Blog
En los últimos años, se ha puesto de manifiesto la necesidad de que la comunidad científica internacional disponga de mecanismos ágiles para compartir resultados de investigación con el fin de dar respuesta a desafíos como las pandemias, la crisis climática, la pérdida de biodiversidad o la transición energética. En este sentido, las tareas de I+D se han vuelto intensivas en el uso tanto de datos como de software especializado. Un ejemplo concreto se produjo durante la pandemia de COVID-19, cuando la compartición de datos habilitó la secuenciación rápida del genoma del SARS‑CoV‑2, resultando fundamental para el desarrollo de la vacuna de la COVID-19 en tiempo récord.
Es, por tanto, el momento de impulsar la ciencia abierta. Pero para que la ciencia abierta sea una realidad, es imprescindible evitar la fragmentación de los recursos de I+D. Más allá de las publicaciones científicas, es necesario conectar repositorios de datos distribuidos y promover herramientas software, que sean interoperables para facilitar la reutilización efectiva de los conjuntos de datos científicos.
En este contexto nace EOSC (European Open Science Cloud), una iniciativa europea que pretende conectar a la comunidad científica para hacer realidad la ciencia abierta y maximizar su impacto para la sociedad. EOSC ofrece al personal investigador en Europa un entorno multidisciplinar, abierto y de confianza donde poder publicar, descubrir y reutilizar datos, así como herramientas y servicios software en el ámbito científico.
¿Qué es EOSC? Acceso federado a recursos científicos
European Open Science Cloud es la iniciativa europea para crear un entorno abierto y de confianza donde la comunidad investigadora pueda publicar, descubrir y reutilizar datos científicos, así como servicios software de investigación. Su enfoque es federar y escalar recursos científicos en Europa, promoviendo la interoperabilidad entre disciplinas. La ambición de EOSC es acelerar las prácticas de ciencia abierta, aumentando la productividad científica y reforzando la reproducibilidad de la investigación de tal manera que se maximice su impacto en la sociedad. Para ello, EOSC se concibe como un “sistema de sistemas”, es decir, en lugar de centralizar todos los datos y servicios en una única plataforma, EOSC interconecta plataformas ya existentes (es decir, realiza una federación en lugar de una integración) como repositorios de datos, infraestructuras de investigación, o proveedores de servicios software científicos.
La Comisión Europea sitúa EOSC como el espacio común europeo para datos de I+D y lo alinea con el objetivo europeo de conseguir alcanzar una economía y sociedad basadas en datos. En términos de impacto, esto favorece los siguientes aspectos:
- Investigación colaborativa, no sólo dentro de una misma disciplina científica sino también entre disciplinas diferentes y diversos territorios.
- Reutilización y combinación de recursos científicos digitales (como conjuntos de datos o servicios software), así como el impulso de la ciencia ciudadana.
- Impacto en la sociedad a través de políticas basadas en evidencia, al mejorar la trazabilidad, disponibilidad e interoperabilidad de datos que sustentan decisiones públicas.
Para hacer EOSC una realidad, se construye un modelo federado basado en nodos que actúan como puntos de entrada coordinados. Sobre ellos se establecen políticas comunes y capacidades compartidas (por ejemplo, autenticación federada, catálogos y guías de interoperabilidad) que permiten la reutilización de datos y servicios. Este enfoque se concreta en la Federación EOSC, que conecta infraestructuras y comunidades para ofrecer un acceso y reutilización de recursos científicos más homogénea.
¿Qué es la Federación EOSC?
Según el EOSC Federation Handbook (documento de referencia que describe su estructura operativa, marco legal y de gobernanza, y operativa técnica), la Federación EOSC (EOSC Federation) es una red distribuida de nodos. Estos nodos están interconectados y son capaces de colaborar para compartir y gestionar conocimiento y recursos científicos (como conjuntos de datos, software y servicios) entre comunidades temáticas y geográficas, cumpliendo los principios FAIR. Es decir, es una red distribuida que habilita capacidades para desarrollar una ciencia abierta interoperable, segura y fiable a escala europea, entre disciplinas y fronteras.
Como veíamos, el elemento básico de esta federación son los EOSC Nodes (nodos EOSC) que funcionan como puntos de entrada para la comunidad científica a la federación. Se trata de plataformas operadas por organizaciones o consorcios de alcance territorial o temático, que integran:
- Un conjunto de capacidades esenciales para operar, como, por ejemplo, servicios de autenticación y acceso o catálogo de recursos.
- Un conjunto de recursos, como, por ejemplo, productos de datos de investigación.
Una parte de esos recursos se selecciona como Node Exchange, representando lo que el nodo comparte con la federación. Al agregarse las contribuciones de varios nodos, se constituyen el EOSC Exchange, es decir, la oferta global de recursos de la federación.
Para que todo ello funcione, se definen las Federating Capabilities como capacidades comunes (técnicas y también organizativas, como soporte a usuarios) que permiten que los servicios funcionen entre nodos y no como silos aislados. Estas capacidades se habilitan mediante servicios federadores operados por uno o varios nodos y se apoyan en interfaces y guías de interoperabilidad recogidas en el EOSC Interoperability Framework. La siguiente imagen representa gráficamente este proceso:
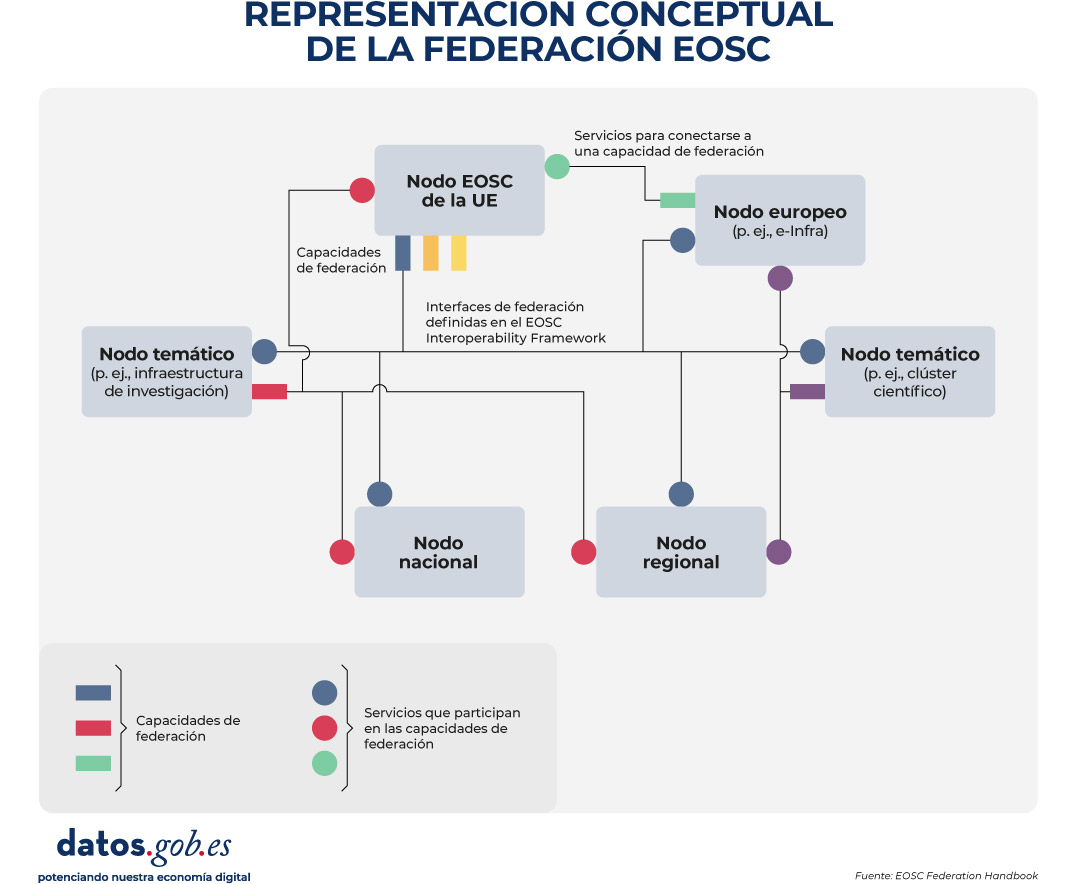
Figura 1. Representación conceptual de la Federación EOSC (fuente: EOSC Federation Handbook).
Existen dos capacidades federadas obligatorias: por una parte la infraestructura de autenticación y autorización (AAI) y, por otra, los catálogos de recursos que permiten a la comunidad científica descubrir y acceder a recursos ofrecidos por los nodos, no sólo manualmente sino por medio de servicios informáticos. Estas primeras capacidades se articulan en el EOSC EU Node.
EOSC EU Node: el primer nodo operativo
En este modelo federado, el EOSC EU Node (promovido por la Comisión Europea) es especialmente relevante como primer nodo de la Federación EOSC, proporcionando un conjunto inicial de datos, herramientas y servicios, y actuando como nodo de referencia para facilitar la interconexión de otros nodos.
Este nodo permite al personal investigador acceder con credenciales institucionales a capacidades como máquinas virtuales, recursos como GPUs, cuadernos interactivos, flujos científicos de trabajo en contenedores, almacenamiento, transferencia de datos y herramientas colaborativas, además de conectarse a un catálogo de recursos para descubrir resultados de investigación (conjuntos de datos científicos, publicaciones o servicios software especializados) procedentes de infraestructuras federadas.
Conclusiones
EOSC permite transformar recursos científicos dispersos en un ecosistema interoperable y reutilizable que permita a la comunidad científica desarrollar los objetivos de la ciencia abierta. La Federación EOSC, mediante nodos conectados y capacidades federadas (tales como AAI, catálogos o guías de interoperabilidad), facilita el acceso a datos FAIR, servicios y herramientas software, acelerando la colaboración científica y la reproducibilidad, además de permitir el impulso de propuestas de ciencia ciudadana e fomentar el impacto de los resultados científicos en la sociedad. Finalmente, cabe destacar que EOSC no sustituye lo que ya existe, sino que lo conecta, lo hace interoperable y lo proyecta a escala europea. En España avanza la definición de un nodo nacional para conectar capacidades existentes con la Federación EOSC. Por ello, la participación temprana de repositorios, infraestructuras, centros de investigación, universidades y proveedores de servicios será clave para construir una oferta representativa, definir prioridades y maximizar el impacto científico y social.
Jose Norberto Mazón, Catedrático de Lenguajes y Sistemas Informáticos de la Universidad de Alicante. Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Blog
Los datos abiertos de salud son uno de los activos más valiosos de nuestra sociedad. Bien gestionados y compartidos de forma responsable, pueden salvar vidas, impulsar descubrimientos médicos o incluso optimizar recursos hospitalarios. Sin embargo, durante décadas, estos datos han permanecido fragmentados en silos institucionales, con formatos incompatibles y barreras técnicas y legales que dificultaban su reutilización. Ahora, la Unión Europea está cambiando radicalmente el panorama con una estrategia ambiciosa que combina dos enfoques complementarios:
- Facilitar el acceso abierto a estadísticas y datos agregados no sensibles.
- Crear infraestructuras seguras para compartir datos personales de salud bajo estrictas garantías de privacidad.
En España, esta transformación ya está en marcha a través del Espacio Nacional de Datos de Salud o grupos de investigación que están a la vanguardia en el uso innovador de datos de salud. Iniciativas como IMPACT-Data, que integra datos médicos para impulsar la medicina de precisión, demuestran el potencial de trabajar con datos de salud de manera estructurada y segura. Y para facilitar que todos estos datos sean fáciles de encontrar y reutilizar se implementan estándares como HealthDCAT-AP.
Todo ello está perfectamente alineado con la estrategia europea del Reglamento del Espacio Europeo de Datos de Salud (EHDS), publicado oficialmente en marzo de 2025 que se integra también con la Directiva de Datos Abiertos (ODD), en vigor desde 2019. Aunque ambos marcos regulatorios tienen alcances distintos, su interacción ofrece oportunidades extraordinarias para la innovación, la investigación y la mejora de la atención sanitaria en toda Europa.
Un reciente informe elaborado por Capgemini Invent para data.europa.eu analiza estas sinergias. En este post, exploramos las principales conclusiones de este trabajo y reflexionamos sobre su relevancia para el ecosistema español de datos abiertos.
Dos marcos complementarios para un objetivo común
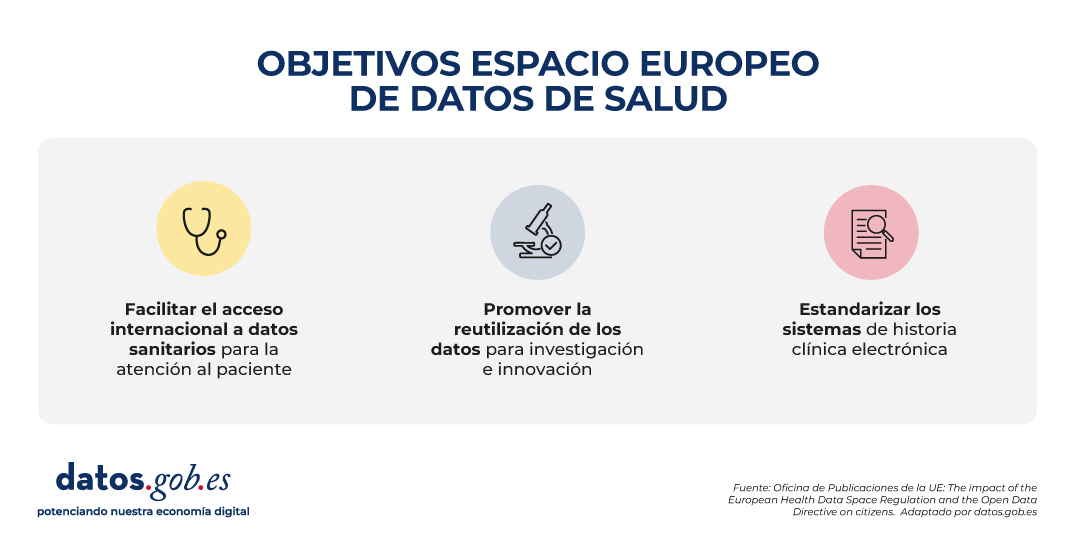
Por un lado, el Espacio Europeo de Datos de Salud se centra específicamente en datos de salud y persigue tres objetivos fundamentales:
- Facilitar el acceso internacional a datos sanitarios para la atención al paciente (uso primario).
- Promover la reutilización de estos datos para investigación, políticas públicas e innovación (uso secundario).
- Estandarizar técnicamente los sistemas de historia clínica electrónica (HCE) para mejorar la interoperabilidad transfronteriza.
Por su parte, la Directiva de Datos Abiertos tiene un alcance más amplio: promueve que el sector público ponga a disposición de cualquier usuario datos gubernamentales para su reutilización libre. Esto incluye los conjuntos de datos de alto valor (High-Value Datasets) que deben publicarse gratuitamente, en formatos legibles por máquina y a través de API en seis categorías entre las que no se encontraba “salud” originalmente. Sin embargo, en la propuesta de ampliación de las nuevas categorías que publicó la UE sí aparece la categoría de salud.
La complementariedad entre ambos marcos regulatorios es evidente: mientras la ODD facilita el acceso abierto a estadísticas sanitarias agregadas y no sensibles, el EHDS regula el acceso controlado a datos individuales de salud bajo condiciones estrictas de seguridad, consentimiento y gobernanza. Juntos, conforman un sistema escalonado de compartición de datos que maximiza su valor social sin comprometer la privacidad, en total cumplimiento con el Reglamento General de Protección de Datos (RGPD).
Principales beneficios ordenador por grupos de usuarios
El informe analiza cuatro grupos de usuarios principales y examina tanto los beneficios potenciales como los desafíos que enfrentan al combinar datos del EHDS con datos abiertos.
-
Pacientes: empoderamiento informado con barreras prácticas
Los pacientes europeos obtendrán acceso más rápido y seguro a sus propias historias clínicas electrónicas, especialmente en contextos transfronterizos gracias a infraestructuras como MyHealth@EU. Este proyecto resulta especialmente útil para ciudadanos europeos que se encuentren desplazados en otro país europeo. .
Otro proyecto interesante que informa a la ciudadanía es PatientsLikeMe que reúne a más 850.000 pacientes con enfermedades raras o crónicas en una comunidad online que comparte información de interés sobre tratamientos y otras cuestiones.
-
Profesionales de la salud potencial subordinado a la integración
Por otro lado, los profesionales sanitarios podrán acceder antes y de manera más sencilla a datos clínicos de pacientes, incluso a través de fronteras, mejorando la continuidad asistencial y la calidad del diagnóstico y tratamiento.
La combinación con datos abiertos podría amplificar estos beneficios si se desarrollan herramientas que integren ambas fuentes de información directamente en los sistemas de historia clínica electrónica.
3. Responsables políticos: datos para mejores decisiones
Los cargos públicos son beneficiarios naturales de la convergencia entre EHDS y datos abiertos. La posibilidad de combinar datos salud detallados (previa solicitud y autorización a través de los Organismos de Acceso a Datos Sanitarios que cada Estado miembro debe establecer) con información estadística y contextual abierta permitiría desarrollar políticas basadas en evidencia mucho más sólida.
El informe menciona casos de uso como la combinación de datos de salud con información medioambiental para evaluar impactos sanitarios. Un ejemplo real es el proyecto francés Green Data for Health, que cruza datos abiertos sobre contaminación acústica con información sobre prescripciones de medicamentos para el sueño de más de 10 millones de habitantes, investigando correlaciones entre ruido ambiental y trastornos del sueño.
4. Investigadores y reutilizadores: los principales beneficiarios inmediatos
Los investigadores, académicos e innovadores constituyen el grupo que más directamente se beneficiará de la sinergia EHDS-ODD ya que disponen de las habilidades y herramientas necesarias para localizar, acceder, combinar y analizar datos de múltiples fuentes. Además, su trabajo ya implica habitualmente la integración de diversos conjuntos de datos.
Un estudio reciente publicado en PLOS Digital Health sobre el caso de Andalucía demuestra cómo los datos abiertos en salud pueden democratizar la investigación en IA sanitaria y mejorar la equidad en el tratamiento.
El desarrollo del EHDS está siendo apoyado por programas europeos como EU4Health, Horizon Europe y proyectos específicos como TEHDAS2, que ayudan a definir estándares técnicos y pilotar aplicaciones reales.
Recomendaciones para maximizar el impacto
El informe concluye con cuatro recomendaciones clave que resultan particularmente relevantes para el ecosistema español de datos abiertos:
- Estimular la investigación en la intersección EHDS-datos abiertos mediante financiación específica. Es fundamental incentivar que los investigadores que combinan estas fuentes traduzcan sus hallazgos en aplicaciones prácticas: protocolos clínicos mejorados, herramientas de decisión, estándares de calidad actualizados.
- Evaluar y facilitar el uso directo por profesionales y pacientes. Promover la alfabetización en datos y desarrollar aplicaciones intuitivas integradas en los sistemas existentes (como las historias clínicas electrónicas) podría cambiar esta situación.
- Fortalecer la gobernanza mediante educación y marcos regulatorios claros. A medida que se vayan operativizando las entidades técnicas del EHDS , será esencial contar con una regulación clara que defina unos marcos regulatorios comunes..
- Monitorizar, evaluar y adaptar. El período 2025-2031 verá la entrada en vigor gradual de los distintos requisitos del EHDS. Se recomienda realizar evaluaciones periódicas para valorar cómo se está utilizando realmente el EHDS, qué combinaciones con datos abiertos están generando más valor, y qué ajustes son necesarios.
Además, para que todo esto funcione, el informe sugiere que portales como data.europa.eu (y por extensión, datos.gob.es) deberían destacar ejemplos prácticos que demuestren cómo se complementan los datos abiertos con los datos protegidos de espacios sectoriales, inspirando así nuevas aplicaciones.
En general, el papel de los portales de datos abiertos será fundamental en este ecosistema emergente: no solo como proveedores de conjuntos de datos de calidad, sino también como facilitadores de conocimiento, espacios de encuentro entre comunidades y catalizadores de innovación. El futuro de la sanidad europea se está escribiendo ahora, y los datos abiertos tienen un papel protagonista en esa historia.
Entrevista
¿Sabes por qué es tan importante categorizar conjuntos de datos? ¿Conoces la referencias que existen para hacerlo acorde al estándar global, europeo y nacional? En este pódcast te contamos las claves sobre la categorización de datasets y te guiamos para poder hacerlo en tu organización.
- David Portolés, Jefe de Proyecto del Servicio de Asesoramiento.
- Manuel Ángel Jáñez, Experto Senior en Datos.
Resumen / Transcripción de la entrevista
1. ¿A qué nos referimos cuando hablamos de catalogar datos y por qué es tan importante hacerlo?
David Portolés: Cuando hablamos de catalogar datos, lo que se quiere es describirlos de forma estructurada. Es decir, hablamos de metadatos: información relacionada con los datos. ¿Por qué es tan importante? Porque gracias a estos metadatos se logra la interoperabilidad. Esta palabra puede sonar complicada, pero simplemente significa que los sistemas puedan comunicarse entre sí de forma autónoma.
Manuel Ángel Jañez: Exacto, como dice David, categorizar no es solo etiquetar. Se trata de dotar a los datos de propiedades que los hagan comprensibles, accesibles y reutilizables. Para eso necesitamos acuerdos o estándares. Si cada productor define sus propias reglas, los consumidores no podrán interpretarlos correctamente, y se pierde valor. Categorizar es alcanzar consensos entre lo general y lo específico, y esto no es nuevo: es una evolución de la documentación en bibliotecas, adaptada al entorno digital.
2. Entonces entendemos que interoperabilidad es hablar el mismo idioma para sacar el máximo provecho. ¿Qué referencias existen a nivel global, europeo y nacional?
Manuel Ángel Jáñez: La forma de describir datos es de forma abierta, usando estándares o especificaciones de referencia, de marcos.
- A nivel global: DCAT (una recomendación del W3C) permite modelar catálogos, conjuntos de datos, distribuciones, servicios, etc. En esencia, todas las entidades que son clave y que luego se reutilizan en el resto de perfiles.
- A nivel europeo: DCAT-AP, el perfil de aplicación en portales de datos en la Unión Europea, particularmente los correspondientes al sector público. Es en esencia lo que se usa para el perfil español, DCAT-AP-ES.
- En España: DCAT-AP-ES, es el contexto en el que se incorporan restricciones más concretas a nivel español. Es un perfil basado en la Norma Técnica de Interoperabilidad (NTI) de 2013. Este perfil añade características nuevas, evoluciona el modelo para hacerlo compatible con el estándar europeo, añade características relacionadas con los conjuntos de alto valor (HVD) y adapta la norma al presente del ecosistema de datos.
David Portolés: Con una buena descripción, el reutilizador puede buscar, recuperar y localizar los conjuntos de datos que son de su interés y, por otro lado,descubrir otros datasets nuevos que no había contemplado. Los estándares, los modelos, los vocabularios compartidos. La principal diferencia entre ellos es el grado de detalle que aplican. La clave es llegar al compromiso entre que sean lo más generales posible para que no sean restrictivos, pero, por otro lado, hay que concretar, se precisa que también sean específicos. Aunque hablamos mucho de datos abiertos, estos estándares también se aplican a datos protegidos que pueden ser descritos. El universo de aplicación de estos estándares es muy amplio.
3. Centrándonos en DCAT-AP-ES, ¿qué ayuda o recursos existen para que un usuario pueda implantarlo?
David Portolés: DCAT-AP-ES es un conjunto de reglas y modelos base de aplicación. Como toda norma técnica tiene una guía de aplicación y, además, hay una guía de implementación online con ejemplos, convenciones, preguntas frecuentes y espacios de discusión técnica y divulgativa. Esta guía tiene un propósito muy claro, la idea es crear una comunidad en torno a esta norma técnica, con el propósito de generar una base de conocimiento accesible para todos, un canal de soporte transparente y abierto para todo aquel que quiera participar.
Manuel Ángel Jañez: Los recursos disponibles no parten de cero. Todo está alineado con iniciativas europeas como SEMIC, que impulsa la interoperabilidad semántica en la UE. Queremos una herramienta viva y dinámica que evolucione con las necesidades, bajo un enfoque participativo, con buenas prácticas, debates, armonización del perfil, etc. En definitiva, se busca que el modelo sea útil, sea robusto, fácil de mantener en tiempo y suficientemente flexible para que cualquier persona pueda participar en su mejora.
4. ¿Hay alguna implementación temática ya existente en DCAT-AP-ES?
Manuel Ángel Jáñez: Sí, se han dado pasos importantes en esa dirección. Por ejemplo, ya se ha incluido el modelo de conjuntos de alto valor, clave para datos relevantes para la economía o sociedad, útiles para IA, por ejemplo. DCAT-AP-ES se inspira en perfiles como DCAT-AP v2.1.1 (2022) que incorpora algunas mejoras semánticas, pero aún quedan implementaciones temáticas por incorporar en DCAT-AP-ES, como las series de datos. La idea es que las extensiones temáticas permitan la modelización para conjuntos de datos específicos.
David Portolés: Como dice Manu, la idea es que sea un modelo vivo. Las futuras extensiones posibles son:
- Datos geográficos: GeoDCAT-AP (europeo).
- Datos estadísticos: StatDCAT-AP.
Además, habrá que tener en cuenta futuras directivas sobre datos de alto valor.
5. ¿Y qué próximos objetivos tiene el desarrollo de DCAT-AP-ES?
David Portolés: El objetivo principal es lograr la plena adopción por parte de:
-
Proveedores: que modifiquen la forma en que o ofrecen y difunden sus metadatos relativos a sus conjuntos de datos con este nuevo paradigma.
-
Reutilizadores: que integren el nuevo perfil en sus desarrollos, en sus sistemas, y en todas las integraciones que hayan hecho hasta ahora, y que puedan hacer productos derivados mucho mejores.
Manuel Ángel Jáñez: También mantener coherencia con estándares internacionales como DCAT-AP. Queremos seguir apostando por un modelo de gobernanza técnica ágil, participativo y alineado con tecnologías emergentes (como datos protegidos, infraestructuras de datos soberanos y espacios de datos). En resumen: que DCAT-AP-ES sea útil, flexible y preparado para el futuro.
Clips de la entrevista
1. ¿Por qué es importante catalogar los datos?
2. ¿Cómo podemos describir datos en formatos abiertos?
Entrevista
La cultura colaborativa y los proyectos ciudadanos de datos abiertos son clave para el acceso democrático a la información. Esto contribuye a un conocimiento libre que permite impulsar la innovación y empoderar a la ciudadanía.
En este nuevo episodio del pódcast de datos.gob.es, nos acompañan dos profesionales ligados a proyectos ciudadanos que han revolucionado la forma en que accedemos, creamos y reutilizamos el conocimiento. Damos la bienvenida a:
- Florencia Claes, profesora titular y coordinadora de Cultura Libre en la Universidad Rey Juan Carlos, y ex presidenta de Wikimedia España.
- Miguel Sevilla-Callejo, investigador del CSIC (Consejo Superior de Investigaciones Científicas) y vicepresidente de la asociación OpenStreetMap España.
Resumen de la entrevista / Transcripción de la entrevista
1. ¿Cómo definiríais la cultura libre?
Florencia Claes: Es cualquier expresión cultural, científica, intelectual, etc. que como autoras o autores permitimos que cualquier otra persona las utilice, las aproveche, las reaproveche, las intervenga y las vuelva a lanzar a la sociedad, para que otra persona haga lo mismo con ese material.
En la cultura libre entran en juego las licencias, esos permisos de uso que nos indican qué es lo que podemos hacer con esos materiales o con esas expresiones de la cultura libre.
2. ¿Qué papel tienen los proyectos colaborativos dentro de la cultura libre?
Miguel Sevilla-Callejo: Tener unos proyectos que sean capaces de aglutinar estas iniciativas de cultura libre es muy importante. Los proyectos colaborativos son iniciativas horizontales en las que puede aportar cualquier persona. En torno a ellos se estructura un consenso para hacer crecer ese proyecto, esa cultura.
3. Los dos estáis ligados a proyectos colaborativos como son Wikimedia y OpenStreetMap. ¿Cómo impactan estos proyectos en la sociedad?
Florencia Claes: Claramente el mundo no sería el mismo sin Wikipedia. No concebimos un mundo sin Wikipedia, sin acceso libre a la información. Creo que Wikipedia está asociado a la sociedad en la que estamos actualmente. Ha construido lo que somos hoy, también como sociedad. El hecho de que sea un espacio colaborativo, abierto, libre, hace que cualquiera pueda sumarse e intervenirlo y que tenga un rigor alto.
Entonces, ¿cómo impacta? Impacta en que (va a sonar un poco cursi, pero…) podemos ser mejores personas, podemos conocer más, podemos tener más información. Impacta en que cualquier persona con acceso a internet, claro está, puede beneficiarse de sus contenidos y aprender sin tener que pasar necesariamente por un muro de pago o estar registrado en una plataforma y cambiar datos para poder apropiarse o acercarse a la información.
Miguel Sevilla-Callejo: A OpenStreetMap le llamamos la Wikipedia de los mapas, porque en muy buena parte de su filosofía está copiado o clonado de la filosofía de Wikipedia. Si os imagináis Wikipedia, lo que hace la gente es que mete artículos enciclopédicos. Lo que hacemos en OpenStreetMap es meter datos espaciales. Construimos un mapa de manera colaborativa y esto supone que la página openstreetmap.org, que es donde podrías ir a mirar los mapas, es solo la punta del iceberg. Es ahí donde OpenStreetMap está un poco más difuso y oculto, pero la mayor parte de las páginas web, mapas e información espacial que estáis viendo en Internet, muy probablemente en su gran mayoría, procede de los datos de la gran base de datos libre, abierta y colaborativa que es OpenStreetMap.
Muchas veces estáis leyendo un periódico y veis un mapa y esos datos espaciales están sacados de OpenStreetMap. Incluso se utilizan en agencias: en la Unión Europea, por ejemplo, se está utilizando OpenStreetMap. Se usa en información de empresas privadas, de administraciones públicas, particulares, etc. Y, además, al ser libre se reaprovecha constantemente.
A mí me gusta traer siempre a colación proyectos que hemos hecho aquí, en la ciudad de Zaragoza. Hemos generado toda la red peatonal urbana, o sea, todas las aceras, los pasos de cebra, las zonas por las que se puede circular... y con esto se hace un cálculo de cómo te puedes mover por la ciudad andando. Esta información de las aceras, los pasos de peatones y demás no lo encuentras en un sitio web porque no es muy lucrativo, como podría ser por ejemplo moverse en coche, y se puede aprovechar, por ejemplo -que es lo que hicimos en algunos trabajos que dirigí yo en la universidad- para poder saber cómo de diferente es la movilidad con personas invidentes, en silla de ruedas o con un carrito de un bebé.
4. Nos estáis contando que estos proyectos son abiertos. Si un ciudadano nos está escuchando ahora mismo y quiere participar en ellos, ¿qué debe hacer para participar? ¿Cómo puede formar parte de estas comunidades?
Florencia Claes: Lo interesante de estas comunidades es que no necesitas asociarte o ligarte formalmente a ellas para poder contribuir. En Wikipedia simplemente entras a la página de Wikipedia y te haces un usuario, o no, y ya puedes editar. ¿Qué diferencia hay entre hacer tu usuario o no? En que vas a poder tener mejor acceso a las contribuciones que has hecho, pero no necesitamos estar asociados o registrados en ningún sitio para poder editar Wikipedia.
Si hay a nivel local o regional grupos relacionados con la Fundación Wikimedia que reciben ayudas y subvenciones para hacer encuentros o actividades. Ahí está bueno, porque se conoce gente con las mismas inquietudes y que suelen ser muy entusiastas con respecto al conocimiento libre. Como dicen mis amigos, somos una panda de frikis que nos hemos encontrado y sentimos que tenemos un grupo de pertenencia en el que compartimos y planificamos cómo cambiar el mundo.
Miguel Sevilla-Callejo: En OpenStreetMap sucede prácticamente igual, o sea, lo puedes hacer en solitario. Es verdad que hay un poco de diferencia con respecto a Wikipedia. Si vas a la página de openstreetmap.org, en la que tenemos toda la documentación -que es wiki.OpenStreetMap.org- tú puedes entrar ahí y tienes toda la documentación.
Sí que es verdad que para editar en OpenStreetMap sí que se necesita un usuario para hacer un mejor seguimiento de los cambios que hace la gente en el mapa. Si fuera anónimo podría llegar a haber más problema, porque no es como los textos en Wikipedia. Pero como ha dicho Florencia, es mucho mejor si te asocias a una comunidad.
Tenemos grupos locales en diferentes sitios. Una de las iniciativas que hemos reactivado últimamente es la asociación OpenStreetMap España, en la que, como decía Florencia, estamos un grupo a los que nos gustan los datos y las herramientas libres, y ahí compartimos todo el conocimiento. Se acerca mucha gente y nos dicen "oye, acabo de entrar en OpenStreetMap, este proyecto me gusta, ¿cómo puedo hacer esto? ¿cómo puedo hacer lo otro?" Y bueno, siempre es mucho mejor hacerlo con otros colegas que hacerlo tú solo. Pero lo puede hacer cualquiera.
5. ¿Qué desafíos os habéis encontrado a la hora de implementar estos proyectos colaborativos y garantizar su sostenibilidad en el tiempo? ¿Cuáles son los principales retos, tanto técnicos como sociales, a los que hacéis frente?
Miguel Sevilla-Callejo: Uno de los problemas que encontramos en todos estos movimientos que son tan horizontales y en los que hay que buscar consensos para saber hacia dónde avanzar, es que al final es relativamente problemático lidiar con una comunidad muy diversa. Siempre surgen roces, diferentes puntos de vista... Esto yo creo que es lo más problemático. Lo que sucede es que, en el fondo, como nos mueve a todos el entusiasmo por el proyecto, terminamos llegando a acuerdos que hacen crecer el proyecto, como se puede ver en los propios Wikimedia y OpenStreetMap, que siguen creciendo y creciendo.
Desde el punto de vista técnico, para algunas cosas en concreto, tienes que tener una cierta destreza informática, pero vamos muy, muy básica. Por ejemplo, hemos hecho mapatones, que consisten en que nos reunimos en un área con ordenadores y empezamos a poner información espacial en zonas, por ejemplo, donde ha habido una catástrofe natural o algo así. La gente básicamente, sobre una imagen de satélite, va colocando casitas donde va viendo - casitas ahí en mitad del Sahel, por ejemplo, para ayuda a ONG como Médicos Sin Fronteras-. Eso es muy fácil: lo abres en el navegador, abres OpenStreetMap y enseguida, con cuatro indicaciones, eres capaz de editar y contribuir.
Sí que es verdad que, si quieres hacer cosas un poco más complejas, tienes que tener más destreza informática. Entonces sí que es verdad que siempre nos adaptamos. Hay gente que está metiendo datos en plan muy pro, incluyendo edificios, importando datos del catastro… y hay gente como hace poco una chica aquí en Zaragoza, que descubrió el proyecto y está metiendo los datos que va encontrando con una aplicación en el móvil.
Sí que de verdad encuentro un cierto sesgo de género en el proyecto. A mí eso dentro de OpenStreetMap me preocupa un poco, porque es verdad que una gran mayoría de las personas que estamos editando, incluidos a la comunidad, somos hombres y eso al final sí que se traduce en que algunos datos tienen cierto sesgo. Pero bueno, estamos trabajando en ello.
Florencia Claes: En ese sentido, en el entorno Wikimedia, también nos pasa eso. Tenemos, más o menos a nivel mundial, un 20% de mujeres participantes en el proyecto contra 80% de varones y eso hace que, por ejemplo, en el caso de Wikipedia, haya preferencia por artículos sobre futbolistas a veces. No es preferencia, sino simplemente que las personas que editan tienen esos intereses y como son más hombres, pues tenemos más futbolistas, y echamos en falta artículos relacionados, por ejemplo, con la salud de la Mujer.
Entonces sí nos enfrentamos a sesgos y nos enfrentamos a esa coordinación de la comunidad. A veces participa gente con muchos años, gente nueva… y lograr un equilibrio es importantísimo y muy difícil. Pero lo interesante es cuando logramos tener presente o recordar que el proyecto está por encima de nosotros, que estamos construyendo algo, que estamos regalando algo, que estamos participando en algo muy grande. Cuando volvemos a tomar conciencia de eso, las diferencias se tranquilizan y volvemos a centrarnos en el bien común que, al fin y al cabo, creo que es el objetivo de estos dos proyectos, tanto del entorno Wikimedia como de OpenStreetMap.
6. Como comentabais, tanto Wikimedia como OpenStreetMap son proyectos construidos por voluntarios. ¿Cómo se garantiza la calidad y precisión de los datos?
Miguel Sevilla-Callejo: Lo interesante de todo esto es que la comunidad es muy amplia y hay muchos ojos observando. Cuando hay una falta de rigurosidad en la información, tanto en Wikipedia -que lo conoce la gente más- pero también en OpenStreetMap, saltan las alarmas. Tenemos sistemas de seguimiento y es relativamente sencillo ver disfunciones en los datos. Entonces podemos actuar rápidamente. Esto da una capacidad, en OpenStreetMap en concreto, de reacción y actualización de los datos prácticamente inmediata y de resolución de aquellas problemáticas que puedan surgir también bastante rápida. Sí que es verdad que tiene que haber una persona atenta de ese lugar o de esa zona.
A mí siempre me ha gustado hablar de los datos de OpenStreetMap como una especie de - refiriendo como se hace en el software- mapa beta, que tiene lo ultimísimo, pero puede haber algunos errores mínimos. Entonces, como un mapa fuertemente actualizado y de gran calidad, se puede utilizar para muchas cosas, pero para otras por supuesto que no, porque tenemos otra cartografía de referencia que se está construyendo por la administración pública.
Florencia Claes: En el entorno Wikimedia también funcionamos así, por la masa, por la cantidad de ojos que están mirando lo que hacemos y lo que hacen otros. Cada uno, dentro de esta comunidad, va asumiendo roles. Hay roles que están pautados, como los de administradores o bibliotecarios o bibliotecarias, pero hay otros que simplemente son: a mí me gusta patrullar, entonces lo que hago es estar pendiente de los artículos nuevos y podría estar mirando los artículos que se publican a diario para ver si necesitan algún apoyo, alguna mejora o si, por el contrario, están tan mal que necesitan ser retirados de la parte principal o borrados.
La clave de estos proyectos es la cantidad de gente que participa y todo es de forma voluntaria, altruista. La pasión es muy es muy alta, el nivel de compromiso es muy alto. Entonces la gente cuida mucho esas cosas. Tanto cuando se curan datos para subir a Wikidata o se escribe un artículo en Wikipedia, cada persona que lo hace, lo hace con mucho cariño, con mucho celo. Después pasa el tiempo y está pendiente de ese material que subió, a ver cómo siguió creciendo, si se utilizó, si se enriqueció más o si por el contrario se le borró algo.
Miguel Sevilla-Callejo: Respecto a la calidad de los datos, me parece interesante, por ejemplo, una iniciativa que ha tenido ahora el Sistema de Información Territorial de Navarra. Han migrado todos sus datos para la planificación y la guía de las rutas de emergencias a OpenStreetMap, tomando sus datos. Ellos se han implicado en el proyecto, han mejorado la información, pero tomando lo que ya había [en OpenStreetMap], considerando que tenían una gran calidad y que les resultaba mucho más útil que utilizar otras alternativas, lo cual pone de manifiesto la calidad y la importancia que puede llegar a tener este proyecto.
7. Estos datos también pueden servir para generar recursos educativos abiertos, junto con otras fuentes de conocimiento. ¿En qué consisten estos recursos y qué papel juegan en la democratización del conocimiento?
Florencia Claes: Los REA, los recursos educativos abiertos, deberían ser la norma. Cada docente que genera contenidos debería ponerlos a disposición de la ciudadanía y deberían estar construidos por módulos a partir de recursos libres. Sería lo ideal.
¿Qué papel tiene el entorno Wikimedia en esto? Desde albergar información que puede ser utilizada a la hora de construir los recursos, como proporcionar espacios para realizar ejercicios o para tomar, por ejemplo, datos y hacer un trabajo con SPARQL. O sea, hay diferentes formas de abordar los proyectos Wikimedia en relación a los recursos educativos abiertos. Se puede desde intervenir y enseñarle al alumnado cómo identificar datos, cómo verificar las fuentes, hasta simplemente hacer una lectura crítica de cómo está presentada la información, cómo está curada, y hacer, por ejemplo, una valoración entre idiomas.
Miguel Sevilla-Callejo: En OpenStreetMap es muy similar. Lo interesante y único es cuál es la naturaleza de los datos. No es exactamente información en diferentes formatos como en Wikimedia. Aquí la información es esa base de datos espaciales libre que es OpenStreetMap. Entonces los límites son la imaginación.
Me acuerdo que había un compañero que iba a unas conferencias y hacía una tarta con el mapa de OpenStreetMap. Se la daba a comer a la gente y les decía: "¿Veis? Estos son mapas que hemos podido comer porque son libres". Para hacer cartografía más seria o más informal o lúdica, el límite es solo tu imaginación. Sucede exactamente igual que con Wikipedia.
8. Para acabar, ¿cómo se puede motivar a los ciudadanos y organizaciones para que participen en la creación y mantenimiento de proyectos colaborativos ligados a la cultura libre y datos abiertos?
Florencia Claes: Yo creo que hay que hacer claramente lo que decía Miguel de la tarta. Hay que hacer una tarta e invitar a la gente a comer tarta. Hablando en serio sobre qué podemos hacer para motivar a la ciudadanía a reutilizar estos datos, yo creo, sobre todo por experiencia personal y por los grupos con los que yo he trabajado en estas plataformas, que la interfaz sea amigable es un paso importantísimo.
En Wikipedia en 2015 se activó el editor visual. El editor visual hizo que nos incorporamos muchísimas más mujeres a editar Wikipedia. Antes se editaba solo en código y el código, pues a primera vista puede parecer hostil o distante o “eso no va conmigo”. Entonces, tener interfaces donde la gente no necesite tener demasiados conocimientos para saber que este es un paquete que tiene tal tipo de datos y lo voy a poder leer con tal programa o lo voy a poder volcar en tal cosa y que sea sencillo, que sea amigable, que sea atractivo… Eso creo que nos va a quitar muchísimas barreras y que va a dejar de lado esa idea de que el dato es para los informáticos. Y creo que los datos van más allá, que realmente podemos aprovecharlos todas y todos de muy diferentes formas. Entonces creo que es una de las barreras que deberíamos vencer.
Miguel Sevilla-Callejo: A nosotros no sucedió que hasta más o menos 2015 (perdóname si no es exactamente la fecha), teníamos un interfaz que era bastante horrible, casi como la edición de código que tenéis en Wikipedia, o peor, porque había que meter los datos sabiendo el etiquetado, etc. Era muy complejo. Y ahora tenemos un editor que básicamente tú estás en OpenStreetMap, le das a editar y sale un interfaz súper sencillo. Ya ni siquiera hay que poner etiquetado en inglés, está todo traducido. Hay muchas cosas preconfiguradas y la gente puede meter los datos inmediatamente y de una manera muy sencilla. Entonces eso lo que ha permitido es que se acerque mucha más gente al proyecto.
Otra cosa muy interesante, que también pasa en Wikipedia, aunque es verdad que está mucho más centrado en la interfaz web, es que en torno a OpenStreetMap se ha generado un ecosistema de aplicaciones y servicios que ha posibilitado que, por ejemplo, aparezcan aplicaciones móviles que, de una manera muy rápida, muy sencilla, permiten meter los datos directamente a pie sobre el terreno. Y esto posibilita que la gente pueda meter los datos de una manera sencilla.
Quería de todas maneras incidir otra vez, aunque ya sé que estamos reiterando todo el rato en la misma circunstancia, pero creo que es importante comentarlo, porque creo que eso se nos olvida dentro de los proyectos: necesitamos que la gente sea consciente otra vez de que los datos son libres, que pertenecen a la comunidad, que no está en manos de una empresa privada, que se puede modificar, que se pueden transformar, que detrás lo que hay es una comunidad de gente voluntaria, libre, pero que eso no quita calidad a los datos, y que llega a todos lados. Para que la gente se acerque y no nos vean como un bicho raro. Yo creo que Wikipedia está mucho más integrado dentro del conocimiento de la sociedad y ahora con la inteligencia artificial mucho más, pero nos pasa en OpenStreetMap, que te miran así como diciendo “pero, ¿qué me estás contando si yo utilizo otra aplicación en el móvil?” o está utilizando la nuestra, está utilizando datos de OpenStreetMap sin saberlo. Entonces nos falta acercarnos más a la sociedad, que nos conozcan más.
Volviendo al tema de la asociación, ese es uno de nuestros objetivos, que la gente nos conozca, que sepa que esos datos son abiertos, que se pueden transformar, los pueden utilizar y que son libres de tenerlos para construir, como decía antes, lo que quieran y el límite es su imaginación.
Florencia Claes: Creo que deberíamos integrar de alguna forma mediante gamificación, mediante juegos en el aula, la incorporación de mapas, de datos dentro del aula, dentro del día a día en la escolarización. Creo que ahí tendríamos un punto a favor. Dado que estamos dentro de un ecosistema libre, podemos integrar en las mismas páginas de los repositorios de datos herramientas de visualización o de reaprovechamiento que creo que harían todo bastante más amable y daría cierto poder a la ciudadanía, los empoderaría de tal forma que se animaría a utilizarlos.
Miguel Sevilla-Callejo: Es interesante que tenemos cosas que conectan ambos proyectos (también se nos olvida a veces a la gente de OpenStreetMap y de Wikipedia), que hay datos que podemos intercambiar, coordinar y sumar. Y eso también se sumaría a lo que acabas de decir.
Clips de la entrevista
1. ¿En qué consisteOpenStreetMap?
2. ¿Cómo ayuda Wikimedia en la creación de Recursos Educativos Abiertos?
2.
Blog
Una de las misiones de la inteligencia artificial contemporánea es ayudarnos a encontrar, ordenar y digerir información, especialmente con la ayuda de los grandes modelos de lenguaje. Estos sistemas han llegado cuando más necesitamos gestionar un conocimiento que producimos y compartimos en masa, pero que después nos cuesta abarcar y consumir. Su valor radica en encontrar rápidamente las ideas y los datos que necesitamos, con el fin de que podamos dedicar nuestro esfuerzo y tiempo a pensar o, lo que es lo mismo, empezar a subir la escalera con uno o dos peldaños de ventaja.
Los sistemas basados en IA nos ayudan a navegar cualquier ecosistema de conocimiento, algo que es útil tanto en la investigación académica como en los estudios de tendencias en el mundo de la empresa. Las herramientas de IA analítica pueden analizar miles de papers para mostrarnos qué autores colaboran entre sí o cómo se agrupan los temas, creándonos a demanda un mapa interactivo y filtrable de la literatura. La IA generativa, la gran esperada, puede partir de una pregunta de investigación y devolvernos subcontenido útil como una síntesis o un contraste de enfoques. La primera nos muestra el terreno sobre el mapa, mientras que la segunda nos sugiere por dónde podemos avanzar.
Herramientas prácticas
Empezando por las más analíticas y dejando las mixtas o generativas para el final, recorremos cuatro herramientas prácticas para la investigación que integran la IA como funcionalidad, y una bola extra.
Es una herramienta basada sobre todo en la conexión entre autores, temas y artículos, que nos muestra redes de citas y nos permite crear el grafo completo de la literatura en torno a un tema. Como punto de partida, Inciteful nos pide el título o la URL de un paper, aunque también podemos simplemente buscar por nuestro tema de investigación. También existe la posibilidad de introducir los datos de dos artículos, para que nos enseñe cómo se conectan entre sí.
Figura 1. Captura de pantalla en Inciteful: pantalla inicial de búsqueda y conexión entre papers.
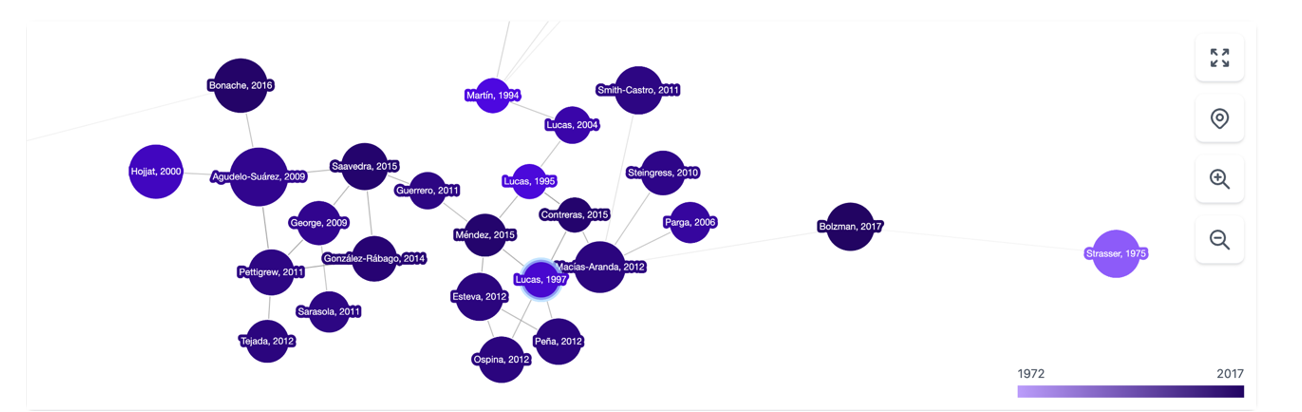
Figura 2. Captura de pantalla en Inciteful: red de nodos con artículos y autores.
En Scite, la integración de la IA es más evidente y práctica: ante una pregunta, crea una única respuesta resumen combinando la información de todas las referencias. La herramienta analiza la semántica de los papers para extraer cuál es la naturaleza de cada cita: cuántas citas lo apoyan (símbolo del check), lo cuestionan (interrogación) o solo lo mencionan (barra). Esto nos permite algo tan valioso como añadir contexto a las métricas de impacto de un artículo en nuestra bibliografía.
Figura 3. Captura de pantalla en Scite: pantalla inicial de búsqueda.

Figura 4. Captura de pantalla en Scite: valoración de las citas de un artículo.
Además de integrar las funcionalidades de las anteriores, se trata de un producto digital muy completo que no solo permite navegar de paper en paper en forma de red visual, sino que también hace posible establecer alertas sobre un tema o un autor al que seguimos y crear listas de papers. Además, el propio sistema sugiere qué otros papers te pueden interesar, todo en el estilo de un sistema de recomendación como los de Spotify o Netflix. También permite hacer listas públicas, como en Google Maps, y trabajar de forma colaborativa con otros usuarios.
Figura 5. Captura de pantalla en Research Rabbit: lista personalizada de artículos.
Cuenta con el aval del gobierno británico, la Universidad de Stanford o la NASA, y está basada al cien por cien en IA generativa. Su funcionalidad estrella es la capacidad de hacer preguntas directas a un paper o a una colección de artículos, y finalmente obtener un informe dirigido a cuestiones concretas con todas las referencias. Aunque, en realidad, la característica más sorprendente es la capacidad de mejora de la pregunta inicial del usuario: la herramienta evalúa de forma instantánea la calidad de la pregunta y realiza sugerencias para hacerla más precisa o interesante.

Figura 6. Captura de pantalla en Elicit: sugerencias de mejora para la pregunta inicial.
Bola extra: Consensus
Lo que empezó como un humilde GPT personalizado dentro de la versión Plus de ChatGPT ha terminado siendo todo un producto digital para la investigación. A partir de una pregunta, intenta sintetizar el consenso científico en torno a esa temática, indicando si hay acuerdo o discrepancia entre los estudios. De una manera sencilla y visual muestra cuántos apoyan una afirmación, cuántos la ponen en duda y qué conclusiones predominan, además de proporcionar un pequeño informe para obtener una orientación rápida.
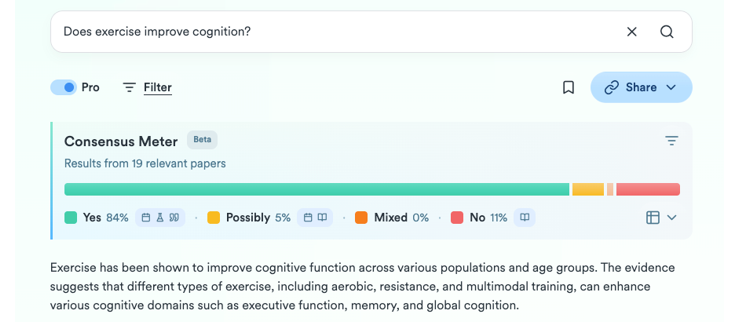
Figure 7. Screenshot on Consensus: impact metrics from a question.
El botón de la profundidad
En los últimos meses ha aparecido una nueva funcionalidad en las plataformas de los grandes modelos de lenguaje comerciales enfocada a la investigación en profundidad. En concreto, se trata de un botón con este mismo nombre, “investigación en profundidad” o “deep research”, que ya podemos encontrar en ChatGPT, versión Plus (con peticiones limitadas) o Pro, y en Gemini Advanced, aunque prometen que gradualmente se irá abriendo al uso gratuito y permiten algunas pruebas sin coste.
Figura 8. Captura de pantalla en ChatGPT Plus: botón Investigación en profundidad.
Figura 9. Captura de pantalla en Gemini Advanced: botón Deep Research.
Esta opción, que debemos activar antes de lanzar el prompt, funciona como un atajo: el modelo genera un informe sintético y organizado sobre el tema, reuniendo información clave, datos y contexto. Antes de iniciar la investigación, es posible que el sistema nos haga alguna pregunta adicional para centrar mejor la búsqueda.

Figura 10. Captura de pantalla en ChatGPT Plus: preguntas para acotar la investigación
Debemos tener en cuenta que, una vez resueltas estas dudas, el sistema inicia un proceso que puede tardar mucho más que una respuesta normal. En concreto, en ChatGPT Plus puede requerir hasta 10 minutos. Una barra de progreso nos va indicando el avance.
Figura 11. Captura de pantalla en ChatGPT Plus: inicio de la investigación y barra de progreso
Lo que obtenemos ahora es un informe completo, considerablemente preciso, incluyendo ejemplos y enlaces que nos pueden poner rápidamente en la pista de lo que estamos buscando.

Figura 12. Captura de pantalla de ChatGPT Plus: resultado de la investigación (fragmento).
Cierre
Las herramientas diseñadas para aplicar la IA a favor de la investigación no son infalibles ni definitivas, pueden todavía incurrir en errores y alucinaciones, pero no es menos cierto que la investigación con IA ya es un proceso radicalmente distinto a la investigación sin ella. La búsqueda asistida consiste, como prácticamente todo cuando hablamos de IA, en no desdeñar por imperfecto lo que puede ser útil, dedicar algo de tiempo a probar nuevos usos que pueden ahorrarnos muchas horas más adelante, y centrar su papel en lo que sí puede hacer para mantener nuestro enfoque en los siguientes pasos..
Contenido elaborado por Carmen Torrijos, experta en IA aplicada al lenguaje y la comunicación. Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Entrevista
El conocimiento abierto es aquel que puede ser reutilizado, compartido y mejorado por otros usuarios e investigadores sin restricciones notables. Esto incluye datos, publicaciones académicas, software y otros recursos disponibles. Para profundizar en esta temática contamos con representantes de dos instituciones cuyo objetivo es impulsar la producción científica y que esta sea dispuesta en abierto para su reutilización:
- Mireia Alcalá Ponce de León, técnica de recursos de información del área de aprendizaje, investigación y ciencia abierta del Consorcio de Servicios Universitarios de Cataluña (CSUC).
- Juan Corrales Corrillero, gestor del repositorio de datos del Consorcio Madroño.
Resumen / Transcripción de la entrevista
1. ¿Podéis explicar brevemente a qué se dedican las instituciones para las que trabajáis?
Mireia Alcalá: El CSUC es el Consorcio de Servicios Universitarios de Cataluña y es una organización que tiene como objetivo ayudar a universidades y centros de investigación que están en Cataluña a mejorar su eficiencia a través de proyectos colaborativos. Estamos hablando de unas 12 universidades y casi unos 50 centros de investigación.
Ofrecemos servicios en muchas áreas: cálculo científico, administración electrónica, repositorios, administración en la nube, etc. y también ofrecemos servicios bibliotecarios y de ciencia abierta, que es lo que nos toca más de cerca. En el área de aprendizaje, investigación y ciencia abierta, que es donde estoy trabajando, lo que hacemos es intentar facilitar la adopción de nuevas metodologías por parte del sistema universitario y de investigación, sobre todo, en la ciencia abierta, y damos apoyo a la gestión de datos de investigación.
Juan Corrales: El Consorcio Madroño es un consorcio de bibliotecas universitarias de la Comunidad de Madrid y de la de la UNED (Universidad Nacional de Educación a Distancia) para la cooperación bibliotecaria. Buscamos incrementar la producción científica de las universidades que forman parte del consorcio y también incrementar la colaboración entre las bibliotecas en otros ámbitos. Estamos también, al igual que el CSUC, muy involucrados con la ciencia abierta: en promocionar la ciencia abierta, en proporcionar infraestructuras que la faciliten, no solamente para los miembros del Consorcio Madroño, sino también de forma global. Aparte, también damos otros servicios bibliotecarios y creamos estructuras para ellos.
2. ¿Qué requisitos debe de cumplir una investigación para qué se considere abierta?
Juan Corrales: Para que una investigación se considere abierta hay muchas definiciones, pero quizás una de las más importantes es la que da la Estrategia Nacional de Ciencia Abierta que tiene seis pilares.
Uno de ellos es que hay que poner en acceso abierto tanto los datos de investigación como las publicaciones, los protocolos, las metodologías... Es decir, todo tiene que estar accesible y, en principio, sin barreras para todo el mundo, no solamente para los científicos, no solamente para las universidades que pueden pagar el acceso a estos datos de investigación o a estas publicaciones.
También es importante utilizar plataformas de código abierto que podamos personalizar. El código abierto es software que cualquiera, en principio con conocimientos, puede modificar, personalizar y redistribuir, como contrapunto al software privado de muchas empresas, que no permite hacer todas estas gestiones.
Otro punto importante, aunque este estemos todavía lejos de llegar en la mayoría de las instituciones, es permitir la revisión por pares abiertas, porque permite saber quién ha hecho una revisión, con qué comentarios, etc. Se puede decir que permite volver a hacer el ciclo de revisión por pares y mejorarlo.
Un último punto es la ciencia ciudadana: permitir a los ciudadanos de a pie formar parte de la ciencia, que no solamente se haga dentro de las universidades o institutos de investigación.
Y otro punto importante es añadir nuevas formas de medir la calidad de la ciencia.
Mireia Alcalá: Estoy de acuerdo con lo que dice Juan. A mí también me gustaría añadir que, para que un proceso de investigación se considere abierto, lo tenemos que mirar globalmente. Es decir, que incluya todo el ciclo de vida de los datos. No podemos hablar de que una ciencia es abierta si solo nos fijamos en que los datos al final estén en abierto. Ya desde el principio de todo el ciclo de vida del dato, es importante que se usen plataformas y se trabaje de una manera más abierta y colaborativa.
3. ¿Por qué es importante que universidades y centros de investigación pongan sus estudios y datos a disposición de la ciudadanía?
Mireia Alcalá: Yo creo que es clave que las universidades y los centros compartan sus estudios, porque gran parte de la investigación, tanto aquí en España como a nivel europeo o mundial, se financia con dinero público. Por lo tanto, si la sociedad es quien está pagando la investigación, lo lógico es que también se beneficie de sus resultados. Además, abrir el proceso de investigación puede ayudar a que sea más transparente, más responsable, etc.
Se ha visto que gran parte de la investigación hecha hasta hoy en día no es reutilizable, ni reproducible. ¿Esto qué quiere decir? Que los estudios que se han hecho, casi en el 80% de los casos otra persona no puede cogerlo y volver a utilizar esos datos. ¿Por qué? Porque no siguen los mismos estándares, las mismas maneras, etc. Por lo tanto, yo creo que tenemos que hacer que sea extensivo a todos los sitios y un ejemplo claro está en época de pandemia. Con la COVID-19, investigadores de todo el mundo trabajaron juntos, compartiendo datos y hallazgos en tiempo real, trabajando de la misma manera, y se vio que la ciencia fue mucho más rápida y eficiente.
Juan Corrales: Los puntos claves ya los ha tocado todos Mireia. Aparte, se podría añadir que acercar la ciencia a la sociedad puede hacer que todos los ciudadanos sintamos que la ciencia es algo nuestro, no solamente de científicos o universitarios. Es algo en lo que podemos participar y esto puede ayudar también a frenar quizás los bulos, las fake news, a tener una visión más exhaustiva de las noticias que nos llegan a través de redes sociales y a poder filtrar qué puede ser real y qué puede ser falso.
4. ¿Qué investigaciones deben publicarse en abierto?
Juan Corrales: Ahora mismo, según la ley que tenemos en España, la última Ley de ciencia, deben publicarse en abierto todas las publicaciones que están financiadas principalmente por fondos públicos o en las que participan instituciones públicas. Esto realmente no ha tenido mucha repercusión hasta el año pasado, porque, aunque la ley salió hace dos años, en la anterior también se decía, también hay una ley de la Comunidad de Madrid que dice lo mismo… pero desde el año pasado se está teniendo en cuenta en la evaluación que hace la ANECA (la Agencia de Evaluación de la Calidad) a los investigadores. Desde entonces casi todos los investigadores han tenido como algo prioritario publicar sus datos e investigaciones en abierto. Sobre todo, con los datos era algo que no se estaba haciendo prácticamente hasta ahora.
Mireia Alcalá: A nivel estatal es como dice Juan. Nosotros a nivel autonómico también tenemos una ley del 2022, la Ley de la ciencia, que básicamente dice exactamente lo mismo que la ley española. Pero a mí también me gusta que la gente conozca que no solo tenemos que tener en cuenta la legislación estatal, sino las convocatorias de donde se consigue el dinero para financiar los proyectos. Básicamente en Europa, en los programas marco como el Horizon Europe, se dice claramente que, si tú recibes una financiación de la Comisión Europea, tendrás que hacer un plan de gestión de datos al inicio de tu investigación y publicar los datos siguiendo los principios FAIR.
5.Entre otras cuestiones, tanto el CSUC como el Consorcio Madroño se encargan de dar soporte a entidades e investigadores que quieren poner sus datos a disposición de la ciudadanía, ¿cómo debe ser un proceso de apertura de datos de datos de investigación? ¿Qué retos son los más habituales y cómo los solucionan?
Mireia Alcalá: En nuestro repositorio que se llama RDR (de Repositori de Dades de Recerca), son básicamente las instituciones participantes las que se encargan de dar apoyo al personal investigador. El investigador llega al repositorio cuando ya está en la fase final de la investigación y necesita publicar para ayer los datos y entonces todo es mucho más complejo y lento. Se tarda más en verificar estos datos y hacer que sean encontrables, accesibles, interoperables y reutilizables.
En nuestro caso particular, tenemos una checklist que pedimos que todo dataset cumpla para garantizar este mínimo de calidad en los datos, para que se puedan reutilizar. Estamos hablando de que tenga identificadores persistentes como ORCID para el investigador o ROR para identificar las instituciones, que tenga documentación que explique cómo reutilizar esos datos, que tenga una licencia, etc. Como tenemos este checklist, los investigadores, a medida que van depositando, van mejorando sus procesos y empiezan a trabajar y a mejorar la calidad de los datos desde el principio. Es un proceso lento.
El principal reto, yo creo que es que el investigador asuma que eso que él tiene son datos, porque la mayoría lo desconoce. La mayoría de los investigadores creen que los datos son unos números que ha sacado una máquina que mide la calidad del aire, y desconoce que un dato puede ser una fotografía, una lámina de una excavación arqueológica, un sonido captado en una determinada atmósfera, etc. Por lo tanto, el principal reto es que todo el mundo entienda qué es un dato y que su dato puede ser valioso para otros.
¿Y cómo lo solucionamos? Intentando hacer mucha formación, mucha sensibilización. En los últimos años, desde el Consorcio, hemos trabajado para formar al personal de curación de datos, el que se dedica a ayudar a los investigadores directamente a fairificar estos datos. También estamos empezando a hacer sensibilización directamente con los investigadores para que usen las herramientas y entiendan un poco todo este nuevo paradigma que es la gestión de datos.
Juan Corrales: En el Consorcio Madroño, hasta noviembre, la única forma de abrir datos era que los investigadores pasaran un formulario con los datos y sus metadatos a los bibliotecarios, y eran los bibliotecarios los que los subían para asegurar que eran FAIR. Desde noviembre, también permitimos a los investigadores que suban los datos directamente al repositorio, pero no se publican hasta que han sido revisados por bibliotecarios expertos, que verifican que los datos y metadatos tienen calidad. Es muy importante que los datos estén bien descritos para que puedan ser fácilmente encontrables, reutilizables e identificables.
En cuanto a los retos, están todos los que ha dicho Mireia - que los investigadores muchas veces no saben que tienen datos- y también, aunque la ANECA ha ayudado mucho con las nuevas obligaciones a que se publiquen datos de investigación, muchos investigadores quieren poner sus datos corriendo en los repositorios, sin tener en cuenta que tienen que ser datos de calidad, que no basta con ponerlos, sino que es importante que esos datos después se puedan reutilizar.
6. ¿Qué actividades y herramientas proporcionáis desde vuestras instituciones u otras similares para ayudar a las organizaciones a alcanzar el éxito en esta tarea?
Juan Corrales: Desde Consorcio Madroño, el propio repositorio que utilizamos, la herramienta donde se suben los datos de investigación, facilita que los datos sean FAIR, porque ya proporciona identificadores únicos, plantillas para los metadatos bastante completas que se pueden personalizar, etc. También tenemos otra herramienta que ayuda a crear los planes de gestión de datos para que los investigadores, para que antes de crear sus datos de investigación, empiecen a planificar cómo van a trabajar con ellos. Eso es algo muy importante y que desde las instituciones europeas se está impulsando desde hace ya mucho, y también desde la Ley de la ciencia y la Estrategia Nacional de Ciencia Abierta.
Después, más que las herramientas, es muy importante también la revisión por parte de bibliotecarios expertos.
Hay otras herramientas que ayudan a evaluar la calidad de un dataset, de los datos de investigación, como son Fair EVA o de F-Uji, pero lo que hemos comprobado es que esas herramientas al final lo que están evaluando más es la calidad del repositorio, del software que se está utilizando, y de los requisitos que estás pidiendo a los investigadores para subir estos metadatos, porque todos nuestros datasets tienen una evaluación bastante alta y bastante similar. Entonces, para lo que sí nos sirven esas herramientas es para mejorar tanto los requisitos que estamos poniendo a nuestros datasets, a nuestros conjuntos de datos, como para poder mejorar las herramientas que tenemos, en este caso el software de Dataverse, que es el que estamos utilizando.
Mireia Alcalá: A nivel de herramientas y actividades vamos a la par, porque con el Consorcio Madroño tenemos relación desde hace años, e igual que ellos tenemos todas estas herramientas que ayudan y facilitan el poner los datos de la mejor manera posible ya desde el principio, por ejemplo, con la herramienta para hacer planes de gestión de datos.
Aquí en el CSUC se ha trabajado también en los últimos años de una manera muy intensa en poder cerrar este gap en el ciclo de vida de los datos, abarcando temas de infraestructuras, almacenaje, cloud, etc. para que, en el momento que se analicen y se gestionen los datos, los investigadores tengan también un sitio donde poder ir. Después del repositorio, ya pasamos a todos los canales y portales que permiten difundir y visibilizar toda esta ciencia, porque no tiene sentido que hagamos repositorios y estén allí a modo de silo, sino que tienen que estar interconectados. Desde hace ya muchos años se ha trabajado muy bien en hacer protocolos de interoperabilidad y en seguir los mismos estándares. Por lo tanto, los datos tienen que estar disponibles en otros sitios, y tanto el Consorcio Madroño como nosotros estamos en todos los sitios posibles y más.
7. ¿Nos podéis contar un poco más sobre estos repositorios que ofrecéis? Además de ayudar a los investigadores a poner sus datos a disposición de la ciudadanía, también ofrecéis un espacio, unos repositorios digitales donde albergar estos datos, para que puedan ser localizados por los usuarios.
Mireia Alcalá: Si hablamos específicamente de datos de investigación, como tenemos un mismo repositorio tanto el Consorcio Madroño como nosotros, vamos a dejar que Juan nos explique el software y las especificaciones, y yo me voy a centrar en otros repositorios de producción científica que también ofrece el CSUC. Aquí lo que hacemos es coordinar diferentes repositorios cooperativos según la tipología del recurso que contiene. Por lo tanto, tenemos TDX para tesis, RECERCAT para documentos de investigación, RACO para revista científicas o MACO, para monografías en acceso abierto. En función de tipo de producto, disponemos de un repositorio concreto, porque no todo puede estar en un mismo sitio ya que cada output de la investigación tiene unas particularidades diferentes. Aparte de los repositorios, que son cooperativos, también tenemos otros espacios que hacemos para instituciones concretas, ya sea con una solución más estándar o algunas funcionalidades más personalizadas. Pero básicamente es esto: tenemos para cada tipo de output que hay en la investigación, un repositorio específico que se adapta a cada una de las particularidades de estos formatos.
Juan Corrales: En el caso de Consorcio Madroño, nuestro repositorio se llama e-cienciaDatos, pero está basado en el mismo software que el repositorio del CSUC, que es el Dataverse. Es un software de código abierto, con lo cual puede ser mejorado y personalizado. Aunque en principio el desarrollo está gestionado desde la Universidad de Harvard, en Estados Unidos, estamos participando en su desarrollo instituciones de todo el mundo -no sé si treinta y tantos países hemos participado ya en su desarrollo-.
Entre otras cosas, por ejemplo, las traducciones al catalán la han hecho desde el CSUC, la traducción al español la hemos hecho desde el Consorcio Madroño y también hemos participado en otros pequeños desarrollos. La ventaja que tiene este software es que facilita mucho que los datos sean FAIR y compatible con otros puntos que tienen mucha más visibilidad, porque, por ejemplo, el CSUC es mucho más grande, pero en el Consorcio Madroño estamos seis universidades, y es raro que alguien vaya a buscar un dataset en el Consorcio Madroño, en e-cienciaDatos, directamente. Lo normal es que lo busquen desde Google o un portal europeo o internacional. Con estas facilidades que tiene Dataverse, lo pueden buscar desde cualquier sitio y pueden terminar encontrando los datos que tenemos en el Consorcio Madroño o en el CSUC.
8. ¿Qué otras plataformas con datos en abierto de investigaciones, a nivel español o europeo, recomiendan?
Juan Corrales: Por ejemplo, a nivel español está la FECYT, la Fundación Española de Ciencia y Tecnología, que tiene un recolector que recoge los datos de investigación de todas las instituciones españolas prácticamente. Ahí aparecen todas las publicaciones de todas las instituciones: de Consorcio Madroño, de CSUC y muchísimas más.
Luego, en concreto para datos de investigación, hay muchas investigaciones que conviene ponerlas en un repositorio temático, porque es donde van a buscar los investigadores de esa rama de la ciencia. Tenemos alguna herramienta que ayuda a elegir el repositorio temático. A nivel europeo está Zenodo, que tiene mucha visibilidad, pero no tiene el apoyo de calidad de los datos del CSUC o el Consorcio Madroño. Y eso es algo que se nota muchísimo a nivel de reutilización después.
Mireia Alcalá: A nivel nacional, fuera de las iniciativas de Consorcio Madroño y la nuestra, los repositorios de datos aún no están muy extendidos. Conocemos algunas iniciativas en desarrollo, pero todavía es pronto para ver sus resultados. Sin embargo, sí que conozco algunas universidades que han adaptado sus repositorios institucionales para poder también añadir datos. Y aunque esto es una solución válida para aquellas que no tengan más opción, se ha visto que los softwares utilizados en repositorios que no están diseñados para gestionar las particularidades de los datos - que puede ser la heterogeneidad, el formato, la diversidad, el gran tamaño, etc.-. quedan un poco cojos. Después, como decía Juan, a nivel europeo, sí que está establecido que Zenodo es el repositorio multidisciplinario y multiformato, que nace a raíz de un proyecto europeo de la Comisión. Coincido con él que, como es un repositorio de autoarchivo y autopublicación - es decir, yo Mireia Alcalá puedo ir en cinco minutos, poner cualquier documento que tengo allí, nadie se lo ha mirado, pongo los mínimos metadatos que me piden y lo publico-, está claro que la calidad es muy variable. Hay cosas que realmente son utilizables y están perfectas, pero hay otras que necesitan un poco más de cariño.
Como decía Juan, también a nivel disciplinar es importante destacar que, en todas esas áreas que tengan un repositorio disciplinar, los investigadores tienen que ir allí, porque es donde van a poder usar sus metadatos más adecuados, donde todo el mundo trabajará de la misma manera, donde todo el mundo sabrá dónde buscar esos datos… Para quien tenga interés existe un directorio que se llama re3data, que es básicamente un directorio de todos estos repositorios multidisciplinares y disciplinares. Por lo tanto, es un buen sitio para quien tenga interés y no conozca qué hay en su disciplina. Que vaya allí, que es un buen recurso.
9. ¿Qué acciones consideráis como prioritarias a realizar desde las instituciones públicas de cara a promover el conocimiento abierto?
Mireia Alcalá: Yo básicamente lo que diría es que las instituciones públicas deben centrarse en hacer y establecer políticas claras sobre ciencia abierta, porque es verdad que hemos avanzado mucho en los últimos años, pero hay veces que los investigadores están un poco desconcertados. Y aparte de las políticas, sobre todo es ofrecer incentivos a toda la comunidad investigadora, porque hay mucha gente que está haciendo el esfuerzo de cambiar su manera de trabajar para impregnarse de la ciencia abierta y a veces no ve cómo revierte todo ese esfuerzo de más que está haciendo en cambiar su manera de trabajar para hacerlo de esta manera. O sea que yo diría esto: políticas e incentivos.
Juan Corrales: Desde mi punto de vista, las políticas teóricas que tenemos ya a nivel nacional, a nivel autonómico, suelen ser bastante correctas, bastante buenas. El problema es que muchas veces no se ha intentado hacerlas cumplir. Hasta ahora, por lo que hemos visto por ejemplo con la ANECA -que ha promocionado el uso de los repositorios de datos o de artículos de investigación-, no se han empezado a utilizar de forma masiva realmente. O sea, que los incentivos son necesarios, que no sea solamente por obligación. Hay que convencer, como ha dicho también Mireia, a los investigadores, que vean como algo suyo el publicar en abierto, que es algo que les beneficia tanto a ellos como a toda la sociedad. Lo que creo que eso más importante es eso: la concienciación a los investigadores.
Clips de la entrevista
1. ¿Por qué deben universidad e investigadores compartir sus estudios en formatos abiertos?
2. ¿Qué requisitos debe cumplir una investigación para que se considere abierta?
Blog
La ciencia ciudadana se está consolidando como una de las fuentes de referencia más relevantes en la investigación contemporánea. Así lo reconoce el Centro Superior de Investigaciones Científicas (CSIC) que define la ciencia ciudadana como una metodología y un medio para el fomento de la cultura científica en la que confluyen estrategias propias de la ciencia y de la participación ciudadana.
Ya hablamos hace un tiempo de la importancia que la ciencia ciudadana tenía en la sociedad. Hoy en día, los proyectos de ciencia ciudadana no solo han aumentado en número, diversidad y complejidad, sino que también han impulsado un significativo proceso de reflexión sobre cómo la ciudadanía puede contribuir activamente a la generación de datos y conocimiento.
Para llegar a este punto, programas como Horizonte 2020, que reconocía explícitamente la participación ciudadana en ciencia, han jugado un papel fundamental. Más en concreto, el capítulo "Ciencia con y para la sociedad” dio un importante empuje a este tipo de iniciativas en Europa y también en España. De hecho, a raíz de la participación española en dicho programa, así como en iniciativas paralelas, los proyectos españoles han ido aumentando su envergadura y las conexiones con iniciativas internacionales.
Este creciente interés por la ciencia ciudadana también se traduce en políticas concretas. Ejemplo de ello es la actual Estrategia Española de Ciencia, Tecnología e Innovación (EECTI), para el periodo 2021-2027 que incluye “la responsabilidad social y económica de la I+D+I a través de la incorporación de la ciencia ciudadana”.
En definitiva, comentamos hace un tiempo, las iniciativas de ciencia ciudadana buscan incentivar una ciencia más democrática, que responda a los intereses de toda la ciudadanía y que genere información que se pueda reutilizar en pro de la sociedad. A continuación, mostramos algunos ejemplos de proyectos de ciencia ciudadana que ayudan a recolectar datos cuya reutilización puede tener un impacto positivo en la sociedad:
Proyecto AtmOOs Academic: Educación y ciencia ciudadana sobre contaminación atmosférica y movilidad.
En este programa, Thigis desarrolló una prueba piloto de ciencia ciudadana sobre movilidad y medio ambiente con los alumnos de un colegio del distrito del Eixample de Barcelona. Este proyecto, que ya es replicable en otros centros educativos, consiste en recoger datos de patrones de movilidad del alumnado para analizar cuestiones relacionadas con la sostenibilidad.
En la web de AtmOOs Academic se pueden visualizar los resultados de todas las ediciones que llevan realizándose anualmente desde el curso 2017-2018 y muestran información sobre los vehículos que emplean los alumnos para ir a clase o las emisiones generadas según etapa escolar.
WildINTEL: Proyecto de investigación sobre el monitoreo de vida en Huelva
La Universidad de Huelva y la Agencia Estatal de Investigaciones Científicas (CSIC) colaboran para construir un sistema de monitoreo de vida silvestre para obtener las variables esenciales de biodiversidad. Para llevarlo a cabo, se utilizan cámaras de fototrampeo de captura remota de datos e inteligencia artificial.
El proyecto WildINTEL se centra en el desarrollo de un sistema de monitoreo que sea escalable y reproducible, facilitando así la recolección y gestión eficiente de datos sobre biodiversidad. Este sistema incorporará tecnologías innovadoras para proporcionar estimaciones demográficas precisas y objetivas de las poblaciones y comunidades.
A través de este proyecto, que empezó en diciembre de 2023 y seguirá ejecutándose hasta diciembre de 2026, se espera conseguir herramientas y productos para mejorar la gestión de la biodiversidad no solo en la provincia de Huelva sino en toda Europa.
IncluScience-Me: Ciencia ciudadana en el aula para impulsar la cultura científica y la conservación de la biodiversidad.
Este proyecto de ciencia ciudadana que combina educación y biodiversidad surge de la necesidad de abordar la investigación científica en las escuelas. Para ello, el alumnado toma el rol de persona investigadora para abordar un reto real: rastrear e identificar los mamíferos que habitan en sus entornos cercanos para ayudar a la actualización de un mapa de distribución y, por ende, a su conservación.
IncluScience-Me nace en la Universidad de Córdoba y, en concreto, en el Grupo de Investigación en Educación y Gestión de la Biodiversidad (Gesbio), y ha sido posible gracias a la participación de la Universidad de Castilla-La Mancha y el Instituto de Investigación en Recursos Cinegéticos de Ciudad Real (IREC), con la colaboración de la Fundación Española para la Ciencia y la Tecnología - Ministerio de Ciencia, Innovación y Universidades.
La Memoria del Rebaño: Corpus documental de la vida pastoril.
Este proyecto de ciencia ciudadana que lleva activo desde julio de 2023 tiene como objetivo recabar conocimientos y experiencias de pastores y pastoras, en activo y jubilados, sobre el manejo de rebaños y la actividad ganadera.
La entidad responsable del programa es el Institut Català de Paleoecología Humana i Evolució Social aunque también colaboran el Museu Etnogràfic de Ripoll, Institució Milà i Fontanals-CSIC, Universidad Autònoma de Barcelona y Universidad Rovira i Virgili.
A través del programa, se ayuda a interpretar el registro arqueológico y contribuye a conservar los conocimientos de la práctica pastoril. Además, pone en valor la experiencia y los conocimientos de las personas mayores, un trabajo que contribuye a acabar con la connotación negativa de la “vejez” en una sociedad que prima la “juventud”, es decir, que pasen de ser considerados sujetos pasivos a ser considerados sujetos sociales activos.
Plastic Pirates España: Estudio de la contaminación por plástico en ríos europeos.
Es un proyecto de ciencia ciudadana que se ha llevado a cabo durante el último año con jóvenes de entre 12 y 18 años de las comunidades de Castilla y León y Cataluña pretende contribuir a generar evidencias científicas y concienciación ambiental sobre los residuos plásticos en los ríos.
Para ello, grupos de jóvenes de diferentes centros educativos, asociaciones y agrupaciones juveniles, han participado en campañas de muestreo donde se recogen datos de la presencia de residuos y basuras, principalmente plásticos y microplásticos en las riberas y agua de los ríos.
En España este proyecto lo ha coordinado el Centro Tecnológico BETA de la Universidad de Vic - Universidad Central de Cataluña junto a la Universidad de Burgos y la Fundación Oxígeno. Puedes acceder a más información en su página web.
Estos son algunos ejemplos de proyectos de ciencia ciudadana. Puedes consultar más en el Observatorio de Ciencia Ciudadana en España, una iniciativa que recoge múltiples recursos didácticos, informes y más información de interés sobre la ciencia ciudadana y su impacto en España. ¿Conoces algún otro proyecto? Mándanoslo a dinamizacion@datos.gob.es y podemos darlo a conocer a través de nuestros canales de difusión.
Blog
Existen una serie de datos muy valiosos, pero que por su naturaleza no se pueden abrir al gran público. Son datos confidenciales sobre los que recaen derechos de terceros que impiden su puesta a disposición a través de plataformas abiertas, pero que pueden ser fundamentales para investigaciones que promuevan avances para toda la sociedad, en campos como el diagnóstico médico, la evaluación de políticas públicas, la detección o enjuiciamiento de infracciones penales, etc.
Para facilitar la extracción de valor de estos datos, respetando la normativa vigente y los derechos vinculados, se han puesto a disposición de los investigadores unos entornos de tratamiento seguro, conocidos como salas seguras. El objetivo es que los investigadores puedan solicitar y, posteriormente, utilizar e integrar los datos contenidos en ciertas bases de datos en poder de organismos para llevar a cabo trabajos con fines científicos de interés público. Todo ello de manera controlada, segura y preservando la privacidad. Por ello, los investigadores e instituciones que tengan acceso a los datos estarán obligados a guardar absoluta reserva sobre los mismos y a no difundir ninguna información identificable.
En este contexto, el Instituto Nacional de Estadística (INE), la Agencia Estatal de Administración Tributaria (AEAT), distintas instancias de la Seguridad Social, el Servicio Público de Empleo Estatal (SEPE) y el Banco de España han firmado un convenio para dinamizar el acceso controlado a este tipo de datos. El acuerdo se enmarca en la estrategia de la Unión Europea y el Reglamento de Gobernanza de Datos (Data Governance Act o DGA en inglés), como te contamos en este artículo. Una de las ventajas de este convenio es que facilita el cruce de datos de diferentes organismos a través de Es_Datalab.
Es_Datalab, acceso conjunto a múltiples bases de datos
ES_DataLab es un laboratorio de microdatos restringido para investigadores que desarrollan proyectos con fines científicos y de interés público. El acceso a los microdatos se da en un entorno que garantiza la confidencialidad de la información, ya que no permite la identificación directa de las unidades, procedentes de distintas bases de datos.
Para acceder a este entorno se debe realizar una solicitud que se describe aquí y el acceso solo será válido durante el periodo especificado que dure la investigación. El proceso es el siguiente:
- El investigador debe ser reconocido como "entidad de investigación". Actualmente existe un registro de entidades (universidades, institutos de investigación, departamentos de investigación de administraciones públicas, etc.) que se irá ampliando a medida que nuevos organismos soliciten su incorporación.
- Una vez acreditada, la entidad debe solicitar el acceso a los microdatos, para lo cual es necesario presentar una propuesta de investigación.
A través de Es_ Datalab, se puede acceder a diversos microdatos, recogidos en este enlace. En este sentido, ES_Datalab facilita el cruce de bases de datos de las instituciones participantes, maximizando el valor que los datos pueden ofrecer al desarrollo de la investigación.
A continuación, te mostramos algunos ejemplos de los datos ofrecidos por cada uno de los organismos, ya sea a través de ES_datalab para su cruce con otras fuentes, o en sus propios entornos de tratamiento seguro.
Instituto Nacional de Estadística
Actualmente pone a disposición microdatos relativos conjuntos de datos del INE, entre los que se encuentran:
- Resultados de encuestas que recogen información sobre la inserción laboral de titulados universitarios, la estructura salarial, la población activa, las condiciones de vida, la salud en España, etc.
- Estadísticas sobre diversos aspectos sociales y económicos, como matrimonios o defunciones, actividades de protección medioambiental, filiales de empresas en el exterior, etc.
- Censos, tanto generales de población como por actividades económicas (por ejemplo, el censo agrario).
El INE, a su vez, cuenta con su propia sala segura que facilita el acceso a datos confidenciales para la realización de análisis estadísticos con fines científicos de interés público.
Agencia Estatal de la Administración Tributaria
Los microdatos relativos a las bases de datos que la AEAT ofrece incluyen información detallada sobre:
- Datos sobre las principales partidas contenidas en diversos modelos, como por ejemplo el modelo 100, relativo a la declaración anual del IRPF, el modelo 576, sobre matriculaciones de vehículos, o el modelo 714, del Impuesto sobre patrimonio, entre otros.
- Estadísticas de comercio exterior, con datos tanto totales como segmentados por sector de actividad.
También cabe destacar la aportación del Instituto de Estudios Fiscales, que se nutre de datos de la Agencia Estatal de la Administración Tributaria. Ligado al Ministerio de Hacienda, ha puesto a disposición de los ciudadanos un Área de estadística del Instituto de Estudios Fiscales, así como su propia sala segura. Entre sus bases de datos destacan, por ejemplo, las muestras de IRPF, los paneles de hogares, los paneles de renta o la base de datos económicos del sector español (BADESPE). La descripción de los productos y el protocolo de petición de datos se encuentra disponible aquí.
Seguridad Social
La Seguridad Social concede acceso a microdatos que hacen referencia a bases de datos como:
- La Muestra Continua de Vidas Laborales (MCVL), que incluye datos individuales, actuales e históricos, de bases de cotización, afiliaciones (vida laboral), pensiones, convivientes, Impuesto sobre la Renta de Personas Físicas (IRPF), etc.
- Los afiliados a la Seguridad Social con información mensual de relaciones laborales, por fechas de alta y baja de empresas, tipo de contrato, colectivo, régimen, provincia, etc.
- Las prestaciones reconocidas en el ejercicio anterior, que incluye pensiones de jubilación, incapacidad permanente, incapacidad temporal y nacimiento y cuidado del menor.
- Otras bases de datos como diversas liquidaciones presupuestarias, los expedientes de regulación temporal de empleo (ERTE) por COVID-19, los reconocimientos médicos del Instituto Social de la Marina (ISM) o datos sobre la formación marítima de estudiantes.
Las salas seguras de la Seguridad Social, disponibles en Madrid, Barcelona y Albacete, permiten el tratamiento de esta y otra información protegida ofreciendo acceso a una serie de puestos seguros con diversos programas y lenguajes de programación (SAS, STATA, R, Python y LibreOffice). También se permite el acceso remoto a través de dispositivos seguros (llamados “dispositivos bastionados”) que se distribuyen entre los investigadores.
Gracias a estos datos se han podido realizar estudios sobre el impacto de la edad de Jubilación sobre la mortalidad o el uso de los permisos de paternidad en España.
Banco de España
También encontramos en Es_Datalab microdatos relativos al Banco de España y a bases de datos como:
- Bases de datos sobre empresas, con información sobre empresas individuales, grupos empresariales no financieros consolidados o la estructura de grupos empresariales.
- Datos macroeconómicos, como la deuda del sector público o los préstamos a personas jurídicas.
- Otros datos relativos a indicadores de sostenibilidad o el panel de hogares.
BELab es el laboratorio de datos protegidos gestionado por el Banco de España, que ofrece acceso in situ (Madrid) y en remoto. Sus datos han permitido el desarrollo de proyectos sobre los efectos del salario mínimo interprofesional en las empresas españolas, la gestión de la tecnología en el sector textil o el machine learning aplicado al riesgo de crédito, entre otros. Puedes conocer todos los proyectos aquí, tanto los finalizados como los que todavía están en marcha.
Impulso a la reutilización de datos gracias al Reglamento de Gobernanza de Datos
Todas estas medidas forman parte del planteamiento y procesos armonizados llevado a cabo en ejecución de las previsiones del Reglamento de Gobernanza de Datos (Data Governance Act o DGA en inglés) para facilitar y fomentar la utilización con fines de investigación científica de los datos que obren en poder de los organismos del sector público, por razones de interés público. Asimismo, a fin de incentivar la reutilización de categorías específicas de datos que obren en poder de organismos del sector público, se ha habilitado en datos.gob.es el “Punto Único de Información Nacional” (NSIP por sus siglas en inglés), gestionado por la Dirección General del Dato.
Con ello, se busca contribuir al avance de la investigación científica en nuestro país, al tiempo que se protege la confidencialidad de los datos sensibles. Las Salas Seguras son un recurso importante para la reutilización de datos protegidos en poder del sector público. Permiten un tratamiento controlado de la información, preservan la privacidad y otros derechos vinculados a los datos, al mismo tiempo que facilitan el cumplimiento del Reglamento de Gobernanza de Datos europeo.
Blog
IMPaCT, la Infraestructura de Medicina de Precisión asociada a la Ciencia y la Tecnología, es un programa innovador que busca revolucionar la atención médica. Coordinado y financiado por el Instituto de Salud de Carlos III su objetivo es impulsar el despliegue efectivo de la medicina personalizada de precisión.
La medicina personalizada es un enfoque médico que reconoce que cada paciente es único. A través del análisis de las características genéticas, fisiológicas y de estilo de vida de cada persona, se realizan tratamientos a medida más eficientes y seguros, con menos efectos secundarios. El acceso a esta información, además, es clave para avanzar en prevención y detección temprana, así como en investigación y avances médicos.
IMPaCT consta de 3 ejes estratégicos:
- Eje 1 Medicina predictiva: Programa COHORTE. Es un proyecto de investigación epidemiológica que consiste en el desarrollado y puesta en marcha de una estructura para el reclutamiento de 200.000 personas para que participen en un estudio prospectivo.
- Eje 2 Ciencia de datos: Programa DATA. Es un programa enfocado en el desarrollo de un sistema común, interoperable e integrado, de recogida y análisis de datos clínicos y moleculares. A través de él se elaboran criterios, técnicas y buenas prácticas para la recolección de información de historias clínicas electrónicas, imágenes médicas y datos genómicos.
- Eje 3 Medicina genómica: Programa GENÓMICA. Es una infraestructura cooperativa para el diagnóstico de enfermedades raras y genéticas. Entre otras cuestiones, elabora procedimientos normalizados para el correcto desarrollo de los análisis genómicos y la gestión de los datos obtenidos, así como para la estandarización y homogeneización de la información y los criterios empleados.
Además de estos ejes, existen dos líneas estratégicas transversales: una centrada en la ética e integridad científica y otra en la internacionalización, como se resume en el siguiente visual.

Fuente: IMPaCT-Data
A continuación, nos vamos a centrar en el funcionamiento y resultados de IMPaCT-Data, el proyecto ligado al eje 2.
IMPaCT-Data, un entorno integrado para el análisis de datos interoperables
IMPaCT-Data se orienta al desarrollo y validación de un entorno de integración y análisis conjunto de datos clínicos, moleculares y genéticos, para su uso secundario, con el objetivo final de facilitar la implementación eficaz y coordinada de la medicina personalizada de precisión en el Sistema Nacional de Salud. Actualmente está formado por un consorcio de 45 entidades asociadas por un convenio con vigencia hasta el 31 de diciembre de 2025.
A través de este programa, se busca la creación de una infraestructura en la nube de datos médicos para investigación, así como de los protocolos necesarios para coordinar, integrar, gestionar y analizar dichos datos. Para ello se sigue una hoja de ruta con los siguientes objetivos técnicos:

Fuente: IMPaCT-Data.
Resultados de IMPaCT-Data
Como vemos, esta infraestructura, aún en desarrollo, ofrecerá un entorno de investigación virtual para el análisis de los datos a través de diversos servicios y productos:
- Nube federada IMPaCT-Data. Incluye el acceso a datos públicos y de acceso controlado, así como herramientas y flujos de trabajo para el análisis de datos genómicos, historias clínicas e imágenes. En este vídeo se muestra cómo se realiza el acceso de usuarios federado y la ejecución de trabajos mediante el uso de recursos computacionales compartidos. Esto permite visualizar y acceder a los resultados en formato HTML y en crudo, así como a sus metadatos. Aquellos que quieran profundizar en las opciones de acceso de usuario, pueden ver este otro vídeo, donde se muestra la vinculación de las cuentas institucionales a la cuenta IMPaCT-Data y el uso de pasaportes y visados para el acceso local a datos protegidos.
- Recopilación de herramientas software para el análisis de los datos de IMPaCT-Data. Estas herramientas son de acceso público a través del dominio IMPaCT-Data en bio.tools, un registro de componentes software y bases de datos dirigido a investigadores en el campo de las ciencias biológicas y biomédicas. Incluye herramientas muy diversas. Por un lado, encontramos soluciones generales, por ejemplo, enfocadas en la privacidad a través de acciones relacionadas con la desidentificación y anonimización de datos (FAIR4Health Data Privacy Tool). Por otro, hay herramientas concretas, centradas en cuestiones muy específicas, como el metaanálisis de la expresión génica (ImaGEO).
- Guías con recomendaciones y buenas prácticas para la recolección de información médica. Actualmente hay tres guías disponibles: “Recomendaciones de IMPaCT-Data sobre datos y software”, “Consideraciones adicionales de IMPaCT-Data a la convocatoria para proyectos IMPaCT 2022” y “Recomendaciones de IMPaCT-Data sobre datos y software”.
A ellos hay que sumar diversos entregables relacionados con aspectos técnicos del proyecto, como comparaciones de técnicas o pruebas de concepto, así como publicaciones científicas.
Impulsando casos de uso a través de demostradores
Uno de los objetivos de IMPaCT-Data es contribuir a la evaluación de tecnologías asociadas a los desarrollos del proyecto, a través de un ecosistema de demostradores. Con ello se busca favorecer las aportaciones de empresas, entidades y grupos académicos para impulsar mejoras y conseguir la implementación del proyecto a gran escala.
Para cumplir este objetivo, se organizan distintas actividades donde se evalúan componentes concretos en colaboración con miembros de IMPaCT-Data. Un ejemplo es el servidor de terminologías ORBITS para la codificación de fenotipos clínicos en códigos HPO (Human Phenotype Ontology), dirigido a extraer y codificar de manera automática información contenida en reportes clínicos no estructurados usando procesamiento del lenguaje natural. Para ello utiliza la terminología HPO, cuyo objetivo es estandarizar la recopilación de datos fenotípicos, haciéndolos accesibles para el posterior análisis.
Otro ejemplo de demostradores hace referencia a la compartición de datos médicos virtualizados entre diferentes centros para proyectos de investigación, dentro de un entorno gobernado, eficiente y seguro, donde se cumplen todos los estándares de calidad de datos definidos por cada entidad.
Un proyecto estratégico alineado con Europa
IMPaCT-Data se enmarca directamente en la Estrategia nacional para el uso secundario de los datos del sistema de salud nacional, descrita en el PERTE de salud (Proyectos estratégicos para la recuperación y transformación económica), siendo sus conocimientos, experiencia y aportaciones muy valiosa de cara al desarrollo del Espacio Nacional de datos de Salud.
Además, los desarrollos de IMPaCT-Data está directamente alineados con las líneas maestras propuestas por GAIA-X, tanto a nivel general como en el entorno específico de salud.
El impacto del proyecto en Europa queda patente, también, en su participación en el proyecto Europeo GDI (Genomic Data Infrastructure), que busca facilitar el acceso a datos genómicos, fenotípicos y clínicos en toda Europa, donde se está usando IMPaCT-Data como instrumento a nivel nacional.
Todo ello pone de manifiesto que gracias a IMPaCT-Data se podrán impulsar proyectos de investigación en biomedicina no solo en España, sino también en Europa, contribuyendo de este modo a la mejorar la salud pública y el tratamiento individualizado de los pacientes.
Blog
En el sector médico, el acceso a la información puede transformar vidas. Este es uno de los principales motivos por los que las comunidades de compartición y apertura de datos o la ciencia abierta ligada a la investigación médica se han convertido en un recurso muy valioso. Los grupos de investigación médica que abogan por el uso y reutilización de datos dirigen esta transformación, impulsando la innovación, mejorando la colaboración y acelerando el avance de la ciencia.
Como vimos en el caso de la Fundación FISABIO los datos abiertos en el sector salud fomentan la colaboración entre investigadores, aceleran el proceso de validación de resultados en estudios y, en definitiva, ayudan a salvar vidas. Esta tendencia no solo facilita descubrimientos más rápidos, sino que también ayuda a crear soluciones más eficaces. En España, el Consejo Superior de Investigación Científicas (CSIC) apuesta por la apertura de datos y algunos reconocidos hospitales también comparten los resultados de sus investigaciones protegiendo los datos sensibles de sus pacientes.
En este post, exploraremos cómo los grupos de investigación y comunidades de salud están compartiendo y reutilizando datos para impulsar investigaciones pioneras y expondremos casos de uso más inspiradores. Desde el desarrollo de nuevos tratamientos hasta la identificación de tendencias en salud pública, los datos están redefiniendo el panorama de la investigación médica y abriendo nuevas oportunidades para mejorar la salud global.
Grupos de investigación médica que apuestan el trabajo con datos compartidos
En España, existen diversos grupos de investigación y comunidades que comparten sus descubrimientos de manera más libre a través de plataformas y bases de datos que facilitan la colaboración global y la reutilización de datos en el campo de la salud. A continuación, destacamos algunos de los casos más influyentes, demostrando cómo el acceso a la información puede acelerar el progreso científico y mejorar los resultados en salud.
-
H2O – Health Outcomes Observatory: repositorio de datos clínicos
H2O es una asociación estratégica entre el sector público y privado para crear un sólido modelo de infraestructura y gobernanza de datos que permita recopilar e incorporar los resultados de los pacientes a escala en la toma de decisiones sanitarias a nivel individual y poblacional. El enfoque de H2O otorga a los pacientes el control definitivo de sus y garantiza que solo ellos ejerzan ese control. En este consorcio participan hospitales de todo el mundo, entre los que se encuentran los españoles Hospital Universitario Fundación Jiménez Díaz o el Hospital Vall d’Hebron. La Unidad de investigación de España recoge los resultados de salud que reportan los pacientes y otros datos clínicos para construir un observatorio que mejore la atención al paciente.
-
Instituto de Salud Carlos III: IMPaCT: proyectos de investigación de ciencia abierta
En el marco de la infraestructura IMPaCT se desarrollan diferentes proyectos aprobados en las ayudas para Proyectos de Investigación de Medicina Personalizada de Precisión de la Acción en Salud:
- Programa COHORTE – Medicina predictiva
- Programa DATA: Ciencia de datos
- Programa GENÓMICA - Medicina genómica
La información, datos, metadatos y productos científicos generados en IMPaCT son de acceso abierto, para hacer la ciencia más accesible, eficiente, democrática y transparente. En este proyecto, participan hospitales e institutos de investigación de toda España.
-
Datos POP Salud: proyecto de investigación médica del Instituto de Salud Carlos III (ISCIII) y la Plataforma de Organizaciones de Pacientes (POP)
Es un proyecto de datos desarrollado colaborativamente entre ISCIII y POP para mejorar el conocimiento y evidencia sobre la realidad clínica, laboral y social de los pacientes crónicos, sin duda algo crucial para nosotros. En esta iniciativa participan 36 organizaciones nacionales de pacientes, 16 sociedades científicas y 3 administraciones públicas, entre los que destacan el Ministerio de Derechos Sociales y Agenda 2030, el Instituto de Salud Carlos III y la Agencia Española de Medicamentos y Productos Sanitarios.
-
Iniciativa Europea de Imagen de Cáncer: proyecto europeo para obtener imágenes oncológicas y apoyar en la investigación contra el cáncer.
Uno de los objetivos del Plan Europeo de Lucha contra el Cáncer es aprovechar al máximo el potencial de los datos y las tecnologías digitales como la inteligencia artificial (IA) o la informática de alto rendimiento (HPC). La piedra angular de la iniciativa será una infraestructura europea federada para datos de imágenes de cáncer, desarrollada por la Federación Europea de IMages CAncer (EUCAIM). El proyecto comienza con 21 centros clínicos de 12 países entre los que se encuentran 4 centros españoles situados en Valencia, Barcelona, Sevilla y Madrid.
-
4CE: Consorcio de investigación
Es un consorcio internacional para el estudio de la pandemia de COVID-19 a partir de los datos de la historia clínica electrónica (HCE). El objetivo del proyecto -dirigido por el grupo internacional de usuarios académicos i2b2 -es informar a médicos, epidemiólogos y al público en general sobre los pacientes de COVID-19 con datos adquiridos a través del proceso de atención sanitaria. La plataforma ofrece datos agregados que están disponibles en la propia web del proyecto divididos entre datos de adultos y datos pediátricos. En ambos casos, los datos deben de ser utilizados con fines académicos y de investigación; el proyecto no permite el uso de los datos para orientación médica o diagnóstico clínico.
En conclusión, la apuesta por la compartición y reutilización de datos en la investigación médica está demostrando ser un catalizador fundamental para el avance científico y la mejora de la salud pública. A través de iniciativas como H2O, IMPaCT, y la Iniciativa Europea de Imagen de Cáncer, vemos cómo la accesibilidad en la gestión de datos está redefiniendo la forma en que abordamos la investigación y el tratamiento de enfermedades.
La integración de prácticas de análisis de datos promete un futuro donde la innovación en salud se logre de manera más rápida, equitativa y eficiente, ofreciendo así mejores resultados para los pacientes a nivel global.