Blog
La construcción del ecosistema de uso secundario de los datos de salud electrónica en el Espacio Europeo de Datos de Salud (EEDS) plantea un escenario significativo de oportunidades para la investigación española, para la innovación y el emprendimiento. Para ello, la Unión Europea está impulsando multitud de proyectos estratégicos en los que participan hospitales, fundaciones de investigación sanitaria, universidades, centros de investigación y empresas españolas. La lista de proyectos es extensa y atiende a satisfacer al menos dos objetivos: potenciar la generación de infraestructuras capaces de generar conjuntos de datos de calidad y promover condiciones para su reutilización.
El papel de España. Fortalezas en el despliegue del Espacio Europeo de Salud
España ofrece condiciones significativamente favorables no sólo para participar sino también para contribuir significativamente a las tareas de creación del EEDS:
- En primer lugar, nuestro sistema público de salud se caracteriza por un alto nivel de integración y estructuración. A diferencia de los sistemas basados en mecanismos de reembolso, en los que puede existir una atomización en el ámbito de la provisión de servicios, en nuestro sistema disponemos de un marco de referencia clara en atención primaria, especialidades médicas y servicios hospitalarios.
- Por otra parte, la experiencia desplegada por nuestros entornos de salud a partir del Reglamento General de Protección de Datos (RGPD) y, particularmente, las lecciones aprendidas a partir de la disposición adicional decimoséptima sobre tratamientos de datos de salud de la Ley Orgánica 3/2018, de 5 de diciembre, de Protección de Datos Personales y garantía de los derechos digitales (LOPDGDD) constituyen una experiencia valiosa.
- La apertura del Espacio Nacional de Datos de Salud promovido por el Gobierno de España e impulsado por el Ministerio para la Transformación Digital y de la Función Pública, el Ministerio de Sanidad y las Comunidades Autónomas permite el despliegue de una infraestructura esencial para el EEDS.
El Espacio Nacional de Datos de Salud se presentó el pasado 29 de enero. En el evento se resaltó cómo este proyecto representa un cambio de paradigma que revoluciona la gestión del dato sanitario, impulsando un modelo federado, seguro y ético que preserva la soberanía y privacidad de la información mientras facilita su uso para investigación, innovación y políticas públicas. Su funcionamiento se basa en un catálogo federado de metadatos y un riguroso proceso de acceso y análisis en entornos seguros, que busca potenciar la ciencia abierta y los avances científicos y tecnológicos, beneficiando a pacientes, investigadores, gestores e industria.
Lecciones aprendidas desde los Proyectos Europeos
El camino que arranca el Reglamento (UE) 2025/327 del Parlamento Europeo y del Consejo, de 11 de febrero de 2025, relativo al Espacio Europeo de Datos de Salud, y por el que se modifican la Directiva 2011/24/UE y el Reglamento (UE) 2024/2847 (EEDSR) plantea retos significativos que se abordan en los proyectos de investigación financiados con fondos europeos y nacionales. Las lecciones aprendidas en algunos de ellos pueden ser de extraordinaria utilidad para la comunidad investigadora y de emprendimiento en nuestro país. No podemos olvidar que partimos de fortalezas significativas.
1.-Cumplimiento desde el diseño
La existencia de una nueva normativa obliga a desplegar un análisis riguroso del estado del arte en nuestras organizaciones, no sólo para implementar su despliegue sino también para asegurar las condiciones previas de confiabilidad legal de los conjuntos de datos y de la investigación que se proponga.
2.-Accountability: responsabilidad proactiva y solidez documental
En nuestro país venimos de una larga tradición de “accountability”. El EEDSR va a imponer al solicitante de datos un conjunto de requisitos documentales relevantes, como, por ejemplo, haber previsto las garantías para prevenir cualquier uso indebido de los datos de salud electrónicos. Esta cuestión tampoco podrá descuidarse desde el punto de vista de los tenedores de datos, quienes también tendrán que cumplir algunos requisitos. Por ejemplo, demostrar que los datos son legítimos y reutilizables es una cuestión ética y jurídicamente documentable; y el procedimiento simplificado para el acceso a los datos de salud electrónicos a través de un tenedor fiable de datos de salud obliga a este a documentar la seguridad de su espacio de datos o las capacidades para evaluar las solicitudes de acceso a datos de salud.
Uno de los principales escollos a los que nos enfrentamos en este periodo intermedio de implantación del EEDS reside precisamente en la cultura organizativa para la generación de evidencias verificables. A medida que la estandarización y el conjunto de reglas comunes del EEDS escalen será necesario profundizar en la dinámica de la responsabilidad proactiva entendida como responsabilidad demostrada.
3. Entornos seguros de procesamiento
En nuestro país, los entornos de salud por su propia definición deben ser entornos seguros. El despliegue del Esquema Nacional de Seguridad (ENS) y el del RGPD, han permitido que la totalidad del sistema de salud, público o privado, haya adoptado modelos de madurez perfectamente coherentes con las condiciones de los entornos de procesamiento seguro que define el EEDSR.
Retos del sistema español
Junto a las fortalezas inherentes a nuestro sistema, es necesario considerar aquellos aspectos que se presentan como retos.
1. Anonimización y seudonimización
En el contexto nacional la citada disposición adicional decimoséptima de la Ley Orgánica 3/2018, de 5 de diciembre, de Protección de Datos Personales y garantía de los derechos digitales, define condiciones específicas para la seudonimización. Estas consisten en la separación funcional entre los equipos que seudonimizan y los que reutilizan los datos, y en la definición de un entorno seguro que prevenga cualquier intento de reidentificación. A ello se suman garantías jurídicas en términos de compromisos individuales de no reidentificación, despliegue de la herramienta de la evaluación de impacto relativa a la protección de datos y supervisión por comités de ética. El reto de la anonimización se muestra más exigente, ya que implica la imposibilidad de vincular bajo ninguna condición los datos de salud con los del paciente original.
2. Reeskilling de los equipos
El Espacio Europeo de Datos de Salud (EEDS) planteará un desafío formativo sin precedentes que atravesará todos los sectores implicados en el ecosistema de datos sanitarios. Los comités de ética de investigación deberán familiarizarse no solo con los usos secundarios admisibles de los datos de salud, sino también con la integración del Reglamento de Inteligencia Artificial y con los principios éticos del marco ALTAI (Assessment List for Trustworthy Artificial Intelligence). Esta necesidad de reeskilling se extenderá igualmente a los sistemas de salud y la administración sanitaria, donde los organismos de acceso a datos (Health Data Access Bodies) requerirán personal altamente cualificado en estos nuevos marcos éticos y regulatorios, al igual que los tenedores fiables de datos que custodiarán la información sensible. El personal de desarrollo y los equipos de tecnologías de la información también deberán adquirir nuevas competencias en ámbitos técnicos críticos, como la catalogación, validación y curación de datos, así como en los estándares de interoperabilidad que permitan la comunicación efectiva entre sistemas. Quizás el reto de capacitación más delicado recaerá sobre los nuevos operadores, que podrán aprovechar las oportunidades de acceso a conjuntos de datos para usos secundarios innovadores. Esto concierne especialmente a las startups tecnológicas del sector salud. Para enfrentar un marco normativo muy exigente, (RGPD, Regalmento de IA, EEDSR), los recursos y capacidades para el cumplimiento legal (compliance) en las pymes españolas es notablemente limitado. Por ello será necesario construir desde el inicio una cultura sólida de protección de datos y desarrollo ético de sistemas de inteligencia artificial confiables.
3. Catalogación de datos: el desafío de la calidad y la estandarización
En el contexto del Espacio Europeo de Datos de Salud, profundizar en la estandarización de los datos mediante las metodologías más funcionales —como OMOP CDM para datos clínicos observacionales, HL7 FHIR para el intercambio dinámico de información, DICOM para imágenes médicas, o terminologías de referencia como SNOMED CT, LOINC y RxNorm— se presenta como un elemento estratégico fundamental para la creación y reutilización de conjuntos de datos de alta calidad. Sin embargo, la adopción de estos estándares no es suficiente por sí sola: los procesos de validación, anotación semántica y enriquecimiento de datos requieren de recursos humanos altamente cualificados capaces de garantizar la coherencia, completitud y precisión de la información, convirtiéndose esta capacitación en una auténtica precondición para la participación efectiva en el ecosistema europeo de datos de salud. El alineamiento con la catalogación estandarizada de conjuntos de datos siguiendo el estándar HealthDCAT-AP (Health Data Catalog Application Profile), que permite describir de manera homogénea los metadatos descriptivos de los recursos de datos sanitarios, se presenta como uno de los retos inmediatos, junto con la implementación de los trabajos que se vienen desplegando en relación con el data utility quality label, una etiqueta de calidad que evalúa la utilidad real de los datos para usos secundarios y que se está convirtiendo en un sello de confianza para usuarios e investigadores.
Si anteriormente en este artículo se subrayaron las altísimas capacidades del sistema sanitario español para generar datos de salud de manera sistemática y en volúmenes significativos, estos aspectos de catalogación, estandarización y certificación de calidad ocuparán un lugar absolutamente central para diseñar condiciones óptimas de competitividad europea en su reutilización, transformando la abundancia de datos en una verdadera ventaja estratégica que permita a España posicionarse como un actor relevante en el panorama de la investigación y la innovación con datos de salud electrónicos.
La experiencia del proyecto EUCAIM (Cancer Image EU)
El Reglamento del Espacio Europeo de Datos de Salud tiene por objeto permitir el uso secundario de los datos sanitarios electrónicos en toda Europa mediante normas armonizadas en un ecosistema federado. En el ámbito del cáncer, el acceso fragmentado a conjuntos de datos de alta calidad ralentiza la investigación, limita la reproducibilidad y socava la capacidad de Europa para desarrollar y validar herramientas de IA fiables para la oncología.
EUCAIM demuestra la viabilidad de un ecosistema para el uso secundario del cáncer a través de un modelo federado que permite el acceso transfronterizo bajo normas armonizadas garantizando un control adecuado de los recursos a nivel local. Y ello se despliega mediante un conjunto de componentes habilitadores:
1) Un entorno de procesamiento seguro (SPE) federado a nivel europeo
EUCAIM está creando un SPE federado para hacer cumplir las condiciones de acceso a los datos, controlar el procesamiento y apoyar el análisis transfronterizo seguro bajo las restricciones del EEDS. Este SPE se ajusta plenamente a los requisitos y medidas que establece el artículo 73 EEDSR en materia de entornos seguros.
2) Superación de la «barrera de la anonimización»
EUCAIM promueve una estrategia de anonimización por capas que combina procesos de anonimización local autónoma por el tenedor de datos con controles de la plataforma para permitir que los conjuntos de datos sigan siendo útiles para la investigación y el desarrollo de la IA. La importancia de este enfoque radica en que pretende conciliar la protección de la privacidad con la necesidad práctica de disponer de conjuntos con grandes volúmenes de datos caracterizados por su diversidad.
3) Catalogación y estandarización de datos
EUCAIM alinea la catalogación con los principios HealthDCAT-AP cuyo objetivo principal es aplicar los principios FAIR, esto es asegurar que los datos sean encontrables, accesibles, interoperables y reutilizables.
4) Reducción de costes legales
EUCAIM ha desplegado un marco de cumplimiento propio orientado al Reglamento General de Protección de Datos y el Reglamento de Inteligencia Artificial. Para ello, se dispone de un marco sólido de cumplimiento a nivel de una plataforma que se despliega en ecosistemas complejos de datos. Este se basa en evaluaciones de impacto en la protección de datos (incluidas en el RGPD) con especial atención a los derechos fundamentales. También incorpora la formación y el reciclaje profesional de los usuarios como requisito funcional, de modo que la capacidad de cumplimiento se convierta en una característica esencial.
5) Apoyo a los usuarios de datos
EUCAIM ofrece ventajas significativas a los usuarios de datos, incluidos los investigadores y los desarrolladores de IA, al establecer un entorno transparente y bien gobernado para el acceso a los datos. La adopción de criterios de gobernanza transparentes, obligaciones claramente definidas y su aplicación técnica por la plataforma, proporcionan a los usuarios de datos la garantía de que su acceso es adecuado y lícito, totalmente auditable y se mantiene estable a lo largo del tiempo. El diseño de la plataforma garantiza que los usuarios puedan aprovechar datos de gran utilidad para análisis avanzados, incluido el procesamiento federado en un entorno seguro. A través de la formación obligatoria y la implementación de procedimientos estandarizados, los equipos se benefician de una menor incertidumbre y están mejor equipados para alinearse con los requisitos de cumplimiento establecidos por el EEDSR, el RGPD y los marcos de gobernanza de la IA.
6) Garantía de los derechos de los pacientes
El enfoque de EUCAIM se basa en la protección de datos desde el diseño y por defecto que une las salvaguardias organizativas con controles técnicos sólidos. Este marco se ha construido expresamente para minimizar el riesgo de uso indebido de los datos, al tiempo que apoya la investigación y la innovación transfronterizas seguras y eficaces en materia de cáncer. El resultado es un sistema en el que la protección de la privacidad no es un obstáculo sino un elemento fundamental que permite el uso responsable de los datos en beneficio de la sociedad y la ciencia. El modelo refuerza la responsabilidad por el uso secundario de los datos sanitarios mediante la combinación de una sólida supervisión de la gobernanza, un registro exhaustivo de las acciones y obligaciones estrictas y exigibles para todas las entidades participantes. Todas las acciones realizadas con los datos de los pacientes se registran y se someten a revisión, lo que garantiza que todos los usos sean totalmente auditables. Esta trazabilidad garantiza que el tratamiento de los datos se mantenga dentro de los límites del uso permitido y que cualquier desviación pueda identificarse y abordarse rápidamente.
Gobernanza multinivel: la clave del éxito sostenible
La lección aprendida más relevante en EUCAIM se refiere a la necesidad imperiosa de una gobernanza multinivel articulada, coherente y operativa. En sentido amplio, resulta indispensable proporcionar herramientas y marcos de gobierno efectivos sobre tres dimensiones fundamentales:
- En primer lugar, sobre los procesos de generación de conjuntos de datos y sus condiciones de compartición, estableciendo criterios claros sobre qué datos se generan, cómo se estandarizan, quién ostenta derechos sobre ellos y bajo qué licencias y restricciones pueden ser compartidos con terceros.
- En segundo lugar, sobre los procesos de solicitud de acceso a datos, definiendo procedimientos transparentes y eficientes para que investigadores, innovadores y responsables de políticas públicas puedan identificar, solicitar y obtener acceso a los datos necesarios para sus proyectos, minimizando las cargas administrativas sin comprometer las garantías éticas y legales.
- En tercer lugar, sobre los procesos de validación de la corrección de los conjuntos de datos y de adhesión al sistema, así como los procedimientos de autorización de acceso a datos, asegurando que solo datos de calidad certificada alimenten la infraestructura y que únicamente usuarios autorizados y con propósitos legítimos accedan a información sensible.
Esta gobernanza procedimental no puede funcionar sin decisiones estratégicas y operativas en relación con la definición de roles y funciones en materia de recursos humanos. Para ello, es necesario contar con perfiles profesionales necesarios como gestores de datos, expertos en ética de la investigación, especialistas en ciberseguridad, curadores de datos y responsables de calidad. En segundo lugar, será fundamental la definición de los entornos seguros de procesamiento donde se ejecutan análisis sobre datos sensibles, garantizando que estos espacios cumplan con los más altos estándares técnicos de seguridad, trazabilidad, auditoría y preservación de la privacidad, y que estén diseñados para operar bajo el principio de confianza cero (zero trust) adaptado al contexto sanitario. Solo mediante esta arquitectura de gobernanza multinivel, que integre dimensiones técnicas, organizativas, éticas y legales en todos los niveles de decisión —desde el diseño de políticas nacionales hasta la gestión operativa diaria de las plataformas—, será posible construir infraestructuras de datos de salud verdaderamente sostenibles, confiables y capaces de generar valor social, científico y económico a largo plazo, posicionando al sistema sanitario español como un actor estratégico en el ecosistema europeo de innovación en salud.
Contenido elaborado por Ricard Martínez Martínez, Director de la Cátedra de Privacidad y Transformación Digital, Departamento de Derecho Constitucional de la Universitat de València. Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Blog
A medida que las organizaciones buscan aprovechar el potencial de los datos para tomar decisiones, innovar y mejorar sus servicios, surge un desafío fundamental: ¿cómo se puede equilibrar la recolección y el uso de datos con el respeto a la privacidad? Las tecnologías PET intentan dar solución a ese reto. En este post, exploraremos qué son y cómo funcionan.
¿Qué son las tecnologías PET?
Las tecnologías PET son un conjunto de medidas técnicas que utilizan diversos enfoques para la protección de la privacidad. El acrónimo PET viene de los términos en inglés “Privacy Enhancing Technologies” que se pueden traducir como “tecnologías de mejora de la privacidad”.
De acuerdo con la Agencia de la Unión Europea para la Ciberseguridad (ENISA) este tipo de sistemas protege la privacidad mediante:
- La eliminación o reducción de datos personales.
- Evitando el procesamiento innecesario y/o no deseado de datos personales.
Todo ello, sin perder la funcionalidad del sistema de información. Es decir, gracias a ellas se puede utilizar datos que de otra manera permanecerían sin explotar, ya que limita los riesgos de revelación de datos personales o protegidos, cumpliendo con la legislación vigente.
Relación entre utilidad y privacidad en datos protegidos
Para comprender la importancia de las tecnologías PET, es necesario abordar la relación que existe entre utilidad y privacidad del dato. La protección de datos de carácter personal siempre supone pérdida de utilidad, bien porque limita el uso de los datos o porque implica someterles a tantas transformaciones para evitar identificaciones que pervierte los resultados. La siguiente gráfica muestra cómo a mayor privacidad, menor es la utilidad de los datos.
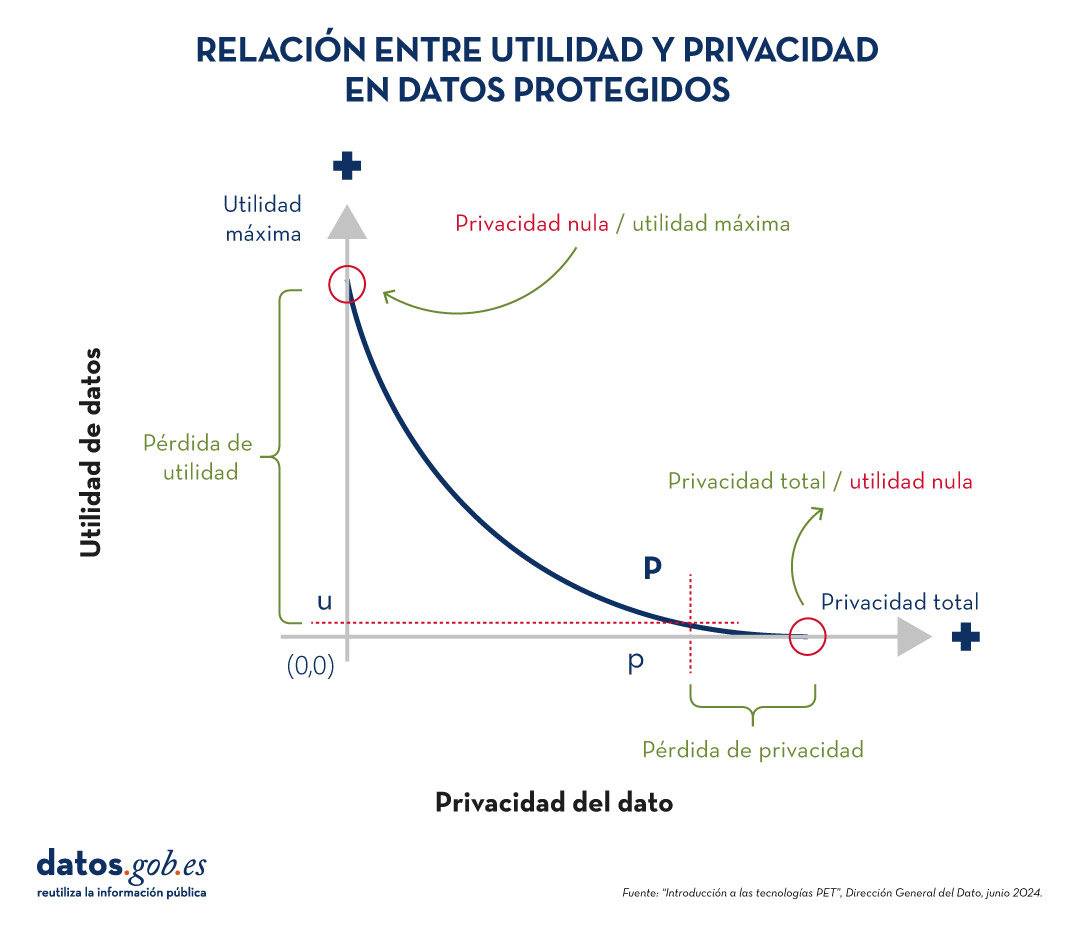
Figura 1. Relación entre utilidad y privacidad en datos protegido. Fuente: “Introducción a las tecnologías PET”, Dirección General del Dato, junio 2024.
Las técnicas PET permiten alcanzar un compromiso entre privacidad y utilidad más favorable. No obstante, hay que tener en cuenta que siempre existirá cierta limitación de la utilidad cuando explotamos datos protegidos.
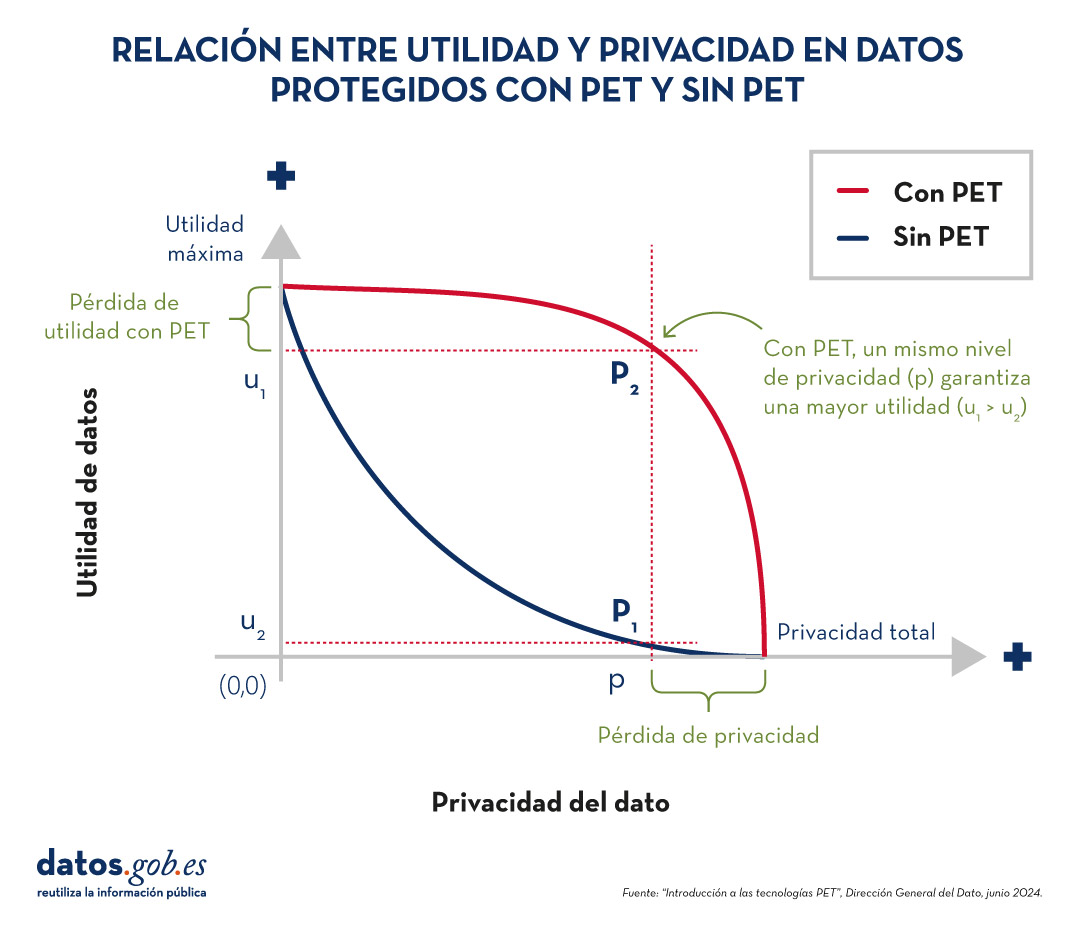
Figura 2. Relación entre utilidad y privacidad en datos protegidos con PET y sin PET. Fuente: “Introducción a las tecnologías PET”, Dirección General del Dato, junio 2024.
Técnicas PET más populares
Para aumentar la utilidad y poder explotar datos protegidos limitando los riesgos, es necesario aplicar una serie de técnicas PET. El siguiente esquema, recoge algunas de las principales:
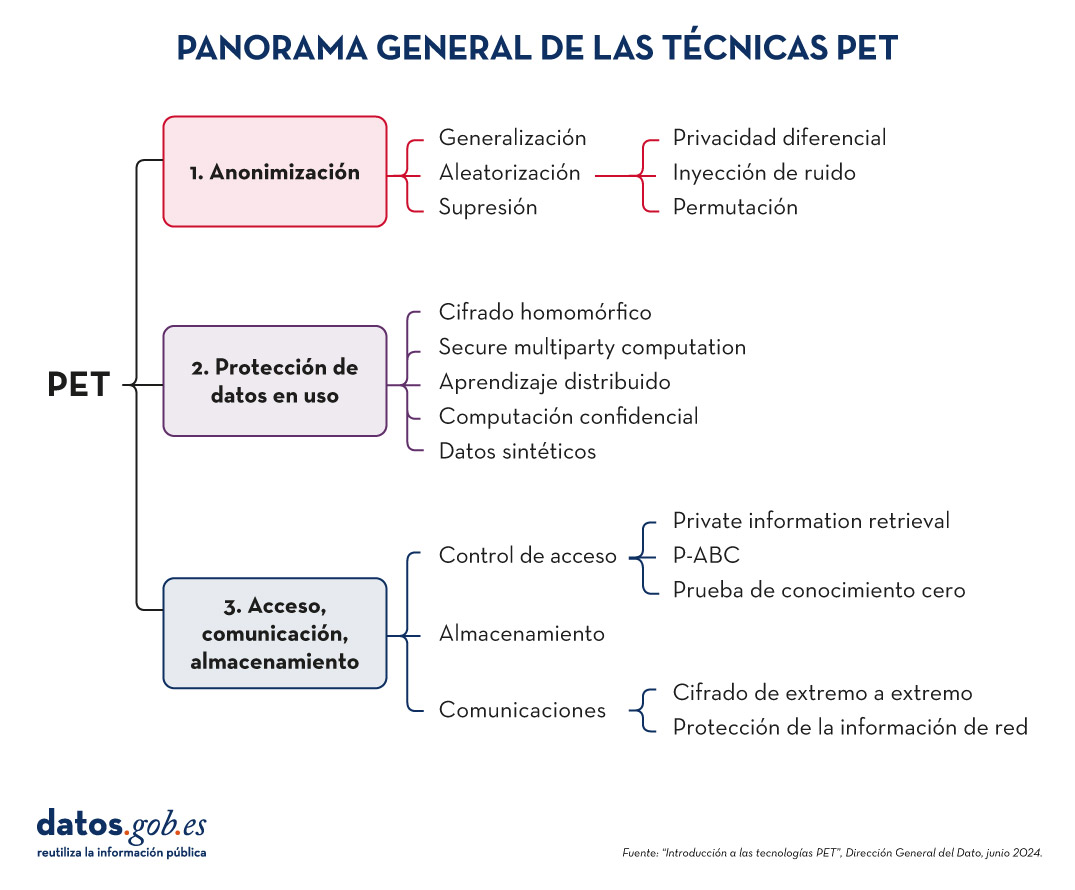
Figura 3. Panorama general de las técnicas PET. Fuente: “Introducción a las tecnologías PET”, Dirección General del Dato, junio 2024.
Como veremos a continuación, estas técnicas abordan distintas fases del ciclo de vida de los datos.
-
Antes de la explotación de los datos: anonimización
La anonimización consiste en transformar conjuntos de datos de carácter privado para que no se pueda identificar a ninguna persona. De esta forma, ya no les aplica el Reglamento General de Protección de Datos (RGPD).
Es importante garantizar que la anonimización se ha realizado de forma efectiva, evitando riesgos que permitan la reidentificación a través de técnicas como la vinculación (identificación de un individuo mediante el cruzado de datos), la inferencia (deducción de atributos adicionales en un dataset), la singularización (identificación de individuos a partir de los valores de un registro) o la composición (pérdida de privacidad acumulada debida a la aplicación reiterada de tratamientos). Para ello, es recomendable combinar varias técnicas, las cuales se pueden agrupar en tres grandes familias:
- Aleatorización: supone modificar los datos originales al introducir un elemento de azar. Esto se logra añadiendo ruido o variaciones aleatorias a los datos, de manera que se preserven patrones generales y tendencias, pero se haga más difícil la identificación de individuos.
- Generalización: consiste en reemplazar u ocultar valores específicos de un conjunto de datos por valores más amplios o menos precisos. Por ejemplo, en lugar de registrar la edad exacta de una persona, se podría utilizar un rango de edades (como 35-44 años).
- Supresión: implica eliminar completamente ciertos datos del conjunto, especialmente aquellos que pueden identificar a una persona de manera directa. Es el caso de los nombres, direcciones, números de identificación, etc.
Puedes profundizar sobre estos tres enfoques generales y las diversas técnicas que los integran en la guía práctica “Introducción a la anonimización de datos: técnicas y casos prácticos”. También recomendamos la lectura del artículo malentendidos comunes en la anonimización de datos.
2. Protección de datos en uso
En este apartado se abordan técnicas que salvaguardan la privacidad de los datos durante la aplicación de tratamientos de explotación.
-
Cifrado homomórfico: es una técnica de criptografía que permite realizar operaciones matemáticas sobre datos cifrados sin necesidad de descifrarlos primero. Por ejemplo, un cifrado será homomórfico si se cumple que, si se cifran dos números y se realiza una suma en su forma cifrada, el resultado cifrado, al ser descifrado, será igual a la suma de los números originales.
- Computación Segura Multipartita (Secure Multiparty Computation o SMPC): es un enfoque que permite que múltiples partes colaboren para realizar cálculos sobre datos privados sin revelar su información a los demás participantes. Es decir, permite que diferentes entidades realicen operaciones conjuntas y obtengan un resultado común, mientras mantienen la confidencialidad de sus datos individuales.
- Aprendizaje distribuido: tradicionalmente, los modelos de machine learning aprenden de forma centralizada, es decir, requieren reunir todos los datos de entrenamiento procedentes de múltiples fuentes en un único conjunto de datos a partir del cual un servidor central elabora el modelo que se desea. En el caso del aprendizaje distribuido, los datos no se concentran en un solo lugar, sino que permanecen en diferentes ubicaciones, dispositivos o servidores. En lugar de trasladar grandes cantidades de datos a un servidor central para su procesamiento, el aprendizaje distribuido permite que los modelos de machine learning se entrenen en cada una de estas ubicaciones, integrando y combinando los resultados parciales para obtener un modelo final.
- Computación confidencial y entornos de computación de confianza (Trusted Execution Environments o TEE): la computación confidencial se refiere a un conjunto de técnicas y tecnologías que permiten procesar datos de manera segura dentro de entornos de hardware protegidos y certificados, conocidos como entornos de computación de confianza.
- Datos sintéticos: son datos generados artificialmente que imitan las características y patrones estadísticos de datos reales sin representar a personas o situaciones específicas. Reproducen las propiedades relevantes de los datos reales, como distribución, correlaciones y tendencias, pero sin información que permita identificar a individuos o casos específicos. Puedes aprender más sobre este tipo de datos en el informe Datos sintéticos: ¿Qué son y para qué se usan?.
3. Acceso, comunicación y almacenamiento
Las técnicas PET no solo abarcan la explotación de los datos. Entre ellas también encontramos procedimientos dirigidos a asegurar el acceso a recursos, la comunicación entre entidades y el almacenamiento de datos, garantizando siempre la confidencialidad de los participantes. Algunos ejemplos son:
Técnicas de control de acceso
- Recuperación Privada de Información (Private information retrieval o PIR): es una técnica criptográfica que permite a un usuario consultar una base de datos o servidor sin que este último pueda saber qué información está buscando el usuario. Es decir, asegura que el servidor no conozca el contenido de la consulta, preservando así la privacidad del usuario.
- Credenciales Basadas en Atributos con Privacidad (Privacy-Attribute Based Credentials o P-ABC): es una tecnología de autenticación que permite a los usuarios demostrar ciertos atributos o características personales (como la mayoría de edad o la ciudadanía) sin revelar su identidad. En lugar de mostrar todos sus datos personales, el usuario presenta solo aquellos atributos necesarios para cumplir con los requisitos de la autenticación o autorización, manteniendo así su privacidad.
- Prueba de conocimiento cero (Zero-Knowledge Proof o ZKP): es un método criptográfico que permite a una parte demostrar a otra que posee cierta información o conocimiento (como una contraseña) sin revelar el propio contenido de ese conocimiento. Este concepto es fundamental en el ámbito de la criptografía y la seguridad de la información, ya que permite la verificación de información sin la necesidad de exponer datos sensibles.
Técnicas de comunicaciones
- Cifrado extremo a extremo (End to End Encryption o E2EE): esta técnica protege los datos mientras se transmiten entre dos o más dispositivos, de forma que solo los participantes autorizados en la comunicación pueden acceder a la información. Los datos se cifran en el origen y permanecen cifrados durante todo el trayecto hasta que llegan al destinatario. Esto significa que, durante el proceso, ningún individuo u organización intermediaria (como proveedores de internet, servidores de aplicaciones o proveedores de servicios en la nube) puede acceder o descifrar la información. Una vez que llegan a destino, el destinatario es capaz de descifrarlos de nuevo.
- Protección de información de Red (Proxy & Onion Routing): un proxy es un servidor intermediario entre el dispositivo de un usuario y el destino de la conexión en internet. Cuando alguien utiliza un proxy, su tráfico se dirige primero al servidor proxy, que luego reenvía las solicitudes al destino final, permitiendo el filtrado de contenidos o el cambio de direcciones IP. Por su parte, el método Onion Routing protege el tráfico en internet a través de una red distribuida de nodos. Cuando un usuario envía información usando Onion Routing, su tráfico se cifra varias veces y se envía a través de múltiples nodos, o "capas" (de ahí el nombre "onion", que significa "cebolla" en inglés).
Técnicas de almacenamiento
- Almacenamiento garante de la confidencialidad (Privacy Preserving Storage o PPS): su objetivo es proteger la confidencialidad de los datos en reposo e informar a los custodios de los datos de una posible brecha de seguridad, utilizando técnicas de cifrado, acceso controlado, auditoría y monitoreo, etc.
Estos son solo algunos ejemplos de tecnologías PET, pero hay más familias y subfamilias. Gracias a ellas, contamos con herramientas que nos permiten extraer valor de los datos de forma segura, garantizando la privacidad de los usuarios. Datos que pueden ser de gran utilidad en múltiples sectores, como la salud, el cuidado del medio ambiente o la economía.
Blog
La irrupción de la inteligencia artificial (IA) y, en particular ChatGPT, se ha convertido en uno de los principales temas de debate en los últimos meses. Esta herramienta ha eclipsado incluso otras tecnologías emergentes que habían adquirido un protagonismo en los más diversos ámbitos (jurídicos, económicos, sociales o culturales). Caso, por ejemplo, la web 3.0, el metaverso, la identidad digital descentralizada o los NFT y, en particular, las criptomonedas.
Resulta incuestionable la relación directa que existe entre este tipo de tecnología y la necesidad de disponer de datos suficientes y adecuados, siendo precisamente esta última dimensión cualitativa la que justifica que los datos abiertos estén llamados a desempeñar un papel de especial importancia. Aunque, al menos de momento, no es posible saber cuántos datos abiertos proporcionados por las entidades del sector público utiliza ChatGPT para entrenar su modelo, no hay duda de que los datos abiertos son una fuente especialmente significativa a la hora de mejorar su funcionamiento.
La regulación sobre el uso de los datos por la IA
Desde el punto de vista jurídico, la IA está despertando un especial interés por lo que se refiere a las garantías que deben respetarse a la hora de su aplicación práctica. Así, se están impulsando diversas iniciativas que pretenden regular específicamente las condiciones para proceder a su utilización, entre las que destaca la propuesta que está tramitando la Unión Europea, donde los datos son objeto de especial atención.
Ya en el ámbito estatal, hace unos meses se aprobó la Ley 15/2022, de 12 de julio, integral para la igualdad de trato y la no discriminación. Esta normativa exige a las Administraciones Públicas que favorezcan la implantación de mecanismos que contemplen garantías relativas a la minimización de sesgos, transparencia y rendición de cuentas, en concreto por lo que respecta a los datos utilizados para el entrenamiento de los algoritmos que se empleen para la toma de decisiones.
Por parte de las comunidades autónomas existe un creciente interés a la hora de regular el uso de los datos por parte de los sistemas de IA, reforzándose en algún caso las garantías relativas a la transparencia. También, a nivel municipal se están promoviendo protocolos para la implantación de la IA en los servicios municipales en los que las garantías aplicables a los datos, en particular desde la perspectiva de su calidad, se conciben como una exigencia prioritaria.
La posible colisión con otros derechos y bienes jurídicos: la protección de datos de carácter personal
Más allá de las iniciativas regulatorias, el uso de los datos en este contexto ha sido objeto de una especial atención por lo que se refiere a las condiciones jurídicas en que resulta admisible. Así, puede darse el caso de que los datos que se utilicen estén protegidos por derechos de terceros que impidan —o al menos dificulten— su tratamiento, tal y como sucede con la propiedad intelectual o, singularmente, la protección de datos de carácter personal. Esta inquietud constituye una de las principales motivaciones de la Unión Europea a la hora de promover el Reglamento de Gobernanza de Datos, regulación donde se plantean soluciones técnicas y organizativas que intentan compatibilizar la reutilización de la información con el respeto de tales bienes jurídicos.
Precisamente, la posible colisión con el derecho a la protección de datos de carácter personal ha motivado las principales medidas que se han adoptado en Europa respecto del uso de ChatGPT. En este sentido, el Garante per la Protezione dei Dati Personali ha acordado cautelarmente la limitación del tratamiento de datos de ciudadanos italianos, la Agencia Española de Protección de Datos ha iniciado de oficio actuaciones de inspección frente a OpenAI como responsable del tratamiento y, con una proyección supranacional, el Supervisor Europeo de Protección de Datos (EDPB) ha creado un grupo de trabajo específico.
La incidencia de la regulación sobre datos abiertos y reutilización
La regulación española sobre datos abiertos y reutilización de la información del sector público establece algunas previsiones que han de tenerse en cuenta por los sistemas de IA. Así, con carácter general, la reutilización será admisible si los datos se hubieren publicado sin sujeción a condiciones o, en el caso de que se fijen, cuando se ajuste a las establecidas a través de licencias u otros instrumentos jurídicos; si bien, cuando se definan, las condiciones han de ser objetivas, proporcionadas, no discriminatorias y estar justificadas por un objetivo de interés público.
Por lo que se refiere a las condiciones de reutilización de la información proporcionada por las entidades del sector público, su tratamiento sólo se permitirá si no se altera el contenido ni se desnaturaliza su sentido, debiéndose citar la fuente de la que se hubieren obtenido los datos y la fecha de su actualización más reciente.
Por otra parte, los conjuntos de datos de alto valor adquieren un especial interés para estos sistemas de IA caracterizados por la intensa reutilización de contenidos de terceros dado el carácter masivo de los tratamientos de datos que llevan a cabo y la inmediatez de las peticiones de información que formulan quienes las utilizan. En concreto, las condiciones establecidas legalmente para la puesta a disposición de estos conjuntos de datos de alto valor por parte de las entidades públicas determinan que existan muy pocas limitaciones y, asimismo, que se facilite enormemente su reutilización al tratarse de datos que han de estar disponibles de manera gratuita, ser susceptibles de tratamiento automatizado, suministrarse a través de API y proporcionarse en forma de descarga masiva, siempre que proceda.
En definitiva, teniendo en cuenta las particularidades de esta tecnología y, por tanto, las circunstancias tan singulares en las que tratan los datos, parece oportuno que las licencias y, en general, las condiciones en las que las entidades públicas permiten su reutilización sean revisadas y, en su caso, actualizadas para hacer frente a los retos jurídicos que se están empezando a plantear.
Contenido elaborado por Julián Valero, catedrático de la Universidad de Murcia y Coordinador del Grupo de Investigación “Innovación, Derecho y Tecnología” (iDerTec).
Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Noticia
En los próximos días comenzará una época de sol, calor, playa y, en muchos casos, más tiempo libre, lo que convierte a esta estación en una oportunidad perfecta para ampliar nuestra formación sobre una gran variedad de temáticas, entre las que no puede faltar los datos, una materia transversal a los distintos sectores.
Cada vez son más los cursos relacionados con Big Data, ciencia, analítica e incluso periodismo de datos que encontramos en las ofertas estivales de los centros de formación. Existe un interés creciente por ampliar formación sobre estas materias debido a la alta demanda de perfiles profesionales con estas capacidades.
Bien seas estudiante o un/a profesional en activo, a continuación, te mostramos algunos ejemplos de cursos de verano que pueden ser de gran interés para ampliar tus conocimientos durante estas semanas:
Ciencia de datos
La Universidad de Castilla-La Mancha imparte el curso “Ciencia de datos: impacto en la sociedad”, el 22 y 23 de junio en el campus de Albacete, donde se hablará de las nuevas formas de formas de adquisición y uso de los datos fruto de los avances en tecnología e inteligencia artificial.
La Universidad de Deusto ofrecerá este verano una formación online sobre "Análisis de datos y machine learning aplicado". Este curso, que comenzará el próximo 27 de junio, te enseñará a dominar las principales tecnologías de análisis y procesamiento de grandes cantidades de datos, además de algunas técnicas para aumentar el valor de los datos analizados, fomentando una óptima toma de decisiones.
La Universidad de Alicante se centra en la inteligencia artificial con el curso “Introducción al Deep Learning” del 11 al 15 de julio de 2022, en modalidad presencial. El curso comenzará explicando conceptos básicos y el uso de paquetes básicos y avanzados como NumPy, Pandas, scikit-learn o tf.Keras, para luego continuar profundizando en redes neuronales.
La Universidad de Alcalá de Henares hablará de “Introducción al data science financiero con R” en un curso presencial del 20 al 24 de junio. El objetivo del curso es doble: familiarizar al alumno con el uso del lenguaje estadístico y mostrar algunas de las técnicas ligadas al cálculo estadístico avanzado, así como sus aplicaciones prácticas.
Datos abiertos
La Universidad Complutense de Madrid oferta, un año más, su curso "Big & Open Data. Análisis y programación con R y Python" del 4 al 22 de julio de 2022 (en horario de mañana de 9:00 a 14:00 horas, de lunes a viernes). En él se hablará del ciclo de vida del dato, ejemplos de casos de uso del Big Data o la ética aplicada a la gestión de datos masivos, entre otros temas.
Sistemas de Información Geográfica
Si eres un apasionado de los datos geográficos, la Universidad de Santiago imparte el curso “Introducción en sistemas de información geográfica y cartografía con el entorno R” del 5 al 8 de julio de 2022. En formato presencial y con 29 horas lectivas, busca introducir al alumno en el análisis espacial, la visualización y el trabajo con archivos raster y vectorial. Durante el curso se abordarán los principales métodos de interpolación geoestadística.
La Universidad de Alcalá de Henares, por su parte, impartirá el curso "Aplicaciones de los SIG a la Hidrología", del 6 al 8 de julio, también en formato presencial. Se trata de un curso práctico que abarca desde las distintas fuentes de datos hidro-meteorológicos hasta la realización de análisis de evapotranspiración y escorrentía, y obtención de resultados.
Periodismo de datos
El Institut de Formació Contínua – IL3 de la Universitat de Barcelona organizará del 4 al 7 de julio de 2022 el curso online en castellano "Bulos y periodismo de datos". Esta formación de 8 horas de duración te aportará los conocimientos necesarios para comprender, identificar y combatir el fenómeno de la desinformación. Además, conocerás las herramientas esenciales que se utilizan en el periodismo de datos, la verificación de datos (fact-checking) políticos y la investigación basada en peticiones de transparencia.
Protección de datos
La Universidad Internacional Menéndez Pelayo impartirá un curso sobre "Estrategias para la protección de datos ante los desafíos del entorno digital" los próximos 4, 5 y 6 de julio. El programa está dirigido a alumnos relacionados con el mundo empresarial, la prestación de servicios digitales, las administraciones públicas, investigadores e interesados en la materia. "Smart-cities y tratamiento de datos personales" o "el Comité Europeo de Protección de Datos y las iniciativas europeas del paquete digital" serán solo algunos de los temas que abordará este curso.
Otra de las formaciones relacionadas con la protección de datos que se impartirá durante los próximos meses será "¿Son nuestros datos realmente nuestros? Riesgos y garantías de la protección de datos personales en las sociedades digitales". La Universidad Internacional de Andalucía será la encargada de impartir este curso que se celebrará de manera presencial en Sevilla a partir del día 29 de agosto y en el que se abordará la situación actual de la protección de datos personales en el marco de la Unión Europea. A través de esta formación descubrirás cuáles son los beneficios y riesgos a los que se enfrenta el tratamiento de nuestros datos personales.
Además de esta formaciones específicas de verano, aquellos usuarios que lo deseen también pueden acudir a las grandes plataformas de cursos MOOC, como Coursera, EDX o Udacity, que ofrecen cursos interesantes de manera continua para que cualquier estudiante pueda comenzar su aprendizaje en el momento que precise.
Estos son solo algunos ejemplos de cursos que actualmente tienen matrícula abierta para este verano, aunque la oferta es muy amplia y variada. Además, cabe destacar que el verano aún no ha comenzado y que en las próximas semanas podrían surgir nuevas formaciones relacionados con el campo de los datos. Si conoces alguna más que sea de interés, no dudes en dejarnos un comentario aquí debajo o escribirnos a contacto@datos.gob.es