Blog
The construction of the ecosystem for the secondary use of e-health data in the European Health Data Space (EHDS) poses a significant scenario of opportunities for Spanish research, innovation and entrepreneurship. To this end, the European Union is promoting a multitude of strategic projects in which hospitals, health research foundations, universities, research centres and Spanish companies participate. The list of projects is extensive and aims to satisfy at least two objectives: to promote the generation of infrastructures capable of generating quality datasets and to promote conditions for their reuse.
The role of Spain. Strengths in the deployment of the European Health Area
Spain offers significantly favourable conditions not only to participate but also to contribute significantly to the tasks of creating the EHDS
- First, our public health system is characterized by a high level of integration and structuring. Unlike systems based on reimbursement mechanisms, in which there may be an atomisation in the field of service provision, in our system we have a clear frame of reference in primary care, medical specialities and hospital services.
- On the other hand, the experience deployed by our health environments from the General Data Protection Regulation (GDPR) and, particularly, the lessons learned from the seventeenth additional provision on health data processing of Organic Law 3/2018, of 5 December, on the Protection of Personal Data and guarantee of digital rights (LOPDGDD) they constitute a valuable experience.
- The opening of the National Health Data Space promoted by the Government of Spain and promoted by the Ministry for Digital Transformation and Public Function, the Ministry of Health and the Autonomous Communities allows the deployment of an essential infrastructure for the EHDS.
The National Health Data space was presented on January 29. The event highlighted how this project represents a paradigm shift that revolutionizes the management of health data, promoting a federated, secure and ethical model that preserves the sovereignty and privacy of information while facilitating its use for research, innovation and public policies. Its operation is based on a federated catalog of metadata and a rigorous process of access and analysis in secure environments, which seeks to promote open science and scientific and technological advances, benefiting patients, researchers, managers and industry.
Lessons learned from European Projects
The path taken by Regulation (EU) 2025/327 of the European Parliament and of the Council of 11 February 2025 on the European Health Data Space, amending Directive 2011/24/EU and Regulation (EU) 2024/2847 (EEDSR), poses significant challenges that are addressed in research projects funded by European and national funds. The lessons learned in some of them can be extraordinarily useful for the research and entrepreneurship community in our country. We cannot forget that we start from significant strengths.
1.-Compliance by design
The existence of a new regulation requires a rigorous analysis of the state of the art in our organizations, not only to implement its deployment but also to ensure the preconditions of legal reliability of the datasets and the research that is proposed.
2.-Accountability: proactive responsibility and documentary strength
In our country we come from a long tradition of accountability. The EEDSR will impose on the data requester a set of relevant documentary requirements, such as, for example, having provided safeguards to prevent any misuse of electronic health data. This issue cannot be neglected from the point of view of data holders, who will also have to meet certain requirements. For example, proving that data is legitimate and reusable is an ethical and legally documentable issue; and the simplified procedure for accessing electronic health data through a trusted health data holder requires the latter to document the security of its data space or capabilities to evaluate requests for access to health data.
One of the main obstacles we face in this intermediate period of implementation of the EHDS lies precisely in the organizational culture for the generation of verifiable evidence. As standardization and the set of common rules of the EEDS scale, it will be necessary to deepen the dynamics of proactive responsibility understood as demonstrated responsibility.
3. Secure processing environments
In our country, health environments by their very definition must be safe environments. The deployment of the National Security Scheme (ENS) and the GDPR have allowed the entire health system, public or private, to adopt maturity models that are perfectly consistent with the conditions of the secure processing environments defined by the EEDSR.
Challenges of the Spanish system
Along with the inherent strengths of our system, it is necessary to consider those aspects that present themselves as challenges.
1. Anonymisation and pseudonymisation
In the national context, the aforementioned seventeenth additional provision of Organic Law 3/2018, of 5 December, on the Protection of Personal Data and guarantee of digital rights, defines specific conditions for pseudonymisation. These consist of the functional separation between the teams that pseudonymize and those that reuse data, and the definition of a secure environment that prevents any attempt at re-identification. In addition, there are legal guarantees in terms of individual commitments not to re-identify, deployment of the impact assessment tool related to data protection and supervision by ethics committees. The challenge of anonymization is more demanding, since it implies the impossibility of linking health data with those of the original patient under any conditions.
2. Reeskilling of teams
The European Health Data Space (EHDS) will pose an unprecedented training challenge that will cut across all sectors involved in the health data ecosystem. Research ethics committees should familiarise themselves not only with the permissible secondary uses of health data, but also with the integration of the Artificial Intelligence Regulation and with the ethical principles of the ALTAI (Assessment List for Trustworthy Artificial Intelligence) framework. This need for reeskilling will also extend to health systems and health administration, where Health Data Access Bodies will require highly qualified personnel in these new ethical and regulatory frameworks, as well as reliable data holders who will safeguard sensitive information. Development staff and IT teams will also need to acquire new skills in critical technical areas, such as cataloguing, validation, and curation of data, as well as in interoperability standards that enable effective communication between systems. Perhaps the most sensitive training challenge will fall on new entrants, who will be able to take advantage of opportunities to access datasets for innovative secondary uses. This especially concerns technology startups in the health sector. To face a very demanding regulatory framework (GDPR, Regalmento de AI, EEDSR), the resources and capabilities for legal compliance in Spanish SMEs is notably limited. For this reason, it will be necessary to build a solid culture of data protection and ethical development of reliable artificial intelligence systems from the beginning.
3. Data cataloguing: the challenge of quality and standardization
In the context of the European Health Data Space, deepen the standardization of data through the most functional methodologies – such as OMOP CDM for observational clinical data, HL7 FHIR for dynamic information exchange, DICOM for medical imaging, or reference terminologies such as SNOMED CT, LOINC and RxNorm— is presented as a key strategic element for the creation and re-use of high-quality datasets. However, the adoption of these standards is not enough on its own: the processes of validation, semantic annotation and data enrichment require highly qualified human resources capable of ensuring the coherence, completeness and accuracy of the information, making this training a real precondition for effective participation in the European health data ecosystem. Alignment with the standardized cataloguing of datasets following the HealthDCAT-AP (Health Data Catalog Application Profile) standard, which allows the descriptive metadata of health data resources to be described in a homogeneous way, is presented as one of the immediate challenges, along with the implementation of the work that has been deployed in relation to the data utility quality label, a quality label that assesses the real usefulness of data for secondary uses and is becoming a seal of trust for users and researchers.
If previously in this article the very high capacities of the Spanish health system to generate health data in a systematic way and in significant volumes were highlighted, these aspects of cataloguing, standardization and quality certification will occupy an absolutely central place in designing optimal conditions of European competitiveness in their reuse, transforming the abundance of data into a real strategic advantage that allows Spain to position itself as a relevant player in the research and innovation landscape with electronic health data.
The experience of the EUCAIM project (Cancer Image EU)
The European Health Data Space Regulation aims to enable the secondary use of electronic health data across Europe through harmonised rules in a federated ecosystem. In the cancer arena, fragmented access to high-quality datasets slows down research, limits reproducibility and undermines Europe's ability to develop and validate reliable AI tools for oncology.
EUCAIM demonstrates the viability of an ecosystem for the secondary use of cancer through a federated model that allows cross-border access under harmonized rules guaranteeing adequate control of resources at the local level. And this is deployed through a set of enabling components:
1) A Secure Processing Environment (SPE) federated at European level
EUCAIM is creating a federated PES to enforce data access conditions, control processing, and support secure cross-border analysis under EEDS restrictions. This PES is fully in line with the requirements and measures laid down in Article 73 EEDSR for safe environments.
2) Overcoming the "anonymisation barrier"
EUCAIM promotes a layered anonymization strategy that combines dataholder-autonomous local anonymization processes with platform controls to enable datasets to remain useful for AI research and development. The importance of this approach lies in the fact that it aims to reconcile the protection of privacy with the practical need to have sets with large volumes of data characterized by their diversity.
3) Data cataloguing and standardization
EUCAIM aligns cataloguing with the HealthDCAT-AP principles whose main objective is to apply the FAIR principles, that is, to ensure that data is findable, accessible, interoperable and reusable.
4) Reduction of legal costs
EUCAIM has deployed its own compliance framework aimed at the General Data Protection Regulation and the Artificial Intelligence Regulation. To do this, a robust compliance framework is in place at the platform level that is deployed across complex data ecosystems. This is based on data protection impact assessments (included in the GDPR) with a particular focus on fundamental rights. It also incorporates training and professional retraining of users as a functional requirement, so that compliance capability becomes an essential feature.
5) Support for data users
EUCAIM offers significant advantages to data users, including researchers and AI developers, by establishing a transparent and well-governed environment for data access. The adoption of transparent governance criteria, clearly defined obligations and their technical application by the platform, provide data users with the guarantee that their access is adequate and lawful, fully auditable and remains stable over time. The platform's design ensures that users can leverage powerful data for advanced analytics, including federated processing in a secure environment. Through mandatory training and implementation of standardized procedures, teams benefit from less uncertainty and are better equipped to align with compliance requirements set forth by the EEDSR, GDPR, and AI governance frameworks.
6) Guarantee of patients' rights
EUCAIM's approach is based on data protection by design and by default that unites organisational safeguards with robust technical controls. This framework has been purpose-built to minimise the risk of data misuse, while supporting safe and effective cross-border cancer research and innovation. The result is a system in which the protection of privacy is not an obstacle but a fundamental element that allows the responsible use of data for the benefit of society and science. The model reinforces accountability for the secondary use of health data by combining strong governance oversight, a comprehensive record of actions, and strict and enforceable obligations for all participating entities. All actions taken with patient data are recorded and reviewed, ensuring that all uses are fully auditable. This traceability ensures that the processing of data is kept within the limits of the permitted use and that any deviations can be identified and addressed quickly.
Multi-level governance: the key to sustainable success
The most relevant lesson learned at EUCAIM concerns the imperative need for articulated, coherent and operational multilevel governance. In a broad sense, it is essential to provide effective governance tools and frameworks on three fundamental dimensions:
- Firstly, on the processes for generating datasets and their sharing conditions, establishing clear criteria on what data is generated, how it is standardised, who holds rights over it and under what licences and restrictions it can be shared with third parties.
- Second, on data access request processes, defining transparent and efficient procedures so that researchers, innovators, and policymakers can identify, request, and obtain access to the data needed for their projects, minimizing administrative burdens without compromising ethical and legal guarantees.
- Thirdly, on the processes of validating the correctness of the datasets and adherence to the system, as well as the procedures for authorising access to data, ensuring that only data of certified quality feed the infrastructure and that only authorised users with legitimate purposes access sensitive information.
This procedural governance cannot function without strategic and operational decisions regarding the definition of human resources roles and functions. To do this, it is necessary to have the necessary professional profiles such as data managers, experts in research ethics, cybersecurity specialists, data curators and quality managers. Secondly, it will be essential to define the secure processing environments where analyses are carried out on sensitive data, ensuring that these spaces comply with the highest technical standards of security, traceability, auditing and privacy preservation, and that they are designed to operate under the principle of zero trust) adapted to the health context. Only through this multi-level governance architecture, which integrates technical, organizational, ethical and legal dimensions at all levels of decision-making – from the design of national policies to the day-to-day operational management of platforms – will it be possible to build health data infrastructures that are truly sustainable, reliable and capable of generating long-term social, scientific and economic value. positioning the Spanish healthcare system as a strategic player in the European healthcare innovation ecosystem.
Content prepared by Ricard Martínez Martínez, Director of the Chair of Privacy and Digital Transformation, Department of Constitutional Law, University of Valencia. The contents and views expressed in this publication are the sole responsibility of the author.
Blog
As organisations seek to harness the potential of data to make decisions, innovate and improve their services, a fundamental challenge arises: how can data collection and use be balanced with respect for privacy? PET technologies attempt to address this challenge. In this post, we will explore what they are and how they work.
What are PET technologies?
PET technologies are a set of technical measures that use various approaches to privacy protection. The acronym PET stands for "Privacy Enhancing Technologies" which can be translated as "privacy enhancing technologies".
According to the European Union Agency for Cibersecurity this type of system protects privacy by:
- The deletion or reduction of personal data.
- Avoiding unnecessary and/or unwanted processing of personal data.
All this, without losing the functionality of the information system. In other words, they make it possible to use data that would otherwise remain unexploited, as they limit the risks of disclosure of personal or protected data, in compliance with current legislation.
Relationship between utility and privacy in protected data
To understand the importance of PET technologies, it is necessary to address the relationship between data utility and data privacy. The protection of personal data always entails a loss of usefulness, either because it limits the use of the data or because it involves subjecting them to so many transformations to avoid identification that it perverts the results. The following graph shows how the higher the privacy, the lower the usefulness of the data.

Figure 1. Relationship between utility and privacy in protected data. Source: "Introduction to PET technologies", Directorate-General for Data, June 2024.
PET techniques allow a more favourable privacy-utility trade-off to be achieved. However, it should be borne in mind that there will always be some limitation of usability when exploiting protected data.
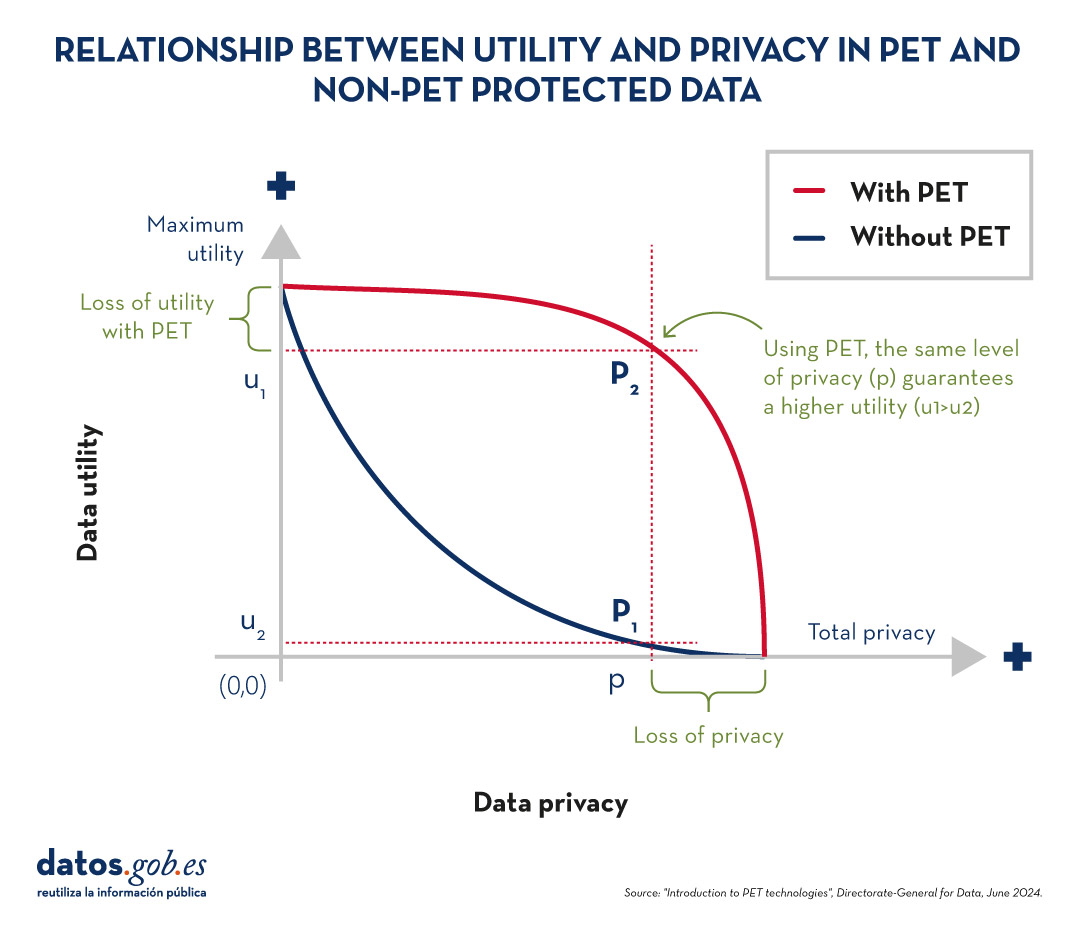
Figure 2. Relationship between utility and privacy in PET and non-PET protected data. Source: "Introduction to PET technologies", Directorate-General for Data, June 2024.
Most popular PET techniques
In order to increase usability and to be able to exploit protected data while limiting risks, a number of PET techniques need to be applied. The following diagram shows some of the main ones:
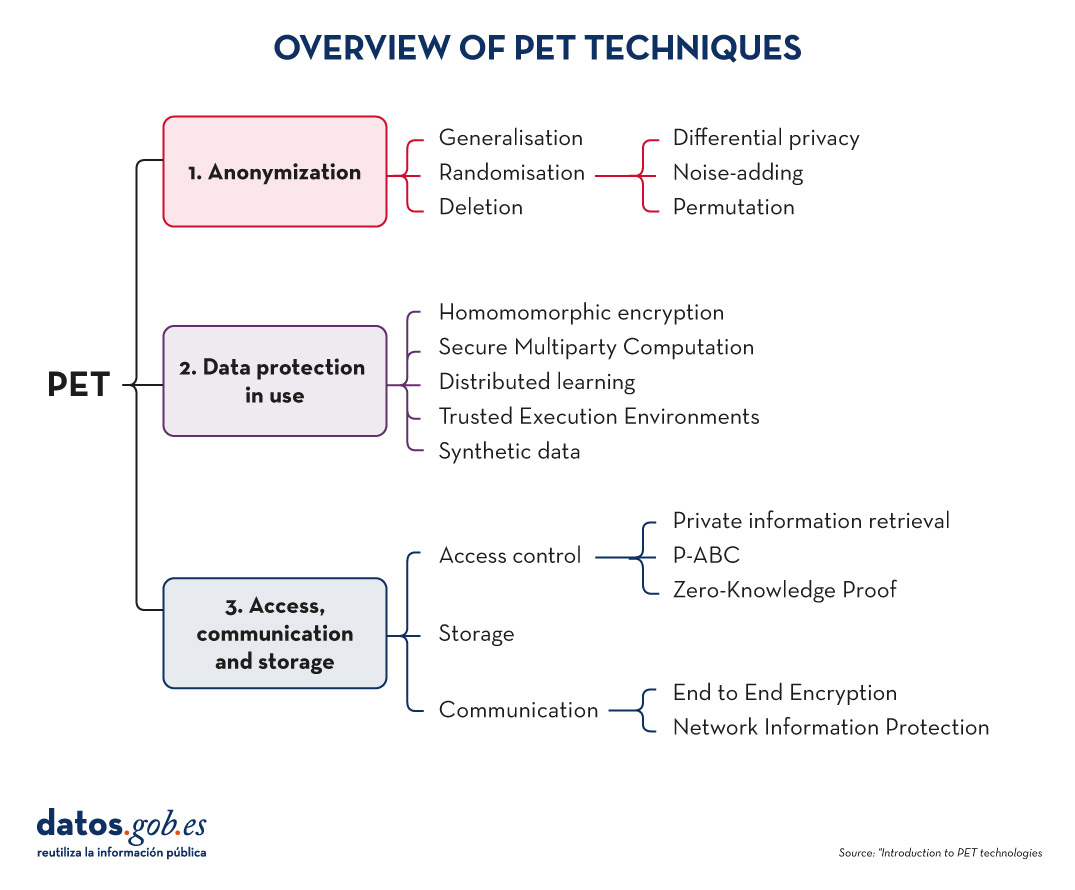
Figure 3. Overview of PET techniques. Source: "Introduction to PET technologies", Directorate-General for Data, June 2024.
As we will see below, these techniques address different phases of the data lifecycle.
Before data mining: anonymisation
Anonymisation is the transformation of private data sets so that no individual can be identified. Thus, the General Data Protection Regulation (GDPR) no longer applies to them.
It is important to ensure that anonymisation has been done effectively, avoiding risks that allow re-identification through techniques such as linkage (identification of an individual by cross-referencing data), inference (deduction of additional attributes in a dataset), singularisation (identification of individuals from the values of a record) or compounding (cumulative loss of privacy due to repeated application of treatments). For this purpose, it is advisable to combine several techniques, which can be grouped into three main families:
- Randomisation: involves modifying the original data by introducing an element of chance. This is achieved by adding noise or random variations to the data, so that general patterns and trends are preserved, but identification of individuals is made more difficult.
- Generalisation: is the replacement or hiding of specific values in a data set with broader or less precise values. For example, instead of recording the exact age of a person, a range of ages (such as 35-44 years) could be used.
- Deletion: implies the complete removal of certain data from the set, especially those that can identify a person directly. This is the case for names, addresses, identification numbers, etc.
You can learn more about these three general approaches and the various techniques involved in the practical guide "Introduction to data anonymisation: techniques and practical cases". We also recommend reading the article Common misunderstandings in data anonymisation.
Data protection in use
This section deals with techniques that safeguard data privacy during the implementation of operational processing.
-
Homomomorphic encryption: is a cryptographic technique which allows mathematical operations to be performed on encrypted data without first decrypting it. For example, a cipher will be homomorphic if it is true that, if two numbers are encrypted and a sum is performed in their encrypted form, the encrypted result, when decrypted, will be equal to the sum of the original numbers.
- Secure Multiparty Computation or SMPC: is an approach that allows multiple parties to collaborate to perform computations on private data without revealing their information to the other participants. In other words, it allows different entities to perform joint operations and obtain a common result, while maintaining the confidentiality of their individual data.
- Distributed learning: traditionally, machine learning models learn centrally, i.e., they require gathering all training data from multiple sources into a single dataset from which a central server builds the desired model. In el distributed learning, data is not concentrated in one place, but remains in different locations, devices or servers. Instead of moving large amounts of data to a central server for processing, distributed learning allows machine learning models to be trained at each of these locations, integrating and combining the partial results to obtain a final model.
- Trusted Execution Environments or TEE: trusted computing refers to a set of techniques and technologies that allow data to be processed securely within protected and certified hardware environments known as trusted computing environments.
- Synthetic data: is artificially generated data that mimics the characteristics and statistical patterns of real data without representing specific people or situations. They reproduce the relevant properties of real data, such as distribution, correlations and trends, but without information to identify specific individuals or cases. You can learn more about this type of data in the report Synthetic data:. What are they and what are they used for?
3. Access, communication and storage
PET techniques do not only cover data mining. These also include procedures aimed at ensuring access to resources, communication between entities and data storage, while guaranteeing the confidentiality of the participants. Some examples are:
Access control techniques
-
Private information retrieval or PIR: is a cryptographic technique that allows a user to query a database or server without the latter being able to know what information the user is looking for. That is, it ensures that the server does not know the content of the query, thus preserving the user's privacy.
-
Privacy-Attribute Based Credentials or P-ABC: is an authentication technology that allows users to demonstrate certain personal attributes or characteristics (such as age of majority or citizenship) without revealing their identity. Instead of displaying all his personal data, the user presents only those attributes necessary to meet the authentication or authorisation requirements, thus maintaining his privacy.
- Zero-Knowledge Proof or ZKP: is a cryptographic method that allows one party to prove to another that it possesses certain information or knowledge (such as a password) without revealing the content of that knowledge itself. This concept is fundamental in the field of cryptography and information security, as it allows the verification of information without the need to expose sensitive data.
Communication techniques
-
End to End Encryption or E2EE: This technique protects data while it is being transmitted between two or more devices, so that only authorised participants in the communication can access the information. Data is encrypted at the origin and remains encrypted all the way to the recipient. This means that, during the process, no intermediary individual or organisation (such as internet providers, application servers or cloud service providers) can access or decrypt the information. Once they reach their destination, the addressee is able to decrypt them again.
- Network Information Protection (Proxy & Onion Routing): a proxy is an intermediary server between a user's device and the connection destination on the Internet. When someone uses a proxy, their traffic is first directed to the proxy server, which then forwards the requests to the final destination, allowing content filtering or IP address change. The Onion Routing method protects internet traffic over a distributed network of nodes. When a user sends information using Onion Routing, their traffic is encrypted multiple times and sent through multiple nodes, or "layers" (hence the name "onion", meaning "onion").
Storage techniques
- Privacy Preserving Storage (PPS): its objective is to protect the confidentiality of data at rest and to inform data custodians of a possible security breach, using encryption techniques, controlled access, auditing and monitoring, etc.
These are just a few examples of PET technologies, but there are more families and subfamilies. Thanks to them, we have tools that allow us to extract value from data in a secure way, guaranteeing users' privacy. Data that can be of great use in many sectors, such as health, environmental care or the economy.
Blog
The emergence of artificial intelligence (AI), and ChatGPT in particular, has become one of the main topics of debate in recent months. This tool has even eclipsed other emerging technologies that had gained prominence in a wide range of fields (legal, economic, social and cultural). This is the case, for example, of web 3.0, the metaverse, decentralised digital identity or NFTs and, in particular, cryptocurrencies.
There is an unquestionable direct relationship between this type of technology and the need for sufficient and appropriate data, and it is precisely this last qualitative dimension that justifies why open data is called upon to play a particularly important role. Although, at least for the time being, it is not possible to know how much open data provided by public sector entities is used by ChatGPT to train its model, there is no doubt that open data is a key to improving their performance.
Regulation on the use of data by AI
From a legal point of view, AI is arousing particular interest in terms of the guarantees that must be respected when it comes to its practical application. Thus, various initiatives are being promoted that seek to specifically regulate the conditions for its use, among which the proposal being processed by the European Union stands out, where data are the object of special attention.
At the state level, Law 15/2022, of 12 July, on equal treatment and non-discrimination, was approved a few months ago. This regulation requires public administrations to promote the implementation of mechanisms that include guarantees regarding the minimisation of bias, transparency and accountability, specifically with regard to the data used to train the algorithms used for decision-making.
There is a growing interest on the part of the autonomous communities in regulating the use of data by AI systems, in some cases reinforcing guarantees regarding transparency. Also, at the municipal level, protocols are being promoted for the implementation of AI in municipal services in which the guarantees applicable to the data, particularly from the perspective of their quality, are conceived as a priority requirement.
The possible collision with other rights and legal interests: the protection of personal data
Beyond regulatory initiatives, the use of data in this context has been the subject of particular attention as regards the legal conditions under which it is admissible. Thus, it may be the case that the data to be used are protected by third party rights that prevent - or at least hinder - their processing, such as intellectual property or, in particular, the protection of personal data. This concern is one of the main motivations for the European Union to promote the Data Governance Regulation, a regulation that proposes technical and organisational solutions that attempt to make the re-use of information compatible with respect for these legal rights.
Precisely, the possible collision with the right to the protection of personal data has motivated the main measures that have been adopted in Europe regarding the use of ChatGPT. In this regard, the Garante per la Protezione dei Dati Personali has ordered a precautionary measure to limit the processing of Italian citizens' data, the Spanish Data Protection Agency has initiated ex officio inspections of OpenAI as data controller and, with a supranational scope, the European Data Protection Supervisor (EDPB) has created a specific working group.
The impact of the regulation on open data and re-use
The Spanish regulation on open data and re-use of public sector information establishes some provisions that must be taken into account by IA systems. Thus, in general, re-use will be admissible if the data has been published without conditions or, in the event that conditions are set, when they comply with those established through licences or other legal instruments; although, when they are defined, the conditions must be objective, proportionate, non-discriminatory and justified by a public interest objective.
As regards the conditions for re-use of information provided by public sector bodies, the processing of such information is only allowed if the content is not altered and its meaning is not distorted, and the source of the data and the date of its most recent update must be mentioned.
On the other hand, high-value datasets are of particular interest for these AI systems characterised by the intense re-use of third-party content given the massive nature of the data processing they carry out and the immediacy of the requests for information made by users. Specifically, the conditions established by law for the provision of these high-value datasets by public bodies mean that there are very few limitations and also that their re-use is greatly facilitated by the fact that the data must be freely available, be susceptible to automated processing, be provided through APIs and be provided in the form of mass downloading, where appropriate.
In short, considering the particularities of this technology and, therefore, the very unique circumstances in which the data are processed, it seems appropriate that the licences and, in general, the conditions under which public entities allow their re-use be reviewed and, where appropriate, updated to meet the legal challenges that are beginning to arise.
Content prepared by Julián Valero, Professor at the University of Murcia and Coordinator of the "Innovation, Law and Technology" Research Group (iDerTec).
The contents and points of view reflected in this publication are the sole responsibility of the author.
Noticia
The coming days will see the beginning of a season of sun, heat, beach and, in many cases, more free time, which makes this season a perfect opportunity to expand our training on a wide variety of subjects, among which data, a cross-cutting subject in different sectors, cannot be missing.
There are an increasing number of courses related to Big Data, science, analytics and even data journalism that we find in the summer offers of training centres. There is a growing interest in further training in these subjects due to the high demand for professional profiles with these skills.
Whether you are a student or a working professional, here are some examples of summer courses that may be of great interest to broaden your knowledge during these weeks:
Data science
The University of Castilla-La Mancha is offering the course "Data science: impact on society" on 22 and 23 June at the Albacete campus, where the new ways of acquiring and using data resulting from advances in technology and artificial intelligence will be discussed.
This summer, the University of Deusto will offer online training on "Data analysis and applied machine learning". This course, which will begin on 27 June, will teach you to master the main technologies for analysing and processing large amounts of data, as well as some techniques to increase the value of the data analysed, promoting optimal decision-making.
The University of Alicante focuses on artificial intelligence with the course "Introduction to Deep Learning" from 11 to 15 July 2022, in classroom mode. The course will begin by explaining basic concepts and the use of basic and advanced packages such as NumPy, Pandas, scikit-learn or tf.Keras, and then continue to delve deeper into neural networks.
The University of Alcalá de Henares will talk about "Introduction to financial data science with R" in an on-site course from 20 to 24 June. The aim of the course is twofold: to familiarise students with the use of the statistical language and to show some of the techniques linked to advanced statistical calculation, as well as its practical applications.
Open data
The Complutense University of Madrid offers, once again this year, its course “Big & Open Data. Analysis and programming with R and Python” from 4 to 22 July 2022 (mornings from 9:00 to 14:00, Monday to Friday). The course will cover the data life cycle, examples of Big Data use cases and ethics applied to the management of massive data, among other topics.
Geographic Information Systems
If you are passionate about geographic data, the University of Santiago is offering the course "Introduction to geographic information systems and cartography with the R environment" from 5 to 8 July 2022. In classroom format and with 29 teaching hours, it aims to introduce students to spatial analysis, visualisation and working with raster and vector files. The main geostatistical interpolation methods will be covered during the course.
The University of Alcalá de Henares, for its part, will give the course "Applications of GIS to Hydrology", from 6 to 8 July, also in classroom format. This is a practical course that covers everything from the different sources of hydro-meteorological data to carrying out evapotranspiration and runoff analyses and obtaining results.
Data journalism
El Institut de Formació Contínua – IL3 de la Universitat de Barcelona organizará del 4 al 7 de julio de 2022 el curso online en castellano “Bulos y periodismo de datos”. Esta formación de 8 horas de duración te aportará los conocimientos necesarios para comprender, identificar y combatir el fenómeno de la desinformación. Además, conocerás las herramientas esenciales que se utilizan en el periodismo de datos, la verificación de datos (fact-checking) políticos y la investigación basada en peticiones de transparencia.
Data protection
The Menéndez Pelayo International University will hold a course on "Strategies for data protection in the face of the challenges of the digital environment" on 4, 5 and 6 July. The programme is aimed at students related to the business world, the provision of digital services, public administrations, researchers and those interested in the subject. “Smart-cities and personal data processing” or “the European Data Protection Committee and the European initiatives of the digital package” will be just some of the topics to be addressed in this course.
Another of the training courses related to data protection that will be given over the coming months will be "Are our data really ours? Risks and guarantees of personal data protection in digital societies". The International University of Andalusia will be responsible for giving this course, which will be held in person in Seville from 29 August, and which will address the current situation of personal data protection within the framework of the European Union. Through this training you will discover the benefits and risks involved in the processing of our personal data.
In addition to this specific summer training, those users who wish to do so can also go to the large MOOC course platforms, such as Coursera, EDX or Udacity, which offer interesting courses on a continuous basis so that any student can start learning whenever they need to.
These are just a few examples of courses that are currently open for enrolment this summer, although the offer is very wide and varied. Moreover, it should be noted that the summer has not yet begun and new training courses related to the field of data could emerge in the coming weeks. If you know of any other course that might be of interest, do not hesitate to leave us a comment below or write to us at contacto@datos.gob.es.