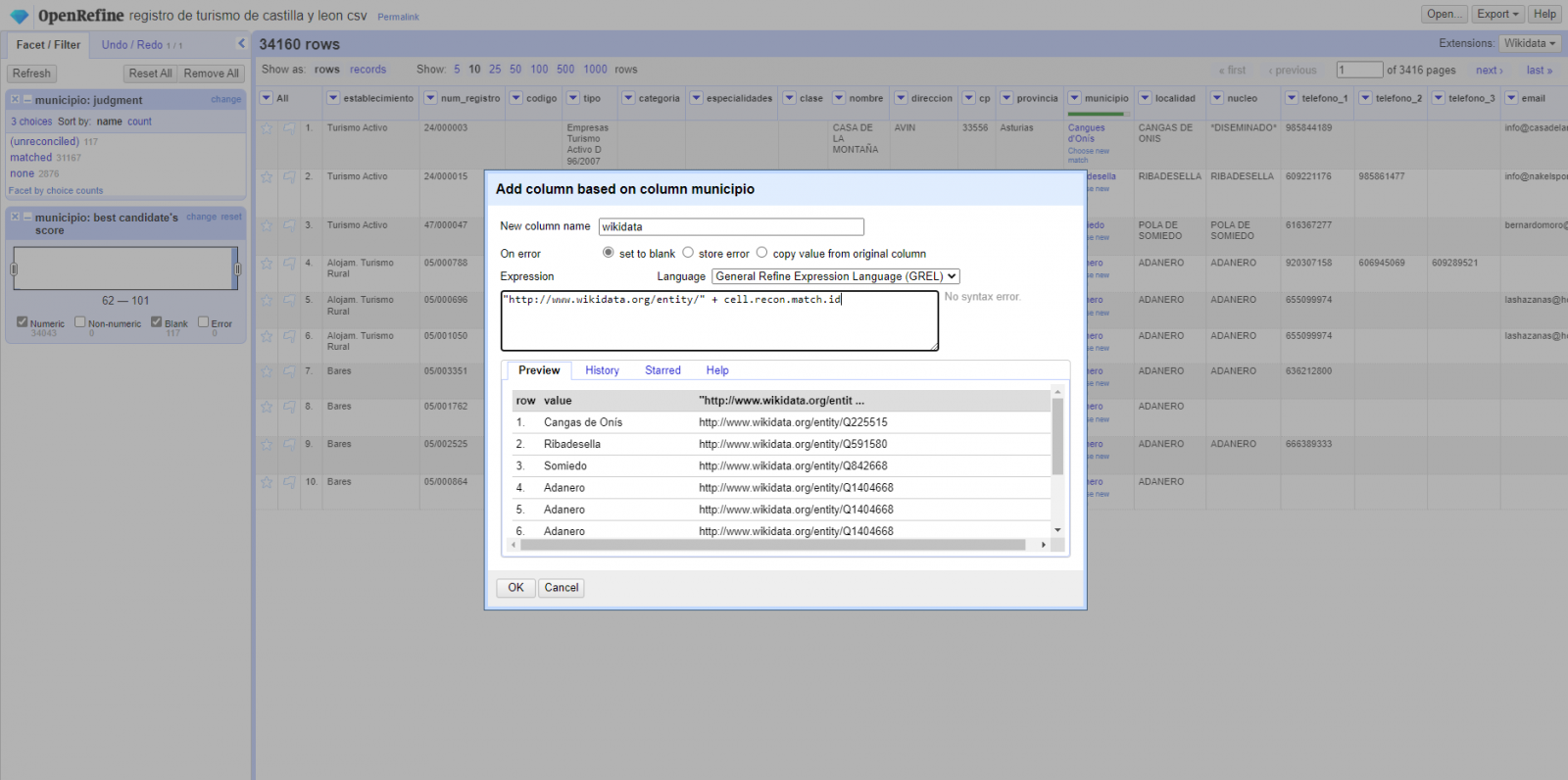
Figura 4. Generación de nueva columna con valores reconciliados
Paso 5
El proceso lo repetimos modificando en el paso 4 el “Edit Column → Add column based in this column” por “Add columns from reconciled values” (Figura 5). De esta forma, podremos elegir la propiedad de la columna reconciliada.
En este ejercicio hemos elegido la propiedad “image” con identificador P18 y la propiedad “population” con identificador P1082. No obstante, podríamos añadir todas las propiedades que consideremos útiles, como el número de habitantes, el listado de monumentos de interés, etc. Cabe destacar que al igual que enriquecemos los datos con Wikidata, podemos hacerlo con otros servicios de reconciliación.
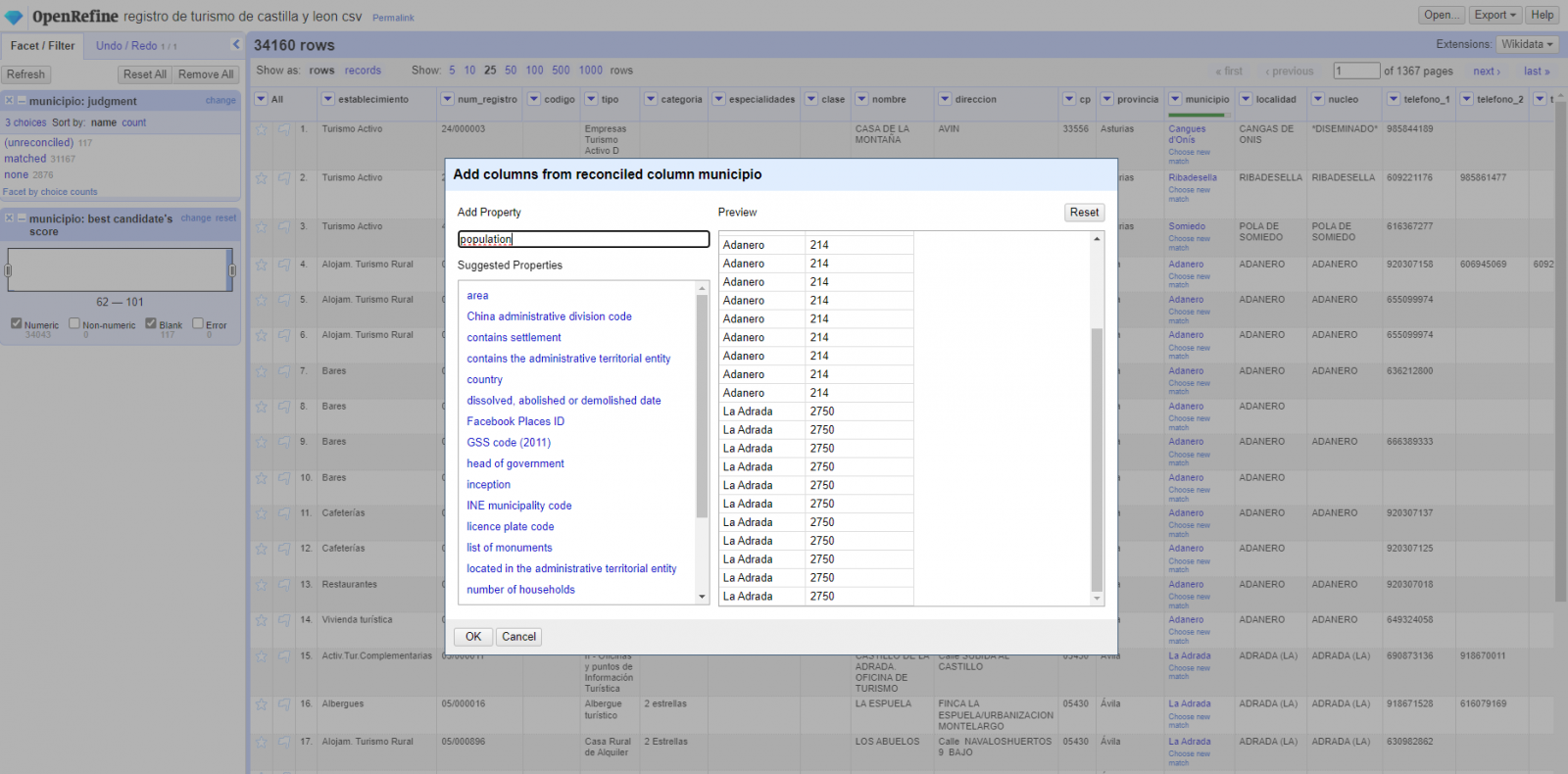
Figura 5. Elección propiedad para reconciliación
En el caso de la propiedad “image”, debido a la visualización, queremos que el valor de las celdas tenga forma de link, por lo que hemos realizado varios ajustes. Estos ajustes han sido la generación de varias columnas según los valores reconciliados, adecuación de las columnas mediante comandos en lenguaje GREL (lenguaje propio de OpenRefine) y unión de los diferentes valores de ambas columnas. Puedes consultar estos ajustes y más técnicas para mejorar tu manejo de OpenRefine y adaptarlo a tus necesidades en el siguiente User Manual.
6. Visualización del mapa
6.1 Generación del mapa con "Google My Maps"
Para generar el mapa personalizado mediante la herramienta My Maps, hemos seguidos los siguientes pasos:
- Iniciamos sesión con una cuenta Google y vamos a "Google My Maps", teniendo acceso de forma gratuita sin tener que descargar ningún tipo de software.
- Importamos las tablas de datos preprocesados, uno por cada nueva capa que añadimos al mapa. Google My Maps permite importar archivos CSV, XLSX, KML y GPX (Figura 6), los cuales deberán tener asociada información geográfica. Para realizar este paso, primero se debe crear una capa nueva desde el menú de opciones lateral.
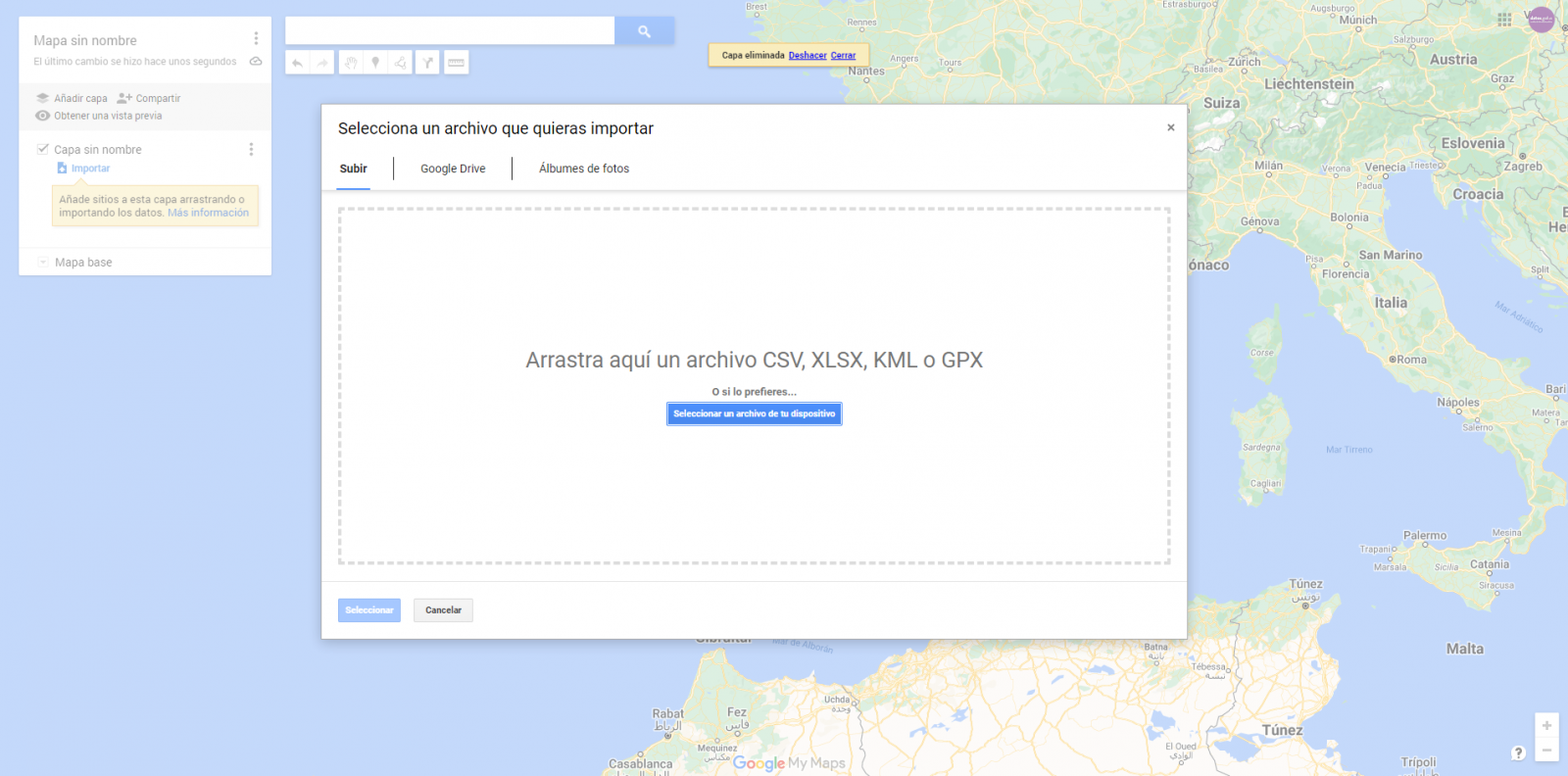
Figura 6. Importación de archivos en "Google My Maps"
- En este caso práctico, importaremos tablas de datos preprocesados que contienen una variable con la latitud y otra con la longitud. Esta información geográfica se reconocerá automáticamente. My Maps también reconoce direcciones, códigos postales, países, ...
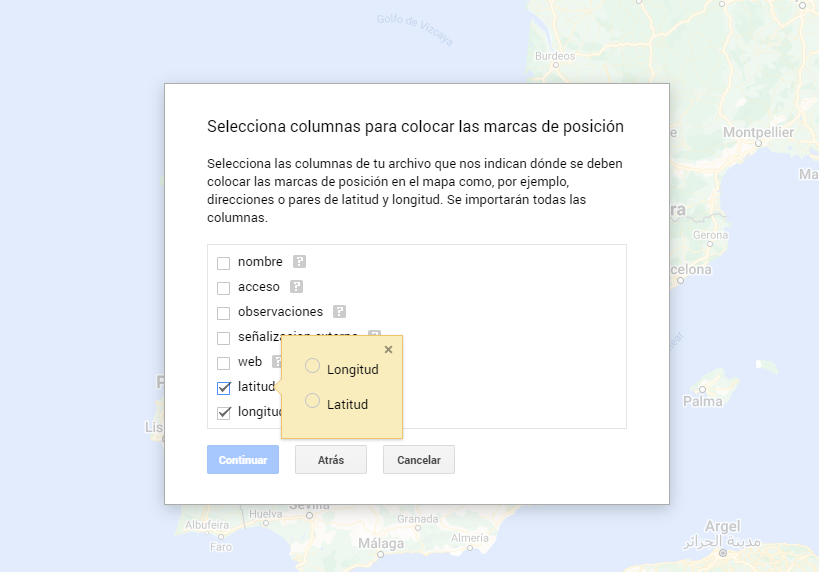
Figura 7. Selección columnas con valores de posición
- Mediante la opción de editar estilo que aparece en el menú lateral izquierdo, en cada una de las capas, podemos personalizar los pines, editando el color y su forma.

Figura 8. Edicción de pines de posición
- Por último, podemos elegir el mapa base que queremos visualizar en la parte inferior de la barra lateral de opciones.
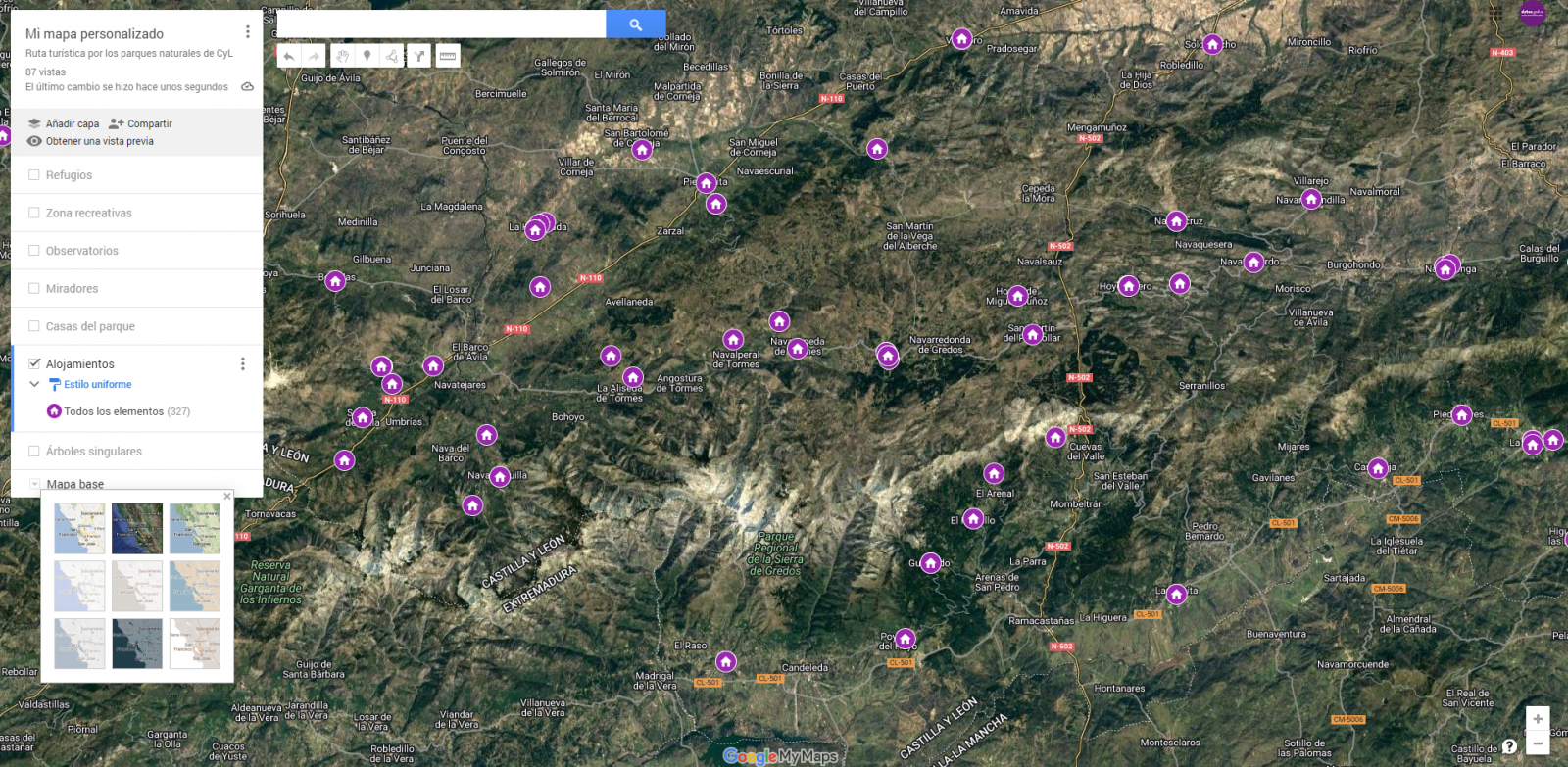
Figura 9. Selección de mapa base
Si quieres conocer más sobre los pasos para la generación de mapas con “Google My Maps”, consulta el siguiente tutorial paso a paso.
6.2 Personalización de la información a mostrar en el mapa
Durante el preprocesamiento de las tablas de datos, hemos realizado un filtrado de la información según el enfoque del ejercicio, que es la generación de un mapa para realizar rutas tusísticas por los espacios naturales de Castilla y León. A continuación, se describe la personalización de la información que hemos llevado a cabo para cada uno de los conjuntos de datos.
- En el conjunto de datos perteneciente a los árboles singulares de los espacios naturales, la información a mostrar para cada registro es el nombre, las observaciones, la señalización y la posición (latitud/longitud)
- En el conjunto de datos perteneciente a las casas del parque de los espacios naturales, la información a mostrar para cada registro es el nombre, las observaciones, la señalización, el acceso, la web y la posición (latitud/longitud)
- En el conjunto de datos perteneciente a los miradores de los espacios naturales, la información a mostrar para cada registro es el nombre, las observaciones, la señalización, el acceso y la posición (latitud/longitud)
- En el conjunto de datos perteneciente a los observatorios de los espacios naturales, la información a mostrar para cada registro es el nombre, las observaciones, la señalización y la posición (latitud/longitud)
- En el conjunto de datos perteneciente a los refugios de los espacios naturales, la información a mostrar para cada registro es el nombre, las observaciones, la señalización, el acceso y la posición (latitud/longitud). Dado que los refugios pueden encontrarse en estados muy diferentes y que algunos registros no ofrecen información en el campo “observaciones”, hemos decidido filtrar para que nos muestre solamente aquellos que tengan información en dicho campo.
- En el conjunto de datos perteneciente a las áreas recreativas de los espacios naturales, la información a mostrar para cada registro es el nombre, las observaciones, la señalización, el acceso y la posición (latitud/longitud). Hemos decidido filtrar para que nos muestre solamente aquellos que tengan información en los campos de “observaciones” y “acceso”.
- En el conjunto de datos perteneciente a los alojamientos, la información a mostrar para cada registro es el nombre, tipo de establecimiento, categoría, municipio, web, teléfono y la posición (latitud/longitud). Hemos filtrado el “tipo” de establecimiento para que nos muestre solamente los que están categorizados como alojamientos de turismo rural y hemos filtrado para que nos muestre los que son de 2 estrellas.
A continuación, tenemos la visualización del mapa personalizado que hemos creado. Seleccionando el icono para agrandar el mapa que aparece en la esquina superior derecha, podrás acceder su visualización en pantalla completa.
6.3 Funcionalidades sobre el mapa (capas, pines, rutas y vista inmersiva 3D)
En este punto, una vez creado el mapa personalizado, explicaremos diversas funcionalidades que nos ofrece "Google My Maps" durante la visualización de los datos.
-
Capas
Mediante el menú desplegable de la izquierda, podemos activar y desactivar las capas a mostrar según nuestras necesidades.
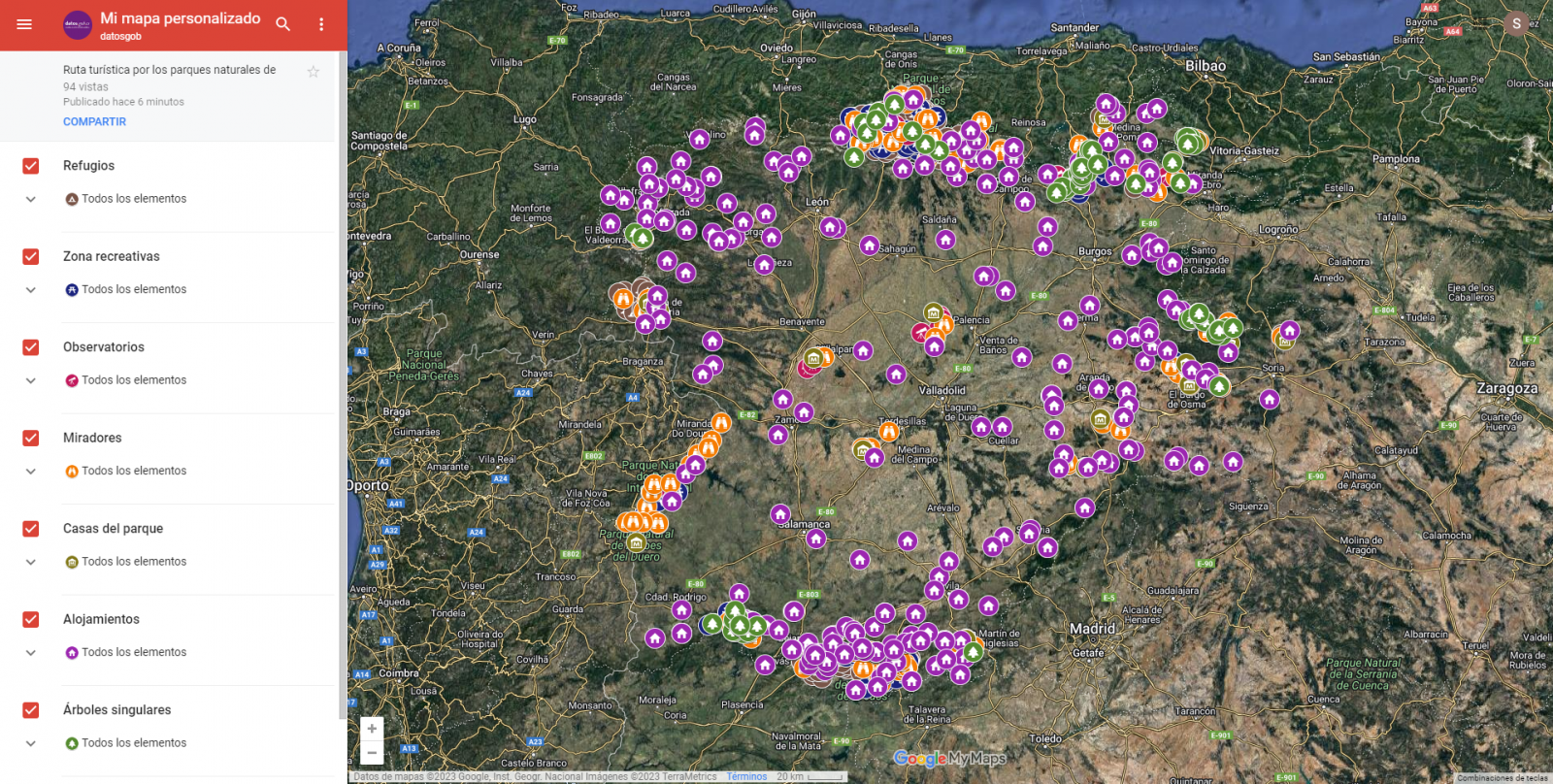
Figura 10. Capas en "My Maps"
-
Pines
Pinchando en cada uno de los pines del mapa podemos acceder a la información asociada a esa posición geográfica.
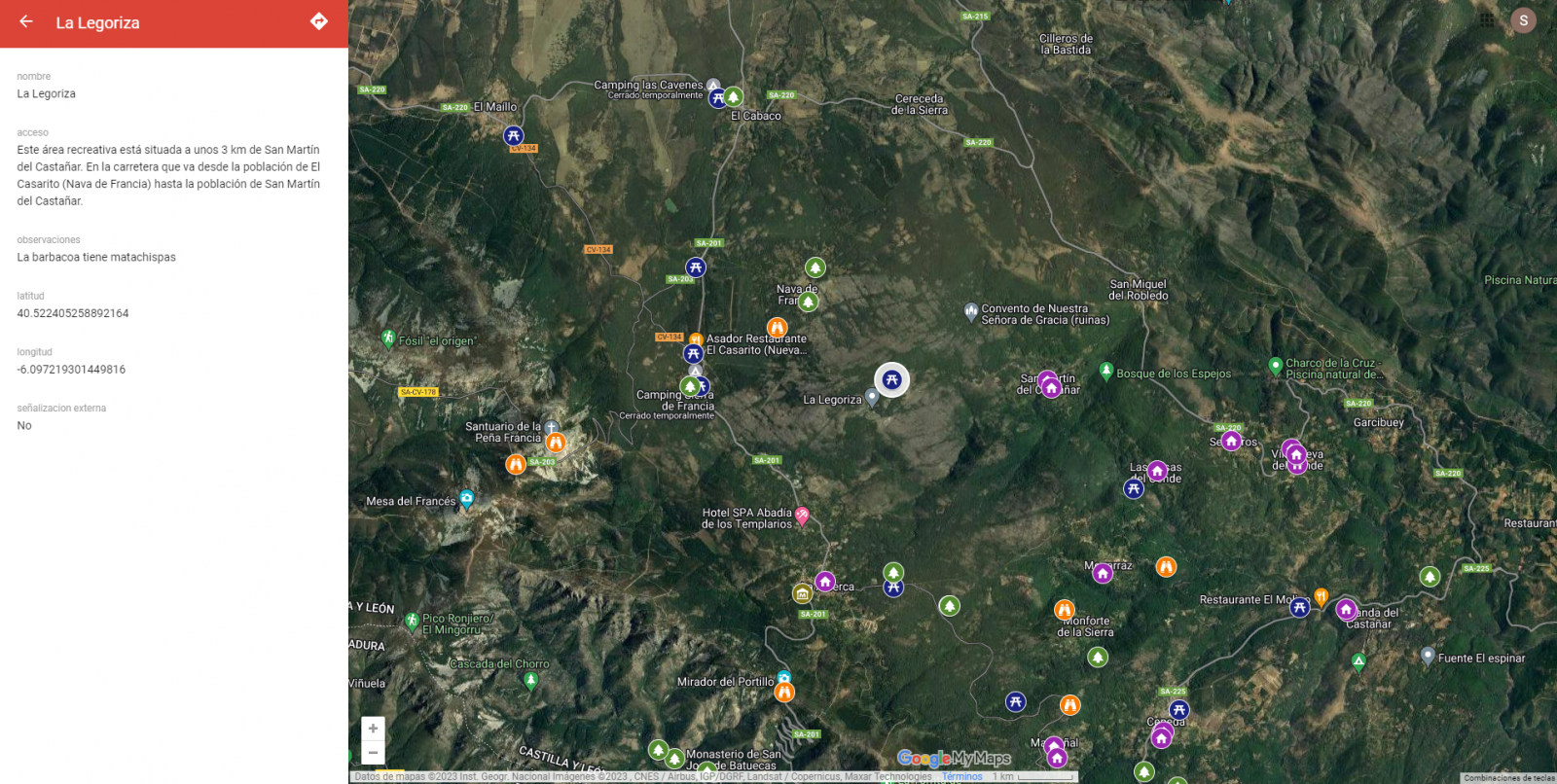
Figura 11. Pines en "My Maps"
-
Rutas
Podemos crear una copia del mapa sobre la que añadir nuestros recorridos personalizados.
En las opciones del menú lateral izquierdo, seleccionamos “copiar mapa”. Una vez copiado el mapa, mediante el símbolo de añadir indicaciones, situado debajo de la barra buscador, generaremos una nueva capa. A esta capa podremos indicarle dos o más puntos, junto al medio de transporte y nos creará el trazado junto a las indicaciones de trayecto.

Figura 12. Rutas en "My Maps"
-
Mapa inmersivo en 3D
Mediante el símbolo de opciones que aparece en el menú lateral, podemos acceder a Google Earth, desde donde podemos realizar una exploración del mapa inmersiva en 3D, destacando el poder observar la altitud de los distintos puntos de interés. También puedes acceder mediante el siguiente enlace.
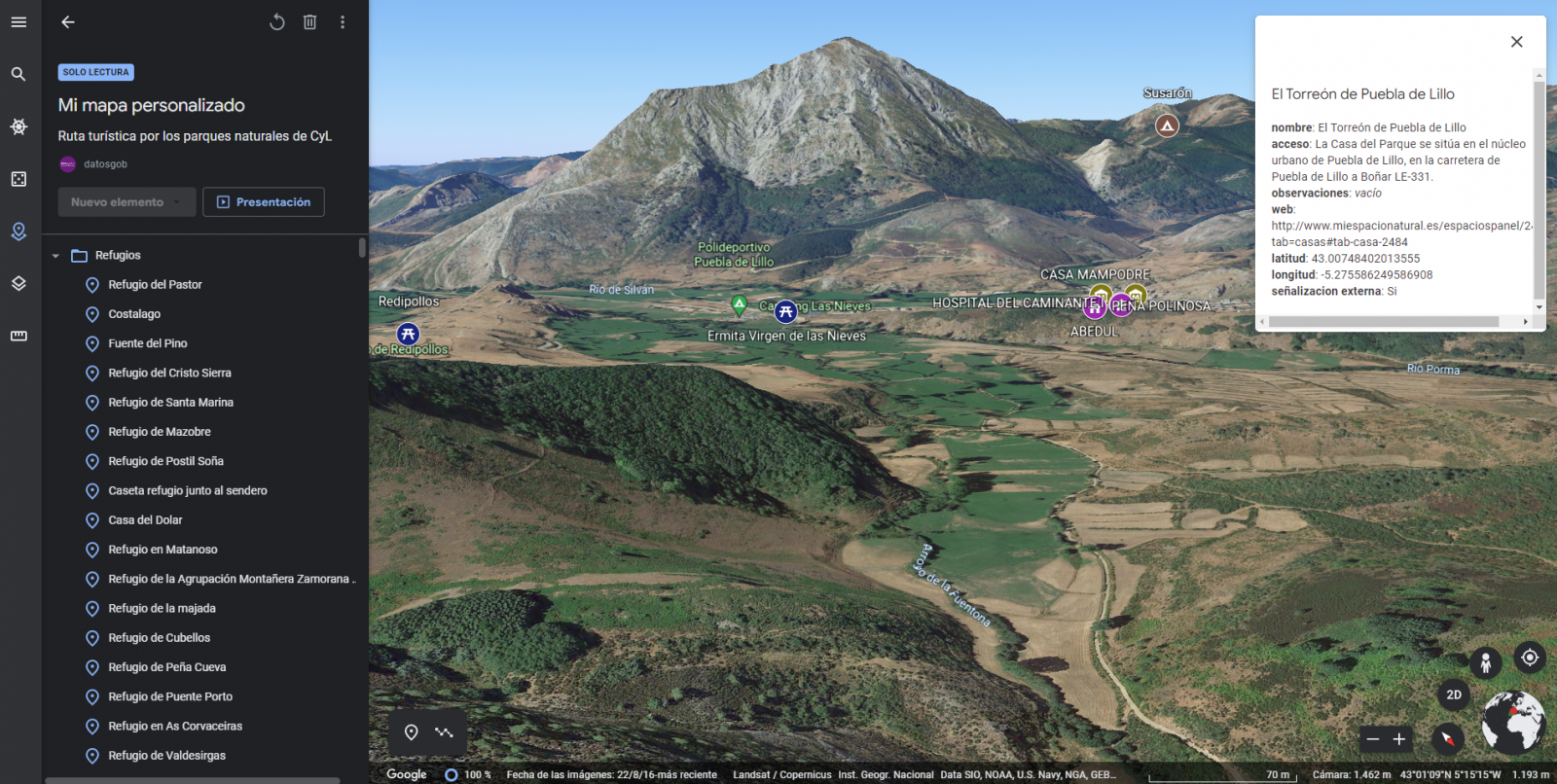
Figura 13. Vista inmersiva en 3D
7. Conclusiones del ejercicio
La visualización de datos es uno de los mecanismos más potentes para explotar y analizar el significado implícito de los datos. Cabe destacar la vital importancia que los datos geográficos tienen en el sector del turismo, lo cual hemos podido comprobar en este ejercicio.
Como resultado, hemos desarrollado un mapa interactivo con información aportada por los datos abiertos enriquecidos (Linked Data), la cual hemos personalizado según nuestros intereses.
Esperemos que esta visualización paso a paso te haya resultado útil para el aprendizaje de algunas técnicas muy habituales en el tratamiento y representación de datos abiertos. Volveremos para mostraros nuevas reutilizaciones. ¡Hasta pronto!