Noticia
Un síntoma que refleja la madurez de un ecosistema de datos abiertos es la posibilidad de encontrar conjuntos de datos y casos de uso relativos a diferentes sectores de actividad. Así lo considera el propio Portal de Datos Abiertos Europeo en su índice de madurez. La clasificación de los datos y de sus usos por categorías temáticas impulsa la reutilización, ya que permite a los usuarios localizar y acceder a estos de forma más específica. Además, permite detectar necesidades en áreas concretas, identificar sectores prioritarios y estimar más fácilmente el impacto.
En España encontramos distintos repositorios temáticos, como UniversiData, en el caso de la educación superior, o TURESPAÑA, para el sector turístico. Sin embargo, el hecho de que las competencias de determinadas materias estén distribuidas por las Comunidades Autónomas o Ayuntamientos complica la localización de datos de una misma temática.
Datos.gob.es reúne los datos abiertos de todos los organismos públicos españoles que hayan llevado a cabo un proceso de federación con el portal. Por ello en nuestro catálogo puedes encontrar conjuntos de datos de distintos publicadores segmentados por 22 categorías temáticas, las consideradas por la Norma Técnica de Interoperabilidad.

Número de conjuntos de datos por categoría a fecha de junio 2021
Pero además de mostrar los conjuntos de datos divididos por temática también es importante mostrar datasets destacados, casos de uso, guías y demás recursos de ayuda por sector, de tal forma que los usuarios puedan acceder más fácilmente a los contenidos relacionados con sus áreas de interés. Por ello, en datos.gob.es hemos puesto en marcha una serie de apartados web centrados en distintos sectores de actividad, con contenidos específicos para cada área.
4 sectoriales que se irán ampliando a otras áreas de interés
Actualmente en datos.gob.es puedes encontrar 4 sectoriales: Medio ambiente, Cultura y ocio, Educación y Transporte. Estos sectores se han destacado por diferentes motivos estratégicos:
- Medio ambiente: Los datos de medio ambiente son fundamentales para conocer cómo cambia nuestro entorno y poder así luchar contra el cambio climático, la contaminación y la deforestación. La propia Comisión Europea considera los datos de medio ambiente datos de alto valor en la Directiva 2019/1024. En datos.gob.es puedes localizar datos de calidad del aire, predicción meteorológica, escasez de agua, etc. Todos ellos fundamentales para impulsar soluciones que logren un mundo más sostenible.
- Transporte: En la Directiva 2019/1024 también se destaca la importancia de los datos de transporte. Muchas veces en tiempo real, estos datos facilitan la toma de decisiones encaminadas a la gestión eficiente del servicio y la mejora de la experiencia de los viajeros. Los datos de transporte son de los más utilizados para crear servicios y aplicaciones (por ejemplo, aquellas que informan del estado de tráfico, los horarios de los autobuses, etc.). A esta categoría pertenecen datasets como las incidencias de tráfico en tiempo real o los precios de los carburantes.
- Educación: Con la llegada de la COVID-19, muchos alumnos tuvieron que seguir sus estudios desde sus hogares, a través de soluciones digitales que no siempre estaban preparadas. En los últimos meses, a través de iniciativas como el Desafío Aporta, se ha hecho un esfuerzo para impulsar la creación de soluciones que incorporen datos abiertos con el fin de mejorar la eficiencia del ámbito educativo, impulsar mejoras -como la personalización de la educación- y lograr un acceso más universal al conocimiento. Algunos de los datasets de educación que podemos encontrar en el catálogo son las titulaciones impartidas por las universidades españolas, o encuestas sobre el gasto de los hogares en educación.
- Cultura y ocio: Los datos de cultura y ocio son una categoría de gran importancia a la hora de reutilizarse para desarrollar, por ejemplo, contenidos educativos y de aprendizaje. Los datos culturales pueden ayudar a generar nuevo conocimiento que nos ayude a conocer nuestro pasado, presente y futuro. Algunos ejemplos de conjuntos de datos son la ubicación de monumentos o los listados de obras de arte.
Estructura de cada sector
Cada página de sector cuenta con una estructura homogénea, que facilita la localización de contenidos disponibles igualmente en otras secciones.
Empieza con un destacado donde se aprecian algunos ejemplos de conjuntos de datos destacados pertenecientes a esta categoría, y un enlace para acceder a todos los datasets de esta temática en el catálogo.
Continua con noticias relacionadas con los datos y el sector en cuestión, que pueden abarcar desde eventos o información sobre iniciativas concretas (como Procomún en el ámbito de los datos educativos o el Pacto Verde en medio ambiente) hasta las últimas novedades a nivel estratégico y operativo.
Por último, encontramos tres secciones relacionadas con los casos de uso: innovación, empresas reutilizadoras y aplicaciones. En la primera se cuenta, a través de artículos, ejemplos de usos novedosos, muchas veces ligados a tecnologías disruptivas como la Inteligencia Artificial. En las dos últimas, hallamos fichas concretas de empresas y aplicaciones que utilizan datos abiertos de dicha categoría para generar un beneficio para la sociedad o la economía.
Sección de destacados en la home
Además de la creación de páginas sectoriales, en el último año, datos.gob.es también ha incorporado una sección de datasets destacados. El objetivo es dar una mayor visibilidad a aquellos conjuntos de datos que cumplen una serie de características: han sido los últimos en actualizarse, se encuentran en formato CSV o se puede acceder a ellos vía API o servicios web.

¿Qué otros sectoriales te gustaría destacar?
En los planes de datos.gob.es está el continuar aumentado el número de sectores a destacar. Por ello, te invitamos a dejar en comentarios cualquier propuesta que consideres adecuada.
Noticia
2020 llega a su fin y en este año tan atípico nos va a tocar vivir unas Navidades diferentes, más tranquilas y con nuestro núcleo más cercano. ¿Qué mejor para disfrutar de esos momentos de calma que formarte y mejorar tus conocimientos sobre datos y nuevas tecnologías?
Tanto si estás buscando una lectura que te haga mejorar tu perfil profesional a la que dedicar tu tiempo libre en estas fechas tan especiales, como si quieres ofrecer a tus seres más queridos un regalo didáctico e interesante, desde datos.gob.es queremos proponerte algunas recomendaciones de libros sobre datos y tecnologías disruptivas que esperamos sean de tu interés. Hemos seleccionado libros en castellano e inglés, para que también puedas poner en práctica tu conocimiento de este idioma.
¡Toma nota porque todavía estás a tiempo de incluir alguno en tu carta a los Reyes Magos!
INTELIGENCIA ARTIFICIAL, naturalmente. Nuria Oliver, ONTSI, red.es (2020)
¿De qué trata?: Este libro es el primero de la nueva colección que publica el ONTSI llamada “Pensamiento para la sociedad digital”. Sus páginas ofrecen un breve recorrido por la historia de la inteligencia artificial, describiendo su impacto en la actualidad y abordando los retos que presenta desde diversos puntos de vista.
¿A quién va dirigido?: Esta dirigido especialmente a tomadores de decisiones, profesionales del sector público y privado, profesores y estudiantes universitarios, organizaciones del tercer sector, investigadores y medios de comunicación, pero también es una buena opción para lectores que quieran introducirse y acercarse al complejo mundo de la inteligencia artificial.
Artificial Intelligence: A Modern Approach, Stuart Russell
¿De qué trata?: Interesante manual que introduce al lector en el campo de la Inteligencia Artificial a través de una estructura ordenada y una redacción comprensible.
¿A quién va dirigido?: Este libro de texto es una buena opción para utilizar como documentación y referencia en diferentes cursos y estudios en Inteligencia Artificial a diferentes niveles. Para aquellos que quieran convertirse en expertos en la materia.
Situating Open Data: Global Trends in Local Contexts, Danny Lämmerhirt, Ana Brandusescu, Natalia Domagala – African Minds (Octubre 2020)
¿De qué trata?: Este libro proporciona varios relatos empíricos sobre las prácticas de datos abiertos, la implementación local de iniciativas globales y el desarrollo de nuevos ecosistemas de open data.
¿A quién va dirigido?: Será de gran interés para los investigadores y defensores de los datos abiertos y para quienes están en las administraciones gubernamentales o las asesoran en el diseño y la implementación de iniciativas efectivas de open data. Puedes descargar su versión en PDF a través de este enlace.
The Elements of Statistical Learning: Data Mining, Inference, and Prediction, Second Edition (Springer Series in Statistics), Trevor Hustle, Jerome Friedman. – Springer (Mayo 2017)
¿De qué trata?: Este libro describe diversos conceptos estadísticos en una variedad de campos como la medicina, la biología, las finanzas y el marketing en un marco conceptual común. Si bien el enfoque es estadístico, el énfasis está en las definiciones más que en las matemáticas.
¿A quién va dirigido?: Es un recurso valioso para los estadísticos y cualquier persona interesada en la minería de datos en la ciencia o la industria. También puedes descargar su versión digital aquí.
Europa frente a EEUU y China: Prevenir el declive en la era de la inteligencia artificial, Luis Moreno, Andrés Pedreño – Kdp (2020)
¿De qué trata?: Este interesante libro aborda los motivos del retraso europeo respecto a la potencia que sí tienen EEUU y China, y sus consecuencias, pero sobre todo propone soluciones a la problemática que se expone en la obra.
¿A quién va dirigido?: Se trata de una reflexión para aquellos interesados en pensar acerca del cambio que Europa necesitaría, en palabras de su autor, “alejada cada vez más de la revolución que impone el nuevo paradigma tecnológico”.
¿De qué trata?: Este libro hace una llamada de atención acerca de la problemática que puede desencadenar el mal uso de los algoritmos y propone algunas ideas para no caer en errores.
¿A quién va dirigido?: En estas páginas no aparecen conceptos demasiado técnicos, ni hay fórmulas ni explicaciones complejas, aunque sí se tratan problemas densos que necesitan la atención del autor.
Data Feminism (Strong Ideas), Catherine D’Ignazio, Lauren F. Klein. MIT Press (2020)
¿De qué trata?: Estas páginas abordan una nueva forma de pensar sobre la ciencia de datos y su ética basada en las ideas del pensamiento feminista.
¿A quién va dirigido?: A todos/as aquellos/as que tienen interés en reflexionar sobre los sesgos integrados en los algoritmos de las herramientas digitales que utilizamos en todos los ámbitos de la vida.
Open Cities | Open Data: Collaborative Cities in the Information, Scott Hawken, Hoon Han, Chris Pettit – Palgrave Macmillan, Singapore (2020)
¿De qué trata?: Este libro explica la importancia de abrir los datos en las ciudades a través de una variedad de perspectivas críticas, y presenta estrategias, herramientas y casos de uso que facilitan tanto dicha apertura como su reutilización.
¿A quién va dirigido?: Perfecto para aquellos integrados en la cadena de valor del dato en las ciudades y quienes tienen que elaborar estrategias de open data en el marco de una ciudad inteligente, pero también para los ciudadanos preocupados por la privacidad y que quieran saber qué sucede -y qué puede suceder- con los datos que generan las ciudades.
Aunque nos encantaría incluirlos a todos en esta lista, son muchos los libros interesantes sobre datos y tecnología que llenan las estanterías de cientos de librerías y tiendas online. Si tienes alguna recomendación extra que nos quieres hacer, no dudes en dejarnos tu título favorito en comentarios. Los miembros que formamos el equipo de datos.gob.es estaremos encantados de leer vuestras recomendaciones esta Navidad.
Noticia
En los últimos meses en los que hemos pasado tanto tiempo en casa, nos hemos dado cuenta de la importancia de la cultura. La música, el cine, la lectura o la pintura han hecho mucho más llevaderas esas horas que pasábamos en nuestro hogar.
Las instituciones culturales poseen mucha información de valor. Esta información incluye las colecciones que administran las instituciones culturales, es decir, las obras que han compartido de forma digital y gratuita los museos o las bibliotecas. Pero también incluye el conocimiento disponible sobre dichas colecciones. Todo este material, si se comparte en abierto, puede reutilizarse para desarrollar, por ejemplo, contenidos educativos y de aprendizaje, documentales o animaciones.
¿Qué tipos de datos culturales puedo encontrar en datos.gob.es?
En datos.gob.es disponemos de un amplio catálogo de datos culturales. Actualmente hay 2.300 conjuntos de datos que se han agrupado bajo una categoría denominada “cultura y ocio”. Ente esos conjuntos de datos encontramos información estatal, regional y local. Los publicadores que más datos de este tipo comparten son la Comunidad Autónoma de País Vasco, el Centro de Investigaciones Sociológicas, el Instituto Nacional de Estadística y la Biblioteca Nacional de España.
De esos conjuntos de datos, algunos de los más populares son:
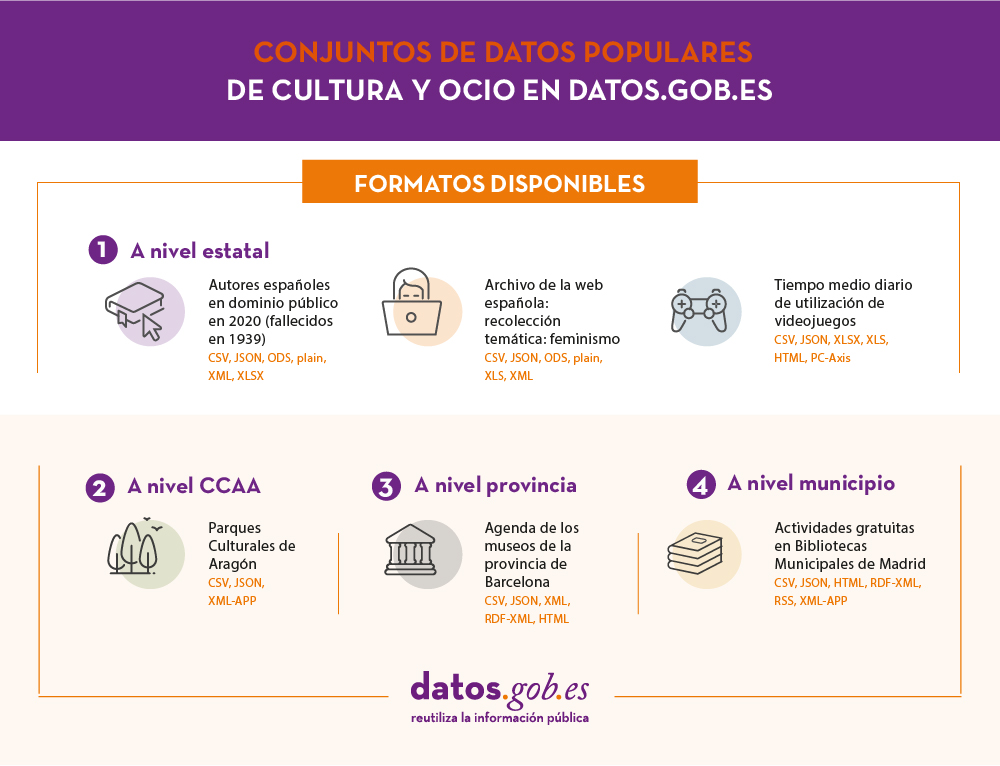
Puedes acceder a estos conjuntos de datos a traves de los siguientes enlaces:
- Autores españoles en dominio público
- Archivo de la web española: recolección temática: feminismo
- Parques Culturales de Aragón
- Agenda de los museos de la provincia de Barcelona
- Actividades gratuitas en Bibliotecas Municipales de Madrid
Como vemos, la mayoría de estos conjuntos de datos tienen que ver con el ámbito literario, uno de los más prolíferos y avanzados a la hora de abrir sus datos. Sin embargo, en el catálogo también podemos encontrar datos relacionados con el ámbito pictórico, cinematográfico o musical.
Una ventaja de los conjuntos de datos culturales es su carácter transversal. Por ejemplo, conjuntos de datos como la recolección temática sobre feminismo o los relativos a la inmigración nos proporcionan información sobre nuestra sociedad, algo importante para comprender cómo éramos y somos.
Desde datos.gob.es te invitamos a visitar nuestro catálogo de datos y bucear entre todos los conjuntos de datos.
Blog
¿Sabías que el patrimonio digital abierto es fundamental a la hora de comprender el mundo que nos rodea, impulsar una economía más creativa y cumplir con los objetivos educativos acordados? Se calcula que alrededor del 90% del patrimonio cultural mundial todavía no ha sido digitalizado. Del 10% restante que sí ha sido digitalizado, tan solo el 34% está disponible de forma online mientras que apenas el 3% de ese trabajo se encuentra abierto.
La mayoría de instituciones culturales cuentan con una gran cantidad de información de alto valor. Esta información se suele encontrar principalmente en forma de colecciones, pero también en las fichas de autores, fechas, técnica utilizada, etc. Tanto las obras como su información son susceptible de convertirse en datos abiertos.
Algunos ejemplos de museos que sí han digitalizado y abierto su colección son The Rijksmuseum (Países Bajos), el Statens Museum for Kunst (Dinamarca) o el Metropolitan Museum (Estados Unidos).
¿Qué nuevos productos se pueden crear reutilizando datos culturales?
Las nuevas tecnologías nos ofrecen un sinfín de posibilidades a la hora de crear nuevos productos a través de la reutilización de los datos culturales. Es el caso de las nuevas plataformas educativas como BNEscolar, que permiten el aprendizaje del arte desde un punto de vista diferente. Los datos abiertos culturales sirven incluso para generar juegos de scaperoom o nuevas piezas de arte. También se pueden utilizar como herramientas de diseño o para complementar películas y documentales.
En definitiva, se puede establecer que los datos culturales están dotados de un gran valor que, a través de una mayor apertura, podrían suponer grandes beneficios para la creación de nuevas iniciativas que aporten beneficios para toda la sociedad.

Aplicación
Durante el juego de escape “Cuadros de una exposición” tendremos que conseguir las pistas suficientes que nos ayuden a escapar de la exposición. Para ello habrá que aunar conocimientos sobre música, arte y una dosis suficiente de ingenio para encontrar la palabra mágica que nos permita salir. Podemos resumir los objetivos generales de este juego en dos:
- Conocer la historia y la obra “Cuadros de una exposición” de M. Mussorgsky.
- Descubrir el concepto de música programática y ejemplos a partir de objetos de la BDH.
Pon a prueba tu ingenio para superar los diferentes retos propuestos en este juego, y descubrir el código secreto que te permitirá escapar de la Academia de las Artes de San Petesburgo. ¿Estás preparado?
Aplicación
Visit Valencia es una aplicación móvil desarrollada por el Ayuntamiento de Valencia. Gracias a ella los turistas pueden conocer qué ver y qué hacer en la ciudad.
Entre sus funcionalidades destacan:
- Una guía completa de la ciudad con los monumentos, museos, oficinas de turismo y lugares de interés por zonas. También da la posibilidad de acceder a un plano turístico interactivo.
- Permite descargar guías y planos de Valencia, el metro, el autobús y el tranvía.
- Permite valorar los lugares que se visitan y compartir opiniones.
- Facilita la compra online de entradas con descuento, así como el acceso a la Valencia Tourist card, que permite viajar gratis en el transporte público y entrar gratis o con descuento a museos y monumentos.
- Ofrece rutas por la ciudad y toda la información sobre la agenda de eventos, incluyendo un buscador para filtrar por fechas.
- Permite localizar los restaurantes más cercanos y hacer una reserva de manera inmediata.
- Incluye información sobre la predicción meteorológica.
Blog
¿Se puede considerar que una obra de arte es un dato? Al hablar de datos abiertos, solemos pensar en datos estadísticos, meteorológicos, geoespaciales… pero no en una pintura, una canción o un libro. Recursos también susceptibles de convertirse en datos abiertos.
Cuando hablamos de datos abiertos culturales hacemos referencia a publicaciones, fotografías o colecciones musicales creadas y distribuidas por instituciones pertenecientes al sector cultural. No se trata simplemente de digitalizar los fondos, sino de enriquecerlos con metadatos que aporten la máxima información posible (autor, fecha, técnica, etc.) y facilitar el acceso en unas condiciones que favorezcan su reutilización.
En este sentido, las bibliotecas parecen haber tomado la delantera en la apertura de información. Tenemos el ejemplo de la Biblioteca Nacional de España, que puso en marcha el portal de datos abiertos datos.bne.es y ha lanzado distintos proyectos basados en la reutilización de sus datos, como BNEscolar. Otro ejemplo es la Fundación Biblioteca Virtual Miguel de Cervantes, cuyo catálogo está compuesto por más de 230.000 registros abiertos a la reutilización.
Los museos, por su parte, están abrazando más lentamente el compromiso con el open data, aunque cada vez hay más instituciones que apuestan por compartir sus colecciones de manera abierta.
Dos ejemplos de grandes museos que han abierto sus colecciones
El 7 de febrero de 2017, el Museo Metropolitano de Nueva York implementó una nueva política de datos abiertos. El museo crea, organiza y difunde una amplia gama de imágenes y datos digitales que documentan la historia del museo y su colección -formada por más de dos millones de obras de arte que van desde la antigua Grecia hasta los grandes maestros europeos como Rafael, Rembrandt o Velázquez-. Con esta política, las imágenes de obras de arte seleccionadas que están en el dominio público -y por tanto carecen de derechos de autor- se han puesto a disposición de los usuarios sin restricciones ni coste, de acuerdo con la designación Creative Commons Zero (CC0).
La web del museo cuenta con un buscador, donde se muestran las distintas piezas de la colección. El usuario puede separar aquellas que están bajo la licencia CC0, gracias a una herramienta de filtrado. En total son 406.000 imágenes de alta resolución, acompañadas de información básica como título, artista, fecha, medio y dimensiones.
Otro ejemplo es el Museo Nacional de Ámsterdam o Rijksmuseum, dedicado al arte, la artesanía y la historia de esta región, y que posee una gran colección de pinturas del Siglo de Oro neerlandés. El Rijksmuseum cuenta con un espacio de datos abiertos donde se recogen reproducciones digitales y datos asociados, que son puestos a disposición del público de manera gratuita para todo tipo de fines, también comerciales. Cuando las obras están libres de derechos de autor, se indica explícitamente en los metadatos descriptivos correspondientes. En estos casos, el aviso de derechos de autor establece "Dominio público", con una referencia a la licencia Creative Commons Zero (CC0).


Paginas web del Museo Metropolitano de Nueva York y del Rijksmuseum
¿Por qué los museos deberían abrir sus colecciones?
En esta entrevista a los responsables del Museo de Bretaña, pionero en la apertura de datos entre los museos franceses, los entrevistados destacan cómo gracias a la apertura de su colección han conseguido una mayor visibilidad. “La apertura de datos le aporta al museo una imagen positiva e innovadora dentro del sector cultural francés. También genera nuevos conocimientos sobre las colecciones, gracias a los comentarios de los visitantes online”. Este museo cuenta con una colección de 700.000 piezas, de las cuales más de 200,000 son ahora visibles y reutilizables online, entre ellas imágenes de dominio público de alta resolución gratuitas para descargar y usar.
En la misma línea argumental se desarrolla este estudio, donde se analiza el impacto de las pinturas y sus metadatos incluidos en wikidata y la Wikipedia en inglés. El estudio muestra cómo las pinturas incluidas en Wikipedia no se utilizan únicamente para ilustrar contenidos relacionados con el arte, sino también para enriquecer otro tipo de entradas sobre temáticas diversas, como la historia (por ejemplo, los cuadros de reyes que nos muestran el aspecto que tenían) o conceptos básicos (mostrar cómo es una sirena a través de una representación pictórica de la misma). Estas pinturas ayudan a complementar la información textual al mismo tiempo que atraen la atención de los usuarios sobre las colecciones del museo, impulsando un aumento en las vistas.
Un campo lleno de retos, pero también de oportunidades
Abrir las obras de los museos conlleva una serie de retos, como la necesidad de realizar una evaluación legal para conocer quiénes son los titulares de derechos y los contratos vigentes, de tal forma que siempre se respete los derechos de autor, o los retos técnicos que conlleva. Se necesita una infraestructura tecnológica, así como recursos para catalogar correctamente todas las obras con sus metadatos correspondientes (puedes conocer la experiencia del Museo del Prado en esta entrevista).
Pero, por otro lado, si se superan estos retos el museo ganará múltiples beneficios, empezando por el aumento de la visibilidad y de las posibilidades de su reutilización para crear productos y servicios de valor.
Blog
La apertura de los datos relacionados con la labor académica y de investigación conlleva múltiples ventajas, como la mejora de la transparencia, las posibilidades de replicar los estudios para chequear su validez o una mayor visibilidad e impacto que impulsan el reconocimiento del investigador. En este sentido, la Ley 14/2011, de 1 de junio, de la Ciencia, la Tecnología y la Innovación resalta la necesidad de impulsar el acceso abierto a los contenidos de investigación, incluyendo la obligatoriedad cuando la investigación haya sido financiada con fondos públicos estatales.
Esta situación genera una serie de retos para los investigadores de ámbitos como las humanidades, que muchas veces carecen de los conocimientos técnicos y los recursos necesarios para publicar sus trabajos en formatos accesibles, abiertos, gratuitos y actualizados. Por ello, muchas veces recurren a la contratación de colaboradores técnicos ajenos a la investigación.
Con el objetivo de dar una solución a esta situación surgió LINHD, un centro de investigación en Humanidades Digitales puesto en marcha desde la Universidad Nacional de Educación a Distancia (UNED). LINHD -cuyas siglas significan Laboratorio de Innovación en Humanidades Digitales- busca crear un nuevo marco de trabajo, donde se creen equipos de trabajo interdisciplinares e híbridos, con expertos en áreas técnicas y de humanidades que colaboren para fomentar la innovación y el intercambio de ideas. También ofrece formación, y servicios de asesoría, consultoría y tecnológicos.
LINHD constituye uno de los elementos clave del diálogo en las Humanidades Digitales y un centro pionero en España dentro de este ámbito. Y lo es porque se ocupa de materias fundamentales para el desarrollo de las nuevas tecnologías, competitividad y productividad de las humanidades.
El laboratorio surgió de una iniciativa que pretendía conectar digitalmente los datos de investigación de la propia universidad, para poder darles transparencia y visualizarlos mediante la tecnología de datos enlazados (proyecto UNEDATA), pero pronto creció acogiendo y desarrollando múltiples proyectos y servicios, con instituciones entre las que destacan el Instituto Goethe en Alemania, el Museo Thyssen o la Biblioteca Nacional, y convirtiéndose en el primer centro de investigación de humanidades digitales en el ámbito hispánico de referencia internacional y único de sus características.
A través de esta filosofía se promueven proyectos de tecnología aplicadas a las humanidades, con especial incidencia en campos como el arte, la filosofía, la historia, la geografía o la educación. Así han surgido proyectos que van desde ediciones digitales o visualizaciones de resultados hasta museos y bibliotecas virtuales.
Además, el laboratorio ha sido reconocido como Clarin-K center junto con dos centros de la UPF y la UPV, constituyendo el primer “Knowledge Center” de una ERIC-European Research Infrastructure Consortium en España.
LINHD también colabora con la Infraestructura de Investigación Digital en Artes y Humanidades DARIAH, que busca mejorar y desarrollar la investigación digital de humanidades en Europa.
Uno de sus principales proyectos es Postdata ERC Starting Grant, una plataforma digital desarrollada en el marco del programa Horizonte 2020 y dirigida por la investigadora Elena González Blanco, que permite comparar tradiciones poéticas utilizando tecnologías de la semántica web. Está dirigida tanto a académicos como a usuarios no experimentados en la temática u empresas que quieran reutilizar estos recursos para crear aplicaciones con fines culturales, educativos, turísticos, etc. Puedes ver más proyectos aquí.
LINHD es un foco de atracción de talento internacional para la investigación puntera en tecnología y humanidades digitales. Está abierto a nuevos investigadores que quieran compartir ideas y proyectos, difundirlos o buscar colaboradores. Las personas interesadas tienen que escribir a info_participar@linhd.uned.es, incluyendo los datos de contacto y una descripción del proyecto.
Noticia
Cada 1 de enero nuevos escritores, pintores, músicos y artistas de todas las áreas entran a engrosar la lista de autores en dominio público. Esto significa que sus obras artísticas podrán ser editadas, reproducidas o difundidas públicamente, sin las restricciones establecidas por los derechos de autor.
En España, las obras artísticas pasan a dominio público una vez transcurridos 70 años de la muerte de su autor, de acuerdo con la ley de propiedad intelectual de 1987. No obstante, para los autores fallecidos antes de dicho año, el plazo será de 80 años. Por tanto, este año entran en dominio público las obras de aquellos autores fallecidos en 1939.
La BNE y el patrimonio intelectual de libre acceso
Cada año, la Biblioteca Nacional de España estudia, publica y digitaliza la obra de autores que forman parte de su catálogo y que ese año pasan a dominio público. Este año la lista está formada por 181 autores, entre los que se encuentran Antonio Machado, Ciro Bayo o Agustín Espinosa. Las obras de estos autores están disponibles en la Biblioteca Digital Hispánica, el portal que da acceso a los fondos digitalizados de la BNE.
La lista de autores en dominio público es abierta y colaborativa, por lo que cualquier persona interesada puede colaborar en su elaboración proponiendo autores españoles con obras en el catálogo de la Biblioteca Nacional de España, fallecidos entre 1900 y 1939, y que todavía no estén incluidos en los listados.
Además, con el objetivo de enriquecer la información, la BNE ha puesto en marcha un proyecto colaborativo titulado Del dominio público: autores españoles fallecidos en 1939, dentro de su plataforma comunidad.bne.es, desarrollada junto a Red.es. Los usuarios que deseen compartir su conocimiento y experiencia podrán ayudar a ampliar los datos que la BNE tiene sobre estos autores, añadiendo información como el lugar y año de nacimiento, la ocupación y/o la reseña biográfica del autor. Este proyecto se une a otros como La mujer del XIX [escrito en femenino], donde se rescatan distintos artículos autoras de prestigio como Blanca de los Ríos, Pardo Bazán o Patrocinio Biedma, integrados en la obra Las mujeres españolas, americanas y lusitanas pintadas por sí mismas, para que los usuarios puedan clasificar los estereotipos presentados, catalogar las ilustraciones que acompañan a muchos de los textos y completar datos sobre sus autoras.
Con la información disponible, la BNE ha creado ficheros completos, que se han publicado como conjuntos de datos abiertos y reutilizables, en diferentes formatos, en el catálogo de datos.gob.es.
Esta acción se enmarca dentro de la estrategia de la BNE para la apertura e impulso de la reutilización de sus datos y colecciones digitales, junto con otros proyectos como BNEscolar.
Noticia
Tras Año Nuevo, parece que las Navidades llegan a su fin, pero todavía nos queda una fecha que todos tenemos marcada en nuestra agenda: el día de Reyes. Grandes y pequeños esperamos levantarnos el 6 de enero y descubrir qué nos han traído los sabios de oriente. Y que mejor regalo que un libro que pueda ayudarnos a ampliar nuestros conocimientos y habilidades.
Para aquellos que todavía no hayan terminado sus compras de Navidad y estén apurando al último minuto, en datos.gob.es hemos recogido una selección de libros sobre datos y tecnologías disruptivas que pueden ser una buena opción para regalar a tus seres queridos. Tenemos libros de todos los niveles: más básicos, para animar a tus parientes más jóvenes a estudiar una carrera centrada en la gestión y análisis de datos (profesiones que serán muy demandadas en los próximos años) o más avanzados, para aquellos profesionales que quieren mejorar sus conocimientos y adquirir una ventaja competitiva para impulsar su carrera en 2020.
Las bases de Big Data, de Rafael Caballero y Enrique Martín.
¿De qué trata? Libro de divulgación que explica qué es y cómo funciona el Big Data, incluyendo detalles y curiosidades que permiten al lector comprender mejor el mundo de los grandes datos, su procesamiento y el negocio que supone. También explica aspectos básicos del ecosistema Hadoop o las bases de datos, tanto relacionales como no relacionales.
¿A quién va dirigido? Se trata de un libro introductorio y fácil de leer. El libro no da una visión técnica, pero sí detallada y crítica para que lector tenga ganas de seguir profundizando en la materia.
Storytelling con datos. Visualización de datos para profesionales, de Cole Nussbaumer Knaflic.
¿De qué trata? Un libro para aprender a contar historias utilizando los datos. Cole Nussbaumer nos habla de los fundamentos de la visualización de datos a través de ejemplos reales que ayudan a comprender de una manera sencilla la teoría. El libro ayuda al usuario a reflexionar sobre las historias que quiere contar y cómo quiere contarlas, enseñándole a elegir distintos tipos de gráficos y herramientas según la audiencia a la que se dirija.
¿A quién va dirigido? Se trata de un libro sencillo y rápido de leer, perfecto para aquellos que trabajen con datos, no tengan un perfil muy técnico y quieran mejorar la forma en la que muestran los resultados.
Introduction to Data Science: Data Analysis and Prediction Algorithms with R, de Rafael A. Irizarry.
¿De qué trata? Rafael A. Irizarry presenta conceptos y habilidades para solucionar los desafíos del análisis de datos del mundo real. El libro abarca concepto de probabilidad, inferencia estadística, regresión lineal, aprendizaje automático, programación en R, visualización de datos, creación de algoritmos predictivos, organización de archivos con shell UNIX / Linux, control de versiones con Git y GitHub y preparación de documentos reproducibles.
¿A quién va dirigido? A estudiantes de primer curso de ciencia de datos, por lo que es perfecto para introducirte en esta temática.
Learning Path: Understanding Tool Integration for Big Data Architecture, de O'Reilly Media
¿De qué trata? El libro explica cómo integrar los componentes de Hadoop con el objetivo de implementar soluciones de big data para una variedad de casos de uso, incluidos análisis de flujo de clics, problemas de series de tiempo, transferencia de datos entre Hadoop y bases de datos relacionales, y aplicaciones en el sector financiero.
¿A quién va dirigido? Libro dirigido a profesionales con conocimientos técnicos relativos al universo de los datos o estudiantes avanzados.
Prediction Machines: The Simple Economics of Artificial Intelligence de Ajay Agrawal, Joshua Gans y Avi Goldfarb
¿De qué trata? El libro parte de una pregunta: ¿cómo deberían las empresas establecer estrategias, los gobiernos diseñar políticas y los ciudadanos planificar sus vidas en un mundo marcado por la tecnología y la Inteligencia Artificial? 3 eminentes economistas tratan de aclarar esta cuestión desmitificando la inteligencia artificial y examinándola a través de la teoría económica estándar.
¿A quién va dirigido? A todos aquellos que quieran comprender la realidad de la inteligencia artificial, aunque va especialmente dirigido a emprendedores, líderes de negocios o responsables de políticas públicas.
The State of Open Data: Histories and Horizons, de Tim Davies, Stephen B. Walker y Mor Rubinstein.
¿De qué trata? Libro que repasa las lecciones aprendidas en los 10 años del movimiento open data y mira al futuro para hacer reflexionar al lector sobre cómo responderán las iniciativas de datos abiertos a las nuevas preocupaciones sobre privacidad, y la inclusión de inteligencia artificial.
¿A quién va dirigido? Para aquellas personas implicadas en el ecosistema de datos abiertos, pero también aquellos que tengan curiosidad por la evolución del movimiento. El libro también se encuentra disponible en versión gratuita aquí.
Como en años anteriores, la lista es solo una selección que hemos elaborado en base a recomendaciones de los expertos que colaboran con datos.gob.es, pero sabemos que hay muchos más libros interesantes sobre estas temáticas. Por ello te animamos a dejar nuevas recomendaciones en los comentarios.