Documentación
1. Introducción
Las visualizaciones son representaciones gráficas de datos que permiten comunicar de manera sencilla y efectiva la información ligada a los mismos. Las posibilidades de visualización son muy amplias, desde representaciones básicas, como los gráficos de líneas, de barras o de sectores, hasta visualizaciones configuradas sobre cuadros de mando interactivos.
En esta sección de “Visualizaciones paso a paso” estamos presentando periódicamente ejercicios prácticos de visualizaciones de datos abiertos disponibles en datos.gob.es u otros catálogos similares. En ellos se abordan y describen de manera sencilla las etapas necesarias para obtener los datos, realizar las transformaciones y los análisis que resulten pertinentes para, finalmente, posibilitar la creación de visualizaciones interactivas que nos permitan obtener unas conclusiones finales a modo de resumen de dicha información. En cada uno de estos ejercicios prácticos, se utilizan sencillos desarrollos de código convenientemente documentados, así como herramientas de uso gratuito. Todo el material generado está disponible para su reutilización en el repositorio Laboratorio de datos de GitHub.
A continuación, y como complemento a la explicación que encontrarás seguidamente, puedes acceder al código que utilizaremos en el ejercicio y que iremos explicando y desarrollando en los siguientes apartados de este post.
Accede al repositorio del laboratorio de datos en Github.
Ejecuta el código de pre-procesamiento de datos sobre Google Colab.
2. Objetivo
El objetivo principal de este ejercicio es mostrar cómo realizar un análisis de redes o de grafos partiendo de datos abiertos sobre viajes en bicicleta de alquiler en la ciudad de Madrid. Para ello, realizaremos un preprocesamiento de los datos con la finalidad de obtener las tablas que utilizaremos a continuación en la herramienta generadora de la visualización, con la que crearemos las visualizaciones del grafo.
Los análisis de redes son métodos y herramientas para el estudio y la interpretación de las relaciones y conexiones entre entidades o nodos interconectados de una red, pudiendo ser estas entidades personas, sitios, productos, u organizaciones, entre otros. Los análisis de redes buscan descubrir patrones, identificar comunidades, analizar la influencia y determinar la importancia de los nodos dentro de la red. Esto se logra mediante el uso de algoritmos y técnicas específicas para extraer información significativa de los datos de red.
Una vez analizados los datos mediante esta visualización, podremos contestar a preguntas como las que se plantean a continuación:
- ¿Cuál es la estación de la red con mayor tráfico de entrada y de salida?
- ¿Cuáles son las rutas entre estaciones más frecuentes?
- ¿Cuál es el número medio de conexiones entre estaciones para cada una de ellas?
- ¿Cuáles son las estaciones más interconectadas dentro de la red?
3. Recursos
3.1. Conjuntos de datos
Los conjuntos de datos abiertos utilizados contienen información sobre los viajes en bicicleta de préstamo realizados en la ciudad de Madrid. La información que aportan se trata de la estación de origen y de destino, el tiempo del trayecto, la hora del trayecto, el identificador de la bicicleta, …
Estos conjuntos de datos abiertos son publicados por el Ayuntamiento de Madrid, mediante ficheros que recogen los registros de forma mensual.
Estos conjuntos de datos también se encuentran disponibles para su descarga en el siguiente repositorio de Github.
3.2. Herramientas
Para la realización de las tareas de preprocesado de los datos se ha utilizado el lenguaje de programación Python escrito sobre un Notebook de Jupyter alojado en el servicio en la nube de Google Colab.
"Google Colab" o, también llamado Google Colaboratory, es un servicio en la nube de Google Research que permite programar, ejecutar y compartir código escrito en Python o R sobre un Jupyter Notebook desde tu navegador, por lo que no requiere configuración. Este servicio es gratuito.
Para la creación de la visualización interactiva se ha usado la herramienta Gephi
"Gephi" es una herramienta de visualización y análisis de redes. Permite representar y explorar relaciones entre elementos, como nodos y enlaces, con el fin de entender la estructura y patrones de la red. El programa precisa descarga y es gratuito.
Si quieres conocer más sobre herramientas que puedan ayudarte en el tratamiento y la visualización de datos, puedes recurrir al informe "Herramientas de procesado y visualización de datos".
4. Tratamiento o preparación de datos
Los procesos que te describimos a continuación los encontrarás comentados en el Notebook que también podrás ejecutar desde Google Colab.
Debido al alto volumen de viajes registrados en los conjuntos de datos, definimos los siguientes puntos de partida a la hora de analizarlos:
- Analizaremos la hora del día con mayor tráfico de viajes
- Analizaremos las estaciones con un mayor volumen de viajes
Antes de lanzarnos a analizar y construir una visualización efectiva, debemos realizar un tratamiento previo de los datos, prestando especial atención a su obtención y a la validación de su contenido, asegurándonos que se encuentran en el formato adecuado y consistente para su procesamiento y que no contienen errores.
Como primer paso del proceso, es necesario realizar un análisis exploratorio de los datos (EDA), con el fin de interpretar adecuadamente los datos de partida, detectar anomalías, datos ausentes o errores que pudieran afectar a la calidad de los procesos posteriores y resultados. Si quieres conocer más sobre este proceso puedes recurrir a la Guía Práctica de Introducción al Análisis Exploratorio de Datos.
El siguiente paso es generar la tabla de datos preprocesada que usaremos para alimentar la herramienta de análisis de redes (Gephi) que de forma visual nos ayudará a comprender la información. Para ello modificaremos, filtraremos y uniremos los datos según nuestras necesidades.
Los pasos que se siguen en este preprocesamiento de los datos, explicados en este Notebook de Google Colab, son los siguientes:
- Instalación de librerías y carga de los conjuntos de datos
- Análisis exploratorio de los datos (EDA)
- Generación de tablas preprocesadas
Podrás reproducir este análisis con el código fuente que está disponible en nuestra cuenta de GitHub. La forma de proporcionar el código es a través de un documento realizado sobre un Jupyter Notebook que, una vez cargado en el entorno de desarrollo, podrás ejecutar o modificar de manera sencilla.
Debido al carácter divulgativo de este post y para favorecer el entendimiento de los lectores no especializados, el código no pretende ser el más eficiente sino facilitar su comprensión, por lo que posiblemente se te ocurrirán muchas formas de optimizar el código propuesto para lograr fines similares. ¡Te animamos a que lo hagas!
5. Análisis de la red
5.1. Definición de la red
La red analizada se encuentra formada por los viajes entre distintas estaciones de bicicletas en la ciudad de Madrid, teniendo como principal información de cada uno de los viajes registrados la estación de origen (denominada como “source”) y la estación de destino (denominada como “target”).
La red está formada por 253 nodos (estaciones) y 3012 aristas (interacciones entre las estaciones). Se trata de un grafo dirigido, debido a que las interacciones son bidireccionales y ponderado, debido a que cada arista entre los nodos tiene asociado un valor numérico denominado "peso" que en este caso corresponde al número de viajes realizados entre ambas estaciones.
5.2. Carga de la tabla preprocesada en Gephi
Mediante la opción “importar hoja de cálculo” de la pestaña archivo, importamos en formato CSV la tabla de datos previamente preprocesada. Gephi detectará que tipo de datos se están cargando, por lo que utilizaremos los parámetros predefinidos por defecto.


5.3. Opciones de visualización de la red
5.3.1 Ventana de distribución
En primer lugar, aplicamos en la ventana de distribución, el algoritmo Force Atlas 2. Este algoritmo utiliza la técnica de repulsión de nodos en función del grado de conexión de tal forma que los nodos escasamente conectados se separan respecto a los que tiene una mayor fuerza de atracción entre sí.
Para evitar que los componentes conexos queden fuera de la vista principal, fijamos el valor del parámetro "Gravedad en Puesta a punto" a un valor de 10 y para evitar que los nodos queden amontonados, marcamos la opción “Disuadir Hubs” y “Evitar el solapamiento”.

Dentro de la ventana de distribución, también aplicamos el algoritmo de Expansión con la finalidad de que los nodos no se encuentren tan juntos entre sí mismos.

Figura 3. Ventana distribución - algoritmo de Expansión
5.3.2 Ventana de apariencia
A continuación, en la ventana de apariencia, modificamos los nodos y sus etiquetas para que su tamaño no sea igualitario, sino que dependa del valor del grado de cada nodo (nodos con un mayor grado, mayor tamaño visual). También modificaremos el color de los nodos para que los de mayor tamaño sean de un color más llamativo que los de menor tamaño. En la misma ventana de apariencia modificamos las aristas, en este caso hemos optado por un color unitario para todas ellas, ya que por defecto el tamaño va acorde al peso de cada una de ellas.
Un mayor grado en uno de los nodos implica un mayor número de estaciones conectadas con dicho nodo, mientras que un mayor peso de las aristas implica un mayor número de viajes para cada conexión.

5.3.3 Ventana de grafo
Por último, en la zona inferior de la interfaz de la ventana de grafo, tenemos diversas opciones como activar/desactivar el botón para mostrar las etiquetas de los distintos nodos, adecuar el tamaño de las aristas con la finalizad de hacer más limpia la visualización, modificar el tipo de letra de las etiquetas, …

A continuación, podemos ver la visualización del grafo que representa la red una vez aplicadas las opciones de visualización mencionadas en los puntos anteriores.

Figura 6. Visualización del grafo
Activando la opción de visualizar etiquetas y colocando el cursor sobre uno de los nodos, se mostrarán los enlaces que corresponden al nodo y el resto de los nodos que están vinculados al elegido mediante dichos enlaces.
A continuación, podemos visualizar los nodos y enlaces relativos a la estación de bicicletas “Fernando el Católico". En la visualización se distinguen con facilidad los nodos que poseen un mayor número de conexiones, ya que aparecen con un mayor tamaño y colores más llamativos, como por ejemplo "Plaza de la Cebada" o "Quevedo".

5.4 Principales medidas de red
Junto a la visualización del grafo, las siguientes medidas nos aportan la principal información de la red analizada. Estas medias, que son las métricas habituales cuando se realiza analítica de redes, podremos calcularlas en la ventana de estadísticas.

- Nodos (N): son los distintos elementos individuales que componen una red, representando entidades diversas. En este caso las distintas estaciones de bicicletas. Su valor en la red es de 243
- Enlaces (L): son las conexiones que existen entre los nodos de una red. Los enlaces representan las relaciones o interacciones entre los elementos individuales (nodos) que componen la red. Su valor en la red es de 3014
- Número máximo de enlaces (Lmax): es el máximo posible de enlaces en la red. Se calcula mediante la siguiente fórmula Lmax= N(N-1)/2. Su valor en la red es de 31878
- Grado medio (k): es una medida estadística para cuantificar la conectividad promedio de los nodos de la red. Se calcula promediando los grados de todos los nodos de la red. Su valor en la red es de 23,8
- Densidad de la red (d): indica la proporción de conexiones existentes entre los nodos de la red con respecto al total de conexiones posibles. Su valor en la red es de 0,047
- Diámetro (dmax ): es la distancia de grafo más larga entre dos nodos cualquiera de la res, es decir, cómo de lejos están los 2 nodos más alejados. Su valor en la red es de 7
- Distancia media (d): es la distancia de grafo media promedio entre los nodos de la red. Su valor en la red es de 2,68
- Coeficiente medio de clustering (C): Índica cómo los nodos están incrustados entre sus nodos vecinos. El valor medio da una indicación general de la agrupación en la red. Su valor en la red es de 0,208
- Componente conexo: grupo de nodos que están directa o indirectamente conectados entre sí, pero no están conectados con los nodos fuera de ese grupo. Su valor en la red es de 24
5.5 Interpretación de los resultados
La probabilidad de grados sigue de forma aproximada una distribución de larga cola, donde podemos observar que existen unas pocas estaciones que interactúan con un gran número de ellas mientras que la mayoría interactúa con un número bajo de estaciones.
El grado medio es de 23,8 lo que indica que cada estación interacciona de media con cerca de otras 24 estaciones (entrada y salida).
En el siguiente gráfico podemos observar que, aunque tengamos nodos con grados considerados como altos (80, 90, 100, …), se observa que el 25% de los nodos tienen grados iguales o inferiores a 8, mientras que el 75% de los nodos tienen grados inferiores o iguales a 32.

La gráfica anterior se puede desglosar en las dos siguientes correspondientes al grado medio de entrada y de salida (ya que la red es direccional). Vemos que ambas tienen distribuciones de larga cola similares, siendo su grado medio el mismo de 11,9.
Su principal diferencia es que la gráfica correspondiente al grado medio de entrada tiene una mediana de 7 mientras que la de salida es de 9, lo que significa que existe una mayoría de nodos con grados más bajos en los de entrada que los de salida.


El valor del grado medio con pesos es de 346,07 lo cual nos indica la media de viajes totales de entrada y salida de cada estación.

La densidad de red de 0,047 es considerada una densidad baja indicando que la red es dispersa, es decir, contiene pocas interacciones entre distintas estaciones en relación con las posibles. Esto se considera lógico debido a que las conexiones entre estaciones estarán limitadas a ciertas zonas debido a la dificultad de llegar a estaciones que se encuentra a largas distancias.
El coeficiente medio de clustering es de 0,208 significando que la interacción de dos estaciones con una tercera no implica necesariamente la interacción entre sí, es decir, no implica necesariamente transitividad, por lo que la probabilidad de interconexión de esas dos estaciones mediante la intervención de una tercera es baja.
Por último, la red presenta 24 componentes conexos, siendo 2 de ellos componentes conexos débiles y 22 componentes conexos fuertes.
5.6 Análisis de centralidad
Un análisis de centralidad se refiere a la evaluación de la importancia de los nodos en una red utilizando diferentes medidas. La centralidad es un concepto fundamental en el análisis de redes y se utiliza para identificar nodos clave o influyentes dentro de una red. Para realizar esta tarea se parte de las métricas calculadas en la ventana de estadísticas.
- La medida de centralidad de grado indica que cuanto más alto es el grado de un nodo, más importante es. Las cinco estaciones con valores más elevados son: 1º Plaza de la Cebada, 2º Plaza de Lavapiés, 3º Fernando el Católico, 4º Quevedo, 5º Segovia 45.

- La media de centralidad de cercanía indica que cuanto más alto sea el valor de cercanía de un nodo, más central es, ya que puede alcanzar cualquier otro nodo de la red con el menor esfuerzo posible. Las cinco estaciones que valores más elevados poseen son: 1º Fernando el Católico 2º General Pardiñas, 3º Plaza de la Cebada, 4º Plaza de Lavapiés, 5º Puerta de Madrid.

Figura 13. Distribución medida centralidad de cercanía

- La medida de centralidad de intermediación indica que cuanto mayor sea la medida de intermediación de un nodo, más importante es dado que está presente en más rutas de interacción entre nodos que el resto de los nodos de la red. Las cinco estaciones que valores más elevados poseen son: 1º Fernando el Católico, 2º Plaza de Lavapiés, 3º Plaza de la Cebada, 4º Puerta de Madrid, 5º Quevedo.

 FIgura 16. Visualización grafo centralidad de intermediación
FIgura 16. Visualización grafo centralidad de intermediación
Con la herramienta Gephi se pueden calcular gran cantidad de métricas y parámetros que no se reflejan en este estudio ,como por ejemplo, la medida de vector propio o distribucción de centralidad "eigenvector".
5.7 Filtros
Mediante la ventana de filtrado, podemos seleccionar ciertos parámetros que simplifiquen las visualizaciones con la finalidad de mostrar información relevante del análisis de redes de una forma más clara visualmente.

A continuación, mostraremos varios filtrados realizados:
- Filtrado de rango (grado), en el que se muestran los nodos con un rango superior a 50, suponiendo un 13,44% (34 nodos) y un 15,41% (464 aristas)

- Filtrado de aristas (peso de la arista), en el que se muestran las aristas con un peso superior a 100, suponiendo un 0,7% (20 aristas)

Figura 19. VIsualización grafo filtrado de arista (peso)
Dentro de la ventana de filtros, existen muchas otras opciones de filtrado sobre atributos, rangos, tamaños de particiones, las aristas, … con los que puedes probar a realizar nuevas visualizaciones para extraer información del grafo. Si quieres conocer más sobre el uso de Gephi, puedes consultar los siguientes cursos y formaciones sobre la herramienta.
6. Conclusiones del ejercicio
Una vez realizado el ejercicio, podemos apreciar las siguientes conclusiones:
- Las tres estaciones más interconectadas con otras estaciones son Plaza de la Cebada (133), Plaza de Lavapiés (126) y Fernando el Católico (114).
- La estación que tiene un mayor número de conexiones de entrada es la Plaza de la Cebada (78), mientras que la que tiene un mayor número de conexiones de salida es la Plaza de Lavapiés con el mismo número que Fernando el Católico (57)
- Las tres estaciones con un mayor número de viajes totales son Plaza de la Cebada (4524), Plaza de Lavapiés (4237) y Fernando el Católico (3526).
- Existen 20 rutas con más de 100 viajes. Siendo las 3 rutas con un mayor número de ellos: Puerta de Toledo – Plaza Conde Suchil (141), Quintana Fuente del Berro – Quintana (137), Camino Vinateros – Miguel Moya (134).
- Teniendo en cuenta el número de conexiones entre estaciones y de viajes, las estaciones de mayor importancia dentro de la red son: Plaza la Cebada, Plaza de Lavapiés y Fernando el Católico.
Esperemos que esta visualización paso a paso te haya resultado útil para el aprendizaje de algunas técnicas muy habituales en el tratamiento y representación de datos abiertos. Volveremos para mostraros nuevas reutilizaciones. ¡Hasta pronto!
Blog
Los datos abiertos son una herramienta útil para tomar decisiones informadas que incentiven el éxito de un proceso y mejorar su eficacia. Desde una visión sectorial, los datos abiertos aportan información relevante sobre el sector legal, el educativo o el de la salud. Todos ellos, junto a otros muchos ámbitos, emplean fuentes abiertas para medir el cumplimiento de una mejora o desarrollar herramientas que faciliten el trabajo a los profesionales.
Los beneficios del uso de los datos abiertos son amplios y su variedad va de la mano de la innovación tecnológica: cada día surgen más oportunidades para emplear datos abiertos en el desarrollo de soluciones innovadoras. Ejemplo de ello puede ser el desarrollo urbanístico alineado con los valores de sostenibilidad que defiende la Organización de las Naciones Unidas (ONU).
Las ciudades ocupan el 3% de la superficie terrestre; sin embargo, emiten el 70% de las emisiones de carbono y consumen más del 60% de los recursos de todo el mundo, según la ONU. En 2023, más de la mitad de la población mundial vive en ciudades y se prevé que esta cifra siga creciendo. En 2030 se estima que más de 5.000 millones de personas vivirían en ciudades, es decir, más del 60% de la población de todo el mundo.
A pesar de la tendencia, las infraestructuras y los barrios no cumplen con las condiciones adecuadas de desarrollo sostenible y el objetivo es “Lograr que las ciudades y los asentamientos humanos sean inclusivos, seguros y sostenibles”, tal y como se reconoce en el ODS número 11. La planificación y gestión adecuada de los recursos urbanos son cuestiones de peso a la hora de crear y mantener comunidades basadas en la sostenibilidad. En este contexto, los datos abiertos juegan un importante papel para medir el cumplimiento de este ODS y así alcanzar la meta de ciudades sostenibles.
En definitiva, los datos abiertos se constituyen como una herramienta fundamental para el fortalecimiento y progreso del desarrollo sostenible de las ciudades.
En esta infografía, hemos recogido casos de uso que emplean conjuntos de datos abiertos para monitorizar y/o mejorar la eficiencia energética, el transporte y la movilidad urbana, la calidad del aire y el nivel de ruido. Cuestiones que contribuyen al buen funcionamiento de los centros urbanos.
Haz clic en la infografía para verla en tamaño real

Noticia
El pasado 13 de marzo se celebró una jornada del Grupo de Trabajo de Movilidad del Hub Gaia-X España, donde se abordaron los principales retos del sector en lo referente a proyectos sobre la compartición y explotación de datos. La sesión, que se desarrolló en la Escuela Técnica Superior de Ingenieros de Caminos, Canales y Puertos de la Universidad Politécnica de Madrid, permitió a los asistentes conocer de primera mano los principales retos del sector, así como algunos de los proyectos de datos punteros de la industria de la movilidad. El evento fue también un punto de encuentro en el que se compartieron ideas y reflexiones entre los actores clave del sector.
La jornada comenzó con la presentación del Ministerio de Transportes, Movilidad y Agenda Urbana, intervención que destacó la gran importancia del Punto de Acceso Nacional de Transporte Multimodal, un proyecto de ámbito europeo, que permite concentrar toda la información de la oferta de transporte de viajeros del país en un único punto nacional, con el objetivo de proporcionar los cimientos para impulsar el desarrollo de los servicios de movilidad del futuro.
A continuación, la Oficina del Dato de la Secretaría de Estado de Inteligencia Artificial (SEDIA) aportó la visión del modelo de desarrollo de Espacios de Datos y los principios de diseño de dichos espacios alineados con los valores europeos. Se destacó la importancia de las redes de negocio en base a ecosistemas de datos, el carácter intersectorial de la industria de la Movilidad y el importante papel de los datos abiertos en los espacios de datos del sector.
Seguidamente, se presentaron casos de uso por parte de Vicomtech, Amadeus, i2CAT y el Ayuntamiento de Alcobendas, que permitieron conocer de primera mano algunos ejemplos de uso de tecnología para proyectos de compartición de datos (tanto de espacios de datos como de data lakes, o lagos de datos).
Finalmente, se presentó un estudio inicial de la Fundación i2CAT, FACTUAL Consulting y EIT Urban Mobility sobre los componentes básicos de los futuros espacios de datos de movilidad en España. El estudio, que puede descargarse aquí en español, aborda el potencial de los espacios de datos de movilidad para el mercado español. Aunque se centra en España, recoge un enfoque sobre la investigación tanto nacional como internacional , enmarcado en el contexto europeo para establer estándares, el desarrollo de los componentes técnicos que habilitan los espacios de datos, los primeros proyectos faro y el abordaje de desafíos comunes para cumplir hitos en materia de movilidad sostenible en Europa.
Las presentaciones utilizadas en la sesión están disponibles en este enlace.
Noticia
Actualizado: 21/03/2024
En enero de 2023, la Comisión Europea publicó un listado de conjuntos de datos de alto valor que los organismos del sector público deberían poner a disposición de la ciudadanía en un plazo máximo de 16 meses. El principal objetivo de establecer la lista de conjuntos de datos de alto valor es garantizar que los datos públicos de mayor potencial socioeconómico se pongan a disposición para su reutilización con una restricción jurídica y técnica mínima, y sin coste alguno. Dentro de estos conjuntos de datos del sector público, algunos como los meteorológicos o los relativos a la calidad del aire, resultan especialmente interesantes para desarrolladores y creadores de servicios como aplicaciones o páginas webs, que reportan valor añadido e importantes beneficios para la sociedad, el medioambiente o la economía.
La publicación del Reglamento se acompañó de unas preguntas frecuentes para ayudar a los organismos públicos a entender el beneficio de los HVDS (High Value Datasets) en la sociedad y la economía, así como para explicar algunos aspectos sobre la obligatoriedad y las ayudas para la publicación.
En línea con esta propuesta, la Vicepresidenta Ejecutiva para una Europa adaptada a la era digital, Margrethe Vestager, declaró lo siguiente en la nota de prensa lanzada por la Comisión Europea:
“Poner a disposición del público conjuntos de datos de gran valor beneficiará tanto a la economía como a la sociedad, por ejemplo, ayudando a combatir el cambio climático, reduciendo la contaminación atmosférica urbana y mejorando las infraestructuras de transporte. Se trata de un paso práctico hacia el éxito de la Década Digital y la construcción de un futuro digital más próspero”.
De forma paralela, Thierry Breton, Comisario de Mercado Interior, quiso añadir también las siguientes palabras a colación del anuncio del listado de los datos de alto valor: “Los datos son una piedra angular de nuestra competitividad industrial en la UE. Con la nueva lista de conjuntos de datos de alto valor estamos desbloqueando una gran cantidad de datos públicos en beneficio de todos. Las nuevas empresas y las pymes podrán utilizar estos para desarrollar nuevos productos y soluciones innovadoras que mejoren la vida de los ciudadanos de la UE y de todo el mundo”.
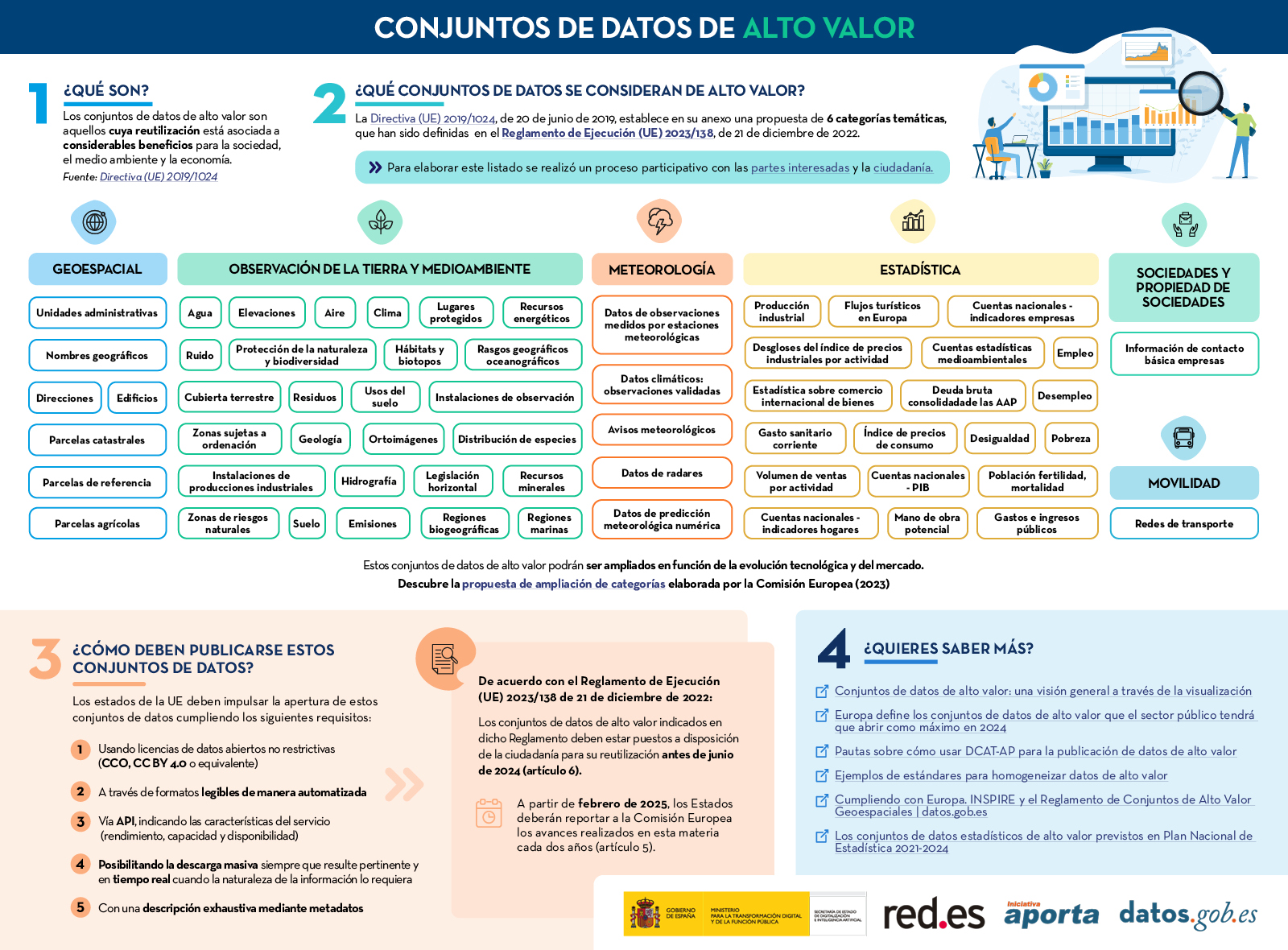
Seis categorías para aglutinar los nuevos conjuntos de datos de alto valor
De este modo, el reglamento se crea al amparo de la Directiva Europea de Datos Abiertos, que define seis categorías para diferenciar los nuevos conjuntos de datos de alto valor solicitados:
- Geoespaciales
- De observación de la Tierra y medioambiente
- Meteorológicos
- Estadísticos
- De empresas
- De movilidad
No obstante, tal y como recoge la nota de prensa de la Comisión Europea, esta gama temática podría ampliarse posteriormente en función de la evolución de la tecnología y el mercado. Así, los conjuntos de datos estarán disponibles en formato legible por máquina, a través de una interfaz de programación de aplicaciones (API) y, si fuera relevante, también con opción de descarga masiva.
Además, la reutilización de conjuntos de datos como los de movilidad o geolocalización de edificios puede ampliar las oportunidades de negocio disponibles para sectores como la logística o el transporte. De forma paralela, los datos de observación meteorológica, de radar, de calidad del aire o de contaminación del suelo también pueden apoyar la investigación y la innovación digital, así como la elaboración de políticas en la lucha contra el cambio climático.
En definitiva, una mayor disponibilidad de datos y, en especial de alto valor, tiene la capacidad de impulsar el espíritu empresarial ya que estos conjuntos de datos pueden ser un recurso importante para que las pymes desarrollen nuevos productos y servicios digitales, lo que a su vez también puede atraer nuevos inversores.
Descubre más en esta infografía:
Documentación
Este informe recoge varias temáticas relevantes para la comunidad europea de datos geoespaciales.
Por un lado, el capítulo dedicado a la "modernización INSPIRE y avance hacia los datos abiertos" trata la evaluación realizada por la Comisión Europea de la directiva INSPIRE y cómo ésta debe avanzar en un futuro próximo. Entre otras conclusiones, determina la oportunidad de simplificación técnica para favorecer una mayor interoperabilidad, además de la necesaria convergencia con la Directiva 2019/1024 sobre datos abiertos, incidiendo en la importancia de puesta a disposición de datos de alto valor (HVDs). En este sentido, el informe incluye una valoración sobre qué temas de datos Inspire son considerados HVDs.
La segunda temática gira en torno al "papel de la información geoespacial para las ciudades inteligentes", donde los datos completos, actualizados y con referencia geoespacial, son considerados un activo fundamental en los proyectos de ciudades inteligentes.
En tercer lugar, el informe recoge un avance de situación sobre determinados aspectos clave analizados en un informe anterior (2021), relacionados, entre otras cuestiones relevantes, con la disponibilidad de OGC API endpoints o el descubrimiento de servicios de streaming de datos procedentes de las APIs de SensorThings.
Por último, el documento, a modo de conclusión, detalla hoja de ruta de potencial interés para el portal de datos europeo de cara a seguir avanzando para mejorar la disponibilidad de información geoespacial.
Este informe se encuentra disponible en el siguiente enlace: "Tendencias geoespaciales 2022: Oportunidades para data.europa.eu a partir de las tendencias emergentes en la comunidad geoespacial"
Documentación
1. Introducción
Las visualizaciones son representaciones gráficas de datos que permiten comunicar de manera sencilla y efectiva la información ligada a los mismos. Las posibilidades de visualización son muy amplias, desde representaciones básicas, como puede ser un gráfico de líneas, barras o sectores, hasta visualizaciones configuradas sobre cuadros de mando o dashboards interactivos. Las visualizaciones juegan un papel fundamental en la extracción de conclusiones utilizando el lenguaje visual, permitiendo además detectar patrones, tendencias, datos anómalos o proyectar predicciones, entre otras muchas funciones.
En esta sección de “Visualizaciones paso a paso” estamos presentando periódicamente ejercicios prácticos de visualizaciones de datos abiertos disponibles en datos.gob.es u otros catálogos similares. En ellos se abordan y describen de manera sencilla las etapas necesarias para obtener los datos, realizar las transformaciones y análisis que resulten pertinentes para, finalmente, la creación de visualizaciones interactivas de las que podemos extraer información resumida en unas conclusiones finales. En cada uno de estos ejercicios prácticos se utilizan sencillos desarrollos de código convenientemente documentados, así como herramientas de uso gratuito. Todo el material generado está disponible para su reutilización en el repositorio del laboratorio de datos de Github perteneciente a datos.gob.es.
En este ejercicio práctico, hemos realizado un sencillo desarrollo de código que está convenientemente documentado apoyandonos en herramientas de uso gratuito.
Accede al repositorio del laboratorio de datos en Github.
Ejecuta el código de pre-procesamiento de datos sobre Google Colab.
2. Objetivo
El objetivo principal de este post es mostrar cómo realizar una visualización interactiva partiendo de datos abiertos. Para este ejercicio práctico hemos utilizado un dataset proporcionado por el Ministerio de Justicia que contiene información sobre los resultados toxicológicos realizados en accidentes de tráfico, que cruzaremos con los datos que publica la Jefatura Central de Tráfico que contienen el detalle sobre el parque de vehículos matriculados en España.
A partir de este cruce de datos analizaremos y podremos observar las ratios de resultados toxicológicos positivos en relación con el parque de vehículos matriculados.
Cabe destacar que el Ministerio de Justicia pone a disposición de los ciudadanos diversos cuadros de mando donde visualizar los datos sobre los resultados toxicológicos realizados en accidentes de tráfico. La diferencia radica en que este ejercicio práctico hace hincapié en la parte didáctica, mostraremos cómo procesar los datos y cómo diseñar y construir las visualizaciones.
3. Recursos
3.1. Conjuntos de datos
Para este caso práctico se ha utilizado un conjunto de datos proporcionado por el Ministerio de Justicia, el cual contiene información sobre los resultados toxicológicos realizados en accidentes de tráfico. Este conjunto de datos se encuentra en el siguiente repositorio de Github:
También se han utilizado los conjuntos de datos del parque de vehículos matriculados en España. Estos conjuntos de datos son publicados por parte de la Jefatura Central de Tráfico, organismo dependiente del Ministerio del Interior. Se encuentran disponibles en la siguiente página del catálogo de datos de datos.gob.es:
3.2. Herramientas
Para la realización de las tareas de preprocesado de los datos se ha utilizado el lenguaje de programación Python escrito sobre un Notebook de Jupyter alojado en el servicio en la nube de Google Colab.
Google Colab o también llamado Google Colaboratory, es un servicio gratuito en la nube de Google Research que permite programar, ejecutar y compartir código escrito en Python o R desde tu navegador, por lo que no requiere la instalación de ninguna herramienta o configuración.
Para la creación de la visualización interactiva se ha usado la herramienta Google Data Studio.
Google Data Studio es una herramienta online que permite realizar gráficos, mapas o tablas que pueden incrustarse en sitios web o exportarse como archivos. Esta herramienta es sencilla de usar y permite múltiples opciones de personalización.
Si quieres conocer más sobre herramientas que puedan ayudarte en el tratamiento y la visualización de datos, puedes recurrir al informe \"Herramientas de procesado y visualización de datos\".
4. Tratamiento o preparación de los datos
Antes de lanzarnos a construir una visualización efectiva, debemos realizar un tratamiento previo de los datos, prestando especial atención a la obtención de los mismos y validando su contenido, asegurando que se encuentran en el formato adecuado y consistente para su procesamiento y que no contienen errores.
Los procesos que te describimos a continuación los encontrarás comentados en el Notebook que también podrás ejecutar desde Google Colab. Link al notebook de Google Colab
Como primer paso del proceso es necesario realizar un análisis exploratorio de los datos (EDA) con el fin de interpretar adecuadamente los datos de partida, detectar anomalías, datos ausentes o errores que pudieran afectar a la calidad de los procesos posteriores y resultados. Un tratamiento previo de los datos es esencial para garantizar que los análisis o visualizaciones creados posteriormente a partir de ellos son confiables y consistentes. Si quieres conocer más sobre este proceso puedes recurrir a la Guía Práctica de Introducción al Análisis Exploratorio de Datos.
El siguiente paso es la generación de las tablas de datos preprocesados que usaremos para generar las visualizaciones. Para ello ajustaremos las variables, realizaremos el cruce de datos entre ambos conjuntos y filtraremos o agruparemos según sea conveniente.
Los pasos que se siguen en este preprocesamiento de los datos son los siguientes:
- Importación de librerías
- Carga de archivos de datos a utilizar
- Detención y tratamiento de datos ausentes (NAs)
- Modificación y ajuste de las variables
- Generación de tablas con datos preprocesados para las visualizaciones
- Almacenamiento de las tablas con los datos preprocesados
Podrás reproducir este análisis, ya que el código fuente está disponible en nuestra cuenta de GitHub. La forma de proporcionar el código es a través de un documento realizado sobre un Jupyter Notebook que una vez cargado en el entorno de desarrollo podrás ejecutar o modificar de manera sencilla. Debido al carácter divulgativo de este post y para favorecer el entendimiento de los lectores no especializados, el código no pretende ser el más eficiente, sino facilitar su comprensión por lo que posiblemente se te ocurrirán muchas formas de optimizar el código propuesto para lograr fines similares. ¡Te animamos a que lo hagas!
5. Generación de las visualizaciones
Una vez hemos realizado el preprocesamiento de los datos, vamos con las visualizaciones. Para la realización de estas visualizaciones interactivas se ha usado la herramienta Google Data Studio. Al ser una herramienta online, no es necesario tener instalado un software para interactuar o generar cualquier visualización, pero sí es necesario que las tablas de datos que le proporcionemos estén estructuradas adecuadamente, para ello hemos realizado los pasos anteriores para la preparación de los datos.
El punto de partida es el planteamiento de una serie de preguntas que la visualización nos ayudará a resolver. Proponemos las siguientes:
-
¿Cómo está distribuido el parque de vehículos en España por comunidades autónomas?
-
¿Qué tipo de vehículo está implicado en mayor y en menor medida en accidentes de tráfico con resultados toxicológicos positivos?
-
¿Dónde se producen más hallazgos toxicológicos en víctimas mortales de accidentes de tráfico?
¡Vamos a buscar las respuestas viendo los datos!
5.1. Parque de vehículos matriculados por CCAA y por típo de vehículo
Esta representación visual se ha realizado teniendo en cuenta el número de vehículos matriculados en las distintas comunidades autónomas, desglosando el total por tipo de vehículo. Los datos, correspondientes a la media de los registros mes a mes de los años 2020 y 2021, están almacenados en la tabla “parque_vehiculos.csv” generada en el preprocesamiento de los datos de partida.
Mediante un mapa coroplético podemos visualizar qué CCAAs son las que poseen un mayor parque de vehículos. El mapa se complementa con un gráfico de anillo que aporta información de los porcentajes sobre el total por cada CCAA.
Según se definen en la “Guía de visualización de datos de la Generalitat Catalana” los mapas coropléticos o de coropletas muestran los valores de una variable sobre un mapa pintando las áreas de cada región afectada de un color determinado. Son utilizados cuando se quieren encontrar patrones geográficos en los datos que están categorizados por zonas o regiones.
Los gráficos de anillo, englobados en los gráficos de sectores, utilizan una representación circular que muestra cómo se distribuyen proporcionalmente los datos.
Una vez obtenida la visualización, mediante la pestaña desplegable, aparece la opción de filtrar por tipo de vehículo.
Ver la visualización en pantalla completa
5.2. Ratio resultados toxicológicos positivos para los distintos tipos de vehículos
Esta representación visual se ha realizado teniendo en cuanta las ratios de los resultados toxicológicos positivos por número de vehículos a nivel nacional. Contabilizamos como resultado positivo cada vez que un sujeto da positivo en el análisis de cada una de las sustancias, es decir, un mismo sujeto puede contabilizar varias veces en el caso de que sus resultados sean positivos para varias sustancias. Para ello se ha generado durante el preprocesamiento de datos la tabla “resultados_vehiculos.csv”
Mediante un gráfico de barras apiladas, podemos evaluar los ratios de los resultados toxicológicos positivos por número de vehículos para las distintas sustancias y los distintos tipos de vehículos.
Según se definen en la “Guía de visualización de datos de la Generalitat Catalana” los gráficos de barras se utilizan cuando se quiere comparar el valor total de la suma de los segmentos que forman cada una de las barras. Al mismo tiempo, ofrecen información sobre cómo son de grandes estos segmentos.
Cuando las barras apiladas suman un 100%, es decir, que cada barra segmenteada ocupa la altura de la representación, el gráfico se puede considerar un gráfico que permite representar partes de un total.
La tabla aportan la misma información de una forma complementaria.
Una vez obtenida la visualización, mediante la pestaña desplegable, aparece la opción de filtrar por tipo de sustancia.
Ver la visualización en pantalla completa
5.3. Ratio resultados toxicológicos positivos para las CCAAs
Esta representación visual se ha realizado teniendo en cuenta las ratios de los resultados toxicológicos positivos por el parque de vehículos de cada CCAA. Contabilizamos como resultado positivo cada vez que un sujeto da positivo en el análisis de cada una de las sustancias, es decir, un mismo sujeto puede contabilizar varias veces en el caso de que sus resultados sean positivos para varias sustancias. Para ello se ha generado durante el preprocesamiento de datos la tabla “resultados_ccaa.csv”.
Hay que remarcar que no tiene por qué coincidir la CCAA de matriculación del vehículo con la CCAA donde se ha registrado el accidente, no obstante, ya que este es un ejercicio didáctico y se presupone que en la mayoría de los casos coinciden, se ha decido partir de la base de que ambos coinciden.
Mediante un mapa coroplético podemos visualizar que CCAAs son las que poseen las mayores ratios. A la información aportada en la primera visualización sobre este tipo de gráficos, hay que añadir lo siguiente.
Según se define en la “Guía de visualización de datos para Entidades Locales” uno de los requisitos de los mapas coropléticos o de coropletas es utilizar una medida o dato numérico, un dato categórico para el territorio y un dato geográfico de polígono.
La tabla y el gráfico de barras aportan la misma información de una forma complementaria.
Una vez obtenida la visualización, mediante la pestaña despegable, aparece la opción de filtrar por tipo de sustancia.
Ver la visualización en pantalla completa
6. Conclusiones del estudio
La visualización de datos es uno de los mecanismos más potentes para explotar y analizar el significado implícito de los datos, independientemente del tipo de dato y el grado de conocimiento tecnológico del usuario. Las visualizaciones nos permiten construir significado sobre los datos y la creación de narrativas basadas en la representación gráfica. En el conjunto de representaciones gráficas de datos que acabamos de implementar se puede observar lo siguiente:
-
El parque de vehículos de las Comunidades Autónomas de Andalucía, Cataluña y Madrid corresponde a cerca del 50% del total del país.
-
Las ratios de resultados toxicológicos positivos más altas se presentan en las motocicletas, siendo del orden de tres veces superior a la siguiente ratio, los turismos, para la mayoría de las sustancias.
-
Las ratios de resultados toxicológicos positivos más bajas se presentan en los camiones.
-
Los vehículos de dos ruedas (motocicletas y ciclomotores) presentan ratios en \"cannabis\" superiores a los obtenidos en \"cocaina\", mientras que los vehículos de cuatro ruedas (turismos, furgonetas y camiones) presentan ratios en \"cocaina\" superiores a los obtenidos en \"cannabis\".
-
La comunidad autónoma donde mayor es la ratio para el total de sustancias es La Rioja.
Cabe destacar que en las visualizaciones tienes la opción de filtrar por tipo de vehículo y tipo de sustancia. Te animamos a lo que lo hagas para sacar conclusiones más específicas sobre la información concreta en la que estés más interesado.
Esperemos que esta visualización paso a paso te haya resultado útil para el aprendizaje de algunas técnicas muy habituales en el tratamiento y representación de datos abiertos. Volveremos para mostraros nuevas reutilizaciones. ¡Hasta pronto!
Documentación
Este informe, que publica el Portal de Datos Europeo, analiza el potencial de reutilización de los datos en tiempo real. Los datos en tiempo real ofrecen información con alta frecuencia de actualización sobre el entorno que nos rodea (por ejemplo, información sobre el tráfico, datos meteorológicos, mediciones de la contaminación ambiental, información sobre riesgos naturales, etc.).
El documento resume los resultados y conclusiones de un seminario web organizado por el equipo del Portal de Datos Europeo celebrado el pasado 5 de abril de 2022, donde se explicaron diferentes formas de compartir datos en tiempo real desde plataformas de datos abiertos.
En primer lugar, el informe hace un repaso sobre el fundamento de los datos en tiempo real e incluye ejemplos que justifican el valor que aporta este tipo de datos para, a continuación, describir dos enfoques tecnológicos sobre cómo compartir datos en tiempo real del ámbito de IoT y el transporte. Incluye, además, un bloque que resume las principales conclusiones de las preguntas y comentarios de los participantes que giran, principalmente, en torno a difentes necesidades de fuentes de datos y funcionalidades requeridas para su reutilización.
Para terminar, basándose en el feedback y la discusión generada, se proporciona un conjunto de recomendaciones y acciones a corto y medio plazo sobre cómo mejorar la capacidad para localizar fuentes de datos en tiempo real a través del Portal de Datos Europeo.
Este informe se encuentra disponible en el siguiente enlace: "Datos en tiempo real: Enfoques para integrar fuentes de datos en tiempo real en data.europa.eu"
Aplicación
Con el objetivo de aprovechar todo el potencial de los catálogos de datos abiertos pertenecientes a una entidad como Puertos del Estado, se ha desarrollado un cuadro de mando para visualizar el estado del tráfico portuario en tiempo real y durante todos los días del año.
De forma muy intuitiva y gracias a una clasificación que permite ver la información relativa a cada categoría: mercancías, buques, contenedores y pasaje, este dashboard integra todos los datos de los Anuarios Estadísticos desde el año 1962 hasta el 2021.
En definitiva, se trata de un cuadro de mando de libre acceso que permite el análisis cruzado de variables mediante filtros y la descarga de todos los datos de los Anuarios desde 1962 en XLSX y CSV.
Blog
Los portales de datos abiertos están experimentando un importante crecimiento en el número de conjuntos de datos que están siendo publicados en la categoría de transporte y movilidad. Sirva como ejemplo el portal de datos abiertos de la UE que ya cuenta con casi 48.000 conjuntos de datos en la categoría de transporte o el propio portal español datos.gob.es, que registra en torno a 2.000, si incluimos los que están dentro de la categoría de sector público. Una de las razones principales del crecimiento en la publicación de los datos relacionados con el transporte es la existencia de tres directivas que tienen entre sus objetivos maximizar la reutilización de conjuntos de datos en el área. La directiva PSI de reutilización de información del sector público en combinación con las directivas INSPIRE sobre infraestructura de información espacial e ITS sobre implantación de los sistemas de transporte inteligentes, junto con otros desarrollos legislativos, hacen que cada vez resulte más complicado justificar que los datos de transporte y movilidad permanezcan cerrados.
En este sentido, en España, la ley 37/2007 en su redacción de noviembre de 2021, añade la obligación de publicar datos abiertos a las sociedades mercantiles pertenecientes al sector público institucional que actúen como compañías aéreas. Con ello se consigue dar un paso más allá respecto a las más frecuentes obligaciones con los datos de los servicios públicos de transporte de viajeros por ferrocarril y carretera.
Además, los datos abiertos están en el corazón de las estrategias de movilidad inteligente, conectada y respetuosa con el medio ambiente, tanto en el caso de la estrategia española “es.movilidad”, como en el caso de la estrategia de movilidad sostenible propuesta por la comisión europea. En ambos casos los datos abiertos se han introducido como uno de los vectores de innovación clave en la transformación digital del sector para contribuir a la consecución de los objetivos de mejora en la calidad de vida de los ciudadanos y de protección al medio ambiente.
Sin embargo, se suele hablar mucho menos de la importancia y necesidad de los datos abiertos durante la fase de investigación, que después conduce a las innovaciones que todos disfrutamos. Y sin esta etapa en la que los investigadores trabajan para adquirir un mejor conocimiento del funcionamiento de las dinámicas de transporte y movilidad de las que todos somos parte, y en la que los datos abiertos tienen un papel fundamental, no sería posible obtener innovaciones relevantes o políticas públicas bien informadas. En este sentido vamos a revisar dos iniciativas muy relevantes en las que se están realizando esfuerzos coordinados plurinacionales en el ámbito de la investigación en movilidad y transporte.
El sistema de información y seguimiento de la investigación y la innovación en el transporte
A nivel europeo, la UE también apoya con firmeza la investigación e innovación en transporte, consciente de que necesita adaptarse a realidades globales como el cambio climático y la digitalización. La agenda estratégica de investigación e innovación en el transporte (STRIA) describe lo que está haciendo la UE para acelerar la investigación y la innovación necesarias para cambiar radicalmente el transporte apoyando prioridades como la electrificación, el transporte conectado y automatizado o la movilidad inteligente.
En este sentido, el sistema de información y seguimiento de la investigación y la innovación en el transporte (TRIMIS) es la herramienta que la Comisión Europea mantiene para proporcionar información de acceso abierto sobre la investigación y la innovación (I+i) en el transporte y que se lanzó con la misión de apoyar la formulación de las políticas públicas en el ámbito del transporte y la movilidad.
TRIMIS mantiene actualizado un cuadro de mando con el que visualizar los datos sobre investigación e innovación en transporte y ofrece una descripción general y datos detallados sobre la financiación y las organizaciones involucradas en estas investigaciones. La información puede filtrarse por las siete prioridades de STRIA y también incluye datos sobre la capacidad de innovación del sector del transporte.
Si nos fijamos en la distribución geográfica de los fondos de investigación que proporciona TRIMIS, vemos que España aparece en quinto lugar, muy lejos de Alemania y Francia. Los sistemas de transporte en los que se está haciendo un mayor esfuerzo son el transporte por carretera y aéreo, beneficiarios de más de la mitad del esfuerzo total.
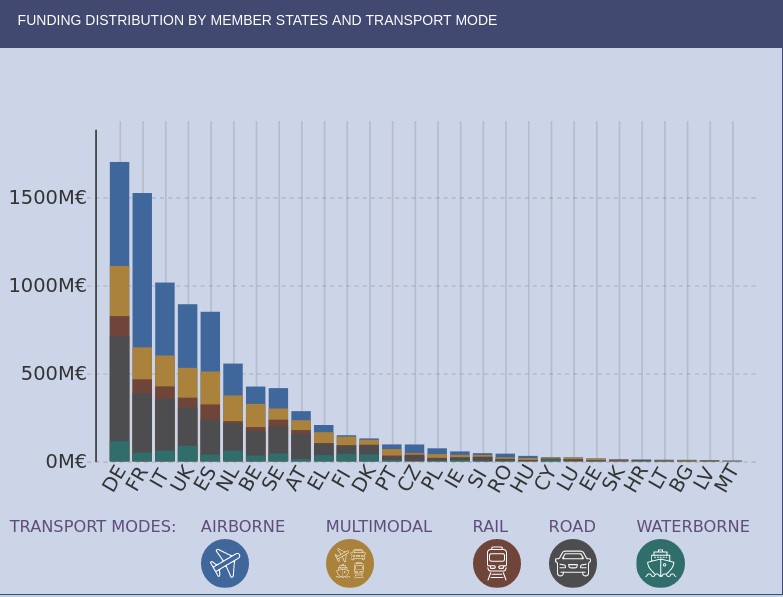
Sin embargo, encontramos que en el área estratégica de Servicios y movilidad inteligente (SMO), que se evalúan en términos de su contribución a la sostenibilidad general del sistema de energía y transporte, en España se está liderando el esfuerzo investigador al mismo nivel que Alemania. Cabe destacar además que el esfuerzo que se está realizando en España en lo que se refiere al transporte multimodal es superior al de otros países.
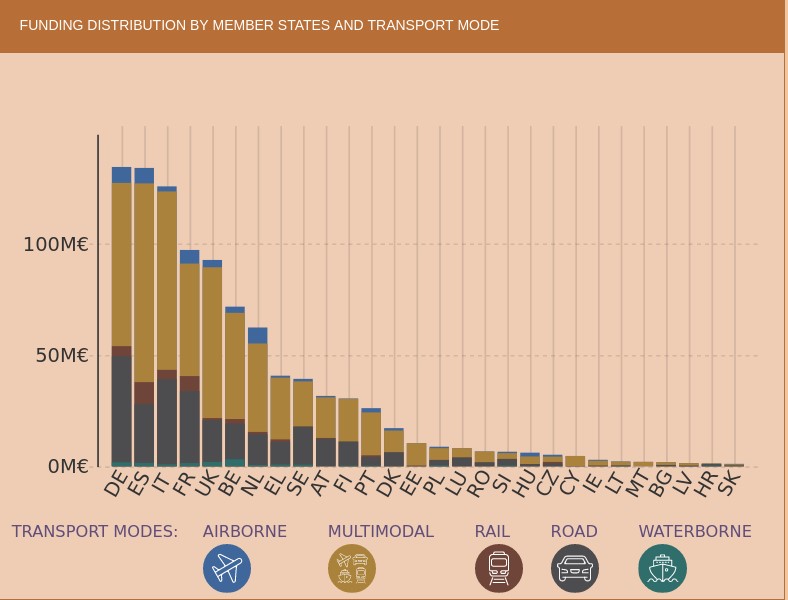
Como ejemplo del esfuerzo investigador que se está realizando en España tenemos el conjunto de datos piloto para implementar capacidades semánticas sobre la información de incidencias de tráfico relacionadas con la seguridad en la red estatal de carreteras españolas, excepto País Vasco y Cataluña, que publica la Dirección General de Tráfico y que utiliza una ontología para representar incidentes de tráfico que ha desarrollado a Universidad de Valencia.
El área de los sistemas y servicios de movilidad inteligente pretende contribuir a la descarbonización del sector del transporte europeo y entre sus principales prioridades están el desarrollo de sistemas que conecten los servicios de movilidad urbana y rural y promuevan el cambio modal, el uso sostenible del suelo, la suficiencia en la demanda de viajes y los modos de viaje activos y ligeros; el desarrollo de soluciones de gestión de datos de movilidad e infraestructura digital pública de acceso justo o la implantación de la intermodalidad, la interoperabilidad y el acoplamiento sectorial.
La iniciativa 100 preguntas en el ámbito de la movilidad
La Iniciativa de 100 Preguntas, lanzada por The Govlab en colaboración con Schmidt Futures, pretende identificar las 100 preguntas más importantes del mundo en una serie de dominios críticos para el futuro de la humanidad, como son el género, la migración o la calidad del aire.
Uno de estos dominios está dedicado precisamente al transporte y la movilidad urbana y tiene como objetivo identificar preguntas en las cuales los datos y la ciencia de datos tienen un gran potencial para obtener respuestas que contribuyan a impulsar importantes avances en conocimiento e innovación sobre los dilemas públicos más importantes y los problemas más graves que tienen que resolverse.
De acuerdo con la metodología utilizada, la iniciativa finalizó el 28 de julio la cuarta etapa en la que el público en general realizó la votación con la que se decidieron cuáles serían las 10 preguntas finales que deben ser abordadas. Las 48 preguntas iniciales fueron propuestas por un grupo de expertos en movilidad y científicos de datos por lo que están concebidas para que puedan ser respondidas con datos y pensadas para que, si se consiguen resolver, puedan tener un impacto transformador para las políticas de movilidad urbana.
En la próxima etapa, el grupo de trabajo de GovLab identificará cuáles son los conjuntos de datos que podrían proporcionar respuestas a las preguntas seleccionadas, algunas tan complejas como saber “¿dónde quieren ir los viajeros pero realmente no pueden y cuáles son las razones por las que no pueden alcanzar su destino con facilidad?” o “¿cómo podemos incentivar a las personas a realizar viajes en modos sostenibles, como caminar, andar en bicicleta y/o transporte público, en lugar de vehículos de motor personales?”
Otras preguntas están relacionadas con las dificultades encontradas por los reutilizadores y que han sido puestas de manifiesto con frecuencia en artículos de investigación como “Open Transport Data for maximising reuse in multimodal route”: “¿Cómo se pueden compartir los datos de transporte/movilidad recopilados con dispositivos como teléfonos inteligentes, y ponerlos a disposición de los investigadores, planificadores urbanos y legisladores?"
En algunos casos es previsible que los conjuntos de datos necesarios para responder las preguntas no estén disponibles o pertenezcan a compañías privadas por lo que también se intentará definir cuáles son los nuevos conjuntos de datos que deben generarse para ayudar a llenar los vacíos identificados. El objetivo final es proporcionar una definición clara de los requisitos de datos para responder a las preguntas y facilitar la formación de colaboraciones de datos que contribuyan a avanzar en la obtención de estas respuestas[2].
En definitiva, los cambios en el modo en que utilizamos el transporte y los estilos de vida, como el uso de teléfonos inteligentes, aplicaciones web móviles y redes sociales, junto con la tendencia a alquilar, en lugar de poseer un medio de transporte en particular, han abierto nuevos caminos hacia la movilidad sostenible y unas enormes posibilidades en el análisis e investigación de los datos capturados por estas aplicaciones.
Por ello las iniciativas globales para coordinar los esfuerzos de investigación son esenciales ya que las ciudades necesitan bases de conocimiento sólidas a las que recurrir para que las decisiones políticas sobre desarrollo urbano, transporte limpio, igualdad de acceso a oportunidades económicas y calidad de vida en los centros urbanos sean efectivas. No debemos olvidar que todo este conocimiento es además clave para que puedan establecerse adecuadamente prioridades y, de este modo, podamos aprovechar al máximo los escasos recursos públicos de los que habitualmente disponemos para afrontar los desafíos.
Contenido elaborado por Jose Luis Marín, Senior Consultant in Data, Strategy, Innovation & Digitalization.
Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Aplicación
Park4Dis es una aplicación móvil cuyo objetivo principal es facilitar la búsqueda de aparcamiento a personas con movilidad reducida. Para poder ofrecer este servicio, monitoriza la información de más de 250 ciudades europeas, principalmente españolas, sumando más de 45.000 plazas para personas con movilidad reducida.
Dado que se trata de una plataforma gratuita, interurbana y transversal, Park4Dis permite mostrar de forma resumida y accesible, tanto la ubicación de las plazas de aparcamiento como la normativa local relativa a otros estacionamientos permitidos
A través de las colaboraciones y acuerdos con Ayuntamientos y Administraciones Públicas de toda España, la plataforma puede ofrecer este servicio en tiempo real, gracias a los datos abiertos relativos a los estacionamientos y normativa de cada localidad. De igual modo, Park4Dis también se nutre de la información faciltiada por su red de voluntarios y la implicación de empresas socialmente responsables.