Blog
Los datos abiertos pueden transformar cómo interactuamos con nuestras ciudades, ofreciendo oportunidades para mejorar la calidad de vida. Cuando se ponen a disposición del público, permiten el desarrollo de aplicaciones innovadoras y herramientas que abordan desafíos urbanos, desde la accesibilidad hasta la seguridad vial y la participación.
La información en tiempo real puede tener impactos positivos en la ciudadanía. Por ejemplo, aplicaciones que utilizan datos abiertos pueden sugerir las rutas más eficientes, considerando factores como el tráfico y las obras en curso; la información sobre la accesibilidad de espacios públicos puede mejorar la movilidad de personas con discapacidades; los datos sobre rutas ciclistas o peatonales animan a optar por modos de transporte más ecológicos y sanos, y el acceso a datos urbanos puede empoderar a la ciudadanía para participar en la toma de decisiones sobre su ciudad. En otras palabras, el empleo ciudadano de datos abiertos no solo mejora la eficiencia de la ciudad y sus servicios, sino que también promueve una ciudad más inclusiva, sostenible y participativa.
Para ilustrar estas ideas, en este artículo se abordan mapas para “navegar” ciudades, realizados con datos abiertos. Es decir, se muestran iniciativas que mejoran la relación de la ciudadanía con su entorno urbano desde diferentes aspectos como la accesibilidad, la seguridad escolar o la participación ciudadana. El primer proyecto es Mapcesible, que permite a usuarios y usuarias mapear y evaluar la accesibilidad de diferentes lugares en España. El segundo, Eskola BideApp, una aplicación móvil diseñada para apoyar los caminos escolares seguros. Y finalmente, unos mapas que fomentan la transparencia y la participación ciudadana en la gestión urbana. El primero identifica la contaminación acústica, el segundo ubica los servicios disponibles en varias áreas que se encuentran a un máximo de 15 minutos y el tercero visualiza los bancos que hay en la ciudad. Estos mapas utilizan diversas fuentes de datos públicos para ofrecer una visión detallada de diferentes aspectos de la vida urbana.
La primera iniciativa es un proyecto de una gran fundación, la segunda, una propuesta colaborativa y local, y la tercera, un proyecto personal. Aunque parten de planteamientos muy diferentes, las tres tienen en común el uso de datos públicos y abiertos y la vocación de ayudar a entender y vivir la ciudad. La variedad de orígenes de estos proyectos indica que el uso de datos públicos y abiertos no está limitado a grandes organizaciones.
A continuación, realizamos un resumen de cada proyecto, seguido de una comparación y una reflexión sobre el empleo de datos públicos y abiertos en entornos urbanos.
Mapcesible, mapa para personas con movilidad reducida
Mapcesible se lanzó en 2019 para evaluar la accesibilidad de diversos espacios como comercios, aseos públicos, estacionamientos, alojamientos, restaurantes, espacios culturales y entornos naturales.

Figura 1. Mapcesible. Fuente: https://mapcesible.fundaciontelefonica.com/intro
Este proyecto cuenta con el apoyo de organizaciones como la ONG Confederación Española de Personas con Discapacidad Física y Orgánica (COCEMFE) y la empresa ILUNION. Actualmente cuenta con más de 40.000 espacios accesibles evaluados y miles de usuarios y usuarias.

Figura 2. Mapcesible. Fuente: https://mapcesible.fundaciontelefonica.com/filters
Mapcesible utiliza datos abiertos como parte de su funcionamiento. Específicamente, la aplicación incorpora catorce conjuntos de datos de organismos oficiales, incluyendo del Ministerio de Agricultura y Medioambiente, ayuntamientos de diferentes ciudades (incluidos Madrid y Barcelona) y de los gobiernos autonómicos. Estos datos abiertos se combinan con la información aportada por las personas usuarias de la aplicación, que pueden mapear y evaluar la accesibilidad de los lugares que visitan. Esta combinación de datos oficiales y colaboración ciudadana permite a Mapcesible proporcionar información actualizada y detallada sobre la accesibilidad de diversos espacios en toda España, beneficiando así a las personas con movilidad reducida.
Eskola BideAPP, aplicación para definir trayectos escolares seguros
Eskola BideAPP es una aplicación desarrollada por Montera34 –un equipo que se dedica a la visualización de datos y el desarrollo de proyectos colaborativos— en alianza con la Asociación Solasgune para apoyar los caminos escolares. Eskola BideAPP ha servido para garantizar que los niños y las niñas puedan acceder a sus escuelas de manera segura y eficiente. El proyecto usa sobre todo datos públicos del callejero de OpenStreetMap, por ejemplo, datos geográficos y cartográficos de calles, aceras, cruces, así como datos recabados durante el proceso de creación de rutas seguras para que los niños y las niñas vayan andando a sus colegios con el objetivo de promover su autonomía y la movilidad sostenible.
La aplicación ofrece un panel de control interactivo para visualizar los datos recopilados, la generación de mapas en papel para sesiones con el alumnado, y la creación de informes para técnicos municipales. Utiliza tecnologías como QGIS (un sistema de información geográfica de software libre y de código abierto) y un entorno de desarrollo para el lenguaje de programación R, dedicado a la computación estadística y gráficos.
El proyecto se divide en tres etapas principales:
- Recolección de datos mediante cuestionarios en las aulas.
- Análisis y discusión de resultados con los niños para co-diseñar rutas personalizadas.
- Prueba de las rutas diseñadas.

Figura 3. Eskola BideaAPP. Foto de Julián Maguna (Solasgune). Fuente: https://montera34.com/project/eskola-bideapp/
Pablo Rey, uno de los promotores de Montera34 junto con Alfonso Sánchez, informa para este artículo de que Eskola BideAPP, desde 2019, se ha usado en ocho municipios, incluidos Derio, Erandio, Galdakao, Gatika, Plentzia, Leioa, Sopela y Bilbao. Sin embargo, ahora mismo sólo está operativa en los dos últimos mencionados. “La idea es implementarla en Portugalete a principios de 2025”, añade.
Merece la pena recordar los mapas de Montera34 que mostraban el “efecto” AirBnB en San Sebastián y en otras ciudades, y los análisis de datos y mapas publicados durante la epidemia de COVID-19, que también visualizaban datos públicos. Además, Montera34 ha usado datos públicos para analizar la abstención, segregación escolar, contratos menores o poner los datos abiertos a disposición del público. Para este último proyecto, Montera34 ha comenzado por las ordenanzas del ayuntamiento de Bilbao y las actas de sus plenos, de manera que no solo estén disponibles en un documento PDF sino en forma de datos abiertos y accesibles.
Mapas de Madrid sobre contaminación acústica, servicios y ubicación de bancos
Abel Vázquez Montoro ha realizado diversos mapas con datos abiertos que resultan muy interesantes, por ejemplo, el elaborado con datos del Mapa Estratégico de Ruido (MER) ofrecido por el Ayuntamiento de Madrid y datos del catastro. El mapa muestra el ruido que afecta a cada edificio, fachada y planta en Madrid.

Figura 4. Mapas del ruido en Madrid. Fuente: https://madb.netlify.app/
Este mapa se organiza como un dashboard con tres secciones: datos generales de la zona visible en el mapa, mapa dinámico en 2D y 3D con opciones configurables e información detallada de edificios específicos. Se trata de una plataforma abierta, gratuita y de uso no comercial que usa software libre y de código abierto como GitLab — una plataforma web de gestión de repositorios Git— y QGIS. El mapa permite evaluar el cumplimiento de las normativas de ruido y el impacto en la calidad de vida, ya que también calcula el riesgo para la salud asociado a los niveles de ruido, utilizando la proporción de riesgo atribuible (RA%).
15-minCity es otro mapa interactivo que visualiza el concepto de la "ciudad de 15 minutos" aplicado a diferentes áreas urbanas; es decir, calcula cuán accesibles son diferentes servicios dentro de un radio de 15 minutos a pie o en bicicleta desde cualquier punto de la ciudad seleccionada.

Figura 5. 15-minCity. Fuente: https://whatif.sonycsl.it/15mincity/15min.php?idcity=9166
Por último, "Dónde sentarse en Madrid" es otro mapa interactivo que expone la ubicación de bancos y otros lugares para sentarse en espacios públicos de Madrid, destacando las diferencias entre barrios ricos (generalmente con más asientos públicos) y pobres (con menos). Este mapa utiliza la herramienta para creación de mapas, Felt, para visualizar y compartir información geoespacial de forma accesible. El mapa presenta diferentes tipos de asientos, incluyendo bancos tradicionales, asientos individuales, gradas y otros tipos de estructuras para sentarse.

Figura 6. Dónde sentarse en Madrid. Fuente: https://felt.com/map/Donde-sentarse-en-Madrid-TJx8NGCpRICRuiAR3R1WKC?loc=40.39689,-3.66392,13.97z
Sus mapas visualizan datos públicos de información demográfica (por ejemplo, datos poblacionales distribuidos por edades, género y nacionalidades), información urbanística sobre el uso del suelo, edificaciones y espacios públicos, datos socioeconómicos (por ejemplo, renta, empleo y otros indicadores económicos de los diferentes distritos y barrios), datos medioambientales, incluyendo calidad del aire, zonas verdes y otros aspectos relacionados, y datos sobre la movilidad.
¿Qué tienen en común?
| Nombre | Promotor/a | Tipo de datos usados | Afán de lucro | Usuarios/as | Características |
|---|---|---|---|---|---|
| Mapcesible | Fundación Telefónica. | Combina datos generados por usuarios/as y datos públicos (14 conjuntos de datos abiertos de organismos oficiales) | Sin ánimo de lucro. | Más de 5.000 | App colaborativa, disponible en iOS y Android, más de 40.000 puntos accesibles mapeados. |
| Eskola BideAPP | Montera34 y Asociación Solasgune. | Combina datos generados por usuarios/as y públicos (cuestionarios en aulas) y algunos datos abiertos. | Sin ánimo de lucro. | 4.185 | Enfocada en rutas escolares seguras, usa QGIS y R para procesamiento de datos |
| Mapa Estratégico de Ruido (MER) | Ayuntamiento de Madrid. | Datos geográficos y de zona visible en 2D y 3D | Sin ánimo de lucro. | No existen cifras públicas | Permite evaluar el cumplimiento de las normativas de ruido y el impacto en la calidad de vida, ya que también calcula el riesgo para la salud asociado |
| 15 min-City | Sony GSL | Servicios y datos geográficos. | Sin ánimo de lucro. | No existen cifras públicas | Mapa interactivo que visualiza el concepto de la "ciudad de 15 minutos" aplicado a diferentes áreas urbanas |
| MAdB "Dónde sentarse en Madrid" | Particular | Datos públicos (demográficos, electorales, urbanísticos, socioeconómicos, etc.) | Sin ánimo de lucro. | No existen cifras públicas | Mapas interactivos de Madrid |
Figura 7. Tabla comparativa de las soluciones
Estos proyectos comparten el enfoque de emplear datos abiertos para mejorar el acceso a los servicios urbanos, aunque difieren en sus objetivos específicos y en la forma de recopilar y presentar la información. Mapcesible, Eskola BideApp, MAdB y "Dónde sentarse en Madrid" tienen un gran valor.
Por un lado, Mapcesible ofrece información unificada y actualizada que permite a personas con discapacidad moverse por la ciudad y acceder a los servicios. Eskola BideApp involucra a la comunidad en el diseño y testeo de rutas seguras para ir caminando al colegio; esto no solo mejora la seguridad vial, sino que también empodera a los y las más jóvenes para que sean agentes activos en la planificación urbana. Entretanto, 15-min city, MER y los mapas desarrollados por Vázquez Montoro visualizan datos complejos sobre Madrid de manera que la ciudadanía pueden entender mejor cómo funciona su ciudad y cómo se toman las decisiones que les afectan.
En su conjunto, el valor de estos proyectos radica en su capacidad para crear una cultura de datos, enseñando a valorar, interpretar y utilizar la información para mejorar las comunidades.
Contenido elaborado por Miren Gutiérrez, Doctora e investigadora en la Universidad de Deusto, experta en activismo de datos, justicia de datos, alfabetización de datos y desinformación de género. Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor
Entrevista
En este episodio vamos a profundizar en la importancia de tres de las categorías de conjuntos de datos de alto valor relacionadas entre sí. Se trata de los datos de observación de la Tierra y el medio ambiente, los datos geoespaciales y los datos de movilidad. Para hablarnos de ellas, hemos entrevistado a dos expertos en la materia:
- Paloma Abad Power, subdirectora adjunta del Centro Nacional de Información Geográfica (CNIG).
- Rafael Martínez Cebolla, geógrafo del Gobierno de Aragón.
Con ellos hemos explorado cómo estos conjuntos de datos de alto valor están transformando nuestro entorno, contribuyendo al desarrollo sostenible y a la innovación tecnológica.
Resumen de la entrevista
1. ¿Qué son los datos de alto valor y por qué son importantes?
Paloma Abad Power: Según la normativa, estos conjuntos de datos de alto valor son los que garantizan un mayor potencial socioeconómico y para ello deben ser fáciles de encontrar, es decir, deben ser accesibles, interoperables y utilizables. ¿Y qué es lo que significa esto? Pues que los conjuntos de datos deben tener sus descripciones, es decir, los metadatos en línea, que informen de las estadísticas y de sus propiedades, y que se puedan descargar o utilizar de forma fácil.
En muchos casos, estos datos suelen ser datos de referencia, es decir, datos que sirven para generar otro tipo de datos, como los datos temáticos, o pueden generar valor añadido.
Rafael Martínez Cebolla: Se podrían definir como aquellos conjuntos de datos que representan fenómenos que sirven para la toma de una decisión, para cualquier política pública o para cualquier acción que pueda emprender una persona física o jurídica.
En ese sentido, hay ya unas directivas, que ya no son tan recientes, como la Directiva del Marco del Agua o la Directiva INSPIRE, que motivaban esa necesidad de disponer datos compartidos bajo unos estándares que posibiliten el desarrollo sostenible de nuestra sociedad.
2. Estos datos de alto valor vienen marcados por una Directiva europea y un Reglamento de ejecución en el que se dictaban seis categorías de conjuntos de datos de alto valor. En esta ocasión nos vamos a centrar en tres de ellas: los datos de observación de la Tierra y el medio ambiente, los datos geoespaciales y los datos de movilidad. ¿Qué tienen en común estas tres categorías de datos y qué conjuntos de datos concretos abarcan?
Paloma Abad Power: En mi opinión estos datos tienen en común la componente geográfica, es decir, son datos ubicados sobre la Tierra y, por tanto, sirven para solucionar problemas de diferente naturaleza y vinculados a la sociedad.
Así, por ejemplo, tenemos, con una cobertura nacional, el Plan Nacional de Ortofotografía Aérea (PNOA), que son las imágenes aéreas, el Sistema de Información de Ocupación del Suelo (SIOSE), las parcelas catastrales, las líneas límite, los nombres geográficos, las carreteras, las direcciones postales, los lugares protegidos - que pueden ser tanto de tipo ambiental, como también los castillos, es decir, patrimonio histórico-, etc. Y estas categorías abarcan casi todos los temas definidos por los anexos de la directiva INSPIRE.
Rafael Martínez Cebolla: Hay que saber distinguir qué es información geográfica pura, con una referencia geográfica directa, frente a otro tipo de fenómenos que tienen referencias geográficas de tipo indirecto. En este mundo actual, el 90% de la información puede ser ubicada, ya sea de manera directa o indirecta. Hoy más que nunca, el tag geográfico es obligatorio para cualquier corporación que quiera implantar una determinada actividad, ya sea social, cultural, ambiental o económica: la implantación de energías renovables, dónde voy a ir a comer hoy, etc. Estos conjuntos de datos de alto valor potencian esas referencias geográficas, sobre todo de tipo indirecto, que nos sirven para tomar una decisión.
3. ¿Cuáles son los organismos que publican estos conjuntos de datos de alto valor? En otras palabras, ¿dónde podría un usuario localizar conjuntos de datos de estas categorías?
Paloma Abad Power: Es necesario destacar el papel del Sistema Cartográfico Nacional, que es un modelo de actuación donde participan las organizaciones de la AGE (Administración General del Estado) y las comunidades autónomas. Está coordinando la coproducción de muchos productos únicos, financiados por estas organizaciones.
Estos productos se publican a través de servicios web interoperables. Los publica, en este caso, el Centro Nacional de Información Geográfica (CNIG), quien también se encarga de muchos de los metadatos de estos productos.
Se podrían localizar a través de los catálogos de la IDEE (Infraestructura de Datos Espaciales de España) o el Catálogo Oficial de Datos y Servicios INSPIRE, que también, a su vez, está en datos.gob.es y en el European Data Portal.
¿Y quién puede publicar? Todos los organismos que tengan un mandato legal sobre un producto y ese producto esté clasificado dentro del Reglamento. Ejemplos: todos los organismos cartográficos de las Comunidades Autónomas, la Dirección General de Catastro, Patrimonio Histórico, el Instituto Nacional de Estadística, el Instituto Geológico y Minero (IGME), el Instituto Hidrográfico de la Marina, el Ministerio de Agricultura, Pesca y Alimentación (MAPA), el Ministerio para la Transición Ecológica y el Reto Demográfico, etc. Son multitud de organismos y muchos de ellos, como he comentado, participan en el Sistema Cartográfico Nacional. Dan los datos y se genera un único servicio para el ciudadano.
Rafael Martínez Cebolla: El Sistema Cartográfico Nacional define muy bien el grado de competencias que asumen las administraciones. Es decir, la administración pública a todas las escalas es la que provee de datos oficiales, ayudada por la empresa privada, algunas veces, a través de la contratación pública.
La Administración General del Estado llega hasta unas escalas 1:25.000 en el caso del Instituto Geográfico Nacional (IGN) y luego el reparto competencial del resto de escalas es para las administraciones autonómicas o locales. Además, hay una serie de actores, como las confederaciones hidrográficas, los departamentos estatales o el Catastro, que tienen bajo sus competencias la obligación legal de generar estos conjuntos de datos.
Para mí es un ejemplo de cómo se ha de repartir, aunque es cierto que luego hay que engranar muy bien, a través de organismos colegiados, para que la producción cartografía esté bien incardinada.
Paloma Abad Power: También se hacen proyectos colaborativos, como, por ejemplo, un mapa ciudadano, técnicamente conocido como mapa X, Y, Z, que consiste en capturar la cartografía de todas las organizaciones a nivel nacional y local. Es decir, desde escalas pequeñas 1:1.000.000 o 1:50.000.000, hasta escalas muy grandes, como 1:1000, para proporcionar al ciudadano un único mapa multiescala y que se pueda servir a través de servicios web interoperables y normalizados.
4. ¿Tenéis algún otro ejemplo de aplicación directa de este tipo de datos?
Rafael Martínez Cebolla: Un ejemplo claro lo vimos con la pandemia, con los datos de movilidad que publicó el Instituto Nacional de Estadística. Fueron unos datos muy útiles para la administración, para la toma de decisiones, y con los que tenemos que aprender mucho más para la gestión de futuras pandemias y crisis, también de tipo económico. Nos tienen que servir para aprender y desarrollar nuestros sistemas de alerta temprana.
Yo creo que ahí está la línea de trabajo: datos que sean útiles para la ciudadanía en general. Por eso digo que la movilidad ha sido un ejemplo claro, porque era el propio ciudadano quien estaba informando a la administración sobre cómo se estaba moviendo.
Paloma Abad Power: Yo voy a aportar algún dato. Por ejemplo, según las estadísticas de los servicios del Sistema Cartográfico Nacional, el dato más demandado son las imágenes aéreas y los modelos digitales del terreno. En 2022 eran 8 millones de peticiones y en 2023 pasaron a 19 millones de peticiones, solamente en el caso de las ortoimágenes.
Rafael Martínez Cebolla: Me gustaría añadir que ese aumento también es porque se están haciendo bien las cosas. Por un lado, se mejoran los sistemas de descubrimiento. Mi sensación general es que proyectos de ejemplos exitosos hay muchos, tanto de la propia administración como de empresas que necesitan esa información base para generar sus productos.
Había una aplicación que se generó muy rápidamente con la desescalada - ibas a una página web y te decía hasta donde llegaba a tu término municipal-, porque la gente quería salir y andar. Este ejemplo surge de datos espaciales que se han salido de la administración pública. Yo creo que ahí radica la importancia de ejemplos exitosos, que salen de personas que ven una necesidad imperiosa.
5. ¿Y cómo se incentiva esa reutilización?
Rafael Martínez Cebolla: Yo tengo un sinfín de ejemplos. La incentivación pasa también por la promoción y el marketing, cosa que algunas veces nos ha fallado desde la administración pública. Tú te ciñes a unas competencias y parece que con que lo pongas en un sitio web ya vale. Y no es solo eso.
Nosotros estamos incentivando la reutilización de dos maneras. Por un lado, interna, en la propia administración, enseñándoles que la información geográfica sirve para la planificación y evaluación de las políticas públicas. Y os pongo el ejemplo de Atlas de Salud Pública del Gobierno Aragón, que fue premiado en el año antes de la pandemia por una sociedad ibérica de epidemiología. Para ellos fue útil para saber cómo era la salud del aragonés y qué medidas de prevención tenían que tomar.
En cuanto a los incentivos externos, en el caso del Instituto Geográfico de Aragón, se vio que el perfil que entraba al geoportal era muy técnico. Los formatos que se utilizaban eran también muy técnicos, con lo cual no se llegaba a la ciudadanía en general. Para solucionarlo se promocionaron portales como la IDE didáctica, un portal para enseñar geografía, que llega a cualquier ciudadano que quiera aprender sobre el territorio aragonés.
Paloma Abad Power: Me gustaría resaltar el beneficio económico que esto supone, como se mostró, por ejemplo, en el estudio económico que realizó el Centro Nacional de Información Gráfica con la Universidad de Leuven para medir el beneficio económico de la Infraestructura de Datos Espaciales de España. Se midió el beneficio que suponía que las empresas privadas utilizasen los servicios gratuitos y libres, en vez de utilizar, por ejemplo, Google Maps u otras fuentes que no son abiertas.
Rafael Martínez Cebolla: Para lo bueno y para lo malo, porque la calidad del dato oficial algunas veces nos gustaría que fuera mejor. Tanto Paloma, en la Administración General del Estado, como yo, en la administración autonómica, algunas veces sabemos que hay datos oficiales donde hay que invertir más dinero para que la calidad del dato sea mejor y pueda ser reutilizable.
Pero sí que es cierto que esos estudios son clave para saber en qué dimensión se mueven los conjuntos de datos de alto valor. Es decir, el tener estudios que informen del beneficio real que supone tener una infraestructura de datos espaciales a nivel estado o a nivel autonómico para mí es clave para dos cosas: para que el ciudadano entienda su importancia y, sobre todo, para que el político que llega cada N años entienda la evolución que han tenido estas plataformas y la revolución relativa a la información geoespacial que hemos vivido en los últimos 20 años.
6. También el Instituto Geográfico de Aragón ha realizado un informe sobre las ventajas de la reutilización de este tipo de datos, ¿verdad?
Rafael Martínez Cebolla: Sí, se publicó a comienzos de este año. Llevamos haciendo este informe desde hace tres o cuatro años de forma interna, porque sabíamos que íbamos a dar el salto hacia una infraestructura de conocimiento espacial y queríamos ver el impacto de implantar un grafo de conocimiento dentro de la infraestructura de datos. El Instituto Geográfico de Aragón ha hecho un esfuerzo en estos últimos años para analizar el beneficio económico que reporta el disponer de esta infraestructura para el ciudadano en sí, no para la propia administración. Es decir, cuánto dinero se ahorra el ciudadano aragonés en sus impuestos por tener esta infraestructura. Hoy sabemos que disponer de una plataforma de información geográfica ahorra aproximadamente 2 millones de euros al año a la ciudadanía aragonesa.
A mí me gustaría ver el informe del próximo enero o febrero, porque creo que el salto va a ser importante. El grafo de conocimiento se implantó en abril del año pasado y ese gap se va a notar en el año que estamos viviendo. Hemos notado un aumento considerable de peticiones, tanto a nivel de visualización como de descarga.
Básicamente de un año al otro, hemos casi duplicado tanto el número de accesos como de descargas. Esto afecta a la componente tecnológica: la tienes que volver a rediseñar. Te está descubriendo más gente, está accediendo más gente a tus datos y, por tanto, tienes que, dedicarle más inversión a la componente tecnológica, porque está siendo el cuello de botella.
7. ¿Cuáles creeis que son los retos que se afrontarán en los próximos años?
Paloma Abad Power: En mi opinión, el primer reto es conocer al usuario para darle un mejor servicio. El usuario técnico, los universitarios, los usuarios de la calle, etc. Estamos pensando en hacer una encuesta cuando el usuario vaya a utilizar nuestra información geográfica. Pero claro, ese tipo de encuestas a veces frena el uso de la información geográfica. Ese es el gran reto: conocer al usuario para hacer servicios más amigables, aplicaciones, etc. Saber llegar a lo que quiere y dárselo mejor.
También hay otro reto a nivel técnico. Cuando empezaron las infraestructuras espaciales el nivel técnico era muy elevado, tenías que saber lo que era un servicio de visualización, los metadatos, conocer los parámetros, etc. Esto hay que eliminarlo, que el usuario simplemente diga yo quiero, por ejemplo, consultar y visualizar la longitud del río Ebro, de forma más amigable. O por ejemplo la palabra LiDAR, que era el modelo digital italiano con una alta precisión. Todos estos vocablos hay que hacérselos mucho más amigables al usuario.
Rafael Martínez Cebolla: Sobre todo, que sean descubiertos. Mi percepción es que hay que seguir potenciando el descubrimiento de los datos espaciales sin necesidad de explicarle al usuario no avezado, o incluso a unos técnicos, que tenemos que tener un dato, un metadato, un servicio…. No, no. Básicamente es que desde los buscadores generalistas se pueda encontrar los conjuntos de datos de alto valor sin necesidad de saber que existe una cosa que se llama infraestructura de datos espaciales.
Se trata de publicar los datos bajo unos estándares amigables, bajo unas versiones accesibles y, sobre todo, publicarlos en direcciones URIs permanentes, que no vayan a cambiar. Es decir, que el dato vaya mejorando en calidad, pero no vaya a cambiar nunca.
Y sobre todo, desde el punto de vista técnico, tanto las infraestructuras de datos espaciales y los geoportales como las infraestructuras de conocimiento tenemos que conseguir que los nodos de información de alto valor se relacionan entre sí desde el punto semántico y geográfico. Entiendo que los grafos de conocimiento van a ayudar en este sentido. Es decir, la movilidad tiene que tener relación con la observación del territorio, con los datos de salud pública o con los datos estadísticos, que también tienen componente geográfico. Esa relación semántica geográfica para mí es clave.
Clips de la entrevista
1. ¿Qué son los datos de alto valor y por qué son importantes?
2. ¿Dónde puede un usuario localizar datos geográficos?
3. ¿Cómo se está incentivando la reutilización de datos con componente geográfica?
Blog
Muchas personas utilizan aplicaciones para desplazarse en su día a día. Apps como Google Maps, Moovit o CityMapper facilitan la ruta más rápida y eficaz para llegar a un destino. Sin embargo, lo que muchos usuarios desconocen es que tras estas plataformas se encuentra una valiosa fuente de información: los datos abiertos. Gracias a la reutilización de conjuntos de datos públicos, como los relacionados con la calidad del aire, el tráfico o el transporte público, estas aplicaciones pueden ofrecer un mejor servicio.
En este post, exploraremos cómo la reutilización de datos abiertos por parte de estas plataformas potencia un ecosistema urbano más inteligente y sostenible.
Google Maps: agrega información de calidad del aire y datos de transporte en GTFS.
Más de mil millones de personas utilizan Google Maps mensualmente alrededor del mundo. El gigante tecnológico ofrece un mapa mundial actualizado y gratuito que obtiene sus datos de diferentes fuentes, algunas de ellas, abiertas.
Una de las funciones que brinda la app es la información sobre la calidad del aire en la ubicación en la que se encuentra el usuario. El Índice de Calidad del Aire (ICA) es un parámetro que viene determinado por cada país o región. La referencia europea se puede consultar en este mapa que muestra calidad del aire por zonas geolocalizadas en tiempo real.
Para mostrar la calidad de aire de la ubicación del usuario, Google Maps aplica un modelo basado en un enfoque multicapa conocido como “enfoque de fusión”. Este método combina datos de varias fuentes de entrada y pondera las capas con un procedimiento sofisticado. Las capas de entrada son:
- Estaciones de monitorización de referencia de los gobiernos
- Redes de sensores comerciales
- Modelos de dispersión mundiales y regionales
- Modelos de polvo y humo de incendios
- Información obtenida por satélite
- Datos del tráfico
- Información auxiliar como la superficie
- Meteorología
En el caso de España, esta información se obtiene de fuentes de datos abiertos como el Ministerio de Transición Ecológica y Reto Demográfico, el Instituto Geográfico Nacional (que le permite obtener la cartografía con nombres oficiales de carreteras, poblaciones, etc.) la Conselleria de Medio Ambiente, Territorio y Vivienda de la Xunta de Galicia o la Comunidad de Madrid. Puedes consultar aquí las fuentes de datos abiertos que se utilizan en otros países del mundo.
Otra funcionalidad que ofrece Google Maps para planificar las mejores rutas para llegar a un destino es la información sobre el transporte público. Estos datos son proporcionados de manera voluntaria por las empresas públicas que ofrecen el servicio de transporte en cada ciudad. Para que estos datos abiertos estén a disposición del usuario, primero se vuelcan en Google Transit y deben cumplir el estándar abierto de transporte público GTFS (General Transit Feed Specification). Además, Google Maps también integra datos de transporte en GTFS del Punto de Acceso Nacional.
Moovit: reutiliza datos abiertos para ofrecer información en tiempo real
Moovit es otra de las aplicaciones de movilidad urbana, que utiliza datos abiertos y colaborativos para facilitar a los usuarios la planificación de sus desplazamientos en transporte público.
Desde su lanzamiento en 2012, la app de descarga gratuita ofrece información en tiempo real de las distintas opciones de transporte, sugiere las mejores rutas para llegar al destino indicado, guía al usuario durante su recorrido (cuánto tiene que esperar, cuántas paradas faltan, cuándo tiene que bajar, etc.) y realiza actualizaciones constantes ante cualquier alteración en el servicio.
Como otras apps de movilidad, también está disponible en modalidad offline y permite guardar las rutas y líneas frecuentes en “Favoritos”. Además, se trata de una solución inclusiva ya que integra VoiceOver (iOs) o TalkBack (Android) para personas invidentes.
La plataforma no solo aprovecha datos abiertos proporcionados por gobiernos y autoridades locales, sino que también recopila información de sus usuarios, lo que le permite ofrecer un servicio dinámico y constantemente actualizado.
CityMapper: nace como reutilizador de datos abiertos de movilidad
El equipo de desarrollo de CityMapper reconoce que la aplicación nació con un ADN abierto que todavía se mantiene. Reutilizan conjuntos de datos abiertos de, por ejemplo, OpenStreetMap a nivel global o RENFE y Cercanías Bilbao a nivel nacional. A medida que la aplicación está disponible en más ciudades, mayor es la lista de fuentes de referencia de datos abiertos de las que obtiene información.
La plataforma ofrece información en tiempo real sobre rutas de transporte público, incluyendo autobuses, trenes, metro o bicicletas compartidas. También añade opciones para desplazarse a pie, en bici o en sistemas de transporte compartido. Está diseñada para proporcionar la ruta más eficiente y rápida para llegar a un destino, integrando datos de diferentes medios de transporte en una sola interfaz.
Tal y como publicamos en el informe monográfico “Innovación municipal a través de datos abiertos” CityMapper utiliza principalmente open data de las autoridades de transporte locales normalmente utilizando el estándar GTFS (General Transit Feed Specification). No obstante, cuando estos datos no son suficientes o no son suficientemente precisos, CityMapper los combina con conjuntos de datos generados por los propios usuarios de la aplicación que colaboran voluntariamente. También utiliza datos mejorados y gestionados por el trabajo de los propios empleados locales de la empresa. Todos estos datos se combinan con algoritmos de inteligencia artificial desarrollados para optimizar las rutas y ofrecer recomendaciones ajustadas a las necesidades de los usuarios.
En conclusión, el uso de datos abiertos en el transporte impulsa una transformación significativa en el sector de la movilidad en ciudades. Gracias al aporte que ofrecen a las aplicaciones, los usuarios pueden acceder a datos actualizados y precisos, planificar sus viajes de manera eficiente y tomar decisiones informadas. Los gobiernos, por su parte, han asumido el rol de facilitadores al hacer posible la difusión de datos mediante plataformas abiertas, optimizando recursos y fomentando la colaboración entre distintos sectores. Además, los datos abiertos han creado nuevas oportunidades para los desarrolladores y el sector privado, quienes han contribuido con soluciones tecnológicas, como pueden ser Google Maps, Moovit o CityMapper. En definitiva, el potencial de los datos abiertos para transformar el futuro de la movilidad urbana es algo innegable.
Aplicación
AUVASA Pay es una aplicación móvil que ofrece información en tiempo real sobre la red pública de autobuses de Valladolid. A través de AUVASA Pay se pueden consultar detalles como los tiempos de espera en parada o incluso comprar títulos de transporte en formato QR y recargar la tarjeta de transporte para utilizarla en los autobuses.
Esta aplicación utiliza datos abiertos de Open Street Map para mostrar los mapas de la ciudad. Además, ofrece conjuntos de datos abiertos sobre el transporte público en Valladolid disponibles para su descarga y reutilización bajo licencia Creative Commons en Datos abiertos - AUVASA
Documentación
La revolución digital está transformando los servicios municipales, impulsada por la creciente adopción de tecnologías de inteligencia artificial (IA) que también se benefician de los datos abiertos. Estos avances tienen potencial para redefinir la manera en que los municipios ofrecen servicios a sus ciudadanos, proporcionando herramientas para mejorar la eficiencia, accesibilidad y sostenibilidad. El presente informe analiza casos de éxito en el despliegue de aplicaciones y plataformas que buscan mejorar diversos aspectos de la vida en los municipios, destacando su potencial para liberar algo más del vasto potencial aún por explotar de los datos abiertos y las tecnologías asociadas a la inteligencia artificial.
Las aplicaciones y plataformas descritas en este informe tienen un alto potencial de replicabilidad en diferentes contextos municipales, ya que abordan problemas que son comunes. La replicación de estas soluciones puede llevarse a cabo mediante la colaboración entre municipios, empresas y desarrolladores, así como a través de la liberación y estandarización de datos abiertos.
A pesar de los beneficios, la adopción de datos abiertos para la innovación municipal también presenta importantes desafíos. Debe garantizarse la calidad, actualización y estandarización de los datos publicados por las entidades locales, así como la interoperabilidad entre diferentes plataformas y sistemas. Además, es necesario reforzar la cultura de datos abiertos entre todos los actores implicados, incluidos los ciudadanos, los desarrolladores, las empresas y las propias administraciones públicas.
Los casos de uso analizados se dividen en cuatro secciones. A continuación, se describen cada una de estas secciones y se muestran algunos ejemplos de las soluciones incluidas en el informe.
Transporte y Movilidad
Uno de los desafíos más significativos en las áreas urbanas es la gestión del transporte y la movilidad. Las aplicaciones que utilizan datos abiertos han demostrado ser efectivas en la mejora de estos servicios. Por ejemplo, aplicaciones como Park4Dis facilitan la localización de plazas de aparcamiento para persona con movilidad reducida, utilizando datos de múltiples municipios y contribuciones de voluntarios. CityMapper, que ha alanzado escala global, por otro lado, ofrece rutas de transporte público optimizadas en tiempo real, integrando datos de diversos modos de transporte para proporcionar la ruta más eficiente. Estas aplicaciones no solo mejoran la movilidad, sino que también contribuyen a la sostenibilidad al reducir la congestión y las emisiones de carbono.
Medio Ambiente y Sostenibilidad
La creciente conciencia sobre la sostenibilidad ha impulsado el desarrollo de aplicaciones que promueven prácticas ecológicas. CleanSpot, por ejemplo, facilita la localización de puntos de reciclaje y la gestión de residuos urbanos. La aplicación incentiva la participación ciudadana en la limpieza y el reciclaje, contribuyendo a la reducción de la huella ecológica. Liight, por su parte, gamifica comportamientos sostenibles, recompensando a los usuarios por acciones como reciclar o usar el transporte público. Estas aplicaciones no solo mejoran la gestión ambiental, sino que también educan y motivan a los ciudadanos a adoptar hábitos más sostenibles.
Optimización de Servicios Públicos Básicos
Las plataformas de gestión de servicios urbanos, como Gestdropper, utilizan datos abiertos para monitorizar y controlar infraestructuras urbanas en tiempo real. Estas herramientas permiten una gestión más eficiente de recursos como el alumbrado público, redes de agua y mobiliario urbano, optimizando el mantenimiento, la respuesta ante incidencias y reduciendo costes operativos. Por otra parte, el despliegue de sistemas de gestión de citas previas, como CitaME, ayuda a reducir los tiempos de espera y mejorar la eficiencia en la atención al ciudadano.
Agregadores de Servicios a los Ciudadanos
Las aplicaciones que centralizan información y servicios públicos, como Badajoz Es Más y AppValencia, mejoran la accesibilidad y la comunicación entre las administraciones y los ciudadanos. Estas plataformas proporcionan datos en tiempo real sobre transporte público, eventos culturales, turismo y trámites administrativos, facilitando la vida en el municipio tanto a los residentes como a los turistas. Por ejemplo, al integrar múltiples servicios en una sola aplicación, se mejora la eficiencia y se reduce la necesidad de desplazamientos innecesarios. Estas herramientas también apoyan a las economías locales al promover eventos culturales y servicios comerciales.
Conclusiones
La utilización de datos abiertos y tecnologías de inteligencia artificial está transformando la gestión municipal, mejorando la eficiencia, accesibilidad y sostenibilidad de los servicios públicos. Los casos de éxito presentados en este informe describen cómo estas herramientas pueden beneficiar tanto a los ciudadanos como a las administraciones públicas convirtiendo las ciudades en entornos más inteligentes, inclusivos y sostenibles, y respondiendo mejor a las necesidades y bienestar de sus habitantes y visitantes.
Para profundizar en el contenido del informe, hemos grabado un pódcast y una video-entrevista donde el autor nos cuenta las claves de esta guía. Además, se ha elaborado una infografía y un resumen ejecutivo.
Escucha el pódcast con el autor
Mira la vídeo-entrevista con el autor
Blog
España, como parte de la Unión Europea, está comprometida con la implementación de las directivas europeas sobre datos abiertos y reutilización de la información del sector público. Esto incluye la adopción de iniciativas como el Reglamento de Implementación (UE) 2023/138, emitido por la Comisión Europea, que define directrices específicas para las entidades gubernamentales con respecto a la disponibilidad de conjuntos de datos de alto valor (High value datasets en inglés o HVD) . Estos datos se categorizan en temáticas previamente detalladas en discusiones anteriores: Geoespacial, Observación de la Tierra y Medio Ambiente, Meteorología, Estadística, Sociedades y Propiedades de Sociedades, y Movilidad. En este artículo nos centraremos en el último grupo mencionado.
La categoría de Movilidad engloba colecciones de datos que caen bajo el dominio de la "Redes de Transporte", como se demarca en el Anexo I de la Directiva 2007/2/CE del Parlamento Europeo y del Consejo, de 14 de marzo de 2007, por la que se establece una infraestructura de información espacial en la Comunidad Europea (INSPIRE). En concreto, esta Directiva hace referencia a que se deben poner a disposición de los usuarios los conjuntos de datos relativos a redes de carreteras, ferrocarril, transporte aéreo y vías navegables, con sus correspondientes infraestructuras, las conexiones entre redes diferentes y la red transeuropea de transporte, según la definición de la Decisión no 1692/96/CE del Parlamento Europeo y del Consejo, de 23 de julio de 1996, sobre las orientaciones comunitarias para el desarrollo de la red transeuropea de transporte.
Además, se incluyen los conjuntos de datos tal como se describe en la Directiva 2005/44/CE del Parlamento Europeo y del Consejo, de 7 de septiembre de 2005, relativa a los servicios de información fluvial (SIF) armonizados en las vías navegables interiores de la Comunidad. Esta Directiva establece un marco armonizado para la creación de una red transeuropea de información fluvial (RIS, por sus siglas en inglés). El objetivo principal de la Directiva es mejorar el tráfico y el transporte fluvial y se aplican a los canales, ríos, lagos y puertos capaces de albergar buques de entre 1.000 y 1.500 toneladas. Estos conjuntos de datos incluyen:
| Conjunto de datos | Conjuntos de datos sobre vías navegables interiores |
|---|---|
| Datos estáticos |
|
| Datos dinámicos |
|
| Cartas electrónicas y de navegación interior (ENC Fluvial según la norma SIVCE Fluvial) |
|
Figura 1: Tabla con los conjuntos de datos de alto valor relativos a la Directiva 2005/44/CE para la creación de una red transeuropea de información fluvial.
Para que todos podamos aprovechar al máximo la información disponible, el Reglamento define algunas reglas básicas sobre cómo se comparten estos datos:
- Uso libre y fácil. Los datos tienen que estar listos para usarse y compartirse con todos y para cualquier fin reconociendo y citando la fuente de los datos, tal como prescribe la licencia tipo Creative Commons BY 4.0.
- Fácil de leer y usar. Se presentarán de una manera que tanto las personas como las computadoras puedan entenderlos fácilmente y estará todo explicado en público.
- Acceso directo y sencillo. Habrá maneras especiales (llamadas APIs) que permiten a los programas acceder a los datos automáticamente. Además, el usuario podrá alternativamente descargar mucha información de una vez.
- Siempre al día. Es importante que los datos estén actualizados, así que existirá el acceso a la versión más reciente. Pero si el usuario necesita acceder a los datos previos, también se podrá ver las versiones anteriores.
- Detallados y precisos. Los datos se compartirán con tanto detalle como sea posible, hasta un nivel muy fino de precisión, de manera que se cubra todo el territorio al combinarse.
- Información sobre la información. Habrá "información sobre la información" (metadatos) que contará todo sobre los datos. Los elementos de metadatos contendrán como mínimo los recogidos en el anexo del Reglamento (CE) nº 1205/2008 de la Comisión, de 3 de diciembre de 2008.
- Entendible y ordenado: Se explicará bien cómo están organizados los datos y qué significa todo, de manera que sea fácil de entender para todos (estructura y semántica).
- Lenguaje común. Los datos usarán vocabularios, listas controladas y categorías que sean reconocidos y aceptados a nivel europeo o mundial.
¿En España quién es el responsable de la creacion y mantenimiento de los datos de movilidad?
En España, la responsabilidad de la creación y mantenimiento de los datos de movilidad recae generalmente en distintas entidades gubernamentales, dependiendo del tipo de movilidad y del ámbito territorial:
- Nivel nacional. El Ministerio de Transportes y Movilidad Sostenible es el organismo principal encargado de la movilidad en cuanto a infraestructuras y transportes a nivel nacional. Este incluiría datos sobre carreteras, ferrocarriles, transporte aéreo y marítimo.
- Nivel autonómico y local. Las comunidades autónomas y los ayuntamientos también desempeñan un papel importante en la movilidad urbana y regional. Se encargan de la movilidad urbana, el transporte público y las vías públicas, dentro de sus respectivas jurisdicciones.
- Entidades públicas empresariales. Hay entidades como ADIF (acrónimo de Administrador de Infraestructuras Ferroviarias), AENA (acrónimo de Aeropuertos Españoles y Navegación Aérea), Puertos del Estado y otras que gestionan datos específicos relacionados con su campo de acción en el transporte ferroviario, aéreo y marítimo, respectivamente.
En España, el Ministerio de Transportes y Movilidad Sostenible, en colaboración con las comunidades autónomas, juega un rol clave en proporcionar acceso a una amplia gama de datos de movilidad. En conformidad con INSPIRE y LISIGE (la Ley 14/2010 de 5 de julio sobre las infraestructuras y los servicios de información geográfica en España, que transpone la Directiva INSPIRE), ofrece recursos como el Geoportal de la Infraestructura de Datos Espaciales de España (IDEE), donde la ciudadanía y los profesionales pueden acceder a datos y servicios geográficos, especialmente en lo referente a movilidad.
¿Cumple España con el Reglamento de los HVD de movilidad?
Para resolver esta pregunta nos tenemos que ir al el Geoportal de INSPIRE que es donde se encuentra disponible la información oficial clasificada como conjuntos de datos de alto valor en Europa. En concreto en la categoría de movilidad.

Figura 2: Captura del Geoportal Inspire.
A abril de 2024 España tiene publicado en el Geoportal de INSPIRE la siguiente información:
- Zonas de servicio portuarias de España. Las zonas de servicio portuarias de los puertos de interés general del Estado, incluyen la información cartográfica y alfanumérica de la zona de servicio terrestre y de la zona I y II de aguas. El Sistema Portuario español de titularidad estatal está integrado por 46 puertos de interés general, gestionados por 28 Autoridades Portuarias.
- Redes de Transporte de España. La Red de Transporte de la Información Geográfica de Referencia del Sistema Cartográfico Nacional de España, es una red tridimensional de cobertura nacional, definida y publicada en conformidad con la Directiva INSPIRE, que contempla cinco modos de transporte: red viaria, raíl, vías navegables, aéreo y cable, junto con sus respectivas conexiones intermodales y las infraestructuras asociadas a cada modo. Dicha información tiene la geometría lineal de los viales y la puntual de los portales y puntos kilométricos.
- Red de Transporte Ferroviario de ADIF de España. Conjunto de datos geográficos de carácter público sobre la adaptación de la Tramificación Común de ADIF a la normativa INSPIRE (Redes de Transporte Anexo I).
La publicación de estos conjuntos de datos de alto valor responde positivamente a la pregunta de si España cumple con el reglamento de HVD, y supone un logro que refleja el compromiso continuo de nuestro país con la transparencia y el acceso a datos de movilidad.
El esfuerzo conjunto entre el Ministerio de Transportes, Movilidad y Agenda Urbana, el Sistema Cartográfico Nacional y las Comunidades Autónomas y las Entidades Públicas Empresariales subraya la importancia de un enfoque colaborativo para la gestión de la información de movilidad.
La disponibilidad de estos datos destaca el compromiso de España en publicar datos de alto valor y subraya la importancia de mejorar continuamente el acceso a la información para optimizar la navegación interior y los datos de movilidad.
Contenido elaborado por Mayte Toscano, Senior Consultant en Tecnologías ligadas a la economía del dato. Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Documentación
1. Introducción
Las visualizaciones son representaciones gráficas de datos que permiten comunicar, de manera sencilla y efectiva, la información ligada a los mismos. Las posibilidades de visualización son muy amplias, desde representaciones básicas como los gráficos de líneas, de barras o métricas relevantes, hasta visualizaciones configuradas sobre cuadros de mando interactivos.
En esta sección de “Visualizaciones paso a paso” estamos presentando periódicamente ejercicios prácticos haciendo uso de datos abiertos disponibles en datos.gob.es u otros catálogos similares. En ellos se abordan y describen de manera sencilla las etapas necesarias para obtener los datos, realizar las transformaciones y los análisis pertinentes para, finalmente obtener unas conclusiones a modo de resumen de dicha información.
En cada ejercicio práctico se utilizan desarrollos de código documentados y herramientas de uso gratuito. Todo el material generado está disponible para su reutilización en el repositorio de GitHub de datos.gob.es.
En este ejercicio concreto, exploraremos la actual situación de la penetración de los vehículos eléctricos en España y las perspectivas de futuro de esta tecnología disruptiva en el transporte.
Accede al repositorio del laboratorio de datos en Github.
Ejecuta el código de pre-procesamiento de datos sobre Google Colab.
En este vídeo, el autor te explica que vas a encontrar tanto en el Github como en Google Colab.
2. Contexto: ¿Por qué es importante el vehículo eléctrico?
La transición hacia una movilidad más sostenible se ha convertido en una prioridad global, situando al vehículo eléctrico (VE) en el centro de numerosas discusiones sobre el futuro del transporte. En España, esta tendencia hacia la electrificación del parque automovilístico no solo responde a un creciente interés por parte de los consumidores en tecnologías más limpias y eficientes, sino también a un marco regulatorio y de incentivos diseñado para acelerar la adopción de estos vehículos. Con una creciente oferta de modelos eléctricos disponibles en el mercado, los vehículos eléctricos representan una pieza clave en la estrategia del país para reducir las emisiones de gases de efecto invernadero, mejorar la calidad del aire en las ciudades y fomentar la innovación tecnológica en el sector automotriz.
Sin embargo, la penetración de los vehículos eléctricos en el mercado español enfrenta una serie de desafíos, desde la infraestructura de carga hasta la percepción y el conocimiento del consumidor sobre estos vehículos. La expansión de la red de carga, junto con las políticas de apoyo y los incentivos fiscales, son fundamentales para superar las barreras existentes y estimular la demanda. A medida que España avanza hacia sus objetivos de sostenibilidad y transición energética, el análisis de la evolución del mercado de vehículos eléctricos se convierte en una herramienta esencial para entender el progreso realizado y los obstáculos que aún deben superarse.
3. Objetivo
Este ejercicio se centra en mostrar al lector técnicas para el tratamiento, visualización y análisis avanzado de datos abiertos mediante Python. Adoptaremos para ello el enfoque “aprender haciendo”, de tal forma que el lector pueda comprender la utilización de estas herramientas en el contexto de la resolución de un reto real y de actualidad como es el estudio de la penetración del VE en España. Este enfoque práctico no solo mejora la comprensión de las herramientas de ciencia de datos, sino que también prepara a los lectores para aplicar estos conocimientos en la resolución de problemas reales, ofreciendo una experiencia de aprendizaje rica y directamente aplicable a sus propios proyectos.
Las preguntas a las que trataremos de dar respuesta a través de nuestro análisis son:
- ¿Qué marcas de vehículos lideraron el mercado en 2023?
- ¿Qué modelos de vehículos fueron los más vendidos en el 2023?
- ¿Qué cuota de mercado absorbieron los vehículos eléctricos en el 2023?
- ¿Qué modelos de vehículos eléctricos fueron los más vendidos en el 2023?
- ¿Cómo han evolucionado las matriculaciones de vehículos a lo largo del tiempo?
- ¿Observamos algún tipo de tendencia respecto a la matriculación de vehículos eléctricos?
- ¿Cómo esperamos que evolucionen las matriculaciones de vehículos eléctricos el próximo año?
- ¿Cuál es la reducción de emisiones de CO2 que podemos esperar gracias a las matriculaciones obtenidas durante el próximo año?
4. Recursos
Para completar el desarrollo de este ejercicio requeriremos el uso de dos categorías de recursos: Herramientas Analíticas y Conjuntos de Datos.
4.1. Conjunto de datos
Para completar este ejercicio utilizaremos un conjunto de datos provisto por la Dirección General de Tráfico (DGT) a través de su portal estadístico, también disponible desde el catálogo Nacional de Datos Abiertos (datos.gob.es). El portal estadístico de la DGT es una plataforma en línea destinada a ofrecer acceso público a una amplia gama de datos y estadísticas relacionadas con el tráfico y la seguridad vial. Este portal incluye información sobre accidentes de tráfico, infracciones, matriculaciones de vehículos, permisos de conducción y otros datos relevantes que pueden ser útiles para investigadores, profesionales del sector y el público en general.
En nuestro caso, utilizaremos su conjunto de datos de matriculaciones de vehículos en España disponibles vía:
- Catálogo de Datos Abiertos del Gobierno de España.
- Portal estadístico de la DGT.
Aunque durante el desarrollo del ejercicio mostraremos al lector los mecanismos necesarios para su descarga y procesamiento, incluimos en el repositorio de GitHub asociado los datos preprocesados*, de tal forma que el lector pueda proceder directamente al análisis de los mismos en el caso de que lo desee.
*Los datos utilizados en este ejercicio fueron descargados el 04 de marzo de 2024. La licencia aplicable a este conjunto de datos puede encontrarse en https://datos.gob.es/avisolegal.
4.2. Herramientas analíticas
- Lenguaje de programación: Python – es un lenguaje de programación ampliamente utilizado en análisis de datos debido a su versatilidad y a la amplia gama de bibliotecas disponibles. Estas herramientas permiten a los usuarios limpiar, analizar y visualizar grandes conjuntos de datos de manera eficiente, lo que hace de Python una elección popular entre los científicos de datos y analistas.
- Plataforma: Jupyter Notebooks – es una aplicación web que permite crear y compartir documentos que contienen código vivo, ecuaciones, visualizaciones y texto narrativo. Se utiliza ampliamente para la ciencia de datos, análisis de datos, aprendizaje automático y educación interactiva en programación.
- Principales librerías y módulos:
- Manipulación de datos: Pandas – es una librería de código abierto que proporciona estructuras de datos de alto rendimiento y fáciles de usar, así como herramientas de análisis de datos.
- Visualización de datos:
- Matplotlib: es una librería para crear visualizaciones estáticas, animadas e interactivas en Python.
- Seaborn: es una librería basada en Matplotlib. Proporciona una interfaz de alto nivel para dibujar gráficos estadísticos atractivos e informativos.
- Estadística y algoritmia:
- Statsmodels: es una librería que proporciona clases y funciones para la estimación de muchos modelos estadísticos diferentes, así como para realizar pruebas y exploración de datos estadísticos.
- Pmdarima: es una librería especializada en la modelización automática de series temporales, facilitando la identificación, el ajuste y la validación de modelos para pronósticos complejos.
5. Desarrollo del ejercicio
Es aconsejable ir ejecutando el Notebook con el código a la vez que se realiza la lectura del post, ya que ambos recursos didácticos son complementarios en las futuras explicaciones
El ejercicio propuesto se divide en cuatro fases principales.
5.1 Configuración inicial
Este apartado podrás encontrarlo en el punto 1 del Notebook.
En este breve primer apartado, configuraremos nuestro Jupyter Notebook y nuestro entorno de trabajo para poder trabajar con el conjunto de datos seleccionado. Importaremos las librerías Python necesarias y crearemos algunos directorios donde almacenaremos los datos descargados.
5.2 Preparación de datos
Este apartado podrás encontrarlo en el punto 2 del Notebook.
Todo análisis de datos requiere una fase de acceso y tratamiento de los mismos hasta obtener los datos adecuados en el formato deseado. En esta fase, descargaremos los datos del portal estadístico y los transformaremos al formato Apache Parquet antes de proceder a su análisis.
Aquellos usuarios que quieran profundizar en esta tarea, tienen a su disposición la Guía Práctica de Introducción al Análisis Exploratorio de Datos.
5.3 Análisis de datos
Este apartado podrás encontrarlo en el punto 3 del Notebook.
5.3.1 Análisis descriptivo
En esta tercera fase, comenzaremos nuestro análisis de datos. Para ello, responderemos las primeras preguntas apoyándonos en herramientas de visualización de datos que además nos permitirán familiarizarnos con los mismos. Mostramos a continuación algunos ejemplos del análisis:
- Top 10 Vehículos matriculados en el 2023: En esta visualización representamos los diez modelos de vehículos con mayor número de matriculaciones durante el año 2023, indicando además el tipo de combustión de estos. Las principales conclusiones son:
- Los únicos vehículos de fabricación europea que aparecen en el Top 10 son el Arona y el Ibiza de la marca española SEAT. El resto son asiáticos.
- Nueve de los diez vehículos están propulsados por Gasolina.
- El único vehículo del Top 10 con un tipo de propulsión diferente es el DACIA Sandero GLP (Gas Licuado de Petróleo).
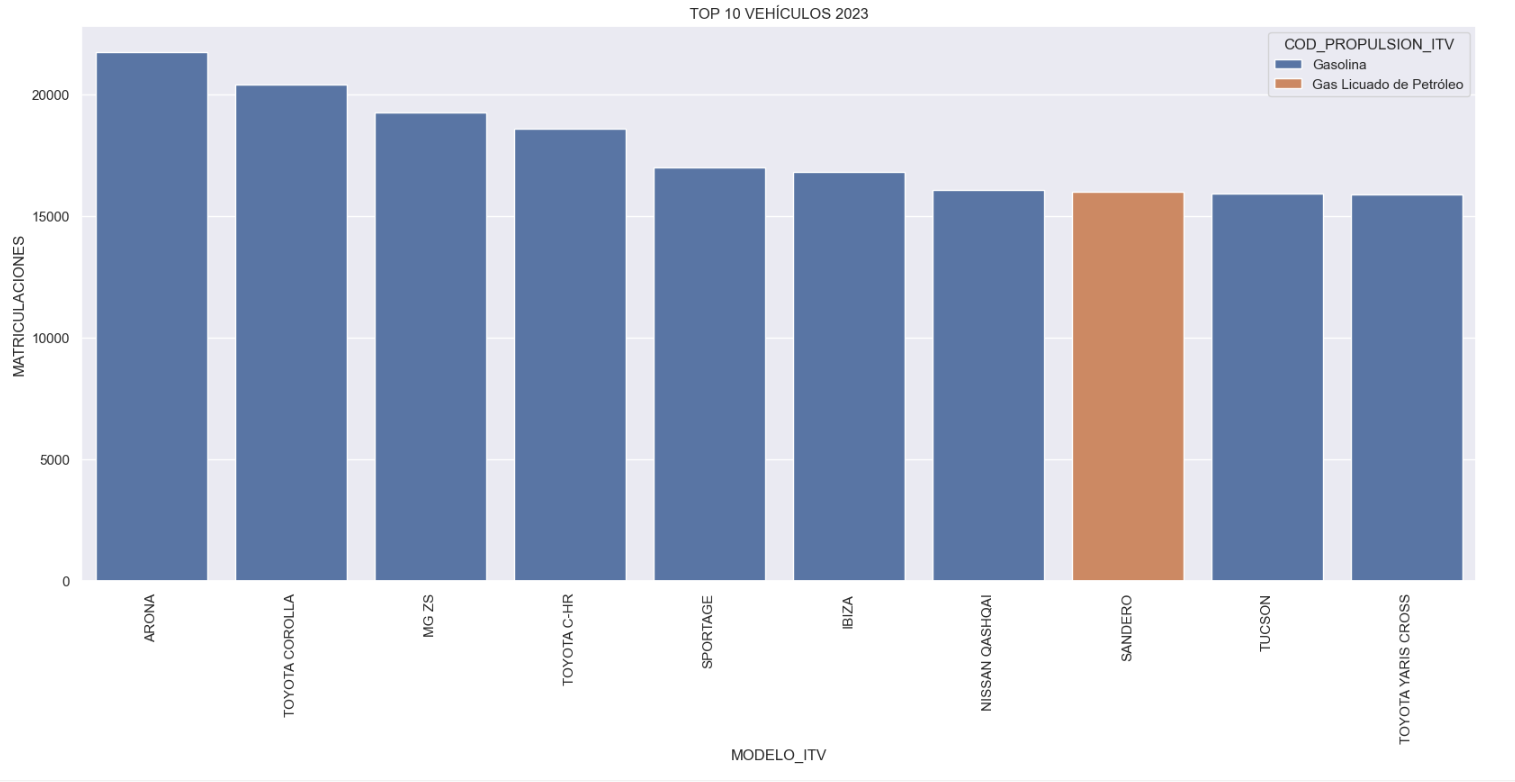
Figura 1. Gráfica "Top 10 Vehículos matriculados en el 2023"
- Cuota de mercado por tipo de propulsión: En esta visualización representamos el porcentaje de vehículos matriculado por cada tipo de propulsión (vehículos de gasolina, diésel, eléctricos u otros). Vemos cómo la inmensa mayoría del mercado (>70%) la absorbieron vehículos de gasolina, siendo los diésel la segunda opción, y como los vehículos eléctricos alcanzaron el 5.5%.
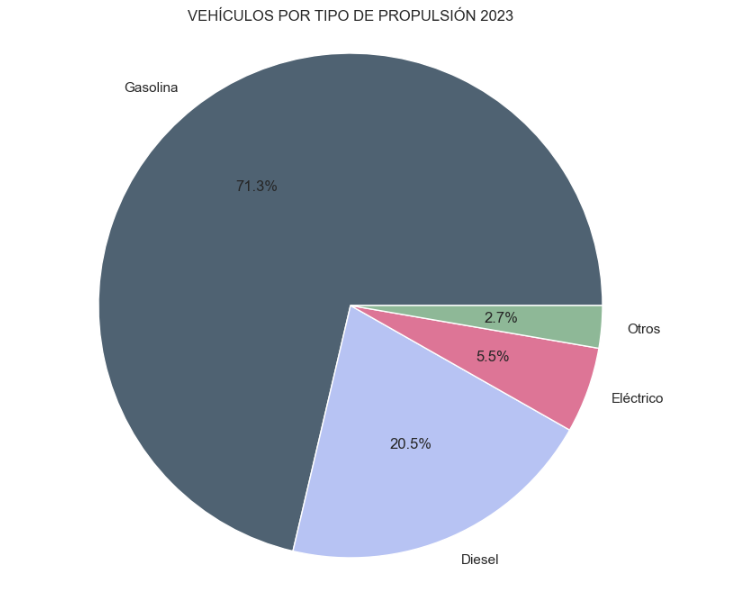
Figura 2. Gráfica "Cuota de mercado por tipo de propulsión".
- Evolución histórica de las matriculaciones: Esta visualización representa la evolución de las matriculaciones de vehículos en el tiempo. En ella se muestra el número de matriculaciones mensual entre enero de 2015 y diciembre de 2023 distinguiendo entre los tipos de propulsión de los vehículos matriculados.Podemos observar varios aspectos interesantes en este gráfico:
- Apreciamos un comportamiento estacional anual, es decir, observamos patrones o variaciones que se repiten a intervalos regulares de tiempo. Vemos cómo recurrentemente en junio/julio aparecen altos niveles de matriculación mientras que en agosto/septiembre decrecen drásticamente. Esto es muy relevante, pues el análisis de series temporales con factor estacional tiene ciertas particularidades.
- Es muy notable también la enorme caída de matriculaciones producida durante los primeros meses del COVID.
- Vemos también como los niveles de matriculación post-covid son inferiores a los previos.
- Por último, podemos observar cómo entre los años 2015 y 2023 la matriculación de vehículos eléctricos va creciendo paulatinamente.
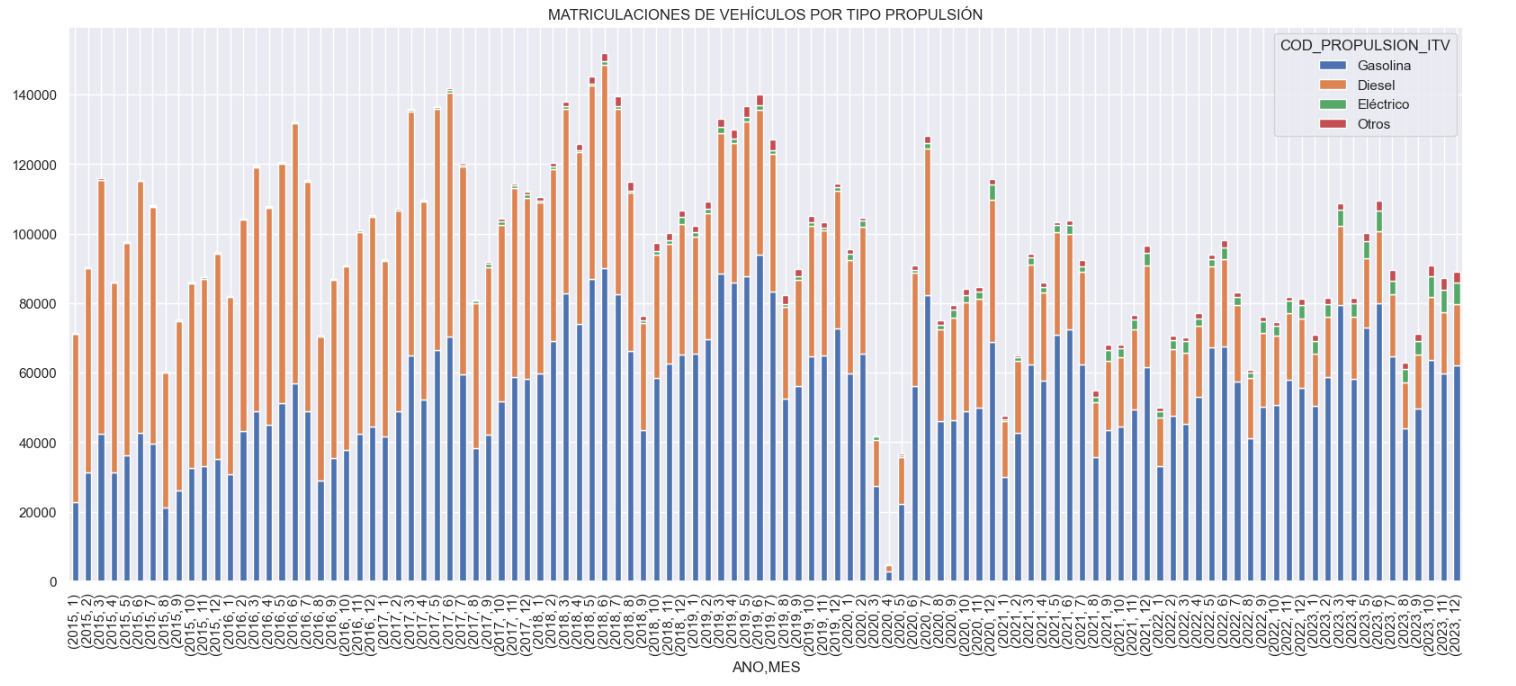
Figura 3. Gráfica "Matriculaciones de vehículos por tipo de propulsión".
- Tendencia en la matriculación de vehículos eléctricos: Analizamos ahora por separado la evolución de vehículos eléctricos y no eléctricos utilizando mapas de calor como herramienta visual. Podemos observar comportamientos muy diferenciados entre ambos gráficos. Observamos cómo el vehículo eléctrico presenta una tendencia de incremento de matriculaciones año a año y, a pesar de suponer el COVID un parón en la matriculación de vehículos, los años posteriores han mantenido la tendencia creciente.
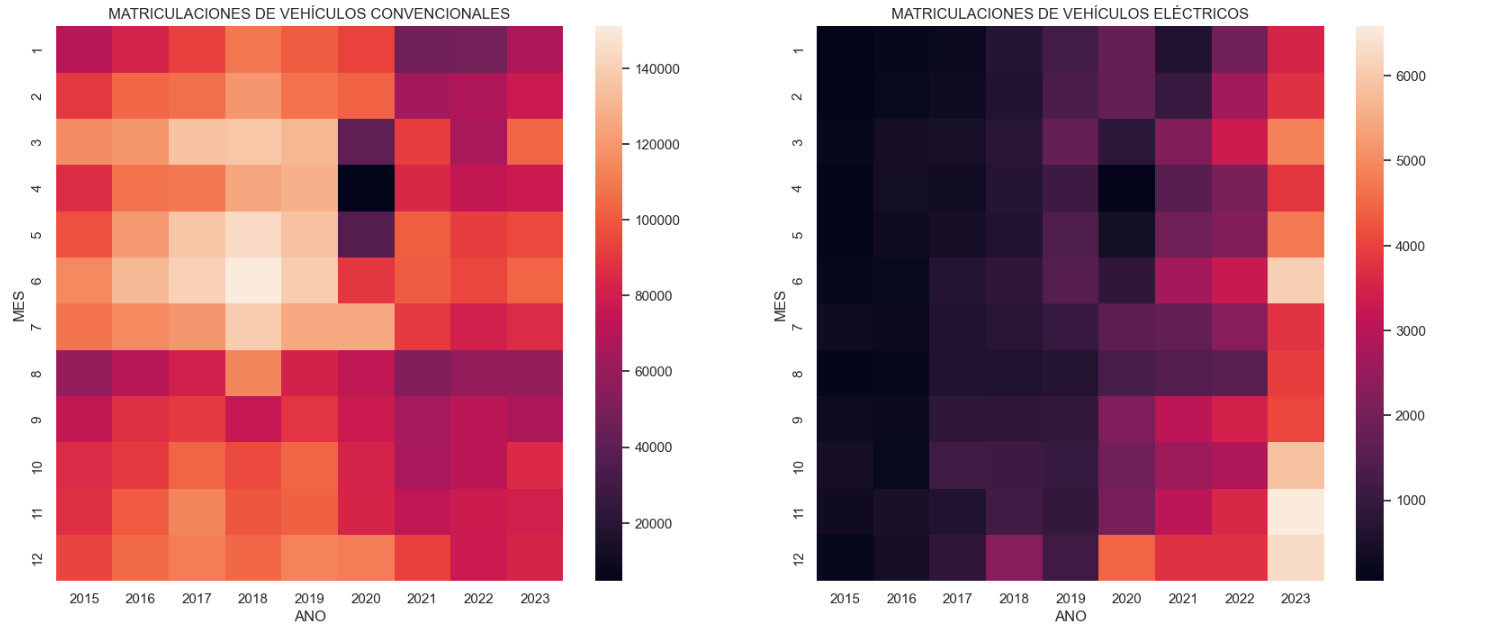
Figura 4. Gráfica "Tendencia en la matriculación de vehículos convencionales vs eléctricos".
5.3.2. Analítica predictiva
Para dar respuesta a la última de las preguntas de forma objetiva, utilizaremos modelos predictivos que nos permitan realizar estimaciones respecto a la evolución del vehículo eléctrico en España. Como podemos observar, el modelo construido nos propone una continuación del crecimiento en las matriculaciones esperadas a lo largo del año serán de 70.000, alcanzando valores cercanos a las 8.000 matriculaciones solo en el mes de diciembre del 2024.
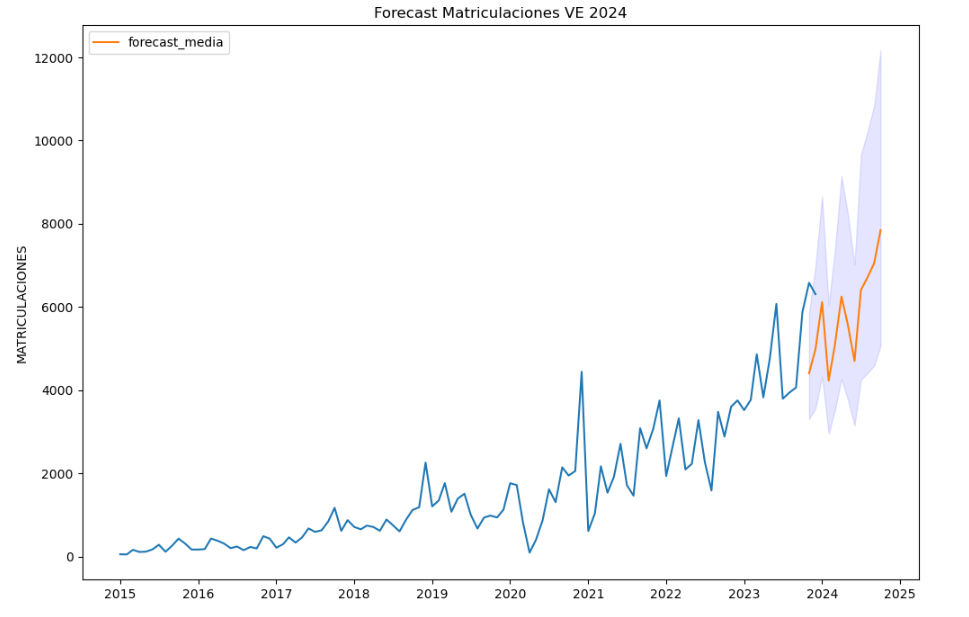
Figura 5. Gráfica "Predicción de matriculaciones de vehículos electricos".
5. Conclusiones del ejercicio
Como conclusión del ejercicio, podremos observar gracias a las técnicas de análisis empleadas como el vehículo eléctrico está penetrando cada vez a mayor velocidad en el parque móvil español aunque aún se encuentre a una distancia grande de otras alternativas como el Diésel o la Gasolina, por ahora liderado por el fabricante Tesla. Veremos en los próximos años si el ritmo crece al nivel necesario para alcanzar los objetivos de sostenibilidad fijados y si Tesla sigue siendo líder a pesar de la fuerte entrada de competidores asiáticos.
6. ¿Quieres realizar el ejercicio?
Si quieres conocer más sobre el Vehículo Eléctrico y poner a prueba tus capacidades analíticas, accede a este repositorio de código donde podrás desarrollar este ejercicio paso a paso.
Además, recuerda que tienes a tu disposición más ejercicios en el apartado sección de “Visualizaciones paso a paso”.
Contenido elaborado por Juan Benavente, ingeniero superior industrial y experto en Tecnologías ligadas a la economía del dato.Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Noticia
El Consejo de Ministros aprobó en febrero de este año el Proyecto de Ley (PL) de Movilidad Sostenible, una apuesta por un sistema de transporte digital e innovador en el que los datos abiertos de movilidad tendrán un papel fundamental.
La norma, además de regular soluciones innovadoras como el transporte a demanda, los coches compartidos o el uso temporal de vehículos, fomentará la promoción de los datos abiertos de administraciones, gestores de infraestructura y operadores públicos y privados. Todo ello, tal y como se puntualiza en el Capítulo III título V del Proyecto de Ley “reportará enormes beneficios a la ciudadanía, por ejemplo, para la nueva movilidad y su contribución al Pacto Verde Europeo”.
Este Proyecto de Ley está alineado con la Estrategia Europea de Datos, que tiene entre sus objetivos crear un mercado único de datos que garantice la competitividad global y la soberanía de los datos de Europa a través de la creación de espacios de datos europeos comunes en nueve sectores estratégicos. En concreto, se prevé la creación y desarrollo de un espacio común europeo de datos relativos a la movilidad para situar a Europa en la vanguardia del desarrollo de un sistema de transportes inteligente, incluidos los automóviles conectados y otros modos de transporte. En esta línea, la Comisión Europea presentó su Estrategia de movilidad sostenible e inteligente, que incluye una acción dedicada a la innovación, datos e inteligencia artificial para una movilidad más inteligente. Siguiendo la estela europea, España ha lanzado este Proyecto de Ley de Movilidad Sostenible.
En este post analizamos las ventajas que el uso de los datos abiertos puede ofrecer al sector, aquellas obligaciones que marca el PL y que afectarán a los datos, y los próximos pasos para constituir el Espacio de Datos Integrado de Movilidad.
Ventajas del uso de datos abiertos sobre movilidad sostenible
El Ministerio de Transporte y Movilidad Sostenible en el apartado web creado para la Ley, identifica algunos beneficios que el acceso y uso de los datos abiertos de transporte y movilidad pueden ofrecer tanto al entramado empresarial como a las administraciones públicas y el conjunto de la ciudadanía en general:
- Favorecer el desarrollo de aplicaciones que permitan a los ciudadanos la adopción de decisiones sobre la planificación de sus viajes y durante el desarrollo de estos.
- Mejorar las condiciones de prestación de los servicios y de la experiencia durante el viaje.
- Incentivar la investigación, crear nuevos desarrollos y negocios a partir de los datos generados en el ecosistema del transporte y la movilidad.
- Posibilitar que las administraciones públicas tengan un mayor conocimiento del sistema de transportes y movilidad para mejorar así la definición de las políticas públicas y la gestión del sistema.
- Impulsar el uso de estos datos para otros fines de interés público que puedan surgir.

Asegurar el acceso a datos abiertos de movilidad
Para hacer buen uso de estos datos y aprovechar así todas las ventajas que ofrecen, el Proyecto de Ley determina una estrategia que garantiza la disponibilidad de datos abiertos en el ámbito del transporte y la movilidad. Esta estrategia afecta a:
- las empresas de transporte y los gestores de infraestructuras, que deben impulsar la digitalización y proporcionar parte importante de los datos, con unas características y funcionalidades específicas.
- las administraciones y entidades públicas ya estaban obligados a garantizar la apertura de sus datos desde el diseño, así como su reutilización en base a la ya existe.
En resumen, se respetan las pautas de reutilización que ya define la Ley 37/2007 para el sector pública y además se recoge la necesidad de regular el acceso a esta información y el modo de utilización de estos datos por parte de terceros, es decir, empresas del sector.
Espacio de Datos Integrado de Movilidad
Acorde a la Estrategia Europea de Datos que mencionábamos al inicio del post, el PL determina la obligatoriedad de crear el Espacio de Datos Integrado de Movilidad (EDIM) bajo la dirección del Ministerio de Transportes y Movilidad Sostenible, en coordinación con la Secretaría de Estado de Digitalización e Inteligencia Artificial. En el EDIM compartirán sus datos las ya mencionadas empresas de transporte, los gestores de infraestructuras y las administraciones, algo que permitirá optimizar la toma de decisiones de todos los actores a la hora de planificar la ejecución de nuevas infraestructuras y la puesta en marcha de nuevos servicios.
El Proyecto de Ley define algunas características del Espacio de Datos Integrado de Movilidad como la estructura modular, que incluirá información de manera sistemática de distintas áreas de movilidad urbana, metropolitana e interurbana, tanto de personas como de mercancías.
En concreto, el EDIM, según el artículo 14, recogería datos “en soporte digital de forma gratuita, no discriminatoria y actualizada” sobre:
- Oferta y demanda de los diferentes modos de transporte y movilidad, información sobre los servicios de transporte público y servicios de movilidad competencia de las administraciones
- Situación financiera y costes de prestación de los servicios de todos los modos de transporte público, inversiones en infraestructuras de transporte, inventario de infraestructuras y terminales de transporte, condiciones y grado de accesibilidad.
- Otros datos que se acuerden en la Conferencia Sectorial de Transportes.
En el se identifican ejemplos de este tipo de datos e información sobre la responsabilidad de su suministro, formato, frecuencia de actualización y otras características.
Tal y como refiere el PL, los datos y la información gestionada por el EDIM aportarán una visión integrada para analizar y facilitar la gestión de la movilidad, mejorando el diseño de soluciones sostenibles y eficientes, y la transparencia en el diseño de las políticas públicas de transportes y movilidad. Además, la Ley promoverá la creación de un sandbox o entorno de pruebas que sirva de incubadora para proyectos innovadores sobre movilidad. El resultado de las pruebas permitirá tanto al promotor como a la administración adquirir un aprendizaje observando el mercado en un entorno controlado.
Punto de Acceso Nacional de Transporte Bimodal
Por otro lado, el Proyecto de Ley también contempla la creación de un Punto de Acceso Nacional de Transporte Bimodal que recogerá la información comunicada al Ministerio de Transportes y Movilidad Sostenible en el marco de la acción prioritaria “Suministro de servicios de información sobre desplazamientos multimodales en toda la Unión” de la Directiva 2010/40/UE que hace referencia al transporte de mercancías y/o personas en más un medio de transporte.
Esta información será de acceso libre y gratuito y servirá también para nutrir al EDIM en el área relativa a la caracterización de transporte y movilidad de personas, así como al Catálogo nacional de Información Pública mantenido por la Administración General del Estado.
El Proyecto de Ley define que la prestación de servicios a la ciudadanía en los que se utilicen datos sobre transporte y movilidad del Punto de Acceso Nacional de Transporte Multimodal deberá hacerse de forma justa, neutra, imparcial, no discriminatoria y transparente. Y añade que el Ministerio de Transportes y Movilidad Sostenible propondrá unas reglas de uso de dichos datos en un plazo de 12 meses tras la entrada en vigor de esta Ley.
El Proyecto de Ley de Movilidad Sostenible está actualmente en trámite parlamentario, ya que se ha remitido a las Cortes para su tramitación urgente y aprobación en 2024.
Aplicación
Esta aplicación muestra la ubicación de las estaciones de recargas para vehículos eléctricos dentro de la Comunidad de Castilla y León. El usuario puede seleccionar la provincia de su interés y acceder a la información de las estaciones disponibles. Para cada estación se proporciona diversa información, como su situación, la empresa proveedora, el número de estaciones de carga y los conectores disponibles.
Además, dentro de la app el usuario también puede encontrar información sobre los programas de incentivos a la movilidad eléctrica, como el Plan MOVES III.
Los datos geográficos de dichos cargadores se han obtenido de los servidores de la plataforma pública de Datos Abiertos de Castilla y León.
Aplicación
La aplicación ofrece a los usuarios información en tiempo real del estado del aparcamiento: plazas libres y plazas ocupadas. Mediante un plano del aparcamiento, el usuario podrá visualizar directamente el estado de ocupación de cada una de las plazas (libre u ocupada) y del aparcamiento completo (número de plazas libres y plazas ocupadas). Igualmente, muestra la opción de consultar la ruta de acceso al aparcamiento desde la posición del usuario. Otro de los tipos de datos que ofrece son las tarifas vigentes de utilización del aparcamiento.
Los datos que utiliza la aplicación para mostrar información, como puede ser el conjunto de datos sobre sensores del parking, se encuentran disponibles en el portal de transparencia del Ayuntamiento de Villanueva de la Serena.